
Adaptive Block-Based Compressed Video Sensing Based on Saliency Detection and Side Information


Abstract
:1. Introduction
2. Compressed Sensing Overview
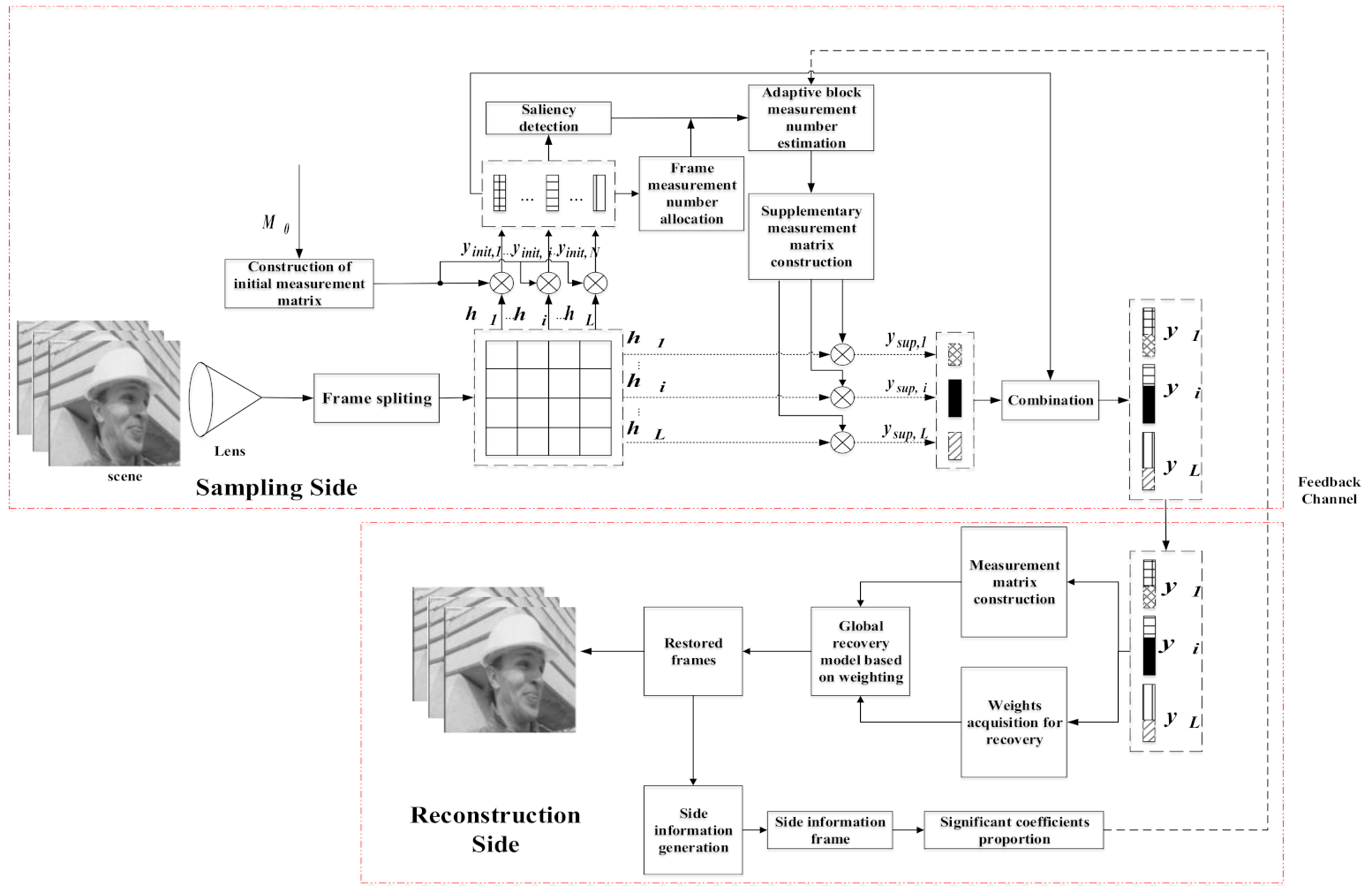
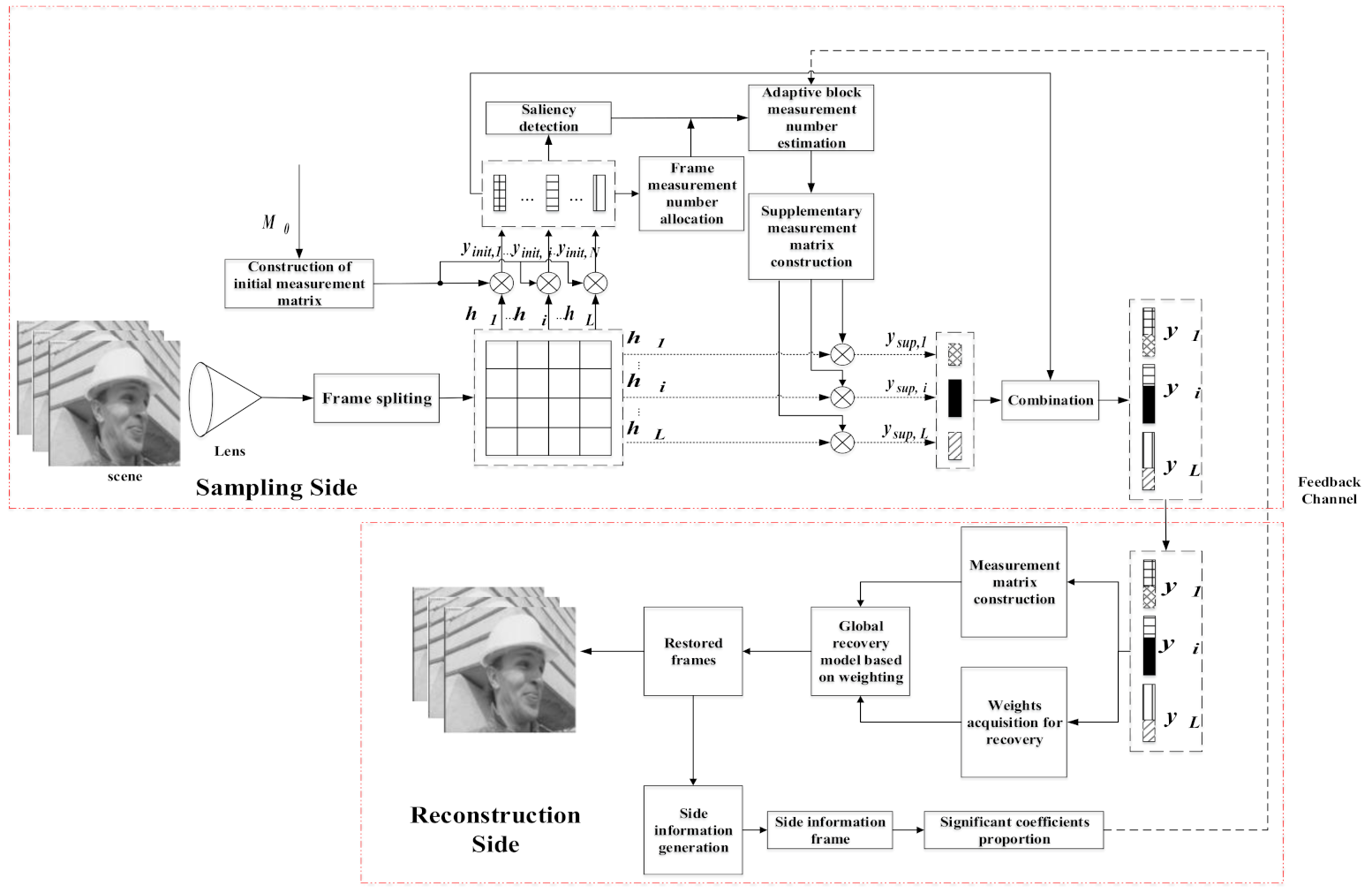
3. The Proposed Scheme
3.1. Frame Measurement Number Allocation
3.2. Saliency Detection
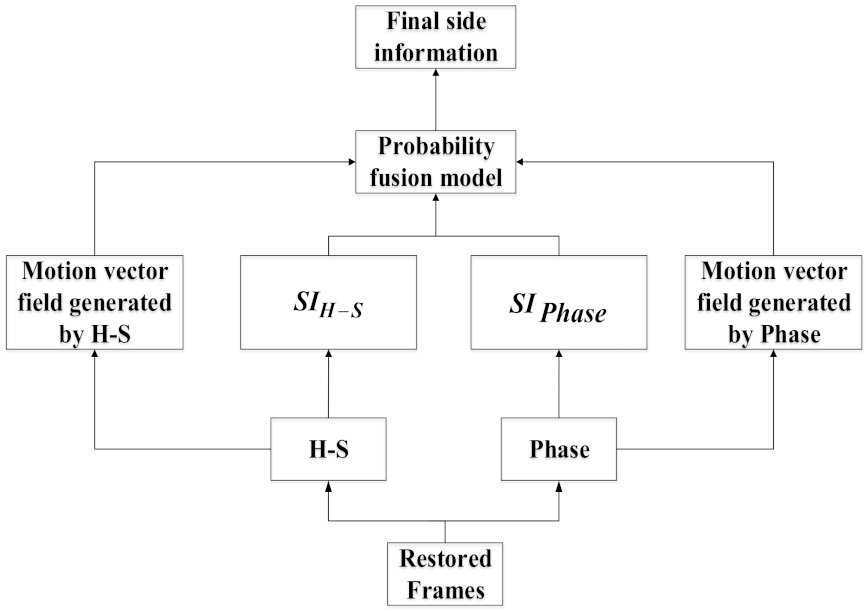
3.3. Side Information Generation
3.4. Adaptive Block Measurement Number Estimation
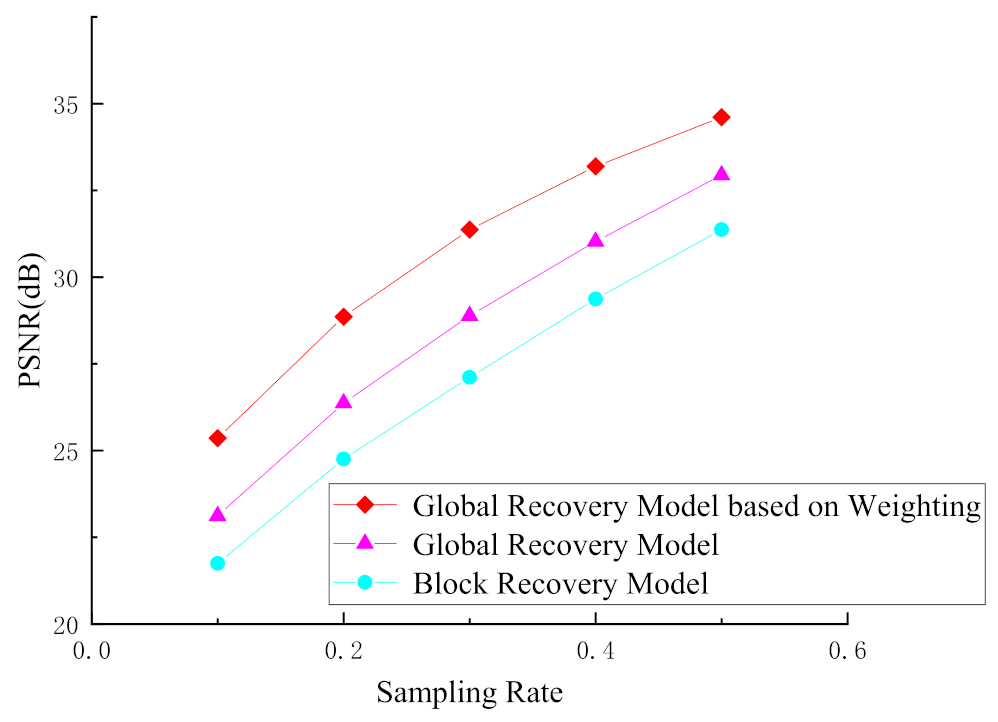
3.5. Global Recovery Model Based on Weighting
4. Simulation Results
4.1. Evaluation of Different GOP Sizes
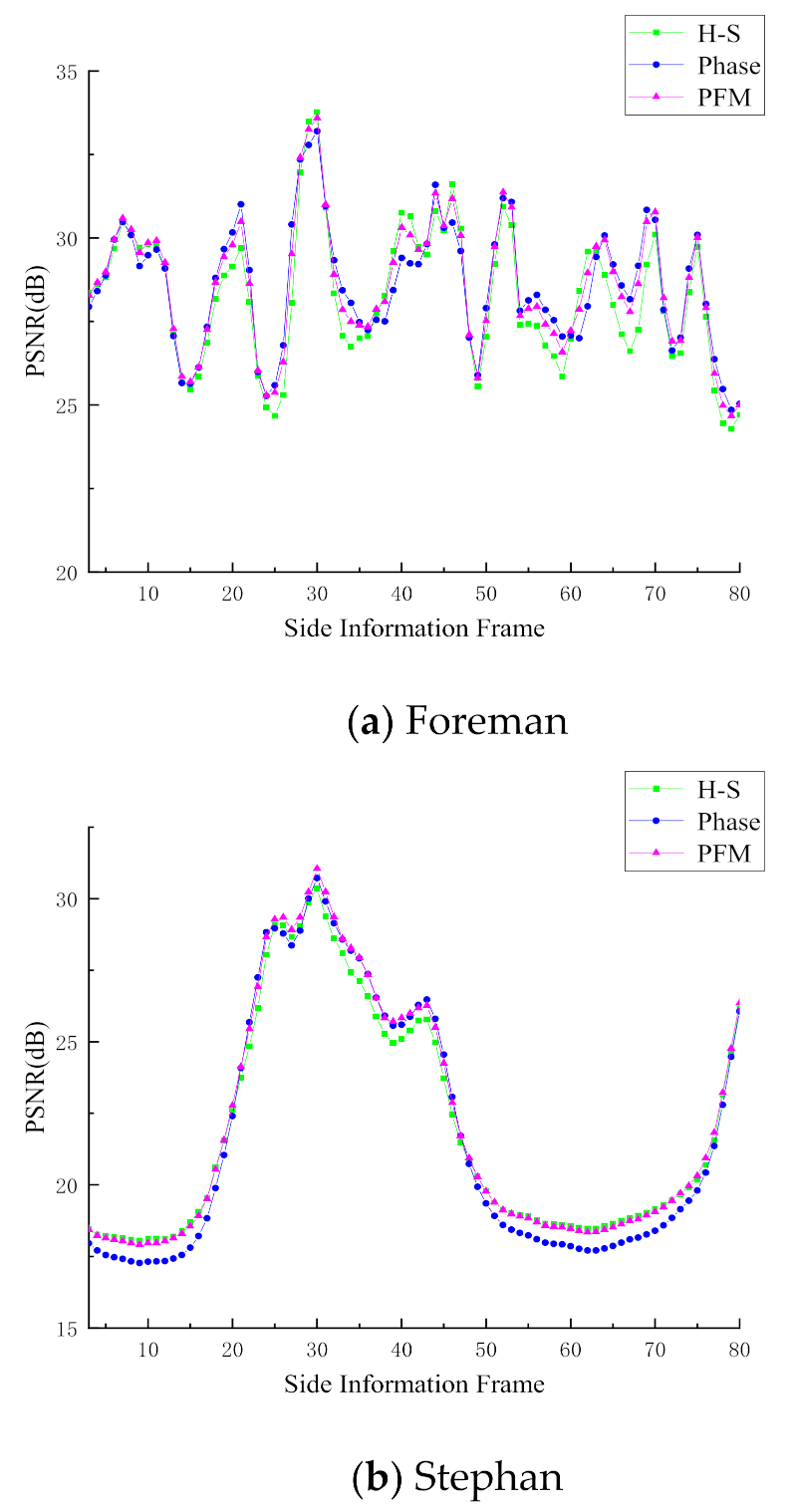
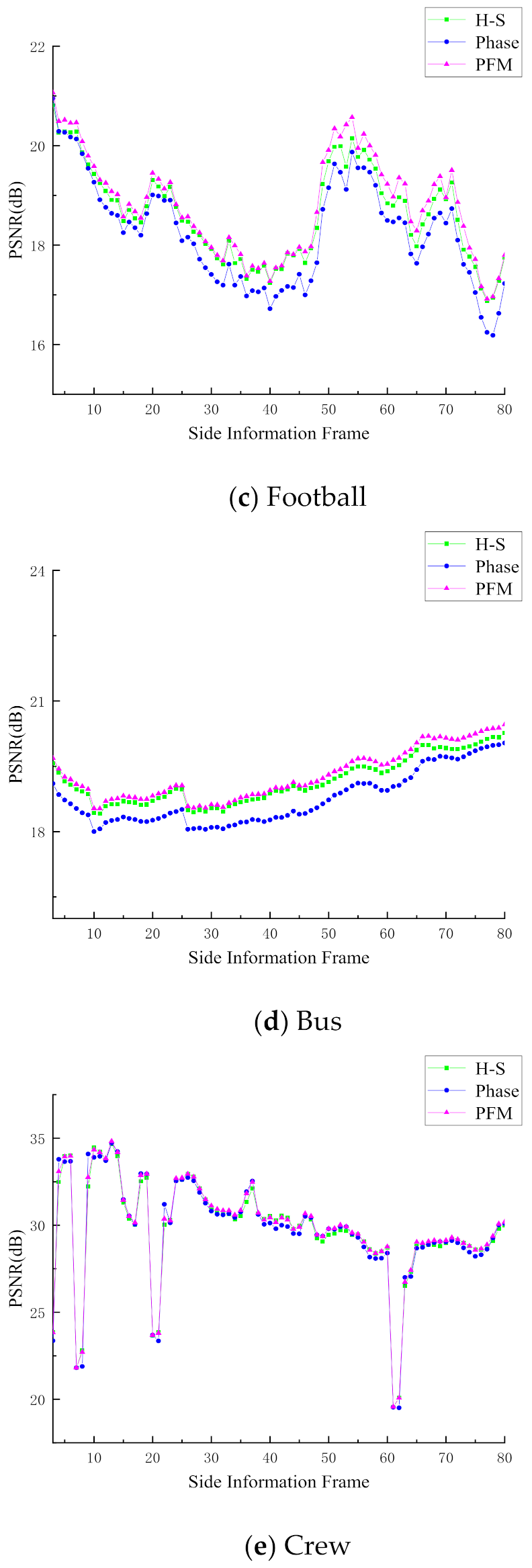
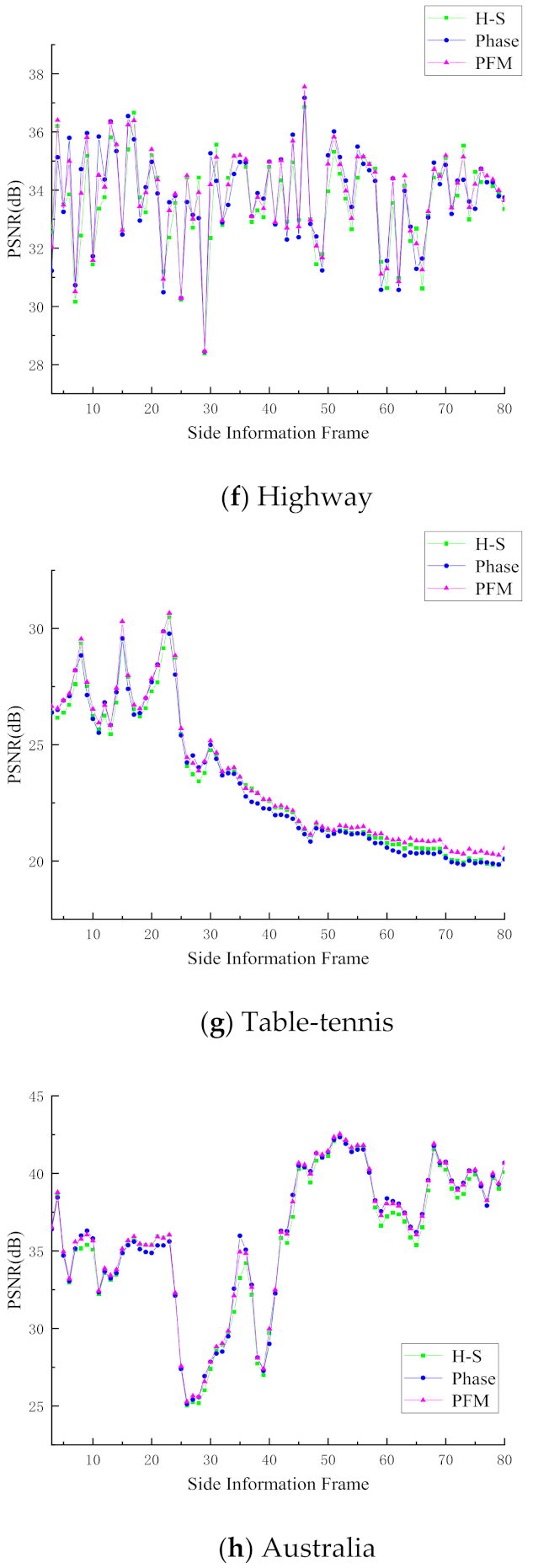
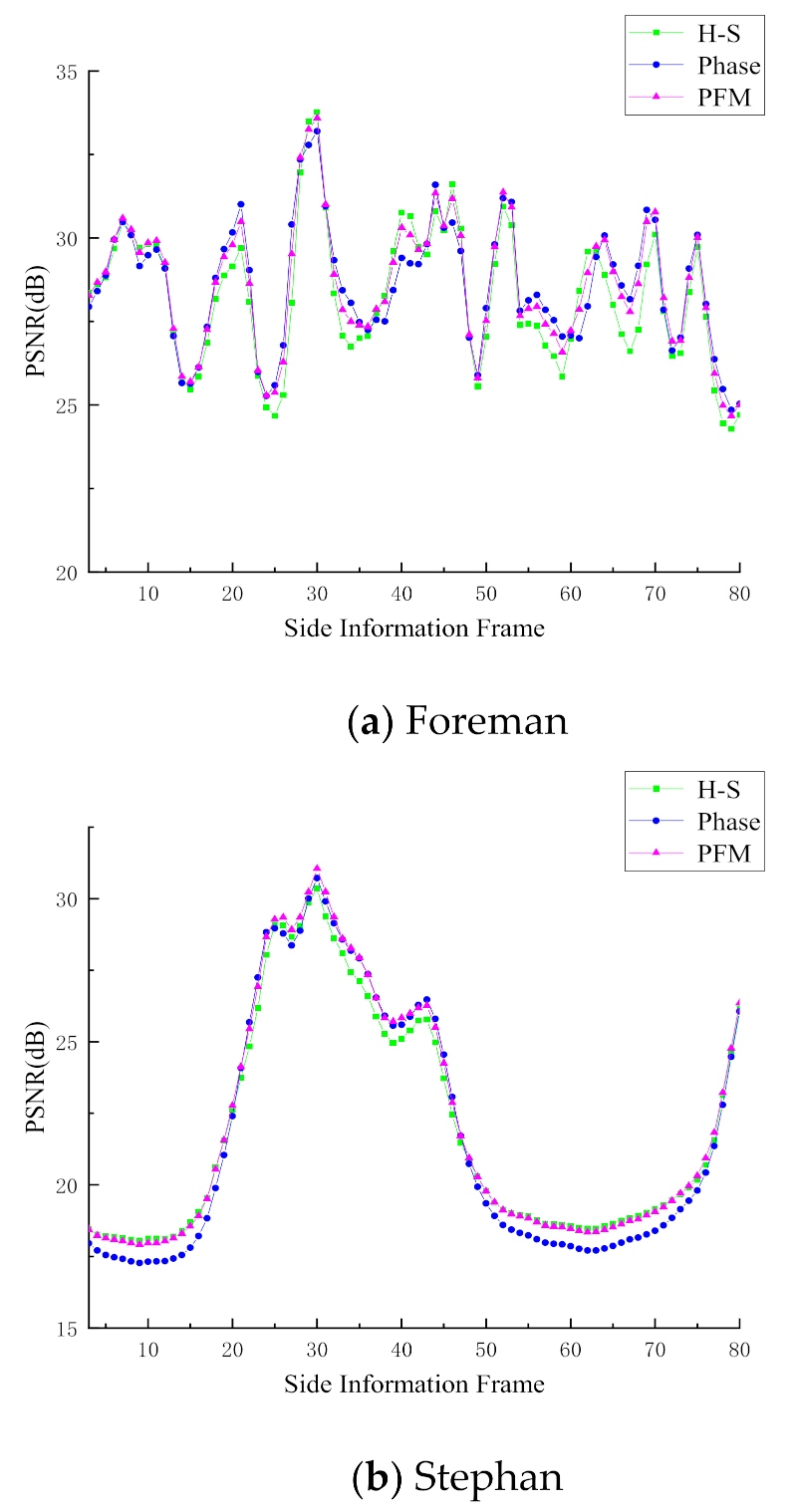
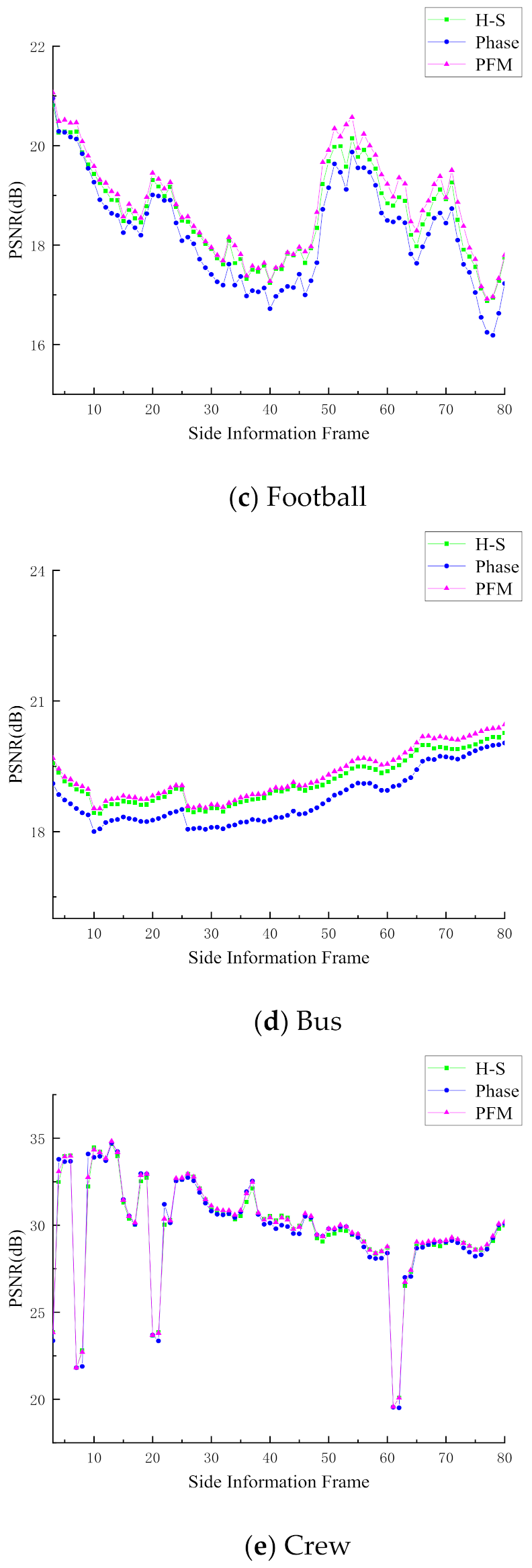
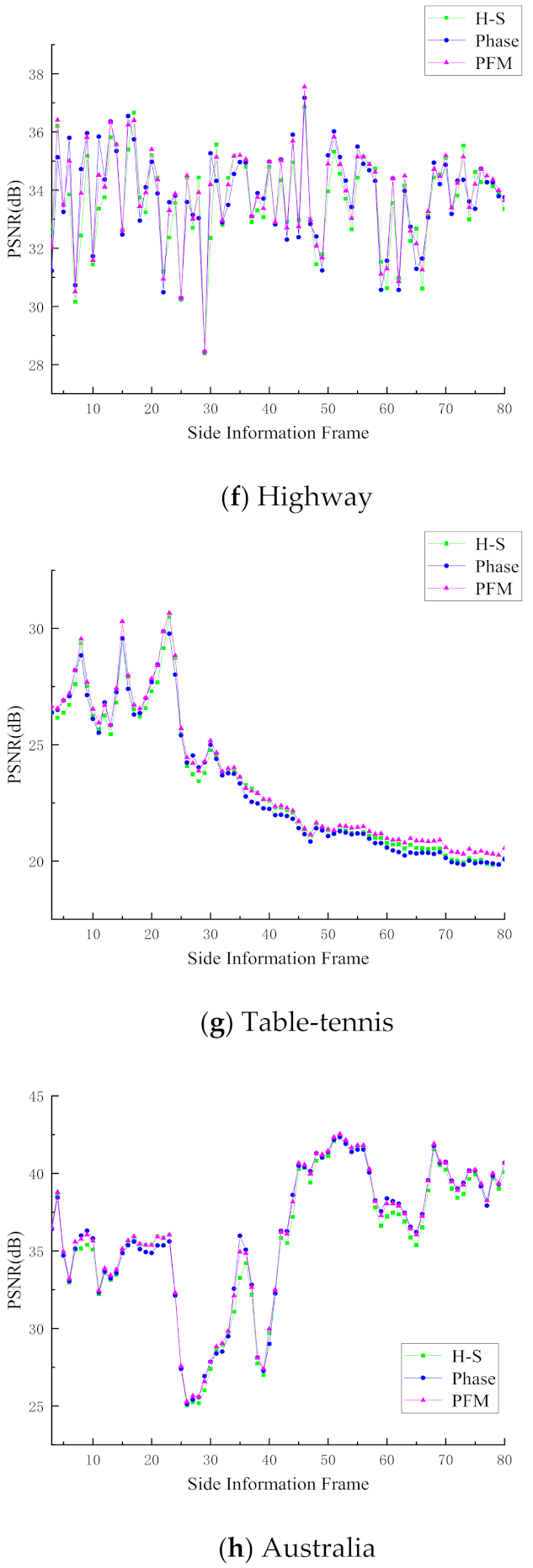
4.2. Evaluation of Side Information Generation
4.3. Evaluation of the Global Recovery Model Based on Weighting
4.4. Overall Performance Comparison
