1. Introduction
Random Boolean Networks (RBNs for short) are strongly simplified models of gene regulatory networks (GRNs), proposed by one of us (Kauffman) more than 50 years ago, which have also been widely studied as abstract models of complex systems, thanks to the fact that their dynamical behavior can be tuned from ordered to disordered by modifying a few key parameters. They have also been applied to different biological phenomena, such as, e.g., cell differentiation [
1,
2,
3], as well as to different fields, including robotics [
4,
5,
6], the study of evolutionary processes [
7,
8,
9] and the simulation of social systems [
10,
11,
12,
13].
It is possible to compare the behavior of RBNs to that of real biological GRNs, and thus, to draw inferences about their dynamics. The dynamics of RBNs is dissipative, so finite networks tend, after a transient has died out, to a limited number of different attractor states, which are either constant (fixed points) or periodic (limit cycles). It has been hypothesized that different attractors, which are persisting states where different nodes can take mutually coherent activation values, correspond to different cell types in multicellular organisms. On the basis of this correspondence, interesting scaling relationships regarding the number of genes and the number of different cell types or the duration of the cell cycle have been proposed, thus lending support to the hypothesis that ensembles of
critical or
slightly ordered (see below) RBNs can be useful to simulate the behavior of real gene networks [
14,
15,
16]. This hypothesis has been strengthened by works showing that they can reproduce available data on HeLa cells [
17] and on the distribution of avalanches of gene perturbations in yeast [
18,
19,
20].
Both the topology and the transition functions of RBNs are indeed random, as described in
Section 2.1, so they are well-suited to identify generic properties of these systems. At the time of their invention [
21], very few detailed gene regulatory circuits were known (e.g., the lac-operon studied by Monod and Jacob), so the idea behind the use of random nets was that of exploring the possible outcomes of a web of interacting regulatory elements, without aiming at precise descriptions of specific circuits or organisms. This is why the study of specific networks was not pursued in those times, in favor of the search for the generic properties of statistical ensembles of networks. In a nutshell, the idea is that even evolved networks might share some of these generic properties.
It is, however, possible to use the Boolean framework to describe a specific gene regulatory circuit, if sufficient information is available, see, e.g., [
22,
23,
24,
25,
26,
27,
28,
29], although in this case the connections and the dynamical laws are no longer random, as they are based on available knowledge about how some genes affect some other ones.
Nowadays, the progress of genomic and related technologies makes it possible to guess the structure of several circuits. However, the number of well-known cases is still limited, and there are important uncertainties concerning the larger networks in which these approximately known circuits are embedded. Therefore, the search for generic properties using random networks is still an important research topic.
In RBNs, it is possible to identify regions of parameter space such that the typical dynamical behavior of a network belonging to those regions is either ordered (e.g., fixed points or periodic orbits) or disordered (e.g., pseudo-chaotic). Note that these remarks regard typical behaviors, while those of single network realizations (which are largely random) may of course be widely different from the typical ones. It was previously suggested that the separatrices between ordered and disordered regions may be particularly interesting, since networks whose parameters fall in those regions might be endowed with peculiar properties [
14]. We will refer to those regions and networks as “dynamically critical regions (networks)”, or simply as “critical regions (networks)”.
It has been conjectured that critical networks should, at the same time, be robust and able to adapt to environmental changes. In changing environments, they should thus have an advantage over ordered or disordered nets; therefore, evolution should have driven biological networks to those regions [
7,
8]. This idea has been called the Criticality Principle [
14,
30,
31,
32], and it is the topic of this Special Issue. It has been suggested that the same reasoning applies also to networks that are ordered, but that have positions, in parameter space, that close to a critical region [
14,
20,
33]. It can be noted that this hypothesis can also be extended to non-biological systems, as discussed in [
6,
9,
32,
34].
Because of their importance, critical networks have received a close examination, and have been the subject of several papers. Particular attention has been given to the number of attractors, to their scaling with the number of nodes, and to their dependence upon some key model parameters, such as, e.g., the fraction of so-called canalizing nodes [
35,
36,
37,
38]. However, there are also some important features that have remained largely neglected: this paper is dedicated to exploring the existence and the properties of a relatively large set of nodes that take the same value in all the attractors, a set that will here be called the “common sea” (CS). The nodes that do not belong to the common sea will be called specific nodes, as they take different “specific” values in different attractors, and their set will be called the “specific part” (SP).
As it has been observed, the study of RBNs is actually a study of families of different network realizations generated with the same parameters; therefore, it is necessary to clearly specify what the CS is. As described in detail in
Section 2, RBNs are generated at random, either by drawing connections or by choosing Boolean functions, according to some probability distribution. The behavior of a specific network realization (defined by the set of connections and of the associated Boolean functions) might largely depend upon some idiosyncrasies of that realization, but the typical behavior of a large family of networks does not. For example, we might be interested in knowing how the number of attractors is affected by the choice of a given subset of the possible Boolean functions: in this case, we should study the dynamical behavior of different realizations, which all share the limitation to that subset. First, for each realization, it will be necessary to study the number of different attractors. Second, different realizations will be considered, and the appropriate statistical measures (e.g., average, median, standard deviation, etc.) will be taken. In this way, we will be able to associate a specific number (e.g., the average number of attractors) to a set of parameter values, when the analysis is limited to that subset of Boolean functions. The final step of the analysis might be that of studying, e.g., the way in which, in this case, the number of attractors depends upon the number of nodes.
Attractor states of RBNs are either constant (fixed points) or periodic (cycles) in time. However, for reasons discussed in
Section 2.3, it makes sense to always make use of Boolean constant vectors instead of oscillating ones. Therefore, we define, for each dynamical attractor, a (constant) pseudo-attractor, whose components are identical to the (binarized) time averages of the corresponding components of the true attractor. How this is achieved is precisely described in
Section 2.3. The mapping from true dynamical attractors to pseudo-attractors is not injective, so in
Appendix B, we provide an estimate of how it affects the number of different asymptotic states (i.e., number of pseudo-attractors vs. number of true dynamical attractors.)
We define the common sea as the set of nodes that take the same values in all the pseudo-attractors of a given network realization. By studying different realizations, with different parameter values, we will be able to understand how the CS depends upon the features of the network. We will study the properties of the common sea on different networks generated using the same set of parameters (in particular, the connectivity
k and the bias
b, defined below in
Section 2). Then, we will compare these properties in families of networks with different parameters, with a particular focus on critical networks.
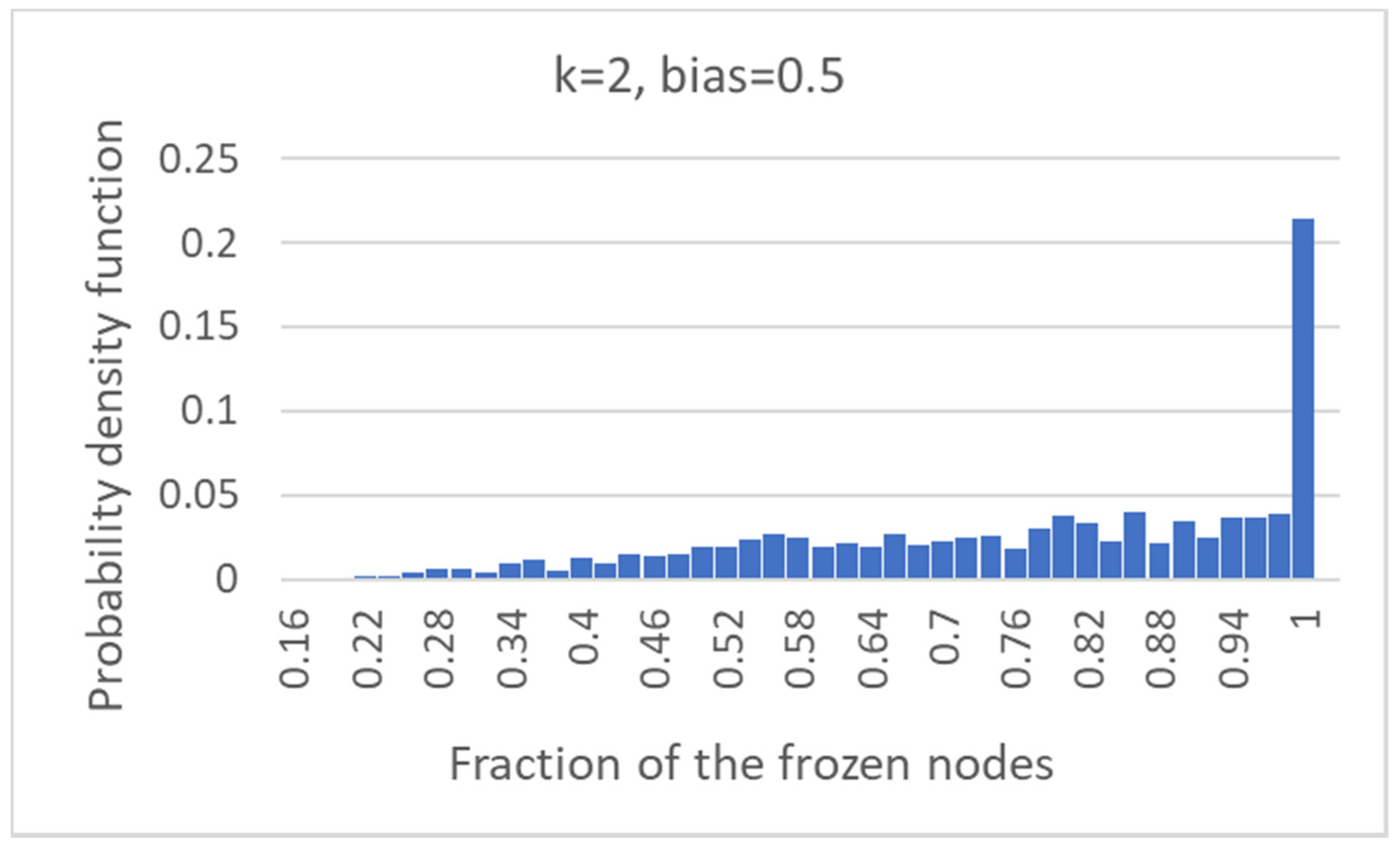
Note that the concept of “common sea” is a new one, and that it differs from previous definitions. Fixed points are sometimes referred to as “frozen nodes” in the literature on RBNs [
14], and whole portions of the network are sometimes called “frozen sea” [
15]. The definition of the common sea is different, since (i) it is based on pseudo-attractors, so that also nodes that oscillate in the “true” dynamical attractor may belong to the CS and (ii) it requires that the nodes take the same value in all the attractors, so that some nodes that are “frozen” in some attractors may not belong to the CS. Property (i) distinguishes the common sea also from the “stable cores” defined in [
39,
40]
It is also interesting to observe the internal organization of the common sea and of the specific part. In the cases that are described in this paper, the overall network is not made by disjoint subparts: although this is not prohibited, it is extremely unlikely within the range of parameters that are explored. However, once the CS of a given network realization is identified, we can look at the topology of the network that is composed of its nodes only. For reasons detailed in
Section 2, we identify the subparts of the CS with its so-called weakly connected components (WCCs) [
41] and we refer to the whole process as “fragmentation”.
