
Real-Time Tool Detection for Workflow Identification in Open Cranial Vault Remodeling

 ,
,  ,
,  , , and
, , and 
Abstract
:1. Introduction
2. Materials and Methods
2.1. Experimental Set Up
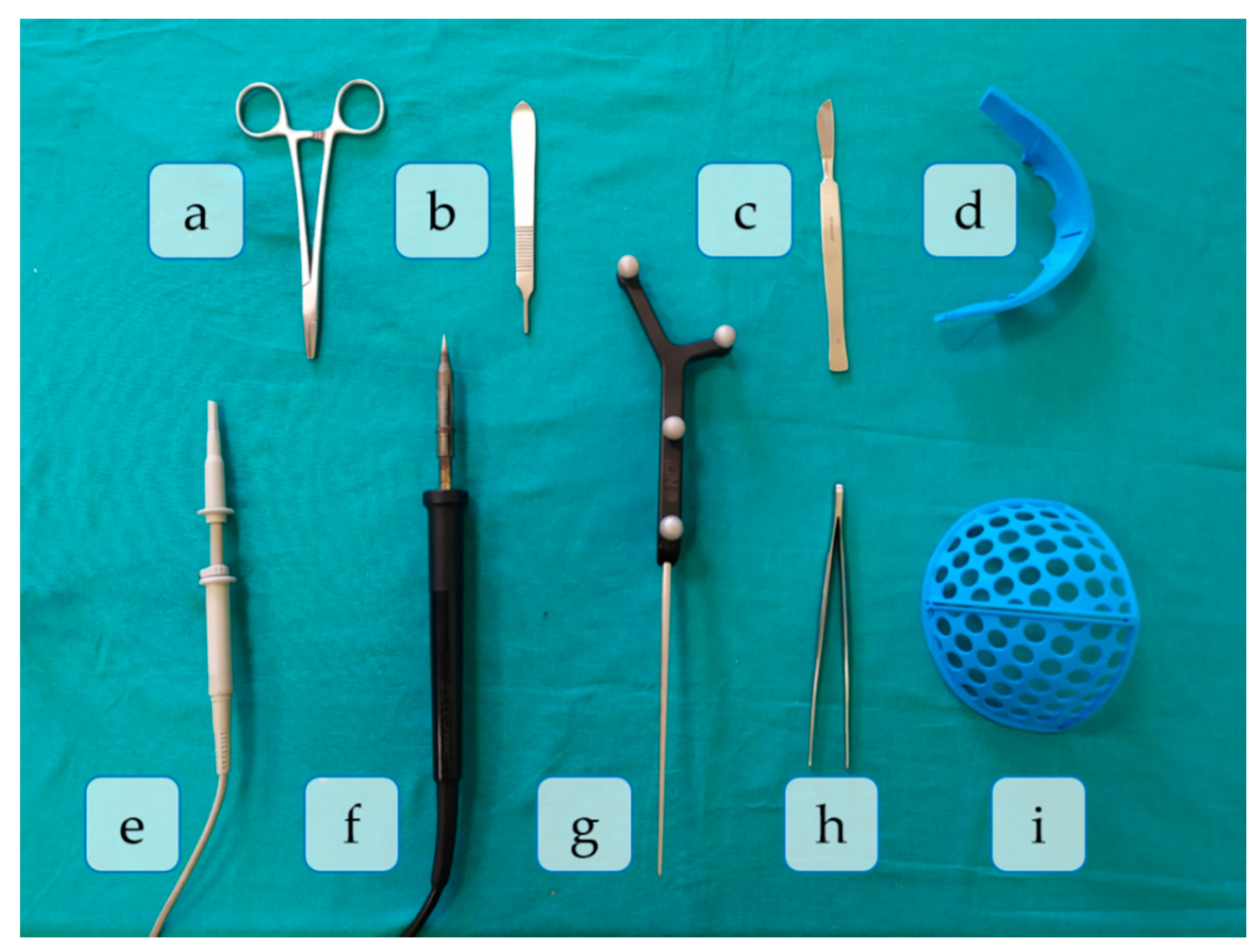
- P1.
