
The Causal Interaction between Complex Subsystems


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Information Flow between Two Subspaces of a Complex System
3. Information Flow between Linear Subsystems and Its Estimation
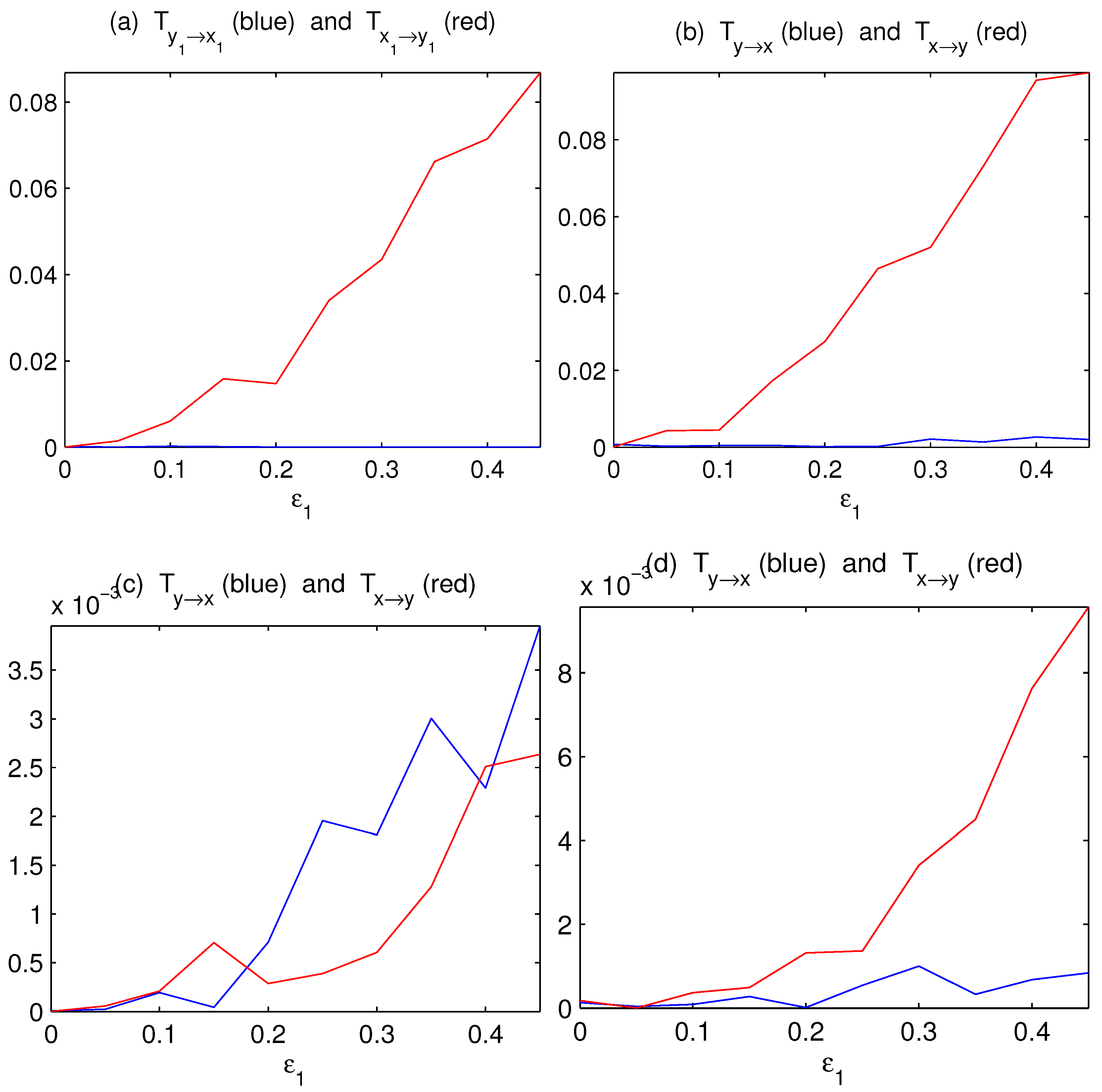
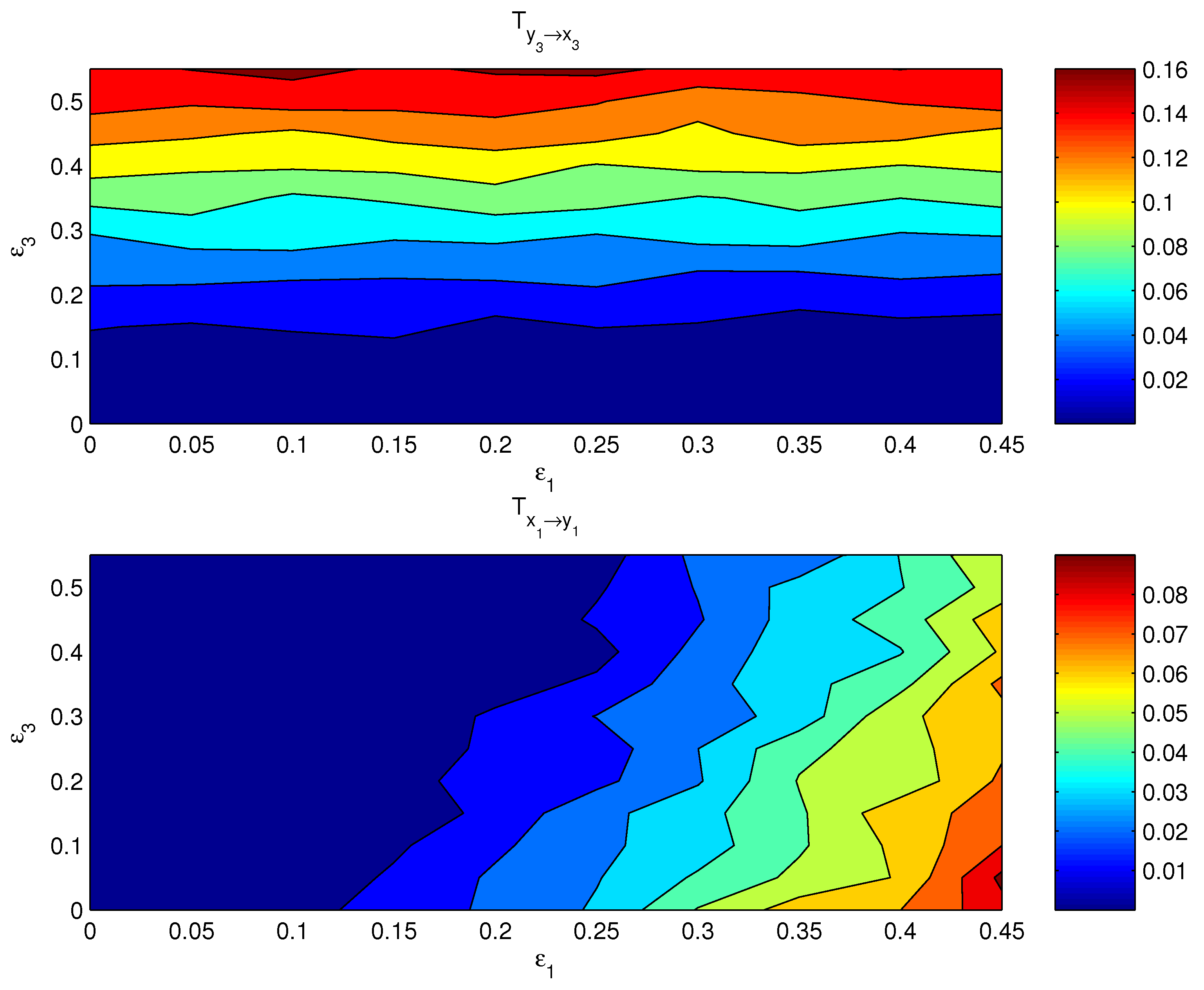
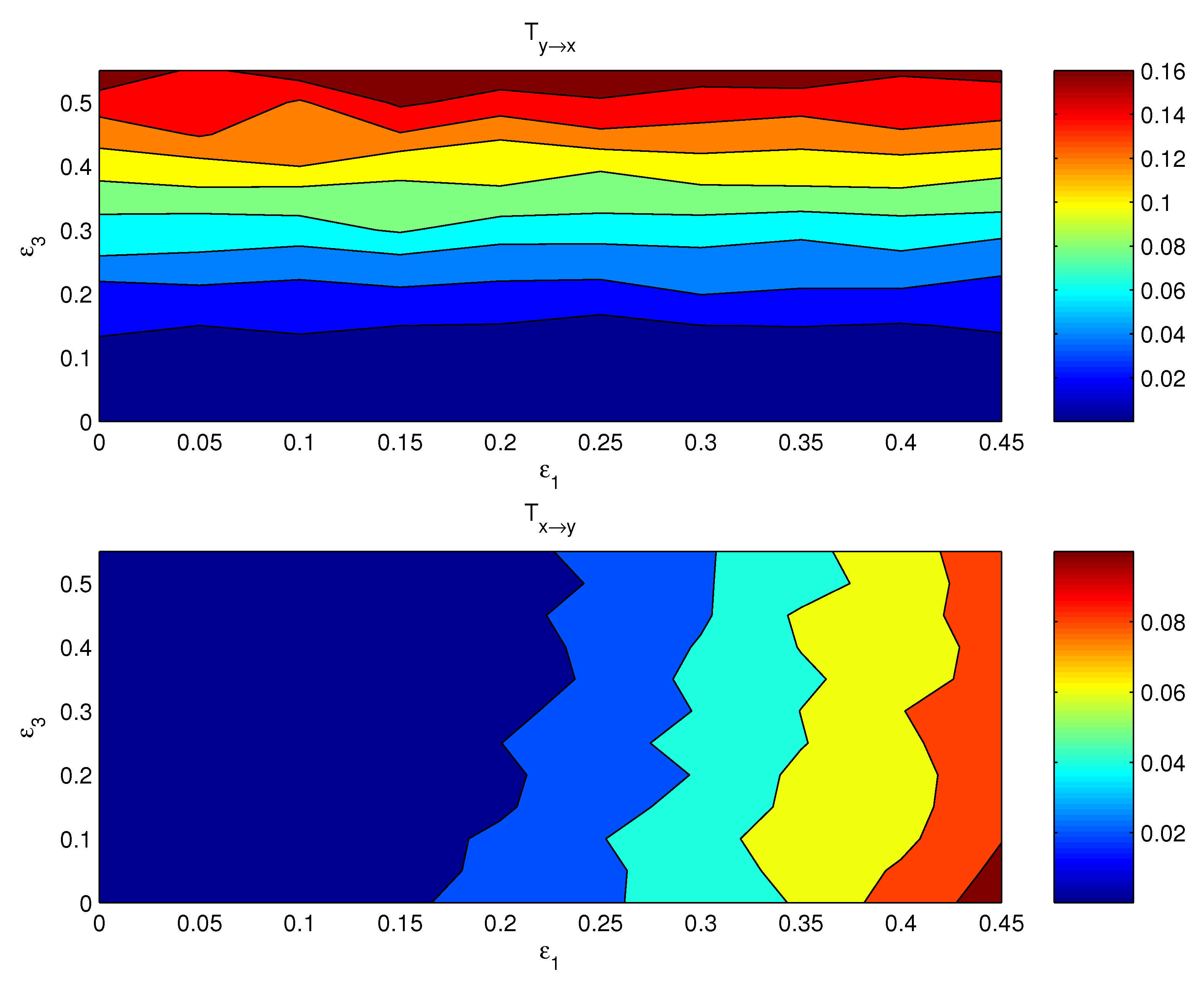
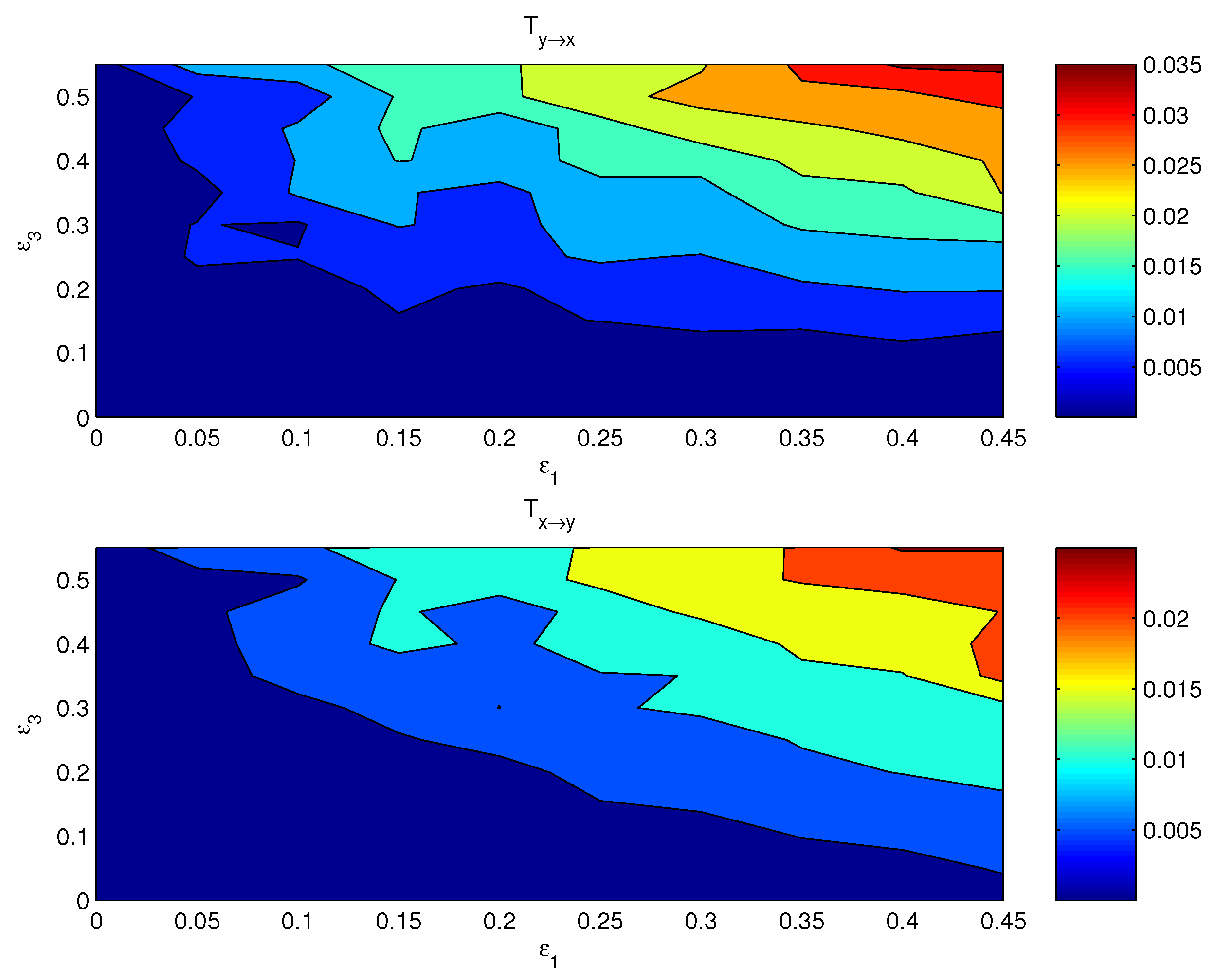
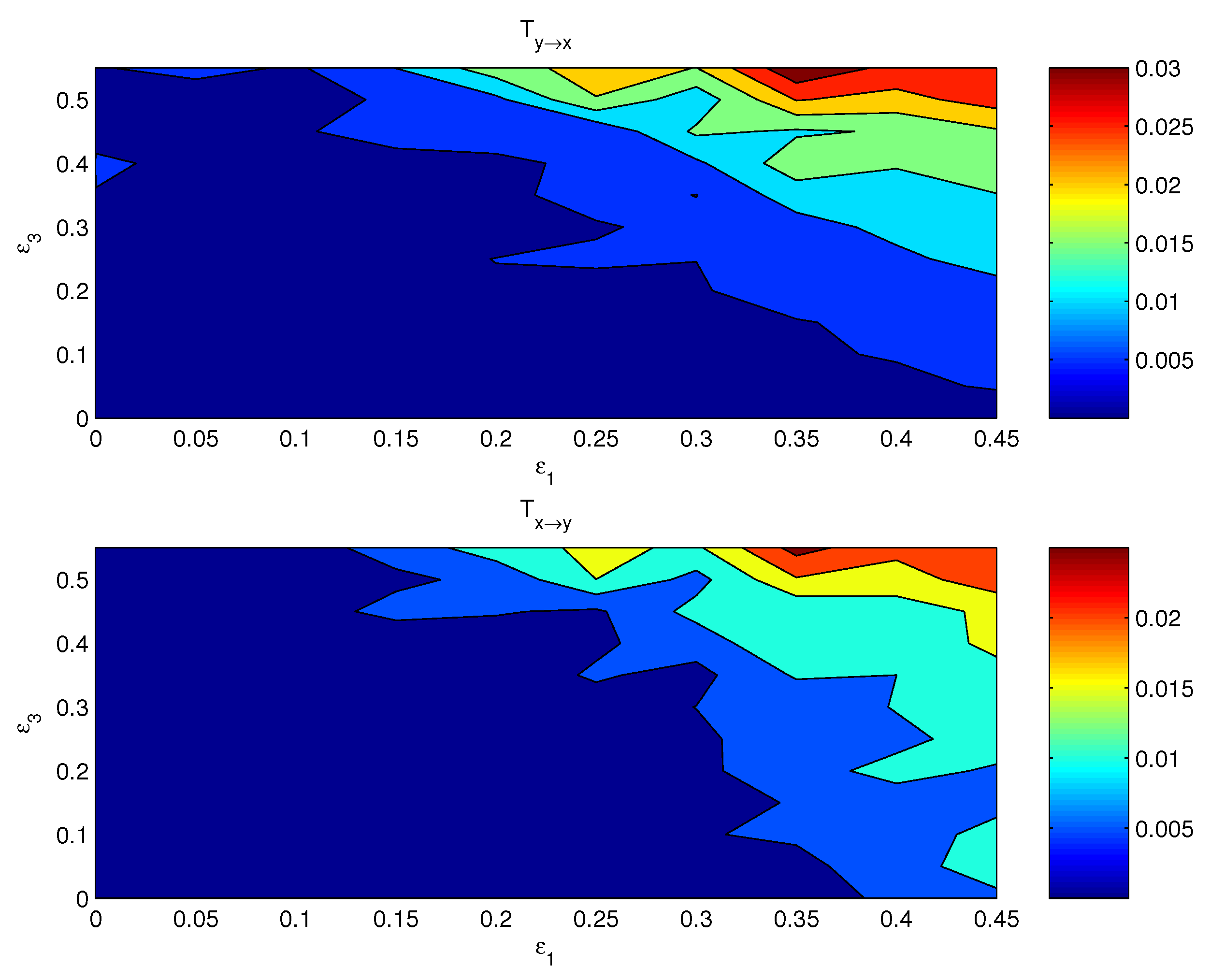
4. Validation
4.1. One-Way Causal Relation
4.2. Mutually Causal Relation
5. Summary
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Intergovenmental Panel on Climate Change (IPCC). The Sixth Assessment Report, Climate Change 2021: The Physical Science Basis. Available online: https://www.ipcc.ch/report/ar6/wg1/#FullReport (accessed on 15 November 2021).
- Friston, K.J.; Harrison, L.; Penny, W. Dynamic causal modeling. Neuroimage 2003, 19, 1273–1302. [Google Scholar] [CrossRef]
- Li, B.; Daunizeau, J.; Stephan, K.E.; Penny, W.; Hu, D.; Friston, K. Generalised filtering and stochastic DCM for fMRI. Neuroimage 2011, 58, 442–457. [Google Scholar] [CrossRef]