As it will be detailed in
Section 3, in the CS there is sometimes only one WCC per network realization, but in other cases, there are more than one, although one usually finds a dominant subpart that comprises many more nodes than the others. Of course, a similar fragmentation analysis can be conducted on the specific part, and here we often find a more evenly distributed situation, with more fragments of more similar size. It is natural to refer to these WCCs as “islands”, and to the specific parts as “specific islands”. It should be emphasized that these are not completely independent parts, and that some changes in one WCC (for example, the knock-out of a gene) can affect the values of nodes in other WCCs.
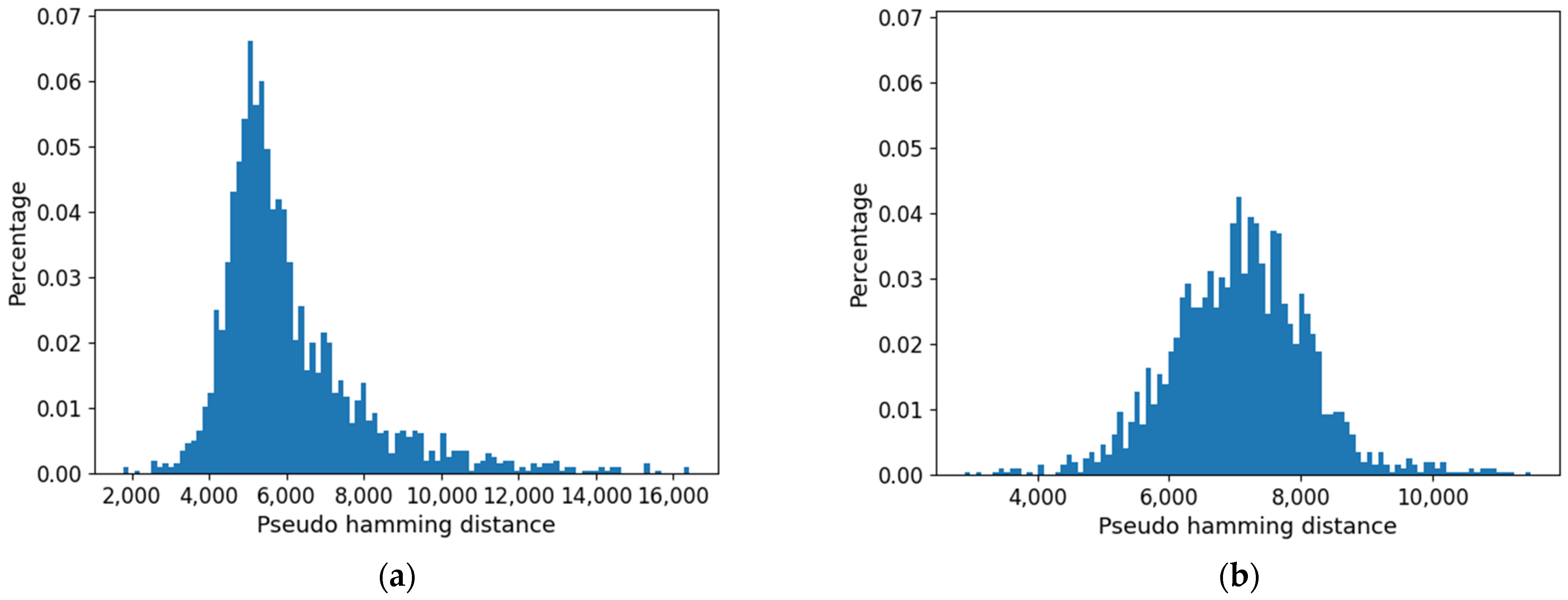
Another important feature is the distribution of distances between pairs of pseudo-attractors, the natural choice being their Hamming distance. Note that distances are limited from above by the size of the common sea, which, for a quite large set of parameter values, comprises a large fraction of the network nodes. The distribution of distances in different ensembles of Boolean networks will also be presented in
Section 3.
While this work deals mainly with the properties of dynamical models (i.e., in-silico networks), the motivations for interest in RBNs are deeply rooted in biology, so we will also briefly discuss some experimental results about the biological analogue of the common sea and of the distribution of distances, which are made possible by the available technology, identifying the model pseudo-attractors with observed cell types.
We stress that we do not aim to perform a careful comparison of the model behavior with experimental data, which would require, inter alia, a more thorough analysis of the effects of binarization, an analysis of the behavior of RBNs with different parameter values and maybe a larger data set. Indeed, we do not provide in the paper any direct quantitative comparison of model with data. Our goal is rather that of showing that the study of an abstract RBN model brings us to look at experimental single-cell data with an interesting system-level perspective, which differs from the more specific questions that are usually addressed. To the best of our knowledge, no study of the “common sea” and of the distance distribution has been proposed and single-cell data have been mainly used to identify genes with expression levels that are associated with specific cell types, or for network reconstruction ((different types of) distances between pairs of cell types are often computed, e.g., for the purpose of clustering [
42] or looking for the number of differentially expressed genes [
43], but we are not aware of studies that are specifically devoted to the distributions of gene distances). We had already encountered a similar situation in our previous works on avalanches of gene expression changes in S. Cerevisiae [
18,
19,
20], where it was also possible to use data, which had been collected to address specific biological questions, to answer interesting generic, system-level questions.
In the experiments we consider here, the expression levels of many genes in a single cell are measured. These data are very noisy; therefore, it is necessary to sum the contributions of several instances (of the same type) to obtain a reliable average profile for a given cell type. In this way, one obtains a set of values that might be compared with the components of the “average attractor” mentioned above, taking into account, however, that the latter are restricted to the interval [0,1] while the former are not. The biological literature refers to these typical expression profiles as pseudo-cells [
44,
45], which should, of course, not be confused with the pseudo-attractors of this paper, which are defined for simulation models only. In order to compare them with Boolean pseudo-attractors, it is necessary to cast real-valued experimental data on pseudo-cells in Boolean form. This can be achieved by defining a threshold, so that a gene can be considered active if and only if its activation exceeds the threshold. In this way, we can define Boolean pseudo-cell types by associating to each gene the value 0 if its activation value is smaller than the threshold, and the value 1 otherwise. A large, important set of human single-cell data will be analyzed in this way, and the results will be presented in
Section 4.
Section 2 of the paper is organized as follows.
A synthetic description of the RBN model, which makes it possible to read the paper without any a priori knowledge of RBNs (without, of course, covering all their main properties). Since some slightly different versions of RBNs have been proposed, it is also precisely stated which one is used in this paper;
The main method to evaluate whether Boolean networks are dynamically ordered, critical or disordered (Derrida parameter);
The definitions of average attractor, pseudo-attractor, common sea, specific part;
The methods used to analyze the common and specific parts;
The methods used to collect and to represent single-cell data, obtained from the literature.
In
Section 3, the common sea will be studied through simulations, emphasizing how its size depends upon the main system parameters. We will deal mostly with dynamical critical networks, but we will also consider some cases of ordered networks, for the sake of comparison. A simplified, mean-field analytical estimate of the size of the common sea will also be provided in
Appendix A. We will consider networks with different values of the number of inputs per node,
k, and of the bias
b of the Boolean functions, which is defined in
Section 2 as the average value of the number of outputs equal to “1” in their truth table, and we will see how the size of the CS depends upon these two parameters. They may be varied independently, but the requirement that the network be critical (i.e., that the value of the Derrida parameter be 1) defines a relationship between them. Thus, there may be critical networks with different pairs of values of
k and
b. It will be interesting to observe that the size of the CS is not uniquely determined by the constraint of criticality. The distribution of distances between pairs of attractors will also be studied in
Section 3.
Section 4 is dedicated to the analysis of experimental data, using Boolean pseudo-cell types as analogues of Boolean pseudo-attractors to identify the biological “common sea” and to study the distribution of distances. Boolean pseudo-cell types are obtained from real-valued data, and they heavily depend upon the choice of the threshold. In single-cell experiments, one often finds a large fraction of null values, so a possible choice is that of regarding as identical only those genes that take exactly the same activation values in each cell type: this corresponds to adopting a vanishing threshold. It is, however, unlikely that nonzero activation values that are identical will be found under this quite severe requirement. Moreover, the high noise level makes it appropriate to consider nonvanishing threshold values. Of course, if we adopt a very high threshold, all the nodes will turn out to be unexpressed. There is no firm a-priori reason to fix a particular value of the threshold, but we will suggest some possible heuristic criteria in
Section 4.
Several results will be presented in
Section 3 and
Section 4, so in the final part,
Section 5, we will summarize those that seem, to us, to be the most relevant and stress their importance. We will also indicate promising directions for future work, distinguishing some improvements that are quite straightforward from other improvements that require more care.
