
A New Strategy in Boosting Information Spread

Abstract
:1. Introduction
2. Related Work
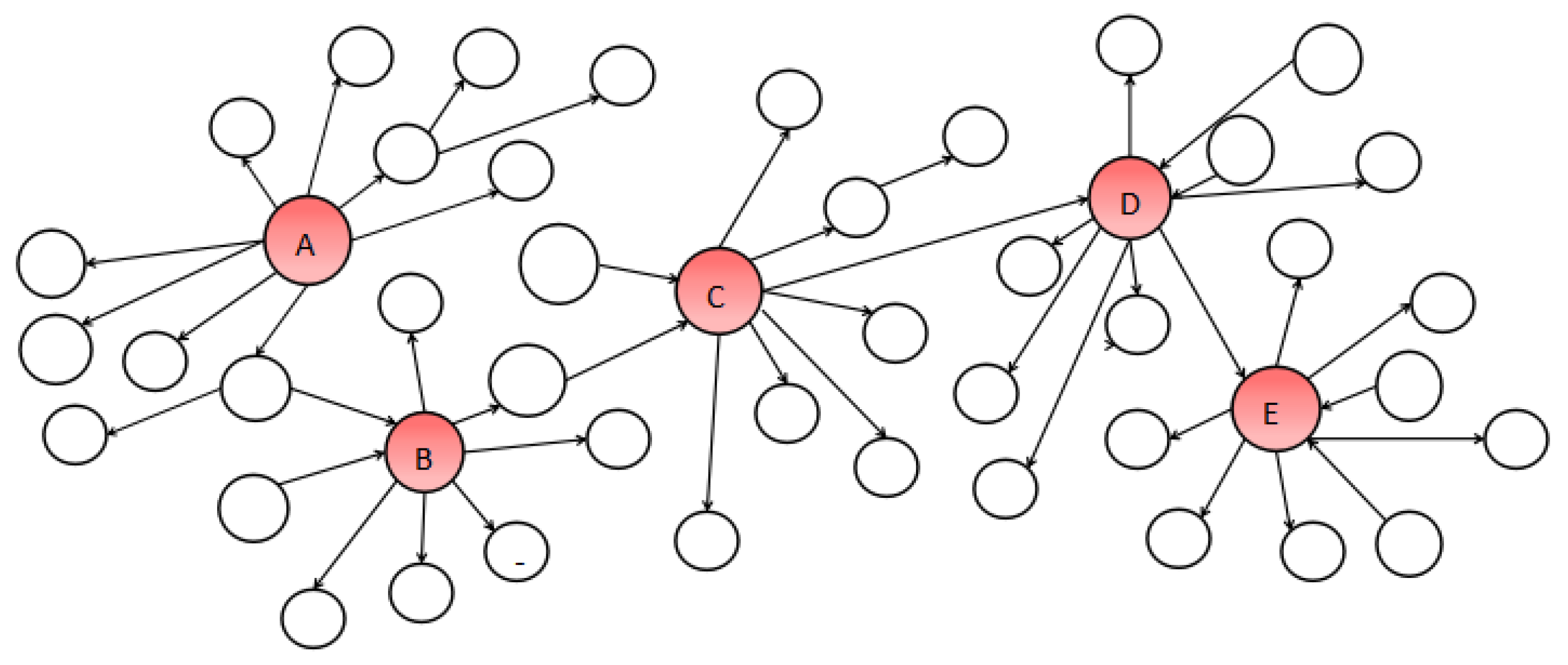
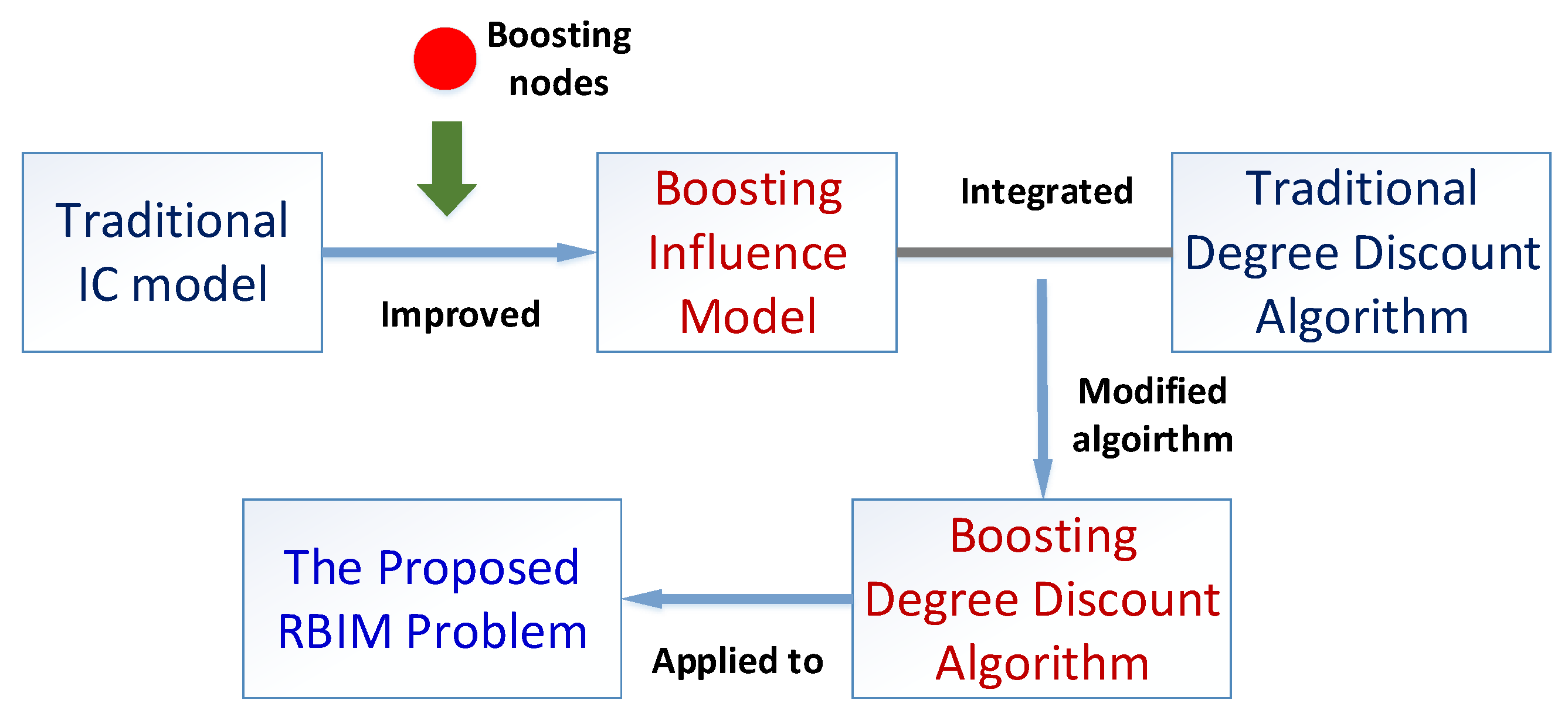
3. Proposed Methodology
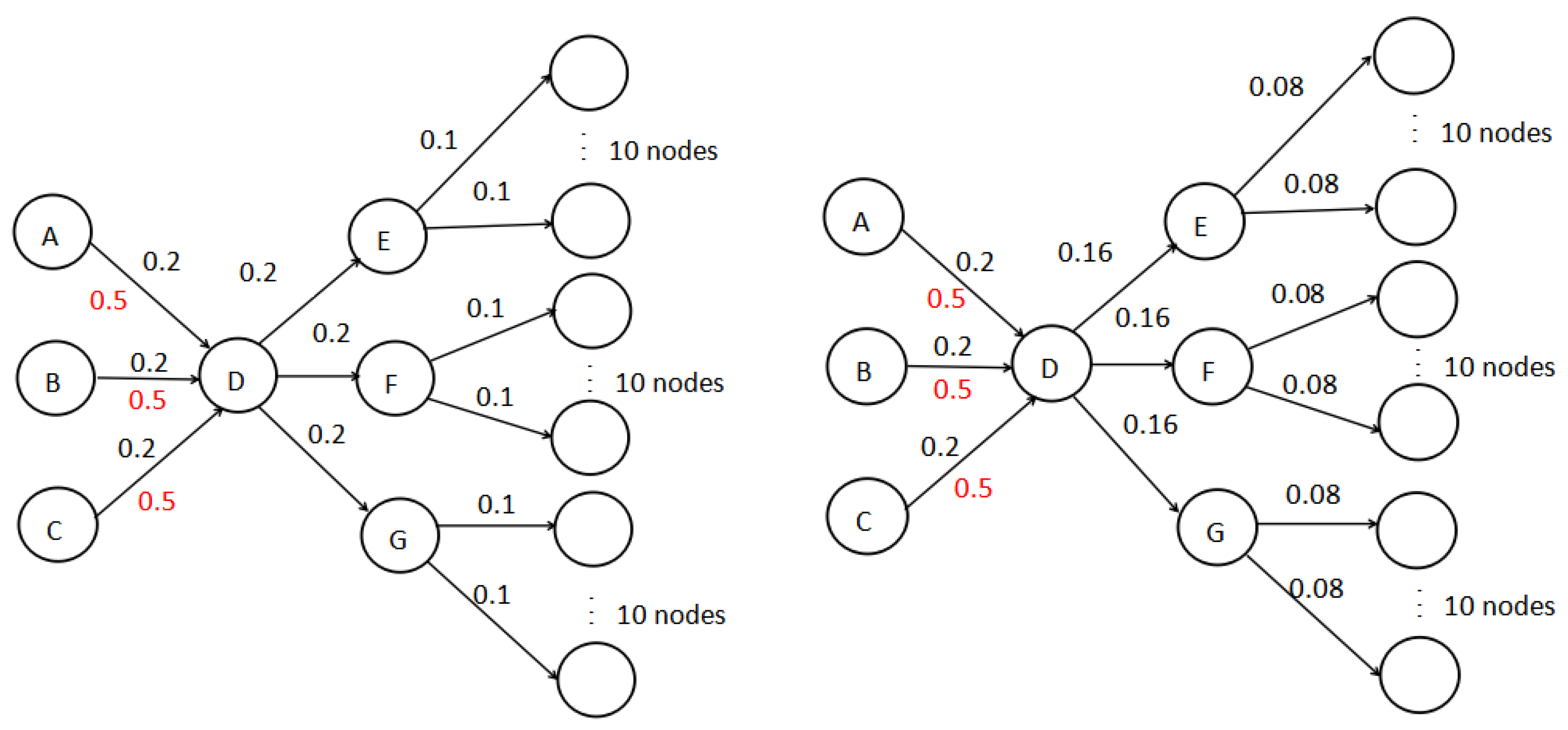
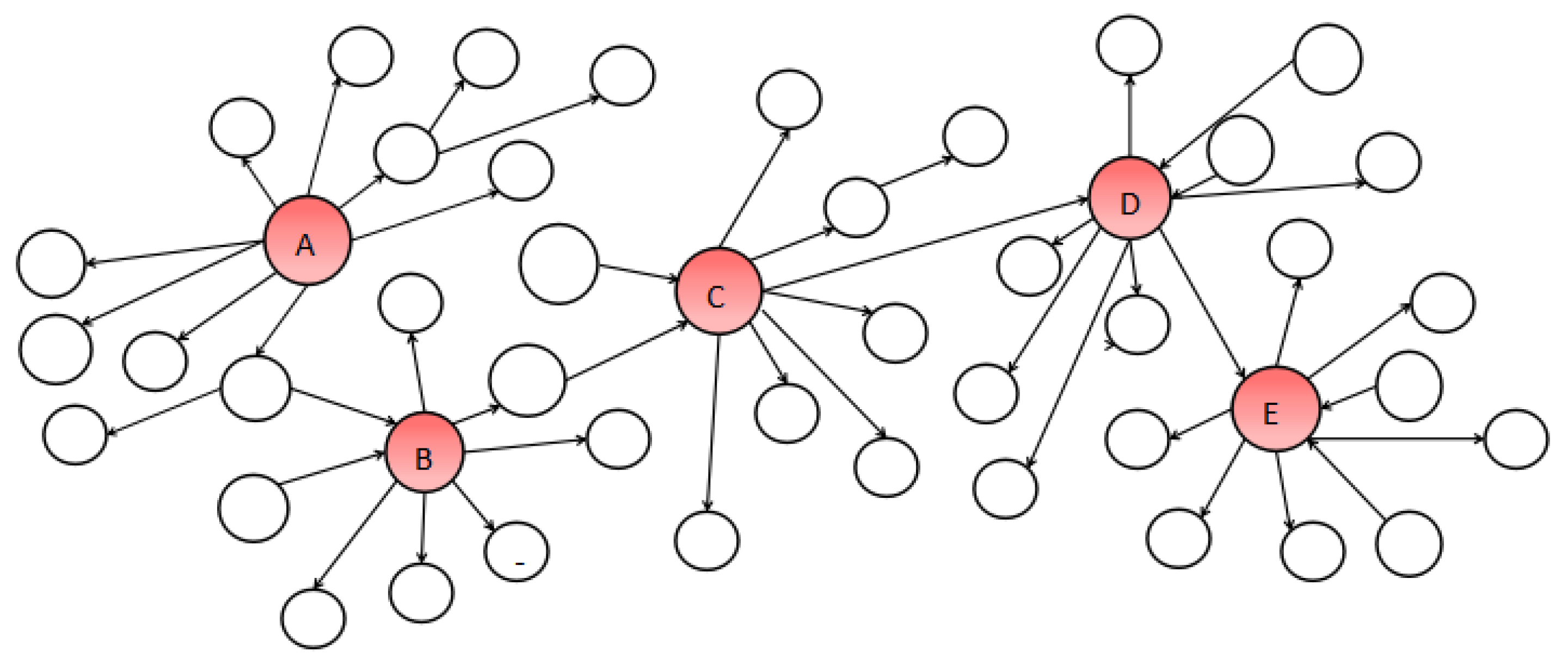
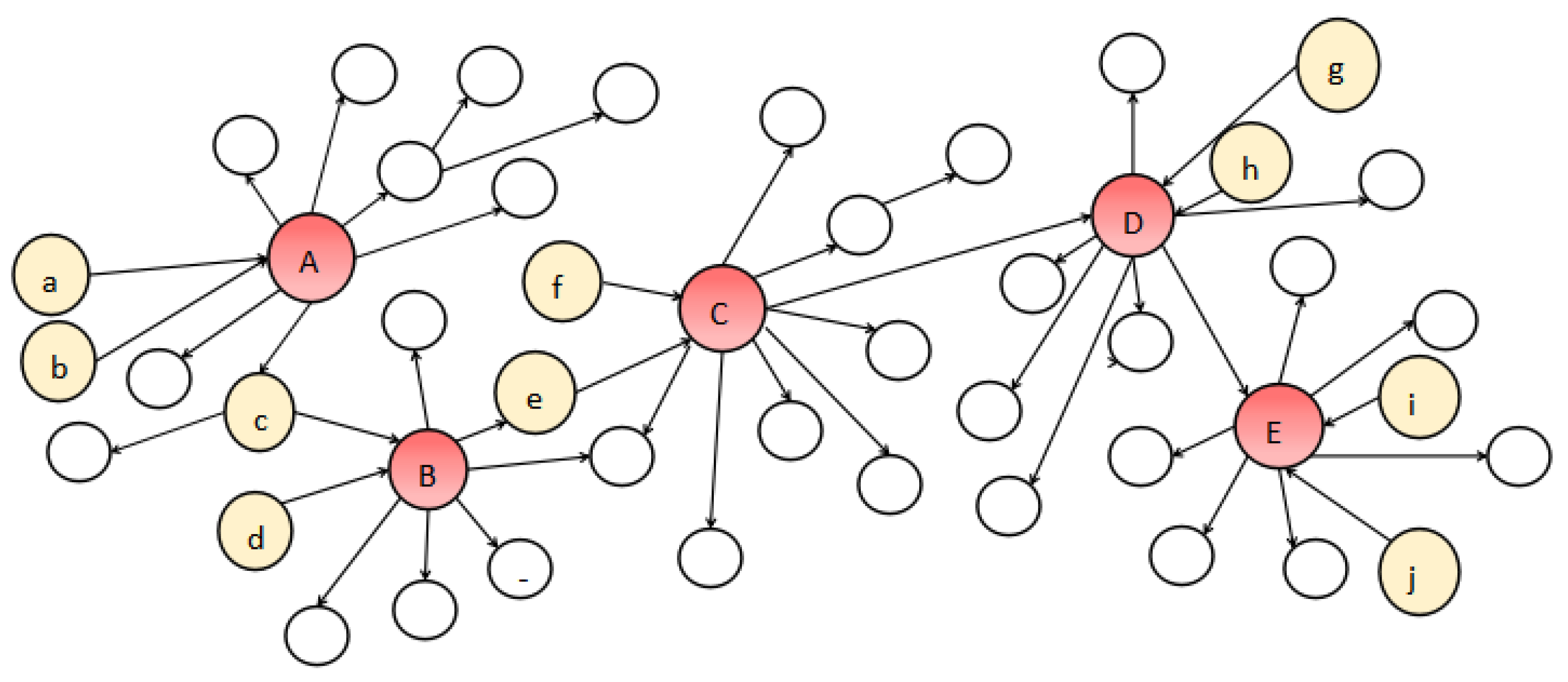
3.1. Boosting Influence Model
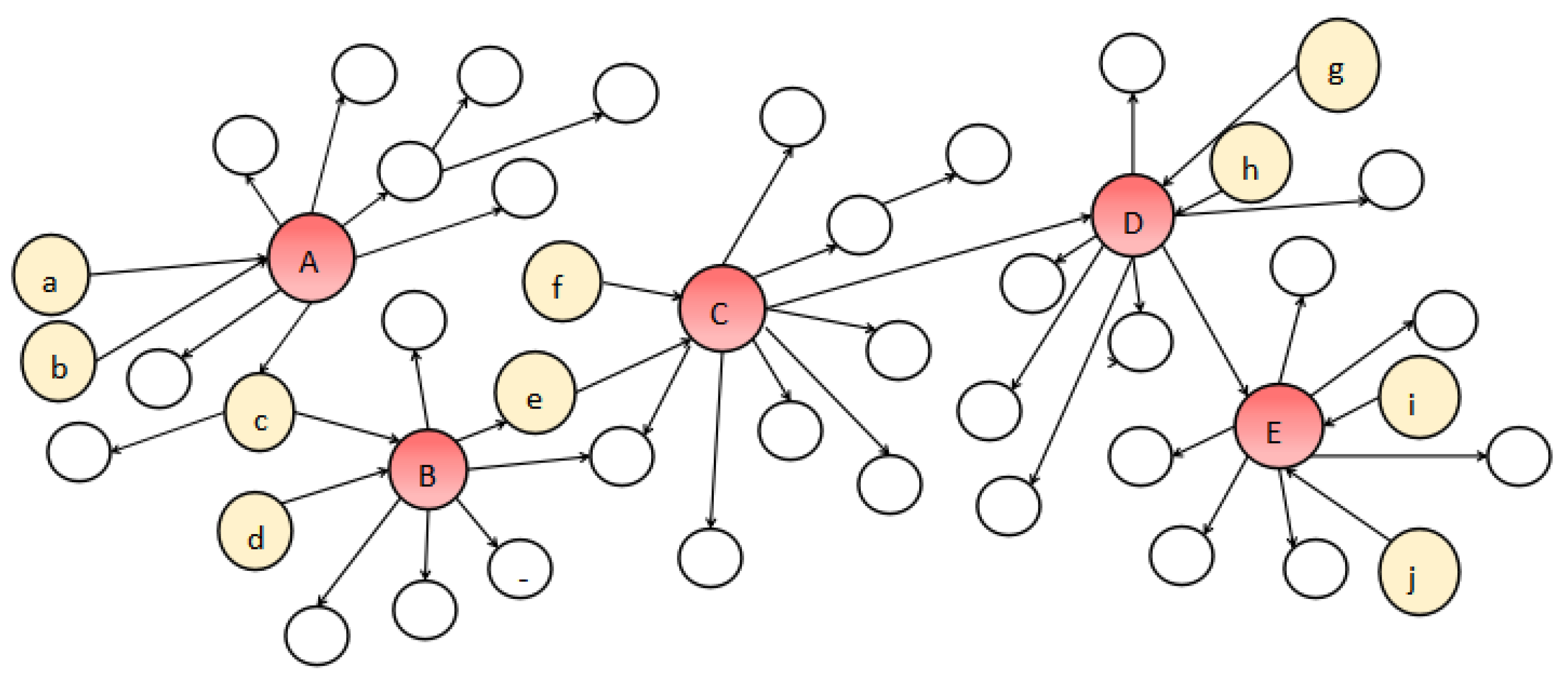
3.2. Realistic Budgeted Influence Maximization Problem (RBIM)
3.3. The New Strategy
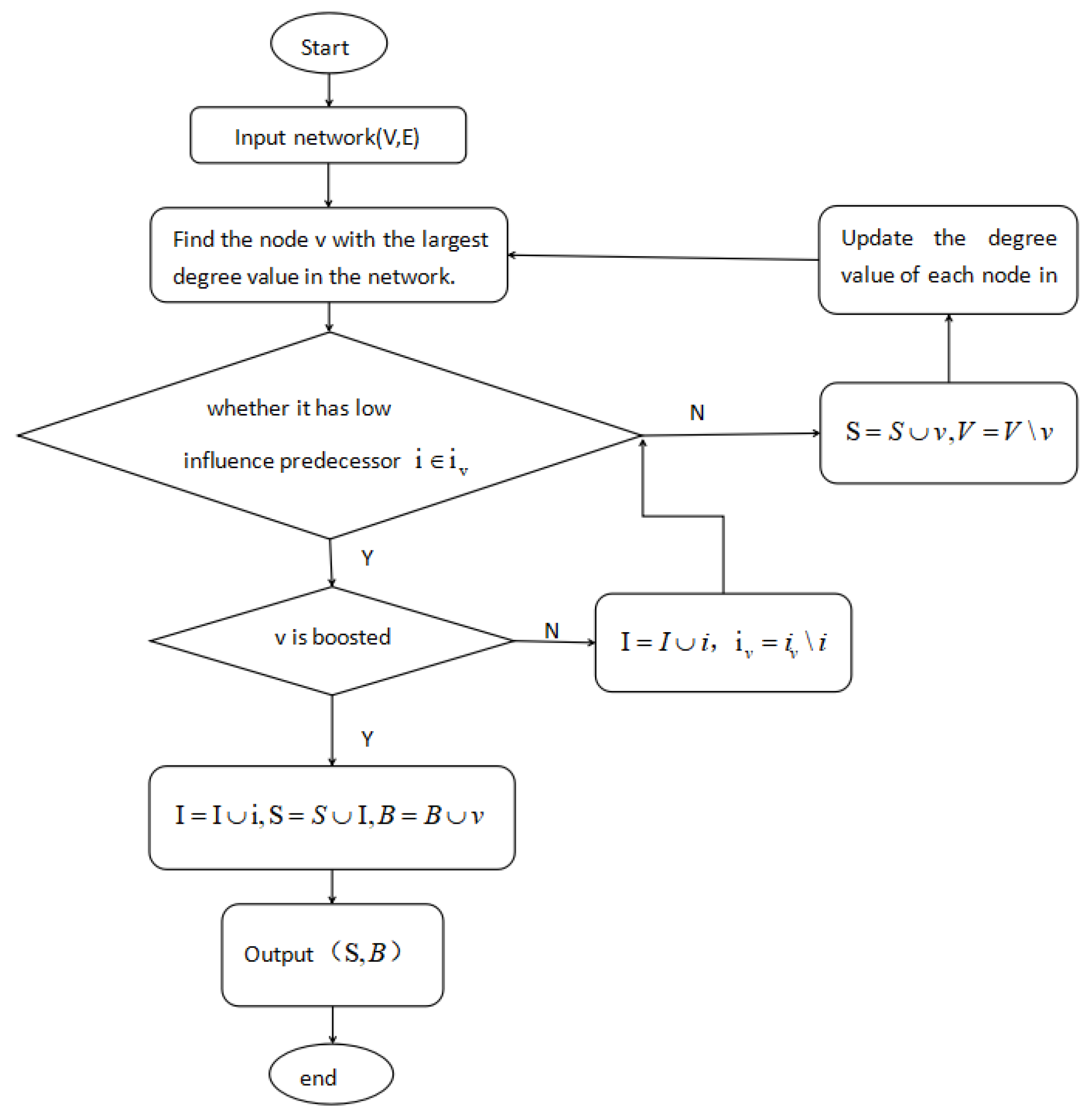
3.4. Improved Degree Discount Algorithm Introduction
| Algorithm 1 B(Boosting)-degree discount algorithm . |
| initialize (S represents the seed nodes set, and B represents the boosting nodes set) |
| for each node v do |
| calculate the degree |
| compute its input degree |
| end for |
| for i in (1:k) do |
| select |
| for i in and do |
| if then |
| if then |
| , |
| else |
| break |
| end if |
| else |
| continue |
| end if |
| end for |
| end for |
| if u in S then |
| for each neighbor of u do |
| end for |
| else |
| for each input degree m of u do |
| for each neighbor n of m do |
| if then |
| end if |
| end for |
| end for |
| end if |
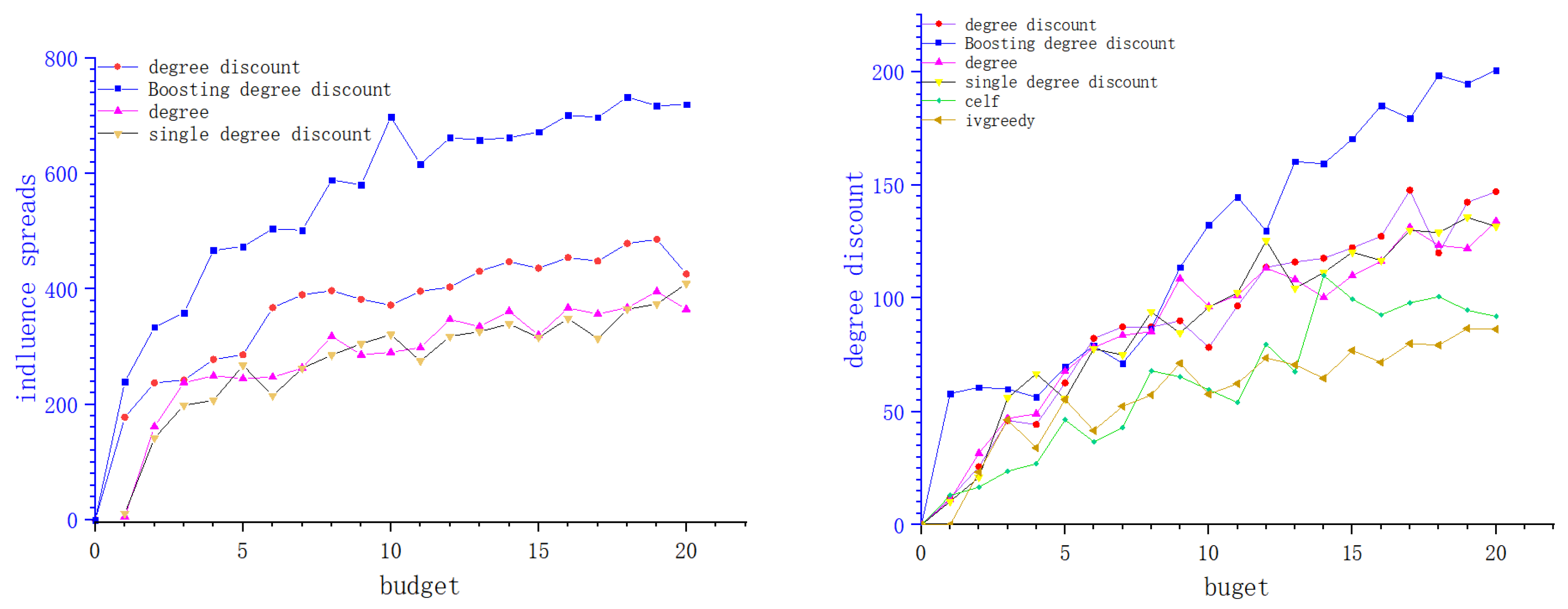
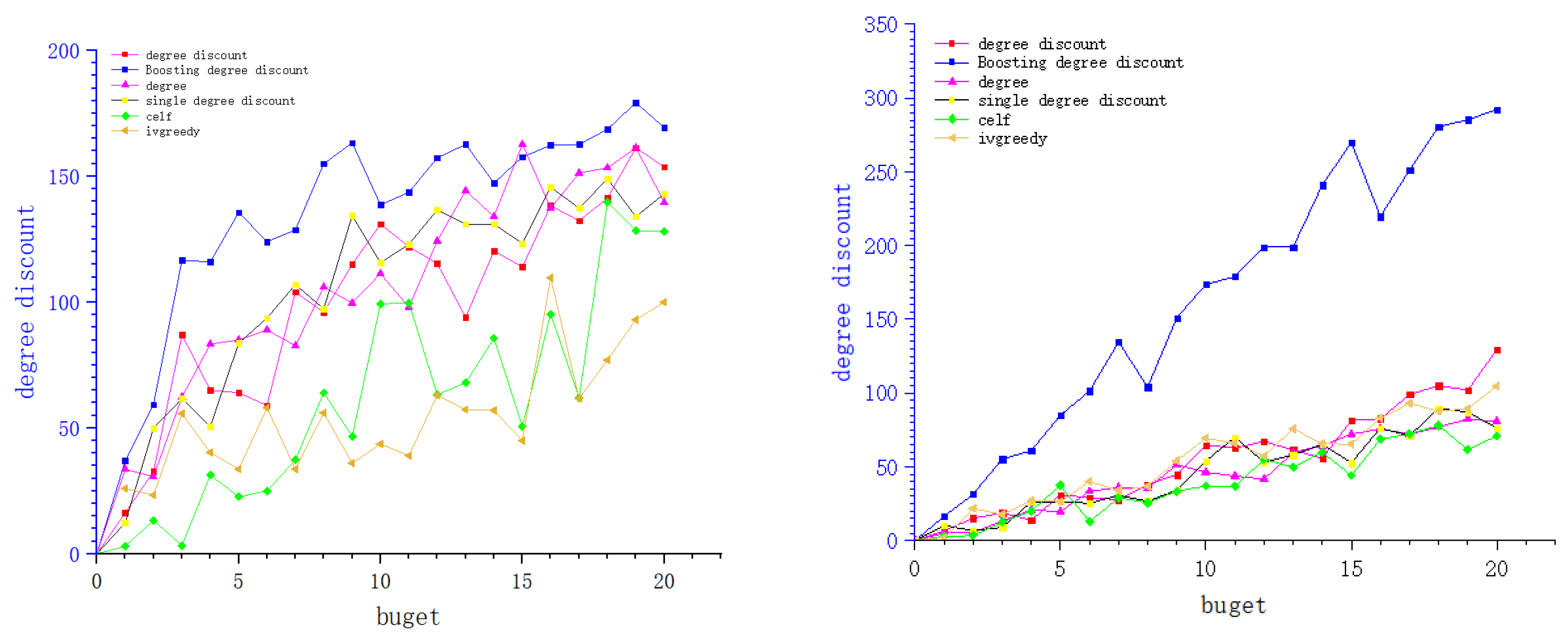
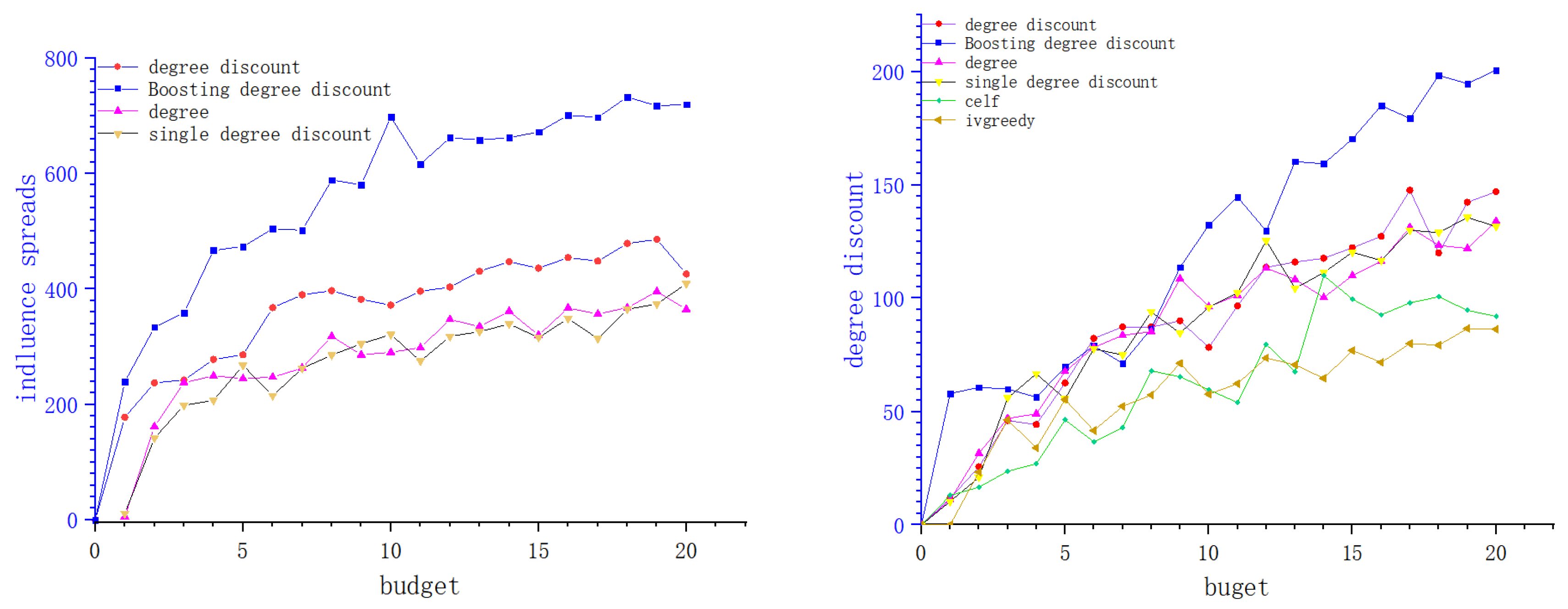
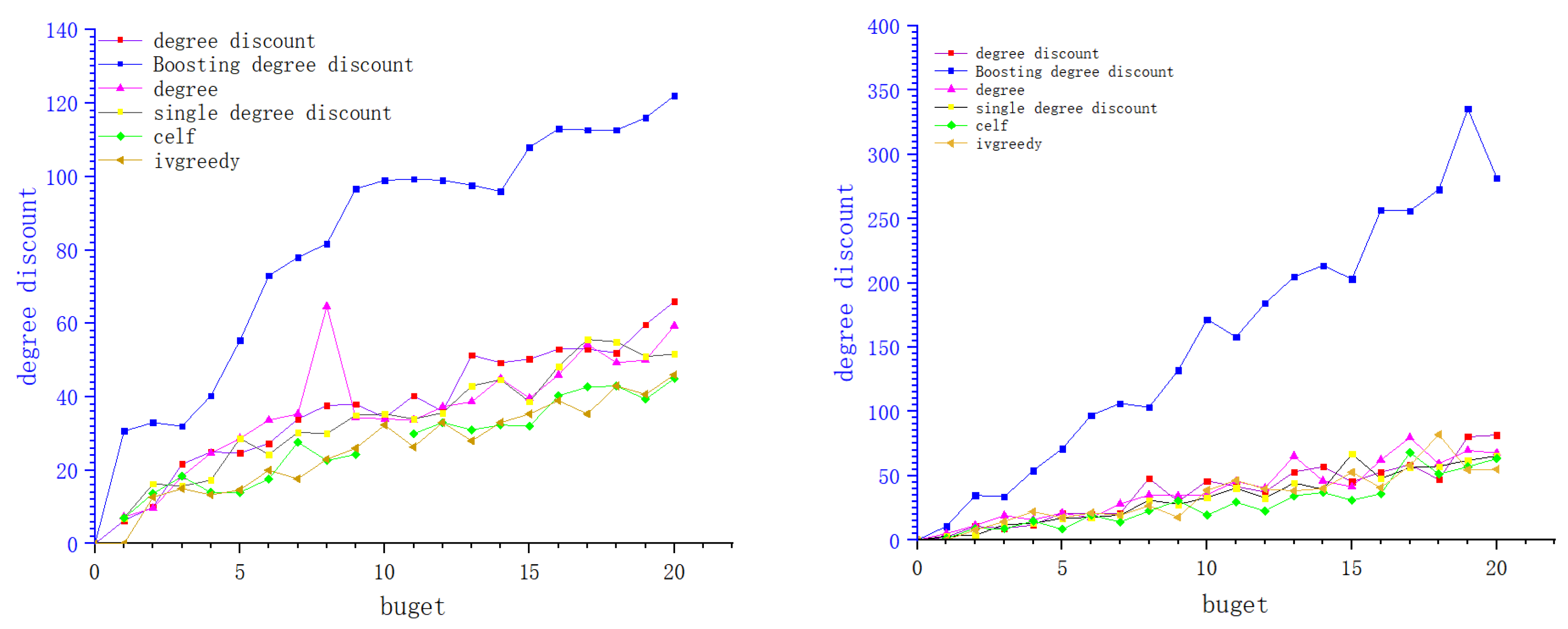
4. Experiments
4.1. Data Sets
4.2. Baseline Algorithms
4.3. Experiments and Results
