Regarding the censoring data, the censoring variable
is generated as
independently of the initially observed variable
. An algorithm is provided by [
29]. Another important point for this study is the selection of the shrinkage parameters and the bandwidth parameter for the local polynomial approach for the introduced six estimators. In this study, the improved Akaike information criterion
, proposed by [
30], is used. It can be calculated as follows:
where
is the estimated coefficient based on the shrinkage parameter
, and the bandwidth
and
is the variance of the model, and
denotes the number of nonzero regression coefficients. Note that, due to the projection (hat) matrix, the introduced estimation procedures (except ridge regression) cannot be written; the number of nonzero coefficients is used instead of the hat matrix.
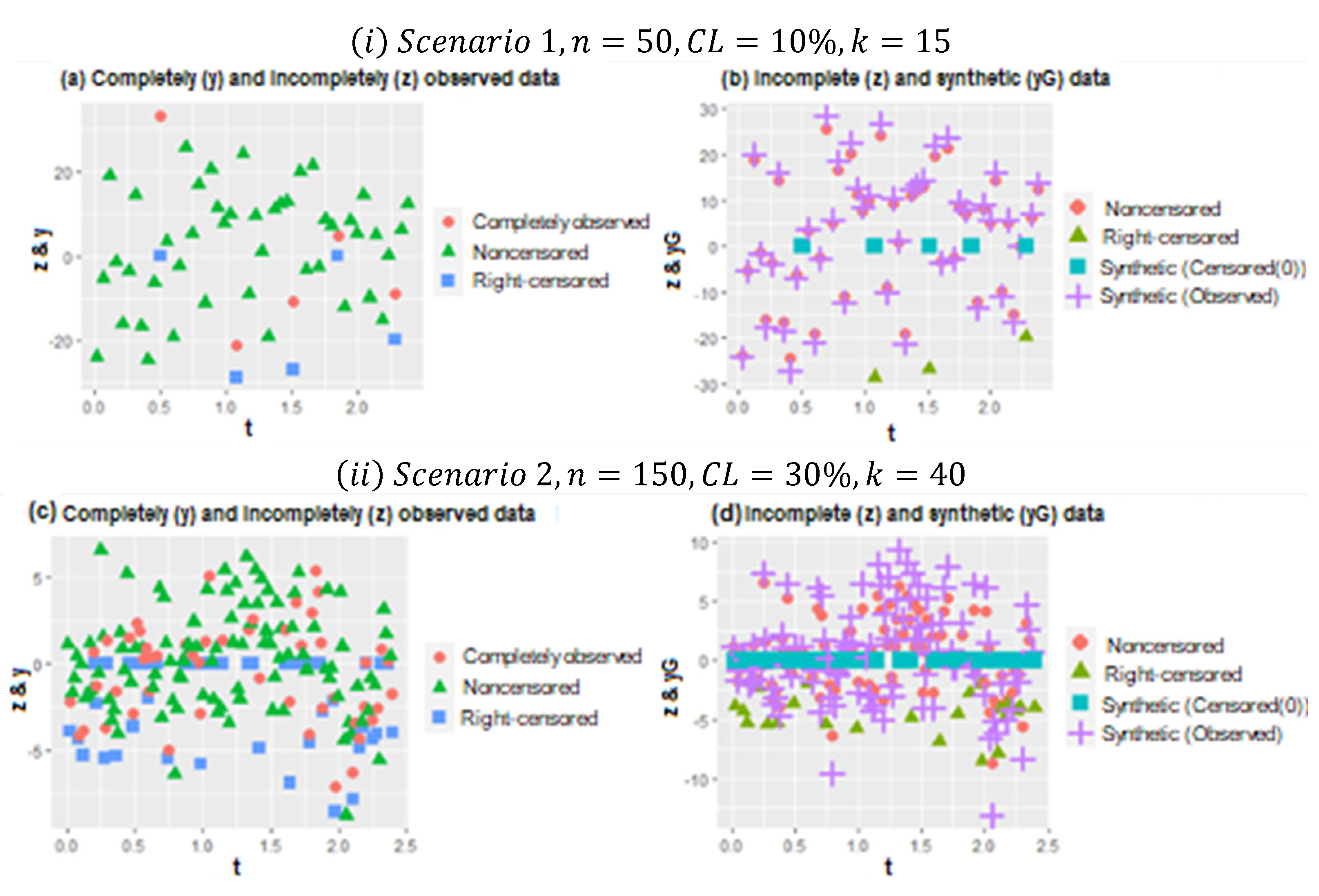
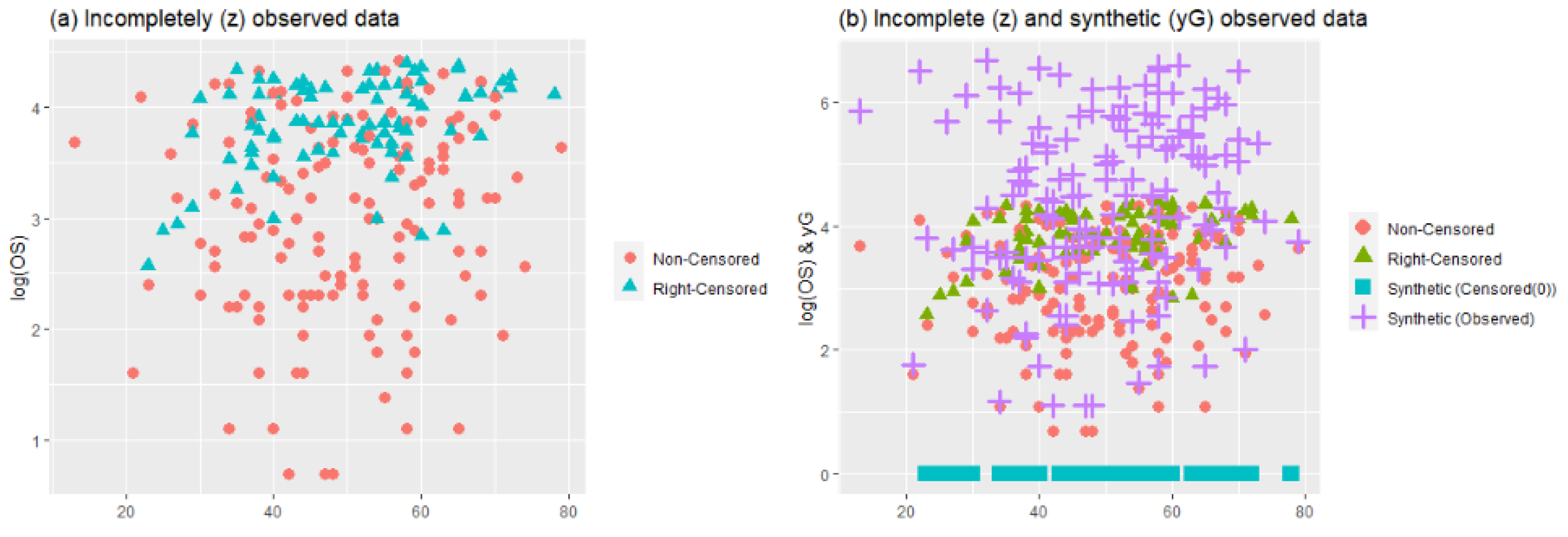
In
Figure 1, two plots (
) are represented for the different configurations of Scenarios 1 and 2. In plot (
), scatter plots of the data points for
and
are given. In panel (b) of (
), the working procedure of synthetic data transformation can be seen clearly. It gives zero to right-censored observations and increases the magnitude of observed data points. Thus, it makes equal the expected value of the synthetic response variable and original response variable, as indicated in
Section 2. Similarly, plot (
) shows the scatter plots of data points for
, which makes it possible to see heavily censored cases. In panel (b) of (
), due to heavy censorship, the magnitude of the increments in the observed data points is larger than (
i), which is the working principle of the synthetic data. This is a disadvantage because it significantly manipulates the data structure, although it still solves the censorship problem.
