
Semi-Parametric Estimation Using Bernstein Polynomial and a Finite Gaussian Mixture Model



Abstract
:1. Introduction
2. Background
The Gaussian Mixture Model and Em Algorithm
- (i)
- E-step: The conditional expectation of the complete-data log-likelyhood given the observed data, using the current fit , is defined byThe posterior probability that belongs to the component of the mixture at the iteration, is expressed asFinally, we obtain
- (ii)
- M-step: It consists of a global maximization of with respect to .The updated estimates are stated by
3. Proposed Approach
- Step 1
- We consider the Bernstein estimator of the density function f, which is defined as
- Step 2
- Step 3
- We consider the shrinkage density estimator form defined byand we use the EM algorithm to estimate the parameter of the proposed model.
- 1.
- E-step: The conditional expectation of the complete-data log-likelihood given the observed data, using the current , is provided bywhere is a discrete random vector, following a multivariate Bernoulli distribution with vector parameters . Using Bayes’s formula, we obtain the posterior probability in the iteration denoted byand
- 2.
- M-step: It consists of a global maximization of with respect to .The updated estimate of is indicated by
4. Convergence
- (A1)
- For almost and for all , the partial derivatives , and of the density g exist and satisfy that and are bounded, respectively, by , and , where and are integrable and , satisfies
- (A2)
- The Fisher information matrix is positively defined at .