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Jalili, M.; Orouskhani, Y.; Asgari, M.; Alipourfard, N.; Perc, M. Link prediction in multiplex online social networks. R. Soc. Open Sci. 2017, 4, 160863. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, H.; Mishra, S.; Thai, M.T. Recent advances in information diffusion and influence maximization in complex social networks. Opportunistic Mob. Soc. Netw. 2014, 37, 37. [Google Scholar]
- Tan, W.; Blake, M.B.; Saleh, I.; Dustdar, S. Social-network-sourced big data analytics. IEEE Internet Comput. 2013, 17, 62–69. [Google Scholar] [CrossRef]
- He, Q.; Wang, X.; Huang, M.; Lv, J.; Ma, L. Heuristics-based influence maximization for opinion formation in social networks. Appl. Soft Comput. 2018, 66, 360–369. [Google Scholar] [CrossRef]
- AskariSichani, O.; Jalili, M. Influence maximization of informed agents in social networks. Appl. Math. Comput. 2015, 254, 229–239. [Google Scholar] [CrossRef]
- Martinčić-Ipšić, S.; Močibob, E.; Perc, M. Link prediction on Twitter. PLoS ONE 2017, 12, e0181079. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhuang, H.; Sun, Y.; Tang, J.; Zhang, J.; Sun, X. Influence Maximization in Dynamic Social Networks. In Proceedings of the 2013 IEEE 13th International Conference on Data Mining, Dallas, TX, USA, 7–10 December 2013; pp. 1313–1318. [Google Scholar]
- Richardson, M.; Domingos, P. Mining knowledge-sharing sites for viral marketing. In Proceedings of the Eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Edmonton, AB, Canada, 23–26 July 2002; pp. 57–66. [Google Scholar]
