
Research on Channel Selection and Multi-Feature Fusion of EEG Signals for Mental Fatigue Detection



Abstract
1. Introduction
2. Methods
2.1. Channel Selection Based on ReliefF
| Algorithm 1. Relief algorithm |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| Algorithm 2. ReliefF algorithm |
|
|
|
|
|
|
Equation (5), |
|
|
|
|
|
|
|
|
2.2. Common Channel Selection Based on Weight Addition
2.3. Common Channel Selection Based on Weighted Classification Performance Using a Single Channel
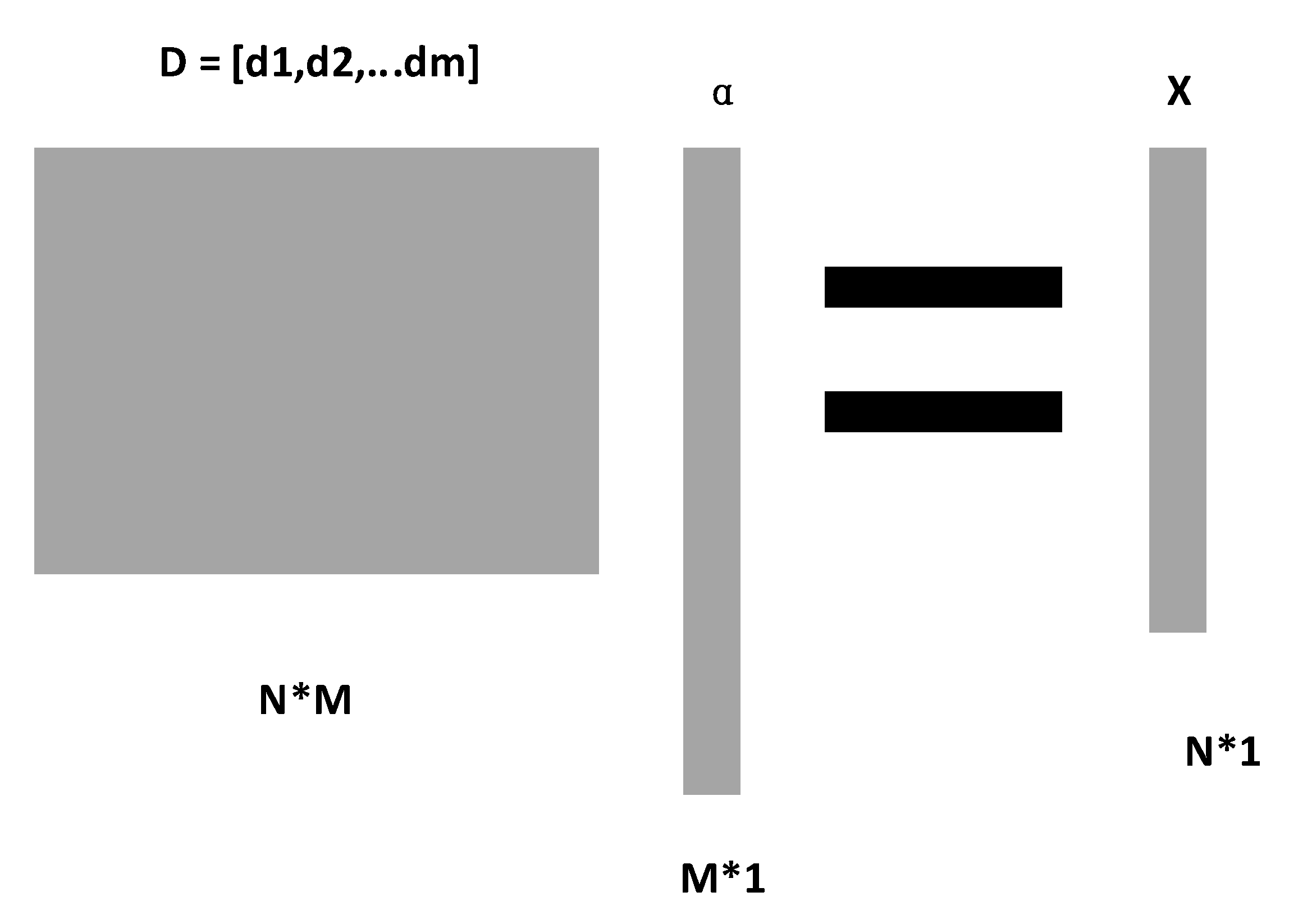
2.4. Feature Fusion Based on Sparse Representation
2.4.1. Feature Extraction
2.4.2. Sparse Representation
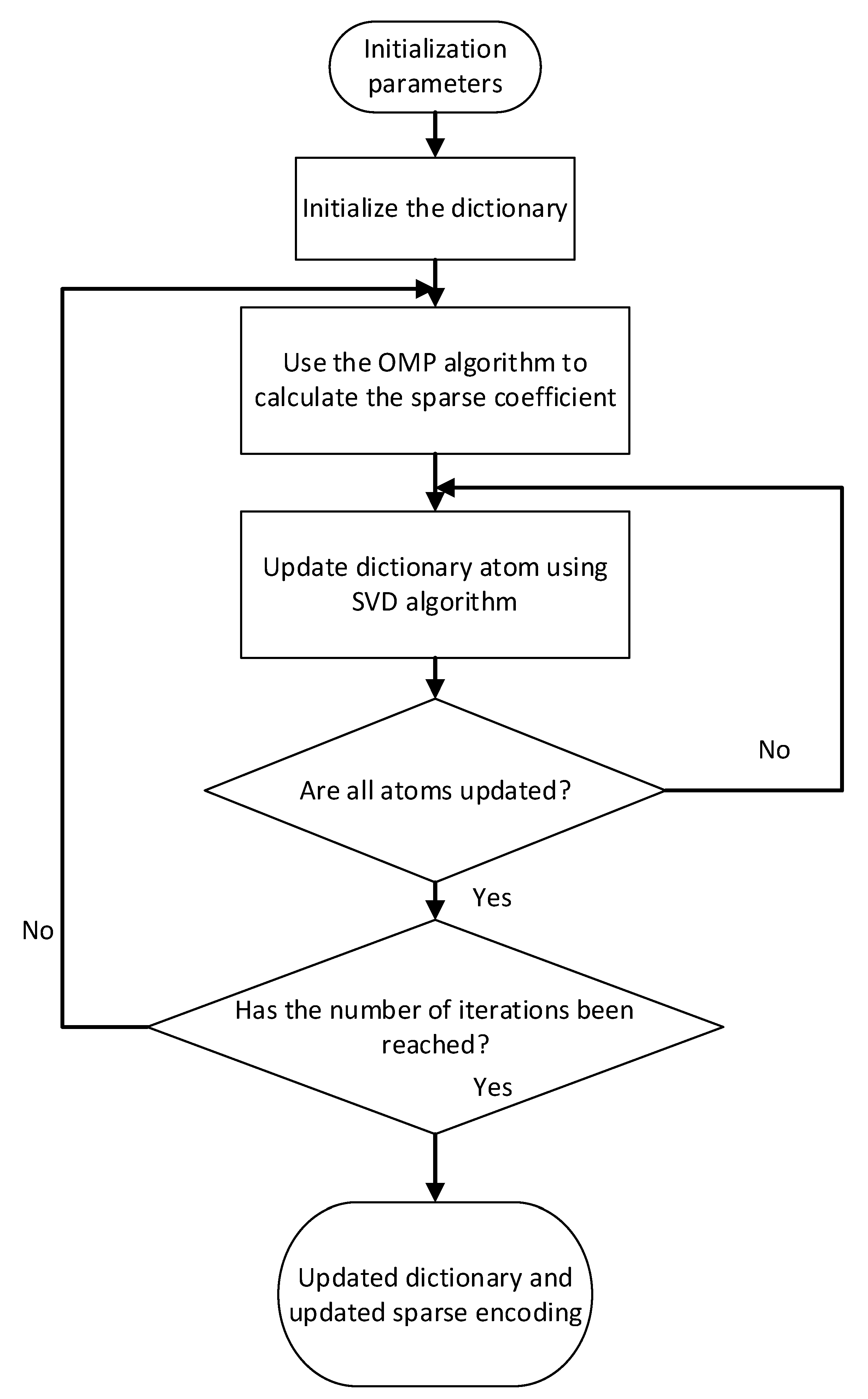
2.4.3. Multi-Class Feature Fusion Based on K-SVD
3. Experimental Setup