- Friston, K.J.; Ungerleider, L.G.; Jezzard, P.; Turner, R. Characterizing modulatory interactions between V1 and V2 in human cortex with fMRI. Hum. Brain Mapp. 1995, 2, 211–224. [Google Scholar] [CrossRef]
- Karl, J. Friston, Joshua Kahan, Adeel Razi, Klaas Enno Stephan, Olaf Sporns. On nodes and modes in resting state fMRI. NeuroImage 2014, 99, 533C547. [Google Scholar]
- Qiu, P.; Jiang, J.; Liu, Z.; Cai, Y.; Huang, T.; Wang, Y.; Liu, Q.; Nie, Y.; Liu, F.; Cheng, J.; et al. BMAL1 knockout macaque monkeys display reduced sleep and psychiatric disorders. Natl. Sci. Rev. 2019, 6, 87–100. [Google Scholar] [CrossRef]
- Wang, X.-J.; Hu, H.; Huang, C.; Keennedy, H.; Li, C.T.; Logothetis, N.; Lu, Z.-L.; Luo, Q.; Poo, M.-M.; Tsao , D.; et al. Computational neuroscience: A frontier of the 21st century. Natl. Sci. Rev. 2020, 7, 1418–1422. [Google Scholar] [CrossRef] [PubMed]
- Granger, C. Investigating causal relations by econometric models and cross-spectral methods. Econometrica 1969, 37, 424. [Google Scholar] [CrossRef]
