Analyzing data streams is a challenging issue as it requires a continuous examination of the received data. This is because hidden insights and patterns, as well as the data, are expected to evolve; therefore, stream or online learning applications are prone to lose their accuracy if they are not monitored appropriately.
Concept drift describes a phenomenon that occurs when the accuracy of the prediction model starts to decrease over time, which results in the model becoming obsolete after a short while. Therefore, there is a critical need for advanced capabilities that can be leveraged to adapt perfectly to the changes that occur. Just to explain, concept drift is caused by alterations in the underlying distribution of incoming data [
12]. These altered data negatively affect the entire model if they are treated as normal. The prediction model must be smart enough to detect any variation in the input data and treat it immediately and effectively. In particular, the model should anticipate the occurrence of concept drift so that the readiness and preparation take place before the moment of its occurrence. This would ensure that there is no interruption or delay when replacing the prediction model.
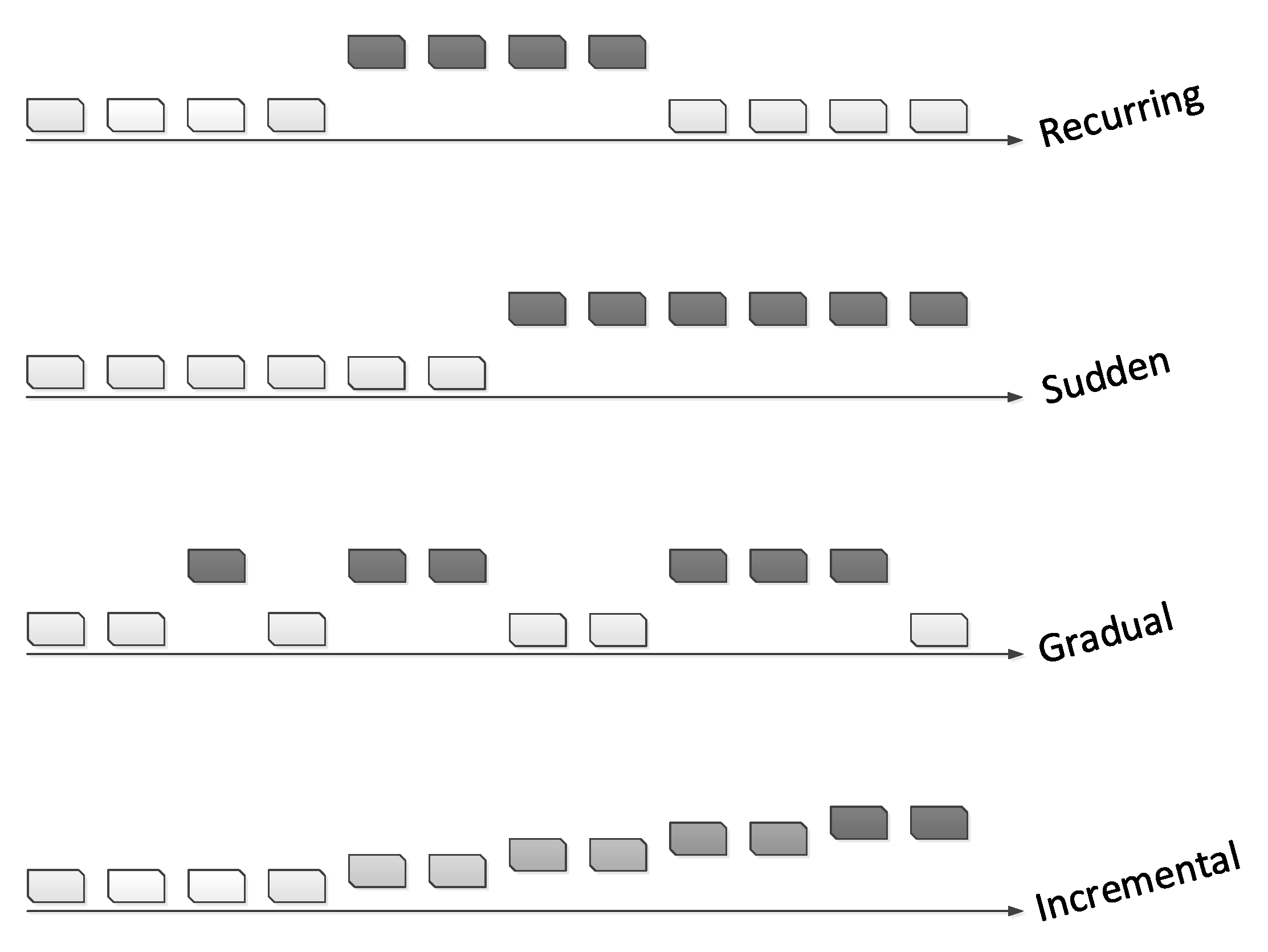
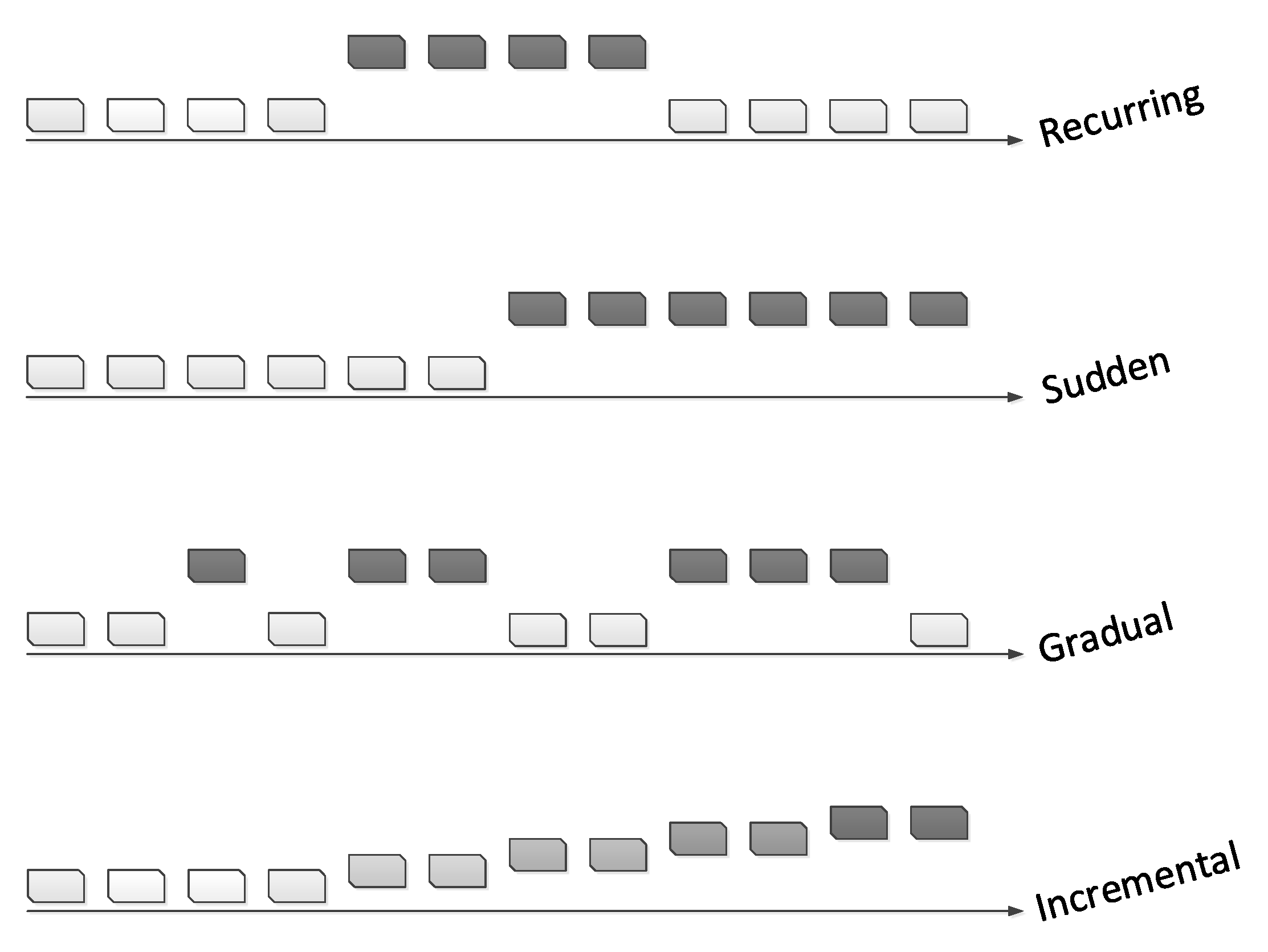
Generally, there are four types of concept drifts, as shown in
Figure 1. The first step in tackling any problem is to understand it well. Lu et al. [
11] pointed out that an understanding of concept drift can be accomplished by defining the following factors: occurrence time, period of concept drift (when), degree or severity of drifting cases (how), and the affected area or region of the feature space (where).
