Interpretable Multi-Head Self-Attention Architecture for Sarcasm Detection in Social Media


Abstract
1. Introduction
- Propose a novel, interpretable model for sarcasm detection using self-attention.
- Achieve state-of-the-art results on diverse datasets and exhibit the effectiveness of our model with extensive experimentation and ablation studies.
- Exhibit the interpretability of our model by analyzing the learned attention maps.
2. Related Work
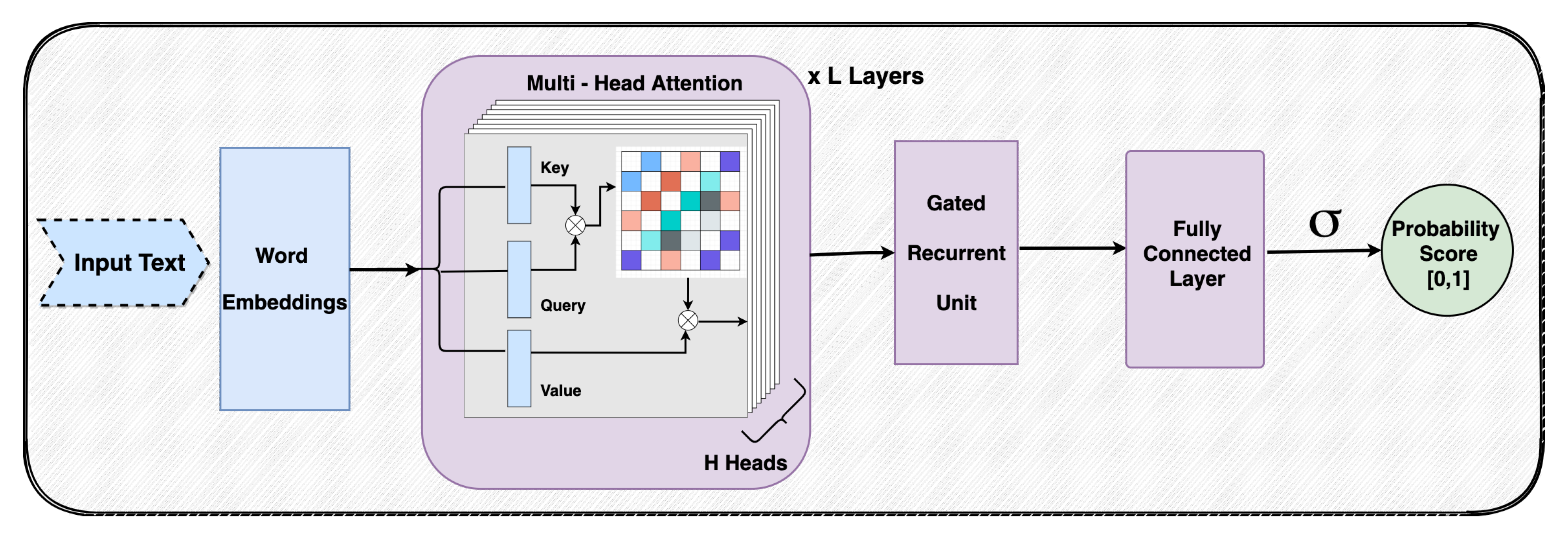
3. Proposed Approach
3.1. Data Pre-Processing
3.2. Multi-Head Self-Attention
3.3. Gated Recurrent Units
3.4. Classification
3.5. Model Interpretability
4. Experiments
4.1. Datasets
4.1.1. Twitter, 2013
4.1.2. Dialogues, 2016
4.1.3. Twitter, 2017
4.1.4. Reddit, 2018
4.1.5. Headlines, 2019
4.2. Implementation Details
4.3. Evaluation Metrics
5. Results
5.1. Ablation Study
5.1.1. Ablation 1
5.1.2. Ablation 2
5.1.3. Ablation 3
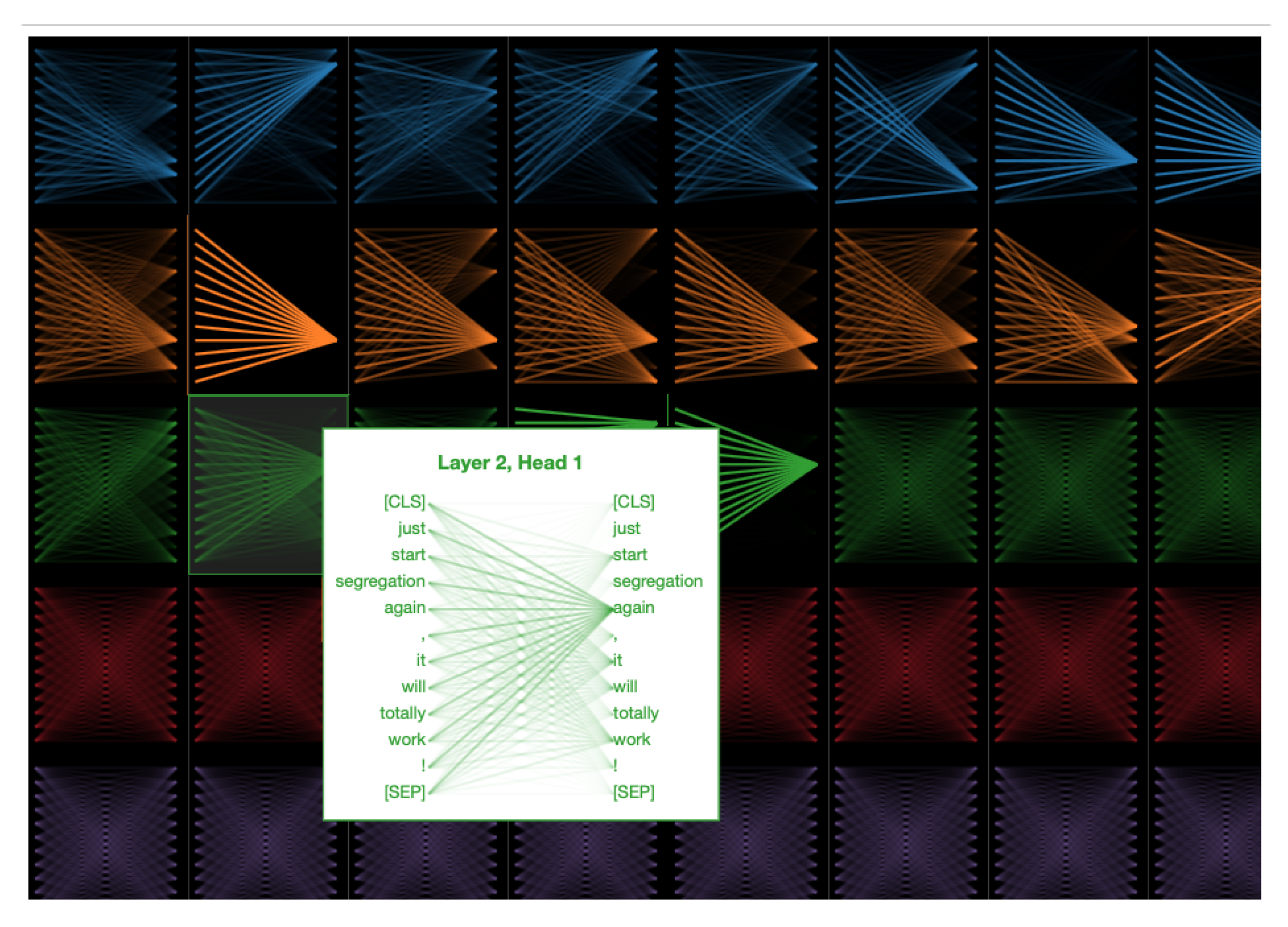
6. Model Interpretability
6.1. Attention Analysis
6.2. Failure Cases
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Shamay-Tsoory, S.G.; Tomer, R.; Aharon-Peretz, J. The neuroanatomical basis of understanding sarcasm and its relationship to social cognition. Neuropsychology 2005, 19, 288. [Google Scholar] [CrossRef] [PubMed]
- Skalicky, S.; Crossley, S. Linguistic Features of Sarcasm and Metaphor Production Quality. In Proceedings of the Workshop on Figurative Language Processing, New Orleans, LA, USA, 6 June 2018; pp. 7–16. [Google Scholar]
- Kreuz, R.J.; Caucci, G.M. Lexical influences on the perception of sarcasm. In Proceedings of the Workshop on Computational Approaches to Figurative Language, Association for Computational Linguistics, Rochester, NY, USA, 26 April 2007; pp. 1–4. [Google Scholar]
- Joshi, A.; Sharma, V.; Bhattacharyya, P. Harnessing context incongruity for sarcasm detection. In Proceedings of the 53rd Annual Meeting of the ACL and the 7th IJCNLP, Beijing, China, 26–31 July 2015; pp. 757–762. [Google Scholar]
- Ghosh, A.; Veale, T. Magnets for sarcasm: Making sarcasm detection timely, contextual and very personal. In Proceedings of the 2017 Conference on EMNLP, Copenhagen, Denmark, 7–11 September 2017; pp. 482–491. [Google Scholar]
