
Learning Numerosity Representations with Transformers: Number Generation Tasks and Out-of-Distribution Generalization


Abstract
:1. Introduction
2. Methods
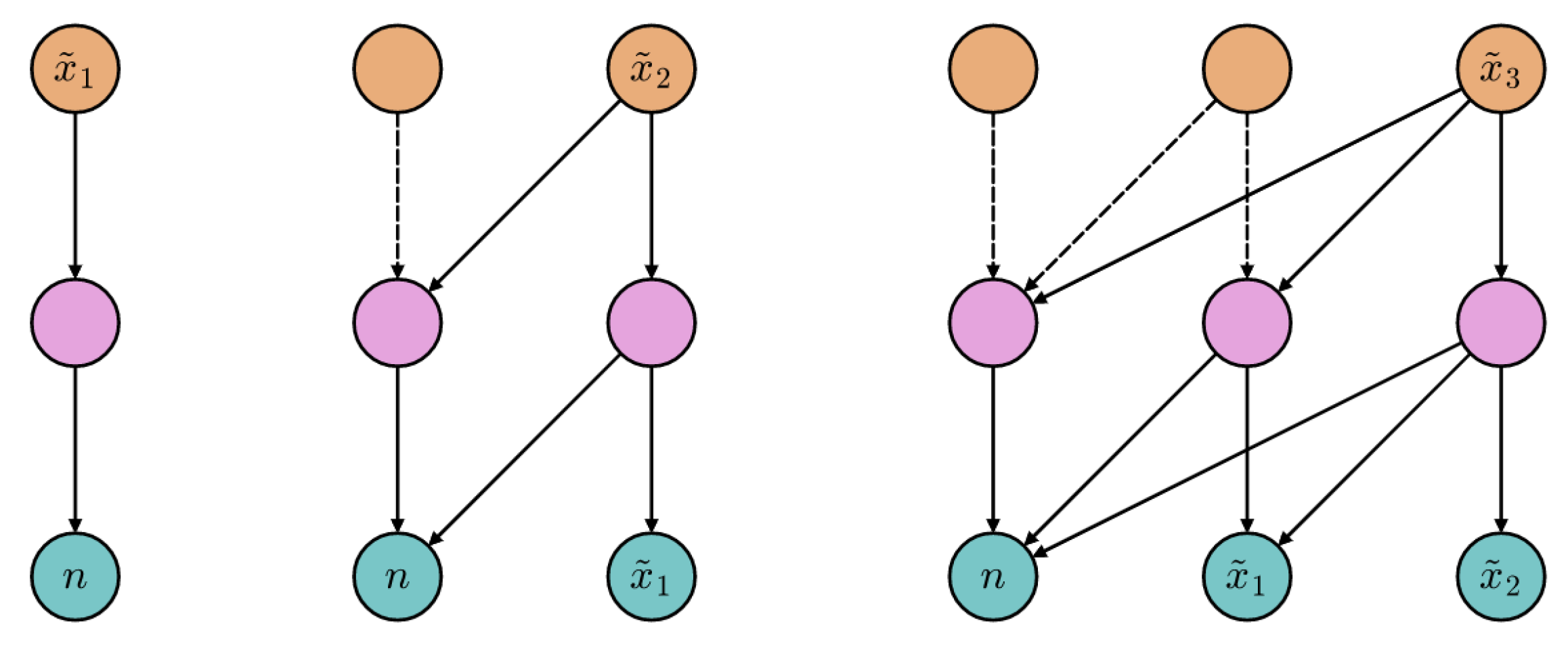
2.1. Problem Formulation
2.2. Model Architecture
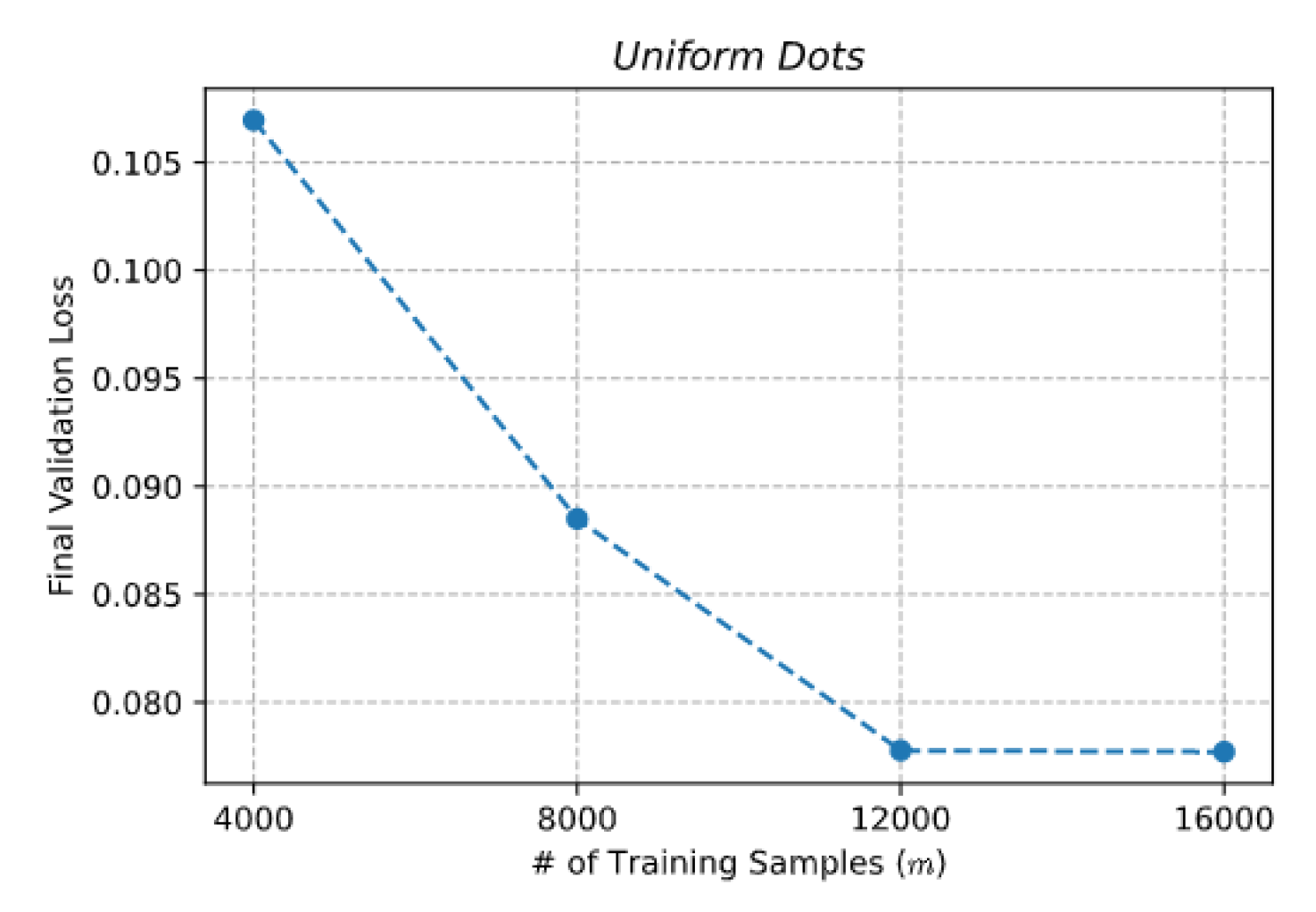
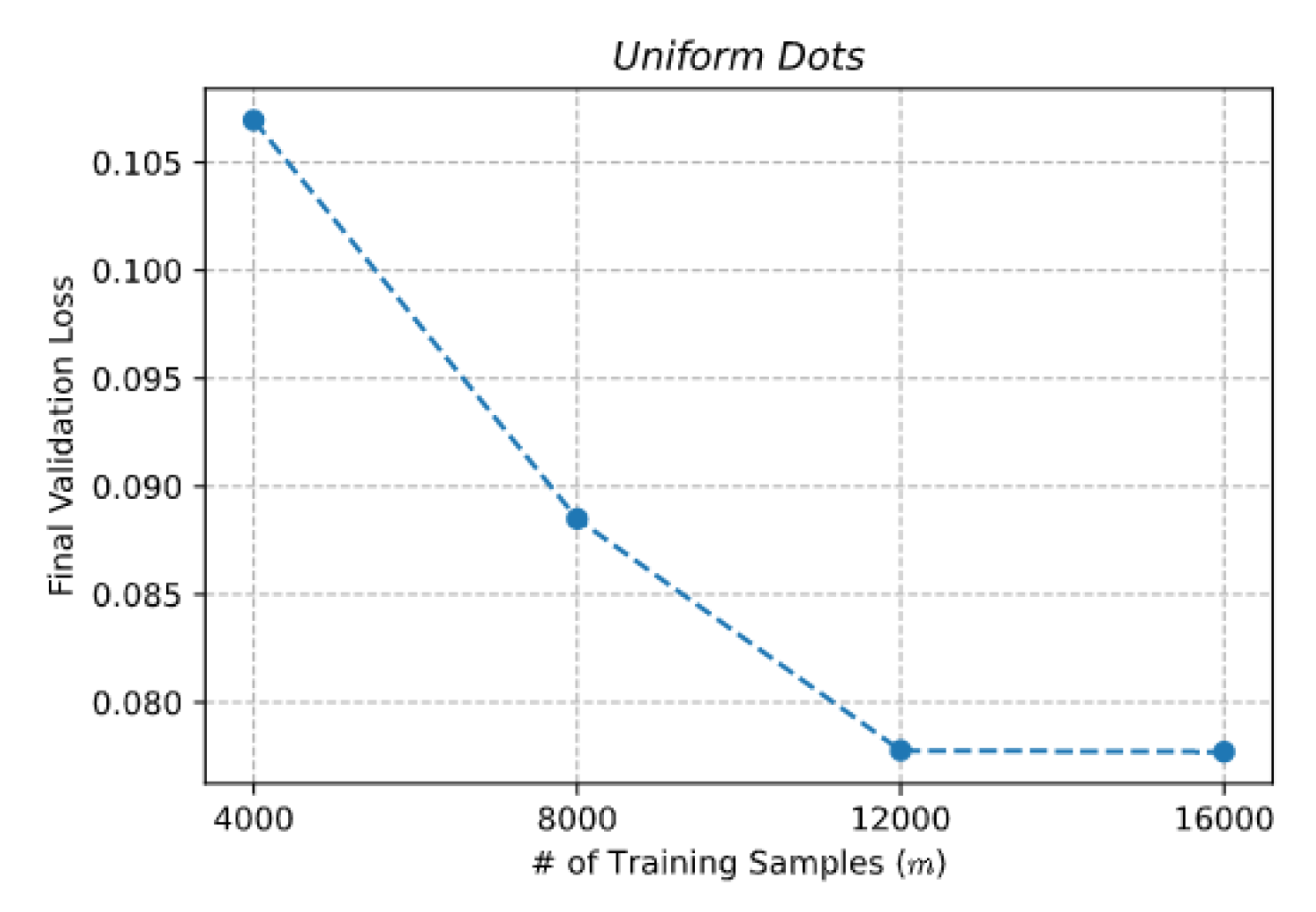
2.3. Datasets
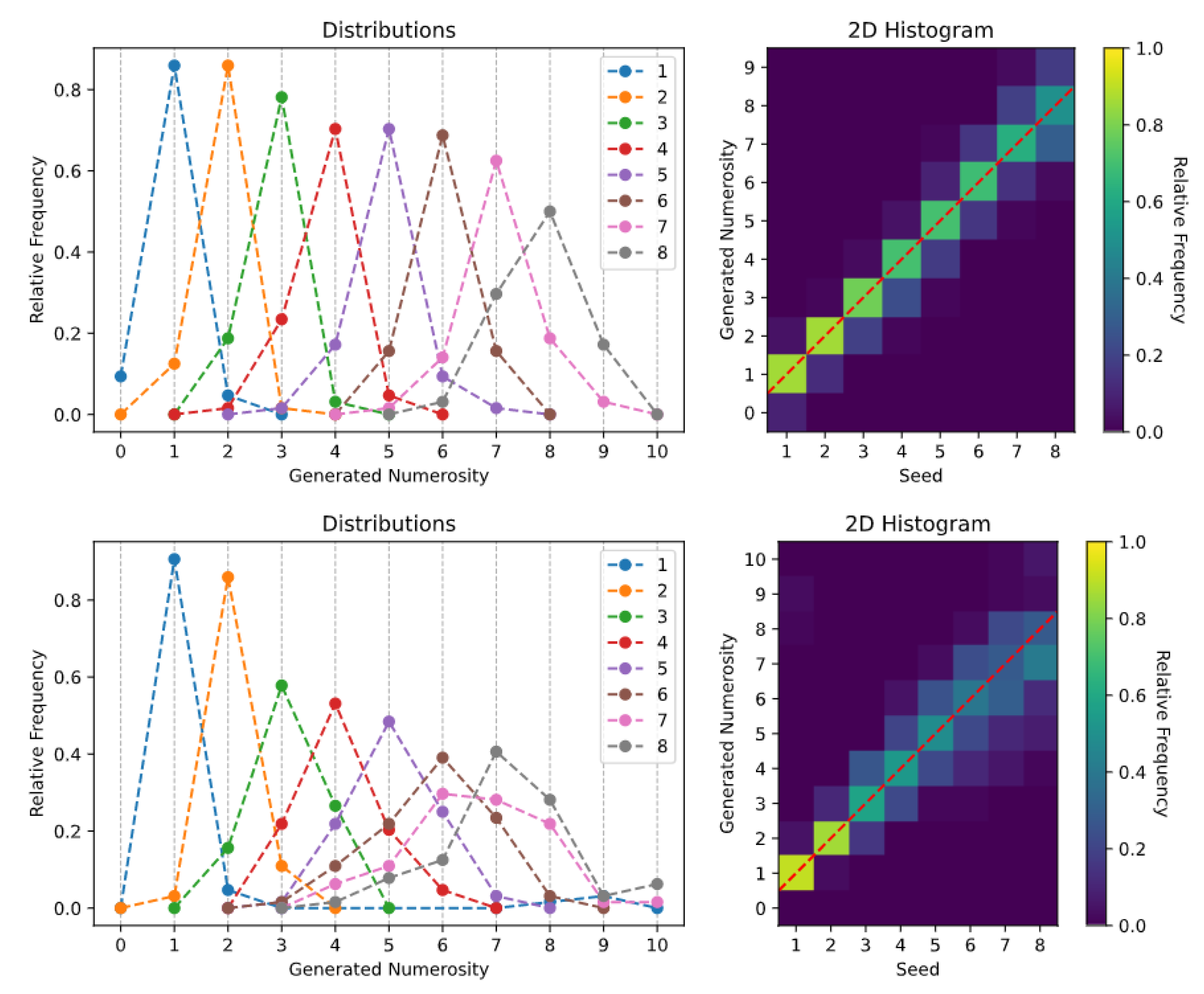
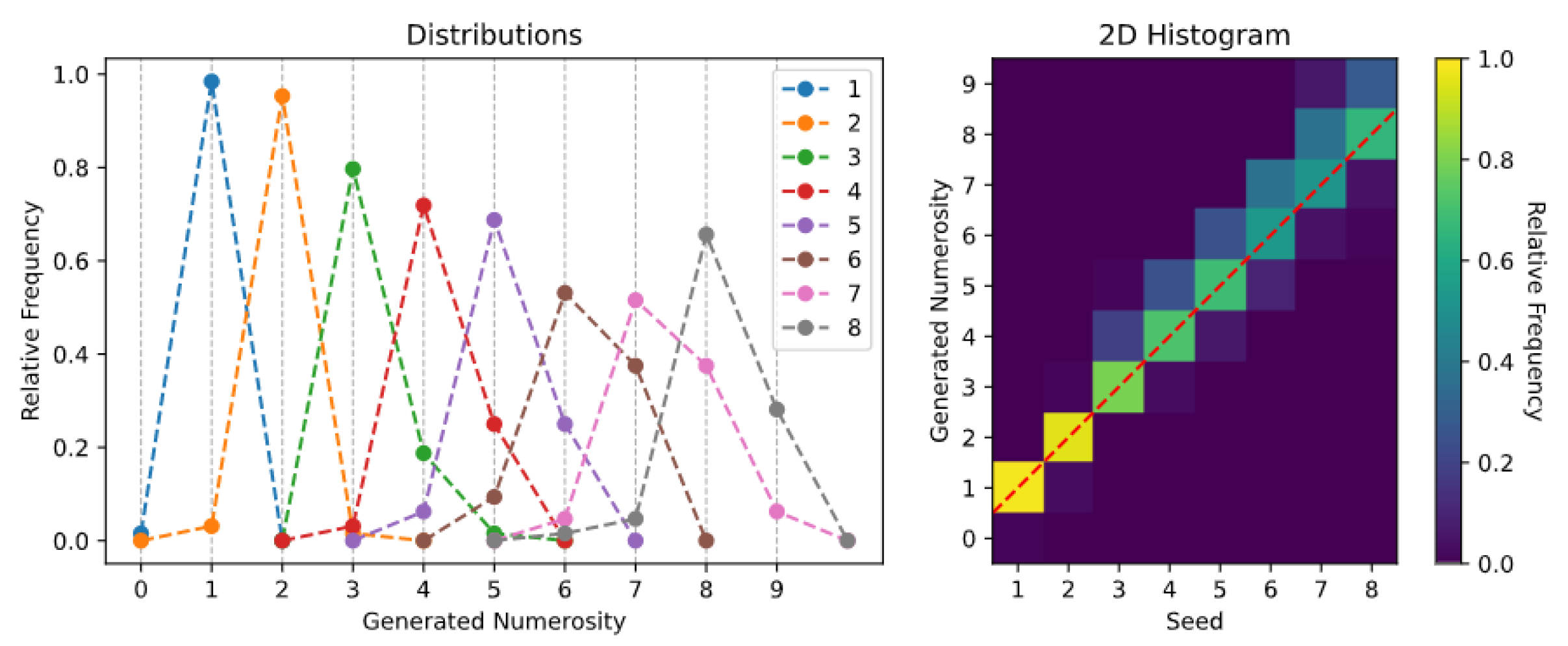
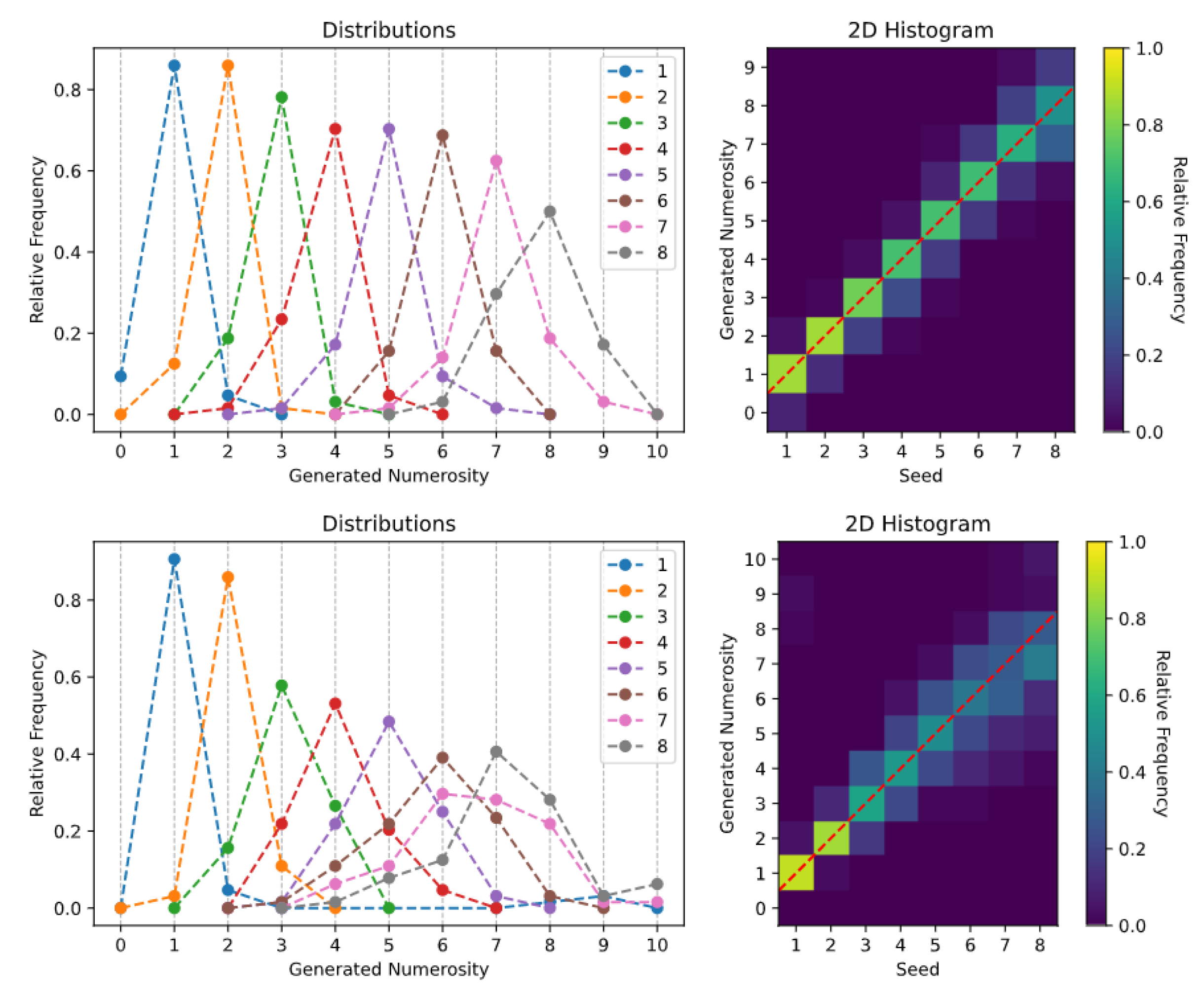
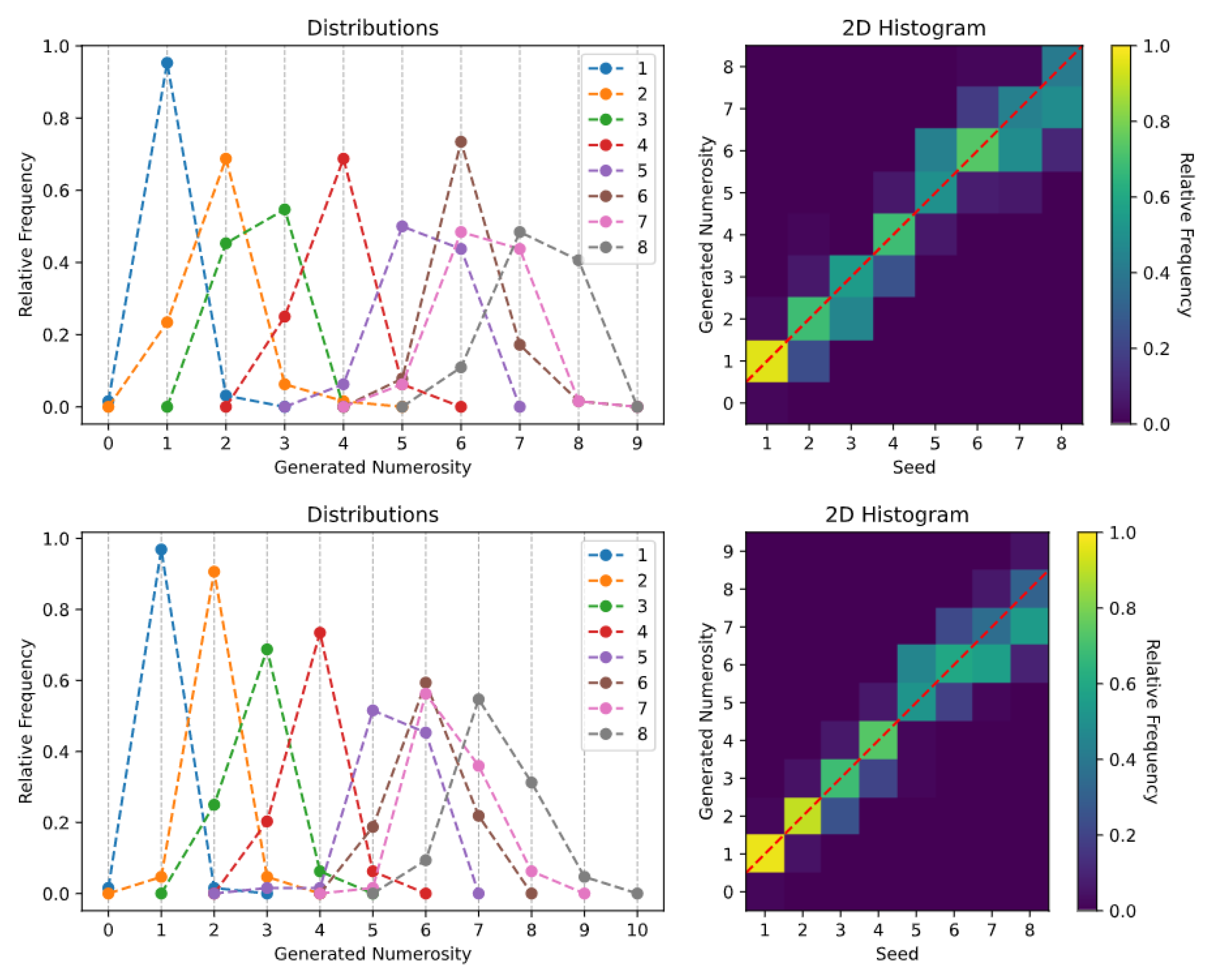
2.4. Generative Tasks
- Spontaneous generation over trained numerosities. In this case, the sampling process was initially conditioned on the numerosity representations learned during the Transformer training (i.e., the rows of ). That is, the learned SoSs were provided as initial seed.
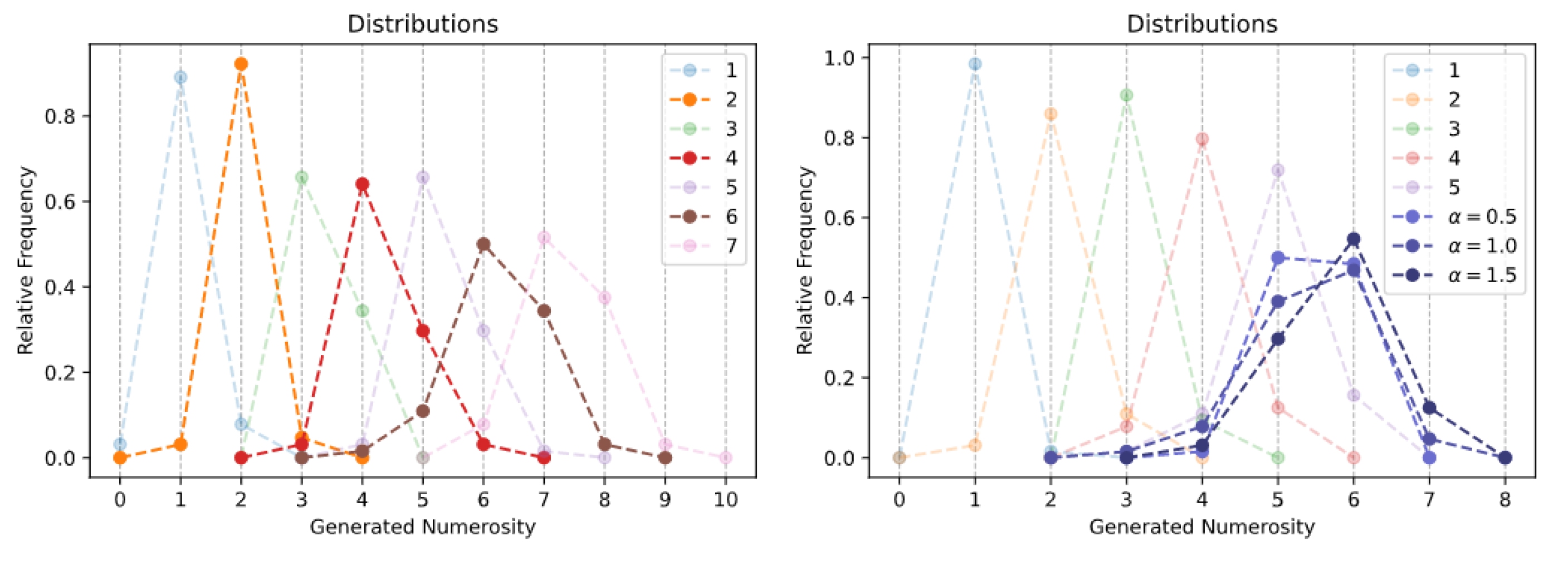
