Author Contributions
Conceptualization, H.V.G., M.R.E. and T.R.; methodology, H.V.G., M.R.E., T.R., M.A.S.-F. and U.E.; software, M.R.E. and T.R.; validation, M.R.E., T.R. and H.V.G.; formal analysis, H.V.G.; investigation, H.V.G., M.R.E. and T.R.; resources, H.V.G., T.R. and A.B.; data curation, M.R.E.; writing—original draft preparation, H.V.G., M.A.S.-F. and U.E.; writing—review and editing, H.V.G., M.R.E., M.A.S.-F. and U.E.; visualization, M.R.E.; supervision, H.V.G.; project administration, H.V.G. and A.B.; funding acquisition, H.V.G., A.B. and T.R. All authors have read and agreed to the published version of the manuscript.
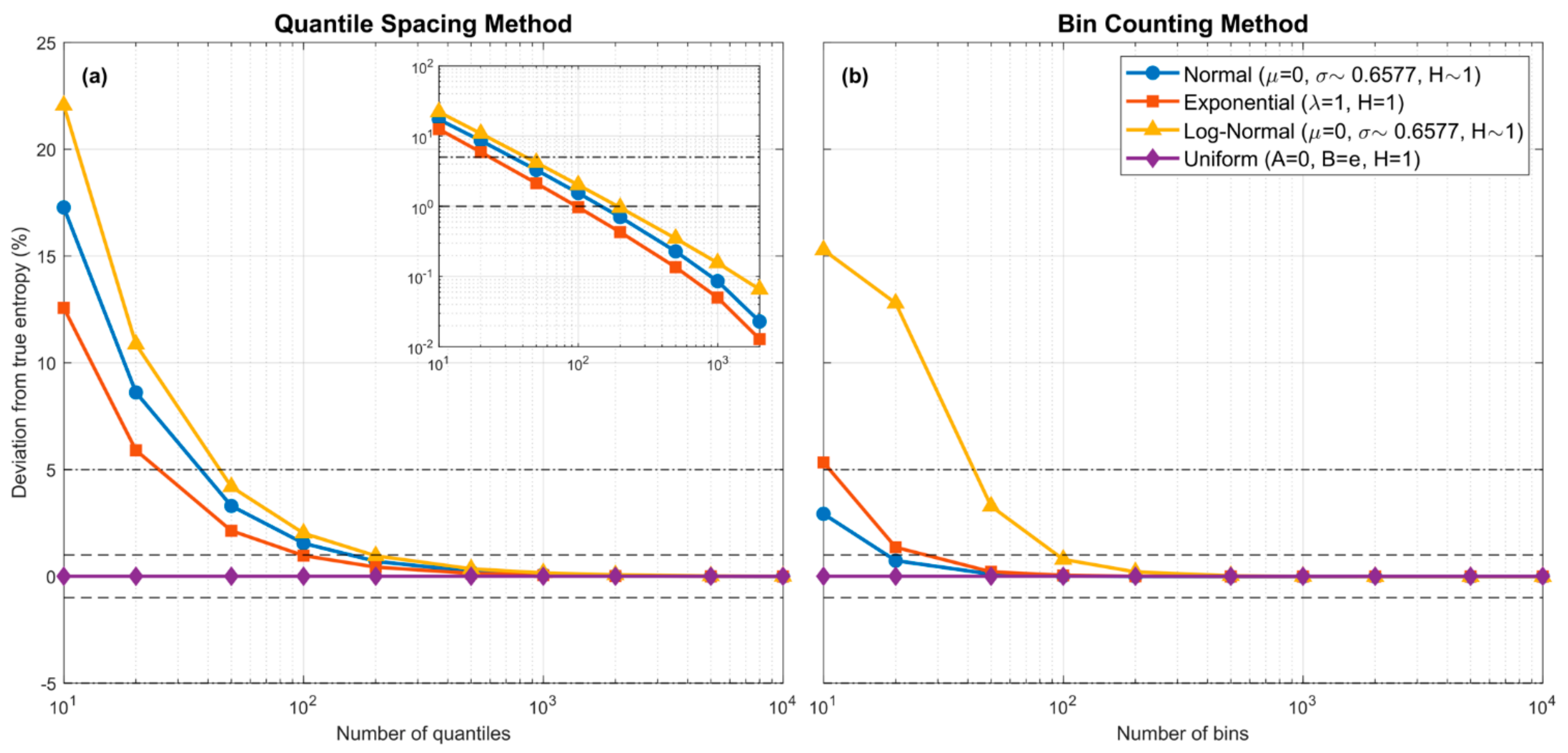
Figure 1.
Plots showing how entropy estimation bias associated with the piecewise-constant approximation of various theoretical pdf forms varies with the number of quantiles ((a); QS method) or number of equal-width bins ((b); BC method) used in the approximation. The dashed horizontal lines indicate and bias error. No sampling is involved and the bias is due purely to the piecewise constant assumption. For QS, the locations of the quantiles are set to their theoretical values. To address the “infinite support” issue, were set to be the locations where and respectively, with . In both cases, bias approaches zero as the number of piecewise-constant units is increased. For the QS method, the decline in bias is approximately linear in the log-log space (see inlay in the left subplot).
Figure 1.
Plots showing how entropy estimation bias associated with the piecewise-constant approximation of various theoretical pdf forms varies with the number of quantiles ((a); QS method) or number of equal-width bins ((b); BC method) used in the approximation. The dashed horizontal lines indicate and bias error. No sampling is involved and the bias is due purely to the piecewise constant assumption. For QS, the locations of the quantiles are set to their theoretical values. To address the “infinite support” issue, were set to be the locations where and respectively, with . In both cases, bias approaches zero as the number of piecewise-constant units is increased. For the QS method, the decline in bias is approximately linear in the log-log space (see inlay in the left subplot).
