Abstract
We consider information-theoretic bounds on the expected generalization error for statistical learning problems in a network setting. In this setting, there are K nodes, each with its own independent dataset, and the models from the K nodes have to be aggregated into a final centralized model. We consider both simple averaging of the models as well as more complicated multi-round algorithms. We give upper bounds on the expected generalization error for a variety of problems, such as those with Bregman divergence or Lipschitz continuous losses, that demonstrate an improved dependence of on the number of nodes. These “per node” bounds are in terms of the mutual information between the training dataset and the trained weights at each node and are therefore useful in describing the generalization properties inherent to having communication or privacy constraints at each node.
1. Introduction
A key feature of machine learning systems is their ability to generalize new and unknown data. Such a system is trained on a particular set of data but must then perform well even on new data points that have not previously been considered. This ability, deemed generalization, can be formulated in the language of statistical learning theory by considering the generalization error of an algorithm (i.e., the difference between the population risk of a model trained on a particular dataset and the empirical risk for the same model and dataset). We say that a model generalizes well if it has a small generalization error, and because models are often trained by minimizing empirical risk or some regularized version of it, a small generalization error also implies a small population risk, which is the average loss over new samples taken randomly from the population. It is therefore of interest to find an upper bound on the generalization error and understand which quantities control it so that we can quantify the generalization properties of a machine learning system and offer guarantees about its performance.
In recent years, it has been shown that information-theoretic measures such as mutual information can be used for generalization error bounds under the assumption of the tail of the distribution of the loss function [1,2,3,4]. In particular, when the loss function is sub-Gaussian, the expected generalization error can scale at most with the square root of the mutual information between the training dataset and the model weights [2]. Such bounds offer an intuitive explanation for generalization and overfitting: if an algorithm uses only limited information from its training data, then this will bound the expected generalization error and prevent overfitting. Conversely, if an algorithm uses all of the information from its training set, in the sense that the model is a deterministic function of the training set, then this mutual information can be infinite, and there is the possibility of overfitting.
Another modern focus of machine learning systems has been that of distributed and federated learning [5,6,7]. In these systems, data are generated and processed in a distributed network of machines. The main differences between the distributed and centralized settings are the information constraints imposed by the network. There has been considerable interest in understanding the impact of both communication constraints [8,9] and privacy constraints [10,11,12,13] on the performance of machine learning systems, as well as designing protocols that efficiently train the systems under these constraints.
Since both communication and local differential privacy constraints can be thought of as special cases of mutual information constraints, they should pair naturally with some form of information theoretic generalization bounding in order to induce control over the generalization error of the distributed machine learning system. The information constraints inherent to the network can themselves give rise to tighter bounds on generalization error and thus provide better guarantees against overfitting. Along these lines, in a recent work [14], a subset of the present authors introduced the framework of using information theoretic quantities for bounding both the expected generalization error and a measure of privacy leakage in distributed and federated learning systems. The generalization bounds in this work, however, are essentially the same as those obtained by thinking of the entire system, from the data at each node in the network to the final aggregated model, as a single, centralized algorithm. Any improved generalization guarantees from these bounds would remain implicit in the mutual information terms involved.
In this work, we develop improved bounds on the expected generalization error for distributed and federated learning systems. Instead of leaving the differences between these systems and their centralized counterparts implicit in the mutual information terms, we bring analysis of the structure of the systems directly to the bounds. By working with the contribution from each node separately, we are able to derive upper bounds on the expected generalization error that scale with the number of nodes K as instead of . This improvement is shown to be tight for certain examples, such as learning the mean of a Gaussian distribution with quadratic loss. We develop bounds that apply to distributed systems in which the submodels from K different nodes are averaged together, as well as bounds that apply to more complicated multi-round stochastic gradient descent (SGD) algorithms, such as in federated learning. For linear models with Bregman divergence losses, these “per node” bounds are in terms of the mutual information between the training dataset and the trained weights at each node and are therefore useful in describing the generalization properties inherent to having communication or privacy constraints at each node. For arbitrary nonlinear models that have Lipschitz continuous losses, the improved dependence of can still be recovered but without a description in terms of mutual information. We demonstrate the improvements given by our bounds over the existing information theoretic generalization bounds via simulation of a distributed linear regression example. A preliminary conference version of this paper was presented in [15]. The present paper completes the work by including all of the missing proof details as well as providing new bounds for noisy SGD in Corollary 4.
