Abstract
By calculating the Kullback–Leibler divergence between two probability measures belonging to different exponential families dominated by the same measure, we obtain a formula that generalizes the ordinary Fenchel–Young divergence. Inspired by this formula, we define the duo Fenchel–Young divergence and report a majorization condition on its pair of strictly convex generators, which guarantees that this divergence is always non-negative. The duo Fenchel–Young divergence is also equivalent to a duo Bregman divergence. We show how to use these duo divergences by calculating the Kullback–Leibler divergence between densities of truncated exponential families with nested supports, and report a formula for the Kullback–Leibler divergence between truncated normal distributions. Finally, we prove that the skewed Bhattacharyya distances between truncated exponential families amount to equivalent skewed duo Jensen divergences.
1. Introduction
1.1. Exponential Families
Let be a measurable space, and consider a regular minimal exponential family [1] of probability measures all dominated by a base measure ():
The Radon–Nikodym derivatives or densities of the probability measures with respect to can be written canonically as
where denotes the natural parameter, the sufficient statistic [1,2,3,4], and the log-normalizer [1] (or cumulant function). The optional auxiliary term allows us to change the base measure into the measure such that . The order D of the family is the dimension of the natural parameter space :
where denotes the set of reals. The sufficient statistic is a vector of D functions. The sufficient statistic is said to be minimal when the functions 1, , …, are linearly independent [1]. The sufficient statistics are such that the probability . That is, all information necessary for the statistical inference of parameter is contained in . Exponential families are characterized as families of parametric distributions with finite-dimensional sufficient statistics [1]. Exponential families include among others the exponential, normal, gamma/beta, inverse gamma, inverse Gaussian, and Wishart distributions once a reparameterization of the parametric distributions is performed to reveal their natural parameters [1].
When the sufficient statistic is x, these exponential families [1] are called natural exponential families or tilted exponential families [5] in the literature. Indeed, the distributions of the exponential family can be interpreted as distributions obtained by tilting the base measure [6]. In this paper, we consider either discrete exponential families like the family of Poisson distributions (univariate distributions of order with respect to the counting measure) or continuous exponential families like the family of normal distributions (univariate distributions of order with respect to the Lebesgue measure). The Radon–Nikodym derivative of a discrete exponential family is a probability mass function (pmf), and the Radon–Nikodym derivative of a continuous exponential family is a probability density function (pdf). The support of a pmf is (where denotes the set of integers) and the support of a d-variate pdf is . The Poisson distributions have support where denotes the set of natural numbers . Densities of an exponential family all have coinciding support [1].
1.2. Truncated Exponential Families with Nested Supports
In this paper, we shall consider truncated exponential families [7] with nested supports. A truncated exponential family is a set of parametric probability distributions obtained by truncation of the support of an exponential family. Truncated exponential families are exponential families but their statistical inference is more subtle [8,9]. Let be a truncated exponential family of with nested supports . The canonical decompositions of densities and have the following expressions:
where the log-normalizer of the truncated exponential family is:
where is a normalizing term that takes into account the truncated support . These equations show that densities of truncated exponential families only differ by their log-normalizer functions. Let denote the support of the distributions of and the support of . Family is a truncated exponential family of that can be notationally written as . Family can also be interpreted as the (un)truncated exponential family with densities . A truncated exponential family of is said to have nested support when . For example, the family of half-normal distributions defined on the support is a nested truncated exponential family of the family of normal distributions defined on the support .
1.3. Kullback–Leibler Divergence between Exponential Family Distributions
For two -finite probability measures P and Q on such that P is dominated by Q (), the Kullback–Leibler divergence between P and Q is defined by
where denotes the expectation of a random variable [10]. When , we set . Gibbs’ inequality [11] shows that the Kullback–Leibler divergence (KLD for short) is always non-negative. The proof of Gibbs’ inequality relies on Jensen’s inequality and holds for the wide class of f-divergences [12] induced by convex generators :
The KLD is an f-divergence obtained for the convex generator .
1.4. Kullback–Leibler Divergence between Exponential Family Densities
It is well-known that the KLD between two distributions and of amounts to computing an equivalent Fenchel–Young divergence [13]:
where is the moment parameter [1] and
is the gradient of F with respect to . The Fenchel–Young divergence is defined for a pair of strictly convex conjugate functions [14] and related by the Legendre–Fenchel transform by
Amari (1985) first introduced this formula as the canonical divergence of dually flat spaces in information geometry [15] (Equation 3.21), and proved that the Fenchel–Young divergence is obtained as the KLD between densities belonging to the same exponential family [15] (Theorem 3.7). Azoury and Warmuth expressed the KLD using dual Bregman divergences in [13] (2001):
where a Bregman divergence [16] is defined for a strictly convex and differentiable generator by:
Acharyya termed the divergence the Fenchel–Young divergence in his PhD thesis [17] (2013), and Blondel et al. called such divergences Fenchel–Young losses (2020) in the context of machine learning [18] (Equation (9) in Definition 2). This term was also used by the author the Legendre–Fenchel divergence in [19]. The Fenchel–Young divergence stems from the Fenchel–Young inequality [14,20]:
with equality if and only if .
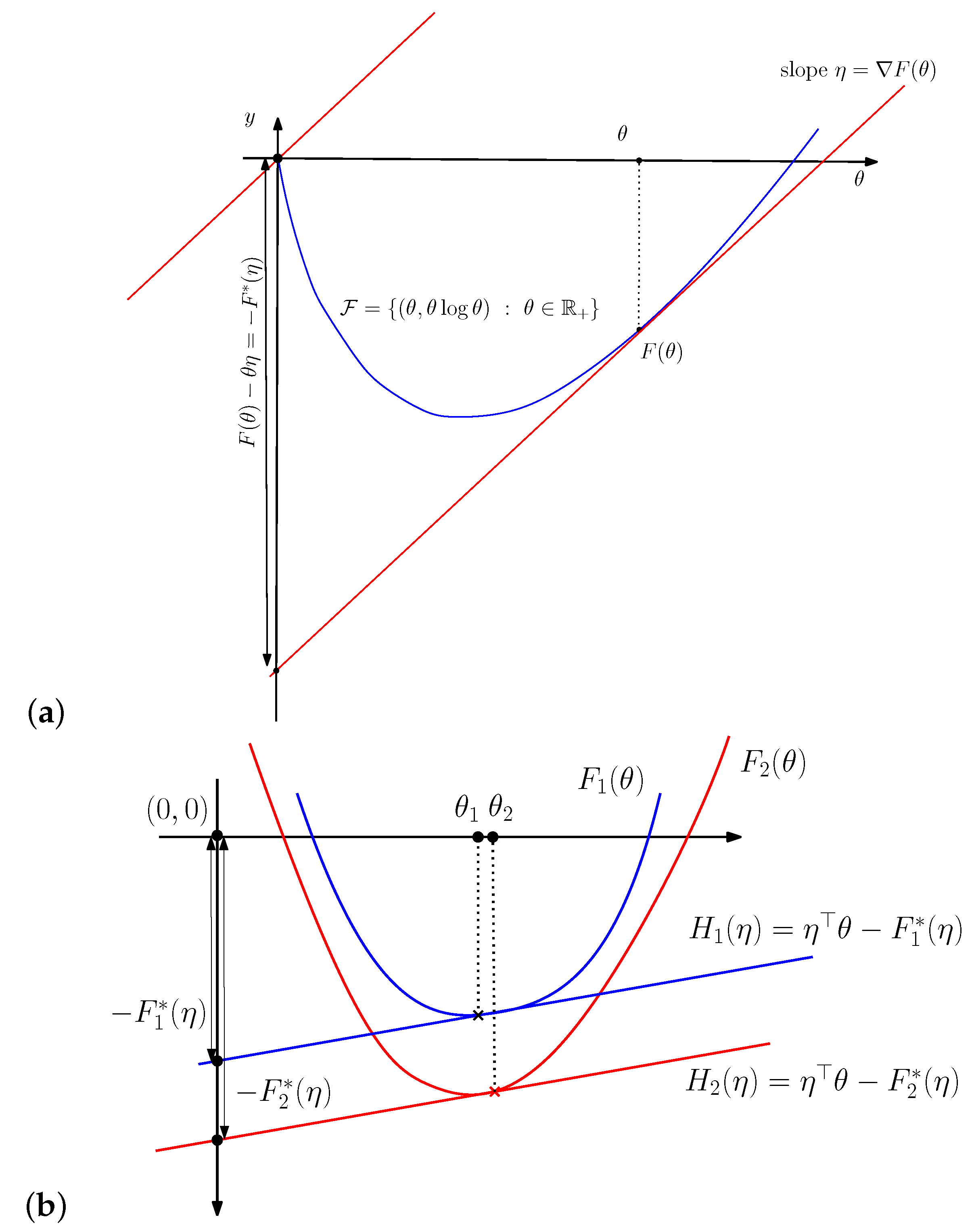
Figure 1 visualizes the 1D Fenchel–Young divergence and gives a geometric proof that with equality if and only if . Indeed, by considering the behavior of the Legendre–Fenchel transformation under translations:
- if then for all , and
- if then for all ,
we may assume without loss of generality that . The function is strictly increasing and continuous since is a strictly convex and differentiable convex function. Thus we have and .