- Skin incision: A bicoronal S-shaped incision is performed over the phantom’s skin using the scalpel.
- P2.
- Cranial surface exposure: The skin is kindly removed towards the anterior part of the head until completely revealing the cranium. Osteotome and forceps are used in this step.
- P3.
- Surgical cutting guides placement: the SO guide and the FT guide are placed on the supraorbital and frontal regions of the skull, respectively.
- P4.
- Fixation of registration pins: both surgical guides are fixed to the bone using surgical pins. In this phase, the SO guide, the FT guide, and the handpiece are present in the surgical field.
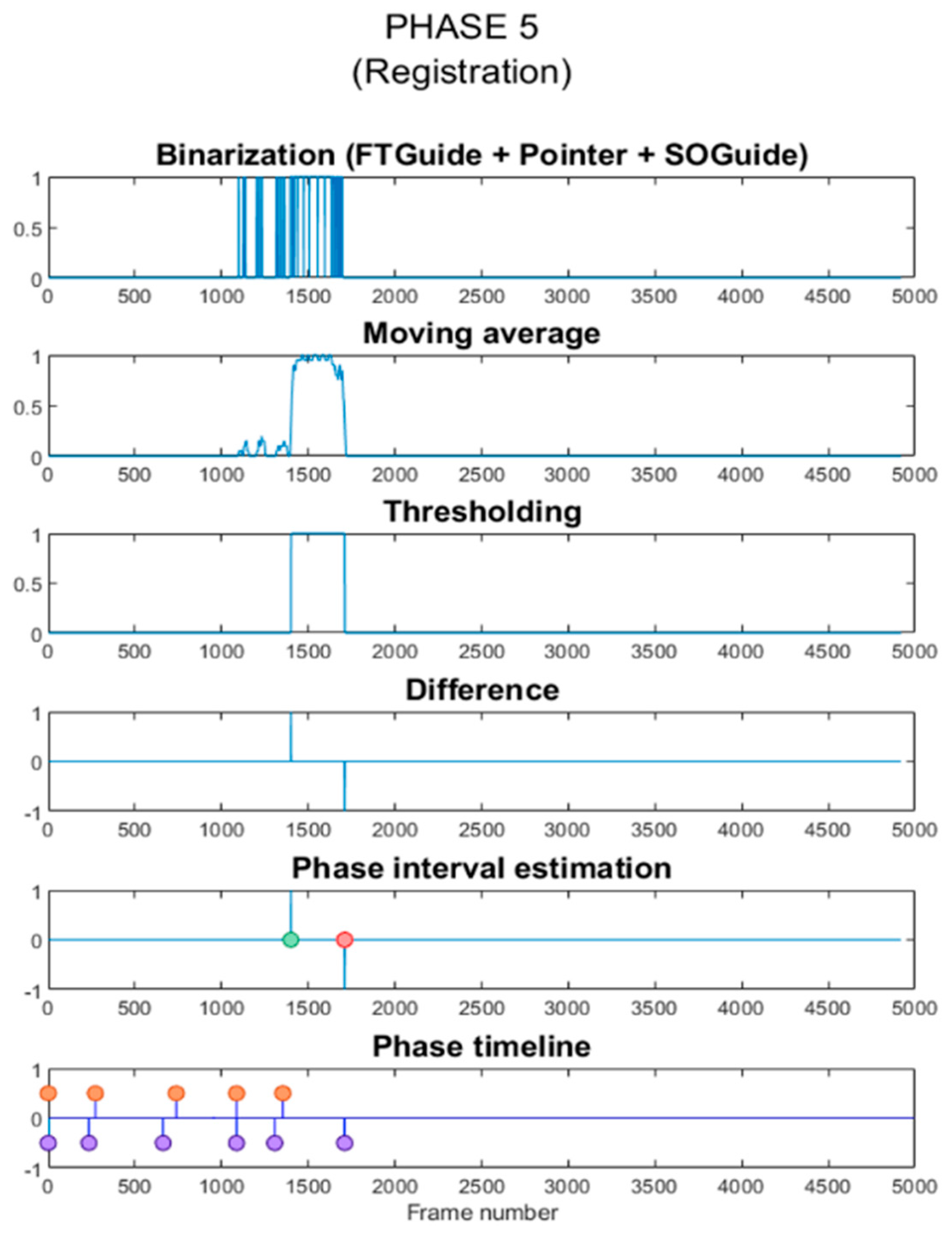
- P5.