- Ilic, S.; Marrese-Taylor, E.; Balazs, J.; Matsuo, Y. Deep contextualized word representations for detecting sarcasm and irony. In Proceedings of the 9th Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis, Brussels, Belgium, 31 October 2018; pp. 2–7. [Google Scholar]
- Ghosh, D.; Fabbri, A.R.; Muresan, S. Sarcasm analysis using conversation context. Comput. Linguist. 2018, 44, 755–792. [Google Scholar] [CrossRef]
- Xiong, T.; Zhang, P.; Zhu, H.; Yang, Y. Sarcasm Detection with Self-matching Networks and Low-rank Bilinear Pooling. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 2115–2124. [Google Scholar]
- Liu, L.; Priestley, J.L.; Zhou, Y.; Ray, H.E.; Han, M. A2text-net: A novel deep neural network for sarcasm detection. In Proceedings of the 2019 IEEE First International Conference on Cognitive Machine Intelligence (CogMI); IEEE: New York, NY, USA, 2019; pp. 118–126. [Google Scholar]
- Carvalho, P.; Sarmento, L.; Silva, M.J.; De Oliveira, E. Clues for detecting irony in user-generated contents: Oh...!! it’s so easy. In Proceedings of the 1st International CIKM Workshop on Topic-Sentiment Analysis for Mass Opinion; Association for Computing Machinery: New York, NY, USA, 2009; pp. 53–56. [Google Scholar]
- González-Ibánez, R.; Muresan, S.; Wacholder, N. Identifying sarcasm in Twitter: A closer look. In Proceedings of the 49th Annual Meeting of the ACL: Human Language Technologies: Short Papers, Portland, OR, USA, 19–24 June 2011; Volume 2, pp. 581–586. [Google Scholar]
- Tsur, O.; Davidov, D.; Rappoport, A. ICWSM—A great catchy name: Semi-supervised recognition of sarcastic sentences in online product reviews. In Proceedings of the Fourth International AAAI Conference on Weblogs and Social Media, Washington, DC, USA, 23–26 May 2010. [Google Scholar]
- Davidov, D.; Tsur, O.; Rappoport, A. Semi-supervised recognition of sarcastic sentences in twitter and amazon. In Proceedings of the Fourteenth Conference on Computational Natural Language Learning; Association for Computational Linguistics: Stroudsburg, PA, USA, 2010; pp. 107–116. [Google Scholar]
- Riloff, E.; Qadir, A.; Surve, P.; De Silva, L.; Gilbert, N.; Huang, R. Sarcasm as contrast between a positive sentiment and negative situation. In Proceedings of the 2013 Conference on EMNLP, Seattle, WA, USA, 18–21 October 2013; pp. 704–714. [Google Scholar]