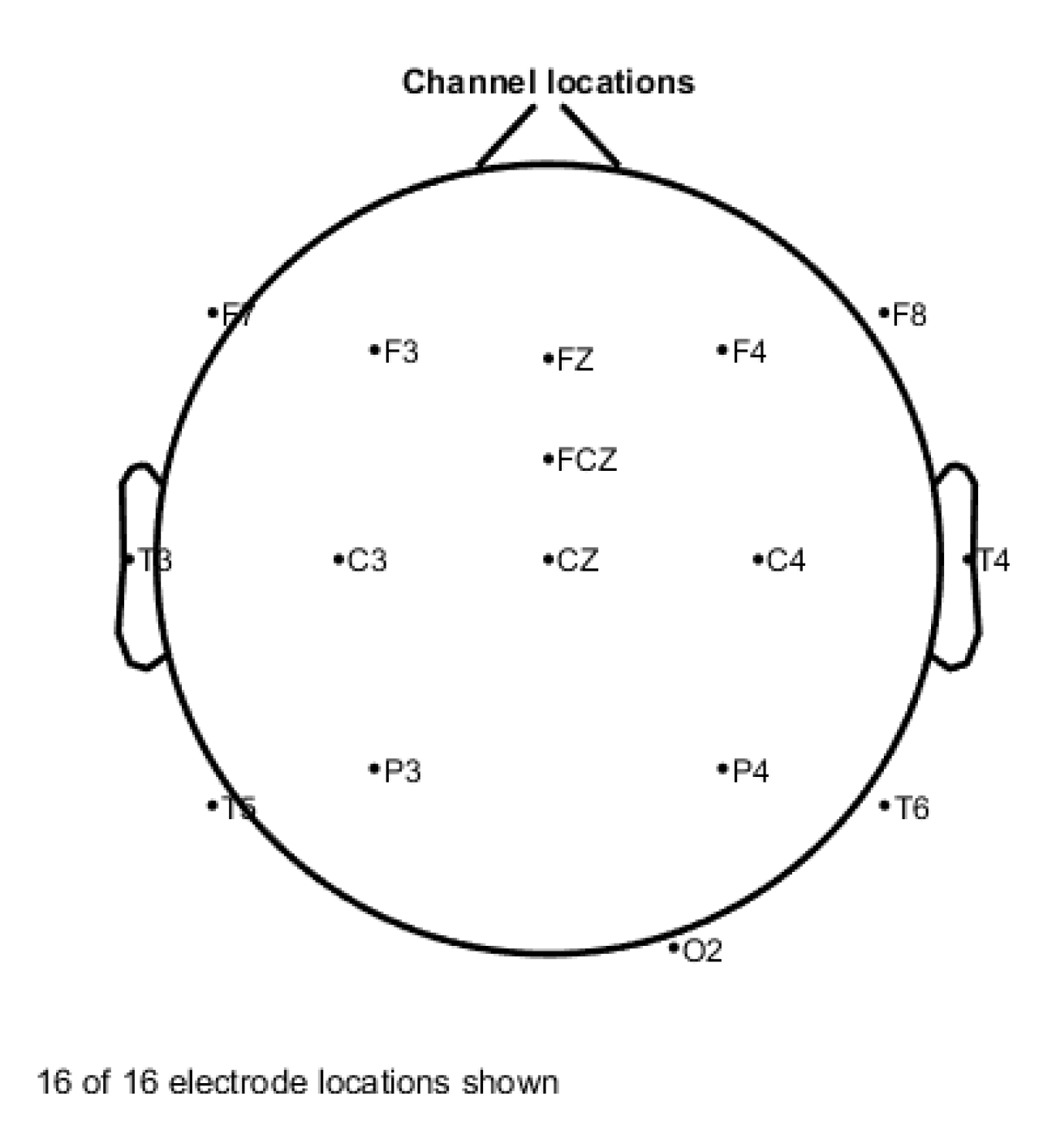
3.1. Subject and Experiment Environment
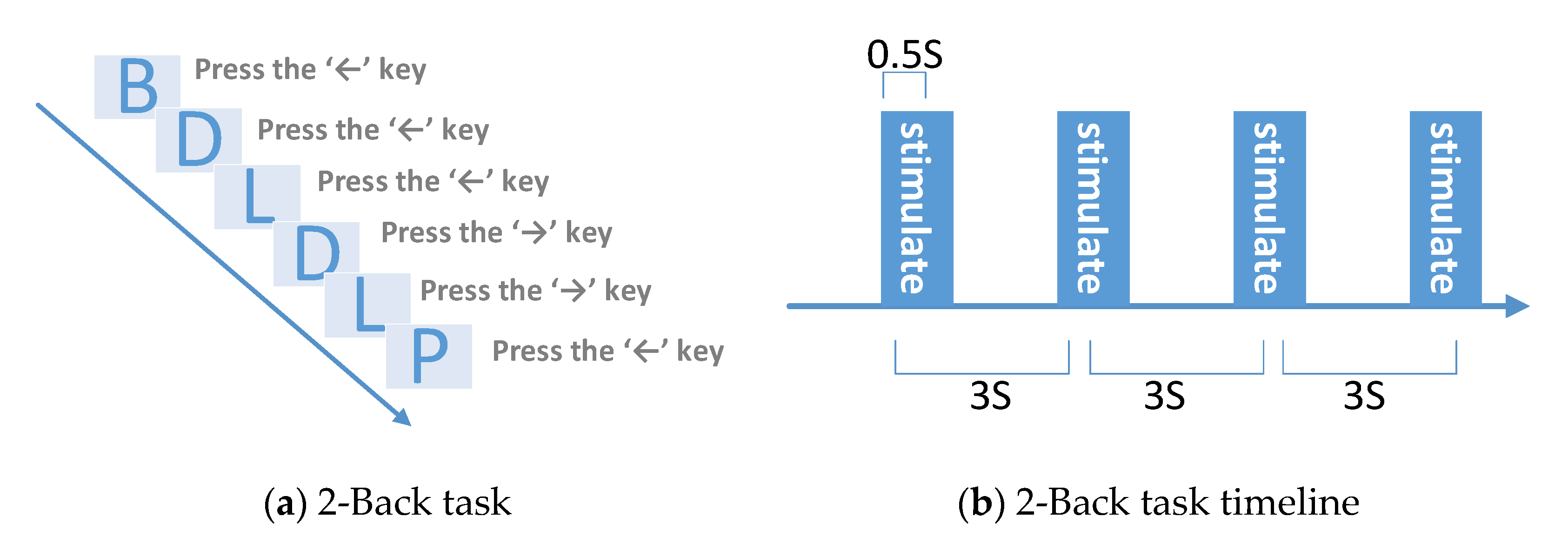
3.2. 2-Back Task
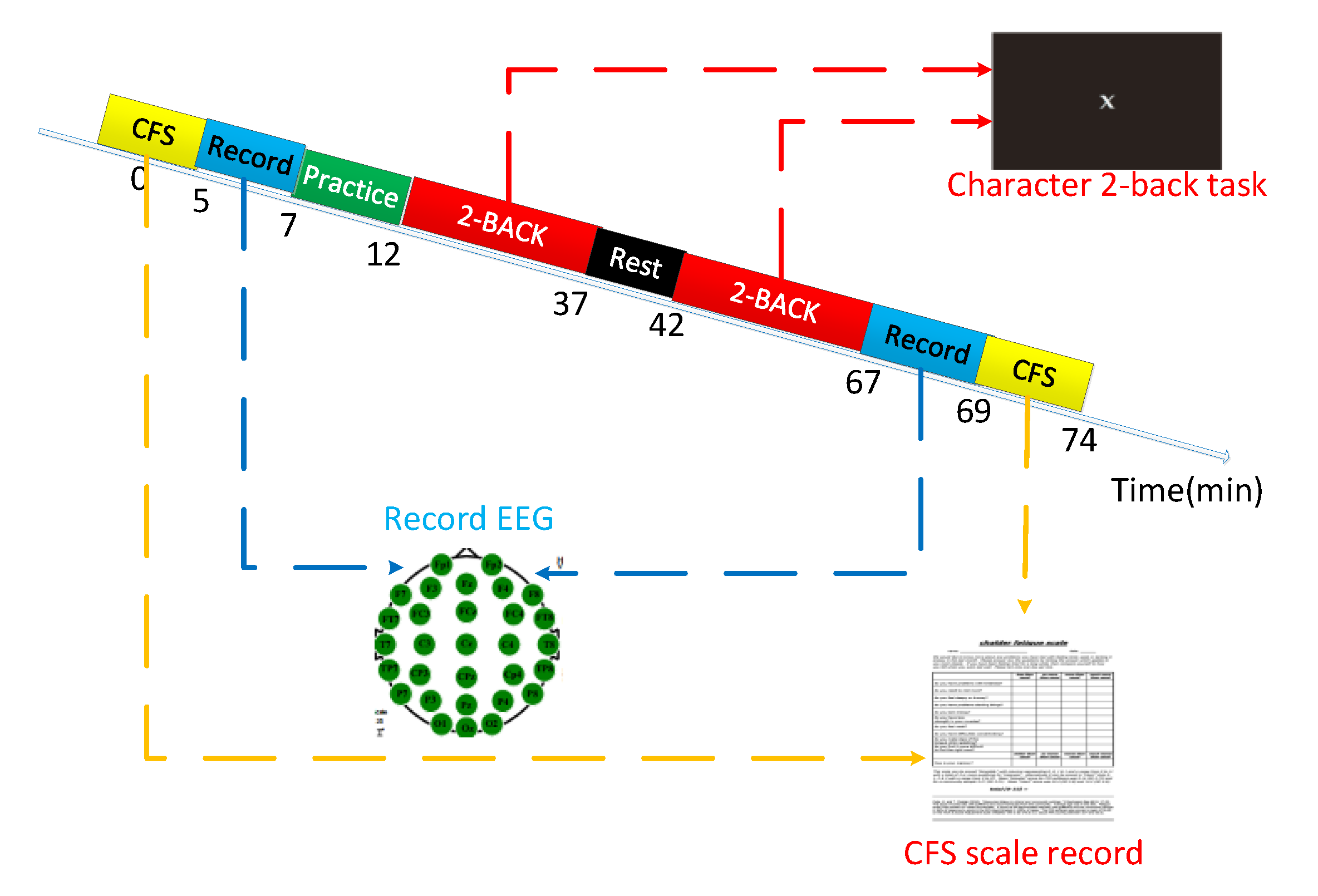
3.3. Experimental Design and Procedures
- Step 1:
- The subject put on an electroencephalogram cap and applied conductive paste to sit on the experimental chair and prepare for the experiment.
