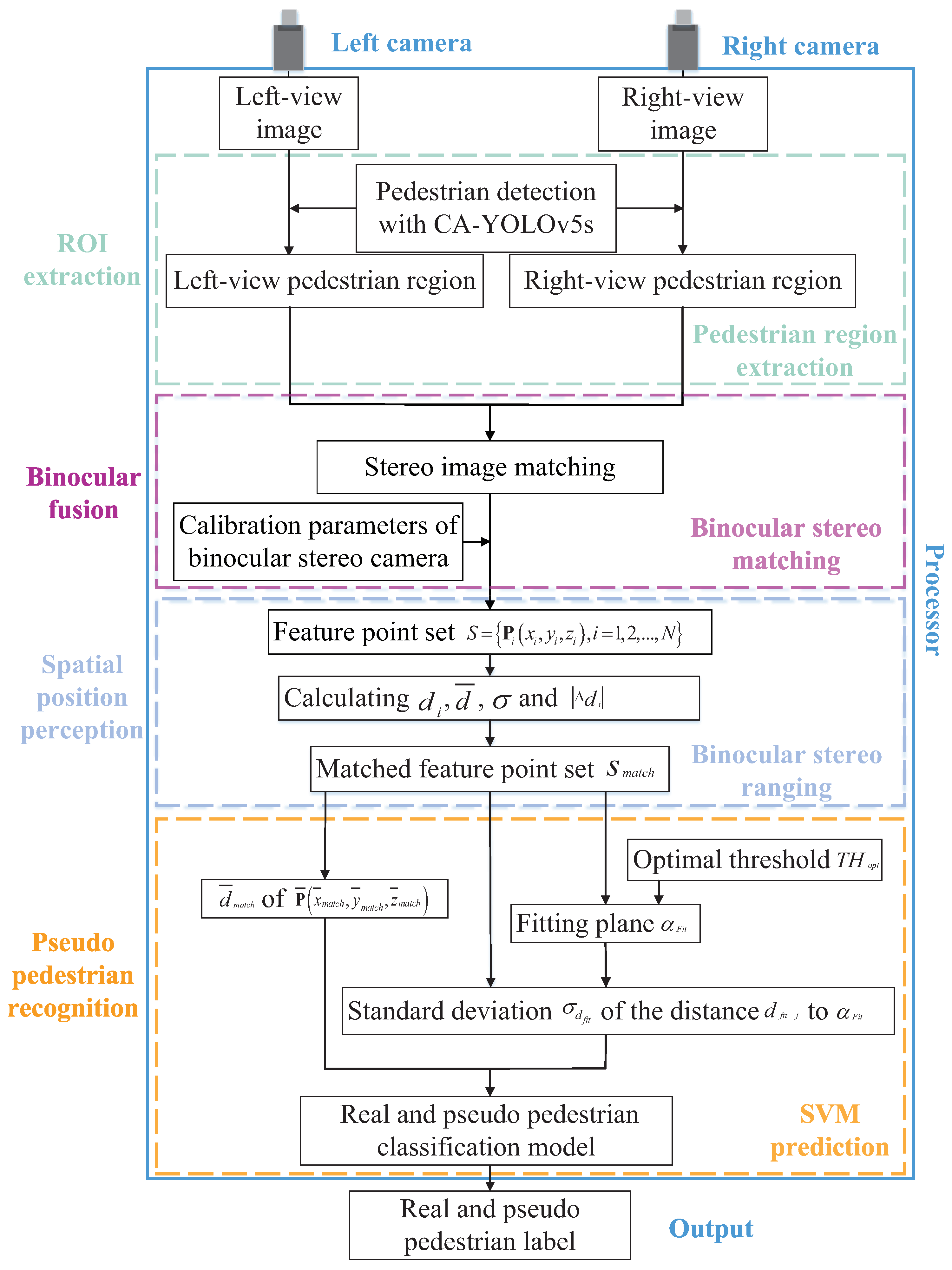
2.1. Principle of Human Stereo Vision
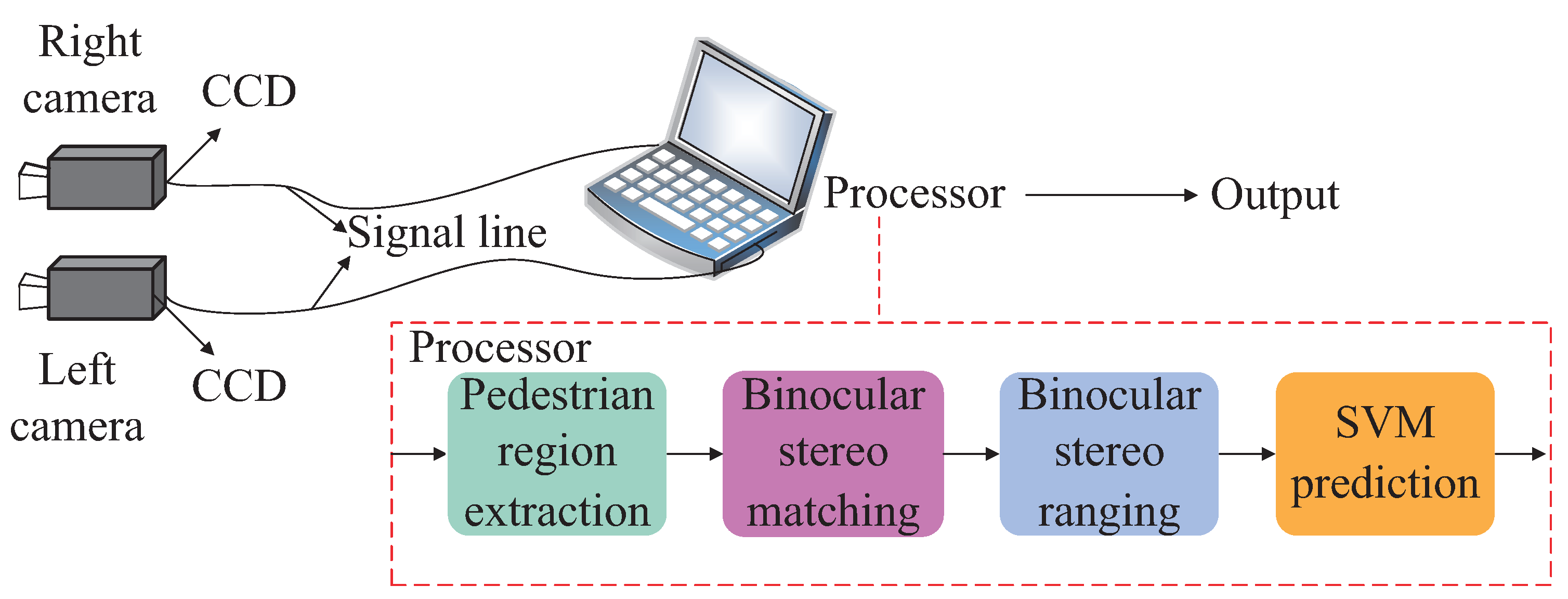
Human stereo vision can perfectly realize the real and pseudo pedestrian detection, so it is the biological theoretical basis of the proposed method in this paper. In human stereo vision system, as shown in
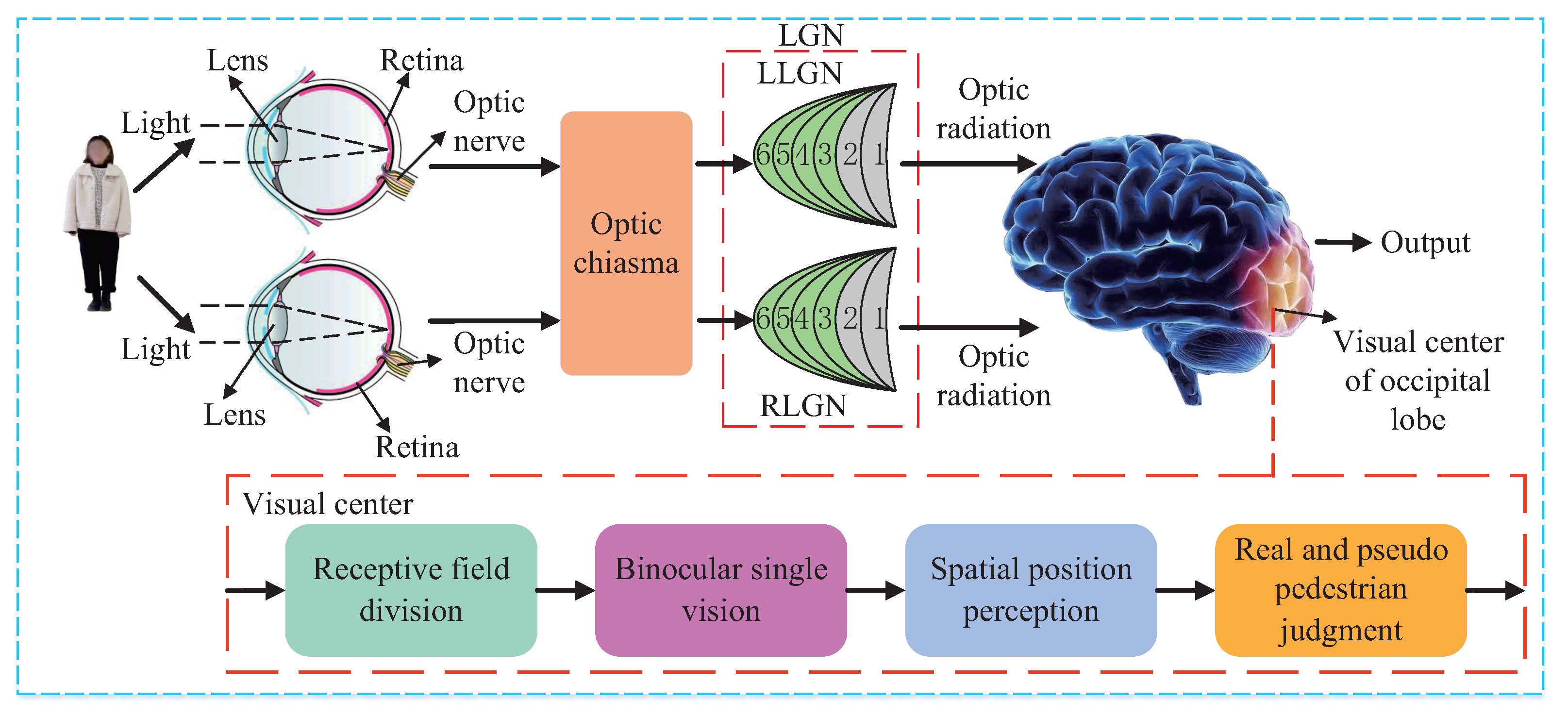
Figure 1, the 3D pedestrian is imaged on the retina through human optical components such as lens, and the photoreceptor cells on the retina convert optical signals into bioelectrical signals which are transmitted to the optic chiasma through the optic nerve. The optic chiasma rearranges the signals and transmits them to the lateral geniculate nucleus (LGN), and the processed signals are sent to the visual center of the occipital lobe through optic radiation. In the visual center of the occipital lobe, the region of interest is extracted by the receptive field division, the binocular single vision is