1. Introduction
Obtaining news from social media has become increasingly prevalent. Nowadays, more people acquire news from social media. Social networks benefit from providing multimedia information for news, with low cost, ease of access, and rapid dissemination. These advantages increasingly attract many people to consume news through them. Unfortunately, these features often are misused by fake-post publishers to spread the news rapidly. The rapid dissemination of fake news may cause negative impacts on society or can even alter the outcomes of an important public event. Thus, early fake-news detection on social media has recently become an active field and has attracted widespread attention.
Fake news is intentionally and verifiably false and could mislead its readerships [
1]. A news article contains two major components: publisher and content. The publisher includes a set of features that identify the author, such as name, age, domain, etc. The content consists of a set of attributes that represent the news article, such as title, body copy, images, videos, etc.
For a given post , the task of fake-news recognition is to predict whether the article is fake or not. This task is often modeled as a binary classification. Although other sources, such as users’ comments about the article and reposts, are indeed helpful, this information in the early stages is often incomplete and noisy. Thus, this work is focused on detecting fake news based on the content.
Thus far, many fake-news recognition systems, including traditional machine learning and deep learning models, have been proposed. Traditional methods first manually extract features from news and then classify them by exploiting these features. In contrast, deep learning models can automatically extract useful features from text or images in the news. Since manual feature-extraction methods are very time-consuming, deep learning methods are preferred over traditional ones.
Ensemble is a popular technique to train multiple models for achieving a composite model, which outperforms individual learners. To a great extent, the success of an ensemble model depends on both the accuracy of each learner and the diversity among them. Ideally, each learner should have high accuracy and must have a low correlation with others.
Existing ensemble fake-news methods [
2,
3,
4,
5,
6,
7,
8,
9,
10] often trained multiple deep or shallow models independently and then combined the outcomes of learners via ensemble mechanisms, such as voting. Thus, these models involve many trainable parameters and a costly training process. Also, they suffer from the scalability aspect and are vulnerable to the overfitting problem.
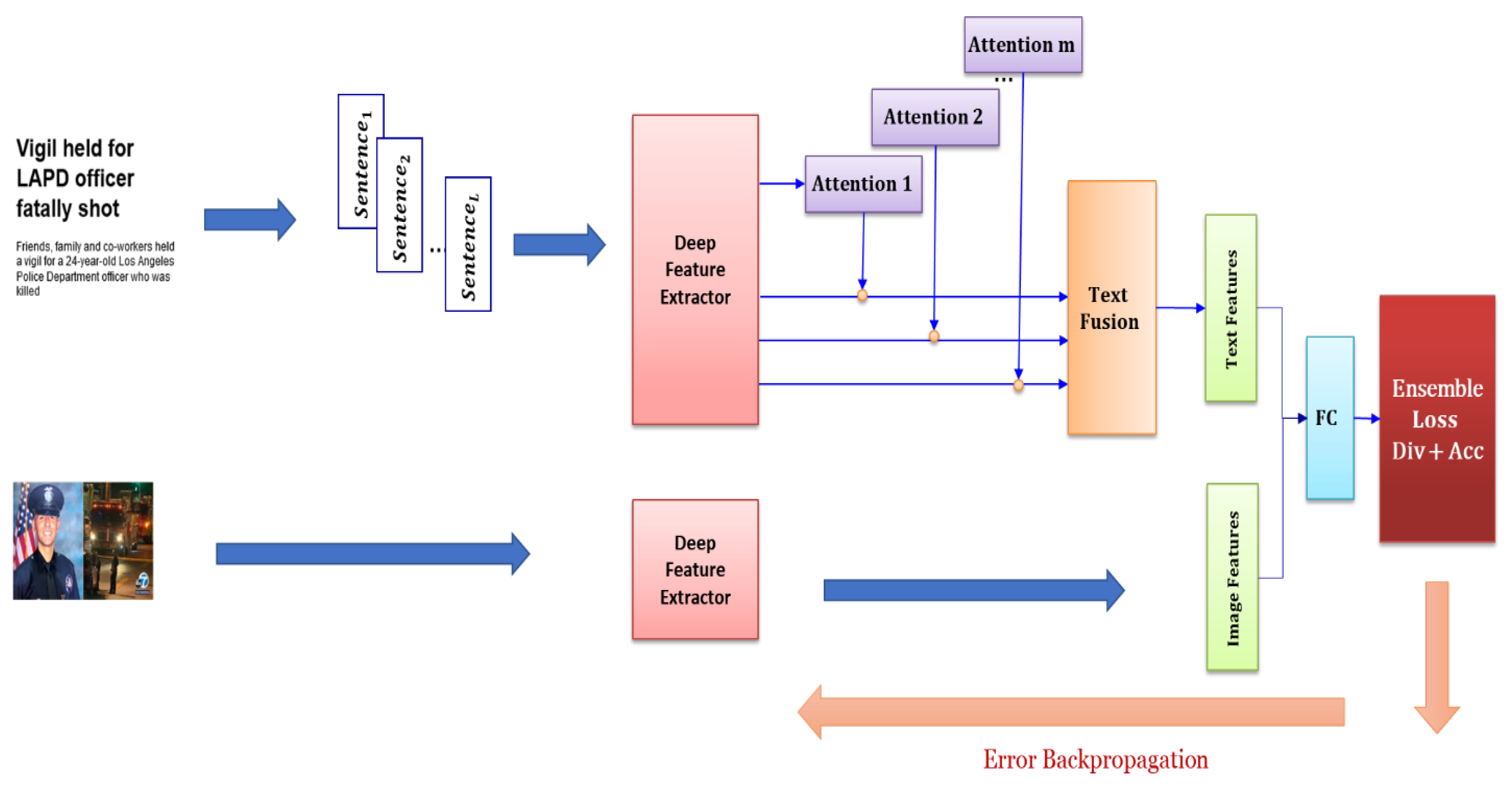
To address these challenges, we propose a novel fake-news detector that utilizes an ensemble of deep learners and attention mechanisms. Our learners are built on top of a
shared deep-feature extractor and differ in their
attention modules. Sharing parameters effectively reduces training time, memory requirements, and the complexity of the proposed model. Also, our model is less prone to the overfitting problem.
