
Phase Transitions in Transfer Learning for High-Dimensional Perceptrons


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
1.1. Models and Learning Formulations
1.2. Main Contributions
1.2.1. Precise Asymptotic Analysis
1.2.2. Phase Transitions
1.3. Related Work
1.4. Organization
2. Technical Assumptions
- and are continuous almost everywhere in . For every and , we have and .
- For any compact interval , there exists a function such thatAdditionally, the function satisfies , where .
3. Sharp Asymptotic Analysis of Soft Transfer Formulation
4. Sharp Asymptotic Analysis of Hard Transfer Formulation
4.1. Asymptotic Predictions
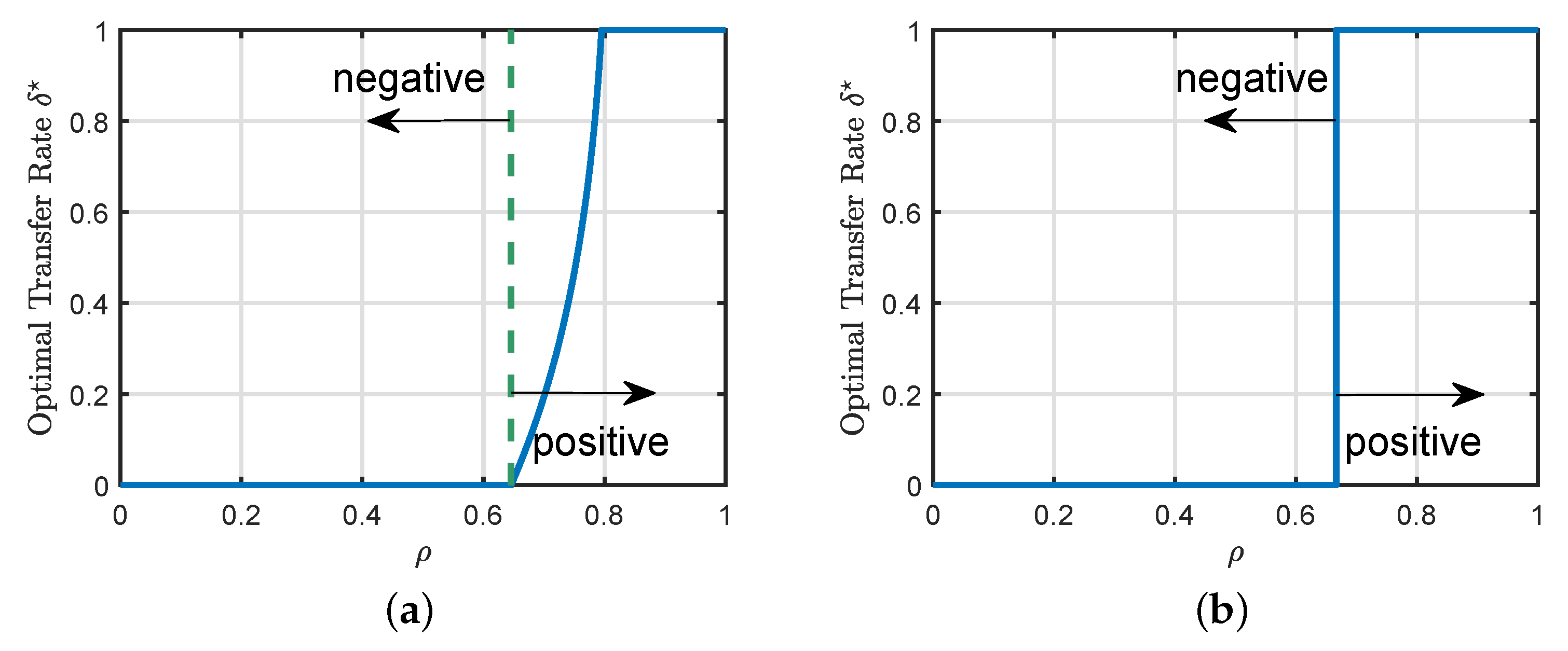
4.2. Phase Transitions
- (a)
- (b)
- (c)
- The data/dimension ratios and satisfy and .
