
Deep Learning Methods for Heart Sounds Classification: A Systematic Review


Abstract
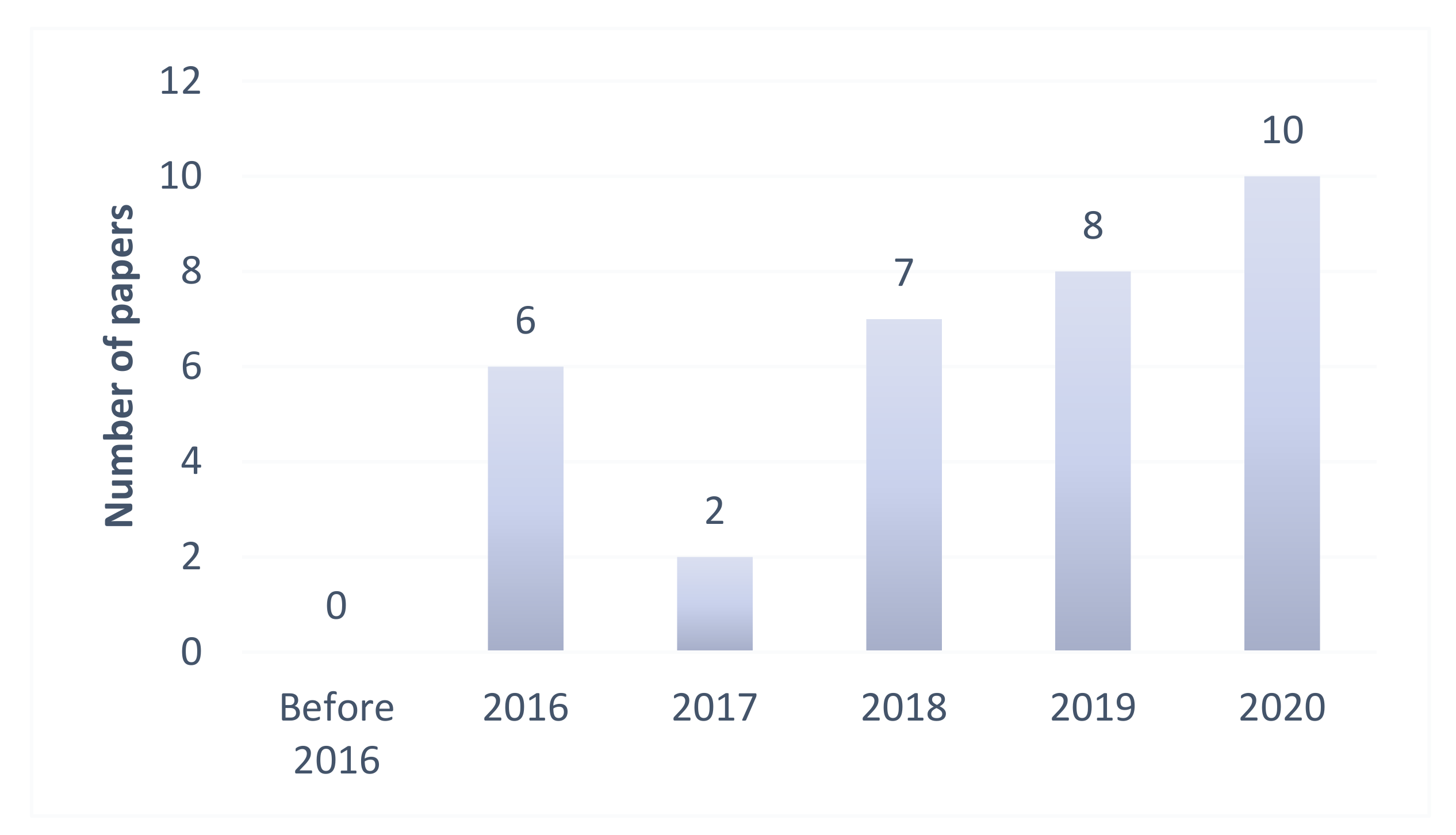
1. Introduction

2. Process of Heart Sounds Classification
2.1. Denoising
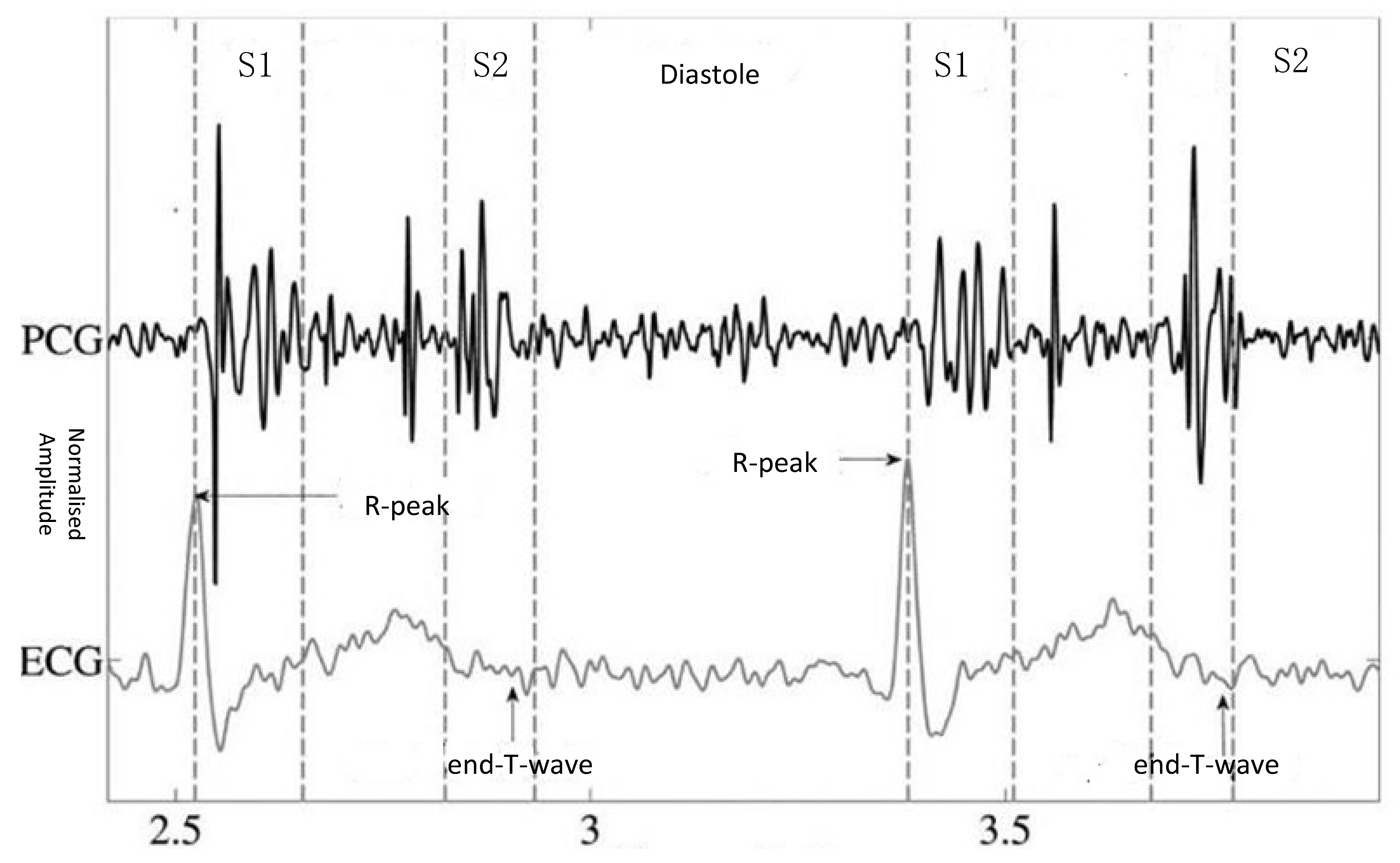
2.2. Segmentation
2.3. Feature Extraction
2.4. Classification
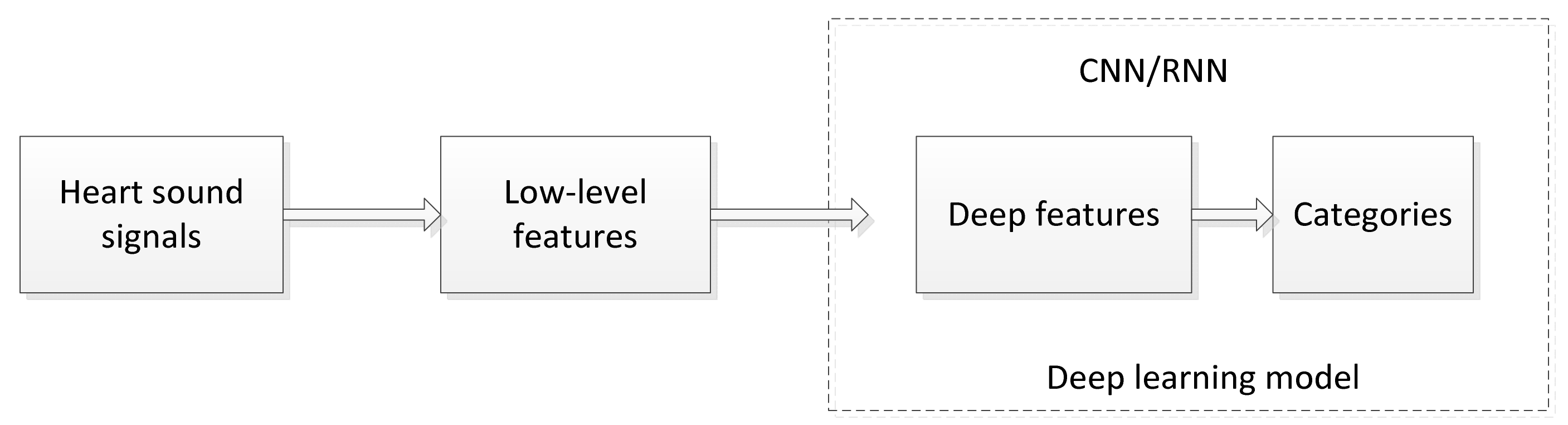
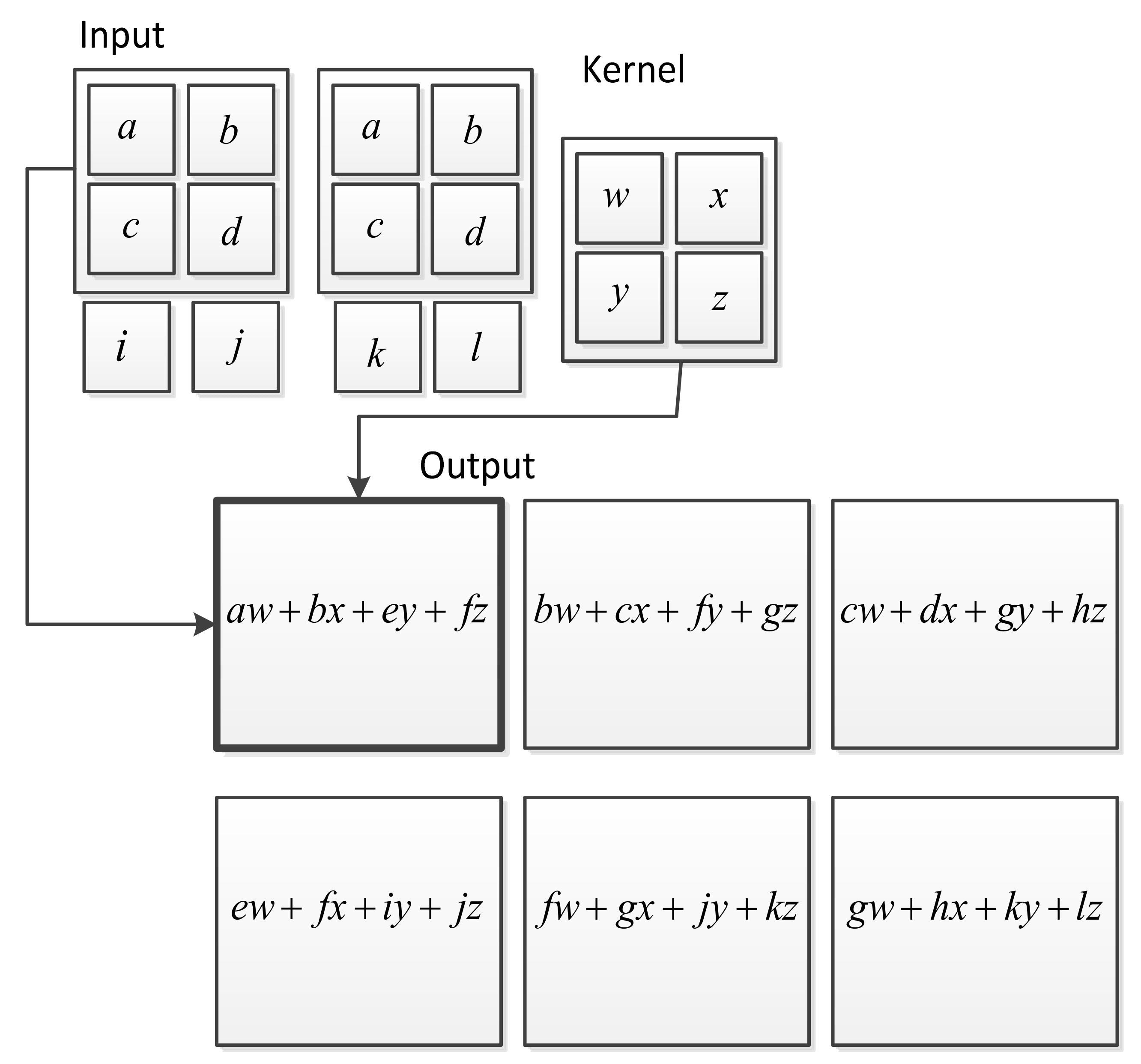
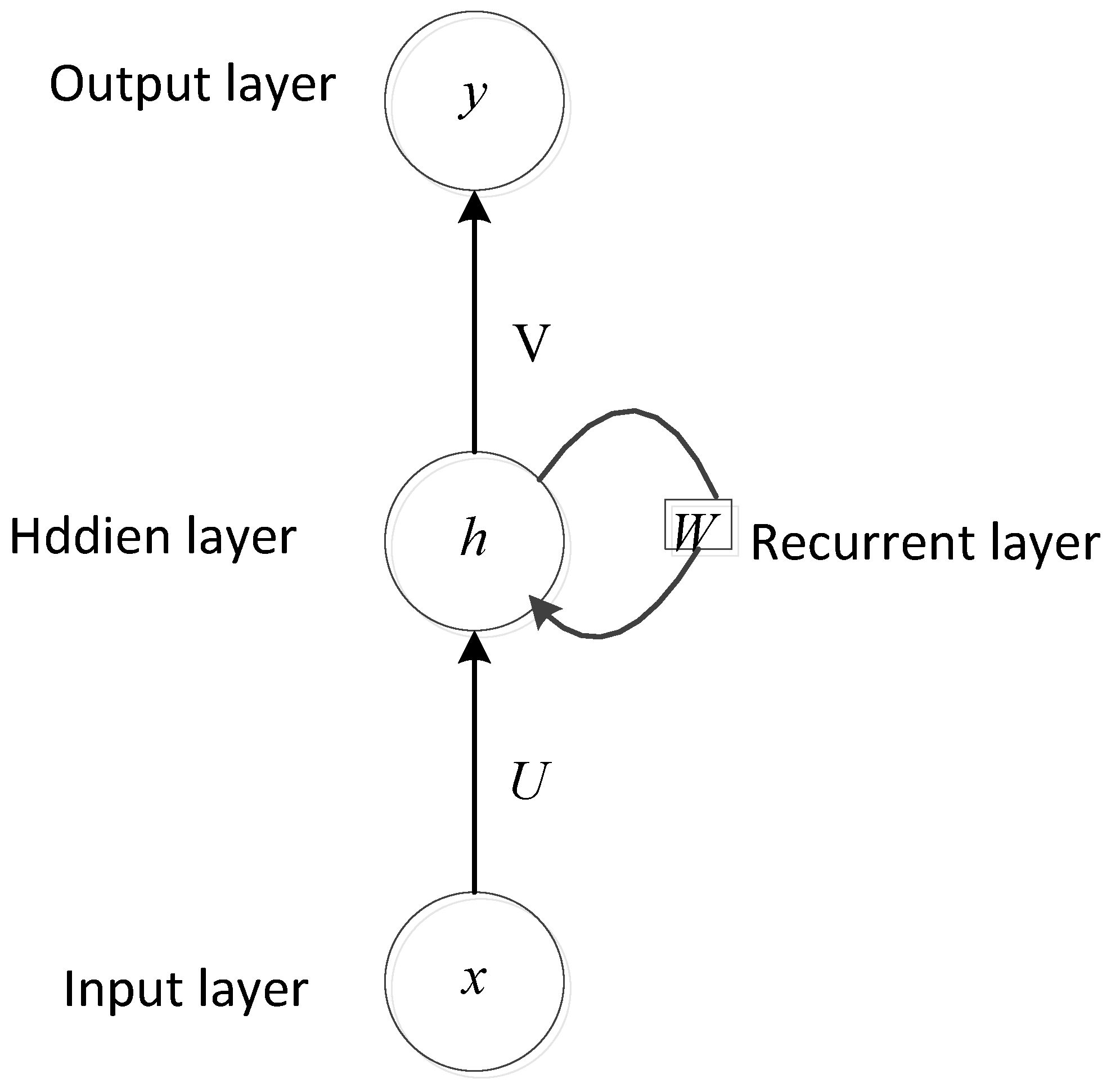
3. Deep Learning for Heart Sounds Classification

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| S. No | Reference | Method | Input Features | Segment | Optimizer | Categories | Performance on Test Dataset MAcc, Se, Sp, Acc |
|---|---|---|---|---|---|---|---|
| CNN-Based Methods | |||||||
| 1 | Maknickas et al., 2017 [25] | 2D-CNN | MFSC | No | RMSprop | N, A | 84.15, 80.63, 87.66, * |
| 2 | Tarik Alafif et al., 2020 [26] | 2D-CNN + transfer learning | MFCC | NO | SGD | N, A | *, *, *, 89.5% |
| 3 | Deng et al., 2020 [24] | CNN + RNN | Improved MFCC | No | Adam | N, A | 0.9834, 0.9866, 0.9801, * |
| 4 | Abduh et al., 2019 [27] | 2D-DNN | MFSC | No | * | N, A | 93.15, 89.30, 97.00, 95.50 |
| 5 | Chen et al., 2018 [28] | 2D-CNN | Wavelet transform + Hilbert–Huang features | No | * | N, M, EXT | 93.25, 98, 88.5, 93 |
| 6 | Rubin et al., 2016 [29] | 2D-CNN | MFCC | Yes | Adam | N, A | 83.99, 72.78, 95.21, * |
| 7 | Nilanon et al., 2016 [30] | 2D-CNN | Spectrograms | No | SGD | N, A | 81.11, 76.96, 85.27, * |
| 8 | Dominguez et al., 2018 [31] | 2D-CNN | Spectrograms | No | * | N, A | 94.16, 93.20, 95.12, 97.05 |
| 9 | Bozkurt et al., 2018 [32] | 2D-CNN | MFCC + MFSC | Yes | * | N, A | 81.5, 84.5, 78.5, 81.5 |
| 10 | Chen et al., 2019 [33] | 2D-CNN | MFSC | No | Adam | N, A | 94.81, 92.73, 96.90, * |
| 11 | Cheng et al., 2019 [34] | 2D-CNN | Spectrograms | No | * | N, A | 89.50, 91.00, 88.00, * |
| 12 | Fatih et al., 2019 [35] | 2D-CNN | Spectrograms | No | * | N, M, EXT | 0.80 (Accuracy on dataset A) 0.79 (Accuracy on dataset B) |
| 13 | Ryu et al., 2016 [36] | 1D-CNN | 1D time-series signals | No | SGD | N, A | 78.69, 66.63, 87.75, * |
| 14 | Xu et al., 2018 [37] | 1D-CNN | 1D time-series signals | No | SGD | N, A | 90.69, 86.21, 95.16, 93.28 |
| 15 | Xiao et al., 2020 [38] | 1D-CNN | 1D time-series signals | No | SGD | N, A | 90.51, 85.29, 95.73, 93.56 |
