
Optimal Information Update for Energy Harvesting Sensor with Reliable Backup Energy




Abstract
:1. Introduction
1.1. Related Work
1.2. Main Contributions
- We consider an information update system where the harvested energy and reliable energy coexist. The goal is to find the optimal policy that achieves the best trade-off between age and reliable energy consumption. Compared to the existing works [23,25], our problem is more practical and general, which will provide some insights for future green and durable update system designs.
- For the case that all the statistics such as channel erasure probability and EH probability are known a priori, we formulate an unconstrained infinite space Markov decision process (MDP) problem, and prove the existence of the optimal policy. By revealing the monotonicity and proportional differential propertyof the value function, we find that the optimal policy is of the threshold-type. Based on this special structure, we propose an efficient algorithm to compute the optimal policy.
- In an unknown environment, we propose an average cost Q-learning algorithm to obtain the updating policy.
- Simulation results show that the optimal policy outperforms other baseline policies when the environmental statistics are known. At the same time, the performance of the policy learned in the unknown environment is very close to the theoretical optimal policy. We also compare the age-reliable energy trade-off curves of the optimal updating policies under different energy supply conditions, which reflects the rationality of mixed energy supplies. The optimal policy can also be particularized to a special case, where the sensor can only utilize the harvested energy and the battery is unit-sized, and its performance coincides with the existing results in [23,25].
1.3. Organization
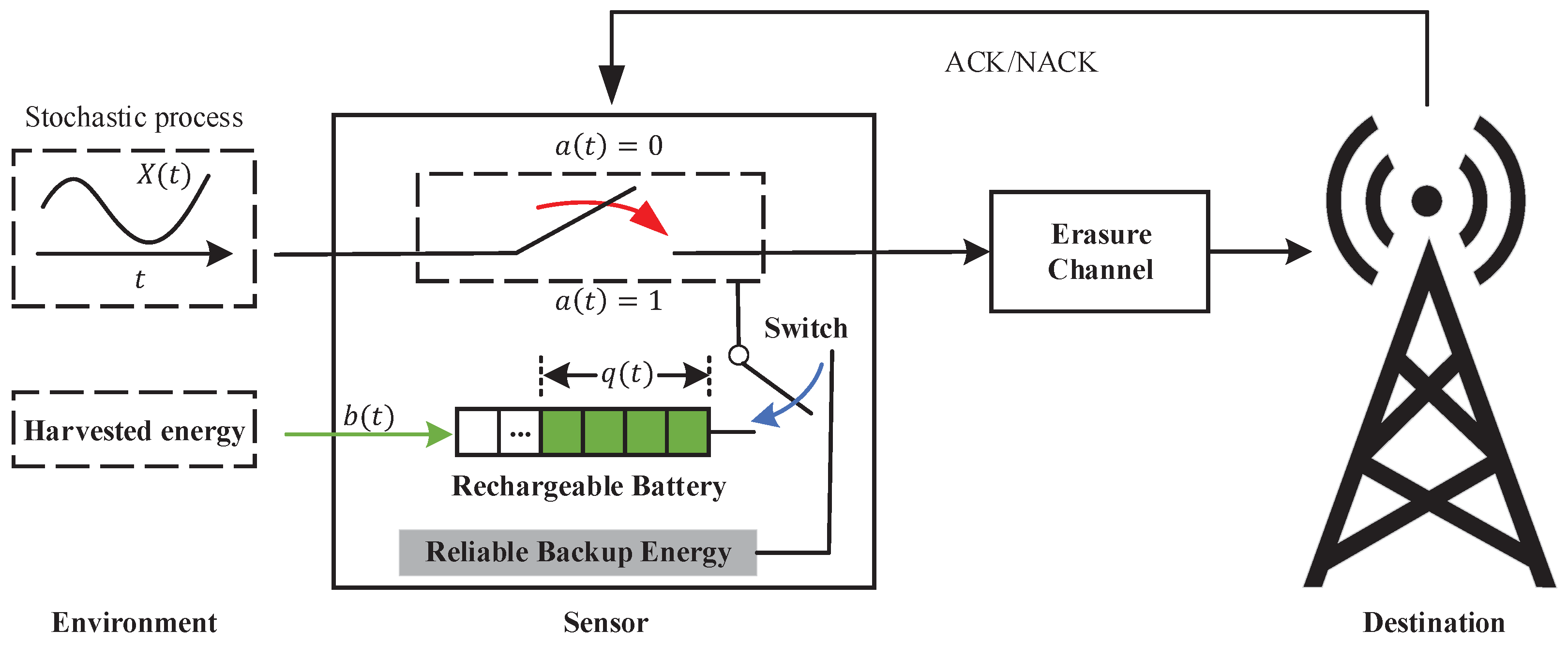
2. System Model and Problem Formulation
2.1. System Model
2.1.1. Age of Information
2.1.2. Description of Energy Supply
2.2. Problem Formulation
3. Optimal Policy Analysis in A Known Environment
3.1. Markov Decision Process Formulation
- State space. The sensor’s state in slot t is a couple of the current destination AoI and the battery state, i.e., . Define . The state space is thus infinite countable.
