1. Introduction
Let be the statistical space associated with the random variable where is the -field of Borel subsets and is a family of probability distributions defined on the measurable space whit an open subset of and We assume that the probability measures are described by densities where is a -finite measure on Given a random sample of the random variable X with density belonging to the parametric family , the most popular estimator for the model parameter is the maximum likelihood estimator (MLE), which maximizes the likelihood function of the assumed model. The MLE has been widely studied in the literature for general statistical models, and it has been shown that, under certain regularity conditions, the sequence of MLEs of is asymptotically normal and it satisfies some desirable properties, such as consistency and asymptotic efficiency. That is, the MLE is the BAN (best asymptotically normal) estimator. However, in many popular statistical models, the MLE is markedly non-robust against deviations, even very small ones, from the parametric conditions.
To overcome the lack of robustness, minimum distance (or minimum divergence) estimators (MDEs) have been developed. MDEs have received growing attention in statistical inference because of their ability to conciliate efficiency and robustness. In parametric estimation, the role of divergence or distance measures is very intuitive: the estimates of the unknown parameters are obtained by minimizing a suitable divergence measure between the estimated from data and the assumed model distributions. There is a growing body of literature that recognizes the importance of MDEs in terms of robustness, without a significant loss of efficiency, with respect to the MLE. See, for instance, the works of Beran [
1], Tamura and Boes [
2], Simpson [
3,
4], Lindsay [
5], Pardo [
6], and Basu et al. [
7] and the references therein.
Let
G denote the unknown distribution function, with associated density
underlying the data. The minimum divergence (distance) functional evaluated at
G,
, is defined as
with
being a distance or divergence measure between the densities
g and
As the true distribution underlying the data is unknown, given a random sample, we could estimate the model parameter
, substituting in the previous expression the true distribution
G by its empirical estimation
Therefore, the MDE of
is given by
When dealing with continuous models, it is convenient to consider families of divergence measures for which non-parametric estimators of the unknown density function are not needed. From this perspective, the density power divergence (DPD) family, leading to the minimum density power divergence estimators (MDPDEs) (see Basu et al. [
7]), as well as the Rényi’s pseudodistance (RP), leading to the minimum Rényi’s pseudodistance estimators (MRPE) (see Broniatowski et al. [
8]) between others, play an important role. The results presented in Broniatowski et al. [
8] in the context of independent and identically distributed random variables were extended for the case of independent but not identically distributed random variables by Castilla et al. [
9].
In many situations we have additional knowledge about the true parameter value, as it must satisfy certain constraints. Then, the restricted parameter space has the form
where
denotes the null vector of dimension
r, and
is a vector-valued function such that the
matrix
exists and is continuous in
and rank
. Here, superscript
T represents the transpose of the matrix. In the following, the restricted parameter space given in (
3) is denoted by
as in most situations, it will represent a composite null hypothesis.
The most popular estimator of
under the non-linear constraint given in (
3) is the restricted MLE (RMLE) that maximizes the likelihood function subject to the constraint
(see Silvey [
10]). The RMLE encounters similar robustness problems to the MLE. To overcome such deficiency, the restricted MDPDEs (RMDPDEs) were introduced in Basu et al. [
11] and their theoretical robustness properties were later studied in Ghosh [
12].
The main purpose in this paper is extending the theory developed for the MRPE to the restricted parameter space setting, yielding to the restricted MRPE (RMPRE), where the parameter space has the form (
3). The rest of the paper is as follows: In
Section 2, MRPE is introduced.
Section 3 presents RMPRE, and its asymptotic distribution as well as its influence function are obtained. In
Section 4, two different test statistics for testing composite null hypothesis, based on the RMRPE, are developed, and explicit expressions of the statistics are presented for testing in normal populations.
Section 5 presents a simulation study, where the robustness of the proposed estimators and test statistics is empirically shown.
Section 6 deals with real-data situations. Finally, some conclusions are presented in
Section 7.
2. Minimum Rényi Pseudodistance Estimators
In this section, we introduce the MRPE. We derive the estimating equations of the MRPE and recall its asymptotic distribution.
Let
be a random sample of size
n from a population having true and unknown density function
modeled by a parametric family of densities
with
The RP between the densities
and
g is given, for
by
The RP can be defined for
taking continuous limits, yielding the expression
Then, the RP coincides with the Kullback–Leibler divergence (KL) between g and , at (see Pardo, 2006).
The RP was considered for the first time by Jones et al. [
13]. Later Broniatowski et al. [
8] established some useful properties of the divergence, such as the positivity of the RP for any two densities and for all values of the parameter
and uniqueness of the minimum RP within a parametric family, that is,
if and only if
The last property justifies the definition of the MRPEs as the minimizer of the RP between the assumed distribution and the empirical distribution of the data. It is interesting to note that the so-called RP by Broniatowski et al. [
8] had been previously considered by Fujisawa and Eguchi [
14] under the name of
-cross entropy. In that paper, some appealing robustness properties of the estimators based on such entropy are shown.
Given a sample
, from Broniatowski et al. [
8] it can be seen that minimizing
leads to the following definition.
Definition 1. Let be a statistical space. The MRPE based on the random sample for the unknown parameter θ is given, for , bywhere Further, at
minimizes the KL divergence, and thus the MRPE coincides with the MLE for
Based on the previous definition (
5), differentiating, we obtain that the estimating equations of the MRPE are given by
with
being
The MRPE is an M-estimator and thus its asymptotic distribution and influence function (IF) can be obtained based on the asymptotic theory of the M-estimators. Broniatowski et al. [
8] studied the asymptotic properties and robustness of the MRPEs. The next result recalls the asymptotic distribution of the MRPEs.
