

A New Deep Learning Method with Self-Supervised Learning for Delineation of the Electrocardiogram



Abstract
1. Introduction
2. Materials and Methods
2.1. Architecture
2.1.1. Base Model
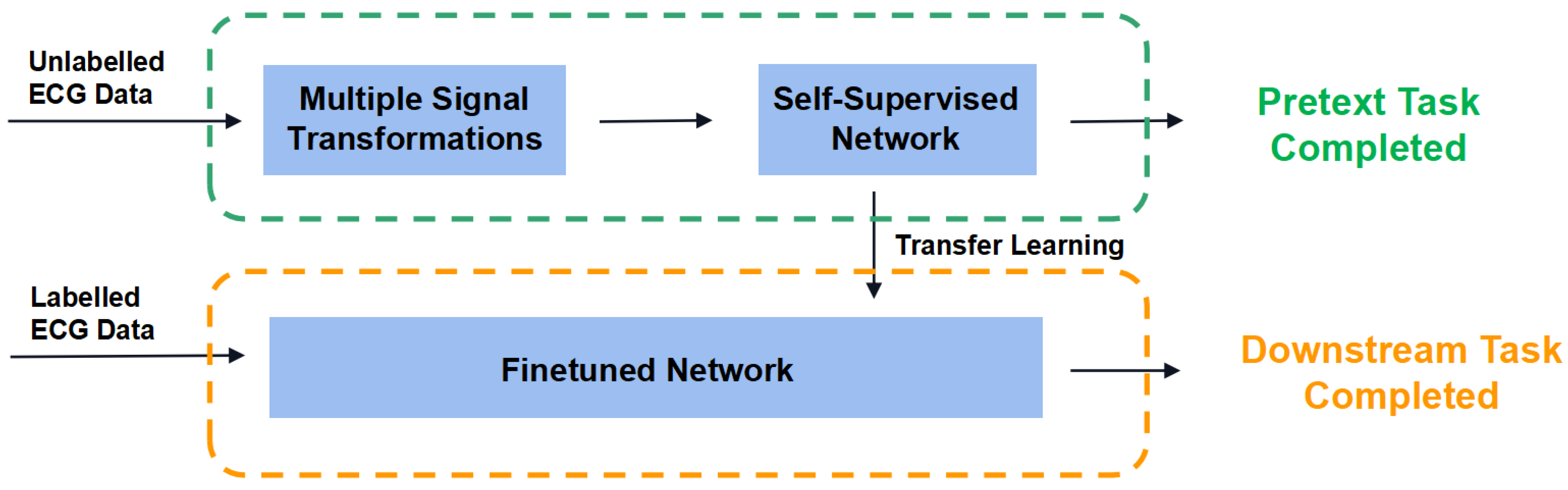
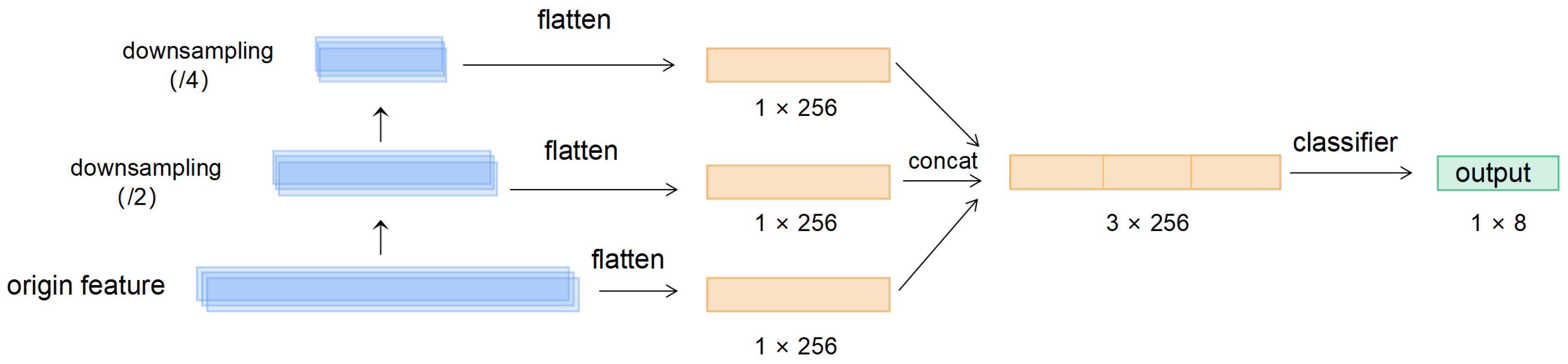
2.1.2. Self-Supervised Learning Structure
2.2. Datasets
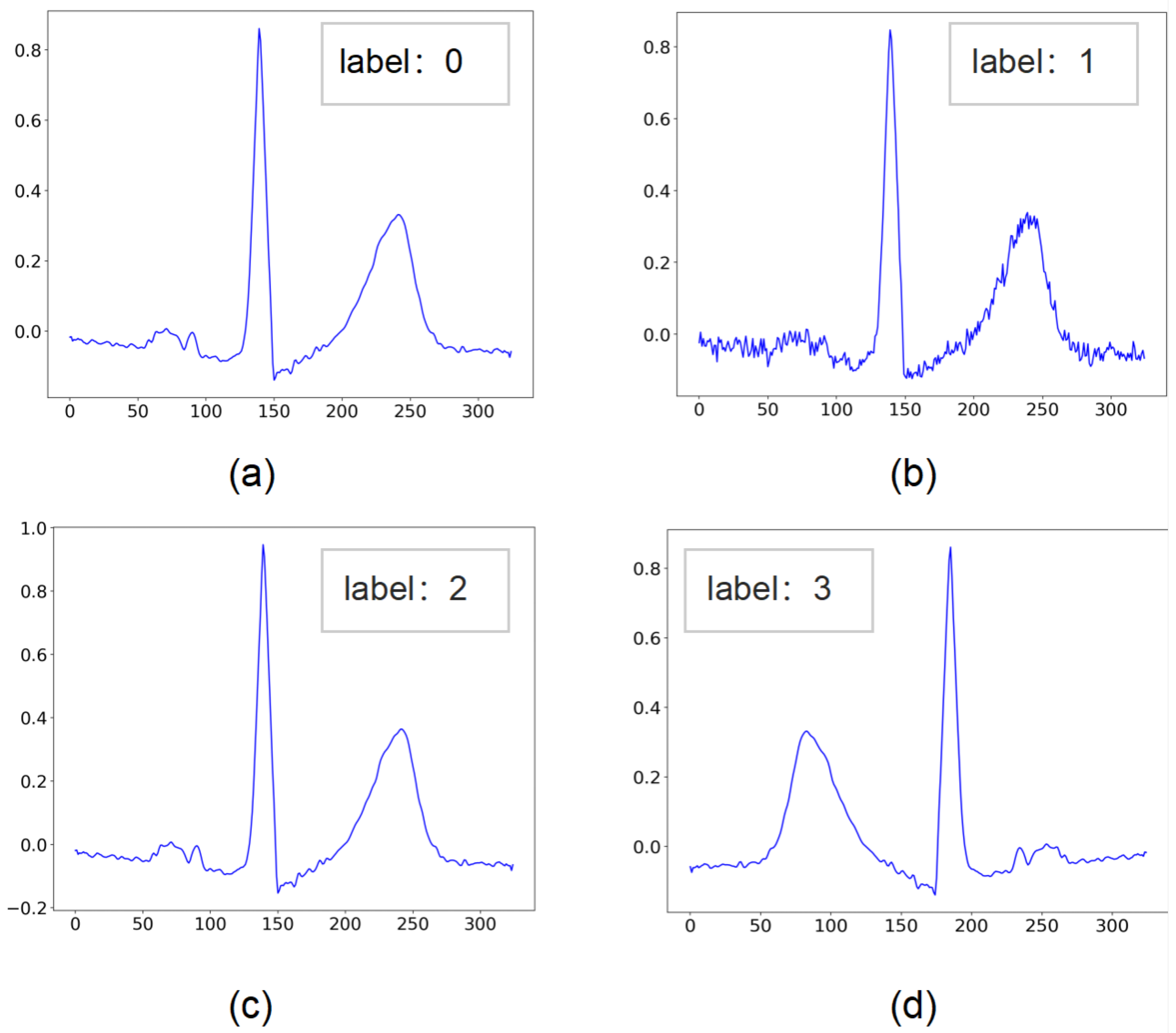
2.2.1. Data for Pretext Task
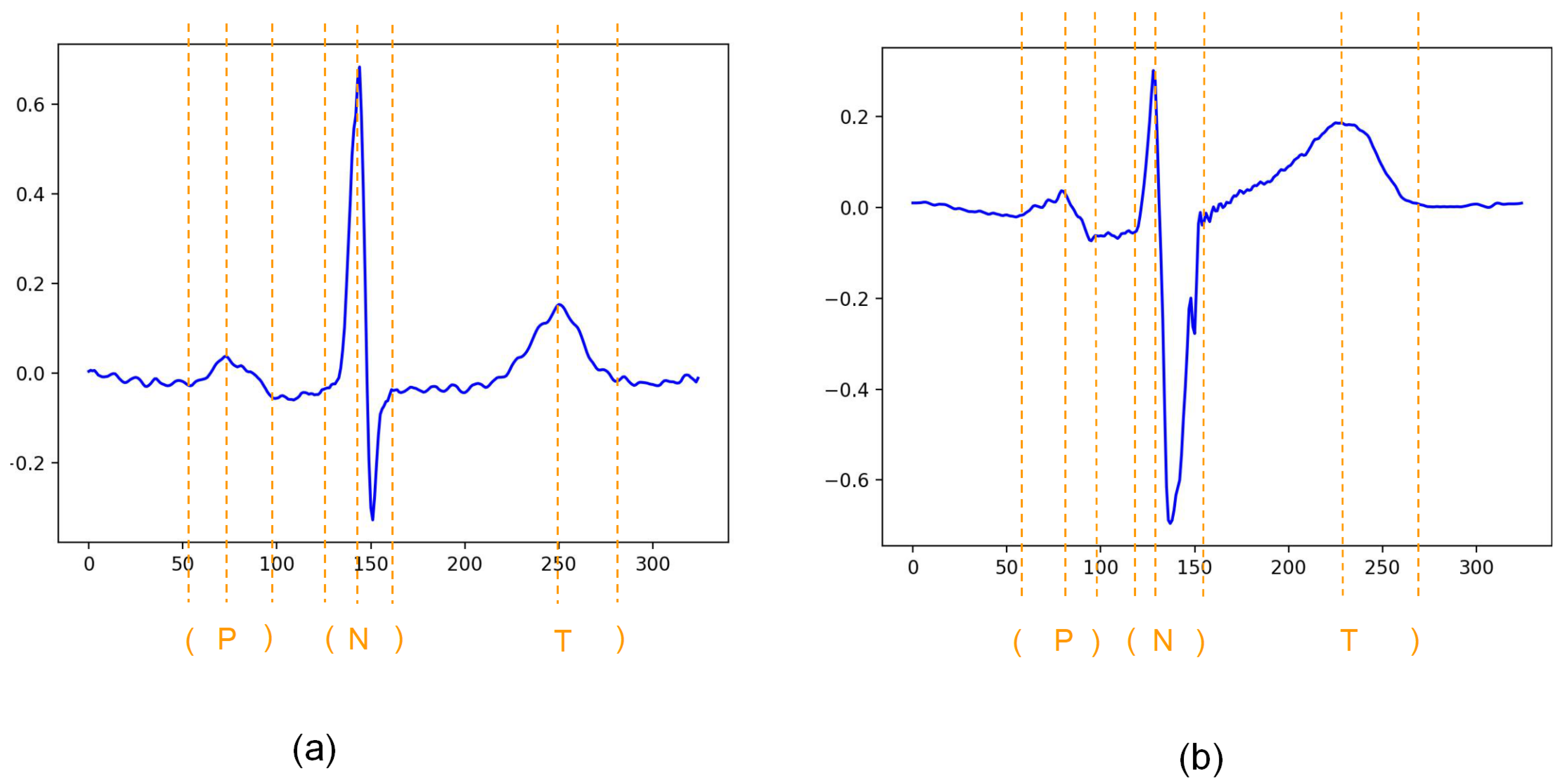
2.2.2. Data for Downstream Task
2.3. Methodology
2.3.1. Dense Hop-Layer Connection
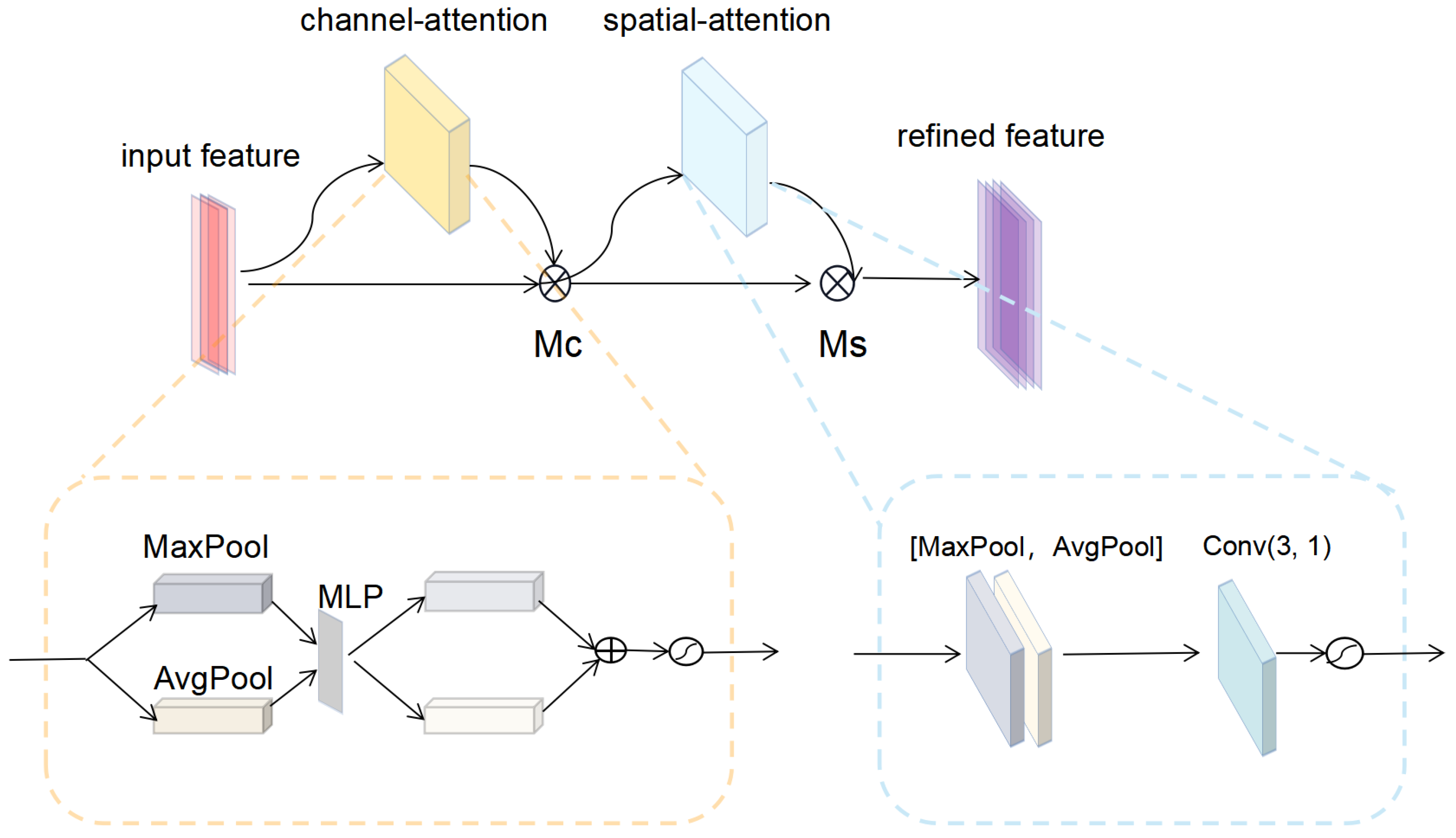
2.3.2. Convolutional Block Attention Module
2.3.3. Feature Pyramid Pooling Module
2.4. Experiments
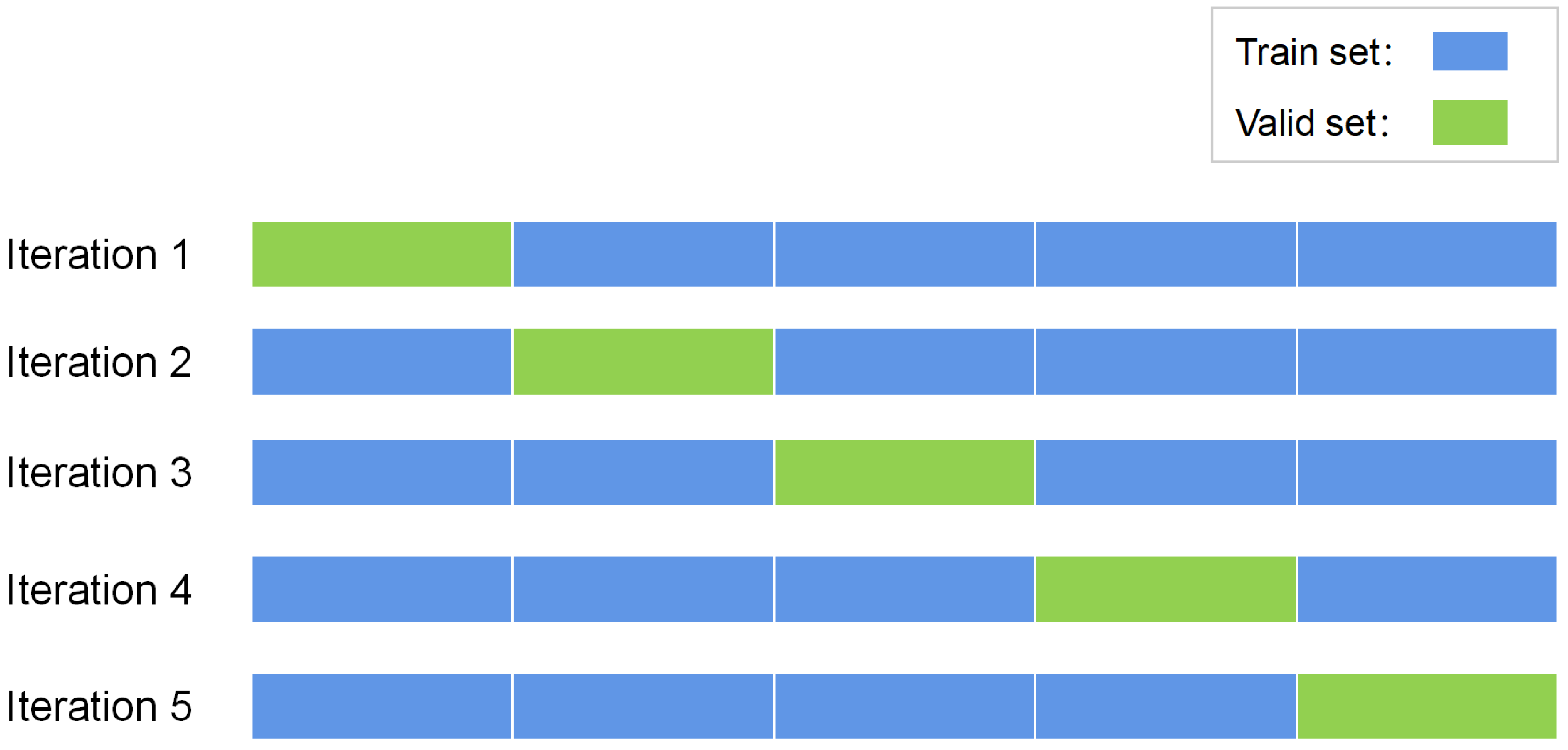
2.4.1. Pretext Task
2.4.2. Downstream Task
2.5. Experimental Environment
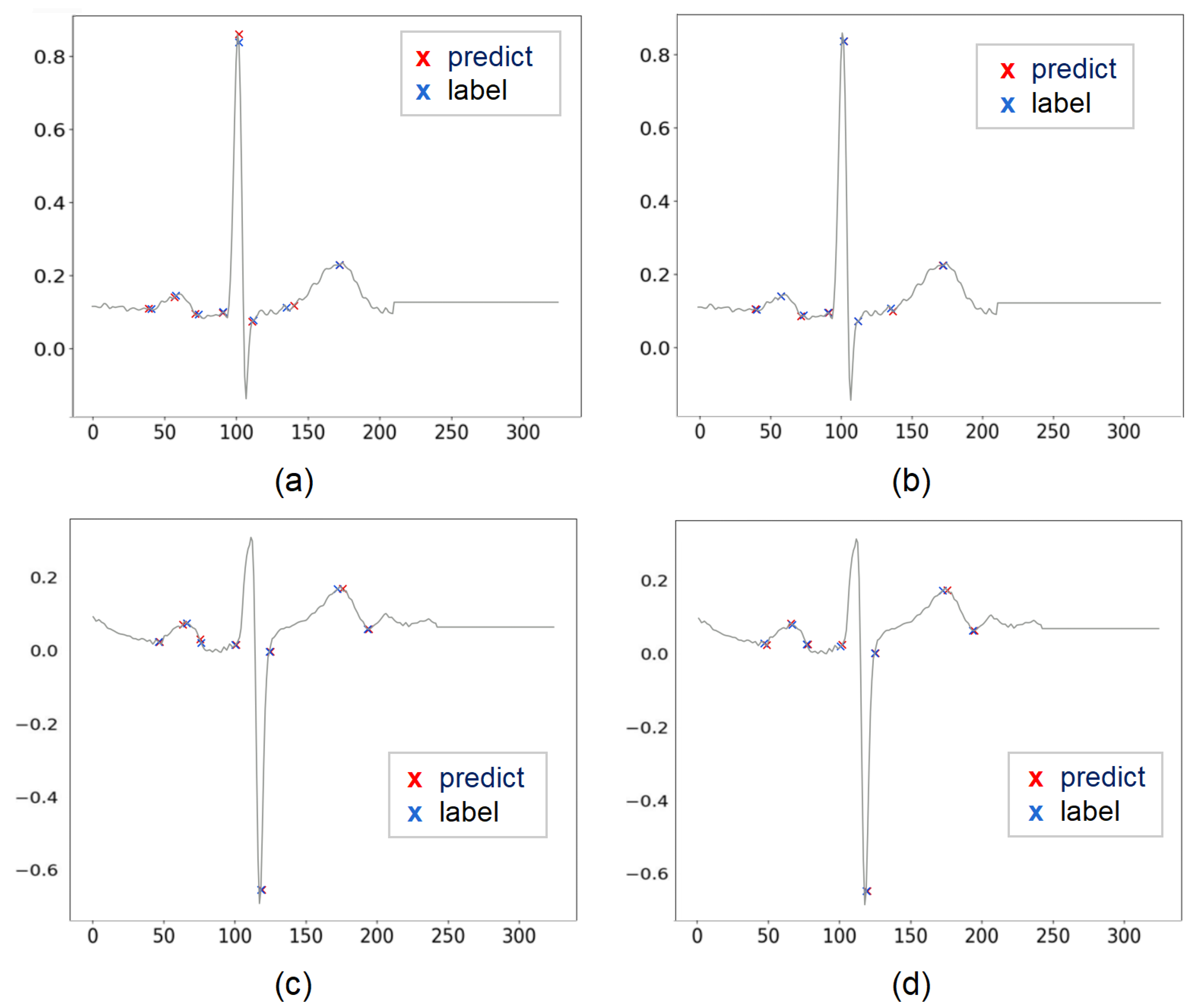
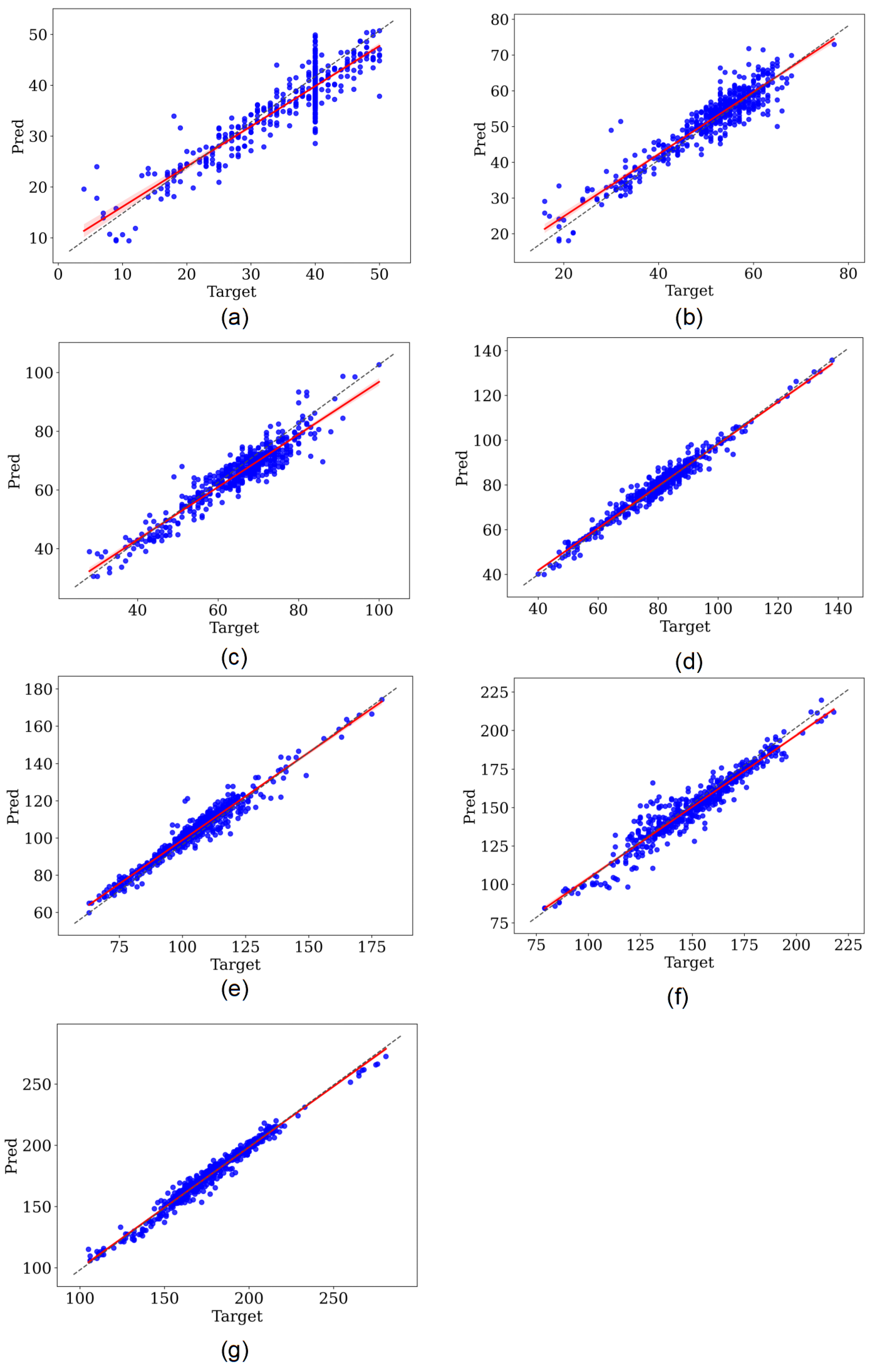
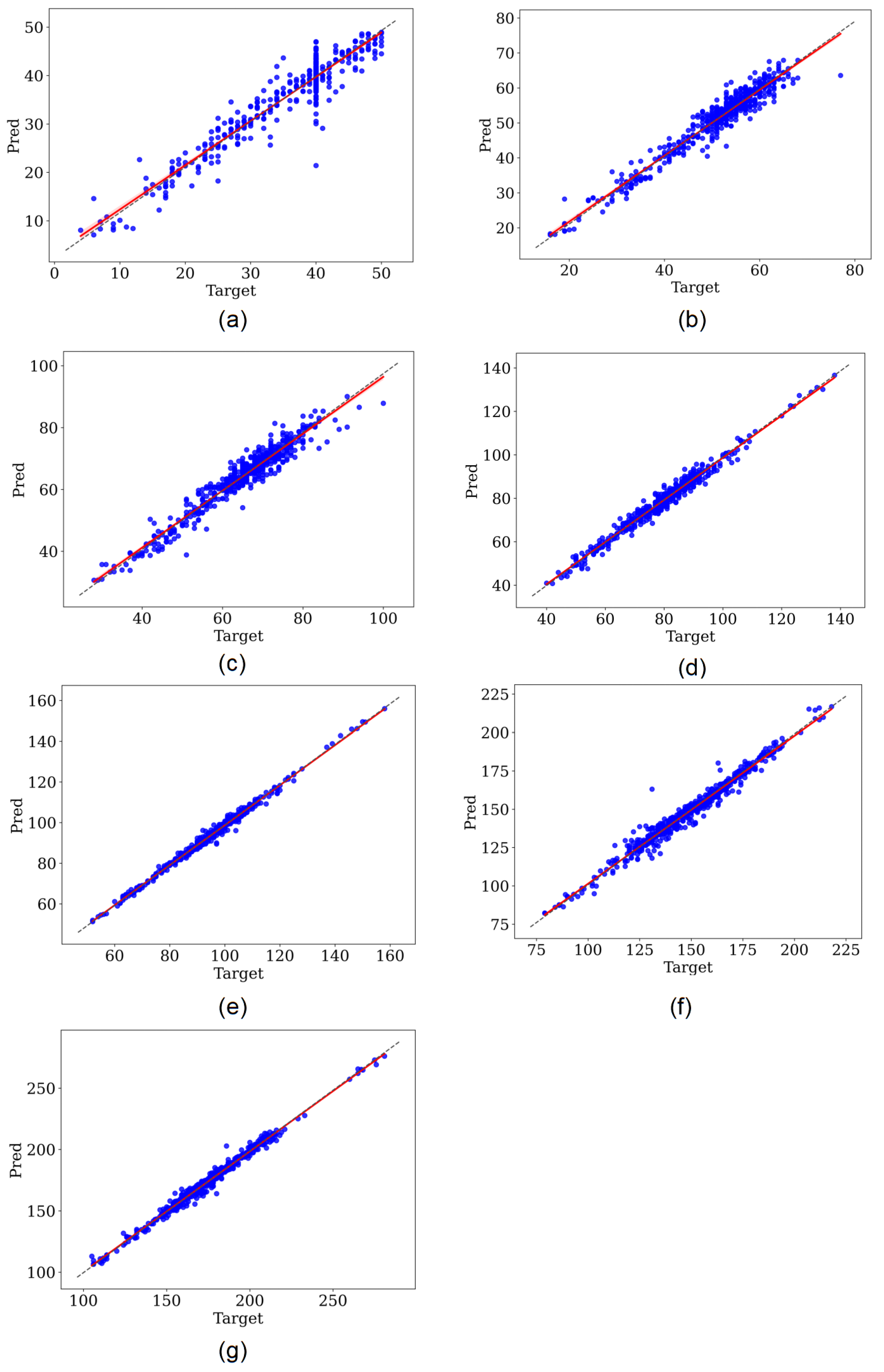
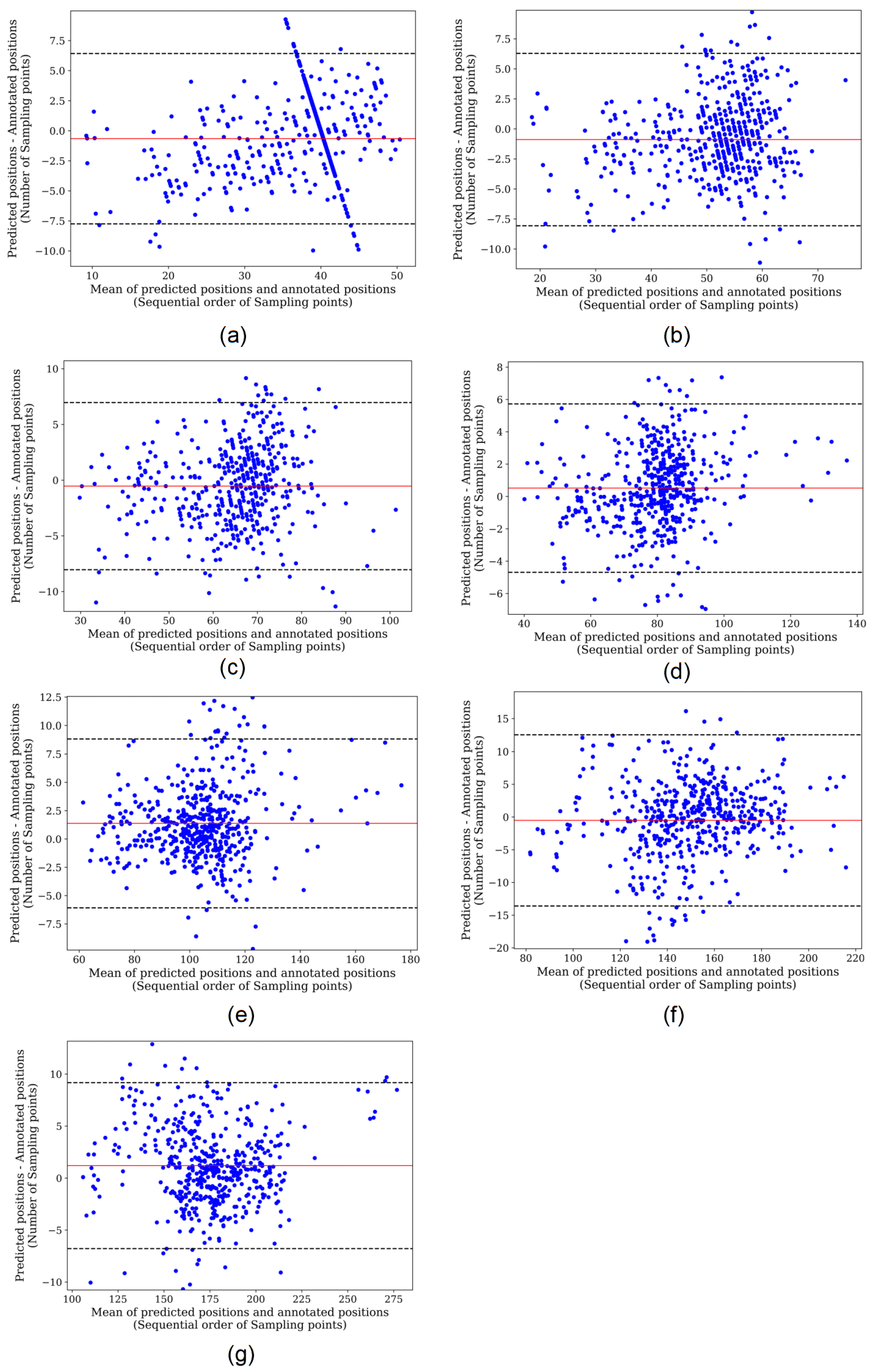
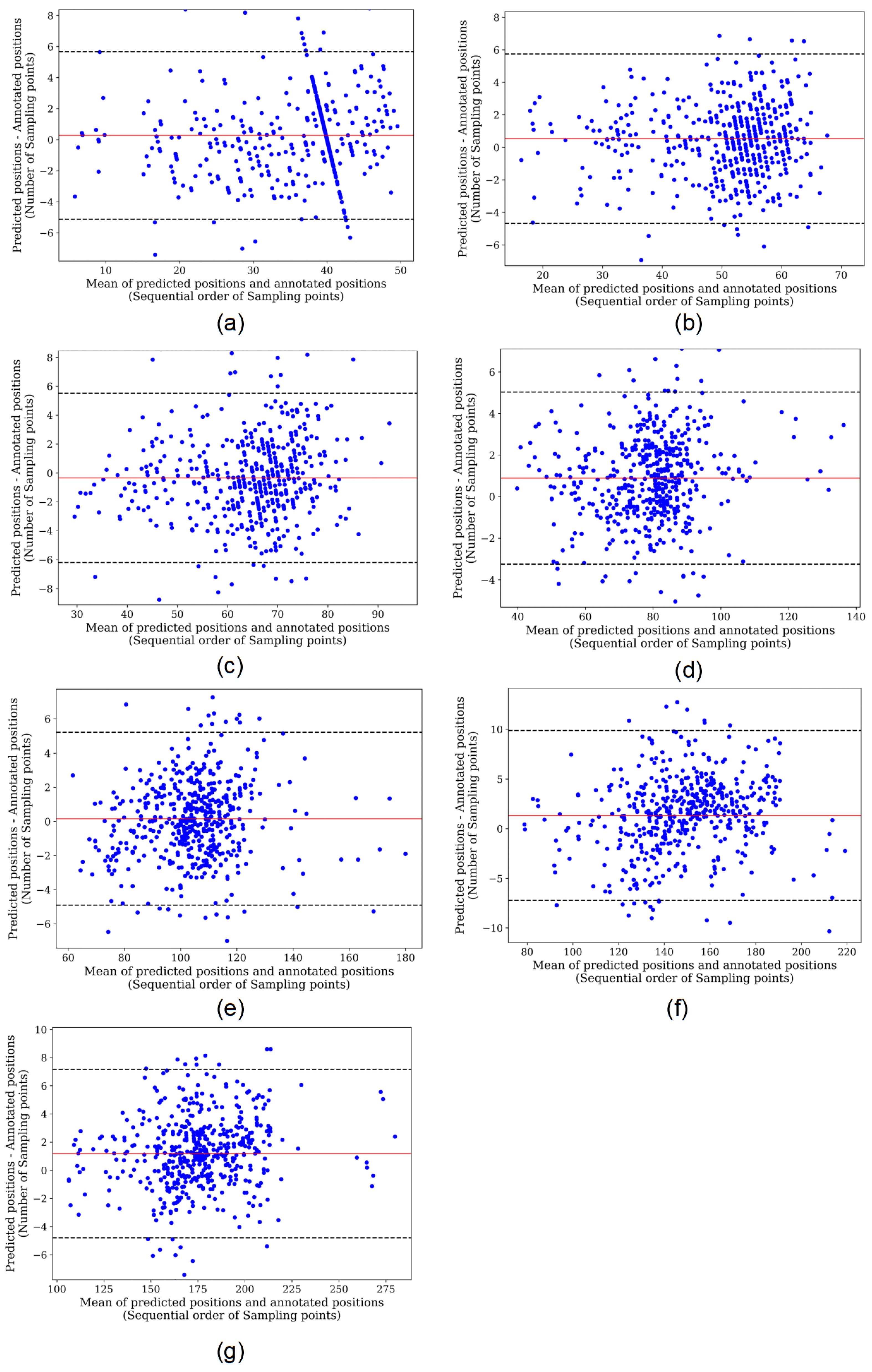
3. Results
4. Discussion
4.1. Comparative Analysis of Fully Supervised Network and Self-Supervised network
4.2. Comparative Analysis of Self-Supervised Network Pretrained on Different Database
4.3. Comparative Analysis with Other Heartbeat Characteristic Points Detection Results
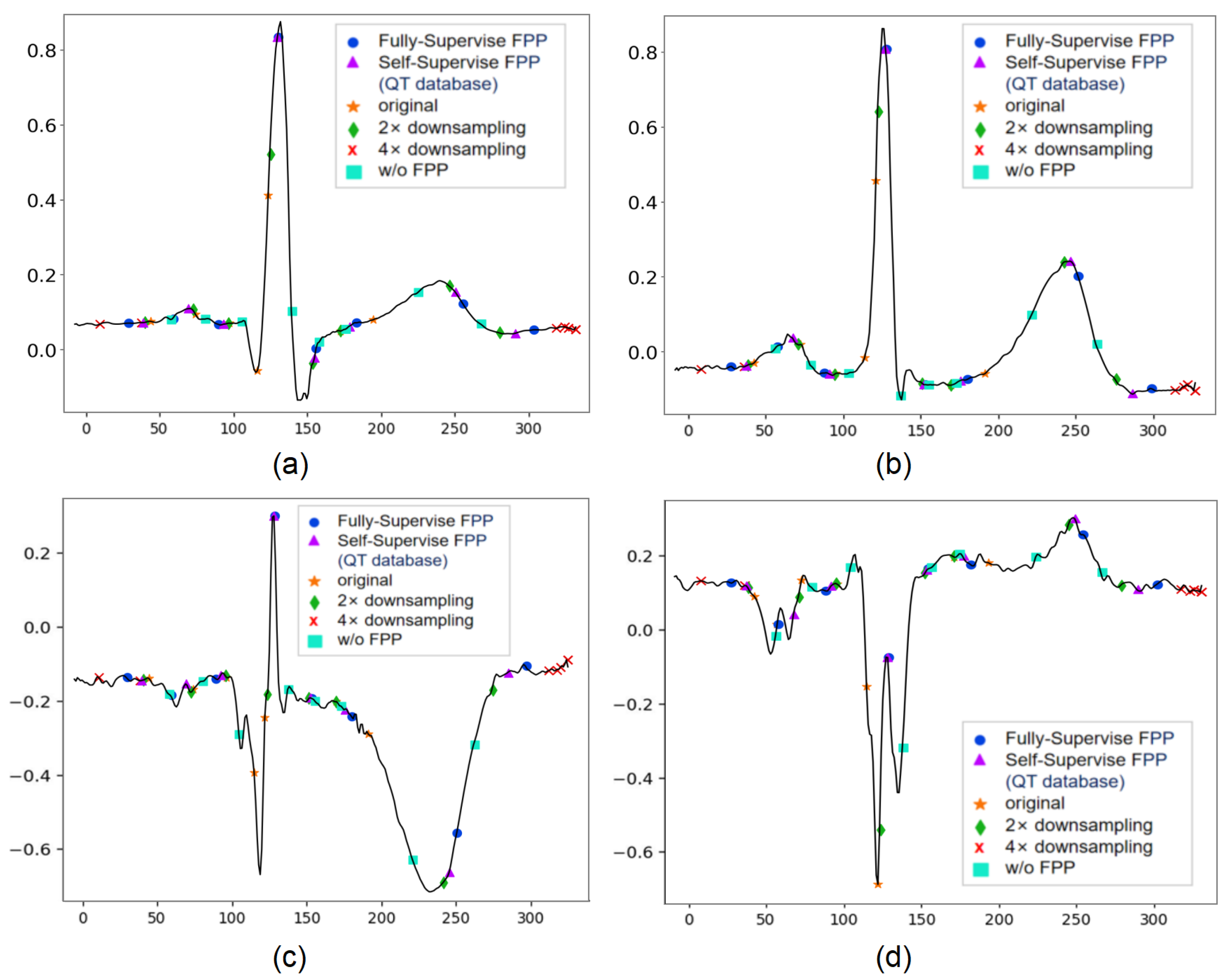
4.4. Analysis of the Validity of the Model Construction
4.5. Limitations of Our Research
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ECG | Electrocardiogram |
