
Path Planning Research of a UAV Base Station Searching for Disaster Victims’ Location Information Based on Deep Reinforcement Learning

 , ,
, ,
Abstract
:1. Introduction
2. Model Construction
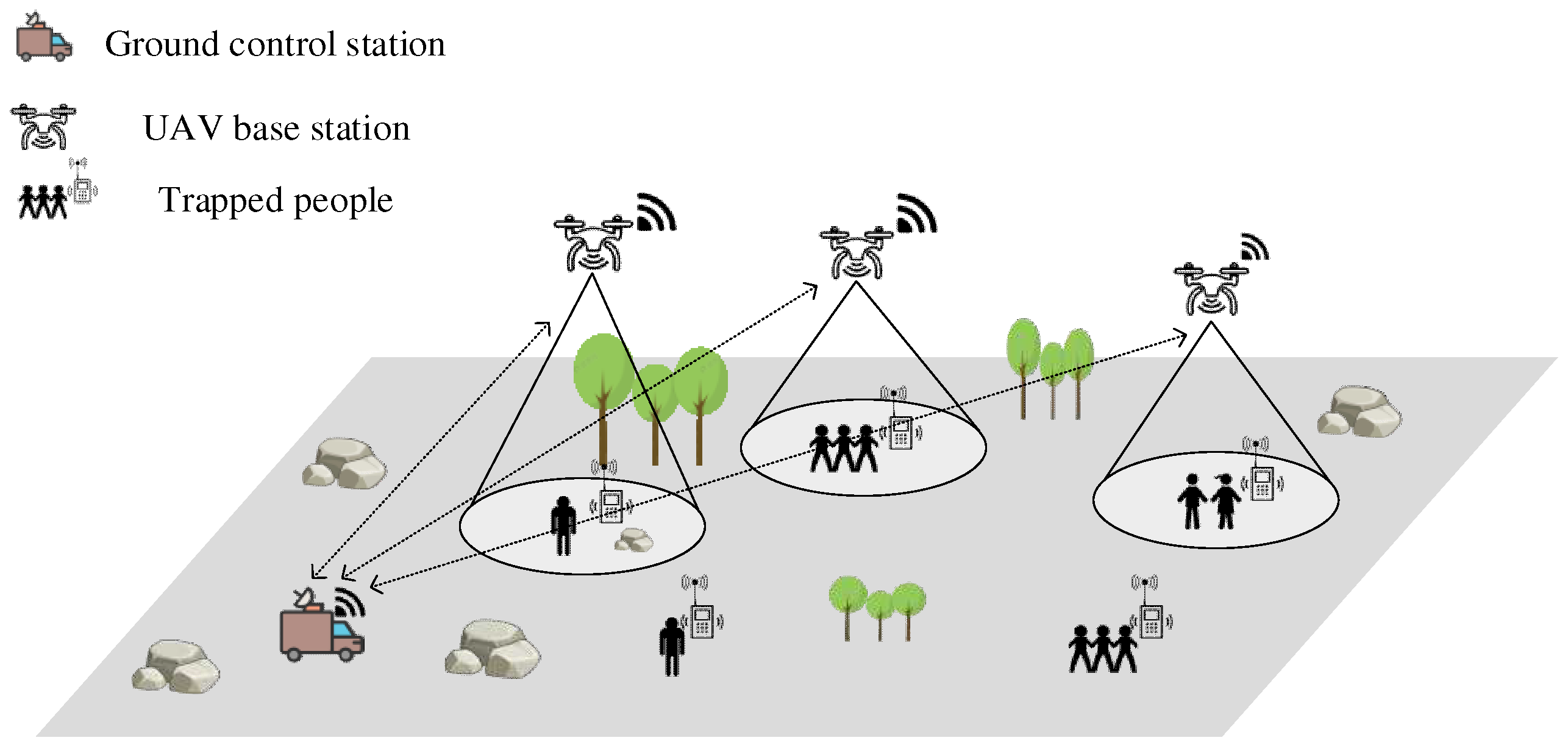
2.1. System Environment Model
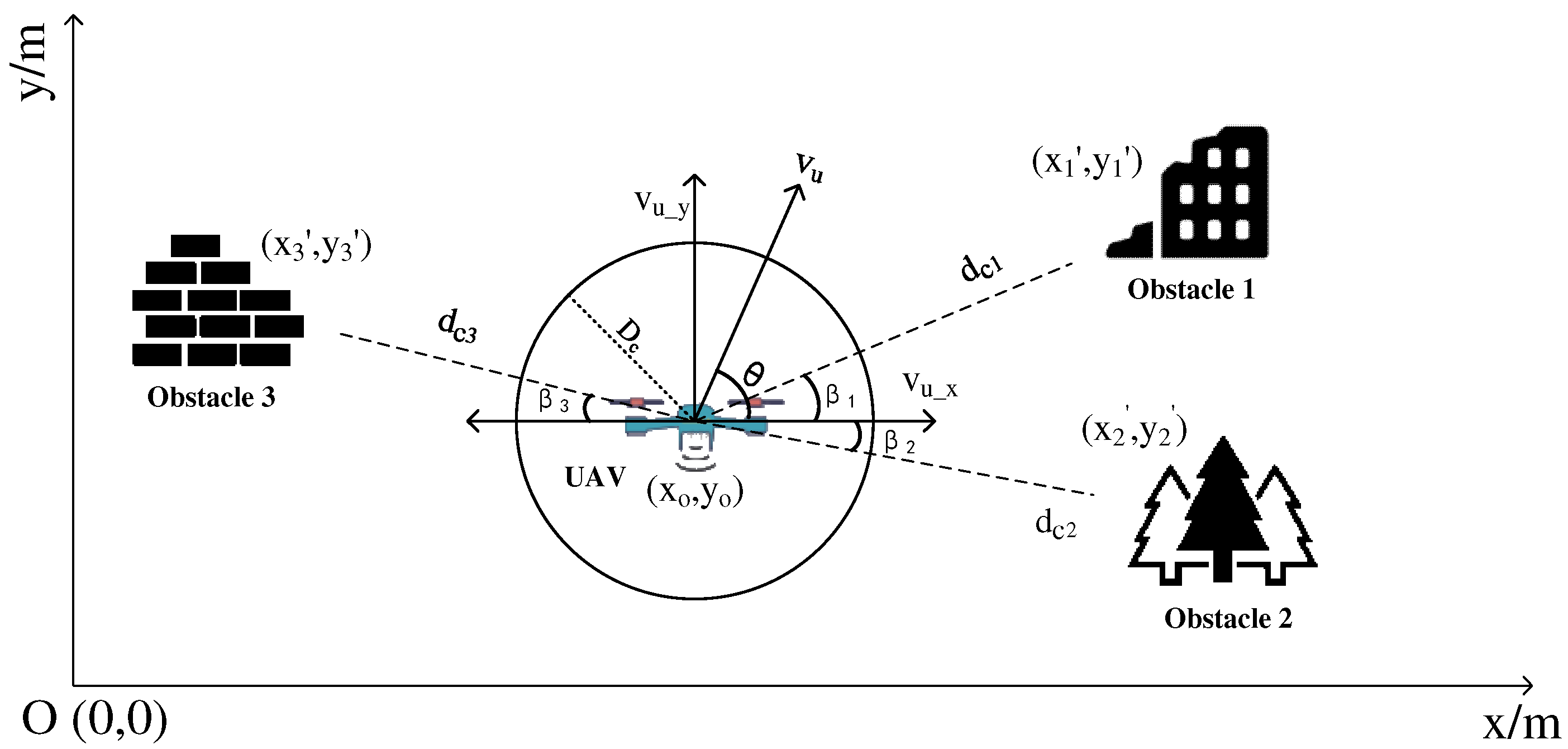
2.2. Obstacle Model
2.3. Ground User Model
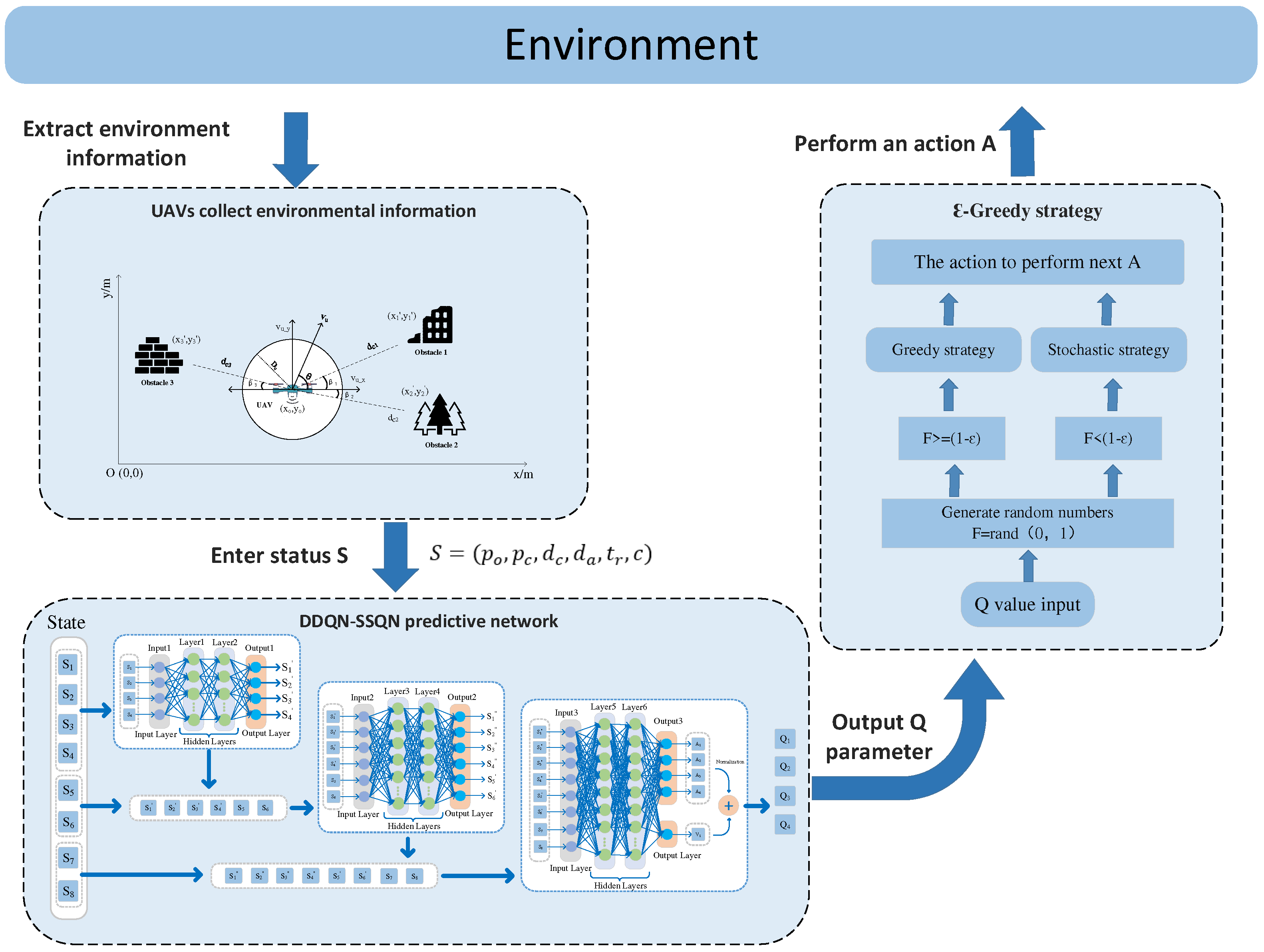
3. DDQN-SSQN UAV Path Planning Algorithm
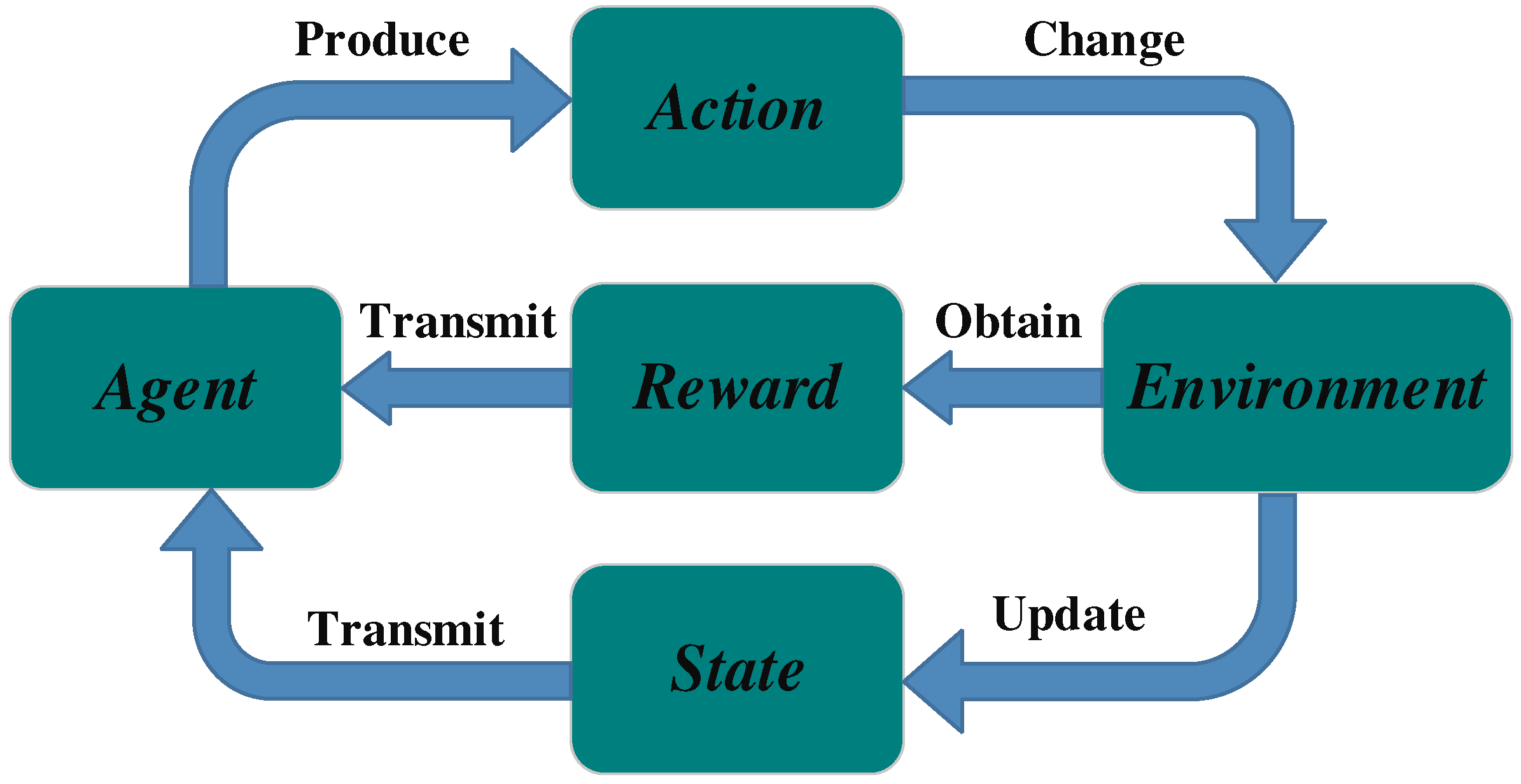
3.1. Deep Reinforcement Learning
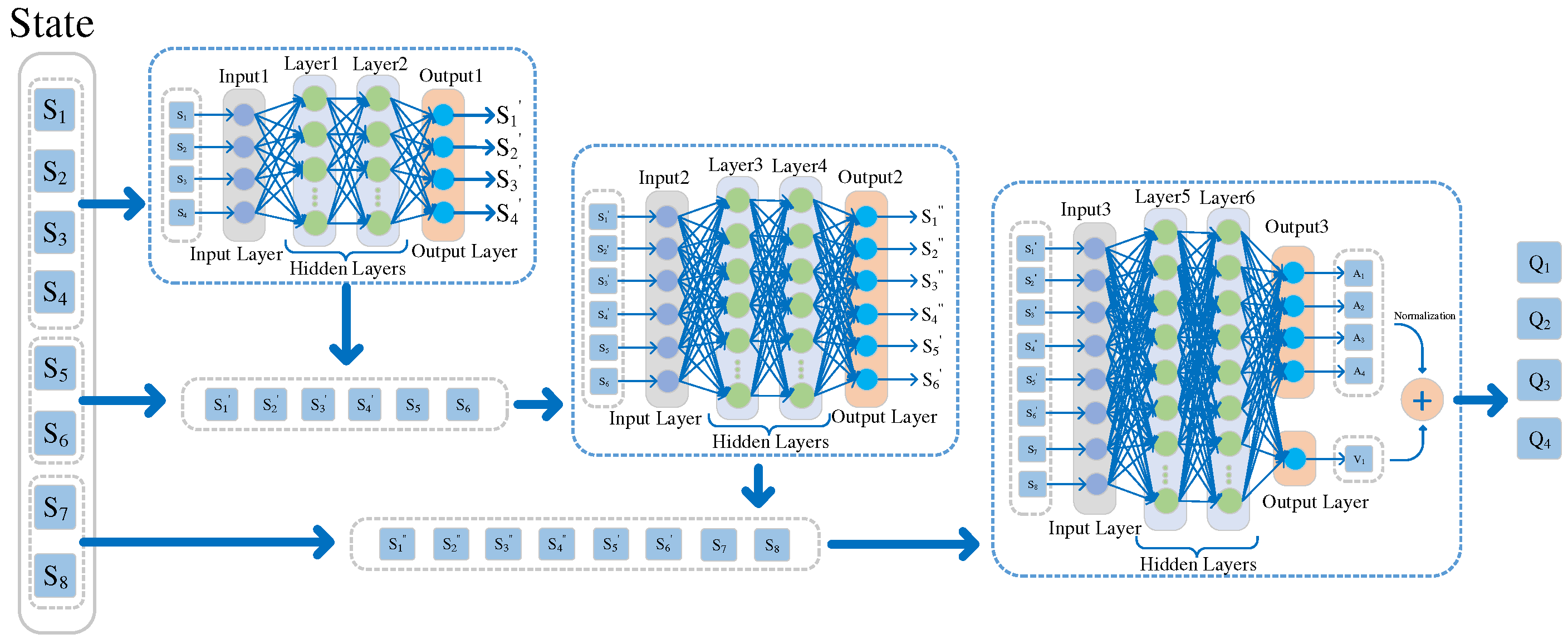
3.2. DDQN-SSQN Algorithm Design
3.3. DDQN-SSQN Algorithm Structure
| Algorithm 1: The Proposed DDQN-SSQN Algorithm Scheme |
 |
4. Experimental Simulation and Analysis
4.1. Simulate Experimental Design
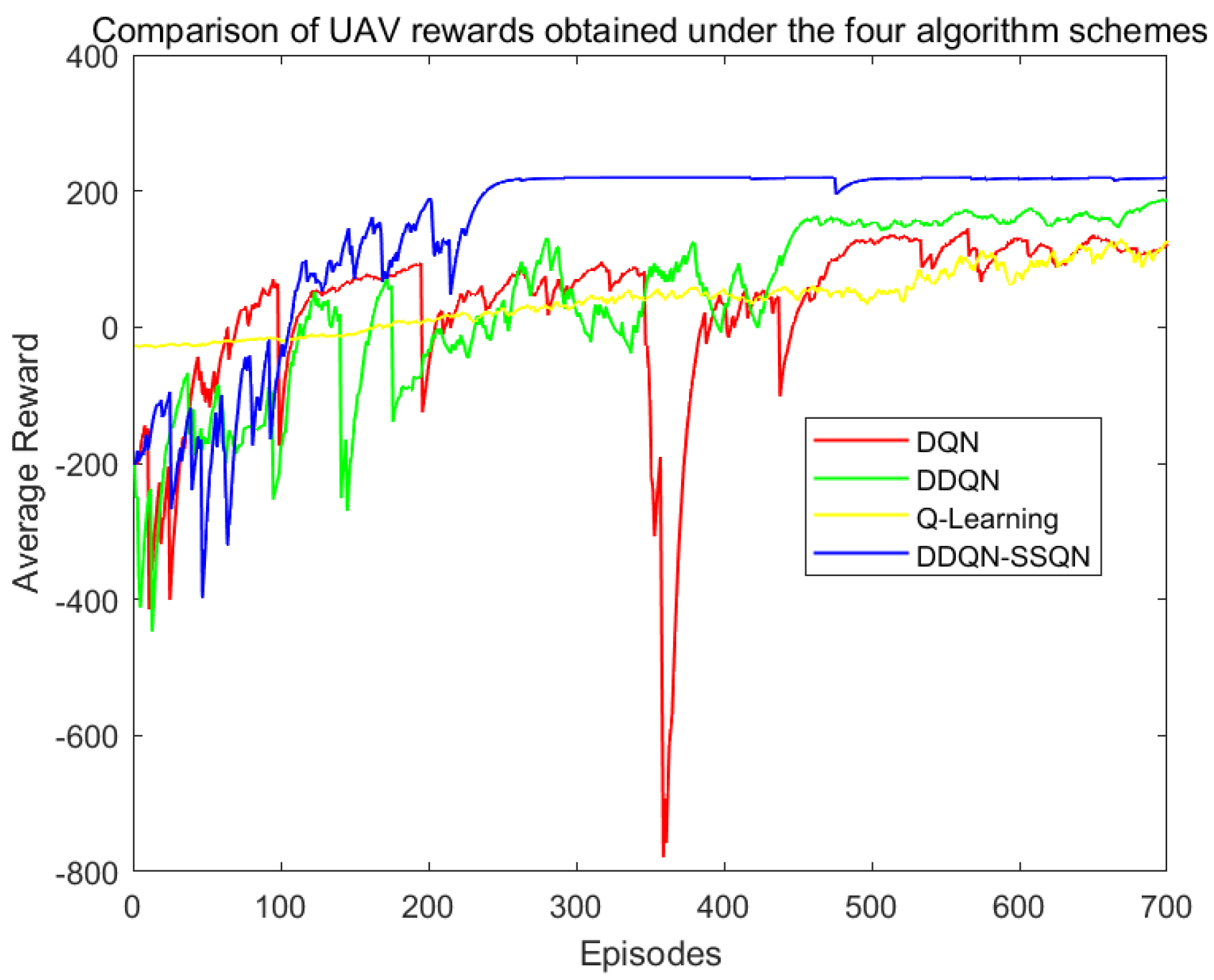
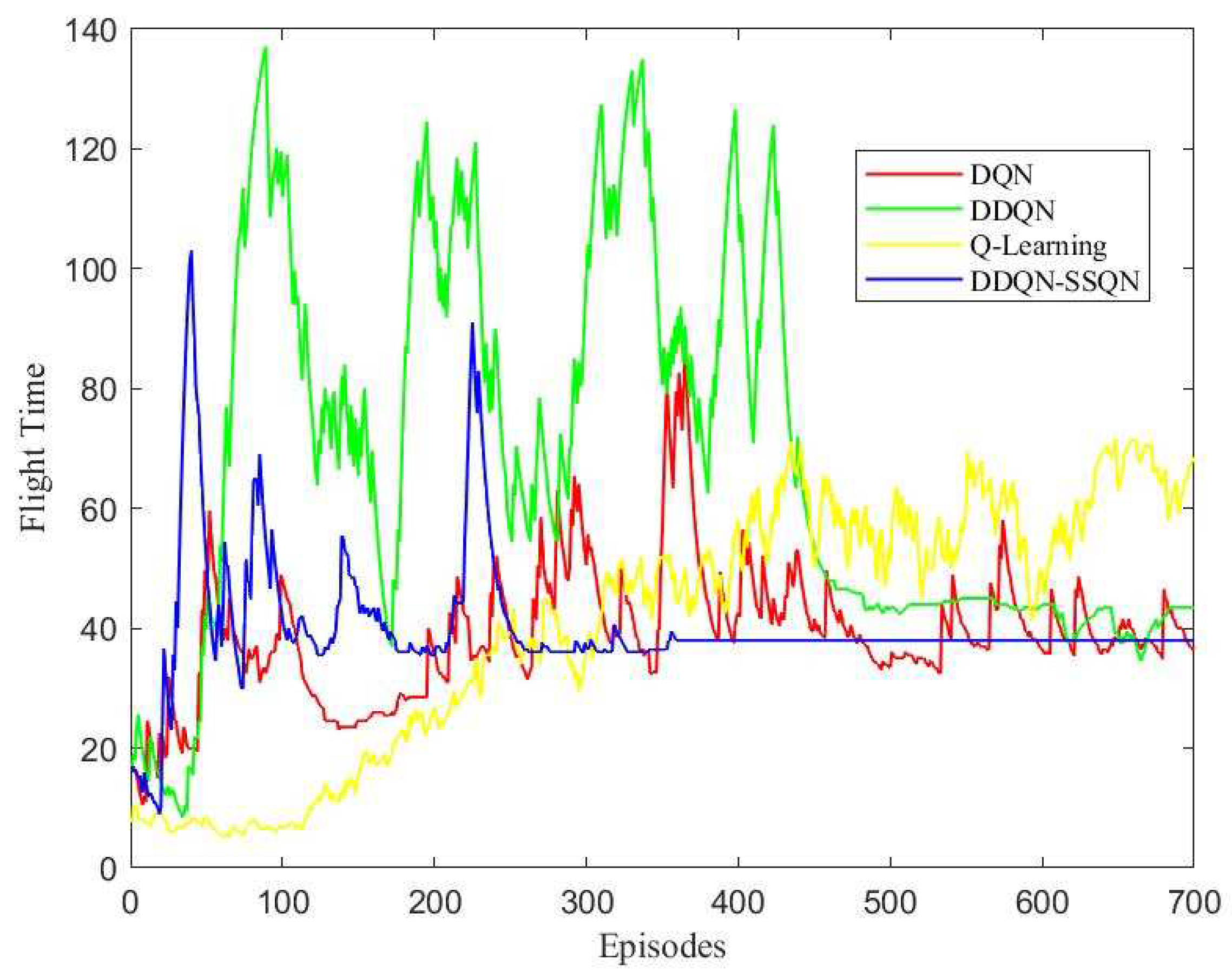
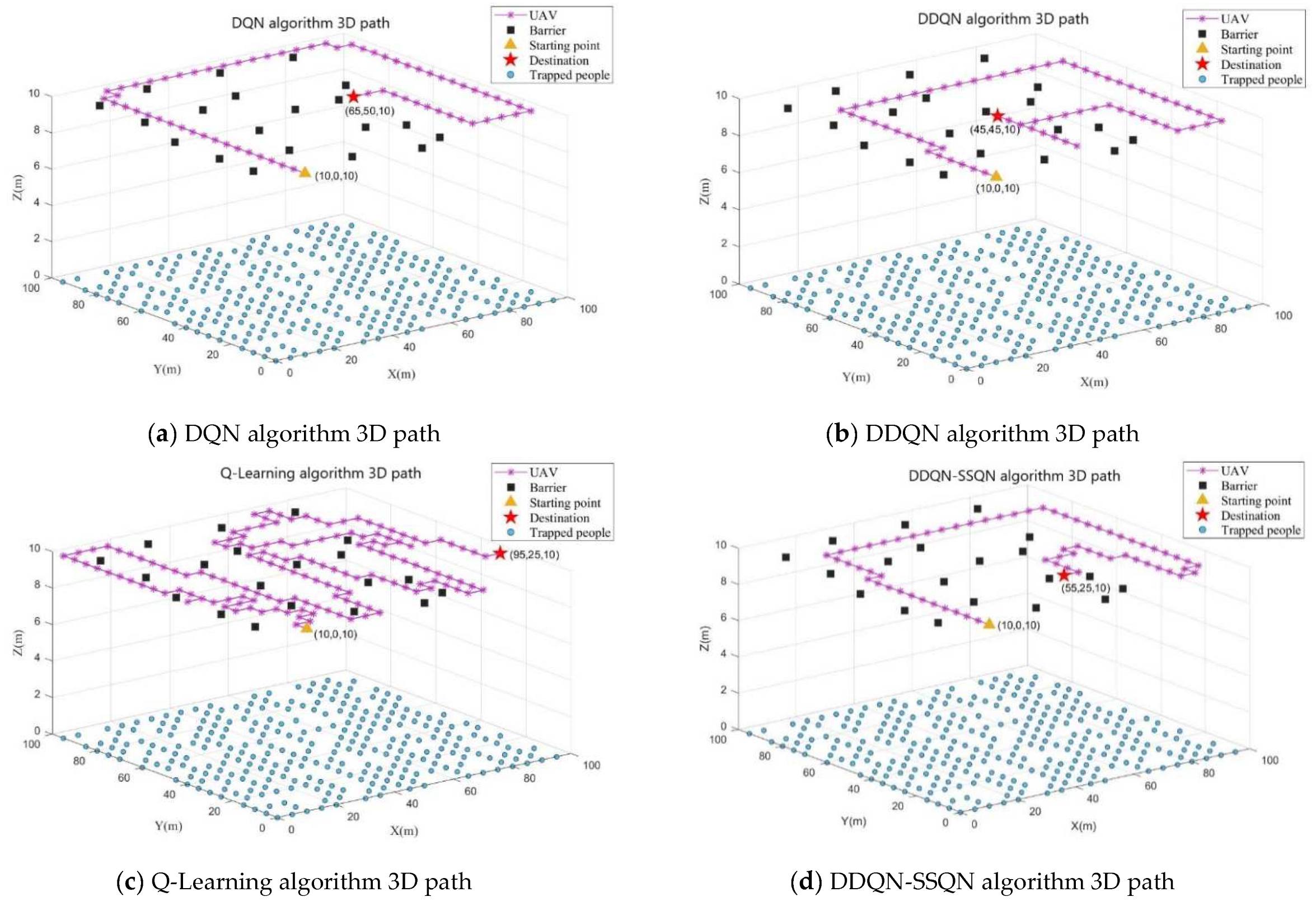
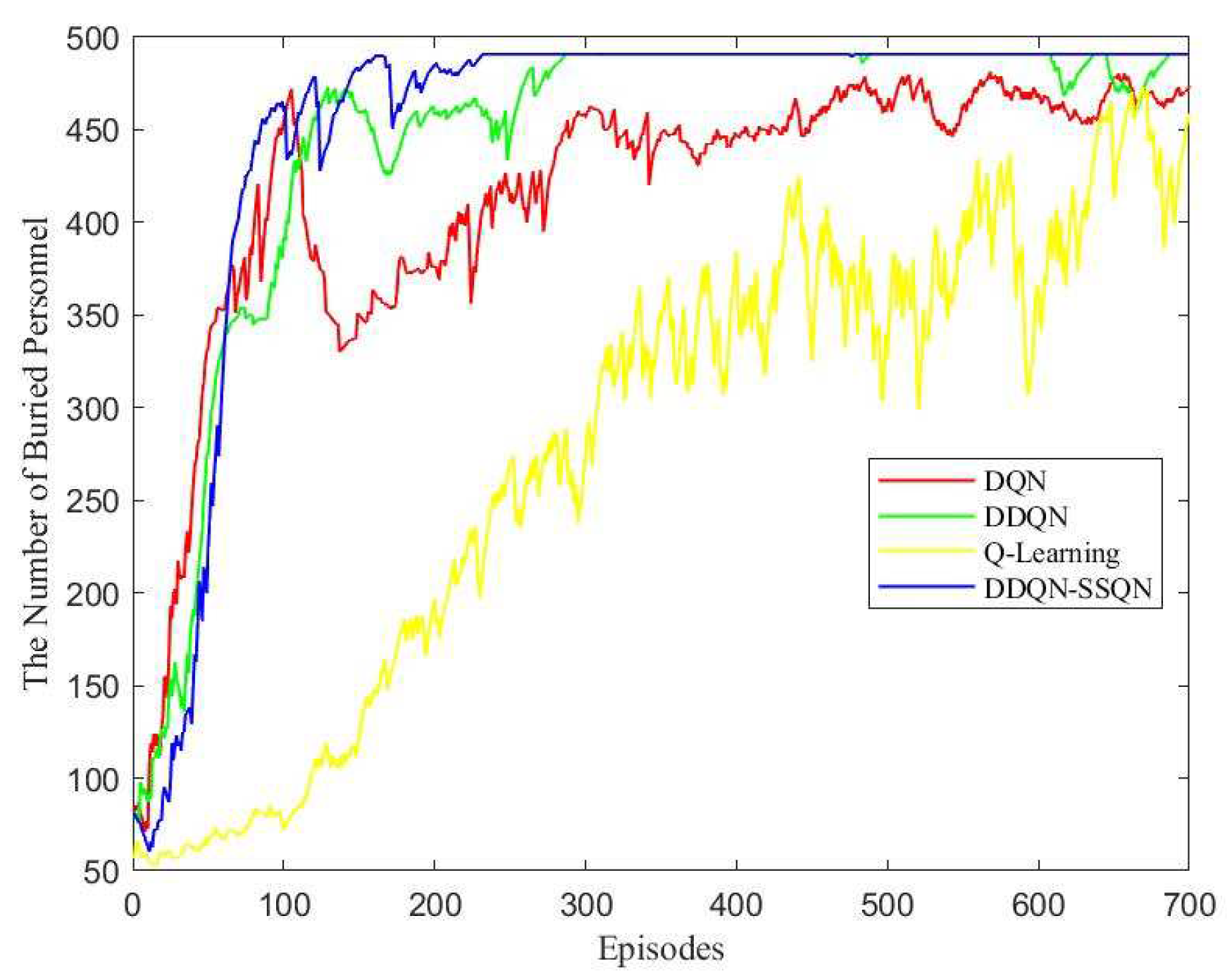
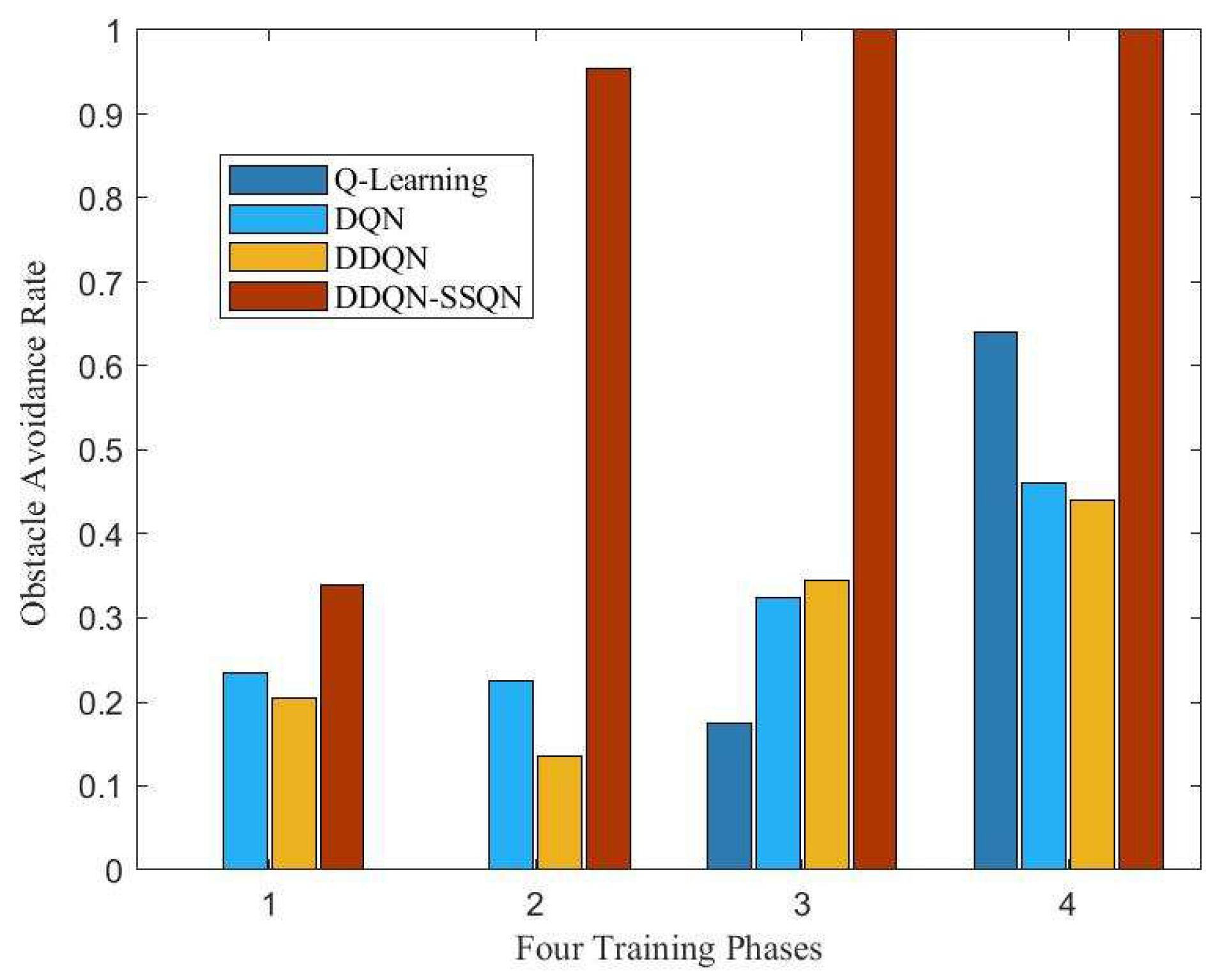
4.2. Analysis of Simulation Result
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, Z.; Guo, J.; Chen, Z.; Yu, L.; Wang, Y.; Rao, H. Robust secure UAV relay-assisted cognitive communications with resource allocation and cooperative jamming. J. Commun. Netw. 2022, 24, 139–153. [Google Scholar] [CrossRef]