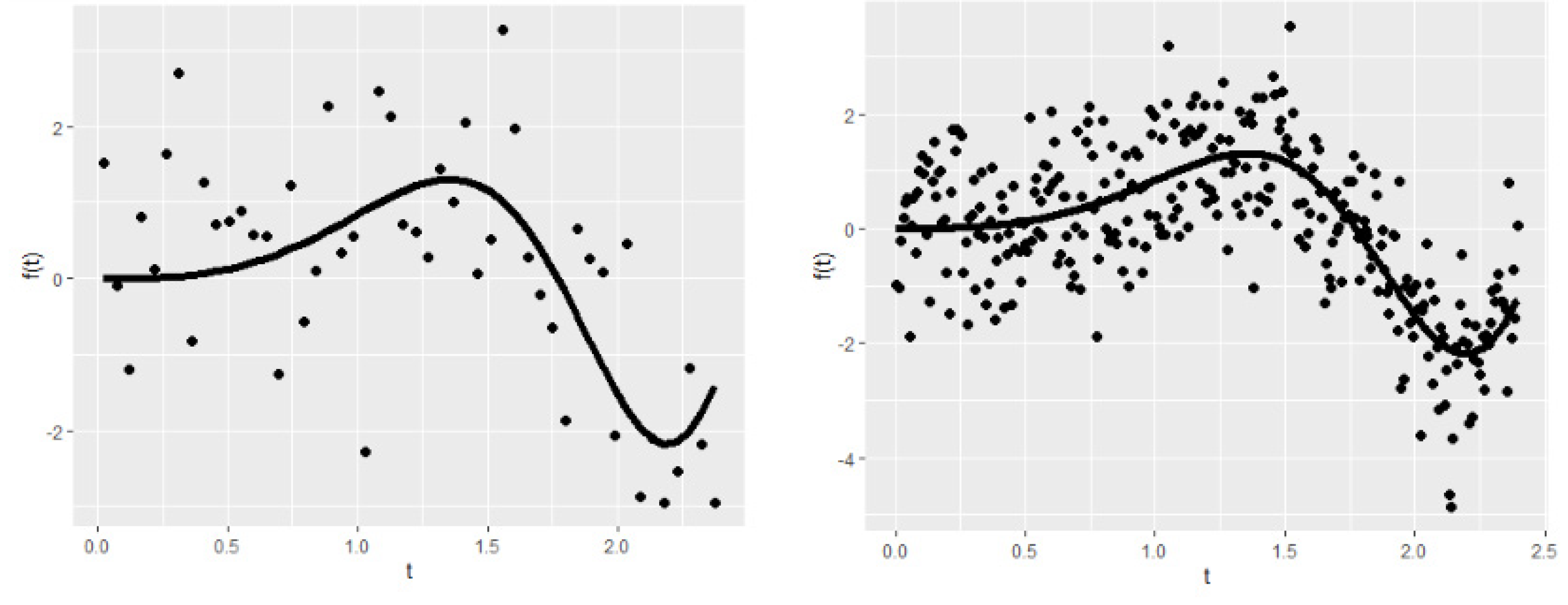
To describe the generated dataset further,
Figure 2 shows the nonparametric component of the right-censored semiparametric model. In panel (a), the smooth function can be seen for the small sample size (
), low censoring level (
), and low number of covariates (
). Panel (b) shows the nonparametric smooth function for
, and
. It should be emphasized that the censoring level or number of the parametric covariates does not affect the shape of the nonparametric component. Thus, there is no need to show all possible generated functions here. Note that the nonparametric component affects the number of covariates and the censoring level indirectly in the estimation process.
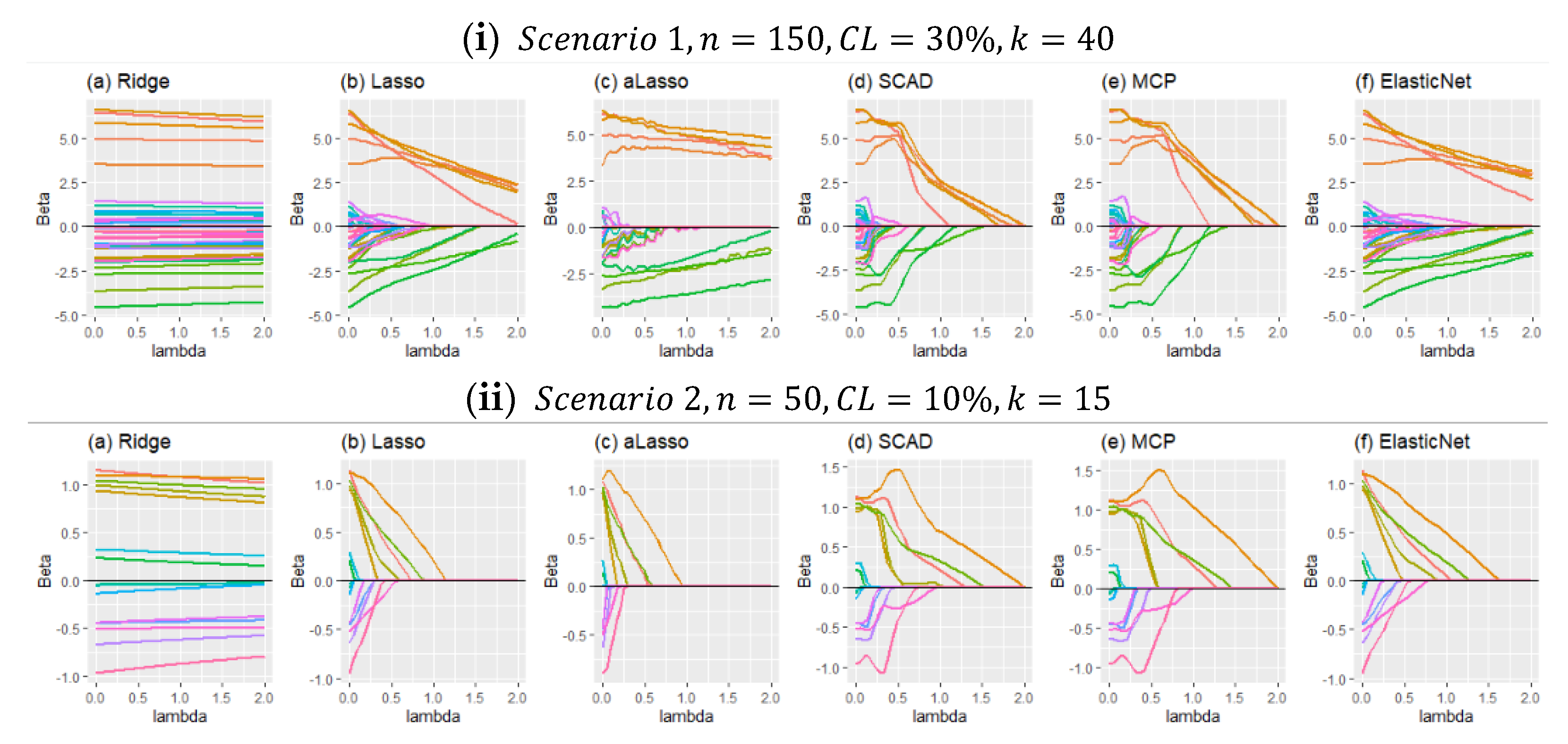
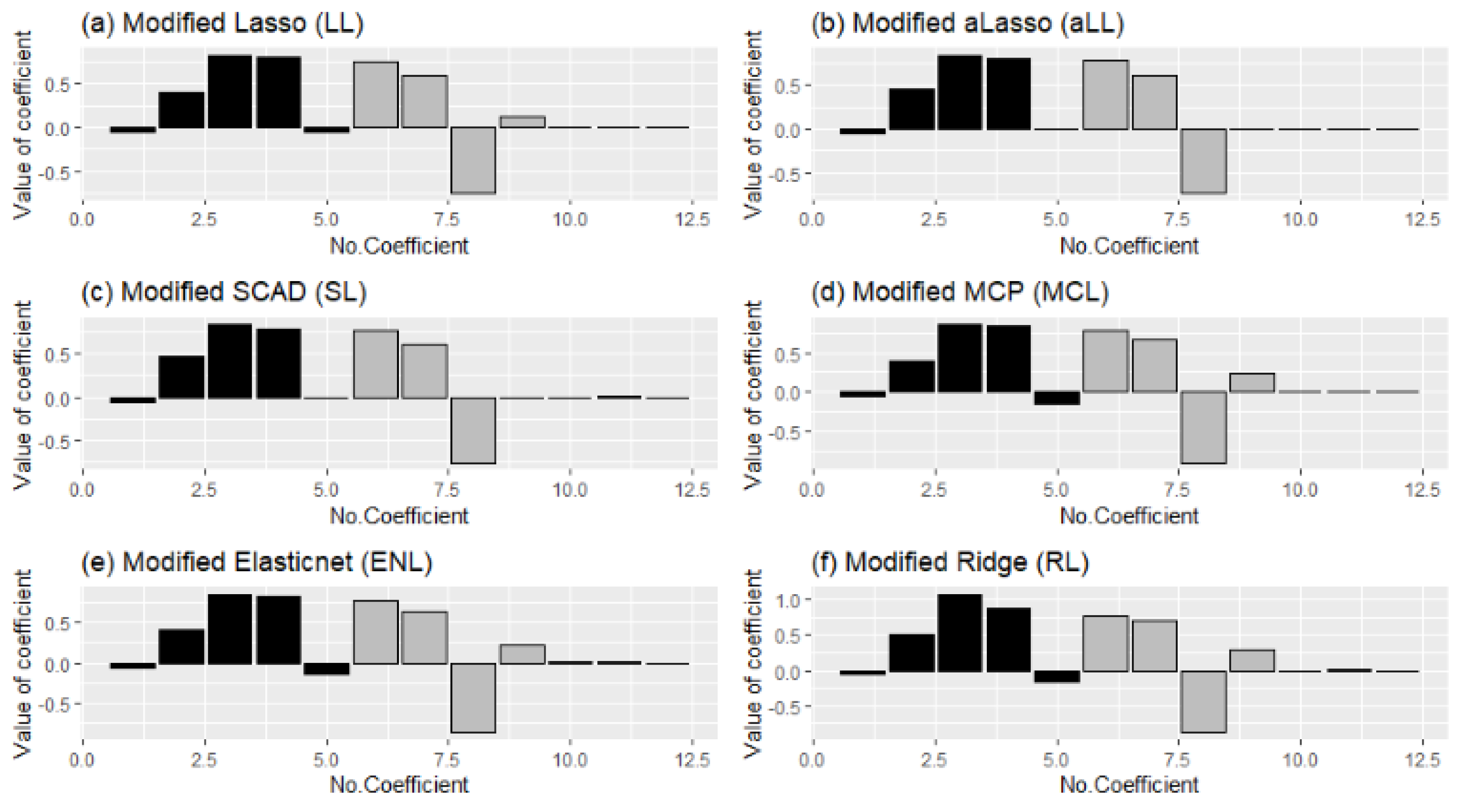
As previously mentioned, this paper introduces six modified estimators based on penalty and shrinkage strategies. In
Figure 3, the shrinkage process of the estimators, according to the shrinkage parameter “lambda,” is provided in panels (i) and (ii). In panel (i), shrunk regression coefficients are shown for scenario 1,
. Panel (ii) is drawn for scenario 2,
. When
Figure 3 is inspected carefully, it can be seen that in panel (i), due to a high censoring level and many covariates, the shrinkage of the coefficients is more challenging than in panel (ii). One of the reasons for that is, in Scenario 2, coefficients are determined as smaller than the coefficients in Scenario 1 while generating data. For both panels, it can be observed that the SCAD and MCP methods behave similarly. As expected, they shrunk the coefficients quicker than the others. Additionally, lasso and ElasticNet seem close to each other for both panels. However, adaptive lasso differs from the others in both panels. The reason for this is discussed with the results given in
Section 5.1.
5.1. Analysis of Parametric Component
In this section, the estimation of the parametric component of a right-censored semiparametric model is analyzed, and results are presented for all simulation scenarios in
Table 2,
Table 3,
Table 4 and
Table 5 and
Figure 4,
Figure 5,
Figure 6 and
Figure 7. The performance of the estimators is evaluated using the metrics given in
Section 4:
,
, sensitivity, specificity, accuracy, and
-score. In addition to the performance criteria, the selection ratio of the methods is calculated for the estimators. The selection ratio can be defined as follows:
Selection Ratio: The ratio of the selected true nonzero coefficients by the corresponding estimator in 1000 simulation repetitions. The formulation can be given by:
where
is the estimated coefficient for
simulation by any of the introduced estimators. Results are given in
Figure 6 and
Figure 7.
