1. Introduction
Beyond 5G and 6G wireless communication systems, target peak data rates of 100 Gb/s to 1 Tb/s with processing latencies between 10–100 ns [
1]. For such high data rate and low latency requirements, the implementation of a Forward Error Correction (FEC) decoder, which is one of the most complex and computationally intense components in the baseband processing chain, is a major challenge [
2]. Low-Density Parity Check (LDPC) codes [
3] are FEC codes with capacity approaching error correction performance [
4] and are part of many communication standards, e.g., DVB-S2x, Wi-Fi, and 3GPP 5G-NR. In contrast to other competitive FEC codes, like Polar and Turbo codes, the decoding of LDPC codes is dominated by data transfers [
2] making very high-throughput decoders in advanced silicon technologies challenging, especially from routing and energy efficiency perspectives. For example, in a state-of-the-art 14 nm silicon technology, the transfer of 8 bits on a 1 mm wire costs about 1 pJ, whereas the cost of an 8 bit integer addition is only 10 fJ, which is two orders of magnitude less than the wiring energy cost. During Message Passing (MP) decoding, two sets of nodes, the Check Node (CN) and Variable Node (VN), iteratively exchange messages over the edges of a bipartite graph (Tanner graph of the LDPC code). High-throughput decoding can be achieved by mapping the Tanner graph one-to-one onto hardware, i.e., dedicated processing units are instantiated for each node and the edges of the Tanner graph are hardwired. Unrolling and pipelining the decoding iterations can further boost the throughput towards 1 Tb/s [
5], called unrolled full parallel (FP) decoders in the following. However, FP decoders imply large routing challenges, since every edge in the Tanner graph corresponds to
wires, with
I being the number of decoding iterations and
being the quantization-width of the exchanged messages. Moreover, to enable good error correction performance, the Tanner graph exhibits limited locality and regularity, which makes efficient routing even more difficult. This problem is even exacerbated in advanced silicon technologies, as routing scales much worse than transistor density [
6].
Finite Alphabet Message Passing (FA-MP) decoding has been investigated as a method to mitigate the routing challenges in FP LDPC decoders to reduce the bit-width, i.e., the quantization-width
, of the exchanged messages and, thus, the number of necessary wires [
7,
8,
9]. In contrast to conventional MP decoding algorithms like the Belief Propagation (BP) and its approximations, i.e., Min-Sum (MS), Offset Min-Sum (OMS) and Normalized Min-Sum (NMS) [
10], FA-MP use non-uniform quantizers and the node operations are derived by maximizing MI between exchanged messages. Nodes in state-of-the-art FA-MP decoders have to be implemented as Lookup-Tables (LUTs). Since the size of the LUT exponentially increases with the node degree and
, investigations were performed to decompose this multidimensional LUT (mLUT) into a chain or tree with only two-input LUTs (denoted as sequential LUT (sLUT) in this paper) yielding only a linear dependency of the node degree but at the cost of a decreased communications performance [
11,
12]. The Minimum-LUT (Min-LUT) decoder [
13] approximates the CN update by a simple minimum search and can be implemented as Minimum-mLUT (Min-mLUT) or Minimum-sLUT (Min-sLUT), i.e., with mLUT or sLUT for VNs, respectively. Other approaches, e.g., Mutual Information-Maximizing Quantized Belief Propagation (MIM-QBP) [
14,
15,
16] and Reconstruction-Computation-Quantization (RCQ) [
17,
18], are adding non-uniform quantizers and reconstruction mappings to the outputs and inputs of the nodes, respectively, and performing the standard functional operations inside the nodes, e.g., additions for VNs and minimum search for CNs. The reconstruction mappings generally increase the bit resolution required for node internal representation and processing. It can be shown that this approach is equivalent in terms of error correction performance compared to the mLUT, if the internal quantization after the reconstruction mapping is sufficiently large.
Based on the framework of MIM-QBP and RCQ, the proposed MIC decoder [
19] realizes CN updates by a minimum search and VN updates by integer computations that are designed to realize the information maximizing mLUT mappings either exactly or approximately. In this paper, we provide more detailed explanations, extend the discussion to irregular LDPC codes and present a comprehensive implementation analysis. The new contributions of this paper (
Notation: Random variables are denoted by sans-serif letters
x, random vectors by bold sans-serif letters
x, realizations by serif letters
x and vector-valued realizations by bold serif letters
x. Sets are denoted by calligraphic letters
. The distribution
of a random variable x is abbreviated as
.
denotes a Markov chain, and
,
,
denotes the real numbers, integers and Galois field 2, respectively.) are summarized as follows:
We provide a novel criterion for the resolution of internal node operations to ensure that the MIC decoder can always replace the information maximizing VN mLUT exactly;
we show that this MIC decoder has the same communication performance compared to an MI maximizing Min-mLUT decoder;
we make an objective comparison between different FA-MP decoder implementations (Min-mLUT, Min-sLUT, MIC) in an advanced silicon technology and compare them with a state-of-the-art MS decoder for throughput towards 1 Tb/s;
we show that our MIC decoder implementation outperforms state-of-the-art FP decoders in terms of routing complexity, area efficiency and energy efficiency and enables the processing of larger block sizes in state-of-the-art FP decoders since the routing complexity is largely reduced.
The remainder of this paper is structured as follows:
Section 2 reviews the system model, conventional decoding techniques for LDPC codes such as BP and NMS decoding, and Information Bottleneck (IB) based quantization.
Section 3 describes the Min-mLUT and Min-sLUT decoder design for regular and irregular LDPC codes. In
Section 4, we introduce the proposed MIC decoder and, in
Section 5, we discuss the MIC decoder implementation along with a detailed comparison with state-of-the-art FP MP decoders. Finally,
Section 6 concludes the paper.
3. LUT Decoder Design
This section describes the design of the LUT decoder that is optimized via Discrete Density Evolution (DDE) [
11] to maximize
extrinsic information between the codebits and its messages, under the assumption that the Tanner graph is cycle free. In contrast to the BP algorithm, the LUT is optimized to process the quantizer labels
z in (
7) directly and the bit resolution of the message exchange on the Tanner graph is limited to
bits, e.g., 3 or 4 bits. Furthermore, we exploit the signed integer-based representation to simplify the CN update by using the label-based minimum search [
13]. In the Min-mLUT decoder design, the VN update functions are optimized to maximize MI. For the Min-sLUT decoder design, the VN update is decomposed into a sequence of two-dimensional updates that generally results in a MI loss compared to the Min-mLUT decoder design.