| QTDB | QT Database |
| MITDB | MIT-BIH Arrhythmia Database |
| NSRDB | MIT-BIH Normal Sinus Rhythm Database |
| CBAM | Convolutional Block Attention Module |
| MAE | Mean Absolute Error |
References
- Sbrollini, A.; De Jongh, M.C.; Ter Haar, C.C.; Treskes, R.W.; Man, S.; Burattini, L.; Swenne, C.A. Serial electrocardiography to detect newly emerging or aggravating cardiac pathology: A deep-learning approach. Biomed. Eng. Online 2019, 18, 15. [Google Scholar] [CrossRef] [PubMed]
- Cheng, C.M.; Zhou, J.; Yu, H.; Zhang, Q.; Gao, L.; Yin, X.; Dong, Y.; Lin, Y.; Li, D.; Yang, Y. Identification of important risk factors for all-cause mortality of acquired long QT syndrome patients using random survival forests and non-negative matrix factorization. Heart Rhythm. 2020, 18, 426–433. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; Zheng, C.; Tai, C. Detection of ECG characteristic points using wavelet transforms. IEEE Trans. Biomed. Eng. 2002, 42, 21–28. [Google Scholar]
- Martínez, J.P.; Almeida, R.; Olmos, S.; Rocha, A.P.; Laguna, P. A wavelet-based ECG delineator: Evaluation on standard databases. IEEE Trans. Biomed. Eng. 2004, 51, 570–581. [Google Scholar] [CrossRef] [PubMed]
- Martínez, A.; Alcaraz, R.; Rieta, J.J. Application of the phasor transform for automatic delineation of single-lead ECG fiducial points. Physiol. Meas. 2010, 31, 1467. [Google Scholar] [CrossRef] [PubMed]