- Registration: the OTS and the tracked tool (pointer) are used to record the position of reference points on the surgical guides for intraoperative registration. Both surgical guides can also be identified in the image.
- P6.
- Frontal bone osteotomy: after removing the surgical guides, the frontal bone is cut with the motor.
- P7.
- SO bar bone osteotomy: the motor is now used to cut the SO bar bone with the aid of the osteotome, to avoid damaging the brain.
- P8.
- Intraoperative navigation of remodeled bones: the positions of the remodeled SO bar and frontals bones are navigated with the pointer once they are placed back on the patient. This data is then compared with the preoperative surgical plan to ensure correct placement of the fragments.
- P9.
- Screwing: the remodeled bone fragments are fixed and stabilized using resorbable plates and pins. Pins are welded to the adjacent bone tissue using the handpiece. Forceps hold the resorbable plates in place while pins are inserted.
- P10.
- Skin placement: with the aid of the forceps, the skin is repositioned.
- P11.
- Suturing: the skin is sutured with surgical scissors and forceps.
2.2. Data Acquisition
- Training dataset: This included roughly 10,000 frames obtained from thirteen video streams. Eleven of these contained the combinations of tools appearing in the surgical phases, with the phantom and the surgical sheet in the background. However, instead of replicating the surgical procedure, we showed the tools from different perspectives and varying positions, partially covering them repeatedly with the hand (or other tools) or even taking them out from the FOV to a certain extent. The other two videos recorded the empty hands and the simulated patient individually over the green surgical sheet background. Only in the latter case, we manipulated the phantom to show the skin, the skull, the bone fragments, and the brain, keeping it static in the other videos. The surgical sheet was wrinkled differently in all video streams to teach the model to ignore the background and only focus on the foreground. Moreover, we acquired the videos under varying illumination conditions: natural light, artificial light, and moving shadows.
- Testing dataset: This was obtained from a single video of roughly six minutes duration recorded during a fast simulation of a complete craniosynostosis surgery. This video was recorded on a different day and by another user, repeating the experiment set up from scratch. As a result, this video’s composition differed sufficiently from the training recordings to prevent overfitting. The illumination conditions were changed several times per phase during the video recording to test the system’s robustness against varying lighting circumstances. As in the training videos, we worked with natural light, ambient light, and moving shadows. We extracted all the frames of that video (4920) and labeled them to calculate the evaluation metrics described in Section 2.6. Furthermore, the same video was directly streamed in a specifically developed 3D Slicer module to predict, in real-time, the tools that appeared on each frame (see Section 2.5).