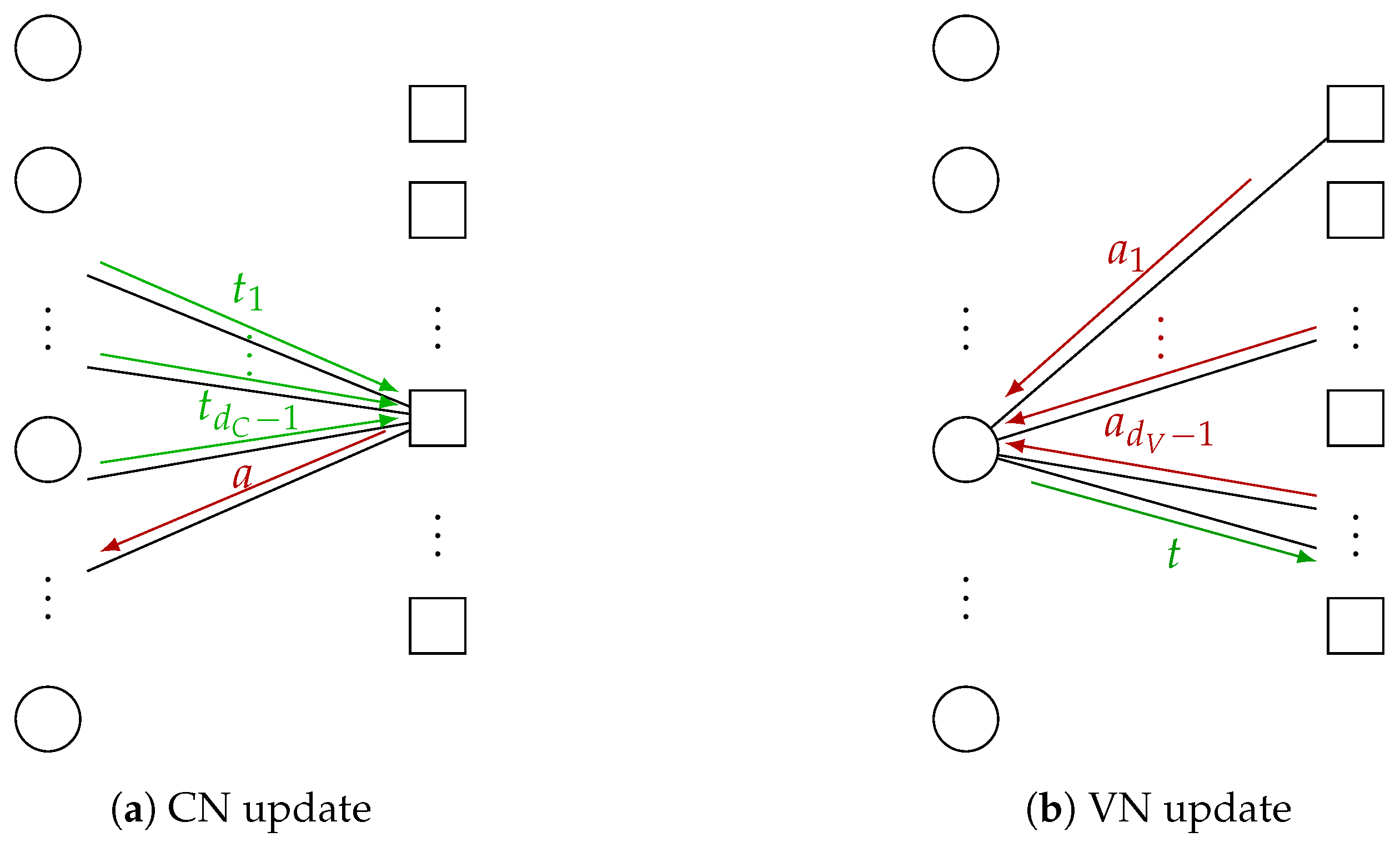
In the following, we review the calculation of the CN and VN distributions for each iteration that are required for the design of the MI maximizing VN update. As illustrated in
Figure 4, we omit the iteration index
i and consider messages of an arbitrary CN and VN for CN degrees
and VN degrees
to calculate the distributions that are required for the Min-mLUT design.
3.1. Check Node LUT Design
The LUT decoder design is based on discrete alphabets
,
and
for the channel information, the VN-to-CN and the CN-to-VN messages, respectively. For the first iteration, the VN-to-CN messages
for
are initialized by the signed integer valued channel information, i.e.,
. The distribution of the
VN-to-CN messages
and an arbitrary codebit
c of a check equation
is [
11]
with
as the modulo 2 sum of connected codebits. The VN-to-CN messages
are processed by a CN update function that generates quantized output messages
that are represented only by
bits.
Given the distribution in (
10), the CN update (We keep the node degrees
or
as index of random variables to indicate that the distribution changes with the corresponding degrees.)
that maximizes MI is determined by the solution of the quantization problem for binary input (
)
As discussed in
Section 2.3, the optimal solution of (
11) is found via dynamic programming.
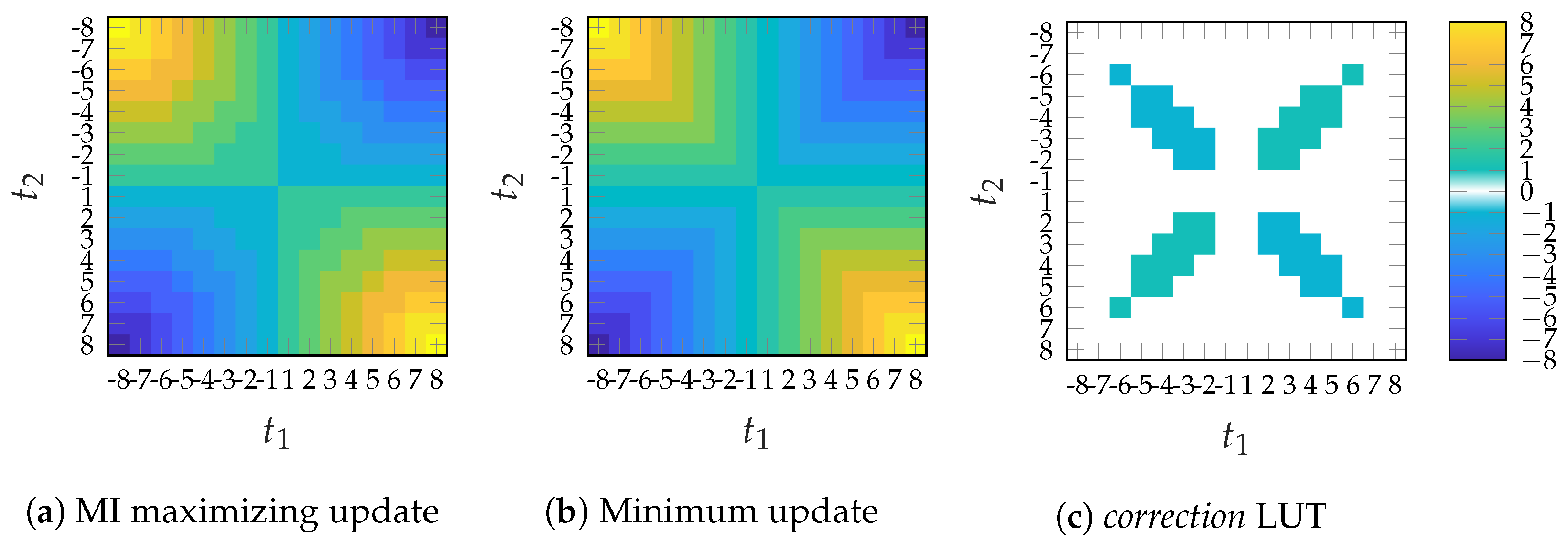
However, we utilize the minimum update [
13] as a CN update for all iterations as an approximation of the MI maximizing CN update in (
11). We observed that the output of the minimum update is quite close to the optimal IB update. As visualized for a degree 3 CN in
Figure 5, the difference between the optimal IB CN and the minimum update can be interpreted as an additive
correction LUT where only a small fraction of entries are nonzero. For the label-based minimum search, the CN update rule reads
If the CN update function is given, the conditional distribution of the CN-to-VN messages
is
In the design via DDE, the connections between VNs and CNs are considered on average by the degree distribution [
26]. Hence, the design considers only the marginal CN-to-VN message distribution
that includes averaging over all possible CN degrees by
3.2. Variable Node LUT Design
For designing the VN update, we require the joint distribution of the discrete channel information
together with the CN-to-VN messages
combined in
and a codebit
c [
11]
where
for
and
is the set of all possible states of the vector
a, i.e.,
. Given the distribution (
15), the individual degree-dependent VN update
that maximizes MI
is determined as the solution of the optimization problem (
)
The parameter
defines the bit-width of the messages exchanged between VN and CN and controls the complexity of the message exchange. The optimization problem in (
16) is the channel quantization problem for binary input (
Section 2.3). The optimal solution is a deterministic input–output relation that can be stored as a
dimensional LUT with
entries, e.g., for
and
, we have approximately
million entries. Furthermore, the communication performance can be increased by considering the degree distribution in the design of the node updates [
13,
26]. The gain in communication performance generally depends on the degree distribution and the message resolution
[
13]. However, a comparison of the different design approaches in [
13,
26] is beyond the scope of this paper. The distribution of the VN-to-CN messages for the next iteration in (
10) is
Again, the marginal distribution is determined by averaging over all possible VN degrees, i.e.,
In case of a regular LDPC code, there is only one possible degree for all VNs and CNs, i.e., the summation term in (
14) and (
18) vanishes but all other steps remain the same.