4.3. Sufficient Condition
5. Remarks
5.1. Learning Formulations
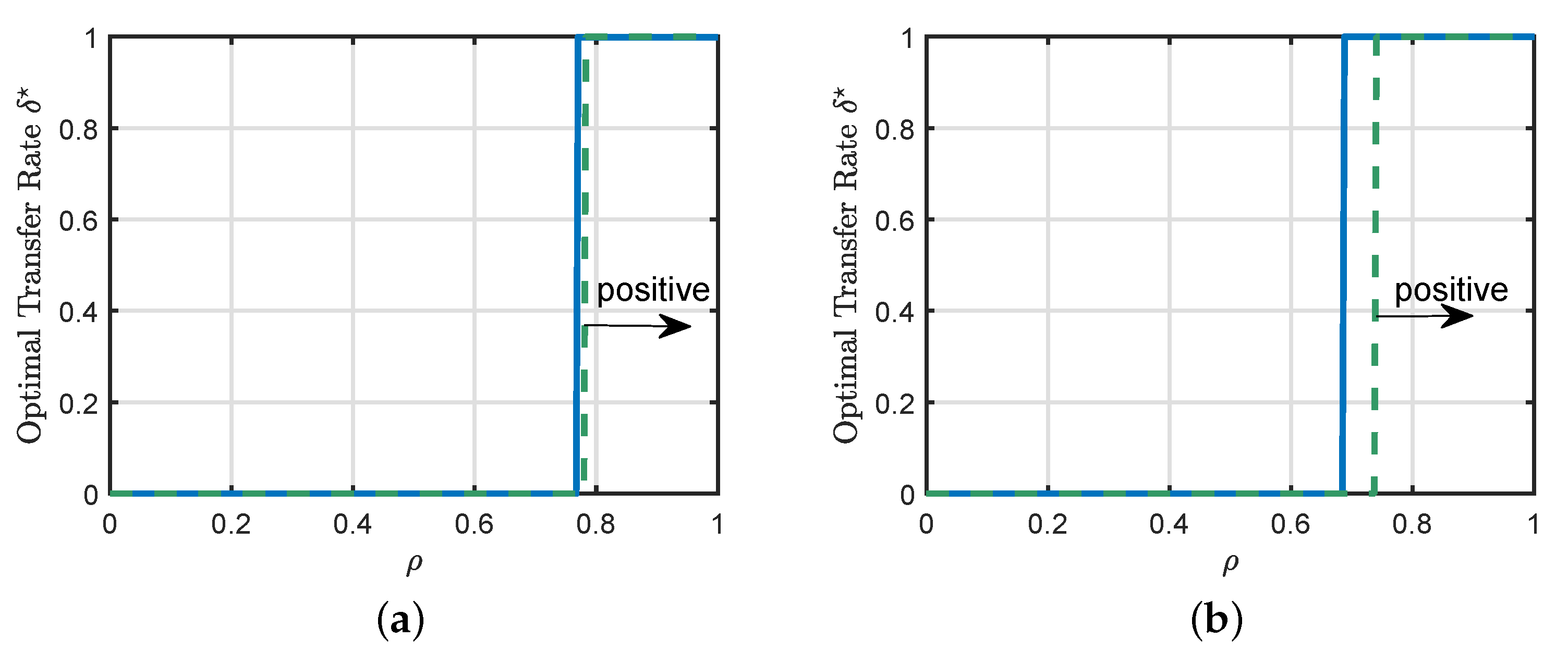
5.2. Transition from Negative to Positive Transfer
6. Additional Simulation Results
6.1. Model Assumptions
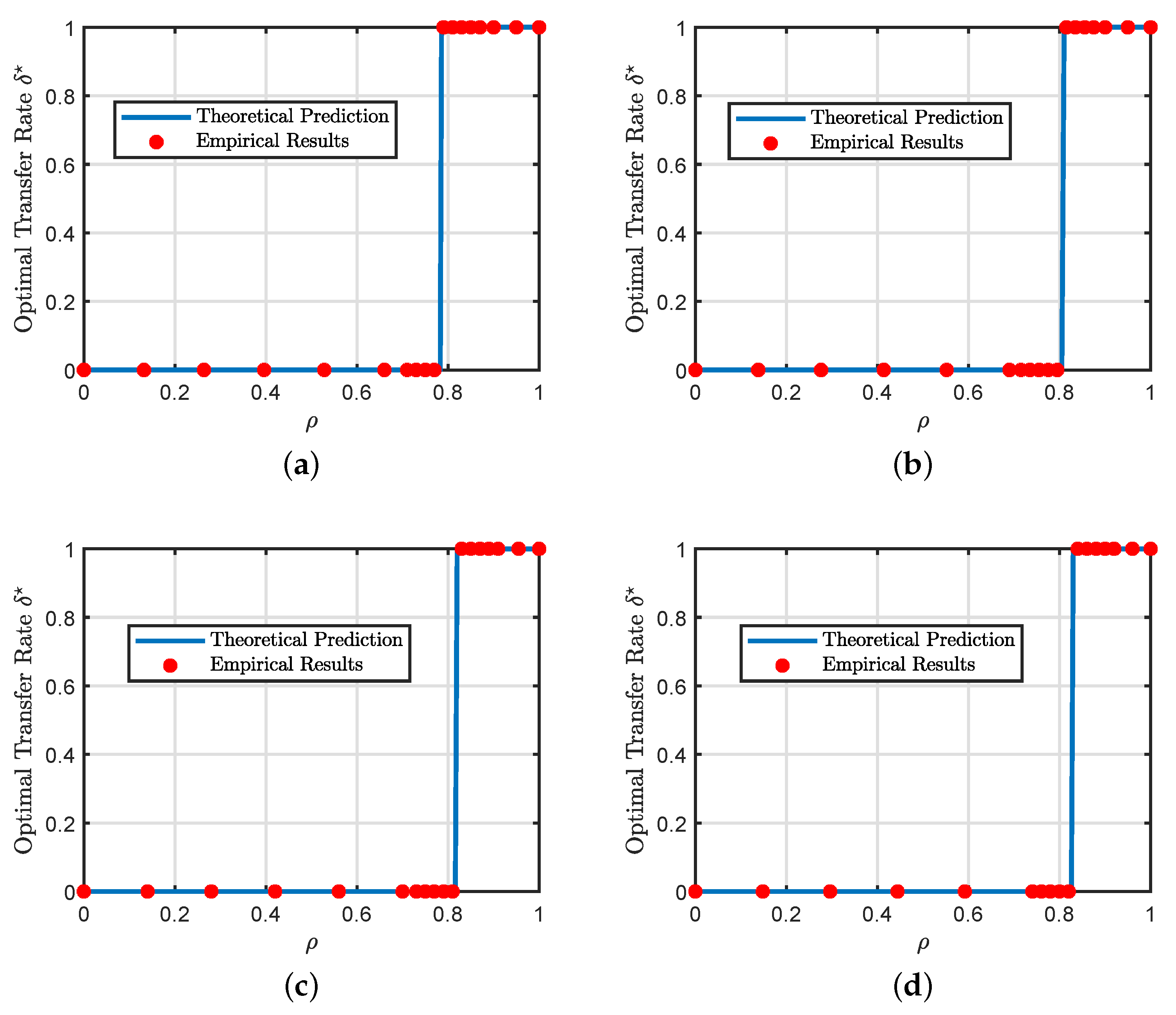
6.2. Phase Transitions in the Hard Formulation
6.3. Sufficient Condition for the Hard Formulation
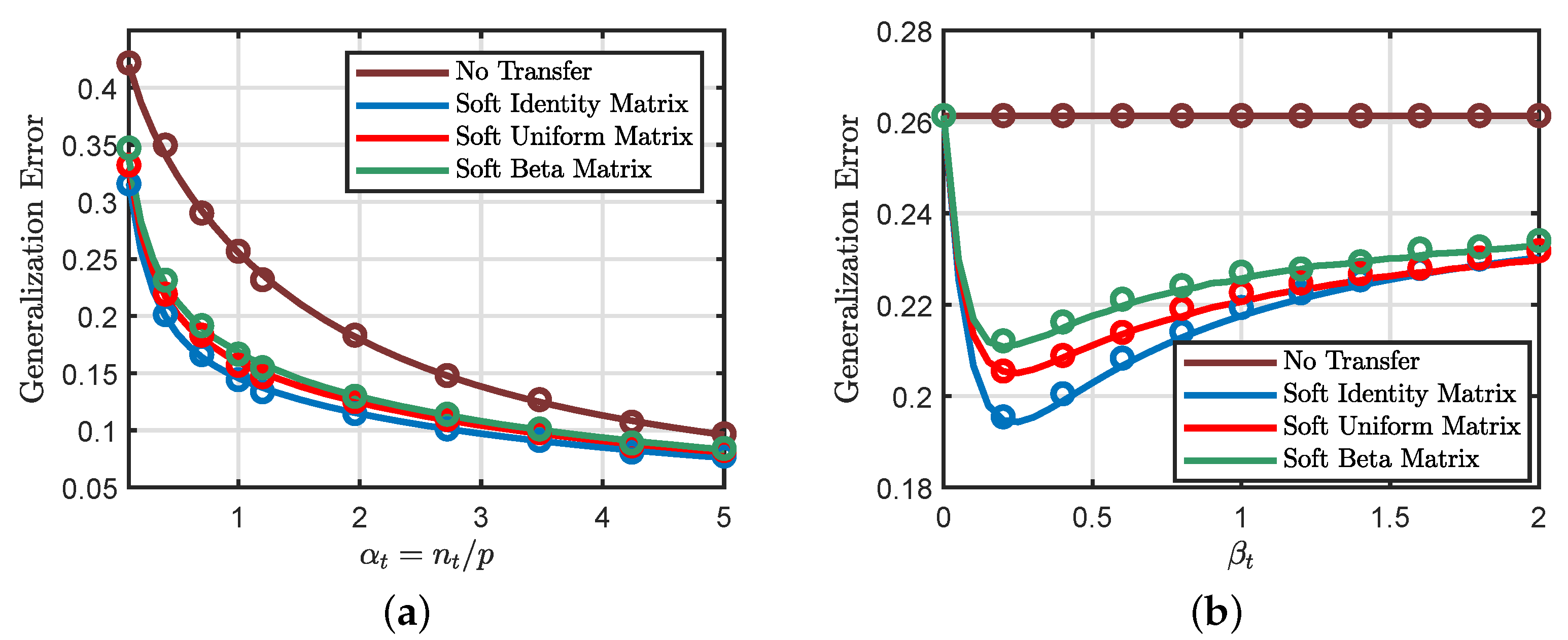
6.4. Soft Transfer: Impact of the Weighting Matrix and Regularization Strength
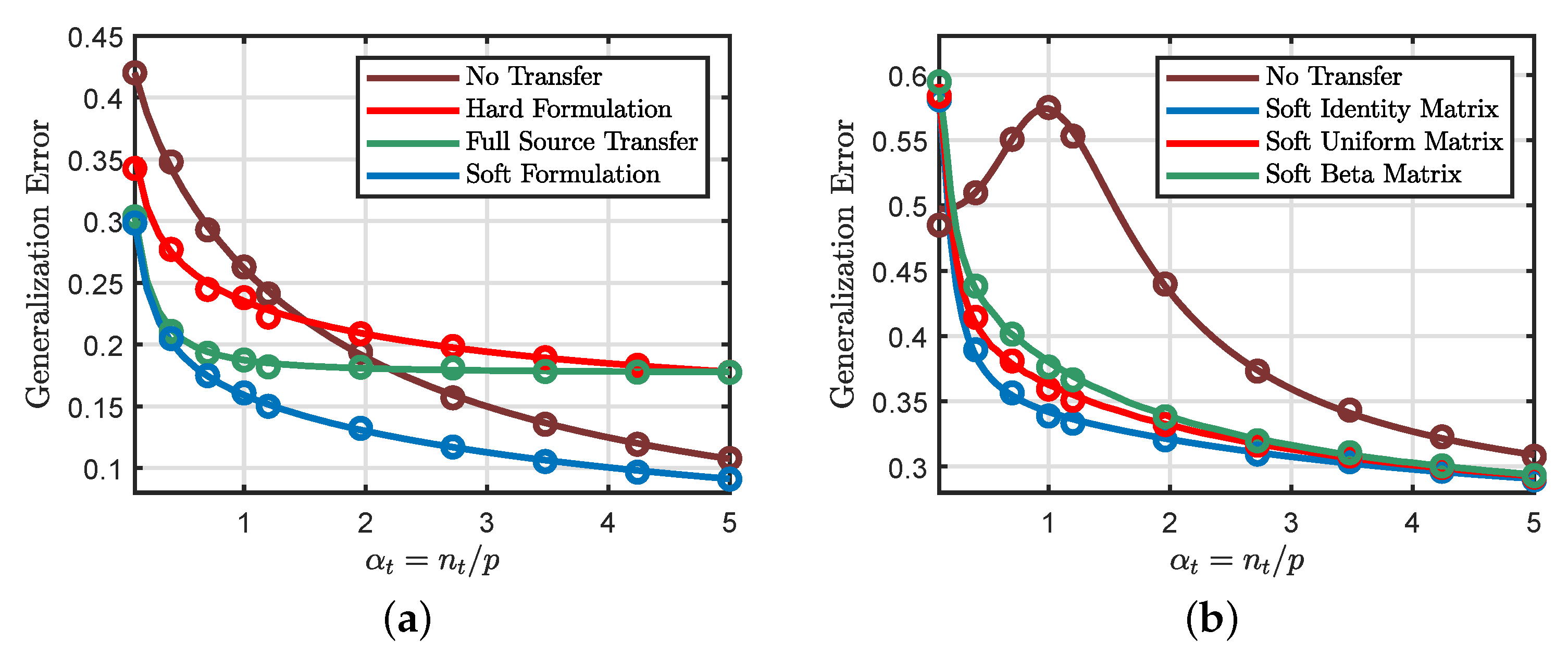