Table 1 and
Table 2 include the RMSE scores for the estimated coefficients calculated from (4.1) and
of the model for Scenarios 1 and 2. The best scores are indicated with bold text. If the two tables are inspected carefully, two observations can be made about the performance of the methods for both Scenarios 1 and 2. Regarding Scenario 1, when the sample size is small
), ENL and SL estimators give smaller RMSE scores and higher
values than the other four methods. On the other hand, when the sample size becomes larger (
), aLL takes the lead in terms of estimation performance. The results for different censoring levels show that aLL is less affected by censorship than SL and the other methods. This can be observed in
Table 1 clearly.
In
Table 2, RMSE and
scores are provided for all simulation configurations of Scenario 2. The results can be distinguished from the results in
Table 1 by the higher
values obtained from the modified ridge estimator. However, the RMSE scores of the modified ridge estimator are the largest. This can be explained by the fact that the ridge penalty uses all covariates, whether sparse or nonsparse. Therefore, the estimated model based on the ridge penalty has larger
values. On the other hand, the RMSE scores prove that for small sample sizes (
), ENL and aLL perform satisfactorily. Moreover, as in the case of Scenario 1, when the sample size becomes larger, aLL gives the most satisfying performance. SL- and LL-based estimators also show good performances in the general frame. If
Table 2 is inspected in detail, it can be seen that when
, the SL method comes to the front for both low (
) and high (
) censoring levels. The same is true for the aLL method regarding strength against censorship.
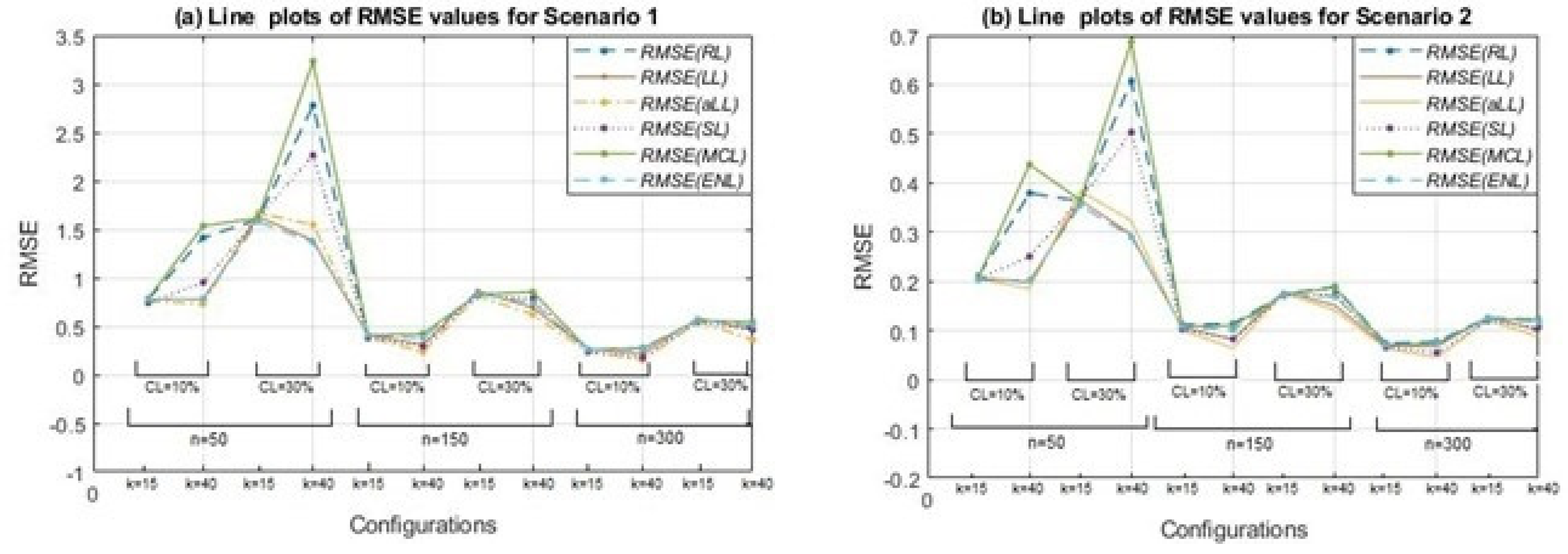
Figure 4 presents the line plots of the RMSE scores for all simulation cases. As expected, the negative effects of increment on the censoring level and the positive effect of growth on the sample size can be clearly observed from panels (a) and (b). For both scenarios, a peak can be seen when the sample size is small (
) and the censorship level increases from 10% to 30%. The methods most affected by censorship are MCL, RL, and SL. The least affected are aLL, lasso, and ENL. Thus,
Figure 4 supports the results and inferences obtained from
Table 2 and
Table 3.
Together with the RMSE scores, one other important metric to evaluate the performance of the parametric component estimation is
-score, which measures the true selection made by the estimators for the sparse and nonzero subsets based on the confusion matrix given in
Table 1. In this context,
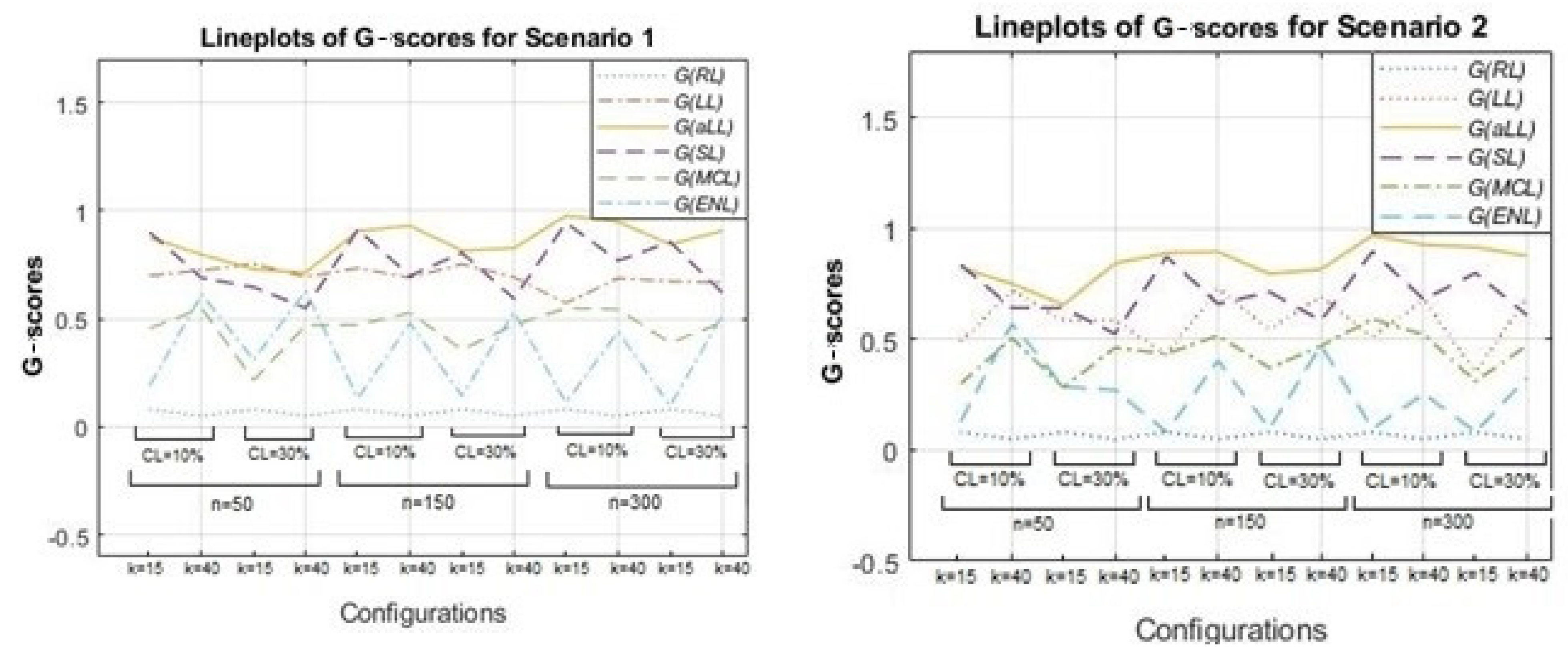
Figure 5 is drawn to illustrate the
-scores of the methods for all simulation combinations using line plots. Note that the
-score changes between the range [0,1] and the lines of methods that are close to 1 are notated as better than the others in terms of successful determination of sparsity.
