
Scheduling Strategy Design Framework for Cyber–Physical System with Non-Negligible Propagation Delay



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. System Model
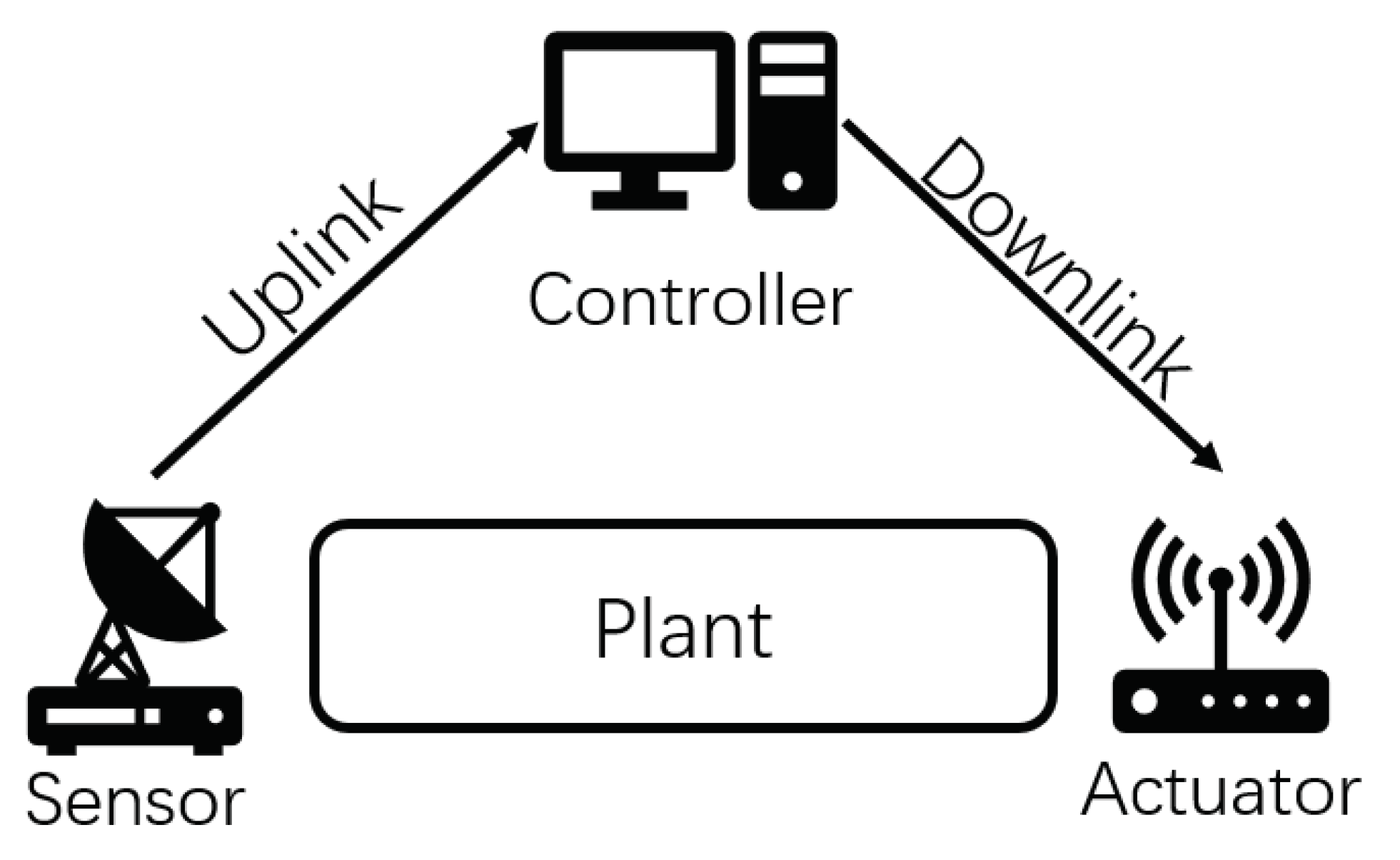
2.1. The Plant of the Single-Loop CPS
2.2. The Communication Process of the Single-Loop CPS
2.3. The Control Process of the Single-Loop CPS
3. Semi-Predictive Framework and MDP Modeling
3.1. The Packet Outdate Problem
3.2. Main Idea of the Semi-Predictive Framework
3.3. MDP Modeling of the Semi-Predictive Framework
4. Online and Offline Scheduling Strategies
4.1. Sufficient Conditions for the Strategies’ Existence
4.2. Lookup Table-Based Optimal Offline Strategy
4.3. Neural Network-Based Suboptimal Online Strategy
| Algorithm 1: Deep Q Network Algorithm. |
 |
5. Numerical Simulation
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
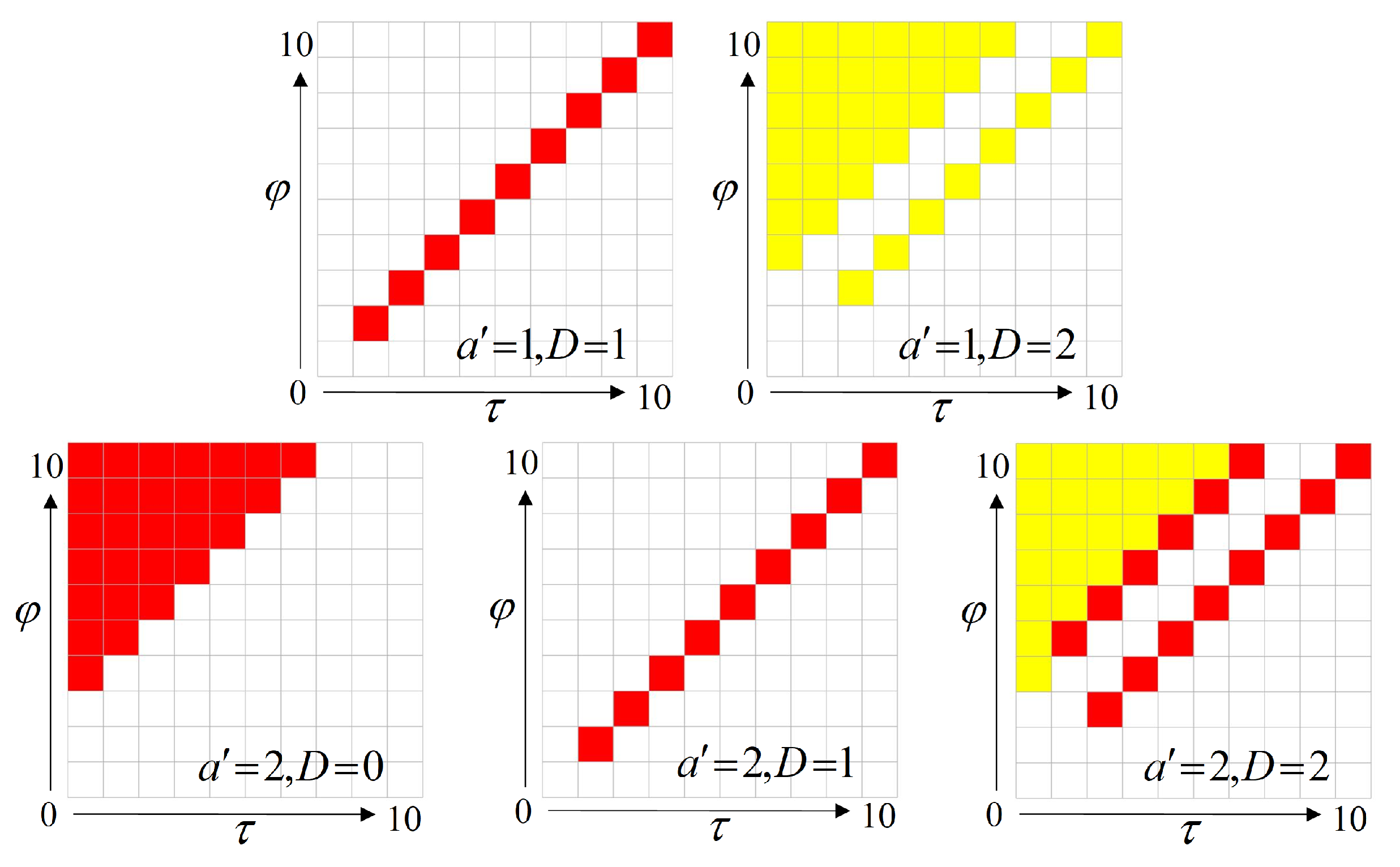
Appendix A. Construction Rules of the State Transition Probability Matrix
Appendix B. Proof of Theorem 1
Appendix B.1. Scheduling 1 Subsystem per Time Slot without Delay
- (1)
- The initial estimation age is equal to the control age:
- (2)
- The current subsystem waits for the completion of the scheduling of other subsystems, that is, silence time slots, and then schedules the uplink transmission when it is scheduled again. If the uplink transmission fails, the subsystem waits another (k − 1) time slots and tries again until the uplink transmission is successful. This step takes time slots. At the end of this step, the estimated age is 0, and the control age is ;
- (3)
- After the current subsystem silences for time slots, it switches to schedule downlink transmission continuously until it succeeds. This step takes time slots. At the end of this step, the estimated age is equal to the control age: . Then it finishes a close control loop.

Appendix B.2. Scheduling L Subsystems per Time Slot without Delay
