Abstract
In this work, we focus on a general family of measures of divergence for estimation and testing with emphasis on conditional independence in cross tabulations. For this purpose, a restricted minimum divergence estimator is used for the estimation of parameters under constraints and a new double index (dual) divergence test statistic is introduced and thoroughly examined. The associated asymptotic theory is provided and the advantages and practical implications are explored via simulation studies.
1. Introduction
The concept of distance or divergence is known since at least the time of Pearson, who, in 1900, considered the classical goodness-of-fit (gof) problem by considering the distance between observed and expected frequencies. The problem for both discrete and discretized continuous distributions have been in the center of attention for the last 100+ years. The classical set-up is the one considered by Pearson where a hypothesized m-dimensional multinomial distribution, say is examined as being the underlying distributional mechanism for producing a given sample of size N. The problem can be extended to examine the homogeneity (in terms of the distributional mechanisms) among two independent samples or the independence among two population characteristics. In all such problems we are dealing with cross tabulations or crosstabs (or contingency tables). Problems of such nature appear frequently in a great variety of fields including biosciences, socio-economic and political sciences, actuarial science, finance, business, accounting, and marketing. The need to establish for instance, whether the mechanisms producing two phenomena are the same or not is vital for altering economic policies, preventing socio-economic crises or enforcing the same economic or financial decisions to groups with similar underlying mechanisms (e.g., retaining the insurance premium in case of similarity or having different premiums in case of diversity). It is important to note that divergence measures play a pivotal role also in statistical inference in continuous settings. Indeed, for example, in [1] the authors investigate the multivariate normal case while in a recent work [2], the modified skew-normal-Cauchy (MSNC) distribution is considered, against normality.
Let us consider the general case of two m-dimensional multinomial distributions for which each probability depends on an s-dimensional unknown parameter, say . A general family of measures introduced by [3] is the family defined by
where is a positive indicator (index) value, and , is a class of functions s.t. strictly convex, and by convention, and = .
Note that the well known Csiszar family of measures [4] is obtained for the special case where the indicator is taken to be equal to 0 while the classical Kullback–Leibler (KL) distance [5] is obtained if the indicator is equal to 0 and at the same time the function is taken to be .
The function
is associated with the Freeman–Tukey test when , with the recommended Cressie and Read (CR) power divergence [6] when , with the Pearson’s chi-squared divergence [7] when and with the classical KL distance when .
Finally, the function
produces the BHHJ or -power divergence [8] given by
Assume that the underlying true distribution of an m-dimensional multinomial random variable with N experiments, is
where is, in general, unknown, belonging to the parametric family
The sample estimate of is easily obtained by where is the observed frequency for the i-th category (or class).
Divergence measures can be used for estimating purposes by minimizing the associated measure. The classical estimating technique is the one where (1) we take and . Then, the resulting minimization is equivalent to the classical maximization of the likelihood producing the well-known Maximum Likelihood Estimator (MLE, see ([9], Section 5.2)). In general, the minimization with respect to the parameter of interest of the divergence measure, gives rise to the corresponding minimum divergence estimator (see, e.g., [6,10,11]). For the case where constraints are involved the case associated with Csiszar’s family of measures was recently investigated [12]. For further references, please refer to [13,14,15,16,17,18,19,20,21].
Consider the hypothesis
where is the vector of the true but unknown probabilities of the underlying distribution and the vector of the corresponding probabilities of the hypothesized distribution which is unknown and falls within the family of with the unknown parameters satisfying in general, certain constraints, e.g., of the form , under which the estimation of the parameter will be performed. The purpose of this work is twofold: having as a reference the divergence measure given in (1), we will first propose a general double index divergence class of measures and make inference regarding the parameter estimators involved. Then, we proceed with the hypothesis problem with the emphasis given to the concept of conditional independence. The innovative idea proposed in this work is the duality in choosing among the members of the general class of divergences, one for estimating and one for testing purposes which may not be necessarily, the same. In that sense, we propose a double index divergence test statistic offering the greatest possible range of options, both for the strictly convex function and the indicator value .