- Clavier, L.; Boucher, J.M.; Lepage, R.; Blanc, J.J.; Cornily, J.C. Automatic P-wave analysis of patients prone to atrial fibrillation. Med. Biol. Eng. Comput. 2002, 40, 63–71. [Google Scholar] [CrossRef] [PubMed]
- Camps, J.; Rodríguez, B.; Mincholé, A. Deep learning based QRS multilead delineator in electrocardiogram signals. In Proceedings of the 2018 Computing in Cardiology Conference (CinC), Maastricht, The Netherlands, 23–26 September 2018; Volume 45, pp. 1–4. [Google Scholar]
- Jimenez-Perez, G.; Alcaine, A.; Camara, O. Delineation of the electrocardiogram with a mixed-quality-annotations dataset using convolutional neural networks. Sci. Rep. 2021, 11, 863. [Google Scholar] [CrossRef] [PubMed]
- Abrishami, H.; Han, C.; Zhou, X.; Campbell, M.; Czosek, R. Supervised ECG interval segmentation using LSTM neural network. In Proceedings of the International Conference on Bioinformatics & Computational Biology (BIOCOMP), Las Vegas, NV, USA, 19–21 March 2018; pp. 71–77. [Google Scholar]
- Wang, X.; He, K.; Gupta, A. Transitive invariance for self-supervised visual representation learning. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1329–1338. [Google Scholar]
- Huang, G.; Liu, Z.; Laurens, V.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Saeed, A.; Ozcelebi, T.; Lukkien, J. Multi-task self-supervised learning for human activity detection. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2019, 3, 1–30. [Google Scholar] [CrossRef]