Appendix B.3. Scheduling L Subsystems per Time Slot with Delay
References
- Zhang, X.M.; Han, Q.L.; Ge, X.; Ding, D.; Ding, L.; Yue, D.; Peng, C. Networked control systems: A survey of trends and techniques. IEEE/CAA J. Autom. Sin. 2020, 7, 1–17. [Google Scholar] [CrossRef]
- Lin, J.; Yu, W.; Zhang, N.; Yang, X.; Zhang, H.; Zhao, W. A Survey on Internet of Things: Architecture, Enabling Technologies, Security and Privacy, and Applications. IEEE Internet Things J. 2017, 4, 1125–1142. [Google Scholar] [CrossRef]
- Xu, H.; Yu, W.; Griffith, D.; Golmie, N. A Survey on Industrial Internet of Things: A Cyber–Physical Systems Perspective. IEEE Access 2018, 6, 78238–78259. [Google Scholar] [CrossRef]
- Lu, C.; Saifullah, A.; Li, B.; Sha, M.; Gonzalez, H.; Gunatilaka, D.; Wu, C.; Nie, L.; Chen, Y. Real-Time Wireless Sensor-Actuator Networks for Industrial Cyber–Physical Systems. Proc. IEEE 2016, 104, 1013–1024. [Google Scholar] [CrossRef]
- Liu, W.; Nair, G.; Li, Y.; Nesic, D.; Vucetic, B.; Poor, H.V. On the Latency, Rate, and Reliability Tradeoff in Wireless Networked Control Systems for IIoT. IEEE Internet Things J. 2021, 8, 723–733. [Google Scholar] [CrossRef]
- Han, B.; Zhu, Y.; Jiang, Z.; Hu, Y.; Schotten, H.D. Optimal Blocklength Allocation Towards Reduced Age of Information in Wireless Sensor Networks. In Proceedings of the 2019 IEEE Globecom Workshops (GC Wkshps), Waikoloa, HI, USA, 9–13 December 2019; pp. 1–6. [Google Scholar]
- Han, B.; Jiang, Z.; Zhu, Y.; Schotten, H.D. Recursive Optimization of Finite Blocklength Allocation to Mitigate Age-of-Information Outage. In Proceedings of the 2020 IEEE International Conference on Communications Workshops (ICC Workshops), Dublin, Ireland, 7–11 June 2020; pp. 1–6. [Google Scholar]
- Li, D.; Wu, S.; Wang, Y.; Jiao, J.; Zhang, Q. Age-Optimal HARQ Design for Freshness-Critical Satellite-IoT Systems. IEEE Internet Things J. 2020, 7, 2066–2076. [Google Scholar] [CrossRef]