2. Materials and Methods
As anticipated in the introductory
Section 1, we will here describe both methods and definitions that are relevant to this work. The chosen methods are quite well-known, while some definitions are original.
2.1. Random Boolean Networks
RBNs have been very popular, and they are addressed in many papers. We will not provide a complete bibliography, but we will rather refer the reader to some original or review works [
14,
16,
40,
46]. Several variants of the original model have been introduced and it is, therefore, necessary to precisely define which one is used here. A RBN is a time-discrete, directed network of N nodes, or genes, which can take one of two possible values, sometimes called activation values or states of the node (we will use 0 and 1 in the following). Each node has a fixed set of input nodes (or input links) and a fixed set of output nodes: information flows from the input nodes to our node, and from our node to its output ones. We will consider only the so-called quenched model, which is the only one that makes sense if one thinks of a finite gene regulatory network. The alternative annealed model may be a useful approximation that allows one to perform some analytical calculations in the case of very large networks (N → ∞) [
40,
47]. A fixed Boolean function is associated with each node, which determines the value of that node at time
t + 1 from the values of its input nodes at the previous time step
t (self-connections being prohibited). In the simulations of this paper, the updating is synchronous, i.e., all nodes’ values are updated at each time step.
The nodes are numbered from 1 to
N, and a state of the network is a
N-dimensional Boolean vector
X = (
x1…
xN), whose components are the activation values of the corresponding genes. The set of Boolean functions defines a mapping
X(
t) →
X(
t + 1), i.e., a time-discrete dynamical system.
Note that, while the network is built in a random way (detailed below), the dynamics of a single network are deterministic, i.e., the state at time t determines the state at time t + 1. It is easy to see that a finite network always tends in a finite number of steps to a constant state, or to a cycle (i.e., a state where X(t + T) = X(t) for some finite T, the period of the cycle). Fixed points are cycles with T = 1.
Since asymptotic states are cycles of finite length, so are the possible attractors of the network. The basin of attraction of an attractor is the set of states that tend towards that attractor under the mapping (1).
Both connections and Boolean functions are chosen at random in RBNs, although sometimes with different approaches. We will follow Kauffman’s original proposal, thus assuming that all the nodes have the same number k of incoming links, coming from the other nodes, chosen at random with uniform probability. In the case of large sparse networks, this procedure gives rise to an approximately Poissonian distribution of outgoing connectivities. Of course, other alternatives are possible, but the “classical” model has proven able to describe some interesting features.
The Boolean functions are also chosen at random for each node, independently of those of the other nodes. They are the transition functions of the model, i.e., they determine the state at time t + 1 of the node, on the basis of the values of its inputs at time t. Sometimes they are chosen with uniform probability in a set of functions, identified because of some peculiar features or because they appear to be biologically plausible. Another procedure, followed in this work, is that of assigning at random, for each possible set of input values, an output value equal to 1 with probability b, which is called the bias of that set of Boolean functions (the probability of assigning 0 being, of course, 1 − b).
2.2. Determining the Dynamical Regime
As previously observed, the dynamical behavior is particularly important. Ordered and disordered dynamical regimes are usually described as systems’ behaviors supporting, respectively, short attractors with fairly regular basins of attraction and long attractors with sensitive dependence upon initial conditions (this is why disordered states are often called “chaotic” even if in RBNs the time step and the values of the variables are discrete). In ordered networks, a change at one node (i.e., a bit flip) propagates in one step, on average, to less than one other node: starting from a random initial condition, therefore, an ordered system rapidly reaches a stable condition where the majority of nodes are frozen (i.e., constant in time); if this asymptotic behavior is perturbed, there is a very high probability of coming back to it. On the contrary, in disordered networks, a perturbation at one node propagates in one time step, on average, to more than one other node: very close initial conditions could rapidly diverge toward different attractors, and attractors typically have long periods, with large portions of oscillating nodes. If perturbed, the system therefore has a high probability of changing its asymptotic behavior. Critical systems are at the boundary between these two dynamical regimes, where a change at one node propagates in one time step on an average to exactly one other node.
There are two main different ways to identify ordered and disordered regions: (i) a static one, based upon the knowledge of the nodes average connectivity and the bias of the Boolean functions [
48] and (ii) a dynamical one based upon the actual study of the spreading of perturbations through the system [
14,
47,
49]. Here, we will use only this latter approach (note that the two provide the same results if the system is ergodic [
50]).
The approach considers the short time evolution of the distance between two initial states that differ by a small fraction of nodes. At each time step, the difference between the states of the two runs is measured by means of the Hamming distance
h(
t), the number of nodes that have different activations. If the network is operating in the disordered regime, then small Hamming distances tend to diverge and the ratio
h(
t + 1)/
h(
t) is likely to increase; on the other hand, networks in the ordered regime exhibit convergence for nearby states, so
h(
t + 1)/
h(
t) tends to decrease. Critical states separate those cases,
h(
t + 1)/
h(
t) tends to remain the same. In the search for generic properties, one should, as usual, average over many pairs of initial states and over ensemble of random networks. Denoting these averages by square brackets, one can now define the Derrida parameter
λ as follows:
The λ parameter can be regarded as a discrete analogue of the Lyapunov exponent of continuous dynamical systems: the network is ordered if λ < 1, disordered if λ > 1 and critical if λ = 1.
Several previous studies have focused on the identification of the parameters that are responsible of the various dynamical behaviors, and on the features of the system’s phase space (attractors and basins of attraction). It has been shown that, for ensembles of networks generated in the way described above, there is a relationship between the number of connections per node and the bias that characterizes critical states, i.e.,
For example, networks with k = 2 and b = ½2 are critical.
2.3. Definitions of Average Attractor, Pseudo-Attractor, Common Sea and Specific Part
The identification of which genes “take the same value” in different cyclic attractors requires some care, since cycles in RBNs depend to a large extent upon the choice of synchronous updating, which does not have a sound biological basis [
46]. Synchronous RBNs are Markovian systems, whose state
X(
t + 1) depends upon
X(
t), forgetting the previous states of all the nodes of the network. The action of a gene on the activation of other genes takes place through the action of its corresponding protein; therefore, the notion of a single time step corresponds to assuming a common decay time of the different regulatory proteins, which is not supported by biological data. In previous papers [
51,
52,
53], we proposed a different model, the gene–protein model, where a distribution of decay times is introduced. However, this more complicated model would require further parameters: in this paper, we therefore focus on the much better known “classical” RBNs. Indeed, cycles are not robust with respect to, e.g., small perturbations [
54] or to asynchronous updating [
55], which is, however, also unrealistic.
Moreover, with a view to a possible comparison with experimental data that are not time dependent, it is advisable to resort to an approximate description of the dynamical attractors’ constant “pseudo-attractors”, precisely defined as follows.
Let A be a (possibly time dependent) dynamical attractor, let Ak be its k-th component and, if Ak changes in time, let fk1 ∈ [0,1] be the ratio between (the number of states in the cycle where Ak = 1), and the overall period T of the cycle. Let also θ a real number in [0,1]. To every dynamical attractor A, we associate its “pseudo-attractor” A′, whose component A′k takes the value
Obviously, constant states in A are mapped onto the same states in A′, while oscillating states are mapped onto the constant state 1 if their time average exceeds the threshold θ, and onto the constant state 0 if the average is equal to or smaller than the threshold.
In the following, we will often use the term attractor to refer also to pseudo-attractors (when necessary, we will call them precisely pseudo-attractors). The introduction of pseudo-attractors represents a kind of coarse graining, which maps different true dynamical attractors onto the same pseudo-attractor; a simulation-based estimate of the loss of detailed information that is associated to this coarse graining is provided in
Appendix B.
The common sea (CS) is defined in
Section 1 as the set of nodes that take equal values in all the pseudo-attractors of a given network realization, which, in turn, is defined by its topology (which genes are connected to which other genes) and by its Boolean functions (which are generated once and for all for each realization). By varying the initial conditions, different attractors can be discovered. Note that, for a network of
N nodes, there are 2
N possible initial conditions, a number that quickly becomes huge—so the actual search of attractors is necessarily bound to explore only a subset of all the possible initial conditions. This is, however, a well-known problem in the study of RBNs (except in the case of very small networks) and it affects the study of all their important properties. Extensive simulations (in our work we used 10,000 initial conditions for each network realization), however, allow the identification of those attractors that have a significant basin of attraction. It may be argued that attractors with very small attraction basins, which may be overlooked in this way, are also unlikely to play any significant role in biological systems.
The specific part (SP) is the set of all the nodes that do not belong to the CS. Note that, since the SP is often composed of relatively small subparts, they are often called the “specific islands” (to match the use of the term “sea” for the common part).
2.4. Methods to Analyze the Fragmentation of the CS and of the SP
As anticipated in
Section 1, using the “lens” of pseudo-attractors, it is possible to identify meaningful subparts in the common and specific parts of RBNs. This does not happen with an appreciable probability in the case of the whole network, with the parameter values used in this study. The fragmentation of the CS and of the SP can be extremely interesting since it might highlight intermediate-level structures that spontaneously form in networks that are otherwise fully random.
To analyze the fragmentation of the CS or of the SP (let us refer to the latter to simplify the writing), we first identify it, from its definition, and we highlight its nodes. In the example of
Figure 1 below, its nodes are yellow, while those of the CS are blue. We look at the links between the nodes in the SP and, ignoring the direction of the arrows, we identify its Weakly Connected Components. Let us recall that a directed graph is weakly connected if, replacing its edges with undirected edges, a connected graph is obtained, i.e., one where there is a path between any pair of vertices. A WCC is a maximal connected subgraph of the undirected graph.
