1. Introduction
Generalized linear models (GLMs) were first introduced by Nelder and Wedderburn [
1] and later expanded upon by McCullagh and Nelder [
2]. The GLMs represent a natural extension of the standard linear regression models, which enclose a large variety of response variable distributions, including distributions of count, binary, or positive values. Let
be independent response variables. The classical GLM assumes that the density function of each random variable
belongs to the exponential family, having the form
for
where the functions
and
are known. Therefore, the observations are independent but not identically distributed, depending on a location parameter
and a nuisance parameter
Further, we denote by
the expectation of the random variable
and we assume that there exists a monotone differentiable function, so called link function
g, verifying
with
the regression parameter vector. The
-vector of explanatory variables,
is assumed to be nonrandom, i.e., the design matrix is fixed. Correspondingly, the location parameter depends on the explanatory variables
the density function given in (
1) can be written as
empathizing its dependence of
and
.
The maximum likelihood estimator (MLE) and the quasilikelihood estimators were well studied for the GLMs, and it is well known that they are asymptotically efficient but lack robustness in the presence of outliers, which can result in a significant estimation bias. Jaenada and Pardo [
3] revised the different robust estimators in the statistical literature and studied the lack of robustness of the MLE as well. Among others, Stefanski et al. [
4] studied optimally bounded score functions for the GLM and generalized the results obtained by Krasker and Welsch [
5] for classical LRMs. Künsch et al. [
6] introduced the so-called conditionally unbiased bounded-influence estimate, and Morgenthaler [
7], Cantoni and Ronchetti [
8], Bianco and Yohai [
9], Croux and Hesbroeck [
10], Bianco et al. [
11], and Valdora and Yohai [
12] continued the development of robust estimators for the GLMs based on general M-estimators. Later, Ghosh and Basu [
13] proposed robust estimators for the GLM, based on the density power divergence (DPD) introduced in Basu et al. [
14].
There are not many papers considering robust tests for GLMs. In this sense, Basu et al. [
15] considered robust Wald-type tests based on the minimum DPD estimator, but assuming random explanatory variables for the GLM. The main purpose of this paper is to introduce new robust Wald-type tests based on the MRPE under fixed (not random) explanatory variables.
Broniatowski et al. [
16] presented robust estimators for the parameters of the linear regression model (LRM) with random explanatory variables and Castilla et al. [
17] considered Wald-type test statistics, based on MRPE, for the LRM. Toma and Leoni–Aubin [
18] defined new robustness and efficient measures based on the RP and Toma et al. [
19] considered the MRPE for general parametric models, and constructed a model selection criterion for regression models. The term “Rényi pseudodistance” (RP) was adopted in Broniatowski et al. [
16] because of its similarity with the Rényi divergence (Rényi [
20]), although this family of divergences was considered previously in Jones et al. [
21]. Fujisawa and S. Eguchi [
22] used the RP under the name of
-cross entropy, introduced robust estimators obtained by minimizing the empirical estimate of the
-cross entropy (or the
-divergence associated to the
-cross entropy) and studied their properties. Further, Hirose and Masuda [
23] considered the
likelihood function to find robust estimation. Using the
-divergence, Kawashima and Fujisawa [
24,
25] presented robust estimators for sparse regression and sparse GLMs with random covariates. The robustness of all the previous estimators is based on density power weight,
which gives a small weight to outliers observations. This idea was also developed by Basu et al. [
15] for the minimum DPD estimator and was considered some years ago by Windham [
26]. More concretely, Basu et al. [
14] considered the density power function multiplied by the score function.
The outline of the paper is as follows: in
Section 2, some results in relation to the MRPEs for GLMs, previously obtained in Jaenada and Pardo [
3], are presented.
Section 3 introduces and studies Wald-type tests based on the MRPE for testing linear null hypothesis for the GLMs. In
Section 4, the influence function of the MRPE as well as the influence functions of the Wald-type tests are derived. Finally, we empirically examine the performance of the proposed robust estimators and Wald-type test statistics for the Poisson regression model through a simulation study in
Section 5, and we illustrate its applicability with real data sets for binomial and Poisson regression.
2. Asymptotic Distribution of the MRPEs for the GLMs
In this Section, we revise some of the results presented in Jaenada and Pardo [
3] in relation to the MRPE. Let
be INIDO random variables with density functions with respect to some common dominating measure,
respectively. The true densities
are modeled by the density functions given in (
1), belonging to the exponential family. Such densities are denoted by
highlighting its dependence on the regression vector
the nuisance parameter
and the observation
,
In the following, we assume that the explanatory variables
are fixed, and therefore the response variables verify the INIDO set up studied in Castilla et al. [
27].