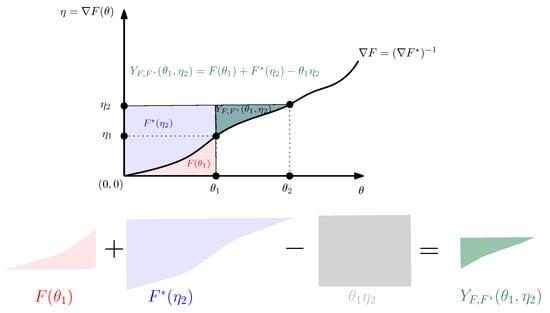
Figure 1.
Visualizing the Fenchel–Young divergence.
Figure 1.
Visualizing the Fenchel–Young divergence.
The Bregman divergence amounts to a dual Bregman divergence [13] between the dual parameters with swapped order: where for . Thus the KLD between two distributions and of can be expressed equivalently as follows:
The symmetrized Kullback–Leibler divergence between two distributions and of is called Jeffreys’ divergence [21] and amounts to a symmetrized Bregman divergence [22]:
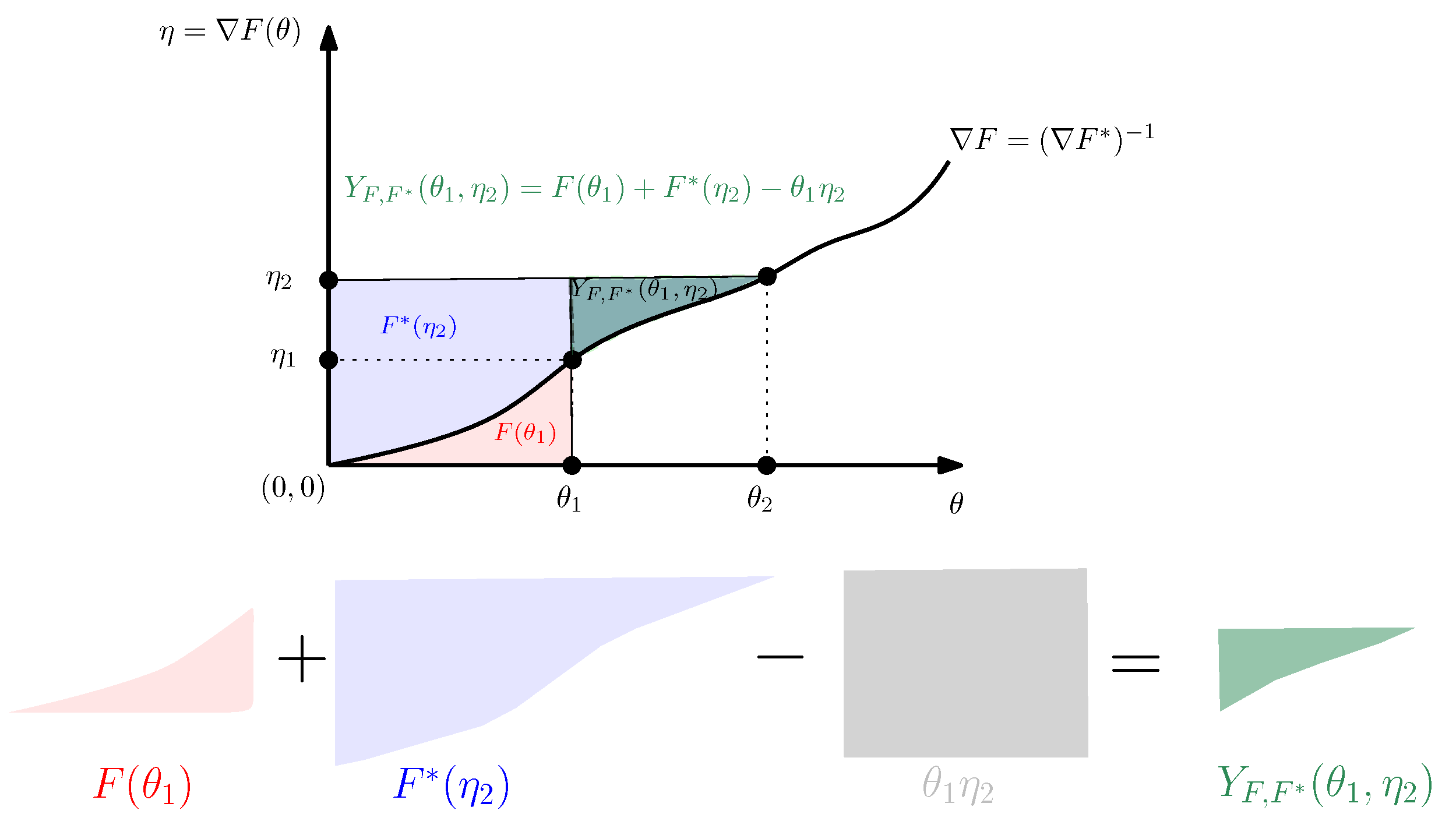
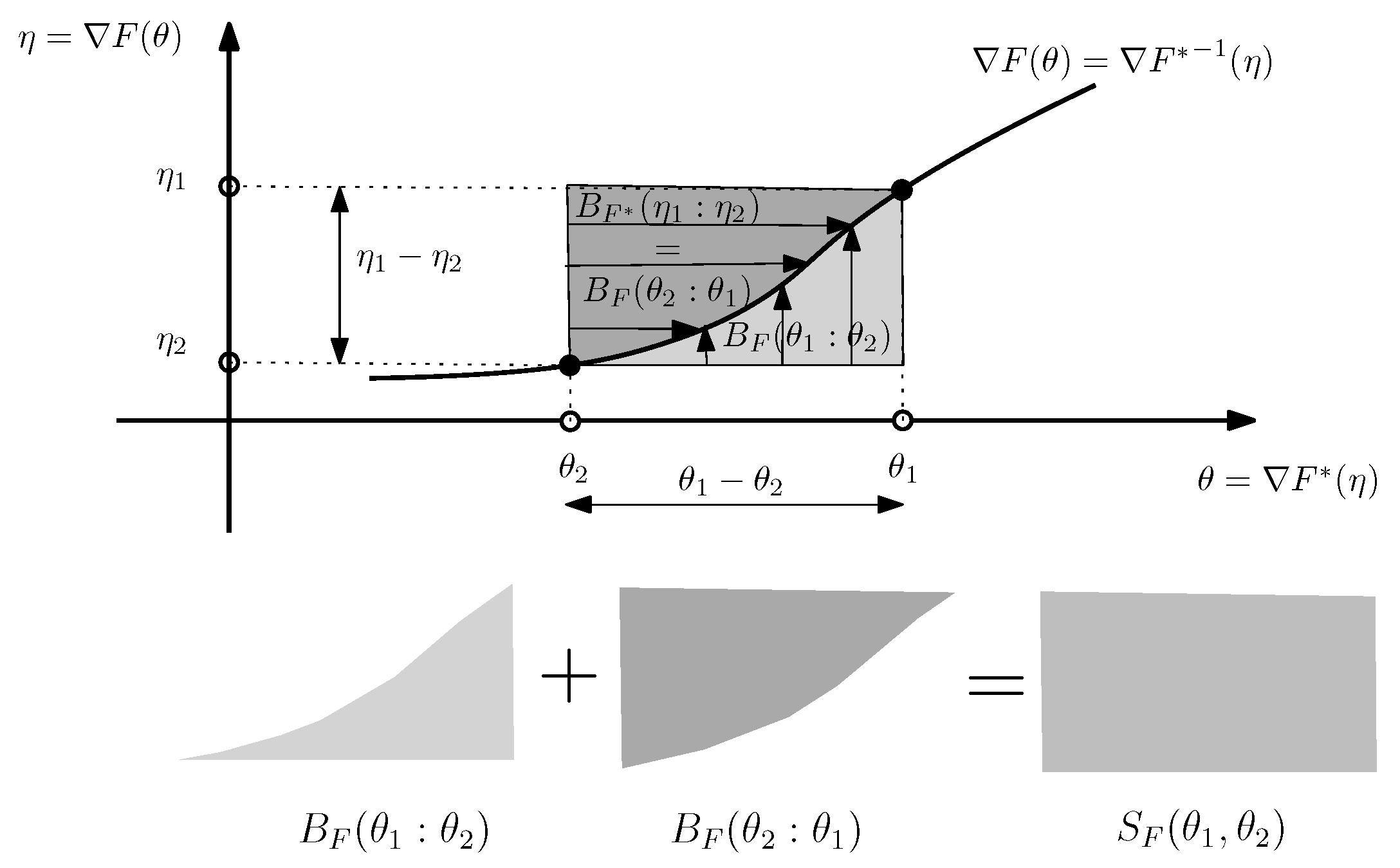
Note that the Bregman divergence can also be interpreted as a surface area:
Figure 2 illustrates the sided and symmetrized Bregman divergences.
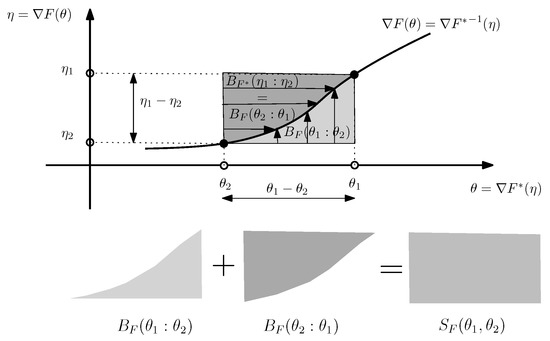
Figure 2.
Visualizing the sided and symmetrized Bregman divergences.
1.5. Contributions and Paper Outline
We recall in Section 2 the formula obtained for the Kullback–Leibler divergence between two exponential family densities equivalent to each other [23] (Equation (29)). Inspired by this formula, we give a definition of the duo Fenchel–Young divergence induced by a pair of strictly convex functions and (Definition 1) in Section 3, and prove that the divergence is always non-negative provided that upper bounds . We then define the duo Bregman divergence (Definition 2) corresponding to the duo Fenchel–Young divergence. In Section 4, we show that the Kullback–Leibler divergence between a truncated density and a density of a same parametric exponential family amounts to a duo Fenchel–Young divergence or equivalently to a duo Bregman divergence on swapped parameters (Theorem 1). That is, we consider a truncated exponential family [7] of an exponential family such that the common support of the distributions of is contained in the common support of the distributions of and both canonical decompositions of the families coincide (see Equation (2)). In particular, when is also a truncated exponential family of , then we express the KLD between two truncated distributions as a duo Bregman divergence. As examples, we report the formula for the Kullback–Leibler divergence between two densities of truncated exponential families (Corollary 1), and illustrate the formula for the Kullback–Leibler divergence between truncated exponential distributions (Example 6) and for the Kullback–Leibler divergence between truncated normal distributions (Example 7).