- Antelmi, A.; Cordasco, G.; Spagnuolo, C.; Szufel, P. Social Influence Maximization in Hypergraphs. Entropy 2021, 23, 796. [Google Scholar] [CrossRef]
- Domingos, P.; Richardson, M. Mining the network value of customers. In Proceedings of the Seventh ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 26–29 August 2001; ACM: New York, NY, USA, 2001; pp. 57–66. [Google Scholar]
- Kempe, D.; Kleinberg, J.; Tardos, É. Maximizing the spread of influence through a social network. In Proceedings of the Ninth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 24–27 August 2003; pp. 137–146. [Google Scholar]
- Li, S.; Zhu, Y.; Li, D.; Kim, D.; Ma, H.; Huang, H. Influence maximization in social networks with user attitude modification. In Proceedings of the 2014 IEEE International Conference on Communications (ICC), Sydney, NSW, Australia, 10–14 June 2014; pp. 3913–3918. [Google Scholar]
- Ding, J.; Sun, W.; Wu, J.; Guo, Y. Influence maximization based on the realistic independent cascade model. Knowl.-Based Syst. 2020, 191, 105265. [Google Scholar] [CrossRef]
- Chen, D.; Lü, L.; Shang, M.S.; Zhang, Y.C.; Zhou, T. Identifying influential nodes in complex networks. Phys. A Stat. Mech. Its Appl. 2012, 391, 1777–1787. [Google Scholar] [CrossRef] [Green Version]