For each of the response variables
, the RP between the theoretical density function belonging to the exponential family,
and the true density underlying the data,
can be defined, for
as
where
does not depend on
We consider
a random sample of independent but nonhomogeneous observations of the response variables with fixed predictors
Since only one observation of each variable
is available, a natural estimate of its true density
is the degenerate distribution at the the observation
Consequently, in the following we denote
the density function of the degenerate variable at the point
Then, substituting in (
2) the theoretical and empirical densities, yields to the loss
If we consider the limit when
tends to zero we get
Last expression coincides with the Kullback–Leibler divergence, except for the constant
More details about Kullback–Leiber divergence can be seen in Pardo [
28].
For the seek of simplicity, let us denote
and
The expression (
3) can be rewritten as
Based on the previous idea, we shall define an objective function averaging the RP between all the the RPs. Since minimizing
in
is equivalent to maximizing
we define a loss function averaging those quantities as
Based on (
5), we can define the MRPE of the unknown parameter
,
by
with
defined in (
5)
at
The MRPE coincides with the MLE at
, and therefore the proposed family can be considered a natural extension of the classical MLE.
Now, since the MRPE is defined as a maximum, it must annul the first derivatives of the loss function given in (
5). The estimating equations of the parameters
and
are given by
For the first equation, we have
The previous partial derivatives can be simplified as
and
See Ghosh and Basu [
13] for more details. Now using the simplified expressions, we can write the estimating equation for
as
being
and
Subsequently, the estimating equation for
is given by
and thus, the estimating equation for
is given by
being
and
Under some regularity conditions, Castilla et al. [
27] established the consistency and asymptotic normality of the MRPEs under the INIDO setup. Before stating the consistence and asymptotic distribution of the MRPEs for the GLM, let us introduce some useful notation. We define
for all
and
Theorem 1. Let be a random sample from the GLM defined in (1). The MRPE is consistent and its asymptotic distribution is given bywhere denotes the design matrix, is the k-dimensional identity matrix and the matrices and are defined bywithand Proof. The consistency is proved for general statistical models in Castilla et al. [
27] and the asymptotic distribution of the MRPEs for GLM is derived in Jaenada and Pardo [
3]. □
3. Wald Type Tests for the GLMs
In this section, we define Wald-type tests for linear null hypothesis of the form
being
a
full rank matrix and
a
r-dimensional vector
. If the nuisance parameter
is known, as with logistic and Poisson regression, the matrix
Additionally, choosing
gives rise to a null hypothesis defined by a linear combination of the regression coefficients,
, with
known or unknown. Further, the simple null hypothesis is a particular case when choosing
as the identity matrix of rank
k,
with
In the following we assume that there exist a matrix
verifying
Definition 1. Let be the MRPE of for the GLM. The Wald-type tests, based on the MRPE, for testing (11) are defined by The following theorem presents the asymptotic distribution of the Wald-type test statistics,
Theorem 2. The Wald-type test follows asymptotically, under the null hypothesis presented in (11), a chi-square distribution with degrees of freedom equal to the dimension of the vector in (12) Under the null hypothesis given in (11) the asymptotic distribution of the Wald-type test statistics is a chi-square distribution with r degrees of freedom. Proof. Now, the result follows taking into account that is a consistent estimator of □
Based on the previous convergence, the null hypothesis in (
11) is rejected, if
being
the
percentile of a chi-square distribution with
r degrees of freedom.
Finally, let
be a parameter point verifying
i.e.,
is not on the null hypothesis. The next result establishes that the Wald-type tests given in (
14) are consistent (see Fraser [
29]).
Theorem 3. Let be a parameter point verifying Then the Wald-type tests given in (14) are consistent, i.e., Remark 1. In the proof of the previous Theorem was established the approximate power function of the Wald-type tests defined in (13),whereandFrom the above expression, the necessary sample size n for the Wald-type tests to have a predetermined power, is given by , withbeingand the integer part. In accordance with Maronna et al. [
30], the breakdown point of the estimators
of a parameter
is the largest amount of contamination that the data may contain such that
still gives enough information about
The derivation of a general breakdown points it is in general not easy, so it may deserve a separate paper where it may be jointly considered the replacement finite-sample breakdown point introduced by Donoho and Huber [
31]. Although breakdown point is an important theoretical concept in robust statistics, perhaps is more useful the definition of breakdown point associated to a finite sample: replacement finite-sample break down point. More details can be seen in Section 3.2.5 of Maronna et al. [
30].