2.3. Deep Learning Networks
2.4. Training of the Networks
2.5. Phase Estimation
2.6. Performance Evaluation
3. Results
3.1. Tool Detection
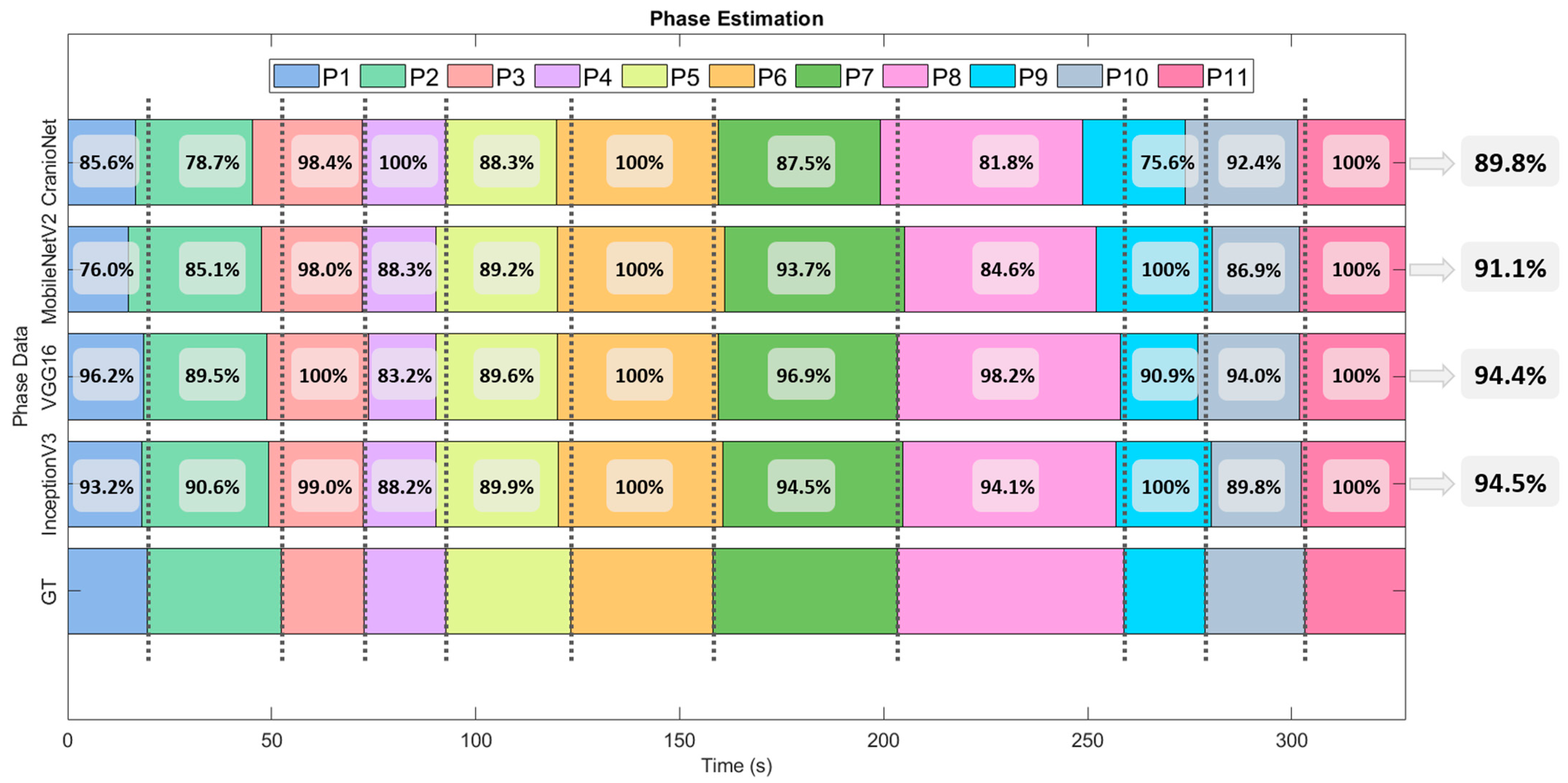
3.2. Phase Detection
4. Discussion
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Esteva, A.; Robicquet, A.; Ramsundar, B.; Kuleshov, V.; DePristo, M.; Chou, K.; Cui, C.; Corrado, G.; Thrun, S.; Dean, J. A guide to deep learning in healthcare. Nat. Med. 2019, 25, 24–29. [Google Scholar] [CrossRef] [PubMed]
- Maxwell, A.; Li, R.; Yang, B.; Weng, H.; Ou, A.; Hong, H.; Zhou, Z.; Gong, P.; Zhang, C. Deep learning architectures for multi-label classification of intelligent health risk prediction. BMC Bioinform. 2017, 18, 523. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhao, Z.; Chen, Z.; Voros, S.; Cheng, X. Real-time tracking of surgical instruments based on spatio-temporal context and deep learning. Comput. Assist. Surg. 2019, 24, 20–29. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jin, A.; Yeung, S.; Jopling, J.; Krause, J.; Azagury, D.; Milstein, A.; Fei-Fei, L. Tool detection and operative skill assessment in surgical videos using region-based convolutional neural networks. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision, Lake Tahoe, NV, USA, 12–15 March 2018; pp. 691–699. [Google Scholar]
- Zhao, Z.; Cai, T.; Chang, F.; Cheng, X. Real-time surgical instrument detection in robot-assisted surgery using a convolutional neural network cascade. Healthc. Technol. Lett. 2019, 6, 275–279. [Google Scholar] [CrossRef]
- Quellec, G.; Lamard, M.; Cochener, B.; Cazuguel, G. Real-time task recognition in cataract surgery videos using adaptive spatiotemporal polynomials. IEEE Trans. Med. Imaging 2015, 34, 877–887. [Google Scholar] [CrossRef]
- Al Hajj, H.; Lamard, M.; Conze, P.H.; Cochener, B.; Quellec, G. Monitoring tool usage in surgery videos using boosted convolutional and recurrent neural networks. Med. Image Anal. 2018, 47, 203–218. [Google Scholar] [CrossRef] [Green Version]
- Forestier, G.; Riffaud, L.; Jannin, P.; Forestier, G.; Riffaud, L.; Jannin, P. Automatic phase prediction from low-level surgical activities. Int. J. Comput. Assist. Radiol. Surg. 2015, 10, 833–841. [Google Scholar] [CrossRef] [Green Version]