- Action space. The sensor’s action in time slot t takes value from the action set .
- Transition probabilities. Denote as the transition probability that current state transits to next state after taking action . Suppose the current state and action , then the transition probability is divided into two following cases conditioned on different values of action.Case 1. ,Case 2. ,
- One-step cost. For the current state , the one-step cost of taking action a is expressed by
3.2. The Existence of the Optimal Stationary Deterministic Policy
- (a)
- The optimal expected discounted cost satisfies the Bellman equation as follows:where the state–action value function is defined as
- (b)
- The policy π determined by the right hand side of (13) is γ-optimal, and .
- (c)
- can be solved by value iteration algorithm. Specifically, let be the cost-to-go function and for all state . For all , we have:where is obtained as follows:Then the equation holds for every state and γ.
- (a)
- value function is non-decreasing in Δ, i.e., for any and any battery state , we haveand
- (b)
- value function is non-increasing in q, i.e., for AoI and any battery state , we have
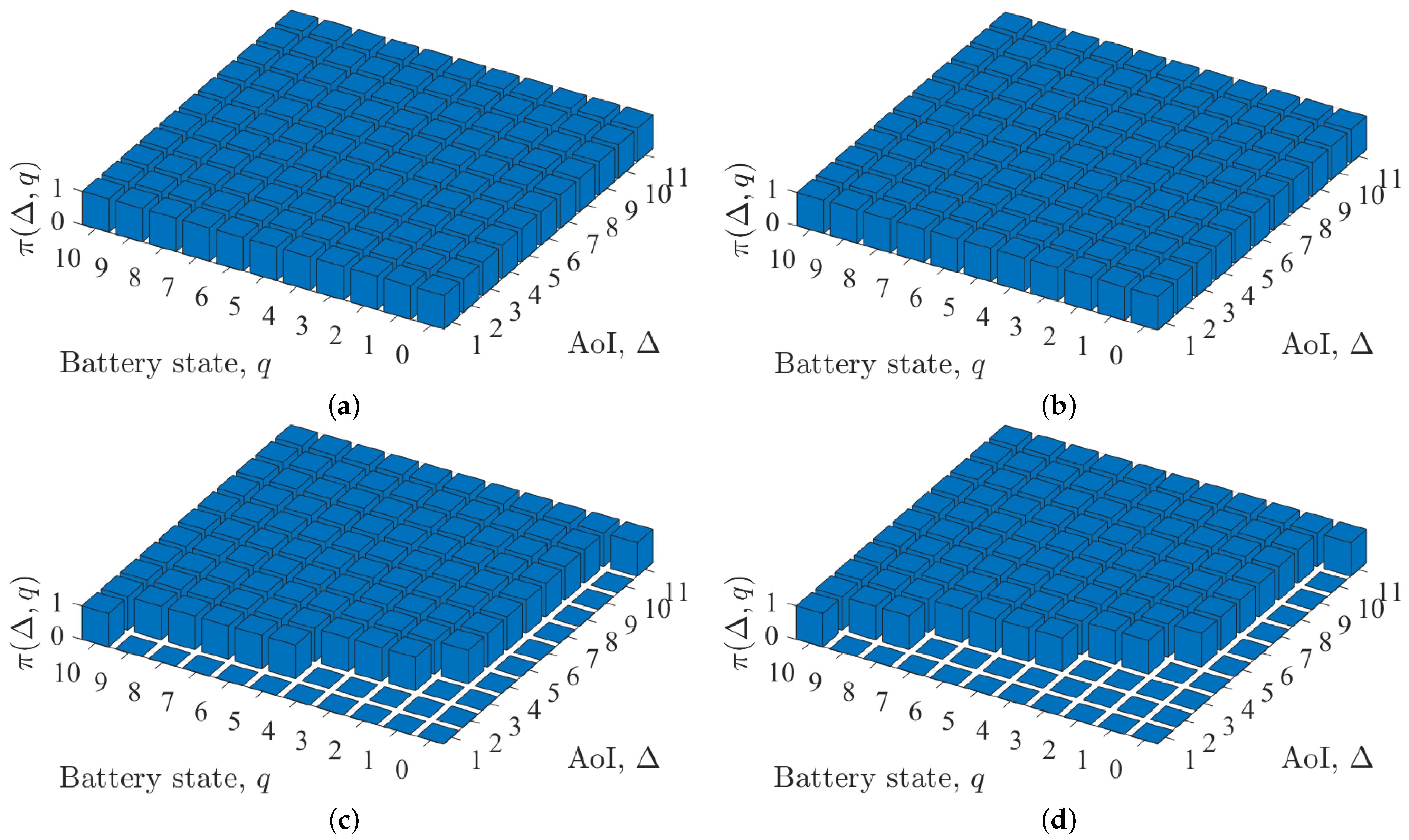
3.3. Structure Analysis of Optimal Policy
- (a)
- value function isnon-decreasingin Δ, i.e., for any and any battery state , we haveand
- (b)
- value function is non-increasing in q, i.e., for AoI and any battery state , we have
3.4. Modified Relative Value Iteration Algorithm Design
| Algorithm 1 Modified relative value iteration algorithm. |
| Input: |
| Iteration number K, |
| Iteration threshold , |
| Maximum of AoI N, |
| Maximum of battery state B, |
| Reference state . |
| Output: |
