1. Introduction
The concept of entropy is very central to information theory. In source coding, the expected number of bits required (per letter) to encode a source with (finite) alphabet set
and probability distribution
P is the Shannon entropy
. If the compressor does not know the true distribution
P, but assumes a distribution
Q (mismatch), then the number of bits required for compression is
, where
is the entropy of
P relative to
Q (or the Kullback–Leibler divergence). In his seminal paper, Shannon [
1] argued that
can also be regarded as a measure of uncertainty. Subsequently, Rényi [
2] introduced an alternate measure of uncertainty, now known as
Rényi entropy of order
, as
where
and
. Rényi entropy can also be regarded as a generalization of the Shannon entropy as
. Refer Aczel and Daroczy [
3] and the references therein for an extensive study of various measures of uncertainty and their characterizations.
In 1965, Campbell [
4] gave an operational meaning to Rényi entropy. He showed that, instead of expected code lengths, if one minimizes the cumulants of code lengths, then the optimal cumulant is Rényi entropy
, where
with
being the order of the cumulant. He also showed that the optimal cumulant can be achieved by encoding sufficiently long sequences of symbols. Sundaresan (Theorem 8 of [
5]) (c.f. Blumer and McElice [
6]) showed that, in the mismatched case, the optimal cumulant is
, where
is called
α-entropy of P relative to Q or
Sundaresan’s divergence [
7]. Hence,
can be interpreted as the penalty for not knowing the true distribution. The first term in (
3) is sometimes called the Renyi cross-entropy and is analogous to the first term of (
1).
with equality if and only if
.
-divergence can also be regarded as a generalization of the Kullback–Leibler divergence as
. Refer to [
5,
8,
9] for detailed discussions on the properties of
. Lutwak et al. also independently identified
in the context of maximum Rényi entropy and called it an
α-Rényi relative entropy (Equation (
4) of [
10]).
, for
, also arises in robust inference problems (see [
11] and the references therein).
In [
12], Massey studied a guessing problem where one is interested in the expected number of guesses required to guess a random variable
X that assumes values from an infinite set, and found a lower bound in terms of Shannon entropy. Arıkan [
13] studied it for a finite alphabet set and showed that Rényi entropy arises as the optimal solution in minimizing moments of the number of guesses. Subsequently, Sundaresan [
5] showed that the penalty in guessing according to a distribution
Q when the true distribution is
P, is given by
. It is interesting to note that guesswork has also been studied from a large deviations point of view [
14,
15,
16,
17,
18]. Bunte and Lapidoth [
8] studied a problem on partitioning of tasks and showed that Rényi entropy and Sundaresan’s divergence play a similar role in the optimal number of tasks performed. We propose, in this paper, a variant of this problem where the tasks in each subset of the partition are performed according to the decreasing order of probabilities. We show that Rényi antropy and Sundaresan’s divergences arise as optimal solutions in this problem too. Huleihel et al. [
19,
20] studied the memoryless guessing problem, a variant of Arıkan’s guessing problem, with i.i.d. (independent and identically distributed) guesses and showed that the minimum attainable factorial moments of number of guesses is the Rényi entropy. We show, in this paper, that the minimum factorial moment in the mismatched case is measured by the Sundaresan’s divergence.
We observe that, in all these problems, the objective is to minimize usual moments or factorial moments of random variables, and Rényi entropy and Sundaresan’s divergence arise in optimal solutions. The relationship between source coding and guessing is well-known in the literature. Arıkan and Merhav established a close relationship between lossy source coding and guessing with distortion using large deviation techniques [
14,
21]. The same for the lossless case was done by Hanawal and Sundaresan [
17]. In this paper, we establish a general framework for all the five problems in the IID-lossless case. We then use this to establish upper and lower bounds for the mismatched version of these problems. This helps us find an equivalence among all these problems, in the sense that knowing an asymptotically optimal solution in one problem helps us find the same in all other problems.
Our Contributions in the Paper:
- (a)
a general framework for the problems on source coding, guessing and tasks partitioning;
- (b)
lower and upper bounds for the general framework of these problems both in matched and mis-matched cases;
- (c)
a unified approach to derive bounds for the mismatched version of these problems;
- (d)
a generalized tasks partitioning problem; and
- (e)
establishing operational commonality among the problems.
