
The Free Energy Principle for Perception and Action: A Deep Learning Perspective



Abstract
1. Introduction
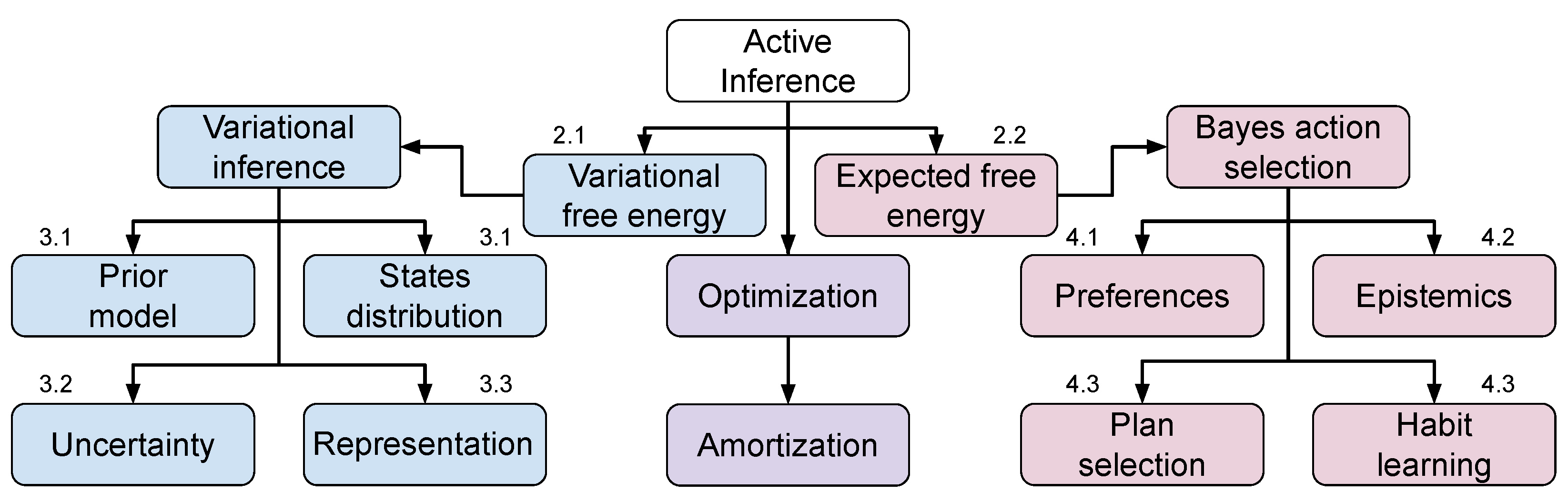
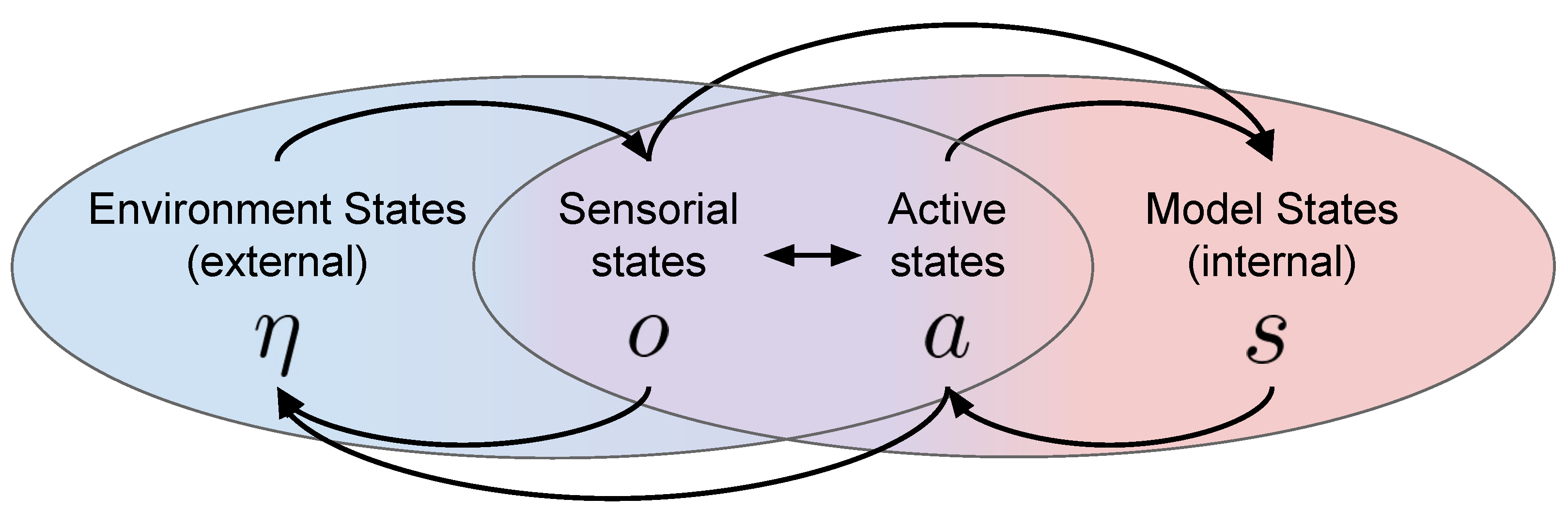
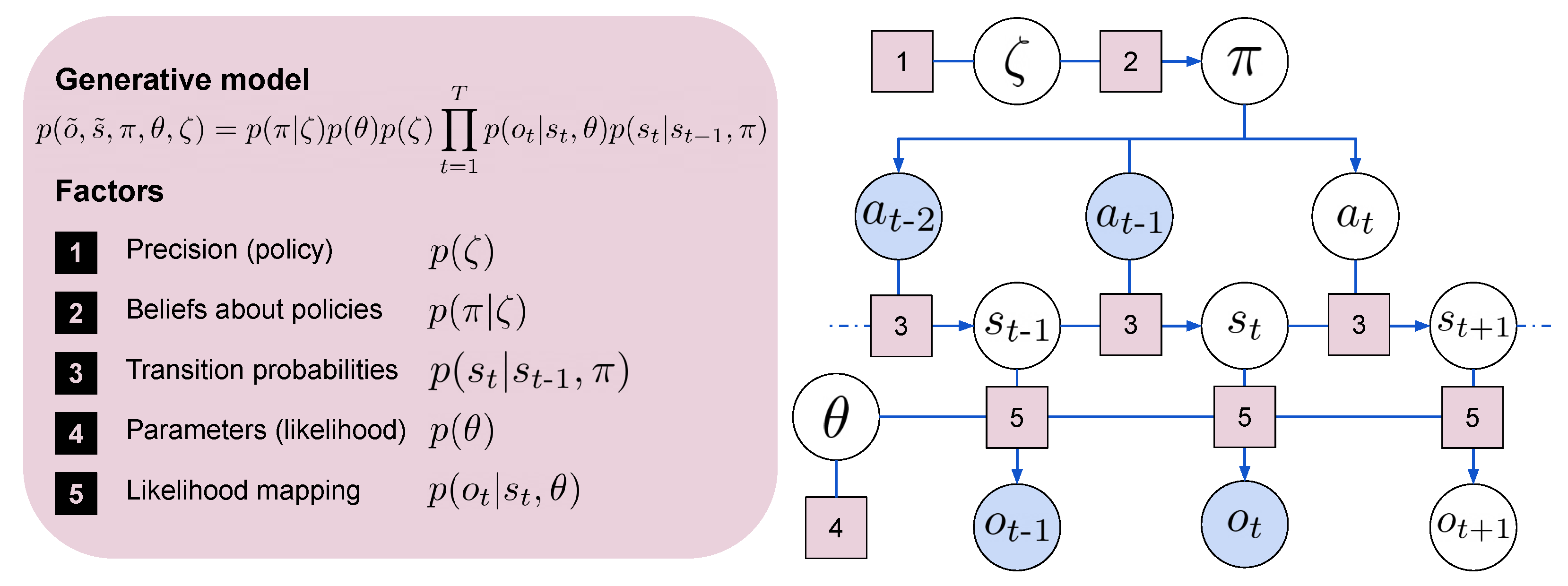
2. The Free Energy Principle and Active Inference
2.1. Variational Free Energy
2.2. Expected Free Energy
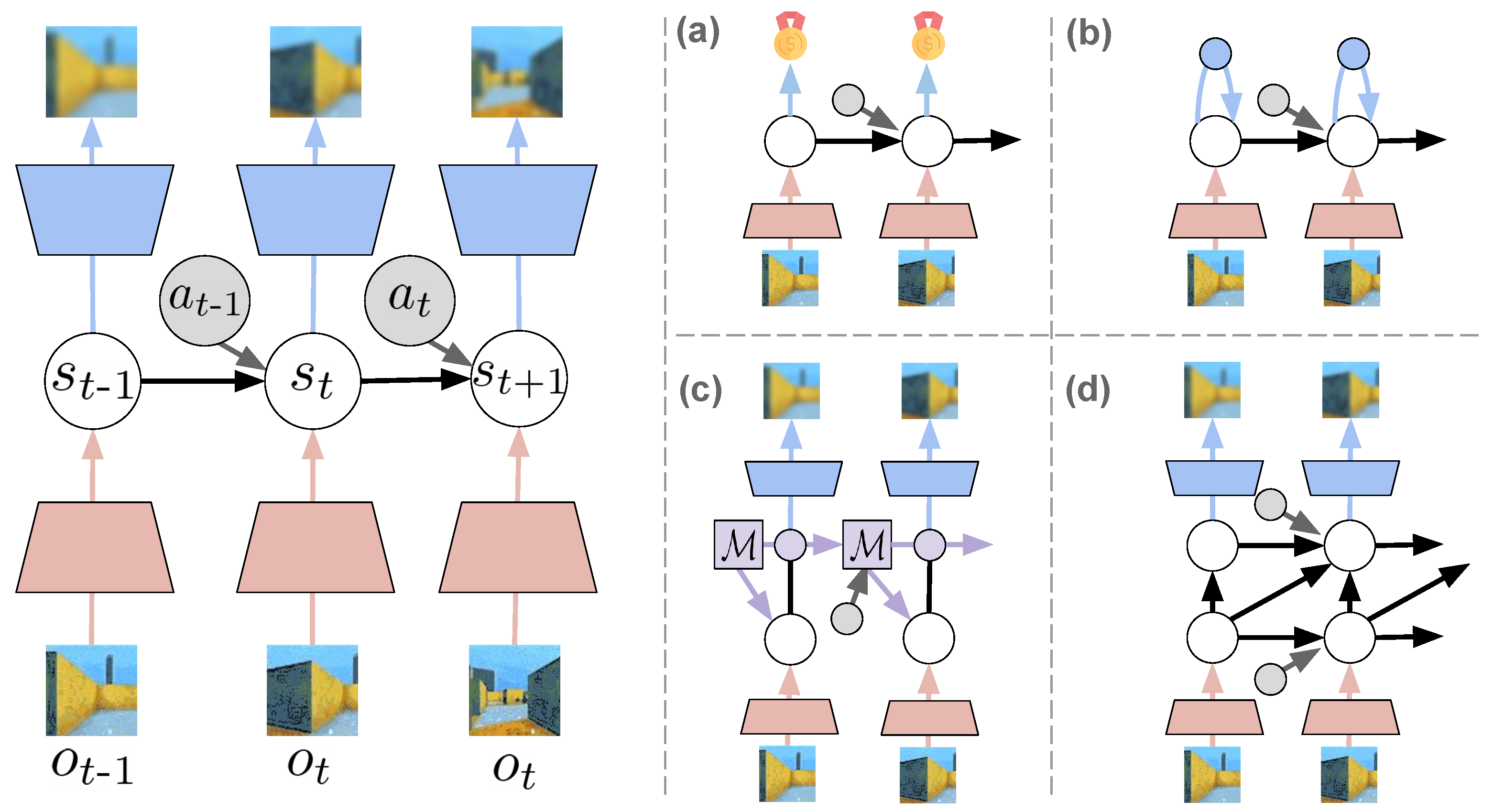
3. Variational World Models
3.1. Models
3.2. Uncertainty
3.3. Representation
3.4. Summary
4. Bayesian Action Selection
4.1. Preferences Modeling
4.2. Epistemics, Exploration, and Ambiguity
4.3. Plans, Habits, and Search Optimization
4.4. Summary
5. Discussion and Perspectives
Author Contributions
Funding
Conflicts of Interest
References
- Friston, K.J.; Stephan, K.E. Free-energy and the brain. Synthese 2007, 159, 417–458. [Google Scholar] [CrossRef] [PubMed]
- Friston, K.; FitzGerald, T.; Rigoli, F.; Schwartenbeck, P.; Doherty, J.O.; Pezzulo, G. Active inference and learning. Neurosci. Biobehav. Rev. 2016, 68, 862–879. [Google Scholar] [CrossRef] [PubMed]
- Parr, T.; Rees, G.; Friston, K.J. Computational Neuropsychology and Bayesian Inference. Front. Hum. Neurosci. 2018, 12, 61. [Google Scholar] [CrossRef]
- Demekas, D.; Parr, T.; Friston, K.J. An Investigation of the Free Energy Principle for Emotion Recognition. Front. Comput. Neurosci. 2020, 14, 30. [Google Scholar] [CrossRef]
- Henriksen, M. Variational Free Energy and Economics Optimizing with Biases and Bounded Rationality. Front. Psychol. 2020, 11, 549187. [Google Scholar] [CrossRef]
- Constant, A.; Ramstead, M.J.D.; Veissière, S.P.L.; Campbell, J.O.; Friston, K.J. A variational approach to niche construction. J. R. Soc. Interface 2018, 15, 20170685. [Google Scholar] [CrossRef]
- Bruineberg, J.; Rietveld, E.; Parr, T.; van Maanen, L.; Friston, K.J. Free-energy minimization in joint agent-environment systems: A niche construction perspective. J. Theor. Biol. 2018, 455, 161–178. [Google Scholar] [CrossRef]
- Perrinet, L.U.; Adams, R.A.; Friston, K.J. Active inference, eye movements and oculomotor delays. Biol. Cybern. 2014, 108, 777–801. [Google Scholar] [CrossRef]
- Parr, T.; Friston, K.J. Active inference and the anatomy of oculomotion. Neuropsychologia 2018, 111, 334–343. [Google Scholar] [CrossRef]
- Brown, H.; Friston, K.; Bestmann, S. Active Inference, Attention, and Motor Preparation. Front. Psychol. 2011, 2, 218. [Google Scholar] [CrossRef]
- Parr, T.; Friston, K.J. Working memory, attention, and salience in active inference. Sci. Rep. 2017, 7, 14678. [Google Scholar] [CrossRef] [PubMed]
- Mirza, M.B.; Adams, R.A.; Mathys, C.D.; Friston, K.J. Scene Construction, Visual Foraging, and Active Inference. Front. Comput. Neurosci. 2016, 10, 56. [Google Scholar] [CrossRef] [PubMed]
- Heins, R.C.; Mirza, M.B.; Parr, T.; Friston, K.; Kagan, I.; Pooresmaeili, A. Deep Active Inference and Scene Construction. Front. Artif. Intell. 2020, 3, 81. [Google Scholar] [CrossRef] [PubMed]
- Biehl, M.; Pollock, F.A.; Kanai, R. A Technical Critique of Some Parts of the Free Energy Principle. Entropy 2021, 23, 293. [Google Scholar] [CrossRef]
- Friston, K.J.; Da Costa, L.; Parr, T. Some Interesting Observations on the Free Energy Principle. Entropy 2021, 23, 1076. [Google Scholar] [CrossRef]
- Friston, K. Life as we know it. J. R. Soc. Interface 2013, 10, 20130475. [Google Scholar] [CrossRef]
- Kirchhoff, M.; Parr, T.; Palacios, E.; Friston, K.; Kiverstein, J. The Markov blankets of life: Autonomy, active inference and the free energy principle. J. R. Soc. Interface 2018, 15, 20170792. [Google Scholar] [CrossRef]
- Rubin, S.; Parr, T.; Da Costa, L.; Friston, K. Future climates: Markov blankets and active inference in the biosphere. J. R. Soc. Interface 2020, 17, 20200503. [Google Scholar] [CrossRef]