Figure 5 is formed by two panels: Scenario 1 (left) and Scenario 2 (right). As expected, for all methods except for RL (which does not involve any sparse subset and is therefore not shown in
Figure 5 and
Table 4), the
-scores diminish when the censoring level is high, and the number of covariates (
) is large. In addition, there is an increasing trend from the small to large sample sizes for LL, aLL, SL, and MCL. This trend is most evident for the aLL line, which makes aLL distinguishable. However, interestingly, ENL is not influenced by the change in sample size, and the
-scores of ENL do not take a value greater than 0.5. In general, aLL, SL, and LL provide the highest
-scores. All
-scores for the simulation study are provided in
Table 4 and
Table 5 together with the accuracy values of the methods.
Table 4 and
Table 5 present the accuracy rates and
-scores for all methods and simulation configurations for both Scenarios 1 and 2. Note that, because the ridge penalty is unable to shrink the estimated coefficients towards zero, the specificity of RL is always calculated as zero. Thus, RL does not have a
-score. When the tables are examined, it can be clearly seen that the prominent methods are aLL, LL, and SL. The aLL produces satisfactory results for each simulation configuration. On the other hand, the other two methods, LL and SL, give good results under different conditions. When this situation is examined in detail, it can be seen that the SL method produces better results when
, and the LL method when
with aLL. In addition, it can be said that the level of censorship and the sample size do not affect this situation, except for an increase or decrease in the values. These inferences apply to both scenarios. Here, the difference between the scenarios emerges in the size of the
-scores and accuracy values obtained. It can be said that they are slightly less than the values obtained for Scenario 2.
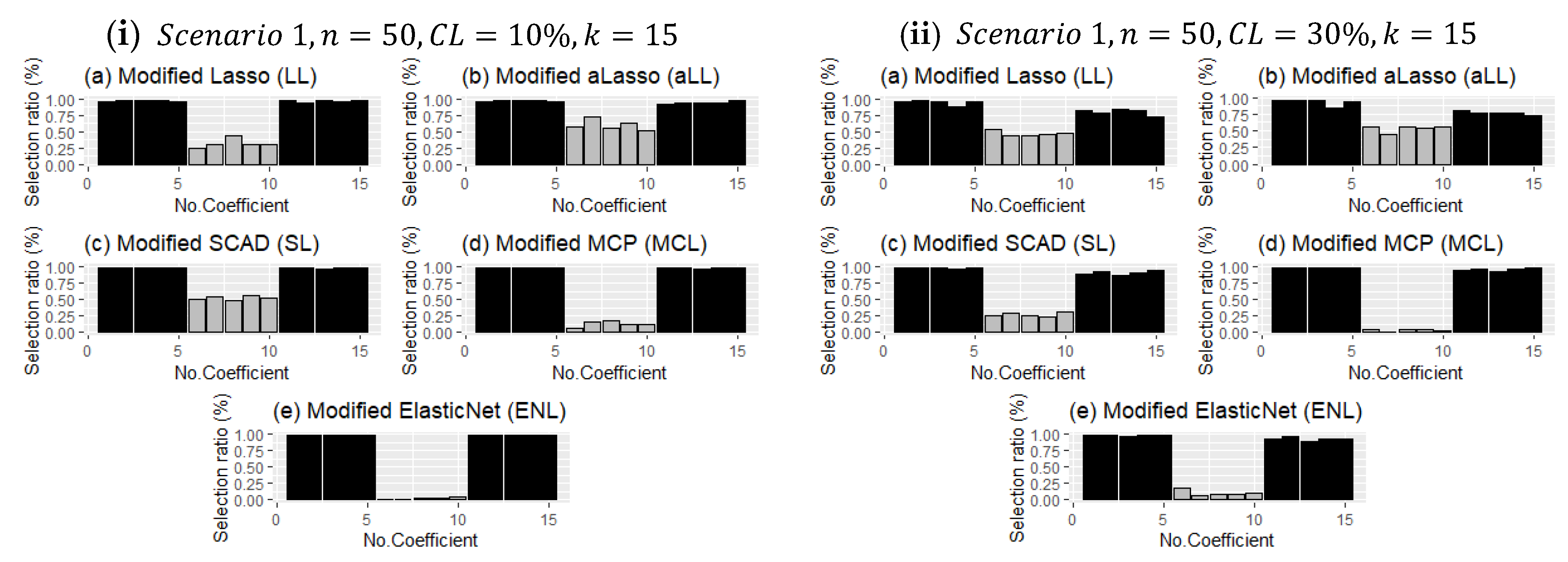
Unlike the evaluation criteria given in
Section 4, the frequency of choosing the correct coefficients for each method in the simulation study is analyzed, and the results are presented for both scenarios in
Figure 6 and
Figure 7 with bar plots.
Figure 6 presents two panels (I and ii), which demonstrate the impact of censorship, one of the main purposes of this article. As expected, as censorship increases, the frequency of selection decreases for the nonzero coefficients. The point here is to reveal which methods are less affected by this. It can be observed in
Figure 6 that the MCL and ENL methods are less affected by censorship in terms of the frequency of selection of nonzero coefficients. However, since these methods are less efficient than the SL, LL, and aLL methods in determining ineffective coefficients, their overall performance is lower (see
Table 4 and
Table 5). On the other hand, the SL, LL, and aLL methods make a balanced selection for both subsets (no effect-non-zero), which indirectly makes them more resistant to censorship.