Organisation of the Paper:
In
Section 2, we present our unified framework, and find conditions under which lower and upper bounds are attained. In
Section 3, we present four well-known information-theoretic problems, namely, Campbell’s source coding, Arıkan’s guessing, Huleihel et al.’s memoryless guessing, and Bunte–Lapidoth’s tasks partitioning, and re-establish and refine major results pertaining to these problems. In
Section 4, we propose and solve a generalized tasks partitioning problem. In
Section 5, we establish a connection among the aforementioned problems. Finally, we summarize and conclude the paper in
Section 6.
2. A General Minimization Problem
In this section, we present a general minimization problem whose optimum solution evaluates to Rényi entropy. We will later show that all problems stated in
Section 3 are particular instances of this general problem.
Proposition 1. Let be such that for some . Then, for ,where denotes the expectation with respect to probability distribution P on , is the Rényi entropy of order α, and . The lower bound is achieved if and only ifwhere . Proof. Observe that
where
is due to the generalised log-sum inequality (Equation (4.1) of [
22]) applied to the function
; and
follows from the hypothesis that
. By taking log and then dividing by
, we obtain (
4). Equality holds in
if and only if
for some constant
and in (b) if and only if
. This completes the proof. □
The left-side of (
4) is called
normalised cumulant of of order ρ. The measure
in (
5) that attains the lower bound in (
4) is called an
α-scaled measure or
escort measure of
P. This measure also arises in robust inference (Equation (
7) of [
11]) and statistical physics [
23]. The above proposition can also be proved using a variational formula as follows. By a version of Donsker–Varadhan variational formula (Propostion 4.5.1 of [
24]), for any real-valued
f on
, we have
where the max is over all probability distributions
Q on
. Taking
and
in (
6), we have
where (a) is by the log-sum inequality (Equation (4.1) of [
22]) and (b) is by applying the constraint
. For
, the inequalities in (a) and (b) are reversed, and the last max is replaced by min. Hence, (
4) follows as the last max is equal to
by (Theorem 1 of [
25]). Equality in
and
holds if and only if
. In addition, the last max is attained when
. This completes the proof. The following is the analogous one for Shannon entropy.
Proposition 2. Let be such that . Then,Equality in (7) is achieved if and only if . Proof. where the penultimate inequality is due to the log-sum inequality. Equality holds in both inequalities if and only if
. □
It is interesting to note that
and
as
in (
4). We now extend Propositions 1 and 2 to sequences of random variables. Let
be the set of all
n-length sequences of elements of
, and
be the
n-fold product distribution of
P on
, that is, for
,
.
Corollary 1. Given any , if is such that for some , then
- (a)
For , - (b)
where denotes the expectation with respect to probability distribution on .
Proof. It is easy to see that and . Applying Propositions 1 and 2, dividing throughout by n and taking , the results follow. □
3. Problem Statements and Known Results
In this section, we discuss Campbell’s source coding problem, Arıkan’s guessing problem, Huleihel et al.’s memoryless guessing problem, and Bunte–Lapidoth’s tasks partitioning problem. Using the general framework presented in the previous section, we re-establish known results, and present a few new results relating to these problems.
3.1. Source Coding Problem
Let
X be a random variable that assumes values from a finite alphabet set
according to a probability distribution
P. The tuple
is usually referred to as a
source. A
binary codeC is a mapping from
to the set of finite length binary strings. Let
be the length of code
. The objective is to find a
uniquely decodable code that minimizes the expected code-length, that is,
over all uniquely decodable codes
C. Kraft and McMillan independently proved the following relation between uniquely decodable codes and their code-lengths.
Kraft-McMilan Theorem [
26]:
If C a uniquely decodable code, thenConversely, given a length sequence that satisfies the above inequality, there exists a uniquely decodable code C with the given length sequence.Thus, one can confine the search space for
C to codes satisfying the Kraft–McMillan inequality (
11).