| 16 | Humayun et al., 2020 [39] | tConv-CNN (1D-CNN) | 1D time-series signals | Yes | Adam | N, A | 81.49, 86.95, 76.02, * |
| 17 | Humayun et al., 2018 [40] | 1D-CNN | 1D time-series signals | Yes | SGD | N, A | 87.10, 90.91, 83.29, * |
| 18 | Li et al., 2019 [41] | 1D-CNN | Spectrograms | No | * | N, A | *, *, *, 96.48 |
| 19 | Li et al., 2020 [42] | 1D-CNN | 497 features from time, amplitude, high-order statistics, cepstrum, frequency cyclostationary and entropy domains | Yes | Adam | N, A | *, 0.87, 0.721, 0.868 |
| 20 | Xiao et al., 2020 [43] | 1D-CNN | 1D time-series signals | No | N, A | *, 0.86, 0.95, 0.93 | |
| 21 | Shu Lih Oh et al., 2020 [44] | 1D-CNN WaveNet | 1D time-series signals | NO | Adam | N, AS, MS, MR, MVP | 0.953, 0.925, 0.981, 0.97 |
| 22 | Baghel et al., 2020 [45] | 1D-CNN | 1D time-series signals | No | SGD | N, AS, MS, MR, MVP | *, *, *, 0.9860 |
| RNN-Based Methods | |||||||
| 23 | Latif et al., 2018 [46] | RNN (LSTM, BLSTM, GRU, BiGRU) | MFCC | Yes | * | N, A | 98.33, 99.95, 96.71, 97.06 (LSTM) 98.61, 98.86, 98.36, 97.63 (BLSTM) 97.31, 96.69, 97.93, 95.42 (GRU) 97.87, 98.46, 97.28, 97.21 (BiGRU) |
| 24 | Khan et al., 2020 [47] | LSTM | MFCC | No | * | N, A | *, *, *, 91.39 |
| 25 | Yang et al., 2016 [48] | RNN | 1D time-series signals | No | * | N, A | 80.18, 77.49, 82.87, * |
| 26 | Raza et al., 2018 [49] | LSTM | 1D time-series signals | No | Adam | N, M, EXT | *, *, *, 80.80 |
| 27 | Westhuizen et al., 2017 [50] | Bayesian LSTM LSTM | 1D time-series signals | No | N, A | 0.798, 0.707, 0.889, 0.798 0.7775, 0.675, 0.880, 0.778 | |
| Hybrid Methods | |||||||
| 28 | Wu et al., 2019 [51] | Ensemble CNN | pectrograms + MFSC + MFCC | No | * | N, A | 89.81, 91.73, 87.91, * |
| 29 | Noman et al., 2019 [52] | Ensemble CNN | (1D time-series signals + MFCC) | Yes | Scikit | N, A | 88.15, 89.94, 86.35, 89.22 |
| 30 | Tschannen et al., 2016 [53] | 2D-CNN+SVM | Deep features | Yes | * | N, A | 81.22, 84.82, 77.62, * |
| 31 | Potes et al., 2016 [23] | AdaBoost + 1D-CNN | Time and frequency features, MFCC | Yes | * | N, A | 86.02, 94.24, 77.81, * |
| 32 | Gharehbaghi et al., 2019 [54] | STGNN + MTGNN | Time-series signal | No | * | N, A | *, 82.8, *, 84.2 |
| 33 | Deperlioglu et al., 2020 [55] | AEN | 1D time-series signals | No | * | N, M, EXT | 0.9603 (Accuracy for normal), 0.9191 (Accuracy for extrasystole), 0.9011 (Accuracy for murmur) |
3.1. CNN Methods for Heart Sounds Classification