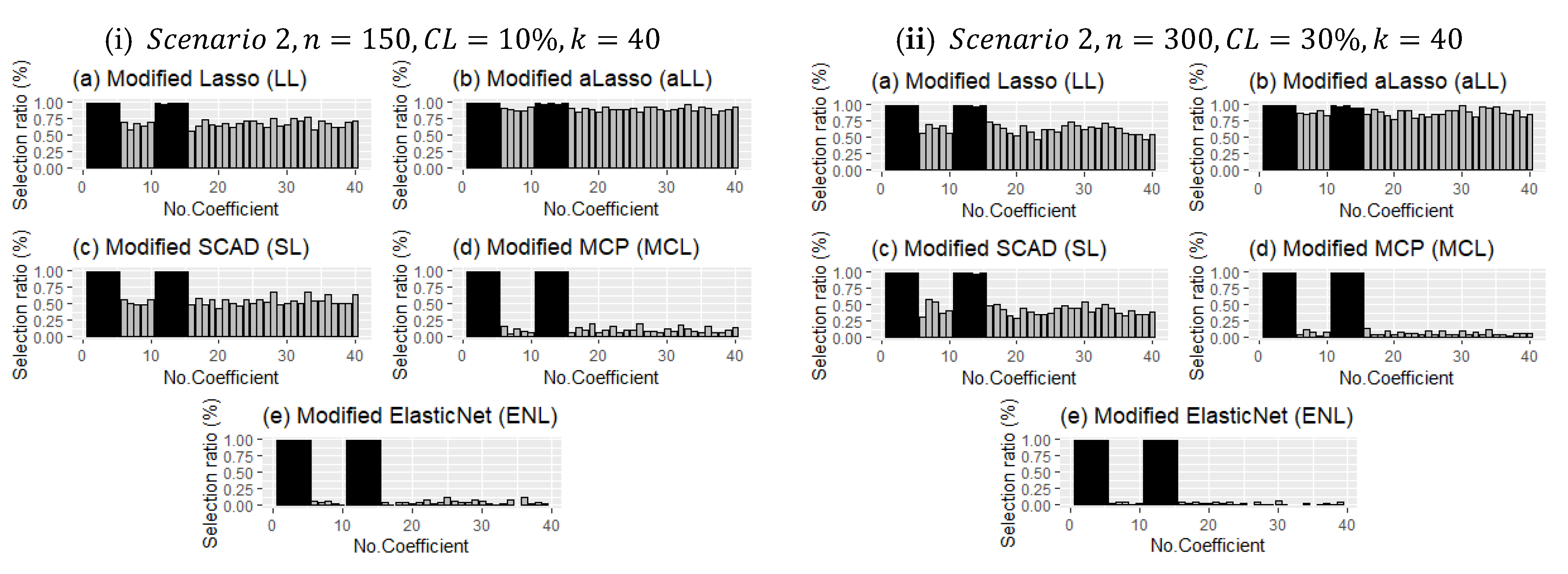
Figure 7 presents the different configurations for Scenario 2. It shows both effects of sample size and censoring level increment and bar plots for
. The detection performance of the methods of nonzero coefficients is less affected than in
Figure 6. However, the selection of the ineffective set plays a decisive role in terms of the performance of each of the methods. For example, MCL and ENL performed poorly in the correct determination of ineffective coefficients when the censorship level increased, but LL, aLL, and SL were able to make the right choice under heavy censorship.
5.2. Analysis of Nonparametric Component
This section is prepared to show the behaviors of the estimation of nonparametric components by the introduced six estimators. Performance scores of the methods are given in
Table 6 and
Table 7, and
and
metrics are used. Additionally,
Figure 8 and
Figure 9 are provided to show the real smooth function versus all estimated curves for individual simulation repeats. These figures can provide information about the variation of the estimates according to both scenarios and censoring effects. Finally, in
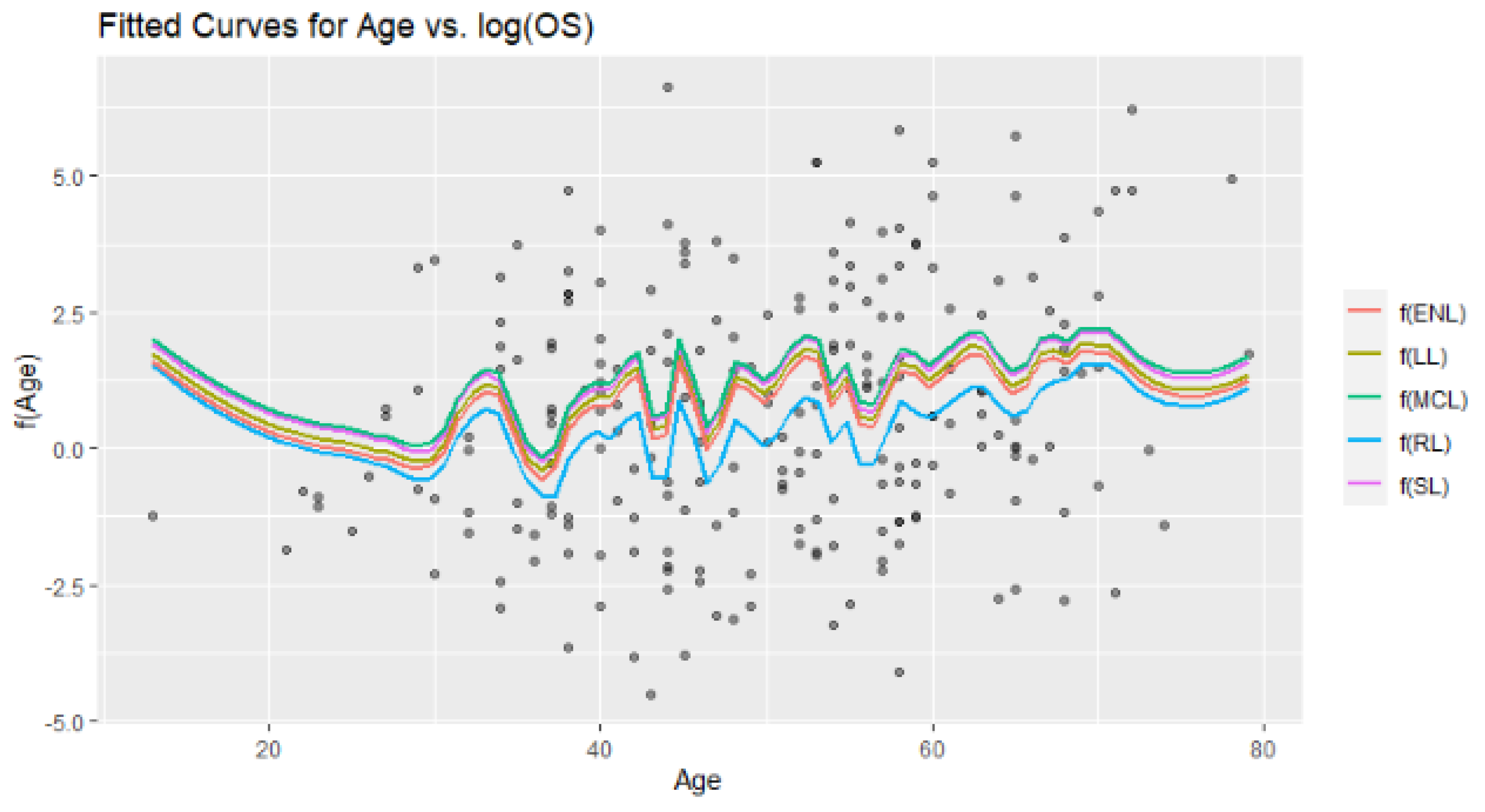
Figure 10, estimated curves obtained from all methods are inspected with four different configurations.
