1. Introduction
Consider a data matrix, each row of which corresponds to a case, and each column represents a variable. Suppose that every variable has the meaning that a larger value indicates better. For example, ref. [
1] investigated the efforts of countries to attain the SDGs (Sustainable Development Goals) and reported the 17 SDG scores for each country. The scores ranged from 0 to 100. In the report, a ranking of 163 countries on the basis of the average of the 17 scores was provided. We call such a procedure of ranking the simple sum method.
However, we sometimes find a paradoxical phenomenon in the simple sum method, in that a particular variable of a higher-score group is less than that of the remaining group. See
Table 1 for illustration, where we separate the SDGs data into two groups: the 10 top countries on the basis of the simple sum method and the remaining 153 countries. The average values of each variable for the two groups are compared. On almost all the variables, the 10 top countries have larger averages than the remaining countries, as expected. However, there are reverse relations in the SDGs 12 and 13. The 10 top countries have an average value lower than the remaining countries on the two goals.
In this paper, we propose a linear weighting method that can avoid the reversal relation (in a random-decision sense). The higher-score group separated by the linear weight has average values greater than the remaining group with respect to all the variables. The idea behind the method is the objective general index (OGI; [
2]), which is constructed to have a positive correlation with all the variables. The purpose of the OGI is the ranking and not the separation. The OGI is interpreted as a minimization problem of a free energy functional [
3,
4], which is the sum of the negative entropy and an internal energy functional. This interpretation also works in the current setting; see
Section 2.
The problem of determining weights is unsupervised in the sense that no one knows the correct weights and classifications, which has been consistently discussed (e.g., [
5,
6]). There are many weighting methods for such purposes. Among them, the principal component analysis (PCA) is widely used. The PCA, however, does not always give positive weights; so, some modifications are necessary. It is known that a nonnegative version of the principal component analysis is a nonconvex and NP-hard optimization problem [
7]. Another approach is the factor analysis, where a factor model refers to a set of multivariate distributions that have common latent factors (e.g., [
8]). Although the factor analysis is quite flexible, it needs additional assumptions such as variance–covariance structures and often does not have a unique solution. In contrast, the quantile general index we propose is reduced to a convex optimization problem and is essentially unique as we will demonstrate. The Hirsch index (or h-index) is widely used for the evaluation of scientific research reports [
9], and its further application has been recently investigated by [
10]. We numerically compare our method with the h-index in
Section 5.
The name of the quantile general index comes from the quantile regression developed by [
11]. Indeed, the objective function we use is similar to those of the quantile regression; see the explicit form in
Section 3. The essential difference here is that our problem is unsupervised, whereas the regression problems are supervised.
The general indices determine an ordering of the data. The problem of well ordering multivariate data was discussed by [
12], where methods of ordering were classified into four categories: marginal ordering, reduced ordering, partial ordering, and conditional ordering. Our method is considered as marginal ordering on the weighted sum.
The paper is organized as follows. In
Section 2, we define the quantile general index for continuous distributions and show that it is characterized by the maximum entropy principle. In
Section 3, a finite-sample counterpart of the quantile general index is derived. In
Section 4, a practical method that avoids the ambiguity of data lying on the separating hyperplane is proposed. We apply the method to the SDG data in
Section 5, and we conclude in
Section 6.
2. Quantile General Index for Continuous Distributions
The quantile general index for continuous probability distributions is defined first. The assumption of continuity avoids the difficulty caused by the non-smoothness of the objective function. The sample counterpart of the index is constructed in the subsequent section.
Suppose that we have a random vector
following a probability distribution
on
, where ⊤ denotes the vector transpose. We assume that
has the probability density function
so that
for an event
. For given
, we denote the expectation of a random variable
by
and the conditional expectation of
given an event
A by
We deal with a class of general indices
of
, where
and
are called the weight vector and the threshold, respectively. Here
denotes the set of positive numbers. The quantities
and
c may depend on the underlying distribution
but do not depend on
itself.
For a given
g of the form (
1), the half spaces separated by the hyperplane
are denoted by
The quantile general index is defined as follows.