For the design of the MI maximizing Min-mLUT decoder, we start with an initial VN-to-CN distribution
and iterate over (
10), (
13)–(
18) and declare convergence if
approaches the maximum value of one bit for binary input after
I number of iterations.
3.3. Sequential LUT Design
For the sequential design approach sLUT, the node update is split into a sequence of degree two updates that are optimized independently to maximize MI. This approach serves as an approximation of the mLUT design described in
Section 3.2 and reduces the number of possible memory locations within each update. In general, multidimensional optimization without decomposition conserves more MI compared to a design that decomposes the optimization problem into a sequence of two-dimensional updates [
11,
12] or more general nested tree decompositions [
13].
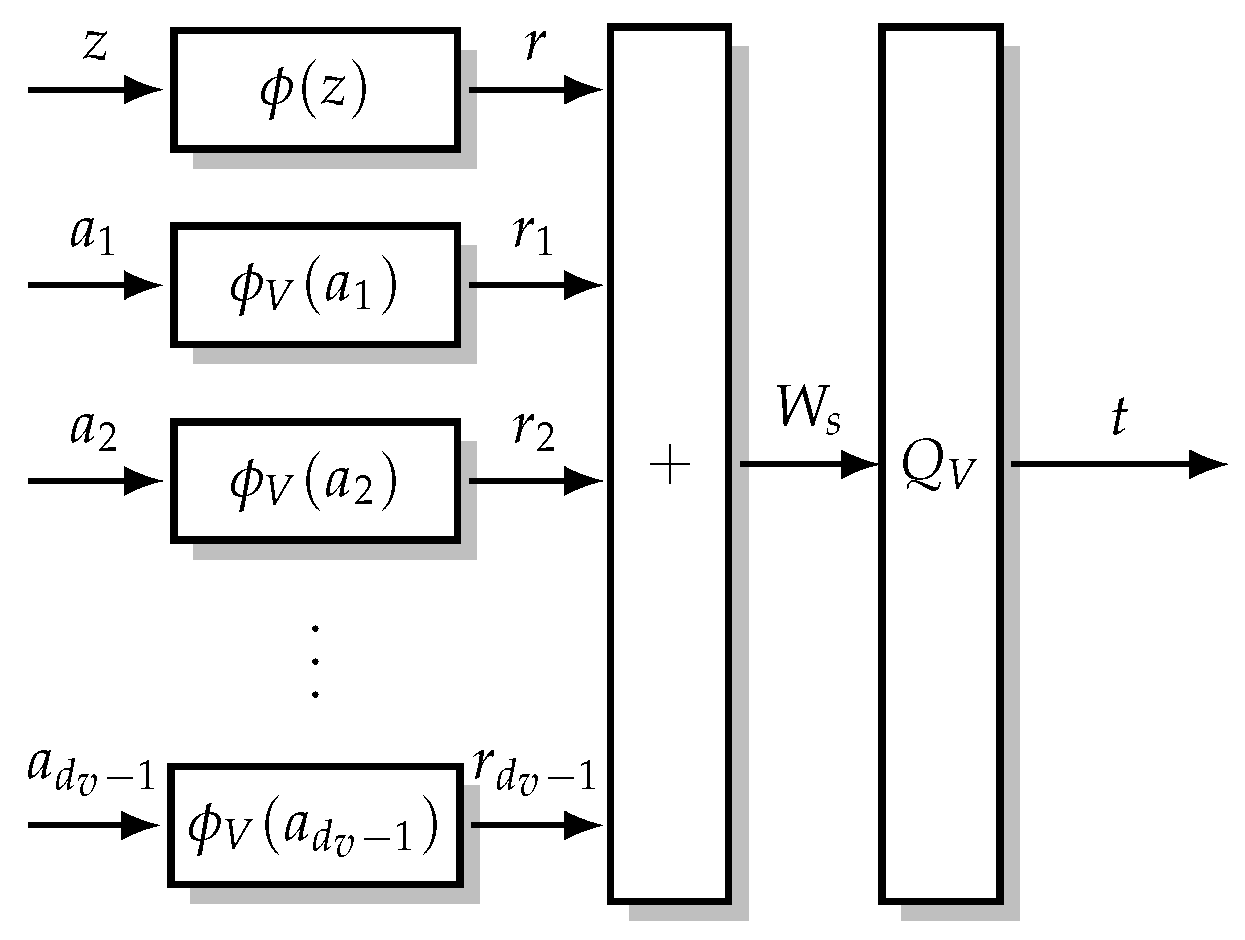
4. Minimum-Integer Computation Decoder Design
The MI maximizing Min-mLUT decoder realizes the discrete VN updates by LUTs with
entries leading to prohibitively large implementation complexity. Nevertheless, determining these multidimensional LUTs in the laboratory is feasible with sufficient computing resources. Thus, the idea is to search for the MI maximizing mLUTs but implement the corresponding discrete functions by relatively simple operations in order to avoid performance degradations. As visualized in
Figure 6, the computational domain framework [
14,
16] replaces the VN update by an operation that is decomposed into
- (i)
mappings and of the -bit CN-to-VN messages and -bit channel information z into node internal -bit signed integers with and , respectively;
- (ii)
execution of integer additions for -bit signed integers;
- (iii)
threshold quantization to bits determining the VN-to-CN message t.
Figure 6.
VN update for computational domain framework [
14,
16]. The
-bit channel information
and the
-bit CN-to-VN messages
are transformed to
-bit signed integers. This transformation generally increases the required bit resolution for the representation, i.e.,
and
. The internal signed integers are summed and quantized back into a
-bit VN-to-CN message
.
Figure 6.
VN update for computational domain framework [
14,
16]. The
-bit channel information
and the
-bit CN-to-VN messages
are transformed to
-bit signed integers. This transformation generally increases the required bit resolution for the representation, i.e.,
and
. The internal signed integers are summed and quantized back into a
-bit VN-to-CN message
.