Technical Preliminaries
Suppose we have independent and identically distributed (i.i.d.) data ∼ for , and let . Suppose further that is the output of a potentially stochastic algorithm. Let be a real-valued loss function and define
to be the population risk for weights (or model) w. We similarly define
to be the empirical risk on dataset s for model w. The generalization error for dataset s is then
In addition, the expected generalization error is
where the expectation is also over any randomness in the algorithm. Below, we present some standard results for the expected generalization error that will be needed:
Theorem 1
(Leave-One-Out Expansion; Lemma 11 in [16]). Let be a version of S with replaced by an i.i.d. copy . Denote . Then, we have
Proof.
In many of the results in this paper, we will use one of the two following assumptions:
Assumption 1.
The loss function satisfies
for , , where and are taken independently from the marginals for W and Z, respectively,
The next assumption is a special case of the previous one with :
Assumption 2.
The loss function is sub-Gaussian with parameter in the sense that
Theorem 2
(Theorem 2 in [3]). Under Assumption 1, we have
where
For a continuously differentiable and strictly convex function , we define the associated Bregman divergence [17,18] between two points to be
where denotes the usual inner product.
2. Distributed Learning and Model Aggregation
Now suppose that there are K nodes each having n samples. Each node has a dataset , with taken i.i.d. from . We use to denote the entire dataset of size . Each node locally trains a model with algorithm . After each node locally trains its model, the models are then combined to form the final model using an aggregation algorithm (see Figure 1). In this section, we will assume that and that the aggregation is performed by simple averaging (i.e., ). Define to be the total algorithm from the data S to the final weights such that . In this section, if we say that Assumption 1 or 2 holds, we mean that it holds for each algorithm . As in Theorem 1, we use to denote the entire dataset S with sample replaced by an independent copy , and similarly, we use to refer to the sub-dataset at node k, with sample replaced by an independent copy :
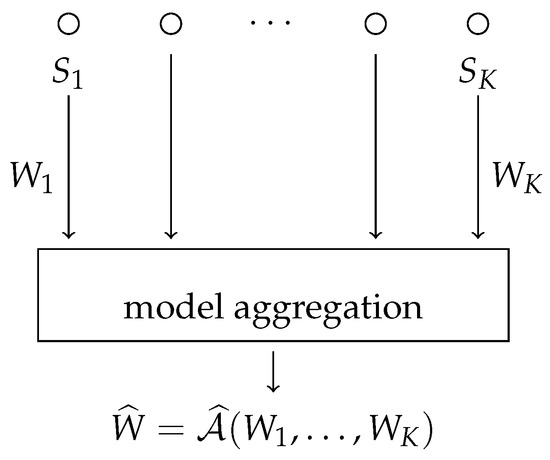
Figure 1.
The distributed learning setting with model aggregation.
Theorem 3.
Suppose that is a convex function of for each z and that represents the empirical risk minimization algorithm on local dataset in the sense that
Then, we have
Proof.
In the above display, Equation (4) follows by the convexity of ℓ via Jensen’s inequality, and Equation (5) follows by minimizing the empirical risk over each node’s local dataset, which exactly corresponds to what each node’s local algorithm does. □
While Theorem 3 seems to be a nice characterization of the generalization bounds for the aggregate model (in that the aggregate generalization error cannot be any larger than the average generalization errors over each node), it does not offer any improvement in the expected generalization error that one might expect when given total samples instead of just n samples. A naive application of the generalization bounds from Theorem 2, followed by the data processing inequality , runs into the same problem.
2.1. Improved Bounds
In this subsection, we demonstrate bounds on the expected generalization error that remedy the above shortcomings. In particular, we would like to demonstrate the following two properties:
- (1)
- The bound should decay with the number of nodes K in order to take advantage of the total dataset from all K nodes.
- (2)
- The bound should be in terms of the information theoretic quantities , which can represent (or be bounded from above by) the capacities of the channels over which the nodes are communicating. This can, for example, represent a communication or local differential privacy constraint for each node.
At a high level, we will improve on the bound from Theorem 3 by taking into account the fact that a small change in will only change by a fraction of the amount that it will change . In the case where W is a linear or location model, and the loss ℓ is a Bregman divergence, we can obtain an upper bound on the expected generalization error that satisfies properties (1) and (2) as follows:
Theorem 4
(Linear or Location Models with Bregman Loss). Suppose the loss ℓ takes the form of one of the following:
- (i)
- ;
- (ii)
- .
In addition, assume that Assumption 1 holds. Then, we have
and
Proof.
