1. Introduction
1.1. Confirmation Bias and Conformity
The practice of exchanging ideas, sharing concepts and values between different minds, is a fundamental process that allows humans and other living agents to coordinate and operate socially. By sharing ideas, individuals and communities can better pursue their pragmatic goals and improve their understanding of the world and each other. Humans are compulsory cooperators [
1]: human survival itself is predicated on the ability to access and leverage bodies of accumulated cultural knowledge. Over the course of evolutionary history, humans have developed an exquisitely sensitive capacity to discriminate reliable sources of information from unreliable ones, and to learn from other relevant human agents to improve their understanding or model of their world [
2,
3].
This epistemic process is not, however, without its flaws. There is evidence that humans process information by reasoning heuristically, which is hypothesised to limit the consumption of energy and facilitate rapid decision-making [
4,
5]. One such heuristic is confirmation bias, which implies that, all other things being equal, individuals prefer sticking to their own beliefs over changing their minds [
6]. There is an extensive literature documenting the phenomenon of
confirmation bias and its relation to cognitive dissonance. Individuals faced with information that conflicts with their core beliefs may be prone to cognitive dissonance, which is experienced as undesirable [
7,
8,
9]. Tolerance for cognitive dissonance varies across individuals, but in general, the phenomenon significantly influences decision-making [
8,
10]. To avoid such dissonance, individuals tend to selectively seek information from ‘others like me’, others who they expect will share similar ideas, concepts, and values [
8]. Confirmation bias has a social influence; in particular, individuals prefer sampling data from their in-group, and will seek to confirm their own ideas by foraging for confirmatory information from their in-group [
11,
12]. To make sure that they have access to other like-minded allies, agents are more likely to choose to belong to communities where their deeply held beliefs are promoted and shared, which limits the cognitive effort that is already expanded in the foraging of information [
10]. In-group delivery of information influences how strongly this information is integrated, especially if group membership is important for the individual [
13]. This sampling extends beyond other agents, to choice of media and environment. For instance, individuals generally choose news sources that fit their expectations [
8].
This phenomenon of confirmation bias is echoed in another heuristic: conformity, the need to cohere with the beliefs of one’s in-group [
14,
15]. It is adaptive for agents to conform to the behaviours of others in their niche, in part for the very reasons highlighted above [
16]. Conformity limits how much information any given agent has to gather to act appropriately, and the sources sampled from their in-group are generally trusted [
17]. This is partly due to the fact that members of an in-group can be most precisely predicted: their behaviours are normed, and expected by the members of the group, in ways that generally benefit its members [
18,
19]. However, conformity has other benefits as well. Being able to sample from the group entails a continued relationship to other members. This will also enable members to acquire pragmatic resources beyond information (e.g., food and shelter), as the group generally provides for its members [
20,
21]. Being cut off from the group can lead to existential difficulties [
22,
23]. Group members can be sanctioned if they fail to conform to the norms, including epistemic norms [
24,
25].
1.2. The Spread of Ideas
These two heuristics—namely, confirmation bias and conformity—mutually reinforce each other. Specifically, to save energy, confirmation bias leads to agents’ being drawn to groups that validate their opinion, and thus increases the probability of behavioural and epistemic conformity [
26]. Importantly, these two heuristics form the basis for information spread. Agents spread information through media and through connections to one another, given a network structure [
27]. The spread of ideas and behaviours from one agent to another serves both local and larger-scale coordination [
27,
28].
The spread of ideas is facilitated when agents are already attuned to them. Individuals are more likely to adopt ideas that they believe will have a positive effect on them, especially if the outcome of sharing that information will be positive [
29]. According to Falk and Scholz, this entails that sharing among group members of news that dovetails with group norms is likely to lead to the adoption of these ideas among the other group members, following the conformity heuristic mentioned earlier. One way to predict whether information will be coherent with the group norms is to assess it with respect to one’s own value system. Naturally, similar individuals within a given group who share values will be more likely to spread ideas [
30,
31].
This notion of attunement or synchronisation is fundamental. Synchronisation across network nodes lowers the cost of information flow [
32], and increases the certainty of the message being spread, as well as the quality of its reception, even if the message itself may be prone to errors [
33,
34]. Specifically, a message will be more intelligible to group members who share a common set of codes, and agents are more likely to integrate new information if it fits with their understanding of the world [
35,
36,
37].
Hashtags have been shown to be heavy carriers of information in echo-chambers. They tend to be used in partisan ways, to reach people of similar mindsets, as well as to signal one’s own partisanship affiliation [
38]. The spread of information is optimised through hashtags as pseudo-meta-linguistic categorisation makers [
39].
1.3. Communities Forming around Ideas
Thus, the beliefs and epistemic communities of agents develop together, synchronously. We label communities formed in this process of belief sharing as ‘epistemic communities’. Such communities share and spread a worldview, or a paradigm, and normalise sampling behaviours (i.e., manners of observing and engaging with the shared social world) that reinforce this view of the world [
40]. Individuals in the community are tied together by these epistemic practices, further reinforcing the social signals which act as evidence for the shared model of the world [
19].
One example of these communities is the
echo-chamber, a phenomenon that has been studied significantly in social media [
38,
41,
42,
43,
44,
45,
46,
47]. Echo-chambers are an extreme example of epistemic communities, and they have components that enforce their formation and maintenance [
48,
49,
50]. Echo-chambers tie people with similar views together, and tend to actively work against the engagement with, and assessment and evaluation of, external sources (e.g., information provided by members of the outgroup) [
42,
48]. Echo-chambers can become epistemically vulnerable when members can no longer assess whether a piece of information is true or not [
48,
51]. Similarly, only having access to a few sources limits how much information can be gathered, and relevant sources of evidence may fall through the gaps [
49,
52]. According to [
52], error will be propagated, and it will be difficult to check errors against anything, as most minds in the echo-chamber are synchronised and therefore poised to make the same mistakes.
1.4. Volatility and Habit Formation
Studies on the perception of environmental volatility range from economics to psycho-education for the autism spectrum [
53,
54,
55]. Optimal inference in a changing world requires integrating incoming sensory data with beliefs about the intrinsic volatility of the environment. Intuitively, environments with higher volatility change more quickly and thus have a shorter intrinsic timescale—and conversely for environments with lower volatility. For example, autistic individuals tend to pay more attention to small changes in the environment, giving them a better ability to track potentially important fluctuations in information [
53]. On the other hand, this increased attention to environmental fluctuations may also lead to increased sensitivity to random, non-informative changes in the environment, a phenomenon that might be called (from a signal-detection perspective) a higher ‘false-positive’ rate [
53].
When this type of precision dynamics [
56] is applied to the social field at large, emergent epistemic phenomena can be explained. For instance, during the COVID-19 pandemic, the certainty around knowledge was very low, as information about the pandemic and the biology of the virus was limited [
57,
58]. In addition, alternative sources of information (e.g., anti-vaccine conspiracies) had become more prevalent and more influential in some social networks [
59]. The gravity of the affliction, and the strength of the governmental response, also made any information on the topic vitally important, and worth one’s attention [
60]. This prompted an intensive use of information technology in order for individuals to find answers (“doing one’s own research”). This excessive use points to the awareness by laypeople of the high volatility of the topic. The authors of [
61] measured emotional volatility on social media in China during the pandemic, and explored the social dynamics underlying the emotional volatility.
Individuals can deal with volatility by using various coping mechanisms. One such mechanism is to constrain the uncertainty related to their own behaviours via
habit formation [
62,
63,
64,
65,
66,
67,
68,
69,
70,
71]. In this paper, we model habit formation as a form of behavioural reinforcement, where behaviours become more probable as a function of how often they are engaged in [
72,
73]. If behaviour is initially goal- or information-driven, habit-learning can then ‘zero-in’ and isolate the invariant features of such (initially) goal-directed behaviour [
74], mirroring the so-called transition from ‘model-based’ to ‘model-free’ decision-making in reinforcement learning [
75,
76]. After an agent has engaged in a given behaviour enough, even if that behaviour is initially pursued in a goal-driven manner, a habit can then be formed and become hard to ‘unlearn’ [
77]. This view also supports the idea that, initially, habit-formation can be goal-driven. In the current context of echo chamber formation, confirmation bias may serve as the original ‘motivation’ that later underwrites preferential sampling behaviour. In combination with habit learning, it may then become impossible to stop enacting this peer-specific sampling, even in the face of changing information.
1.5. An Active Inference Model of Epistemic Communities
This paper introduces a computational model of epistemic communities, wherein individual agents share information with one another and come to form beliefs not only about their local environment, but also about the beliefs of other agents in their community. To understand this phenomenon, we leverage the active inference framework, a first-principles theory of cognition, which explains the manner in which agents select actions based on their causal model or understanding of the world. Active inference says that organisms act to minimise a quantity called variational free energy, which quantifies the divergence between expected and sensed data. From this point of view, to select an action is to infer ‘what I must be doing, given what I believe and what I sense’. Extensive work has been done in the field of active inference to study social systems and the way in which the minimisation of free energy could give rise to (eventually large-scale) behavioural coordination [
3,
15,
78,
79,
80,
81,
82,
83]. However, much of this work is still theoretical.
At first glance, it might appear difficult to model a phenomenon like confirmation bias using an active inference formulation, because action selection in active inference is guided by the principle of maximising Bayesian surprise or salience, which requires constantly seeking out information that is expected to ‘challenge’ one’s world model [
84,
85,
86].
However, the key notion that allows ‘confirmation bias’ to nonetheless emerge under active inference is ultimately the subjective nature of information gain, also known as ‘epistemic value’. Crucially, this Bayesian surprise or information gain term is always an expected surprise—that is, what counts as an ‘information-maximising’ observation is always defined in relation to agent’s set of beliefs or generative model. Due to this inherent subjectivity, the true informativeness or epistemic value of an action can be arbitrarily far from the agent’s expectation thereof. Taking advantage of this, in the model presented here, we endow agents with what we refer to as epistemic confirmation bias. This is implemented by building a prior belief into the generative model, namely that agents are more likely to sample informative observations from agents with whom they agree a priori. Therefore, agents will sample agents with whom they agree under the (not necessarily true) belief that such agents are more likely to provide higher quality information.
We can make two important distinctions between the kind of polarisation that we observe in traditional opinion dynamics and the kind achieved through multi-agent active inference modelling. First, in traditional approaches, the implementation of bounded confidence to motivate polarisation is essentially a hard-coded restriction on the agents’ ability to perceive and therefore update their beliefs [
87,
88,
89,
90]. By contrast, in the active inference approach, polarisation is instead motivated by the positive effect of confirmation bias, which is integrated directly in the agents’ (likelihood) model of the world, which allows agents to acquire more evidence about their environment if the information comes from another agent that shares the same worldview. This means that agents are motivated implicitly in their generative models to gain more evidence about the world if this evidence confirms their preexisting beliefs. Second, in the traditional approaches, agents can directly perceive the ‘belief state’ of other agents, and thus, the opinion of one agent directly influences that of another [
87,
89]. This is an unrealistic assumption, since human agents have to infer the belief states of others by interpreting their behaviour. This aspect of belief inference is a cornerstone of the active inference approach: the belief of another agent is modelled as a hidden state of the world—thus agents do not have direct access to each others’ belief states. Instead, through inference, they come to hold beliefs about each others’ beliefs, in addition to a belief about some agent-independent ‘world states’ [
19,
91].
More recently, researchers have begun to build Bayesian models of opinion dynamics, motivated by the Bayesian brain hypothesis and the notion that decision-making is inherently probabilistic [
92,
93,
94,
95,
96]. Generally, the active inference approach falls within the theoretical umbrella of Bayesian agent-based modelling, because there is a deep assumption that environmental states are inherently hidden (in our case, the belief states of other agents) and need to be inferred on the basis of prior beliefs and sensory observations (i.e., observing the behaviour of other agents). However, as sketched above, a crucial point that distinguishes approaches like active inference and planning as inference from the general Bayesian approach is the notion that
actions themselves are inferred [
97,
98] While there have been models that use Bayesian inference for the inference of opinions (i.e., Bayesian belief states about some particular idea), the process of action selection within these works is still often added on after the fact using an arbitrary decision rule (e.g., a softmax function of an arbitrary value vector). Action selection is often cast as a noisy signal of the true belief state, such as in [
96], which is then used to update neighbouring agents’ beliefs through Bayesian inference. Crucially, in active inference, behaviour itself is cast as the result of inference, specifically by sampling actions from a posterior distribution over actions. The posterior over actions is obtained by minimising the expected free energy of future beliefs, conditioned on actions. In other words, actions are selected in order to achieve goals and minimise future uncertainty, i.e., to maximise a lower bound on Bayesian model evidence.
Importantly for our purposes, one can supplement this goal-directed aspect of policy inference, driven by the expected free energy, with inflexible ‘prior preferences over actions’, i.e., habits. If this prior preference over actions is learned over time, then in the context of the opinion dynamics model presented here, this can lead to a propensity to continue sampling agents that have been sampled previously. The idea of choosing actions through inference in accordance with the minimisation of uncertainty is powerful as a modelling technique, because through the choice of policy preferences one can encode various social behaviours, such as conformity, habit formation, hostility, or indifference, while in this report, only habit formation, conformity, and polarisation are explored, we emphasise the potential of augmenting the current model to capture a wider range of features observed in human social behaviour.
1.6. Hypotheses
In this paper, we present a multi-agent model of opinion dynamics based on the active inference formulation. Our simulated agents are situated in a social network where they observe the behaviour of other agents and update their beliefs about a pair of abstract, mutually exclusive “Ideas” (e.g., the truth values of two competing claims), as well as the beliefs of their neighbours in the social network. Agents themselves have a prior preference to announce their beliefs via an action that is observable by other agents (e.g., posting/tweeting a “hashtag”). We show that the proposed active inference model can replicate confirmation bias, exposure effects, the formation of echo-chambers, and the exacerbation of these phenomena via habit-learning. These effects can be modelled by changing the parameters of individual generative models, i.e., the cognitive features of the individuals comprising the group. We also uncover interesting interactions between individual-level cognitive features and the network architecture that constrains their social interactions. The large-scale behaviour of the model can be used to test three hypotheses, which are motivated by the existing literature. We formulate and test three hypotheses as follows:
Hypothesis 1. We cast confirmation bias in active inference as a form of ‘biased curiosity,’ in which agents selectively gather information from other agents with whom (they believe) they agree, under the assumption that like-minded agents provide higher-quality, more reliable information. We hypothesise that this ‘epistemic confirmation bias’ can mediate the formation of echo-chambers and polarisation in social networks of active inference agents. However, we further hypothesise that epistemic confirmation bias and network connectivity will bidirectionally modulate the formation of polarised epistemic communities, tuning the collective trade-off between deadlock (polarisation) and agreement (consensus).