formed through fusion, the stereo vision is achieved through spatial position perception, and the real and pseudo pedestrian judgment is made accordingly.
When viewing an object, the optic chiasma rearranges the signals from the right visual field of the left eye and the right visual field of the right eye and transmits them to the left LGN (LLGN), and rearranges the signals from the left visual field of the left eye and the left visual field of the right eye and transmits them to the right LGN (RLGN) [
26]. For LLGN, the light intensity
of the optical signal perceived at the right visual field of the left retina
from the right visual field of the left eye at time
t can be expressed by Equation (
1), while the light intensity
of the optical signal perceived at the right visual field of the right retina
from the right visual field of the right eye at time t can be expressed by Equation (
2). For RLGN, the light intensity
of the optical signal perceived at the left visual field of the left retina
from the left visual field of the left eye at time t can be expressed by Equation (
3), while the light intensity
of the optical signal perceived at the left visual field of the right retina
from the left visual field of the right eye at time t can be expressed by Equation (
4).
Wherein and are the coordinates of the corresponding imaging points in the right visual field of the left and right retina, respectively; and are the coordinates of the corresponding imaging points in the left visual field of the left and right retina respectively; and are the adjustable coefficients of the left and right eye respectively; and are the radiation power of light with wavelength received at and respectively; and are the radiation power of light with wavelength received at and , respectively; and are the spectral response functions of the left and right eye, respectively; and are the upper and lower wavelength limits of human eye perception.