5. Numerical Studies
5.1. Comparison Study
- 1.
- Let us suppose that X is concentrated on a finite support ; then, we work with the sample values , where .
- 2.
- For the density functions concentrated on , we can use the transformed sample , which transforms the range to the interval .
- 3.
- For the support , we can use the transformed sample , which transforms the range to the interval .
- (a)
- The beta mixture density ;
- (b)
- The beta mixture density ;
- (c)
- The normal mixture density ;
- (d)
- The chi-squared density.
- (e)
- The gamma mixture density ;
- (f)
- The gamma mixture density .
- -
- We first generated a random sample of size n from the models’ density .
- -
- We then split the generated data into a training set of a size of of the considered sample and a test set of a size of of the considered sample.
- -
- We applied the proposed estimator, using the observed data only from the training set, in order to estimate the density function.
- -
- The test set was then used to compute the estimation errors , and .
- -
- -
- Using the proposed estimator, we obtained better results than those given by the other estimators in a large part of the cases.
- -
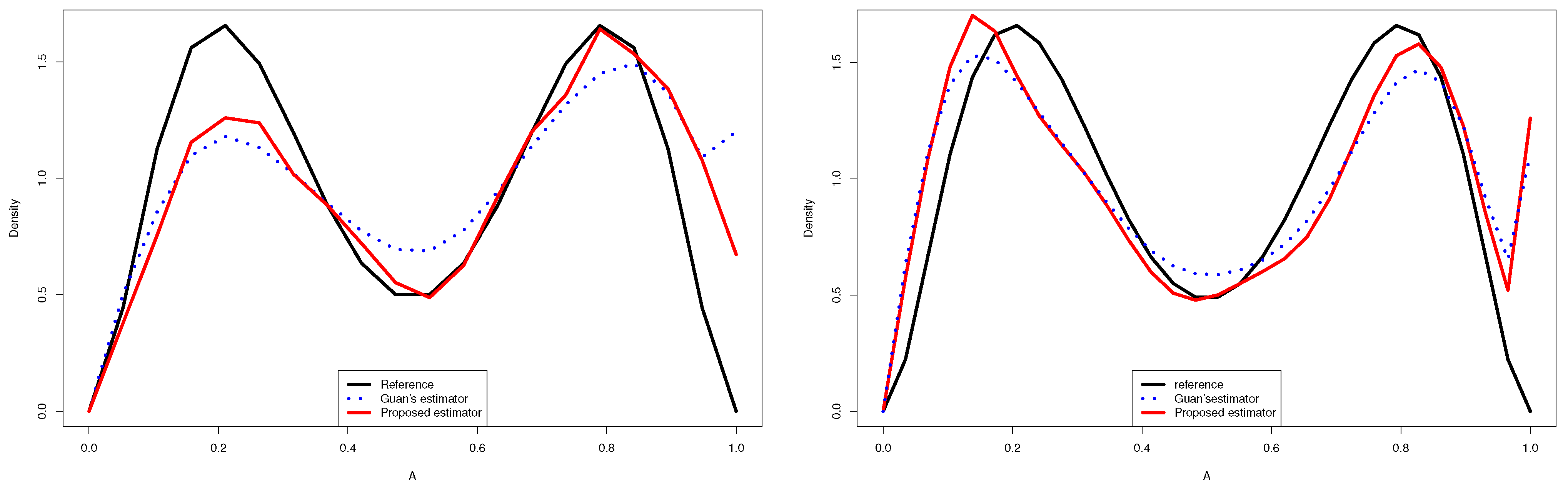
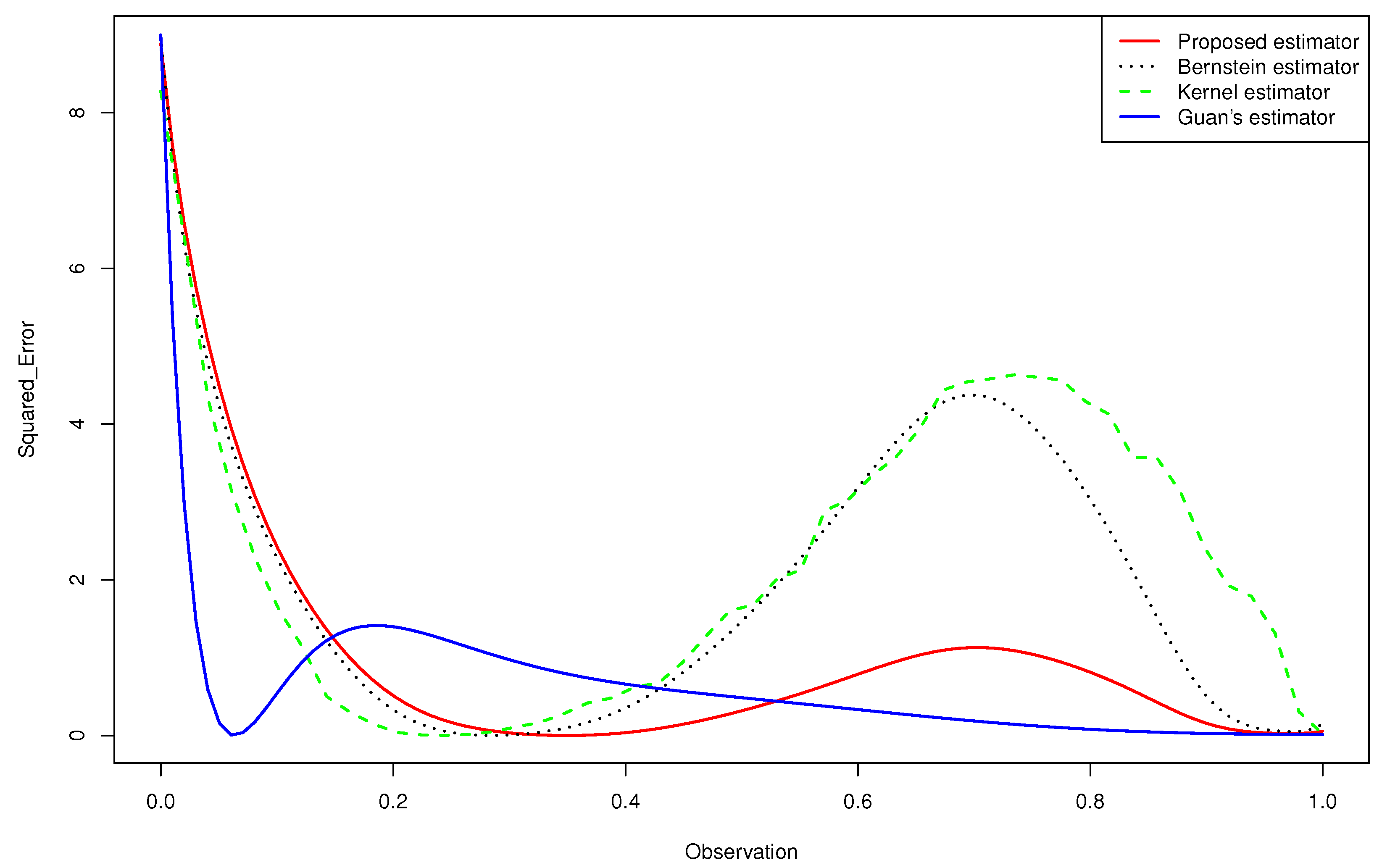
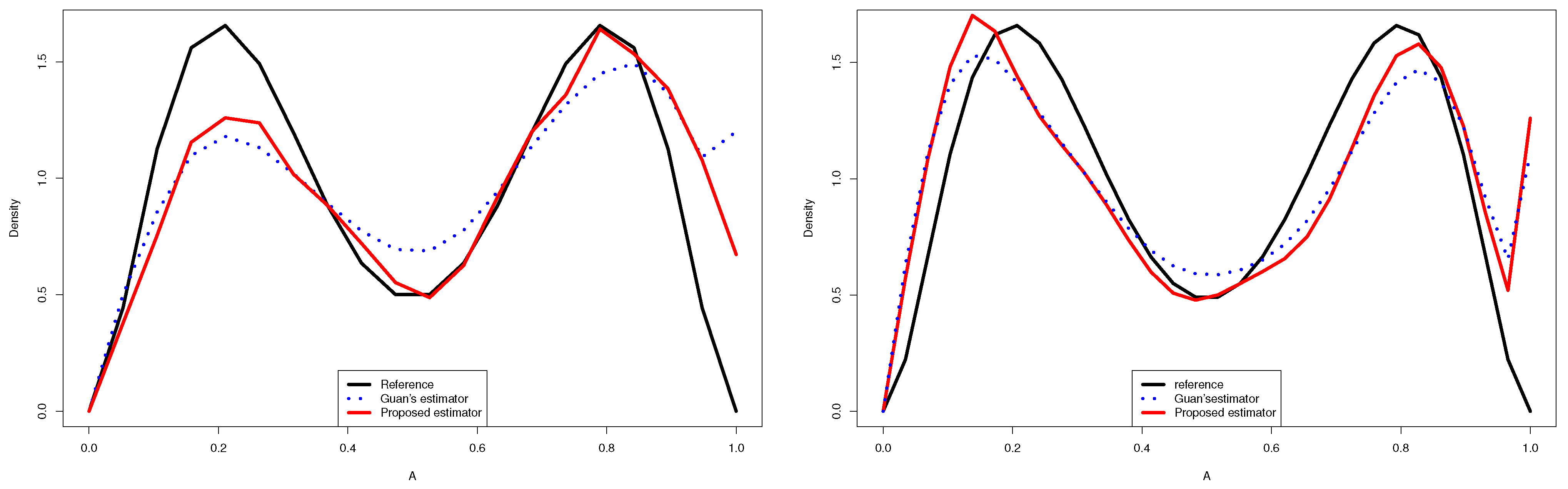
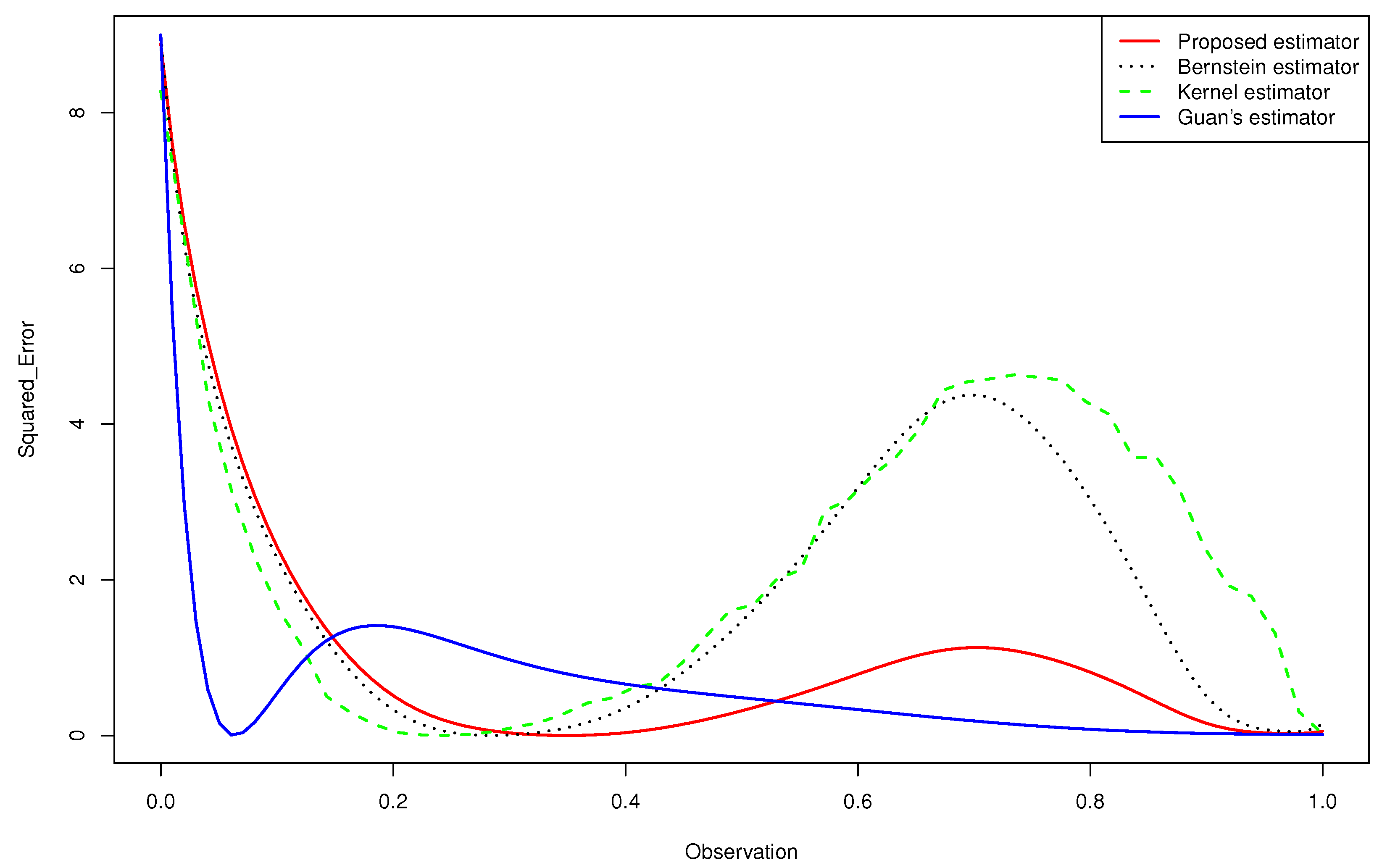
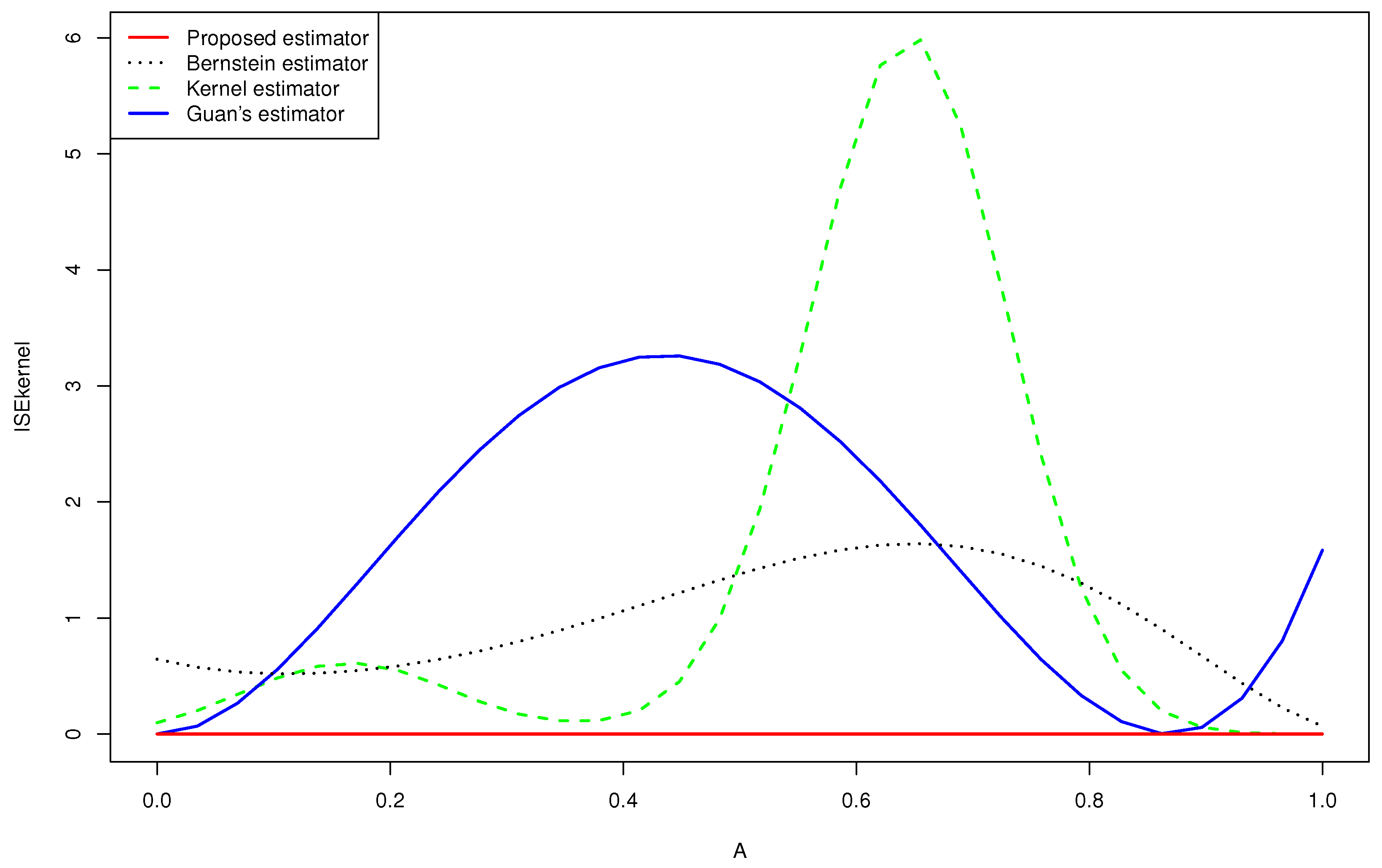
- The Figure 2 and 3 give a better sense of where the error is located.
- -