Note that the subparts thus identified are not totally independent of each other. For example, by knocking out (i.e., permanently silencing) a gene in a WCC of the SP, the values of genes in the CS or in other WCCs can be modified. For example, 48% of the knock-outs (KOs) applied to the largest WCC of the specific part in
Figure 1 reach one or more of the other WCCs of the specific part, while no KO applied in these WCCs is able to reach the other WCCs. The avalanches were computed following the method presented in [
18,
19,
20]. However, the notion of a WCC captures the idea of some form of modularity, in that the interactions within the component play a key role in determining its behavior. This is likely to be true when the WCCs have similar sizes, while if one component is much larger than the others, it may have a strong effect.
2.5. Methods to Represent Single-Cell Data
As already observed, we used, in this study, data from the literature, without directly performing laboratory experiments. There are several gene expression databases available in the literature. However, it is difficult to find sufficiently pure genetic profiles: until recent years, in fact, the profiles of cell types derived from bulk type analyses, in which many different cells are mixed in the sample, without the possibility of knowing the exact composition of the cell types under scrutiny. On the other hand, in the last few years, databases of expression of single cells (SC in the following) have flourished, giving rise to “atlases” that store the data of a huge number of SCs. Thus, it is now possible to profile thousands of single cells of the same type [
56,
57], giving rise to a cell atlas of whole organisms [
45,
58,
59].
A very useful atlas for our purposes is described in [
45], concerning a comprehensive cell landscape for humans. Single cells were processed using microwell-seq16 and sequenced at around 3000 reads per cell. The dataset contain 599,926 different single cells. The data include samples of both fetal and adult tissue and cover 63 human tissue types. As described in [
45], further analyses make it possible to further refine the classification, leading to the identification of 102 different clusters that can be mapped to the starting tissues, allowing interesting observations. In this work, however, we were limited to using the initial classification of 63 types, performed by human experts.
Single cell data are very noisy and, moreover, the activities of single cells are influenced by their own phase of functioning and by the surrounding environment. However, since many different exemplars of each type are available, it is possible to aggregate all the contributions into a single profile that then constitutes the “average profile” of the cell type to which the single cells refer. For this purpose, we used the data from [
45], after having normalized them using the DESeq2 [
60] method. These “pseudo-cells”, therefore, have some similarities with the average attractors of
Section 2.3, although in the case of biological data, they are not bound to stay within the range [0,1].
In order to compare experimental data with simulation results, it is necessary to cast the data on pseudo-cells in binary form, thus giving rise to a binary pseudo-cell type. This can be achieved by introducing a threshold χ, according to one of two possible approaches. In the simplest one, the real-valued components of the pseudo-cell type are compared with a fixed threshold (the same for all the genes of all cell types). However, since the maximum expression values of different genes may be very different, the use of a single threshold is questionable. In the second type of approach, each gene expression level is re-scaled as a fraction of the maximum observed value of that gene in all cell types.
The two approaches can be formalized as follows:
Approach 1: Let C be the vector of the pseudo-cell, whose real-valued components Ck are the aggregate levels of expression of the various genes. Then, the Boolean pseudo cell type is represented by the vector D whose components:
Take the value 0, if Ck < χ;
Take the value 1, if Ck ≥ χ.
Approach 2: Let Mk be the maximum observed value of the k-th gene, and let C′ be the vector obtained by C by dividing each component by the corresponding Mk (C′k = Ck/Mk).
Then, the Boolean pseudo cell type is represented by the vector D’ whose components:
Take the value 0, if C′k < χ;
Take the value 1, if C′k ≥ χ
4. A Look at Experimental Data
The study of mathematical models allows the identification of interesting questions, which can provide useful insights and viewpoints concerning real genetic regulatory systems. In turn, the analysis of biological data can provide indications about the validity and the limitations of theoretical models, thus leading to a (hopefully fruitful) feedback between theory and simulation on one side, observation and experiments on the other. In this paper, we introduced, in the RBN model, the notions of common sea and specific part, and we examined their properties. It is now interesting to look at the applicability of these notions to biological data, keeping in mind that models are anyway the main focus of this paper.
Let us also preface that it would not make much sense to present here quantitative comparisons between the results of our simulations and biological data. The former were meant to uncover the main properties of these new concepts, and were based on extensive simulations of networks of limited size (in most cases, composed of 100 nodes), while the numbers of genes in biological multicellular organisms are much larger (27.341 in the case discussed in this section). However, we find that even a qualitative comparison can be useful and provide novel viewpoints useful both for models and for data analyses.
In order to apply the notions of CS and SP, it is necessary to associate our pseudo-attractors to biological entities. Although other alternatives are possible (see, e.g., [
1,
61,
62]), here, we follow the original Kauffman hypothesis [
14,
15], which identifies attractors with typical long-lived states of a cell; that is, in multicellular organisms, with cell types.
It is important to make use of single-cell data, since bulk data may mix contributions from different types. As described in
Section 2, we will refer to an important set of such data [
45], concerning a comprehensive cell landscape for humans, which contains 599,926 different single cells and 27.341 genes. Since single cell data are very noisy, and often plagued by false negatives, we construct pseudo-cell types by averaging all the contributions into a single profile, and then binarizing them with a threshold, as described in the Methods section. These Boolean pseudo-cell types can then then be considered the biological analogues of the pseudo-attractors.
As described in
Section 2, there are two alternative ways to binarize the data; the corresponding results are given here below
4.1. Approach 1
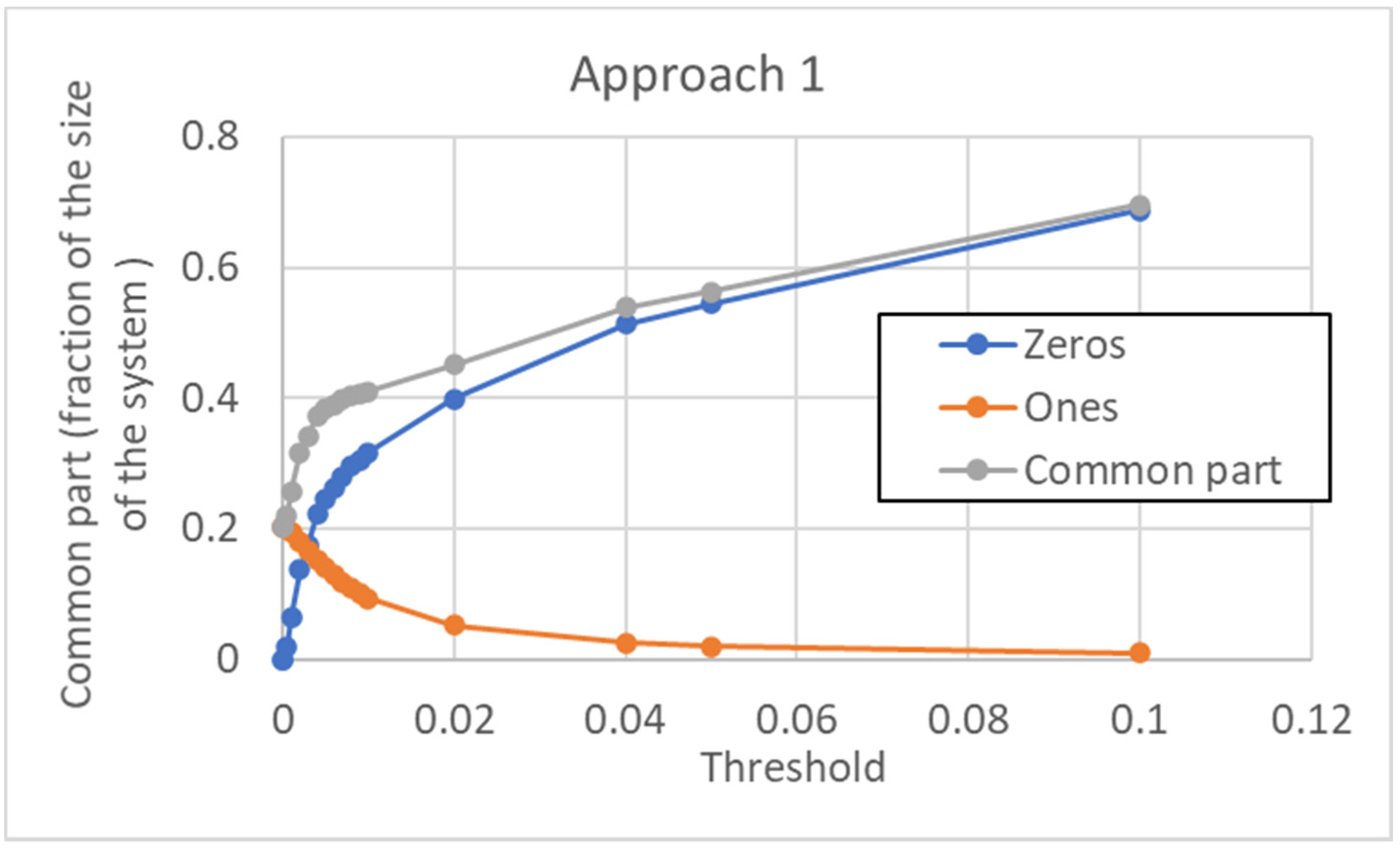
According to this approach, a unique threshold value is used for every gene of the pseudo-cell. The size of the common sea depends, of course, upon the chosen threshold, in a way that is illustrated in
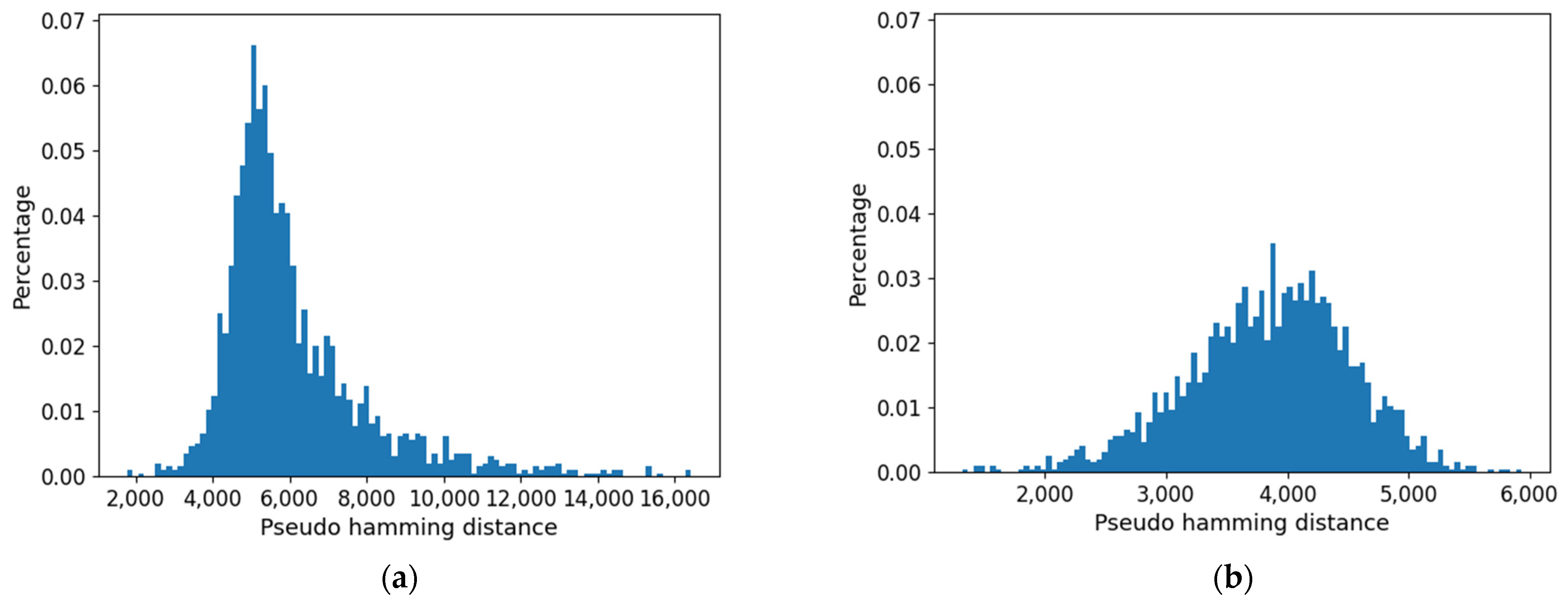
Figure 14. Note that the minimum size of the CS (at null threshold) is about 20%. It increases when the threshold is increased, and this is achieved by a much larger number of 0s than 1s in the type.