- Maturana, H.R.; Varela, F.J.; Maturana, H.R. Autopoiesis and Cognition: The Realization of the Living; D. Reidel Pub. Co.: Dordrecht, The Netherlands, 1980. [Google Scholar]
- Kirchhoff, M.D. Autopoiesis, free energy, and the life–mind continuity thesis. Synthese 2018, 195, 2519–2540. [Google Scholar] [CrossRef]
- Blei, D.M.; Kucukelbir, A.; McAuliffe, J.D. Variational Inference: A Review for Statisticians. J. Am. Stat. Assoc. 2017, 112, 859–877. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Wise, R.A. Dopamine, learning and motivation. Nat. Rev. Neurosci. 2004, 5, 483–494. [Google Scholar] [CrossRef] [PubMed]
- Glimcher, P.W. Understanding dopamine and reinforcement learning: The dopamine reward prediction error hypothesis. Proc. Natl. Acad. Sci. USA 2011, 108, 15647–15654. [Google Scholar] [CrossRef] [PubMed]
- Silver, D.; Singh, S.; Precup, D.; Sutton, R.S. Reward is enough. Artif. Intell. 2021, 299, 103535. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing Atari with Deep Reinforcement Learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Badia, A.P.; Piot, B.; Kapturowski, S.; Sprechmann, P.; Vitvitskyi, A.; Guo, D.; Blundell, C. Agent57: Outperforming the Atari Human Benchmark. arXiv 2020, arXiv:2003.13350. [Google Scholar]
- Vinyals, O.; Babuschkin, I.; Czarnecki, W.M.; Mathieu, M.; Dudzik, A.; Chung, J.; Choi, D.H.; Powell, R.; Ewalds, T.; Georgiev, P.; et al. Grandmaster level in StarCraft II using multi-agent reinforcement learning. Nature 2019, 575, 350–354. [Google Scholar] [CrossRef]
- Schrittwieser, J.; Antonoglou, I.; Hubert, T.; Simonyan, K.; Sifre, L.; Schmitt, S.; Guez, A.; Lockhart, E.; Hassabis, D.; Graepel, T.; et al. Mastering Atari, Go, chess and shogi by planning with a learned model. Nature 2020, 588, 604–609. [Google Scholar] [CrossRef]
- Akkaya, I.; Andrychowicz, M.; Chociej, M.; Litwin, M.; McGrew, B.; Petron, A.; Paino, A.; Plappert, M.; Powell, G.; Ribas, R.; et al. Solving Rubik’s Cube with a Robot Hand. arXiv 2019, arXiv:1910.07113. [Google Scholar]
- Ueltzhöffer, K. Deep active inference. Biol. Cybern. 2018, 112, 547–573. [Google Scholar] [CrossRef]
- Çatal, O.; Verbelen, T.; Nauta, J.; De Boom, C.; Dhoedt, B. Learning Perception and Planning with Deep Active Inference. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 3952–3956. [Google Scholar] [CrossRef]
- Fountas, Z.; Sajid, N.; Mediano, P.; Friston, K. Deep active inference agents using Monte-Carlo methods. In Advances in Neural Information Processing Systems; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M.F., Lin, H., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2020; Volume 33, pp. 11662–11675. [Google Scholar]
- Buckley, C.L.; Kim, C.S.; McGregor, S.; Seth, A.K. The free energy principle for action and perception: A mathematical review. J. Math. Psychol. 2017, 81, 55–79. [Google Scholar] [CrossRef]
- Da Costa, L.; Parr, T.; Sajid, N.; Veselic, S.; Neacsu, V.; Friston, K. Active inference on discrete state-spaces: A synthesis. J. Math. Psychol. 2020, 99, 102447. [Google Scholar] [CrossRef] [PubMed]
- Lanillos, P.; Meo, C.; Pezzato, C.; Meera, A.A.; Baioumy, M.; Ohata, W.; Tschantz, A.; Millidge, B.; Wisse, M.; Buckley, C.L.; et al. Active Inference in Robotics and Artificial Agents: Survey and Challenges. arXiv 2021, arXiv:2112.01871. [Google Scholar]
- Gershman, S.; Goodman, N. Amortized inference in probabilistic reasoning. Proc. Annu. Meet. Cogn. Sci. Soc. 2014, 36, 516–522. [Google Scholar]
- Razavi, A.; van den Oord, A.; Vinyals, O. Generating Diverse High-Fidelity Images with VQ-VAE-2. arXiv 2019, arXiv:1906.00446. [Google Scholar]
- Karras, T.; Aittala, M.; Laine, S.; Härkönen, E.; Hellsten, J.; Lehtinen, J.; Aila, T. Alias-Free Generative Adversarial Networks. arXiv 2021, arXiv:2106.12423. [Google Scholar]
- Vahdat, A.; Kautz, J. NVAE: A Deep Hierarchical Variational Autoencoder. arXiv 2021, arXiv:2007.03898. [Google Scholar]