For the MIC decoder design, we derive a criterion for sufficient internal node resolution such that the mLUT mapping is replaced exactly. Note that the information maximizing mLUT is generated offline and is replaced by an integer function that replaces its functionality exactly or approximately during execution.
To keep the notation simple, we omit the dependency on the iteration index i and node degree in this section.
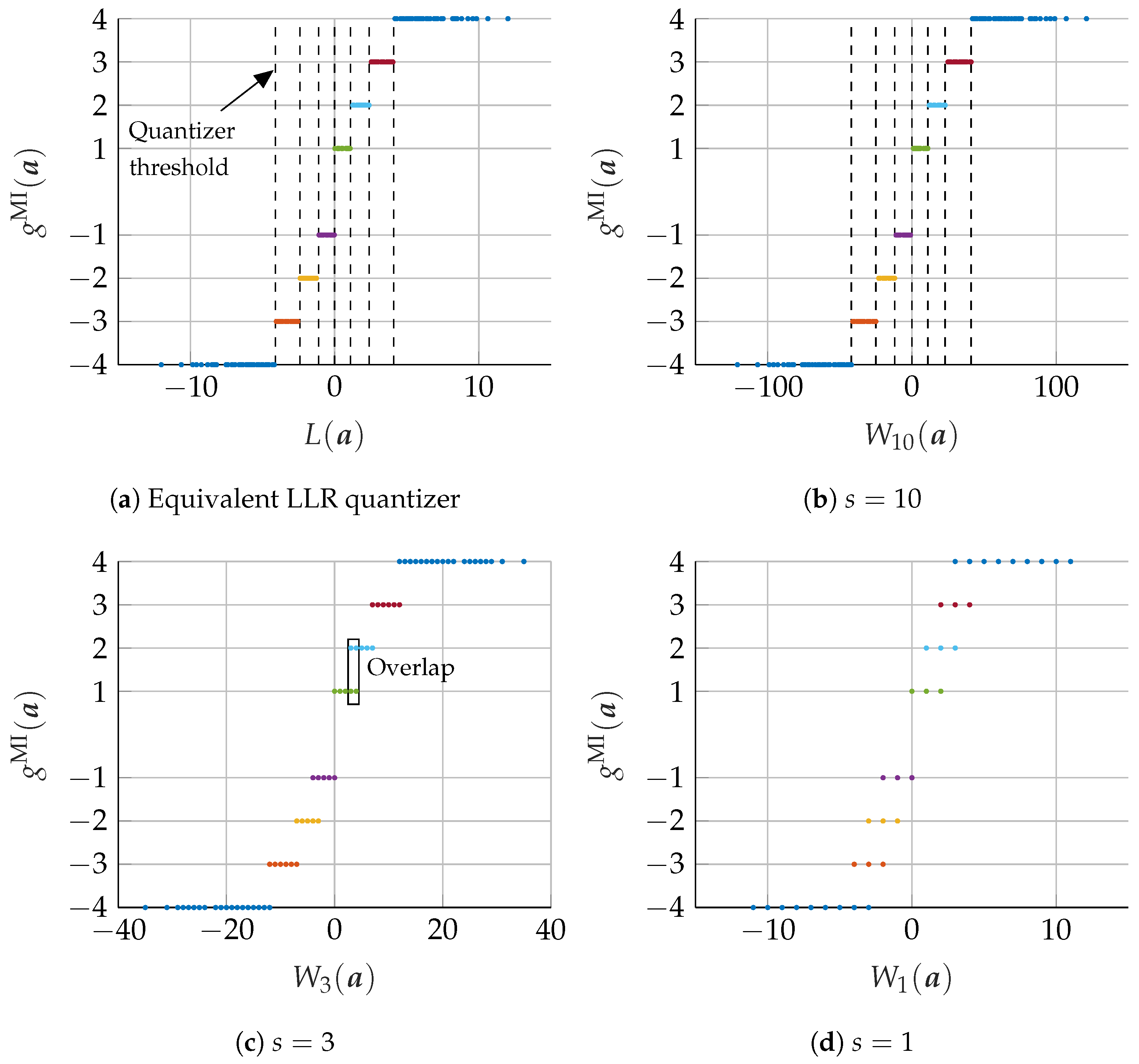
4.1. Equivalent LLR Quantizer
To motivate the integer calculation of the MIC approach, we review the connection between the equivalent LLR quantizer and the VN update of the BP algorithm. Analogous to the VN update of the BP algorithm in (
5), the LLR of the combined message vector
equals the addition of the LLRs of the channel output
z and of the individual messages
, i.e., for every possible combination
, the LLR of the combined message is
The LLRs
of the individual messages are determined by (
14) during DDE. As described in
Section 2.3, the information maximizing quantizer for binary input separates the LLR
by using a
threshold quantizer
, i.e., the relation
can be determined that achieves the same output as the information optimal mLUT in (
16). However, to ensure that (
20) produces the same output as the information optimal mLUT, calculations over real numbers are required. In the next subsection, we show that we can exploit (
20) to find a calculation that requires only a finite resolution. We also provide a condition to limit the resolution that is required for exact calculation of the information optimal mLUT.
4.2. Computations over Integers
The VN update structure using the computational domain framework is visualized in
Figure 6. As suggested by [
14,
16], a possible choice for the integer mappings
and
is given by scaling and rounding the corresponding LLRs
and
, respectively. In addition to [
14,
16], we provide further insights on the optimal choice of the scaling factor based on the relation between the VN update of the BP algorithm and the MI maximizing quantizer design. More precisely, based on the established relation in (
20), we define an integer mapping for the channel information
z and the CN-to-VN messages
in order to replace the computations over real numbers by computations over signed integers (With ⌊·⌉ as round to nearest integer (away from 0 if fraction part is .5))
Compared to (
20), the LLRs
and
have been multiplied by a non-negative scaling factor
s and quantized to the next
-bit signed integer
r and
, respectively. Subsequently, the sum of integers is limited again to
bits by threshold quantizer
. We can interpret the scaling and rounding operation also directly as a mapping of signed integer messages
z and
to
-bit signed integer messages
that requires
bits for the representation, depending on the scaling factor
s.
In the following, we show that we can always find a threshold quantizer
that maps the summation
into a VN-to-CN message
that is identical to the VN-to-CN message of the information optimal VN update in (
20), i.e.,
. First, we consider the set of messages
that are mapped into a specific output
t via the information maximizing VN update
in (
16). Thus, we can identify a corresponding set of integers
. By varying the scaling factor
s, we can always find a scaling value
such that the sets of integer values
for all
are
non-overlapping intervals, i.e.,
with
and
. Condition (
23) ensures that any two different clusters
and
can be separated by a simple threshold operation. The value
is the minimum separation between the LLRs
of the elements of any two neighbouring clusters in (
20) and is always larger than zero since
is a threshold quantizer. If we consider a scaled version of the LLRs
with any real valued scaling factor
, we can always find a threshold quantizers
that achieves the same output as the information optimal mLUT. Scaling the LLRs
by a factor of
ensures that the minimum separation between any two neighbouring clusters is
. Since the influence of the rounding operation can be bounded by
, scaling with a factor of at least
ensures that any two neighbouring clusters
and
are separated by at least one integer and, thus, condition (
23) is satisfied. Hence, we can always find a corresponding integer function
in (
21) that generates exactly the same output as
in (
20).