Thus, the estimation problem can be examined considering expression (1) using a function and an indicator :
the minimization of which with respect to the unknown parameter, will produce the restricted minimum divergence (rMD) estimator
for some constraints . Observe that the unknown vector of underlying probabilities has been replaced by the vector of the corresponding sample frequencies . Then, the testing problem will be based on
where and may be different from the corresponding quantities used for the estimation problem in (4). Finally, the duality of the proposed methodology surfaces when the testing problem is explored via the dual divergence test statistic formulated on the basis of the double--double- divergence given by
where and .
The remaining parts of this work are: Section 2 presents the formal definition and the asymptotic properties of the rMD estimator (rMDE). Section 3 deals with the general testing problem with the use of rMDE. The associated set up for the case of three-way contingency tables is developed in Section 4 with a simulation section emphasizing on the conditional independence of three random variables. We close this work with some conclusions.
2. Restricted Minimum -Power Divergence Estimator
In what follows, we will provide the formal definition and the expansion of the rMD estimator and prove its asymptotic normality. The assumptions required for establishing the results of this section for the rMD estimator under constraints, are provided below:
Assumption 1.
- are the constrained functions on the s-dimensional parameter , , and ;
- There exists a value , such that ;
- Each constraint function has continuous second partial derivatives;
- The and matricesare of full rank;
- p() has continuous second partial derivatives in a neighbourhood of ;
- satisfies the Birch regularity conditions (see Appendix A and [22]).
Definition 1.
Under assumptions – the rMD estimator of is any vector in Θ, such that
In order to derive the decomposition of the Implicit Function Theorem (IFT) is exploited according to which if a function has an invertible derivative at a point then itself is invertible in a neighbourhood of this point but it cannot be expressed in closed form [23].
Theorem 1.
Under Assumptions –, the rMD estimator of is such that
where is unique in a neighbourhood of and
Proof.
Let V be a neighbourhood of on which has continuous second partial derivatives where is the interior of the unit cube of dimension m. Let
with
where and , are the coefficients of the constraints.
It holds that
and by denoting , the matrix
is nonsingular at with .
Using the IFT a neighbourhood U of exists, such that is nonsingular and a unique differentiable function , such that and and . By the chain rule and for we obtain
Then
where
and
since
Expanding around and using (10) gives, for ,
Since eventually and then is the unique solution of the system
and . Hence, coincides with rMDE given in (9). □
The theorem below establishes the asymptotic normality of rMDE which is a straightforward extension of Theorem 2.4 [11] since by the Central Limit Theorem we know that
with the asymptotic variance-covariance matrix given by .
Theorem 2.
Remark 1.
The proposed class of estimators forms a family of estimators that goes beyond the indicator α since it is easy to see that estimators obtained for the Csiszar’s φ family are given for in (1) and also the standard equiprobable model.
3. Statistical Inference
In this section, we introduce the double index divergence test statistic
with and and make the additional assumptions by which we focus on the Csiszar’s family of measures for testing purposes (the notation is used for clarity) and the equiprobable model:
Assumption 2.
- .
The Theorem below provides the asymptotic distribution of (12) under Assumptions –. Assumption will be later relaxed and a general asymptotic result will be presented in the next subsection. A discussion about Assumption will also be made in the sequel.
Proof.
It is straightforward that
which by Theorem 2, expression (11), and for reduces to
which implies that
Combining the above we obtain
and
where
The expansion of around yields
where
Then, under , (see (14)) is a projection matrix of rank since the trace of the matrices and is equal to s and , respectively.
Then, the result follows from the fact (see ([24], p. 57)) that has a chi-squared distribution with degrees of freedom equal to the rank of the variance-covariance matrix of the random vector as long as it is a projection matrix. □
Remark 2.
Relaxation of Assumption : Arguing as in [11], when the true model is not the equiprobable the result of Theorem 3 holds true as long as and approximately true when .
Asymptotic Theory of the Dual Divergence Test Statistic
Having established the two main results of the work, namely the decomposition of the proposed restricted estimator (Theorem 1) together with its asymptotic properties (Theorem 2), as well as the asymptotic distribution of the associated test statistic under the class of Csiszar -functions (Theorem 3) we continue below extended in a natural way the results of [11] for the dual divergence test statistic. The extensions presented in this section are considered vital due to their practical impication on cross tabulations discussed in Section 4. The proofs will be omitted since both results (Theorems 4 and 5) follow along the lines of previous results (see Theorems 3.4 and 3.9 of [11]). In what follows we adopt the following notation:
Theorem 4.