Figure 1 shows the proposed architecture. The proposed text feature extractor is similar to the hierarchical attention network (HAN) [
11], with the difference being that we obtained sentence representation from the pretrained XLNet [
12], which is much faster than word embedding, followed by bidirectional GRU and attention in HAN. Moreover, we have multiple attention modules to encode the input document. Here, the proposed loss function forces each module to attend to the different parts of the document on one hand and attain good classification accuracy on the other hand.
The proposed ensemble model is trained in an end-to-end paradigm using the standard of backpropagation (BP).
In summary, the contributions of this paper are as follows:
We propose an ensemble of deep learners built on a shared feature extractor to identify fake news. Our model has fewer parameters and training time compared with existing ensemble models. As a result, it is less prone to the overfitting problem.
We develop a novel loss function that enforces each learner to focus on a different aspect of the input news using an attention mechanism. This encourages each model to have high performance. The model is trained in an end-to-end learning paradigm using the standard BP.
The remainder of the paper is organized as follows.
Section 2 reviews related fake-news detection methods with a focus on multimodal content-based approaches.
Section 3 presents the proposed ensemble model and its implementation details.
Section 4 reports the experimental results and comparisons with peer state-of-the-art methods. Finally,
Section 5 concludes with remarks along with recommendations for future work.
2. Background
A major challenge in a fake-news detection task is the classification of news using available features. Features can be derived from many sources, such as body copy, attached images or videos, user profiles, social context, users’ comments, or reposts. The early discovery of fake news mostly relies on its content. A list of possible features of content include:
Author or publisher of the news.
Title: summary text intended to draw readers’ attention to the main topic of the news.
Body copy: the main body of news that describes the details of the news. News stories are usually a big claim that shows the direction of the publisher.
Images/videos: Part of a news article that provides visual cues for the story.
Here, we review related work from three categories: (1) single modal, (2) multimodal (text and image), and (3) ensemble approaches.
2.1. Single Modality-Based Methods
Textual attributes refer to statistical or semantic features extracted from the content of the text and have been studied in fake-news discovery literature [
1,
13,
14,
15]. For example, Reis et al. [
16] used several types of features, such as language (syntax), lexical, psycholinguistic, semantic, and news sources. Afterward, they applied several machine learning methods, such as kNN, naïve Bayes, SVM, and random forest to the extracted features and compared the results.
Unfortunately, linguistic patterns are not yet well understood, because they depend on specific events and domain-related knowledge [
17]. Therefore, it is difficult to design manual features from the text for the traditional machine learning models. To overcome this limitation, deep learning models are utilized to automatically extract features and identify fake news simultaneously.
Inspired by the pioneering work in [
11], De Sarkar et al. [
18] presented a deep learning model for fake-news detection with two major components: the
S and
D modules. The
S module generates a sentence embedding for each sentence in the source news. The
D module takes sentence embedding as input and creates document embedding using an attention mechanism.
HDSF (hierarchical discourse-level structure for fake-news detection) [
19] incorporated a hierarchical discourse-level structure of fake and real news articles. This method is developed based on the dependence parsing of the document at the sentence level using bidirectional LSTM.
FakeBert [
20] proposed a BERT (bidirectional encoder representations from transformers)-based [
21] encoder that helped it to obtain a deeper sense of news context. Here, the BERT encoder has been followed by several parallel 1-D convolutional blocks with different kernel lengths. The outputs of the blocks were concatenated and passed to a dense classifier. The reported results show that the BERT outperforms unidirectional embeddings, such as Glove [
22].
2.2. Multimodal Methods
Visual cues contain valuable information to detect fake news [
1,
23]. While few studies have focused on validating the multimedia content of the news, some research has considered these features [
23,
24,
25,
26].
TI-CNN (text and image information-based CNN) [
27] combined the explicit and latent features of text and image information into a unified feature space and then used the learned features to identify fake news.
EANN (event adversarial neural networks for multimodal fake-news detection) [
28] is a multimodal approach aimed at learning an event-invariant representation using domain-adaptation techniques. In this way, it removes tight dependence on the specific events in the collected dataset and achieves better generalization ability on the unseen events.
As these studies indicate the importance of visual features, we consider the visual content in our model.
2.3. Ensemble Methods
Several ensemble models for fake-news recognition have been presented in the literature to enhance the accuracy of the task. Rot et al. [
6] developed two models based on CNN and bidirectional LSTM to extract features from news and then passed the obtained representations to an MLP model for the final classification.
Huang et al. [
5] set up an ensemble model using four deep models, namely, embedding LSTM, depth LSTM, LIWC CNN, and N-gram. It utilized a metaheuristic method named “self-adaptive harmony search” (SAHS) to find the optimized weights of each model [
10].