- Goldberger, A.L.; Amaral, L.A.; Glass, L.; Hausdorff, J.M.; Ivanov, P.C.; Mark, R.G.; Mietus, J.E.; Moody, G.B.; Peng, C.K.; Stanley, H.E. PhysioBank, PhysioToolkit, and PhysioNet: Components of a new research resource for complex physiologic signals. Circulation 2000, 101, e215–e220. [Google Scholar] [CrossRef] [PubMed]
- Laguna, P.; Mark, R.G.; Goldberg, A.; Moody, G.B. A database for evaluation of algorithms for measurement of QT and other waveform intervals in the ECG. In Proceedings of the Computers in Cardiology, Lund, Sweden, 7–10 September 1997. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Meghrazi, M.A.; Tian, Y.; Mahnam, A.; Bhattachan, P.; Lankarany, M. Multichannel ECG recording from waist using textile sensors. Biomed. Eng. Online 2020, 19, 48. [Google Scholar] [CrossRef] [PubMed]
- Xia, Z.; Wang, G.; Fu, D.; Wang, H.; Chen, M.; Xie, P.; Yang, H. Real-time ECG delineation with randomly selected wavelet transform feature and random walk estimation. In Proceedings of the 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 18–21 July 2018; pp. 1–4. [Google Scholar]
- Wu, W.; Huang, Y.; Wu, X. ECG Characteristic Detection Using DenseNet based on Attention Mechanism and Feature Pyramid. In Proceedings of the 2022 3rd International Conference on Pattern Recognition and Machine Learning (PRML), Chengdu, China, 22–24 July 2022; pp. 6–13. [Google Scholar]
