1. Introduction
The COVID-19 pandemic brought to the forefront the urgent need to rapidly create healthcare solutions and responses to emerging and existing health problems. Data driven approaches based on artificial intelligence (AI), machine learning (ML) and statistics offer powerful ways to rapidly address these problems. Medical data records are generated by millions of individuals everyday, creating an abundance of data to be used for developing healthcare solutions and facilitating new research. For example, electronic medical records (EMRs) can enhance patient care, reduce costs, identify eligible patients easily and improve research efficiency [
1]. Healthcare data can streamline clinical research processes and improve data quality [
2]. Data in healthcare are also being used for disease progress modeling, risk analysis and much more [
3]. Use of supervised and unsupervised machine learning on public health data has been used for outbreak detection, hospital readmission, feature association with outcomes and more [
4]. However, irrespective of the abundance of healthcare data, research and work in the field is often restricted due to limited public access to healthcare records. The records are protected by privacy laws like the Health Insurance Portability and Accountability Act (HIPAA) in the United States [
5,
6] and General Data Protection Regulations (GDPR) in the European Union [
7]. Even though these laws allow access to de-identified information, the process of de-identification delays research, is quite costly and can lead to large penalties if data get leaked. In addition to standard de-identification methods, such as binning ages, lose information that may results in loss of the utility of data for some tasks.
Many research articles based on EMR are thus not accompanied by any data, hindering future research and validation. The release of synthetic healthcare data offers a viable solution to provide timely access to EMR data without compromising patient privacy. This would be highly effective during a healthcare crisis such as the current COVID-19 pandemic. Access to COVID-19 data can be extremely fruitful, enabling widespread research and progress. Access to the data can enable exploration of alternative strategies to combat COVID-19 spread [
8,
9]. Synthetic COVID-19 healthcare datasets can come to our rescue and have been shown to be useful as proxies for real data [
10].
The COVID-19 pandemic also revealed great health inequities around the world. In the United States (US), racial and ethnic minorities suffered far greater rates of COVID-19 mortality [
11]. Health inequities have been a long-term problem. National Institute of Health (NIH) policies exist to create more representative randomized clinical trials such that clinical trial results include diverse subgroups [
12,
13]. To support the development of equitable analysis and fair predictive models, it is essential that synthetic versions of healthcare data faithfully represent diverse minority subgroups. Inspired by machine learning fairness research, we refer to this as the “synthetic data fairness problem”.
Health inequities among different populations is an ongoing health problem. Inequitable representation of subgroups in synthetic data could lead to inaccurate analysis where conclusions and predictive models do not generalize to the real data. Commonly in EMR, health outcomes are influenced by covariates such as age, gender, race, obesity and comorbidities. In ML fairness, these covariates are often referred to as “protected attributes”. To be “fair”, a synthetic data model must ensure that the synthetic data represent the real data across different subgroups defined by these covariates/protected attributes. For example, in the American Time Usage Study (ATUS) [
14], the average sleep duration of an individual is affected by their age, thus the synthetic data must correctly capture the proportion of subjects in each age group and accurately represent the sleep habits within each subgroup.
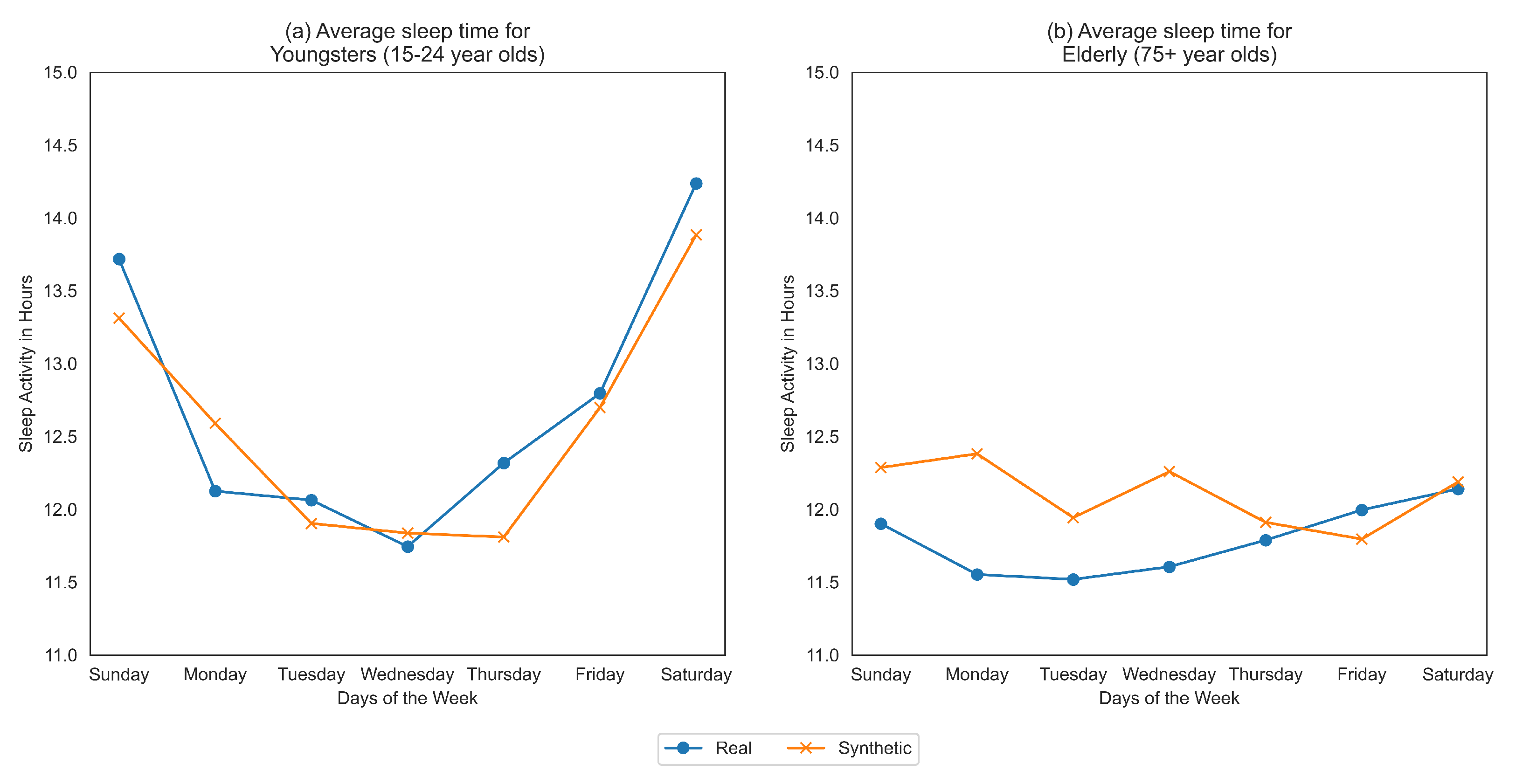
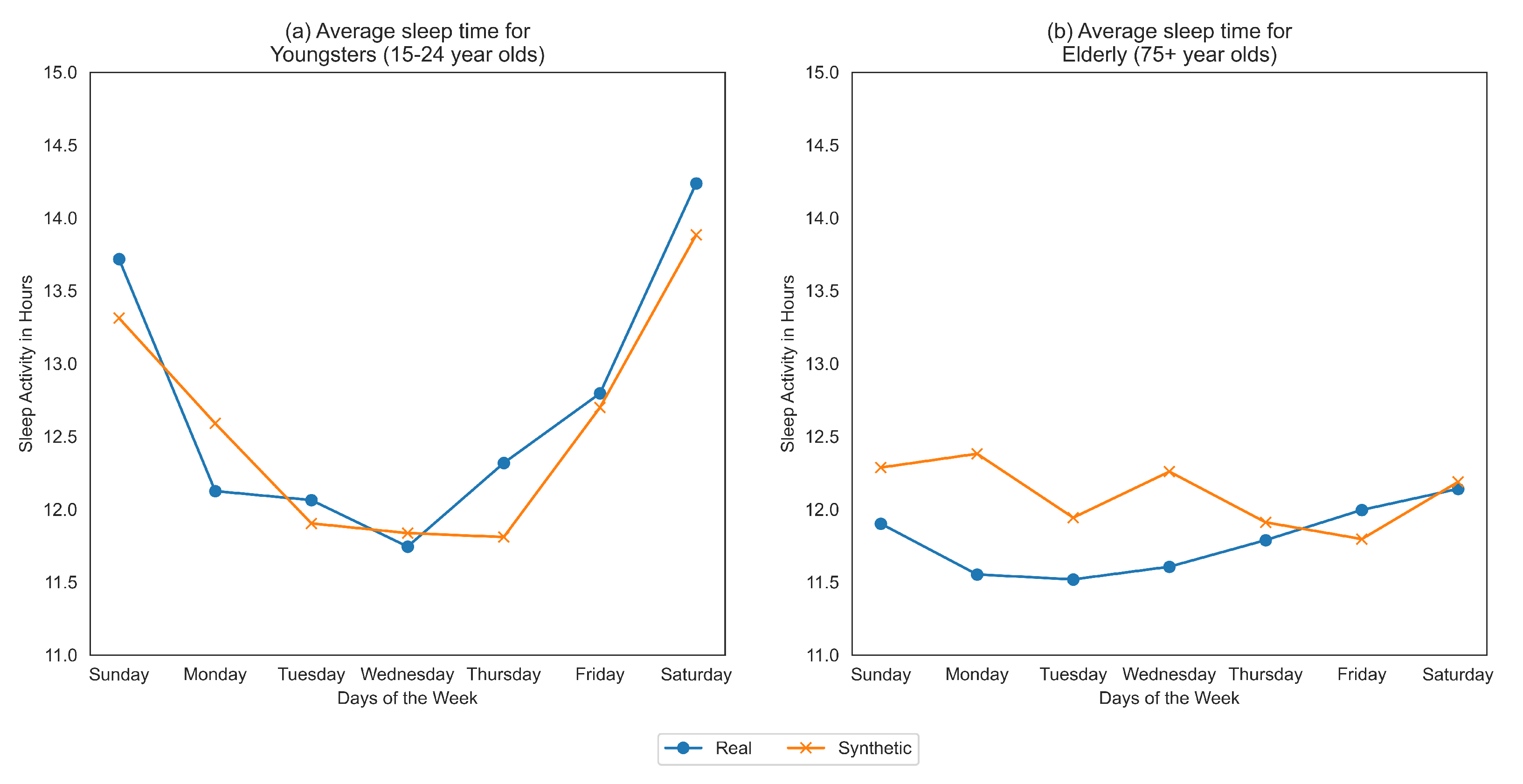
Figure 1 demonstrates that sleep habits of elderly people (aged 75+ years old) are more poorly represented than the subgroup of aged 15-24 year olds using “co-variate plots” based on the synthetic data generated in [
15].