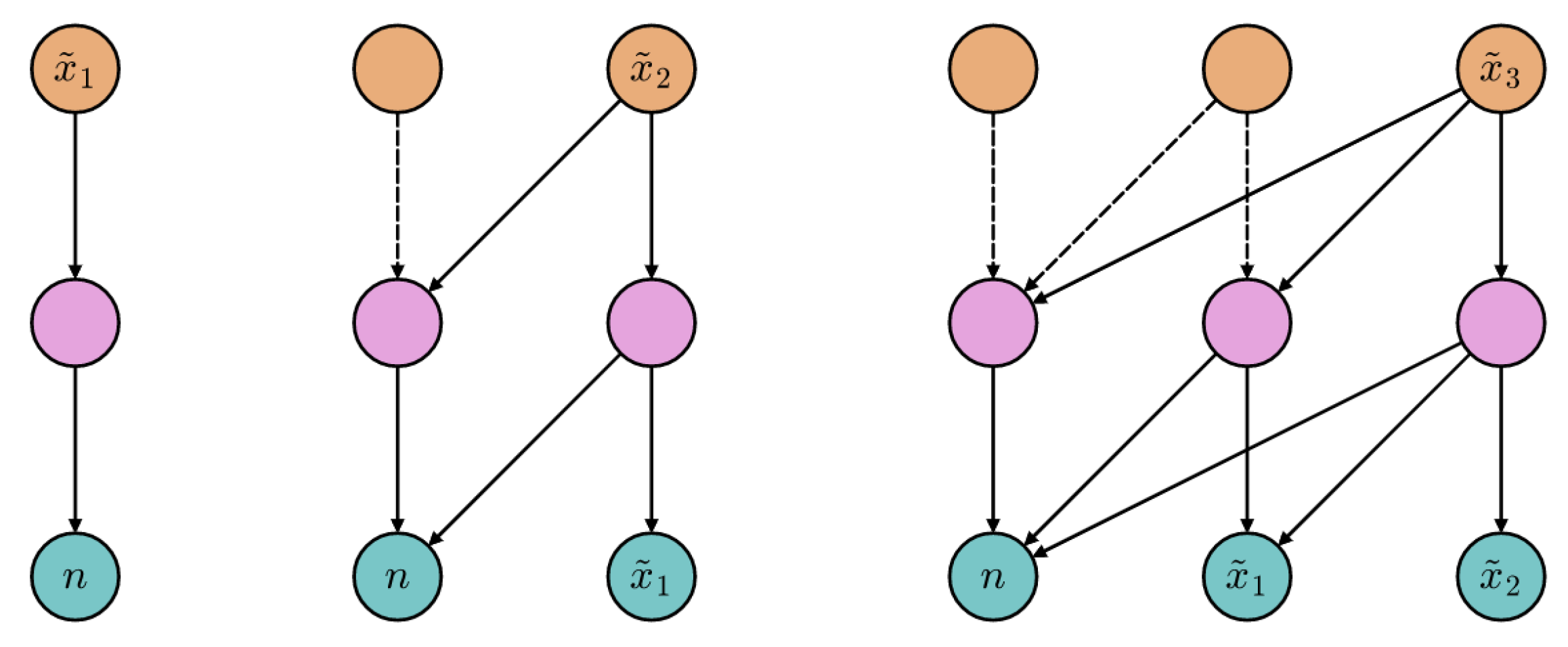
- Spontaneous generation over interpolated numerosities. In this case, we tested whether the generative process could be biased toward specific numerosities that were never encountered during training (but nevertheless fell in the training interval) by injecting a novel SoS as initial seed. Defining as the row of corresponding to the training numerosity i, the desired conditioning n is injected by simply setting . In other words, the new representation of n is linearly interpolated from the two closest SoSs.
- Spontaneous generation over extrapolated numerosities. The generative capability was further pushed by exploring whether the Transformer could be biased to produce numerosities falling outside the training range. The proposed extrapolation mechanism relies