Under Assumptions – we have
Remark 3.
Consider the case where Assumption is relaxed. Then, the asymptotic distribution of the test statistic is estimated to be approximately where
as long as or . For further elaboration of this remark we refer to [11].
Remark 4.
Observe that if then and the asymptotic distribution becomes , while for away from 0 the distribution is proportional to with proportionality index . However, for not equiprobable models these statements hold true as long as is close to zero.
Consider now the hypothesis with contiguous alternatives [25,26]
where is an m-dimensional vector of known real values with components satisfying the assumption .
Observe that as N tends to infinity, the local contiguous alternative converges to the null hypothesis at the rate . Alternatives, such as those in (16), are known as Pitman transition alternatives or Pitman (local) alternatives or local contiguous alternatives to the null hypothesis [25].
Theorem 5.
Under Assumptions – and for the hypothesis (16) we have
which represents a non-central chi-squared distribution with k degrees of freedom and non-centrality parameter for which =
Remark 5.
Observe that under Assumption () the asymptotic distribution is independent of Φ, and . As a result the associated power of the test is where a the percentile of the distribution. If assumption is relaxed then the distribution is approximately non-central chi-squared with proportionality index .
4. Cross Tabulations and Dual Divergence Test Statistic
In this section, we try to take advantage of the methodology proposed earlier for the analysis of cross tabulations. In particular we focus on the case of three categorical variables, say , and Z with corresponding, , and K. Then, assume that the probability mass of a realization of a randomly selected subject is denoted by , where here and in what follows , , unless otherwise stated. The associated probability vector is given as where
and the parameter space as . The sample estimator of is , where is the frequency of the corresponding cell.
In this set up the dual divergence test statistics is given as
where as above and the rMD estimator as
For , and special cases of the functions and , classical restricted minimum divergence estimators and associated test statistics can be derived from (18) and (17), respectively. For example, for , , and , = the likelihood ratio test statistic with the restricted maximum likelihood estimator can be derived, while for , = and we obtain the chi-squared test statistic with the restricted minimum chi-squared estimator . For , = and the dual divergence test statistic reduces to the power divergence test statistic with the restricted minimum power divergence estimator whereas for reduces to the Freeman–Tukey test statistic with the restricted minimum Freeman–Tukey estimator .
The hypothesis of conditional independence between X, Y, and Z is given for any triplet by
where
Under the constrained functions
the above hypothesis with unknown, becomes
where
Remark 6.
For practical purposes, the choice of the values of the indices is motivated by the work of [8] where, in an attempt to achieve a compromise between robustness and efficiency of estimators, they recommended the use of small values in the region. In the following subsection, our analysis will reconfirm their findings since as it will be seen, values of both indices close to (0) (than to one (1)) will be found to be associated with a good performance not only in terms of estimation but also in terms of goodness of fit as it will be reflected in the size and the power of the test.
Simulation Study
In this simulation study, we use the rMD estimator and the associated dual divergence test statistic for the analysis of cross tabulations. Specifically, we are going to compare in terms of size and power classical tests with those that can be derived through the proposed methodology, for the problem of conditional independence of three random variables in contingency tables. We test the hypothesis of conditional independence for a contingency table, thus in this case we have probabilities of the multinomial model, unknown parameters to estimate and two constraint functions which are given by
For a better understanding of the behaviour of the dual divergence test statistic given in (17) we compare it with the four classical tests-of-fit mentioned earlier in Section 4, namely with the , , and . The proposed test is applied for , and six different values of and , , = , , , , , and . Note that, the critical values used in this simulation study, are the asymptotic critical values based on the asymptotic distribution with b as in (15) for the double index family of test statistics, and the for the classical test statistics. For the analysis we used 100,000 simulations and sample sizes equal to (small sample sizes) and (moderate sample sizes).
In this study, we have used the model previously considered by [27] given by
where and with
For we take the model under the null hypothesis of conditional independence while for values we take the models under the alternative hypotheses. We considered the following values of w = , , , and . Note that the larger the value of w the more we deviate from the null model. For the simulation study, we used the software [28], while for the constrained optimization the function from the package [29].