- Bozorgi, A.; Samet, S.; Kwisthout, J.; Wareham, T. Community-based influence maximization in social networks under a competitive linear threshold model. Knowl.-Based Syst. 2017, 134, 149–158. [Google Scholar] [CrossRef]
- Rahimkhani, K.; Aleahmad, A.; Rahgozar, M.; Moeini, A. A fast algorithm for finding most influential people based on the linear threshold model. Expert Syst. Appl. 2015, 42, 1353–1361. [Google Scholar] [CrossRef]
- Ganesh, A.; Massoulié, L.; Towsley, D. The effect of network topology on the spread of epidemics. In Proceedings of the IEEE 24th Annual Joint Conference of the IEEE Computer and Communications Societies, Miami, FL, USA, 13–17 March 2005; Volume 2, pp. 1455–1466. [Google Scholar]
- Woo, J.; Chen, H. Epidemic model for information diffusion in web forums: Experiments in marketing exchange and political dialog. Springerplus 2016, 5, 5–66. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tzoumas, V.; Amanatidis, C.; Markakis, E. A Game-Theoretic Analysis of a Competitive Diffusion Process over Social Networks. In International Workshop on Internet and Network Economics; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- He, Q.; Wang, X.; Huang, M.; Cai, Y.; Zhang, C.; Ma, L. An adaptive approach for handling two-dimension influence maximization in social networks. Int. J. Commun. Syst. 2017, 31, e3780. [Google Scholar] [CrossRef]
- Liu, B.; Cong, G.; Zeng, Y.; Xu, D.; Chee, Y.M. Influence Spreading Path and Its Application to the Time Constrained Social Influence Maximization Problem and Beyond. IEEE Trans. Knowl. Data Eng. 2014, 26, 1904–1917. [Google Scholar] [CrossRef] [Green Version]
