
A Generic Formula and Some Special Cases for the Kullback–Leibler Divergence between Central Multivariate Cauchy Distributions



Abstract
:1. Introduction
2. Multivariate Cauchy Distribution and Kullback–Leibler Divergence
3. Definitions and Propositions
3.1. Integral Representation for
3.2. Multiple Power Series
3.3. Integral Representation for
4. Expression of
5. Expression of
5.1. First Step: Eigenvalue Expression
5.2. Second Step: Polar Decomposition
5.3. Third Step: Expression for H(t,y) by Humbert and Beta Functions
5.4. Final Step
6. KLD between Two Central MCDs

{kind=link}
7. Particular Cases: Univariate and Bivariate Cauchy Distribution
7.1. Case of
7.2. Case of
- or
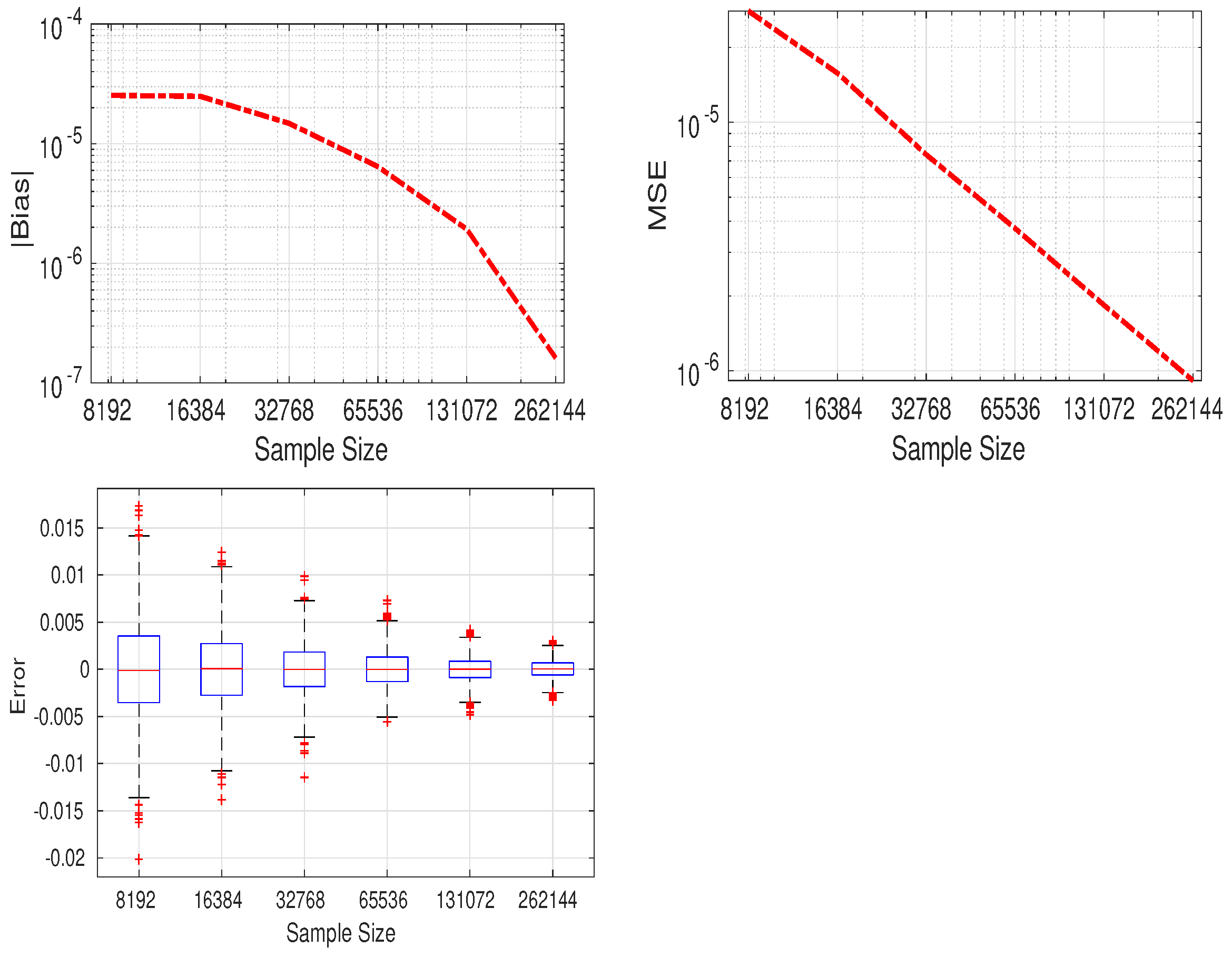
8. Implementation and Comparison with Monte Carlo Technique
8.1. Case
8.2. Case
8.3. Case and

9. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
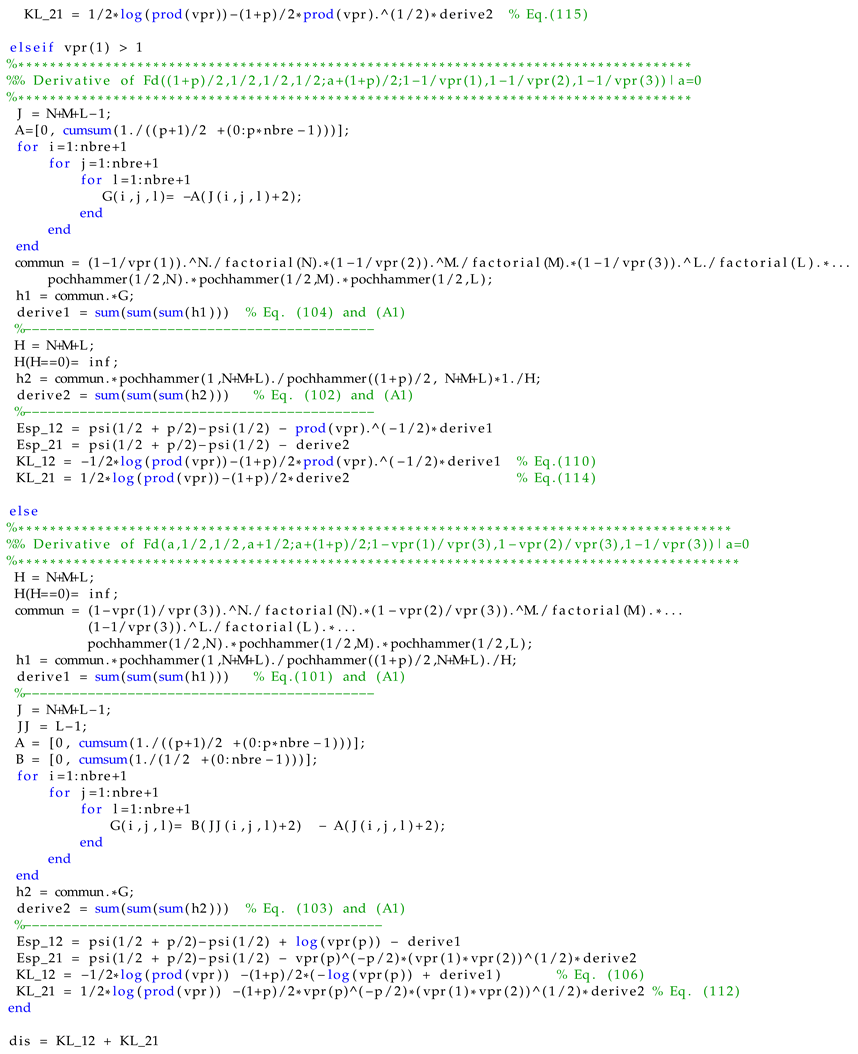
Appendix A. Lauricella Function
Appendix B. Demonstration of Derivative
Appendix B.1. Demonstration
Appendix B.2. Demonstration
Appendix B.3. Demonstration
Appendix B.4. Demonstration
Appendix C. Computations of Some Equations
Appendix C.1. Computation
Appendix C.2. Computation
Appendix C.3. Computation
References
- Ollila, E.; Tyler, D.E.; Koivunen, V.; Poor, H.V. Complex Elliptically Symmetric Distributions: Survey, New Results and Applications. IEEE Trans. Signal Process. 2012, 60, 5597–5625. [Google Scholar] [CrossRef]
- Kotz, S.; Nadarajah, S. Multivariate T-Distributions and Their Applications; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar] [CrossRef]
- Press, S. Multivariate stable distributions. J. Multivar. Anal. 1972, 2, 444–462. [Google Scholar] [CrossRef] [Green Version]
- Sahu, S.; Singh, H.V.; Kumar, B.; Singh, A.K. Statistical modeling and Gaussianization procedure based de-speckling algorithm for retinal OCT images. J. Ambient. Intell. Humaniz. Comput. 2018, 1–14. [Google Scholar] [CrossRef]
- Ranjani, J.J.; Thiruvengadam, S.J. Generalized SAR Despeckling Based on DTCWT Exploiting Interscale and Intrascale Dependences. IEEE Geosci. Remote Sens. Lett. 2011, 8, 552–556. [Google Scholar] [CrossRef]
- Sadreazami, H.; Ahmad, M.O.; Swamy, M.N.S. Color image denoising using multivariate cauchy PDF in the contourlet domain. In Proceedings of the 2016 IEEE Canadian Conference on Electrical and Computer Engineering (CCECE), Vancouver, BC, Canada, 15–18 May 2016; pp. 1–4. [Google Scholar] [CrossRef]