- Veltman, C.E.; Boogers, M.J.; Meinardi, J.E.; Al Younis, I.; Dibbets-Schneider, P.; Van der Wall, E.E.; Bax, J.J.; Scholte, A.J. Reproducibility of planar 123I-meta-iodobenzylguanidine (MIBG) myocardial scintigraphy in patients with heart failure. Eur. J. Nucl. Med. Mol. Imaging 2012, 39, 1599–1608. [Google Scholar] [CrossRef] [PubMed]
- Vázquez-Seisdedos, C.R.; Neto, J.E.; Reyes, E.J.M.; Klautau, A.; de Oliveira, R.C.L. New approach for T-wave end detection on electrocardiogram: Performance in noisy conditions. Biomed. Eng. Online 2011, 10, 77. [Google Scholar] [CrossRef] [PubMed]
- Hesar, H.D.; Mohebbi, M. A Multi Rate Marginalized Particle Extended Kalman Filter for P and T Wave Segmentation in ECG Signals. IEEE J. Biomed. Health Inform. 2019, 23, 112–122. [Google Scholar] [CrossRef] [PubMed]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Input Shapes | Output Shapes |
|---|---|---|
| Input | (324, 1) | (324, 1) |
| Conv | (324, 1) | (324, 64) |
| Pooling | (324, 64) | (162, 64) |
| Dense Block | (162, 64) | (162, 320) |
| TransitionLayer | (162, 320) | (81, 160) |
| Dense Block | (81, 160) | (81, 288) |
| TransitionLayer | (81, 288) | (40, 144) |
| Dense Block | (40, 144) | (40, 208) |
| TransitionLayer | (40, 208) | (20, 104) |
| Pooling | (20, 104) | (21, 104) |
| Conv | (21, 104) | (20, 128) |
| Dropout | (20, 128) | (20, 128) |
| Flatten | (20, 128) | 2560 |
| Fully-connected | 2560 | 256 |