Hypothesis 2. We also consider the effect of agents’ beliefs about the volatility of their social environments. In particular, we examine how beliefs about social volatility impact exploratory sampling of other agents’ perspectives, which itself may interact with epistemic confirmation bias to determine the formation of echo-chambers. In particular, we hypothesise that beliefs about less quickly changing social environments (a belief in lower social volatility) will increase the likelihood of polarisation, as opposed to consensus.
Hypothesis 3. Finally, we also hypothesise that we can model selective exposure effects and conformity through habit formation, which naturally emerges through Bayes-optimal learning of a prior distribution over policies. We hypothesise that a greater learning rate for habit formation will lead to clusters within the network, thus amplifying and quickening the formation of echo-chambers.
Using the multi-agent active inference model of opinion dynamics, we achieve simulation outcomes that reproduce phenomena observed in the opinion dynamics literature, such as polarisation and consensus. In the sections to follow, we first describe the generative model that each agent uses to engage in active inference, and then discuss how we couple the agents together in an opinion dynamics network. We conclude by presenting numerical results that investigate each of the three hypotheses laid out above.
2. An Active Inference Model of Opinion Dynamics
2.1. Overview
We present a multi-agent active inference model of opinion dynamics on an idealised social network. In the model, a group of agents simultaneously update their beliefs about an abstract, binary hidden state (that represents two conflicting “Ideas”) and the opinion states about these ideas, held by a limited set of neighbouring agents. Each agent also generates an action that is observable to other agents. In the context of digital social networks like Twitter, these observable actions could be analogised to ‘posts’, ‘tweets’ or ‘hashtags’, i.e., some abstract expression carrying information about the belief state of the agent generating that expression. Hereafter we refer to these actions as ‘tweeting a Hashtag’ and describe agents‘ behaviour as the decision to ‘tweet Hashtag 1 vs. Hashtag 2’, etc. Over time, each agent updates a posterior distribution (or belief) about which of the two Ideas is true, as well as a belief about what a connected set of other agents in the network believe (namely, those agents whom they ‘follow‘ or are ‘followed by’ in the social network). Both of these inferences are achieved by observing the behaviour of other agents, where, crucially, this behaviour depends on each agent’s beliefs (notably about other agents). In our formulation, agents can only observe the behaviour of other agents to whom they are specifically connected.
It is worth emphasising that in this formulation, there is no true hidden state that corresponds to the competing truth status of the two “Ideas.” Rather, this abstract binary hidden state is only contained in the generative model or internal representation of each agent. The only ‘real’ states of the system are the agents and their observable behaviour.
In the sections to follow, we first briefly summarise the previous literature on computational approaches to the study of opinion dynamics. We then review the formalism of active inference, from the specification of the generative models that each agent uses to represent their external world, to the update equations for state estimation and decision-making. Finally, we describe the simulations of multi-agent dynamics by linking an ensemble of such active inference agents into a network.
2.2. Opinion Dynamics Models
In previous models of opinion dynamics, individual agents are often characterised by one or a few variables that encode the current belief or opinion held by that agent [
99,
100,
101]. Collections of agents then update their respective opinion variables by ‘observing’ other variables that (either deterministically or stochastically) depend on the opinions of other agents in the ensemble. The nature of the inter-agent interactions varies across different models, ranging from homogeneous, ‘mean-field’-like global potentials [
102,
103] to structured, heterogeneous networks with fixed or dynamic weights between agents [
104,
105]. The opinion variables can take scalar or vector-values [
106,
107], and have either discrete or continuous support [
108,
109,
110,
111].
Bayesian variants of opinion dynamics models explicitly take into account the
uncertainty associated with the observations and decisions of agents, where now the updates to opinion variables become (exact or approximate) Bayesian updates [
95,
96,
112,
113]. The active inference model we present here is an example of such a Bayesian approach, with a few crucial distinctions, such as the approximate (as opposed to exact) nature of the Bayesian belief updating, and the fact that actions, in addition to opinions, are the result of inference. We will detail these distinctions further in the sections below on active inference.
2.3. Active Inference
Active inference is a biologically motivated framework that rests on first principles of self-organisation in complex, adaptive systems [
86,
97,
114]. Particularly, it is premised on the notion that the internal states of any biological system are statistically insulated from the environment that generates sensory observations, and thus must engage in inference (about the causes of its sensory states) to behave optimally [
115]. Active inference finesses this fundamental uncertainty by adding a Bayesian twist, proposing that biological systems entertain or entail a generative model of the latent environmental causes of their sensory inputs. Therefore, unlike classic reinforcement learning or reflexive behavioural algorithms (e.g., state-action policy mapping [
72,
116]), actions taken under active inference are guided by internal beliefs, which themselves are optimised with respect to an internal ‘world model,’ or representation of the world’s causal and data-generating structure.
Crucially, active inference agents represent their own actions (and their typical sensory consequences) in their generative model. By performing inference with respect to both hidden environment states of the world and the consequences of their own actions, active inference agents can evince behaviour that both (1) achieves their goals or fulfils preferences and (2) actively reduces uncertainty in the agent’s world model [
86,
97,
115]. An active inference agent’s only imperative is to increase model evidence, or equivalently, to
reduce surprise. Processes such as learning, perception, planning, and goal-directed behaviour emerge from this single drive to increase evidence for the agent’s generative model of the world.
In active inference, the agents never act directly on sensory data, but rather change their beliefs about what causes that data. Thus, the core step in active inference consists of optimising these beliefs using a generative model. This process is also known as Bayesian inference or Bayesian model inversion. Inference answers the question: “what is my best guess about the state of the world, given my sensory data and prior beliefs”? This can be formalised using Bayes’ rule:
where the optimal belief about ‘hidden’ or latent variables
, given some sensory data
y, is called the
posterior distribution. Bayes’ rule yields an analytic relationship between the generative model
and the posterior. Bayesian inference consists in calculating (either analytically or approximately)
. Active inference is no different: perception (the generation of a best guess about the current hidden states of the world) is formalised as the computation of a posterior distribution over hidden states
s, and action (the
active part of active inference) is formalised as the computation of a posterior distribution over policies
. In active inference, however, this problem is turned into one of
approximate Bayesian inference, where instead of finding the optimal posterior
, active inference agents instead approximate this optimal posterior with a variational posterior
, i.e., a belief over hidden states that is parameterised by variational parameters
. The reason for this is that the exact inference is often computationally intractable. The marginalisation problem involved in exact Bayesian inference (expressed in Equation (
1)) is often intractable for many realistic generative models. Variational inference turns this intractable calculation of the marginal into an optimisation problem, where a variational upper bound on
surprise known as variational free energy (also known as negative model evidence in statistics) is minimised:
where
is the Kullback–Leibler divergence, a non-negative measure of difference between probability distributions, where
when
. Variational inference thus consists of optimising the variational parameters
in order to minimise the free energy, which itself renders the variational posterior a better approximation to the true posterior. When variational inference is exact, the bound becomes exact and the free energy reduces to the surprise or negative log evidence. The remaining (negative) surprise can be itself used as a score for model averaging and model selection [
117,
118].
Active inference agents achieve perception and action by minimising the surprise bound in Equation (
2) with respect to variational beliefs about particular variables of their generative model. Optimising beliefs about variables that represent latent environmental states (often denoted
s) is proposed as a formal model of perception, while optimising beliefs about variables that correspond to policies or control of the environment (often denoted by
u or
) is the formal analogue of planning and action. Therefore, active inference agents infer both hidden states (perception) and policies (action) through a process of variational inference. The update equations used for perception and planning under active inference are detailed in
Section 2.10,
Section 2.11 and
Section 2.12.
Specifying a generative model is critical to determining the behaviour of active inference agents. In the following sections we introduce the discrete state space model, a partially observed Markov decision process or POMDP, with which we equip agents in the multi-agent opinion dynamics setting.
2.4. Generative Model
Formally, the generative model is a joint probability distribution
over observations
o and latent variables
. Intuitively, one can think of the generative model as the agent’s ‘representation’ of its environment, and specifically how that environment elicits observations [
119]. In the discrete generative model described below, this generative model comprises assumptions about how hidden states
and actions
are probabilistically related to one another and to observations
.
In the current study, agents entertain
partially observed Markov decision process generative models, or POMDPs [
120,
121]. POMDPs are a class of decision-making models commonly used to simulate planning and decision-making in environments where agents must at each timestep select one of a discrete set of mutually exclusive options. This is often represented using several random variables: a discrete set of actions
u (also known as control states); hidden states
s, which evolve according to (action-dependent) Markovian dynamics; and observations
o, which probabilistically depend upon current hidden states. In most active inference models using POMDP generative models, hidden states, observations, and actions are discrete random variables—namely, they can take one of a finite set of values at a given time.
We include an additional latent variable, policies , in the generative model. Policies are simply sequences of control states u. Using the terminology above, our generative model can be written down as where . The tilde notation denotes a sequence of random variables over time, e.g., .
We can now write down the Markovian generative model as follows:
The observation likelihood represents the agent’s probabilistic understanding of the relationship between hidden states and concurrent observations . Because both observations and states are discrete, this likelihood distribution will be represented as a multidimensional array, which we hereafter denote by . Similarly, the transition distributions , which are denoted by , encode the agent’s beliefs about how hidden states and control states determine subsequent hidden states. It is by changing actions that the agent can exert control on its environment, since the evolution of hidden states depends both on the past state and on the concurrent action . Finally, the distribution represents the mapping between policies and actions.
In many POMDP models, we segregate observations
and hidden states (and controls)
(resp.
) into distinct
modalities (for observations) and
factors (for hidden states/control states):
where the superscripts refer to the index of the modality or factor index, respectively.
Observation modalities can be thought of as sensory ‘channels’ that provide distinct sorts of information. For example, in the context of human cognition, observation modalities might correspond to the information originating in different sense organs, e.g., the ears, eyes, or skin.
Hidden state factors may be thought of as the generative model’s latent representation of different features of the external world. Each of these factors has its own dynamics and can be thought of as statistically independent of other factors. For instance, an object might be described by both its spatial location and its colour—‘location’ and ‘colour’ would thus be candidates for distinct hidden state factors in a generative model of an object. This factorisation is motivated by our intuition that something like an object’s colour and location are independent. An additional, minor note is that control states (the agent’s representation of its own actions or ability to intervene on hidden states) are also divided into a set of control factors, with one control factor for every hidden state factor.
Given this factorisation, at any given time a single observation will thus comprise a set of modality-specific observations, one from each sensory channel, and a hidden state will comprise of a set of hidden states, one from each distinct hidden state factor.
Now that we have introduced the class of discrete generative models with which our active inference agents will be endowed, we are now in a position to articulate the particular structure of the generative model for a single agent. From here, using active inference to perform inference and action with respect to each single agent’s generative model, we can then ‘link together’ ensembles of these agents to form a complete opinion dynamics simulation.
2.5. An Individual Model of Opinion Formation
We describe a generative model of opinion formation for a single agent. Note that each active inference agent in the multi-agent simulations described below will be equipped with this same basic generative model. A single agent (hereafter: the ‘focal agent’) observes the actions of other agents, forms beliefs about an abstract binary environmental state, and chooses actions, which themselves are observable to other agents. The focal agent’s action consists of two simultaneous choices: an ‘expression’ action (choosing which observable expression to make) and an ‘observation’ action (choosing which other agent to attend to). As mentioned above, we analogise the ‘expression’ actions to posts made by users on online social networks (e.g., ‘tweets’, ‘re-tweets’, ‘shares’, ‘likes’), and the contents of these actions we refer to as ‘Hashtags.’ Crucially, an agent can only observe one neighbouring agent at a time. Therefore, at each timestep, a focal agent both tweets its own Hashtag and chooses to read the Hashtag tweeted by another single agent. See
Figure 1 and
Table 1 for a summary of the distributions and random variables that comprise a single agent’s generative model of opinion formation.
2.5.1. Hidden States
Each agent’s generative model comprises hidden states that fall into four categories—however, the actual number of hidden state factors per agent depends on their local network connectivity, so that a particular agent will usually have more than four hidden state factors. Nevertheless, we classify each hidden state factor into one of these four categories:
: A binary random variable that encodes the agent’s beliefs about an abstract environmental state that represents the truth value of two mutually exclusive Ideas or claims. This binary variable can thus take a value of either 0 or 1, to which we assign arbitrary labels of Idea 1 and Idea 2. If Idea 1 is true, then necessarily Idea 2 is false, and vice versa.
(shortened to: ): A set of binary random variables, each of which corresponds to a particular neighbour’s belief about which of the two Ideas is true. As a representation of another agent’s belief, we hereafter refer to this class of hidden state factor (and corresponding posteriors) as ‘meta-beliefs’. The values of this variable we label Believe Idea 1 and Believe Idea 2. Each agent will have one hidden state factor belonging to this category for each of its K neighbours, e.g., .
(shortened to: ): A binary random variable corresponding to what the focal agent is currently doing. By analogy with Twitter and other digital social media platforms, we refer to this action as ‘tweeting‘ or ‘posting’, and the variable can take a value of either 0 or 1, representing one of two possible contents (’Hashtags’). These two actions are thus labeled Tweet Hashtag 1 () and Tweet Hashtag 2 ().
(shortened to: ): A multinomial random variable with as many discrete levels as the focal agent has neighbours, representing which of their neighbours’ actions the focal agent is currently attending to. For example, for an agent with three neighbours, this variable could take three values: , which we label Attend Neighbour 1, Attend Neighbour 2, and Attend Neighbour 3, respectively.
For a single agent’s generative model, the precise number of ‘meta-belief’ hidden state factors (those belonging to the class of factors) depends on how many neighbours the focal agent has. For instance, if a given agent i has three neighbours, then that agent’s generative model will have three meta-belief hidden state factors: , , and , each representing the belief state of one of agent i’s three neighbours. Each agent has only one hidden state factor belonging to the other categories: , , and . However, the cardinality (i.e., number of levels) for the hidden state factor will be equal to the focal agent’s number of neighbours. In the case of our agent i with three neighbours, therefore, the possible values of will be , corresponding to the action of attending to one of the three neighbours.
2.5.2. Control States
Each agent is also equipped with two control state factors. These state factors are the agent’s representation of its own actions in the environment. Control factors interact with hidden state factors to determine the next hidden state—thus, certain hidden state factors are deemed ‘controllable’ if they are paired with a control factor. In the current model, these two control state factors are paired with hidden state factors in Categories 3 and 4 above:
: A binary random variable corresponding to which ‘tweet action’ to take, i.e., Tweet Hashtag 1 vs. Tweet Hashtag 2. This control factor interacts with the hidden state factor.