Furthermore, an approximate integer calculation is found if the integer valued range of
and
are limited to
-bits
where
is the bit resolution that is required for exact representation if the largest magnitude of the individual LLRs in (
20) is
. If condition (
23) is not fulfilled, we select the output cluster that maximizes MI. If (
24) is satisfied, the required bit resolution of the summation
in (
21) is limited by
To consider the influence of this new mapping in the design of subsequent iterations, we also update the VN-to-CN distribution in (
17).
We note that the MIC design approach can also be applied for the design of CN operations and can also be used to generate exact or approximate representations of nested tree decompositions similar to the sLUT method. However, the corresponding investigations are beyond the scope of this paper.
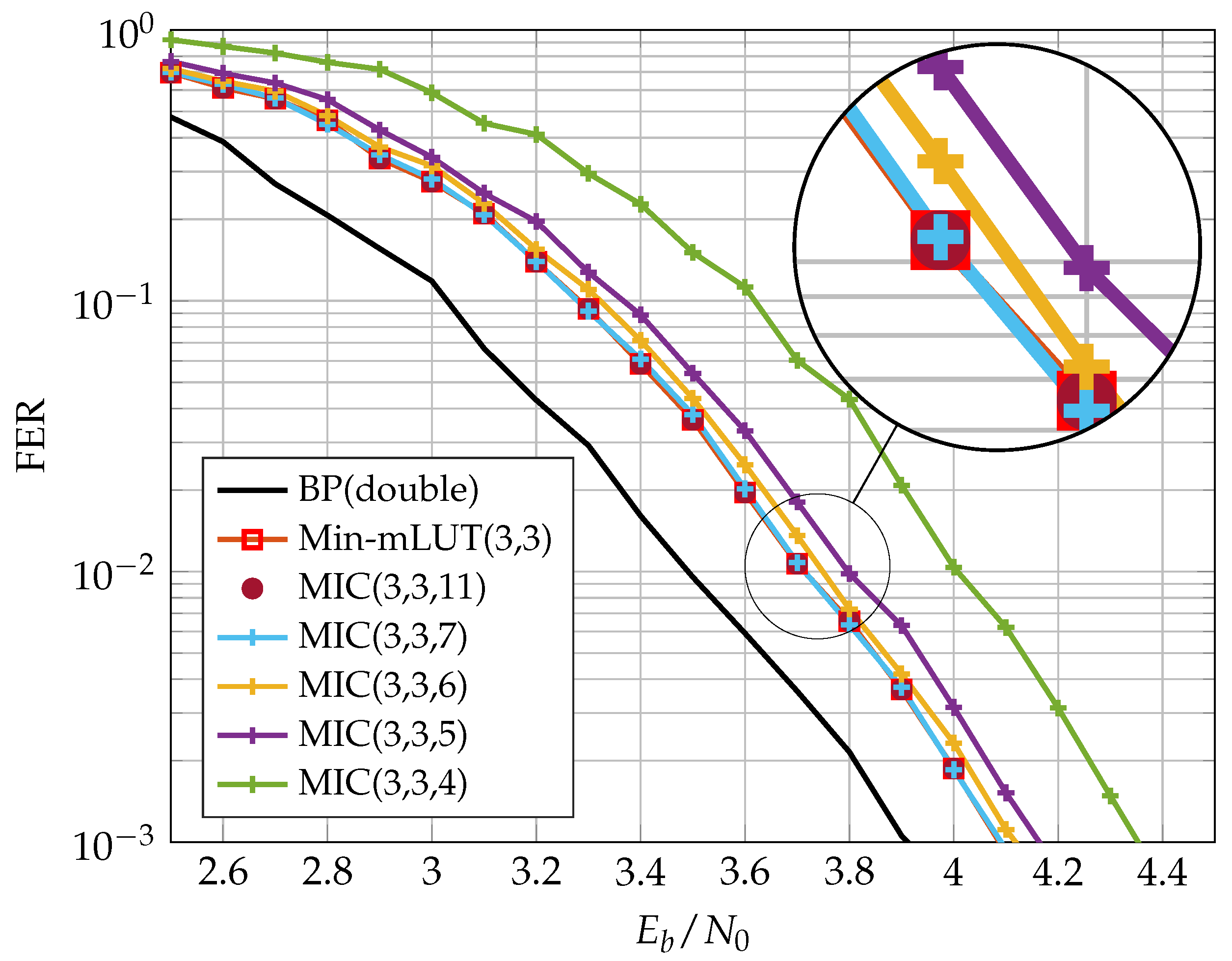
4.3. FER Results
In this section, we discuss the communication performance of the proposed MIC decoder for an irregular LDPC code from the 802.11n standard [
27] of length
with rate
and edge degree distributions
and
. The realization of the MIC decoder is characterized by three quantization parameters and specified by MIC(
). In contrast, the Min-mLUT decoder with label based minimum operation as CN update has only two parameters and is denominated by Min-mLUT(
).
Figure 8 shows the Frame Error Rate (FER) performance of Min-mLUT and MIC for
and
iterations, but varying resolution of internal messages
for MIC.
The BP decoder with double precision serves as our benchmark simulation. The Min-mLUT decoder with
bit quantization for the message exchange and channel information results in a minor performance degeneration of only
dB at a FER of
w.r.t. the benchmark simulation. In comparison, the proposed MIC decoder that replaces the VN update of the Min-mLUT decoder by using the computational domain framework with internal messages of size
results in a loss of 0.25 dB compared to the Min-mLUT decoder. The performance gain of the MIC decoder by using
compared to
is around 0.1 dB. The MIC decoder with
has basically identical FER performance compared to the Min-mLUT decoder. If
, the MIC decoder represents the mLUT functionality exactly by meeting the criterion (
23), but the gain in communication performance compared to the MIC decoder with
is negligible. Additionally, MIC decoding does not require LUTs with up to 262k entries for each iteration.