Definition 1. A general indexis called the quantile general index ofif it satisfies the following two equations:andThe weightis calledthe optimal weight. Let us call
and
the positive and negative group, respectively. Equation (
2) means that the fraction of the positive group is
. The threshold
c is the upper
-quantile of the weighted sum
because
by (
2). We call
the acceptance ratio. Equation (
3) implies that the average of each variable
on the positive group is greater than that on the negative group. Therefore, the reversal relation observed in
Table 1 does not occur if we adopt the quantile general index.
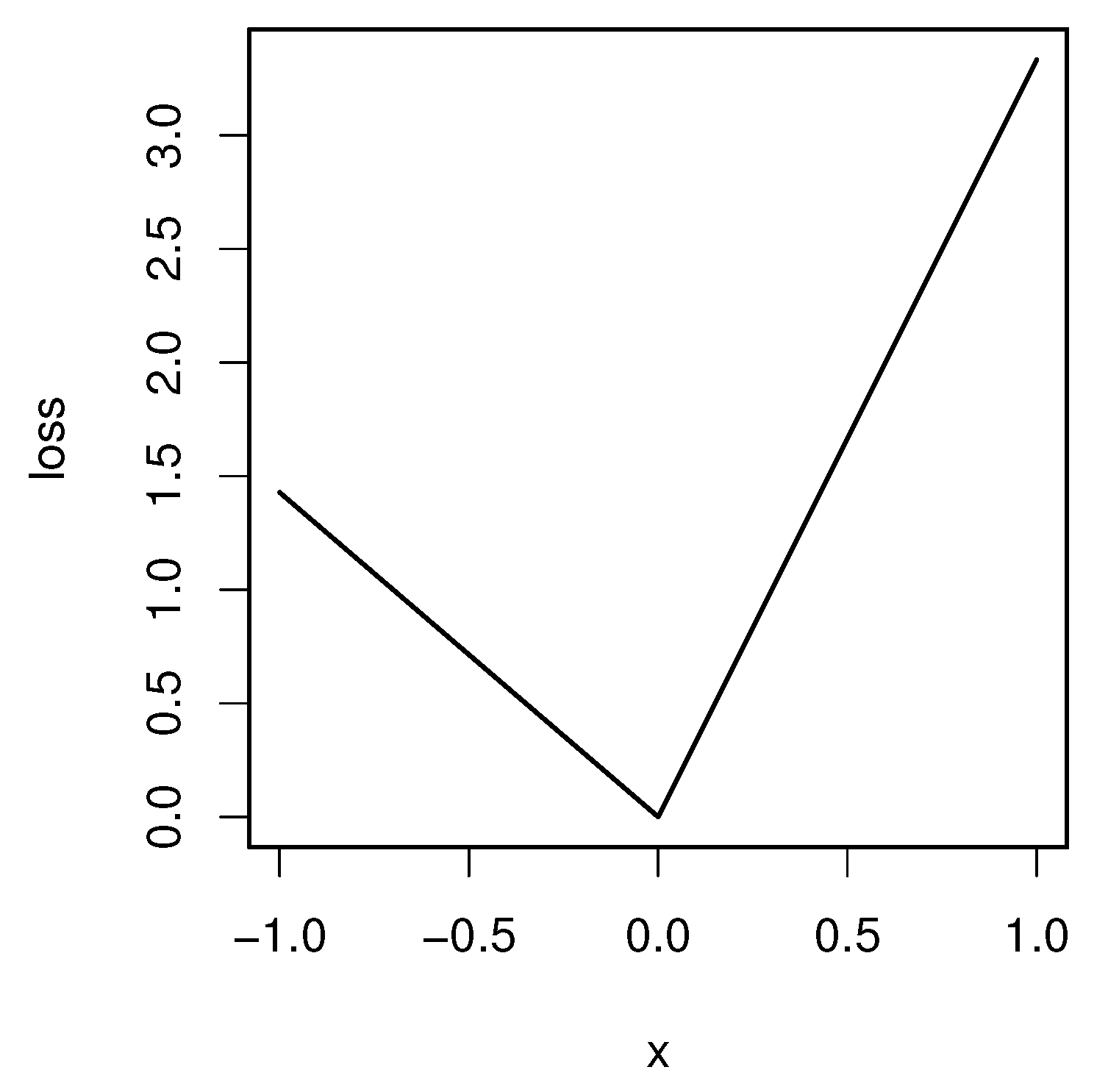
We now state the existence and uniqueness theorem of the quantile general index. For
, we define the “check” loss function
by
where
and
are the positive and negative parts of
u, respectively. See
Figure 1 for the graph of
. The function
is used in quantile regression [
13]. The derivative of
for
is
where
is 1 if
and 0 otherwise. The subgradient (e.g., [
14]) at
can be also defined but is not used here.