- Sun, M.; Xu, X.; Qin, X.; Zhang, P. AoI-Energy-Aware UAV-Assisted Data Collection for IoT Networks: A Deep Rein-forcement Learning Method. IEEE Internet Things J. 2021, 8, 17275–17289. [Google Scholar] [CrossRef]
- Ouahouah, S.; Bagaa, M.; Prados-Garzon, J.; Taleb, T. Deep-Reinforcement-Learning-Based Collision Avoidance in UAV Environment. IEEE Internet Things J. 2022, 9, 4015–4030. [Google Scholar] [CrossRef]
- Shiri, H.; Seo, H.; Park, J.; Bennis, M. Attention-Based Communication and Control for Multi-UAV Path Planning. IEEE Wirel. Commun. Lett. 2022, 11, 1409–1413. [Google Scholar] [CrossRef]
- Sun, R.; Zhao, D.; Ding, L.; Zhang, J.; Ma, H. UAV-Net+: Effective and Energy-Efficient UAV Network Deployment for Extending Cell Tower Coverage with Dynamic Demands. IEEE Trans. Veh. Technol. 2022, 1–13. [Google Scholar] [CrossRef]
- Pan, Z.; Zhang, C.; Xia, Y.; Xiong, H.; Shao, X. An Improved Artificial Potential Field Method for Path Planning and For-mation Control of the Multi-UAV Systems. IEEE Trans. Circuits Syst. II Express Briefs 2022, 69, 1129–1133. [Google Scholar]
- Feng, J.; Zhang, J.; Zhang, G.; Xie, S.; Ding, Y.; Liu, Z. UAV Dynamic Path Planning Based on Obstacle Position Prediction in an Unknown Environment. IEEE Access 2021, 9, 154679–154691. [Google Scholar] [CrossRef]