Furthermore, the distribution of distances (which presents a maximum) is affected by the threshold: as shown in
Figure 15, it is flattened when the threshold is increased. Consistently with the increase in size of the common part, the long tail of large distances tends to disappear.
4.2. Approach 2
According to this approach, a unique threshold value is used for every gene of the re-scaled pseudo-cell type C, as described in
Section 2.5.
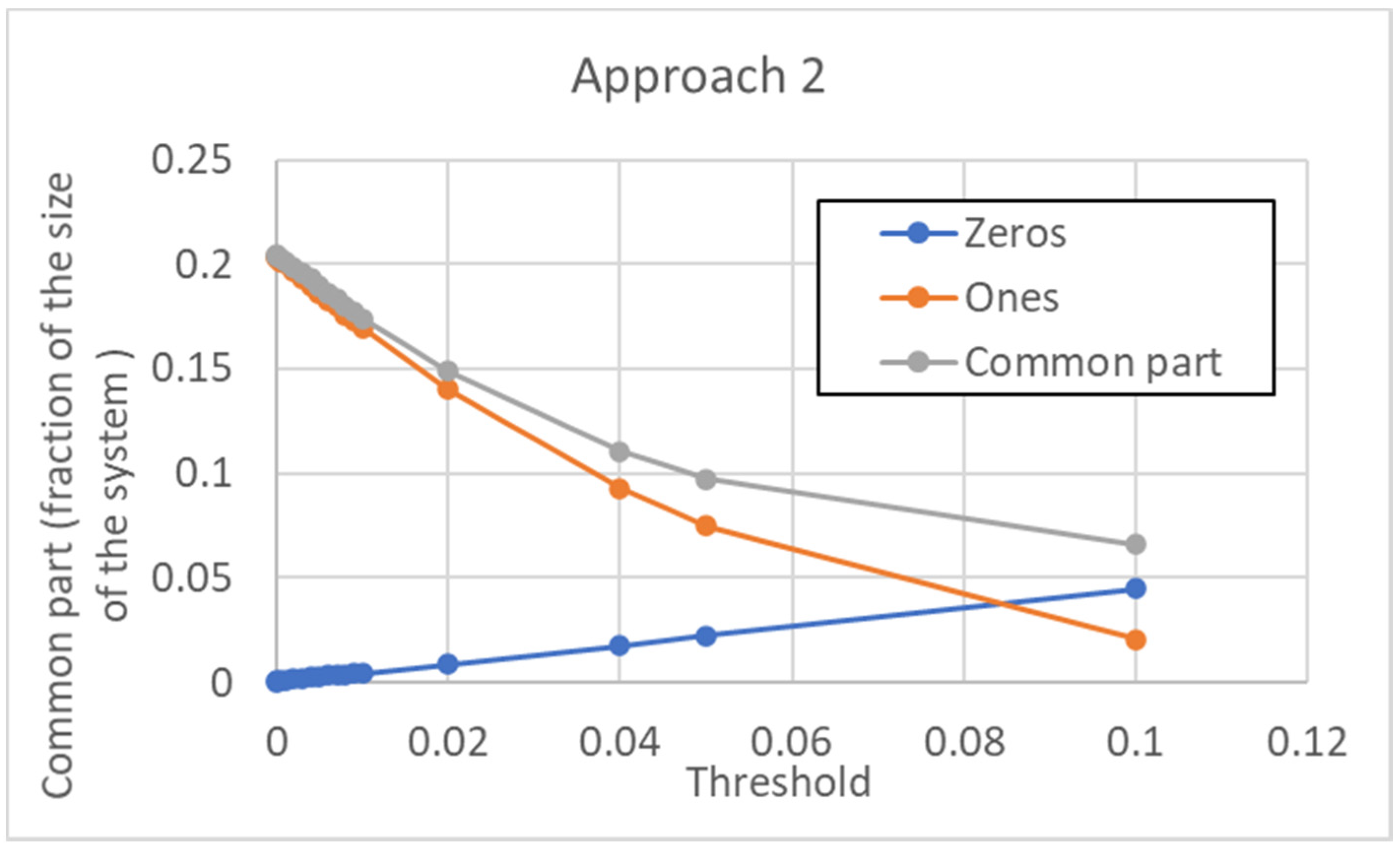
The dependence of the size of the common sea upon the threshold is shown in
Figure 16. Note that, contrary to the previous case, in the initial part, it goes down as the threshold is increased. This shows how important the choice of the threshold can be. In this case, however, the size of the common part increases by further increasing the threshold (when the threshold becomes huge, all the pseudo-genes are, of course, not expressed).
In this case, the distribution of distances is also affected by increasing the value of the threshold (
Figure 17). Consistently with the initial decrease in size of the common part, the maximum is significantly shifted to the right: it is interesting to note that also in this second approach the long tail of the large distances tends to disappear.
5. Conclusions
Let us recall here that the major lessons, which stem from the results described in this paper, can be summarized as follows:
The common sea is an important property of the RBN model;
Criticality does not suffice to determine the size of the CS;
Both the CS and the SP often host different (weakly connected) components;
The study of the model suggests original ways to analyze experimental data, asking novel questions;
The way in which real-valued activation values are binarized plays a crucial role.
5.1. The Common Sea Is An Important Property of the RBN Model
In order to study the behavior of the model, an important step has been the introduction of Boolean pseudo-attractors, which allows one to identify the “common sea” and the “specific islands” of the overall network. While the existence of a large fraction of “frozen” nodes, which take constant values, has been known long since, it should be stressed that the CS is a different notion, so far unexplored, i.e., that of the set of nodes that take the same value in all the pseudo-attractors but are not necessarily frozen. Indeed, in almost 80% of critical nets, the CS comprises oscillating nodes. Note also that the fraction of nodes that belong to the CS increases as the size of the network increases.