2. Kullback–Leibler Divergence between Different Exponential Families
Consider now two exponential families [1] and defined by their Radon–Nikodym derivatives with respect to two positive measures and on :
The corresponding natural parameter spaces are
The order of is D, denotes the sufficient statistics of , and is a term to adjust/tilt the base measure . Similarly, the order of is , denotes the sufficient statistics of , and is an optional term to adjust the base measure . Let and denote the Radon–Nikodym derivatives with respect to the measures and , respectively:
where and denote the corresponding log-normalizers of and , respectively.
The functions and are strictly convex and real analytic [1]. Hence, those functions are infinitely many times differentiable on their open natural parameter spaces.
Consider the KLD between and such that (and hence ). Then the KLD between and was first considered in [23]:
Recall that the dual parameterization of an exponential family density is with [1], and that the Fenchel–Young equality is for . Thus the KLD between and can be rewritten as
This formula was reported in [23] and generalizes the Fenchel–Young divergence [17] obtained when (with , , and and ).
The formula of Equation (29) was illustrated in [23] with two examples: the KLD between Laplacian distributions and zero-centered Gaussian distributions, and the KLD between two Weibull distributions. Both these examples use the Lebesgue base measure for and .
Let us report another example that uses the counting measure as the base measure for and .
Example 1.

Consider the KLD between a Poisson probability mass function (pmf) and a geometric pmf. The canonical decompositions of the Poisson and geometric pmfs are summarized in Table 1. The KLD between a Poisson pmf and a geometric pmf is equal to
Table 1.
Canonical decomposition of the Poisson and the geometric discrete exponential families.
Since , we have
Note that we can calculate the KLD between two geometric distributions and as
We obtain:
3. The Duo Fenchel–Young Divergence and Its Corresponding Duo Bregman Divergence
Inspired by formula of Equation (29), we shall define the duo Fenchel–Young divergence using a dominance condition on a pair of strictly convex generators.