- Pearl, J. Causality: Models, Reasoning, and Inference, 2nd ed.; Cambridge University Press: New York, NY, USA, 2009. [Google Scholar]
- Imbens, G.W.; Rubin, D.B. Causal Inference for Statistics, Social, and Biomedical Sciences; Cambridge University Press: Cambridge, UK, 2015. [Google Scholar]
- Batchelor, G.K. The Theory of Homogeneous Turbulence; Cambridge University Press: Cambridge, UK, 1953; 197p. [Google Scholar]
- Landau, L.D.; Lifshitz, E.M. Statistical Physics, 2nd Revised and Enlarged ed.; Pergamon Press: Oxford, UK, 1969. [Google Scholar]
- Preisendorfer, R. Principal Component Analysis in Meteorology and Oceanography; Elsevier: Amsterdam, The Netherlands, 1998; 418p. [Google Scholar]
- Friston, K.J.; Frith, C.D.; Liddle, P.F.; Frackowiak, R.S. Functional connectivity: The principal-component analysis of large (PET) data sets. J. Cereb. Blood Flow Metab. 1993, 13, 5–14. [Google Scholar] [CrossRef]
- Friston, K.; Phillips, J.; Chawla, D.; Buchel, C. Nonlinear PCA: Characterizing interactions between modes of brain activity. Philos. Trans. R. Soc. Lond. B Biol. Sci. 2000, 355, 135–146. [Google Scholar] [CrossRef][Green Version]
- Liang, X.S. Information flow and causality as rigorous notions ab initio. Phys. Rev. E 2016, 94, 052201. [Google Scholar] [CrossRef]
- Liang, X.S.; Kleeman, R. Information transfer between dynamical system components. Phys. Rev. Lett. 2005, 95, 244101. [Google Scholar] [CrossRef]
- Liang, X.S. Information flow within stochastic systems. Phys. Rev. E 2008, 78, 031113. [Google Scholar] [CrossRef]
- Liang, X.S. Unraveling the cause-effect relation between time series. Phys. Rev. E 2014, 90, 052150. [Google Scholar] [CrossRef] [PubMed]
- Liang, X.S. Normalized multivariate time series causality analysis and causal graph reconstruction. Entropy 2021, 23, 679. [Google Scholar] [CrossRef] [PubMed]
- Majda, A.J.; Harlim, J. Information flow between subspaces of complex dynamical systems. Proc. Natl. Acad. Sci. USA 2007, 104, 9558–9563. [Google Scholar] [CrossRef]