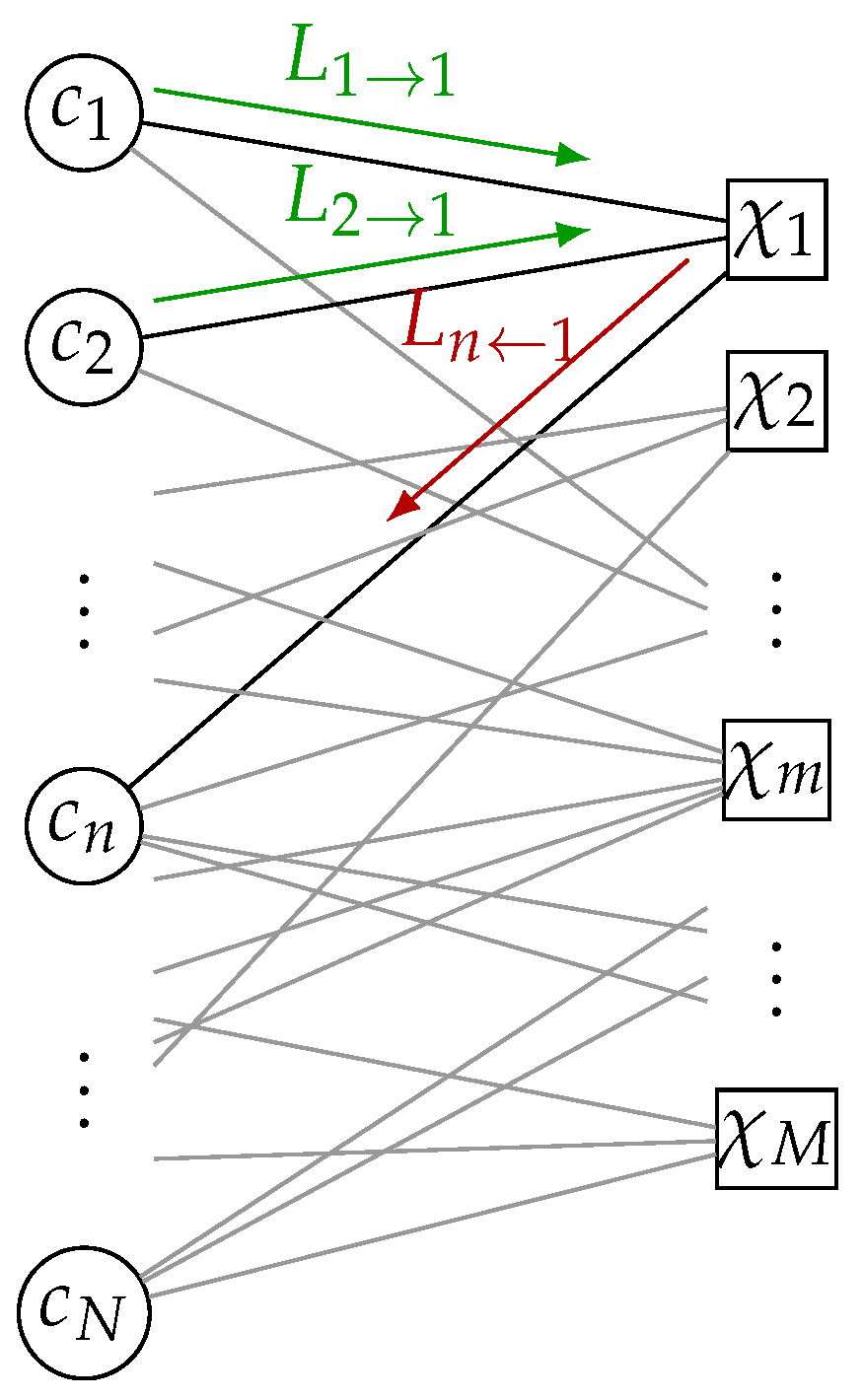
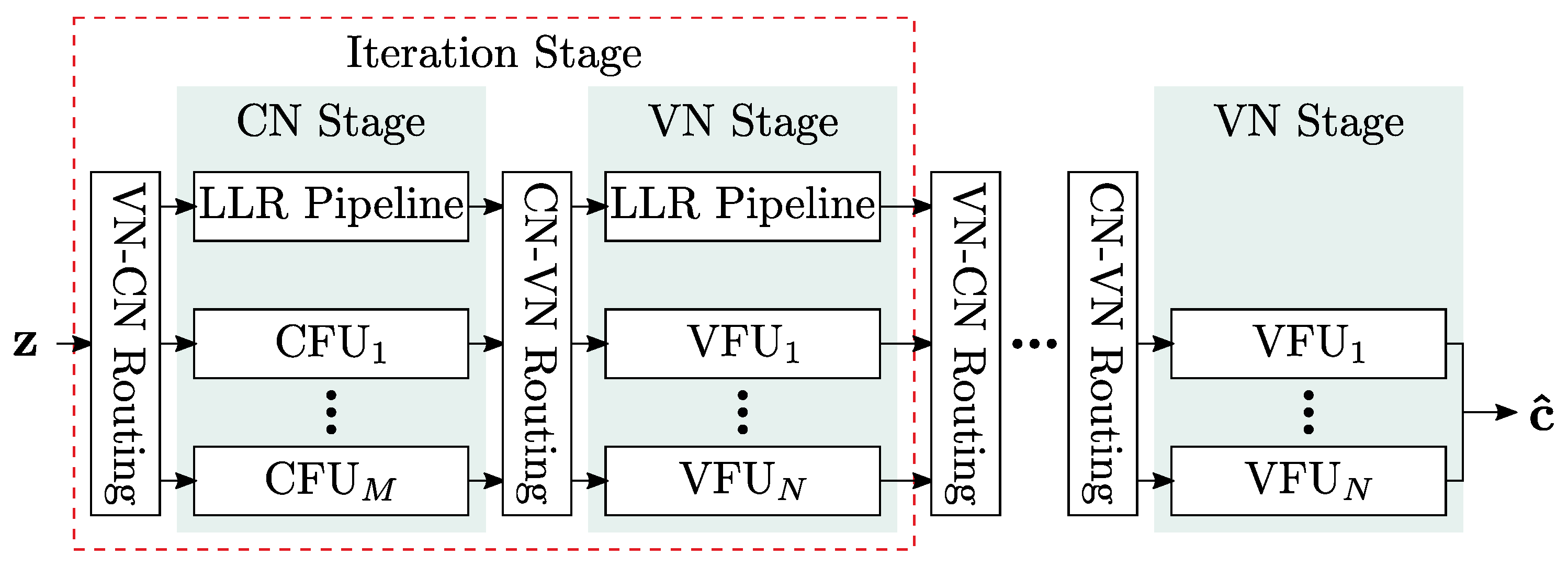
5. Finite Alphabet Message Passing (FA-MP) Decoder Implementation
In this section, we investigate the implementation complexity of different LUT-based FA-MP decoders in terms of area, throughput, latency, power, area efficiency, and energy efficiency and compare them with a state-of-the-art Normalized Min-Sum (NMS) decoder. As already stated, we focus on unrolled full parallel (FP) decoder architectures that enable throughput towards 1 Tb/s. The architecture template is shown in
Figure 9. Input to the decoder are compressed messages
z from the channel quantizer. The decoder uses two-phase decoding. Hence, each iteration consists of two stages: one stage comprises
M Check Node Functional Units (CFUs) and the second stage
N Variable Node Functional Units (VFUs). The stages are connected by hardwired routing networks, which implement the edges of the Tanner graph. Since the decoding iterations are unrolled, the decoder consists of
stages. Deep pipelining is applied to increase the throughput. For more details on this architecture, the reader is referred to [
5].
In FP decoders that use the NMS algorithm, node operations are implemented as additions and minimum searches on uniformly quantized messages [
5]. In contrast, node functionality in Finite Alphabet (FA) decoders is implemented as LUTs. Implementing a single LUT as memory is impractical in Application-Specific Integrated Circuit (ASIC) technologies since the area and power overhead would be too large. Hence, a single LUT is transformed into
Boolean functions
with
being the number of inputs of the LUT, which is the node degree multiplied by
.
b can consist of up to
product terms if
b is represented in sum-of-product form. State-of-the-art logic synthesis tools try to minimize
b such that it can be mapped onto a minimum number of gates. Despite this optimization, the resulting logic can be very large for higher node degrees and/or
, making this approach unsuitable for efficient FP decoder implementation. It was shown in [
7] that the mLUT can be decomposed into a set of two-input sLUTs arranged in a tree structure, which largely reduces the resulting logic at the cost of a small degradation in error correction performance. To compare these approaches with our new decoder, we implemented four different types of FP decoders:
NMS decoder with extrinsic message scaling factor of 0.75;
Two LUT-based decoders: in these decoders, we implemented the VN operation by LUTs and the CN operations by a minimum search on the quantized messages. The latter corresponds to the CN Processor implementation of [
7]. The LUTs are implemented either as a single LUT (mLUT), or as a tree of two-input LUTs (sLUT);
Our new MIC decoder in which the VN is replaced by the new update algorithms, presented in the previous section.
