1. Introduction
Software defect prediction is an indispensable part of software development because it can reduce the time and energy required for software testing during development. Software defect prediction is divided into two parts: the construction of software metrics [
1], which is to count the features in the software code, and the model design, which is involved in the design of corresponding algorithms for different learning tasks and software metrics to achieve software defect prediction.
Traditional machine learning methods directly use software code features (such as changes in data and previous defects) to classify software defects. For example, Liu et al. [
2] solved the cumulative unbalance problem using the SMOTE (synthetic minority oversampling technique) algorithm and solved the data noise problem using the ENN (extended nearest neighborhood) algorithm, as well as optimized the four-layer BP (backpropagation) network using the simulated annealing algorithm, and predicted the classification. Bashir et al. [
3] proposed a feature selection method based on maximum likelihood logistic regression, which was beneficial to the selection of optimal feature subsets and can predict defect modules more accurately. Goyal [
4] proposed a new filtering technique to effectively predict defects using support vector machines for the imbalanced data classification problem. The input of the prediction model based on machine learning is dependent on the software measurement elements; therefore, it needs to be changed continuously with the development of the software, which can potentially waste substantial time and energy in the reconstruction of the software measurement element.
With the development of deep learning, success has been achieved in NLP (natural language processing), image, audio, etc.; scholars used deep learning to learn deeper semantic features in code. Farid et al. [
5] proposed a hybrid model to extract the semantics from an abstract syntax tree (AST) using a convolution neural network (CNN), and then used Bi-LSTM (bidirectional long short-term memory) to preserve key features while ignoring other features to improve the accuracy of software defect prediction. Deng et al. [