: A multinomial random variable corresponding to which neighbour to attend to, e.g., Attend Neighbour 1, Attend Neighbour 2, and Attend Neighbour 3. This control factor interacts with the hidden state factor.
2.5.3. Observation Modalities
Just as we did for the hidden states, now we describe three categories of observation modalities for a single agent’s generative model:
or : A binary random variable representing the focal agent’s observation of its own tweet actions—these ‘self-observations’ take the values of Hashtag 1 and Hashtag 2.
or : A ternary random variable representing the observation of a neighbour agent’s actions—these take the values of Null, Hashtag 1, and Hashtag 2. Each agent has one ‘tweet observation’ modality for each of its K neighbours: , in the same way that the number of factors depends on the number of neighbours. The purpose of the Null observation level will be clarified later on.
or : A multinomial random variable representing the observation of which neighbour the focal agent is attending to. This random variable has as many discrete levels as the focal agent has neighbours. For example, for an agent with three neighbours, this variable could take three values: , which we label Attend Neighbour 1, Attend Neighbour 2, and Attend Neighbour 3.
A focal agent receives a full multi-modality observation per timestep:
Each single observation is thus a collection of observations, one from each modality. Because one observation is collected from each modality at every timestep, the cardinality of some modalities is increased by 1, creating an additional observation level which we can call the “Null” observation level. The Null observation is included to effectively ‘block’ the focal agent from seeing the Hashtags of neighbours they are not actively attending to. This observation level is designed to have maximal ambiguity with respect to hidden states—in other words, seeing a Null observation affords no information about hidden states and thus has no effect on inference. This will become more clear when the observation and transition likelihoods of the generative model are described.
2.6. Likelihoods
Having specified the random variables that form the support of a single agent’s POMDP generative model, we can now move onto describing the likelihoods that determine how hidden states relate to observations, and how hidden states relate to each other over time. The construction of these likelihoods is indispensable for understanding both the belief updating and the choice behaviour of active inference agents.
We begin with the observation likelihood model
. This is also known as the ‘sensory likelihood’ or observation model, and is parameterised by a series of categorical distributions whose parameters we collectively encode as the columns of a multidimensional array called
. In other words:
The entire
array is actually a set of tensors, with one sub-tensor per observation modality:
Each modality-specific likelihood tensor is a potentially multidimensional array that encodes the conditional dependencies between each combination of hidden states and observations for that modality. For example, in a likelihood array with two hidden state factors, entry encodes the conditional probability , i.e., with the probability of observing outcome i within observation modality m under hidden state factor 1 being level j and hidden state factor 2 being level k. In the case of the generative model for opinion formation, these likelihood arrays will be of much higher dimensions than 3-D tensors; we will thus generally refer to the elements of a modality-specific array with the notation , where the ellipses refer to an indefinite number of indexable lagging dimensions.
Each agent in the opinion dynamic model will have one array per observation modality. We will now step through them to describe their role in the generative model.
2.6.1. Self Tweet Likelihood
The array
represents the agent’s beliefs about how hidden states relate to
(which content the agent is tweeting, either
Hashtag 1 or
Hashtag 2). By construction,
encodes an assumption that
only depends on
, the controllable hidden state factor corresponding to the tweet action. This is an unambiguous or isomorphic mapping, which we can express as follows:
In other words, the agent believes that the
factor unambiguously signals its true value via the
observation modality. Each column of the matrix in Equation (
6) represents a (conditioning) value of
, and each row represents a (conditioned) value of
. The value of
does not depend on any of the other hidden state factors, which means that this identity matrix is uniformly ‘tiled’ across the other dimensions of the
array that represent the mapping between the remaining hidden state factors
and
.
2.6.2. Neighbour Tweet Likelihood
The array
represents the focal agent’s beliefs about how hidden states relate to
, the focal agent’s observation of neighbour
k’s tweet content.
encodes an assumption that
probabilistically depends on neighbour
k’s belief about the two Ideas, i.e., that
depends on
. This can be expressed as:
where
represents a
vector of 0s, and
is a
matrix that represents the ‘Hashtag semantics,’ i.e., the assumed relationship between neighbour
k’s beliefs and what Hashtag they are expected to tweet. Importantly, the first row of the likelihood matrix in Equation (
7) represents the probability of encountering the
Null observation, for the various settings of hidden states. This observation always has probability 0 when the focal agent is sampling neighbour
k, as represented by the condition
. Otherwise, when
, the
Null value will be expected with certainty. This can be expressed as:
This inclusion of the
Null is necessary to ensure that a focal agent only expects to read one of neighbour
k’s tweet, if they are actively attending to neighbour
k—otherwise, they receive a ‘blank’ observation that affords no information about hidden states (as represented by a maximally ambiguous likelihood over hidden states, i.e., a row of 1s). The lower two rows of the likelihood matrix in Equation (
7) are occupied by the Hashtag semantics
, which we stipulatively define with a ‘Hashtag reliability’ parameter
:
Here, parameterises two Bernoulli distributions that, respectively, map between the two levels of and the two levels of . In the limiting case of , this means that the focal agent believes that neighbour i’s tweet content is unambiguous evidence for what Idea neighbour k believes in. On the other hand, as , comes to resemble a maximum entropy distribution, in this case, according to the focal agent’s generative model, neighbour k’s tweet activity provides no information about its beliefs.
This basic conditional relationship outlined in Equations (
7)–(
9) enables agents to update their beliefs about the beliefs of their neighbours
according what they observe their neighbours tweeting. Intuitively, this mapping captures the focal agents’ beliefs that what their neighbours tweet is representative of what they believe. The accuracy of this mapping (the value of
) determines how strongly Hashtags reflect opinions or the strength of beliefs. However, in order to allow agents to update their beliefs about the truth-values of the Ideas per se (i.e., update a posterior distribution over
), we also construct
such that agents believe that the validity or truth-values of the Ideas themselves
probabilistically relate to
. Importantly, we make this conditional relationship ‘biased’ in the sense that, according to
, tweet observations are more precisely related to a particular setting of the
factor, if and only if
is aligned with that belief, i.e., when
. This can be formalised as an increased precision
for subsets of those conditional distributions encoded by
, importantly those subsets when
. As we will describe later, in the context of action, this leads to an ‘epistemic’ drive for the focal agent to attend to neighbours who (are believed to) share their opinions, leading to a
confirmation bias effect. We therefore refer to this ‘biased precision’
as the
epistemic confirmation bias (ECB).
Note that this additional precision term
exponentiates the Hashtag semantics matrix
, which is already parameterised by the ‘Hashtag reliability’ parameter
. In the context of inference, an increasing value of
means that the focal agent believes that tweet observations
will provide more information about hidden states, only in the case that the neighbour
k generating that tweet has ‘correct’ beliefs, i.e., their beliefs are aligned with the true Idea. In the context of decision-making, this means that agents believe that most informative observations come from those neighbours that have the ‘correct’ beliefs. Under active inference, actions that evince informative observations (i.e., observations that resolve the most uncertainty) are preferred. This drive is known as the ‘epistemic value’ or ‘salience’ [
86]. Therefore, higher levels of
will lead to increased epistemic value associated with sampling only those neighbours that the focal agent believes have veridical beliefs, according to its own beliefs about
.
2.6.3. Neighbour Attend Likelihood
The array
represents the agent’s beliefs about how hidden states relate to
. This observation model is constructed such that
only depends on
, and specifically that agents can always unambiguously infer who they are currently attending to, based on
. This can be expressed succinctly as a
K-dimensional identity matrix:
where
K is the number of the focal agent’s neighbours. Since the value of
does not depend on any hidden state factors besides
,
is ‘tiled’ across the remaining dimensions of the
array.
2.6.4. Transition Model
Now we move onto the transition likelihood model
. This is also known as the ‘dynamical likelihood’ and it is parameterised by a series of categorical distributions whose parameters are stored in a tensor
B:
As there are multiple hidden state factors in our generative model, the full
array is actually split into a collection of sub-arrays, one for each hidden state factor:
Each sub-array contains the categorical parameters of the factor-specific transition likelihood . Note that this construction means that hidden state factors are assumed to be independent by the generative model. In the context of the opinion dynamics model, this means that a single agent assumes that the hidden state both does not affect and is not affected by the belief states of neighbouring agents , and furthermore that the belief states of neighbours do not affect one another. In the following sections, we summarise the transition models for each hidden state factor.
2.6.5. Environmental Dynamics and Volatility
The dynamics of
according a focal agent’s generative model are described by
. Since this is an uncontrollable hidden state factor, it can be expressed as a simple
matrix, which expresses the focal agent’s beliefs about the probability that
(which Idea is “true”) switches over time. We parameterise this matrix with a precision parameter that we call ‘inverse environmental volatility’
:
where
I is the
identity matrix. The higher the value of
, the more the focal agent believes that the same Idea remains valid over time (e.g.,
Idea 1 is likely to remain the ‘valid’ idea from one timestep to the next). Consequently, a lower value of
(and thus a higher value of ‘environmental volatility’) means that the focal agent believes that the truth value of the two Ideas changes less predictably over time (the hidden state is likely to oscillate between
and
).
2.6.6. Meta-Belief Dynamics and Volatility
The dynamics of
, or the meta-belief associated with neighbour
k according to a focal agent’s generative model, is described by
. Like
,
is an an uncontrollable hidden state factor, and the
array can thus be expressed as a
matrix. Like
, we parameterise
with a precision parameter that we term ‘inverse social volatility’
:
The interpretation of is similar to that of : a higher value of implies that the focal agent assumes that its neighbours have ‘stubborn’ opinions and are not likely to change over time. A lower value means that the focal agent assumes that its neighbours‘ opinions can easily change over time, or that its neighbours are ‘fickle’.
2.6.7. Tweet Control
Now we discuss the controllable dynamics of the hidden state factor corresponding to the Hashtag that the focal agent is tweeting:
or
. Under the focal agent’s generative model, this factor only depends on the control state factor
, and the corresponding
array can thus be expressed as an identity matrix that maps from the action (
Tweet Hashtag 1 vs.
Tweet Hashtag 1) at timestep
to the next tweet value at timestep
t:
This means that the agent can unambiguously determine what it tweets next (the value of ) by means of actions .
2.6.8. Neighbour Attendance Control
Similarly for the dynamics of
, under the focal agent’s generative model, this factor only depends on the control state factor
, and the corresponding
array can thus be expressed as an identity matrix that maps from the action of which of
K neighbours to attend to at timestep
, to the next value of
at timestep
t, namely which neighbour is being attended to:
Just like the dynamics of , is thus fully controllable by the agent, i.e., determined by the value of .
2.7. Priors
The next component of the generative model is the priors over observations , hidden states , and actions . In discrete active inference models, we represent these as vectors , , and , respectively.
2.7.1. Observation Prior
In active inference, goal-directed action is often motivated by appealing to a baseline prior over observations
that specifies the agent’s preferences to encounter particular outcomes over others. This caches out value in terms of log probabilities or information, rather than classical constructs like ‘reward.’ Interestingly, this prior over observations does not come into play when performing inference about hidden states (i.e., it is not part of the generative model in Equation (
3)), but only during decision-making and action. Under active inference, actions are selected to minimise a quantity called the
expected free energy, a quasi-value function that scores policies by their ability to bring expected observations in alignment with preferred observations, while also maximising information gain (see the
Section 2.11 for more details). In the current model, we do not rely on this
vector to encode goals, but rather motivate action through a conditional action prior (see the section on the
vector below). For this reason, in our model the
is a flat distribution over observations and does not contribute to decision-making in this context.
2.7.2. State Prior
The prior over hidden states at the initial timestep is encoded by the so-called vector, . The vector encodes the agent’s beliefs about the initial state of the world, prior to having made any observations. In the context of the opinion formation generative model, it encodes baseline beliefs about which Idea is true, the meta-beliefs of the focal agent’s neighbours, as well as the initial tweet that the focal agent is making and the initial neighbour to whom the focal agent is attending.
2.7.3. Empirical Prior over Hashtag Control State:
We furnish the generative model with a special conditional prior over Hashtag control states
, parameterised by a mapping denoted by
. This quasi-likelihood or link function renders the prior over Hashtag control states
an
empirical prior, because of an explicit dependence on
. Under active inference, the final posterior over control states
becomes a Bayesian average of the ‘value’ of each control state, as determined by the (negative) expected free energy (see the corresponding
Section 2.11 below), as well as the prior probability of each control state as encoded by
. In the current model, we make the prior over control states an
empirical prior parameterised by a ‘link function’ denoted by the
vector. This makes the prior over the Hashtag control state
conditionally dependent on the
hidden state factor of the generative model. In practice, this implies that the prior over those control states corresponding to tweet actions
depends on the posterior over
, the hidden state corresponding to which Idea is true. This can be expressed as follows:
where the mapping encoded by the entries of
is an identity matrix that maps each value of
to a single Hashtag control state (value of
). At each timestep we approximate the prior at timestep
t over
with the agent’s current posterior belief
. The following sections on belief updating explain how one optimises the variational posterior over hidden states
using observations. Once approximated in this way, we can re-express the empirical prior over Hashtag control states
as:
Agents are therefore more likely to take the action if they believe more in Idea 1 than in Idea 2 (as reflected in the value of ), and likewise are more likely to take the action if they believe more in Idea 1 than in Idea 2. This empirical prior formulation thus renders the probability of taking a particular Tweet Hashtag action directly proportional to the agent’s belief in one of the two Ideas, as encoded in the variational posterior .
2.7.4. Prior over Neighbour Attendance Control State:
In addition to the prior over Hashtag control states
, the generative model also contains a prior over the
control state
. We parameterise this prior over control states using a categorical distribution
, whose probability itself is given by a Dirichlet distribution with parameters
:
The Dirichlet parameters , unlike the parameters of categorical distributions, are positive but not constrained to integrate to . As hyperparameters of a conjugate prior distribution, they are often analogised to ‘pseudo-counts’ that score the prior number of times a given action has been taken (in this case, sampling a particular neighbour via the control state ). For instance, if the vector for an agent with three neighbours is initialised to have the values , this means that the focal agent has a built-in propensity to take the action rather than the actions or . Furthermore, in turn, taking the action is twice as probable as taking the action . As we will see in the following sections, this ‘habit vector’ can be learned over time by optimising a variational beliefs over , which involves incrementing a Dirichlet vector that parameterises the posterior .
2.8. Summary
This concludes the specification of a single agent’s generative model for opinion formation. Now that we have specified this generative model, we move on to define the family of the approximate posteriors (the agent’s beliefs) over hidden states and policies as well as the variational free energy. In conjunction with the generative model, these can be used to derive the update equations used to perform active inference.