3.2. RNN Methods for Heart Sounds Classification
3.3. Hybrid Methods for Heart Sounds Classification
4. Discussion
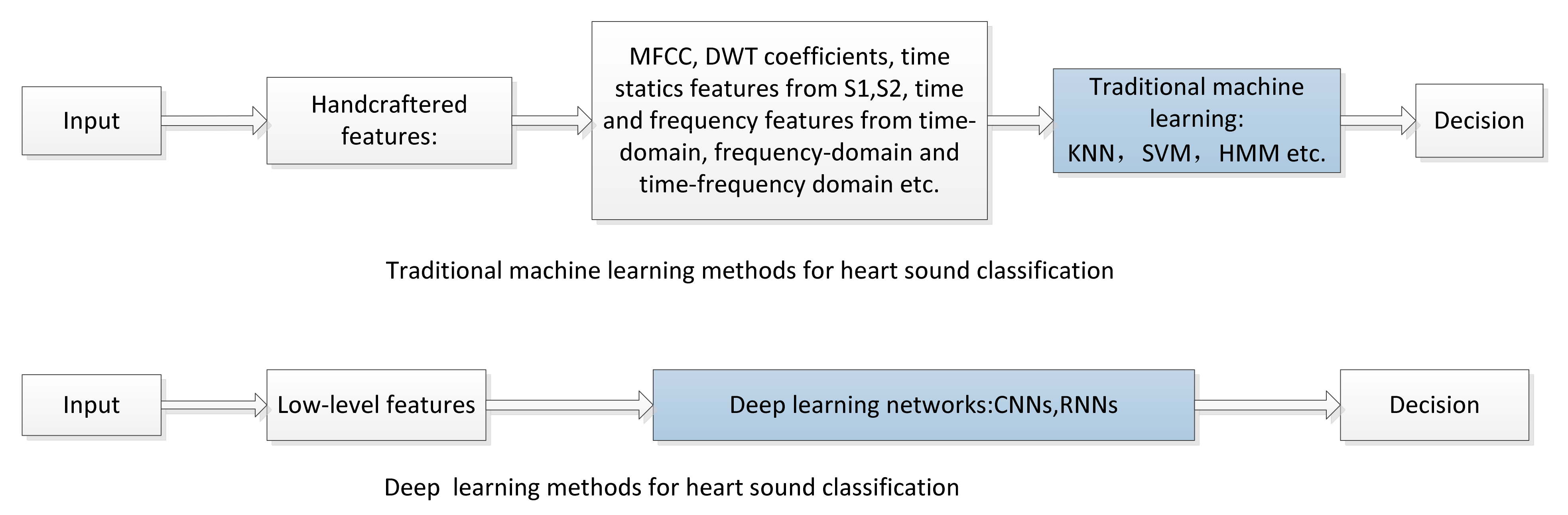
4.1. Comparison of Deep Learning and Traditional Machine Learning Methods
4.2. Trends and Challenges
4.2.1. Training with Limited Heart Sound Data
4.2.2. Training Efficiency
4.2.3. More Powerful Models
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- WHO. Cardiovascular Diseases (CVDs) [EB/OL]. Available online: https://www.who.int/zh/news-room/fact-sheets/detail/cardiovascular-diseases-(cvds) (accessed on 1 May 2020).
- Liu, C.; Springer, D.; Li, Q.; Moody, B.; Juan, R.A.; Chorro, F.J.; Castells, F.; Roig, J.M.; Silva, I.; Johnson, A.E.W.; et al. An open access database for the evaluation of heart sound algorithms. Physiol. Meas. 2016, 37, 2181–2213. [Google Scholar] [CrossRef]
- Liu, C.; Murray, A. Applications of Complexity Analysis in Clinical Heart Failure. Complexity and Nonlinearity in Cardiovascular Signals; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- Springer, D.B.; Tarassenko, L.; Clifford, G.D. Logistic Regression-HSMM-Based Heart Sound Segmentation. IEEE Trans. Biomed. Eng. 2016, 63, 822. [Google Scholar] [CrossRef]
- Dwivedi, A.K.; Imtiaz, S.A.; Rodriguez-Villegas, E. Algorithms for Automatic Analysis and Classification of Heart Sounds—A Systematic Review. IEEE Access 2019, 7, 8316–8345. [Google Scholar] [CrossRef]
- Li, S.; Li, F.; Tang, S.; Xiong, W. A Review of Computer-Aided Heart Sound Detection Techniques. BioMed Res. Int. 2020, 2020, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Thalmayer, A.; Zeising, S.; Fischer, G.; Kirchner, J. A Robust and Real-Time Capable Envelope-Based Algorithm for Heart Sound Classification: Validation under Different Physiological Conditions. Sensors 2020, 20, 972. [Google Scholar] [CrossRef] [PubMed]
- Kapen, P.T.; Youssoufa, M.; Kouam, S.U.K.; Foutse, M.; Tchamda, A.R.; Tchuen, G. Phonocardiogram: A robust algorithm for generating synthetic signals and comparison with real life ones. Biomed. Signal Process. Control 2020, 60, 101983. [Google Scholar] [CrossRef]
- Giordano, N.; Knaflitz, M. A Novel Method for Measuring the Timing of Heart Sound Components through Digital Phonocardiography. Sensors 2019, 19, 1868. [Google Scholar] [CrossRef] [PubMed]