- Qadir, Z.; Zafar, M.H.; Moosavi, S.K.R.; Le, K.N.; Mahmud, M.A.P. Autonomous UAV Path-Planning Optimization Using Metaheuristic Approach for Predisaster Assessment. IEEE Internet Things J. 2021, 9, 12505–12514. [Google Scholar] [CrossRef]
- Shao, X.X.; Gong, Y.J.; Zhan, Z.H.; Zhang, J. Bipartite Cooperative Coevolution for Energy-Aware Coverage Path Planning of UAVs. IEEE Trans. Artif. Intell. 2022, 3, 29–42. [Google Scholar] [CrossRef]
- Sanchez-Fernandez, A.J.; Romero, L.F.; Bandera, G.; Tabik, S. VPP: Visibility-Based Path Planning Heuristic for Moni-toring Large Regions of Complex Terrain Using a UAV Onboard Camera. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 944–955. [Google Scholar] [CrossRef]
- Chen, J.; Du, C.; Zhang, Y.; Han, P.; Wei, W. A Clustering-Based Coverage Path Planning Method for Autonomous Het-erogeneous UAVs. IEEE Trans. Intell. Transp. Syst. 2021, 1–11. [Google Scholar] [CrossRef]
- Jinqiang, H.; Husheng, W.; Renjun, Z.; Rafik, M.; Xuanwu, Z. Self-organized search-attack mission planning for UAV swarm based on wolf pack hunting behavior. J. Syst. Eng. Electron. 2021, 32, 1463–1476. [Google Scholar] [CrossRef]
- Zhou, X.; Gao, F.; Fang, X.; Lan, Z. Improved Bat Algorithm for UAV Path Planning in Three-Dimensional Space. IEEE Access 2021, 9, 20100–20116. [Google Scholar] [CrossRef]
- Wang, X.; Yang, Y.; Wu, D.; Zhang, Z.; Ma, X. Mission-Oriented 3D Path Planning for High-Altitude Long-Endurance So-lar-Powered UAVs with Optimal Energy Management. IEEE Access 2020, 8, 227629–227641. [Google Scholar] [CrossRef]