Hakak et al. first extracted important features from fake-news datasets and then passed the features to three popular traditional learning algorithms, namely, decision tree, random forest, and extra tree classifier. Similarly, Mahabub et al. [
4] investigated 11 traditional machine learning algorithms, such as kNN, SVM, and random forest, for detection. Then, they selected the three best models using cross-validation and combined the results using the voting mechanism. Hansrajh et al. [
9] trained logistic regression, linear discriminant analysis (LDA) classifier, SVM, stochastic gradient descent, and ridge regression on the LIAR dataset [
29]. Then, it employed “blending,” a variant of the stacking mechanism, to fuse the predictions of base models. Iftikhar et al. [
10] added several linguistic features obtained via the LIWC2015 tool from the text content to the evaluated datasets. It then examined the performance of several base models and ensemble mechanisms, including bagging, boosting (Adaboost and XGBoost), voting, and random forest on four datasets.
Aslam et al. [
3] proposed an ensemble model to identify fake news on the LIAR dataset. It used the bidirectional LSTM-GRU model for the textual content of the input post and a MLP model for other features. The outputs of the models were concatenated and formed the embedding representation. The representation was then forwarded to a single fully connected layer with one output neuron [
9,
30].
Meel et al. [
8] proposed a multimodal ensemble fake-news detection model that utilized a hierarchical attention network (HAN) for text feature extraction and image captioning to extract visual features. It also implemented headline matching with text content, noise variance inconsistency, and error level analysis algorithms. The algorithms were trained independently and combined using the max voting mechanism. Compared to the proposed method, we experimentally showed that our ensemble-based text feature extractor outperformed HAN on both evaluated datasets on a variety of metrics (refer to
Section 3.4). Also, while the authors showed that the combined model achieves promising results, the model demands costly training and evaluation processes.
Das et al. [
7] used a variety of pretrained network models to extract features from news text content. Each model is followed by an output layer that produces probabilities for real and fake classes. Afterwards, it used soft voting and hard voting to combine the predictions. Additionally, it presented an heuristic post-processing approach that boosted the F1 score of the ensemble from 98.31% to 98.31% on the COVID-19 fake-news dataset from the CONSTRAINT COVID19 competition, thereby achieving state-of-the-art performance on this dataset. However, the current results indicate that several teams obtained an accuracy of 100% and surpassed it.
As observed, existing methods often train multiple independent models and then combine the results using ensemble mechanisms. In the case of using deep networks as base learners, this strategy requires many parameters and a costly training process. These models are also prone to the overfitting problem.
3. Materials and the Proposed Method
The proposed method, called “diverse ensemble of fake-news detectors” (DEFD) aims to detect fake news based on its content. To understand the meaning of news, we need to process the sentences that form it. Considering that different sections of a post do not equally contribute to identifying its fakeness, we utilize an attention mechanism to automatically learn their importance weights.
The proposed model consists of a consensus of learners that have a common structure to simplify the model and prevent overfitting. The difference among these learners only lies in their attention modules. Given that the success of an ensemble model depends on how different the learners are, we aim to have each learner consider various aspects of the post. Thus, we try to make them as different as possible in the proposed loss function.
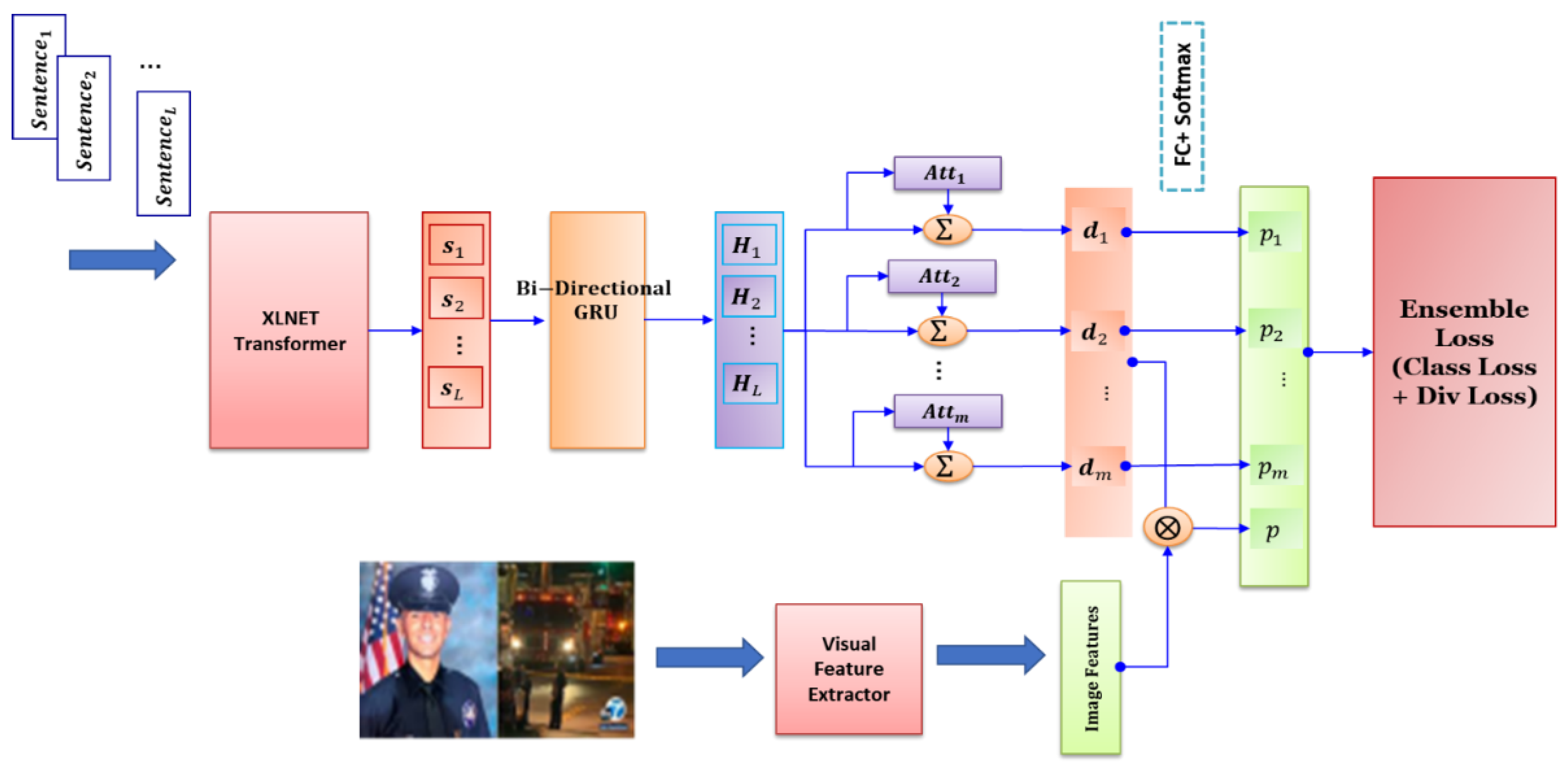
Figure 2 illustrates the architecture of the proposed model, in which two parallel components are utilized to extract features from the image and text of given news. Then, the extracted features are merged and categorized. In the following, different parts of the proposed model are discussed in more detail.