The optical signal causes ion exchange in the Na
+-K
+ ion pumps in the photoreceptor cells of the retina, resulting in a change in the electric potential, which is voltage [
27]. Thus, the optical signals
and
at the right visual field of the left and right retina are converted into the bioelectrical signals
and
in the right visual field by photoelectric conversion (PEC), as expressed by Equations (
5) and (
6). The optical signals
and
at the right left field of the left and right retina are converted into the bioelectrical signals
and
in the left visual field by PEC, as expressed by Equations (
7) and (
8).
The bioelectrical signals
and
in the right visual field are transmitted to the optic chiasma (OC) through the optic nerve, where they are rearranged and sent to the LLGN. The bioelectrical signals received by the LLGN can be expressed by Equation (
9). The bioelectrical signals
and
in the left visual field are transmitted to the optic chiasma through the optic nerve, where they are rearranged and sent to the RLGN. The bioelectrical signals received by the RLGN can be expressed by Equation (
10).
The bioelectrical signals
in the LLGN are sent to the left brain through optic radiation (OR). The bioelectrical signals
received by the left brain can be expressed by Equation (
11), which represents the right visual field. The bioelectrical signals
in the RLGN are sent to the right brain through optic radiation. The bioelectrical signals
received by the right brain can be expressed by Equation (
12), which represent the left visual field.
In the visual center of the occipital lobe, the bioelectrical signals
and
are combined into a bioelectrical signal
representing the whole visual field, which can be expressed by Equation (
13).
Visual cortex cells only respond significantly to the bioelectrical signal
in their receptive field (RF), as expressed by Equation (
14).
The bioelectrical signal
has a hierarchical structure, in which different layers correspond to the different bioelectrical signals from the left and right eyes, respectively. The visual cortex of the brain fuses the layered bioelectrical signals
in the receptive field to form a single object image, that is, binocular single vision, then the spatial position perception is realized, as expressed by Equation (
15).
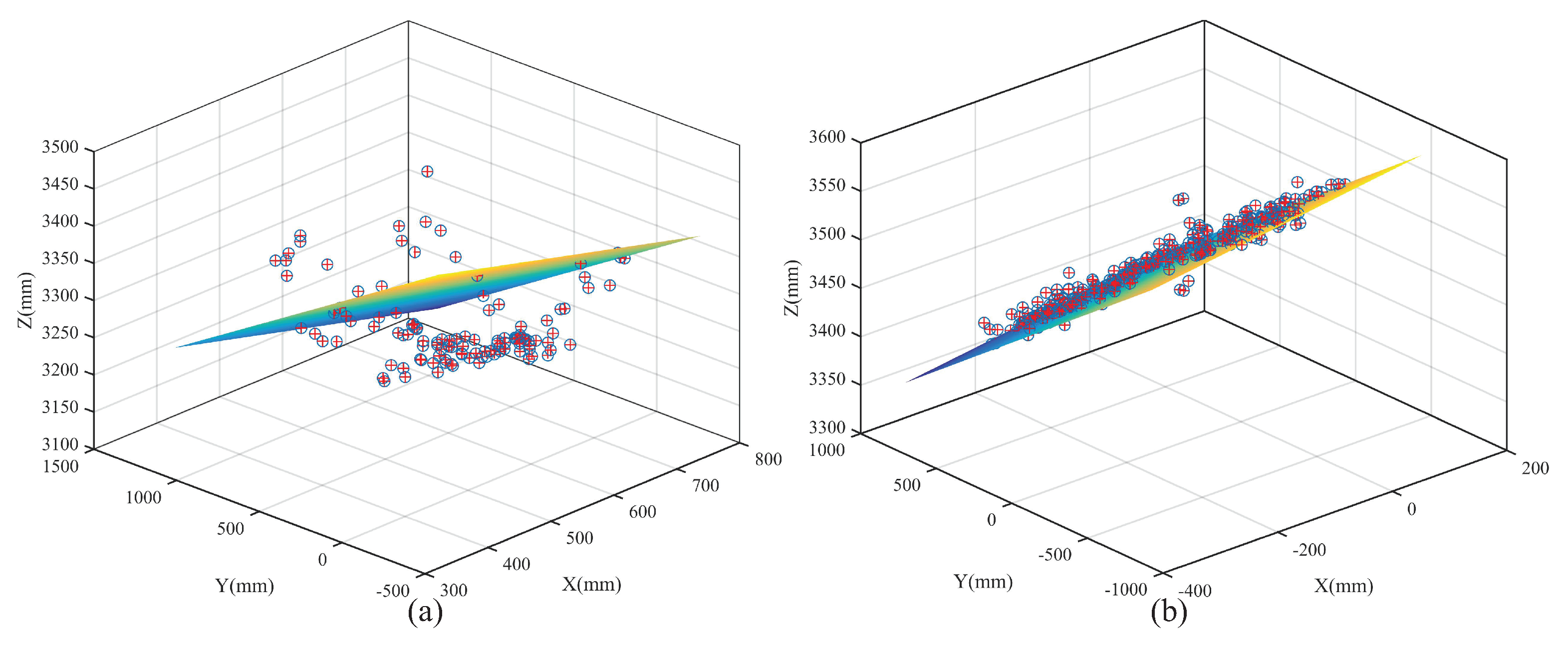
Finally, the real and pseudo pedestrian judgment is made by the brain according to the perceived stereo vision information
and the judgment result is output, as expressed by Equation (