| Pooling (downsampling 2×) | (20, 128) | (10, 128) |
| Flatten | (10, 128) | 1280 |
| Fully-connected | 1280 | 256 |
| Pooling (downsampling 4×) | (10, 128) | (5, 128) |
| Flatten | (5, 128) | 640 |
| Fully-connected | 640 | 256 |
| Concatenation | 256 × 3 | 768 |
| Fully-connected | 768 | 256 |
| Fully-connected | 256 | 8 |
| Method | Pretext Task Database | P-On m ± s (ms) | P-Peak m ± s (ms) | P-Off m ± s (ms) | QRS-On m ± s (ms) | QRS-Off m ± s (ms) | T-Peak m ± s (ms) | T-Off m ± s (ms) |
|---|---|---|---|---|---|---|---|---|
| Fully Supervised [18] | / | −0.32 ± 18.08 | −0.56 ± 17.6 | −5.96 ± 16.84 | −5.8 ± 14.12 | −6.24 ± 18.76 | −0.2 ± 31.36 | 0.84 ± 27.24 |
| Self-Supervised | MITDB | 0.12 ± 20.96 | 0.26 ± 16.16 | −0.8 ± 15.28 | 2.36 ± 9.36 | −2.72 ± 19.2 | −0.8 ± 20.56 | −2.8 ± 23.28 |
| Self-Supervised | NSRDB | −0.08 ± 11.56 | −0.04 ± 11.24 | 0.92 ± 12.36 | −2.2 ± 8.32 | 0.48 ± 9.16 | −2.36 ± 27.24 | −0.68 ± 21.64 |
| Self-Supervised | QTDB | −0.24 ± 10.04 | −0.48 ± 11.69 | −0.28 ± 10.19 | −3.72 ± 8.18 | −4.12 ± 13.54 | −0.68 ± 20.42 | 1.34 ± 21.04 |
| Method | Pretext Task Database | P-On m ± s (ms) | P-Peak m ± s (ms) | P-Off m ± s (ms) | QRS-On m ± s (ms) | QRS-Off m ± s (ms) | T-Peak m ± s (ms) | T-Off m ± s (ms) |
|---|---|---|---|---|---|---|---|---|
| Fully Supervised [18] | / | 8.52 ± 8.48 | 8.32 ± 8.22 | 10.16 ± 8.61 | 7.35 ± 5.94 | 8.09 ± 7.29 | 12.76 ± 12.92 | 8.45 ± 8.74 |