Many reasons may lead to concept drift in daily life. We give examples of real-life problems involving concept drift. Zenisek et al. [
14] presented a concept drift-based approach for improving industrial processes of predictive maintenance, which helped estimate when the maintenance operations must be performed. They carried out real-time monitoring and analysis of equipped sensor data to detect and handle any drift caused by a malfunction in the process. After conducting a real-world case study on radial fans, the authors discussed the potential benefits gained from such an approach for saving time and material and improving the overall process. Similarly, Xu et al. [
15] drew attention to the risks of accumulating digital data in smart cities as a result of the tremendous advances in AI and IoT technologies, which raise the level of information security threats. Therefore, they suggested activating anomaly detection techniques that take into account the concept drift issue that is expected to occur with time on data flow. After conducting their experiment on a real data set, the authors described the effectiveness of their method, which reflects what machine learning can do for cyber security.
Historically, concept drift was handled using different philosophies. We highlight some well-known approaches below.
2.1.1. Mining Data Streams
During the last decade, numerous approaches and algorithms were proposed to deal with evolving data streams [
17]. The ensemble model is one of the models that stream learning researchers are increasingly interested in, owing to its efficacy and feasibility.
Ensemble learning algorithms combine the predictions of multiple base models, each of which is learned using a traditional algorithm such as decision tree; thus, a single classifier’s predictive accuracy will be collectively enhanced [
18,
19]. Many studies have applied the ensemble model to the stream learning approach to deal with issues of concept drift handling [
20].
Bagging and boosting are widely-used ensemble learning algorithms that were shown to be very effective compared with individual base models in improving performance. Bagging operates by resampling (random sampling with replacement) the original training set of size
N to produce several training sets of the same size, each of which is used to train a base model [
21,
22]. Originally, these learning algorithms were intended for batch/offline training. In [
23,
24], an online version of the bagging and boosting algorithms was introduced. Online learning algorithms process each training instance on arrival without the need for storing or reprocessing. The system exhibits all the training instances seen so far.
Let
N be the size of the training data set, then the probability of success is
, as each of the items is equally likely to be selected. The process of bagging creates a set of
M base models, and each of them is trained on a bootstrap sample of size
N through random sampling with replacement. The training set of each base model contains