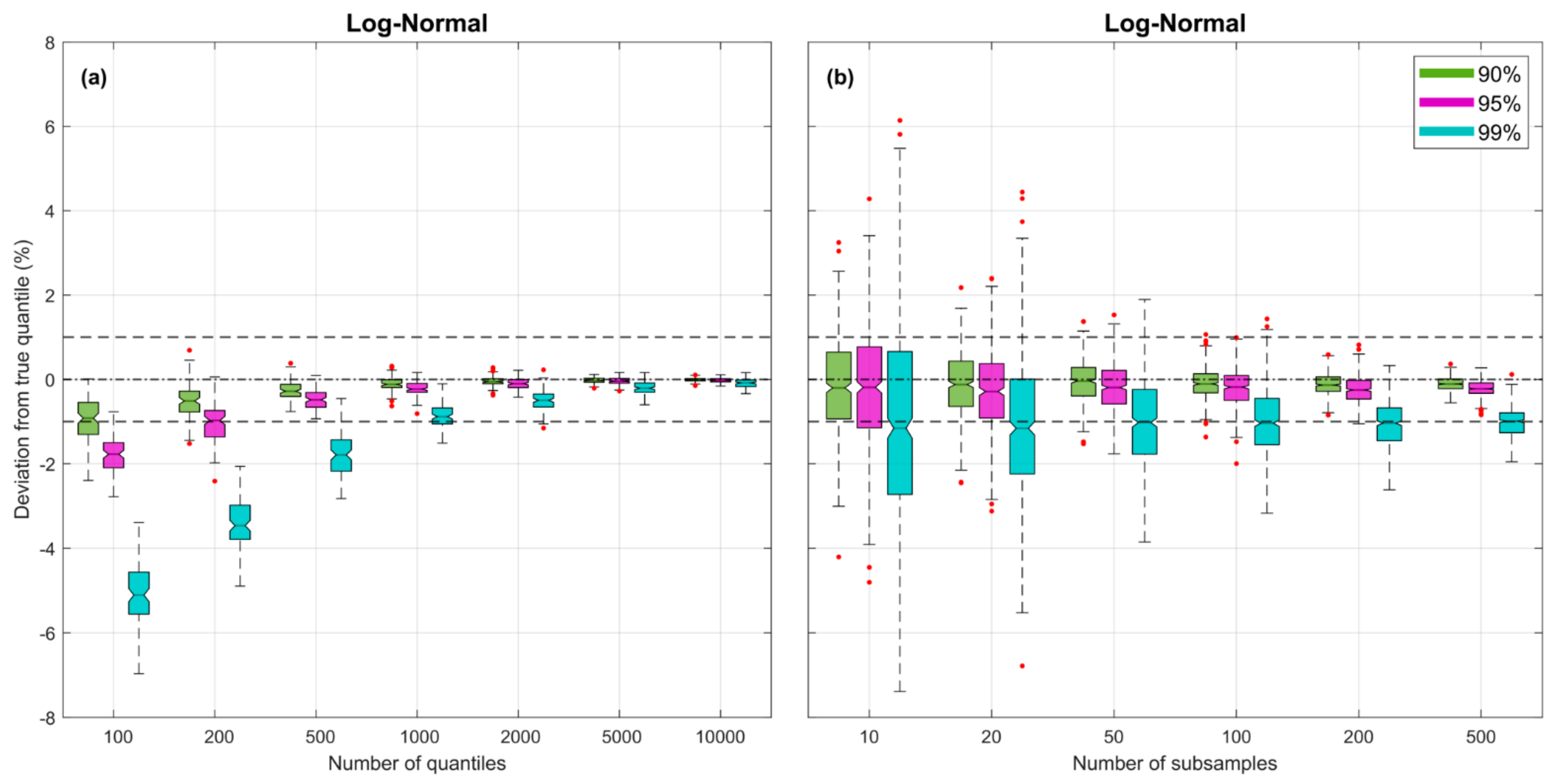
Figure 2.
Plots showing bias and uncertainty associated with estimates of the quantiles derived from random samples, for the Log-Normal pdf. Uncertainty associated with random sampling variability is estimated by repeating each experiment times. In both subplots, for each case, the box plots are shown side by side to improve legibility. (a) Subplot showing results varying for fixed . (b) Subplot showing results varying for fixed .
Figure 2.
Plots showing bias and uncertainty associated with estimates of the quantiles derived from random samples, for the Log-Normal pdf. Uncertainty associated with random sampling variability is estimated by repeating each experiment times. In both subplots, for each case, the box plots are shown side by side to improve legibility. (a) Subplot showing results varying for fixed . (b) Subplot showing results varying for fixed .
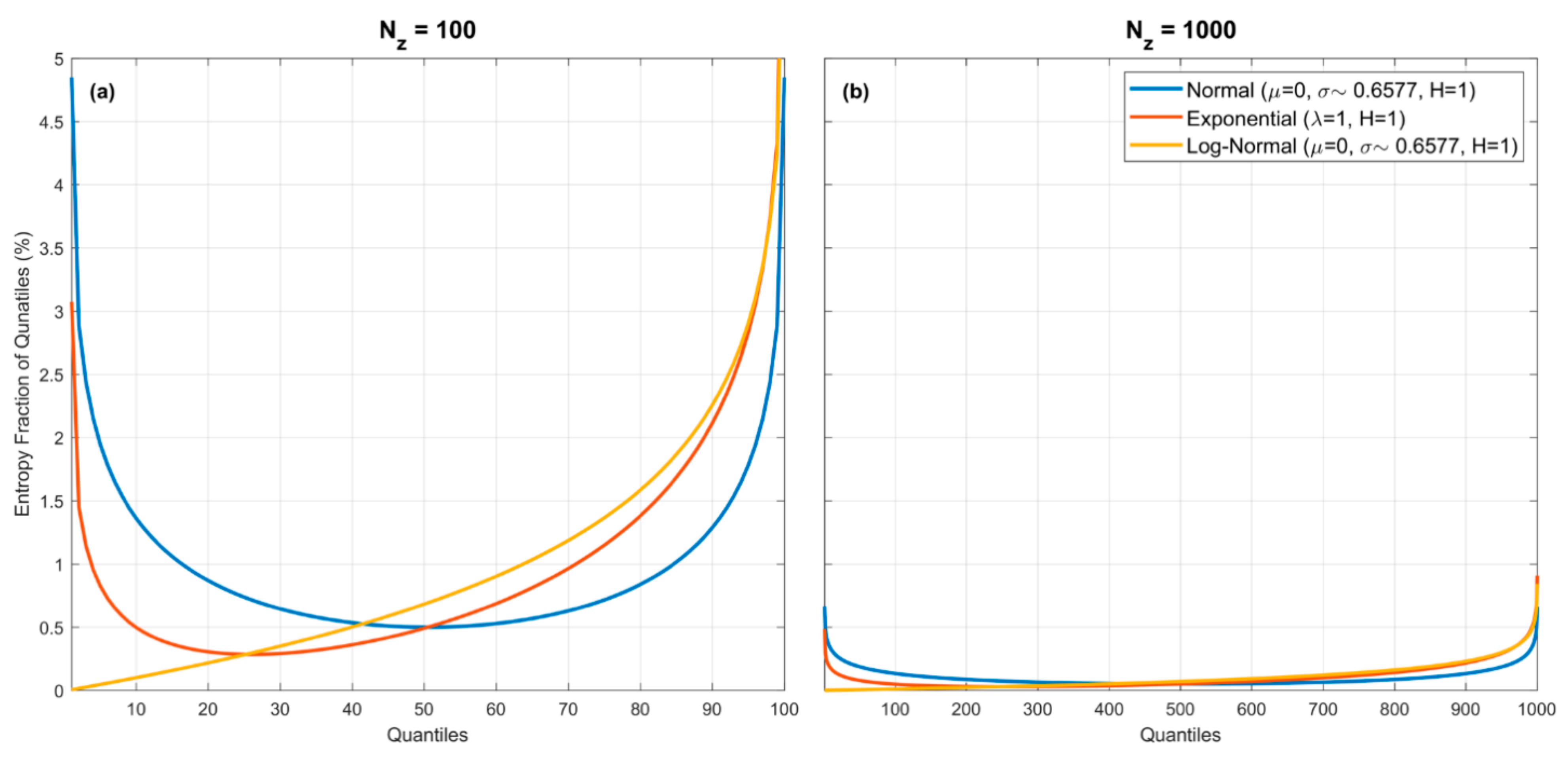
Figure 3.