- Step 2:
- The subject sat and filled in the Chalder fatigue scale.
- Step 3:
- The subject sat quietly on the experimental chair and EEG data were collected for 2 min.
- Step 4:
- The subject began the 2-back task training stage until the accuracy rate reached 0.8 or above.
- Step 5:
- The subject began the first round of 2-back task formal experiment, and the subject’s key response and response time were recorded for 25 min.
- Step 6:
- The subject rested for 5 min.
- Step 7:
- The subject began the second round of the 2-back task formal experiment, and the subject’s key response and response time were recorded for 25 min.
- Step 8:
- The subject sat quietly on the experimental chair and the subject’s EEG data were collected for 2 min.
- Step 9:
- Subject sat and filled in the Chalder fatigue scale.
- Step 10:
- The experiment ended.
4. Results and Discussion
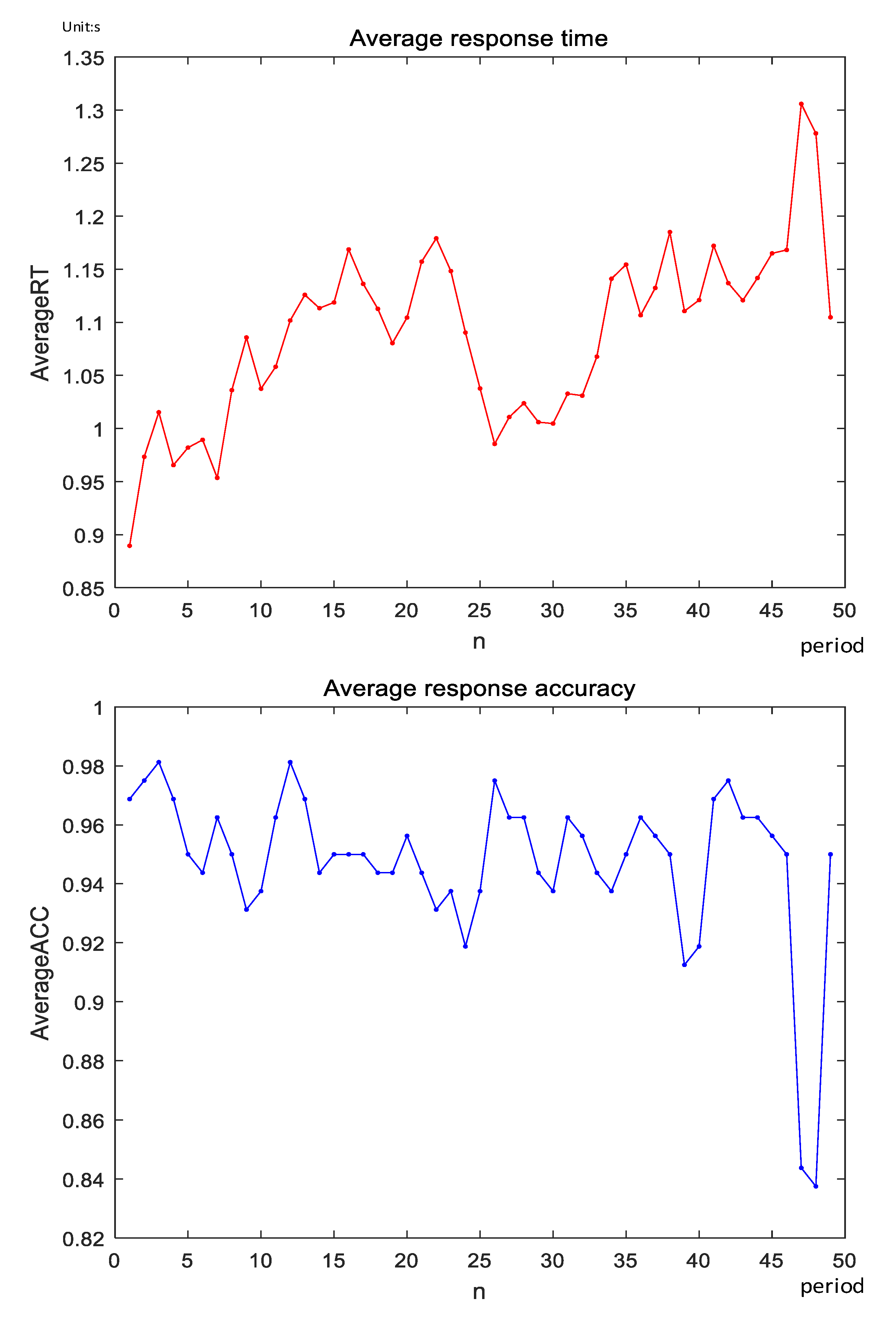
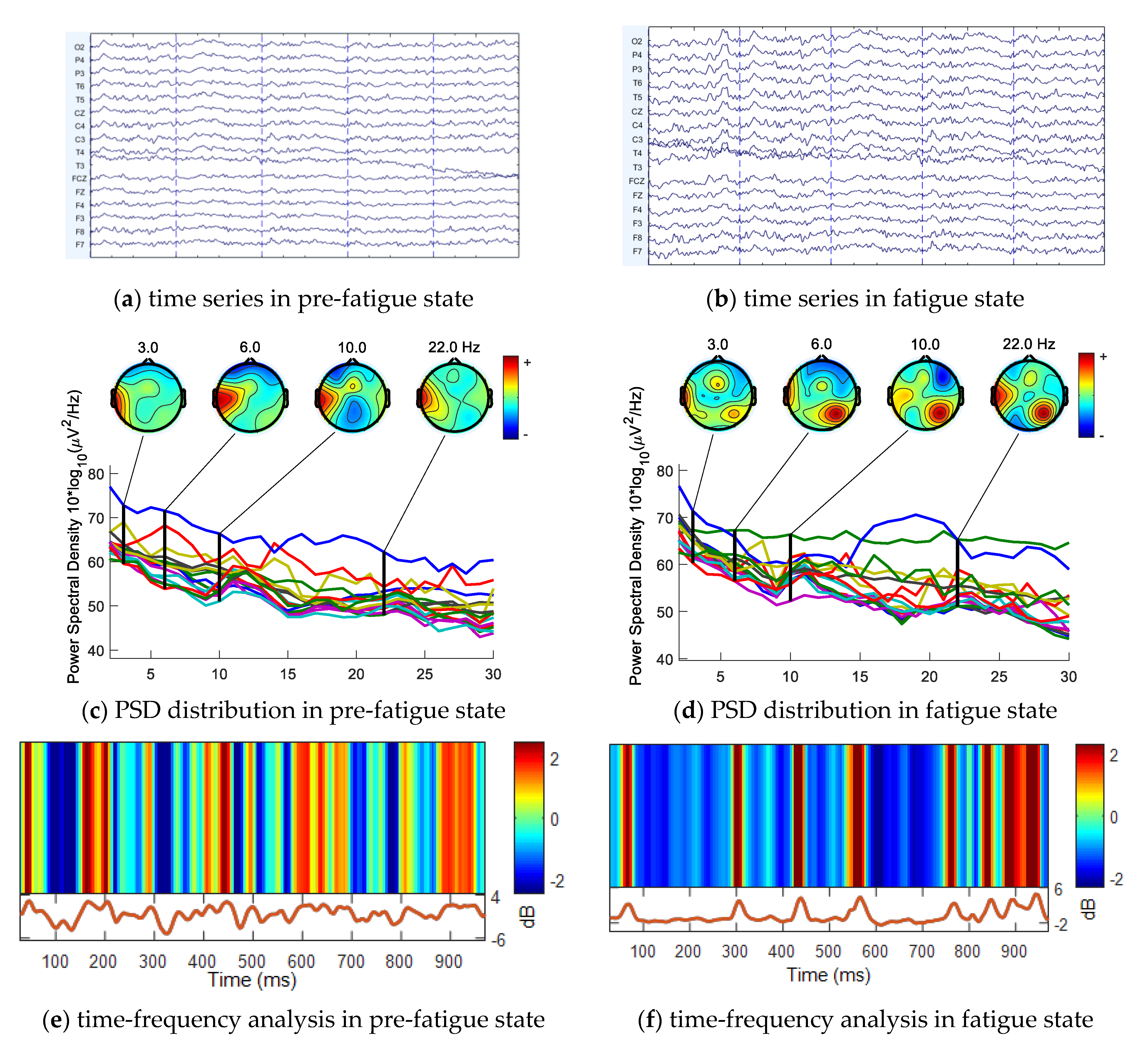
4.1. 2-Back Task Result Analysis
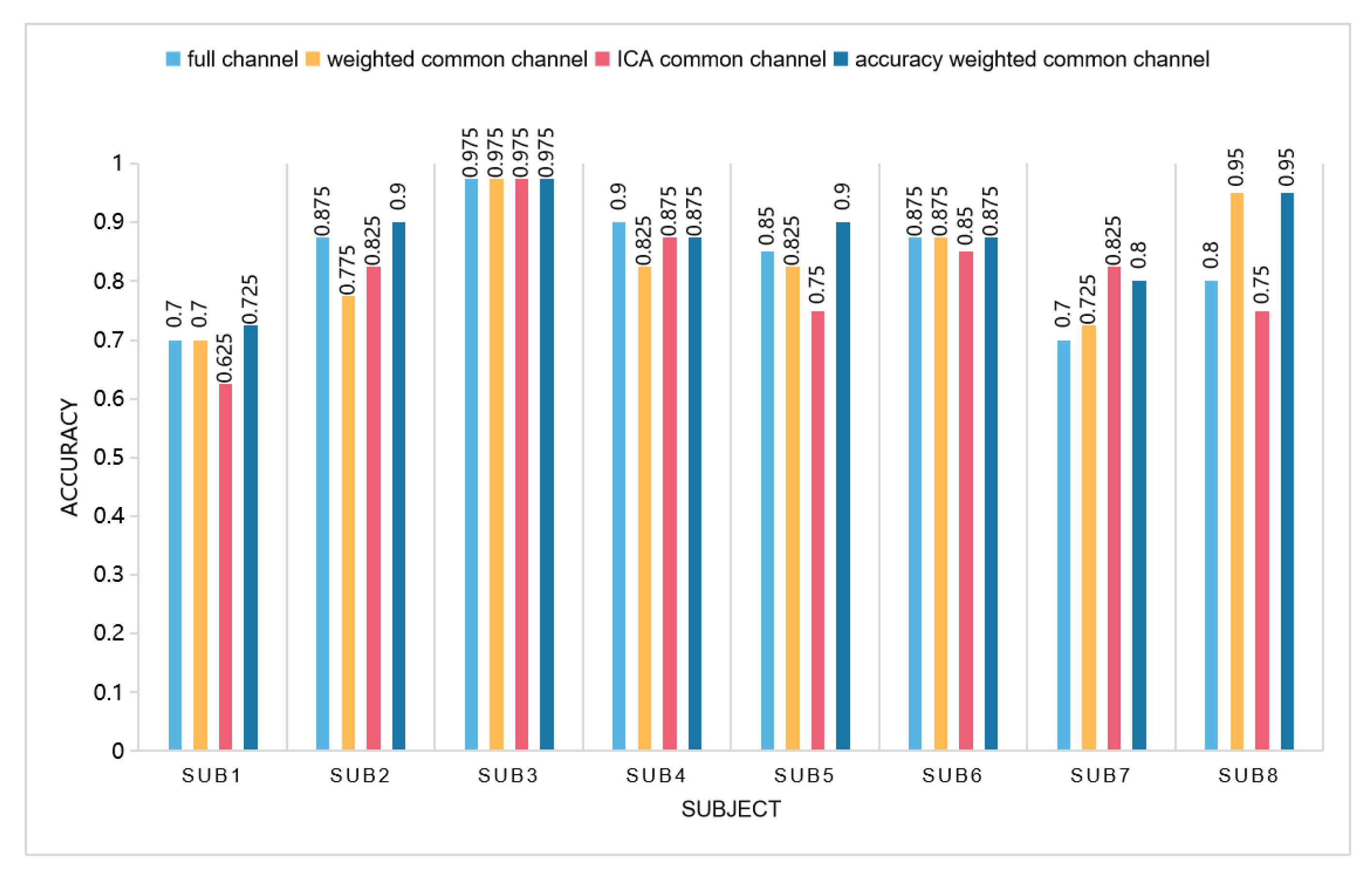
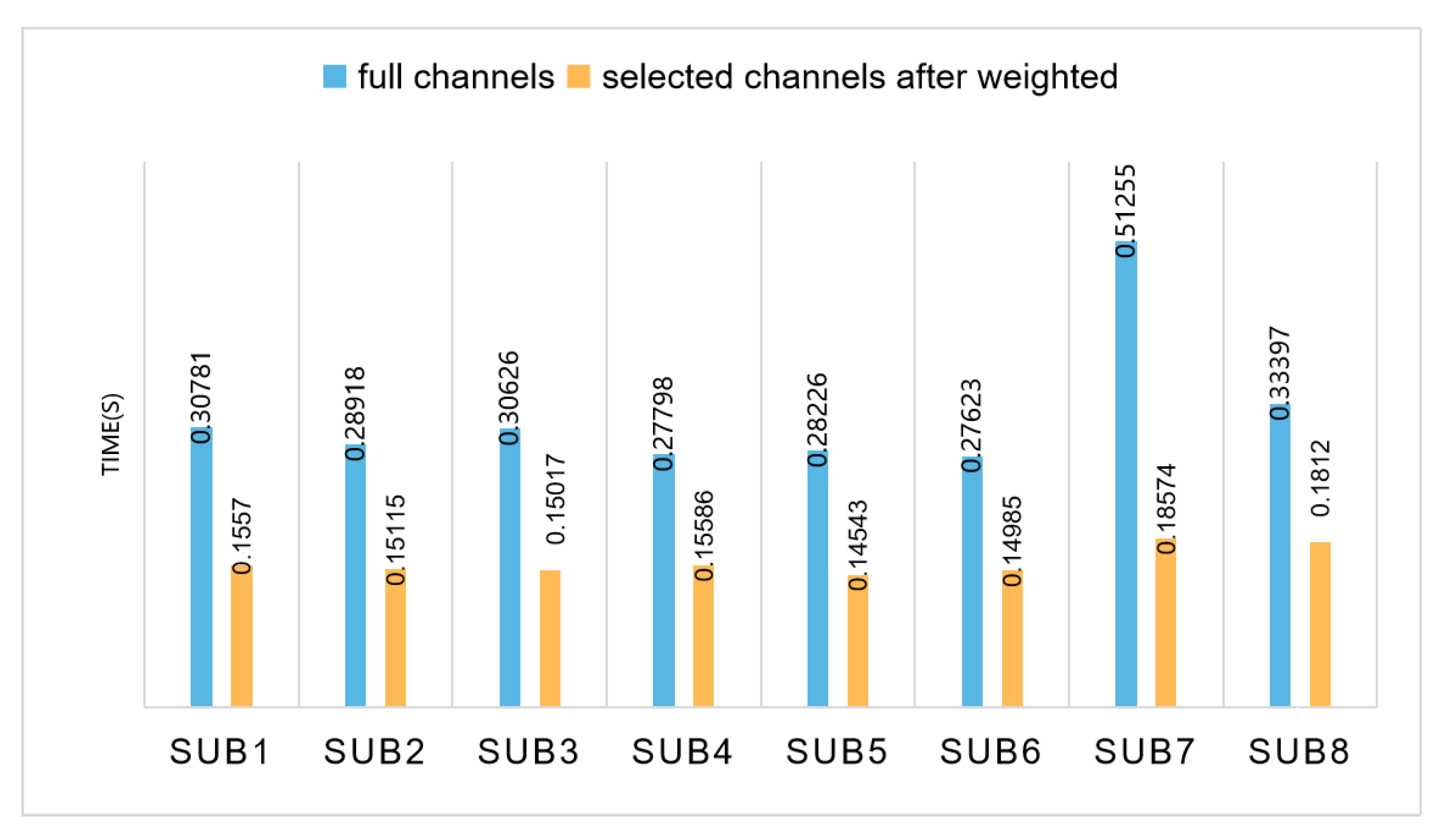
4.2. Channel Selection Result Analysis
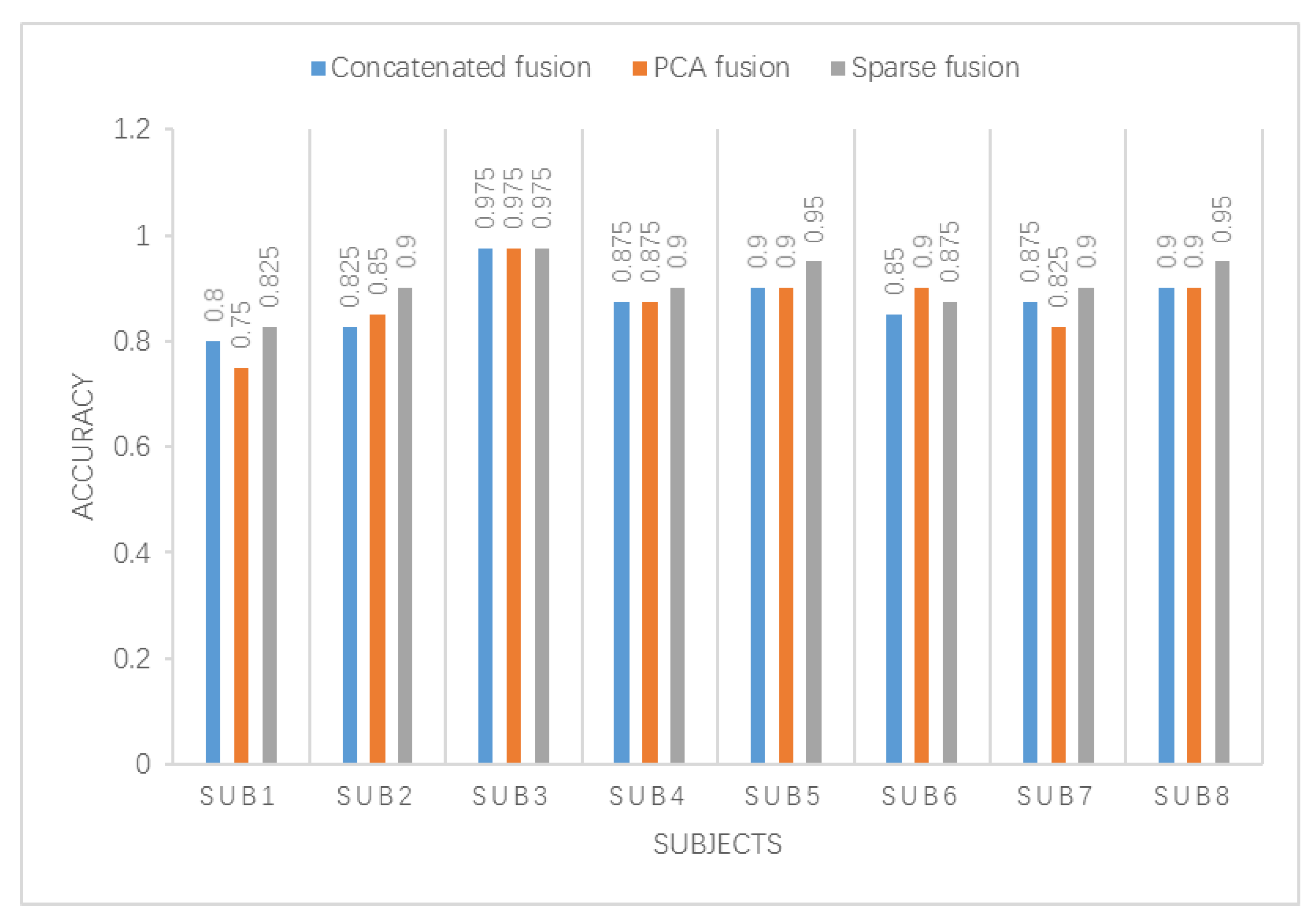
4.3. Feature Fusion Result Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Helton, W.S.; Russell, P.N. Working memory load and the vigilance decrement. Exp. Brain Res. 2011, 212, 429–437. [Google Scholar] [CrossRef] [PubMed]
- Talukdar, U.; Hazarika, S.M. Estimation of mental fatigue during EEG based motor imagery. In Proceedings of the International Conference on Intelligent Human Computer Interaction, Pilani, India, 12–13 December 2016. [Google Scholar]
- Lees, T.; Chalmers, T.; Burton, D. Electroencephalography as a predictor of self-report fatigue/sleepiness during monotonous driving in train drivers. Physiol. Meas. 2018, 39, 105012. [Google Scholar] [CrossRef] [PubMed]
- Craig, A.; Tran, Y.; Wijesuriya, N. Regional brain wave activity changes associated with fatigue. Psychophysiology 2012, 49, 574–582. [Google Scholar] [CrossRef] [PubMed]