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Candes, E.J.; Wakin, M.B. An Introduction to Compressive Sampling. IEEE Signal Process. Mag. 2008, 25, 21–30. [Google Scholar] [CrossRef]
- Chan, W.L.; Charan, K.; Takhar, D.; Kelly, K.F.; Baraniuk, R.G.; Mittleman, D.M. A single-pixel terahertz imaging system based on compressed sensing. Appl. Phys. Lett. 2008, 93, S293. [Google Scholar] [CrossRef] [Green Version]
- Duarte, M.F.; Davenport, M.A.; Takhar, D.; Laska, J.N.; Sun, T.; Kelly, K.F. Single-Pixel Imaging via Compressive Sampling. IEEE Signal Process. Mag. 2008, 25, 83–91. [Google Scholar] [CrossRef] [Green Version]
- Liu, Z.; Elezzabi, A.Y.; Zhao, H.V. Maximum Frame Rate Video Acquisition Using Adaptive Compressed Sensing. IEEE Trans. Circuits Syst. Video Technol. 2011, 21, 1704–1718. [Google Scholar] [CrossRef]
- Hadizadeh, H.; Bajic, I.V. Soft Video Multicasting Using Adaptive Compressed Sensing. IEEE Trans. Multimed. 2021, 23, 12–25. [Google Scholar] [CrossRef] [Green Version]