- Goyal, A.; Lu, W.; Lakshmanan, L.V. CELF++: Optimizing the greedy algorithm for influence maximization in social networks. In Proceedings of the 20th International Conference Companion on World Wide Web, Hyderabad, India, 28 March–1 April 2011; pp. 47–48. [Google Scholar]
- Chen, W.; Wang, Y.; Yang, S. Efficient influence maximization in social networks. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD ’09), Paris France, 28 June–1 July 2009; Association for Computing Machinery: New York, NY, USA, 2009; pp. 199–208. [Google Scholar]
- Chen, W.; Wang, C.; Wang, Y. Scalable influence maximization for prevalent viral marketing in large-scale social networks. In Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 24–28 July 2010; pp. 1029–1038. [Google Scholar]
- Tong, G.; Wu, W.; Tang, S.; Du, D.Z. Adaptive influence maximization in dynamic social networks. R. Soc. Open Sci. 2017, 25, 112–125. [Google Scholar] [CrossRef] [Green Version]
- Shang, J.; Zhou, S.; Li, X.; Liu, L.; Wu, H. CoFIM: A community-based framework for influence maximization on large-scale networks. Knowl.-Based Syst. 2017, 117, 88–100. [Google Scholar] [CrossRef]
- Gong, M.; Song, C.; Duan, C.; Ma, L.; Shen, B. An Efficient Memetic Algorithm for Influence Maximization in Social Networks. IEEE Comput. Intell. Mag. 2016, 11, 22–23. [Google Scholar] [CrossRef]