| Self-Supervised | QTDB | 7.75 ± 8.18 | 7.52 ± 7.01 | 8.89 ± 7.88 | 6.63 ± 5.42 | 7.19 ± 6.6 | 11.47 ± 11.32 | 8.26 ± 8.53 |
| Method | Database | P-On m ± s (ms) | P-Peak m ± s (ms) | P-Off m ± s (ms) | QRS-On m ± s (ms) | QRS-Off m ± s (ms) | T-Peak m ± s (ms) | T-Off m ± s (ms) | MAE of Mean Deviation (ms) |
|---|---|---|---|---|---|---|---|---|---|
| Fully Supervised [18] | QTDB | −0.32 ± 18.08 | −0.56 ± 17.6 | −5.96 ± 16.84 | −5.8 ± 14.12 | −6.24 ± 18.76 | −0.2 ± 31.36 | 0.84 ± 27.24 | 2.84 |
| Self-Supervised | QTDB | −0.24 ± 10.04 | −0.48 ± 11.69 | −0.28 ± 10.19 | −3.72 ± 8.18 | −4.12 ± 13.54 | −0.68 ± 20.42 | 1.34 ± 21.04 | 1.55 |
| Simple-Dense (baseline) | QTDB | 2.2 ± 18.16 | 4.6 ± 18.08 | −2.04 ± 13.11 | 3.72 ± 15.24 | −8.78 ± 18.32 | −1.12 ± 30.27 | 1.68 ± 22.2 | 3.45 |
| TWA | QTDB | N/A | N/A | N/A | 2.8 ± 7.7 | 2.7 ± 9.7 | −2.6 ± 12.2 | −2.7 ± 20.7 | 2.7 |
| MsPE | QTDB | 0.5 ± 15.1 | 5.1 ± 10.9 | 0.5 ± 15.0 | 0.9 ± 8.5 | −0.4 ± 9.6 | −4.5 ± 14.7 | 0.6 ± 20.3 | 1.79 |
| MP-EKF | QTDB | 16 ± 37 | 5 ± 34 | −10 ± 34 | NA | NA | −3 ± 24 | −16 ± 35 | 10.0 |
| U-Net | QTDB | 1.54 ± 22.89 | N/A | 0.32 ± 4.01 | −0.07 ± 8.37 | 3.64 ± 12.55 | N/A | 4.55 ± 31.11 | 2.02 |
| Method | P-On m ± s (ms) | P-Peak m ± s (ms) | P-Off m ± s (ms) | QRS-On m ± s (ms) | QRS-Off m ± s (ms) | T-Peak m ± s (ms) | T-Off m ± s (ms) | MAE of Mean Deviation |
|---|---|---|---|---|---|---|---|---|