- Zilly, J.G.; Srivastava, R.K.; Koutník, J.; Schmidhuber, J. Recurrent Highway Networks. arXiv 2017, arXiv:1607.03474. [Google Scholar]
- Melis, G.; Kočiský, T.; Blunsom, P. Mogrifier LSTM. arXiv 2020, arXiv:1909.01792. [Google Scholar]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models Are Few-Shot Learners. arXiv 2020, arXiv:2005.14165. [Google Scholar]
- Xingjian, S.; Chen, Z.; Wang, H.; Yeung, D.Y.; Wong, W.K.; Woo, W.C. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. Adv. Neural Inf. Process. Syst. 2015, 28, 802–810. [Google Scholar]
- Wang, Y.; Long, M.; Wang, J.; Gao, Z.; Yu, P.S. PredRNN: Recurrent Neural Networks for Predictive Learning using Spatiotemporal LSTMs. In Advances in Neural Information Processing Systems; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Denton, E.; Fergus, R. Stochastic Video Generation with a Learned Prior. arXiv 2018, arXiv:1802.07687. [Google Scholar]
- Lotter, W.; Kreiman, G.; Cox, D. Deep Predictive Coding Networks for Video Prediction and Unsupervised Learning. arXiv 2017, arXiv:1605.08104. [Google Scholar]
- Buesing, L.; Weber, T.; Racaniere, S.; Eslami, S.M.A.; Rezende, D.; Reichert, D.P.; Viola, F.; Besse, F.; Gregor, K.; Hassabis, D.; et al. Learning and Querying Fast Generative Models for Reinforcement Learning. arXiv 2018, arXiv:1802.03006. [Google Scholar]
- Hafner, D.; Lillicrap, T.; Fischer, I.; Villegas, R.; Ha, D.; Lee, H.; Davidson, J. Learning Latent Dynamics for Planning from Pixels. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 5–9 June 2019; Chaudhuri, K., Salakhutdinov, R., Eds.; PMLR: Brookline, MA, USA, 2019; Volume 97, pp. 2555–2565. [Google Scholar]
- Ha, D.; Schmidhuber, J. Recurrent World Models Facilitate Policy Evolution. arXiv 2018, arXiv:1809.01999. [Google Scholar]
- Mazzaglia, P.; Catal, O.; Verbelen, T.; Dhoedt, B. Self-Supervised Exploration via Latent Bayesian Surprise. arXiv 2021, arXiv:2104.07495. [Google Scholar]
- Pathak, D.; Agrawal, P.; Efros, A.A.; Darrell, T. Curiosity-driven Exploration by Self-supervised Prediction. arXiv 2017, arXiv:1705.05363. [Google Scholar]
- Houthooft, R.; Chen, X.; Duan, Y.; Schulman, J.; De Turck, F.; Abbeel, P. VIME: Variational Information Maximizing Exploration. In Proceedings of the 30th International Conference on Neural Information Processing Systems, NIPS’16, Barcelona, Spain, 5–10 December 2016; pp. 1117–1125. [Google Scholar]
- Çatal, O.; Leroux, S.; De Boom, C.; Verbelen, T.; Dhoedt, B. Anomaly Detection for Autonomous Guided Vehicles using Bayesian Surprise. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October–24 January 2020; pp. 8148–8153. [Google Scholar] [CrossRef]
- Hansen, N. The CMA Evolution Strategy: A Tutorial. arXiv 2016, arXiv:1604.00772. [Google Scholar]
- Hubert, T.; Schrittwieser, J.; Antonoglou, I.; Barekatain, M.; Schmitt, S.; Silver, D. Learning and Planning in Complex Action Spaces. arXiv 2021, arXiv:2104.06303. [Google Scholar]
- Von Helmholtz, H. Handbuch der Physiologischen Optik: Mit 213 in den Text Eingedruckten Holzschnitten und 11 Tafeln; Wentworth Press: Sydney, Australia, 1867; Volume 9. [Google Scholar]
- Friston, K. The free-energy principle: A rough guide to the brain? Trends Cogn. Sci. 2009, 13, 293–301. [Google Scholar] [CrossRef]
- Ramstead, M.J.; Kirchhoff, M.D.; Friston, K.J. A tale of two densities: Active inference is enactive inference. Adapt. Behav. 2020, 28, 225–239. [Google Scholar] [CrossRef]
- Friston, K.J.; Parr, T.; de Vries, B. The graphical brain: Belief propagation and active inference. Netw. Neurosci. 2017, 1, 381–414. [Google Scholar] [CrossRef] [PubMed]
- Friston, K.J.; Daunizeau, J.; Kiebel, S.J. Reinforcement Learning or Active Inference? PLoS ONE 2009, 4, e6421. [Google Scholar] [CrossRef] [PubMed]