- Hou, X.; Zhang, L. Saliency Detection: A Spectral Residual Approach. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar] [CrossRef]
- Warnell, G.; Bhattacharya, S.; Chellappa, R.; Basar, T. Adaptive-Rate Compressive Sensing Using Side Information. IEEE Trans. Image Process. 2015, 24, 3846–3857. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, H. Compressive domain spatial-temporal difference saliency-based realtime adaptive measurement method for video recovery. IET Image Process. 2019, 13, 2008–2017. [Google Scholar] [CrossRef]
- Ying, Y.; Wang, B.; Zhang, L. Saliency-Based Compressive Sampling for Image Signals. IEEE Signal Process. Lett. 2010, 17, 973–976. [Google Scholar] [CrossRef]
- Zhang, J.; Xiang, Q.; Yin, Y.; Chen, C.; Luo, X. Adaptive compressed sensing for wireless image sensor networks. Multimed. Tools Appl. 2017, 76, 4227–4242. [Google Scholar] [CrossRef]
- Li, R.; He, W.; Liu, Z.; Li, Y.; Fu, Z. Saliency-based adaptive compressive sampling of images using measurement contrast. Multimed. Tools Appl. 2018, 77, 12139–12156. [Google Scholar] [CrossRef]
- Wang, W.; Chen, J. Side Information Generation Scheme Based on Coefficient Matrix Improvement Model in Transform Domain Distributed Video Coding. Entropy 2020, 22, 1427. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.; Li, J.; Mo, H.; Chen, J. Side information hybrid generation based on improved motion vector field. Multimed. Tools Appl. 2021, 80, 26713–26730. [Google Scholar] [CrossRef]
- Figueiredo, M.; Nowak, R.D.; Wright, S.J. Gradient Projection for Sparse Reconstruction: Application to Compressed Sensing and Other Inverse Problems. IEEE J. Sel. Top. Signal Process. 2008, 1, 586–597. [Google Scholar] [CrossRef] [Green Version]
- Candes, E.J. Compressive sampling. In Proceedings of the International Congress of Mathematicians, Madrid, Spain, 22–30 August 2006; Volume 3, pp. 1433–1452. [Google Scholar] [CrossRef]