Synthetic healthcare data can be useful when (i) it ensures patient privacy, (ii) it has high utility (e.g., produces high quality ML models), and simultaneously (iii) it has good resemblance to the real data from which it is derived [
16]. While this has been shown to be effective at the general level, only limited exploration has been done with covariates. In our recent work, we discuss the covariate analysis for synthetic data evaluation using time-series metrics to highlight the importance of covariate-level resemblance [
17]. This begs the question, is a given synthetic generation method “fair” towards real data subgroups or does it discriminate against certain protected classes to achieve the balance between these aspects of synthetic data generation? We assert that, while utility, resemblance and privacy are key to synthetic data generation, they must be accompanied by (iv) fairness measures relevant to each.
Resemblance in synthetic data generation is a measure of how closely matched are real data (used for training the synthetic data generator) and synthetic data generated by the model. One might argue that we should make the synthetic data as closely resembling to the available real data, but this may yield overfitting and violate the requirement that privacy be preserved by regurgitating examples that too closely resemble the actual subjects. Rather, one should target the resemblance between the synthetic data distribution and the underlying real data distribution, not the exact training samples drawn. Thus, there is a trade-off between resemblance (between synthetic data and real training data) and privacy, similar to the fit vs. robustness trade-off. Alas, avoiding overfitting is only a necessary condition to obtain privacy-preserving data [
18], additional steps must be taken to downgrade the data to protect privacy, which in turn can effect utility [
19].
In this article, when measuring resemblance, our goal is to ensure that the real and synthetic data distributions match at similar levels for all protected subgroups. A synthetic data generation method must capture the intrinsic trends and patterns in the real data, while simultaneously preserving privacy of subjects in all subgroups. To achieve this resemblance, we want to ensure that the synthetically generated data do not deviate significantly from the real data such that it discriminates against certain protected subgroups.
This requires the application of novel fairness metrics that measure equity in synthetic data resemblance. We propose measuring this fairness in resemblance using representational rates and time-series resemblance analysis at the covariate-level. It is important to highlight the distinction between the definitions of “resemblance” and “representation” in the context of this work. “Resemblance”, as mentioned above, is how close is the synthetic data are from the real data while “representation” is used in the context of fairness where based on the fairness metric, it highlights how over, adequate or under-represented a given subgroup is.
Fairness should be part of each aspect of synthetic health data and should be evaluated for the generation method. We propose that fairness in synthetic health data should be measured at each evaluation step. Thus, in this article, we propose metrics for “fairness in resemblance” of the synthetic data with the real data. We also briefly discuss about “fairness in utility” and “fairness in privacy” but studying such aspects has been left as a potential future work.
We demonstrate potential problems with synthetic data fairness using three different synthetic healthcare datasets in prior published research studies [
15,
16,
20]:
Case Study 1 examines the fairness of synthetic version of an extract from the popular MIMIC-III dataset designed to duplicate a prior research study [
16]. The research study explored the impact of race on 30-day mortality based on odds-ratio of various comorbidities and demographic information [
21]. We adapt a metric (log disparity) and a statistical test developed to evaluate the representativeness of the subgroups in randomized clinical trials to find inequities in the synthetic data as compared to the original data. We examine the superset of subgroups defined with respect to the protected attributes, and find subgroups with significant differences in the
proportion of subjects in subgroups occurring in the original and synthetic data.
Case Study 2 explores the fairness of synthetic sleep data generated for various age-groups and genders on the American Time Use Survey (ATUS) dataset [
15]. Examining all subgroups using the log disparity metric demonstrates that the synthetic data capture the proportion of subgroups quite well. Previously authors used covariate plots to qualitative compare the means of the real and synthetic sleep data for different subgroups (similar to
Figure 1). These inferences are subject to viewer bias and expertise, leading to inconsistent results. Thus, we propose new metrics to evaluate fairness in subgroups across temporal trends which build on prior time-series resemblance metrics for synthetic data [
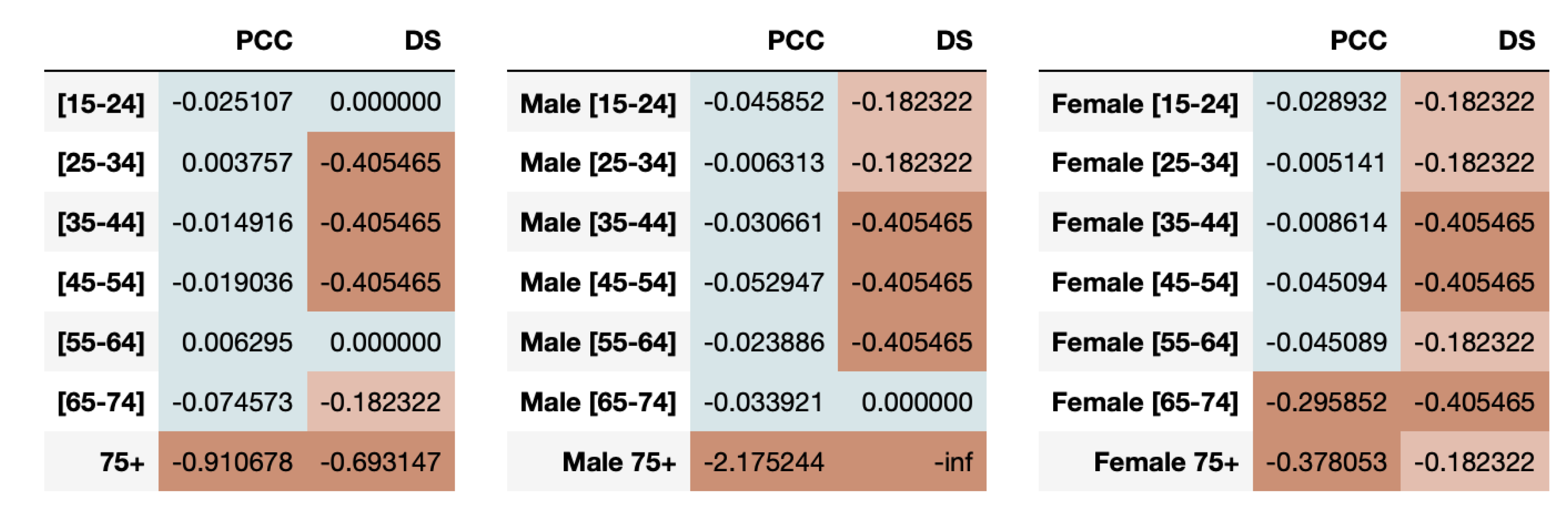
17]. We propose the synthetic data fairness measurement using modified time-series log disparity metric. Here, we apply two different time-series metrics, Pearson’s Correlation Coefficient (PCC) and Directional Symmetry (DS) to demonstrate the problem of fairness across the temporal trends of covariate subgroups. The results showed that the synthetic data did not capture the trends well especially for older people (age 75 and above), indicating bias in synthetic data.
Case Study 3 examines synthetic data from a study on Autism Spectrum Disorder (ASD) claims data [
20] by applying the time-series log disparity metric. These data significantly deviate from the other two, given that it is multivariate (having seven distinct time-series corresponding to different diagnoses) and being exceptionally big (280 K+ records). The results demonstrated that the synthetic dataset has significant biases in the representation of females and some racial/ethnic minority subjects for some diagnoses time-series.
Fairness analysis of synthetically generated healthcare data is essential to preserve utility of synthetic data used in place of real medical data. Covariate-level analysis of fairness metrics provides a comprehensive understanding of this generated synthetic data, enabling us to explain its utility and resemblance better. This article exposes the bias that exists in published synthetic datasets towards certain protected attributes through three case-studies of healthcare datasets. Admittedly, the problem of fairness is quite broad with many existing definitions of fairness [
22] underscored by the condition that not all can be satisfied at the same time [
23]. We therefore present two ways to measure synthetic healthcare fairness, while acknowledging the limitation that these are not comprehensive metrics catering to all definitions of fairness nor do they comprehensively capture the many measures of similarity of real and synthetic data. We propose this article as a starting point for future research in this domain, potentially developing more robust metrics for synthetic healthcare data fairness evaluation and making them a routine part of synthetic data evaluation.
The results in this article, have the following structure:
We introduce metrics for synthetic healthcare data fairness evaluation for covariate-level insights.
We then highlight the inequities in published synthetically generated datasets using three case-studies.
We demonstrate the need for analysis of covariate-level fairness in synthetically generated healthcare data.
Finally, we discuss some future research directions towards making synthetic generators more equitable.
We follow with discussion and details of the methods employed.
1.1. Related Work
Synthetic data generation involves the creation of realistic looking data using a specific method. In the healthcare domain, synthetic data generation requires that the privacy of the patients in the real data is always maintained while achieving high level of utility and resemblance. Generative Adversarial Networks (GANs) [
24] like medGAN [
25], HealthGAN [
20] etc. provide promising solutions that do not require real health data once they are fully trained. As HealthGAN promises the juxtaposition of utility, resemblance and fairness with recently published work (catering to categorical, binary and temporal data) [
20], we focus on the analysis of several available synthetic datasets produced by HealthGAN for this work.