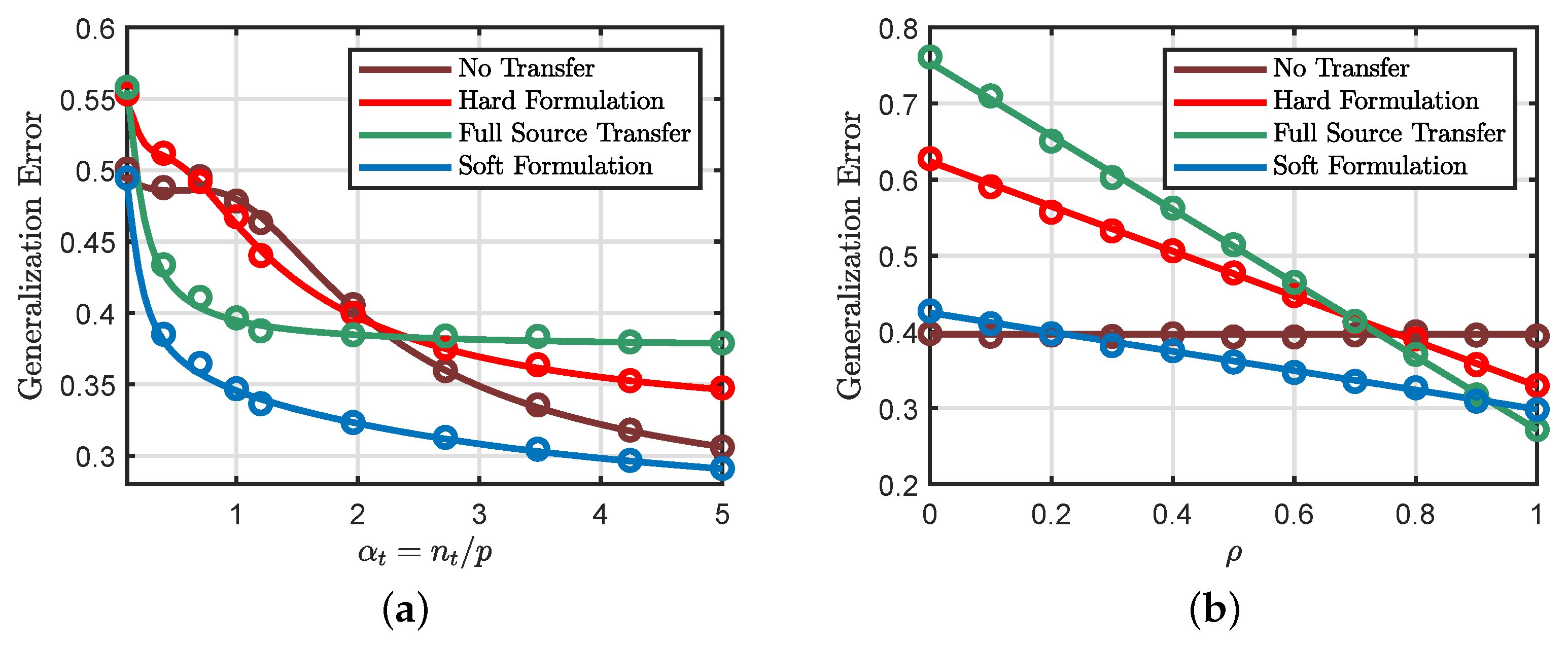
6.5. Soft and Hard Transfer Comparison
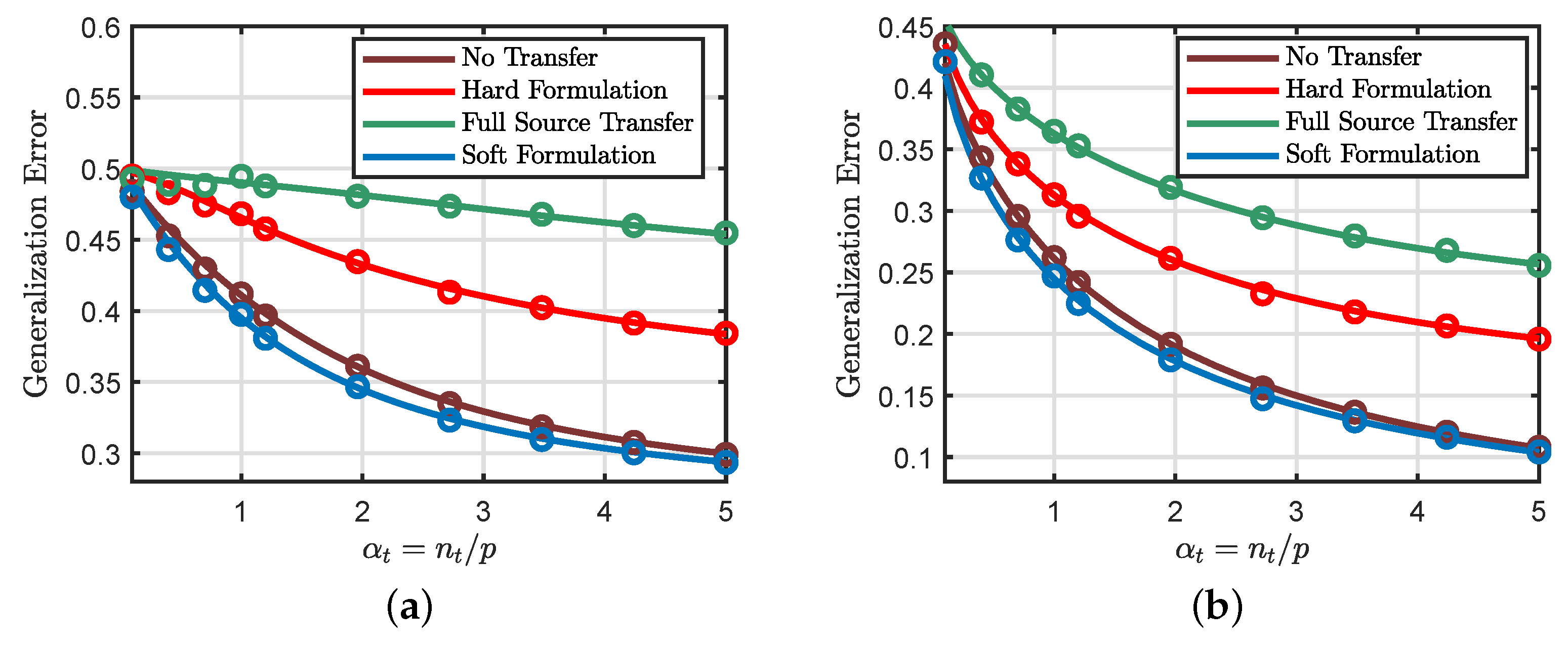
6.6. Effects of the Source Parameters
7. Technical Details
7.1. Technical Tool: Convex Gaussian Min–Max Theorem
- (1)
- There exists a constant ϕ such that the optimal cost converges in probability to ϕ as p goes to .
- (2)
- There exists a positive constant such that with probability going to 1 as .
7.2. Precise Analysis of the Source Formulation
7.3. Precise Analysis of the Soft Transfer Approach