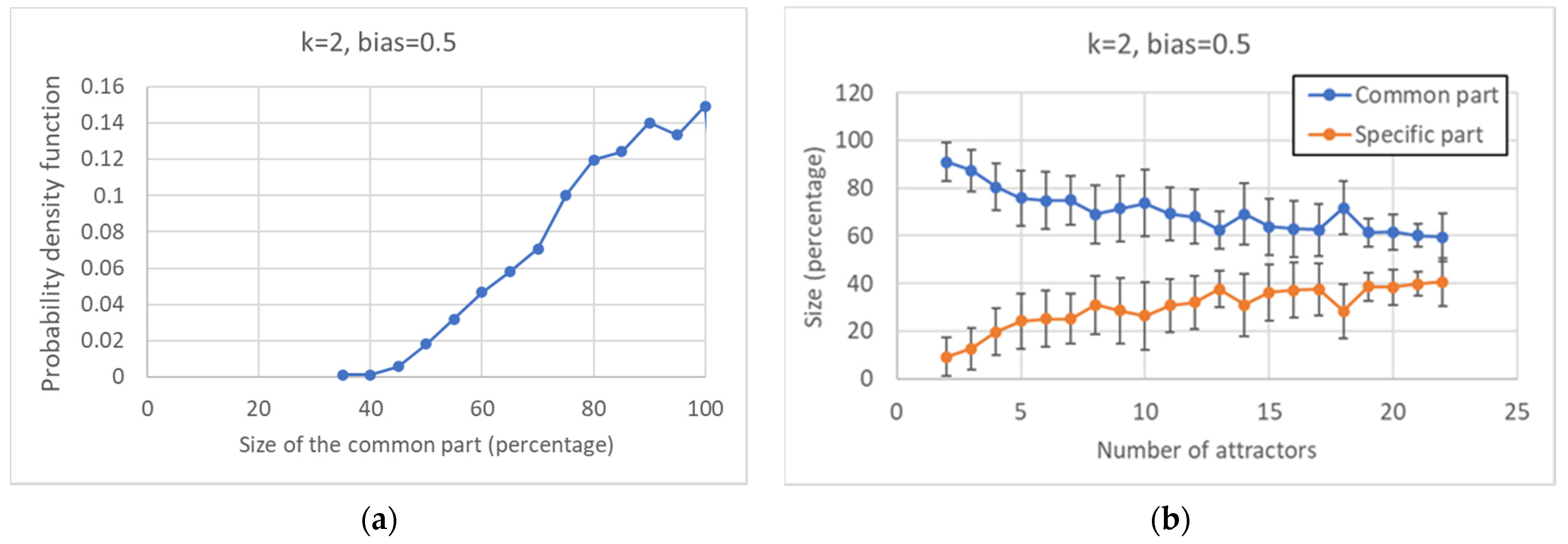
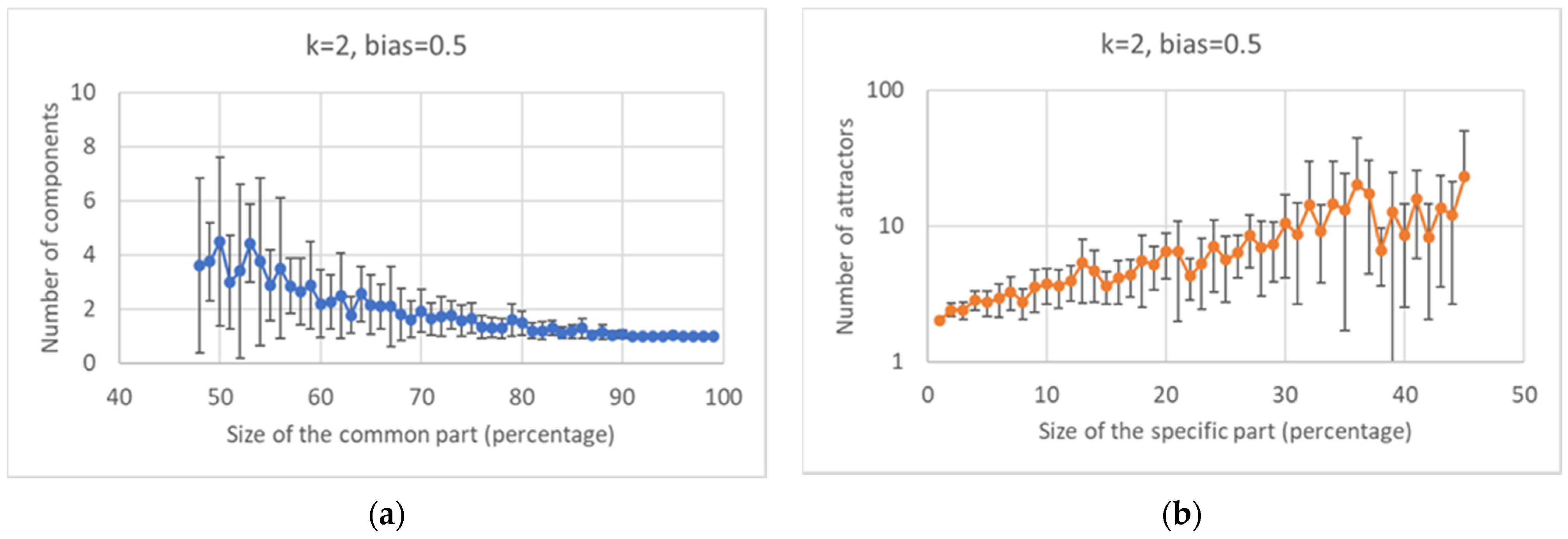
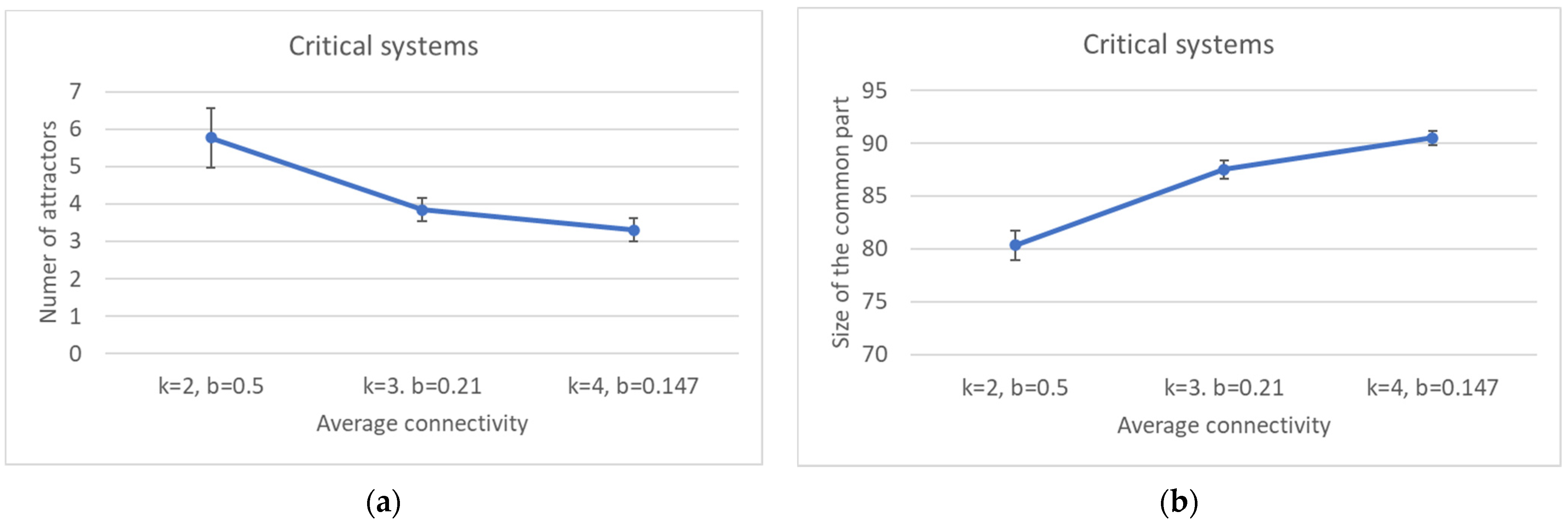
Keeping constant the overall number of nodes, one observes, as it should be expected, that the number of different attractors tends to decrease as the size of the common sea increases.
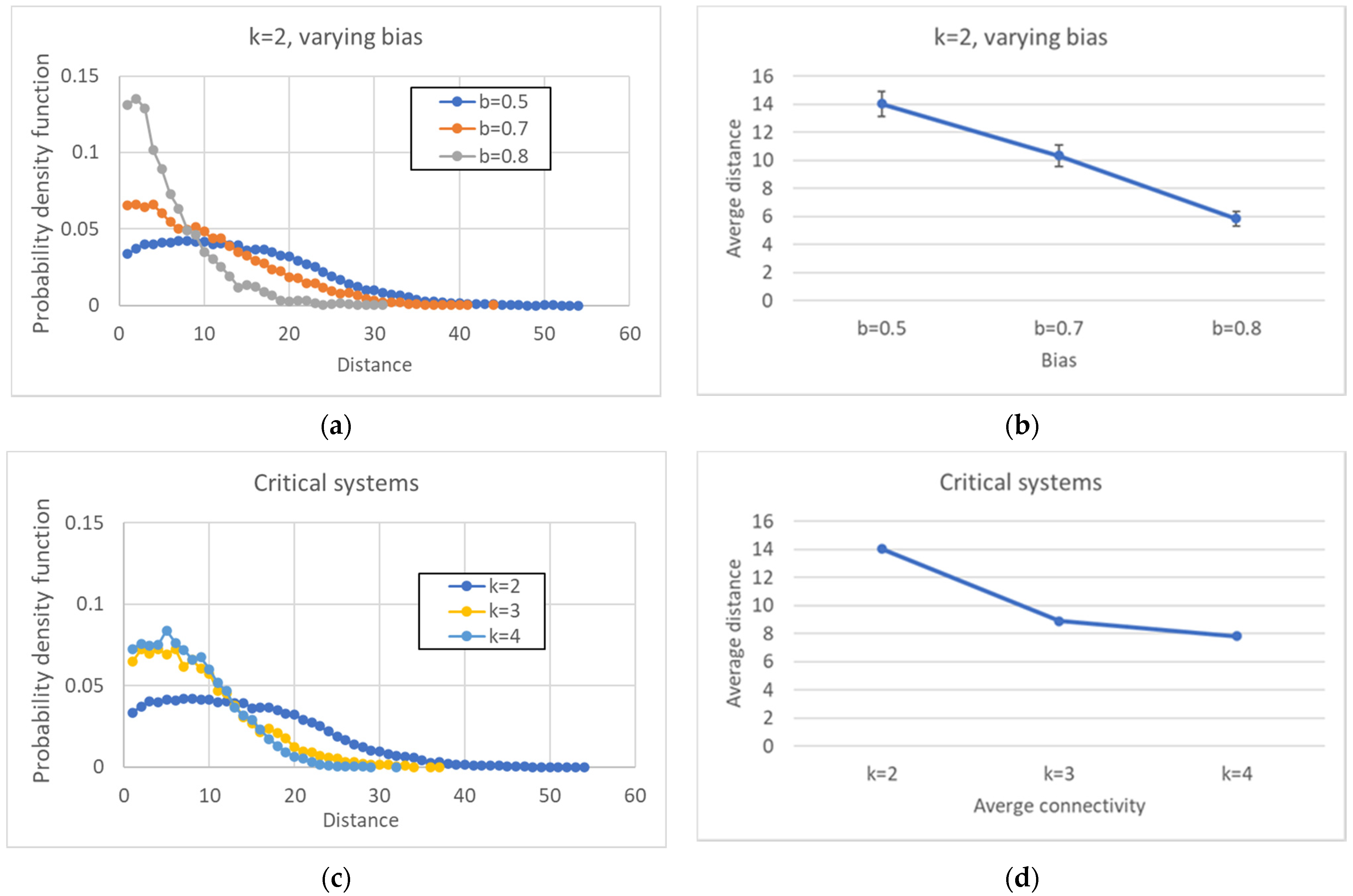
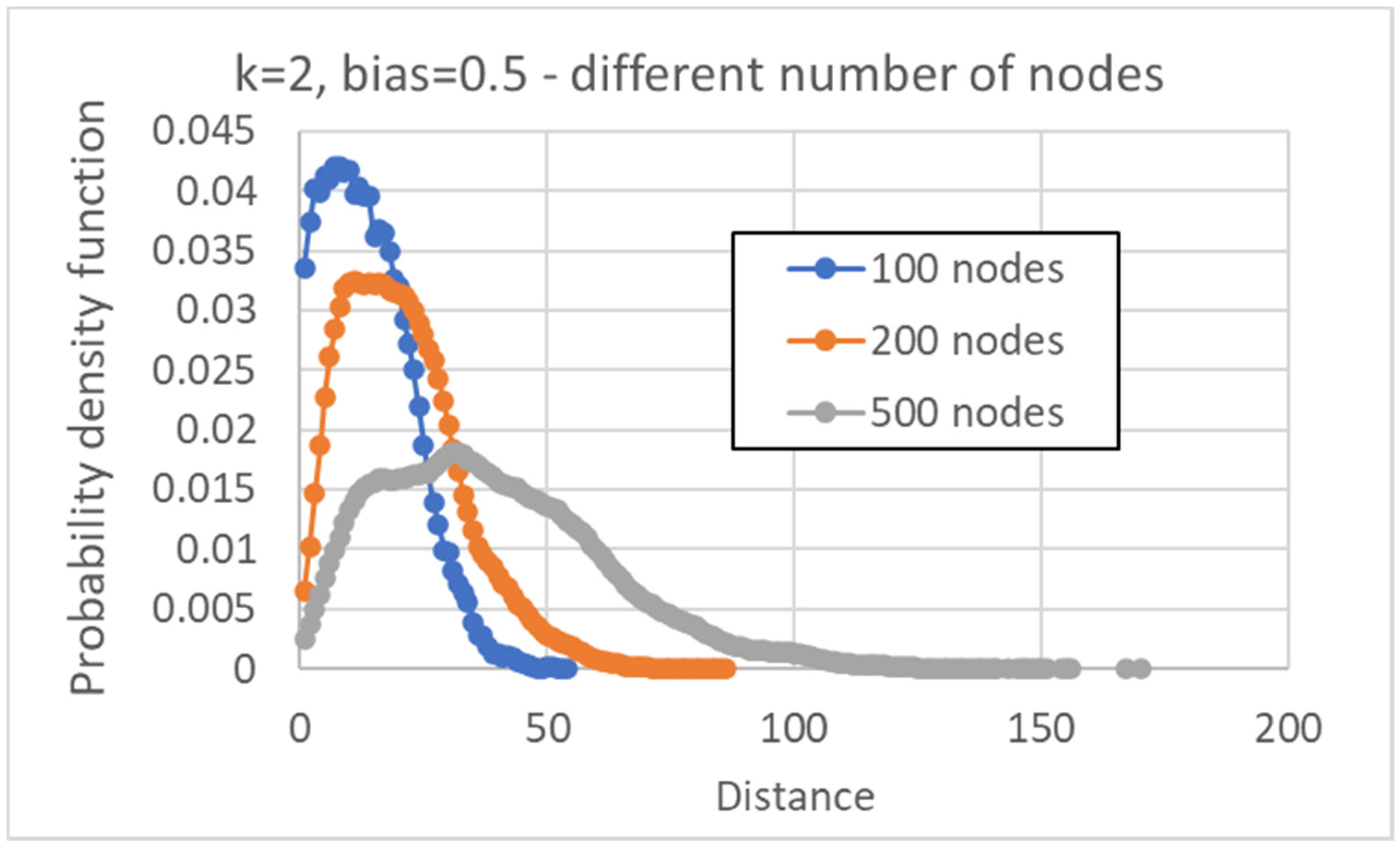
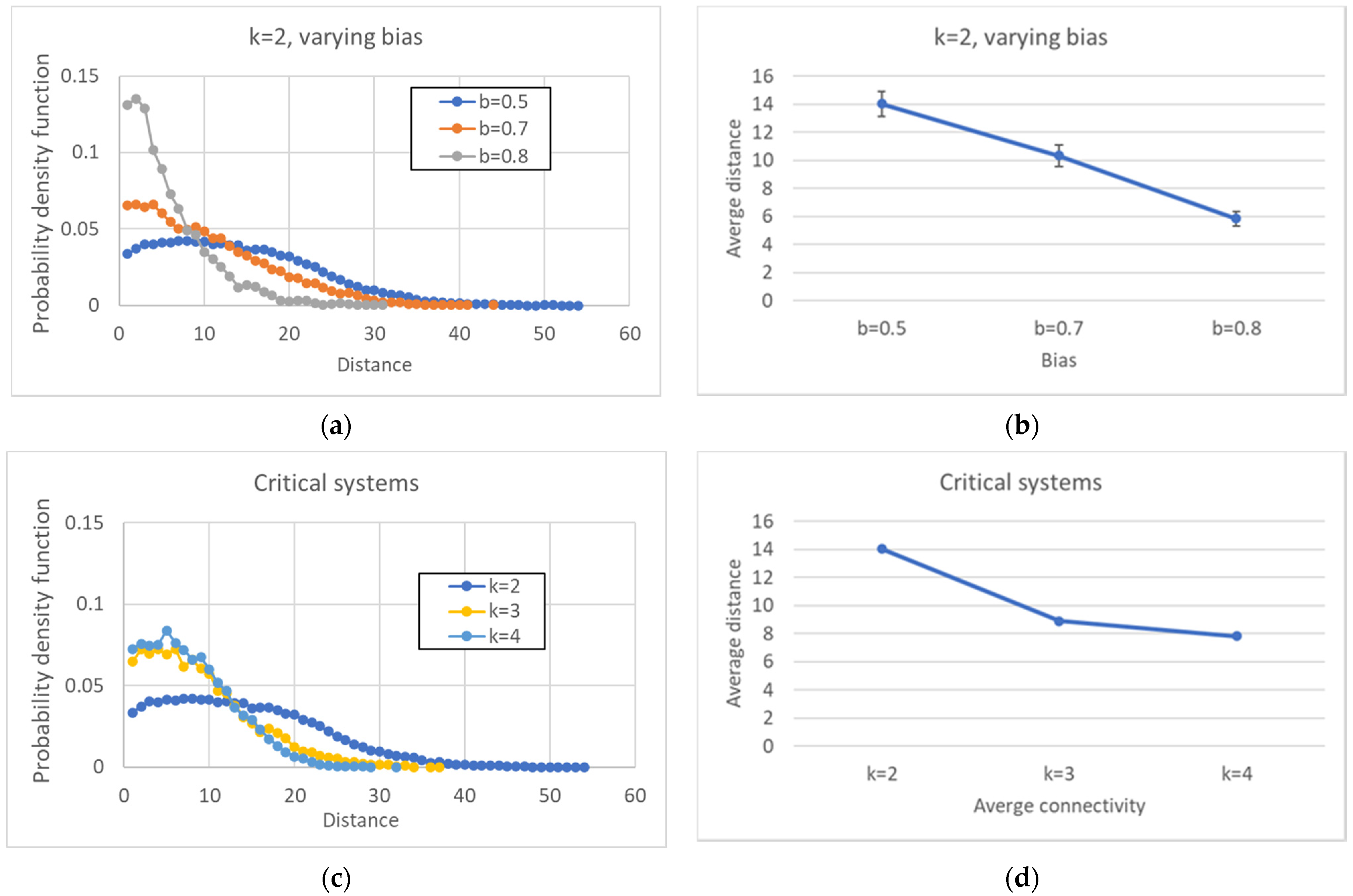
A further comment on the simulation results concerns the distribution of distances between pairs of attractors, which shows a unimodal form, initially