- Itoh, M.; Ishikawa, R.; Inagaki, T. Evaluating body movements of a drowsy driver with pressure distribution sensors. In Proceedings of the FAST-Zero’15: 3rd International Symposium on Future Active Safety Technology toward Zero Traffic Accidents, Gothenburg, Sweden, 9–11 September 2015. [Google Scholar]
- Fernstrom, J.D.; Fernstrom, M.H. Exercise, serum free tryptophan, and central fatigue. J. Nutr. 2006, 136, 553S–559S. [Google Scholar] [CrossRef] [PubMed]
- Chai, R.; Tran, Y.; Naik, G.R. Classification of EEG based-mental fatigue using principal component analysis and Bayesian neural network. In Proceedings of the 2016 38th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Orlando, FL, USA, 16–20 August 2016. [Google Scholar]
- Chen, J.; Wang, H.; Hua, C. Electroencephalography based fatigue detection using a novel feature fusion and extreme learning machine. Cogn. Syst. Res. 2018, 52, 715–728. [Google Scholar] [CrossRef]
- Chai, R.; Tran, Y.; Craig, A. Enhancing accuracy of mental fatigue classification using advanced computational intelligence in an electroencephalography system. In Proceedings of the 2014 36th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Chicago, IL, USA, 26–30 August 2014. [Google Scholar]
- Chai, R.; Naik, G.R.; Ling, S.H. Channels selection using independent component analysis and scalp map projection for EEG-based driver fatigue classification. In Proceedings of the 2017 39th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Jeju, Korea, 11–15 July 2017. [Google Scholar]
- Nguyen, T.; Ahn, S.; Jang, H. Utilization of a combined EEG/NIRS system to predict driver drowsiness. Sci. Rep. 2017, 7, 43933. [Google Scholar] [CrossRef] [PubMed]
- Rohit, F.; Kulathumani, V.; Kavi, R. Real-time drowsiness detection using wearable, lightweight brain sensing headbands. IET Intell. Transp. Syst. 2017, 11, 255–263. [Google Scholar] [CrossRef]