Definition 1
(duo Fenchel–Young divergence). Let and be two strictly convex functions such that for any . Then the duo Fenchel–Young divergence is defined by
When , we have , and we retrieve the ordinary Fenchel–Young divergence [17]:
Note that in Equation (35), we have .
Property 1
(Non-negative duo Fenchel–Young divergence). The duo Fenchel–Young divergence is always non-negative.
Proof.
The proof relies on the reverse dominance property of strictly convex and differentiable conjugate functions:
Lemma 1
(Reverse majorization order of functions by the Legendre–Fenchel transform). Let and be two Legendre-type convex functions [14]. Then if then we have .
Proof .
This property is graphically illustrated in Figure 3. The reverse dominance property of the Legendre–Fenchel transformation can be checked algebraically as follows:
□
Thus we have when . Therefore it follows that since we have
where is the ordinary Fenchel–Young divergence, which is guaranteed to be non-negative from the Fenchel–Young inequality. □
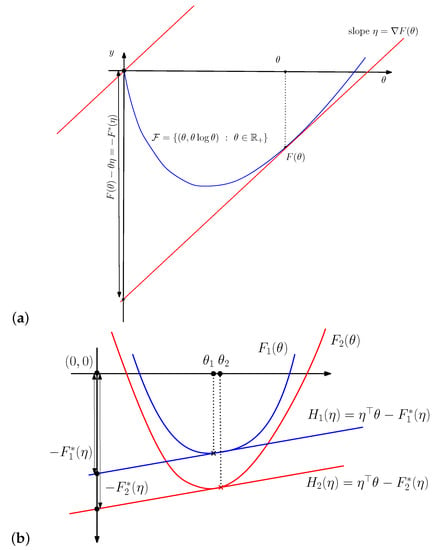
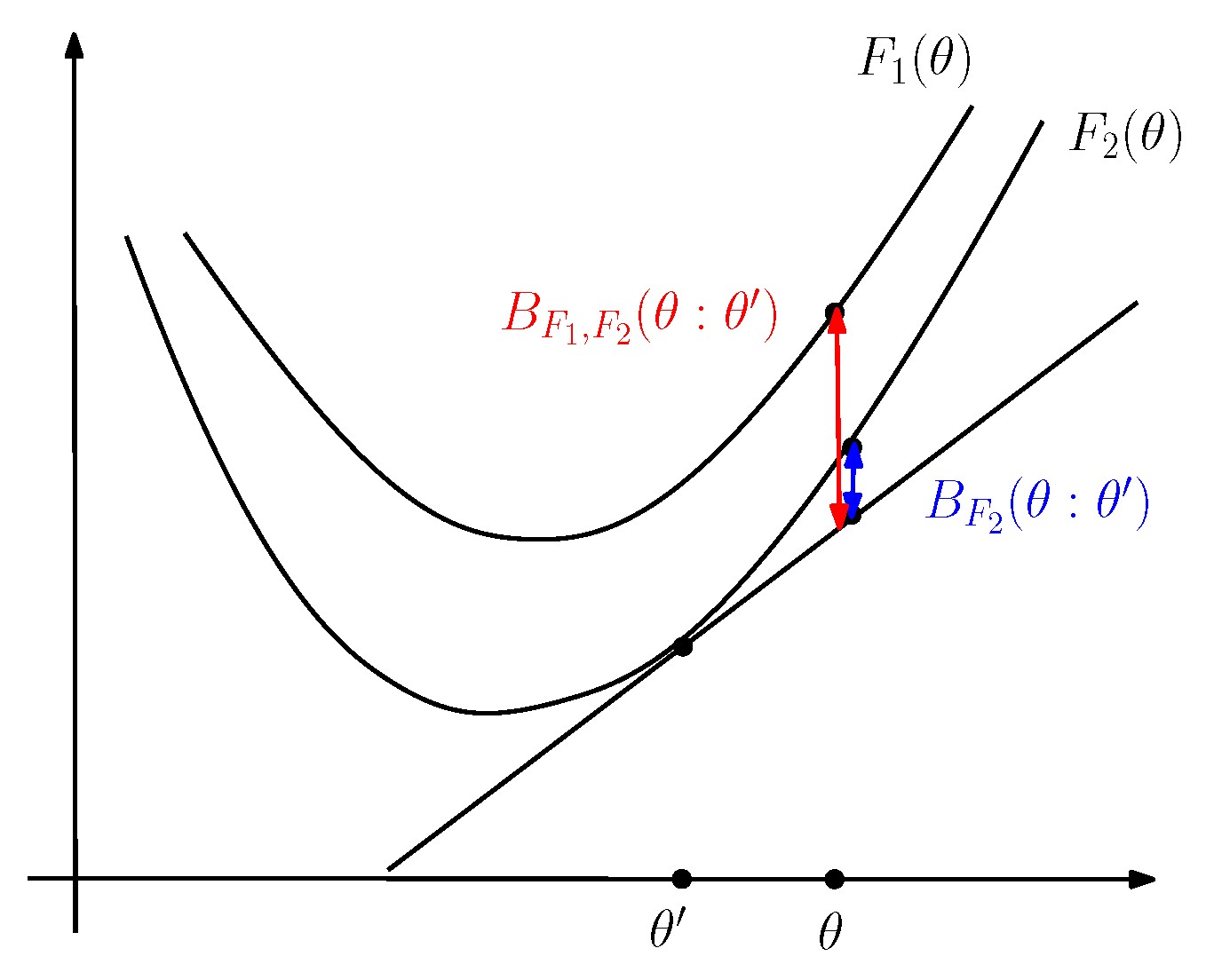
Figure 3.
(a) Visual illustration of the Legendre–Fenchel transformation: is measured as the vertical gap (left long black line with both arrows) between the origin and the hyperplane of the “slope” tangent at evaluated at . (b) The Legendre transforms and of two functions and such that reverse the dominance order: .
Figure 3.
(a) Visual illustration of the Legendre–Fenchel transformation: is measured as the vertical gap (left long black line with both arrows) between the origin and the hyperplane of the “slope” tangent at evaluated at . (b) The Legendre transforms and of two functions and such that reverse the dominance order: .