| Optimal policy for all state . |
| 1: Initialization: , for all |
| 2: for episodes do |
| 3: for state do |
| 4: for action do |
| 5: // Update the state-action value function. |
| 6: end for |
| 7: // Update the value function. |
| 8: // Update the differential value function. |
| 9: end for |
| 10: if then |
| 11: for do |
| 12: if then |
| 13: , // Leverage the threshold structure of the optimal policy. |
| 14: else |
| 15: |
| 16: end if |
| 17: end for |
| 18: break |
| 19: end if |
| 20: end for |
4. Minimize Average Cost in an Unknown Environment
| Algorithm 2 Average cost Q-learning algorithm. |
| Input: |
| Maximum number of episodes K, |
| Maximum iteration number of an episode , |
| Maximum of AoI N, |
| Maximum of battery state B, |
| Initial value of , |
| Initial value of , |
| Initial value of the shift value . |
| Output: |
| Learned policy for all state , |
| Average cost by following the policy . |
| 1: for episodes do |
| 2: // Initialize the shift value at the beginning of every episode. |
| 3: for do |
| 4: Observe the current state |
| 5: Select an action according to -greedy policy in (31) |
| 6: Calculate immediate cost |
| 7: Observe the next state |
| 8: |
| 9: // Update the state-action value function. |
| 10: |
| 11: // Update the shift value. |
| 12: end for |
| 13: Decrease |
| 14: end for |
| 15: fordo |
| 16: // Calculate the learned policy . |
| 17: end for |
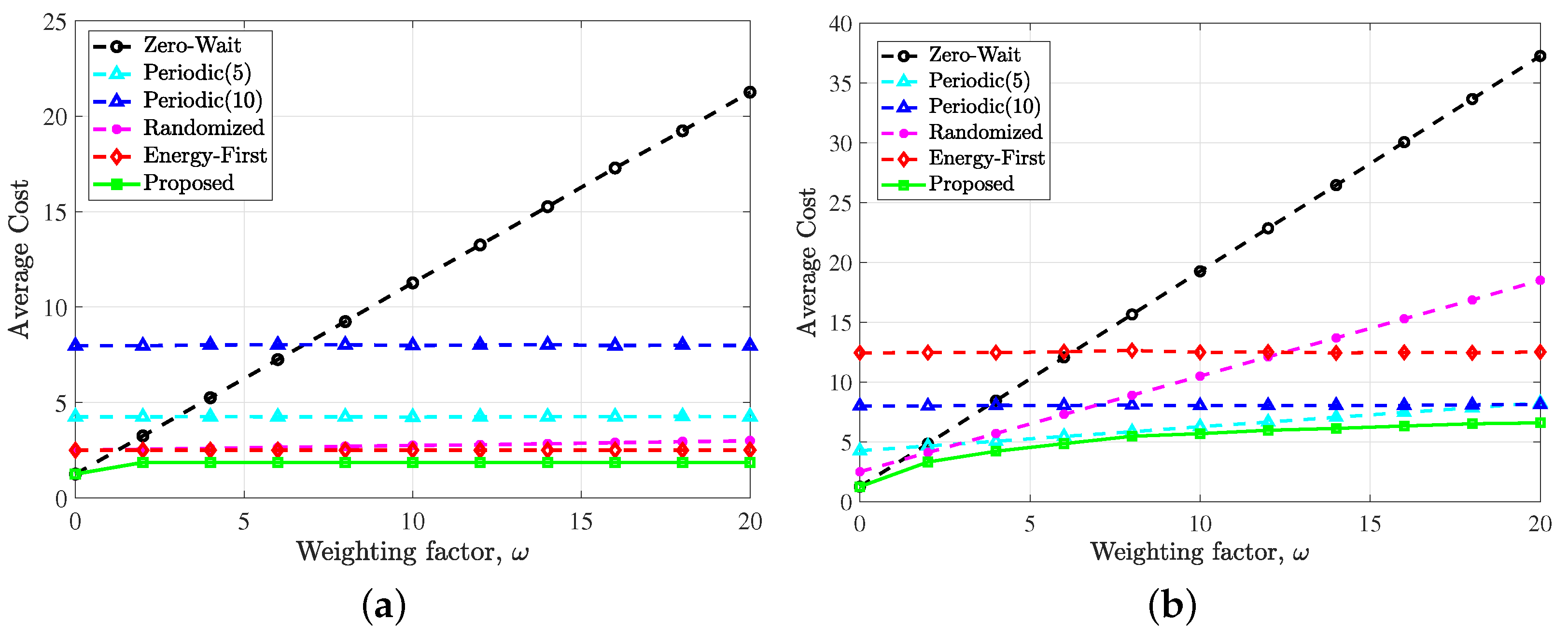
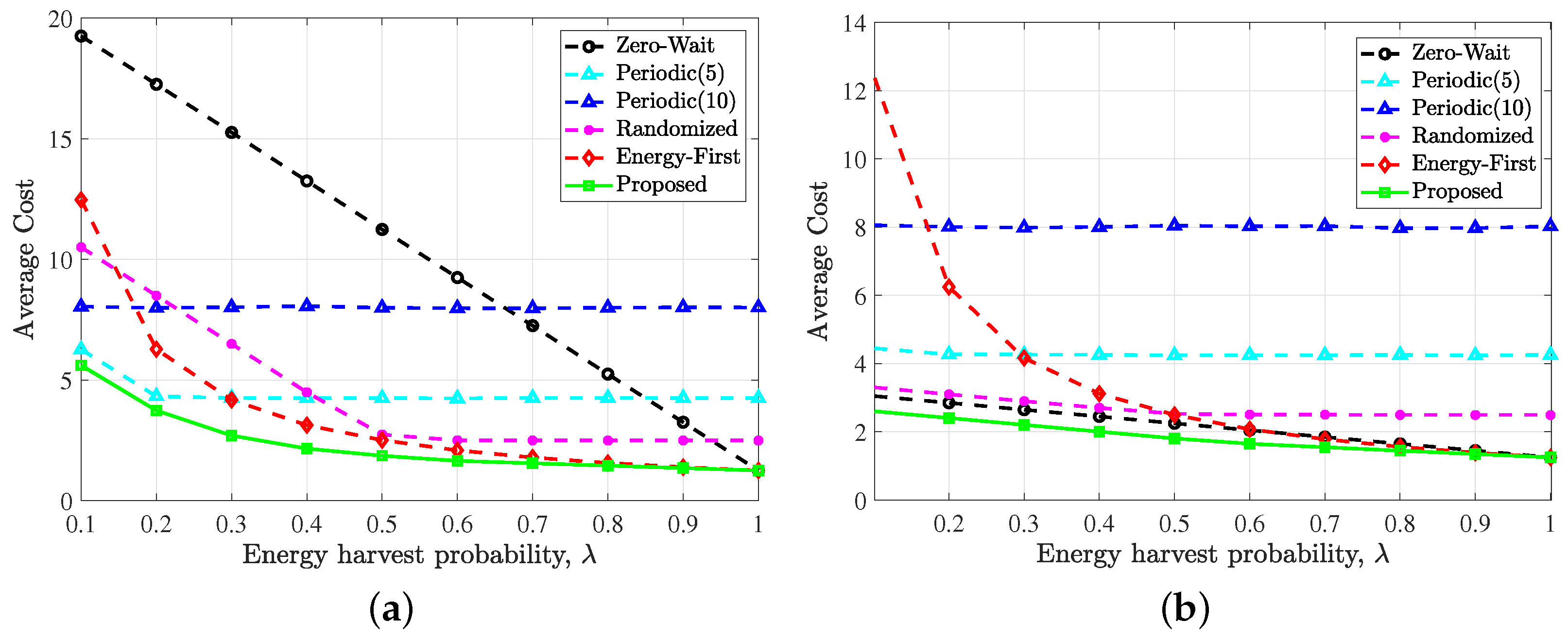
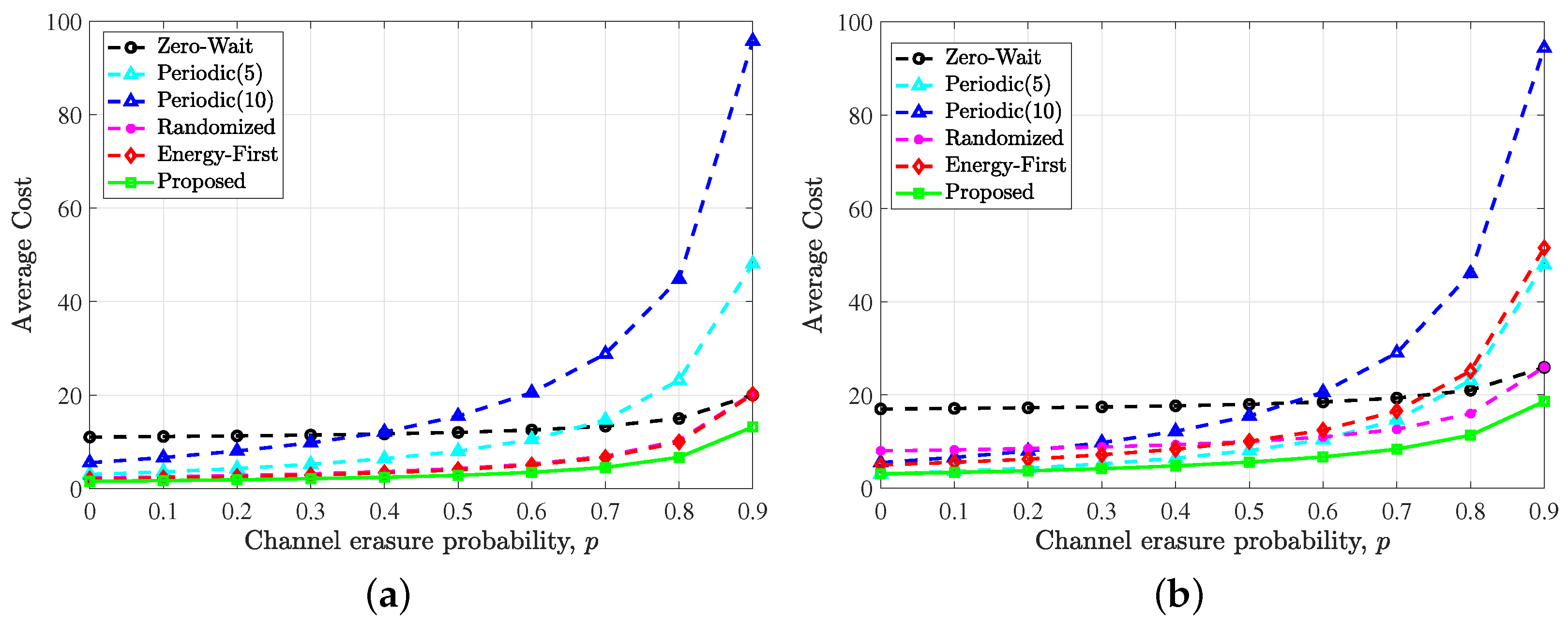
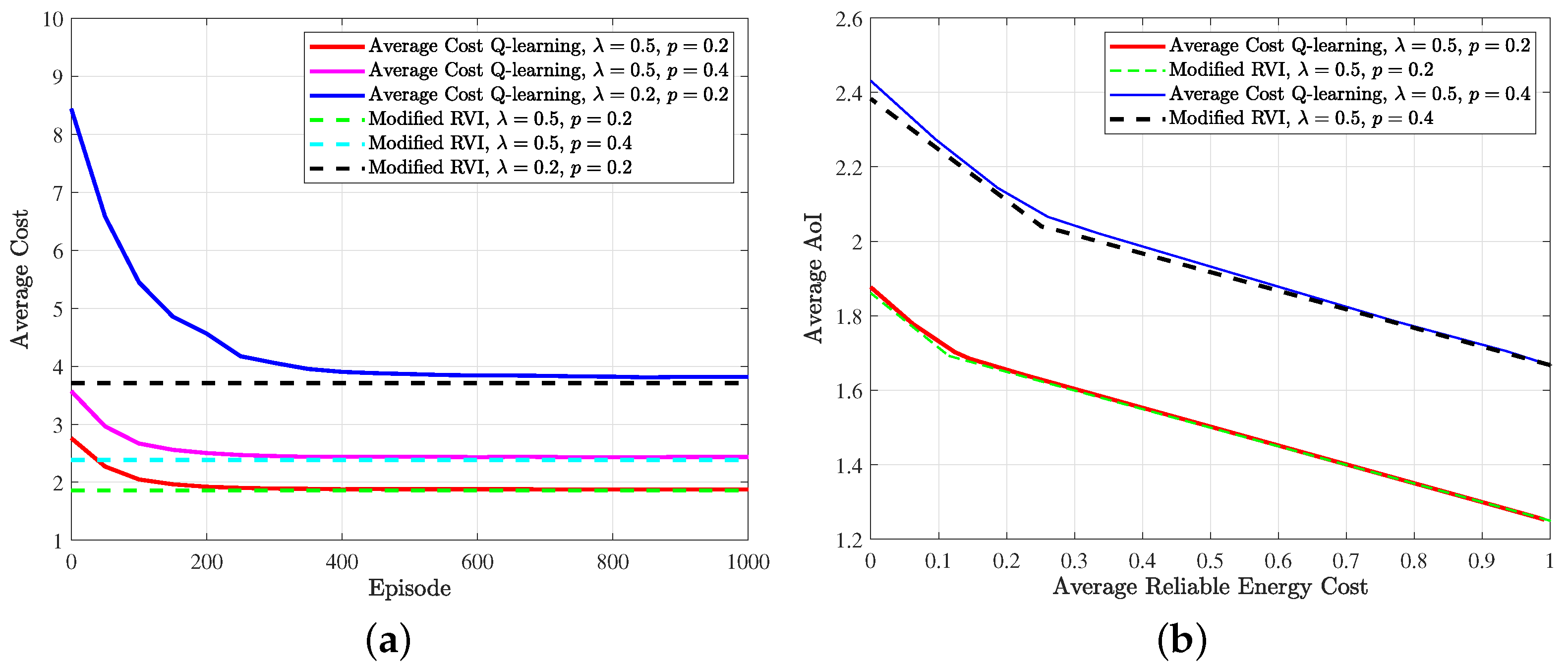
5. Numerical Results
- Zero-wait policy [4]. The sensor generates and transmits an update in every time slot.