6] felt that neural networks in NLP were more capable of learning semantic and contextual features in source code, firstly by extracting the code’s abstract syntax tree, which was then fed into the LSTM (long short-term memory) network, and then a prediction was made on where the file was defective or not. The above methods all took classes or files as research goals and did not consider the relationship between classes or files.
The software is mapped into a graph/network using the theory in the complex network, and the software defect prediction is carried out by studying the graph structure of the software. Šubelj and Bajec [
7] found these existing community structures by mapping software into a dependent class-based network and proposed different applications of community detection in software engineering. Zhou et al. [
8] used two measures of package cohesion and coupling, based on complex network theory, to verify the impact of code structure on software quality. Following the success of graph neural networks, Qu and Yin [
9] mapped the software as a dependent class-based network, using different graph embedding techniques to embed the nodes of the graph into a d-dimensional vector space, the idea of embedding is to keep connected nodes close to each other in the vector space. The feature information can be learned from the graph structure of the software, but the above methods only consider the graph structure and ignore the node level features in the graph.
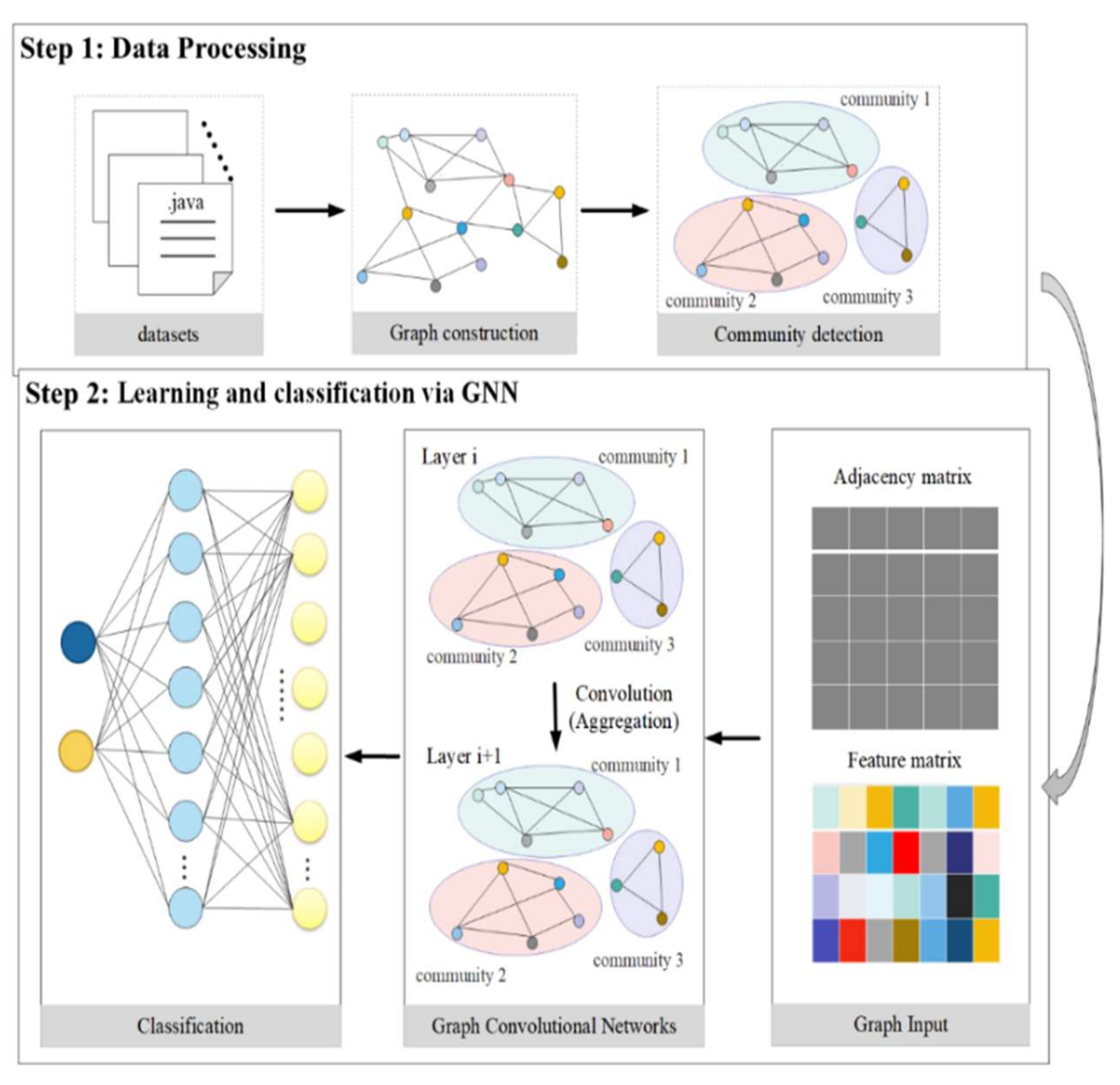
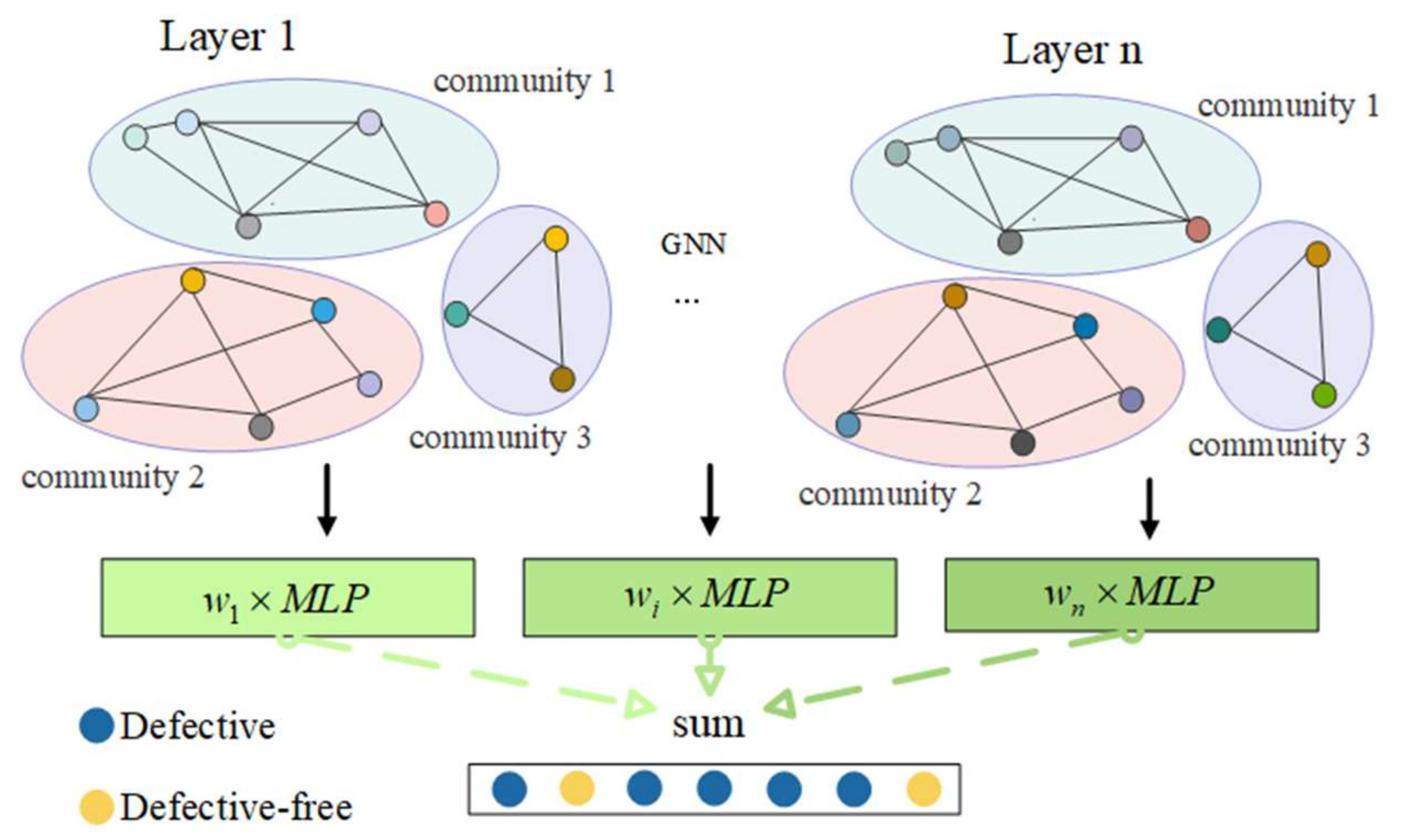
The software defect prediction model based on machine learning and deep learning treats the software module as a single unit, ignoring the interaction between software modules. The software defect prediction model based on the complex network only considers the graph structure of the software, ignoring the properties of the software module itself. Here, in this research, a software defect prediction model based on the complex network and graph neural network is presented. Firstly, the software system is