Theorem 1. Let be the true unknown value of Then,wherewith Castilla et al. [
15] introduced useful notation for the computation of
where
and
and
are as in (
9) and (
10), respectively.
Toma and Leoni-Aubin [
16] defined new robust and efficient measures based on the RP. Later, Toma et al. [
17] considered the MRPE for general parametric models and developed a model selection criterion for regression models. Broniatowski et al. [
8] applied the method to the multiple regression model (MRM) with random covariates. Subsequently, Castilla et al. [
18] developed Wald-type tests based on MRPE for the MRM, and Castilla et al. [
19] studied the MRPE for the MRM in the ultra-high dimensional set-up. Further, Jaenada and Pardo [
20,
21] considered the MRPE and Wald-type test statistics for generalized linear models (GLM). Despite Wald-type test statistics, there exist others relevant test statistics having an important role in the statistical literature: the likelihood-ratio and Rao (or score) tests, which are based on restricted estimators, usually the RMLE. Then, it makes sense to develop robust versions of these popular statistics based on the RMRPE.
3. The Restricted Minimum Rényi Pseudodistance Estimator: Asymptotic Distribution and Influence Function of RMRPE
In this section, we introduce the RMRPE and we derive its asymptotic distribution. Moreover, we study its robustness properties through its influence function (IF).
Definition 2. The RMRPE functional evaluated at the distribution G is defined bygiven that such a minimum exists. Accordingly, given random sample from the distribution G, the RMRPE of θ is defined as Next, the result states the asymptotic distribution of the RMRPE,
Theorem 2. Suppose that the true distribution satisfies the conditions of the model and let us denote by the true parameter. Then, the RMRPE of θ obtained under the constraints has distributionwhereand is defined in (13), evaluated at . To analyze the robustness of an estimator, Hampel et al. [
22] introduced the concept of the influence function (IF). Since then, the IF has been widely used in statistical literature to measure robustness in different statistical contexts. Intuitively, the IF describes the effect of an infinitesimal contamination of the model on the estimate. Then, IFs associated to locally robust (B-robust) estimators should be bounded. Let us now obtain the IF of RMRPE and analyze its boundedness to asses the robustness of the proposed estimators. We consider the contaminated model
with
the indicator function in
and we denote
being
the distribution function associated to
By definition,
is the minimizer of
subject to
Following the same steps as in Theorem 5 in Broniatowski et al. [
8], it can be seen that the influence function of
in
is given by
where
was defined in (
8) and
with the additional condition that
Note that expression (
20) corresponds to the IF of the unrestricted MRPE. Differentiating this last equation gives, at
Based on (
20) and (
21) we have
Note that matrices
and
involved in the expression (
22) are defined except for the model and tuning parameters
and
, and so the boundedness of the IF of the RMRPE depends, therefore, on the boundedness of the factor
Therefore, the boundedness of the IF of the RMRPE depends directly on the boundedness of IF of the MRPE, stated in (
20). The IF of the MRPE has been widely studied for general statistical models, concluding that the MRPEs are robust for positive values of
and that such robustness increases with the tuning parameter. A whole discussion can be found in the work of Broniatowski et al. [
8]. Hence, the same properties hold for RMRPEs.
5. Simulation Study: Application to Normal Populations
In this section, we empirically analyze the performance of the proposed estimators under the normal parametric model and RPTS and Rao-type test statistics for the problem of testing (
26) in terms of efficiency and robustness. We examine the accuracy of the RMRPEs, and we further examine the robustness properties of both families of estimators under different contamination scenarios. Further, we investigate the empirical level and power of the proposed test statistics under different sample sizes and contamination scenarios.
Let us consider a univariate normal model with true parameter value
and the problem of testing
The restricted parameter space is then given by
In order to evaluate the robustness properties of the estimators and test statistics, we introduce contamination in data by replacing a of the observations by a contaminated sample, where denotes the contamination level. We generate five different scenarios of contamination:
Pure data.
Scenario 1: Slightly contaminated data. We replace a of the samples by a contaminated sample from a normal distribution,
Scenario 2: Heavily contaminated data. We replace a of the samples by a contaminated sample from a normal distribution,
Further, in order to evaluate the power of the test, we consider an alternative true parameter value
which does not satisfy the null hypothesis (
33) (or equivalently the restrictions of the parameter space). In this scenario, contaminated parameters are set
for slightly and
for heavily contamination.