We define a convex function
by
The main theorem is stated as follows.
Theorem 1. Let be a random vector with a probability density function on and assume that exists for each i. Let . Then, the function F in (5) admits a minimizer . The optimal is unique, whereas c may not be unique. Furthermore, the general index based on the minimizer of F satisfies the conditions (2) and (3) of the quantile general index. Proof. The proof of existence and uniqueness is given in
Appendix A. We prove that the stationary condition of
F is given by (
2) and (
3). The partial derivatives of
F with respect to
c and
are
and
Note that
, since
from the assumption that
has a continuous distribution. Then, the equations
and
(
) are equivalent to (
2) and (
3). □
Example 1. Let and be independent and identically distributed according to a continuous distribution. By the uniqueness of the optimal weight and symmetry, we have . We denote the upper α-quantile of by . Then, we have from (2) andfrom (3). For example, if has the standard normal distribution and , then , and . The quantile general index is derived from the maximum entropy principle in line with [
4]. The entropy of a density function
p is defined by
Consider a class of transformations
of the form
The push-forward density of
p by
T is defined by
This is the distribution of
when the random variable
follows the distribution
. It is shown that the entropy of the push-forward density is
We also define an internal energy by
where
is the check loss function in (
4). The following theorem characterizes the quantile general index in terms of entropy. The proof is straightforward.
Theorem 2. The minimization problem of (5) is equivalent toThe threshold c in (5) is given by . 3. Quantile General Index for Finite Samples
The quantile general index defined in the preceding section is valid only for continuous distributions. It is useful to define the index also for finite samples. Let be a sample of size n. We denote the i-th coordinate of by . We deal with a class of general indices , where may depend on the whole sample but does not depend on t.
The empirical counterpart of the objective function (
5) is
for
.
Definition 2. A general index of for is called the quantile general index if minimizes the function (6). Remark 1. As described in Section 1, the objective function (6) is similar to that of the quantile regression defined bywhere is a response variable and are regression coefficients. See [13] for a comprehensive study of the quantile regression. The following theorem is proved in a similar way to Theorem 1. See
Appendix A.
Theorem 3. Suppose that there is no hyperplane of that contains all . Then, the objective function F in (6) admits a minimizer . The weight vector is unique. The threshold c is unique if is not an integer. Each case is classified into positive and negative groups according to and , respectively. If the case does not exist, then the fraction of the positive (resp. negative) group is (resp. ), and the conditional expectation of on the positive group is greater than that on the negative group. This is the desired dominance relation.
However, it is not always possible to classify the data into positive and negative groups, because
may become 0 in some cases. Furthermore, the minimization of
is not straightforward, since the function is not differentiable. In order to avoid these issues, we modify the method in
Section 4.
For illustration, we calculate the quantile general index for the following examples.