- Wei, W.; Zhan, G.; Wang, X.; Zhang, P.; Yan, Y. A Novel Method for Automatic Heart Murmur Diagnosis Using Phonocardiogram. In Proceedings of the 2019 International Conference on Artificial Intelligence and Advanced Manufacturing, AIAM, Dublin, Ireland, 16–18 October 2019; Volume 37, pp. 1–6. [Google Scholar] [CrossRef]
- Malarvili, M.; Kamarulafizam, I.; Hussain, S.; Helmi, D. Heart sound segmentation algorithm based on instantaneous energy of electrocardiogram. Comput. Cardiol. 2003, 2003, 327–330. [Google Scholar] [CrossRef]
- Oliveira, J.H.; Renna, F.; Mantadelis, T.; Coimbra, M.T. Adaptive Sojourn Time HSMM for Heart Sound Segmentation. IEEE J. Biomed. Health Inform. 2018, 23, 642–649. [Google Scholar] [CrossRef] [PubMed]
- Kamson, A.P.; Sharma, L.; Dandapat, S. Multi-centroid diastolic duration distribution based HSMM for heart sound segmentation. Biomed. Signal Process. Control. 2019, 48, 265–272. [Google Scholar] [CrossRef]
- Renna, F.; Oliveira, J.H.; Coimbra, M.T. Deep Convolutional Neural Networks for Heart Sound Segmentation. IEEE J. Biomed. Health Inform. 2019, 23, 2435–2445. [Google Scholar] [CrossRef] [PubMed]
- Liu, C.; Springer, D.; Clifford, G.D. Performance of an open-source heart sound segmentation algorithm on eight independent databases. Physiol. Meas. 2017, 38, 1730–1745. [Google Scholar] [CrossRef] [PubMed]
- Chen, T.E.; Yang, S.I.; Ho, L.T.; Tsai, K.H.; Chen, Y.H.; Chang, Y.F.; Wu, C.C. S1 and S2 heart sound recognition using deep neural networks. IEEE Trans. Biomed. Eng. 2017, 64, 372–380. [Google Scholar] [PubMed]
- Liu, Q.; Wu, X.; Ma, X. An automatic segmentation method for heart sounds. Biomed. Eng. Online 2018, 17, 22–29. [Google Scholar] [CrossRef]
- Deng, S.-W.; Han, J.-Q. Towards heart sound classification without segmentation via autocorrelation feature and diffusion maps. Future Gener. Comput. Syst. 2016, 60, 13–21. [Google Scholar] [CrossRef]
- Abduh, Z.; Nehary, E.A.; Wahed, M.A.; Kadah, Y.M. Classification of Heart Sounds Using Fractional Fourier Transform Based Mel-Frequency Spectral Coefficients and Stacked Autoencoder Deep Neural Network. J. Med. Imaging Health Inf. 2019, 9, 1–8. [Google Scholar] [CrossRef]
- Nogueira, D.M.; Ferreira, C.A.; Gomes, E.F.; Jorge, A.M. Classifying Heart Sounds Using Images of Motifs, MFCC and Temporal Features. J. Med Syst. 2019, 43, 168. [Google Scholar] [CrossRef]