4. Influence Function
We derive in this section the IF of the MRPEs of the parameters
and Wald-type statistics based on these MRPEs,
The influence function (IF) of an estimator quantifies the impact of an infinitesimal perturbation in the true distribution of the data on the asymptotic value of the resulting parameter estimate (in terms of the corresponding statistical functional). An estimator is said to be robust if its IF is bounded. If we denote
the true distributions underlying the data, the functional
and associated to the MRPE for the parameters
is such that
The IF of a estimator is defined as the limiting standardized bias due to infinitesimal contamination. That is, given a contaminated distribution at the point
,
with
the degenerate distribution at
, the IF of the estimator
in terms of its associated functional
is computed as
In the following, let us denote
where
and
are the functionals associated the parameters
and
, respectively. Then, they must satisfy the estimating equations of the MRPE given by
where the quantities
and
are defined in
Section 2. Now, evaluating the previous equation at the contaminated distribution
, implicitly differentiating the estimating equations in
and evaluating them at
we can obtain the expression of the IF for the GLM.
We first derive the expression IF of MRPEs at the
direction. For this purpose, we consider the contaminated distributions
with
Here, only the
-th component of the vector of distributions is contaminated. If the true density function
of each variable belongs to the exponential model, we have that
Accordingly, we define
the MRPE when the true distribution underlying the data is
Based on Remark 5.2 in Castilla et al. [
27] the IF of the MRPE at the
direction with
the point of contamination is given by
In a similar manner, the IF in all directions (i.e., all components of the vector of distributions are contaminated) has the following expression
with
the point of contamination. We next derive the expression of the IF for the Wald-type tests presented in
Section 3. The statistical functional associated with the Wald-type tests for the linear null hypothesis (
11) at the distributions
, ignoring the constant
is given by
Again, evaluating the Wald-type test functionals at the contaminated distribution
and implicitly differentiating the expression, we can get the expression of it IF. In particular, the IF of the Wald-type test statistics at the
-th direction and the contamination point
is given by
Evaluating the previous expression at the null hypothesis,
the IF becomes identically zero,
Therefore, it is necessary to consider the second order IF of the proposed Wald-type tests. Twice differentiating in
, we get
Finally, the second order IF of the Wald-type tests in all directions is given by
To asses the robustness of the MRPEs and Wald-type test statistics we must discuss the boundedness of the corresponding IF. The boundedness of the second order IF of the Wald-type test statistics is determined by the boundedness of the IF of the MRPEs. Further, the matrix
is assumed to be bounded, so the robustness of the estimators only depend on the second factor of the IF. Most standard GLMs enjoy such properties for positives values of
, but the influence function is unbounded at
corresponding with the MLE. As an illustrative example,
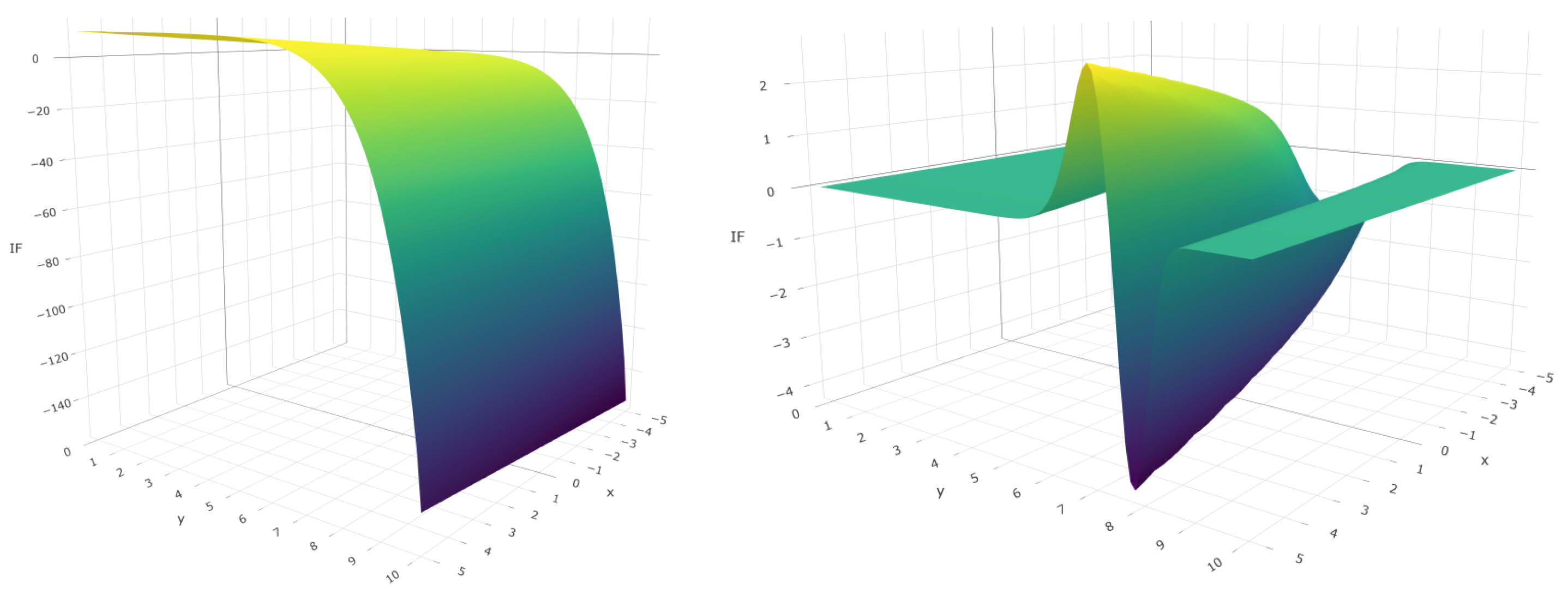