Example 2. Consider the bivariate dataof sample size 4. Let the acceptance ratio be . In this data, any set of three points is not on a straight line. Therefore, there exists the quantile general index by Theorem 3. We show that the solution is , , and . We consider three disjoint subsets of :Let . Then, we haveHence, the optimal c is between and , since c is the upper -quantile of . For such c, the objective function (6) becomesIf F is minimized at some , then it must be and by the stationary condition, but this point does not belong to A. Hence, the optimal point does not exist in A. If , then we haveand the objective function iswhere . It is shown again that the optimal point does not exist in B. Therefore, the optimal point should be located in C, the boundary of A and B. The objective function iswhere . The optimal solution is , , and . The quantile general index is given byThe index does not provide a separation of the data because . In this case, however, a group dominates in the sense that the difference of averagesis a positive vector. If we set the acceptance ratio to , then it is proved in a similar way that the optimal is and . In this case, c is not unique: . The quantile general index isTherefore, and as long as . The separation provides a dominance relation: Example 3. Consider the bivariate dataof sample size 4. Let . In a similar manner to the preceding example, the optimal parameters are shown to be and . The quantile general index isIn this case, no separation of the sample into two groups provides a dominance relation. Indeed, all the possible combinations arewhich are not positive. 4. Practical Implementation
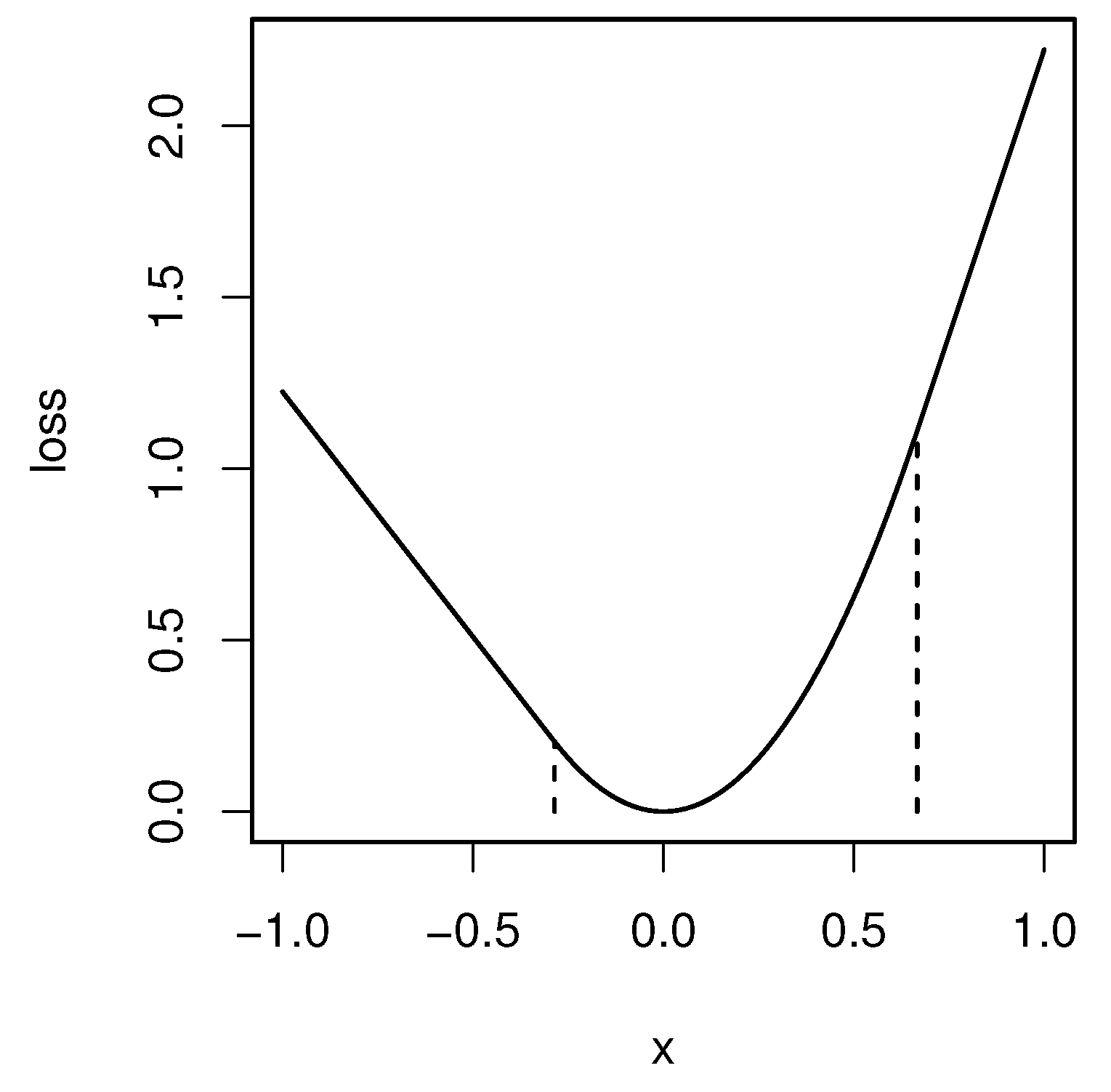
The quantile general index defined in the preceding section has the following two drawbacks.
To overcome these issues, we approximate
F as
where
is a positive constant, and the function
is defined by
The function is called the Moreau envelope of
. See
Figure 2 for the graph of
. It is shown that
uniformly converges to
, as
.
The derivative of
is piecewise linear:
In particular,
is continuously differentiable unlike
.