| model 1 1 | −0.32 ± 18.08 | −0.56 ± 17.6 | −5.96 ± 16.84 | −5.8 ± 14.12 | −6.24 ± 18.76 | −0.2 ± 31.36 | 0.84 ± 27.24 | 2.84 |
| model 2 | −0.24 ± 10.04 | −0.48 ± 11.69 | −0.28 ± 10.19 | −3.72 ± 8.18 | −4.12 ± 13.54 | −0.68 ± 20.42 | 1.34 ± 21.04 | 1.17 |
| model 3 | 2.12 ± 13.36 | 6.24 ± 13.72 | 4.92 ± 15.04 | 5.24 ± 11.72 | −6.4 ± 14.52 | 1.16 ± 24.36 | −4.92 ± 27.8 | 4.43 |
| model 4 | −1.76 ± 12.36 | −2.60 ± 11.4 | −4.16 ± 12.92 | −4.36 ± 9.28 | −6.27 ± 14.0 | −2.2 ± 29.64 | −1.52 ± 23.6 | 3.27 |
| model 5 | −2.32 ± 14.24 | −4.36 ± 13.24 | −6.08 ± 14.46 | −7.4 ± 10.52 | −7.24 ± 16.6 | 8.84 ± 26.28 | 3.52 ± 24.76 | 5.68 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, W.; Huang, Y.; Wu, X. A New Deep Learning Method with Self-Supervised Learning for Delineation of the Electrocardiogram. Entropy 2022, 24, 1828. https://doi.org/10.3390/e24121828
Wu W, Huang Y, Wu X. A New Deep Learning Method with Self-Supervised Learning for Delineation of the Electrocardiogram. Entropy. 2022; 24(12):1828. https://doi.org/10.3390/e24121828
Chicago/Turabian StyleWu, Wenwen, Yanqi Huang, and Xiaomei Wu. 2022. "A New Deep Learning Method with Self-Supervised Learning for Delineation of the Electrocardiogram" Entropy 24, no. 12: 1828. https://doi.org/10.3390/e24121828
APA StyleWu, W., Huang, Y., & Wu, X. (2022). A New Deep Learning Method with Self-Supervised Learning for Delineation of the Electrocardiogram. Entropy, 24(12), 1828. https://doi.org/10.3390/e24121828