- For the case (e) of the gamma mixture, the average and of Guan’s estimator (1.3) were smaller than those obtained by the proposed density estimator (3.4) and the Bernstein estimator (1.2). However, in all the other cases, using an appropriate choice of the degree m, the average and of the proposed density estimator (3.4) were smaller than what achieved by the kernel estimator (1.1), the Bernstein estimator (1.2) and Guan’s estimator (1.3), even when the sample size was large for same cases.
- -
- When we changed the parameters of the gamma mixture density in the sense that we had a smaller bias, our estimator was more competitive than the other approaches and we obtained better results.
- -
- -
- In the considered distribution , by choosing the appropriate m, the curve of the proposed distribution estimator (3.4) was closer to the true distribution than that of Guan’s estimator (1.3), even when the sample size was very large.
- -
- None of the estimators for the gamma mixture density had good approximations near . However, the of the proposed estimator was closer to zero than that of the Bernstein estimator and the kernel estimator, especially near the edge .
- -
- Guan’s estimator and the kernel estimator for the normal mixture density had good approximations near . However, the of the proposed estimator was closer to zero than that of the other estimators, especially near the two edges.
5.2. Real Dataset
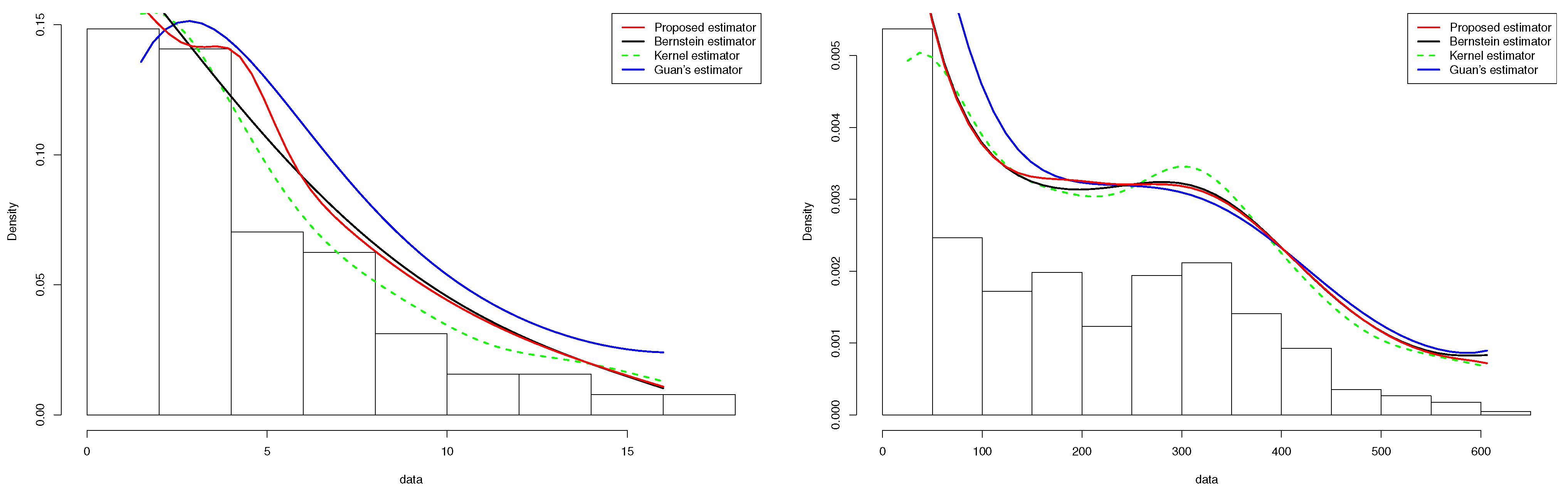
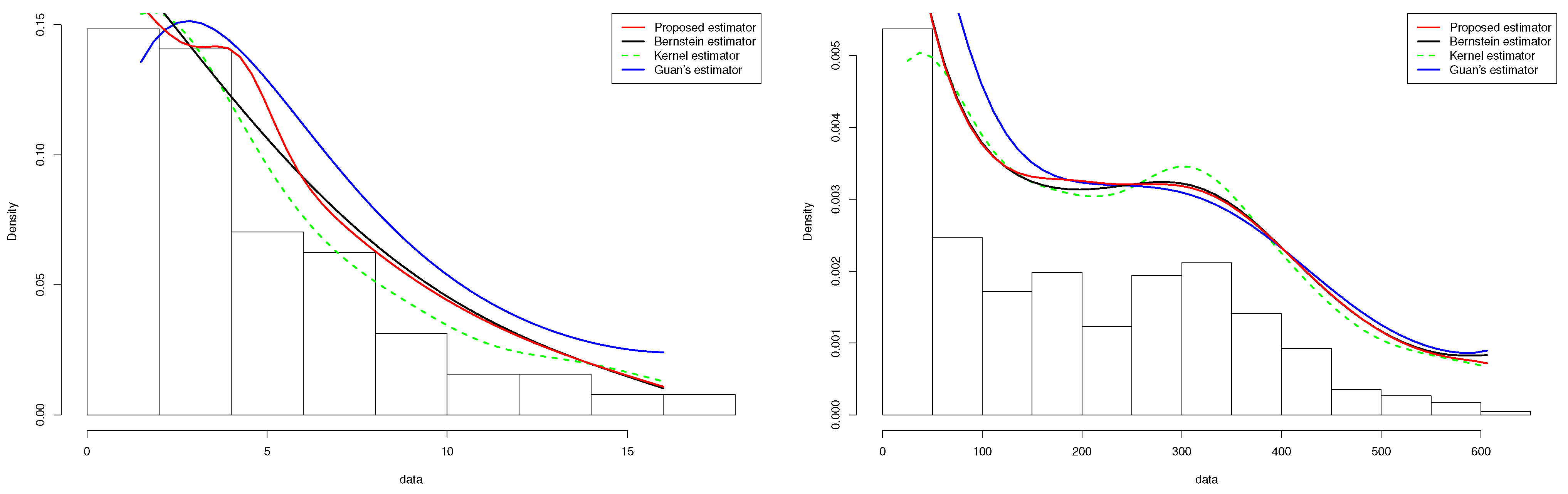
5.2.1. COVID-19 Data
5.2.2. Tuna Data