Definition 3. A general indexis called the quantile general indexwithin toleranceifminimizes.
The gradient of
is
where
These formulas prove the second part of the following theorem. See
Appendix A for the proof of the first part.
Theorem 4. Suppose that there is no hyperplane of that contains all . Then, the objective function in (8) admits a minimizer , and the optimal weight vector is unique. Furthermore, the optimal and defined in (9) satisfyand The Equations (
10) and (
11) correspond to (
2) and (
3) for continuous distributions. The quantity
is interpreted as the probability of assigning the case
to the positive group. We call
the optimal random decision. If the general index
is greater than the threshold
, the case
t is definitely assigned to the positive group because
. Similarly, if the general index is less than
, it is definitely assigned to the negative group.
For numerical computation, we used a general-purpose optimization solver optim in R [
15] with the L-BFGS method.
Example 4 (Continuation of Example 2).
Consider four casesLet and . The optimal and c are numerically obtained as and . The quantile general index is , and the optimal random decision is , so that the optimal separation will be and . This separation happens to satisfy the dominance relation as we have seen in Example 2. Example 5 (Continuation of Example 3).
Consider four casesLet and . The optimal and c are numerically obtained as and . The quantile general index is , and the optimal random decision is . In this case, we cannot decide which of and has to be assigned to the positive group. This result is consistent with the discussion in Example 3. 5. Application to the SDGs Index
We finally compute the quantile general indices of the SDGs data provided by [
1], as introduced in
Section 1. According to [
1], countries with a fraction of missing values greater than 20% were removed from the data and then the missing values were imputed by regional averages. We applied the quantile general index with the acceptance ratio
and tolerance
. The result is summarized in
Table 2. The optimal weight
is shown in the second column of the table. The threshold was
. The other columns of
Table 2 show the average of each variable in the 10 top countries and the remaining countries, respectively. In contrast to
Table 1, we do not observe the reversal relation.
Table 3 shows the general index
and the optimal random decision
of the 10 top countries.
We must be careful with interpretating the result. In particular, the optimal weights had high variation: the ratio of the largest weight (SDG 12) to the smallest weight (SDG 1) was about
, which means that the SDG 1 had only 10% of the impact of the SDG 12 under the quantile general index. This may discourage people or governments contributing to the SDG 1. Our main message in this paper is that there were reversal relations in the SDGs 12 and 13 under the simple sum method, as observed in
Table 1, and such a phenomenon can be avoided by the proposed method. Further discussion should be needed for the use of the quantile general index.
As a reviewer suggested, we also computed the Hirsch index [
9] (or h-index) of the countries based on the original SDG scores. In the current setting, the h-index is defined as the fixed point of the graph
, where
’s are the 17 SDG scores in descending order (normalized into the range
). The 10 top countries based on the h-index are shown in
Table 4. The top three were not changed from the original SDG ranking. We also observed the reversal relations in the SDGs 12 and 13 when we adopted the h-index for separation. See [
10] for a study of the scaling behavior of the h-index.
6. Discussion
We proposed a quantile general index that avoids reversal relations in the separated groups. The weight was defined by the solution of the convex optimization problem (
6) or (
7) for given data. In
Section 5, we applied the proposed method to the SDG data and obtained the 10 top countries based on it. The result actually satisfies the desired properties (
10) and (
11). A side effect is that the obtained weights sometimes had large variation, which may be controversial.
Various applications of our method are expected. For example, one could construct a regional competitive index (e.g., [
16]) based on the quantile general index if it is necessary to select a given number of top regions. The method is also applicable to admission decisions based on entrance examinations in schools or companies, where a fixed fraction of candidates are supposed to pass. Further case studies are needed to support the validity of our approach.
The quantile general index (without approximation) introduced in
Section 3 was reduced to a minimization problem of a nondifferentiable objective function. It is theoretically of interest to develop an exact algorithm and also to estimate the accuracy of the practical method developed in
Section 4. Another problem is to find an algorithm that decides the separability of the data into two groups without the reversal relations. In Example 3, we enumerated all possible combinations to prove that the data was not separable. However, this algorithm requires a large amount computational time when the sample size is large. Faster algorithms would be welcomed. Finally, the relation between the quantile general index and the h-index is also completely unknown.





{kind=link}
{kind=link}