- Karl, F. A Free Energy Principle for Biological Systems. Entropy 2012, 14, 2100–2121. [Google Scholar] [CrossRef]
- Schwartenbeck, P.; Passecker, J.; Hauser, T.U.; FitzGerald, T.H.; Kronbichler, M.; Friston, K.J. Computational mechanisms of curiosity and goal-directed exploration. eLife 2019, 8, e41703. [Google Scholar] [CrossRef]
- Friston, K.J.; Lin, M.; Frith, C.D.; Pezzulo, G.; Hobson, J.A.; Ondobaka, S. Active Inference, Curiosity and Insight. Neural Comput. 2017, 29, 2633–2683. [Google Scholar] [CrossRef]
- Friston, K.; Rigoli, F.; Ognibene, D.; Mathys, C.; Fitzgerald, T.; Pezzulo, G. Active inference and epistemic value. Cogn. Neurosci. 2015, 6, 187–214. [Google Scholar] [CrossRef]
- Hafner, D.; Lillicrap, T.; Norouzi, M.; Ba, J. Mastering Atari with Discrete World Models. arXiv 2021, arXiv:2010.02193. [Google Scholar]
- Hafner, D.; Lillicrap, T.P.; Ba, J.; Norouzi, M. Dream to Control: Learning Behaviors by Latent Imagination. In Proceedings of the ICLR Conference, Addis Abeba, Ethiopia, 26 April–1 May 2020. [Google Scholar]
- Çatal, O.; Nauta, J.; Verbelen, T.; Simoens, P.; Dhoedt, B. Bayesian policy selection using active inference. arXiv 2019, arXiv:1904.08149. [Google Scholar]
- Çatal, O.; Verbelen, T.; Van de Maele, T.; Dhoedt, B.; Safron, A. Robot navigation as hierarchical active inference. Neural Netw. 2021, 142, 192–204. [Google Scholar] [CrossRef]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. arXiv 2014, arXiv:1312.6114. [Google Scholar]
- Rezende, D.J.; Mohamed, S.; Wierstra, D. Stochastic Backpropagation and Approximate Inference in Deep Generative Models. In Proceedings of the 31st International Conference on Machine Learning (ICML), Beijing, China, 21–26 June 2014; Volume 32, pp. 1278–1286. [Google Scholar]
- Tishby, N.; Pereira, F.C.; Bialek, W. The information bottleneck method. arXiv 2000, arXiv:physics/0004057. [Google Scholar]
- Alemi, A.A.; Fischer, I.; Dillon, J.V.; Murphy, K. Deep Variational Information Bottleneck. arXiv 2019, arXiv:1612.00410. [Google Scholar]
- Friston, K.; Da Costa, L.; Hafner, D.; Hesp, C.; Parr, T. Sophisticated Inference. Neural Comput. 2021, 33, 713–763. [Google Scholar] [CrossRef]
- Hornik, K. Approximation capabilities of multilayer feedforward networks. Neural Netw. 1991, 4, 251–257. [Google Scholar] [CrossRef]
- Heiden, E.; Millard, D.; Coumans, E.; Sheng, Y.; Sukhatme, G.S. NeuralSim: Augmenting Differentiable Simulators with Neural Networks. arXiv 2021, arXiv:2011.04217. [Google Scholar]
- Freeman, C.D.; Frey, E.; Raichuk, A.; Girgin, S.; Mordatch, I.; Bachem, O. Brax—A Differentiable Physics Engine for Large Scale Rigid Body Simulation. arXiv 2021, arXiv:2106.13281. [Google Scholar]
- Lovejoy, W.S. A survey of algorithmic methods for partially observed Markov decision processes. Ann. Oper. Res. 1991, 28, 47–65. [Google Scholar] [CrossRef]
- Roy, N.; Gordon, G.; Thrun, S. Finding Approximate POMDP solutions Through Belief Compression. J. Artif. Intell. Res. 2005, 23, 1–40. [Google Scholar] [CrossRef]
- Kurniawati, H.; Hsu, D.; Lee, W.S. Sarsop: Efficient point-based pomdp planning by approximating optimally reachable belief spaces. In Robotics: Science and Systems; Citeseer: Pennsylvania, PA, USA, 2008; Volume 2008. [Google Scholar]
- Heess, N.; Hunt, J.J.; Lillicrap, T.P.; Silver, D. Memory-based control with recurrent neural networks. arXiv 2015, arXiv:1512.04455. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Bengio, Y.; Léonard, N.; Courville, A. Estimating or Propagating Gradients through Stochastic Neurons for Conditional Computation. arXiv 2013, arXiv:1308.3432. [Google Scholar]
- Glynn, P.W. Likelilood ratio gradient estimation: An overview. In Proceedings of the 19th Conference on Winter Simulation, Atlanta, GA, USA, 14–16 December 1987; pp. 366–375. [Google Scholar]