mapped to a graph structure, with the classes as nodes, the dependencies between classes as edges, and traditional metrics as node attributes. Then, the whole graph is broken down into several subgraphs. Lastly, the information of the graph is learned through a multilayer graph neural network. Weights are given to each layer to prevent information loss.
The key contributions of this paper are as follows:
- (1)
The application of the graph neural network in the complex network to make software defect prediction, followed by the use of the graph neural network to combine the structure of the software class graph along with the software’s class-level measurement element (node-level features, e.g., prior fault and new data) to learn new feature vectors. This represents an additional consideration in our model, compared with previous models, which only considered software graph structure or software defect measurement elements.
- (2)
Use of the community detection algorithm to decompose the software graph structure into multiple subgraphs, and use of all the subgraphs as the input of the graph neural network model. This further simplifies the software graph structure, and the learned graph structure is a closely related subgraph.
- (3)
Improvement of the graph convolutional neural network, such that the graph neural network can learn the graph structure features that are conducive to software defect prediction.
The remainder of this paper is organized as follows:
Section 2 introduces the background knowledge of software diagram structure, then introduces community detection algorithms, and finally proposes a framework for software defect prediction.
Section 3 presents the experimental environment, evaluation metrics, experimental setup, and experimental procedure.
Section 4 discusses the results.
Section 5 provides the conclusions and future work.
3. Simulation Experiments
3.1. Experimental Environment and Datasets
Experiments were performed on the Windows-based operating system, the language used was python [
25], and the construction of the graph neural network model was completed through PyTorch [
26] and torch-geometric.