16).
With the above process, the real and pseudo pedestrian judgment is completed by the human stereo vision system.
2.2. Attention Mechanism
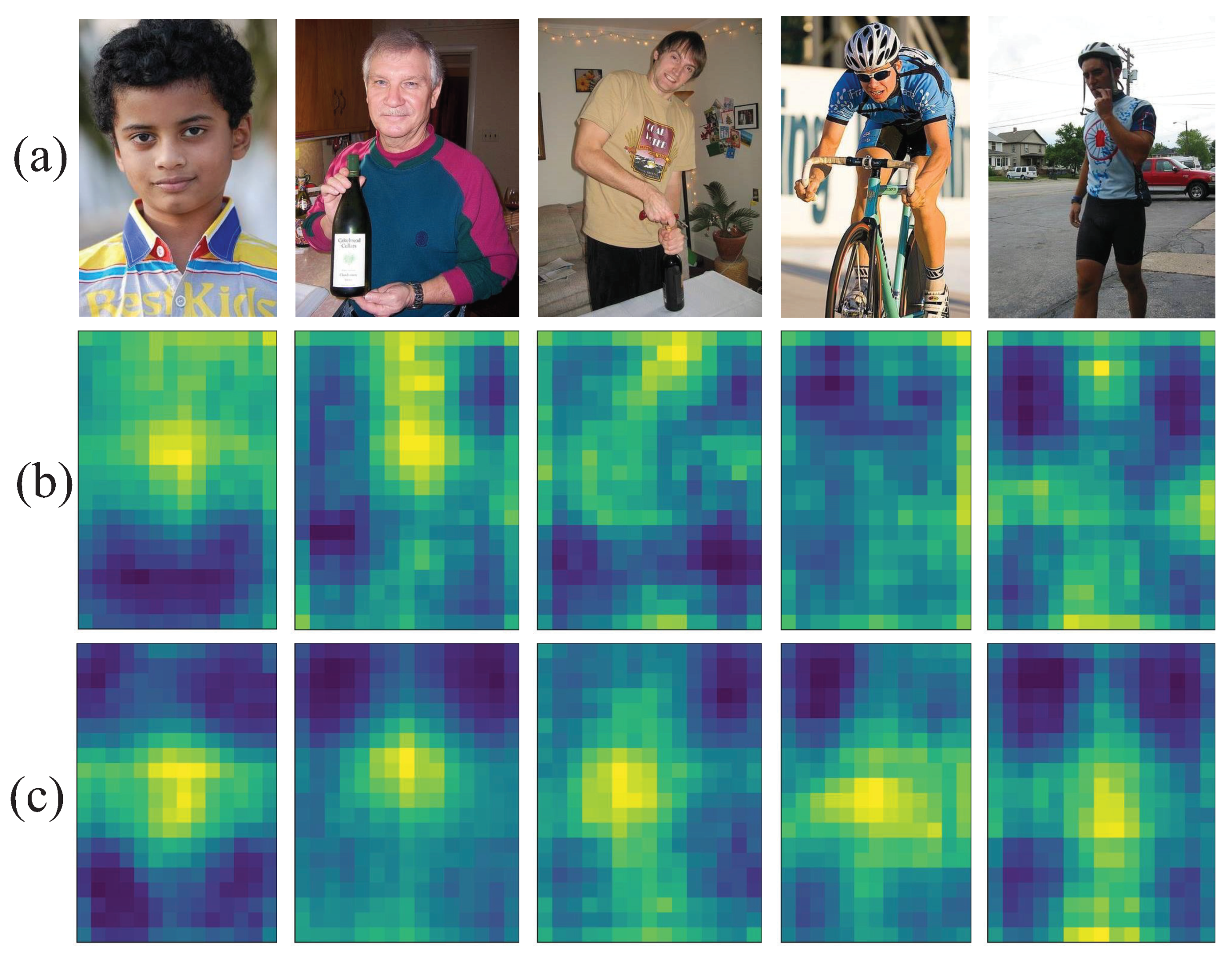
In the pedestrian detection network, more weight can be allocated to the pedestrian area and less weight to the background area through the focusing effect of the attention mechanism, so as to improve the accuracy of pedestrian detection and reduce the network model parameters.
According to its processing mechanism, the attention module can be divided into three types: spatial attention module, channel attention module and mixed attention module [
28,
29,
30,
31,
32]. The spatial attention module carries out average pooling and maximum pooling in the channel direction at the same time using the spatial weight matrix. The spatial attention matrix is obtained by convolution, and a 2D spatial attention map is generated by the activation function, thus the spatial position that needs to be focused on is determined. Moreover, the attention mechanism has also been used in multimodal image fusion [
33,
34,
35] to enhance the pedestrian detection, and has achieved promising results.