Figure 1 plots the IF of the MRPEs for the Poisson regression model with different values of
at one direction. The model is fitted with only one covariate, the parameter
is known for Poisson regression (
) and the true regression vector is fixed
As shown, the IF of the MRPEs with positives values of
are bounded, whereas the IF of the MLE is not, indicating it lack of robustness.
5. Numerical Analysis: Poisson Regression Model
We illustrate the proposed robust method for the Poisson regression model. As pointed out in
Section 1 the Poisson regression model belongs to the GLM with known shape parameter
location parameter
and known functions
and
. Since the nuisance parameter is known, for the seek of simplicity in the following we only use
In Poisson regression, the mean of the response variable is linked to the linear predictor through the natural logarithm, i.e.,
Thus, we can apply the previous proposed method to estimate the vector of regression parameters
with objective function given in Equation (
5).
The results provided are computed in the software R. The minimization of the objective function is performed using the implemented
optim() function, which applies the Nelder–Mead iterative algorithm (Nelder and Mead [
32]). Nelder–Mead optimization algorithm is robust although relatively slow. The corresponding objective function
given in (
5) is highly nonlinear and requires the evaluation of nontrivial quantities. Further, the computation of the Wald-type test statistics defined in (
13) requires to evaluate the covariance matrix of the MRPEs, involving nontrivial integrals. Some simplified expressions of the main quantities defined throughout the paper for the Poisson regression model, such as
or
are given in the
Appendix B. There is no closed expression for these quantities, and they need to be approximated numerically. Since the minimization is iteratively performed, computing such expressions at each step of the algorithm and for each observation may entail an increased computational burden. Nonetheless, the complexity is not significant for low-dimensional data. On the other hand, the optimum in (
5) need not to be uniquely defined, since the objective function may have several local minima. Then, the choice of the initial value of the iterative algorithm is crucial. Ideally, a good initial point should be consistent and robust. In our results the MLE is used as initial estimate for the algorithm.
We analyze the performance of the proposed methods in Poisson regression through a simulation study. We asses the behavior of the MRPE under the sparse Poisson regression model with covariates but only 3 significant variables. We set the 12-dimensional regression parameter and we generate the explanatory variables, , from the standard uniform distribution with variance-covariance matrix having Toeplitz structure, with the -th element being . The response variables are generated from the Poisson regression model with mean To evaluate the robustness of the proposed estimators, we contaminate the responses using a perturbed distribution of the form where b is a realization of a Bernoulli variable with parameter so called the contamination level. That is, the distribution of the contaminated responses lies in a small neighbourhood of the assumed model. We repeat the process for each value of .