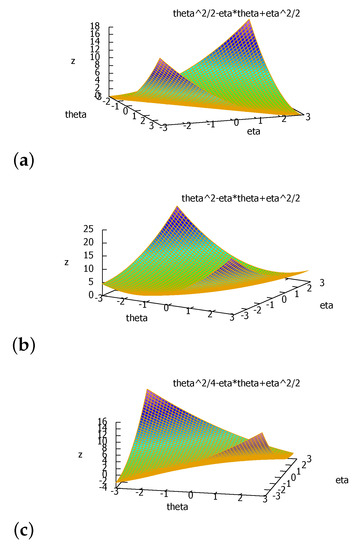
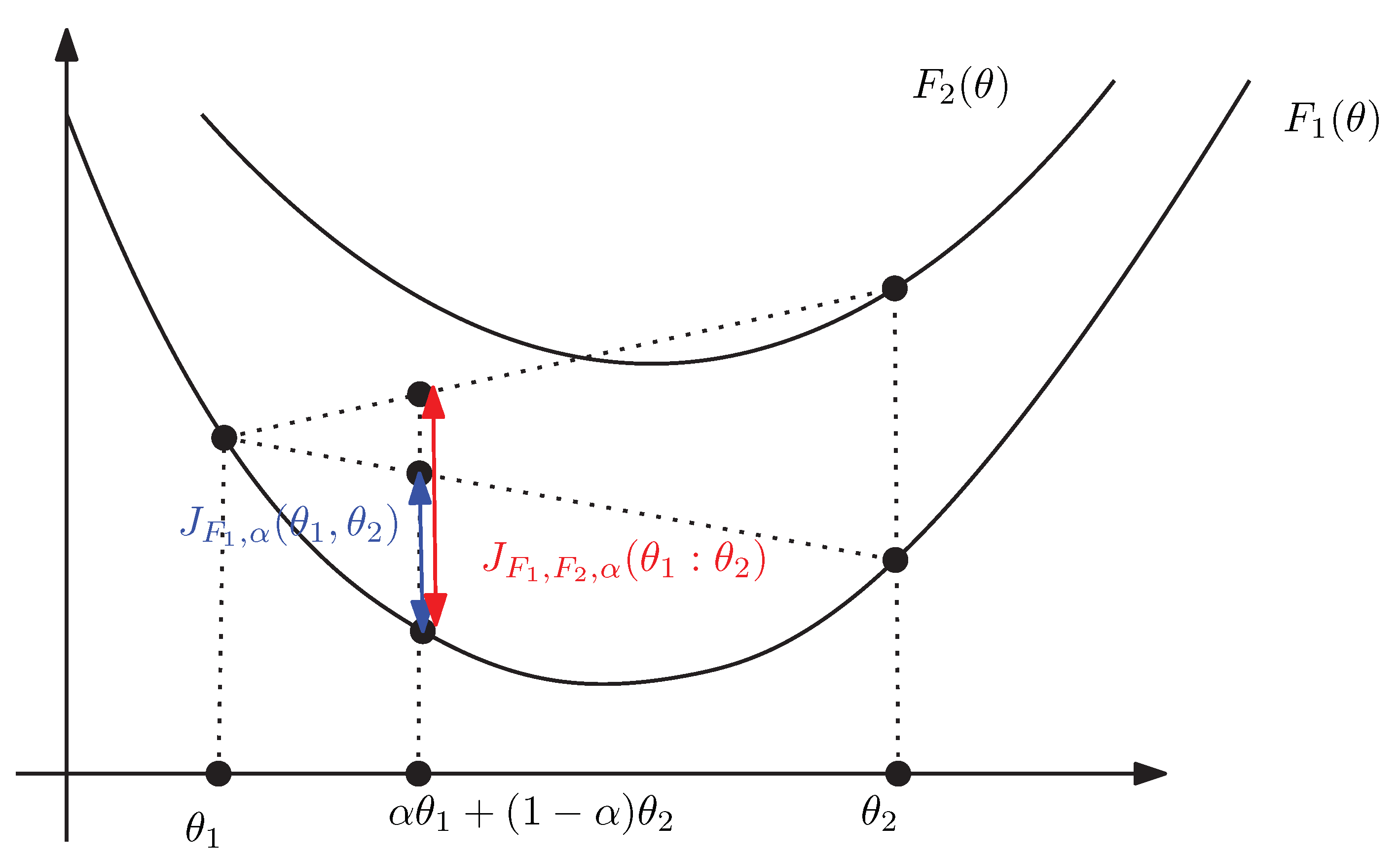
We can express the duo Fenchel–Young divergence using the primal coordinate systems as a generalization of the Bregman divergence to two generators that we term the duo Bregman divergence (see Figure 4):
with .
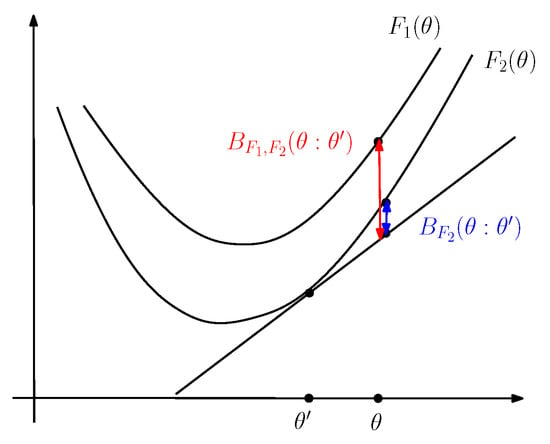
Figure 4.
The duo Bregman divergence induced by two strictly convex and differentiable functions and such that . We check graphically that (vertical gaps).
This generalized Bregman divergence is non-negative when . Indeed, we check that
Definition 2
(duo Bregman divergence). Let and be two strictly convex functions such that for any . Then the generalized Bregman divergence is defined by
Example 2.
Consider for . We have , , and
Let so that for . We check that when . The duo Fenchel–Young divergence is
when . We can express the duo Fenchel–Young divergence in the primal coordinate systems as
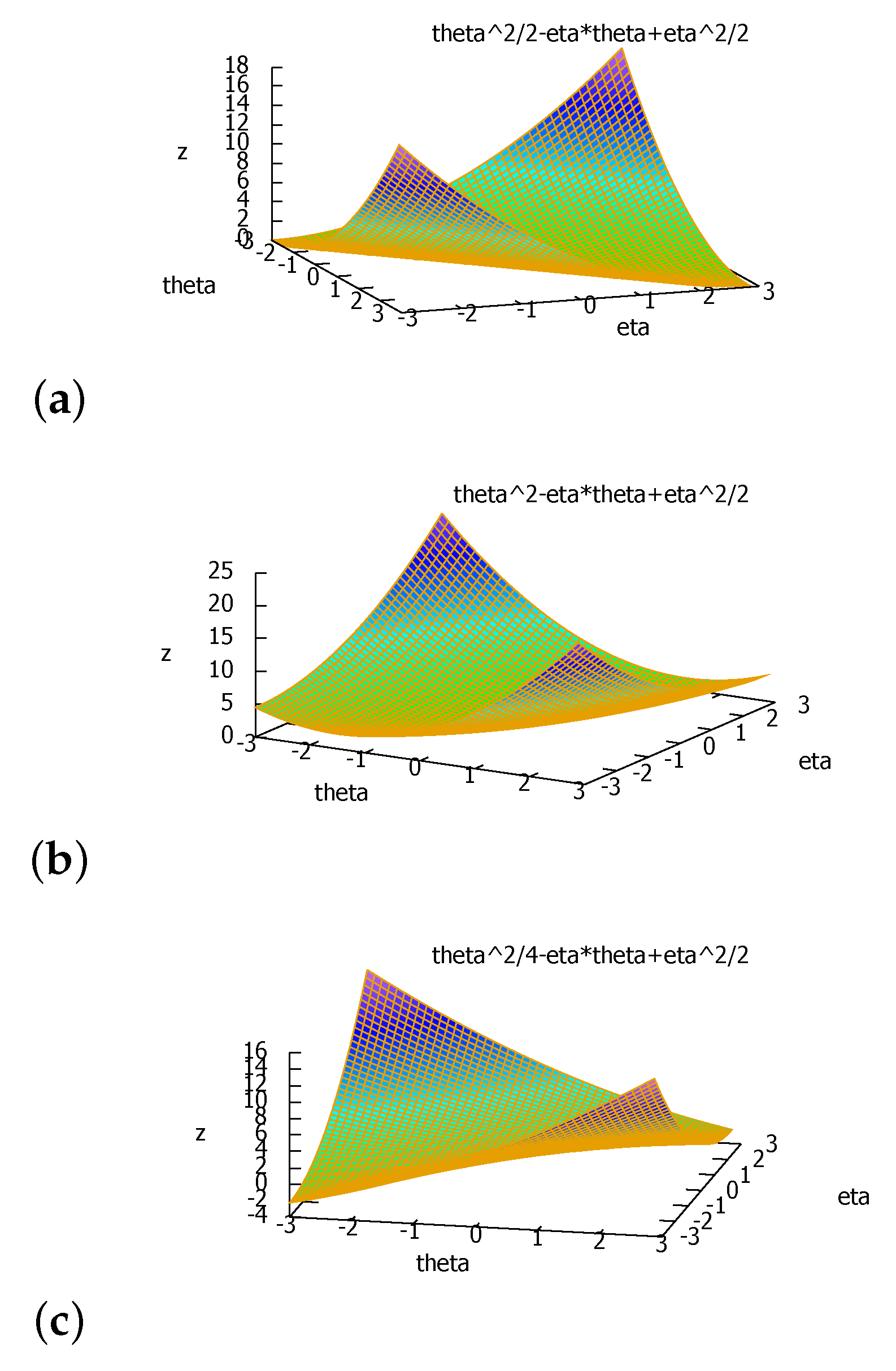
When , , and we obtain , half the squared Euclidean distance as expected. Figure 5 displays the graph plot of the duo Bregman divergence for several values of a.