Here, we restrict our attention to case (ii), but the two cases have nearly identical proofs. Using Theorem 1, we have
In Equation (7), we use to denote . Equation (6) follows the linearity of the inner product and cancels the higher order terms and , which have the same expected values. The key step in Equation (7) then follows by noting that only differs from in the submodel coming from node k, which is multiplied by a factor of when averaging all of the submodels. By backing out of Equation (6) and re-adding the appropriate canceled terms, we get
By applying Theorem 2, this yields
Then, by noting that is non-decreasing and concave, we have
Using the property that conditioning decreases entropy yields
and we have
as desired. □
The result in Theorem 4 is general enough to apply to many problems of interest. For example, if , then the Bregman divergence gives the ubiquitous squared loss (i.e., ). For a comprehensive list of realizable loss functions, the interested reader is referred to [19]. Using F above, Theorem 4 can be applied to ordinary least squares regression, which we will examine in greater detail in Section 4. Other regression models such as logistic regression have loss functions that cannot be described with a Bregman divergence without the inclusion of additional nonlinearity. However, the result in Theorem 4 is agnostic to the algorithm that each node uses to fit its individual model. In this way, each node could fit a logistic model to its data, and the total aggregate model would then be an average over these logistic models. Theorem 4 would still control the expected generalization error for the aggregate model with the extra factor. However, critically, the upper bound would only be for the generalization error that is with respect to a loss of the form , such as quadratic loss.
In order to show that the dependence on the number of nodes K from Theorem 4 is tight for certain problems, consider the following example from [3]. Suppose that Z∼ and so that we are trying to learn the mean of a Gaussian distribution. An obvious algorithm for each node to use is simple averaging of its dataset:
For this algorithm, it can be shown that
and
See Section IV.A. in [3] for further details. If we apply the existing information theoretic bounds from Theorem 2 in an end-to-end way, such as in the approach from [14], we would get
However, for this choice of algorithm at each node, the true expected generalization error can be computed to be
By applying our new bound from Theorem 4, we get
which shows the correct dependence on K and improves upon the result from prior information theoretic methods.
2.2. General Models and Losses
In this section, we briefly describe some results that hold for more general classes of models and loss functions, such as deep neural networks and other nonlinear models:
Theorem 5
(Lipschitz Continuous Loss). Suppose that is Lipschitz continuous as a function of w in the sense that
for any z and that for each k. Then, we have
Proof.
Starting with Theorem 1, we have
where Equation (8) follows from Lipschitz continuity, Equation (9) uses the triangle inequality, and Equation (10) is assumed. □
The bound in Theorem 5 is not in terms of the information theoretic quantities , but it does show that the upper bound can be shown for much more general loss functions and arbitrary nonlinear models.
2.3. Privacy and Communication Constraints
Both communication and local differential privacy constraints can be thought of as special cases of mutual information constraints. Motivated by this observation, Theorem 4 immediately implies corollaries for these types of systems:
Corollary 1
(Privacy Constraints). Suppose each node’s algorithm is an ε-local, differentially private mechanism in the sense that for each . Then, for losses ℓ of the form in Theorem 4, and under Assumption 2, we have
Proof.
Note that
Similarly, it is true that
where the last inequality is only true for . Putting these two displays together gives , and the result follows from Theorem 4. □
Corollary 2
(Communication Constraints). Suppose each node can only transit B bits of information to the model aggregator, meaning that each can only take distinct possible values. Then, for losses ℓ of the form in Theorem 4, and under Assumption 2, this yields
Proof.
The corollary follows immediately from Theorem 4 and
□
3. Iterative Algorithms
We now turn to considering more complicated multi-round and iterative algorithms. In this setting, after T rounds, there is a sequence of weights , and the final model is a function of that sequence, where gives a linear combination of the T vectors . The function could represent, for example, averaging over the T iterates, choosing the last iterate or some weighted average over the iterates. For each round t, each node k produces an updated model based on its local dataset and the previous timestep’s global model . The global model is then updated via an average over all K updated submodels:
The particular example that we will consider is that of a distributed SGD, where each node constructs its updated model by taking one or more gradient steps starting from with respect to random minibatches of its local data. Our model is general enough to account for multiple local gradient steps, as are used in so-called federated learning [5,6,7], as well as noisy versions of SGDs, such as in [20,21]. If only one local gradient step is taken for each iteration, then the update rule for this example could be written as
where is a data point (or minibatch) sampled from on timestep t, is the learning rate, and is some potential added noise. We assume that the data points are sampled without replacement so that the samples are distinct across different values of t. We will also assume, for notational simplicity, that , although the more general result follows in a straightforward manner.