on the attribute vector technique described in [39], where the vector representing the direction of change is computed as ; it represents the direction along which the largest numerosities grow. We conjecture that the representation of a numerosity immediately larger than those included in the training range can be approximated by , for a suitable .
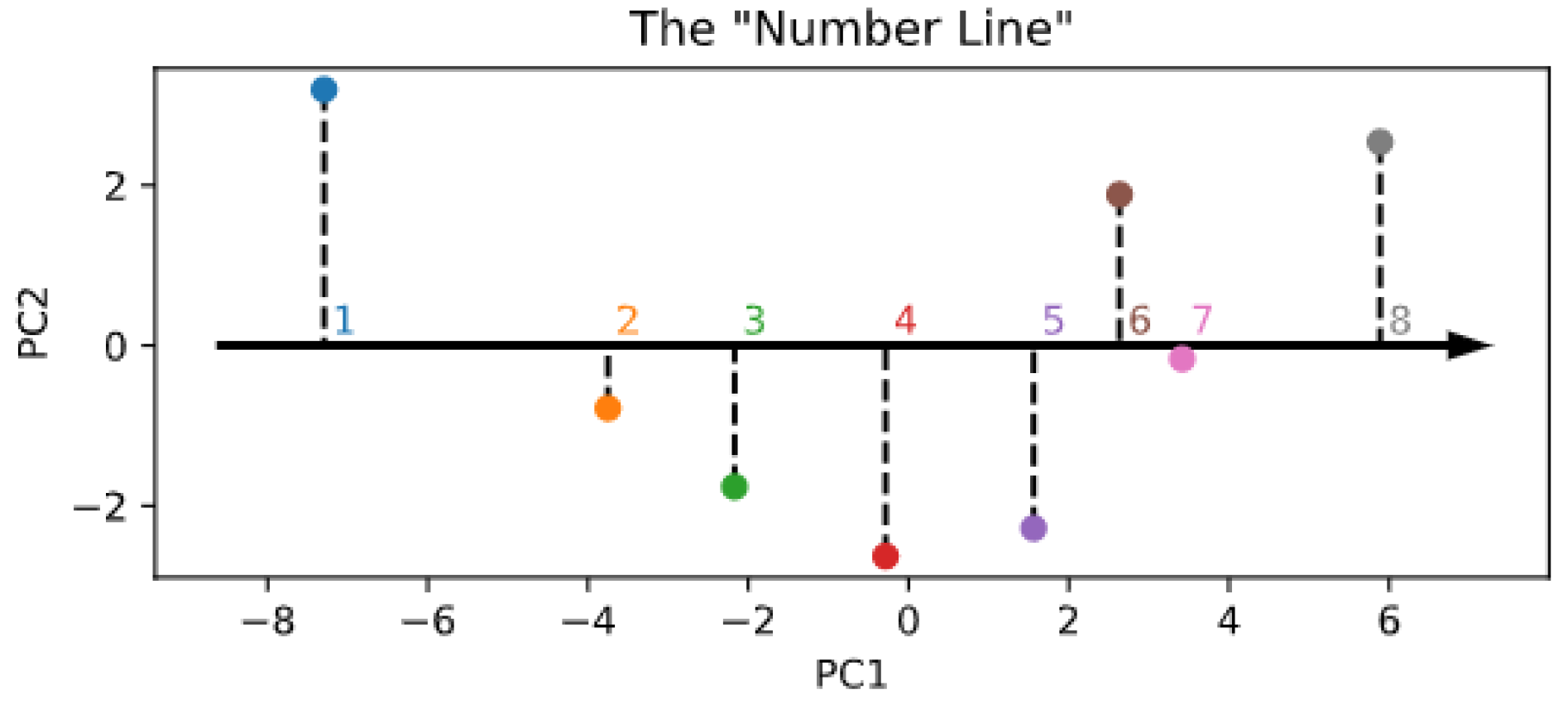
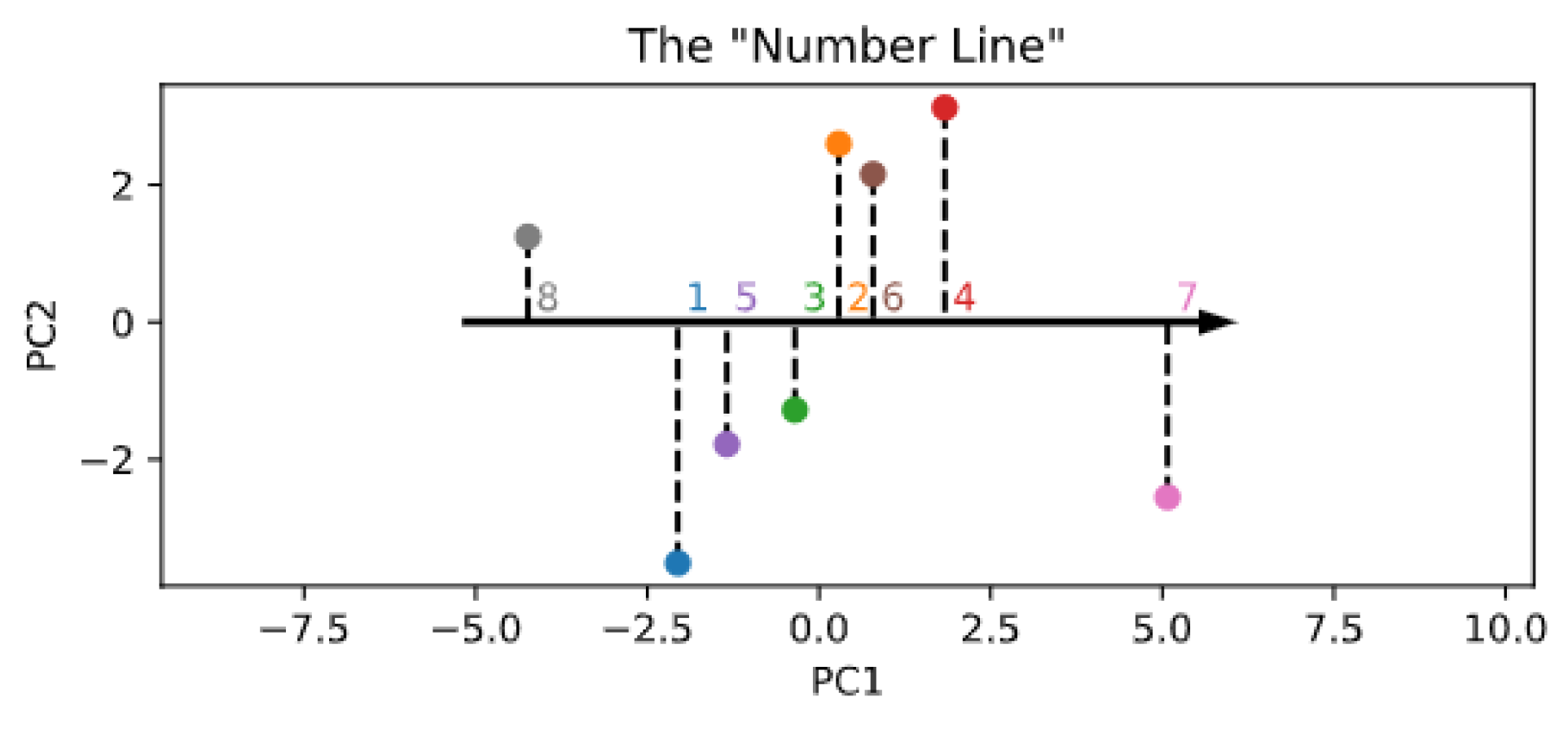
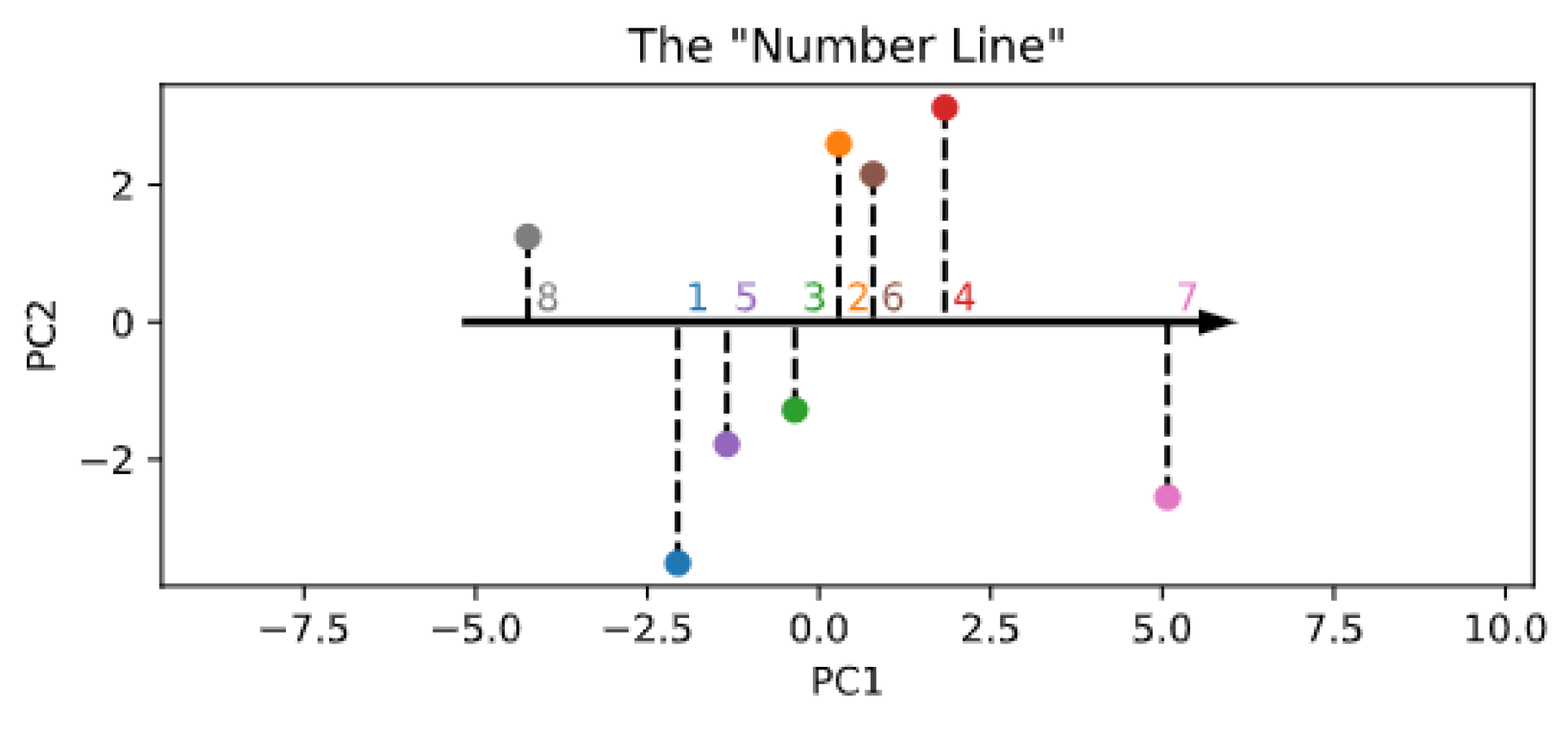
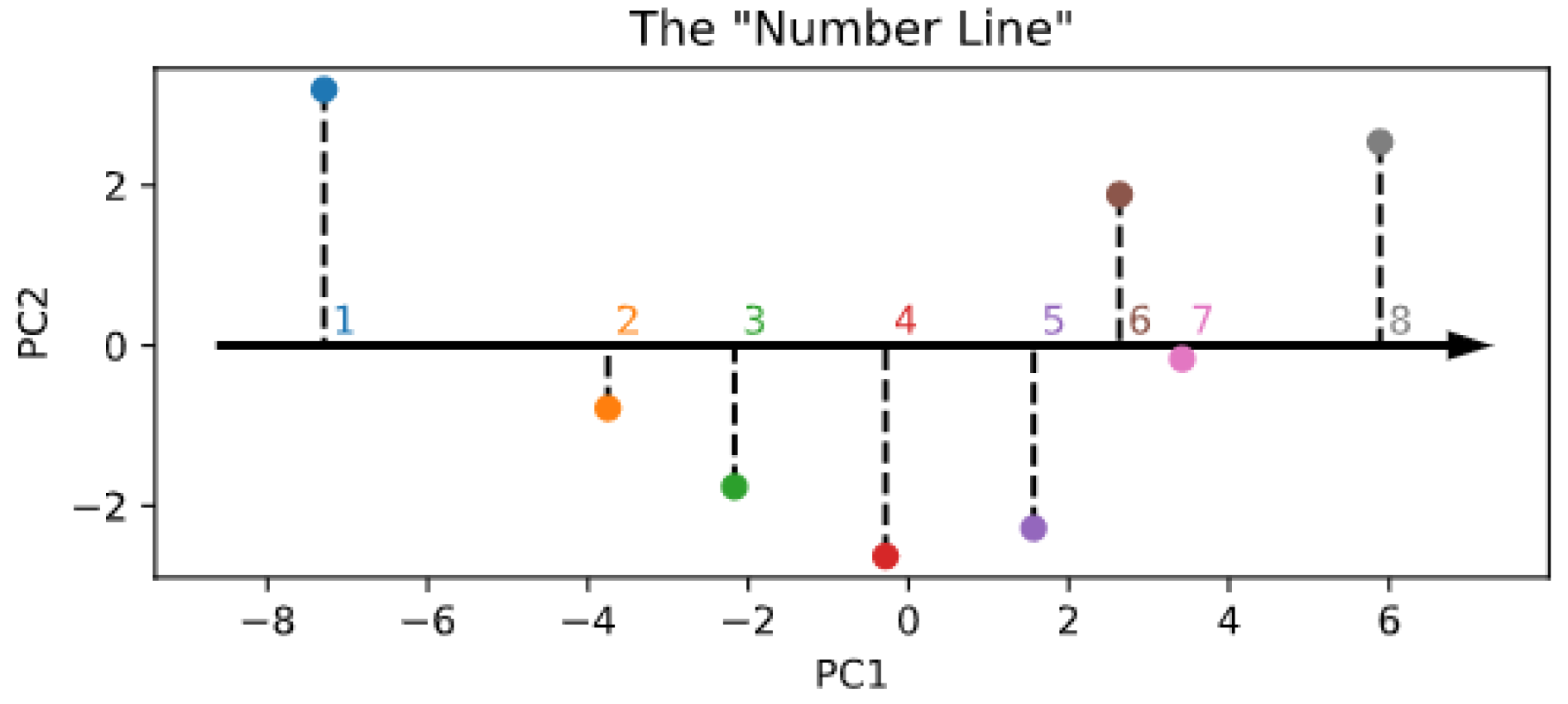
- Spontaneous generation with reduced components. Although the embedding size is constrained by the encoder architecture, numerosity information might in fact be mapped into a lower-dimensional space, akin to an ordered “number line” [40]. To explore the possibility that the learned SoSs could be arranged