- Liu, Q.; Zhang, Y.; Li, M.; Zhang, Z.; Cao, N.; Shang, J. Multi-UAV Path Planning Based on Fusion of Sparrow Search Algo-rithm and Improved Bioinspired Neural Network. IEEE Access 2021, 9, 124670–124681. [Google Scholar] [CrossRef]
- Cheng, Z.; Zhao, L.; Shi, Z. Decentralized Multi-UAV Path Planning Based on Two-Layer Coordinative Framework for Formation Rendezvous. IEEE Access 2022, 10, 45695–45708. [Google Scholar] [CrossRef]
- Huang, Z.; Chen, C.; Pan, M. Multiobjective UAV Path Planning for Emergency Information Collection and Transmis-sion. IEEE Internet Things J. 2020, 7, 6993–7009. [Google Scholar] [CrossRef]
- Airlangga, G.; Liu, A. Online Path Planning Framework for UAV in Rural Areas. IEEE Access 2022, 10, 37572–37585. [Google Scholar] [CrossRef]
- Wu, X.; Lei, Y.; Tong, X.; Zhang, Y.; Li, H.; Qiu, C.; Guo, C.; Sun, Y.; Lai, G. A Non-rigid Hierarchical Discrete Grid Structure and its Application to UAVs Conflict Detection and Path Planning. IEEE Trans. Aerosp. Electron. Syst. 2022. [Google Scholar] [CrossRef]
- Qie, H.; Shi, D.; Shen, T.; Xu, X.; Li, Y.; Wang, L. Joint Optimization of Multi-UAV Target Assignment and Path Planning Based on Multi-Agent Reinforcement Learning. IEEE Access 2019, 7, 146264–146272. [Google Scholar] [CrossRef]