- Parag, P.; Taghavi, A.; Chamberland, J. On Real-Time Status Updates over Symbol Erasure Channels. In Proceedings of the 2017 IEEE Wireless Communications and Networking Conference (WCNC), San Francisco, CA, USA, 19–22 March 2017; pp. 1–6. [Google Scholar]
- Huang, K.; Liu, W.; Li, Y.; Savkin, A.; Vucetic, B. Wireless Feedback Control with Variable Packet Length for Industrial IoT. IEEE Wirel. Commun. Lett. 2020, 9, 1586–1590. [Google Scholar] [CrossRef]
- Liu, C.-F.; Bennis, M. Data-Driven Predictive Scheduling in Ultra-Reliable Low-Latency Industrial IoT: A Generative Adversarial Network Approach. In Proceedings of the 2020 IEEE 21st International Workshop on Signal Processing Advances in Wireless Communications (SPAWC), Atlanta, GA, USA, 26–29 May 2020; pp. 1–5. [Google Scholar]
- Eisen, M.; Gatsis, K.; Pappas, G.J.; Ribeiro, A. Learning in Wireless Control Systems Over Nonstationary Channels. IEEE Trans. Signal Process. 2019, 67, 1123–1137. [Google Scholar] [CrossRef]
- Sun, Y.; Kadota, I.; Talak, R.; Modiano, E. Age of Information: A New Metric for Information Freshness; Morgan & Claypool: San Rafael, CA, USA, 2019. [Google Scholar]
- Sinopoli, B.; Schenato, L.; Franceschetti, M.; Poolla, K.; Jordan, M.I.; Sastry, S.S. Kalman filtering with intermittent observations. IEEE Trans. Autom. Control 2004, 49, 1453–1464. [Google Scholar] [CrossRef]
- Champati, J.P.; Mamduhi, M.H.; Johansson, K.H.; Gross, J. Performance Characterization Using AoI in a Single-loop Networked Control System. In Proceedings of the IEEE INFOCOM 2019—IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Paris, France, 29 April–2 May 2019; pp. 197–203. [Google Scholar]
- Park, P.; Araújo, J.; Johansson, K.H. Wireless networked control system co-design. In Proceedings of the 2011 International Conference on Networking, Sensing and Control, Delft, The Netherlands, 11–13 April 2011; pp. 486–491. [Google Scholar]