along a one- or two-dimensional subspace, we performed a principal component analysis (PCA) on the rows of and used either the first or the first and second principal components to reconstruct the SoSs used to start the generation process and thus establish whether the sampling quality is affected by such dimensionality reduction.
3. Results
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Model Hyperparameters and Supplementary Figures

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
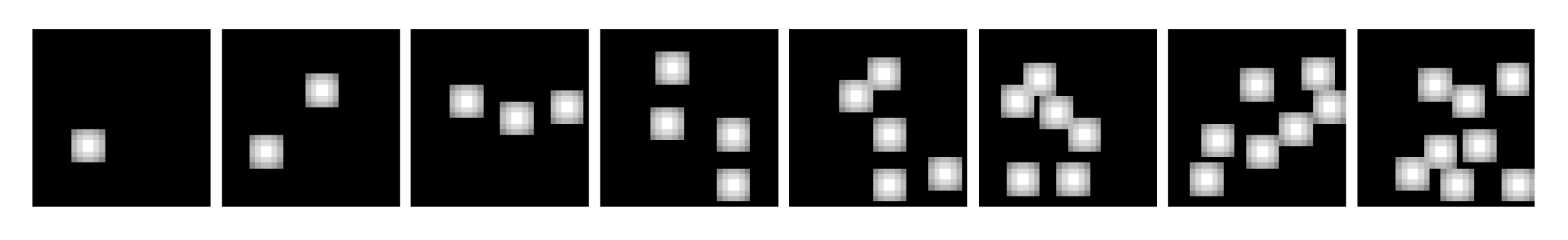{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | Value | ||
|---|---|---|---|
| Size “S” | Size “M” | Size “L” | |
| d_model (d) | 16 | 32 | 64 |
| nhead | 2 | 2 | 4 |
| num_encoder_layers (L) | 6 | 8 | 10 |
| dim_feedforward | 64 | 128 | 256 |





References