Typical channel attention module includes squeeze-and-excitation (SE) and efficient channel attention (ECA). SE samples the input image by global average pooling, learns the dependence to each channel by the shared multilayer perceptron (MLP), and generates the channel attention map by the activation function [
28]. ECA improves the shared MLP part of SE, focusing on the interaction of each channel and its k neighborhood channels, and greatly reduces the network parameters [
29]. The mixed attention module combines different kinds of attention. The convolutional block attention module (CBAM) and coordinate attention (CA) are the typical representatives. CBAM connects the channel attention module with the spatial attention module through convolution, and can obtain the spatial attention and channel attention joint optimized features [
30]. CA embeds the location information into the channel attention module, and decomposes the channel attention module into two 1D feature coding processes, aggregating features along two spatial directions. The network can quickly focus on the region of interest, and the performance of the pedestrian detection network can be effectively improved [
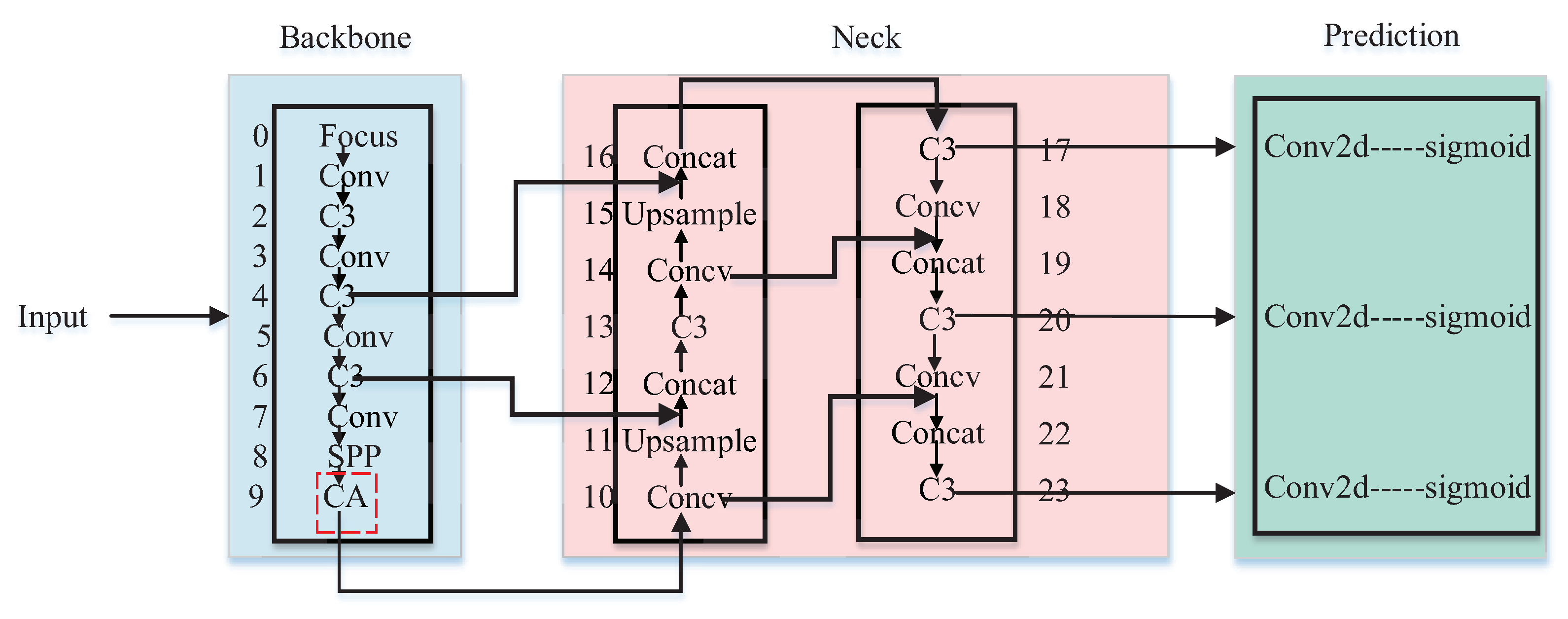
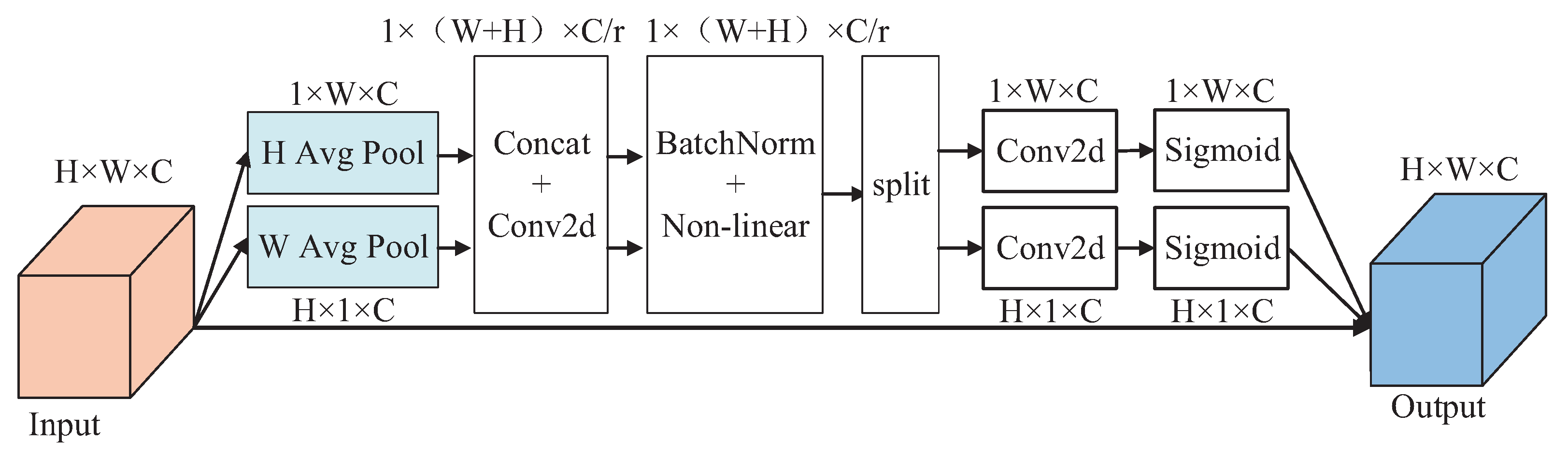
31].











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}