Plots showing percentage entropy fraction associated with each quantile spacing for the Gaussian, Exponential and Log-Normal pdfs, for (a), and (b). For the Uniform pdf (not shown to avoid complicating the figures) the percentage entropy fraction associated with each quantile spacing is a horizontal line (at 1% in the left panel, and at 0.1% in the right panel). Note that the entropy fractions can be proportionally quite large or small at the extremes, depending on the form of the pdf. However, the overall entropy fraction associated with each quantile spacing diminishes with increasing For the examples shown, the maximum contributions associated with a quantile spacing are less than for (a), and become less than for (b).
Figure 3.
Plots showing percentage entropy fraction associated with each quantile spacing for the Gaussian, Exponential and Log-Normal pdfs, for (a), and (b). For the Uniform pdf (not shown to avoid complicating the figures) the percentage entropy fraction associated with each quantile spacing is a horizontal line (at 1% in the left panel, and at 0.1% in the right panel). Note that the entropy fractions can be proportionally quite large or small at the extremes, depending on the form of the pdf. However, the overall entropy fraction associated with each quantile spacing diminishes with increasing For the examples shown, the maximum contributions associated with a quantile spacing are less than for (a), and become less than for (b).
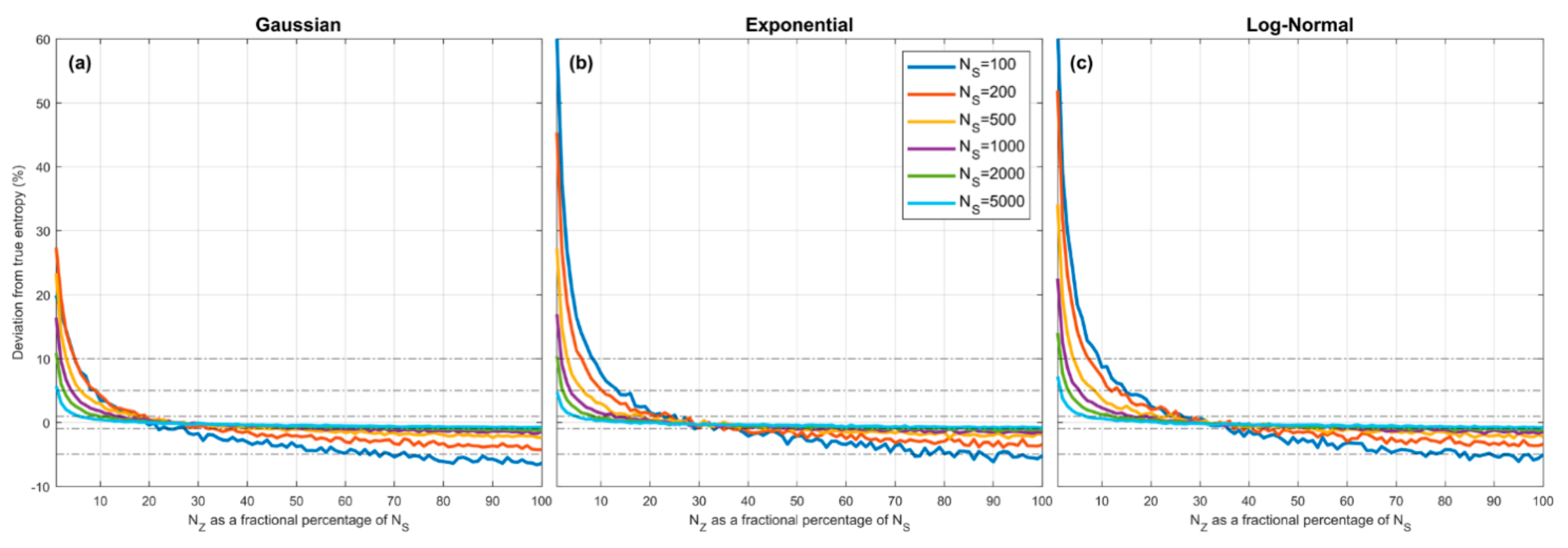
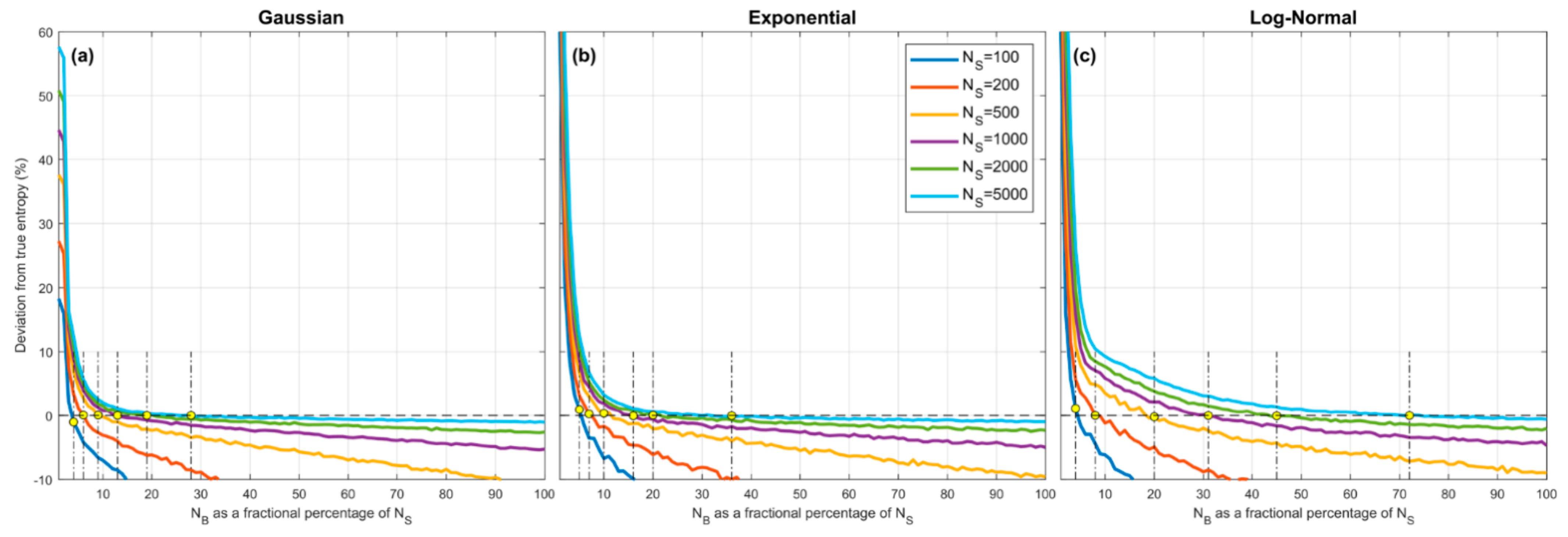
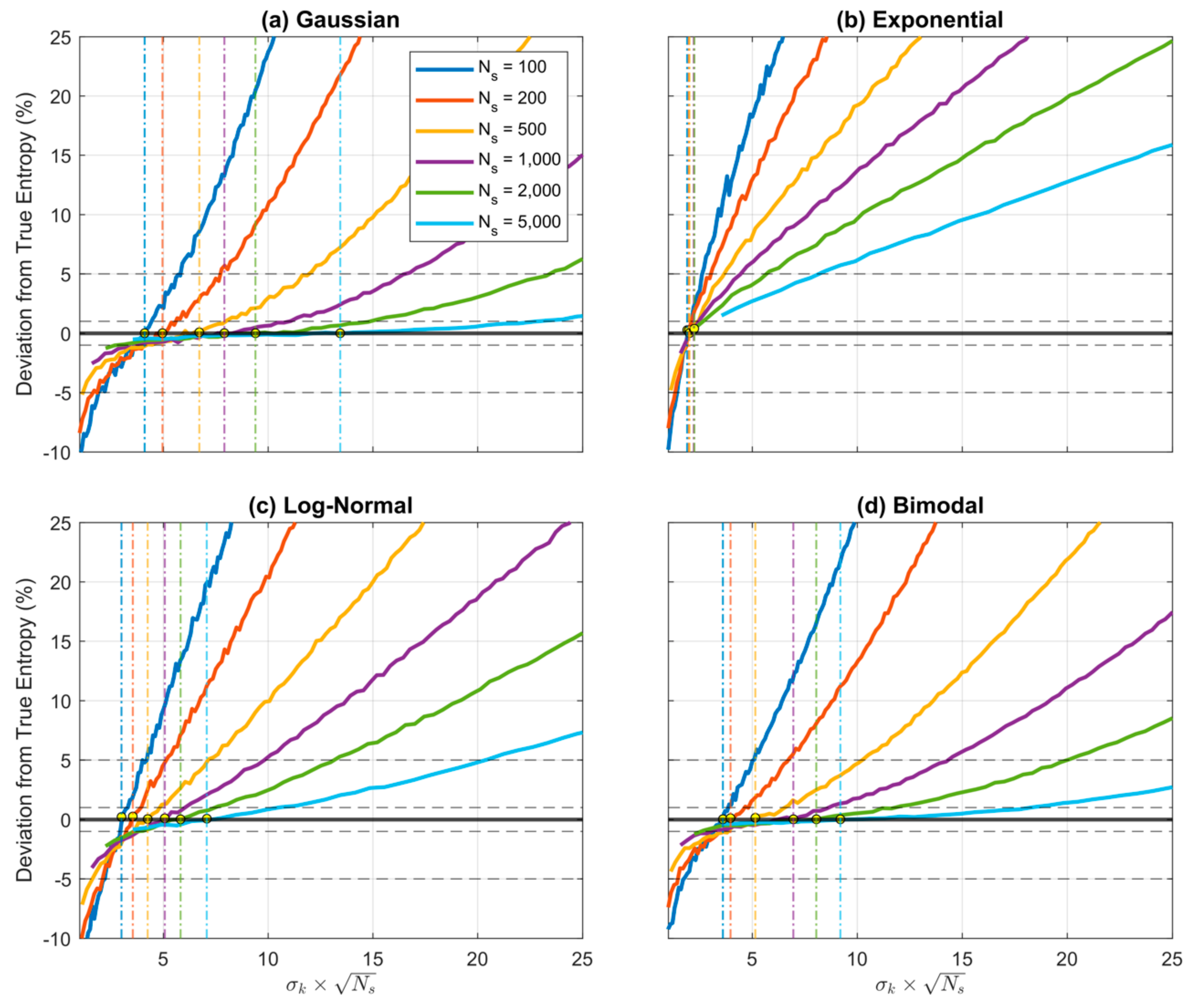
Figure 4.