From Table 1, we can observe that in terms of size the performance of the is adequate for values of both for small and moderate sample sizes. In addition, we can see that for , appears to be liberal while for appears to be conservative. We also note that the size becomes smaller as and increase with . Table 2 provides the size of the classical tests-of-fit from where we can observe that has the best performance among all competing tests for every sample size. In contrast, has the worst performance among all competing tests and appears to be very liberal. Furthermore, appears to be conservative while appears to be liberal. Note that for and , behaves better than the test statistic and its performance is quite close to the performance of the .

Table 1.
Size () calculations (%) of the test statistic for sample sizes . Sizes that satisfy Dale’s criterion are presented in bold.
Table 2.
Size () and power () calculations (%) for the classical tests-of-fit. Sizes that satisfy Dale’s criterion are presented in bold.
In order to examine the closeness of the estimated (true) size to the nominal size we consider the criterion given by Dale [30]. The criterion involves the following inequality
where and is the estimated (true) size. The estimated (true) size is considered to be close to the nominal size if (19) is satisfied with . Note that in this situation the estimated (true) size is close to the nominal one if and is presented in Table 1 and Table 2 in bold. This criterion has been used previously among others by [27,31].
Regarding the proposed test we can see that for small sample sizes the estimated (true) size is close to the nominal for and while for moderate sample sizes for and . With reference to the classical tests-of-fit we can observe that the size of the is close to the nominal for every sample size whereas the size of and is close only for moderate sample sizes. Finally, we note that the estimated (true) size of fails to be close to the nominal both for small and moderate sample sizes.
In Table 3, Table 4 and Table 5, we provide the results regarding the power of the proposed family of test statistics for the three alternatives and sample sizes , while Table 2 provides the results regarding the power of the classical tests-of-fit. The performance tends to be better as we deviate from the null model and as the sample size increases both for the classical and the proposed tests.
Table 3.
Power () calculations (%) of the test statistic for sample sizes .
Table 4.
Power () calculations (%) of the test statistic for sample sizes .
Table 5.
Power () calculations (%) of the test statistic for sample sizes .
As general comments regarding the behaviour of the proposed and the classical tests-of-fit in terms of power we state that the best results for the are obtained for small values of in the range and large values of with . Note that although in terms of power results become better as increases in terms of size these are adequate only for . In addition, we can observe that the performance of is better than the and for every alternative and every sample size for and and slightly better than for small values of and large values of , for example for and . Furthermore, we can observe that for and the size of the test is better than the size of the and slightly worst form the size of the and test statistics while its power is quite better than the power of the and and slightly worst than the . Additionally, we can see that as and tend to 0 the behaviour of the test statistic coincides with the test both in terms of size and power as it was expected.
In order to attain a better insight about the behaviour of the test statistics, we apply Dale’s criterion, not only for the nominal size , but also for a range of nominal sizes that are of interest. Based on the previous analysis, beside the classical tests, we will focus our interest on the , , and . The following simplified notation is used in every Figure, ≡, ≡, ≡, ≡, ≡, ≡, and = . From Figure 1a, we can see that for small sample sizes and satisfy Dale’s criterion for every nominal size while and for nominal sizes greater than and , respectively. Note that the dashed line in Figure 1 denotes the situation in which the estimated (true) size equals to the nominal size and thus lines that lie above this reference line refer to liberal tests while those that lie below to conservative ones. On the other hand, for moderate sample sizes all chosen test statistics satisfy Dale’s criterion except .
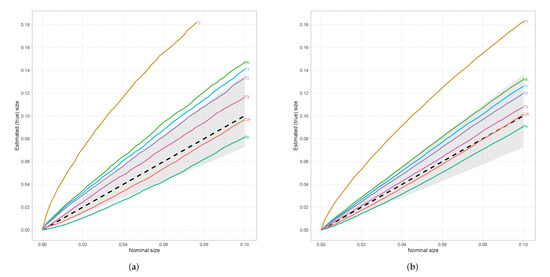
Figure 1.
Estimated (true) sizes against nominal sizes. The shaded area refers to Dale’s criterion. (a) . (b) .