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Rosenblatt, M. Remarks on Some Nonparametric Estimates of a Density Function. Ann. Math. Stat. 1956, 27, 832–837. [Google Scholar] [CrossRef]
- Parzen, E. On Estimation of a Probability Density Function and Mode. Ann. Math. Stat. 1962, 33, 1065–1076. [Google Scholar] [CrossRef]
- Härdle, W. Smoothing Techniques with Implementation in S; S. Springer Science and Business Media: Berlin, Germany, 1991. [Google Scholar]
- Schuster, E.F. Incorporating support constraints into nonparametric estimators of densities. Comm. Stat. Theory Methods 1985, 14, 1123–1136. [Google Scholar] [CrossRef]
- Müller, H.-G. Smooth optimum kernel estimators near endpoints. Biometrika 1991, 78, 521–530. [Google Scholar] [CrossRef]
- Müller, H.-G. On the boundary kernel method for nonparametric curve estimation near endpoints. Scand. J. Statist. 1993, 20, 313–328. [Google Scholar]
- Müller, H.-G.; Wang, J.-L. Hazard rate estimation under random censoring with varying kernels and bandwidths. Biometrika 1994, 50, 61–76. [Google Scholar] [CrossRef]
- Lejeune, M.; Sarda, P. Smooth estimators of distribution and density functions. Comput. Stat. Data Anal. 1992, 14, 457–471. [Google Scholar] [CrossRef]
- Jones, M.C. Simple boundary correction for density estimation kernel. Stat. Comput. 1993, 13, 135–146. [Google Scholar] [CrossRef]
- Chen, S.X. Beta kernel estimators for density functions. Comput. Stat. Data Anal. 1999, 31, 131–145. [Google Scholar] [CrossRef]
- Chen, S.X. Probability density function estimation using gamma kernels. Ann. Inst. Stat. Math. 2000, 52, 471–480. [Google Scholar] [CrossRef]