- Wallace, B.C.; Charniak, E. Sparse, contextually informed models for irony detection: Exploiting user communities, entities and sentiment. In Proceedings of the 53rd Annual Meeting of the ACL and the 7th IJCNLP, Beijing, China, 26–31 July 2015; pp. 1035–1044. [Google Scholar]
- Poria, S.; Cambria, E.; Hazarika, D.; Vij, P. A Deeper Look into Sarcastic Tweets Using Deep Convolutional Neural Networks. In Proceedings of the COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers, Osaka, Japan, 11–16 December 2016; pp. 1601–1612. [Google Scholar]
- Amir, S.; Wallace, B.C.; Lyu, H.; Carvalho, P.; Silva, M.J. Modelling Context with User Embeddings for Sarcasm Detection in Social Media. In Proceedings of the 20th SIGNLL Conference on Computational Natural Language Learning, Berlin, Germany, 11–12 August 2016; pp. 167–177. [Google Scholar]
- Hazarika, D.; Poria, S.; Gorantla, S.; Cambria, E.; Zimmermann, R.; Mihalcea, R. CASCADE: Contextual Sarcasm Detection in Online Discussion Forums. In Proceedings of the 27th International Conference on Computational Linguistics, Santa Fe, NM, USA, 20–26 August 2018; pp. 1837–1848. [Google Scholar]
- Rajadesingan, A.; Zafarani, R.; Liu, H. Sarcasm detection on twitter: A behavioral modeling approach. In Proceedings of the Eighth ACM International Conference on Web Search and Data Mining, Shanghai, China, 2–6 February 2015; pp. 97–106. [Google Scholar]
- Zhang, M.; Zhang, Y.; Fu, G. Tweet sarcasm detection using deep neural network. In Proceedings of the COLING 2016, The 26th International Conference on Computational Linguistics: Technical Papers, Osaka, Japan, 11–16 December 2016; pp. 2449–2460. [Google Scholar]
- Ptáček, T.; Habernal, I.; Hong, J. Sarcasm detection on czech and english twitter. In Proceedings of the COLING 2014, the 25th International Conference on Computational Linguistics: Technical Papers, Dublin, Ireland, 23–29 August 2014; pp. 213–223. [Google Scholar]
- Wang, Z.; Wu, Z.; Wang, R.; Ren, Y. Twitter sarcasm detection exploiting a context-based model. In Proceedings of the International Conference on Web Information Systems Engineering; Springer: Berlin/Heidelberg, Germany, 2015; pp. 77–91. [Google Scholar]