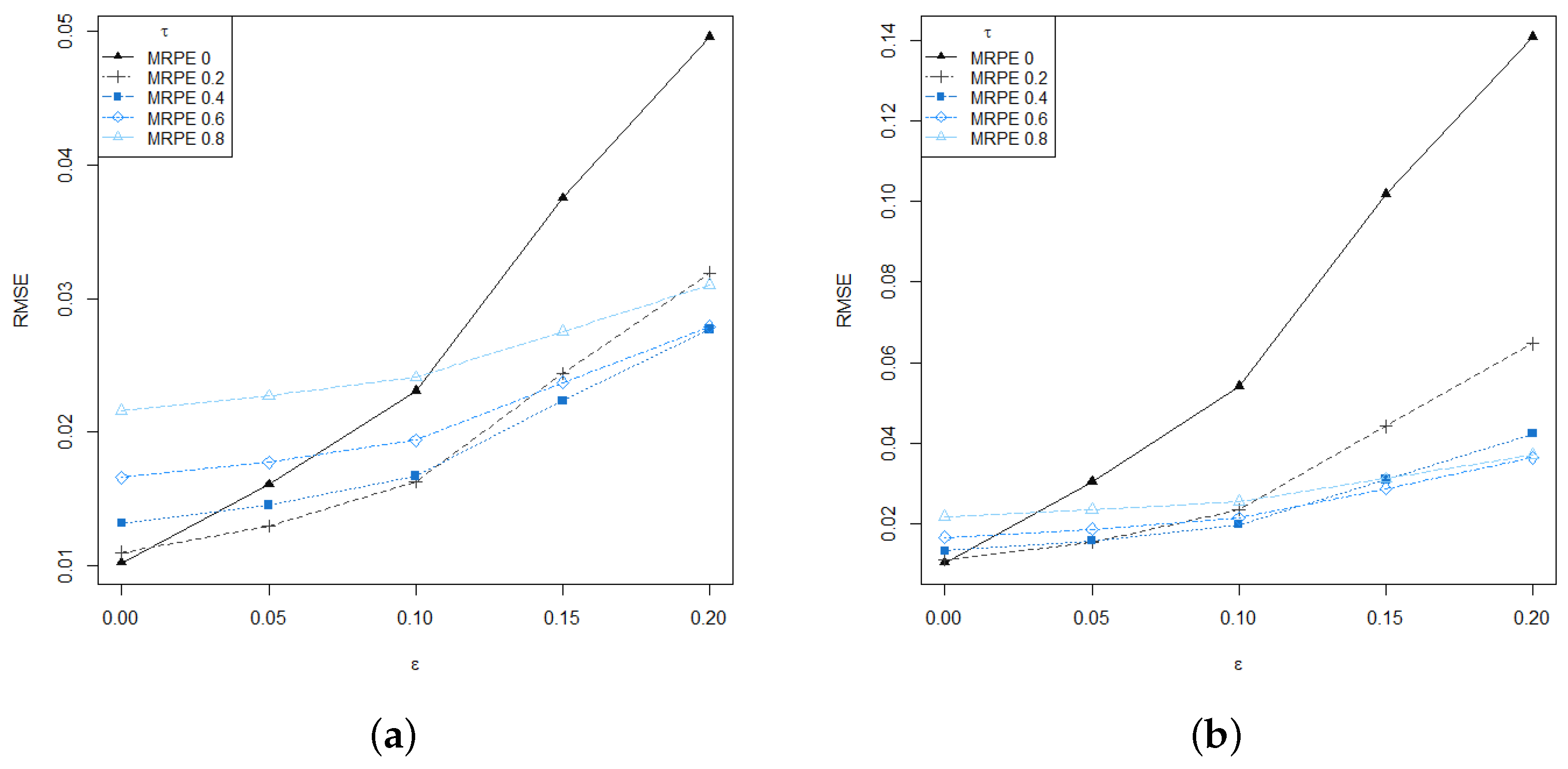
Figure 1 shows the root mean square error (RMSE) of the RMRPE of the scale parameter
, for different values of the tuning parameter
and
over
replications. As expected, large values of the tuning parameter produce more robust estimators, which is particularly advantageous for the heavily contaminated scenario. Furthermore, even when introducing very low levels of contamination in data,
the RMRPE with moderate value of the tuning parameter outperforms the classical MLE, without a significant loss of efficiency in the absence of contamination.
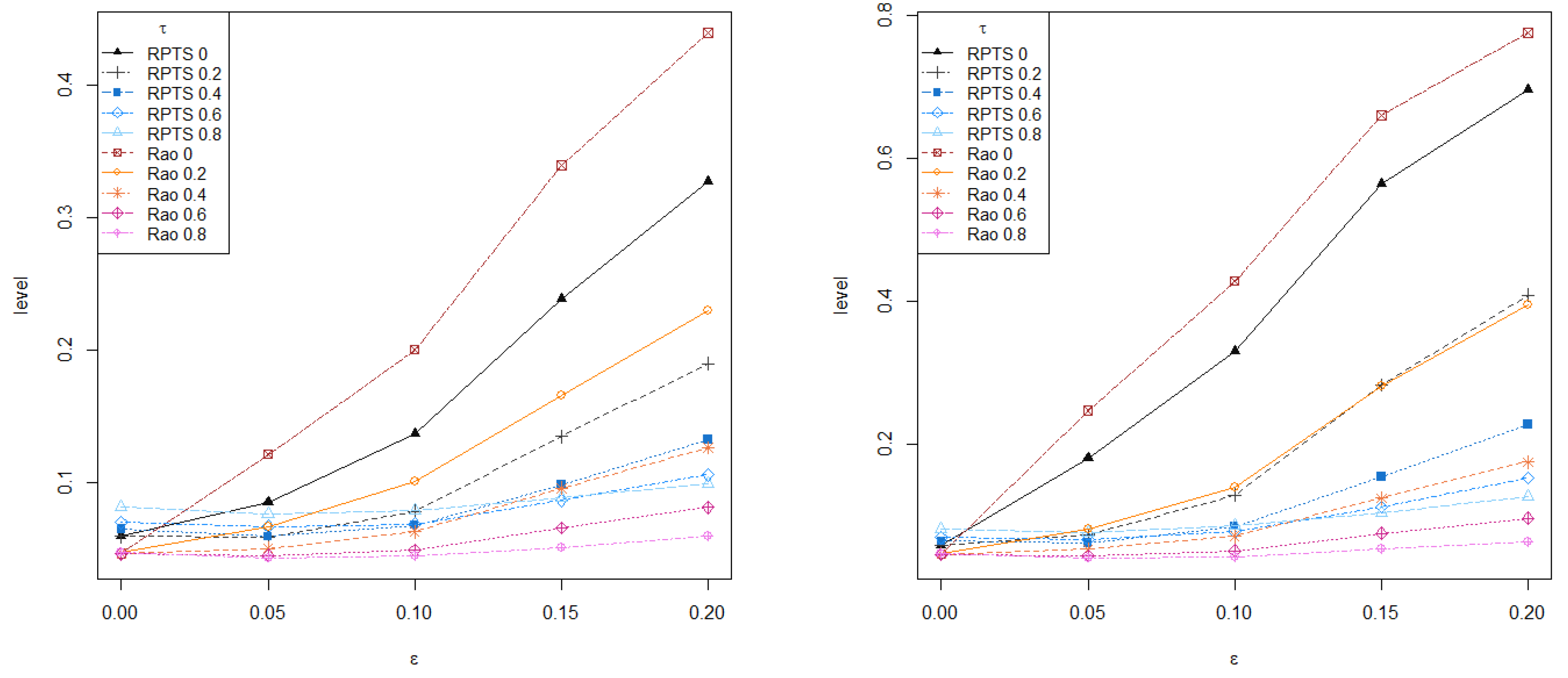
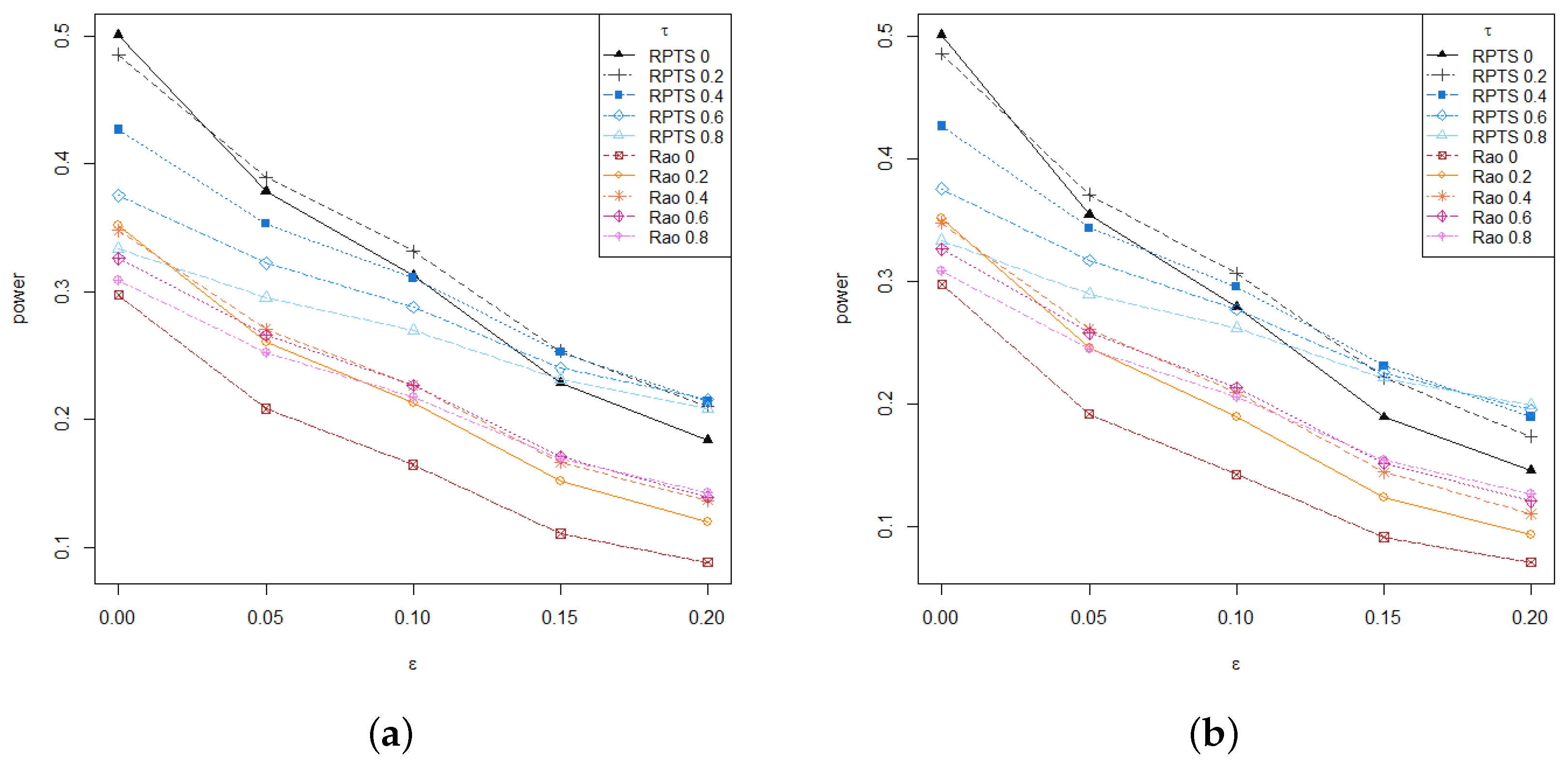
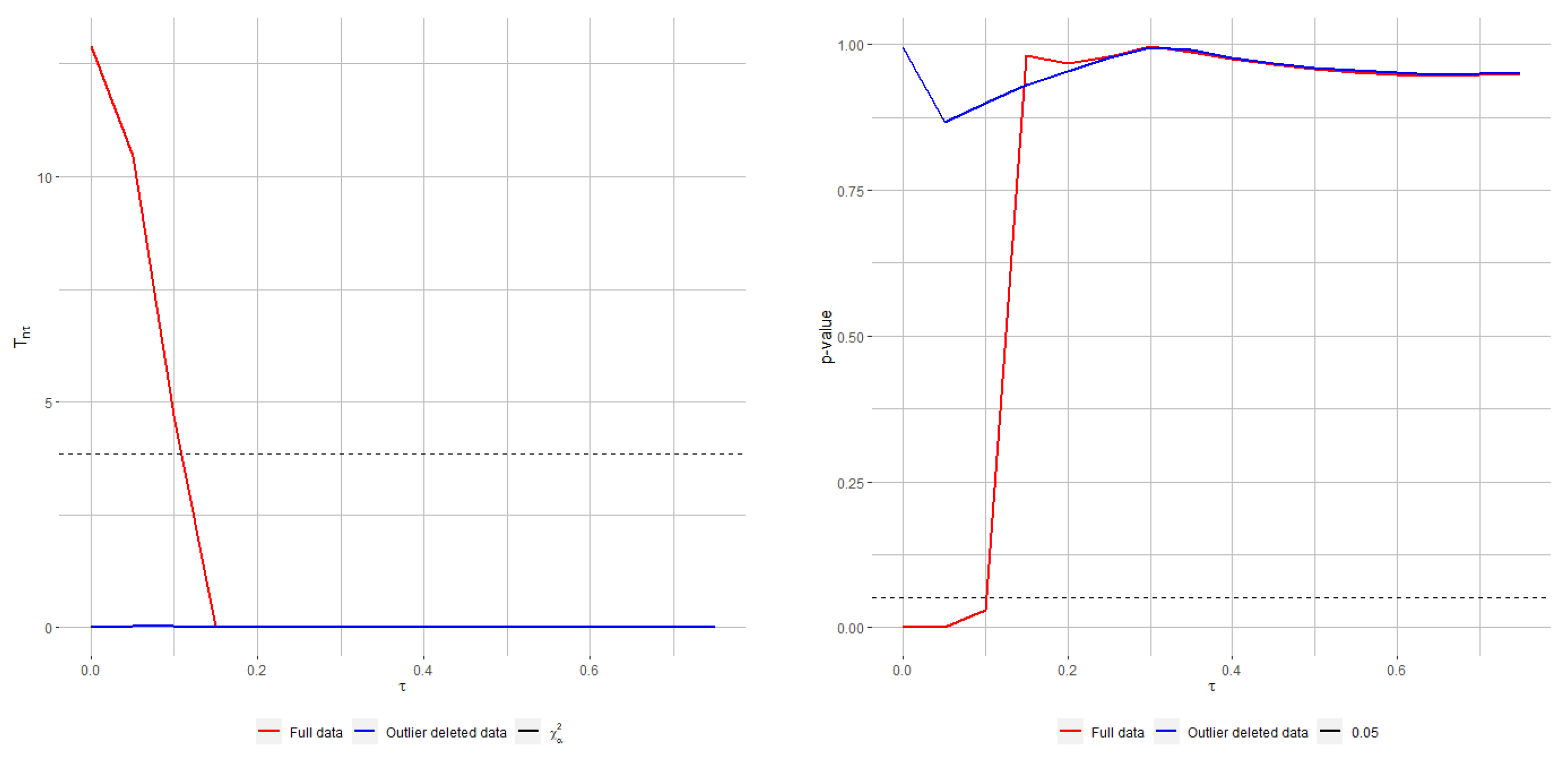
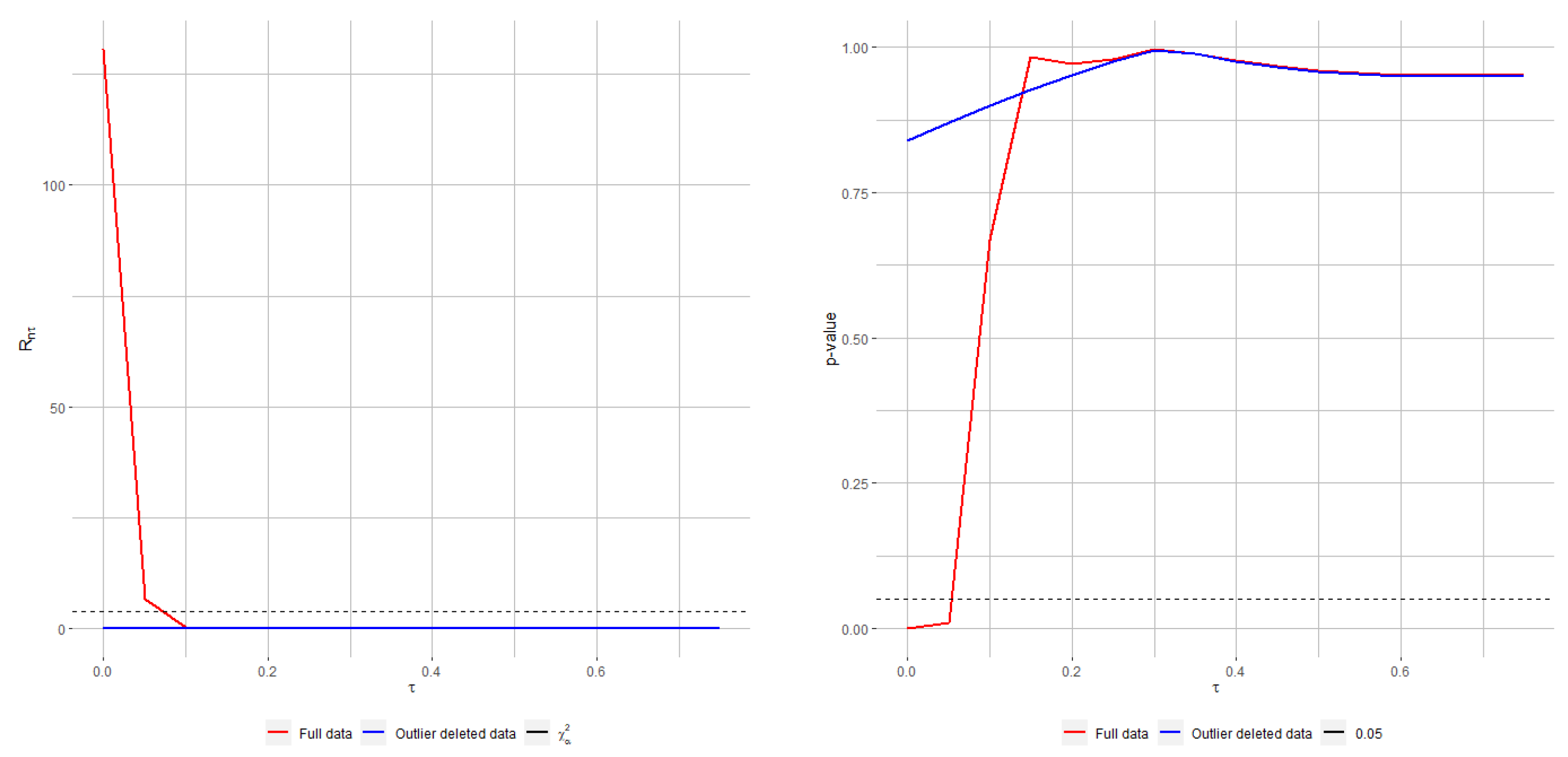