K times the original training examples given by the binomial distribution (Equation (
1)),
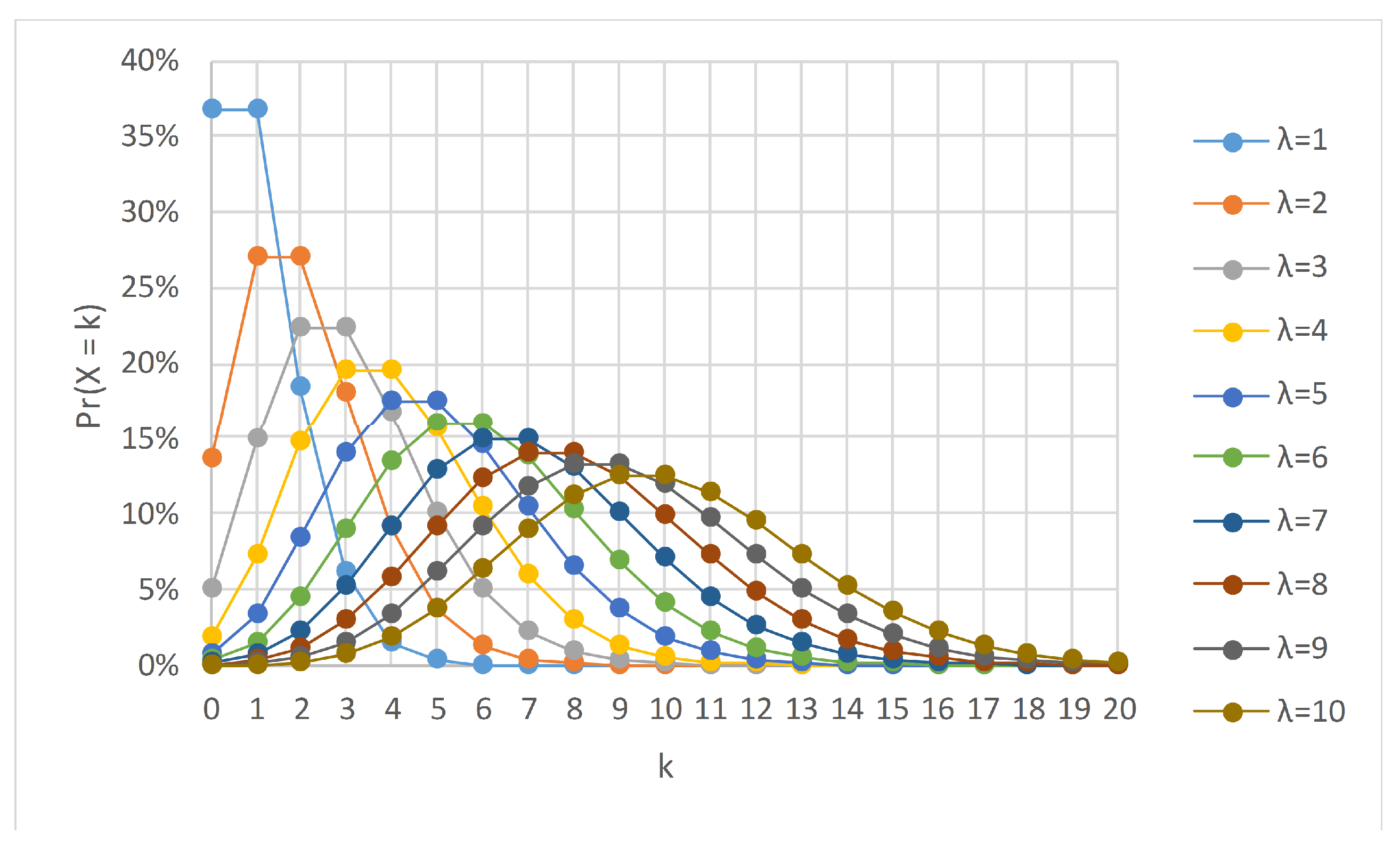
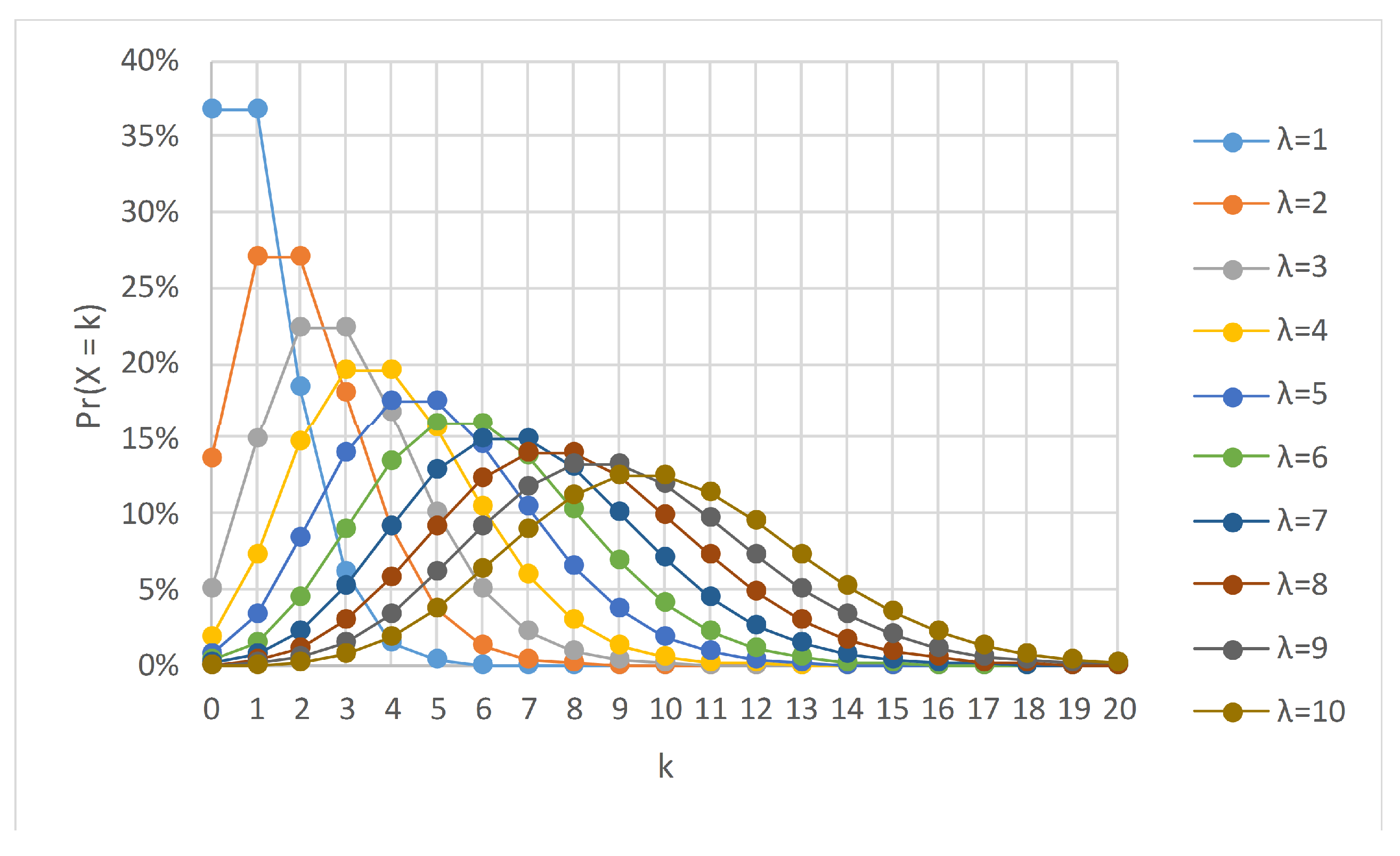
Binomial and Poisson are well-known distributions in probability theory and statistics and were the backbone of several algorithms in machine learning. Coupled together, the binomial distribution can converge to the Poisson as an approximation when the number of trials is large, and the probability of success in any particular trial approaches zero, i.e.,
. Let
, then it can be shown that as
we obtain
The
is the expected number of events in the interval and is also known as the rate parameter. Equation (
2) is the probability density function for the Poisson distribution, denoted by Poisson
. Oza and Russell [
23] argued that in online bagging, the incoming streaming data could be considered as an unlimited training data set in which
, and the distribution of
K tends to a Poisson distribution with
, as given in Equation (
3),
Here, instead of sampling with replacement, each example is given a weight according to Poisson
. A wide range of studies [
23,
24] was carried out in this context to find an optimal solution for handling concept drift. For instance, Bifet and Gavalda [
25] used variable size windows for handling more than one type of concept drift simultaneously. They proposed “Adaptive Windowing” (ADWIN), an algorithm that automatically adjusts the window size based on changes detected in the model’s behavior, i.e., a dynamic monitor for detecting drifting cases was incorporated. The results showed that the proposed technique outperformed the fixed sliding window-based approach in terms of adaption behavior. The algorithm proposed in [
25] was inspired by the work in [
26], a well-known study in this field.
Du et al. [
27] developed a sliding window-based method using entropy for adaptive handling of concept drift. It could determine the appropriate timestamp for retraining the model when the drift occurred. The authors stated that the windows were monitored dynamically to assess their entropy. When the drift occurred, the time window was divided into two parts to calculate the average distance between them. The algorithm then detected the most suitable point for rebuilding the model. Regarding the assessment, five artificial and two real data sets were tested in the experiment. The outcomes revealed outstanding results in terms of recall, precision, and mean delay.
Furthermore, Khamassi et al. [
28] conducted a study in which they tracked concept drift occurrence using two sliding windows. The first window is a self-adaptive variable window that expands and contracts based on the detected drifts. The second window contained a batch of collected instances between two determined errors. The objective was to apply a statistical hypothesis test for comparing the distribution of error distance between the windows. The results of the study showed an early detection of drifts and a minimized false alarm.