Plots showing expected percent error in the QS-based estimate of entropy derived from random samples, as a function of , which expresses the number of quantiles as a fractional percentage of the sample size . Results are averaged over trials obtained by drawing sample sets of size from the theoretical pdf, where and are set to be the smallest and largest data values in the particular sample. Results are shown for different sample sizes , for the Gaussian (a), Exponential (b) and Log-Normal (c) densities. In each case, when is small the estimation bias is positive (overestimation) and can be greater than for , and crosses zero to become negative (underestimation) when The marginal cost of setting too large is low compared to setting too small. As increases, the bias diminishes. The optimal choice is and is relatively insensitive to pdf shape or sample size.
Figure 4.
Plots showing expected percent error in the QS-based estimate of entropy derived from random samples, as a function of , which expresses the number of quantiles as a fractional percentage of the sample size . Results are averaged over trials obtained by drawing sample sets of size from the theoretical pdf, where and are set to be the smallest and largest data values in the particular sample. Results are shown for different sample sizes , for the Gaussian (a), Exponential (b) and Log-Normal (c) densities. In each case, when is small the estimation bias is positive (overestimation) and can be greater than for , and crosses zero to become negative (underestimation) when The marginal cost of setting too large is low compared to setting too small. As increases, the bias diminishes. The optimal choice is and is relatively insensitive to pdf shape or sample size.