For this type of iterative algorithm, we will consider the following timestep-averaged empirical risk quantity:
and the corresponding generalization error, expressed as
Note that Equation (12) is slightly different from the end-to-end generalization error that we would get from considering the final model and whole dataset S. It is instead an average over the generalization error we would get from each model, stopping at iteration t. We perform this so that when we apply the leave-one-out expansion from Theorem 1, we do not have to account for the dependence of on past samples for and . Since we expect the generalization error to decrease as we use more samples, this quantity should result in a more conservative upper bound and be a reasonable surrogate object to study. The next bound follows as a corollary to Theorem 4:
Corollary 3.
For losses ℓ of the form in Theorem 4, and under Assumption 2 (for each ), we have
In the particular example described in Equation (11), where Gaussian noise is added to each iterate, Corollary 3 yields the following. As in [20], we assume that the updates are magnitude-bounded (i.e., ), the stepsizes satisfy for a constant , and that :
Corollary 4.
Under the assumptions above, we have
Proof.
The mutual information terms in Corollary 3 satisfy
Equation (13) follows from the data-processing inequality, Equation (14) is the chain rule for mutual information, and Equation (15) follows from the independence of and . Equation (16) is due to the capacity of the additive white Gaussian noise channel, and Equation (17) just uses the approximation . Thus, we have
□
4. Simulations
We simulated a distributed linear regression example in order to demonstrate the improvement in our bounds over the existing information-theoretic bounds. To accomplish this, we generated synthetic datapoints at each of K different nodes for various values of K. Each datapoint consisted of a pair , where with ∼, and ∼ was the randomly generated true weight that was common to all datapoints. Each node constructed an estimate of using the well-known normal equations which minimize the quadratic loss (i.e., ). The aggregate model was then the average . In order to estimate the old and new information-theoretic generalization bounds (i.e., the bounds from Theorems 2 and 4, respectively), this procedure was repeated times, and the datapoint and model values were binned in order to estimate the mutual information quantities. The value of M was increased until the mutual information estimates were no longer particularly sensitive to the number and widths of the bins. In order to estimate the true generalization error, the expectations for both the population risk and the dataset were estimated by Monte Carlo experimentation, with trials each. The results can be seen in Figure 2, where it is evident that the new information theoretic bound is much closer to the true expected generalization error and decays with an improved rate as a function of K.
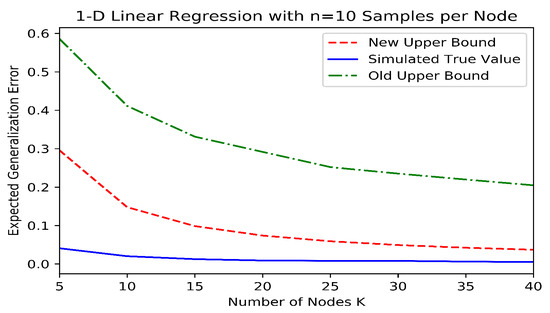
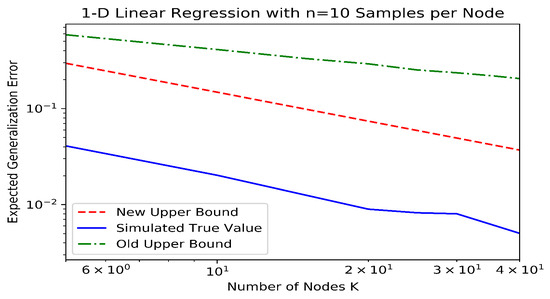
Figure 2.
Information-theoretic upper bounds and expected generalization error for a simulated linear regression example in linear (top) and log (bottom) scales.