- Wang, L.; Hua, C.C.; Jiang, X. Investigation on Driver Fatigue Testing Based on the Combination of Cervical-Lumbar EMG and EEG. J. Northeast. Univ. Nat. Sci. 2018, 39, 102–107. [Google Scholar]
- Zhang, C.; Wang, H.; Fu, R. Automated detection of driver fatigue based on entropy and complexity measures. IEEE Trans. Intell. Transp. Syst. 2013, 15, 168–177. [Google Scholar] [CrossRef]
- Han, C.; Sun, X.; Yang, Y. Brain complex network characteristic analysis of fatigue during simulated driving based on electroencephalogram signals. Entropy 2019, 21, 353. [Google Scholar] [CrossRef] [PubMed]
- Zhao, C.; Zhao, M.; Yang, Y. The reorganization of human brain networks modulated by driving mental fatigue. IEEE J. Biomed. Health Inform. 2016, 21, 743–755. [Google Scholar] [CrossRef] [PubMed]
- Tzimourta, K.D.; Tsoulos, I.; Bilero, T. Direct Assessment of Alcohol Consumption in Mental State Using Brain Computer Interfaces and Grammatical Evolution. Inventions 2018, 3, 51. [Google Scholar] [CrossRef]
- Hu, J.; Min, J. Automated detection of driver fatigue based on EEG signals using gradient boosting decision tree model. Cogn. Neurodyn. 2018, 12, 431–440. [Google Scholar] [CrossRef] [PubMed]
- Peláez Suárez, A.A.; Berrillo Batista, S.; Pedroso Ibáñez, I.; Casabona Fernández, E.; Fuentes Campos, M.; Chacón, L.M. EEG-Derived Functional Connectivity Patterns Associated with Mild Cognitive Impairment in Parkinson’s Disease. Behav. Sci. 2021, 11, 40. [Google Scholar] [CrossRef] [PubMed]
- Ruiz-Gómez, S.J.; Hornero, R.; Poza, J. A new method to build multiplex networks using Canonical Correlation Analysis for the characterization of the Alzheimer’s disease continuum. J. Neural Eng. 2021, 18, 026002. [Google Scholar] [CrossRef] [PubMed]
- Reyes, O.; Morell, C.; Ventura, S. Scalable extensions of the ReliefF algorithm for weighting and selecting features on the multi-label learning context. Neurocomputing 2015, 161, 168–182. [Google Scholar] [CrossRef]