Theorem 5.3.1 of [
26]:
If C is a uniquely decodable code, then . Proof. Choose
, where
is the length of code
assigned to alphabet
x. Since
C is uniquely decodable, from (
11), we have
. Now, an application of Proposition 2 with
yields the desired result. □
Theorem 1. Let be an i.i.d. sequence from following the product distribution . Let , where Q is another probability distribution. Let be a code such that . Then, satisfies Kraft–McMillan inequality and Proof. Choose
, where
is the length of code
assigned to sequence
. Then, we have
An application of Proposition 3 with
yields
. Furthermore, we also have
An application of Proposition 4 with
gives
. □
3.2. Campbell Coding Problem
Campbell’s coding problem is similar to Shannon’s source coding problem except that, instead of minimizing the expected code-length, one is interested in minimizing the normalized cumulant of code lengths, that is,
over all uniquely decodable codes
C, and
. This problem was shown to be equivalent to minimizing buffer overflow probability by Humblet in [
27]. A lower bound for the normalized cumulants in terms of Rényi entropy was provided by Campbell [
4].
Lemma 1 of [
4]:
Let C be a uniquely decodable code. Then,where Proof. Apply Proposition 1 with and . □
Notice that, if we ignore the integer constraint of the length function, then
with
as in Proposition 1, satisfies (
11) and achieves the lower bound in (
12). Campbell also showed that the lower bound in (
12) can be achieved by encoding long sequences of symbols with code-lengths close to (
13).
Theorem 1 of [
4]:
If is a uniquely decodable code such that Proof. Choose
. Then, from (
14), we have
The result follows by applying Propositions 3 and 4 with , and . □
Mismatch Case:
Redundancy in the mismatched case of the Campbell’s problem was studied in [
5,
6]. Sundaresan showed that the difference in the normalized cumulant from the minimum when encoding according to an arbitrary uniquely decodable code is measured by
-divergence up-to a factor of 1 [
5]. We provide a more general version of this result in the following.
Proposition 5. Let X be a random variable that assumes values from set according to a probability distribution P. Let and be an arbitrary length function that satisfies (11). Definewhere the minimum is over all length functions K satisfying (11). Then, there exists a probability distribution such thatwhere . Proof. Since
K satisfies (
11), an application of Proposition 1 with
gives us
. Since
satisfies (
11) and
, applying Proposition 3 with
, and
, we have
that is, the minimum in (
15) is between
and
. Hence,
Let us now define a probability distribution
as
Then,
where
. Applying Propositions 3 and 4 with
,
,
, we obtain
Combining (
17) and (
18), we obtain the desired result. □
We remark that the bound in (
16) can be loose when
is small. For example, for a source with two symbols, say
x and
y, with code lengths
, we have
. However, if one imposes the constraint
, then (
16) simplifies to
which is (Theorem 8 of [
5]).
is, in a sense, the penalty when
does not match the true distribution
P. In view of this, a result analogous to Proposition 5 also holds for the Shannon source coding problem.
3.3. Arıkan’s Guessing Problem
Let be a set of objects with . Bob thinks of an object X (a random variable) from according to a probability distribution P. Alice guesses it by asking questions of the form “Is ?”. The objective is to minimize average number of guesses required for Alice to guess X correctly. By a guessing strategy (or guessing function), we mean a one-one map , where is to be interpreted as the number of questions required to guess x correctly. Arıkan studied the moment of number of guesses and found upper and lower bounds in terms of Rényi entropy.
Theorem 1 of [
13]:
Let G be any guessing function. Then, for , Proof. Let G be any guessing function. Let . Then, we have . An application of Proposition 1 with yields the desired result. □
Arıkan showed that an optimal guessing function guesses according to the decreasing order of
P-probabilities with ties broken using an arbitrary but fixed rule [
13]. He also showed that normalized cumulant of an optimal guessing function is bounded above by the Rényi entropy. Next, we present a proof of this using our general framework.
Proposition 4 of [
13]:
If is an optimal guessing function, then, for , Proof. Let us rearrange the probabilities
in non-increasing order, say
Then, the optimal guessing function
is given by
if
. Let us index the elements in set
as
, according to the decreasing order of their probabilities. Then, for
, we have
That is,
for
. Now, an application of Proposition 3 with
,
,
and
, gives us
□
Arıkan also proved that the upper bound of Rényi entropy can be achieved by guessing long sequences of letters in an i.i.d. fashion.