- Sadreazami, H.; Ahmad, M.O.; Swamy, M.N.S. A Study of Multiplicative Watermark Detection in the Contourlet Domain Using Alpha-Stable Distributions. IEEE Trans. Image Process. 2014, 23, 4348–4360. [Google Scholar] [CrossRef]
- Fontaine, M.; Nugraha, A.A.; Badeau, R.; Yoshii, K.; Liutkus, A. Cauchy Multichannel Speech Enhancement with a Deep Speech Prior. In Proceedings of the 2019 27th European Signal Processing Conference (EUSIPCO), A Coruna, Spain, 2–6 September 2019; pp. 1–5. [Google Scholar]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory (Wiley Series in Telecommunications and Signal Processing); Wiley-Interscience: Hoboken, NJ, USA, 2006. [Google Scholar] [CrossRef]
- Pardo, L. Statistical Inference Based on Divergence Measures; CRC Press: Abingdon, UK, 2005. [Google Scholar]
- Kullback, S.; Leibler, R.A. On Information and Sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Kullback, S. Information Theory and Statistics; Wiley: New York, NY, USA, 1959. [Google Scholar]
- Rényi, A. On Measures of Entropy and Information. In Proceedings of the Fourth Berkeley Symposium on Mathematical Statistics and Probability; University of California Press: Berkeley, CA, USA, 1961; Volume 1, pp. 547–561. [Google Scholar]
- Sharma, B.D.; Mittal, D.P. New non-additive measures of relative information. J. Comb. Inf. Syst. Sci. 1977, 2, 122–132. [Google Scholar]
- Bhattacharyya, A. On a measure of divergence between two statistical populations defined by their probability distributions. Bull. Calcutta Math. Soc. 1943, 35, 99–109. [Google Scholar]
- Kailath, T. The Divergence and Bhattacharyya Distance Measures in Signal Selection. IEEE Trans. Commun. Technol. 1967, 15, 52–60. [Google Scholar] [CrossRef]
- Giet, L.; Lubrano, M. A minimum Hellinger distance estimator for stochastic differential equations: An application to statistical inference for continuous time interest rate models. Comput. Stat. Data Anal. 2008, 52, 2945–2965. [Google Scholar] [CrossRef]
- Csiszár, I. Eine informationstheoretische Ungleichung und ihre Anwendung auf den Beweis der Ergodizität von Markoffschen Ketten. Publ. Math. Inst. Hung. Acad. Sci. Ser. A 1963, 8, 85–108. [Google Scholar]
- Ali, S.M.; Silvey, S.D. A General Class of Coefficients of Divergence of One Distribution from Another. J. R. Stat. Soc. Ser. B (Methodol.) 1966, 28, 131–142. [Google Scholar] [CrossRef]
- Bregman, L. The relaxation method of finding the common point of convex sets and its application to the solution of problems in convex programming. USSR Comput. Math. Math. Phys. 1967, 7, 200–217. [Google Scholar] [CrossRef]