Liu et al. [
29] proposed a fuzzy-based windowing adaptation method that allowed sliding windows to maintain overlapping periods. The data instances were weighted by membership grades to differentiate between the old and new concepts. After evaluating their proposed approach by several data collections, the authors stated that their method yielded a more precise determination of the instances that belonged to different concepts, which in turn enhanced the learning model adaption.
Yang and Fong [
30] presented an optimized version of the very fast decision tree (VFDT) [
31]. Their system prevented the explosion of the tree size and minimized the degradation of accuracy resulting from noise. The incrementally optimized very fast decision tree (iOVFDT) algorithm used a multiple optimization cost function that took into consideration three important aspects, namely accuracy, tree size, and running time. Subsequently, in [
32], the same team of researchers conducted a study comparing the performance of their proposed algorithms with VFDT [
31] and ADWIN [
25] regarding the handling of concept drift. The authors concluded that iOVFDT achieved the best results in terms of accuracy and memory usage.
Krawczyk and Woźniak [
33] suggested using a modified weighted one-class SVM to tackle concept drift cases adequately. They clarified specifically that the data stream was processed as consecutive data chunks with the possibility of having concept drift in one of them, and each data chunk would be trained and tested on the following one. They used artificial and real data sets to evaluate their approach, and the outcomes revealed promising results compared to the one-class very fast decision tree (OcVFDT) [
34]. Similarly, Pratama et al. [
35] proposed an evolving fuzzy system to handle concept drifts in colossal data streams by employing a recurrent version of the type-2 fuzzy neural network. They demonstrated that their approach was flexible enough to be modified to comply with the requirements of the learning problem.
Krawczyk et al. [
36] conducted a comprehensive survey regarding ensemble learning for analyzing data streams. They used the data processing mechanism as the main factor for categorizing the ensemble approach of handling concept drift, i.e., they differentiated between data stream instances being processed individually or collectively (by a chunk-based method). In addition, the study explored several research paths