For MIC and LUT based decoders, we investigated message quantization and . The reference is an NMS decoder with and , respectively. For all decoders, the channel and message quantization were set to be identical, i.e., . We used a different code for our implementation investigation than in the previous sections. This code has a larger block size, which implies increased implementation complexity. The code is a regular LDPC code with and and the number of decoding iterations is .
We applied a Synopsys Design Compiler and IC Compiler II for implementation in a 28 nm Fully-Depleted Silicon-on-Insulator (FD-SOI) technology under worst-case Process, Voltage and Temperature (PVT) conditions (125 °C, 0.9 V for timing, 1.0 V for power). A process with eight metal layers was chosen. Metal layers 1 to 6 are used for routing, with metals 1 and 2 mainly intended for standard cells. The metal layers 7 and 8 are only used for power supply. Power numbers were calculated with back-annotated wiring data and input data for a FER of . All designs were optimized for high throughput with a target frequency of 1 GHz during synthesis and back-end. To assess the routing congestion, we fixed the utilization to 70 % for all designs as a constraint. The utilization specifies the ratio between logic cell area and total area (=logic cell area plus routing area). Thus, by fixing this parameter, all designs have the same routing area available in relation to their logic cell area.
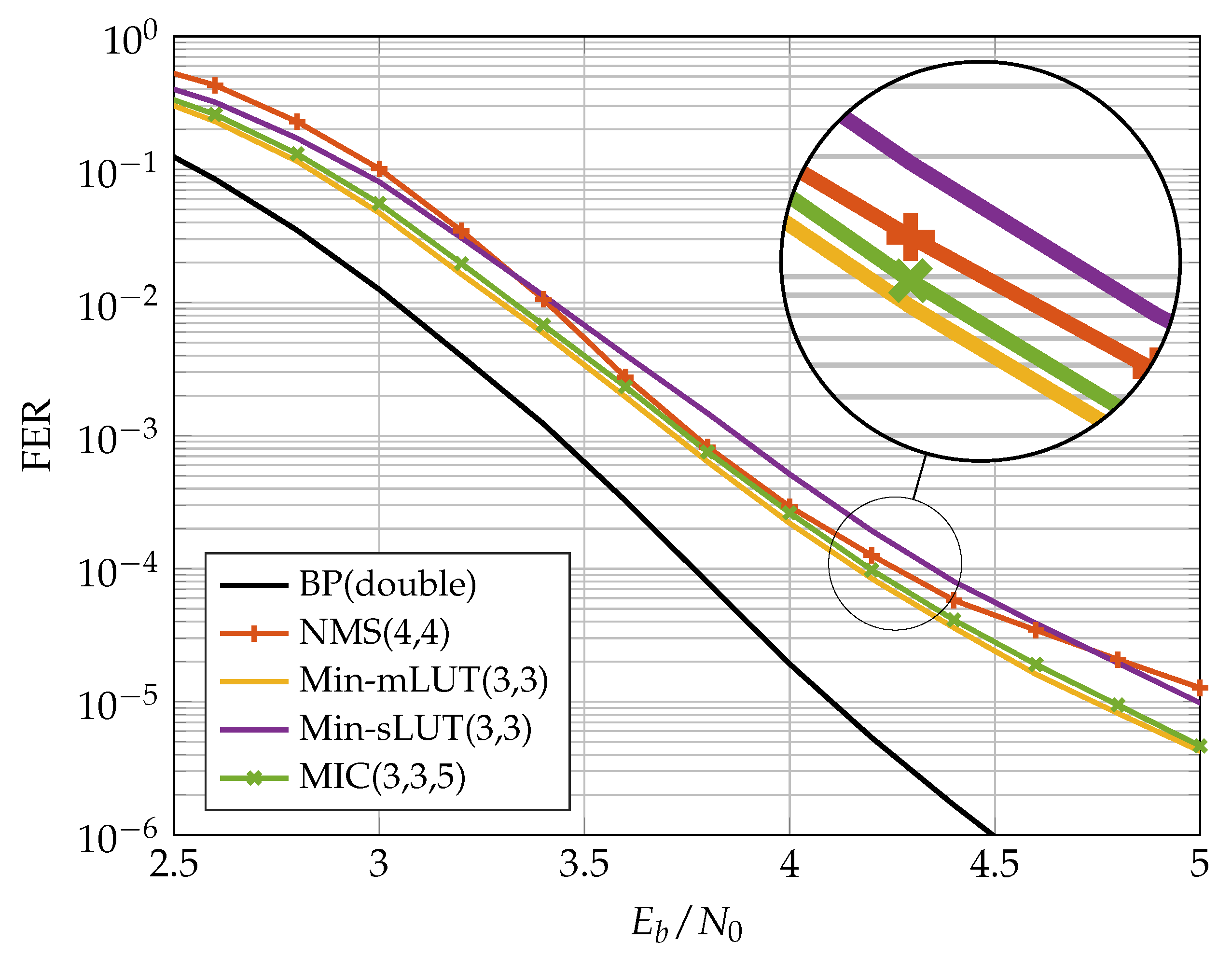
5.1. FER Performance of Implemented FA-MP Decoders
Figure 10 and
Figure 11 show the FER performance for the different decoders. We compare the NMS decoder with the MIC decoder and the two LUT-based decoders. The LUTs of the FA-MP decoders are elaborated to a design Signal-to-Noise-Ratio (SNR) optimized at an FER of
. It should be noted that this may result in an error floor behavior below the target FER. This phenomenon can be mitigated by selecting a larger design SNR at the cost of decreased performance in the waterfall region [
13]. For comparison, we also added the BP performance with double precision floating point number representation.
In the previous section, we showed that, for the code, the MIC decoder achieves the same error correction performance as the Min-mLUT decoder for . A similar observation was made for the code considered here. In our implementation comparison, we reduced such that the MIC’s FER stays below that of the NMS at the target FER of . In this way, we obtained an , which yields a small degradation in the MIC FER compared to the Min-sLUT and Min-mLUT decoders, but outperforms the NMS decoder. We observe that the MIC and Min-mLUT decoders with one bit smaller message quantization have better error correction capability than the NMS decoder at the target FER. In addition, due to the low message quantization and the resulting low dynamic range, the NMS runs into an error floor below FER .
5.2. FD-SOI Implementation Results
Table 2 shows the implementation results for MIC(3,3,5), Min-mLUT(3,3), Min-sLUT(3,3) and NMS(4,4) decoders, whereas
Table 3 shows the implementation results for MIC(4,4,5), Min-mLUT(4,4), Min-sLUT(4,4) and NMS(5,5) decoders. As already stated, we fixed the target frequency to 1 GHz and the utilization to 70% for all decoders. Maximum achievable frequency
f, final utilization, area
A and power consumption
P were extracted from the final layout data. From these data, we can derive the important implementation metrics: throughput, latency, area efficiency and energy efficiency. Since the decoders are pipelined, the coded decoder throughput
T is
. The latency is
(each iteration consists of three pipeline stages, decoder input and output are also buffered, yielding
pipeline stages in total). The area efficiency is defined as
and the energy efficiency as
.