Machine learning models based on biased data have been shown to discriminate based on gender, race etc. [
26]. Very recently, synthetic data generation methods have begun to adopt fairness as one of the key elements of equitable data generation. Differentially private GANs attempt to preserve privacy and mitigate fairness but have shown to lead to decreased synthetic image quality and utility [
27]. Others measured synthetic data fairness by developing models on the data and then calculated fairness metrics like demographic parity, equality of odds etc. [
28]. They too found that models for differentially private data result in more disparity and poorer fairness results. In [
27], the authors looked at group fairness metrics like parity gap, specificity gap, recall gap, etc. on a downstream model generated on the synthetic data. Authors of Fairness GAN also used error rate, demographic parity and equality of opportunity as fairness metrics [
29]. Equalized Odds is another metric used for differential privacy learning fairness [
30]. However, very limited research has been done on fairness of subgroups of covariates, opening a potential area of further exploration of synthetic health data generation.
1.2. Metrics for Health Data Equity
To evaluate healthcare data inequity, researchers developed metrics to compare the observed enrollment rates of protected subgroups with a reference group (i.e., enrollment fractions [
31]) or measure the proportion of target population eligible for the trials (i.e., GIST [
32,
33]). Our recent work developed theorems to create scalable Randomized Clinical Trials (RCT) versions of ML metrics that quantify equities of protected subgroups with respect to any community or population level targets [
34].
The definition of the term “fairness” has a number of definitions that exist in ML literature with corresponding metrics. As per the impossibility theorem of fairness [
23], not all the metrics can be satisfied at the same time, each having their own specific trade-offs.
In synthetic health data generation, we define “fairness” as the ability of the generation method to capture the distribution of the real data subgroups effectively across all protected attributes. Put simply, a fair synthetic health data generation method would produce similar subgroup statistics and trends, leading to real and synthetic data distributions that match at similar levels for all protected subgroups. A synthetic data set could be unfair even if quality metrics applied to the entire synthetic data set are very good. For example, the synthetic data could represent the distribution of a very large majority subgroup very well, but fail to accurately represent the distribution of a small protected subgroup.
Thus, an “equity metric” should measure unwanted bias in the synthetic data when compared to the real data. Here, we define the equity metric in terms of “disparate impact” which measures the bias in two different groups receiving significantly different outcomes as it has been the focus of many recent publications [
35,
36,
37,
38]. For Randomized Clinical Trials (RCTs), we previously designed a set of metrics [
34] to measure RCT representativeness using representational rates based on ML fairness metrics [
39].
In ML, disparate impact is used to quantify the fairness of a trained classification function. Let each data point have an associated label which also has a predicted label produced by the classification function. We assume is the desired positive outcome, similar to previous works. Protected attributes are defined as any subset of the d attributes that can discriminate the population into different groups in which parity is desired in terms of outcomes. A protected subgroup is defined based on one or more protected attributes by a binary membership function . If , then the subject x is in the protected subgroup, otherwise if , it is not. For ease of notation, can be appropriately redefined to represent any particular subgroup.
The ML fairness disparate impact measures the positive prediction rate of both the protected and unprotected groups, requiring them to be similar under the “80 percent rule” defined by the US Equal Employment Opportunity Commission (EEOC) [
40]. Under this rule, the positive outcome prediction of a given subgroup should be at least 80% of the other subgroups to achieve fairness, i.e.,
These probabilities are estimated by frequencies evaluated on training data and the prediction of the ML classifier on the training data.
Our proposed approach builds based on the log disparity metric for quantifying representativeness of Randomized Clinical Trials (RCTs) developed by Qi et al. [
34]. It assumes that there is a theoretical sample of subjects
R, drawn equitably from a target population, and there is the observed sample of subjects,
S, that were actually recruited in the RCT. The observed sample may or may not be equitable. According to a general mapping from ML fairness to RCTs, the ML disparate impact metric is transformed into its RCT version, log disparity, to measure how representative the subgroup
in the actual clinical trial sample
S was as compared to target population sample
R. The log disparity metric for RCT is
where
and can similarly be defined for
). For RCTs,
is estimated from the clinical trial data and
is estimated from surveillance datasets or electronic medical records.
Log disparity was calculated for all possible subgroups defined by protected attributes and the statistical significance was calculated using two-proportion z-test with the Benjamini–Hochberg correction multiple hypothesis testing. An interactive visualization app based on log disparity helps users efficiently assess representations of all subgroups defined over multiple attributes and to visualize any potential inequities for under-representation or missing subgroups. The colored tables and sunburst charts, similar to those in Figure 3, effectively enable users to investigate multiple subgroups with hierarchical information simultaneously and capture the influence of additional attributes on the existing ones.
2. Results
We develop two metrics to quantify fairness on three previously published datasets for MIMIC-III, American Time Use Survey (ATUS) and Autism Spectral Disorder (ASD) claims data for different protected attributes such as age, gender, and race.
We developed a log disparate impact equity metric which is defined as the ratio of odds of subjects of the protected group in the synthetic data to the real data. This is accompanied by statistical tests to identify if the results are statistically significant or not. For temporal healthcare datasets, we present the time-series specific log disparity metric. The metric calculates the resemblance between the real and synthetic time-series for subgroups using two time-series metrics, Pearson’s Correlation Coefficient (PCC) and Directional Symmetry (DS).
The synthetic data try to match the distribution of the real data to achieve utility and resemblance. However, even though it might be able to achieve that on the dataset overall, we are interested to know the resemblance and fairness at the subgroup-level. The metrics are designed to quantify the fairness for subgroups of the protected attributes. These are quantified for both non-temporal and temporal healthcare datasets. The log disparity metric aims to compare the proportions of the subgroups in the synthetic data to the real data, to compute whether the proportions are similar or not. The time-series based disparity metric, quantifies the resemblance in the time-series trends for the synthetic data with the real data. The two metrics enable an outlook on fairness in resemblance for healthcare datasets.
2.1. Log Disparity Metric for Fairness of Rates
The definition of log disparity for clinical trials can be extended to synthetic healthcare data generation. Protected attributes are essential for healthcare data research as they reveal the impact of certain attributes on results of a healthcare study. For example, to verify that a certain drug works for both men and women, the research study must incorporate both men and women during their trials. Thus, when real world healthcare data are collected, it includes a certain proportion of individuals having different protected attributes. Thus, if that data need to be used for clinical research, similar proportions must also be represented in the synthetic health data. However, as synthetic data is not exactly the same as real data (ensuring privacy preservation), we cannot directly measure the same subject’s likelihood of being in both the real and synthetic data.
For synthetic data generation, we are concerned with the overall protected attribute representation between the real and synthetic datasets. The observed rate of records with protected subgroup
in the synthetic data
S should be similar to the observed rate for the same subgroup
in the real data
R.
Using the methods created for RCTs [
34], the synthetic data fairness metric is derived from the ML-Fairness disparate impact metric Equation (
8) and is defined below.
The membership function
is a binary definition of subgroup, i.e., subject is in subgroup or not based on the selected attributes. In Equation (
4), the numerator corresponds to the sample of subjects found in the synthetic data and the denominator represents the sample of subjects found in the real data.
We then adopt the methods developed for visualizations and statistical tests of representativeness of RCTs to synthetic data fairness. As we take the log value for this ratio, we would modify the “80 percent rule” to accommodate this change.
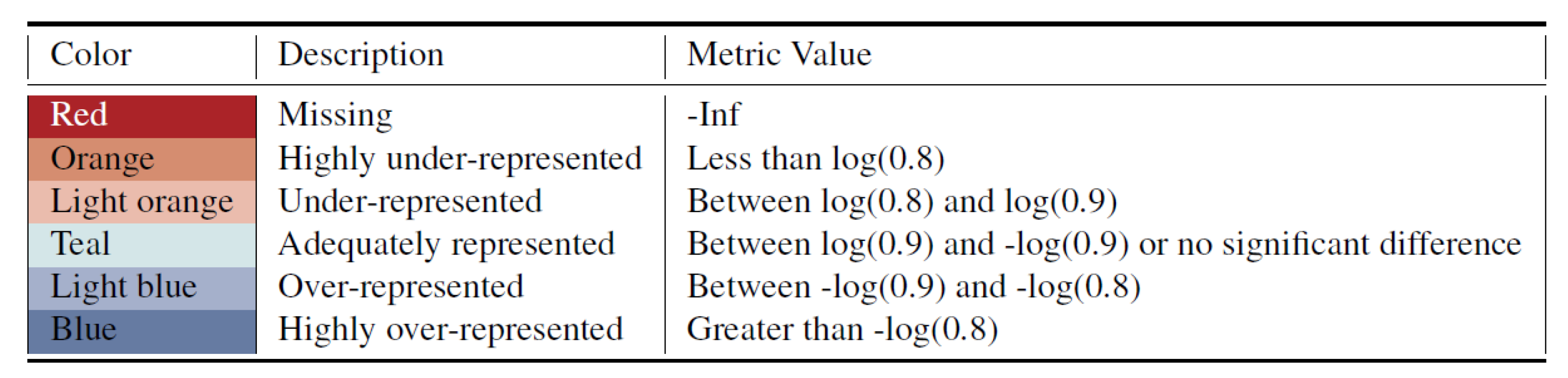
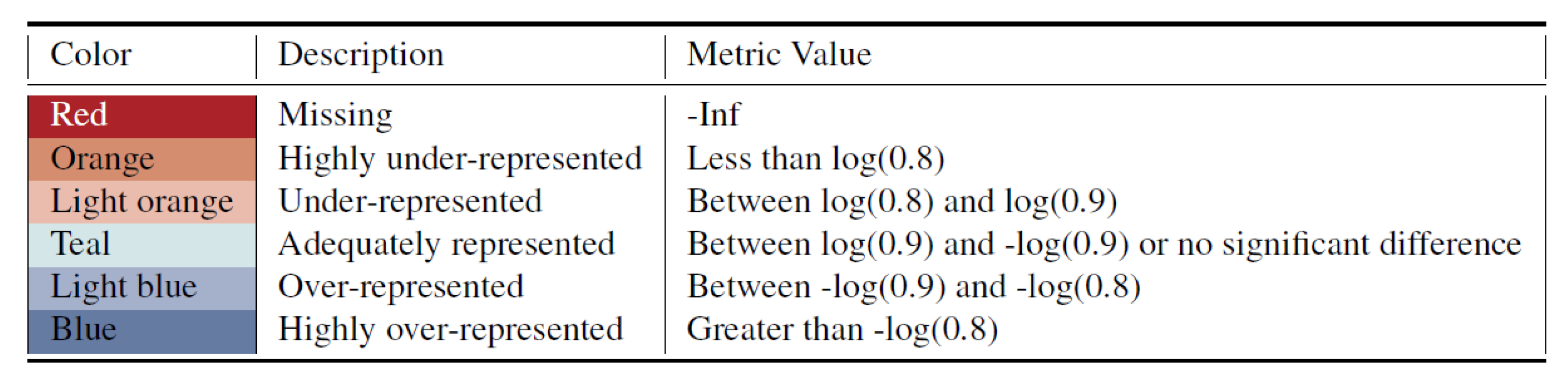
For the proposed metrics, the unfair metric values are further divided by two user-selected thresholds into highly inequitable representation and inequitable representation. We apply the threshold value
(i.e.,“90 percent rule”) to split the adequately represented values with under-/over-representation and use
to discriminate more severe unfairness. Therefore, we categorize the metrics values into six levels and represent them as different colors as shown in
Figure 2. Red is used to indicate if the subgroup is missing entirely from the synthetic data.