- Leblanc, A. A bias-reduced approach to density estimation using Bernstein polynomials. J. Nonparametr. Stat. 2010, 22, 459–475. [Google Scholar] [CrossRef]
- Slaoui, Y. Bias reduction in kernel density estimation. J. Nonparametr. Stat. 2018, 30, 505–522. [Google Scholar] [CrossRef]
- Vitale, R.A. A bernstein polynomial approach to density function estimation. Stat. Inference Relat. Topics 1975, 2, 87–99. [Google Scholar]
- Ghosal, S. Convergence rates for density estimation with Bernstein polynomials. Ann. Stat. 2000, 29, 1264–1280. [Google Scholar] [CrossRef]
- Babu, G.J.; Canty, A.J.; Chaubey, Y.P. Application of Bernstein polynomials for smooth estimation of a distribution and density function. J. Stat. Plan. Inference 2002, 105, 377–392. [Google Scholar] [CrossRef]
- Kakizawa, Y. Bernstein polynomial probability density estimation. J. Nonparametr. Stat. 2004, 16, 709–729. [Google Scholar] [CrossRef]
- Rao, B.L.S.P. Estimation of distribution and density functions by generalized Bernstein polynomials. Indian J. Pure Appl. Math. 2005, 36, 63–88. [Google Scholar]
- Igarashi, G.; Kakizawa, Y. On improving convergence rate of Bernstein polynomial density estimator. J. Nonparametr. Stat. 2014, 26, 61–84. [Google Scholar] [CrossRef]
- Slaoui, Y.; Jmaei, A. Recursive density estimators based on Robbins-Monro’s scheme and using Bernstein polynomials. Stat. Interface 2019, 12, 439–455. [Google Scholar] [CrossRef] [Green Version]