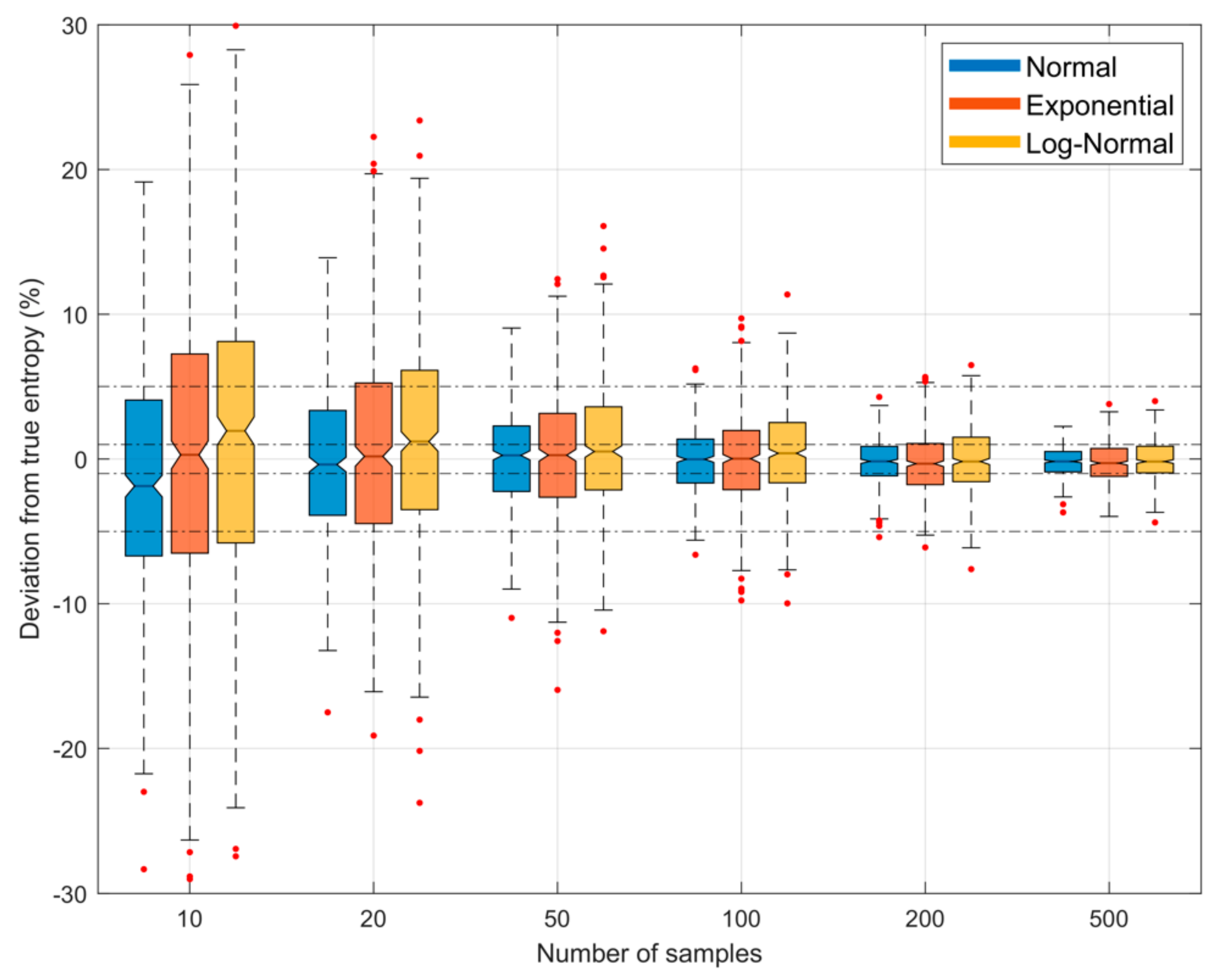
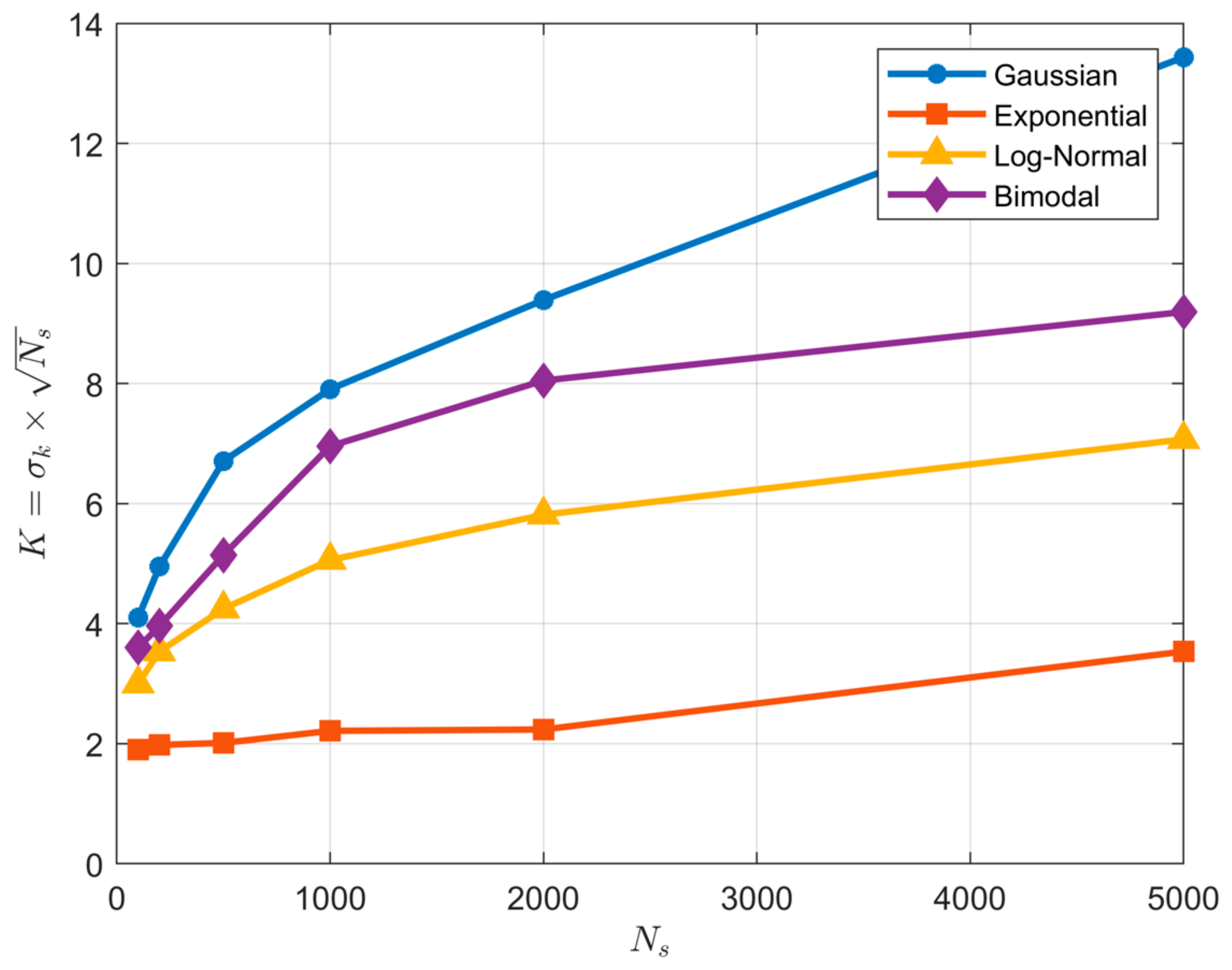
Figure 5.