- Li, B.; Wu, Y. Path Planning for UAV Ground Target Tracking via Deep Reinforcement Learning. IEEE Access 2020, 8, 29064–29074. [Google Scholar] [CrossRef]
- Wei, K.; Huang, K.; Wu, Y.; Li, Z.; He, H.; Zhang, J.; Chen, J.; Guo, S. High-Performance UAV Crowdsensing: A Deep Reinforcement Learning Approach. IEEE Internet Things J. 2022, 9, 18487–18499. [Google Scholar] [CrossRef]
- Zhu, B.; Bedeer, E.; Nguyen, H.H.; Barton, R.; Henry, J. Joint Cluster Head Selection and Trajectory Planning in UAV-Aided IoT Networks by Reinforcement Learning with Sequential Model. IEEE Internet Things J. 2021, 9, 12071–12084. [Google Scholar] [CrossRef]
- Zhu, S.; Gui, L.; Cheng, N.; Sun, F.; Zhang, Q. Joint Design of Access Point Selection and Path Planning for UAV-Assisted Cellular Networks. IEEE Internet Things J. 2019, 7, 220–233. [Google Scholar] [CrossRef]
- Cui, Z.; Wang, Y. UAV Path Planning Based on Multi-Layer Reinforcement Learning Technique. IEEE Access 2021, 9, 59486–59497. [Google Scholar] [CrossRef]
- Wang, Z.; Rong, H.; Jiang, H.; Xiao, Z.; Zeng, F. A Load-Balanced and Energy-Efficient Navigation Scheme for UAV-Mounted Mobile Edge Computing. IEEE Trans. Netw. Sci. Eng. 2022, 9, 3659–3674. [Google Scholar] [CrossRef]