Table 6 and
Table 7 include the MSE and ReMSE values for the two scenarios. For Scenario 1, the aLL method gives more dominant values than others, followed by SL and LL. As expected, RL shows the worst performance; however, the difference from the others is small. Note that, when the sample size becomes larger, all methods begin to give similar results. Dependent on this similarity, the ReMSE scores become closer to one, which is an expected result. Thus, even if the censoring level increases, ReMSE scores may decrease. If the tables are inspected carefully, as mentioned in
Section 5.1, aLL overcomes the censorship problem better than the others regarding Scenario 1, which means that contributions of covariates are high. However, in Scenario 2, SL shows better performance in high censoring levels, especially in small and medium sample sizes. Additionally, it is clearly observed that the number of covariates
affects the performances. In
Table 7, when
, the LL and SL methods show good performances.
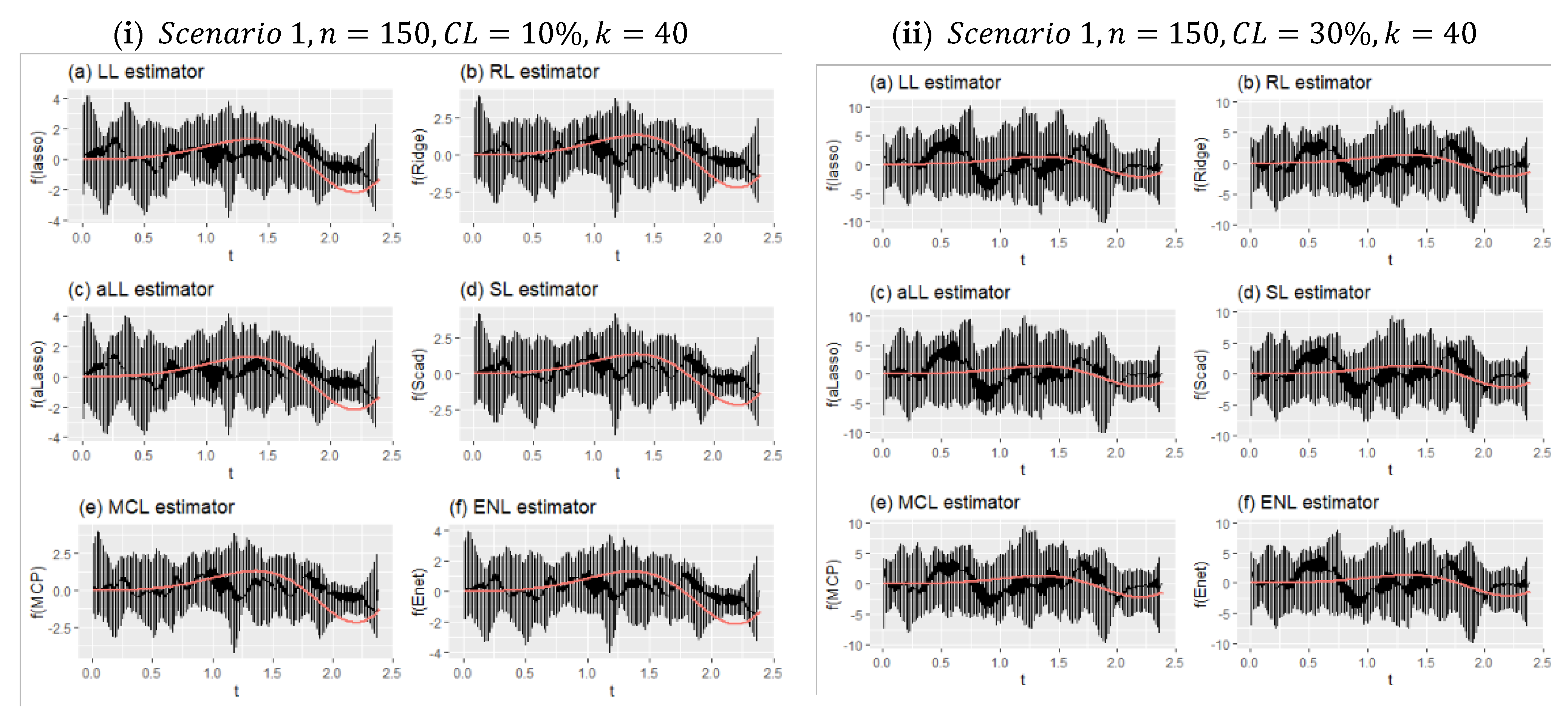
Figure 8 shows two different simulation configurations for Scenario 1. The purpose of this figure is to illustrate the effect of censorship in curve estimation. Therefore, panel (i) is obtained for 10% censorship, and panel (ii) for 30% censorship. As can be seen at a glance, the minimum and maximum points of the prediction points obtained from all simulations around the real curve are shown with vertical lines. This reveals the range of variation of the estimators. Accordingly, when the difference between the effect of censorship panel (i) and panel (ii) is examined, it can be seen how the range of variation widens. It can be said, with the help of the values in
Table 6, that the estimator with the least expansion is aLL and the method with the most is RL. It should also be noted that the SL and LL methods also showed satisfactory results.