Plots showing bias and uncertainty in the QS-based estimate of entropy derived from random samples, as a function of sample size , when the number of quantiles is set to of the sample size (), and and are respectively set to be the smallest and largest data values in the particular sample. The uncertainty shown is due to random sampling variability, estimated by drawing different samples from the parent density. Results are shown for the Gaussian (blue), Exponential (red) and Log-Normal (orange) densities; box plots are shown side by side to improve legibility. As sample size increases, the uncertainty diminishes.
Figure 5.
Plots showing bias and uncertainty in the QS-based estimate of entropy derived from random samples, as a function of sample size , when the number of quantiles is set to of the sample size (), and and are respectively set to be the smallest and largest data values in the particular sample. The uncertainty shown is due to random sampling variability, estimated by drawing different samples from the parent density. Results are shown for the Gaussian (blue), Exponential (red) and Log-Normal (orange) densities; box plots are shown side by side to improve legibility. As sample size increases, the uncertainty diminishes.
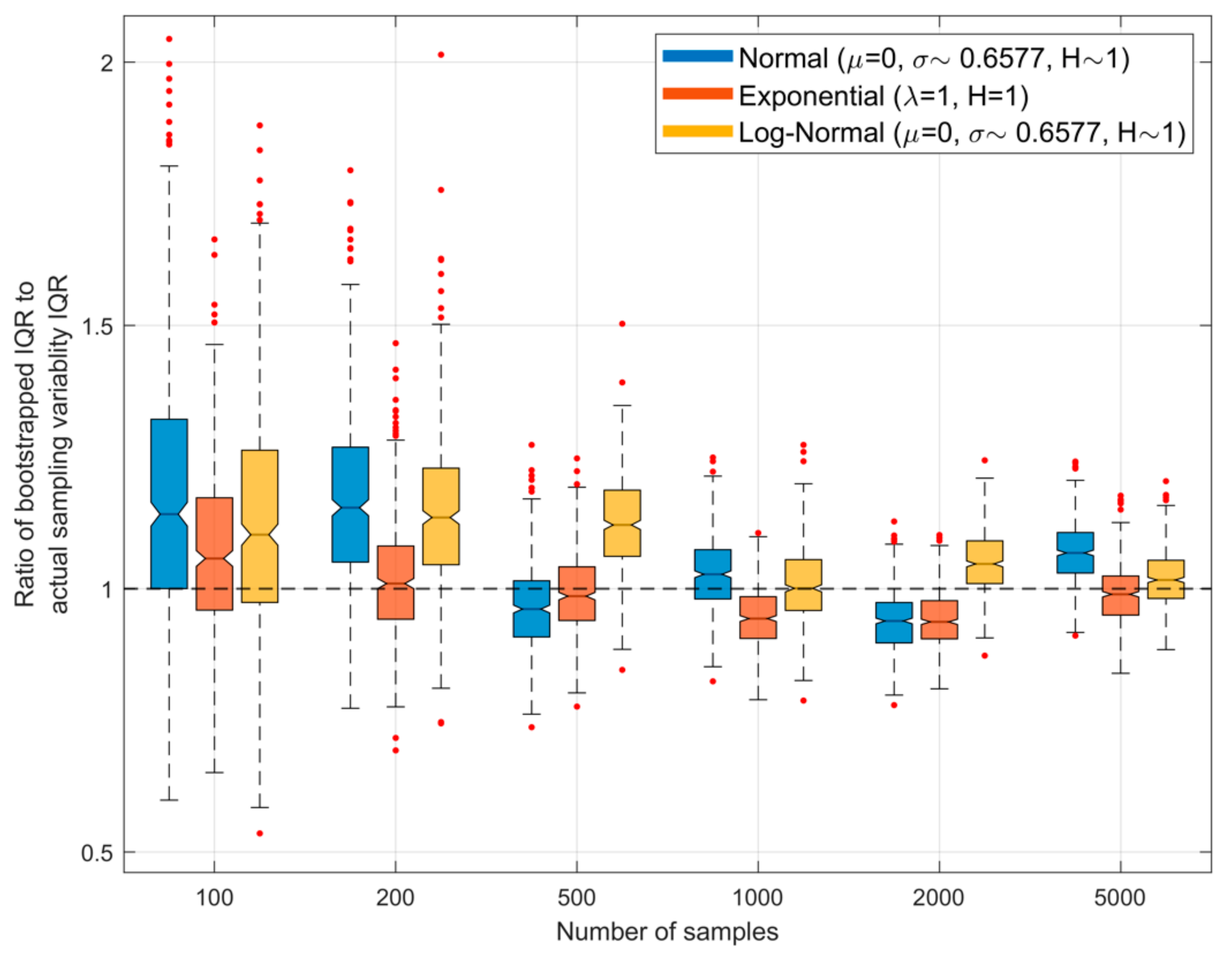
Figure 6.
Plots showing, for different sample sizes and , the ratio of the interquartile range (IQR) of the QS-based estimate of entropy obtained using bootstrapping to that of the actual IQR arising due to random sampling variability. Here, each sample set drawn from the parent density is bootstrapped to obtain different estimates of the associated entropy, and the width of the resulting inter-quartile range is computed. The procedure is repeated for different sample sets drawn from the parent population, and the graph shows the resulting variability as box-plots. The ideal result would be a ratio of 1.0.
Figure 6.
Plots showing, for different sample sizes and , the ratio of the interquartile range (IQR) of the QS-based estimate of entropy obtained using bootstrapping to that of the actual IQR arising due to random sampling variability. Here, each sample set drawn from the parent density is bootstrapped to obtain different estimates of the associated entropy, and the width of the resulting inter-quartile range is computed. The procedure is repeated for different sample sets drawn from the parent population, and the graph shows the resulting variability as box-plots. The ideal result would be a ratio of 1.0.
Figure 7.
Plots showing how expected percentage error in the BC-based estimate of Entropy derived from random samples, varies as a function of the number of bins
for the (
a)
Gaussian, (
b),
Exponential, and (
c)
Log-Normal densities. Results are averaged over
trials obtained by drawing sample sets of size
from the theoretical pdf, where
and
are set to be the smallest and largest data values in the particular sample. Results are shown for different sample sizes
. When the number of bins is small the estimation bias is positive (overestimation) but rapidly declines to cross zero and become negative (underestimation) as the number of bins is increased. In general, the overall ranges of overestimation and underestimation bias are larger than for the QS method (see
Figure 4).
Figure 7.
Plots showing how expected percentage error in the BC-based estimate of Entropy derived from random samples, varies as a function of the number of bins
for the (
a)
Gaussian, (
b),
Exponential, and (
c)
Log-Normal densities. Results are averaged over
trials obtained by drawing sample sets of size
from the theoretical pdf, where
and
are set to be the smallest and largest data values in the particular sample. Results are shown for different sample sizes
. When the number of bins is small the estimation bias is positive (overestimation) but rapidly declines to cross zero and become negative (underestimation) as the number of bins is increased. In general, the overall ranges of overestimation and underestimation bias are larger than for the QS method (see
Figure 4).