Note that these categories are slightly more restrictive than those previously proposed for log disparity of RCTs [
34]. The longitudinal nature of healthcare data is highly important as future poor health events may be influenced by previous events. Thus, it is essential to have stricter bounds for this metric, so we can ensure that the synthetic data fairly captures current real data trends, ensuring better future results.
2.2. Time-Series Disparity
Healthcare data are often longitudinal and hence, the synthetic data generation method must fairly capture the time-series trends across various subgroups of protected attributes. To accomplish this, we propose the time-series log disparity metric as a measure of empirically quantifying fairness in real and synthetic data temporal resemblance. The metric can be used to compare covariate time-series for various subgroups of protected attributes in the dataset.
Let us consider a univariate time-series healthcare dataset which consists of protected attributes
, unprotected attributes
and temporal attributes
. We can stratify this data based on any protected attribute. Let us consider we have a subgroup defined by
and the remainder is defined by
. We can merge each corresponding temporal feature for a subgroup using a function
f to create a univariate time-series for that subgroup. This time series could be from the real data or a sample of the real data,
R, or from the synthetic data,
S. The function
f can be defined using any statistic, for example, the average value, the counts, etc. Thus, the resultant for the time-series
for real data
R is defined below.
Similarly, the same steps can be applied on the synthetic health data
S. This will result in a time-series for the same subgroup in the synthetic data
defined by Equation (
6).
For the real and synthetic time-series above, we can calculate a time-series resemblance metric
. This can be contrasted with a similar resemblance on time-series for the real and synthetic data where
. Then we define the time-series log disparity as follows.
If the data of interest has only one temporal feature then there are only
T observations for the time-series. In the case of multiple temporal features, the first
T observations in the times-series are for the first feature, the next
T observations are for the next feature, and so on. If a given dataset is not in the above format, it can easily be mapped to this format using the workflow described by Dash et al. [
15]. We leverage Pearson’s Correlation Coefficient (PCC) and Directional Symmetry (DS) as two time-series metrics in this article. We note that these are just two examples of time series metrics that could be used. Any other time-series resemblance or error metric could be adapted into an equity metric by stratifying by covariates.
If the dataset is not temporal in nature, the temporal variables would not exist for the particular dataset. In that case, covariate-level univariate analysis based on could be calculated for covariate subgroups using any other of the many existing methods for quantifying differences between distributions.
2.3. Case Study 1: Impact of Race on 30-Day Mortality Using MIMIC-III Dataset
Multiparameter Intelligent Monitoring in Intensive Care (MIMIC) is a public dataset that includes de-identified information about patient demographics and ICU stays for patients [
41]. In [
21], the authors used MIMIC-II to identify the impact of Race on 30-day mortality of the patients. A synthetic version of the analyzed dataset was created based on MIMIC-III using HealthGAN and the results were duplicated [
16]. Thus, we use the synthetic and real versions of the MIMIC-III dataset for our analysis here.
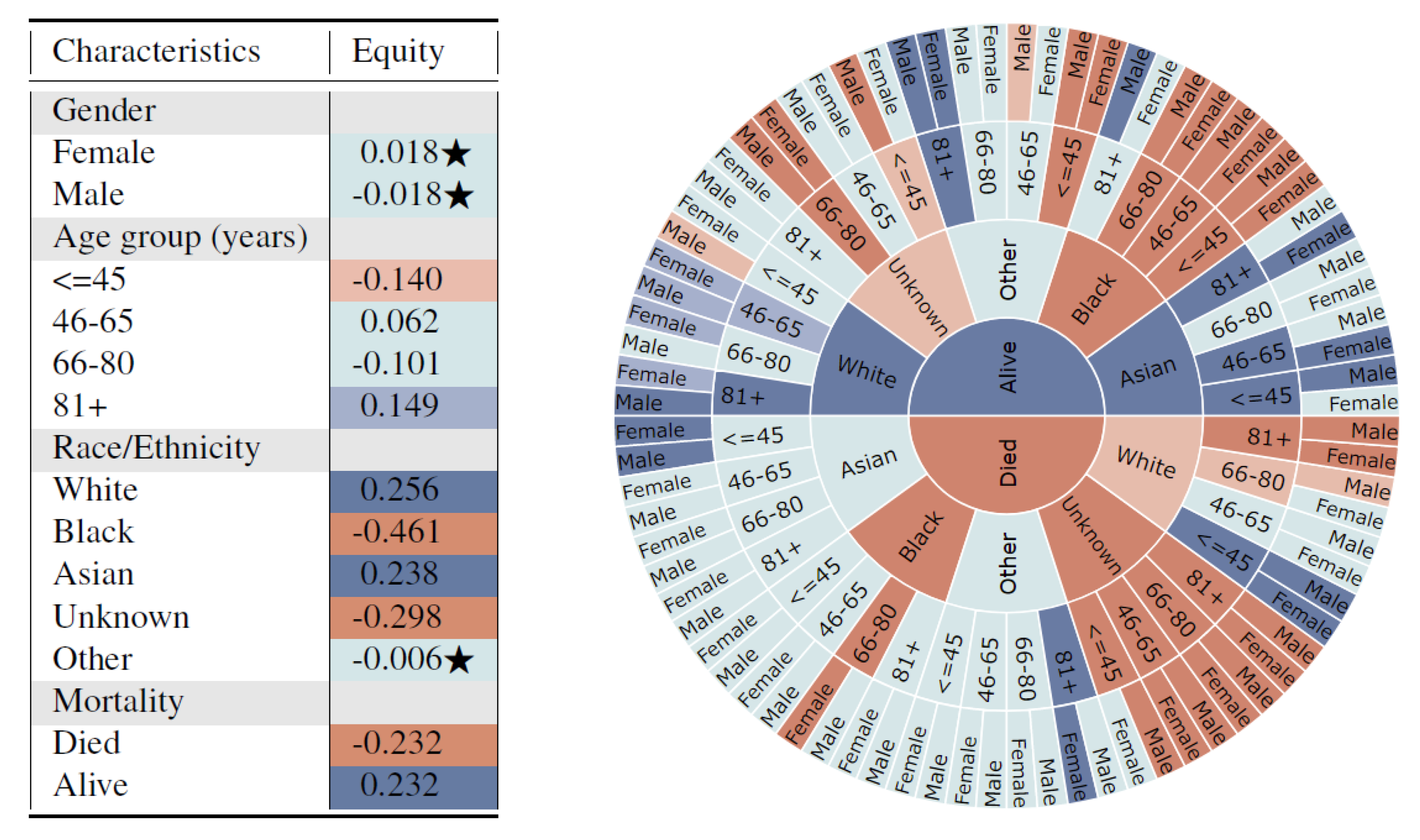
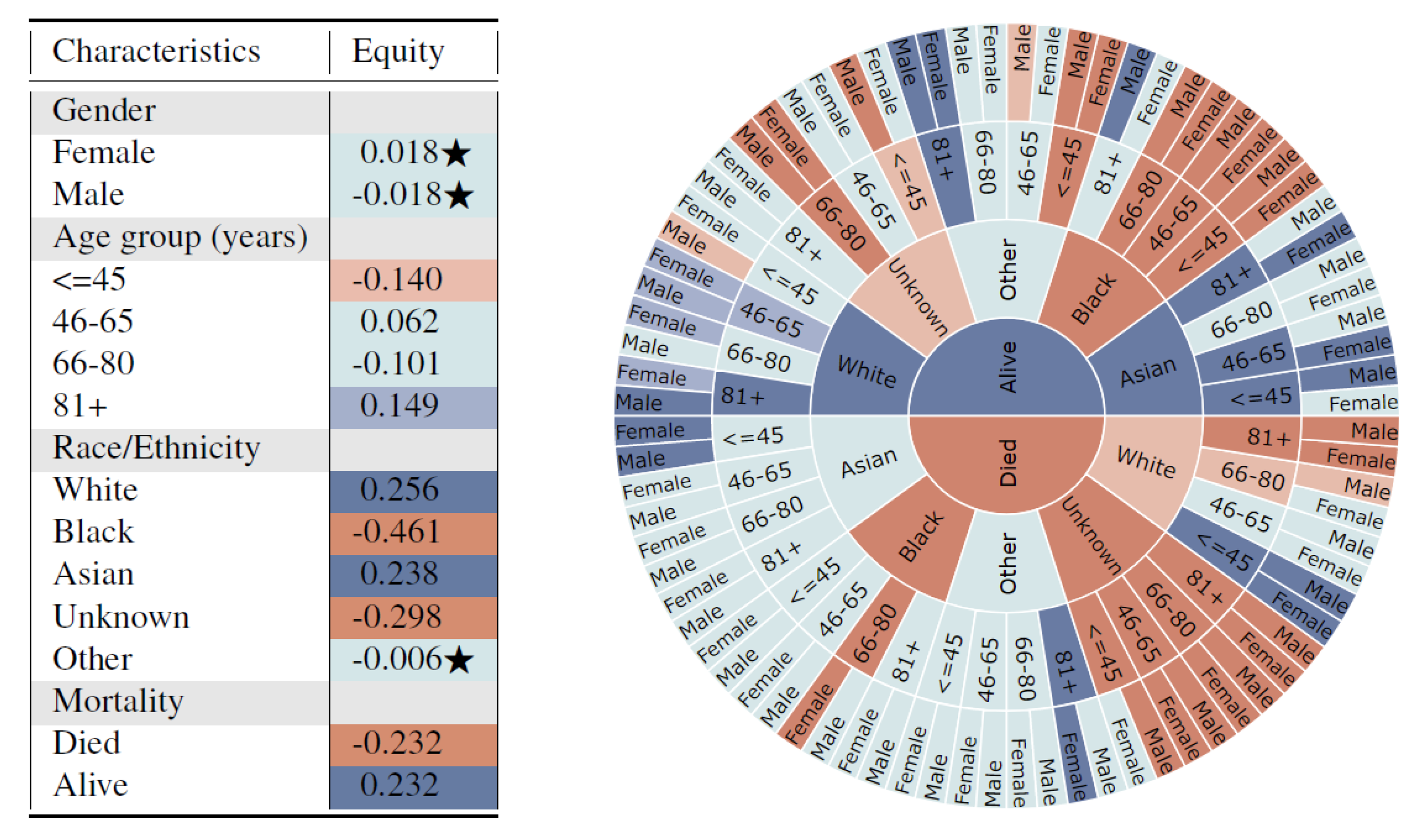
The univariate results of the 13 subgroups in
Figure 3 (left) shows that unfair synthetic data is generated for different race subgroups when compared with the real data, which has the potential to exacerbate biases towards traditionally under-served groups such as Blacks. Additionally, subjects who died are highly under-represented in the synthetic data.