Figure 5.
The duo half squared Euclidean distance is non-negative when : (a) half squared Euclidean distance (), (b) , (c) , which shows that the divergence can be negative then since .
Example 3.
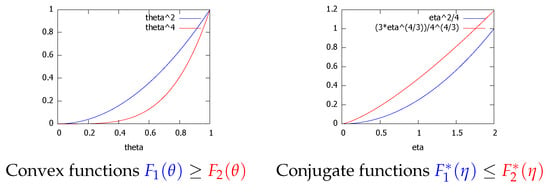
Consider and on the domain . We have for . The convex conjugate of is . We have
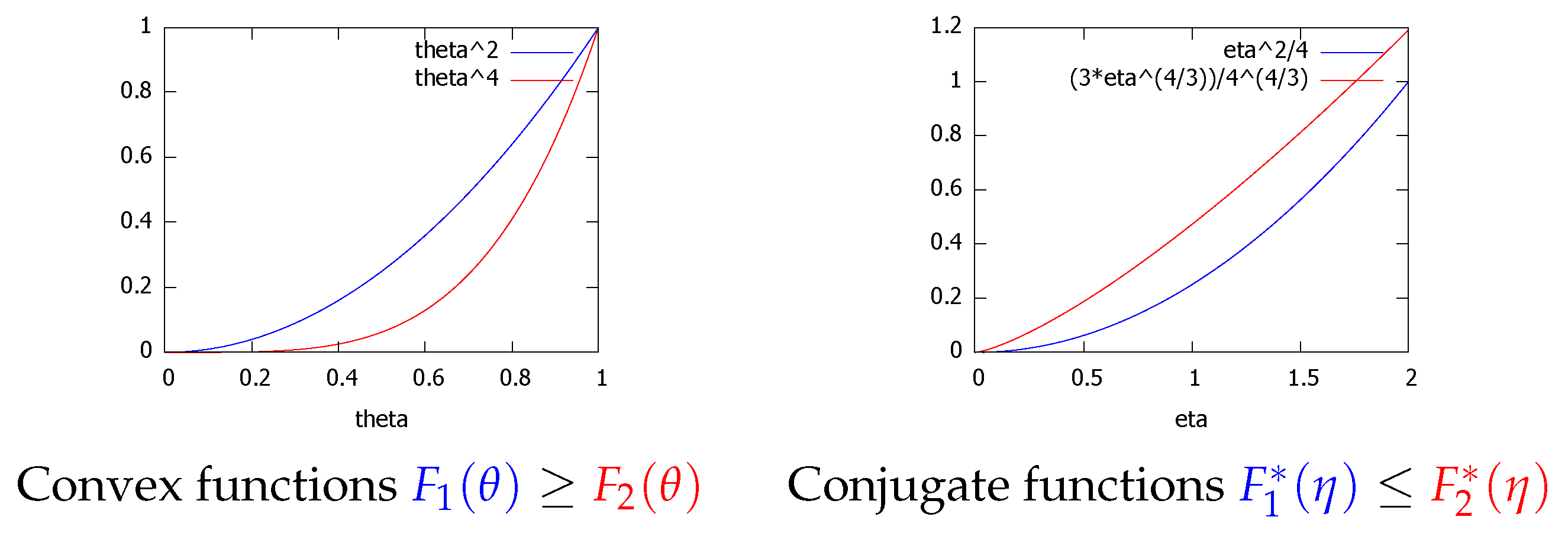
with . Figure 6 plots the convex functions and , and their convex conjugates and . We observe that on and that on .
Figure 6.
The Legendre transform reverses the dominance ordering: for .
We now state a property between dual duo Bregman divergences:
Property 2
(Dual duo Fenchel–Young and Bregman divergences). We have
Proof.
From the Fenchel–Young equalities of the inequalities, we have for and with . Thus we have
Recall that implies that (Lemma 1), , and therefore the dual duo Bregman divergence is non-negative:
□
4. Kullback–Leibler Divergence between Distributions of Truncated Exponential Families
Let be an exponential family of distributions all dominated by with Radon–Nikodym density defined on the support . Let be another exponential family of distributions all dominated by with Radon–Nikodym density defined on the support such that . Let be the common unnormalized density so that
and
with and being the log-normalizer functions of and , respectively.
We have
Since and , we obtain
Observe that since , we have:
Therefore , and the common natural parameter space is .
Notice that the reverse Kullback–Leibler divergence since .
Theorem 1
(Kullback–Leibler divergence between truncated exponential family densities). Let be an exponential family with support , and a truncated exponential family of with support . Let and denote the log-normalizers of and and and the moment parameters corresponding to the natural parameters and . Then the Kullback–Leibler divergence between a truncated density of and a density of is
For example, consider the calculation of the KLD between an exponential distribution (view as half a Laplacian distribution, i.e., a truncated Laplacian distribution on the positive real support) and a Laplacian distribution defined on the real line support.
Example 4.
Let denote the set of positive reals. Let and denote the exponential families of exponential distributions and Laplacian distributions, respectively. We have the sufficient statistic and natural parameter so that . The log-normalizers are and (hence ). The moment parameter . Thus using the duo Bregman divergence, we have:
Moreover, we can interpret that divergence using the Itakura–Saito divergence [24]:
we have
We check the result using the duo Fenchel–Young divergence:
with :
Next, consider the calculation of the KLD between a half-normal distribution and a (full) normal distribution:
Example 5.
Consider and to be the scale family of the half standard normal distributions and the scale family of the standard normal distribution, respectively. We have with and . Let the sufficient statistic be so that the natural parameter is . Here, we have both . For this example, we check that . We have and (with ). We have . The KLD between two half scale normal distributions is
Since and differ only by a constant and the Bregman divergence is invariant under an affine term of its generator, we have
Moreover, we can interpret those Bregman divergences as half of the Itakura–Saito divergence:
It follows that
Since , we have .