3.1. Text Feature Extraction
Our text feature extractor has three components: sentence encoder, post encoder, and attention modules.
3.1.1. Sentence Encoder
Words are first converted to a fixed-length vector using a predefined word embedding such as BERT [
21], word2vec [
31], Glove [
22], or FastTex [
32].
A sentence can be represented as a sequence of words. Suppose is the word of sentence, obtained from a word embedding. Then, a sentence can be denoted by where is the number of words. The sentence encoder should map this sequence to a vector with a fixed-length . In other words, it can be modeled by a function , such that where the output denotes the embedding of the sentence.
A sentence encoder can be implemented by available deep learning models that work on text data, such as Temporal CNN, GRU, or LSTM, or state-of-the-art transformer models, such as BERT and XLNET [
12].
3.1.2. Post Encoder
Each post contains a sequence of sentences. The input of the model is a post. We apply the sentence encoder to each sentence in the input post to attain its vectorized representation . The representations of sentences are further processed by a bidirectional GRU to obtain annotations () for each sentence in the post. Then, we apply attention layers as discussed in the next subsection on these annotations. Subsequently, each attention layer obtains a representation for the given post. Also, we consider an additional representation that provides the whole view of learners from the input document.
3.1.3. Attention Module
The attention module aims to assign larger weights to the more important parts of given news. As an illustrative example, suppose a post contains five sentences. These sentences are processed by a deep network, such as, a bidirectional LSTM, and a state variable is generated at each step (these variables are represented by
in
Figure 3).
deals mostly with the first few sentences of the text, such as
and
, whereas
focuses on the last sentences. The attention module, which is usually implemented by a simple two-layer neural network, has the task of attaining the attention weights,
. The post embedding
is then formed by weighted averaging of the states:
The attention mechanism is based on a similarity function and a context vector, such as
that we aim at attending. First, the alignment scores
(for each
and
) are computed. The function
measures the similarity between
and
or the attention of
to
. Second, the attention weights are normalized by applying the
Softmax function that transforms the similarity scores
to a probability (or normalized) vector
. Many different attention mechanisms are proposed in the literature. They mostly differ in the way the alignment score function
is modeled. Below, we review some important ones [
33].
Multiplicative attention uses inner product similarity to compute
as follows:
The weight matrices and are learned using BP according to the objective function of the task.
This method [
11] first applies a linear transformation followed by a
activation on each state
in the input post. Then, it computes the inner product of the result with the context vector
.
Additive attention computes the similarity score between
and
as:
where
is a weight vector and
is an activation function, such as
. Additive attention often outperforms the multiplicative form. However, it requires more memory and computational cost.
Multidimensional attention computes multiple scores, one for each feature in
by replacing the weight vector
in the additive form with a matrix
:
Let
be the scores (components) obtained from the multidimensional attention. Here, the
dimension of
means the attention of the
feature of
to
. Hence, each feature in
has a score weight. Now, the same procedure is applied to each feature
. First, we normalize the attention weights of feature
,
), using the Softmax function:
Then, we form the
feature of output
as:
In this work, we adopt the modified multiplicative attention to implement the attention mechanism. The main question is: To which feature of vector should we attend? It shows a reference representation that a sentence annotation () should be similar to it to attain a higher representation score. For some tasks, such as visual question answering, the query vector is given as input. However, it is not determined in our task. Thus, we define the context vector as a learnable parameter vector in our model to be learned jointly with other parameters according to the loss function.
3.2. Image Feature Extraction
In addition to text, images can also play an important role in determining whether a given post is fake or not. Therefore, we consider visual information in the proposed model. Feature extraction from images can be done by a pretrained CNN. Also, one can extract objects from the input image and use an attention mechanism to force the learner to focus on specific objects in the image. Here, we simply use a pretrained VGG19 [
34] to mine features from the given image. The features are then processed by several fully connected (FC) layers, each followed by an activation function. The implementation details are provided in
Section 4.3. Finally, as seen in
Figure 2, the text and image features are concatenated and then passed to the loss layer.