- Bengio, Y.; Courville, A.; Vincent, P. Representation learning: A review and new perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Zorzi, M.; Testolin, A.; Stoianov, I.P. Modeling language and cognition with deep unsupervised learning: A tutorial overview. Front. Psychol. 2013, 4, 515. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhuang, C.; Yan, S.; Nayebi, A.; Schrimpf, M.; Frank, M.C.; DiCarlo, J.J.; Yamins, D.L. Unsupervised neural network models of the ventral visual stream. Proc. Natl. Acad. Sci. USA 2021, 118, e2014196118. [Google Scholar] [CrossRef]
- Clark, A. Whatever next? Predictive brains, situated agents, and the future of cognitive science. Behav. Brain Sci. 2013, 36, 181–204. [Google Scholar] [CrossRef]
- Friston, K. The free-energy principle: A unified brain theory? Nat. Rev. Neurosci. 2010, 11, 127–138. [Google Scholar] [CrossRef]
- Hinton, G.E. Learning multiple layers of representation. Trends Cogn. Sci. 2007, 11, 428–434. [Google Scholar] [CrossRef]
- Testolin, A.; Zorzi, M. Probabilistic models and generative neural networks: Towards an unified framework for modeling normal and impaired neurocognitive functions. Front. Comput. Neurosci. 2016, 10, 73. [Google Scholar] [CrossRef] [Green Version]
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef]
- Le, Q.V. Building high-level features using large scale unsupervised learning. In Proceedings of the 2013 IEEE international conference on acoustics, speech and signal processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 8595–8598. [Google Scholar]
- Sadeghi, Z.; Testolin, A. Learning representation hierarchies by sharing visual features: A computational investigation of Persian character recognition with unsupervised deep learning. Cogn. Process. 2017, 18, 273–284. [Google Scholar] [CrossRef]
- Testolin, A.; Stoianov, I.; Zorzi, M. Letter perception emerges from unsupervised deep learning and recycling of natural image features. Nat. Hum. Behav. 2017, 1, 657–664. [Google Scholar] [CrossRef]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. arXiv 2014, arXiv:1406.2661. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 4401–4410. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Higgins, I.; Matthey, L.; Pal, A.; Burgess, C.; Glorot, X.; Botvinick, M.; Mohamed, S.; Lerchner, A. beta-vae: Learning Basic Visual Concepts with a Constrained Variational Framework 2016. Available online: https://openreview.net/forum?id=Sy2fzU9gl (accessed on 15 May 2021).