- Zhang, L.; Jabbari, B.; Ansari, N. Deep Reinforcement Learning Driven UAV-assisted Edge Computing. IEEE Internet Things J. 2022. [Google Scholar] [CrossRef]
- Chang, H.; Chen, Y.; Zhang, B.; Doermann, D. Multi-UAV Mobile Edge Computing and Path Planning Platform Based on Reinforcement Learning. IEEE Trans. Emerg. Top. Comput. Intell. 2021, 6, 489–498. [Google Scholar] [CrossRef]
- Liu, R.; Qu, Z.; Huang, G.; Dong, M.; Wang, T.; Zhang, S.; Liu, A. DRL-UTPS: DRL-based Trajectory Planning for Unmanned Aerial Vehicles for Data Collection in Dynamic IoT Network. IEEE Trans. Intell. Veh. 2022, 1–14. [Google Scholar] [CrossRef]
- Hsu, Y.-H.; Gau, R.-H. Reinforcement Learning-Based Collision Avoidance and Optimal Trajectory Planning in UAV Communication Networks. IEEE Trans. Mob. Comput. 2022, 21, 306–320. [Google Scholar] [CrossRef]
- Xi, Z.; Wu, D.; Ni, W.; Ma, X. Energy-Optimized Trajectory Planning for Solar-Powered Aircraft in a Wind Field Using Reinforcement Learning. IEEE Access 2022, 10, 87715–87732. [Google Scholar] [CrossRef]
- Babu, N.; Donevski, I.; Valcarce, A.; Popovski, P.; Nielsen, J.J.; Papadias, C.B. Fairness-Based Energy-Efficient 3-D Path Planning of a Portable Access Point: A Deep Reinforcement Learning Approach. IEEE Open J. Commun. Soc. 2022, 3, 1487–1500. [Google Scholar] [CrossRef]