The PROMISE dataset [
27], a collection of open-source software projects, serves as the dataset in use. Six projects were picked from this dataset, which contains object-oriented measurement elements for all of the dataset’s measurement items. The dataset is described in
Table 1.
It can be found that there is a class imbalance problem existing in the data. To improve the dataset, we first used the NearMiss algorithm [
28], which reduced the amount of data in the experiment and test. During the experimenting, tenfold cross-validation was used. Each time, 90% of the data were randomly selected for training, 10% of the data were tested, and the results are given using an average of 10 times the data.
3.2. Evaluation Measures
To prove the validity of proposed model, the selected evaluation measures such as the accuracy rate, F-measure, and MCC value were used, which were all obtained through the confusion matrix. The confusion matrix [
29] is shown in
Table 2.
Accuracy refers to the proportion of correct classification to the total number, and the value range is [0, 1]. Higher values indicate better classifier performance. The formula is as follows:
The F-measure is the harmonic average of precision rate and recall rate. Precision rate P refers to the proportion of the number of positive samples correctly classified by the classifier to the overall number of positive samples classified by the classifier, and recall rate R refers to the proportion of the number of positive samples correctly classified by the classifier to the number of desired positive samples. The value range is [0, 1], whereby a higher value indicates better classification. The formula is as follows:
MCC is a more appropriate, balanced metric since it takes into account true examples, true-negative examples, false-positive examples, and false-negative examples. The value range is [−1, 1]. A prediction with a value of 1 is considered to be perfect; a prediction with a value of 0 is considered to be only slightly better than a random guess; and a prediction with a value of −1 is considered to be wholly incongruent with the actual result. The equation reads as follows:
3.3. Experimental Setup
In order to reduce the influence of experimental parameters, some training hyperparameters were set as shown in
Table 3.
The parameters used in the traditional method of SVM (support vector machine) were set as default. The network structure of other models are described below. The network structures of the BP neural network comprised four layers. Without using a classifier, GCN was constructed in accordance with the model described in [
20], which directly derived the result via a graph convolution operation. The GIN structure was developed in accordance with [
23]. The difference is that there was no community division and no final weighted summation. According to the graph neural network framework proposed in this paper, CBGCN (community-based GCN) and CBGIN (community-based GIN) were built. The difference was the graph convolution operation, with the former based on the spectral domain, and the latter based on the spatial domain. The classifier, MLP (multilayer perceptron), and BP neural network were all connected. The specific parameters are shown in
Table 4.
3.4. Experimental Procedure
This section presents some assumptions and limitations during the experiment, and then describes the specific steps of the experiment. The assumptions in this paper are as follows:
- (1)
We focus on software defect prediction within a project, and the training and testing data are derived from one dataset. For example, when experimenting with ant dataset, the training set is selected and the test set is derived from the remainder of the dataset.
- (2)
During the experiments, a small number of defective classes cause the trained model to favor the non-defective classes. Therefore, class imbalance is applied to the entire dataset before training the model.
- (3)
To better estimate the algorithm performance, a tenfold cross-validation is used.
Under the above assumptions, the validity of the software defect prediction framework proposed in this paper can be verified. The specific experimental procedure is as follows:
Step 1: Using the code analysis tool, the software’s class dependence is extracted, and a CSV file is then generated.
Step 2: The labeled nodes and feature metrics are obtained for the nodes from the PROMISE dataset.
Step 3: NetworkX, a third-party package in python, is used to store the graph structure. Then, the python-louvain package in python is used to divide the graph structure into subgraphs.
Step 4: The NearMiss algorithm is applied to deal with data class imbalance. Then, 90% of the processed dataset is chosen at random for the graph neural network model’s training, and 10% is chosen for its testing.
Step 5: The graph structure from step 3 is used as the input to the graph neural network model. The training set labels are picked in step 4 to train the network parameters.
Step 6: Then, 10% of the data in Step 4 are used for testing, before calculating the performance on various evaluation metrices.
Step 7: The process is repeated 10 times from Step 4 onward.