- Baraniuk, R.G. Compressive Sensing [Lecture Notes]. IEEE Signal Process. Mag. 2007, 24, 118–121. [Google Scholar] [CrossRef]
- Donoho, D.L.; Huo, X. Uncertainty principles and ideal atomic decomposition. IEEE Trans. Inf. Theory 2001, 47, 2845–2862. [Google Scholar] [CrossRef] [Green Version]
- Itti, L.; Koch, C.; Niebur, E. A model of saliency-based visual attention for rapid scene analysis. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 1254–1259. [Google Scholar] [CrossRef] [Green Version]
- Johnson, W.; Lindenstrauss, J. Extensions of lipschitz maps into a Hilbert space. Contemp. Math 1984, 26, 189–206. [Google Scholar] [CrossRef]
- Horn, B.; Schunck, B.G. Determining optical flow. Artif. Intell. 1981, 17, 185–203. [Google Scholar] [CrossRef] [Green Version]
- Meyer, S.; Wang, O.; Zimmer, H.; Grosse, M.; Sorkinehornung, A. Phase-based frame interpolation for video. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1410–1418. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sequence | H-S [20] | Phase [21] | PFM |
|---|---|---|---|
| Foreman | 28.24 dB | 28.47 dB | 28.55 dB |
| Stephan | 21.95 dB | 21.68 dB | 22.17 dB |
| Football | 18.62 dB | 18.25 dB | 18.75 dB |
| Bus | 19.16 dB | 18.76 dB | 19.30 dB |
| Crew | 29.72 dB | 29.69 dB | 29.88 dB |
| Highway | 33.60 dB | 33.74 dB | 33.87 dB |
| Table-tennis | 23.25 dB | 23.20 dB | 23.56 dB |
| Australia | 35.71 dB | 36.01 dB | 36.11 dB |
| Sequence | Method | Sampling Rate | ||
|---|---|---|---|---|
| 0.3 | 0.4 | 0.5 | ||
| Foreman | Non-adaptive | 28.74 dB | 30.94 dB | 33.12 dB |
| [4] | 29.66 dB | 32.00 dB | 34.20 dB | |
| [5] | 30.35 dB | 32.12 dB | 33.72 dB | |
| Proposed | 31.37 dB | 33.19 dB | 34.61 dB | |
| Stephan | Non-adaptive | 22.88 dB | 24.50 dB | 26.28 dB |
| [4] | 23.64 dB | 25.63 dB | 27.78 dB | |
| [5] | 23.55 dB | 24.86 dB | 26.58 dB | |
| Proposed | 25.99 dB | 27.76 dB | 29.51 dB | |
| Football | Non-adaptive | 26.42 dB | 28.42 dB | 30.48 dB |