- Liang, X.S. Measuring the importance of individual units in producing the collective behavior of a complex network. Chaos 2021, 31, 093123. [Google Scholar] [CrossRef]
- AI-Sadoon, M.M. Testing subspace Granger causality. Econom. Stat. 2019, 9, 42–61. [Google Scholar]
- Triacca, U. Granger causality between vectors of time series: A puzzling property. Stat. Probab. Lett. 2018, 142, 39–43. [Google Scholar] [CrossRef]
- Lasota, A.; Mackey, M.C. Chaos, Fractals, and Noise: Stochastic Aspects of Dynamics; Springer: New York, NY, USA, 1994. [Google Scholar]
- Tachiiri, K.; Su, X.; Matsumoto, K.K. Identifying the key processes and sectors in the interaction between climate and socio-economic systems: A review toward integrating Earth-human systems. Progress. Earth Planet. Sci. 2021, 8, 24. [Google Scholar] [CrossRef]
- Balbus, J.; Crimmins, A.; Gamble, J.L.; Easterling, D.R.; Kunkel, K.E.; Saha, S.; Sarofim, M.C. Introduction: Climate Change and Human Health. The Impacts of Climate Change on Human Health in the United States: A Scientifi Assessment. U.S. Global Change Research Program: Washington, DC, USA, 2016. [Google Scholar]
- D’Agostino, G.; Scala, A. Networks of Networks: The Last Frontier of Complexity; Springer: New York, NY, USA, 2014. [Google Scholar]
- Kenett, D.Y.; Matjaž, P.; Boccaletti, S. Networks of networks—An introduction. Chaos Solitons Fractals 2015, 80, 1–6. [Google Scholar] [CrossRef]
- DeFord, D.R.; Pauls, S.D. Spectral clustering methods for multiplex networks. Phys. A Stat. Mech. Its Appl. 2019, 533, 121949. [Google Scholar] [CrossRef]






Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liang, X.S. The Causal Interaction between Complex Subsystems. Entropy 2022, 24, 3. https://doi.org/10.3390/e24010003
Liang XS. The Causal Interaction between Complex Subsystems. Entropy. 2022; 24(1):3. https://doi.org/10.3390/e24010003
Chicago/Turabian StyleLiang, X. San. 2022. "The Causal Interaction between Complex Subsystems" Entropy 24, no. 1: 3. https://doi.org/10.3390/e24010003
APA StyleLiang, X. S. (2022). The Causal Interaction between Complex Subsystems. Entropy, 24(1), 3. https://doi.org/10.3390/e24010003