- Hisey, R.; Ungi, T.; Holden, M.S.; Baum, Z.M.C.; Keri, Z.; Fichtinger, G.; Howes, D.W.; McCallum, C. Real-time workflow detection using webcam video for providing real-time feedback in central venous catheterization training. In Medical Imaging 2018: Image-Guided Procedures, Robotic Interventions, and Modeling; Fei, B., Webster, R.J., III, Eds.; SPIE: Bellingham, WA, USA, 2018; Volume 10576, p. 61. [Google Scholar]
- Jin, Y.; Li, H.; Dou, Q.; Chen, H.; Qin, J.; Fu, C.W.; Heng, P.A. Multi-task recurrent convolutional network with correlation loss for surgical video analysis. Med. Image Anal. 2019, 59, 101572. [Google Scholar] [CrossRef]
- Twinanda, A.P.; Shehata, S.; Mutter, D.; Marescaux, J.; De Mathelin, M.; Padoy, N. EndoNet: A Deep Architecture for Recognition Tasks on Laparoscopic Videos. IEEE Trans. Med. Imaging 2017, 36, 86–97. [Google Scholar] [CrossRef] [Green Version]
- Morita, S.; Tabuchi, H.; Masumoto, H.; Yamauchi, T.; Kamiura, N. Real-Time Extraction of Important Surgical Phases in Cataract Surgery Videos. Sci. Rep. 2019, 9. [Google Scholar] [CrossRef]
- Panchal, J.; Uttchin, V. Management of craniosynostosis. Facial Plast. Surg. 2016, 32, 123–132. [Google Scholar] [CrossRef]
- Johnson, D.; Wilkie, A.O.M. Craniosynostosis. Eur. J. Hum. Genet. 2011, 19, 369–376. [Google Scholar] [CrossRef] [Green Version]
- Lajeunie, E.; Le Merrer, M.; Bonaiti-Pellie, C.; Marchac, D.; Renier, D. Genetic study of nonsyndromic coronal craniosynostosis. Am. J. Med. Genet. 1995, 55, 500–504. [Google Scholar] [CrossRef]
- García-Mato, D.; Ochandiano, S.; García-Sevilla, M.; Navarro-Cuéllar, C.; Darriba-Allés, J.V.; García-Leal, R.; Calvo-Haro, J.A.; Pérez-Mañanes, R.; Salmerón, J.I.; Pascau, J. Craniosynostosis surgery: Workflow based on virtual surgical planning, intraoperative navigation and 3D printed patient-specific guides and templates. Sci. Rep. 2019, 9, 1–10. [Google Scholar] [CrossRef]
- García-Mato, D.; Moreta-Martinez, R.; García-Sevilla, M.; Ochandiano, S.; García-Leal, R.; Pérez-Mañanes, R.; Calvo-Haro, J.A.; Salmerón, J.I.; Pascau, J. Augmented reality visualization for craniosynostosis surgery. Comput. Methods Biomech. Biomed. Eng. Imaging Vis. 2020, 1–8. [Google Scholar] [CrossRef]
- Cohen, S.; Frank, R.; Meltzer, H.; Levy, M. Handbook of Craniomaxillofacial Surgery; World Scientific: Singapore, 2014. [Google Scholar] [CrossRef]
- Slater, B.J.; Lenton, K.A.; Kwan, M.D.; Gupta, D.M.; Wan, D.C.; Longaker, M.T. Cranial sutures: A brief review. J. Am. Soc. Plast. Surg. 2008, 121, 170–178. [Google Scholar] [CrossRef] [PubMed]
- Burge, J.; Saber, N.R.; Looi, T.; French, B.; Usmani, Z.; Anooshiravani, N.; Kim, P.; Forrest, C.; Phillips, J. Application of CAD/CAM prefabricated age-matched templates in cranio-orbital remodeling in craniosynostosis. J. Craniofac. Surg. 2011, 22, 1810–1813. [Google Scholar] [CrossRef]