| [4] | 27.57 dB | 28.73 dB | 31.12 dB | |
| [5] | 29.45 dB | 31.52 dB | 33.73 dB | |
| Proposed | 30.08 dB | 32.24 dB | 34.26 dB | |
| Bus | Non-adaptive | 23.43 dB | 25.09 dB | 26.14 dB |
| [4] | 23.71 dB | 25.65 dB | 27.86 dB | |
| [5] | 23.84 dB | 25.37 dB | 26.43 dB | |
| Proposed | 25.79 dB | 27.66 dB | 29.24 dB | |
| Crew | Non-adaptive | 31.37 dB | 33.03 dB | 35.49 dB |
| [4] | 31.49 dB | 33.23 dB | 35.56 dB | |
| [5] | 31.63 dB | 33.26 dB | 35.78 dB | |
| Proposed | 33.44 dB | 35.47 dB | 37.06 dB | |
| Highway | Non-adaptive | 33.66 dB | 35.55 dB | 37.38 dB |
| [4] | 35.12 dB | 37.30 dB | 38.87 dB | |
| [5] | 34.12 dB | 36.29 dB | 37.89 dB | |
| Proposed | 35.21 dB | 37.58 dB | 39.40 dB | |
| Table-tennis | Non-adaptive | 28.38 dB | 30.29 dB | 32.24 dB |
| [4] | 30.86 dB | 32.80 dB | 34.54 dB | |
| [5] | 29.05 dB | 30.88 dB | 32.76 dB | |
| Proposed | 31.16 dB | 33.25 dB | 34.93 dB | |
| Australia | Non-adaptive | 33.46 dB | 34.98 dB | 36.24 dB |
| [4] | 34.28 dB | 36.72 dB | 37.25 dB | |
| [5] | 33.76 dB | 35.78 dB | 36.55 dB | |
| Proposed | 34.42 dB | 36.92 dB | 37.85 dB | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, W.; Wang, J.; Chen, J. Adaptive Block-Based Compressed Video Sensing Based on Saliency Detection and Side Information. Entropy 2021, 23, 1184. https://doi.org/10.3390/e23091184
Wang W, Wang J, Chen J. Adaptive Block-Based Compressed Video Sensing Based on Saliency Detection and Side Information. Entropy. 2021; 23(9):1184. https://doi.org/10.3390/e23091184
Chicago/Turabian StyleWang, Wei, Jianming Wang, and Jianhua Chen. 2021. "Adaptive Block-Based Compressed Video Sensing Based on Saliency Detection and Side Information" Entropy 23, no. 9: 1184. https://doi.org/10.3390/e23091184
APA StyleWang, W., Wang, J., & Chen, J. (2021). Adaptive Block-Based Compressed Video Sensing Based on Saliency Detection and Side Information. Entropy, 23(9), 1184. https://doi.org/10.3390/e23091184