- Huang, K.; Liu, W.; Li, Y.; Vucetic, B. To Retransmit or Not: Real-Time Remote Estimation in Wireless Networked Control. In Proceedings of the ICC 2019—2019 IEEE International Conference on Communications (ICC), Shanghai, China, 21–23 May 2019; pp. 1–7. [Google Scholar]
- An, Z.; Wu, S.; Wang, Y.; Jiao, J.; Zhang, Q. HARQ Based Joint Uplink-Downlink Optimal Scheduling Strategy for Single-Loop WNCS. In Proceedings of the 2020 International Conference on Wireless Communications and Signal Processing (WCSP), Nanjing, China, 21–23 October 2020; pp. 7–12. [Google Scholar]
- Huang, K.; Liu, W.; Li, Y.; Vucetic, B.; Savkin, A. Optimal Downlink—Uplink Scheduling of Wireless Networked Control for Industrial IoT. IEEE Internet Things J. 2020, 7, 1756–1772. [Google Scholar] [CrossRef]
- Wang, X.; Chen, C.; He, J.; Zhu, S.; Guan, X. AoI-Aware Control and Communication Co-design for Industrial IoT Systems. IEEE Internet Things J. 2020, 8, 8464–8473. [Google Scholar] [CrossRef]
- Jiang, Z.; Krishnamachari, B.; Zhou, S.; Niu, Z. Can Decentralized Status Update Achieve Universally Near-Optimal Age-of-Information in Wireless Multiaccess Channels? In Proceedings of the 2018 30th International Teletraffic Congress (ITC 30), Vienna, Austria, 3–7 September 2018; pp. 144–152. [Google Scholar]
- Ayan, O.; Vilgelm, M.; Kellerer, W. Optimal Scheduling for Discounted Age Penalty Minimization in Multi-Loop Networked Control. In Proceedings of the 2020 IEEE 17th Annual Consumer Communications & Networking Conference (CCNC), Las Vegas, NV, USA, 10–13 January 2020; pp. 1–7. [Google Scholar]
- Girgis, A.M.; Park, J.; Liu, C.-F.; Bennis, M. Predictive Control and Communication Co-Design: A Gaussian Process Regression Approach. In Proceedings of the 2020 IEEE 21st International Workshop on Signal Processing Advances in Wireless Communications (SPAWC), Atlanta, GA, USA, 26–29 May 2020; pp. 1–5. [Google Scholar]