- Periodic policy. The sensor periodically generates and sends updates to the destination.
- Randomized policy. The sensor chooses to send an update or stay idle in each time slot with the same probability.
- Energy first policy. The sensor only uses the harvested energy, that is, as long as the battery state is not zero, it will choose to sense and send updates, otherwise it will remain idle.
5.1. Simulation Setup
5.2. Results
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AoI | Age of Information |
| EH | Energy Harvesting |
| MDP | Markov Decision Process |
| RVI | Relative Value Iteration |
| SMART | Semi-Markov Average Reward Technique |
| SMDP | Semi-Markov Decision problems |
Appendix A. Proof of Proposition 1
Appendix B. Proof of Lemma 1
Appendix C. Proof of Theorem 1
- (1):
- For every state and discount factor , the discount value function is finite.
- (2):
- There exists a non-negative value L such that for all and , where , and is a reference state.
- (3):
- There exists a non-negative value , such that for every and .
- (4):
- The inequality holds for all and a.
Appendix D. Proof of Lemma 3
Appendix E. Proof of Theorem 2
Appendix F. Proof of Lemma A1

References
- Kaul, S.; Yates, R.; Gruteser, M. Real-time status: How often should one update? In Proceedings of the IEEE INFOCOM, Orlando, FL, USA, 25–30 March 2012; pp. 2731–2735. [Google Scholar]
- Sun, Y.; Kadota, I.; Talak, R.; Modiano, E. Age of information: A new metric for information freshness. Synth. Lect. Commun. Netw. 2019, 12, 1–224. [Google Scholar] [CrossRef]
- Yates, R.D.; Sun, Y.; Brown, D.R.; Kaul, S.K.; Modiano, E.; Ulukus, S. Age of information: An introduction and survey. IEEE J. Sel. Areas Commun. 2021, 39, 1183–1210. [Google Scholar] [CrossRef]
- Sun, Y.; Uysal-Biyikoglu, E.; Yates, R.D.; Koksal, C.E.; Shroff, N.B. Update or wait: How to keep your data fresh. IEEE Trans. Inf. Theory 2017, 63, 7492–7508. [Google Scholar] [CrossRef]
- Kadota, I.; Sinha, A.; Uysal-Biyikoglu, E.; Singh, R.; Modiano, E. Scheduling policies for minimizing age of information in broadcast wireless networks. IEEE/ACM Trans. Netw. 2018, 26, 2637–2650. [Google Scholar] [CrossRef] [Green Version]
- Hsu, Y.P.; Modiano, E.; Duan, L. Scheduling algorithms for minimizing age of information in wireless broadcast networks with random arrivals. IEEE Trans. Mob. Comput. 2019, 19, 2903–2915. [Google Scholar] [CrossRef]
- Tang, H.; Wang, J.; Song, L.; Song, J. Minimizing age of information with power constraints: Multi-user opportunistic scheduling in multi-state time-varying channels. IEEE J. Sel. Areas Commun. 2020, 38, 854–868. [Google Scholar] [CrossRef] [Green Version]
- Jackson, N.; Adkins, J.; Dutta, P. Capacity over capacitance for reliable energy harvesting sensors. In Proceedings of the 18th International Conference on Information Processing in Sensor Networks, Montreal, QC, Canada, 16–18 April 2019; pp. 193–204. [Google Scholar]
- Ma, D.; Lan, G.; Hassan, M.; Hu, W.; Das, S.K. Sensing, computing, and communications for energy harvesting IoTs: A survey. IEEE Commun. Surv. Tutorials 2019, 22, 1222–1250. [Google Scholar] [CrossRef]
- Sudevalayam, S.; Kulkarni, P. Energy harvesting sensor nodes: Survey and implications. IEEE Commun. Surv. Tutorials 2010, 13, 443–461. [Google Scholar] [CrossRef] [Green Version]
- TEXAS Instruments. BQ25505 Ultra Low-Power Boost Charger with Battery Management and Autonomous Power Multiplexer for Primary Battery in Energy Harvester Applications. BQ25505 Datasheet 2019, 3. Available online: https://www.ti.com/lit/ds/symlink/bq25505.pdf (accessed on 10 March 2019).