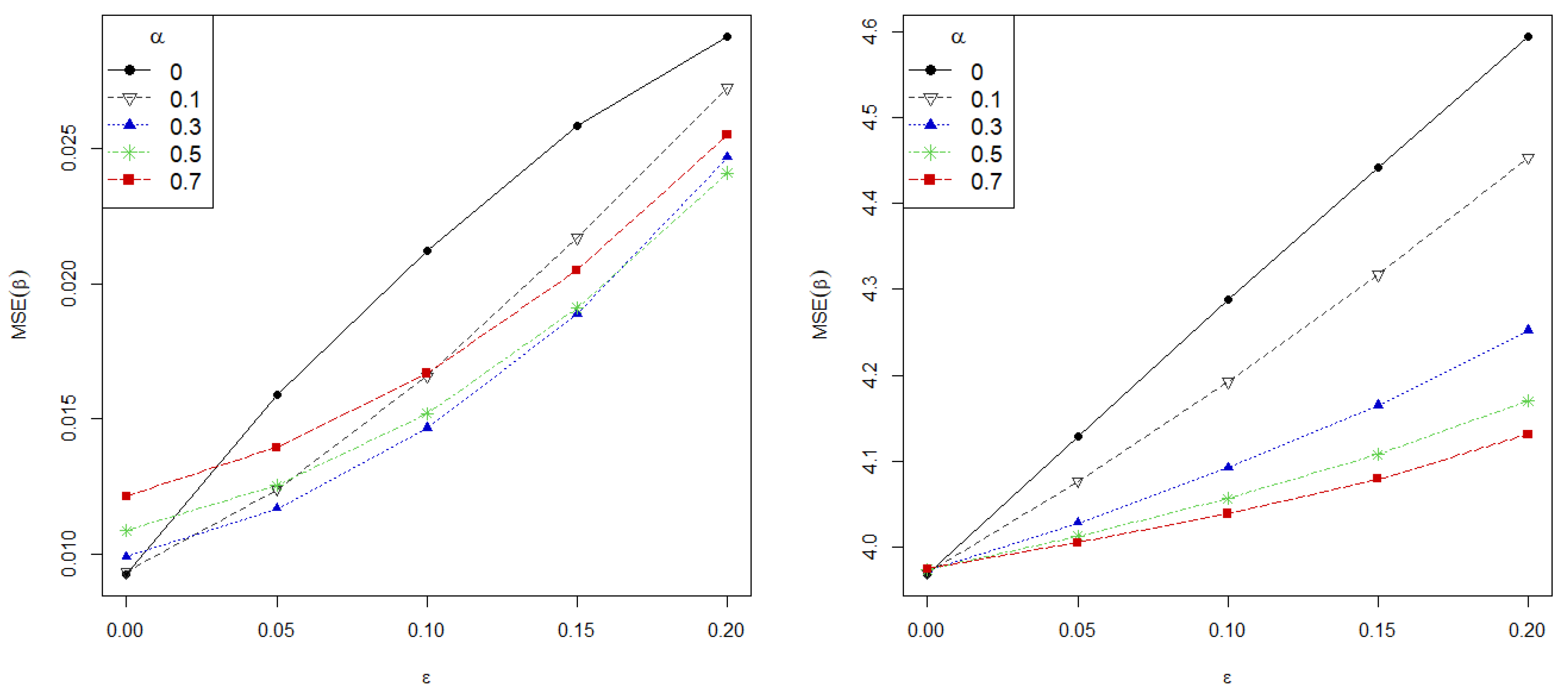
Figure 2 presents the mean squared error of the estimate (MSE),
(left) and the MSE on the prediction (right) against contamination level on data for different values of
and
. The sample size is fixed at
and the MSE on the prediction is calculated using
new observations following the true model. As shown, greater values of
correspond to more robust estimators, revealing the role of the tuning parameter on the robustness gain. Most strikingly, the MSE grows linearly for the MLE, while the proposed estimators manage to maintain a low error in all contaminated scenarios.