- Soeta, Y.; Bito, Y. Detection of features of prosthetic cardiac valve sound by spectrogram analysis. Appl. Acoust. 2015, 89, 28–33. [Google Scholar] [CrossRef]
- Chakir, F.; Jilbab, A.; Nacir, C.; Hammouch, A. Phonocardiogram signals processing approach for PASCAL Classifying Heart Sounds Challenge. Signal Image Video Process. 2018, 12, 1149–1155. [Google Scholar] [CrossRef]
- Potes, C.; Parvaneh, S.; Rahman, A.; Conroy, B. Ensemble of feature based and deep learning-based classifiers for detection of abnormal heart sounds. Proc. Comput. Cardiol. Conf. 2016, 621–624. [Google Scholar] [CrossRef]
- Deng, M.; Meng, T.; Cao, J.; Wang, S.; Zhang, J.; Fan, H. Heart sound classification based on improved MFCC features and convolutional recurrent neural networks. Neural Netw. 2020, 130, 22–32. [Google Scholar] [CrossRef]
- Maknickas, V.; Maknickas, A. Recognition of normal abnormal phonocardiographic signals using deep convolutional neural networks and mel-frequency spectral coefcients. Physiol. Meas. 2017, 38, 1671–1684. [Google Scholar] [CrossRef]
- Alafif, T.; Boulares, M.; Barnawi, A.; Alafif, T.; Althobaiti, H.; Alferaidi, A. Normal and Abnormal Heart Rates Recognition Using Transfer Learning. In Proceedings of the 2020 12th International Conference on Knowledge and Systems Engineering (KSE), Can Tho, Vietnam, 12–14 November 2020; pp. 275–280. [Google Scholar]
- Abduh, Z.; Nehary, E.A.; Wahed, M.A.; Kadah, Y.M. Classification of heart sounds using fractional fourier transform based mel-frequency spectral coefficients and traditional classifiers. Biomed. Signal Process. Control 2019, 9, 1–8. [Google Scholar] [CrossRef]
- Chen, L.; Ren, J.; Hao, Y.; Hu, X. The Diagnosis for the Extrasystole Heart Sound Signals Based on the Deep Learning. J. Med. Imaging Health Inform. 2018, 8, 959–968. [Google Scholar] [CrossRef]
- Rubin, J.; Abreu, R.; Ganguli, A.; Nelaturi, S.; Matei, I.; Sricharan, K. Classifying heart sound recordings using deep convolutional neural networks and mel-frequency cepstral coefficients. In Proceedings of the 2016 Computing in Cardiology Conference (CinC), Vancouver, BC, Canada, 11–14 September 2016; pp. 813–816. [Google Scholar]
- Nilanon, T.; Yao, J.; Hao, J.; Purushotham, S. Normal/abnormal heart sound recordings classification using convolutional neural network. In Proceedings of the Computing in Cardiology Conference (CinC), Vancouver, BC, Canada, 11–14 September 2016; pp. 585–588. [Google Scholar]