- Wu, X.; Tan, L.; Tang, S. Optimal Energy Supplementary and Data Transmission Schedule for Energy Harvesting Transmitter With Reliable Energy Backup. IEEE Access 2020, 8, 161838–161846. [Google Scholar] [CrossRef]
- Wu, J.; Chen, W. Delay-Optimal Scheduling for Energy Harvesting Aided mmWave Communications with Random Blocking. In Proceedings of the ICC 2020—2020 IEEE International Conference on Communications (ICC), Dublin, Ireland, 7–11 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–6. [Google Scholar]
- Draskovic, S.; Thiele, L. Optimal Power Management for Energy Harvesting Systems with A Backup Power Source. In Proceedings of the 2021 10th Mediterranean Conference on Embedded Computing (MECO), Budva, Montenegro, 7–10 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–9. [Google Scholar]
- Sennott, L.I. Average cost optimal stationary policies in infinite state Markov decision processes with unbounded costs. Oper. Res. 1989, 37, 626–633. [Google Scholar] [CrossRef]
- Yates, R.D. Lazy is timely: Status updates by an energy harvesting source. In Proceedings of the 2015 IEEE International Symposium on Information Theory (ISIT), Hong Kong, China, 14–19 June 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 3008–3012. [Google Scholar]
- Bacinoglu, B.T.; Ceran, E.T.; Uysal-Biyikoglu, E. Age of information under energy replenishment constraints. In Proceedings of the 2015 Information Theory and Applications Workshop (ITA), San Diego, CA, USA, 1–6 February 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 25–31. [Google Scholar]
- Arafa, A.; Ulukus, S. Age-minimal transmission in energy harvesting two-hop networks. In Proceedings of the GLOBECOM 2017—2017 IEEE Global Communications Conference, Singapore, 4–8 December 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–6. [Google Scholar]
- Arafa, A.; Ulukus, S. Timely updates in energy harvesting two-hop networks: Offline and online policies. IEEE Trans. Wirel. Commun. 2019, 18, 4017–4030. [Google Scholar] [CrossRef] [Green Version]
- Arafa, A.; Ulukus, S. Age minimization in energy harvesting communications: Energy-controlled delays. In Proceedings of the 2017 51st Asilomar Conference on Signals, Systems, and Computers, Pacific Grove, CA, USA, 29 October–1 November 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1801–1805. [Google Scholar]
- Wu, X.; Yang, J.; Wu, J. Optimal status update for age of information minimization with an energy harvesting source. IEEE Trans. Green Commun. Netw. 2017, 2, 193–204. [Google Scholar] [CrossRef]
- Arafa, A.; Yang, J.; Ulukus, S.; Poor, H.V. Age-minimal transmission for energy harvesting sensors with finite batteries: Online policies. IEEE Trans. Inf. Theory 2019, 66, 534–556. [Google Scholar] [CrossRef] [Green Version]
- Bacinoglu, B.T.; Sun, Y.; Uysal, E.; Mutlu, V. Optimal status updating with a finite-battery energy harvesting source. J. Commun. Netw. 2019, 21, 280–294. [Google Scholar] [CrossRef]
- Feng, S.; Yang, J. Age of information minimization for an energy harvesting source with updating erasures: Without and with feedback. IEEE Trans. Commun. 2021, 69, 5091–5105. [Google Scholar] [CrossRef]
- Arafa, A.; Yang, J.; Ulukus, S.; Poor, H.V. Timely Status Updating Over Erasure Channels Using an Energy Harvesting Sensor: Single and Multiple Sources. IEEE Trans. Green Commun. Netw. 2021, 6, 6–19. [Google Scholar] [CrossRef]
- Baknina, A.; Ulukus, S. Coded status updates in an energy harvesting erasure channel. In Proceedings of the 2018 52nd Annual Conference on Information Sciences and Systems (CISS), Princeton, NJ, USA, 21–23 March 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–6. [Google Scholar]
- Baknina, A.; Ozel, O.; Yang, J.; Ulukus, S.; Yener, A. Sending information through status updates. In Proceedings of the 2018 IEEE International Symposium on Information Theory (ISIT), Vail, CO, USA, 17–22 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 2271–2275. [Google Scholar]
- Ceran, E.T.; Gündüz, D.; György, A. Reinforcement learning to minimize age of information with an energy harvesting sensor with HARQ and sensing cost. In Proceedings of the IEEE INFOCOM 2019—IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Paris, France, 29 April–2 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 656–661. [Google Scholar]
- Hentati, A.; Frigon, J.F.; Ajib, W. Energy harvesting wireless sensor networks with channel estimation: Delay and packet loss performance analysis. IEEE Trans. Veh. Technol. 2019, 69, 1956–1969. [Google Scholar] [CrossRef]
- Leng, S.; Yener, A. Age of Information Minimization for an Energy Harvesting Cognitive Radio. IEEE Trans. Cogn. Commun. Netw. 2019, 5, 427–439. [Google Scholar] [CrossRef]