Figure 8.
Boxplots showing the sampling variability distribution of optimal fractional number of bins (as a percentage of sample size) to achieve zero bias, when using the BC method for estimating entropy from random samples. Results are shown for the Gaussian (blue), Exponential (red) and Log-Normal (orange) densities. The uncertainty estimates are computed by drawing different sample data sets of a given size from the parent distribution. Note that the expected optimal fractional number of bins varies with shape of the pdf, and is not constant but declines as the sample size increases. This is in contrast with the QS method where the optimal fractional number of bins is constant at for different sample sizes and pdf shapes. Further, the variability in optimal fractional number of bins can be large and highly skewed at smaller sample sizes.
Figure 8.
Boxplots showing the sampling variability distribution of optimal fractional number of bins (as a percentage of sample size) to achieve zero bias, when using the BC method for estimating entropy from random samples. Results are shown for the Gaussian (blue), Exponential (red) and Log-Normal (orange) densities. The uncertainty estimates are computed by drawing different sample data sets of a given size from the parent distribution. Note that the expected optimal fractional number of bins varies with shape of the pdf, and is not constant but declines as the sample size increases. This is in contrast with the QS method where the optimal fractional number of bins is constant at for different sample sizes and pdf shapes. Further, the variability in optimal fractional number of bins can be large and highly skewed at smaller sample sizes.
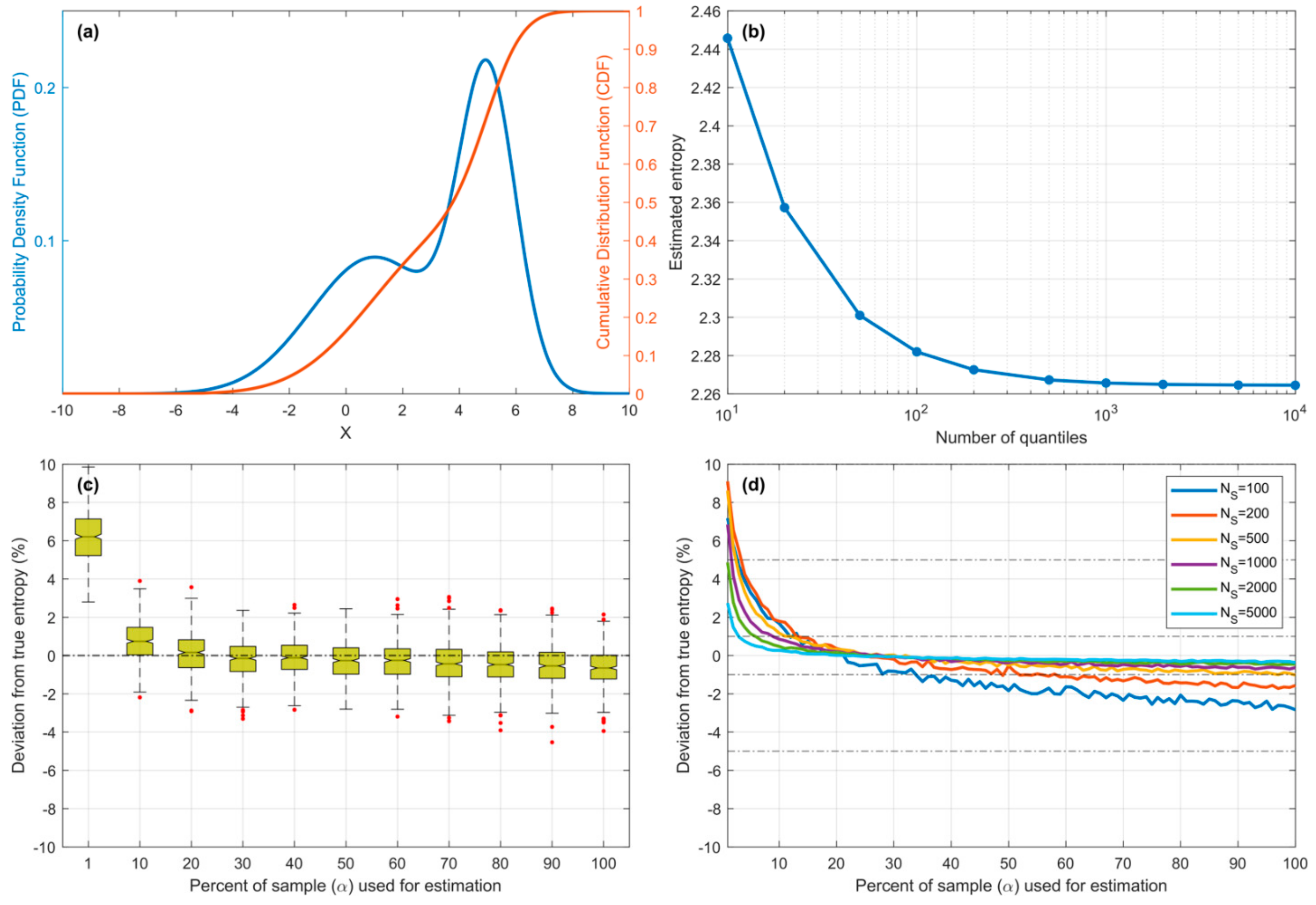
Figure 9.
Plots showing results for the Bimodal pdf. (a) Pdf and Cdf for the Gaussian Mixture model. (b) Showing convergence of entropy computed using piecewise constant approximation as the number of quantiles is increased. (c) Bias and sampling variability of the QS-based estimate of entropy plotted against as a percentage of sample size. (d) Expected bias of QS-based estimate of entropy plotted against as a percentage of sample size, for different sample sizes .
Figure 9.
Plots showing results for the Bimodal pdf. (a) Pdf and Cdf for the Gaussian Mixture model. (b) Showing convergence of entropy computed using piecewise constant approximation as the number of quantiles is increased. (c) Bias and sampling variability of the QS-based estimate of entropy plotted against as a percentage of sample size. (d) Expected bias of QS-based estimate of entropy plotted against as a percentage of sample size, for different sample sizes .
Figure 10.
Plot showing how expected percentage error in the KD-based estimate of Entropy derived from random samples, varies as a function of when using a Gaussian kernel. Results are averaged over trials obtained by drawing sample sets of size from the theoretical pdf, where and are set to be the smallest and largest data values in the particular sample. Results are shown for different sample sizes , for the (a) Gaussian, (b), Exponential, (c) Log-Normal, and (d) Bimodal densities. When the kernel standard deviation (and hence ) is small the estimation bias is negative (underestimation) but rapidly increases to cross zero and become positive (overestimation) as the kernel standard deviation is increased. The location of the crossing point (corresponding to optimal value for (and hence ) varies with sample size and shape of the pdf.
Figure 10.