4. Results and Discussion
The spectral domain-based graph convolutional neural network GCN and the spatial domain-based graph convolutional neural network GIN were chosen for studies to show that this model can increase the performance of software defect detection. The models were consequently divided into two groups, the first of which consisted of SVM, BP, GCN, and CBGCN, and the second of which consisted of SVM, BP, GIN, and CBGIN. SVM and BP, the two most fundamental machine learning algorithms, directly use the original feature vector to forecast software problems. Graph convolution is employed by both model frameworks used in the original paper—GCN and GIN—to obtain the characteristics of the graph structure. Two distinct graph convolution techniques were merged by CBGCN and CBGIN to create this model.
4.1. Experimental Analysis of Graph Convolutional Neural Network Based on Spectral Domain
In this section, the graph convolution method based on the spectral domain is used as the convolution layer of this model. In order to verify that the graph convolution method can improve the performance of software defect prediction, in this work, in addition to the traditional method, the graph convolutional neural network [
20] model was selected as a benchmark model. The results are shown in
Table 5.
It can be seen from
Table 5 that the proposed model has achieved good experimental results in terms of accuracy, F-measure, and MCC in most datasets. In terms of accuracy, it was 7.6% higher than SVM, 5.8% higher than BP, and 13.6% higher than GCN. The F-measure was 10.7% higher than SVM, 7.8% higher than BP, and 13.1% higher than GCN. The MCC index was 12.5% higher than SVM, 12.7% higher than BP, and 27.4% higher than GCN. The data were analyzed from two aspects:
- (1)
Comparing CBGCN with SVM and BP, it was found that our model was better than the BP neural network and SVM according to the evaluation of all metrics from other datasets except for the Ant dataset. It was found that, in the Ant dataset, the result of the BP neural network was also lower than that of the SVM. In individual datasets, the parameters of BP need to be specially set to obtain the best performance, and the structure of the CBGCN classifier is the same as the BP neural network. Therefore, individual datasets need to adjust the parameter settings of the network. However, in terms of average, CBGCN was greatly improved; thus, it can be concluded that useful feature vectors can be learned by incorporating the spectral domain-based graph convolution method into this model.
- (2)