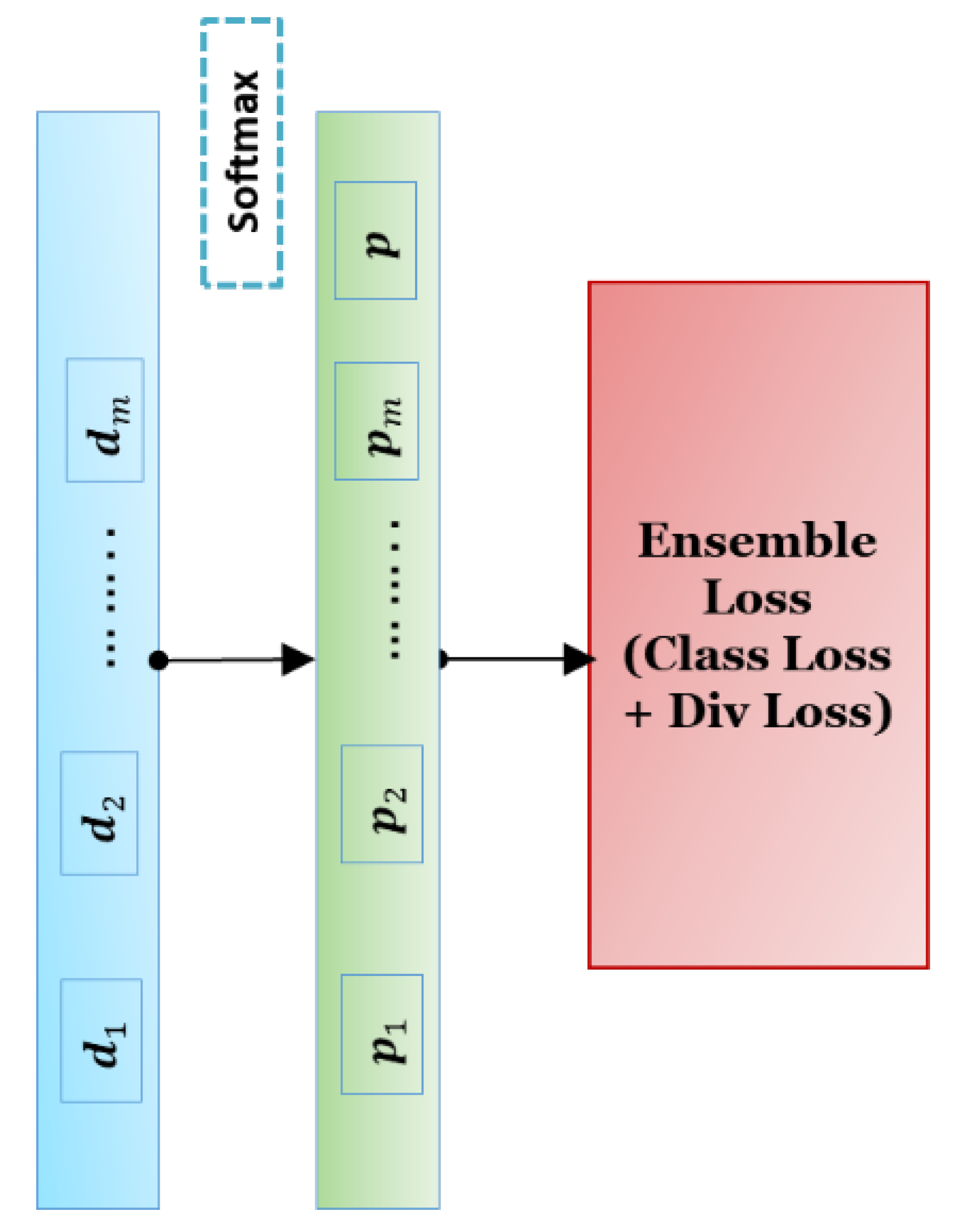
3.3. Loss Function
The classifier gets the extracted features (text + image) and outputs a prediction. It consists of a simple FC (fully connected) layer and the proposed loss layer. The loss function plays a key role in the success of our ensemble model. On one hand, it should reduce the classification error on training data, and on the other hand, it should force learners to focus on distinct parts of the text. To this end, we propose the following hybrid loss function:
where
is the output of the model for the input post, and
is a binary variable that shows the true label of the post (
). Also
as seen in
Figure 4.
The term of loss function should force each learner to have good accuracy. For this purpose, we implement as the mean of classification losses of all learners. Another important decision is to select an appropriate classification loss.
Existing methods simply opt for the standard and popular binary cross-entropy (BCE) loss. However, in a real application, the distribution of classes is expected to be imbalanced. For example, two selected real datasets used in our experiment contain more real posts than fake. Thus, in addition to cross-entropy, we examine another loss called focal loss to deal with the imbalanced nature of the target task.
Let
be the probability of true class predicted by learner
:
The BCE loss between a true label
and prediction of learner
is defined as:
The focal-loss [
35] that is more suitable for imbalanced datasets is defined as follows:
According to Equation (9), the focal loss adds a factor to the cross-entropy loss. Thus, when the hyperparameter is it penalizes hard samples more than easy ones. As such, it alleviates the classification bias to the majority classes in imbalanced datasets.
To enforce each learner to achieve good accuracy, we implement the
as the average of classification losses of all learners:
where
is computed using Equation (8) or (9) according to the selected classification loss.
The
part of our loss function should enforce the diversity of learners. To this end, we propose the following loss function:
where
is a predefined margin. Note that
means that predictions are different. When
, the loss is zero. Also, when both predictions
and
e
and the loss will be increased. Note that the coefficient of the first term should be chosen much larger than the second in practice (
). Thus, their combination yields accurate learners with diverse predictions.
3.4. Combining the Outputs of Learners
The outputs of classifiers are passed to the proposed loss function and the computed loss is backpropagated to the layers to train the model. In the evaluation phase, we use the weighted majority voting mechanism to combine the predictions and output the final decision.