On the other hand,
Figure 2 presents the empirical level and power of both RPTS and Rao-type test statistics based on RMRPEs for different values of the tuning parameter,
under increasing contamination levels. The empirical level and power are computed as the mean number of rejections over
replications. The empirical level produced by the classical ratio and Rao-type tests rapidly increases and separates from levels obtained with any robust test. Regarding the empirical power, all robust tests with moderate and large values of the tuning parameter outperform the classical estimator within their family under contaminated scenarios, but Rao-type test statistics based on RMRPEs are more conservative than RPTSs, thus exhibiting lower levels and powers. Then, the proposed test statistics provides an appealing alternative to classical likelihood ratio and Rao tests, with a small loss of efficiency in favor of a clear gain in terms of robustness.
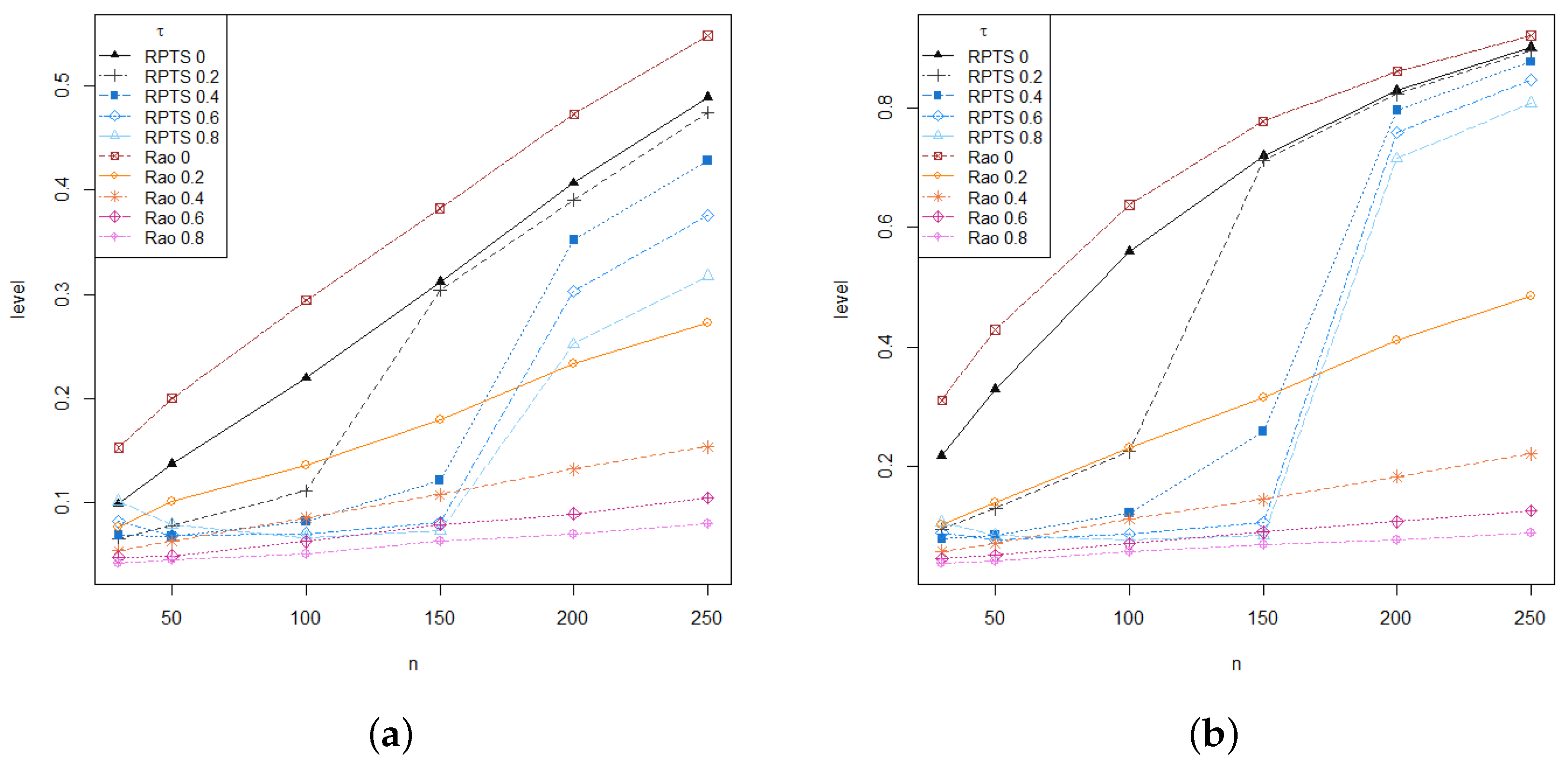
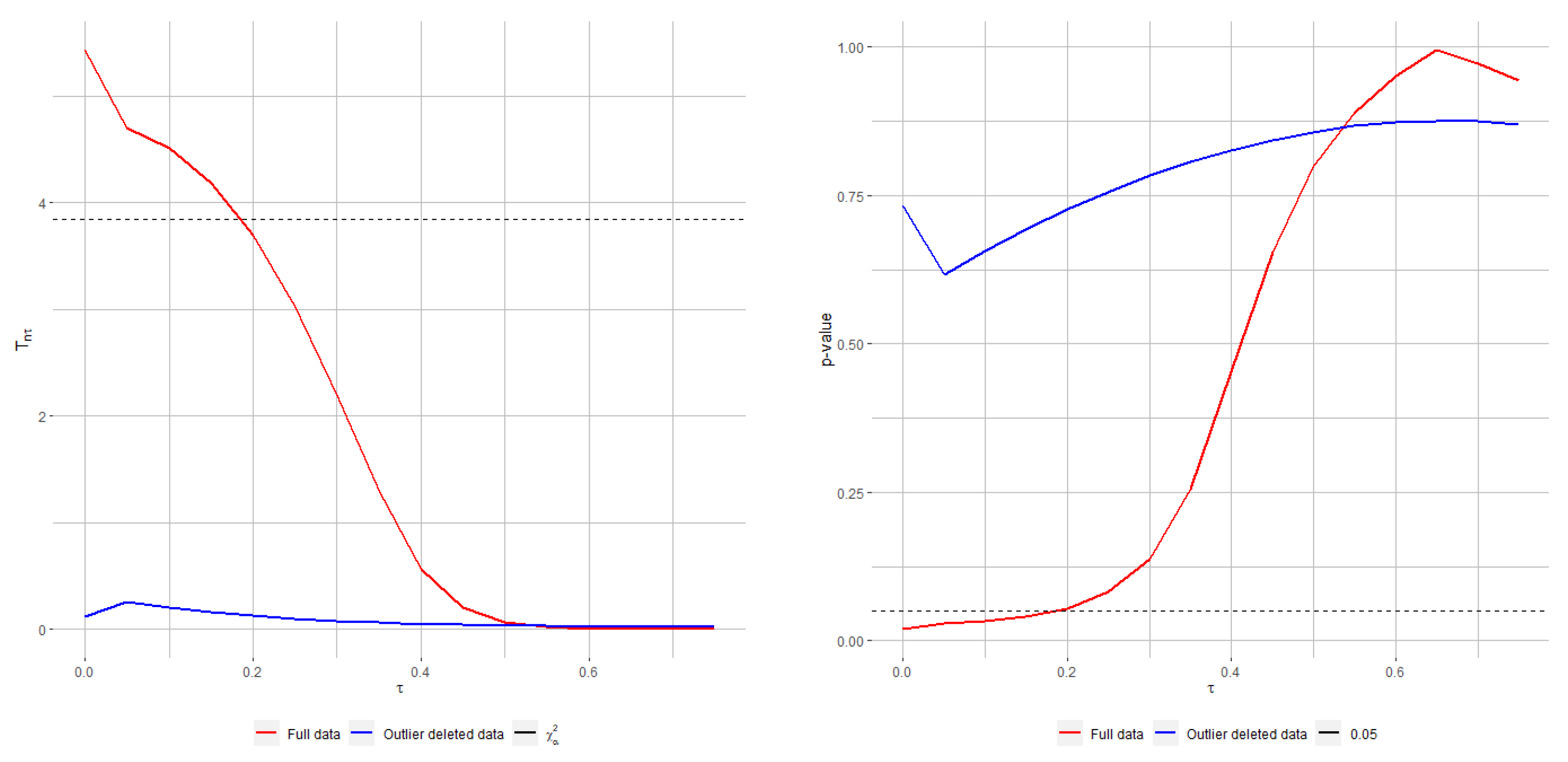
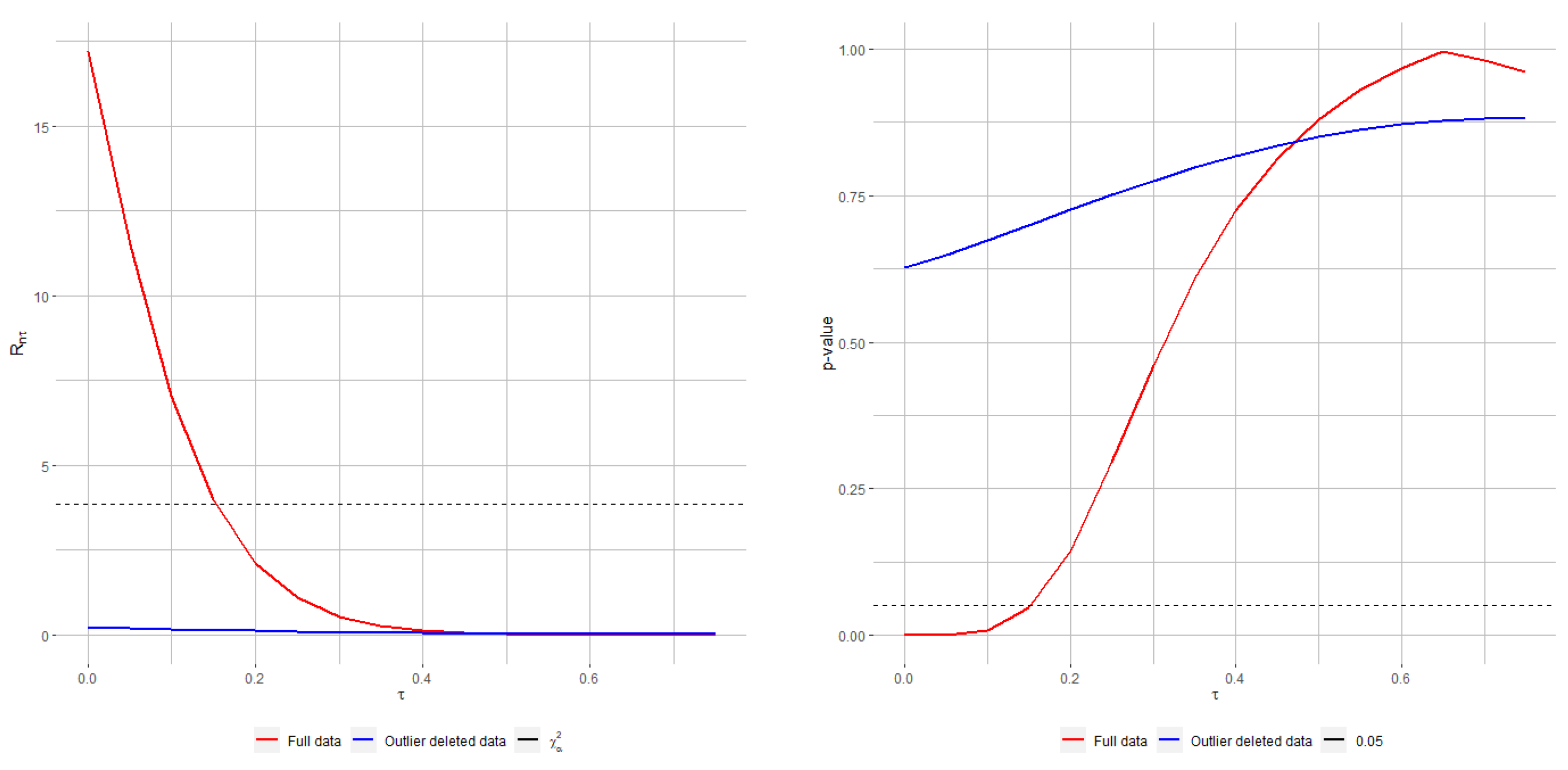
On the other hand, the sample size could play a crucial role in the performance of the tests, even more accentuated when there exists data contamination.
Figure 3 shows the sample size effect on the performance of the tests in terms of empirical level, under a
of contamination level in data. As discussed, Rao-type test statistics based on RMRPEs is more conservative and so tests