- Burbea, J.; Rao, C. On the convexity of some divergence measures based on entropy functions. IEEE Trans. Inf. Theory 1982, 28, 489–495. [Google Scholar] [CrossRef]
- Burbea, J.; Rao, C. On the convexity of higher order Jensen differences based on entropy functions (Corresp.). IEEE Trans. Inf. Theory 1982, 28, 961–963. [Google Scholar] [CrossRef]
- Burbea, J.; Rao, C. Entropy differential metric, distance and divergence measures in probability spaces: A unified approach. J. Multivar. Anal. 1982, 12, 575–596. [Google Scholar] [CrossRef] [Green Version]
- Csiszar, I. Information-type measures of difference of probability distributions and indirect observation. Stud. Sci. Math. Hung. 1967, 2, 229–318. [Google Scholar]
- Nielsen, F.; Nock, R. On the chi square and higher-order chi distances for approximating f-divergences. IEEE Signal Process. Lett. 2014, 21, 10–13. [Google Scholar] [CrossRef] [Green Version]
- Menéndez, M.L.; Morales, D.; Pardo, L.; Salicrú, M. Asymptotic behaviour and statistical applications of divergence measures in multinomial populations: A unified study. Stat. Pap. 1995, 36, 1–29. [Google Scholar] [CrossRef]
- Cover, T.M.; Thomas, J.A. Information theory and statistics. Elem. Inf. Theory 1991, 1, 279–335. [Google Scholar]
- MacKay, D.J.C. Information Theory, Inference and Learning Algorithms; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Ruiz, F.E.; Pérez, P.S.; Bonev, B.I. Information Theory in Computer Vision and Pattern Recognition; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Nielsen, F. Statistical Divergences between Densities of Truncated Exponential Families with Nested Supports: Duo Bregman and Duo Jensen Divergences. Entropy 2022, 24, 421. [Google Scholar] [CrossRef] [PubMed]
- Chyzak, F.; Nielsen, F. A closed-form formula for the Kullback–Leibler divergence between Cauchy distributions. arXiv 2019, arXiv:1905.10965. [Google Scholar]
- Nielsen, F.; Okamura, K. On f-divergences between Cauchy distributions. arXiv 2021, arXiv:2101.12459. [Google Scholar]
- Srivastava, H.; Karlsson, P.W. Multiple Gaussian Hypergeometric Series; Ellis Horwood Series in Mathematics and Its Applications Statistics and Operational Research, E; Horwood Halsted Press: Chichester, UK; West Sussex, UK; New York, NY, USA, 1985. [Google Scholar]
- Mathai, A.M.; Haubold, H.J. Special Functions for Applied Scientists; Springer Science+Business Media: New York, NY, USA, 2008. [Google Scholar]
- Gradshteyn, I.; Ryzhik, I. Table of Integrals, Series, and Products, 7th ed.; Academic Press is an Imprint of Elsevier: Cambridge, MA, USA, 2007. [Google Scholar]