- García-Mato, D.; Pascau, J.; Ochandiano, S. New Technologies to Improve Surgical Outcome during Open-Cranial Vault Remodeling [Online First]. 2020. Available online: https://www.intechopen.com/online-first/new-technologies-to-improve-surgical-outcome-during-open-cranial-vault-remodeling (accessed on 10 May 2021). [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 3rd International Conference on Learning Representations (ICLR 2015 Conference Track Proceedings), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Juan, PR, USA, 17–19 June 1997; pp. 2818–2826. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted residuals and linear bottlenecks. arXiv 2018, arXiv:1801.04381v4. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Pieper, S.; Halle, M.; Kikinis, R. 3D Slicer. In Proceedings of the 2004 2nd IEEE International Symposium on Biomedical Imaging: Nano to Macro (IEEE Cat No. 04EX821), Arlington, VA, USA, 18 April 2004; Volume 1, pp. 632–635. [Google Scholar]
- Fedorov, A.; Beichel, R.; Kalpathy-Cramer, J.; Finet, J.; Fillion-Robin, J.C.; Pujol, S.; Bauer, C.; Jennings, D.; Fennessy, F.; Sonka, M.; et al. 3D Slicer as an image computing platform for the Quantitative Imaging Network. Magn. Reson. Imaging 2012, 30, 1323–1341. [Google Scholar] [CrossRef] [Green Version]
- Tokuda, J.; Fischer, G.S.; Papademetris, X.; Yaniv, Z.; Ibanez, L.; Cheng, P.; Liu, H.; Blevins, J.; Arata, J.; Golby, A.J.; et al. OpenIGTLink: An open network protocol for image-guided therapy environment. Int. J. Med. Robot. Comput. Assist. Surg. 2009, 5, 423–434. [Google Scholar] [CrossRef] [PubMed]
- Betancur, J.; Commandeur, F.; Motlagh, M.; Sharir, T.; Einstein, A.J.; Bokhari, S.; Fish, M.B.; Ruddy, T.D.; Kaufmann, P.; Sinusas, A.J.; et al. Deep Learning for Prediction of Obstructive Disease From Fast Myocardial Perfusion SPECT: A Multicenter Study. JACC Cardiovasc. Imaging 2018, 11, 1654–1663. [Google Scholar] [CrossRef] [PubMed]
- García-Duarte Sáenz, L.; García-Mato, D.; Ochandiano, S.; Pascau, J. Real-Time Workflow Detection using Video Streams in Craniosynostosis Surgery. In Proceedings of the XXXVIII Congreso Anual de la Sociedad Española de Ingeniería Biomédica, Valladolid, Spain, 26 November 2020. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Range |
|---|---|
| Rotation angle | ±15 pixels |
| Width shift | ±10% |
| Height shift | ±10% |
| Shear | ±50% |
| Zoom | ±10% |
| Horizontal flip | Enabled |
| CNN | Number of Epochs | Training Time per Epoch (s) | Total Training Time (min) | Inference Time (s/Frame) |
|---|---|---|---|---|
| CranioNet | 20 | 79.6 | 26.55 | 0.036 |
| MobileNetV2 | 10 | 69.8 | 11.63 | 0.054 |
| VGG16 | 10 | 80.7 | 13.45 | 0.053 |
| InceptionV3 | 10 | 76.2 | 12.70 | 0.059 |
| Tool | CranioNet | MobileNetV2 | VGG16 | InceptionV3 | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| %P | %R | %F1 | %Acc | %P | %R | %F1 | %Acc | %P | %R | %F1 | %Acc | %P | %R | %F1 | %Acc | |