growing, reaching a maximum for a given value of the distance, and declining after that value. The same shape is conserved even when larger networks are considered: in these cases, the maximum shifts to the right and the curve flattens.
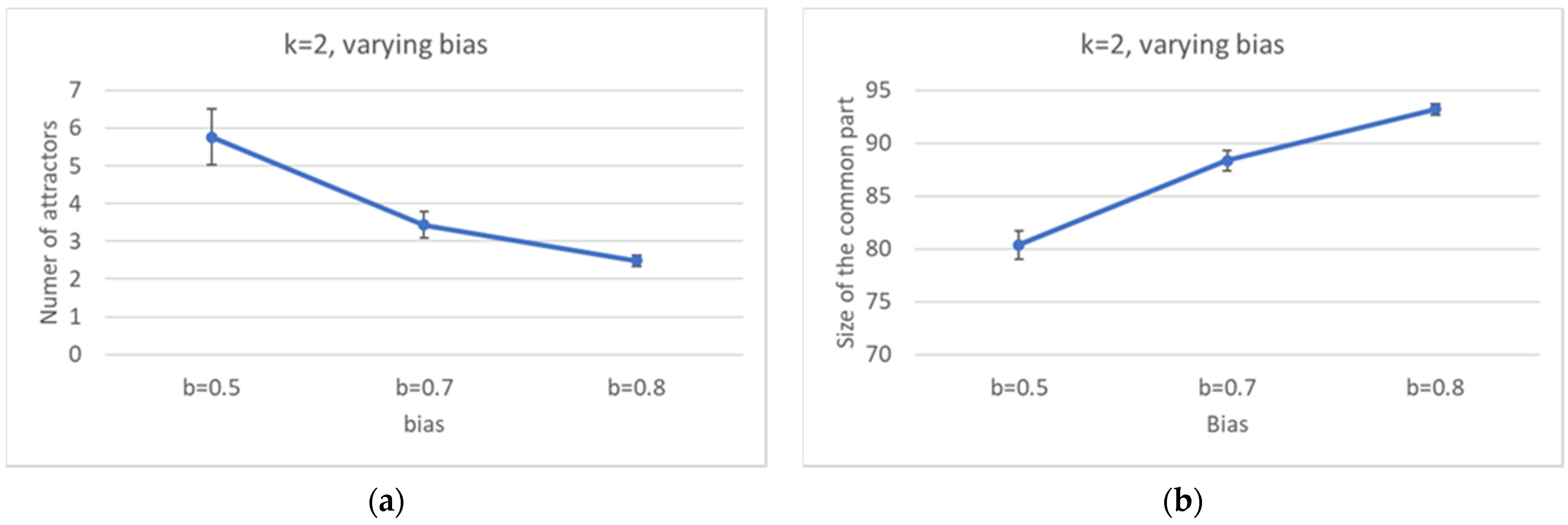
If we abandon the condition that the network be critical, and we move towards more ordered networks (obtained, e.g., by changing the bias while keeping constant the number of nodes N and the connectivity k), then the size of the CS tends to increase, while the number of different attractors decreases.