Thus the Kullback–Leibler divergence between a truncated density and another density of the same exponential family amounts to calculate a duo Bregman divergence on the reverse parameter order: . Let be the reverse Kullback–Leibler divergence. Then .
Notice that truncated exponential families are also exponential families but those exponential families may be non-steep [25].
Let and be two truncated exponential families of the exponential family with log-normalizer such that
with , where denotes the CDF of . Then the log-normalizer of is for .
Corollary 1
(Kullback–Leibler divergence between densities of truncated exponential families). Let be truncated exponential families of the exponential family with support (where denotes the support of ) for . Then the Kullback–Leibler divergence between and is infinite if and has the following formula when :
Proof.
We have and . Therefore . Thus we have
□
Thus the KLD between truncated exponential family densities and amounts to the KLD between the densities with the same truncation parameter with an additive term depending on the log ratio of the mass with respect to the truncated supports evaluated at . We shall illustrate with two examples the calculation of the KLD between truncated exponential families.
Example 6.
Consider the calculation of the KLD between a truncated exponential distribution with support () and another truncated exponential distribution with support (). We have (density of the untruncated exponential family with natural parameter , sufficient statistic and log-normalizer ), , and . Let denote the cumulative distribution function of the exponential distribution. We have and
If then . Otherwise, , and the exponential family is the truncated exponential family . Using the computer algebra system Maxima (https://maxima.sourceforge.io/ accessed on 15 March 2022), we find that
Thus we have:
When and , we recover the KLD between two exponential distributions and :
Note that the KLD between two truncated exponential distributions with the same truncation support is
We also check Corollary 1:
The next example shows how to compute the Kullback–Leibler divergence between two truncated normal distributions:
Example 7.
Let denote a truncated normal distribution with support the open interval () and probability density function defined by:
where is related to the partition function [26] expressed using the cumulative distribution function (CDF) :
with
where is the error function:
Thus we have where .
The pdf can also be written as
where denotes the standard normal pdf ():
and is the standard normal CDF. When and , we have since and .
The density belongs to an exponential family with natural parameter , sufficient statistics , and log-normalizer:
The natural parameter space is where denotes the set of negative real numbers.
The log-normalizer can be expressed using the source parameters (which are not the mean and standard deviation when the support is truncated, hence the notation m and s):
We shall use the fact that the gradient of the log-normalizer of any exponential family distribution amounts to the expectation of the sufficient statistics [1]:
Parameter η is called the moment or expectation parameter [1].
The mean and the variance (with ) of the truncated normal can be expressed using the following formula [26,27] (page 25):
where and . Thus we have the following moment parameter with
Now consider two truncated normal distributions and with (otherwise, we have ). Then the KLD between and is equivalent to a duo Bregman divergence:
Note that .
This formula is valid for (1) the KLD between two truncated normal distributions, or for (2) the KLD between a truncated normal distribution and a (full support) normal distribution. Note that the formula depends on the erf function used in function Φ. Furthermore, when and , we recover (3) the KLD between two univariate normal distributions, since :
Note that for full support normal distributions, we have and .
The entropy of a truncated normal distribution (an exponential family [28]) is . We find that
When , we have and since , (an even function), and . Thus we recover the differential entropy of a normal distribution: .
5. Bhattacharyya Skewed Divergence between Truncated Densities of an Exponential Family
The Bhattacharyya -skewed divergence [29,30] between two densities and with respect to is defined for a skewing scalar parameter as:
where denotes the support of the distributions. The Bhattacharyya distance is
The Bhattacharyya distance is not a metric distance since it does not satisfy the triangle inequality. The Bhattacharyya distance is related to the Hellinger distance [31] as follows:
The Hellinger distance is a metric distance.
Let denote the skewed affinity coefficient so that . Since , we have .
Consider an exponential family with log-normalizer . Then it is well-known that the -skewed Bhattacharyya divergence between two densities of an exponential family amounts to a skewed Jensen divergence [30] (originally called Jensen difference in [32]):
where the skewed Jensen divergence is defined by
The convexity of the log-normalizer ensures that . The Jensen divergence can be extended to full real by rescaling it by , see [33].
Remark 1.
The Bhattacharyya skewed divergence appears naturally as the negative of the log-normalizer of the exponential family induced by the exponential arc linking two densities p and q with . This arc is an exponential family of order 1:
The sufficient statistic is , the natural parameter , and the log-normalizer . This shows that is concave with respect to α since log-normalizers are always convex. Grünwald called those exponential families the likelihood ratio exponential families [34].
Now, consider calculating where with a truncated exponential family of and . We have , where and are the partition functions of and , respectively. Thus we have
and the -skewed Bhattacharyya divergence is
Therefore we obtain
We call the duo Jensen divergence. Since , we check that
Figure 7 illustrates graphically the duo Jensen divergence .
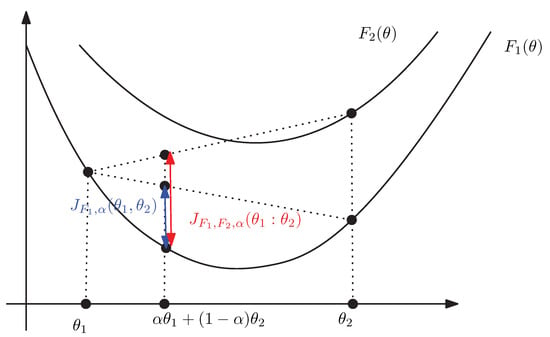
Figure 7.
The duo Jensen divergence is greater than the Jensen divergence for .
Theorem 2.
The α-skewed Bhattacharyya divergence for between a truncated density of with log-normalizer and another density of an exponential family with log-normalizer amounts to a duo Jensen divergence:
where is the duo skewed Jensen divergence induced by two strictly convex functions and such that :
In [30], it is reported that
Indeed, using the first-order Taylor expansion of
when , we check that we have
Thus we have .
Moreover, we have
Similarly, we can prove that
which can be reinterpreted as
6. Concluding Remarks
We considered the Kullback–Leibler divergence between two parametric densities and belonging to truncated exponential families [7] and , and we showed that their KLD is equivalent to a duo Bregman divergence on swapped parameter order (Theorem 1). This result generalizes the study of Azoury and Warmuth [13]. The duo Bregman divergence can be rewritten as a duo Fenchel–Young divergence using mixed natural/moment parameterizations of the exponential family densities (Definition 1). This second result generalizes the approach taken in information geometry [15,35]. We showed how to calculate the Kullback–Leibler divergence between two truncated normal distributions as a duo Bregman divergence. More generally, we proved that the skewed Bhattacharyya distance between two parametric densities of truncated exponential families amounts to a duo Jensen divergence (Theorem 2). We showed asymptotically that scaled duo Jensen divergences tend to duo Bregman divergences generalizing a result of [30,33]. This study of duo divergences induced by pair of generators was motivated by the formula obtained for the Kullback–Leibler divergence between two densities of two different exponential families originally reported in [23] (Equation (29)).