| Forceps | 100 | 100 | 100 | 93.4 | 100 | 100 | 100 | 99.6 | 99.3 | 100 | 100 | 98.8 | 97.8 | 100 | 98.9 | 97.2 |
| FT guide | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | ||||
| Handpiece | 95.8 | 100 | 97.9 | 100 | 100 | 100 | 97.1 | 100 | 98.5 | 100 | 94.2 | 97.0 | ||||
| Motor | 72.5 | 100 | 84.1 | 98.5 | 100 | 99.2 | 100 | 100 | 100 | 98.5 | 97.0 | 97.7 | ||||
| Pointer | 100 | 95.1 | 97.5 | 100 | 99.0 | 99.5 | 100 | 100 | 100 | 98.1 | 99.0 | 98.5 | ||||
| Osteotome | 94.5 | 100 | 97.1 | 100 | 100 | 100 | 100 | 97.2 | 98.6 | 98.5 | 97.1 | 97.8 | ||||
| Scalpel | 100 | 100 | 100 | 100 | 100 | 100 | 96.4 | 100 | 98.2 | 100 | 100 | 100 | ||||
| Scissors | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | ||||
| SO guide | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 99.3 | 99.6 | ||||
| Average | 95.9 | 99.5 | 97.4 | 99.8 | 99.9 | 99.9 | 99.2 | 99.7 | 99.5 | 99.2 | 98.5 | 98.8 | ||||
| Tool | % True Positives (TP) | % True Negatives (TN) | % False Positives (FP) | % False Negatives (FN) |
|---|---|---|---|---|
| Forceps | 100 | 99 | 1 | 0 |
| FT guide | 100 | 100 | 0 | 0 |
| Handpiece | 94 | 100 | 0 | 6 |
| Motor | 97 | 100 | 0 | 3 |
| Pointer | 99 | 100 | 0 | 1 |
| Osteotome | 97 | 100 | 0 | 3 |
| Scalpel | 100 | 100 | 0 | 0 |
| Scissors | 100 | 100 | 0 | 0 |
| SO guide | 99 | 100 | 0 | 1 |
| CNN. | % True Positives (TP) | % True Negatives (TN) | % False Positives (FP) | % False Negatives (FN) |
|---|---|---|---|---|
| CranioNet | 100 | 94 | 6 | 0 |
| MobileNetV2 | 100 | 100 | 0 | 0 |
| VGG16 | 100 | 100 | 0 | 0 |
| InceptionV3 | 97 | 100 | 0 | 3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pose Díez de la Lastra, A.; García-Duarte Sáenz, L.; García-Mato, D.; Hernández-Álvarez, L.; Ochandiano, S.; Pascau, J. Real-Time Tool Detection for Workflow Identification in Open Cranial Vault Remodeling. Entropy 2021, 23, 817. https://doi.org/10.3390/e23070817
Pose Díez de la Lastra A, García-Duarte Sáenz L, García-Mato D, Hernández-Álvarez L, Ochandiano S, Pascau J. Real-Time Tool Detection for Workflow Identification in Open Cranial Vault Remodeling. Entropy. 2021; 23(7):817. https://doi.org/10.3390/e23070817
Chicago/Turabian StylePose Díez de la Lastra, Alicia, Lucía García-Duarte Sáenz, David García-Mato, Luis Hernández-Álvarez, Santiago Ochandiano, and Javier Pascau. 2021. "Real-Time Tool Detection for Workflow Identification in Open Cranial Vault Remodeling" Entropy 23, no. 7: 817. https://doi.org/10.3390/e23070817
APA StylePose Díez de la Lastra, A., García-Duarte Sáenz, L., García-Mato, D., Hernández-Álvarez, L., Ochandiano, S., & Pascau, J. (2021). Real-Time Tool Detection for Workflow Identification in Open Cranial Vault Remodeling. Entropy, 23(7), 817. https://doi.org/10.3390/e23070817