- Dominguez-Morales, J.P.; Jimenez-Fernandez, A.F.; Dominguez-Morales, M.J.; Jimenez-Moreno, G. Deep Neural Networks for the Recognition and Classification of Heart Murmurs Using Neuromorphic Auditory Sensors. IEEE Trans. Biomed. Circuits Syst. 2018, 12, 24–34. [Google Scholar] [CrossRef] [PubMed]
- Bozkurt, B.; Germanakis, I.; Stylianou, Y. A study of time-frequency features for CNN-based automatic heart sound classification for pathology detection. Comput. Biol. Med. 2018, 100, 132–143. [Google Scholar] [CrossRef] [PubMed]
- Chen, W.; Sun, Q.; Wang, J.; Wu, H.; Zhou, H.; Li, H.; Shen, H.; Xu, C. Phonocardiogram Classification Using Deep Convolutional Neural Networks with Majority Vote Strategy. J. Med. Imaging Health Inform. 2019, 9, 1692–1704. [Google Scholar] [CrossRef]
- Cheng, X.; Huang, J.; Li, Y.; Gui, G. Design and Application of a Laconic Heart Sound Neural Network. IEEE Access 2019, 7, 124417–124425. [Google Scholar] [CrossRef]
- Demir, F.; Şengür, A.; Bajaj, V.; Polat, K. Towards the classification of heart sounds based on convolutional deep neural network. Health Inf. Sci. Syst. 2019, 7, 1–9. [Google Scholar] [CrossRef]
- Ryu, H.; Park, J.; Shin, H. Classification of heart sound recordings using convolution neural network. In Proceedings of the 2016 Computing in Cardiology Conference (CinC), Vancouver, BC, Canada, 11–14 September 2016; pp. 1153–1156. [Google Scholar]
- Xu, Y.; Xiao, B.; Bi, X.; Li, W.; Zhang, J.; Ma, X. Pay more attention with fewer parameters: A novel 1-D convolutional neural network for heart sounds classification. In Proceedings of the Computing in Cardiology Conference (CinC), Maastricht, The Netherlands, 23–26 September 2018; Volume 45, pp. 1–4. [Google Scholar]
- Xiao, B.; Xu, Y.; Bi, X.; Li, W.; Ma, Z.; Zhang, J.; Ma, X. Follow the Sound of Children’s Heart: A Deep-Learning-Based Computer-Aided Pediatric CHDs Diagnosis System. IEEE Internet Things J. 2020, 7, 1994–2004. [Google Scholar] [CrossRef]
- Humayun, A.I.; Ghaffarzadegan, S.; Ansari, I.; Feng, Z.; Hasan, T. Towards Domain Invariant Heart Sound Abnormality Detection Using Learnable Filterbanks. IEEE J. Biomed. Health Inform. 2020, 24, 2189–2198. [Google Scholar] [CrossRef] [PubMed]