7.3.1. Formulating the Auxiliary Optimization Problem
7.3.2. Simplifying the AO Problem of the Target Task
7.3.3. Asymptotic Analysis of the Target Scalar Formulation
7.3.4. Specialization to Hard Formulation
7.3.5. Asymptotic Analysis of the Training and Generalization Errors
7.4. Phase Transitions in Hard Formulation
7.5. Sufficient Condition for the Hard Formulation
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement.
Informed Consent Statement.
Data Availability Statement.
Conflicts of Interest
Appendix A. Technical Assumptions
- Squared loss: It is easy to see that the squared loss is a proper strongly convex function in , where 1 is a strong convexity parameter. Moreover, and its sub-differential set can be expressed as follows:where the vector is formed by the concatenation of . Then, there exists such thatwith probability going to 1 as p grow to . The inequality follows using the regularity condition in Assumption 4 and the weak law of large numbers. Then, the squared loss satisfies Assumption 3 for any .
- Logistic loss: Now, we consider the logistic loss applied to a binary classification model (i.e., ). Note that the logistic loss is a proper convex function in . Moreover, and its sub-differential set are given byFirst, observe that the loss satisfies the following inequality:This means that there exists such that the following inequality is valid:Additionally, the following results hold true:This means that there exists such that the following inequality is valid:Then, there exists a universal constant such that Assumption 3 is satisfied for the logistic loss for any .