2.9. Approximate Posteriors and Free Energy
Under active inference, both perception and decision-making are cast as approximate inference problems, wherein the variational free energy (or bound on surprise) is minimised in order to optimise beliefs about hidden states (perception) and beliefs about policies (decision-making/action). In order to derive the equations that perform this optimisation, we therefore have to define the variational free energy. This free energy, equivalent to the bound defined in Equation (
2), requires both an approximate posterior and a generative model. We defined a POMDP generative model for our active inference agents in the previous section; the remaining step before writing out the free energy is then to define an approximate posterior distribution. For compatibility with the categorical prior and likelihood distributions of the generative model defined in Equation (
3), we will also define the approximate posterior as categorical distributions. Additionally, we will invoke a particular factorisation of the approximate posterior, also known as a
mean-field approximation, that allows us to factorise the approximate posterior over hidden states across timesteps. We define the approximate posterior over hidden states and policies as follows:
where the notation
denotes a categorical distribution over some random variable
x with parameters
. While this simplification assumes that posterior beliefs at subsequent timesteps are statistically independent, as we will see below, the Markovian temporal structure of the generative model means that, in practice, beliefs about hidden states at one timestep are contextualised by empirical priors from past timesteps (posterior beliefs from earlier timesteps).
The full free energy for the POMDP generative model and the approximate posterior specified in Equation (
16) can be written as follows:
Equipped with the free energy, we can now derive update equations for hidden state estimation and policy inference that involve minimising .
2.10. State Estimation
Under active inference, hidden state estimation is analogised to perception—this is achieved by optimising the variational posterior over hidden states, given policies. Because our approximate posterior and generative models are defined using categorical distributions, the problem of state estimation becomes minimising free energy gradients of the form , where are the parameters of the approximate posterior distribution over hidden states, .
At each timestep, the agent can take advantage of the mean-field factorisation of the posterior and the Markovian structure of the generative model to update only its beliefs about the current state of the world:
. The optimal posterior at timestep
t is then found by finding the solution to
that minimises the timestep-specific free energy
:
This furnishes a simple belief update scheme for perception, where the optimal posterior is a Bayesian integration of a likelihood term and a prior term .
Further details on the form of the approximate posterior and the derivation of the time-dependent free energy can be found in
Appendix A.
2.11. Policy Inference
Under active inference, policies are also a latent variable of the generative model and thus must be inferred. Accordingly, planning and action also emerge as results of (approximate) Bayesian inference, where now the inference is achieved by optimising a variational posterior over policies .
The optimal posterior that minimises the full variational free energy
is found by taking the derivative of
with respect to
and setting this gradient to 0, yielding the following free-energy-minimising solution for
:
Therefore, in the same way that state estimation or optimisation of
in Equation (
17) resembles a Bayesian average of a likelihood and a prior term, policy inference also becomes an average of the policy prior
and the ‘evidence’ afforded to each policy, scored by
. See
Appendix A for a more detailed derivation of the optimal policy posterior
.
The crucial component in understanding the behaviour of active inference agents lies in the specification of the policy prior,
. Under the standard construct of active inference (However, see alternative derivations as in [
122,
123]), the probability of a policy is defined a priori to be proportional to the negative
expected free energy of that policy:
The expected free energy or EFE is denoted by , and it measures the free energy expected under pursuit of a policy. This expected or predictive nature of the EFE is crucial: although the standard free energy is typically a direct function of observations (and functional of beliefs), when evaluating the consequences of a policy in the future, observations are not known—therefore, the expected free energy must deal with predicted observations or predictive densities over observations. As we will see below, this counterfactual nature of the expected free energy is what endows action selection with inherently both goal-directed and information-seeking components.
The expected free energy is defined mathematically as:
where
represents a generative model ‘biased’ towards the preferences of the agent. We can write this biased generative model at a single timestep as
, where
represents a ‘biased prior’ over observations. Given the factorisation of the approximate posterior
over time as defined in (
16), the EFE for a single timestep can also be defined as follows:
where the first term, the epistemic value, scores policies according to how much information observations
expected under that policy provide about hidden states. This term is expressed here as the divergence between the states predicted under a policy, with and without conditioning on observations. The second term represents the degree to which expected outcomes under a policy will align with the biased prior over observations in the generative model. Since the prior over policies
minimises expected free energy, policies with thus favoured states resolve uncertainty (maximise epistemic value) and satisfy prior preferences (maximise utility).
Having specified the prior over policies in terms of the (negative) expected free energy, we can now rewrite Equation (
18) by expanding the prior in terms of
:
Additionally, in extensions introduced in [
72], one has the option of augmenting the prior over policies with a ‘baseline policy’ or ‘habit vector’
, also referred to as the
distribution. This means that the full expression for the optimal posterior can be written as (expanding
as
):
We introduce this ‘habit vector’
explicitly here, because it will be one of the parameters we explore in the multi-agent model. Note that in the
Section 2.13 below, we reformulate the prior over policies in terms of two separate priors over
control states in order to disentangle the prior over policies that include particular Hashtag control states
from the prior over policies that are specific to neighbour-attendance control states
.
2.12. Action Selection
Action selection results from sampling from the marginal posterior over actions, or ‘control states’. The marginal posterior over actions can be computed by marginalising out the posterior probability of policies using the policy-to-control mapping
:
This marginalisation is necessary because the mapping between policies and actions is not necessarily one-to-one: in the case of multi-timestep policies or multi-factor generative models, a particular control state might be entailed by more than one policy. Therefore, this marginalisation effectively computes the value of each action by summing together the posterior probabilities of all policies that include it. This entailment relation is encoded in the likelihood .
Once the posterior over control states
has been computed, an action
a is simply sampled from this posterior marginal—this is then the action that the agent takes at timestep
t:
2.13. Habit Learning
Under active inference,
learning also emerges as a form of variational inference. However, this inference is not over hidden states, but rather over model parameters [
72]. Such parameter inference is referred to as ‘learning’ because it is often assumed to occur on a fundamentally slower timescale than hidden state and policy inference. However, the update equations for model parameters follow the exact same principles as hidden state inference—namely, we optimise a variational posterior over model parameters
by minimising the variational free energy
.
In the current model, we use ‘habit learning’ as originally described in [
72] to model the development of so-called ‘epistemic habits,’ or the tendency for an originally epistemically motivated behaviour to become habitually driven, mimicking the transfer from model-based to model-free learning in the context of behavioural conditioning [
75,
76]. Technically, habit-learning reduces to updating a variational posterior over the categorical vector
, which parameterises the prior over the neighbour-attendance control state
.
Recall from the
Section 2.7 that
is a vector of categorical parameters whose prior probability is given as a Dirichlet distribution:
The Dirichlet distribution is a conjugate prior for categorical distributions, meaning that the resulting posterior will also be Dirichlet distributed. Motivated by this conjugacy, we can define a variational posterior over the ‘habits’
parameterised by variational Dirichlet parameters
. One then simply augments the generative model from Equation (
3) with the prior over the categorical
parameters, which then allows one to define a new variational free energy, supplemented with the approximate posterior over
. Solving for the free-energy minimising solution with respect to the variational Dirichlet parameters
leads to the following fixed-point solution for
[
124]:
where
is a so-called ‘learning rate’ and
are current posterior beliefs about
controls states. In other words, agents will update their posterior over actions or ‘habit vector’ according to how often they attend to a particular neighbour, as measured by the probability of each
action. In the current work, we eschew the usual ‘separation of timescales’ assumption used in learning simulations (e.g., in [
72,
125]) and update the posterior habit vector
at every timestep, i.e., after every action. This means that agents in this context simultaneously infer which neighbour to attend to, based on the prerogative to minimise expected free energy, while also incorporating a continuously learned ‘habit’ based on the frequencies with which they attend to different neighbours.
2.14. Multi-Agent Simulations
Now that we have introduced the generative model used by single agents and the ensuing inference, action, and learning rules that each agent will use to update its beliefs over time, we proceed to describe the multi-agent simulation itself.
A single multi-agent opinion dynamics simulation consists of a group of
N active inference agents, where in the current work
N ranged from 12–30 agents. Each agent is equipped with the single generative model of opinion formation, as described in the previous sections. All simulations described below were conducted using
pymdp, a freely available Python package for performing active inference in discrete state spaces [
126].
At each timestep, all agents simultaneously (1) update their beliefs as a function of observations and then (2) take an action (i.e., selecting which Hashtag to tweet and which neighbour to attend to). Crucially, each agent’s observations are a function of its own actions at the previous timestep, as well as the actions of a select set of neighbours at the previous timestep. Each agent has a fixed set of neighbours, where the particular neighbours are determined by a randomly chosen network topology. In the current study, we set the neighbour-to-neighbour connectivity for all simulations using Erdős-Rényi (ER) networks with some connection parameter
p, meaning that agents are connected with fixed probability
p [
127]. For the current purposes, we make these networks undirected or symmetric, so that any agents that share an edge can both observe each other’s tweet actions and choose to read each other’s tweets. The components of each agent’s generative model (i.e., the number of observation modalities, number of hidden state factors) is a function of its local connectivity and the number of neighbours that it has. For example, a random agent in the network that was initialised to have three other neighbours will have three hidden state factors corresponding to the ‘meta-beliefs’ of these three neighbours:
, and
as well as three observation modalities that it will use to read each of those neighbours’ tweets:
, and
. Each of those neighbouring active inference agents’ actions (which Hashtag they tweet) will thus feed into the focal agent’s various
modalities at every timestep. Because edges are bidirectional, each of the neighbouring agents themselves will have a hidden state factor and observation modality, in their respective generative models, that represent the beliefs and
Tweet Hashtag X actions of the focal agent.
In the results section to follow, we investigate the opinion dynamics under active inference by testing the hypotheses stated in the
Section 1.6. We do this by systematically varying both the network connectivity
p and the parameters of individual generative models, in an effort to investigate the extent to which ‘epistemic communities’ depend on both network properties and the cognitive features of individuals.
3. Model Parameterisation
3.1. Fixed Parameters
It is worth mentioning the vast parameter space one encounters when simulating multi-agent active inference models. In the current work, each active inference agent is equipped with an entire POMDP generative model that contains hundreds of individual parameters (consider, for example, all the categorical parameters that comprise the observation model ). Importantly, this parameter explosion is exacerbated in the multi-agent setting, since not only does the number of total parameters scale simply in the size of the network N, but connections between agents render this scaling supra-linear in N, since each agent is equipped with hidden state factors and observation modalities, where is the number of neighbours that agent i is connected to.
This means that the possible parameter space that one must explore in order to understand the behaviour of the model is combinatorially explosive. To enable transparency and efficient parameter exploration, we employ several simplifications and low-dimensional parameterisations of every agent’s generative model, which render the resulting space easier to explore.
First of all, we assume that every agent’s observation model relating the tweet content of others to their beliefs has the same basic form. Recall from Equation (
7) the ‘Hashtag semantics’ matrix
that comprises the observation model for the observation of neighbour
k’s tweet content:
, parameterised with a ‘Hashtag reliability’ parameter
. We fix this matrix to have the same parameter
for all agents:
The choice of
was simply chosen since it is the setting of a two-element one-hot vector that is softmax-transformed using a precision parameter of 1.0. The choice of this particular parameter was not motivated by realism, or by construct- or ecological-validity. Instead, we chose it because it intuitively represents a “medium” level of precision, between the limits of precision
and precision
, where the values of
will converge to
and
, respectively. When the precision is
, the value of
occupies a relative average of these extreme values at a value of 0.73. A focal agent believes that if it sees some neighbour
k tweeting
Hashtag 1, then the likelihood that neighbour
k believes in
Idea 1 is 73%, and the likelihood that they believe in
Idea 2 is 27%. The relationship is inverted in case the focal agent sees neighbour
k tweeting
Hashtag 2. In the current study we assume that this basic Hashtag semantics matrix in Equation (
28) is common to all agents, and for all neighbours (relative to some focal agent). This enables us to selectively explore the effect of
epistemic confirmation bias, a single (scalar) precision
that can be used to up- or down-weight columns of the Hashtag semantics matrix, according to whether a given neighbouring agent’s belief aligns with (the focal agent’s belief about) the environmental hidden state factor
(see the section on Neighbour Tweet Likelihood for a more detailed explanation).
Another restriction is in space of network architectures we explore; for the present study, we constrain the connectivity to be defined by random graphs (also known as Erdős–Rényi or ER networks) that are characterised by two parameters: the network size N and the connectivity p. We render the simulations computationally tractable by exploring small networks (in the range of –30 agents) while systematically varying the connection probability p. We also assume that all agents’ transition models (those for both the environmental hidden state factor and meta-belief factors ) are a scaled version of the identity matrix . This further enables their systematic exploration in terms of single scalar (the precision), rather than exploring all possible parameterisations of transition matrices. In addition, while we systematically explore the inverse volatility parameter and epistemic confirmation bias precision , we fix the value of to be for all simulations. We leave the full combinatorial exploration of all parameters, including , to future work.
Finally, while parametrically exploring the dependence of collective outcomes on individual parameters, we usually restricted parameter sweeps to vary at most two parameters at a time. We did this in order to simulate a sufficient number of trials for each condition while also investigating each parameter with as fine a resolution as possible. Under both these constraints, the computation time would explode when varying more than just two parameters simultaneously; we thus fix the values of the non-varied parameters to limit computational burden (e.g., fix while varying and ). In practice, we clamped the value of the fixed parameters to ‘insensitive’ regions of parameter space where we know that the collective measure of interest (e.g., polarisation) did not depend on small changes in that parameter.
3.2. Parameters of Interest
In the following results section we describe four sets of parameters that we systematically varied to investigate their role in determining emergent phenomena in the multi-agent simulations. Below we briefly step through each parameter and rehearse its interpretation, and our motivation for investigating it.
3.2.1. Epistemic Confirmation Bias
Recall from Section Neighbour Tweet Likelihood that epistemic confirmation bias or ECB is a precision parameter that selectively scales the Hashtag semantics matrix of the agent’s observation model, linking and to . The ECB precision scales the Hashtag semantics matrix in such a way that some focal agent i receives evidence for the hidden state factor’s value (Idea 1 vs. Idea 2) from the tweet output of some neighbour k, in proportion to how much neighbour k agrees with agent i.
This means that a focal agent with a higher
believes that tweets more reliable if they come from neighbouring agents that are believed to share the opinion of the focal agent. The consequence of this is an ironically named ‘epistemic’ sort of confirmation bias, where agents believe that more reliable information about
comes from neighbours who are believed to be ‘like-minded’ to themselves. This can be revealed by recalling the expected free energy, the key determinant in action selection under active inference. As decomposed in Equation (
21), this comprises an information gain term and a utility term. By means of the ECB parameter, the epistemic value term is preferentially higher for those actions that entail attending to a neighbour who the focal believes is like-minded. This can be analysed more quantitatively by inspecting the ‘negative ambiguity’ term of the epistemic value,
, which we show to be directly proportional to epistemic confirmation bias:
See
Appendix B for a complete derivation of the relationship between
and epistemic value.