Taking into account the fact that the actual size of each test differs from the targeted nominal size, we have to make an adjustment in order to proceed further with the comparison of the tests in terms of power. We focus our interest in those tests that satisfy Dale’s criterion and follow the method proposed in [32] which involves the so-called receiver operating characteristic (ROC) curves. In particular, let be the survivor function of a general test statistic T, and be the critical value, then ROC curves can be formulated by plotting the power against the size for various values of the critical value c. Note that with we denote the distribution of the test statistic under the null hypothesis and with under the alternative.
Since results are similar for every alternative we restrict ourselves to which refers to an alternative that is neither too close nor too far from the null. For small sample sizes results are presented in Figure 2, where we can see that the proposed test is superior from the classical tests-of-fit in terms of power. However, for moderate sample sizes we can observe in Figure 3 that has the best performance among all competing tests followed by the proposed test-of-fit.
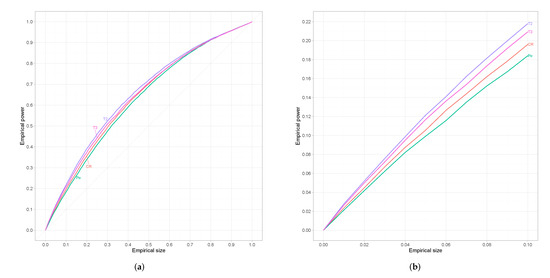
Figure 2.
(a) Empirical ROC curves for n = 25. (b) The same curves magnified over a relevant range of empirical sizes.
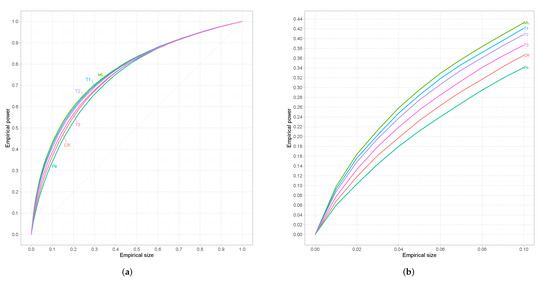
Figure 3.
(a) Empirical ROC curves for n = 45. (b) The same curves magnified over a relevant range of empirical sizes.
From the conducted analysis we conclude that regarding the proposed test there is a trade off between size and power for different choices of the indices and . In particular, we can see that as increases the size becomes smaller in the expense of smaller power, while as increases the power becomes better and the tests more liberal. In conclusion, we could state that for values of and in the range the resulting test statistic provides a fair balance between size and power which makes it an attractive alternative to the classical tests-of-fit where for small sample sizes larger values of the indices are preferable whereas for moderate sample sizes, smaller ones are recommended.
5. Conclusions
In this work, a general divergence family of test statistics is presented for hypothesis testing problems as in (3), under constraints. For estimating purposes, we introduce, discuss and use the rMD (restricted minimum divergence) estimator presented in (8). The proposed double index (dual) divergence test statistic involves two pairs of elements, namely to be used for the estimation problem and to be used for the testing problem. The duality refers to the fact that the two pairs may or may not be the same providing the researcher with the greatest possible flexibility.
The asymptotic distribution of the dual divergence test statistic is found to be proportional to the chi-squared distribution irrespectively of the nature of the multinomial model, as long as the values of the two indicators involved are relative close to zero (less than ). Such values are known to provide a satisfactory balance between efficiency and robustness (see, for instance, [8] or [3]).
The methodology developed in this work can be used in the analysis of contingency tables which is applicable in various scientific fields: biosciences, such as genetics [33] and epidemiology [34]; finance, such as the evaluation of investment effectiveness or business performance [35]; insurance science [36]; or socioeconomics [37]. This work concludes with a comparative simulation study between classical test statistics and members of the proposed family, where the focus is placed on the conditional independence of three random variables. Results indicate that, by selecting wisely the values of the and indices, we can derive a test statistic that can be thought of as a powerful and reliable alternative to the classical tests-of-fit especially for small sample sizes.
Author Contributions
Conceptualization, A.K. and C.M.; data curation, C.M.; methodology, A.K. and C.M; software, C.M.; formal analysis, A.K. and C.M.; writing—original draft preparation, C.M.; writing—review and editing, A.K. and C.M.; supervision, A.K. All authors have read and agreed to the published version of the manuscript.