- Li, J.Q.; Barron, A.R. Mixture density estimation. Adv. Neural Inf. Process. Syst. 2000, 12, 279–285. [Google Scholar]
- Pearson, K. Contributions to the mathematical theory of evolution. Philos. Trans. R. Soc. Lond. Ser. A Math. Phys. Eng. Sci. 1984, 185, 71–110. [Google Scholar]
- McLachlan, G.; Peel, D. Finite Mixture Models; John Wiley and Sons: New York, NY, USA, 2004. [Google Scholar]
- Roeder, K.; Wasserman, L. Practical Bayesian density estimation using mixtures of normals. J. Am. Stat. Assoc. 1997, 92, 894–902. [Google Scholar] [CrossRef]
- Schwarz, G. Estimating the dimension of a model. Ann. Stat. 1978, 6, 461–464. [Google Scholar] [CrossRef]
- Leroux, B. Consistent estimation of a mixing distribution. Ann. Stat. 1992, 20, 1350–1360. [Google Scholar] [CrossRef]
- Guan, Z. Efficient and robust density estimation using Bernstein type polynomials. J. Nonparametr. Stat. 2016, 28, 250–271. [Google Scholar] [CrossRef] [Green Version]
- James, W.; Stein, C. Estimation with quadratic loss. In Breakthroughs in Statistics; Springer: New York, NY, USA, 1992; pp. 443–460. [Google Scholar]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum likelihood from incomplete data via the EM algorithm. J. R. Stat. Soc. Ser. B Stat. Methodol. 1997, 39, 1–22. [Google Scholar]
- Wu, C.J. On the convergence properties of the EM algorithm. Ann. Stat. 1983, 11, 95–103. [Google Scholar] [CrossRef]
- Stein, C. Estimation of the mean of a multivariate normal distribution. Ann. Stat. 1981, 9, 1135–1151. [Google Scholar] [CrossRef]