This captures potential dependencies of variables on a multivariate distribution in a potentially biased data generation model. Furthermore, the sunburst figure clearly indicates a fairness violation for subjects with mortality = death, race/ethnicity = Black, age = 66–80, and gender = Female. This indicates that the synthetic generation model may be severely biased towards certain subgroups and subsequent analysis and decisions based on the synthetic data may not be fair. The proposed method navigates researchers to find places of bias, and helps them model the synthetic data generation more fairly and accurately. For example, additional parity fairness constraints regarding violated protected attributes could be incorporated into the data generation model as is common practice in ML-Fairness research. Furthermore, performance variations across different multi-variate subgroups could be used to evaluate, tune, and improve the generation model.
2.4. Case Study 2: Average Sleep Time of Americans based on ATUS Dataset
We used the ATUS dataset to look at the average sleep times of various subgroups [
15] using the disparate impact metric. As the dataset is temporal, we also applied the time-series log disparity metric.
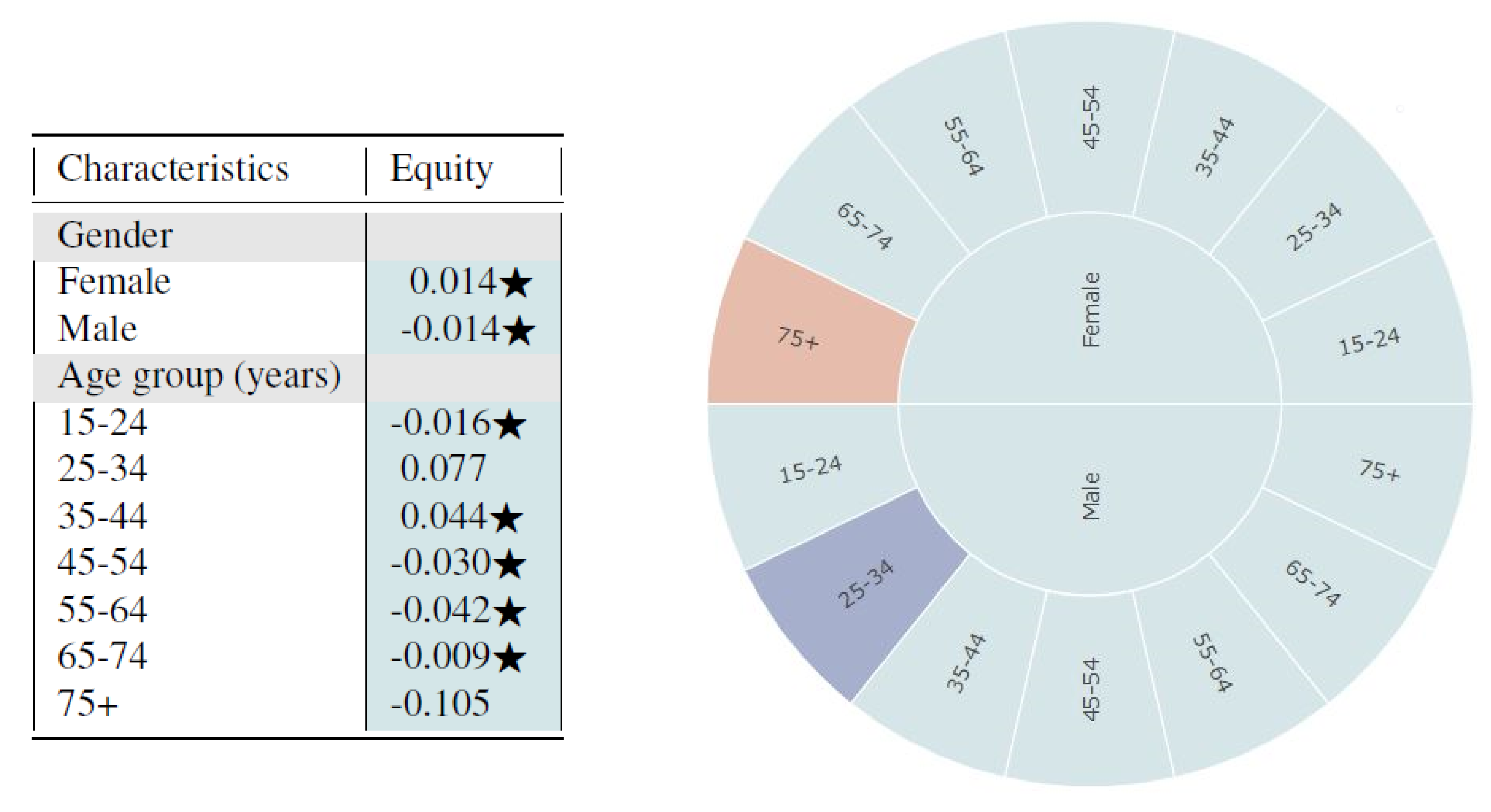
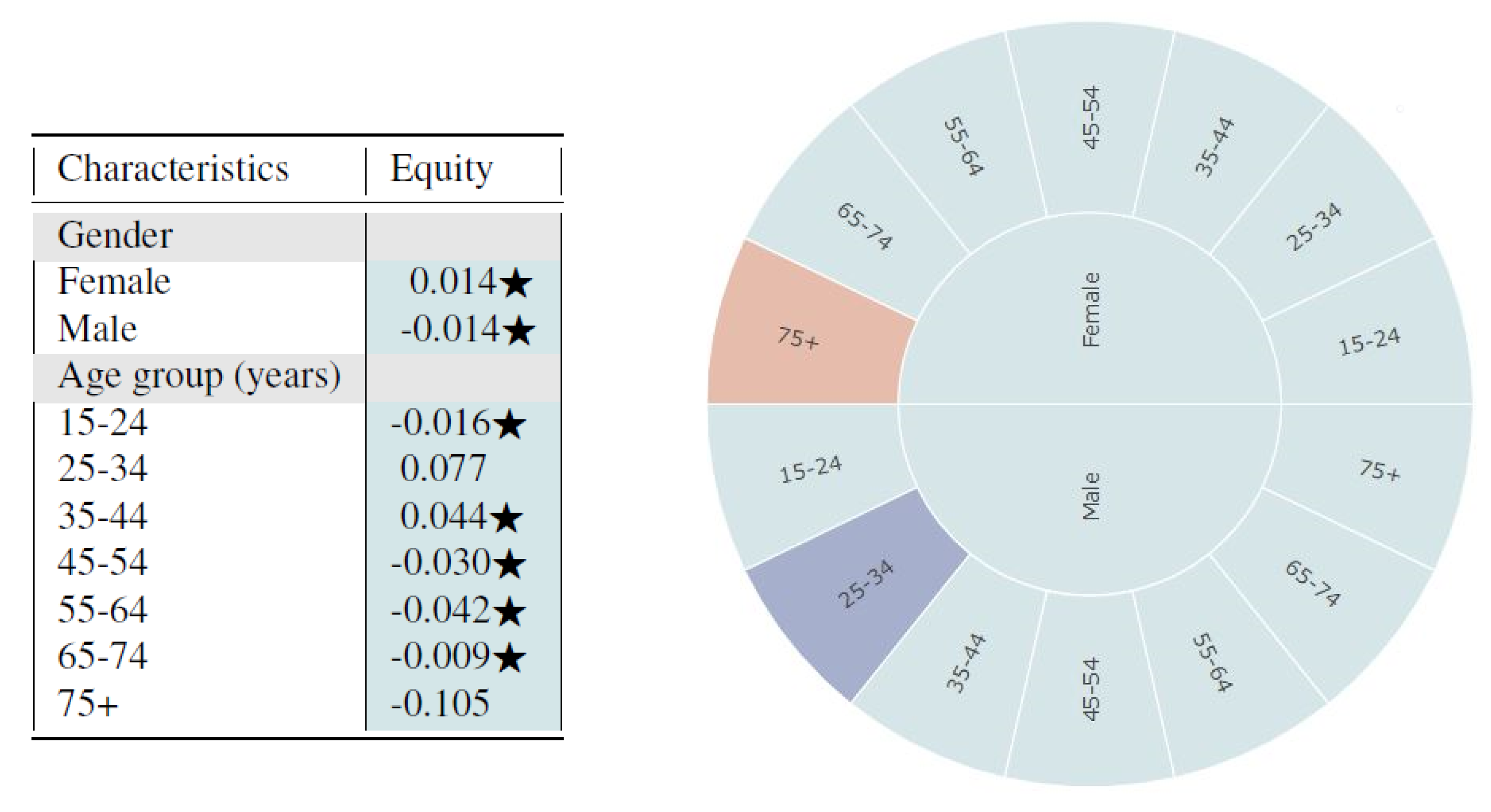
From
Figure 4, we observe that the synthetic data seem to fairly represent all subgroups of gender and age based on the log disparity metric. We find that for most cases, the differences are not even statistically different.