- Xie, H.; Yang, D.; Xiao, L.; Lyu, J. Connectivity-Aware 3D UAV Path Design with Deep Reinforcement Learning. IEEE Trans. Veh. Technol. 2021, 70, 13022–13034. [Google Scholar] [CrossRef]
- Bayerlein, H.; Theile, M.; Caccamo, M.; Gesbert, D. Multi-UAV Path Planning for Wireless Data Harvesting with Deep Reinforcement Learning. IEEE Open J. Commun. Soc. 2021, 2, 1171–1187. [Google Scholar] [CrossRef]
- Li, Y.; Aghvami, A.H.; Dong, D. Path Planning for Cellular-Connected UAV: A DRL Solution with Quantum-Inspired Experience Replay. IEEE Trans. Wirel. Commun. 2022, 21, 7897–7912. [Google Scholar] [CrossRef]
- Khamidehi, B.; Sousa, E.S. Reinforcement Learning-aided Safe Planning for Aerial Robots to Collect Data in Dynamic Environments. IEEE Internet Things J. 2022, 9, 13901–13912. [Google Scholar] [CrossRef]
- Wang, X.; Gursoy, M.C.; Erpek, T.; Sagduyu, Y.E. Learning-Based UAV Path Planning for Data Collection with Inte-grated Collision Avoidance. IEEE Internet Things J. 2022, 9, 16663–16676. [Google Scholar] [CrossRef]
- Li, D.; Yin, W.; Wong, W.E.; Jian, M.; Chau, M. Quality-Oriented Hybrid Path Planning Based on A* and Q-Learning for Unmanned Aerial Vehicle. IEEE Access 2021, 10, 7664–7674. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter Symbols. | Parameter Name | Parameter Setting Value |
|---|---|---|
| Number of states | 8 | |
| Number of movements | 4 | |
| Number of training rounds | 700 | |