To compute the weight of each learner, we keep 20% of the whole training set as validation data. Then, the score of each learner on the validation set is computed. The score function is simply the mean of accuracy and F1-score that makes it suitable for imbalanced datasets. Let
be the score of learner
. The weight
is calculated as:
Finally, the prediction of the given post is computed as:
3.5. Implementation Details
We implement our model using the
Pytorch deep learning library. The input news is first cleaned from the redundant characters and split into sentences using the
BeautifulSoup Python package. Subsequently, the words in the post are tokenized and then converted to a 3D integer tensor as follows:
Here, we consider only the first 50 sentences per post. We use the state-of-the-art XLNet [
12] transformer to obtain the embedding for each sentence in the post. XLNet is a breakthrough in NLP as it surpasses the BERT transformer in many downstream NLP tasks.
Table 1 shows the specification and architecture of the proposed deep model.
The visual feature extractor includes most parameters in our method (10,295,500/10,940,906
94%). Compare to state-of-the-art models used in our experiments: SpotFakePlus [
36] and FakeBERT [
20], DFDD contains fewer parameters than both SpotFakePlus (with 49,312,552 parameters) and FakeBERT (with 25,555,318 parameters).
4. Results and Discussion
This section deals with the experiments conducted to evaluate the effectiveness of the proposed deep model.
4.1. Datasets
We adopt the comprehensive fake-news detection repository named FakeNewsNet dataset [
36]. The repository is collected from two known sources: Gossip and PolitiFact. Both datasets include news content, image, user comments, and labels obtained by fact checking. We adopt the split test/train in [
37] in the experiments (Downloaded from
https://drive.google.com/file/d/1Cdil6K5MSU4ebOVrU-4_4DteW8ANNoa2, accessed on 1 February 2022). In the preprocessing step, logos from news were dropped and samples without images or containing GIFs were removed. The statistics of these datasets are summarized in
Table 2.
4.2. Evaluation Metrics
We utilized standard measures to evaluate the performance of fake-news models including
Accuracy,
Recall,
Precision,
Specificity,
F1 score, and
G-mean, defined as follows:
where
TP,
TN,
FP, and
FN correspond to true positive, true negative, false positive, and false negative, respectively. G-mean is the square root of the product of class-wise accuracies. It is typically used in an imbalanced environment. A large
value indicates that accuracy on both classes is high and balanced.
4.3. Experimental Setup
We compared the proposed DEFD with two peer state-of-the-art methods: FakeBert [
20] and SpotFake-Plus [
36]. We also evaluate the base variant of our model, named DEFD-base, which has only one learner (
).
Both the competing methods only utilize news content to identify its fakeness. The FakeBert only uses the text of a news, whereas the SpotFake-Plus is multimodal and considers both text and visual content of news.
We adopt k-fold (k = 5) cross validation to determine the hyperparameters of the methods. More specifically, we chose the learning rate () from the set , optimizer from . We fixed the margin and select from , and number of learners from .
4.4. Results and Discussion
The classification results of the learned models are reported in
Table 3 and
Table 4. Also, the confusion matrices of the results are illustrated in
Table 5.
As the results indicate, DEFD surpasses the competing methods by a large margin on both datasets. For example, on the Gossip dataset, the proposed method obtained an F1 of 72.54%, whereas SpotFake-Plus and FakeBert reached to 49.76% and 24.25%, respectively. This confirms the efficacy of the proposed model. The fact that FakeBert (single modal) achieved the worst results reveals the importance of visual information in identifying fake news. Besides, although FakeBert and Spot-Fake-Plus obtained good specificity (
true negative rate), they had low recall. A low recall value means that they classified many fake posts as real, that is, they failed to do the primary task of a fake-news detection system. It can be explained as these methods have no strategy to deal with the imbalanced nature of the fake-news identification task. On the other hand, DEFD achieved good balanced class-wise accuracy and has an acceptable recall. It is mainly due to utilizing focal loss function and learning diverse learners that boost the accuracy on minority class (i.e., fake). Meanwhile, the results in
Table 3 and
Table 4 indicate that the difference between the accuracy of DEFD and DEFED-base is negligible, while DEFD outperforms DEFED-base by a large margin in terms of F1 score and G-mean, which reveals that diversity in learners’ predictions helps to achieve high balanced accuracy and confirms the effectiveness of our ensemble mechanism.