Comparing CBGCN with GCN, we found that, except for the Lucene dataset, the experimental results were very similar. Other datasets greatly improved the model, and the average of the evaluation measures was higher; therefore, it can be concluded that the model framework of this paper was more suitable for software defect prediction.
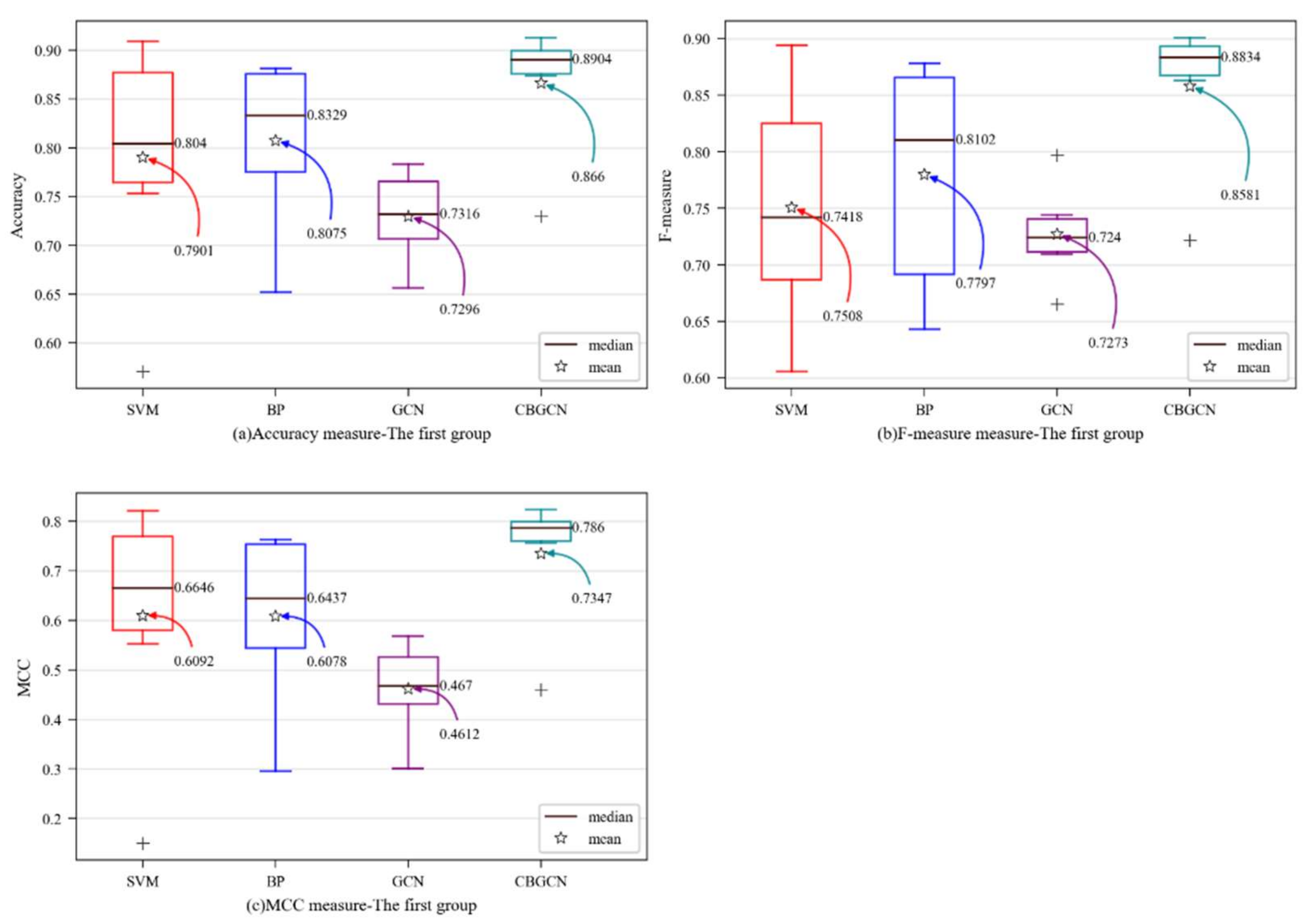
In order to visually observe the performance of the CBGCN algorithm, various evaluation measures were determined as box plots [
30]. The y-axis represents the evaluation metric score, while the prediction method is on x-axis in
Figure 3. The mean and median values are designated as particular values in the figures to aid in analysis.
Figure 3 shows that the model suggested in this paper had each average evaluation index at its highest point, and that the GCN model’s framework was insufficient for predicting software defects. However, according to the experimental results of CBGCN, the graph convolution method based on the spectral domain could enhance each evaluation index of software defect prediction.
4.2. Experimental Analysis of Graph Convolutional Neural Network Based on Spectral Domain
In the experiments in this section, the spatial domain-based graph convolution method is used as the convolution layer of this model. In order to verify that the graph convolution method could still improve the performance of software defect prediction in this work, in addition to the traditional method, the spatial domain-based graph neural network model [
23] was selected as a benchmark model. The results are shown in
Table 6.
Table 6 shows that, in most datasets, the model proposed in this paper achieved good experimental results in terms of accuracy, F-measure, and MCC. On average, the accuracy was 8.5% higher than SVM, 6.8% higher than BP, and 3.5% higher than GIN. The F-measure was 10.8% higher than SVM, 7.9% higher than BP, and 2.4% higher than GIN. The MCC was 14.6% higher than SVM, 14.7% higher than BP, and 7.0% higher than GIN. The results were analyzed from two aspects:
- (1)
Compared with BP, CBGIN was improved on all datasets. It was still lower than SVM in the Ant project, but higher than CBGCN, demonstrating that the classifier network structure and graph convolution method settings could impact the outcomes. Individual datasets require adjusting the network hyperparameters. Overall, there was a substantial improvement in CBGIN. Thus, it can be inferred that this model may acquire valuable feature vectors by incorporating the spatial domain-based graph convolution method.
- (2)
When CBGIN and GIN were compared, it was discovered that the model was improved across all datasets. We can draw the conclusion that the model presented in this paper is more suited for predicting software defects.