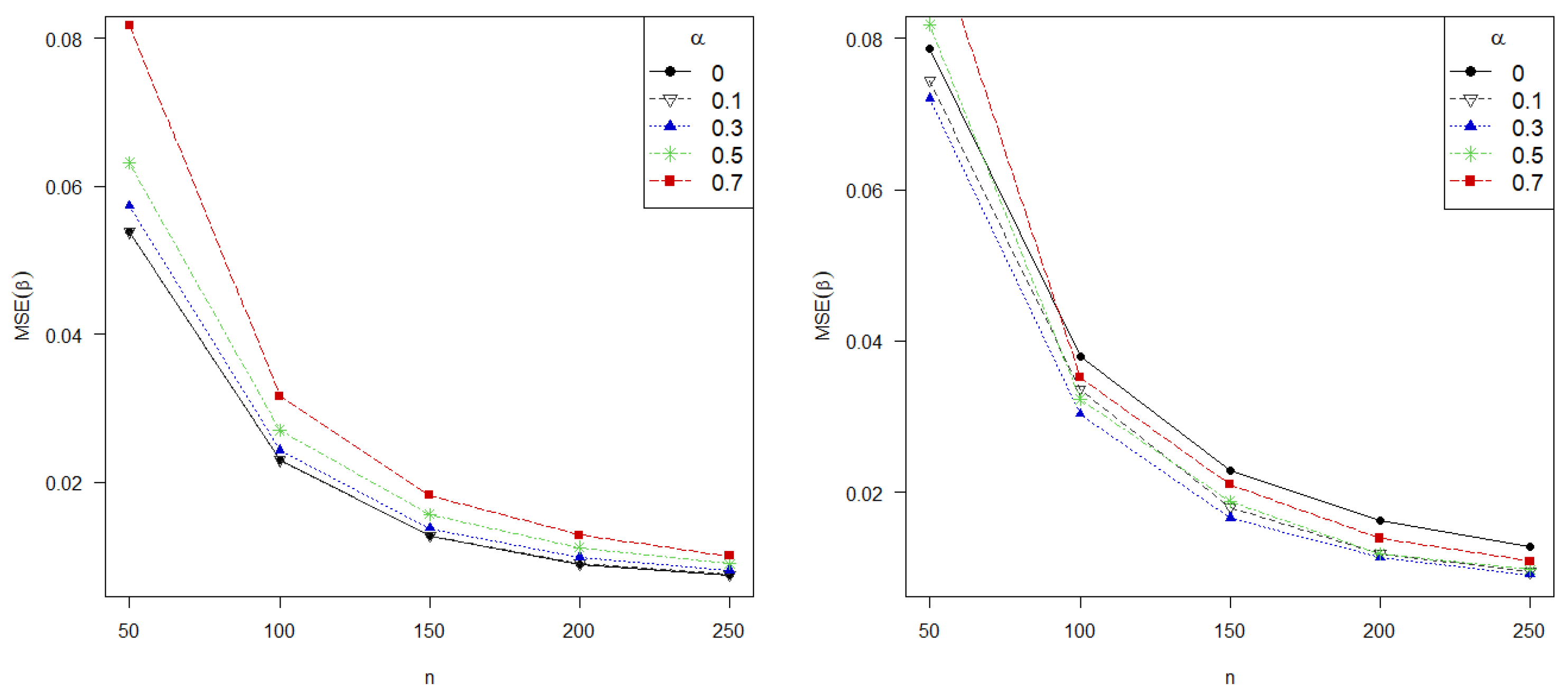
Furthermore, it is to be expected that the error of the estimate decreases with larger samples sizes. In this regard,
Figure 3 shows the MSE for different values of
and
against the sample size in the absence of contamination (left) and under
of contamination. Our proposed estimators are more robust than the classical MLE with almost all contaminated scenarios, since the MSE committed is lower for all positives values of
than for
(corresponding to the MLE), except for too small sample sizes. Conversely, the MLE is, as expected, the most efficient estimator in absence of contamination, closely to our proposed estimators with
, highlighting the importance of
in controlling the trade-off between efficiency and robustness. In this regard, values of
about
perform the best taking into account the low loss of efficiency and the gain in robustness. Finally, note that small sample sizes adversely affect to greater values of
.
On the other hand, one could be interested on testing the significance of the selected variables. For this purpose, we simplify the true model and we examine the performance of the proposed Wald-type test statistics under different true coefficients values. In particular, let us consider a Poisson regression model with only two covariates, generated from the uniform distribution as before, and the linear null hypothesis
That is, we are interested in assessing the significance of the second variable. The sample size if fixed at
and the true value of the component of the regression vector is set
We study the power of the tests under increasing signal of the second parameter
and increasing contamination level. Here, the model is contaminated by perturbing the true distribution with
where
is the mean of the Poisson variable in the absence of contamination,
is the contaminated mean, with
and
b is a realization of a Bernoulli variable with probability of success
Table 1 presents the rejection rate of the Wald-type test statistics for different true values of
under different contaminated scenarios. As expected, stronger signals produce higher power for all Wald-type test. Moreover, the power of the Wald-type test statistics based on the MLE decreases when increasing the contamination, whereas the power of the statistics based on the MRPEs with positives values of
keeps sufficiently high. Then, our proposed robust estimators are able to detect the significance of the variable even in heavily contaminated scenarios.







{kind=link}
{kind=link}
{kind=link}