It is interesting to find applications of the duo Fenchel–Young, Bregman, and Jensen divergences beyond the scope of calculating statistical distances between truncated exponential family densities. Note that in [36], the authors exhibit a relationship between densities with nested supports and quasi-convex Bregman divergences. However, those considered parametric densities are not exponential families since their supports depend on the parameter. Recently, Khan and Swaroop [37] used this duo Fenchel–Young divergence in machine learning for knowledge-adaptation priors in the so-called change regularizer task.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
The author would like to thank the three reviewers for their helpful comments, which led to this improved paper.
Conflicts of Interest
The author declares no conflict of interest.
References
- Sundberg, R. Statistical Modelling by Exponential Families; Cambridge University Press: Cambridge, UK, 2019; Volume 12. [Google Scholar]
- Pitman, E.J.G. Sufficient Statistics and Intrinsic Accuracy; Mathematical Proceedings of the cambridge Philosophical Society; Cambridge University Press: Cambridge, UK, 1936; Volume 32, pp. 567–579. [Google Scholar]
- Darmois, G. Sur les lois de probabilitéa estimation exhaustive. CR Acad. Sci. Paris 1935, 260, 85. [Google Scholar]
- Koopman, B.O. On distributions admitting a sufficient statistic. Trans. Am. Math. Soc. 1936, 39, 399–409. [Google Scholar] [CrossRef]
- Hiejima, Y. Interpretation of the quasi-likelihood via the tilted exponential family. J. Jpn. Stat. Soc. 1997, 27, 157–164. [Google Scholar] [CrossRef]
- Efron, B.; Hastie, T. Computer Age Statistical Inference: Algorithms, Evidence, and Data Science; Cambridge University Press: Cambridge, UK, 2021; Volume 6. [Google Scholar]
- Akahira, M. Statistical Estimation for Truncated Exponential Families; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- Bar-Lev, S.K. Large sample properties of the MLE and MCLE for the natural parameter of a truncated exponential family. Ann. Inst. Stat. Math. 1984, 36, 217–222. [Google Scholar] [CrossRef]
- Shah, A.; Shah, D.; Wornell, G. A Computationally Efficient Method for Learning Exponential Family Distributions. Adv. Neural Inf. Process. Syst. 2021, 34. Available online: https://proceedings.neurips.cc/paper/2021/hash/84f7e69969dea92a925508f7c1f9579a-Abstract.html (accessed on 15 March 2022).
- Keener, R.W. Theoretical Statistics: Topics for a Core Course; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Cover, T.M. Elements of Information Theory; John Wiley & Sons: Hoboken, NJ, USA, 1999. [Google Scholar]
- Csiszár, I. Eine informationstheoretische Ungleichung und ihre Anwendung auf Beweis der Ergodizitaet von Markoffschen Ketten. Magyer Tud. Akad. Mat. Kutato Int. Koezl. 1964, 8, 85–108. [Google Scholar]
- Azoury, K.S.; Warmuth, M.K. Relative loss bounds for on-line density estimation with the exponential family of distributions. Mach. Learn. 2001, 43, 211–246. [Google Scholar] [CrossRef] [Green Version]
- Rockafellar, R.T. Convex Analysis; Princeton University Press: Princeton, NJ, USA, 2015. [Google Scholar]
- Amari, S.I. Differential-geometrical methods in statistics. Lect. Notes Stat. 1985, 28, 1. [Google Scholar]
- Bregman, L.M. The relaxation method of finding the common point of convex sets and its application to the solution of problems in convex programming. Ussr Comput. Math. Math. Phys. 1967, 7, 200–217. [Google Scholar] [CrossRef]
- Acharyya, S. Learning to Rank in Supervised and Unsupervised Settings Using Convexity and Monotonicity. Ph.D. Thesis, The University of Texas at Austin, Austin, TX, USA, 2013. [Google Scholar]
- Blondel, M.; Martins, A.F.; Niculae, V. Learning with Fenchel-Young losses. J. Mach. Learn. Res. 2020, 21, 1–69. [Google Scholar]
- Nielsen, F. An elementary introduction to information geometry. Entropy 2020, 22, 1100. [Google Scholar] [CrossRef] [PubMed]
- Mitroi, F.C.; Niculescu, C.P. An Extension of Young’s Inequality; Abstract and Applied Analysis; Hindawi: London, UK, 2011; Volume 2011. [Google Scholar]
- Jeffreys, H. The Theory of Probability; OUP Oxford: Oxford, UK, 1998. [Google Scholar]
- Nielsen, F.; Nock, R. Sided and symmetrized Bregman centroids. IEEE Trans. Inf. Theory 2009, 55, 2882–2904. [Google Scholar] [CrossRef] [Green Version]
- Nielsen, F. On a variational definition for the Jensen-Shannon symmetrization of distances based on the information radius. Entropy 2021, 23, 464. [Google Scholar] [CrossRef]
- Itakura, F.; Saito, S. Analysis synthesis telephony based on the maximum likelihood method. In Proceedings of the 6th International Congress on Acoustics, Tokyo, Japan, 21–28 August 1968; pp. 280–292. [Google Scholar]
- Del Castillo, J. The singly truncated normal distribution: A non-steep exponential family. Ann. Inst. Stat. Math. 1994, 46, 57–66. [Google Scholar] [CrossRef] [Green Version]
- Burkardt, J. The Truncated Normal Distribution; Technical Report; Department of Scientific Computing Website, Florida State University: Tallahassee, FL, USA, 2014. [Google Scholar]
- Kotz, J.; Balakrishan. Continuous Univariate Distributions, Volumes I and II; John Wiley and Sons: Hoboken, NJ, USA, 1994. [Google Scholar]
- Nielsen, F.; Nock, R. Entropies and cross-entropies of exponential families. In Proceedings of the 2010 IEEE International Conference on Image Processing, Hong Kong, China, 26–29 September 2010; pp. 3621–3624. [Google Scholar]
- Bhattacharyya, A. On a measure of divergence between two statistical populations defined by their probability distributions. Bull. Calcutta Math. Soc. 1943, 35, 99–109. [Google Scholar]
- Nielsen, F.; Boltz, S. The Burbea-Rao and Bhattacharyya centroids. IEEE Trans. Inf. Theory 2011, 57, 5455–5466. [Google Scholar] [CrossRef] [Green Version]
- Hellinger, E. Neue Begründung der Theorie Quadratischer Formen von unendlichvielen Veränderlichen. J. Reine Angew. Math. 1909, 1909, 210–271. [Google Scholar] [CrossRef]
- Rao, C.R. Diversity and dissimilarity coefficients: A unified approach. Theor. Popul. Biol. 1982, 21, 24–43. [Google Scholar] [CrossRef]
- Zhang, J. Divergence function, duality, and convex analysis. Neural Comput. 2004, 16, 159–195. [Google Scholar] [CrossRef] [PubMed]
- Grünwald, P.D. The Minimum Description Length Principle; MIT Press: Cambridge, MA, USA, 2007. [Google Scholar]
- Nielsen, F. The Many Faces of Information Geometry. Not. Am. Math. Soc. 2022, 69. [Google Scholar] [CrossRef]
- Nielsen, F.; Hadjeres, G. Quasiconvex Jensen Divergences and Quasiconvex Bregman Divergences; Workshop on Joint Structures and Common Foundations of Statistical Physics, Information Geometry and Inference for Learning; Springer: Berlin/Heidelberg, Germany, 2020; pp. 196–218. [Google Scholar]
- Emtiyaz Khan, M.; Swaroop, S. Knowledge-Adaptation Priors. arXiv 2021, arXiv:2106.08769. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).