- Leskovec, J.; Krause, A.; Guestrin, C.; Faloutsos, C.; VanBriesen, J.; Glance, N. Cost-effective outbreak detection in networks. In Proceedings of the 13th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Jose, CA, USA, 12–15 August 2007; pp. 420–429. [Google Scholar]
- Lin, Y.; Chen, W.; Lui, J.C. Boosting information spread: An algorithmic approach. In Proceedings of the 2017 IEEE 33rd International Conference on Data Engineering (ICDE), San Diego, CA, USA, 19–22 April 2017; pp. 883–894. [Google Scholar]
- Shi, Q.; Wang, C.; Chen, J.; Feng, Y.; Chen, C. Post and repost: A holistic view of budgeted influence maximization. Neurocomputing 2019, 338, 92–100. [Google Scholar] [CrossRef]
- Shang, J.; Wu, H.; Zhou, S.; Zhong, J.; Feng, Y.; Qiang, B. IMPC: Influence maximization based on multi-neighbor potential in community networks. Physica A 2018, 512, 1085–1103. [Google Scholar] [CrossRef]
- Goldenberg, J.; Libai, B.; Muller, E. Talk of the Network: A Complex Systems Look at the Underlying Process of Word-of-Mouth. Mark. Lett. 2001, 12, 211–223. [Google Scholar] [CrossRef]
- Gong, Y.; Liu, S.; Bai, Y. Efficient parallel computing on the game theory-aware robust influence maximization problem. Knowl.-Based Syst. 2021, 220, 106942. [Google Scholar] [CrossRef]
- Jung, K.; Heo, W.; Chen, W. IRIE: Scalable and Robust Influence Maximization in Social Networks. In Proceedings of the 2012 IEEE 12th International Conference on Data Mining, Brussels, Belgium, 10–13 December 2012; pp. 918–923. [Google Scholar]