- Zheng, X.; Zhou, S.; Jiang, Z.; Niu, Z. Closed-form analysis of non-linear age of information in status updates with an energy harvesting transmitter. IEEE Trans. Wirel. Commun. 2019, 18, 4129–4142. [Google Scholar] [CrossRef] [Green Version]
- Lu, Y.; Xiong, K.; Fan, P.; Zhong, Z.; Letaief, K.B. Online transmission policy in wireless powered networks with urgency-aware age of information. In Proceedings of the 2019 15th International Wireless Communications & Mobile Computing Conference (IWCMC), Tangier, Morocco, 24–28 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1096–1101. [Google Scholar]
- Saurav, K.; Vaze, R. Online energy minimization under a peak age of information constraint. In Proceedings of the 2021 19th International Symposium on Modeling and Optimization in Mobile, Ad hoc, and Wireless Networks (WiOpt), Virtual, 18–21 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–8. [Google Scholar]
- Abd-Elmagid, M.A.; Dhillon, H.S. Closed-form characterization of the MGF of AoI in energy harvesting status update systems. IEEE Trans. Inf. Theory 2022, 68, 3896–3919. [Google Scholar] [CrossRef]
- Gong, J.; Chen, X.; Ma, X. Energy-age tradeoff in status update communication systems with retransmission. In Proceedings of the 2018 IEEE Global Communications Conference (GLOBECOM), Abu Dhabi, United Arab Emirates, 9–13 December 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–6. [Google Scholar]
- Huang, H.; Qiao, D.; Gursoy, M.C. Age-energy tradeoff in fading channels with packet-based transmissions. In Proceedings of the IEEE INFOCOM 2020—IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Toronto, ON, Canada, 6–9 July 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 323–328. [Google Scholar]
- Gu, Y.; Chen, H.; Zhou, Y.; Li, Y.; Vucetic, B. Timely status update in Internet of Things monitoring systems: An age-energy tradeoff. IEEE Internet Things J. 2019, 6, 5324–5335. [Google Scholar] [CrossRef]
- Nath, S.; Wu, J.; Yang, J. Optimum energy efficiency and age-of-information tradeoff in multicast scheduling. In Proceedings of the 2018 IEEE International Conference on Communications (ICC), Kansas City, MO, USA, 20–24 May 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–6. [Google Scholar]
- Gong, J.; Zhu, J.; Chen, X.; Ma, X. Sleep, Sense or Transmit: Energy-Age Tradeoff for Status Update with Two-Thresholds Optimal Policy. IEEE Trans. Wirel. Commun. 2021, 21, 1751–1765. [Google Scholar] [CrossRef]
- Wang, L.; Peng, F.; Chen, X.; Zhou, S. Optimal Update for Energy Harvesting Sensor with Reliable Backup Energy. arXiv 2022, arXiv:2201.01686. [Google Scholar]
- Valentini, R.; Levorato, M. Optimal aging-aware channel access control for wireless networks with energy harvesting. In Proceedings of the 2016 IEEE International Symposium on Information Theory (ISIT), Barcelona, Spain, 10–15 July 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 2754–2758. [Google Scholar]
- Dong, Y.; Fan, P.; Letaief, K.B. Energy harvesting powered sensing in IoT: Timeliness versus distortion. IEEE Internet Things J. 2020, 7, 10897–10911. [Google Scholar] [CrossRef]
- Gindullina, E.; Badia, L.; Gündüz, D. Age-of-information with information source diversity in an energy harvesting system. IEEE Trans. Green Commun. Netw. 2021, 5, 1529–1540. [Google Scholar] [CrossRef]
- Sennott, L.I. Constrained average cost Markov decision chains. Probab. Eng. Informational Sci. 1993, 7, 69–83. [Google Scholar] [CrossRef]
- Puterman, M.L. Markov Decision Processes: Discrete Stochastic Dynamic Programming; John Wiley & Sons: Hoboken, NJ, USA, 2014. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Das, T.K.; Gosavi, A.; Mahadevan, S.; Marchalleck, N. Solving semi-Markov decision problems using average reward reinforcement learning. Manag. Sci. 1999, 45, 560–574. [Google Scholar] [CrossRef] [Green Version]
- Ceran, E.T.; Gündüz, D.; György, A. Average age of information with hybrid ARQ under a resource constraint. IEEE Trans. Wirel. Commun. 2019, 18, 1900–1913. [Google Scholar] [CrossRef] [Green Version]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, L.; Peng, F.; Chen, X.; Zhou, S. Optimal Information Update for Energy Harvesting Sensor with Reliable Backup Energy. Entropy 2022, 24, 961. https://doi.org/10.3390/e24070961
Wang L, Peng F, Chen X, Zhou S. Optimal Information Update for Energy Harvesting Sensor with Reliable Backup Energy. Entropy. 2022; 24(7):961. https://doi.org/10.3390/e24070961
Chicago/Turabian StyleWang, Lixin, Fuzhou Peng, Xiang Chen, and Shidong Zhou. 2022. "Optimal Information Update for Energy Harvesting Sensor with Reliable Backup Energy" Entropy 24, no. 7: 961. https://doi.org/10.3390/e24070961
APA StyleWang, L., Peng, F., Chen, X., & Zhou, S. (2022). Optimal Information Update for Energy Harvesting Sensor with Reliable Backup Energy. Entropy, 24(7), 961. https://doi.org/10.3390/e24070961