Given this relationship, we expect that higher epistemic confirmation bias will drive agents to preferentially attend to the actions of agents that share their beliefs. On a collective level, we hypothesise that ECB will increase the probability of both polarisation (two clusters of oppositely minded agents) and consensus (all agents have the same or similar beliefs about the Idea).
3.2.2. Inverse Social Volatility
Recall the inverse temperature parameter introduced in
Section 2.4, where we parameterised a focal agent’s beliefs about the stochasticity of the social dynamics using precision parameters
(following the notation used in [
84]). The inverse social volatility scales the transition model that describes the dynamics of
, such that a higher
induces an assumption of less stochasticity in the belief evolution of neighbours’ ‘meta-beliefs.’ This relationship also implies that the inverse social volatility is related to the epistemic value of actions that involve attending to particular neighbours. In particular, higher volatility (i.e., more entropy in the columns of the
matrices) leads to higher overall uncertainty in beliefs about hidden states. In other words, for lower values of
the uncertainty of the posterior marginal
will accumulate faster, as long as the focal agent is not attending to neighbour
k. Actions that entail attending to these unattended neighbours will therefore grow in epistemic value, the more time elapses during which those neighbours remain unattended. Importantly, the growth in epistemic value will scale inversely with
(see
Appendix B for details). This means that the particular value of
sets an effective ‘refresh rate’ for how often a neighbour should be re-attended to, in order to resolve uncertainty about their beliefs.
Given this relationship, we hypothesise that high ‘meta-belief’ volatility (low ) will lead agents to re-read their neighbours’ tweet content with a higher rate—whether or not they (believe they) agree with them—in order to resolve uncertainty about their beliefs. We expect that this continuous, epistemically driven ‘re-sampling’ will counteract the tendency of the group to polarise and thus favour collective agreement or consensus. An interesting question will be whether the inverse social volatility parameters directly ‘reverse’ the effect of , where the two jointly determine a collective trade-off between consensus and polarisation.
3.2.3. Learning Rate
The learning rate associated with updating the habit vector over neighbour-attendance control states represents the degree to which agents will preferentially sample those neighbours that they have attended to in the past. In the presence of a higher learning rate, the Dirichlet hyperparameters over the habit vector will be “bumped up" by a larger amount after choosing to attend to any particular agent, such that a focal agent will form preferences to attend to those agents whose Hashtags they habitually read. We expect therefore that a higher value of will lead to increasingly preferential neighbour-attendance patterns among agents, and eventually to a change in the overall collective belief distribution of the group. Specifically, we hypothesise that ‘echo-chamber’-like dynamics will be exacerbated by a higher value of , such that it will be harder to ‘escape’ from polarised dynamics in the presence of a large habit-learning rate .
3.2.4. Network Connectivity
In addition to individual generative model parameters like , , and , we also quantitatively investigate whether and how the topology of agent-to-agent communication determines emergent behaviour. To quantitatively investigate this using a simple, one-dimensional parameterisation, we initialised the agent-to-agent communication network (i.e., which agents can read with other agents’ Hashtags) using a fixed random graph with connection probability p. For random graphs, p encodes the probability that any two agents have an edge between them. In the current context, an edge between any two agents determines whether they can view each other’s Hashtags, and thus form beliefs about one another’s beliefs). We hypothesise that denser communication topologies, represented by random graphs with increasing connection probability p, will obviate the risk of polarisation and lead to consensus with higher probability. In investigating this network effect, we also hope to reveal interactions between (which we hypothesise will induce polarisation) and connection probability p.
In the following sections, we describe the results of numerical experiments wherein we systematically vary the parameters discussed above, and reveal how they modulate the collective formation of ‘epistemic communities’ (e.g., echo-chambers, polarisation, and consensus).
4. Results
In the following sections we summarise the results of numerical experiments that validate the basic dynamics of the opinion formation generative model and then systematically investigate each of our three hypotheses. The results sections are organised as follows.
First, we demonstrate the basic dynamics of an active inference agent engaged in opinion formation. Over time, we show how a single focal agent updates its beliefs about the world in the face of conflicting Hashtag observations from two neighbours. In this process, the agent simultaneously forms beliefs about the abstract, environmental hidden state (Idea 1 vs. Idea 2) as well as beliefs about the meta-beliefs of two neighbouring agents to whose Hashtags it is exposed. We examine the dependence of a single agent’s belief-updating dynamics on different settings of the epistemic confirmation bias and the inverse social volatility under a fixed value of .
Next, we demonstrate the emergent formation of epistemic communities and the diverse dynamics that can be observed under the current active inference model. These are meant as proof-of-principle validation of the opinion dynamics model and the rich sorts of collective behaviours it can give rise to.
Finally, in order to test the three hypotheses that frame our study of epistemic communities under active inference, we systematic vary parameters such as , , , and p to investigate how they determine collective dynamics. In these collective dynamics experiments, we link groups of active inference agents together and simulate their multi-agent dynamics for up to timesteps. We then study collective outcomes by averaging the results of hundreds of independent realisations.
When systematically varying parameter configurations, we define a single condition as a combination of the parameters of interest. This includes the network connectivity p and a vector of generative model parameters, e.g., . For each condition, we ran 100 independent multi-agent simulations with a network size agents. We chose relatively small networks in order to limit the computational burden of each simulation.
4.1. Opinion Formation in a Single Agent
Figure 2 visualises opinion formation in a single active inference agent, and sheds light on the relationship between
and
in determining the rate of belief updating and action selection. We investigate this using a simplified three-agent set-up, where one focal agent is exposed to a sequence of conflicting information from two neighbours. At each timestep, the focal agent chooses to read a Hashtag from one of its two neighbours, and the two neighbours are not actually active inference agents, but are simply sources of a sequence of discrete Hashtag observations (
Hashtag 1 issue from Neighbour 1,
Hashtag 2 issue from Neighbour 2). We can see anecdotally how belief updating and sampling behaviours are bidirectionally modulated by different combinations of
and
. In general,
Figure 2 shows that beliefs in more meta-belief volatility (lower
) lead to higher posterior uncertainty about the
hidden state, as is shown by the red lines in subplots (a) and (c). Higher epistemic confirmation bias
, on the other hand, induces a positive feedback effect, wherein the focal agent comes to agree with one of its two neighbours with high certainty, most likely whichever neighbour it happens to attend to at the first timestep.
With high enough
or high enough
, the focal agent’s beliefs, faced with these two conflicting sources of information, converge to one Idea. This choice is consistently reinforced by the focal agent’s continuing to sample the agent it agrees with (lower insets in each subplot of
Figure 2). There is also an interesting interaction between
and
, such that
drives down posterior uncertainty in the focal agent’s beliefs about its neighbour
. This in turn decreases the information gain term in the expected free energy, such that the agent has stronger prior beliefs about its neighbour’s beliefs and there is less information gain afforded to attending to that neighbour. On the other hand, higher
drives up epistemic value, even in the face of precise beliefs about the neighbour’s belief state, making the agent expect to artificially resolve more uncertainty from its observations.
It is clear that for configurations with high inverse social volatility, as the focal agent’s beliefs converge toward the beliefs of Neighbour 1, it also begins to attend to Neighbour 1 more often than Neighbour 2 (subplot (d)). However, with low inverse social volatility, the focal agent is driven to periodically attend to both neighbours, due to the increasing epistemic value associated with neighbours that are unattended to. Interestingly, when
is low and
is high (
Figure 2c), the focal agent continues to periodically re-attend to the neighbour it disagrees with, due to increasing uncertainty about that neighbour’s belief, induced by high volatility associated with it. Note, however, that the total probability of attending to the like-minded neighbour is still higher due to the presence of high epistemic confirmation bias. In the presence of both low epistemic confirmation bias and low inverse social volatility, posterior uncertainty is high all-around and the focal agent is ‘ambivalent’ between both
Idea 1 and
Idea 2. Nonetheless, the focal agent succeeds in inferring the belief-states of its two neighbours as it repeatedly alternates between sampling them.
4.2. Epistemic Community Dynamics
Figure 3 shows examples of the collective opinion dynamics (i.e., ‘epistemic communities’) that emerge when simulating networks of active inference. Unlike in
Figure 2, in these simulations the observations for every agent are generated by the actions of other active inference agents, who are all collectively reading the Hashtag actions of other agents while and generating their own. We include this to showcase the rich phenomenology displayed by collectives of active inference agents, validating our model alongside known opinion dynamics models that can capture phenomena like consensus and polarisation. In the following sections we investigate the dependence of these dynamics on the parameters of generative models and network density quantitatively.
4.3. The Dependence of Epistemic Communities on and p
We first investigated Hypothesis 1, or how epistemic confirmation bias and network connectivity p determine the collective formation of epistemic communities. We systematically varied both epistemic confirmation bias (15 values of tiling the range ) and network connectivity (15 values of p tiling the range ) in networks of agents, and simulated independent realisations of each condition for timesteps. Other parameters were fixed to constant values (, , ). Note that here, habit-learning was intentionally disabled () to selectively investigate the effect of while excluding the effect of habit learning on epistemic community formation. Within each parameter configuration, every independent realisation and every agent had the same average value of epistemic confirmation bias , but for each agent, we sampled a vector of epistemic confirmation bias values from a normal distribution centred at the parameter setting with a variance of . Note that there are k different ECB parameters per agent because each agent has a collection of arrays, each corresponding to the observation model from a particular neighbour. Each of these k likelihood arrays is parameterised by a single . By sampling across arrays within each agent’s generative model, we implicitly gave each agent a particular bias to believe that certain neighbours were more ‘reliable’ than others—some neighbours contribute more or less to the focal agent’s confirmation bias tendency. Note that this same sort of across-neighbour sampling was performed for the inverse social volatility —in other words, served as the mean of a normal distribution, from which each agent’s vector of neighbour-specific parameters was sampled, one for each .
The aim was to investigate how higher epistemic confirmation bias, particularly in a sparse network, might drive the emergence of epistemic communities through the formation of belief clusters that are both dense and far apart in ‘belief-space.’ In general, it is known in the literature that clusters are more easily formed in sparsely connected networks, but less so in densely connected networks where all agents communicate with each other [
94]. Therefore, one interesting hypothesis for this experiment was that increasing the value of
could achieve the opposite effect: namely, a high degree of polarisation or belief-clustering behaviour in a densely connected network.
To assess the emergence of epistemic communities or clusters of like-minded individuals, we defined the polarisation index
, which measures the degree of ‘epistemic spread’ in a system. It is defined as the difference between the highest and the lowest values of the Bernoulli parameter defining
across all agents at the final timestep of the simulation (where the choice of one ‘side’ of the belief
is arbitrary). This final difference is then averaged across
S independent realisations or trials to give the average value
for a particular condition. This is directly proportional to the ratio of the number of trials in any configuration in which the simulation ends with two opposing clusters, as opposed to consensus, where consensus is defined at the final timestep when all agents’ posterior beliefs about
are on the same side of 0.5.
where
S indicates the number of total trials (here,
).
A high value of (close to 1) indicates more spread-out beliefs and implies clustering, i.e., echo-chamber formation, whereas a low implies that the network of agents have similar beliefs about (i.e., consensus).
Figure 4 shows the effects of varying
and
p on polarisation as measured by
. It is clear from the first column of the heatmap that highly spread out beliefs can occur at all values of the epistemic confirmation bias in the presence of sparse connectivity. Denser networks in general reduce the risk of polarisation, as seen by a drop-off in
as
p increases. However, epistemic confirmation bias can ‘counteract’ this effect to some extent by marginally bumping up the risk of polarisation, even in the presence of denser networks (high
and high
p). The lower subplots of
Figure 4 demonstrate this counteractive effect, where even at high connectivities (e.g.,
) the epistemic confirmation bias can lead to the majority of trials resulting in polarised dynamics.
Why, one might wonder, does polarisation still occur with some probability even when is small? When network connections are sparse, polarisation can still occur by virtue of the agents lacking access to a variety of neighbours—this forces them to attend to one of a limited set of neighbours that they start out connected to. Since all agents are initialised with flat prior beliefs about , this leads to the formation of two clusters, since there is nothing correlating the beliefs of agents who are disconnected. Because there are two beliefs (Idea 1 and Idea 2), this means that on average this fragmentation leads to distinct sub-clusters of connected agents that will believe in one of the two Ideas with approximately 50% probability.
As
increases, even in the presence of increasing connectivity, agents are driven by epistemic value to preferentially attend to the neighbours that (they believe) share their beliefs. This accounts for the slower decrease in polarisation with increasing connectivity
p at higher levels of
shown in
Figure 4. This can be compared to the faster decrease in polarisation induced by
p when
is low (compare the first few rows of the heatmap in
Figure 4 to the last few rows).
However, network connectivity seems to be a stronger effect than in enforcing consensus or at least the lack of polarisation. This is because the exploration entailed by encourages agents to attend to a larger group of neighbours, leading to a higher average spread of beliefs and the ability for agents to serendipitously encounter other agents they agree with. However, because of the density of the network, it is much more difficult for agents to become polarised as they will more frequently be exposed to new information, despite their propensity towards confirmation bias.
4.4. Effect of Inverse Social Volatility on Neighbour Attendance and Polarisation
Next, we explored Hypothesis 2, modelling behaviour under different values of inverse social volatility to see how it would interact with . We swept over (15 values tiling the range ) and (15 values tiling the range ) in networks of agents with connection probability. As explained before, each agent’s generative model was parameterised by a vector of k distinct and parameters, which were sampled from a normal distribution centred around the parameter value characterising the condition. In this case, each sampled value parameterised the different neighbour-specific observation () and transition models () for a particular focal agent.
To assess the extent to which social attendance changes as a function of
and
, we defined the re-attendance rate
r. It scores the maximum number of times an agent samples the same neighbour throughout a parameter configuration, averaged over trials.
where
is the indicator function.
We measured the re-attendance rate and polarisation index for each configuration, averaged across trials.
Figure 5 portrays a complex picture on the relationship between
and
. In the case of high volatility over meta-beliefs (low inverse social volatility), agents are driven to periodically re-attend to neighbours in order to resolve growing uncertainty about their beliefs. This is indicated by a higher average re-attendance rate
(top right heatmap). Interestingly, there is an interaction between re-attendance rate and epistemic confirmation bias, such that in the presence of low volatility (high inverse social volatility)
and low epistemic confirmation bias, the re-attendance rate is minimised. We speculate that a low value of ECB (
) makes the epistemic value of attending to every neighbour equally high purely a function of
. In this case, agents will continually revisit neighbours sequentially, with the attendance-preference for any given neighbour solely dependent on the time elapsed since the last time they were attended to. In the absence of confirmation bias (which normally accelerates the focal agent’s beliefs not only about
but also about
(cf.