- Chang, B.; Zhang, L.; Li, L.; Zhao, G.; Chen, Z. Optimizing Resource Allocation in URLLC for Real-Time Wireless Control Systems. IEEE Trans. Veh. Technol. 2019, 68, 8916–8927. [Google Scholar] [CrossRef]
- Maity, D.; Mamduhi, M.H.; Hirche, S.; Johansson, K.H.; Baras, J.S. Optimal LQG Control Under Delay-Dependent Costly Information. IEEE Control Syst. Lett. 2019, 3, 102–107. [Google Scholar] [CrossRef]
- Mamduhi, M.H.; Maity, D.; Baras, J.S.; Johansson, K.H. A Cross-Layer Optimal Co-Design of Control and Networking in Time-Sensitive Cyber–Physical Systems. IEEE Control Syst. Lett. 2021, 5, 917–922. [Google Scholar] [CrossRef]
- Maity, D.; Baras, J.S. Minimal Feedback Optimal Control of Linear-Quadratic-Gaussian Systems: No Communication is also a Communication. IFAC-PapersOnLine 2020, 53, 2201–2207. [Google Scholar] [CrossRef]
- Schenato, L.; Sinopoli, B.; Franceschetti, M.; Poolla, K.; Sastry, S.S. Foundations of Control and Estimation Over Lossy Networks. Proc. IEEE 2007, 95, 163–187. [Google Scholar] [CrossRef]






Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
An, Z.; Wu, S.; Liu, T.; Jiao, J.; Zhang, Q. Scheduling Strategy Design Framework for Cyber–Physical System with Non-Negligible Propagation Delay. Entropy 2021, 23, 714. https://doi.org/10.3390/e23060714
An Z, Wu S, Liu T, Jiao J, Zhang Q. Scheduling Strategy Design Framework for Cyber–Physical System with Non-Negligible Propagation Delay. Entropy. 2021; 23(6):714. https://doi.org/10.3390/e23060714
Chicago/Turabian StyleAn, Zuoyu, Shaohua Wu, Tiange Liu, Jian Jiao, and Qinyu Zhang. 2021. "Scheduling Strategy Design Framework for Cyber–Physical System with Non-Negligible Propagation Delay" Entropy 23, no. 6: 714. https://doi.org/10.3390/e23060714
APA StyleAn, Z., Wu, S., Liu, T., Jiao, J., & Zhang, Q. (2021). Scheduling Strategy Design Framework for Cyber–Physical System with Non-Negligible Propagation Delay. Entropy, 23(6), 714. https://doi.org/10.3390/e23060714