Author Contributions
Conceptualization, L.P.B., A.D. and H.V.P.; Formal analysis, L.P.B., A.D. and H.V.P.; Investigation, L.P.B., A.D. and H.V.P.; Methodology, L.P.B., A.D. and H.V.P.; Supervision, H.V.P.; Writing—original draft, L.P.B.; Writing—review & editing, L.P.B., A.D. and H.V.P. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by National Science Foundation grant number CCF-1908308.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Russo, D.; Zou, J. How Much Does Your Data Exploration Overfit? Controlling Bias via Information Usage. IEEE Trans. Inf. Theory 2020, 66, 302–323. [Google Scholar] [CrossRef]
- Xu, A.; Raginsky, M. Information-Theoretic Analysis of Generalization Capability of Learning Algorithms. Adv. Neural Inf. Process. Syst. 2017, 30, 2521–2530. [Google Scholar]
- Bu, Y.; Zou, S.; Veeravalli, V.V. Tightening Mutual Information-Based Bounds on Generalization Error. IEEE J. Sel. Areas Inf. Theory 2020, 1, 121–130. [Google Scholar] [CrossRef]
- Aminian, G.; Bu, Y.; Wornell, G.W.; Rodrigues, M.R. Tighter Expected Generalization Error Bounds via Convexity of Information Measures. In Proceedings of the 2022 IEEE International Symposium on Information Theory (ISIT), Espoo, Finland, 26 June–1 July 2022. [Google Scholar]
- McMahan, H.B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-Efficient Learning of Deep Networks from Decentralized Data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 20–22 April 2017. [Google Scholar]
- Konecný, J.; McMahan, H.B.; Ramage, D.; Richtárik, P. Federated Optimization: Distributed Machine Learning for On-Device Intelligence. arXiv 2016, arXiv:1610.02527. [Google Scholar]
- Konečný, J.; McMahan, H.B.; Yu, F.X.; Richtarik, P.; Suresh, A.T.; Bacon, D. Federated Learning: Strategies for Improving Communication Efficiency. arXiv 2016, arXiv:1610.05492. [Google Scholar]
- Lin, Y.; Han, S.; Mao, H.; Wang, Y.; Dally, W.J. Deep Gradient Compression: Reducing the Communication Bandwidth for Distributed Training. In Proceedings of the 6th International Congress on Learning Representations (ICLR), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Barnes, L.P.; Inan, H.A.; Isik, B.; Ozgur, A. rTop-k: A Statistical Estimation Approach to Distributed SGD. IEEE J. Sel. Areas Inf. Theory 2020, 1, 897–907. [Google Scholar] [CrossRef]
- Warner, S.L. Randomized Response: A Survey Technique for Eliminating Evasive Answer Bias. J. Am. Stat. Assoc. 1965, 60, 63–69. [Google Scholar] [CrossRef] [PubMed]
- Dwork, C.; McSherry, F.; Nissim, K.; Smith, A. Calibrating Noise to Sensitivity in Private Data Analysis. In Theory of Cryptography Conference; Halevi, S., Rabin, T., Eds.; Springer: Berlin/Heidelberg, Geramny, 2006. [Google Scholar]
- Kasiviswanathan, S.P.; Lee, H.K.; Nissim, K.; Raskhodnikova, S.; Smith, A. What Can We Learn Privately? SIAM J. Comput. 2011, 40, 793–826. [Google Scholar] [CrossRef]
- Cuff, P.; Yu, L. Differential Privacy as a Mutual Information Constraint. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016; pp. 43–54. [Google Scholar]
- Yagli, S.; Dytso, A.; Poor, H.V. Information-Theoretic Bounds on the Generalization Error and Privacy Leakage in Federated Learning. In Proceedings of the 2020 IEEE 21st International Workshop on Signal Processing Advances in Wireless Communications (SPAWC), Atlanta, GA, USA, 26–29 May 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Barnes, L.P.; Dytso, A.; Poor, H.V. Improved Information Theoretic Generalization Bounds for Distributed and Federated Learning. arXiv 2022, arXiv:2202.02423. [Google Scholar]
- Shalev-Shwartz, S.; Shamir, O.; Srebro, N.; Sridharan, K. Learnability, Stability and Uniform Convergence. J. Mach. Learn. Res. 2010, 11, 2635–2670. [Google Scholar]
- Bregman, L.M. The Relaxation Method of Finding the Common Point of Convex Sets and Its Application to the Solution of Problems in Convex Programming. USSR Comput. Math. Math. Phys. 1967, 7, 200–217. [Google Scholar] [CrossRef]
- Dytso, A.; Fauß, M.; Poor, H.V. Bayesian Risk With Bregman Loss: A Cramér–Rao Type Bound and Linear Estimation. IEEE Trans. Inf. Theory 2022, 68, 1985–2000. [Google Scholar] [CrossRef]
- Banerjee, A.; Merugu, S.; Dhillon, I.S.; Ghosh, J.; Lafferty, J. Clustering with Bregman Divergences. J. Mach. Learn. Res. 2005, 6, 1705–1749. [Google Scholar]
- Pensia, A.; Jog, V.; Loh, P.L. Generalization Error Bounds for Noisy, Iterative Algorithms. In Proceedings of the 2018 IEEE International Symposium on Information Theory (ISIT), Vail, CO, USA, 17–22 June 2018; pp. 546–550. [Google Scholar]
- Wang, H.; Gao, R.; Calmon, F.P. Generalization Bounds for Noisy Iterative Algorithms Using Properties of Additive Noise Channels. arXiv 2021, arXiv:2102.02976. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).