- Aldawish, R.; Kurdi, H. A modified degree discount Heuristic for influence maximization in social networks. Procedia Comput. Sci. 2020, 170, 311–316. [Google Scholar] [CrossRef]
- Kitsak, M.; Gallos, L.K.; Havlin, S.; Liljeros, F.; Muchnik, L.; Stanley, H.E.; Makse, H.A. Identification of influential spreaders in complex networks. Nat. Phys. 2010, 6, 888–893. [Google Scholar] [CrossRef] [Green Version]
- He, Q.; Wang, X.; Lei, Z.; Huang, M.; Cai, Y.; Ma, L. Tifim: A two-stage iterative framework for influence maximization in social networks. Appl. Math. Comput. 2019, 354, 338–352. [Google Scholar] [CrossRef]
- Erdos, P.; Rényi, A. On the evolution of random graphs. Publ. Math. Inst. Hung. Acad. Sci. 1960, 5, 17–60. [Google Scholar]
- Barabási, A.L. Scale-free networks: A decade and beyond. Science 2009, 325, 412–413. [Google Scholar] [CrossRef] [Green Version]
- Watts, D.J.; Strogatz, S.H. Collective dynamics of ‘small-world’ networks. Nature 1998, 393, 440–442. [Google Scholar] [CrossRef]
- Wang, W.; Street, W.N. Modeling and maximizing influence diffusion in social networks for viral marketing. Appl. Netw. Sci. 2018, 3, 1–26. [Google Scholar] [CrossRef] [Green Version]
- Liu, X.; Wu, S.; Liu, C.; Zhang, Y. Social network node influence maximization method combined with degree discount and local node optimization. Soc. Netw. Anal. Min. 2021, 11, 1–18. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| A | B | C | D | |