under the umbrella of the ensemble model, and work was carried out in stream learning. The authors presented open challenges and potential redirection in this important field, e.g., they discussed the need for high-performance capabilities for big data applications. The study suggested methods to improve the scalability of the proposed algorithms or using dedicated big data analytics environments such as Spark [
37] or Hadoop [
38]. Of course, the aim was to use these types of environments by taking into account the phenomenon of concept drift and the streaming nature of incoming data; some studies have proposed good approaches using big data technologies as in [
39], but in classical (batch) machine learning settings.
2.1.2. Random Forest and Its Adaptive Version
On surveying the literature on concept drift issues, we observed that some well-known machine learning algorithms, such as the random forest algorithm, have not been addressed extensively. Random forest is an ensemble learning model that is widely used in classical non-streaming settings. As stated by Marsland [
40], “If there is one method in machine learning that has grown in popularity over the last few years, it is the idea of random forests”. However, the situation is completely different for stream-based learning studies, and few studies have been published concerning the application of the random forest algorithm for handling concept drift.
Abdulsalam et al. [
41] presented a streaming version of the random forest algorithm that used node and tree windows. Their approach, however, does not take concept drift into consideration as the data streams were assumed to be stationary. Therefore, Reference [
42] discussed dynamic streaming random forests to deal with evolving data streams that were prone to changes over time. Their work was an extension of their previous work that added the use of tree windows of flexible size in addition to an entropy-based concept drift detection technique. Subsequently, Saffari et al. [
43] introduced online random forests that combined the ideas of online bagging and extremely randomized forests. They also used a weighting scheme for discarding some trees and starting to grow new ones based on the out-of-bag (OOB) error measure found at certain time intervals. There were some further studies in this field, but no remarkable results were reported regarding the handling of concept drift.
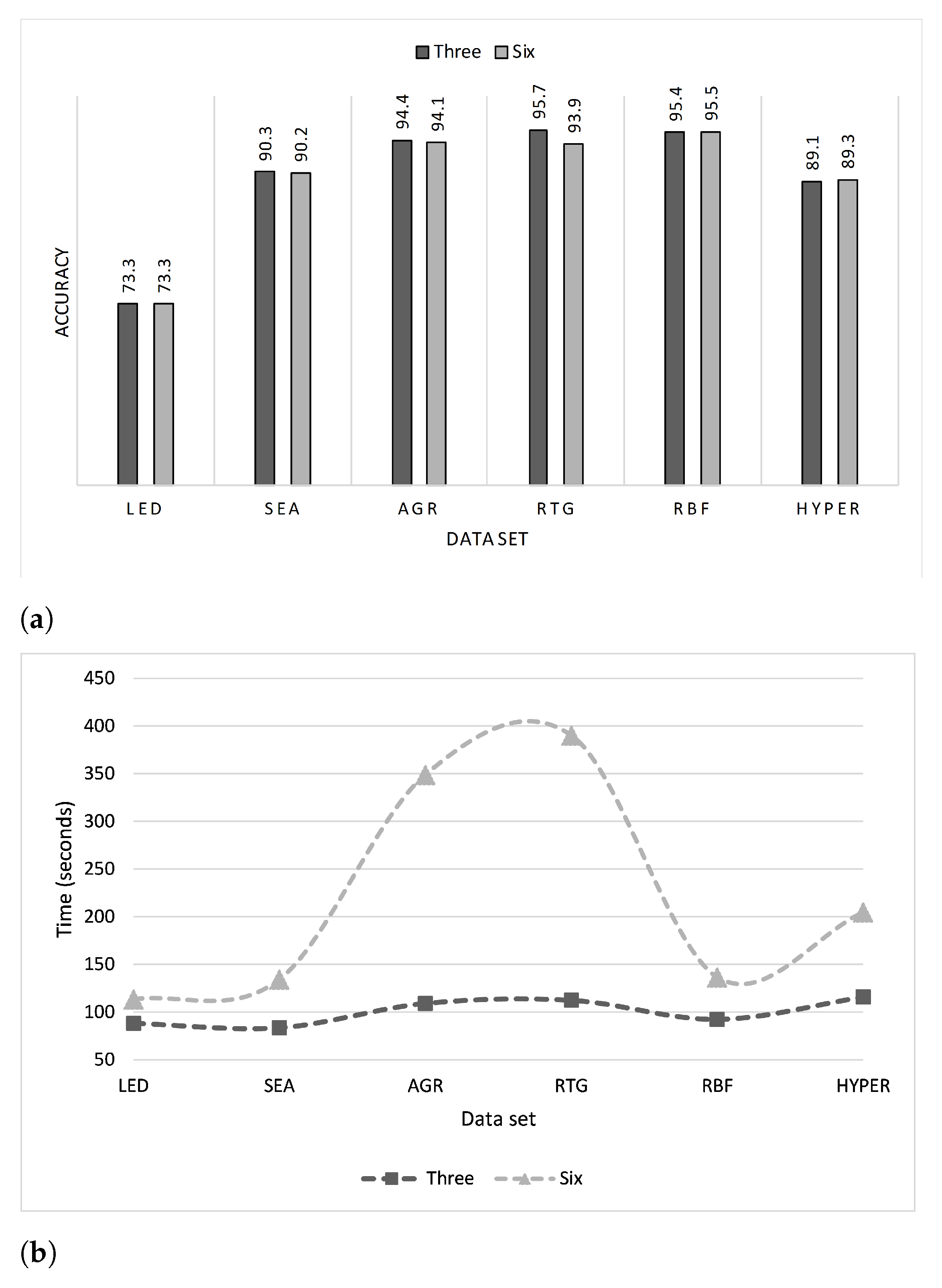