- Oman, S.D. Contracting towards subspaces when estimating the mean of a multivariate normal distribution. J. Multivar. Anal. 1982, 12, 270–290. [Google Scholar] [CrossRef] [Green Version]
- Oman, S.D. Shrinking towards subspaces in multiple linear regression. Technometrics 1982, 24, 307–311. [Google Scholar] [CrossRef]
- Lehmann, E.L.; Casella, G. Theory of Point Estimation; Springer Science and Business Media: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Zitouni, M.; Zribi, M.; Masmoudi, A. Asymptotic properties of the estimator for a finite mixture of exponential dispersion models. Filomat 2018, 32, 6575–6598. [Google Scholar] [CrossRef] [Green Version]
- Redner, R.A.; Walker, H.F. Mixture densities, maximum likelihood and the EM algorithm. SIAM Rev. 1984, 26, 195–239. [Google Scholar] [CrossRef]
- Tibshirani, R.; Walther, G.; Hastie, T. Estimating the number of clusters in a data set via the gap statistic. J. R. Stat. Soc. Ser. 2001, 63, 411–423. [Google Scholar] [CrossRef]
- Chen, S.X. Empirical likelihood confidence intervals for nonparametric density estimation. Biometrika 1996, 83, 329–341. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Density | n | Proposed | Bernstein | Kernel | Guan’s |
|---|---|---|---|---|---|
| Estimator | Estimator | Estimator | Estimator | ||
| 50 | |||||
| 100 | |||||
| 200 | |||||
| 50 | |||||
| 100 | |||||
| 200 | |||||
| 50 | |||||
| 100 | |||||
| 200 | |||||
| 50 | |||||
| 100 | |||||
| 200 | |||||
| 50 | |||||
| 100 | |||||
| 200 | |||||
| 50 | |||||
| 100 | |||||
| 200 |
| Density | n | Proposed | Bernstein | Kernel | Guan’s |