Funding
The research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
The authors wish to express their appreciation to the anonymous referees and the Associated Editor for their valuable comments and suggestions. The authors wish also to express their appreciation to the professor A. Batsidis of the University of Ioannina for bringing to their attention citation [31] which helped greatly the comparative analysis performed in this work. This work was completed as part of the first author PhD thesis and falls within the research activities of the Laboratory of Statistics and Data Analysis of the University of the Aegean.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
The Birch regularity conditions mentioned in Assumption (A5) of Section 2 are stated below (for details see [22])
- The point is an interior point of ;
- for ;
- The mapping is totally differentiable at so that the partial derivatives of with respect to each exist at and has a linear approximation at given byas .
- The Jacobian matrixis of full rank;
- The mapping inverse to exists and is continuous at ;
- The mapping is continuous at every point .
References
- Salicru, M.; Morales, D.; Menendez, M.; Pardo, L. On the Applications of Divergence Type Measures in Testing Statistical Hypotheses. J. Multivar. Anal. 1994, 51, 372–391. [Google Scholar] [CrossRef]
- Contreras-Reyes, J.E.; Kahrari, F.; Cortés, D.D. On the modified skew-normal-Cauchy distribution: Properties, inference and applications. Commun. Stat. Theory Methods 2021, 50, 3615–3631. [Google Scholar] [CrossRef]
- Mattheou, K.; Karagrigoriou, A. A New Family of Divergence Measures for Tests of Fit. Aust. N. Z. J. Stat. 2010, 52, 187–200. [Google Scholar] [CrossRef]
- Csiszár, I. Eine Informationstheoretische Ungleichung und Ihre Anwendung auf Beweis der Ergodizitaet von Markoffschen Ketten. Magyer Tud. Akad. Mat. Kut. Int. Koezl. 1963, 8, 85–108. [Google Scholar]
- Kullback, S.; Leibler, R.A. On Information and Sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Cressie, N.; Read, T.R.C. Multinomial Goodness-of-Fit Tests. J. R. Stat. Soc. Ser. B Methodol. 1984, 46, 440–464. [Google Scholar] [CrossRef]
- Pearson, K. On the criterion that a given system of deviations from the probable in the case of a correlated system of variables is such that it can be reasonably supposed to have arisen from random sampling. Lond. Edinb. Dublin Philos. Mag. J. Sci. 1900, 50, 157–175. [Google Scholar] [CrossRef]
- Basu, A.; Harris, I.R.; Hjort, N.L.; Jones, M.C. Robust and Efficient Estimation by Minimising a Density Power Divergence. Biometrika 1998, 85, 549–559. [Google Scholar] [CrossRef]
- Pardo, L. Statistical Inference Based on Divergence Measures; Chapman and Hall/CRC: New York, NY, USA, 2006. [Google Scholar]
- Morales, D.; Pardo, L.; Vajda, I. Asymptotic Divergence of Estimates of Discrete Distributions. J. Stat. Plan. Inference 1995, 48, 347–369. [Google Scholar] [CrossRef]
- Meselidis, C.; Karagrigoriou, A. Statistical Inference for Multinomial Populations Based on a Double Index Family of Test Statistics. J. Stat. Comput. Simul. 2020, 90, 1773–1792. [Google Scholar] [CrossRef]
- Pardo, J.; Pardo, L.; Zografos, K. Minimum φ-divergence Estimators with Constraints in Multinomial Populations. J. Stat. Plan. Inference 2002, 104, 221–237. [Google Scholar] [CrossRef]
- Read, T.R.; Cressie, N.A. Goodness-of-Fit Statistics for Discrete Multivariate Data; Springer: New York, NY, USA, 1988. [Google Scholar]
- Alin, A.; Kurt, S. Ordinary and Penalized Minimum Power-divergence Estimators in Two-way Contingency Tables. Comput. Stat. 2008, 23, 455–468. [Google Scholar] [CrossRef]
- Toma, A. Optimal Robust M-estimators Using Divergences. Stat. Probab. Lett. 2009, 79, 1–5. [Google Scholar] [CrossRef]