based on RMRPEs with positive values of the tuning parameter produce lower empirical levels. Here, it outperforms the poor performance of the classical Rao-type test statistics with respect to any other. Moreover, when the sample size increases, the performance gap between non-robust and robust methods is widening.
Following the discussions in the preceding sections, larger values of the tuning parameter produce more robust but less efficient estimators. Therefore, the optimal value of
should obtain the best trade-off between efficiency and robustness. Warwick and Jones [
25] first introduced a useful data-based procedure for the choice of the tuning parameter for the MDPDE based on minimizing the asymptotic MSE of the estimator. However, this method depends on the choice of a pilot estimator, and Basak et al. [
26] improved the method by removing the dependency on an initial estimator. The proposed algorithm was developed ad hoc for the MDPDE, but it can be easily adapted to the MRPE and RMRPE by simply substituting the expression of the variance of the MDPDE by the variance of the MRPPE or the RMRPE, respectively.
7. Concluding Remarks
In this paper, we presented for the first time the family of RMRPEs. We derived their asymptotic distribution, and proved some suitable properties as consistency under the parameter restriction and robustness against data contamination. Further, based on these RMRPEs, we generalized two important families of statistics, namely RPTS and Rao-type tests, for testing a composite null hypothesis. Moreover, we obtained some explicit expressions of the RMPREs, RPTS and Rao-type test statistics for testing the variance under a normal population with an unknown mean. It was empirically shown that the proposed RPTS and Rao-type test statistics are robust, unlike classical tests based on the MLE, under normal populations. Indeed, the robustness of the tests is controlled by a tuning parameter , and so larger values of produce more robust estimators (although less efficient). Finally, some classical numerical examples illustrate the theoretical properties and applicability of the proposed methods.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