- Kira, K.; Rendell, L.A. The feature selection problem: Traditional methods and a new algorithm. In Proceedings of the AAAI Tenth National Conference on Artificial Intelligence, San Jose, CA, USA, 12–16 July 1992. [Google Scholar]
- Tong, L.; Zhao, J.; Fu, W. Emotion recognition and channel selection based on EEG Signal. In Proceedings of the 11th International Conference on Intelligent Computation Technology and Automation (ICICTA), Changsha, China, 22–23 September 2018; pp. 101–105. [Google Scholar]
- Cai, D.; He, X.; Han, J. SRDA: An efficient algorithm for large-scale discriminant analysis. IEEE Trans. Knowl. Data Eng. 2007, 20, 1–12. [Google Scholar]
- Zhang, Z.; Xu, Y.; Yang, J. A survey of sparse representation: Algorithms and applications. IEEE Access 2015, 3, 490–530. [Google Scholar] [CrossRef]
- Zhang, Q.; Li, B. Discriminative K-SVD for dictionary learning in face recognition. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2691–2698. [Google Scholar]
- Viola, F.C.; Debener, S.; Thorne, J. Using ICA for the analysis of multi-channel EEG data. In Simultaneous EEG and fMRI. Recording, Analysis, and Application; Oxford University Press: Oxford, UK, 2010; pp. 121–133. [Google Scholar]
- Delorme, A.; Makeig, S. EEGLAB: An open source toolbox for analysis of single-trial EEG dynamics including independent component analysis. J. Neurosci. Methods 2004, 134, 9–21. [Google Scholar] [CrossRef] [PubMed]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Features | Feature Details |
|---|---|
| Frequency domain features | Power spectral density in the beta band (12–30 Hz) |
| Power spectral density in the alpha band (8–12 Hz) | |
| Power spectral density in the theta band (4–8 Hz) | |
| Power spectral density in the delta band (0.5–4 Hz) | |
| Time domain feature | Sample entropy |
| Subject | Accuracy | Precision | F1 Score |
|---|---|---|---|
| Sub1 | 0.825 ± 0.01 | 0.842 ± 0.071 | 0.817 ± 0.079 |