- Hinge loss: Finally, we consider the hinge loss applied to a binary classification model (i.e., ). It is clear that the hinge loss is a proper convex function in . Moreover, is given by . Following [33], the sub-differential set can be expressed as follows:where is a diagonal matrix with diagonal entries . Note that the loss function satisfies the following inequality:This means that there exists such that the following inequality is valid:Moreover, the result in (A8) shows that any element in the sub-differential set satisfies the following:This means that there exists such that the following inequality is valid:Then, there exists a universal constant such that Assumption 3 is satisfied for the hinge loss for any .
Appendix B. Proof of Lemma 1
Appendix B.1. Primal Compactness
Appendix B.2. Dual Compactness
Appendix C. Proof of Lemma 2
Appendix C.1. Auxiliary Convergence
Appendix C.2. Primary Convergence
Appendix D. Proof of Lemma 4
References
- Pratt, L.Y.; Mostow, J.; Kamm, C.A. Direct Transfer of Learned Information among Neural Networks. In Proceedings of the Ninth National Conference on Artificial Intelligence—Volume 2, AAAI’91, Anaheim, CA, USA, 14–19 July 1991; pp. 584–589. [Google Scholar]
- Pratt, L.Y. Discriminability-Based Transfer between Neural Networks. In Advances in Neural Information Processing Systems; Hanson, S., Cowan, J., Giles, C., Eds.; Morgan-Kaufmann: Burlington, MA, USA, 1993; Volume 5, pp. 204–211. [Google Scholar]
- Perkins, D.; Salomon, G. Transfer of Learning; Pergamon: Oxford, UK, 1992. [Google Scholar]
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Tan, C.; Sun, F.; Kong, T.; Zhang, W.; Yang, C.; Liu, C. A Survey on Deep Transfer Learning. arXiv 2018, arXiv:1808.01974. [Google Scholar]
- Rosenstein, M.T.; Marx, Z.; Kaelbling, P.K.; Dietterich, T.G. To transfer or not to transfer. In NIPS Workshop on Transfer Learning; NIPS: Vancouver, BC, Canada, 2005. [Google Scholar]
- Bakker, B.; Heskes, T. Task Clustering and Gating for Bayesian Multitask Learning. J. Mach. Learn. Res. 2003, 4, 83–99. [Google Scholar]
- Ben-David, S.; Schuller, R. Exploiting Task Relatedness for Multiple Task Learning. In Learning Theory and Kernel Machines; Schölkopf, B., Warmuth, M.K., Eds.; Springer: Berlin/Heidelberg, Germany, 2003; pp. 567–580. [Google Scholar]
- Kornblith, S.; Shlens, J.; Le, Q.V. Do Better ImageNet Models Transfer Better? arXiv 2019, arXiv:1805.08974. [Google Scholar]
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How Transferable Are Features in Deep Neural Networks? arXiv 2014, arXiv:1411.1792. [Google Scholar]
- Tommasi, T.; Orabona, F.; Caputo, B. Learning Categories From Few Examples With Multi Model Knowledge Transfer. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 928–941. [Google Scholar] [CrossRef]
- Yang, J.; Yan, R.; Hauptmann, A.G. Adapting SVM Classifiers to Data with Shifted Distributions. In Proceedings of the Seventh IEEE International Conference on Data Mining Workshops (ICDMW 2007), Omaha, NE, USA, 28–31 October 2007; pp. 69–76. [Google Scholar]
- Lampinen, A.K.; Ganguli, S. An Analytic Theory of Generalization Dynamics and Transfer Learning in Deep Linear Networks. arXiv 2019, arXiv:1809.10374. [Google Scholar]
- Dar, Y.; Baraniuk, R.G. Double Double Descent: On Generalization Errors in Transfer Learning between Linear Regression Tasks. arXiv 2021, arXiv:2006.07002. [Google Scholar]
- Saglietti, L.; Zdeborová, L. Solvable Model for Inheriting the Regularization through Knowledge Distillation. arXiv 2020, arXiv:2012.00194. [Google Scholar]
- Stojnic, M. A Framework to Characterize Performance of LASSO Algorithms. arXiv 2013, arXiv:1303.7291. [Google Scholar]
- Thrampoulidis, C.; Abbasi, E.; Hassibi, B. Precise high-dimensional error analysis of regularized M-estimators. In Proceedings of the 2015 53rd Annual Allerton Conference on Communication, Control, and Computing (Allerton), Monticello, IL, USA, 29 September–2 October 2015; pp. 410–417. [Google Scholar]