- Humayun, A.I.; Ghaffarzadegan, S.; Feng, Z.; Hasan, T. Learning front-end filter-bank parameters using convolutional neural networks for abnormal heart sound detection. In Proceedings of the 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 18–21 July 2018; pp. 1408–1411. [Google Scholar]
- Li, F.; Liu, M.; Zhao, Y.; Kong, L.; Dong, L.; Liu, X.; Hui, M. Feature extraction and classification of heart sound using 1D convolutional neural networks. EURASIP J. Adv. Signal Process. 2019, 2019, 1–11. [Google Scholar] [CrossRef]
- Li, F.; Tang, H.; Shang, S.; Mathiak, K.; Cong, F. Classification of Heart Sounds Using Convolutional Neural Network. Appl. Sci. 2020, 10, 3956. [Google Scholar] [CrossRef]
- Xiao, B.; Xu, Y.; Bi, X.; Zhang, J.; Ma, X. Heart sounds classification using a novel 1-D convolutional neural network with extremely low parameter consumption. Neurocomputing 2020, 392, 153–159. [Google Scholar] [CrossRef]
- Oh, S.L.; Jahmunah, V.; Ooi, C.P.; Tan, R.-S.; Ciaccio, E.J.; Yamakawa, T.; Tanabe, M.; Kobayashi, M.; Acharya, U.R. Classification of heart sound signals using a novel deep WaveNet model. Comput. Methods Programs Biomed. 2020, 196, 105604. [Google Scholar] [CrossRef] [PubMed]
- Baghel, N.; Dutta, M.K.; Burget, R. Automatic diagnosis of multiple cardiac diseases from PCG signals using convolutional neural network. Comput. Methods Programs Biomed. 2020, 197, 105750. [Google Scholar] [CrossRef] [PubMed]
- Latif, S.; Usman, M.; Rana, R.; Qadir, J. Phonocardiographic sensing using deep learning for abnormal heartbeat detection. IEEE Sens. J. 2018, 18, 9393–9400. [Google Scholar] [CrossRef]
- Khan, F.A.; Abid, A.; Khan, M.S. Automatic heart sound classification from segmented/unsegmented phonocardiogram signals using time and frequency features. Physiol. Meas. 2020, 41, 055006. [Google Scholar] [CrossRef] [PubMed]
- Yang, T.-C.; Hsieh, H. Classification of acoustic physiological signals based on deep learning neural networks with augmented features. In Proceedings of the 2016 Computing in Cardiology Conference (CinC), Vancouver, BC, Canada, 11–14 September 2016; pp. 569–572. [Google Scholar]
- Raza, A.; Mehmood, A.; Ullah, S.; Ahmad, M.; Choi, G.S.; On, B.W. Heartbeat sound signal classification using deep Learning. Sensors 2019, 19, 4819. [Google Scholar] [CrossRef]
- Van der Westhuizen, J.; Lasenby, J. Bayesian LSTMs in Medicine, Unpublished Paper. 2017. Available online: https://arxiv.org/abs/1706.01242 (accessed on 15 April 2021).