Based on the sunburst, we see only minor multivariate unfairness. Females aged 75 and above are under-represented while males aged 25–34 are over-represented. From observing the figures, one could infer that the synthetic data sample is quite fair in its representation of the proportion of subgroups. However, the metrics based on representational rates are not sufficient for evaluating time-series healthcare datasets since temporal variables are not captured. The multivariate analysis detects some age-relevant unfairness for different gender groups but fails to capture time-series resemblance. Thus, we also applied the time-series log disparity metric on this dataset.
The healthcare data are stratified based on the protected attributes (age, gender) and the resultant time-series for real and synthetic datasets are compared using time-series metrics like Pearson’s Correlation Coefficient (PCC) and Directional Symmetry (DS). The age in the dataset is split into bins: 15–24, 25–34, 35–44, 45–54, 55–64, 65–74 and 75+. We average the sleep time for the various age groups with the results for youngsters (15–24) and elderly (75+) shown in
Figure 1.
From
Figure 1, we clearly see that the trends themselves between the two extreme subgroups are very varied. Youngsters tend to sleep more during the weekends than weekdays while elder people sleep approximately the same across all days of the week. The change in average time slept throughout the day for youngsters is very high, ranging from 11.5 h to 14.5 h which is in complete contrast to elderly people who sleep somewhere between 11.5 and 12.5 h. We also see that the synthetic data more accurately represents the younger population than the older one.
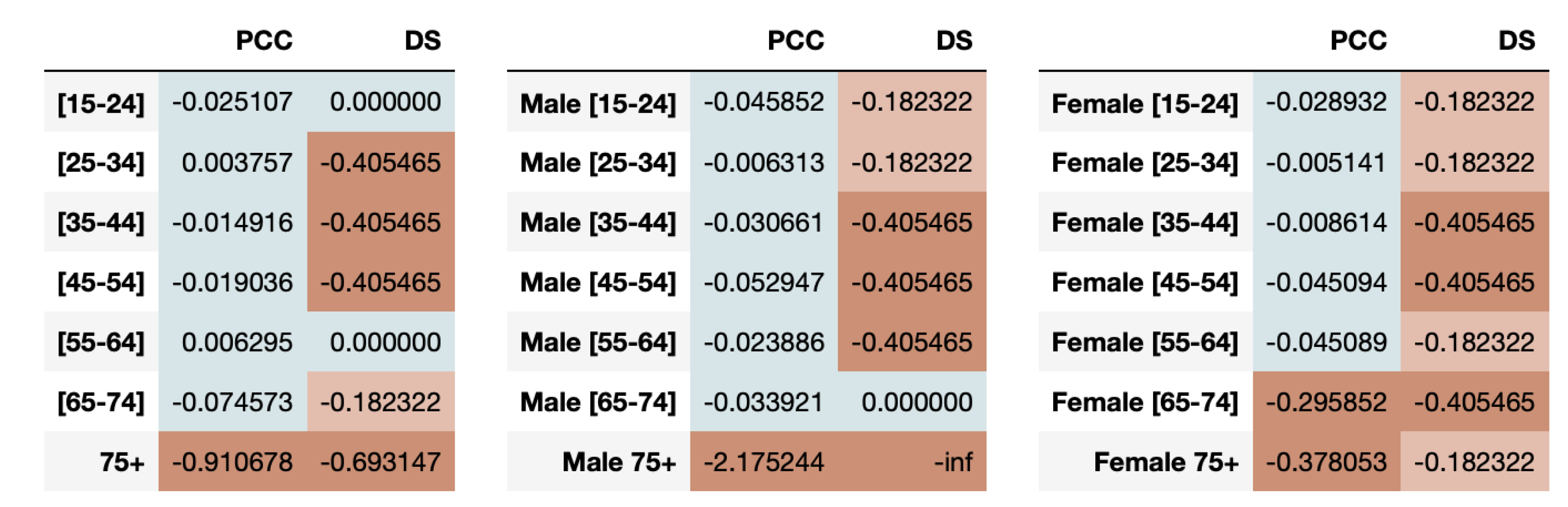
For both youngsters and elderly, even though the average sleep times across days are captured closely by the synthetic data, the directions of the series is often a mismatch between real and synthetic data. This is confirmed by the evaluation of fairness metrics on all the age-groups as shown in
Figure 5. We observe that the resemblance in synthetic time-series for youngsters is high, indicating fairness using both PCC and DS metrics. However, the elder population is highly under-represented as determined by both metrics.
We can also measure the fairness of the synthetic data based on combination of age-groups with gender in the dataset. The results of the PCC and DS disparate impact metrics are presented in
Figure 5.
We note that males aged 35 to 64 are highly under-represented in capturing the directional trends while females aged 35–54 and 65–74 are highly under-represented. The high under-representation of elders aged 75 or older in the synthetic data is observed in both males and females using PCC disparity. However, when we look at the DS metric results, we notice that the synthetic data perform poorly across almost all combinations of age and genders, hinting at its inability to capture the directional trends for protected attributes in this dataset.
It is interesting to note that the results from the two metrics can be contrasting in some cases. For example, for age-group 15–24 and 25–34, PCC shows the groups to be adequately represented but DS shows the age-group 25–34 being under-represented. This underscores the importance of using a comprehensive set of time-series metrics for gaining better insights into synthetic healthcare data fairness.
2.5. Case Study 3: Co-occurring Comorbidities in ASD Patients’ Claims Dataset
The ASD claims data include records of children having multiple diagnosis across a 5-year period used in [
42] with synthetic data generated using HealthGAN [
20]. The real data were accessed inside a secure environment provided from OptumLabs
® Data Warehouse (OLDW), which provides de-identified medical data access. Following OLDW procedures, the HealthGAN synthetic model and summary statistics necessary to calculate the time-series log disparity metric for each time-series/subgroup combination were calculated and exported from OLDW, and then access was terminated. Patient privacy was preserved, since no other additional access to subject data was required.
The real dataset consists of bi-yearly analysis of seven different Comorbid Medical Conditions (CMCs) for each subject. The ASD Prevalence dataset includes records of prevalence of diagnosis for each patient. Each temporal column represents whether the child was diagnosed with that particular CMC during that 6-month period or not. Put simply, each binary column represents whether the child was diagnosed for that disorder (1) or not (0) in that specific time-period. This, creates a time-series of presence or absence of diagnosis across a 10 point time-series for each diagnosis. We calculate the average values of occurrence of the seven CMCs across the 5-year period for each subgroup enabling us to use PCC and DS based time-series log disparity metric for fairness. This creates a set of seven time-series for each subgroup, making it a multivariate time-series problem. Each time-series in the real data is then compared with the corresponding time-series in the synthetic data using the time-series fairness metrics.
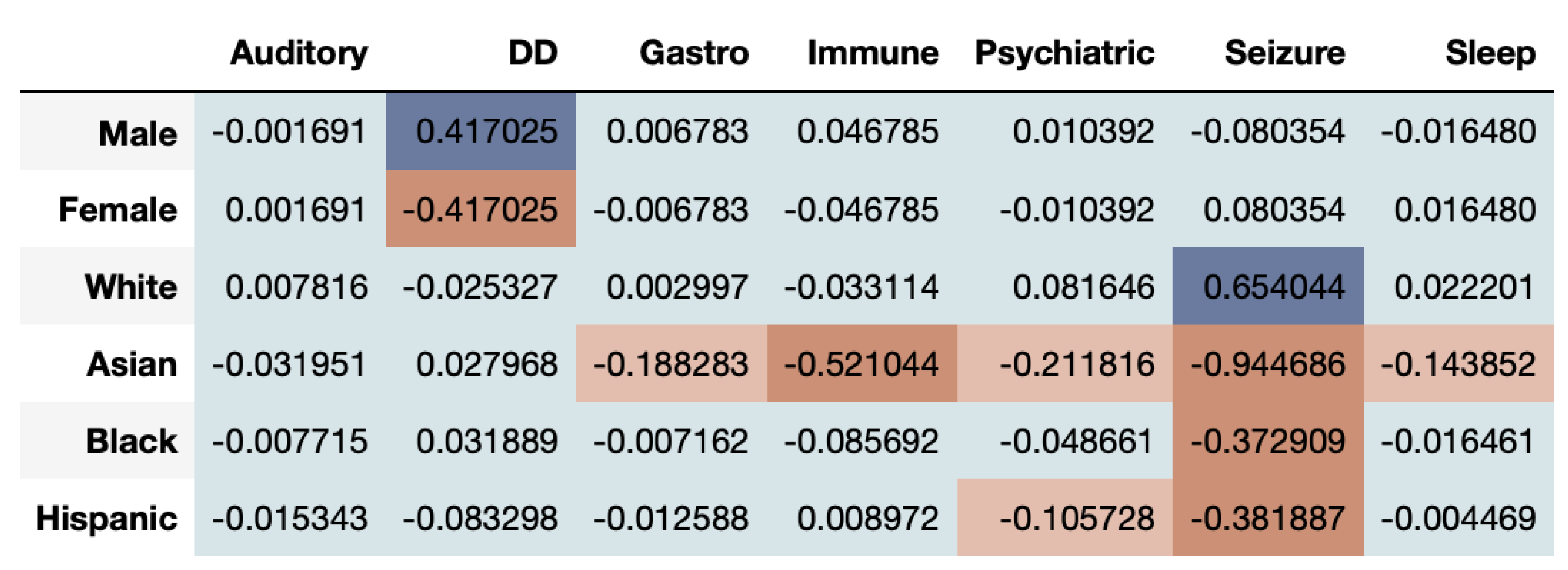
The time-series of ASD prevalence values for each gender and ethnicity are compared between the real and synthetic health datasets using the time-series log disparity metric applied to each CMC.