Proposition 5 of [
13]
Let be a sequence of i.i.d. guesses. Let be an optimal guessing function. Then, for , Proof. Let
be the optimal guessing function from
to
. An application of Corollary 1 with
and
yields
As in the proof of the previous result, we know that
for
. Hence, an application of Proposition 3 with
,
, and
yields
Combining (20) and (21), we obtain the desired result. □
Henceforth, we shall denote the optimal guessing function corresponding to a probability distribution P by .
Mismatch Case:
Suppose Alice does not know the true underlying probability distribution P, and guesses according to some guessing function G. The following proposition tells us that the penalty for deviating from the optimal guessing function can be measured by -divergence.
Proposition 6. Let G be an arbitrary guessing function. Then, for , there exists a probability distribution on such that Proof. Let
G be a guessing function. Define a probability distribution
on
as
Then, we have
Now, an application of Proposition 4 with
,
, and
yields the desired result. □
A converse result is the following.
Proposition 1 of [
5]:
Let be an optimal guessing function associated with Q. Then, for ,where the expectation is with respect to P. Proof. Let us rearrange the probabilities
in non-increasing order, say
By definition,
if
. Then, as in (
19), we have
. Hence, an application of Proposition 3 with
,
, and
proves the result. □
Observe that, given a guessing function
G, if we apply the above proposition for
, where
is as in (22), then we obtain
Thus, the above two propositions can be combined to state the following, which is analogous to Proposition 5 (refer
Section 3.2).
Theorem 6 of [
5]:
Let G be an arbitrary guessing function and be the optimal guessing function for P. For , letThen, there exists a probability distribution such that 3.4. Memoryless Guessing
In memoryless guessing, the setup is similar to that of Arıkan’s guessing problem except that this time the guesser Alice comes up with guesses independent of her previous guesses. Let
be Alice’s sequence of independent guesses according to a distribution
. The guessing function in this problem is defined as
that is, the number of guesses until a successful guess. Sundaresan [
28], inspired by Arıkan’s result, showed that the minimum expected number of guesses required is
, and the distribution that achieves this is surprisingly not the underlying distribution
P, but the “tilted distribution”
.
Unlike in Arıkan’s guessing problem, Huleihel et al. [
19] minimized what are called factorial moments, defined for
as
Huleihel et al. [
19] (c.f. [
20]) studied the following problem.
over all
, where
is the probability simplex that is,
. Let
be the optimal solution of the above problem.
Theorem 1 of [
19]:
For any integer , we have and Proof. Now, the result follows from Proposition 1 with and . Indeed, since is a probability distribution, we have . Hence, , and the lower bound is attained by . □
For a sequence of guesses, the above theorem can be stated in the following way. Let
), where
’s are i.i.d. guesses, drawn from
with distribution
—the
n-fold product distribution of
on
. If the true underlying distribution is
, then
where
. For the mismatched case, we have the following result.
Proposition 7. If the true underlying probability distribution is P, but Alice assumes it as Q and guesses according to its optimal one, namely , then Proof. Due to (23), the result follows easily by taking , , in Propositions 3 and 4. □
3.5. Tasks Partitioning Problem
Encoding of Tasks problem studied by Bunte and Lapidoth [
8] can be phrased in the following way. Let
be a finite set of tasks. A task
X is randomly drawn from
according to a probability distribution
P, which may correspond to the frequency of occurrences of tasks. Suppose these tasks are associated with
M keys. Typically,
. Due to a limited availability of keys, more than one task may be associated with a single key. When a task needs to be performed, the key associated with it is pressed. Consequently, all tasks associated with this key will be performed. The objective in this problem is to minimize the number of redundant tasks performed. Usual coding techniques suggest assigning tasks with high probability to individual keys and leaving the low probability tasks unassigned. It may just be the case that some tasks may have a higher frequency of occurrence than others. However, for an individual, all tasks can be equally important. If
, then one can perform tasks without any redundancy. However, Bunte and Lapidoth [
8] showed that, even when
, one can accomplish the tasks with much less redundancy on average, provided the underlying probability distribution is different from the uniform distribution.
Let be a partition of that corresponds to the assignment of tasks to M keys. Let be the cardinality of the subset containing x in the partition. We shall call A the partition function associated with partition . We shall assume that throughout this section, though some of the results hold even when .