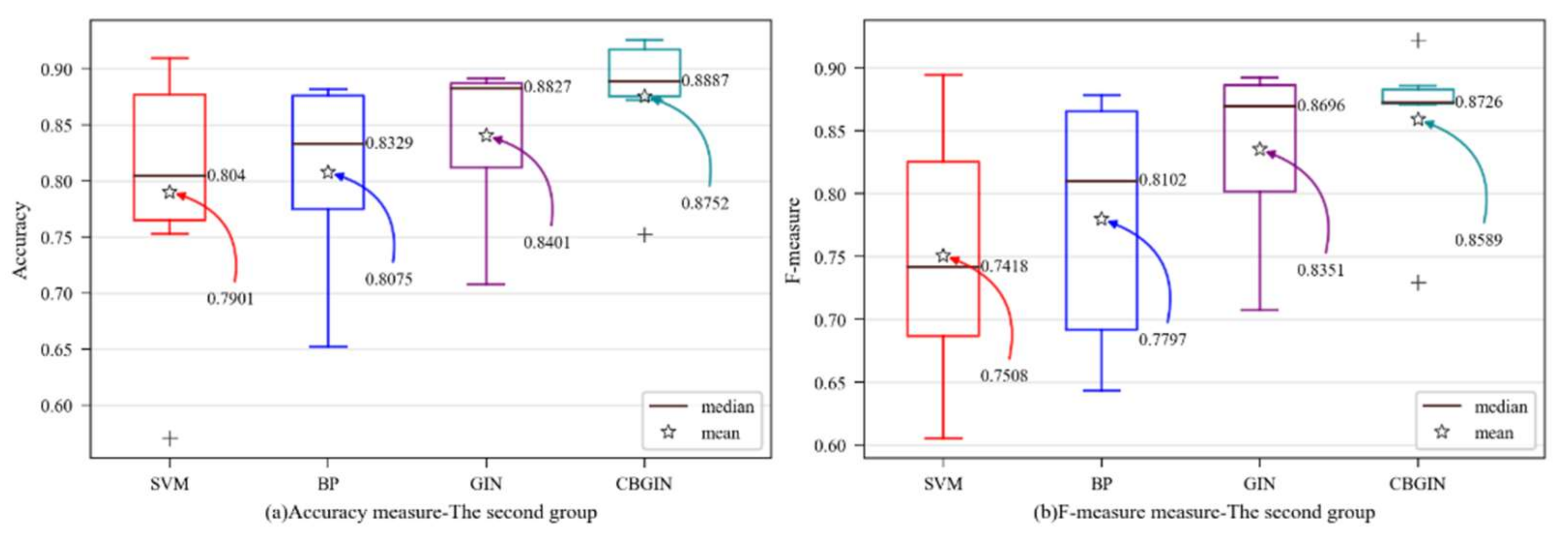
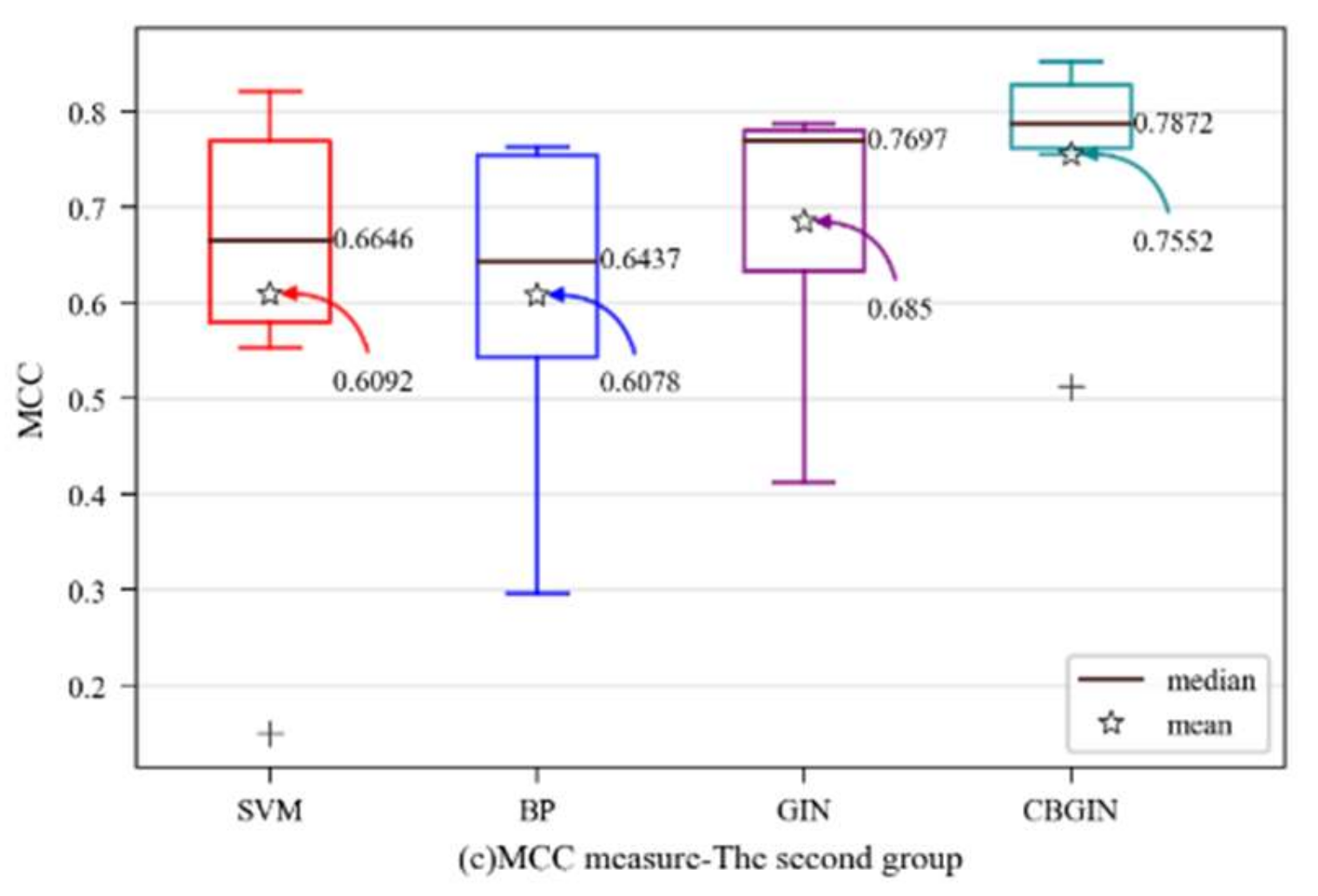
Similarly, in order to visually observe the performance of the CBGIN algorithm, various evaluation metrics were determined as box plots. The y-axis shows the evaluation metric score, while the prediction method is on x-axis in
Figure 4. For better analysis, the mean and median in the figure are marked.
Figure 4 shows that the CBGIN was improved with strong performance across all evaluation metrics, suggesting that the GIN model can use the learned representation vector more effectively and that the enhanced GIN model is more suited for software fault prediction.
The experimental results demonstrated that both the GCN and the GIN graph convolution methods can produce beneficial representation vectors to enhance the accuracy of software defect prediction. This model was improved compared to GIN and GCN, showing that the model suggested in this research can increase the accuracy of software defect prediction.
5. Conclusions and Future Work
In this paper, we mapped the software to the graph structure and simplified the software graph with the community structure according to the complex network theories. Furthermore, we used the convolutional layer in the graph neural network to obtain the graph information of the software. In this way, the software was regarded in its entirety, and independent classes were linked through class dependencies for software defect prediction. The graph convolution layer selected the graph convolution method as GCN and GIN for experiments and used the PROMISE dataset for verification. The experimental results show that the graph neural network could obtain better representation vectors of nodes, thereby improving the performance of software defect prediction.
This research highlights the importance of a software defect prediction framework based on multiple factors, by modeling the software into a more complex network, which considers the connections between the software modules and the attributes of modules. The following suggestions for future work can be derived from this experiment:
- (1)
A more complex network can be constructed, for example, considering developer information, and semantic information of software code can be incorporated into the network.
- (2)
For the improvement of the graph neural network, it can be combined with a community discovery algorithm.
- (3)
The experiments in this paper considered within-project software defect prediction; thus, in the future, cross-project software defect prediction can be considered.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}