- Chen, X.; Duan, Y.; Houthooft, R.; Schulman, J.; Sutskever, I.; Abbeel, P. Infogan: Interpretable representation learning by information maximizing generative adversarial nets. arXiv 2016, arXiv:1606.03657. [Google Scholar]
- Burgess, C.P.; Matthey, L.; Watters, N.; Kabra, R.; Higgins, I.; Botvinick, M.; Lerchner, A. Monet: Unsupervised scene decomposition and representation. arXiv 2019, arXiv:1901.11390. [Google Scholar]
- Dehaene, S. The Number Sense: How the Mind Creates Mathematics; Oxford University Press: Oxford, England, 2011. [Google Scholar]
- Gebuis, T.; Reynvoet, B. The interplay between nonsymbolic number and its continuous visual properties. J. Exp. Psychol. Gen. 2012, 141, 642. [Google Scholar] [CrossRef] [PubMed]
- Stoianov, I.; Zorzi, M. Emergence of a’visual number sense’in hierarchical generative models. Nat. Neurosci. 2012, 15, 194–196. [Google Scholar] [CrossRef]
- Testolin, A.; Zou, W.Y.; McClelland, J.L. Numerosity discrimination in deep neural networks: Initial competence, developmental refinement and experience statistics. Dev. Sci. 2020, 23, e12940. [Google Scholar] [CrossRef]
- Zorzi, M.; Testolin, A. An emergentist perspective on the origin of number sense. Philos. Trans. R. Soc. B Biol. Sci. 2018, 373, 20170043. [Google Scholar] [CrossRef]
- Testolin, A.; Dolfi, S.; Rochus, M.; Zorzi, M. Visual sense of number vs. sense of magnitude in humans and machines. Sci. Rep. 2020, 10, 1–13. [Google Scholar]
- Zanetti, A.; Testolin, A.; Zorzi, M.; Wawrzynski, P. Numerosity Representation in InfoGAN: An Empirical Study. In Proceedings of the International Work-Conference on Artificial Neural Networks, Gran Canaria, Spain, 12–14 June 2019; pp. 49–60. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to Sequence Learning with Neural Networks. In Advances in Neural Information Processing Systems; Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N., Weinberger, K.Q., Eds.; Curran Associates Inc.: Red Hook, NY, USA, 2014; Volume 27. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.u.; Polosukhin, I. Attention is All you Need. In Advances in Neural Information Processing Systems; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Ramsauer, H.; Schäfl, B.; Lehner, J.; Seidl, P.; Widrich, M.; Gruber, L.; Holzleitner, M.; Pavlović, M.; Sandve, G.K.; Greiff, V.; et al. Hopfield networks is all you need. arXiv 2020, arXiv:2008.02217. [Google Scholar]
- Parmar, N.; Vaswani, A.; Uszkoreit, J.; Kaiser, L.; Shazeer, N.; Ku, A.; Tran, D. Image Transformer. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; Volume 80, pp. 4055–4064. [Google Scholar]
- Chen, M.; Radford, A.; Child, R.; Wu, J.; Jun, H.; Luan, D.; Sutskever, I. Generative Pretraining From Pixels. In Proceedings of the 37th International Conference on Machine Learning, Virtual Event, 13–18 July 2020; Volume 119, pp. 1691–1703. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Zhao, S.; Ren, H.; Yuan, A.; Song, J.; Goodman, N.; Ermon, S. Bias and Generalization in Deep Generative Models: An Empirical Study. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 3–8 December 2018; Volume 31. [Google Scholar]
- Kondapaneni, N.; Perona, P. A Number Sense as an Emergent Property of the Manipulating Brain. arXiv 2020, arXiv:2012.04132. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2019; Volume 32. [Google Scholar]
- Abnar, S.; Zuidema, W. Quantifying Attention Flow in Transformers. arXiv 2020, arXiv:cs.LG/2005.00928. [Google Scholar]
- Cenzato, A.; Testolin, A.; Zorzi, M. Long-Term Prediction of Physical Interactions: A Challenge for Deep Generative Models. In International Conference on Machine Learning, Optimization, and Data Science Siena, Italy, 10–13 September 2019; Springer: Berlin/Heidelberg, Germany, 2020; pp. 83–94. [Google Scholar]
- Carter, S.; Nielsen, M. Using Artificial Intelligence to Augment Human Intelligence. Distill 2017. [Google Scholar] [CrossRef] [Green Version]
- Dehaene, S. The neural basis of the Weber–Fechner law: A logarithmic mental number line. Trends Cogn. Sci. 2003, 7, 145–147. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Sella, F.; Berteletti, I.; Lucangeli, D.; Zorzi, M. Spontaneous non-verbal counting in toddlers. Dev. Sci. 2016, 19, 329–337. [Google Scholar] [CrossRef] [PubMed]
- Revkin, S.K.; Piazza, M.; Izard, V.; Cohen, L.; Dehaene, S. Does subitizing reflect numerical estimation? Psychol. Sci. 2008, 19, 607–614. [Google Scholar] [CrossRef]
- Testolin, A.; McClelland, J.L. Do estimates of numerosity really adhere to Weber’s law? A reexamination of two case studies. Psychon. Bull. Rev. 2021, 28, 158–168. [Google Scholar] [CrossRef]
- Harvey, B.M.; Klein, B.P.; Petridou, N.; Dumoulin, S.O. Topographic representation of numerosity in the human parietal cortex. Science 2013, 341, 1123–1126. [Google Scholar] [CrossRef] [Green Version]
- Leslie, A.M.; Gelman, R.; Gallistel, C. The generative basis of natural number concepts. Trends Cogn. Sci. 2008, 12, 213–218. [Google Scholar] [CrossRef] [PubMed]
- Testolin, A. The challenge of modeling the acquisition of mathematical concepts. Front. Hum. Neurosci. 2020, 14. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]


Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Boccato, T.; Testolin, A.; Zorzi, M. Learning Numerosity Representations with Transformers: Number Generation Tasks and Out-of-Distribution Generalization. Entropy 2021, 23, 857. https://doi.org/10.3390/e23070857
Boccato T, Testolin A, Zorzi M. Learning Numerosity Representations with Transformers: Number Generation Tasks and Out-of-Distribution Generalization. Entropy. 2021; 23(7):857. https://doi.org/10.3390/e23070857
Chicago/Turabian StyleBoccato, Tommaso, Alberto Testolin, and Marco Zorzi. 2021. "Learning Numerosity Representations with Transformers: Number Generation Tasks and Out-of-Distribution Generalization" Entropy 23, no. 7: 857. https://doi.org/10.3390/e23070857
APA StyleBoccato, T., Testolin, A., & Zorzi, M. (2021). Learning Numerosity Representations with Transformers: Number Generation Tasks and Out-of-Distribution Generalization. Entropy, 23(7), 857. https://doi.org/10.3390/e23070857