Theorem I.1 of [
8]:
The following results hold.- (a)
For any partition of of size M with partition function A, we have - (b)
If , then there exists a partition of of size at most M with partition function A such thatwhere
Proof. Part (a): Let
. Then, we have
(Prop. III-1 of [
8]). Now, an application of Proposition 1 with
gives us the desired result.
Part (b): For the proof of this part, we refer to [
8]. □
Bunte and Lapidoth also proved the following limit results.
Theorem I.2 of [
8]:
Then, for every , there exists a partition of of size at most with an associated partition function such that where .It should be noted that, in a general set-up of the tasks partitioning problem, it is not necessary that the partition size is of the form ; it can be some (a function of n). Consequently, we have the following result.
Proposition 8. Let be a sequence of positive integers such that , andexists. Then, there exists a sequence of partitions of of size at most with partition functions such that Proof. Let
We first claim that
. Indeed, since
, when
, we have
. On the other hand, when
, we can find an
such that
. Thus, we have
. Consequently,
This proves the claim. From Theorem I.1 of [
11], for any
and
, there exists a partition
of
of size at most
such that the associated partition function
satisfies
Part (a): When
, let us choose
. Then, there exists an
such that
. Thus, we have
Consequently,
. We also note that
for all
.
Thus, .
Part (b): For any
, there exists an
such that
. Thus, we have
Hence, we have
Furthermore, an invocation of Corollary 1 with
and
gives us
□
Remark 1. It is interesting to note that, when , in addition to the fact that , we also have for large values of n.
Mismatch Case:
Let us now suppose that one does not know the true underlying probability distribution P, but arbitrarily partitions . Then, the penalty due to such a partition can be measured by the -divergence as stated in the following theorem.
Proposition 9. Let be a partition of of size M with partition function A. Then, there exists a probability distribution on such that Proof. Define a probability distribution
as
Then,
where the last equality follows due to Proposition III.1 of [
8]. Rearranging terms, we have
. Hence, an application of Propositions 3 and 4 with
,
,
,
, and
yields the desired result. □
A converse result is the following.
Proposition 10. Let X be a random task from following distribution P and . Let Q be another distribution on . If , then there exists a partition (with an associated partition function ) of of size at most M such thatwhere is as in (24).
Proof. Similar to proof of Theorem I.1 of [
8]. □
4. Ordered Tasks Partitioning Problem
In Bunte–Lapidoth’s tasks partitioning problem [
8], one is interested in the average number of tasks associated with a key. However, in some scenarios, it might be more important to minimize the average number of redundant tasks performed, before the intended task. To achieve this, tasks associated with a key should be performed in a decreasing order of their probabilities. With such a strategy in place, this problem draws parallel with Arıkan’s guessing problem [
13].
Let be a partition of that corresponds to the assignment of tasks to M keys. Let be the number of redundant tasks performed until and including the intended task x. We refer to as the count function associated with partition . We suppress the dependence of N on for the sake of notational convenience. If X denotes the intended task, then we are interested in the moment of number of tasks performed, that is, , where .
Lemma 1. For any count function associated with a partition of size M, we have Proof. For a partition
of
, observe that
Since
, for any
, we have
where (a) follows due to the AM–GM inequality. □
Proposition 11. Let X be a random task from following distribution P. Then, the following hold:
- (a)
For any partition of of size M, we have - (b)
Let . Then, there exists a partition of of size at most M with count function N such thatwhere is as in (24).
Proof. Part (a): Applying Proposition 1 with and , we obtain the desired result.
Part (b): If
A and
N are, respectively, the partition and count functions of a partition
, then we have
for
. Once we observe this, the proof is same as Theorem I.1 (b) of [
8]. □
Proposition 12. Let be a sequence of positive integers such that , and exists. Then, there exists a sequence of partitions of of size at most with count functions such that
Proof. Similar to proof of Proposition 8. □
Remark 2. - (a)
If we choose the trivial partition, namely , then the ordered tasks partitioning problem simplifies to Arıkan’s guessing problem, that is, we have , and (26)
simplifies to Hence, all results pertaining to the Arıken’s guessing problem can be derived from the ordered tasks partitioning problem.