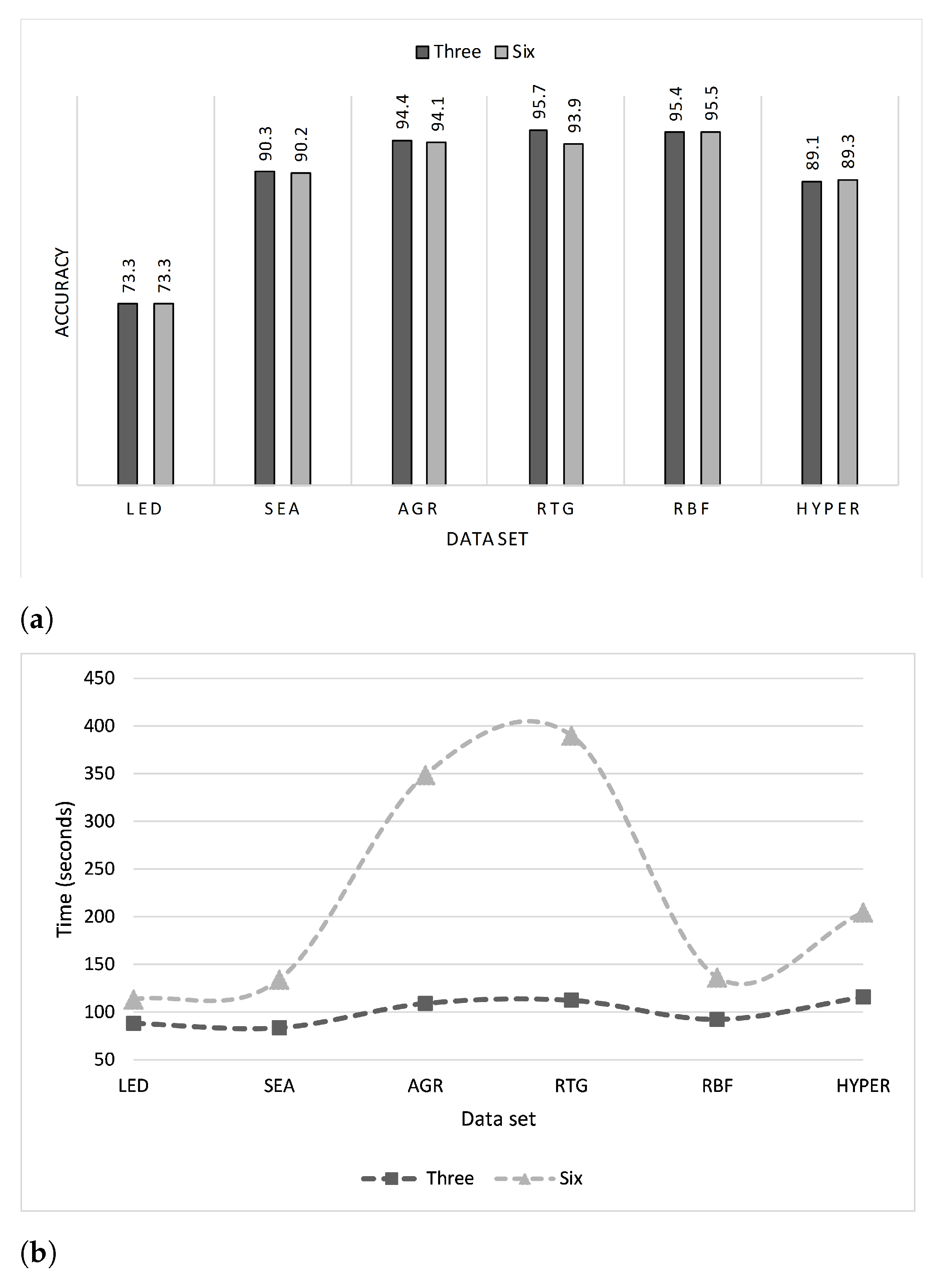
Gomes et al. [
10] proposed the Adaptive Random Forest (ARF) algorithm for classifying evolving data streams. Their approach toward evolving data streams employed resampling along with an adaptive strategy that provided drift monitoring for each tree in two steps: the first was direct training of a new tree when a warning was issued, and in the second step, the tree was instantly replaced if concept drift occurred. The authors compared their proposed approach with different state-of-the-art algorithms, and the results demonstrated its accuracy. Another key point is that a parallel version of the algorithm was built that was found to be three times faster than the serial one.
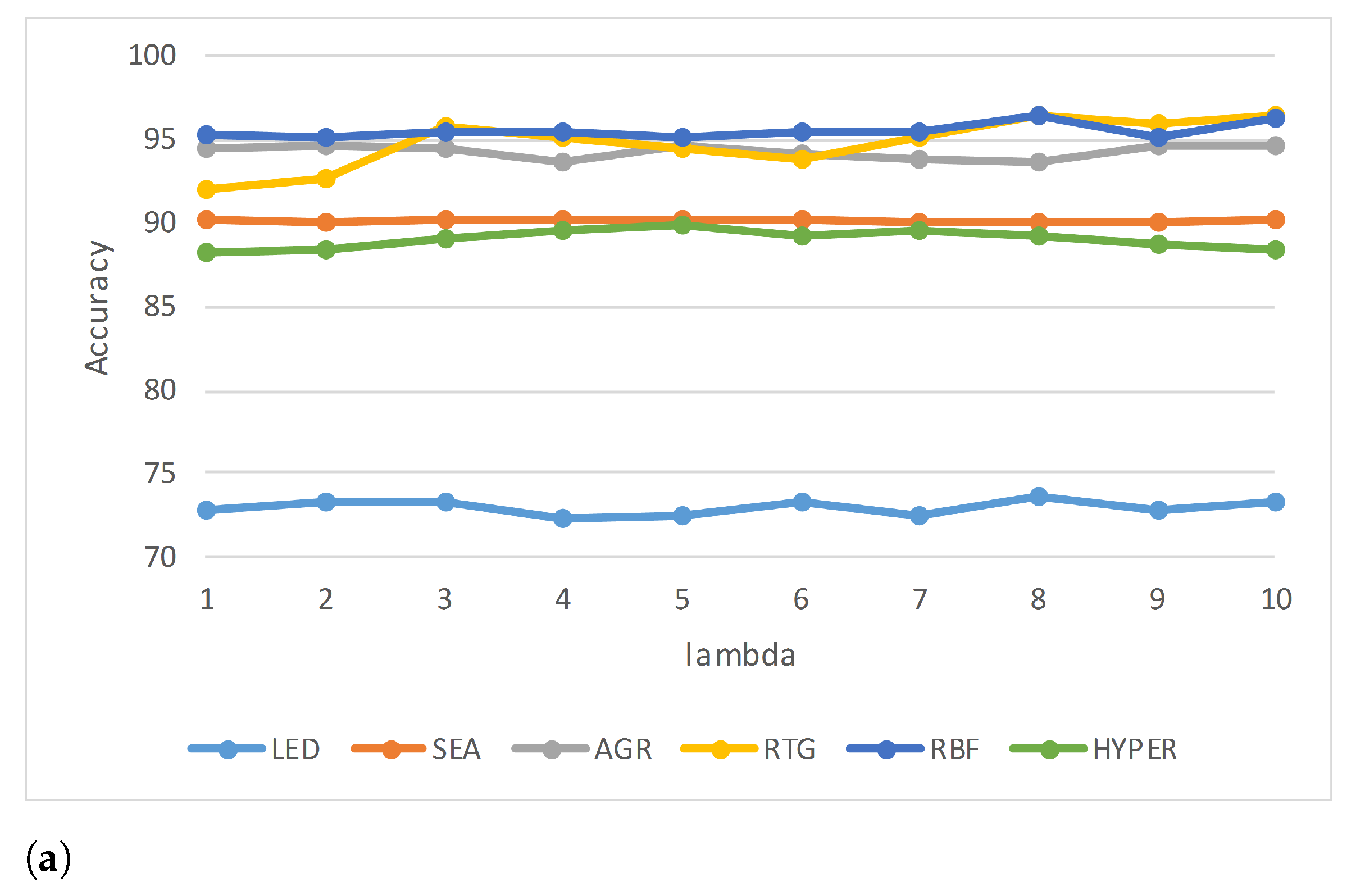
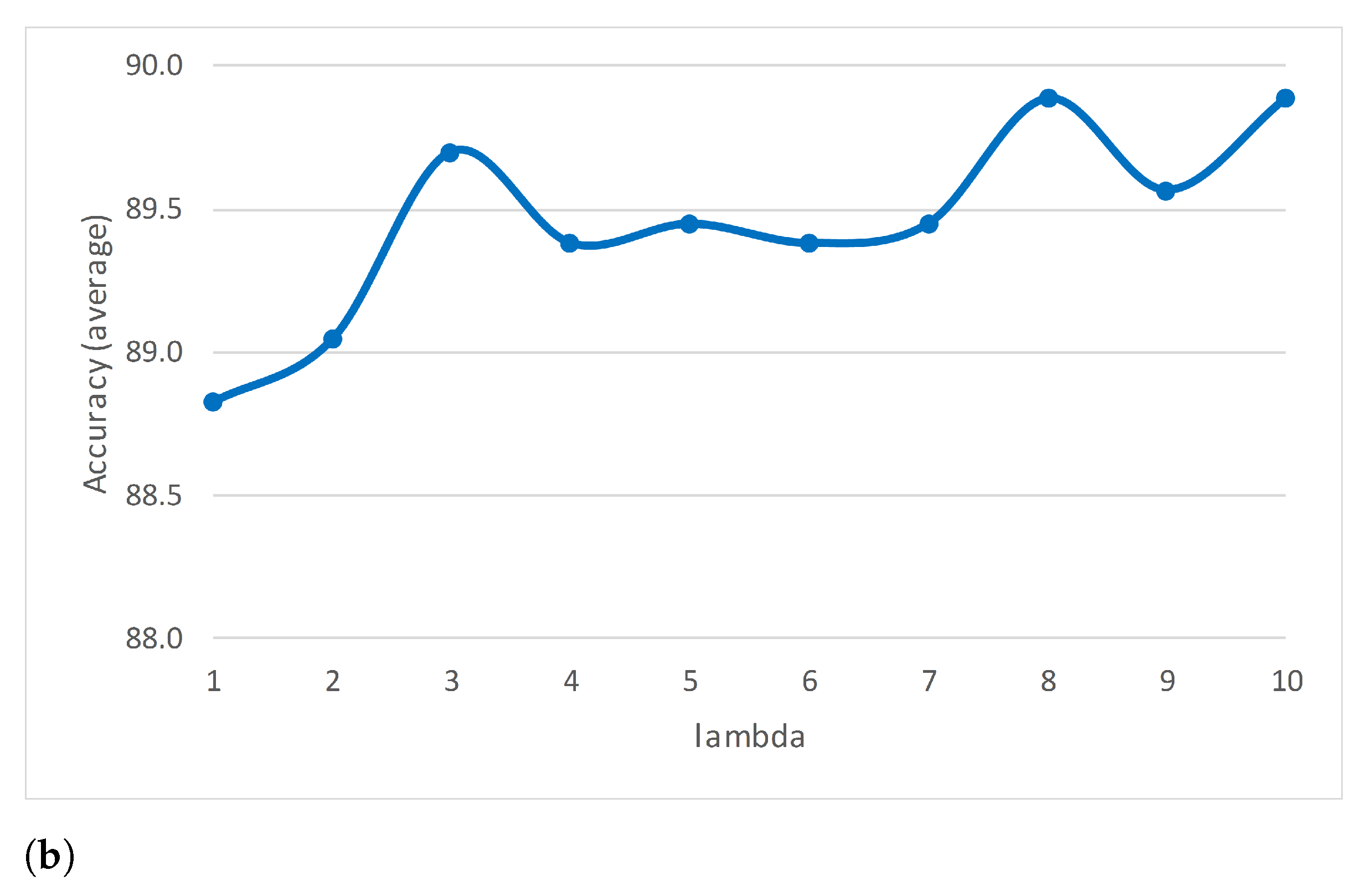
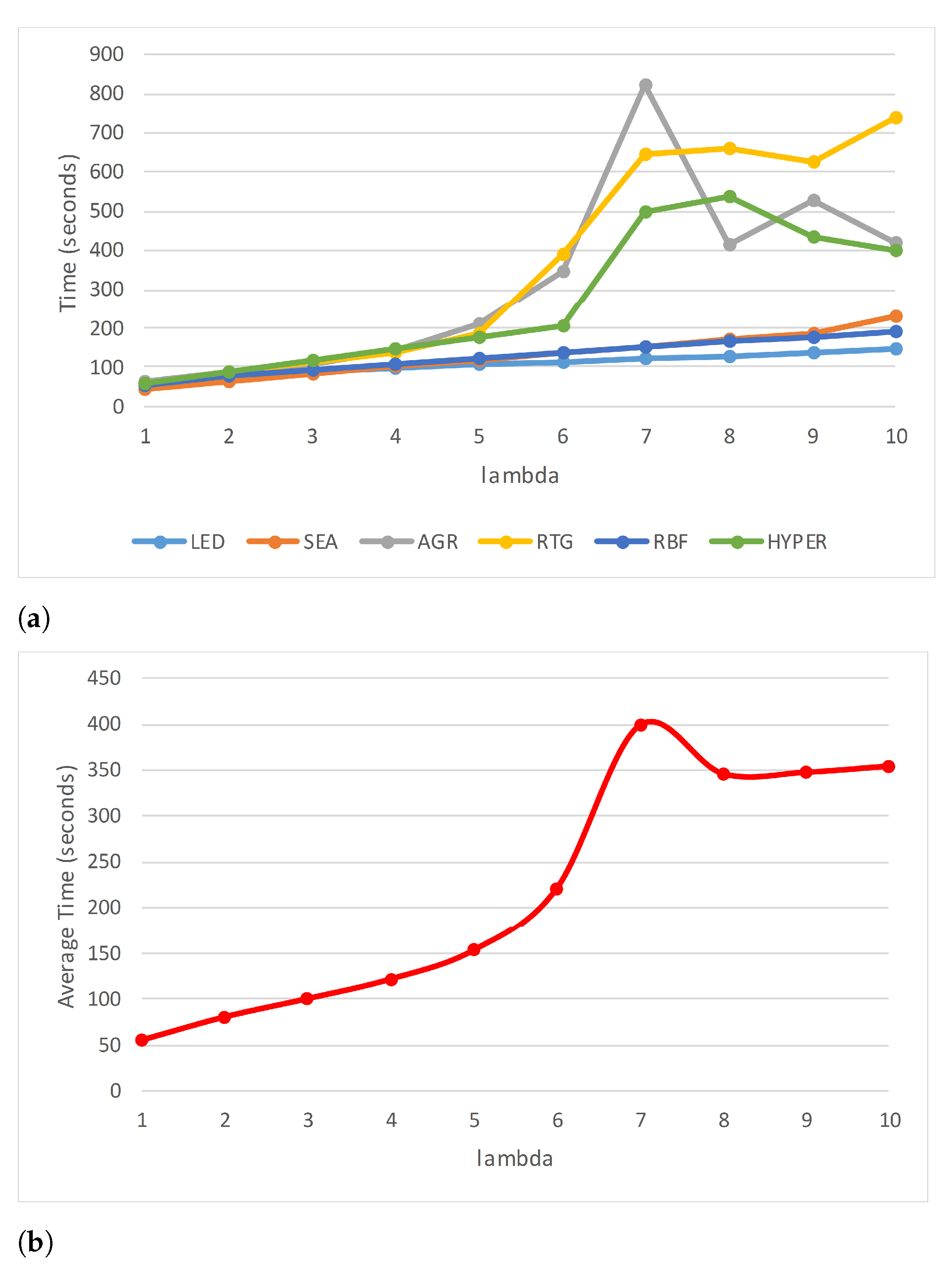
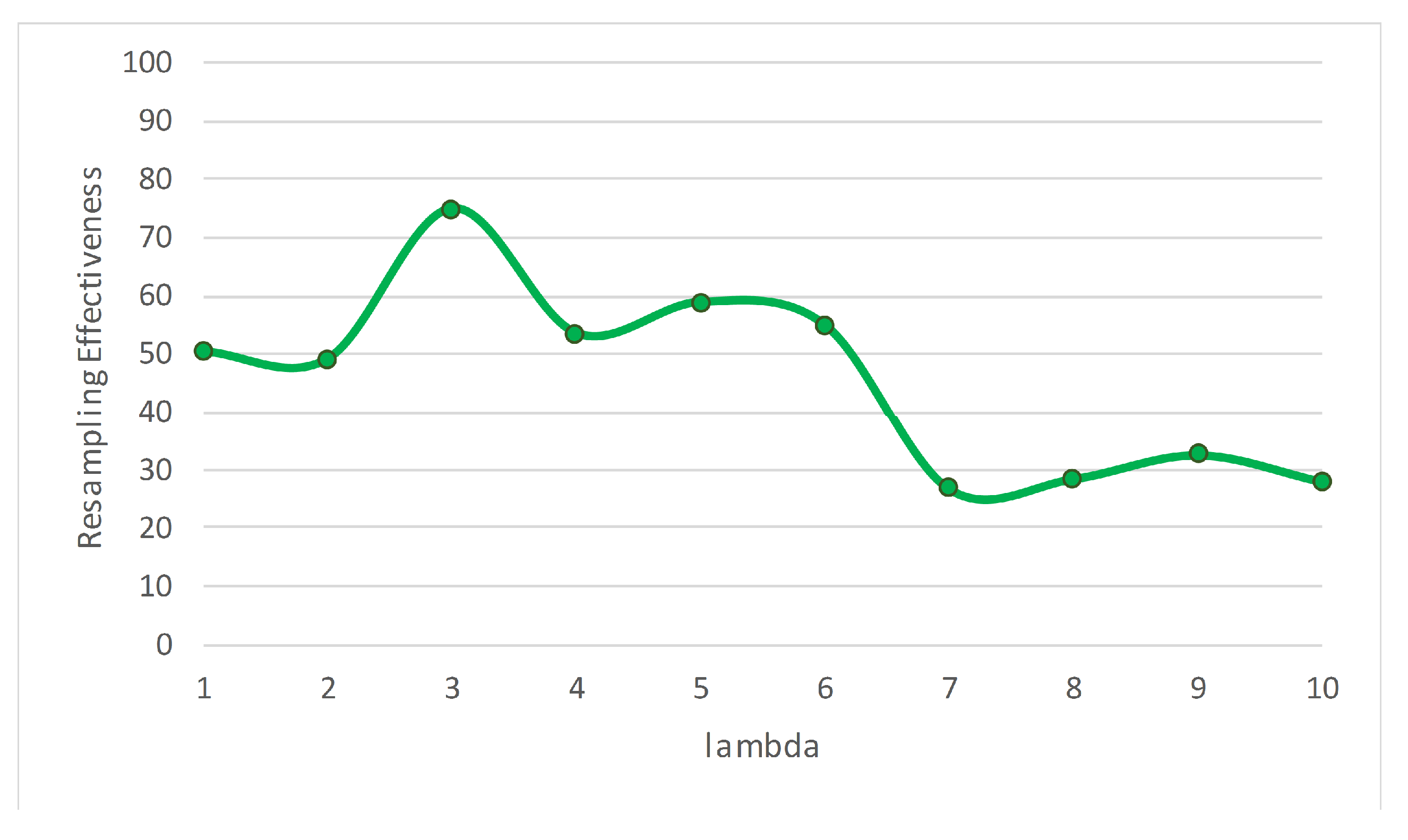
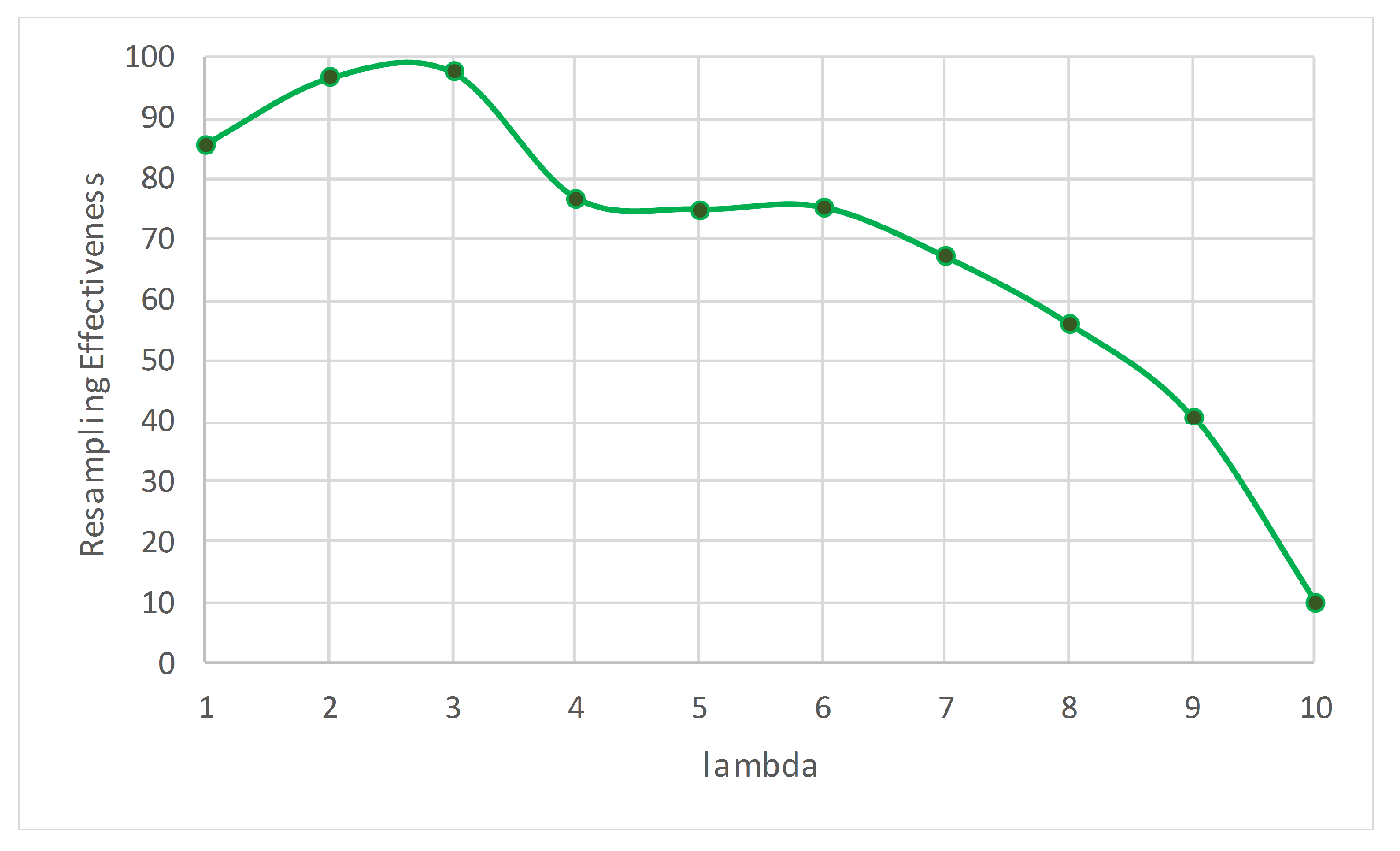
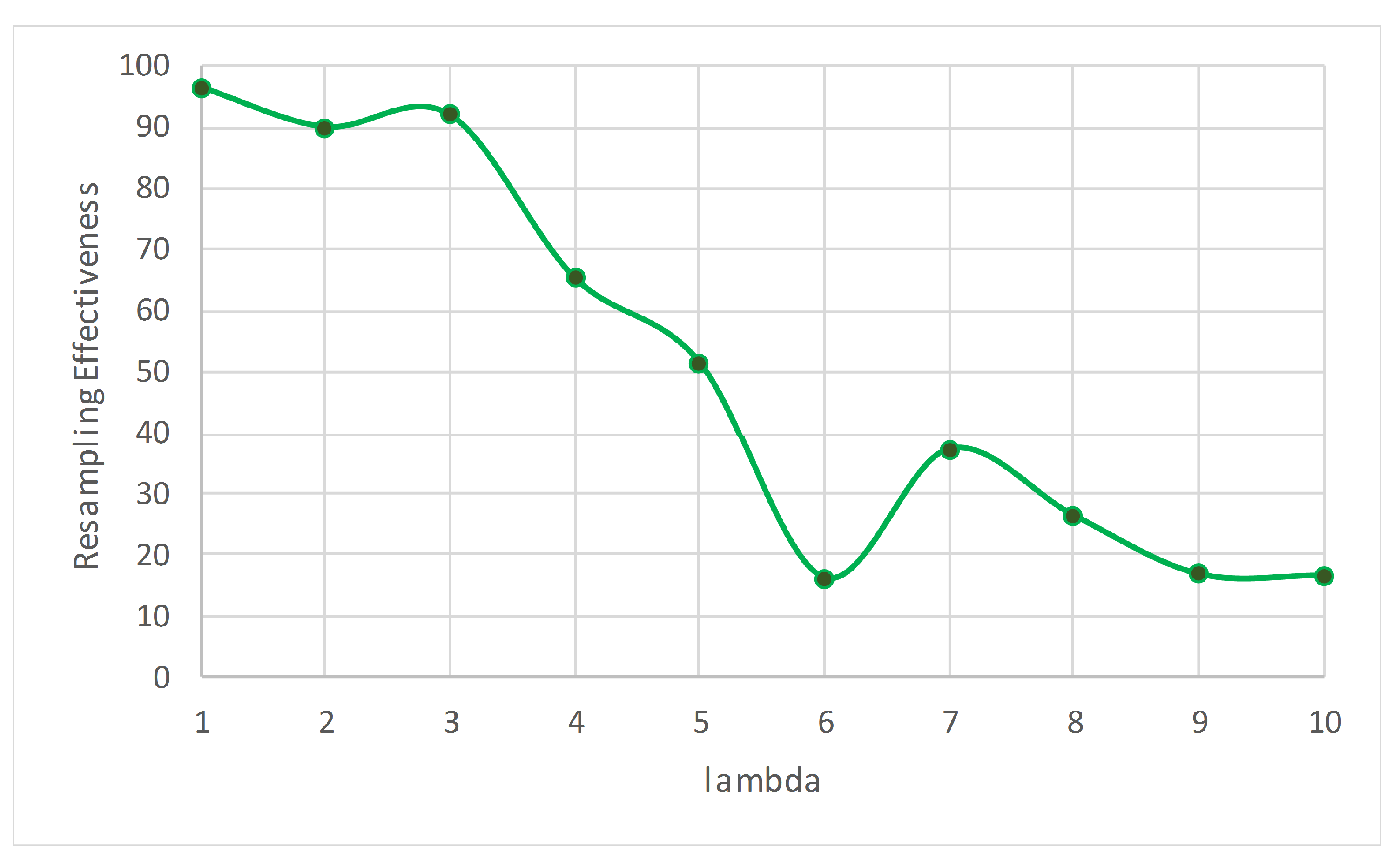
Some streaming algorithms can handle only one type of concept drift; however, ARF can cope with various types. This competitive advantage motivated us to study ARF in more depth to find possible enhancements.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}