- Williams, R.J. Simple Statistical Gradient-Following Algorithms for Connectionist Reinforcement Learning. Mach. Learn. 1992, 8, 229–256. [Google Scholar] [CrossRef]
- Van de Maele, T.; Verbelen, T.; Çatal, O.; De Boom, C.; Dhoedt, B. Active Vision for Robot Manipulators Using the Free Energy Principle. Front. Neurorobot. 2021, 15, 14. [Google Scholar] [CrossRef] [PubMed]
- Lee, A.X.; Nagabandi, A.; Abbeel, P.; Levine, S. Stochastic Latent Actor-Critic: Deep Reinforcement Learning with a Latent Variable Model. arXiv 2020, arXiv:1907.00953. [Google Scholar]
- Igl, M.; Zintgraf, L.; Le, T.A.; Wood, F.; Whiteson, S. Deep Variational Reinforcement Learning for POMDPs. arXiv 2018, arXiv:1806.02426. [Google Scholar]
- Rolfe, J.T. Discrete variational autoencoders. arXiv 2016, arXiv:1609.02200. [Google Scholar]
- Ozair, S.; Li, Y.; Razavi, A.; Antonoglou, I.; van den Oord, A.; Vinyals, O. Vector Quantized Models for Planning. arXiv 2021, arXiv:2106.04615. [Google Scholar]
- Sajid, N.; Tigas, P.; Zakharov, A.; Fountas, Z.; Friston, K. Exploration and preference satisfaction trade-off in reward-free learning. arXiv 2021, arXiv:2106.04316. [Google Scholar]
- Serban, I.V.; Ororbia, A.G.; Pineau, J.; Courville, A. Piecewise Latent Variables for Neural Variational Text Processing. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017; Association for Computational Linguistics: Copenhagen, Denmark, 2017; pp. 422–432. [Google Scholar] [CrossRef]
- Rezende, D.J.; Mohamed, S. Variational Inference with Normalizing Flows. arXiv 2016, arXiv:1505.05770. [Google Scholar]
- Salimans, T.; Kingma, D.P.; Welling, M. Markov Chain Monte Carlo and Variational Inference: Bridging the Gap. arXiv 2015, arXiv:1410.6460. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2021, arXiv:2010.11929. [Google Scholar]
- Rosenblatt, F. The perceptron: A probabilistic model for information storage and organization in the brain. Psychol. Rev. 1958, 65, 386. [Google Scholar] [CrossRef] [PubMed]
- Scarselli, F.; Gori, M.; Tsoi, A.C.; Hagenbuchner, M.; Monfardini, G. The Graph Neural Network Model. IEEE Trans. Neural Netw. 2009, 20, 61–80. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. In Proceedings of the NIPS 2014 Workshop on Deep Learning, Montreal, QC, Canada, 12–13 December 2014. [Google Scholar]
- Toth, P.; Rezende, D.J.; Jaegle, A.; Racanière, S.; Botev, A.; Higgins, I. Hamiltonian Generative Networks. arXiv 2020, arXiv:1909.13789. [Google Scholar]
- Sancaktar, C.; van Gerven, M.A.J.; Lanillos, P. End-to-End Pixel-Based Deep Active Inference for Body Perception and Action. In Proceedings of the 2020 Joint IEEE 10th International Conference on Development and Learning and Epigenetic Robotics (ICDL-EpiRob), Valparaiso, Chile, 26–30 October 2020. [Google Scholar] [CrossRef]
- Ghosh, P.; Sajjadi, M.S.M.; Vergari, A.; Black, M.; Schölkopf, B. From Variational to Deterministic Autoencoders. arXiv 2020, arXiv:1903.12436. [Google Scholar]
- Friston, K.; Schwartenbeck, P.; Fitzgerald, T.; Moutoussis, M.; Behrens, T.; Dolan, R. The anatomy of choice: Active inference and agency. Front. Hum. Neurosci. 2013, 7, 598. [Google Scholar] [CrossRef]
- Parr, T.; Benrimoh, D.A.; Vincent, P.; Friston, K.J. Precision and False Perceptual Inference. Front. Integr. Neurosci. 2018, 12, 39. [Google Scholar] [CrossRef]
- Parr, T.; Friston, K.J. Uncertainty, epistemics and active inference. J. R. Soc. Interface 2017, 14, 20170376. [Google Scholar] [CrossRef]
- Higgins, I.; Matthey, L.; Pal, A.; Burgess, C.P.; Glorot, X.; Botvinick, M.M.; Mohamed, S.; Lerchner, A. Beta-VAE: Learning Basic Visual Concepts with a Constrained Variational Framework. In Proceedings of the ICLR Conference, Toulon, France, 24–26 April 2017. [Google Scholar]
- Razavi, A.; van den Oord, A.; Poole, B.; Vinyals, O. Preventing Posterior Collapse with delta-VAEs. arXiv 2019, arXiv:1901.03416. [Google Scholar]