- Wu, J.M.-T.; Tsai, M.-H.; Huang, Y.Z.; Islam, S.H.; Hassan, M.M.; Alelaiwi, A.; Fortino, G. Applying an ensemble convolutional neural network with Savitzky–Golay filter to construct a phonocardiogram prediction model. Appl. Soft Comput. 2019, 78, 29–40. [Google Scholar] [CrossRef]
- Noman, F.; Ting, C.-M.; Salleh, S.-H.; Ombao, H. Short-segment heart sound classification Using an ensemble of deep convolutional neural networks. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 1318–1322. [Google Scholar]
- Tschannen, M.; Kramer, T.; Marti, G.; Heinzmann, M.; Wiatowski, T. Heart Sound Classification Using Deep Structured Features. In Proceedings of the Computing in Cardiology Conference (CinC), Vancouver, BC, Canada, 11–14 September 2016; Volume 43, pp. 565–568. [Google Scholar] [CrossRef]
- Gharehbaghi, A.; Lindén, M. A deep machine learning method for classifying cyclic time series of biological signals using time-growing neural network. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 4102–4115. [Google Scholar] [CrossRef] [PubMed]
- Deperlioglu, O.; Kose, U.; Gupta, D.; Khanna, A.; Sangaiah, A.K. Diagnosis of heart diseases by a secure Internet of Health Things system based on Autoencoder Deep Neural Network. Comput. Commun. 2020, 162, 31–50. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the Neural Information Processing Systems Foundation, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1090–1105. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the AAAI, San Francisco, CA, USA, 4–9 February 2017; Volume 4, p. 12. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Krishnan, P.T.; Balasubramanian, P.; Umapathy, S. Automated heart sound classification system from unsegmented phonocardiogram (PCG) using deep neural network. Phys. Eng. Sci. Med. 2020, 43, 505–515. [Google Scholar] [CrossRef]
- Schuster, M.; Paliwal, K. Bidirectional recurrent neural networks. IEEE Trans. Signal Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef]
- Neil, D.; Pfeiffer, M.; Liu, S.-C. Phased LSTM: Accelerating Recurrent Network Training for Long or Event-based Sequences. Adv. Neural Inf. Process. Syst. 2016, 29, 3882–3890. [Google Scholar]
- Bentley, G.N.P.; Coimbra, M.; Mannor, S. The Pascal Classifying Heart Sounds Challenge. Available online: http://www.peterjbentley.com/heartchallenge/index.html (accessed on 1 May 2020).
- Yaseen, G.Y.S.; Kwon, S. Classification of heart sound signal using multiple features. Appl. Sci. 2018, 8, 2344. [Google Scholar] [CrossRef]
- Narváez, P.; Gutierrez, S.; Percybrooks, W.S. Automatic Segmentation and Classification of Heart Sounds Using Modified Empirical Wavelet Transform and Power Features. Appl. Sci. 2020, 10, 4791. [Google Scholar] [CrossRef]
- Cho, J.; Lee, K.; Shin, E.; Choy, G.; Do, S. How Much Data Is Needed to Train A Medical Image Deep Learning System to Achieve Necessary High Accuracy? arXiv 2016, arXiv:1511.06348. [Google Scholar]
- Baydoun, M.; Safatly, L.; Ghaziri, H.; El Hajj, A. Analysis of heart sound anomalies using ensemble learning. Biomed. Signal Process. Control 2020, 62, 102019. [Google Scholar] [CrossRef]
- Thomae, C.; Dominik, A. Using deep gated RNN with a convolutional front end for end-to-end classification of heart sound. In Proceedings of the 2016 Computing in Cardiology Conference (CinC), Vancouver, BC, Canada, 11–14 September 2016; pp. 625–628. [Google Scholar]
- Narváez, P.; Percybrooks, W.S. Synthesis of Normal Heart Sounds Using Generative Adversarial Networks and Empirical Wavelet Transform. Appl. Sci. 2020, 10, 7003. [Google Scholar] [CrossRef]
- Ren, Z.; Cummins, N.; Pandit, V.; Han, J.; Qian, K.; Schuller, B. Learning Image-based Representations for Heart Sound Classification. In Proceedings of the 2018 International Conference on Digital Health, Lyon, France, 23–26 April 2018; pp. 143–147. [Google Scholar]
- Humayun, A.I.; Khan, T.; Ghaffarzadegan, S.; Feng, Z.; Hasan, T. An Ensemble of Transfer, Semi-supervised and Supervised Learning Methods for Pathological Heart Sound Classification. arXiv 2018, arXiv:1806.06506. [Google Scholar]
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How transferable are features in deep neural networks? In Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 3320–3328. [Google Scholar]






| Approaches | Strengths | Limitations |
|---|---|---|
| Tradition machine learning | 1. Easy to train. 2. Can effectively and quickly solve the objective function by convex optimization algorithm. | 1. Has a complex data preprocess and the segmenting of heart sound signal is indispensable. 2. Has generalization and robustness issues. |
| Deep learning | 1. Can effectively and automatically learn feature representations and the trained model is very good generally. 2. Good performance in classification. | 1. The training process takes a long-time and is affected by limited datasets. 2. High requirements for hardware configuration. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, W.; Sun, Q.; Chen, X.; Xie, G.; Wu, H.; Xu, C. Deep Learning Methods for Heart Sounds Classification: A Systematic Review. Entropy 2021, 23, 667. https://doi.org/10.3390/e23060667
Chen W, Sun Q, Chen X, Xie G, Wu H, Xu C. Deep Learning Methods for Heart Sounds Classification: A Systematic Review. Entropy. 2021; 23(6):667. https://doi.org/10.3390/e23060667
Chicago/Turabian StyleChen, Wei, Qiang Sun, Xiaomin Chen, Gangcai Xie, Huiqun Wu, and Chen Xu. 2021. "Deep Learning Methods for Heart Sounds Classification: A Systematic Review" Entropy 23, no. 6: 667. https://doi.org/10.3390/e23060667
APA StyleChen, W., Sun, Q., Chen, X., Xie, G., Wu, H., & Xu, C. (2021). Deep Learning Methods for Heart Sounds Classification: A Systematic Review. Entropy, 23(6), 667. https://doi.org/10.3390/e23060667