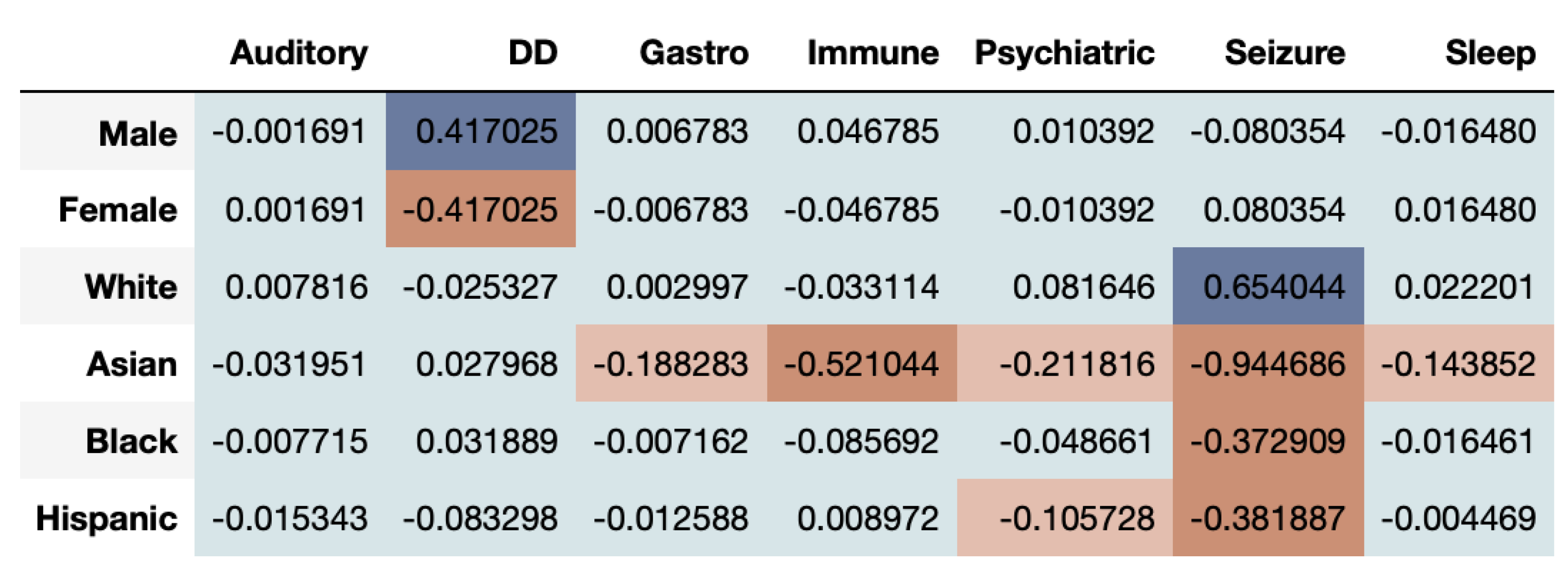
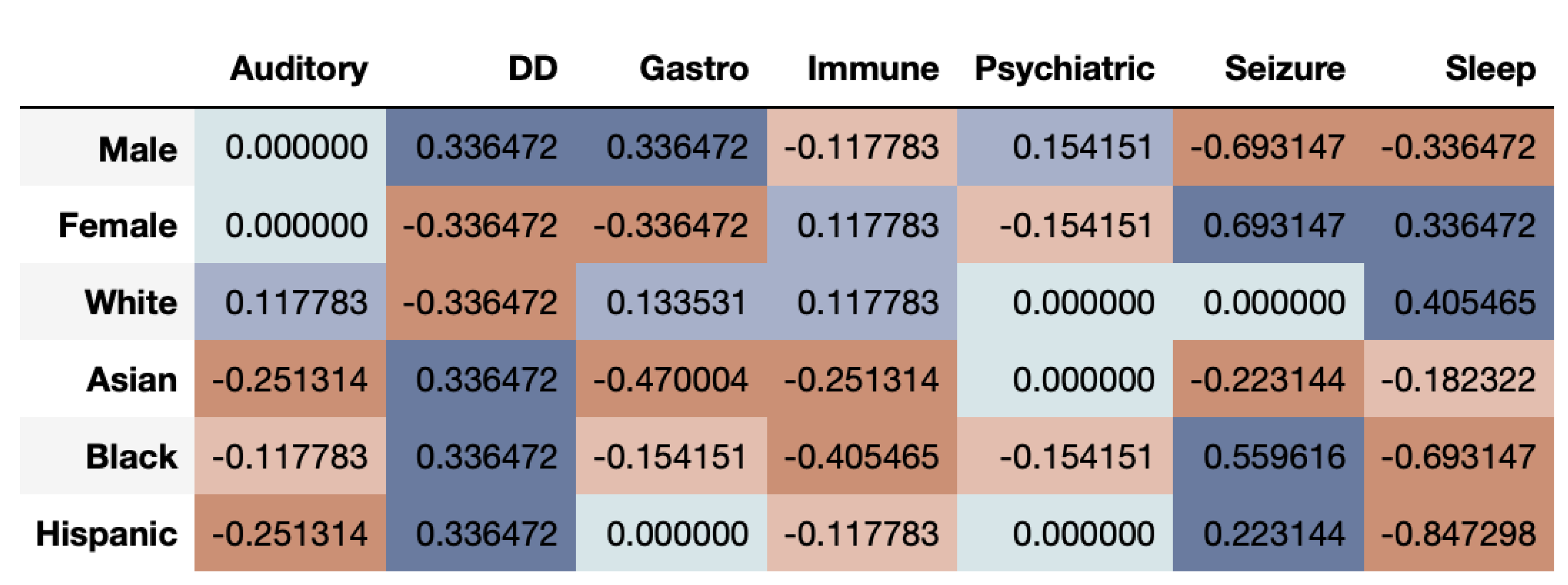
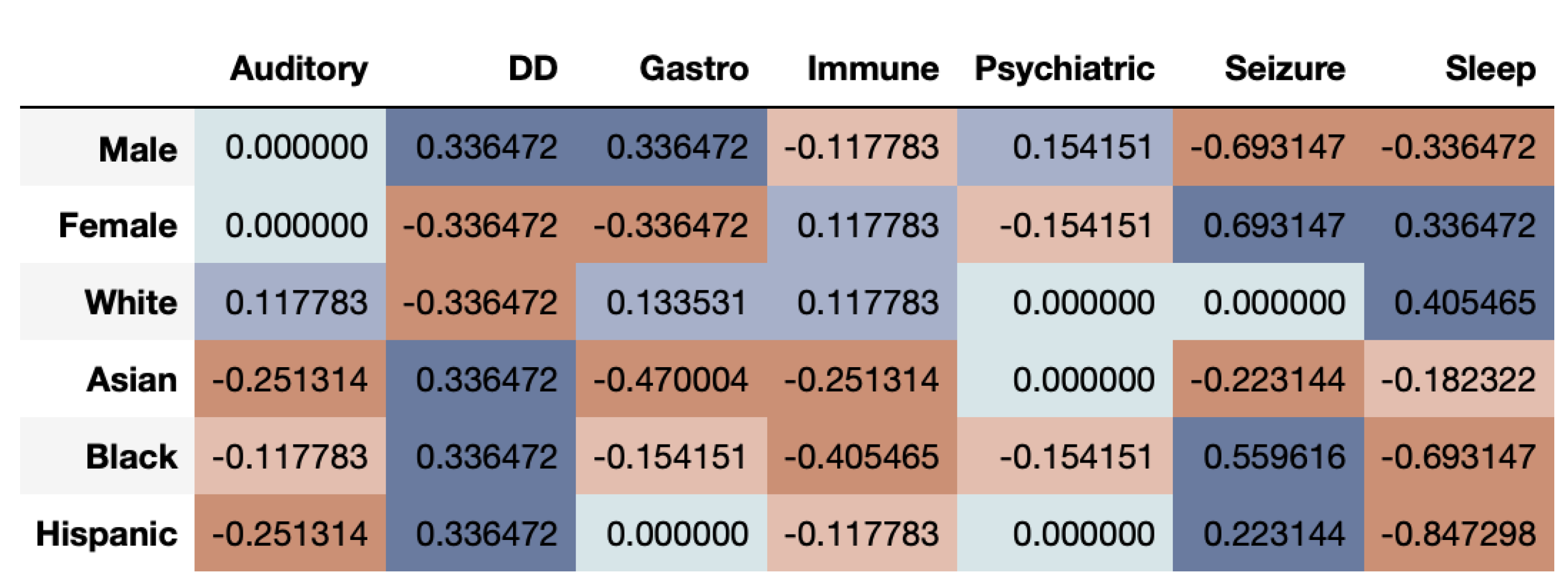
Figure 6 shows that the correlational fairness between real and synthetic dataset shows signs of bias. As we can see, the synthetic data under-represents females for DD. Further, Asians are highly under-represented across CMCs including Gastro, Immune, Psychiatric, Seizure and Sleep. The results based on the DS metric as seen in
Figure 7, provide a very interesting twist to fairness evaluation. We note that a given subgroup can be over-represented across some time-series while being under-represented across others. Whites seem to be generally well represented or even over-represented across both metrics. This underscores that for while capturing the prevalence of diagnosis in the dataset, the synthetic data over-represent some and under-represent other subgroups. If the exact synthetic dataset is used for any analysis, the resultant may be altered by bias introduced in the synthetic data.
From the results of the ASD data, we can clearly see that multivariate time-series have a more complex structure and make fair synthetic data generation difficult. While some groups are over-represented across a particular time-series, the same groups may be under-represented in others.