- (b)
Structurally, ordered tasks partitioning problem differs from the Bunte–Lapidoth’s problem only due the factor in (28). While this factor matters for one-shot results, for a sequence of i.i.d. tasks, this factor vanishes asymptotically.
Mismatch Case:
Let us now suppose that one does not know the true underlying probability distribution P, but arbitrarily partitions and executes tasks within each subset of this partition in an arbitrary order. Then, the penalty due to such a partition and ordering can be measured by the -divergence as stated in the following propositions.
Proposition 13. Let be a partition of of size M with count function N. Then, there exists a probability distribution on such that Proof. Define a probability distribution
as
Then, by Lemma 1, we have
Now, an application of Proposition 4 with
,
,
, and
yields the desired result. □
A converse result is the following.
Proposition 14. Let X be a random task from following distribution P. Let Q be another distribution on . If , then there exists partition (with an associated count function ) of of size at most M such thatwhere is as in (24).
Proof. Identical to the proof of Proposition 11(b). □
5. Operational Connection among the Problems
In this section, we establish an operational relationship among the five problems (refer
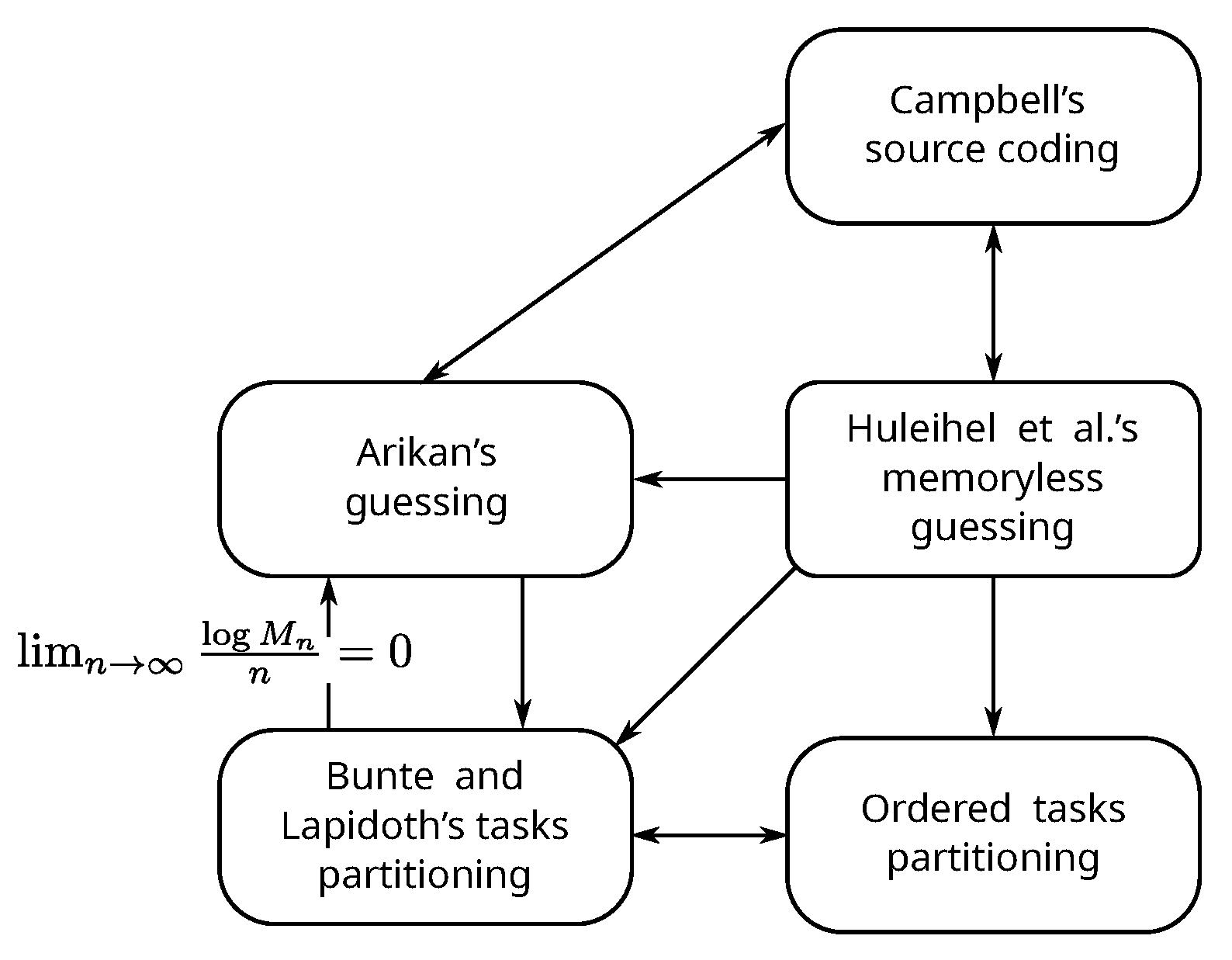
Figure 1) that we studied in the previous section. The relationship we are interested in is “Does knowing an optimal or asymptotically optimal solution in one problem helps us find the same in another?” In fact, we end up showing that, under suitable conditions, all the five problems form an equivalence class with respect to the above-mentioned relation.