|---|---|---|---|---|
| cost (seed) | 1 | 1 | 1 | 3 |
| cost (boost) | 0.3 | 0.3 | 0.3 | 1 |
| New Strategy | Traditional Strategy | |
|---|---|---|
| role of node | seed node, boosting node | seed node, boosting node |
| relationship between different role nodes | The seed node is the predecessor of the boosting node | no connection |
| advantage | The cost is low and the role division of different nodes is obvious | The node iteration process is simple |
| Data Sets | Nodes | Edges | Average Degree |
|---|---|---|---|
| ER_to_directed | 3000 | 35,690 | 11.85 |
| BA_to_directed | 3000 | 23,837 | 7.95 |
| WS_to_directed | 3000 | 23,993 | 8.0 |
| Epinions | 75 k | 508 | 6.70 |
| Wiki-Vote | 7 k | 103 k | 14.57 |
| Dblp | 12 k | 49 k | 3.95 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Liu, S.; Gong, Y. A New Strategy in Boosting Information Spread. Entropy 2022, 24, 502. https://doi.org/10.3390/e24040502
Zhang X, Liu S, Gong Y. A New Strategy in Boosting Information Spread. Entropy. 2022; 24(4):502. https://doi.org/10.3390/e24040502
Chicago/Turabian StyleZhang, Xiaorong, Sanyang Liu, and Yudong Gong. 2022. "A New Strategy in Boosting Information Spread" Entropy 24, no. 4: 502. https://doi.org/10.3390/e24040502
APA StyleZhang, X., Liu, S., & Gong, Y. (2022). A New Strategy in Boosting Information Spread. Entropy, 24(4), 502. https://doi.org/10.3390/e24040502