3. Discussion
The “Synthetic Data Fairness Problem” entails the presence, identification, and ultimately removal of bias and unfairness in synthetically generated data against subgroups defined by protected attributes. The first step in addressing inequity in synthetic data generation is measuring it. In this article, we examined “fairness of resemblance". Resemblance in synthetic data generation is a measure of how closely matched are real data and synthetic data generated by the model. To examine fairness, we define two metrics based on the resemblance for different subgroups: log disparity which measures the difference of prevalence of protected subgroups and time series log disparity which reveal the relative resemblance across time of subjects. We applied these metrics to real and synthetic data created by HealthGAN from prior publications.
3.1. Problems in Published Synthetic Datasets
We demonstrated the presence of unfairness in synthetically generated healthcare datasets using three case studies:
Impact of Race on 30-day Mortality Using MIMIC-III Dataset: Using a very popular medical dataset, MIMIC-III, we found that the synthetic version of the dataset introduced bias across different covariates as identified using the log disparity metric. Whites and Asians were highly over-represented in the synthetic data while Blacks were highly under-represented. On stratifying the results based on grouped covariates, we found that Asians were over-represented for all age-groups except 66–80 for the alive subset. At the same time, Blacks aged up to 80 years were all highly under-represented. The results highlight that different races are being unfairly represented in the synthetic data. MIMIC’s popularity in the healthcare research domain makes this insight quite alarming, where someone might use a synthetically generated dataset without realising the hidden bias.
Average Sleep Time of Americans based on ATUS Data: On observing the sleep times using the log disparity metric, the synthetic dataset appears to adequately represent all genders and ages with a slight over-representation for males aged 25–34 and under-representation of females aged 75 or older. However, as the data are temporal in nature, we evaluated the fairness using the time-series log disparity metric and the results were very biased. Using the PCC metric, both males and females aged 75 or older were highly under-represented. Based on DS metric results, we found that males were under-represented overall when compared to females. The results indicate that looking only at univariate metrics of resemblance and fairness may obscure inequities that would only be revealed when examining multi-variate temporal relations, rendering any future models with high risk of bias.
Co-occurring Comorbidities in ASD Patients’ Claims Dataset: Using time-series log disparity metric on ASD dataset, we found that multivariate time-series are highly complex and synthetic data struggle to capture all time-series trends. These point out areas of improvement for future synthetic data generation methods. We found that Whites are clearly over-represented while Asians are often under-represented. The representation between the two genders vary based on the time-series being considered.
From the metric results of the three case studies across multiple protected attributes, we observe that synthetic data often struggles to capture the proportions that exist in the real data. This can clearly be seen through both log disparity and time-series based metrics. In synthetic healthcare data generation, the data generation method attempts to achieve high utility, and high resemblance while preserving patient privacy. To maintain this privacy, the methods often introduce controlled noise to the real data such that the records generated are realist without being real. However, this is likely to affect the resultant data, leading to different levels of proportions for the various subgroups. This potentially leads to the introduction of bias and fairness in the synthetic data, causing it to deviate from the real data to maintain the trade-offs between utility, resemblance and privacy.
Furthermore, during synthetic data generation, the method does not specifically know what are the protected and unprotected attributes in the dataset, and considers them the same. Thus, it simply tries to replicate the distributions of the real data for all features. As the synthetic data generation process does not consider fairness of the data across protected attributes, it is not bound to exactly replicate the real data. It does not specifically target for equal representation for subgroups of any given protected attribute, potentially leading to changed representations in the synthetic data, and introducing bias.
However, these are problems which can be addressed using generative models which also take fairness into consideration. This shall involve the addition of fairness as one other metric during synthetic data generation such that the model also aims to achieve fairness along with utility, resemblance and privacy.
3.2. Need for Covariate Fairness Metrics
We introduced two metrics for quantifying the fairness in synthetic data, for non-temporal and temporal healthcare records.
Metric on Representation Rates: The log disparity metric that has been shown to be effective in measuring fairness in RCTs is ported into the synthetic data domain. We measure the representation of different covariates (protected attributes), both univariate and multivariate, between the synthetic data and the real data from which it was created. The metric is quite powerful, highlighting stratified groups of individuals in a given dataset which are under or over-represented. In our case studies, we found that the unfairness is more representative across cross-section of covariates. For example, in MIMIC we found that not all Whites are highly over-represented but it is the patients who are 81 or more years older males.
The results highlight the effectiveness of the metric to capture not just univariate but also multivariate protected attribute populations. The metric enabled us identify that even when the proportions across subgroups might appear similar and thus, fair, the truth might be revealed after more in-depth exploration. For example, for ATUS, for both gender and age individually, the metric shows the results to be fair. However, when we look at the combination of protected attributes, it becomes apparent that some subgroups are under-represented (female aged 75+) while others are over-represented (males aged 25–34).
Metrics for Temporal Analysis: We introduced a time-series log disparity metric which uses a time-series based metric to measure fairness for temporal synthetic healthcare datasets. The necessity to capture temporal trends of healthcare datasets is highly essential, as health events of an individual are often time-series, each event being a time-point across the life of an individual. As a result, the metric, such as the one defined here, provide a quantifiable measure to identify whether the synthetic data capture this trend or not. From our case studies, we found that temporal datasets are hard for synthetic data generation methods to capture, often leading to unfair representation of certain covariates. The metric is effective in highlighting that while some subgroup populations might be captured adequately, others may be under-represented. This is clearly visible in
Figure 6, where Whites are adequately represented while Asians are not.
We identified that synthetic healthcare datasets had problems which did not appear without adequate measurement. Even though they satisfy the overall utility, resemblance and privacy constraints, it appears that they tend to get biased towards certain subgroups to achieve these goals. This is highlighted better using covariate-level fairness analysis, which demonstrate that subgroups are often biased towards one or the other class. Using fairness metrics such as those defined in this article, fairness of synthetic data generation methods can be quantified such that the models can be improved.
Measures of Fairness: The introduction of the fairness in synthetic data problem and the associated metrics in this article are proposed as a starting point for potential future research in this direction. We focused on metrics on the fairness of resemblance between synthetic and real data. We adapted existing methods for measuring similarity of distributions stratified by subgroups to create new fairness metrics. Many other approaches could be used such as differences measured in statistical tests or alternative definitions of fairness. To cater to other definitions of fairness, we invite researchers to develop alternative and potentially even better fairness metrics for synthetic data.
While our work was centered around “fairness and resemblance”, fairness of other aspects of synthetic healthcare data needs to be addressed.
Utility and Fairness: The ability of synthetic health data being useful for any real world application or research is derived from its utility. A synthetic data which has high utility would potentially allow development of models which would give similar results if the models were trained on real data instead. Thus, it is important to realise the utility of any given synthetic dataset. For targeted utility, this would require that the synthetic data generation produces data which have equivalent utility for a fixed analysis tasks for all subgroups of protected attributes. For example, the utility could be the accuracy of a classifier on a testing set. This would involve the measurement of utility across each subgroup, potentially defining the “fairness” of the model for that specific subgroup. Here, existing research in ML-Fairness could be readily adapted. If individual fairness across each subgroup is achieved, we would consider the generation methods to be fair in regards to utility.
Utility and Privacy: While trying to achieve overall privacy preservation, we must also evaluate the individual subgroup-level privacy. We must ensure all subgroups, especially the minority groups, are not exposed to attack or data leakage. Andrew et. al. [
16,
19] introduced the privacy measurement metrics nearest neighbors Adversarial Accuracy (nnAA) which can potentially be extended to measure privacy across each subgroup. After ensuring subgroup privacy and overall privacy, the resultant dataset could be considered privacy-fair.
Developing Fair Models: Using fairness metrics, the synthetic data bias can be quantified. Using the results from the metrics, new and more fair synthetic data generation models can be developed. Fairness metrics can be incorporated into the design of generation methods much like fairness measures are used in ML-fairness research. Fairness metrics could capture when synthetic data generation may under-represent the prevalence of minority and other subgroups. They could reveal mode collapse or other limitation of GANs mode [
24], helping researchers to design and tune more accurate synthetic data generation methods. By ensuring subgroup- level fairness in synthetic data, we can check the proportion (and/or presence) of all subgroups and the quality of their representation in the synthetic data. This helps us to detect any mode collapse that happened during model training and thus, potentially rectify it before the synthetic data is used for real-world application.
Fair Synthetic Data Generation: Given the vast majority of fairness definitions, it is essential to define the generation method and the fairness metric it supports. Thus, this would lead to generation of data which is dependent on the problem and its domain. The use of fairness metrics should be an essential step in the direction of optimizing GANs for more realistic, fair, and private healthcare data.
One possible solution is the inclusion of the fairness metrics as part of the loss function or a regularization penalty, potentially leading to the development of a model that can produce different sub-populations with equal representation. This could be achieved with the introduction of conditional GANs (cGANS) [
43] where the under-represented subgroups can be identified and generated in abundance to accommodate their lower representations. The condition would entail the under-represented group, resulting in generation of data specifically for that group such that it has higher proportion.
In synthetic health data generation, we want the synthetic data to closely resemble the real data. In the case studies, the resultant datasets try to preserve the proportions of various subgroups of a given feature. For example, in the ATUS case study, the real data had 13,135 males and 17,391 females while the synthetic data had 12,806 males and 17,194 females. The numbers match closely, which is essential as we want the synthetic data to be an accurate representation version of the real data. However, this might also imply that any bias in the real data due to small sample size is also propagated in the synthetic data. Thus, another possible solution would be to introduce over- and under-sampling of subgroups of a protected attribute as a pre-processing step before feeding it to the generator for training.
Another solution is to use fairness evaluation to determine the under-represented and over-represented classes after training and use it as a feedback loop to the model. This shall involve the downstream classification of synthetically generated healthcare data. The fairness metrics will be evaluated on this dataset, producing the over- and under-representation of certain classes. These insights could be fed back into the synthetic data generator to improve its fairness. Thus, development of synthetic data generation methods must incorporate fairness metrics to generate more robust and representative data.



 ,
, {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}