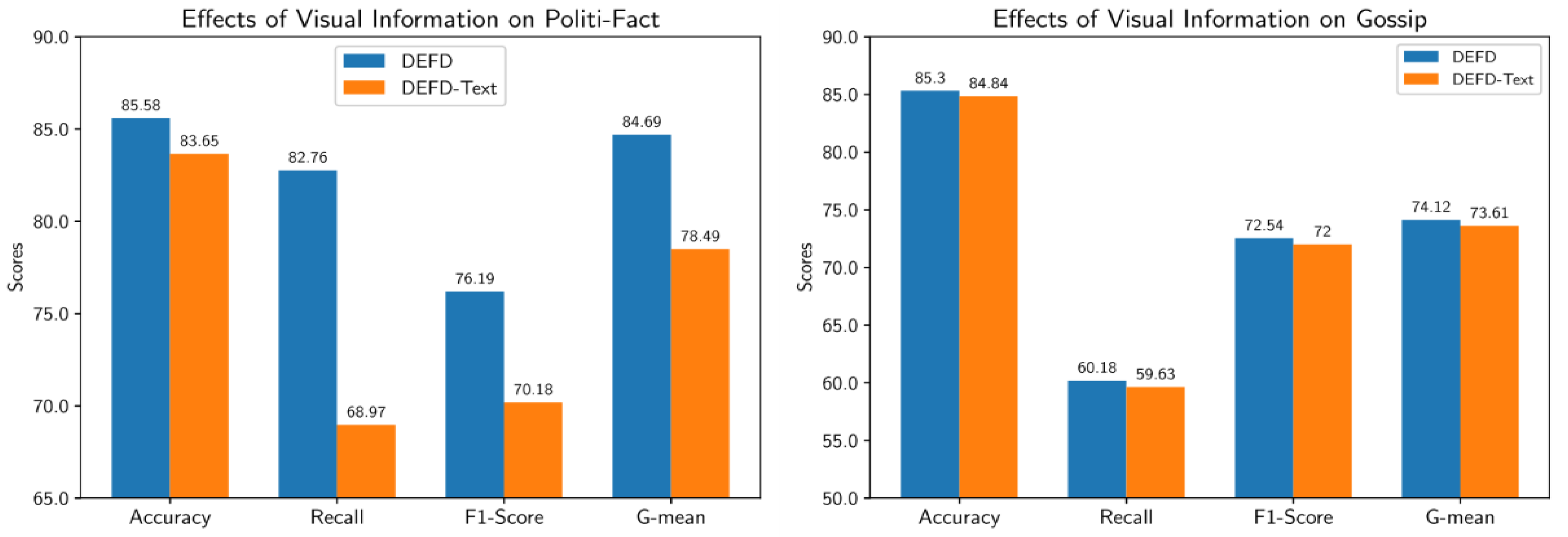
4.4.1. Effects of Visual Information
To investigate the role of visual information in the proposed model, we consider a variant of DEFD named
DEFD-Text that does not include the image feature extractor module. The results obtained by DEFD-Text are compared with DEFD in
Figure 5. As seen, in the Politi-Fact dataset, DEFD considerably outperforms DEFD-Text almost in all evaluation metrics. Besides, the improvement obtained by DEFED on the Gossip dataset is not too much. We can conclude that visual information is helpful in identifying fake posts. However, its usefulness highly depends on the dataset.
4.4.2. Hyperparameter Analysis
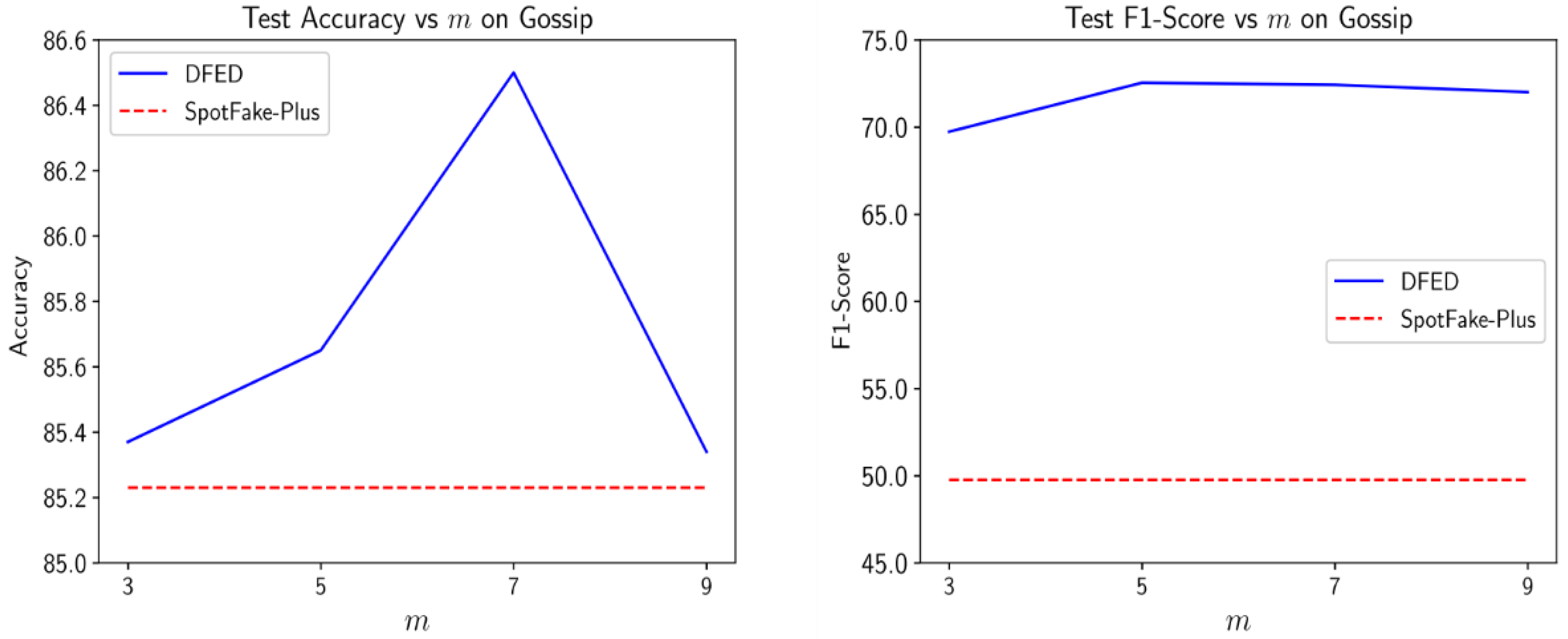
In these experiments, we analyze the effects of two important hyperparameters in our model: (1) the number of learners (m), and (2) the weight of diversity term controlled by the .
Figure 6 shows the influence of the number of learners on the accuracy and score of our method on the Gossip dataset. Also, the results were compared with the SpotFake-Plus to provide a better insight into the sensitivity of results to this hyperparameter. As the value of m increases, the complexity of the model grows, and the performance slightly improves. However, setting
greater than the optimal value increases the chance of the overfitting problem and we observe a slight performance reduction. Nevertheless, the obtained results show less sensitivity to the value of
and DEFD outperforms SpotFake-Plus over different values of
.