Figure 2), this means that uncertainty about neighbours’ beliefs will on average be higher. This will lead to diverse social attendance patterns, such that agents will prefer to constantly sample new neighbours, with no particular neighbour excluded from this uncertainty-driven re-sampling. There seems to be a stark threshold around
above which the re-attendance rate drops off quite rapidly, as long as
. This threshold probably represents the level at which the epistemic value induced by posterior uncertainty (which is a function of
) surpasses the contribution to epistemic value induced by
. For higher values of
(
), the drop off in re-attendance rate with increasing
is countered due to the increased contribution of
to the epistemic value of repeatedly sampling neighbours who are believed to be like-minded. Finally, at high enough values of
(≈9.0), the drop-off of re-attendance rate with increasing
is re-established. This is likely due to the ‘self-inhibiting’ effect of increasing
on epistemic value. When
is high enough, agents come to form very precise beliefs about their neighbours’ beliefs (the entropy of
decreases), which in turn decreases the resolvable uncertainty about those neighbours’ beliefs. We refer the reader to
Appendix B for a more quantitative exploration of this effect that exposes the epistemic value in terms of an entropy term and a negative ambiguity term.
In terms of polarisation, it seems that for , high volatility (low ) encourages polarisation more than low volatility, since agents are driven to re-sample their neighbours (with whom they are likely to agree, due to epistemic confirmation bias), and will end up forming distinct belief clusters. However, for the effect of seems to disappear and we see high polarisation for all values of . We originally hypothesised that if agents are uncertain about the beliefs of their neighbours (low ), it will become more difficult to induce polarisation and purposefully sample those who are thought to agree, due to the competing epistemic value induced by high posterior uncertainty about one’s neighbours’ beliefs, regardless of whether (a focal agent believes) those neighbours to be like-minded. However there is no clear difference between polarisation levels when is high. Nevertheless it is clear that higher induces polarisation for non-volatile networks. A more robust effect is how social volatility induces the tendency to re-attend to neighbours (cf. right panels).
4.5. Habit Formation and Network Initialisation
For the final experiment, we explored Hypothesis 3, regarding the polarisation of networks via habit formation. We swept over (15 values tiling the range ) and (15 values tiling the range ) in networks of agents with connection probability, where and as before . Here, was again normally distributed with a fixed mean (which varied by condition) and variance across the k neighbours of each focal agent, but the learning rate was fixed to the condition-dependent value across all trials and agents.
The learning rate incentivises agents to re-attend to the same neighbour by forming a habit, which competes with the epistemic value of attending to a new neighbour with unknown beliefs. This experiment tested the hypothesis that a higher learning rate, i.e., stronger habit-formation, will increase polarisation.
Figure 6 demonstrates how learning rate
and epistemic confirmation bias
interact to influence outcomes at the collective level. Indeed, a higher learning rate induces more polarisation, implying the formation of more ‘stubborn’ epistemic communities in the network. This effect appears at both low and high levels of epistemic confirmation bias, with on average a higher
observed with increasing learning rate, even at low levels of
. However, it seems the effect is most pronounced at the highest levels of
and
. Examining the average re-attendance
(right column of
Figure 6) reveals a clear effect of
on neighbour re-attendance, with the rate seemingly maximised when the learning rate surpasses a value of
. Interestingly, the effect of ECB on re-attendance is not very strong here, although it seems to have a mild negative effect. Namely, as ECB increases, the re-attendance rate tends to decrease. One counterintuitive explanation for this effect (which is similar to the effect observed in
Figure 5) is the general increase in the epistemic value of attending to neighbours with unknown beliefs that is caused by increasing
. Although by design
is intended to ‘boost’ the epistemic value of only those actions that involve attending to neighbours that the focal agent believes it agrees with, there is still an overall ‘exploration bonus’ that scales with
,
even for actions that entail attending to neighbours with whom the focal agent disagrees. This is because in addition to the ambiguity term of the epistemic value, which captures the ‘confirmation bias’ effect encoded by
, there is also a maximum-entropy component
(see
Appendix B for details). This term is maximised when the posterior uncertainty over meta-beliefs
is high (maximal when
). Therefore, although ECB ‘bends’ the epistemic value landscape towards sampling like-minded neighbours (see
Figure A1 in
Appendix B for a visualisation of this effect), when compared to neighbours with differing beliefs, the inherently uncertainty-resolving nature of the epistemic value as a whole means that higher
still increases the value of actions that involve attending to
any neighbours whose beliefs the focal agent is uncertain about. This may in fact counteract the polarising effects we originally intended to capture by including the ECB parameter. This across-the-board ‘exploration bonus’ conferred by ECB may explain the mild effect we observe here, where increasing
ends up decreasing average re-attendance
. This may indeed explain the decrease observed in
Figure 5 and
Figure 6.
5. Discussion
In this paper, we focused on the way communities form around shared beliefs about abstract entities or meanings, symbolised by an abstract discrete hidden state: an ‘Idea’. Shared belief around a particular ‘Idea’ emerges through coordination, which itself is individually driven by the desire to form accurate (Bayesian beliefs) about the world and the beliefs of one’s community. In particular, we modelled confirmation bias as an ‘epistemic’ phenomenon wherein agents have a biased belief that agents with whom they believe they agree are more likely to provide uncertainty-resolving (information-availing) data—hence the proposed terminology of epistemic confirmation bias.
Twitter provides fertile ground for the academic study of the spread of ideas. The platform is extremely popular, easy to access, and has an API that enables researchers to collect and analyse data. It has also been one of the major vectors for misinformation, leading to large-scale events, like the tensions around the 2016 election results [
128] or the vaccine for SARS-CoV-19 [
129]. With its effective network structure in terms of follower-, like-, and retweet-networks, Twitter provides an ideal environment for the empirical study of the spread of ideas.
The formation of echo-chambers has been well studied on Twitter and Facebook. Echo-chambers tend to reinforce like-mindedness in users, and tend as well to enable the crafting of a shared narrative [
41]. The authors of [
41] analysed the different ways in which different social media platforms’ algorithms influence the mechanisms of formation. They defined the echo-chambers based on the distributions of leanings towards polar attitudes. These attitude distributions were found to range from monomodal to bimodal or more complex. Regardless, polarisation is rarely neutral, and tends to favour opposition between extreme opinions. According to their results, Twitter and Facebook showed the most striking echo-chambers. Using virality models, they also measured information spread. In Twitter and Facebook, information was most likely to be spread to other users sharing similar leanings. Similar findings were shown by [
130] by following the online debates surrounding vaccination hesitancy in Italy. Despite the formation of distinct echo-chambers, they found that community structure within echo-chambers also differed between vaccine advocates and sceptics and influenced information flow. Findings like these and others on polarised social network dynamics inspired us to analogise the model explored in the current work to online digital social media like Twitter, as well as to study how network structures influence echo-chamber formation. Alongside this, we chose to embrace an underlying active inference model as a cognitively inspired, Bayesian model for single agents’ belief formation.
To formalise confirmation bias as a fundamentally Bayesian phenomenon, we constructed our generative model to include a precision parameter that we named
epistemic conformation bias or ECB. Specifically, ECB confers a higher weight to information that comes from peers that the reader (focal agent) believes are like-minded. This in turns leads an agent with higher ECB to selectively sample information that justifies what they already believe. We were able to replicate the formation of epistemic communities in silico, e.g., echo-chambers, on social networks such as Twitter. This unique formulation of confirmation bias as an epistemic phenomenon helps explain how individuals continuously forage their environment for information, but may become stuck in a so-called ‘bad bootstrap’ that simply reinforces existing beliefs about the world, which in the face of new information may lead to sub-optimal behaviour [
131].
In agreement with previous work studying the relationship between synchronisation and network structure, we found that opinion dynamics depend heavily on network density. Our formalism allowed us to systematically vary the parameters of individual agents (e.g., cognitive biases or beliefs) as well as collective properties such as network structure. We found that the density of inter-agent connections, parameterised by connection probability of random graphs, determined the transition between echo-chamber formation (polarisation) and consensus. However, we found that in the presence of high ECB, one could observe polarisation even in the presence of dense connectivity (cf.
Figure 4). This result seems counterintuitive, as we might think that network clustering is a necessary condition for more polarisation. However, clearly defined clusters and group boundaries can sometimes act as buffers [
132,
133,
134,
135,
136]. Sub-clusters exchanging information are likely to average towards their local centre [
137,
138,
139], which entails a form of opinion stability within the group. They are generally sheltered from other opinions since they cut ties to other agents not part of their group, and have been selected out [
140]. However, in networks without clusters, opinions can have a high degree of volatility and reach very polar tendencies even without being entirely clustered. By means of epistemic confirmation bias, agents were likely to give more weight to information that was similar to their own, even in the presence of network neighbours with different opinions.
The clustering phenomenon is exacerbated by adding the capacity to form habits. Specifically, we allowed agents to increase their likelihood of resampling the same agents based on how often they attended to them in the past. Since neighbour-attendance is driven by epistemic value (resolving uncertainty about the and hidden state factors), this tendency to revisit previously sampled neighbours is a form of ‘epistemic habit formation,’ where actions that are initially undertaken based on information gain become solidified over time due to a Pavlovian, model-free mechanism that simply reinforces past behaviour. We found that in addition to ECB, the presence of habit formation exacerbated polarisation, presumably due to the formation of echo-chambers or tight communities of agents that read only the Hashtag content of their like-minded peers. On the other hand, we found that beliefs about social volatility (represented by our parameter) pushed the agents to sample their social environments more frequently and diversely, counteracting the effect of confirmation bias and habit formation in driving polarisation. We speculate that increased social volatility increases each agent’s incentive to sample a diverse array of network neighbours, which in turns lessens their susceptibility to believing in one Idea with high certainty. In other words, increased social volatility (low ) makes agents more ‘curious’ about the beliefs of (potentially non-like-minded) neighbours, which in turns increases their exposure to conflicting information and ‘protects’ them from falling into one or another echo-chamber.
The contributing influence of beliefs about social volatility to exploratory social sampling leads us to consider the role of norms in social settings. If an agent is incentivised (via, e.g., epistemic value or curiosity) to pay attention to neighbours about whom they are uncertain, their social group could be a source of constant surprise, as long as their beliefs about their neighbours are constantly fickle (“I’m not sure what members of my social group believe from one time to the next”). In other words, even in the presence of a group of like-minded peers, we would expect that increased beliefs about social volatility leads to repeated attendance of peers among one another, even if those peers all agree (and believe as much about each other).
6. Conclusions
Our simulation showcased a novel opinion dynamics model based on multi-agent active inference, and highlights many interesting possibilities for future research. We introduced a new parameter, the epistemic confirmation bias, which can modulate the formation of epistemic communities by changing epistemic value in a biased way, namely towards attending preferentially to like-minded agents. In addition to the ECB, we also showed the importance of other features such as network structure and habit formation in contributing to polarised dynamics. However, there are several limitations to this work which warrant further discussion. While we systematised our study design to explore several parameters simultaneously, this search was not exhaustive and vast regions of parameter space remain unexplored. Particular parameters such as the size of the network and the ‘inverse environmental volatility’
remained unexplored (we mainly explored networks with size
and always fixed
), and for computational efficiency we restricted both the resolution and the combinatorics of the parameter combinations explored. Network size is a major computational bottleneck, and thus our results are not guaranteed to generalise to larger networks. In future work, we could leverage distributed computing or GPU-accelerated operations to explore both larger network sizes and parameter combinations. However, in model spaces with high enough dimensions, computational acceleration alone will not suffice; one could thus also reduce the sampled region of parameter space by leveraging efficient search techniques (e.g., optimal experimental design [
141]) or higher-order learning methods such as Bayesian hyperparameter optimisation [
142]. The ‘inverse environmental volatility’ parameter
deserves further mention: as explained in
Section 2.5,
encodes the precision of the transition model
. This can be understood as the the agent’s beliefs about the uncertainty characterising the truth status of the ‘Idea‘ itself. We intentionally fixed this parameter to a constant value of
for all simulations. In other words, all agents believed that the
hidden state changed very slowly or with low uncertainty. As mentioned above, we made this simplification for the current study to limit the volume of the parameter space explored. Additionally, exploring beliefs about the dynamics of
was not particularly relevant to the current study, because we did not include any true hidden environmental dynamics in the simulations. In fact, the agents only observe the behaviour of other agents, and never observe any true signal from the environment itself. Including a veridical, non-social signal from the environment, however, would be an interesting extension for future work.
The generative model used by the single agents was also limited, in the sense that we only modelled beliefs in one of two mutually exclusive Ideas. Previous research into opinion or collective dynamics has shown that such binarity may strongly determine the dynamics of the system [
104,
143]. From a construct-validity standpoint, such binarity also vastly simplifies the semantic complexity found in real epistemic communities. For example, the semantic expression of a particular idea or claim heavily depends on the community in which it circulates. In future designs, we should strive to make the ideas more complex and more porous. By porosity we mean ‘semantic cross-over’, in the sense that multiple ideas may entail more or less similar behavioural consequences, or indeed entail the truth value of one another. This porosity may give rise to groups that believe in the same idea from an inference standpoint, but have a different interpretation of it. Starting from there, we can begin to envisage a specific semantic embedding which leads us to social scripts [
144]. These conceptual embeddings would lead to two different conceptions with distinct causal relations to the environment. The weak conception of the script corresponds to an embedding, linking the observation of an event to the belief in a particular idea. The strong conception of the script leads to a sequencing of the beliefs, such as an entailment relation (e.g., ‘if I believe X, this entails a belief in Y’). This type of conceptual entailment possible under a strong conception of social scripts, combined with the ability to express one’s beliefs, could engender a capacity to act and coordinate through language with other actors.
Future work could explicitly model these entailment relationships among semantic entities by violating the typical independence assumption used to factorise the generative model’s hidden state factors—for instance, instead of having each hidden state factor being conditionally dependent on only other states/control states within that factor, we could ‘mix’ hidden state factors to make states of factor i depend on states of factor j.
Another notable feature to include is the variation of prior beliefs about different ideas or claims. In the current model, agents were often initialised to have uniformly distributed beliefs about around the ‘ambivalence’ line of . Future studies could quantitatively investigate the dependence of epistemic community formation on the initial distribution of prior beliefs and how that distribution intersects with structural features such as network position (e.g., ‘is a very confident agent more influential in determining information spread, when it’s a peripheral vs. central node in the network?’). In this way, we could study ‘historical effects’ such as whether pre-existing echo-chambers or belief distributions influence the susceptibility of the network to incoming information or environmental fluctuations.