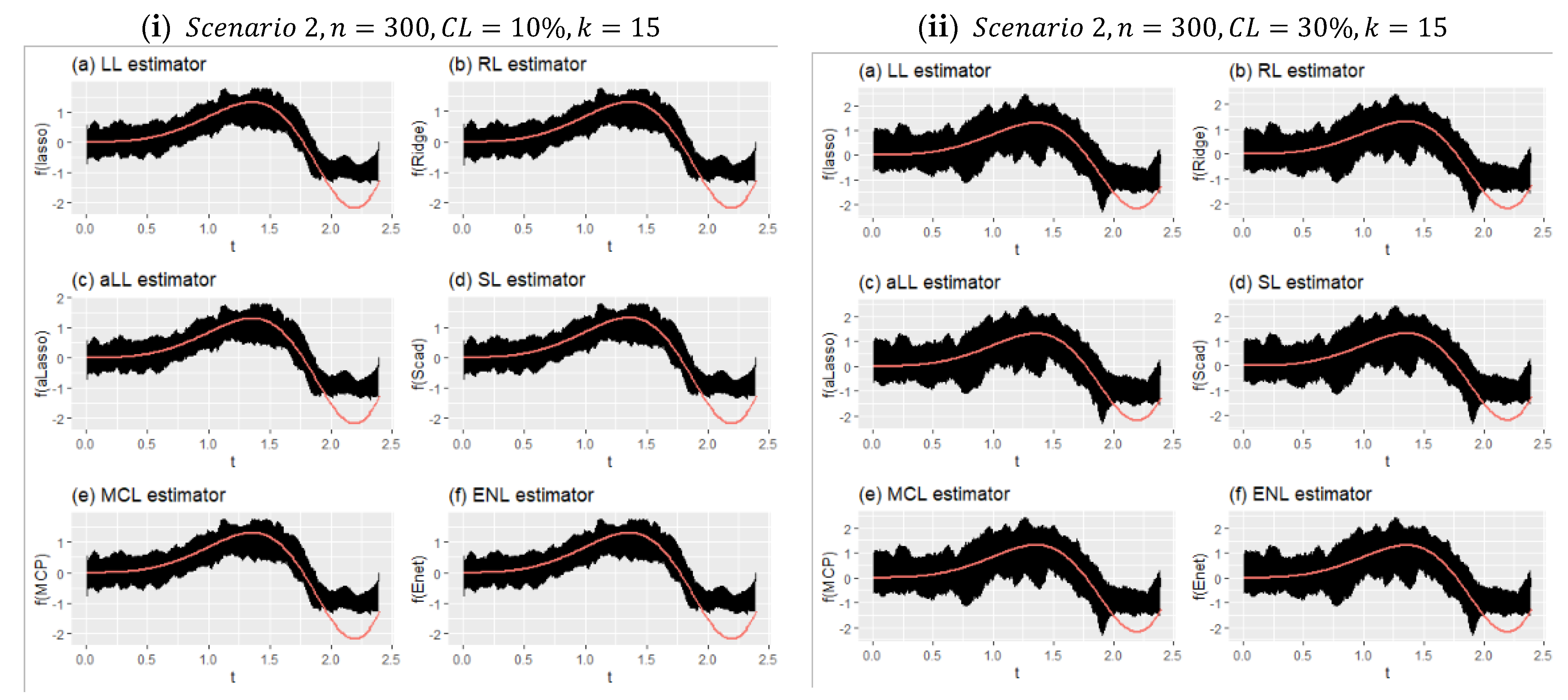
Figure 9 shows the effect of censorship on the estimated curves for Scenario 2 with a large sample size and relatively few covariates (
). Because there are too many data points, the lines appear as a black area. Compared with
Figure 8, the effect of censorship is less, and the estimators obtain curves closer to the true curve. In addition, due to the large sample size, each method estimated very close curves. This can be clearly seen in
Table 7. The obtained performance values were very close to each other. It can therefore be said that the introduced six estimators produce satisfactory results in high samples, and they are relatively less affected by censorship in this scenario.
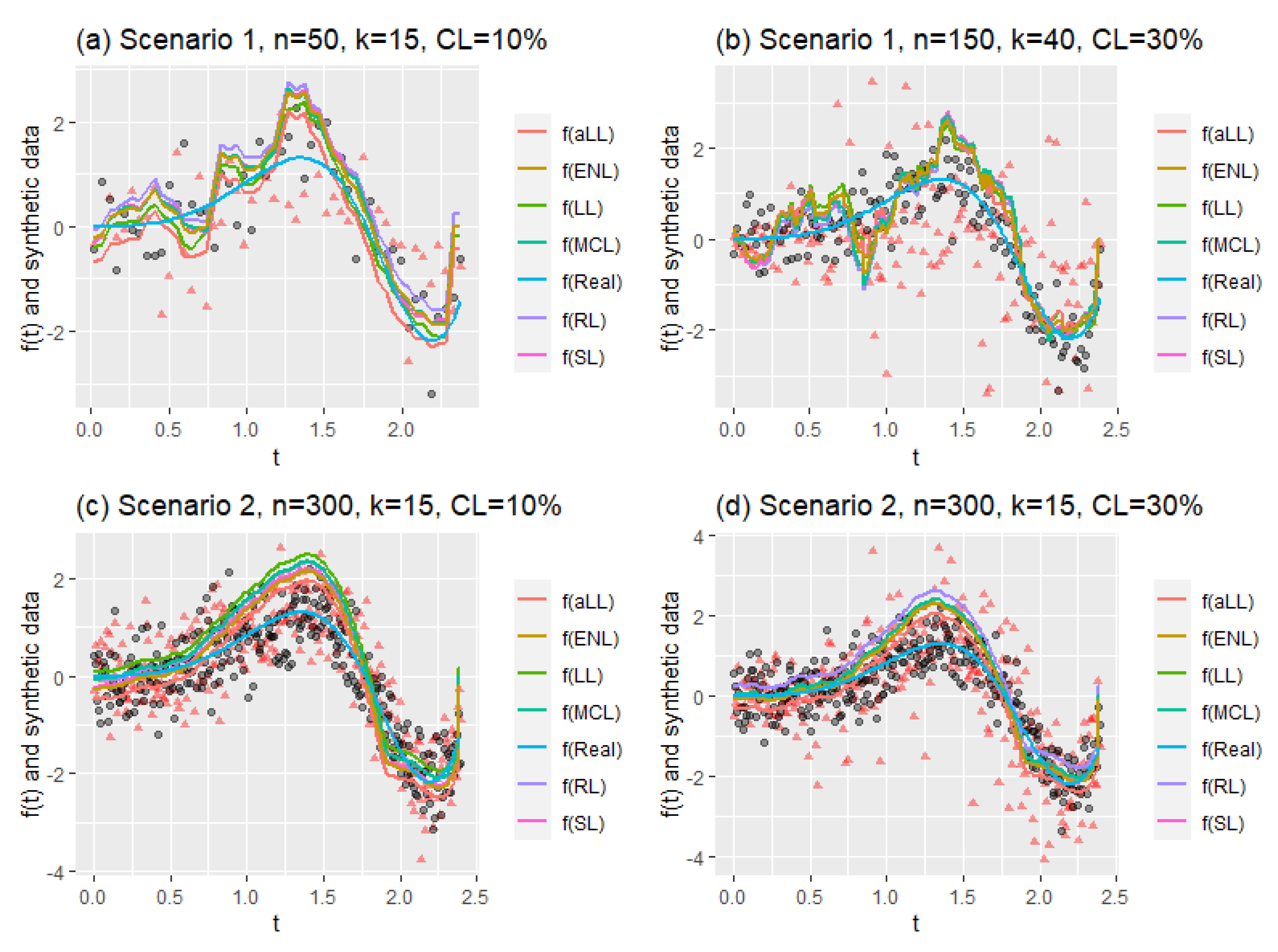
Figure 10 consists of four panels (a)–(d) containing four different simulation cases. The first two panels (a and b) show the estimated curves of Scenario 1 for different sample sizes, different censorship levels, and different numbers of explanatory variables. It can be clearly seen that the curves in panel (a) are smoother than in panel (b). This can be explained by the messy scattering of synthetic data, which can be observed in all panels. The censorship level increases the corruption of the data structure. Similarly, panels (c) and (d) are obtained for Scenario 2, but only to observe the effect of the change in censorship level. However, the effect of the large sample size is clearly visible, and the curves appear smooth in panel (d), despite the deterioration in the data structure. If examined carefully, the aLL method gives the closest curve to the true curve. At the same time, the other methods have shown satisfactory results in representing the data.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}