- Blundell, C.; Cornebise, J.; Kavukcuoglu, K.; Wierstra, D. Weight Uncertainty in Neural Networks. arXiv 2015, arXiv:1505.05424. [Google Scholar]
- Gal, Y.; Ghahramani, Z. Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning. arXiv 2016, arXiv:1506.02142. [Google Scholar]
- Lakshminarayanan, B.; Pritzel, A.; Blundell, C. Simple and Scalable Predictive Uncertainty Estimation using Deep Ensembles. arXiv 2017, arXiv:1612.01474. [Google Scholar]
- Pathak, D.; Gandhi, D.; Gupta, A. Self-Supervised Exploration via Disagreement. arXiv 2019, arXiv:1906.04161. [Google Scholar]
- Sekar, R.; Rybkin, O.; Daniilidis, K.; Abbeel, P.; Hafner, D.; Pathak, D. Planning to Explore via Self-Supervised World Models. In Proceedings of the ICML Conference, Virtual Conference, 12–18 July 2020. [Google Scholar]
- Tschantz, A.; Millidge, B.; Seth, A.K.; Buckley, C.L. Reinforcement Learning through Active Inference. arXiv 2020, arXiv:2002.12636. [Google Scholar]
- Van den Oord, A.; Li, Y.; Vinyals, O. Representation Learning with Contrastive Predictive Coding. arXiv 2019, arXiv:1807.03748. [Google Scholar]
- Caron, M.; Misra, I.; Mairal, J.; Goyal, P.; Bojanowski, P.; Joulin, A. Unsupervised Learning of Visual Features by Contrasting Cluster Assignments. arXiv 2021, arXiv:2006.09882. [Google Scholar]
- Grill, J.B.; Strub, F.; Altché, F.; Tallec, C.; Richemond, P.H.; Buchatskaya, E.; Doersch, C.; Pires, B.A.; Guo, Z.D.; Azar, M.G.; et al. Bootstrap your own latent: A new approach to self-supervised Learning. arXiv 2020, arXiv:2006.07733. [Google Scholar]
- Chen, X.; He, K. Exploring Simple Siamese Representation Learning. arXiv 2020, arXiv:2011.10566. [Google Scholar]
- Zbontar, J.; Jing, L.; Misra, I.; LeCun, Y.; Deny, S. Barlow Twins: Self-Supervised Learning via Redundancy Reduction. arXiv 2021, arXiv:2103.03230. [Google Scholar]
- Chen, Z.; Bei, Y.; Rudin, C. Concept whitening for interpretable image recognition. Nat. Mach. Intell. 2020, 2, 772–782. [Google Scholar] [CrossRef]
- Schwarzer, M.; Anand, A.; Goel, R.; Hjelm, R.D.; Courville, A.; Bachman, P. Data-Efficient Reinforcement Learning with Self-Predictive Representations. arXiv 2021, arXiv:2007.05929. [Google Scholar]
- Ma, X.; Chen, S.; Hsu, D.; Lee, W.S. Contrastive Variational Model-Based Reinforcement Learning for Complex Observations. In Proceedings of the 4th Conference on Robot Learning, Virtual Conference, 16–18 November 2020. [Google Scholar]
- Mazzaglia, P.; Verbelen, T.; Dhoedt, B. Contrastive Active Inference. In Proceedings of the Advances in Neural Information Processing Systems, Virtual Conference, 6–14 December 2021. [Google Scholar]
- Çatal, O.; Wauthier, S.; De Boom, C.; Verbelen, T.; Dhoedt, B. Learning Generative State Space Models for Active Inference. Front. Comput. Neurosci. 2020, 14, 103. [Google Scholar] [CrossRef]
- Friston, K.J.; Rosch, R.; Parr, T.; Price, C.; Bowman, H. Deep temporal models and active inference. Neurosci. Biobehav. Rev. 2017, 77, 388–402. [Google Scholar] [CrossRef]
- Millidge, B. Deep Active Inference as Variational Policy Gradients. arXiv 2019, arXiv:1907.03876. [Google Scholar] [CrossRef]
- Saxena, V.; Ba, J.; Hafner, D. Clockwork Variational Autoencoders. arXiv 2021, arXiv:2102.09532. [Google Scholar]
- Wu, B.; Nair, S.; Martin-Martin, R.; Fei-Fei, L.; Finn, C. Greedy Hierarchical Variational Autoencoders for Large-Scale Video Prediction. arXiv 2021, arXiv:2103.04174. [Google Scholar]
- Tschantz, A.; Baltieri, M.; Seth, A.K.; Buckley, C.L. Scaling Active Inference. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Kaiser, L.; Babaeizadeh, M.; Milos, P.; Osinski, B.; Campbell, R.H.; Czechowski, K.; Erhan, D.; Finn, C.; Kozakowski, P.; Levine, S.; et al. Model-Based Reinforcement Learning for Atari. arXiv 2020, arXiv:1903.00374. [Google Scholar]