Another limitation of this work is the relative simplicity of the dependent measurements we used to characterise collective outcomes. For instance, we measured the degree of collective consensus vs. polarisation through the polarisation metric. This metric is a scalar which quantifies the degree to which the entire network believes in one Idea vs. is split into believing in two Ideas. However, this one-dimensional metric is ambiguous with respect to exactly how beliefs are spread throughout the network, in the case of low consensus—for instance, a low polarisation metric does not disambiguate whether all the agents that believe in one Idea have network connections to each other, or whether they are isolated and only ‘by chance’ believe in the same Idea. Future investigations should thus develop more sensitive metrics, depending on the hypothesis, that take into consideration how individual beliefs correlate with the network topology. In addition, we could calculate polarisation-style metrics using other dimensions of the agents’ beliefs—for example, we could measure polarisation using the so-called ‘meta-beliefs,’ in addition to just the agents’ beliefs about the Idea itself.
In future studies, we hope to investigate individual cognitive differences more quantitatively using the active inference framework. Under active inference, ‘individual differences’ can be formalised as variance among the parameters of generative models across agents—e.g., different settings of the inverse volatility parameters for different agents. Another interesting possibility that is accommodated within the active inference framework is the idea that agents may learn the parameters of their generative models, as opposed to keeping them fixed over time. For example, one could imagine that the epistemic confirmation bias associated with a particular neighbour k could change over time as a function of the reliability of