|---|---|---|---|---|---|
| Estimator | Estimator | Estimator | Estimator | ||
| 50 | |||||
| 100 | |||||
| 200 | |||||
| 50 | |||||
| 100 | |||||
| 200 | |||||
| 50 | |||||
| 100 | |||||
| 200 | |||||
| 50 | |||||
| 100 | |||||
| 200 | |||||
| 50 | |||||
| 100 | |||||
| 200 | |||||
| 50 | |||||
| 100 | |||||
| 200 |
| Density | n | Proposed | Bernstein | Kernel | Guan’s |
|---|---|---|---|---|---|
| Estimator | Estimator | Estimator | Estimator | ||
| 50 | |||||
| 100 | |||||
| 200 | |||||
| 50 | |||||
| 100 | |||||
| 200 | |||||
| 50 | |||||
| 100 | |||||
| 200 | |||||
| 50 | |||||
| 100 | |||||
| 200 | |||||
| 50 | |||||
| 100 | |||||
| 200 | |||||
| 50 | |||||
| 100 | |||||
| 200 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Helali, S.; Masmoudi, A.; Slaoui, Y. Semi-Parametric Estimation Using Bernstein Polynomial and a Finite Gaussian Mixture Model. Entropy 2022, 24, 315. https://doi.org/10.3390/e24030315
Helali S, Masmoudi A, Slaoui Y. Semi-Parametric Estimation Using Bernstein Polynomial and a Finite Gaussian Mixture Model. Entropy. 2022; 24(3):315. https://doi.org/10.3390/e24030315
Chicago/Turabian StyleHelali, Salima, Afif Masmoudi, and Yousri Slaoui. 2022. "Semi-Parametric Estimation Using Bernstein Polynomial and a Finite Gaussian Mixture Model" Entropy 24, no. 3: 315. https://doi.org/10.3390/e24030315
APA StyleHelali, S., Masmoudi, A., & Slaoui, Y. (2022). Semi-Parametric Estimation Using Bernstein Polynomial and a Finite Gaussian Mixture Model. Entropy, 24(3), 315. https://doi.org/10.3390/e24030315