- Srinivas, A.; Laskin, M.; Abbeel, P. CURL: Contrastive Unsupervised Representations for Reinforcement Learning. arXiv 2020, arXiv:2004.04136. [Google Scholar]
- Pezzulo, G.; Rigoli, F.; Friston, K.J. Hierarchical Active Inference: A Theory of Motivated Control. Trends Cogn. Sci. 2018, 22, 294–306. [Google Scholar] [CrossRef] [PubMed]
- Zakharov, A.; Guo, Q.; Fountas, Z. Variational Predictive Routing with Nested Subjective Timescales. arXiv 2021, arXiv:2110.11236. [Google Scholar]
- Wauthier, S.T.; Çatal, O.; De Boom, C.; Verbelen, T.; Dhoedt, B. Sleep: Model Reduction in Deep Active Inference. In Active Inference; Verbelen, T., Lanillos, P., Buckley, C.L., De Boom, C., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 72–83. [Google Scholar]
- Pezzulo, G.; Rigoli, F.; Friston, K. Active Inference, homeostatic regulation and adaptive behavioural control. Prog. Neurobiol. 2015, 134, 17–35. [Google Scholar] [CrossRef] [PubMed]
- Millidge, B.; Tschantz, A.; Buckley, C.L. Whence the Expected Free Energy? arXiv 2020, arXiv:2004.08128. [Google Scholar] [CrossRef]
- Andrychowicz, M.; Wolski, F.; Ray, A.; Schneider, J.; Fong, R.; Welinder, P.; McGrew, B.; Tobin, J.; Pieter Abbeel, O.; Zaremba, W. Hindsight Experience Replay. In Advances in Neural Information Processing Systems; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Warde-Farley, D.; de Wiele, T.V.; Kulkarni, T.D.; Ionescu, C.; Hansen, S.; Mnih, V. Unsupervised Control through Non-Parametric Discriminative Rewards. In Proceedings of the 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Mendonca, R.; Rybkin, O.; Daniilidis, K.; Hafner, D.; Pathak, D. Discovering and Achieving Goals via World Models. arXiv 2021, arXiv:2110.09514. [Google Scholar]
- Lee, L.; Eysenbach, B.; Parisotto, E.; Xing, E.; Levine, S.; Salakhutdinov, R. Efficient Exploration via State Marginal Matching. arXiv 2020, arXiv:1906.05274. [Google Scholar]
- Levine, S. Reinforcement Learning and Control as Probabilistic Inference: Tutorial and Review. arXiv 2018, arXiv:1805.00909. [Google Scholar]
- Millidge, B.; Tschantz, A.; Seth, A.K.; Buckley, C.L. On the Relationship between Active Inference and Control as Inference. arXiv 2020, arXiv:2006.12964. [Google Scholar]
- Sajid, N.; Ball, P.J.; Parr, T.; Friston, K.J. Active Inference: Demystified and Compared. Neural Comput. 2021, 33, 674–712. [Google Scholar] [CrossRef]
- Clark, J.; Amodei, D. Faulty Reward Functions in the Wild; OpenAI: San Francisco, CA, USA, 2016. [Google Scholar]
- Ziebart, B.D.; Maas, A.L.; Bagnell, J.A.; Dey, A.K. Maximum entropy inverse reinforcement learning. In Proceedings of the Twenty-Third AAAI Conference on Artificial Intelligence, Chicago, IL, USA, 13–17 July 2008; Volume 8, pp. 1433–1438. [Google Scholar]
- Abbeel, P.; Ng, A.Y. Apprenticeship Learning via Inverse Reinforcement Learning. In Proceedings of the Twenty-First International Conference on Machine Learning, ICML’04, Banff, AB, Canada, 4–8 July 2004; Association for Computing Machinery: New York, NY, USA, 2004; p. 1. [Google Scholar] [CrossRef]
- Shyam, P.; Jaśkowski, W.; Gomez, F. Model-Based Active Exploration. arXiv 2019, arXiv:1810.12162. [Google Scholar]
- Achiam, J.; Sastry, S. Surprise-Based Intrinsic Motivation for Deep Reinforcement Learning. arXiv 2017, arXiv:1703.01732. [Google Scholar]
- Burda, Y.; Edwards, H.; Pathak, D.; Storkey, A.J.; Darrell, T.; Efros, A.A. Large-Scale Study of Curiosity-Driven Learning. In Proceedings of the 7th International Conference on Learning Representations, ICLR, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization Algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Haarnoja, T.; Zhou, A.; Abbeel, P.; Levine, S. Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; Dy, J., Krause, A., Eds.; PMLR: Brookline, MA, USA, 2018; Volume 80, pp. 1861–1870. [Google Scholar]