Plot showing how expected percentage error in the KD-based estimate of Entropy derived from random samples, varies as a function of when using a Gaussian kernel. Results are averaged over trials obtained by drawing sample sets of size from the theoretical pdf, where and are set to be the smallest and largest data values in the particular sample. Results are shown for different sample sizes , for the (a) Gaussian, (b), Exponential, (c) Log-Normal, and (d) Bimodal densities. When the kernel standard deviation (and hence ) is small the estimation bias is negative (underestimation) but rapidly increases to cross zero and become positive (overestimation) as the kernel standard deviation is increased. The location of the crossing point (corresponding to optimal value for (and hence ) varies with sample size and shape of the pdf.
Figure 11.
Plot showing how the optimal value of the KD hyper-parameter varies as a function of sample size and pdf type when using a Gaussian kernel. In disagreement with Parzen-window theory, the optimal value for does not remain approximately constant as the sample size is varied. Further, the value of varies significantly with shape of the underlying pdf.
Figure 11.
Plot showing how the optimal value of the KD hyper-parameter varies as a function of sample size and pdf type when using a Gaussian kernel. In disagreement with Parzen-window theory, the optimal value for does not remain approximately constant as the sample size is varied. Further, the value of varies significantly with shape of the underlying pdf.
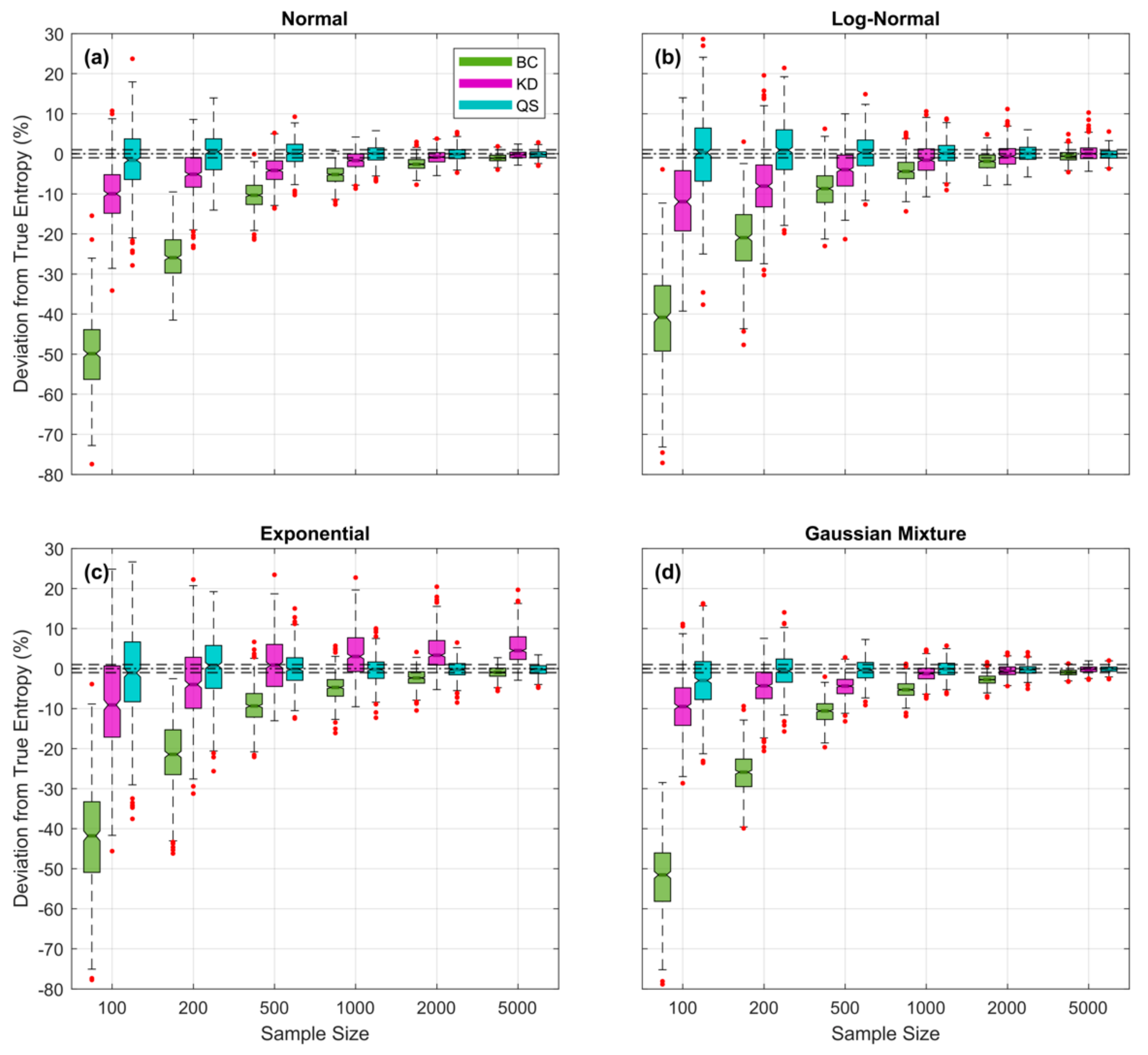
Figure 12.
Plots showing expected percent error in the QS- (blue), KD- (purple) and BC-based (green) estimates of entropy derived from random samples, as a function of sample size for the (a) Gaussian, (b), Log-Normal, (c) Exponential, and (d) Bimodal densities; box plots are shown side by side to improve legibility. Results are averaged over trials obtained by drawing sample sets of size from the theoretical pdf, where and are set to be the smallest and largest data values in the particular sample. For QS, the fractional number of bins was fixed at regardless of pdf form or sample size. For KD and BC, the corresponding hyperparameter (kernel standard deviation and bin width ∆ respectively) was optimized for each random sample by finding the value that maximizes the Likelihood of the sample. Results show clearly that QS-based estimates are relatively unbiased, even for small sample sizes, whereas KD- and BC-based estimates can have significant negative bias when sample sizes are small.
Figure 12.
Plots showing expected percent error in the QS- (blue), KD- (purple) and BC-based (green) estimates of entropy derived from random samples, as a function of sample size for the (a) Gaussian, (b), Log-Normal, (c) Exponential, and (d) Bimodal densities; box plots are shown side by side to improve legibility. Results are averaged over trials obtained by drawing sample sets of size from the theoretical pdf, where and are set to be the smallest and largest data values in the particular sample. For QS, the fractional number of bins was fixed at regardless of pdf form or sample size. For KD and BC, the corresponding hyperparameter (kernel standard deviation and bin width ∆ respectively) was optimized for each random sample by finding the value that maximizes the Likelihood of the sample. Results show clearly that QS-based estimates are relatively unbiased, even for small sample sizes, whereas KD- and BC-based estimates can have significant negative bias when sample sizes are small.



 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}