| Sub2 | 0.90 ± 0.04 | 0.834 ± 0.044 | 0.897 ± 0.1 |
| Sub3 | 0.97 ± 0.005 | 0.962 ± 0.011 | 0.966 ± 0.04 |
| Sub4 | 0.90 ± 0.02 | 0.891 ± 0.05 | 0.91 ± 0.04 |
| Sub5 | 0.95 ± 0.10 | 0.925 ± 0.012 | 0.906 ± 0.083 |
| Sub6 | 0.875 ± 0.02 | 0.84 ± 0.060 | 0.870 ± 0.08 |
| Sub7 | 0.90 ± 0.013 | 0.858 ± 0.121 | 0.89 ± 0.113 |
| Sub8 | 0.95 ± 0.025 | 0.971 ± 0.081 | 0.959 ± 0.004 |
| Subject | Sample Entropy Feature | PSD (Delta Band) | PSD (Theta Band) | PSD (Alpha Band) | PSD (Beta Band) | Sparse Fusion Feature |
|---|---|---|---|---|---|---|
| Sub1 | 0.8 | 0.775 | 0.65 | 0.75 | 0.75 | 0.825 |
| Sub2 | 0.9 | 0.725 | 0.775 | 0.725 | 0.8 | 0.9 |
| Sub3 | 0.95 | 0.95 | 0.675 | 0.55 | 0.7 | 0.97 |
| Sub4 | 0.775 | 0.875 | 0.85 | 0.825 | 0.775 | 0.9 |
| Sub5 | 0.875 | 0.725 | 0.775 | 0.925 | 0.875 | 0.95 |
| Sub6 | 0.85 | 0.575 | 0.875 | 0.6 | 0.8 | 0.875 |
| Sub7 | 0.525 | 0.8 | 0.625 | 0.8 | 0.65 | 0.9 |
| Sub8 | 0.925 | 0.675 | 0.65 | 0.775 | 0.85 | 0.95 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Q.; Liu, Y.; Chen, K.; Wang, L.; Li, Z.; Ai, Q.; Ma, L. Research on Channel Selection and Multi-Feature Fusion of EEG Signals for Mental Fatigue Detection. Entropy 2021, 23, 457. https://doi.org/10.3390/e23040457
Liu Q, Liu Y, Chen K, Wang L, Li Z, Ai Q, Ma L. Research on Channel Selection and Multi-Feature Fusion of EEG Signals for Mental Fatigue Detection. Entropy. 2021; 23(4):457. https://doi.org/10.3390/e23040457
Chicago/Turabian StyleLiu, Quan, Yang Liu, Kun Chen, Lei Wang, Zhilei Li, Qingsong Ai, and Li Ma. 2021. "Research on Channel Selection and Multi-Feature Fusion of EEG Signals for Mental Fatigue Detection" Entropy 23, no. 4: 457. https://doi.org/10.3390/e23040457
APA StyleLiu, Q., Liu, Y., Chen, K., Wang, L., Li, Z., Ai, Q., & Ma, L. (2021). Research on Channel Selection and Multi-Feature Fusion of EEG Signals for Mental Fatigue Detection. Entropy, 23(4), 457. https://doi.org/10.3390/e23040457