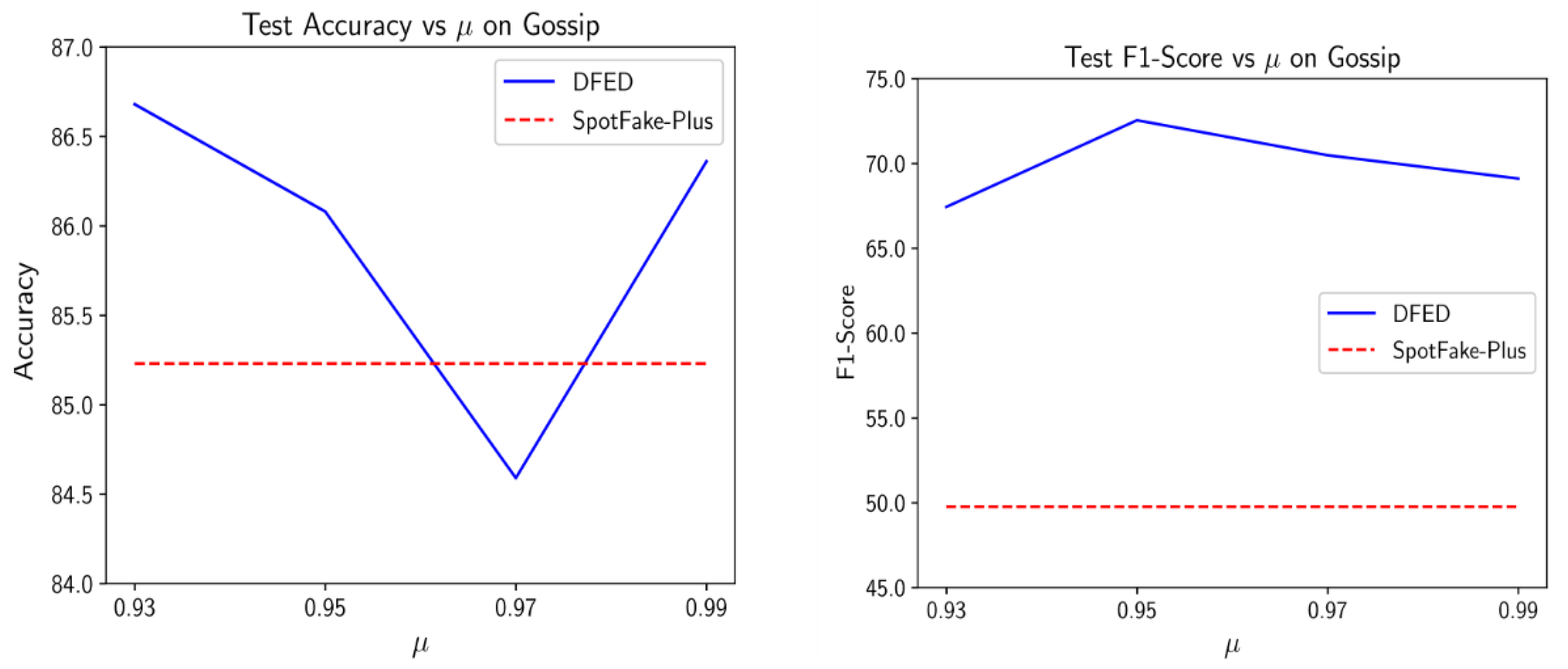
In the next experiment, we analyzed the effects of the proposed diversity term. Since the value of we find out that an appropriate value of is near 1. Therefore, we examine the sensitivity of the performance of DEFD to by varying it over the set .
Figure 7 depicts the obtained results versus different values of
on the Gossip dataset.
As the results indicate, the performance of DEFD peaked around the value. However, the difference between obtained scores is not significant, and setting the around always yields a satisfactory performance. That is especially obvious when looking at the F1-score measure that embeds two crucial factors in our task (i.e., recall and precision).
5. Conclusions
In this research, we studied the multimodal fake-news detection problem solely based on news content, which is considered the best way of early detection of fake posts on social media. Our ensemble model called DEFD boosts the performance of existing ones by exploiting both textual and visual cues of the news. DEFD trains diverse learners attending to different aspects of a given post in order to make predictions about its fakeness.
The proposed hybrid loss function forces each learner to have diverse predictions on the one hand and achieve good classification accuracy on the other hand. We also considered the imbalanced nature of fake-news identification tasks and utilized the focal loss function to prevent classification bias to the majority class (i.e., real category).
We simplified the model by building the learners on a common deep-feature extractor, where each learner has only a specific attention module. This architecture reduces the complexity of our model in terms of space and training time requirements and effectively prevents the overfitting problem. Compared to similar models [
8,
11], we utilized pretrained models, such as XLNET, to directly extract features from the sentences of the input post, which accelerates the training process and decreases the model’s parameters.
Experiments conducted on two real datasets collected from the popular FakeNewsNet repository reveal that the proposed model is indeed effective and surpasses the peer methods by a large margin on both datasets, especially when in addition to accuracy, other classification metrics, such as Recall, F1-score, and G-mean are considered. Also, we analyzed the effect of multiple learners and visual information on the performance of the model through ablation studies. The results confirm that both boost the overall performance of the model. In future work, we aim to extend our work to a cross-dataset scenario. Moreover, extending the work for semisupervised learning (SSL) due to the significant cost of labeling news is valuable. We will also investigate the effects of other attention mechanisms on the model’s performance.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}