- Gordon, Y. On Milman’s inequality and random subspaces which escape through a mesh in . In Geometric Aspects of Functional Analysis; Lindenstrauss, J., Milman, V.D., Eds.; Springer: Berlin/Heidelberg, Germany, 1988; pp. 84–106. [Google Scholar]
- Dhifallah, O.; Thrampoulidis, C.; Lu, Y.M. Phase Retrieval via Polytope Optimization: Geometry, Phase Transitions, and New Algorithms. arXiv 2018, arXiv:1805.09555. [Google Scholar]
- Dhifallah, O.; Lu, Y.M. A Precise Performance Analysis of Learning with Random Features. arXiv 2020, arXiv:2008.11904. [Google Scholar]
- Salehi, F.; Abbasi, E.; Hassibi, B. The Impact of Regularization on High-dimensional Logistic Regression. arXiv 2019, arXiv:1906.03761. [Google Scholar]
- Kammoun, A.; Alouini, M.S. On the Precise Error Analysis of Support Vector Machines. arXiv 2020, arXiv:2003.12972. [Google Scholar]
- Mignacco, F.; Krzakala, F.; Lu, Y.M.; Zdeborová, L. The Role of Regularization in Classification of High-Dimensional Noisy Gaussian Mixture. arXiv 2020, arXiv:2002.11544. [Google Scholar]
- Aubin, B.; Krzakala, F.; Lu, Y.M.; Zdeborová, L. Generalization Error in High-Dimensional Perceptrons: Approaching Bayes Error with Convex Optimization. arXiv 2020, arXiv:2006.06560. [Google Scholar]
- Rockafellar, R.T.; Wets, R.J.B. Variational Analysis; Springer: Berlin/Heidelberg, Germany, 1998. [Google Scholar]
- Thrampoulidis, C.; Oymak, S.; Hassibi, B. Regularized Linear Regression: A Precise Analysis of the Estimation Error. In Proceedings of the 28th Conference on Learning Theory; Grünwald, P., Hazan, E., Kale, S., Eds.; PMLR: Paris, France, 2015; Volume 40, Proceedings of Machine Learning Research. pp. 1683–1709. [Google Scholar]
- Rudelson, M.; Vershynin, R. Non-Asymptotic Theory of Random Matrices: Extreme Singular Values. arXiv 2010, arXiv:1003.2990. [Google Scholar]
- Adachi, S.; Iwata, S.; Nakatsukasa, Y.; Takeda, A. Solving the Trust-Region Subproblem By a Generalized Eigenvalue Problem. SIAM J. Optim. 2017, 27, 269–291. [Google Scholar] [CrossRef]
- Shapiro, A.; Dentcheva, D.; Ruszczyński, A. Lectures on Stochastic Programming: Modeling and Theory, 2nd ed.; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2014. [Google Scholar]
- Andersen, P.K.; Gill, R.D. Cox’s Regression Model for Counting Processes: A Large Sample Study. Ann. Statist. 1982, 10, 1100–1120. [Google Scholar] [CrossRef]
- Newey, W.K.; Mcfadden, D. Chapter 36 Large sample estimation and hypothesis testing. In Handbook of Econometrics; Elsevier: Amsterdam, The Netherlands, 1994; p. 2111. [Google Scholar]
- Schilling, R.L. Measures, Integrals and Martingales; Cambridge University Press: Cambridge, UK, 2005. [Google Scholar]
- Shor, N. Minimization Methods for Non-Differentiable Functions; Springer: Berlin/Heidelberg, Germany, 1985. [Google Scholar]
- Debbah, M.; Hachem, W.; Loubaton, P.; de Courville, M. MMSE analysis of certain large isometric random precoded systems. IEEE Trans. Inf. Theory 2003, 49, 1293–1311. [Google Scholar] [CrossRef]
- Boyd, S.; Vandenberghe, L. Convex Optimization; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Sion, M. On general minimax theorems. Pac. J. Math. 1958, 8, 171–176. [Google Scholar] [CrossRef]







Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dhifallah, O.; Lu, Y.M. Phase Transitions in Transfer Learning for High-Dimensional Perceptrons. Entropy 2021, 23, 400. https://doi.org/10.3390/e23040400
Dhifallah O, Lu YM. Phase Transitions in Transfer Learning for High-Dimensional Perceptrons. Entropy. 2021; 23(4):400. https://doi.org/10.3390/e23040400
Chicago/Turabian StyleDhifallah, Oussama, and Yue M. Lu. 2021. "Phase Transitions in Transfer Learning for High-Dimensional Perceptrons" Entropy 23, no. 4: 400. https://doi.org/10.3390/e23040400
APA StyleDhifallah, O., & Lu, Y. M. (2021). Phase Transitions in Transfer Learning for High-Dimensional Perceptrons. Entropy, 23(4), 400. https://doi.org/10.3390/e23040400