| Discount Factor | 0.95 | |
| Learning Rate | 0.0001 | |
| Experience pool capacity | 100,000 | |
| Update Frequency | 2 | |
| Number of samples taken | 128 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, J.; Gan, Z.; Liang, J.; Wang, C.; Yue, K.; Li, W.; Li, Y.; Li, R. Path Planning Research of a UAV Base Station Searching for Disaster Victims’ Location Information Based on Deep Reinforcement Learning. Entropy 2022, 24, 1767. https://doi.org/10.3390/e24121767
Zhao J, Gan Z, Liang J, Wang C, Yue K, Li W, Li Y, Li R. Path Planning Research of a UAV Base Station Searching for Disaster Victims’ Location Information Based on Deep Reinforcement Learning. Entropy. 2022; 24(12):1767. https://doi.org/10.3390/e24121767
Chicago/Turabian StyleZhao, Jinduo, Zhigao Gan, Jiakai Liang, Chao Wang, Keqiang Yue, Wenjun Li, Yilin Li, and Ruixue Li. 2022. "Path Planning Research of a UAV Base Station Searching for Disaster Victims’ Location Information Based on Deep Reinforcement Learning" Entropy 24, no. 12: 1767. https://doi.org/10.3390/e24121767
APA StyleZhao, J., Gan, Z., Liang, J., Wang, C., Yue, K., Li, W., Li, Y., & Li, R. (2022). Path Planning Research of a UAV Base Station Searching for Disaster Victims’ Location Information Based on Deep Reinforcement Learning. Entropy, 24(12), 1767. https://doi.org/10.3390/e24121767