- Eysenbach, B.; Levine, S. Maximum Entropy RL (Provably) Solves Some Robust RL Problems. arXiv 2021, arXiv:2103.06257. [Google Scholar]
- Silver, D.; Hubert, T.; Schrittwieser, J.; Antonoglou, I.; Lai, M.; Guez, A.; Lanctot, M.; Sifre, L.; Kumaran, D.; Graepel, T.; et al. Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm. arXiv 2017, arXiv:1712.01815. [Google Scholar]
- Maisto, D.; Gregoretti, F.; Friston, K.; Pezzulo, G. Active Tree Search in Large POMDPs. arXiv 2021, arXiv:2103.13860. [Google Scholar]
- Clavera, I.; Fu, V.; Abbeel, P. Model-Augmented Actor-Critic: Backpropagating through Paths. arXiv 2020, arXiv:2005.08068. [Google Scholar]
- Pardo, F.; Tavakoli, A.; Levdik, V.; Kormushev, P. Time Limits in Reinforcement Learning. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; Dy, J., Krause, A., Eds.; PMLR: Brookline, MA, USA, 2018; Volume 80, pp. 4045–4054. [Google Scholar]
- Mhaskar, H.; Liao, Q.; Poggio, T. When and Why Are Deep Networks Better than Shallow Ones? In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, AAAI’17, San Francisco, CA, USA, 4–9 February 2017; AAAI Press: Palo Alto, CA, USA, 2017; pp. 2343–2349. [Google Scholar]
- Novak, R.; Bahri, Y.; Abolafia, D.A.; Pennington, J.; Sohl-Dickstein, J. Sensitivity and Generalization in Neural Networks: An Empirical Study. arXiv 2018, arXiv:1802.08760. [Google Scholar]
- Colbrook, M.J.; Antun, V.; Hansen, A.C. Can stable and accurate neural networks be computed?—On the barriers of deep learning and Smale’s 18th problem. arXiv 2021, arXiv:2101.08286. [Google Scholar]
- Ben-David, S.; Hrubeš, P.; Moran, S.; Shpilka, A.; Yehudayoff, A. Learnability can be undecidable. Nat. Mach. Intell. 2019, 1, 44–48. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Modality | Active Inference | Deep Learning | |
|---|---|---|---|
| States distribution | Gaussian | [32,33,114,123,129] | [49,87] |
| Categorical | [91] | [66,90] | |
| Others | - | [92,93,94] | |
| Prior model | No prior | - | [103] |
| Known prior | [86,102,114] | [70,71,101] | |
| Learned prior | [31,33,68,91,123] | [48,49,66] | |
| Uncertainty | Precision | [33] | [107,108] |
| Ensemble | [91,114] | [112,113] | |
| Dropout | [33] | [130] | |
| Representation | Task-oriented | - | [29] |
| State consistency | [123] | [116,119,121,122,131] | |
| Memory-equipped | [32,124] | [47,48,49,50,66] | |
| Hierarchical | [132] | [127,128] |
| Modality | Active Inference | Deep Learning | |
|---|---|---|---|
| Preferences | Observations | [123] | [137,138,139] |
| States | [68] | [140] | |
| Rewards | [33,114,126,129] | [66,67,87,155] | |
| Learned | [91] | [145,146] | |
| Exploration | Hidden states | * | [51,52,148,149] |
| Likelihood parameters | [33,91,114] | [112,113] | |
| Action selection | Action plans | [32,68] | [55] |
| State-action policy | [123,126] | [150,151] | |
| Amortized search | [33,154] | [29] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mazzaglia, P.; Verbelen, T.; Çatal, O.; Dhoedt, B. The Free Energy Principle for Perception and Action: A Deep Learning Perspective. Entropy 2022, 24, 301. https://doi.org/10.3390/e24020301
Mazzaglia P, Verbelen T, Çatal O, Dhoedt B. The Free Energy Principle for Perception and Action: A Deep Learning Perspective. Entropy. 2022; 24(2):301. https://doi.org/10.3390/e24020301
Chicago/Turabian StyleMazzaglia, Pietro, Tim Verbelen, Ozan Çatal, and Bart Dhoedt. 2022. "The Free Energy Principle for Perception and Action: A Deep Learning Perspective" Entropy 24, no. 2: 301. https://doi.org/10.3390/e24020301
APA StyleMazzaglia, P., Verbelen, T., Çatal, O., & Dhoedt, B. (2022). The Free Energy Principle for Perception and Action: A Deep Learning Perspective. Entropy, 24(2), 301. https://doi.org/10.3390/e24020301