In this section, we assume . First, we make the following observations:
Among the five problems discussed in the previous section, only Arıkan’s guessing and Huleihel et al.’s memoryless guessing have a unique optimal solution; others only have asymptotically optimal solutions.
Optimal solution of Huleihel et al.’s memoryless guessing problem is the -scaled measure of the underlying probability distribution P. Hence, knowledge about the optimal solution of this problem implies knowledge about an optimal (or asymptotically optimal) solution of all other problems.
Among the Bunte–Lapidoth’s and ordered tasks problems, an asymptotically optimal solution of one yields that of the other. The partitioning lemma (Prop. III-2 of [
8]) is the key result in these two problems, as it guarantees the existence of the asymptotically optimal partitions in both these problems.
5.1. Campbell’s Coding and Arıkan’s Guessing
An attempt to find a close relationship between these two problems was made, for example, by Hanawal and Sundaresan (Section II of [
17]). Here, we show the equivalence between asymptotically optimal solutions of these two problems.
Proposition 15. An asymptotically optimal solution exists for Campbell’s source coding problem if and only if an asymptotically optimal solution exists for Arıkan’s guessing problem.
Proof. Let
be an asymptotically optimal sequence of guessing functions, that is,
Define
where
is the normalization constant. Notice that
Let us now define
Then, by (Proposition 1 of [
17]),
Hence,
Thus, we have
We observe that
Consequently, from (
12), we have
Thus, is an asymptotically optimal sequence of length functions for Campbell’s coding problem.
Conversely, given an asymptotically optimal sequence of length functions
for Campbell’s coding problem, define
Let
be the guessing function on
that guesses according to the decreasing order of
-probabilities. Then, by (Proposition 2 of [
17]),
Thus,
Furthermore, from Theorem 1 of [
13], we have
This completes the proof. □
5.2. Arıkan’s Guessing and Bunte–Lapidoth’s Tasks Partitioning Problem
Bracher et al. found a close connection between Arıkan’s guessing problem and Bunte–Lapidoth’s tasks partitioning problem in the context of distributed storage [
29]. In this section, we establish a different relation between these problems.
Proposition 16. An asymptotically optimal solution of Arıkan’s guessing problem gives rise to an asymptotically optimal solution of tasks partitioning problem.
Proof. Let
be an asymptotically optimal sequence of guessing functions. Define
where
is the normalization constant. Let
be the partition function satisfying
guaranteed by (Proposition III-2 of [
8]), where
Thus, we have
where (a) holds because
; and (b) hold because
for
. Hence,
where
is as in (25); and inequality (c) follows from Proposition 4 of [
13] proved in
Section 3. Thus, if
is such that
and if
exists and
, then we have
Since
, we have
. When
, arguing along the lines of proof of Proposition 8(b), it can be shown than
□
Reverse implication of the above result does not hold always due to the additional parameter in the tasks partitioning problem. For example, if and for every , the partition does not provide any information about the underlying distribution. As a consequence, we will not be able to conclude anything about the optimal (or asymptotically optimal) solutions of other problems. However, if is such that increases sub-linearly, then it does help us find asymptotically optimal solutions of other problems.