Hashtags observed by the focal agent. This is easily cast as another form of inference under the Bayesian framework. All one would need to do is define appropriate priors and approximate posteriors over , from which an additional free energy term and appropriate belief updating scheme could be derived. Learning the parameters may add ecological validity to the model as well; for example, agents might become accustomed to their social environment and seek out an epistemic community in order to increase the predictability of their sensory information, thus requiring them to sample their social environment less frequently. This is the kind of phenomenon that could be modelled by letting the inverse social volatilities become free, learnable parameters. With larger networks, we may be able to simulate the emergence of similar but distant sub-communities, which become epistemically similar without coming into direct contact, or only through very distant contact with one another. This leads us to the possibility of simulating the way epistemic and pragmatic practices become cemented, giving way to social meaning semantics and scripts, which seem to separate cultures. Simulating the emergence of similar semantics and scripts across different communities may help us further understand their common underlying processes. Finally, in future studies, we could model an explicit state of conformity, by modelling the agent’s assumptions about the groups they can identify around themselves, and be driven to model their behaviour after the group they feel most kinship to.


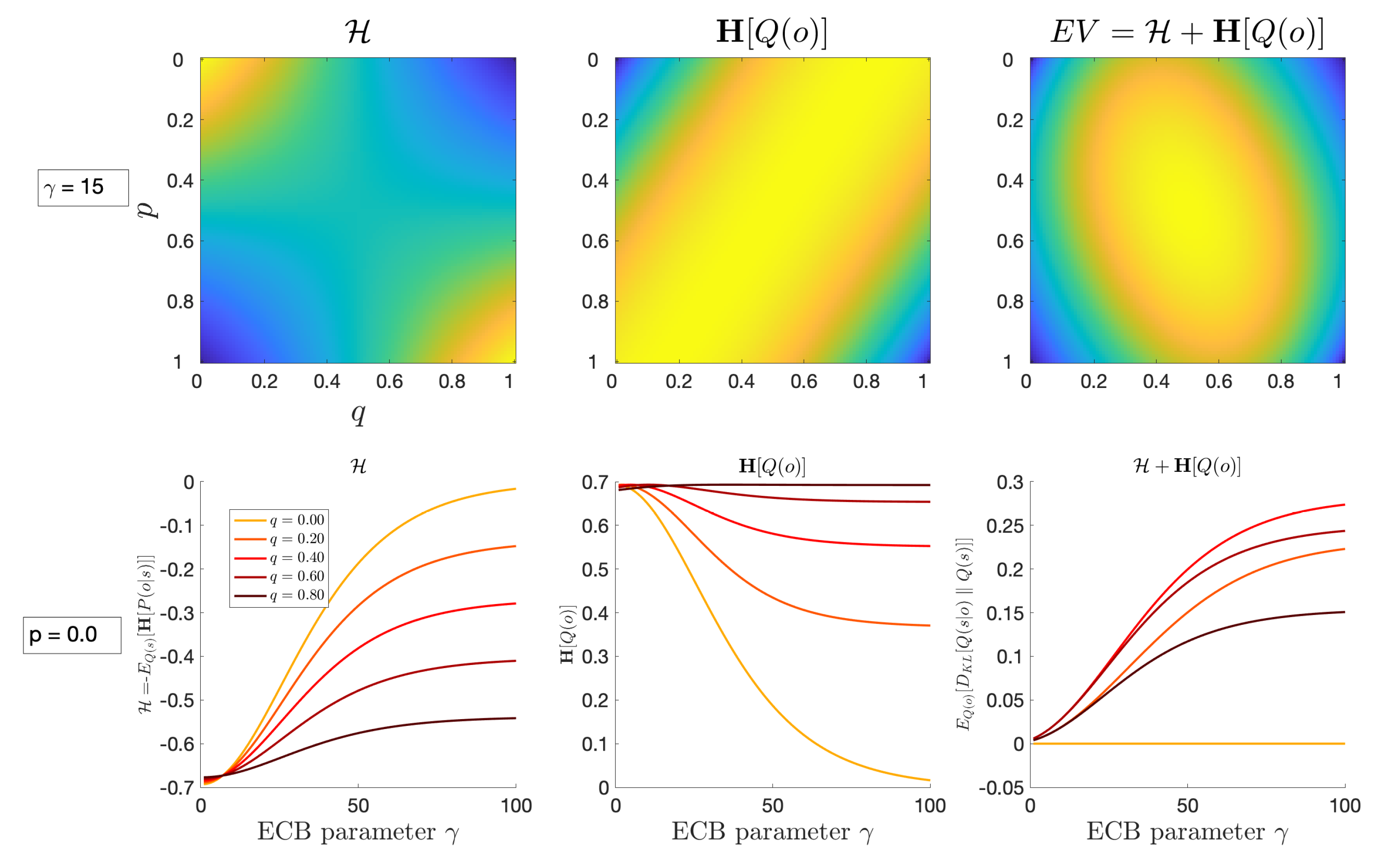
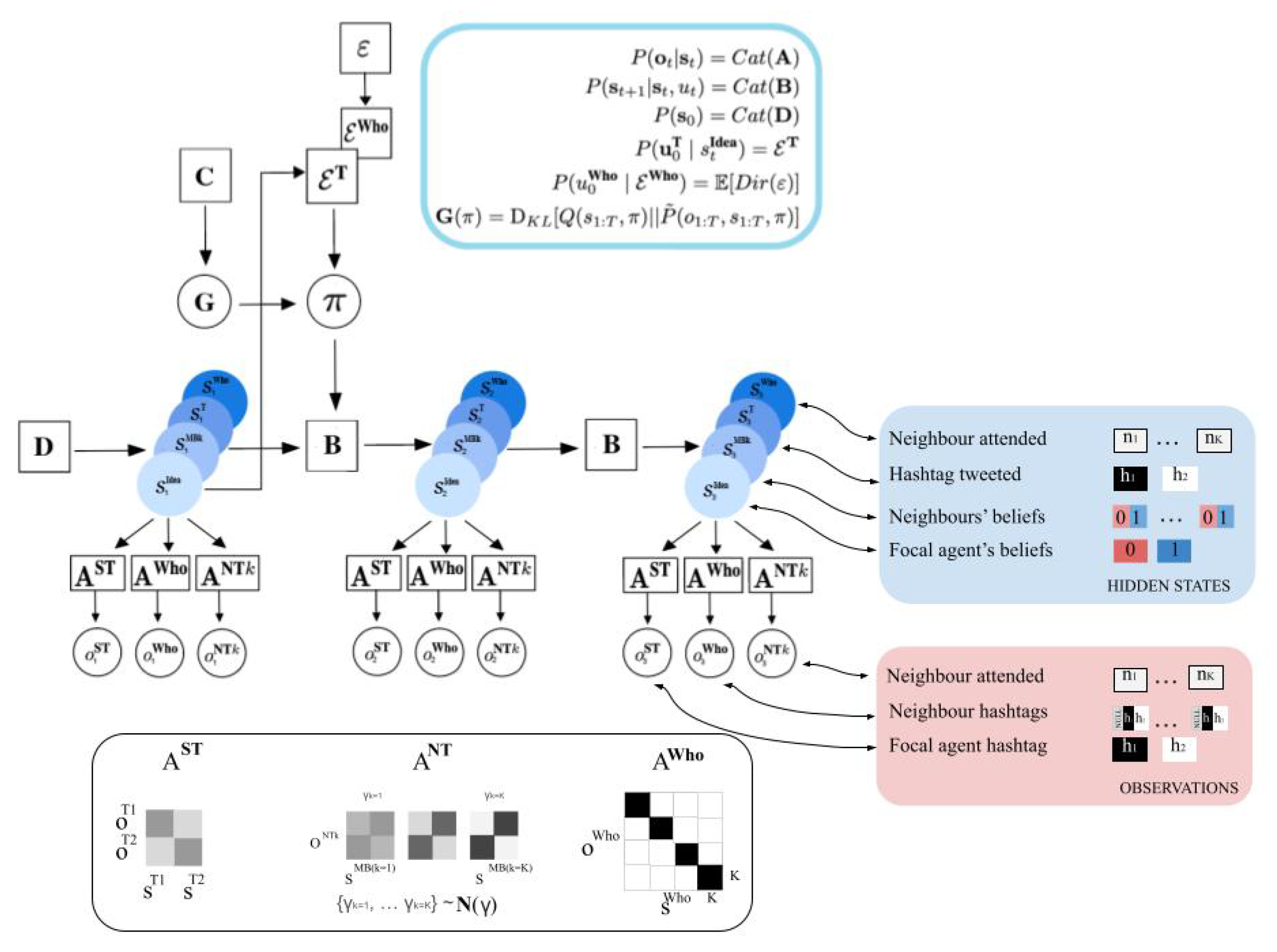
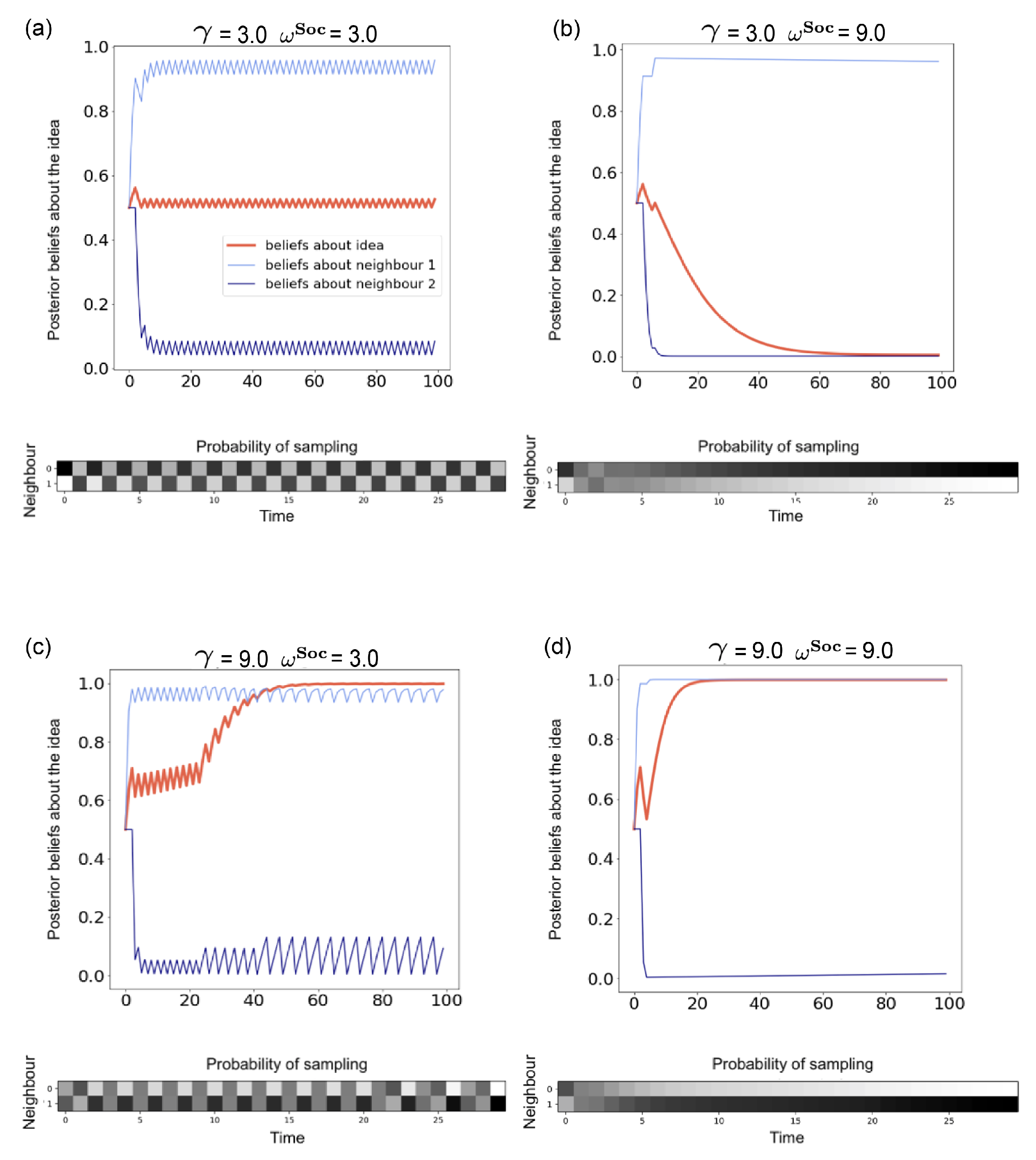
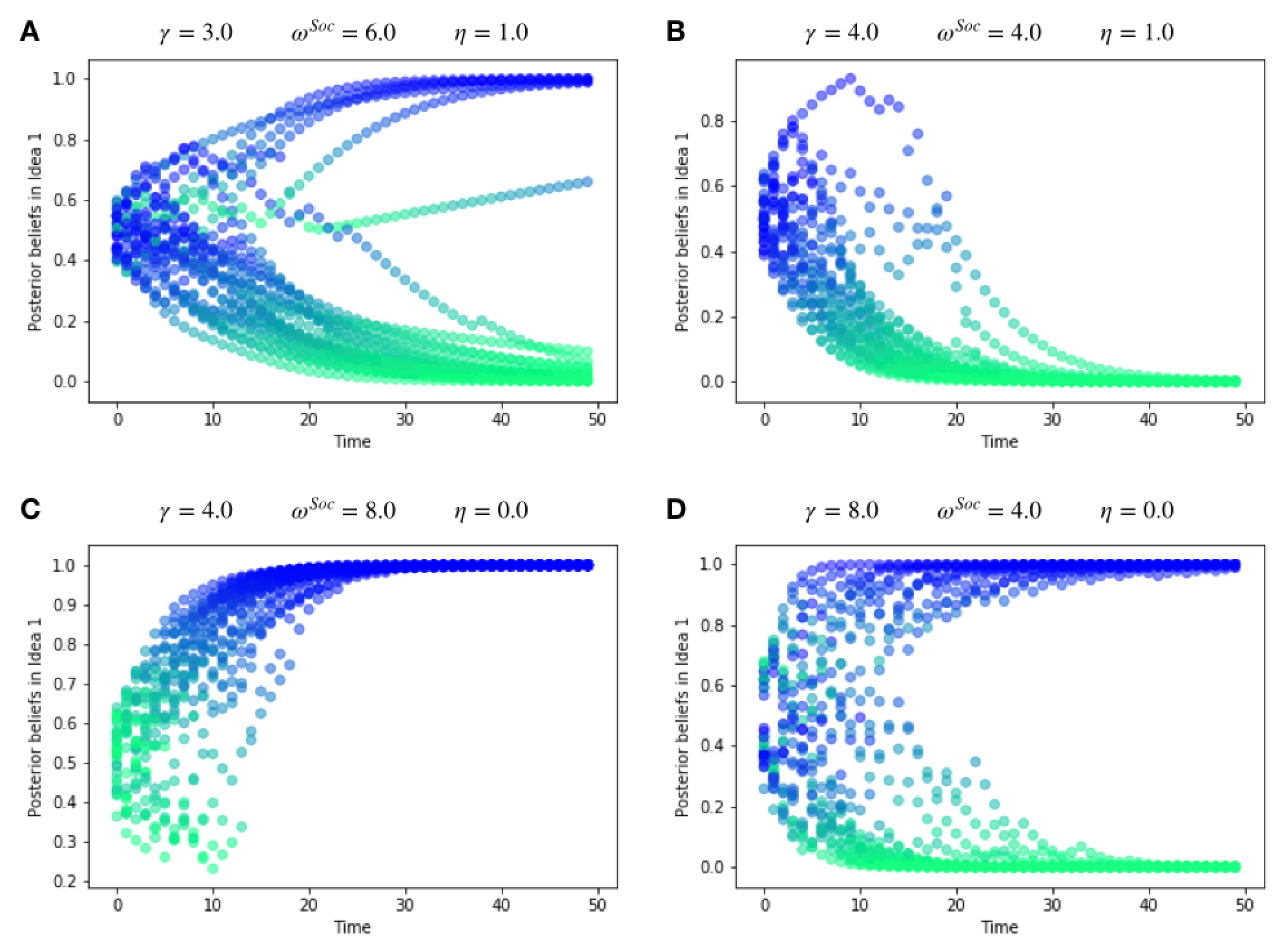
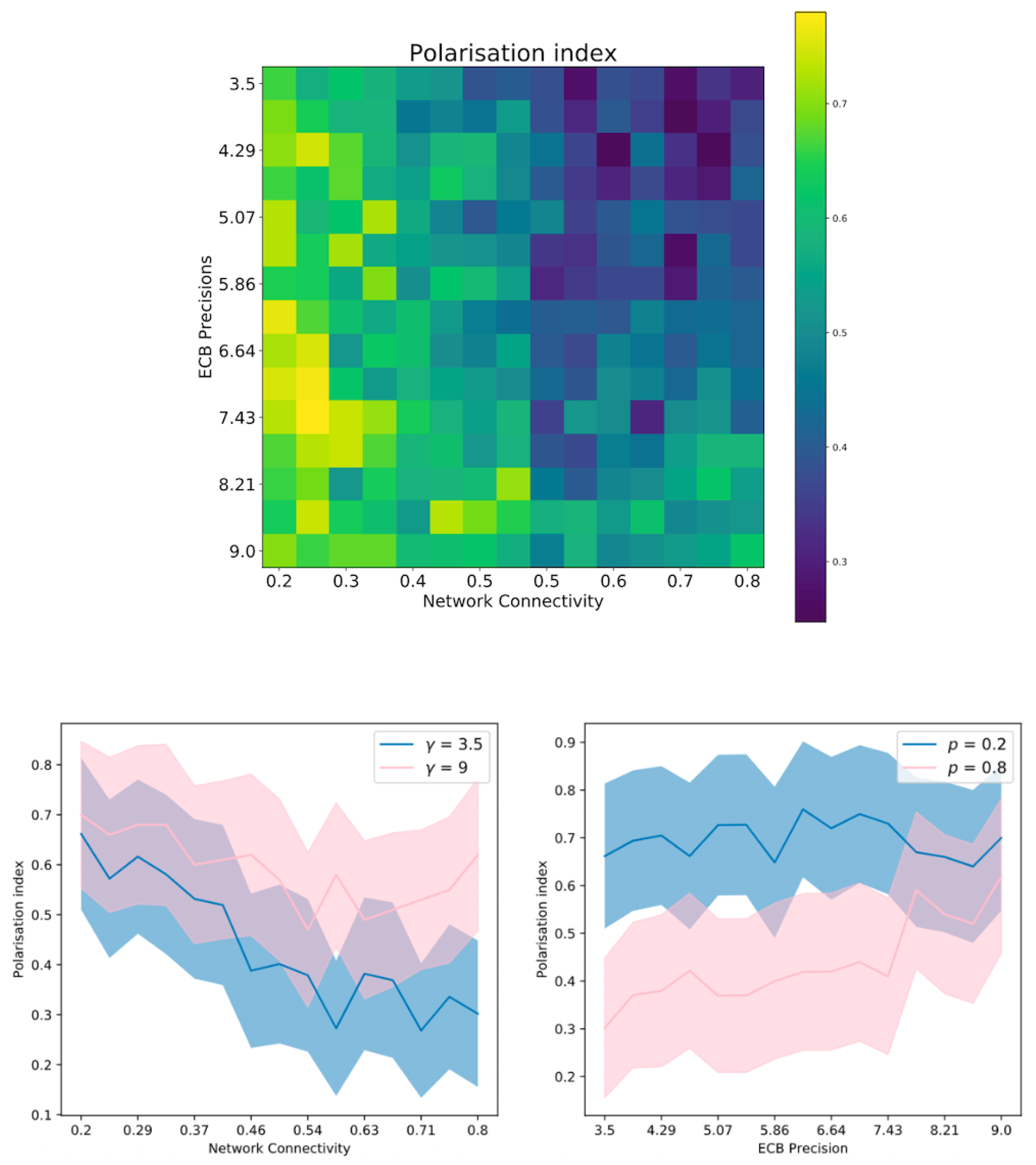
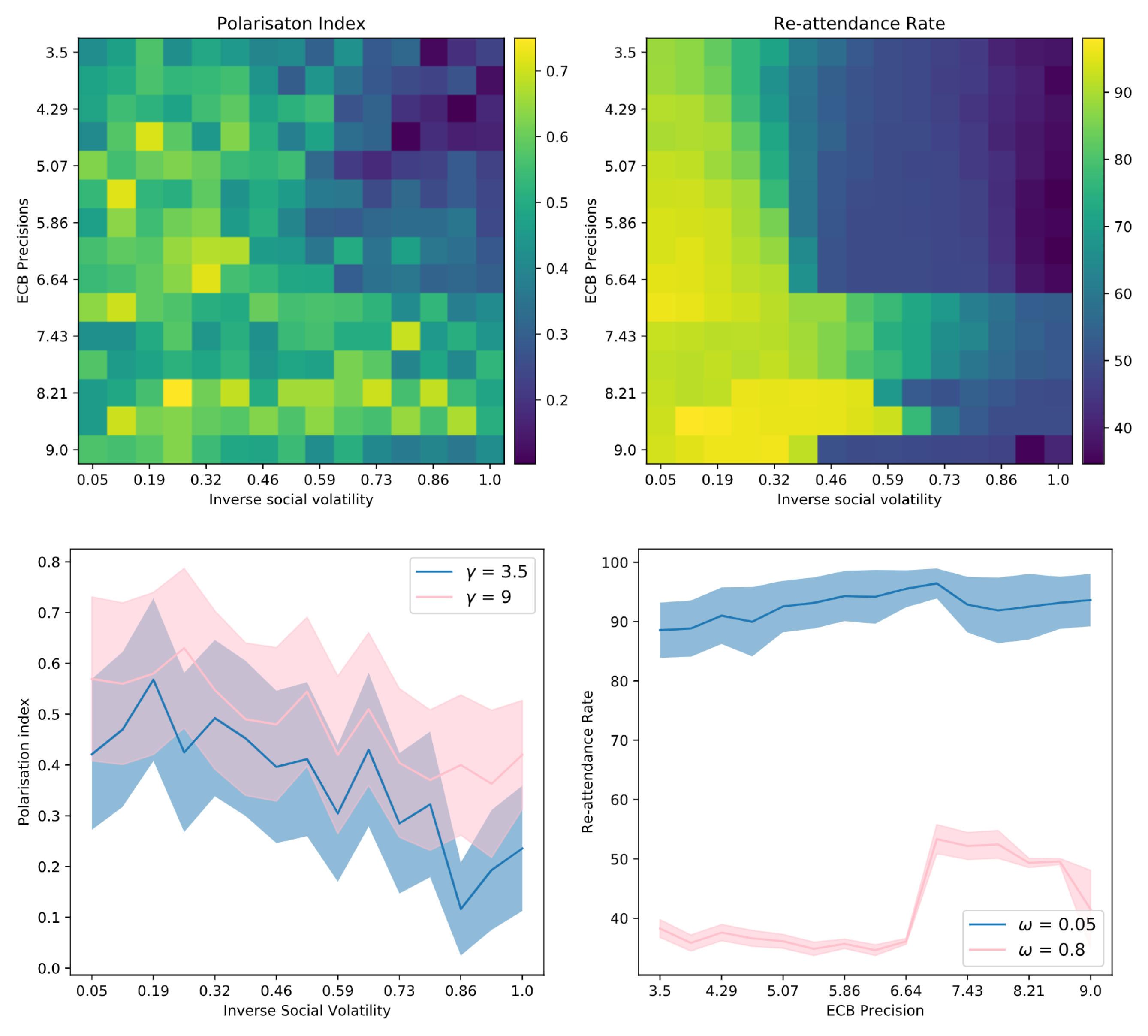
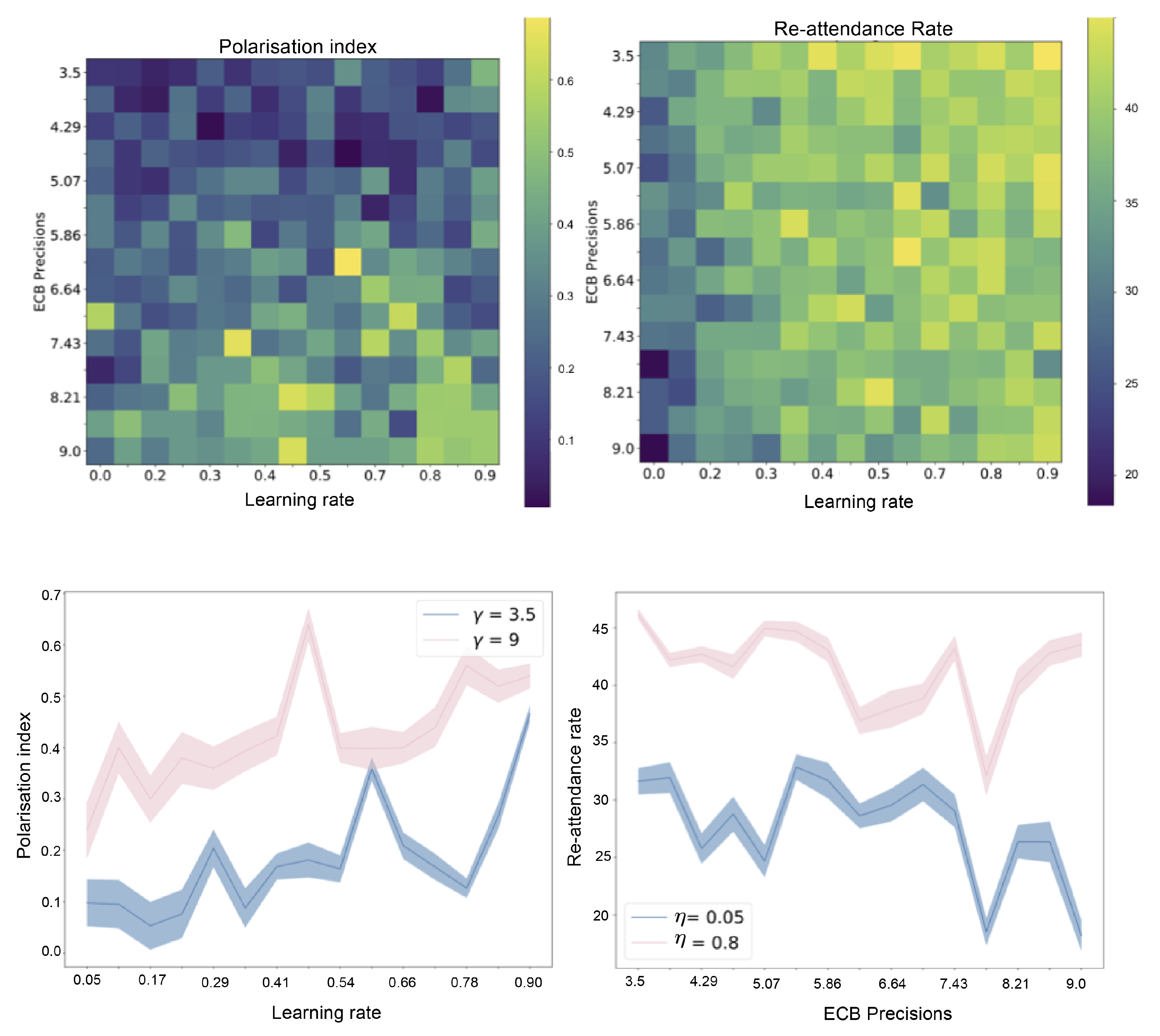

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}