The Min-mLUT decoder has the largest area, the worst area efficiency, and the worst energy efficiency. We see an improvement in these metrics for the Min-sLUT at the cost of a slightly decreased error correction performance. The difference in the implementation metrics largely increases when changes to . The area increases by a factor of 10 for the Min-mLUT(4,4), but only by a factor of 2.7 for the Min-sLUT(4,4) decoder. Moreover, we had to reduce the utilization to 50 % to achieve a routing convergence for the MinmLUT(4,4) decoder. The large area increase is explainable with the increase of the LUT sizes from 512 to 4096 entries per LUT when increasing from 3 to 4. Moreover, the frequency largely breaks down, yielding a very low area efficiency and energy efficiency. The Min-sLUT decoders scale better with increasing . Both Min-sLUT decoders outperform the corresponding NMS decoders in throughput and efficiency metrics.
The MIC decoder has the best implementation metric numbers in all cases. It outperforms all other decoders in throughput, area, area efficiency and energy efficiency while having the same or even slightly improved error correction performance compared to the other decoders. It can also be seen that the MIC decoder has a lower routing complexity compared to the Min-sLUT and the NMS decoder. We observe a large drop in the frequency from 595 MHz down to 183 MHz (70 % decrease) when comparing NMS(4,4) with NMS(5,5) under the utilization constraint of 70 %. The large drop in the frequency is explainable with the increased routing complexity for the given routing area constraint that yields longer wires and corresponding delays. This problem is less severe for the MinsLUT, where the frequency drops from 670 MHz to 492 MHz (27 % decrease). The MIC achieves the highest frequency for all cases and drops from 775 MHz to 633 MHz (18% decrease), only. This shows that the MIC scales much better with increasing .
It should be noted that the CFU implementation is identical for the MIC, Min-mLUT and Min-sLUT decoders. Compared to the corresponding NMS, the CFU implementation is less complex [
19] due to: (i) a 1 bit smaller message quantization, (ii) the omission of the scaling unit, and (iii) the omission of the sign-magnitude to two’s complement conversion. Hence, the CFU complexity of the FA-MP is always lower than that of the NMS independent of the respective CN degree. Moreover, in contrast to the NMS decoder, the messages from the CFUs to the VFUs are transmitted in sign-magnitude representation via the routing network which reduces the toggling rate and thus the average power consumption.
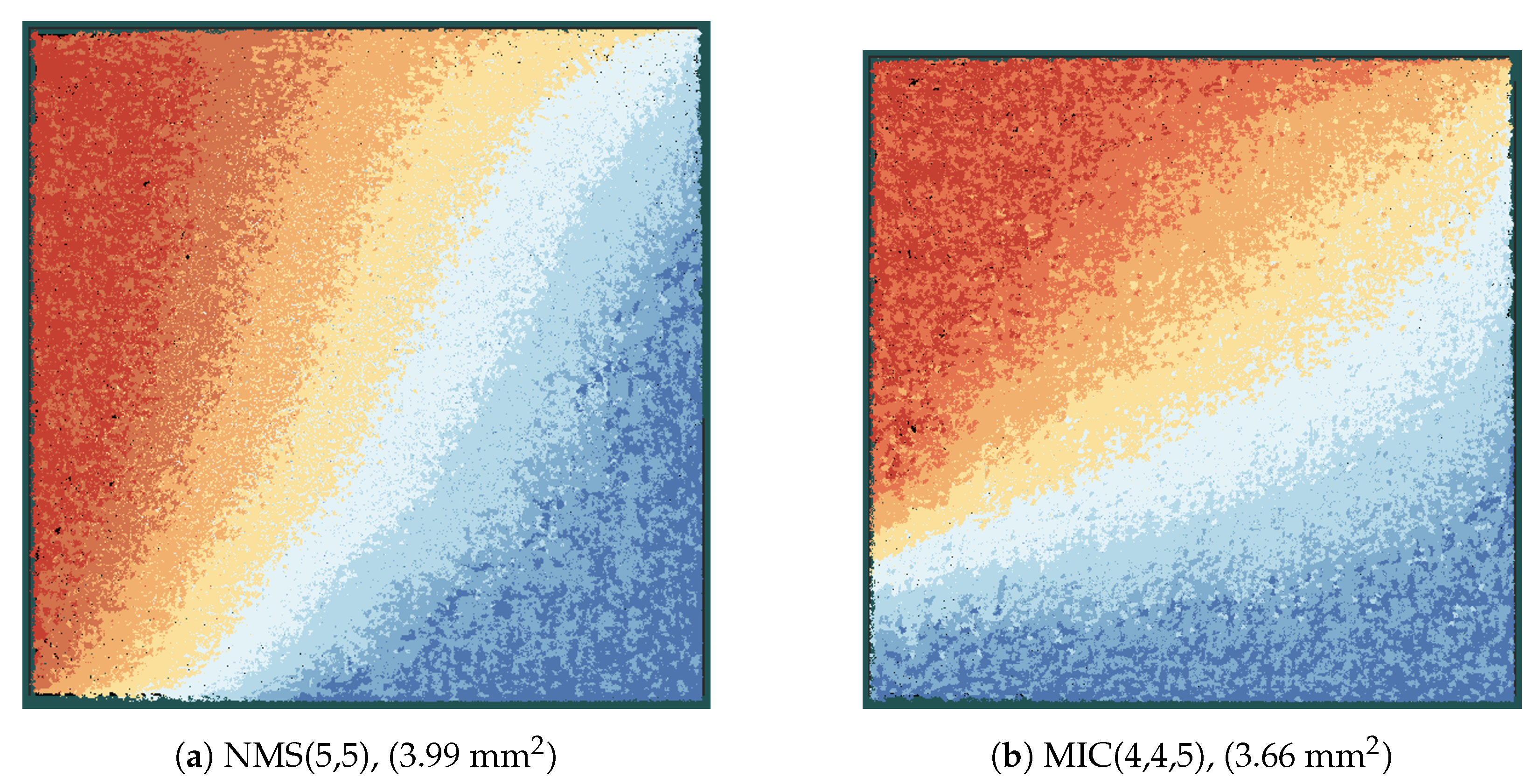
Figure 12 shows the layout of the MIC and the NMS decoder in the same scale. Each color represents one iteration stage, which is composed of CFUs, VFUs, and the routing between the nodes (see also
Figure 9). When comparing the same iteration stages (same color) of the two decoders, we can observe that the iteration stages in the MIC decoder are smaller than the corresponding iteration stages in the NMS decoder, although the frequency of the MIC decoder is more than three times higher compared to the NMS decoder. This shows once again that the MIC has a lower implementation complexity, especially from a routing perspective.
Our analysis shows that the new MIC approach largely improves the implementation efficiency and exhibits better scaling compared to the state-of-the-art sLUT and NMS implementations of FP decoder architectures. This enables the processing of larger block sizes, which is mainly due to the reduced routing complexity. Larger block sizes improve the error correction capability and further increase the throughput of FP architectures.


 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}