Proposition 17. An asymptotically optimal sequence of partition functions with partition sizes for the tasks partitioning problem gives rise to an asymptotically optimal solution for the guessing problem if and
Proof. By hypothesis,
For every
, define the probability distribution
where
. Let
be the guessing function that guesses according to the decreasing order of
-probabilities. Then, by (Proposition 2 of [
17]), we have
Hence,
Furthermore, an application of Theorem 1 of [
13] gives us
This completes the proof. □
5.3. Huleihel et al.’s Memoryless Guessing and Campbell’s Coding
We already know that, if one knows the optimal solution of Huleihel et al.’s memoryless guessing problem, that is, the -scaled measure of the underlying probability distribution P, one has knowledge about the optimal (or asymptotically optimal) solution of Campbell’s coding problem. In this section, we prove a converse statement. We first prove the following lemma.
Lemma 2. Let denote the length function corresponding to an optimal solution for Campbell’s coding problem on the alphabet set endowed with the product distribution . Then, .
Proof. Suppose
. Then, we must have
for every
. Define
. We observe that
, that is, the length function
satisfies (
11). Hence, there exists a code
for
such that
. Then, for
, we have
—a contradiction. □
Proposition 18. An asymptotically optimal solution for Huleihel et al.’s memoryless guessing problem exists if an asymptotically optimal solution exists for Campbell’s coding problem.
Proof. Let
denote a sequence of asymptotically optimal length functions of Campbell’s coding problem, that is,
Let us define
Then, we have
where
. Hence,
where (a) holds because
(refer Lemma 2). If we assume the underlying probability distribution to be
instead of
, and perform memoryless guessing according to the escort distribution of
, namely
, due to Proposition 7, we have
□
6. Summary and Conclusions
This paper was motivated by the need to find a unified framework for the problems on source coding, guessing and the tasks partitioning. To that end, we formulated a general moment minimization problem in the IID-lossless case and observed that the optimal value of its objective function is bounded below by Rényi entropy. We then re-established all achievable lower bounds in each of the above-mentioned problems using the generalized framework. It was interesting to note that the optimal solution did not depend on the moment function
, but only on the underlying probability distribution
P and order of the moment
(refer Proposition 1). We also presented a unified framework for the mismatched version of the above-mentioned problems. This framework not only led to refinement of the known theorems, but also helped us identify a few new results. We went on to extend the tasks partitioning problem by asking a more practical question and solved it using the unified theory. Finally, we established an equivalence among these problems, in the sense that an asymptotically optimal solution of one problem yields the asymptotically optimal solution of all other problems. Although the relationship between source coding and guessing is well-known in the literature [
30,
31,
32,
33], their connection to the tasks partitioning problem, and the connection in the mismatched version of the problems are new.
Our unified framework also has the potential to act as a general tool-set and provide insights for similar problems in information theory. For example, in
Section 4, this framework enabled us to solve a more general tasks partitioning problem, namely, the ordered tasks partitioning problem using this framework. The presented that a unified approach can also be extended and explored further in several ways. This includes (a)
Extension to general alphabet set: The guessing problem was originally studied for countably infinite alphabet set by Massey [
12]. Courtade and Verdú have studied the source coding problem for a countably infinite alphabet set with a cumulant generating function of code word lengths as a design criterion [
31]. It would be interesting to see if memory-less guessing and tasks partitioning problems can also be formulated for countably infinite alphabet sets and relationships among the problems can be extended. (b)
More general sources: Relationship between source coding and guessing is very well-known in the literature. Relationship between guessing and source coding in the ‘with distortion’ case for finite alphabet was established by Merhav and Arıkan [
14] and for a countably infinite alphabet by Hanawal and Sundaresan [
34]. Relationship between Guessing and Campbell’s coding in the universal case was established by Sundaresan [
35]. It would be interesting to see if these can be extended to memoryless guessing and tasks partitioning also, possibly in an unified manner. (c)
Applications: Arıkan showed an application of the guessing problem in a sequential decoding problem [
13]. Humblet showed that the cumulant of code-lengths arises in minimizing the probability of buffer overflow in source coding problems [
27]. Rezaee et al. [
36], Salamatian et al. [
20], and Sundaresan [
28] show the application of guessing in the security aspect of password protected systems. Our unified framework has the potential to help solve problems that arise in real life situations and fall in this framework.




{kind=link}