- Jiménez-Gamero, M.; Pino-Mejías, R.; Alba-Fernández, V.; Moreno-Rebollo, J. Minimum ϕ-divergence Estimation in Misspecified Multinomial Models. Comput. Stat. Data Anal. 2011, 55, 3365–3378. [Google Scholar] [CrossRef]
- Kim, B.; Lee, S. Minimum density power divergence estimator for covariance matrix based on skew t distribution. Stat. Methods Appl. 2014, 23, 565–575. [Google Scholar] [CrossRef]
- Neath, A.A.; Cavanaugh, J.E.; Weyhaupt, A.G. Model Evaluation, Discrepancy Function Estimation, and Social Choice Theory. Comput. Stat. 2015, 30, 231–249. [Google Scholar] [CrossRef]
- Ghosh, A. Divergence based robust estimation of the tail index through an exponential regression model. Stat. Methods Appl. 2016, 26, 181–213. [Google Scholar] [CrossRef]
- Jiménez-Gamero, M.D.; Batsidis, A. Minimum Distance Estimators for Count Data Based on the Probability Generating Function with Applications. Metrika 2017, 80, 503–545. [Google Scholar] [CrossRef]
- Basu, A.; Ghosh, A.; Mandal, A.; Martin, N.; Pardo, L. Robust Wald-type tests in GLM with random design based on minimum density power divergence estimators. Stat. Methods Appl. 2021, 30, 973–1005. [Google Scholar] [CrossRef]
- Birch, M.W. A New Proof of the Pearson-Fisher Theorem. Ann. Math. Stat. 1964, 35, 817–824. [Google Scholar] [CrossRef]
- Krantz, S.G.; Parks, H.R. The Implicit Function Theorem: History, Theory, and Applications; Birkhäuser: Basel, Swiztherland, 2013. [Google Scholar]
- Ferguson, T.S. A Course in Large Sample Theory; Chapman and Hall: Boca Raton, FL, USA, 1996. [Google Scholar]
- McManus, D.A. Who Invented Local Power Analysis? Econom. Theory 1991, 7, 265–268. [Google Scholar] [CrossRef]
- Neyman, J. “Smooth” Test for Goodness of Fit. Scand. Actuar. J. 1937, 1937, 149–199. [Google Scholar] [CrossRef]
- Pardo, J.A. An approach to multiway contingency tables based on φ-divergence test statistics. J. Multivar. Anal. 2010, 101, 2305–2319. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2016. [Google Scholar]
- Johnson, S.G. The NLopt Nonlinear-Optimization Package. 2014. Available online: http://ab-initio.mit.edu/nlopt (accessed on 27 March 2022).
- Dale, J.R. Asymptotic Normality of Goodness-of-Fit Statistics for Sparse Product Multinomials. J. R. Stat. Soc. Ser. B Methodol. 1986, 48, 48–59. [Google Scholar] [CrossRef]
- Batsidis, A.; Martin, N.; Pardo Llorente, L.; Zografos, K. φ-Divergence Based Procedure for Parametric Change-Point Problems. Methodol. Comput. Appl. Probab. 2016, 18, 21–35. [Google Scholar] [CrossRef]
- Lloyd, C.J. Estimating test power adjusted for size. J. Stat. Comput. Simul. 2005, 75, 921–933. [Google Scholar] [CrossRef]
- Dubrova, Y.E.; Grant, G.; Chumak, A.A.; Stezhka, V.A.; Karakasian, A.N. Elevated Minisatellite Mutation Rate in the Post-Chernobyl Families from Ukraine. Am. J. Hum. Genet. 2002, 71, 801–809. [Google Scholar] [CrossRef]
- Znaor, A.; Brennan, P.; Gajalakshmi, V.; Mathew, A.; Shanta, V.; Varghese, C.; Boffetta, P. Independent and combined effects of tobacco smoking, chewing and alcohol drinking on the risk of oral, pharyngeal and esophageal cancers in Indian men. Int. J. Cancer 2003, 105, 681–686. [Google Scholar] [CrossRef]
- Merková, M. Use of Investment Controlling and its Impact into Business Performance. Procedia Econ. Financ. 2015, 34, 608–614. [Google Scholar] [CrossRef][Green Version]
- Geenens, G.; Simar, L. Nonparametric tests for conditional independence in two-way contingency tables. J. Multivar. Anal. 2010, 101, 765–788. [Google Scholar] [CrossRef]
- Bartolucci, F.; Scaccia, L. Testing for positive association in contingency tables with fixed margins. Comput. Stat. Data Anal. 2004, 47, 195–210. [Google Scholar] [CrossRef]



Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).