- Humbert, P. The Confluent Hypergeometric Functions of Two Variables. Proc. R. Soc. Edinb. 1922, 41, 73–96. [Google Scholar] [CrossRef] [Green Version]
- Erdélyi, A. Higher Transcendental Functions; McGraw-Hill: New York, NY, USA, 1953; Volume I. [Google Scholar]
- Koepf, W. Hypergeometric Summation an Algorithmic Approach to Summation and Special Function Identities, 2nd ed.; Universitext, Springer: London, UK, 2014. [Google Scholar]
- Lauricella, G. Sulle funzioni ipergeometriche a piu variabili. Rend. Del Circ. Mat. Palermo 1893, 7, 111–158. [Google Scholar] [CrossRef]
- Mathai, A.M. Jacobians of Matrix Transformations and Functions of Matrix Argument; World Scientific: Singapore, 1997. [Google Scholar]
- Anderson, T.W. An Introduction to Multivariate Statistical Analysis; John Wiley & Sons: Hoboken, NJ, USA, 2003. [Google Scholar]
- Hattori, A.; Kimura, T. On the Euler integral representations of hypergeometric functions in several variables. J. Math. Soc. Jpn. 1974, 26, 1–16. [Google Scholar] [CrossRef]
- Exton, H. Multiple Hypergeometric Functions and Applications; Wiley: New York, NY, USA, 1976. [Google Scholar]
| 0.1 | 0.0694 | 0.0694 | 9.1309 | 0.0694 | 9.1309 | 0.0694 | 9.1309 |
| 0.3 | 0.2291 | 0.2291 | 3.7747 | 0.2291 | 1.1102 | 0.2291 | 1.1102 |
| 0.5 | 0.4292 | 0.4292 | 2.6707 | 0.4292 | 1.2458 | 0.4292 | 6.6613 |
| 0.7 | 0.7022 | 0.7022 | 5.9260 | 0.7022 | 8.2678 | 0.7022 | 1.3911 |
| 0.9 | 1.1673 | 1.1634 | 0.0038 | 1.1665 | 7.2760 | 1.1671 | 1.6081 |
| 0.99 | 1.7043 | 1.5801 | 0.1241 | 1.6267 | 0.0776 | 1.6514 | 0.0529 |
| , , , , , | |
| 1, 1, 1, 0.6, 0.2, 0.3 | |
| 1, 1, 1, 0.3, 0.1, 0.4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bouhlel, N.; Rousseau, D. A Generic Formula and Some Special Cases for the Kullback–Leibler Divergence between Central Multivariate Cauchy Distributions. Entropy 2022, 24, 838. https://doi.org/10.3390/e24060838
Bouhlel N, Rousseau D. A Generic Formula and Some Special Cases for the Kullback–Leibler Divergence between Central Multivariate Cauchy Distributions. Entropy. 2022; 24(6):838. https://doi.org/10.3390/e24060838
Chicago/Turabian StyleBouhlel, Nizar, and David Rousseau. 2022. "A Generic Formula and Some Special Cases for the Kullback–Leibler Divergence between Central Multivariate Cauchy Distributions" Entropy 24, no. 6: 838. https://doi.org/10.3390/e24060838
APA StyleBouhlel, N., & Rousseau, D. (2022). A Generic Formula and Some Special Cases for the Kullback–Leibler Divergence between Central Multivariate Cauchy Distributions. Entropy, 24(6), 838. https://doi.org/10.3390/e24060838