5.2. Criticality Does Not Suffice to Determine the Size of the CS
Perhaps surprisingly, the same happens as the connectivity (the number of inputs per node) is increased, while keeping the network dynamically critical by a corresponding change of the bias. This is an important result: the size of the common part does not depend only upon the dynamical regime, but it differs in different ensembles of critical networks. The ordering effect due to the increased bias seems to slightly prevail on the effect of the increase in the connectivity (which, ceteris paribus, would rather tend to shift a network towards the “chaotic” region).
5.3. Both the CS and the SP Often Host Different (Weakly Connected) Components
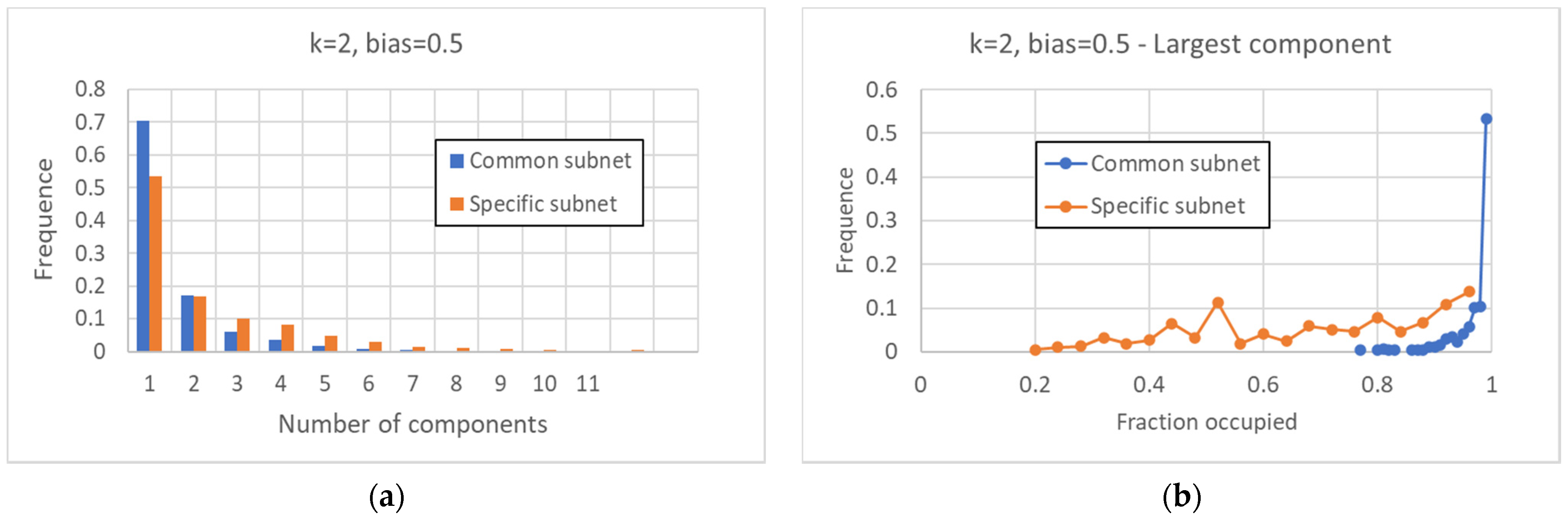
The fragmentation of the CS and of the SP is extremely interesting. In critical networks with k = 2, only in a limited fraction of cases does the CS coincide with the whole network, while about 85% networks allow one to identify also at least one specific island.
Broadly speaking, in critical nets the CS is typically composed of a large (weakly connected) component and one or more smaller ones, while the SP is fragmented in a number of components of similar sizes (of course, these are the phenomena that are most frequently observed, while single network realizations may behave in different ways). The number of different components decreases as the size of the CS increases, and a similar phenomenon happens in the SP. The number of different attractors seems positively correlated with the size of the specific part while it does not seem to show a similar correlation with the number of subparts of the SP (data not shown). This might look surprising but it might be related to the limited size of the networks simulated so far.
The CS and the SP, and their weakly connected components, are emerging intermediate-level structures that can be used to describe the dynamical organization of the network. We suggest that looking at their properties may provide a new viewpoint to describe features of cell types, as described in the following
Section 5.4.
5.4. The Study of the Model Suggests Original Ways to Analyze Experimental Data, Asking Novel Questions
The use of the RBN model highlighted the existence of a significant fraction of nodes in the common sea, an observation that naturally leads one to look for similar features in biological data, such as those exemplified in
Section 4, which, to the best of our knowledge, had not been previously presented. It is important to stress that “playing with the model” can provide new viewpoints and can bring new questions that are useful for the study of experimental data.
While, in this paper, we analyzed some features of families of networks, note that for the notions of common sea, in specific parts, distance distribution can be applied also to specific types of organisms (a specific type of biological organism should correspond to a specific RBN). This opens the way to a number of interesting opportunities. For example, one might determine whether those genes that are always expressed in the CS coincide with the already known set of “constitutive” genes. If this is not the case, then it would be important to understand why. On the other hand, it would be interesting to check whether the set of genes that are always silent in the CS is composed of genes that are active only in particular phases of the life of the organism, such as, e.g., during embryo growth or under environmental conditions that are not represented in the sample under analysis.
In the case of unicellular organisms, where, of course, the notion of cell type cannot be applied, the different attractors are usually interpreted as different modalities of functioning; for example, when some food is lacking, or when some noxious substance is present in the environment. The very notions of CS, SP and distance distribution might be applied also in these cases.
As described in
Section 3.1, it was observed that there may be different WCCs of similar size in a specific part. It might be tempting to try to understand whether the behavior of the various attractors can be approximately described by suitable combinations of the behaviors of these islands. This would be particularly simple if, for example, an island had two or a few “ways of functioning”. This approach might provide an intrinsic (i.e., not
a priori predefined) intermediate-level description of the phase space of the system. This hypothesis is really intriguing; however, its feasibility must be confirmed by further studies of larger networks.
Last but not least, the notions of CS and SP may prove useful in comparing different organisms, if analogous lists of genes can be identified. Studying how they change during evolution would be a wonderful opportunity.
5.5. The Way in Which Real-Valued Activation Values Are Binarized Plays a Crucial Role
We think that virtuous feedback between theory and experimental data is necessary in biology, in a period such as the present one when there is a lack of theoretical foundations and a wealth of experimental data. We show in this paper that such a process can at least be envisaged starting from RBNs and from single-cell gene expression data, focusing on concepts such as the common sea and on the distribution of distances between cell types.
In
Section 4, we showed that the size distribution of the analogue of the CS in human single-cell data depends, to a large extent, upon the choice of the threshold. In our approach 2, we also used gene-specific thresholds, albeit in a very simplified form. The threshold was formally the same for all the genes, but their range was previously rescaled to match the [0,1] interval). It will be very interesting in the future to consider some recent works [
63,
64], which aim at identifying the “best” threshold for binarization from the data themselves, i.e., from observed real-valued activation values (such as, for example, in [
26,
28]. These more sophisticated methods are very interesting and may provide quite strong constraints on the acceptable parameters of the theoretical model. However, as already remarked, a careful comparison of the model behavior with experimental data (which would require not only a more thorough analysis of the effects of binarization, but also an analysis of the behavior of RBNs with different parameter values and maybe a larger data set) lies beyond the scope of the present work; therefore, we prefer to postpone the application of these more sophisticated binarization methods to future works.
While the results presented so far are new and interesting, it is also important to acknowledge some major limitations of the present study, which represent challenges for future works. In some cases, the improvements are quite straightforward:
Most investigations so far concentrated on networks with N = 100 nodes, while different numbers could be explored (thus trying also to identify how the size of the various parts scales with N);
Different combinations of parameter values could be considered;
Different network random topologies could be explored (e.g., scale-free);
The set of Boolean functions might be limited to take into account biological plausibility [
35,
36,
65], i.e., the possibility of being implemented in real wetware.
Other changes might require more care. A major one concerns the fact that real networks are not fully random, but have undergone long periods of evolution. If the size of the SP and its fragmentation are important from an evolutionary perspective, then they are likely to have been modified through generations. One might tentatively suggest that this explains, at least in part, the differences between the CS of simulated networks and that of single-cell data. In the end, this might lead one to question the validity of the fully random model.
Another aspect that requires great care is the effect of the external environment: RBNs are autonomous dynamical systems, while real GRNs are subject to influences from other variables (chemical species, temperature, etc.). If a Boolean network is used to model only a part of the whole human regulatory network (for example, in the networks collected in [
29]), then also the other genes belong to its “environment”, and one should find effective ways to describe their effects. While there may be quite simple ways to achieve this, e.g., by clamping their values, it would still be necessary to define key concepts such as criticality in these cases.
These topics will be the subject of future works.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}