- Joshi, A.; Tripathi, V.; Bhattacharyya, P.; Carman, M. Harnessing sequence labeling for sarcasm detection in dialogue from tv series ‘friends’. In Proceedings of the 20th SIGNLL Conference on Computational Natural Language Learning, Berlin, Germany, 11–12 August 2016; pp. 146–155. [Google Scholar]
- Ghosh, A.; Veale, T. Fracking sarcasm using neural network. In Proceedings of the 7th Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis; Association for Computational Linguistics: San Diego, CA, USA, 2016; pp. 161–169. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. In Proceedings of the HuggingFace’s Transformers: State-of-the-art Natural Language Processing. arXiv 2019, arXiv:1910.03771. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; pp. 3111–3119. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on EMNLP, Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Joulin, A.; Grave, É.; Bojanowski, P.; Mikolov, T. Bag of Tricks for Efficient Text Classification. In Proceedings of the 15th Conference of the European Chapter of the ACL, Valencia, Spain, 3–7 April 2017; pp. 427–431. [Google Scholar]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep contextualized word representations. In Proceedings of the NAACL-HLT, New Orleans, LA, USA, 1–6 June 2018; pp. 2227–2237. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of NAACL: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning deep features for discriminative localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2921–2929. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Oraby, S.; Harrison, V.; Reed, L.; Hernandez, E.; Riloff, E.; Walker, M. Creating and Characterizing a Diverse Corpus of Sarcasm in Dialogue. In Proceedings of the 17th Annual Meeting of the Special Interest Group on Discourse and Dialogue, Los Angeles, CA, USA, 13–15 September 2016; pp. 31–41. [Google Scholar]
- Walker, M.A.; Tree, J.E.F.; Anand, P.; Abbott, R.; King, J. A Corpus for Research on Deliberation and Debate. In Proceedings of the LREC, Istanbul, Turkey, 23–25 May 2012; pp. 812–817. [Google Scholar]
- Khodak, M.; Saunshi, N.; Vodrahalli, K. A Large Self-Annotated Corpus for Sarcasm. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018), Miyazaki, Japan, 7–12 May 2018. [Google Scholar]
- Misra, R.; Arora, P. Sarcasm Detection using Hybrid Neural Network. arXiv 2019, arXiv:1908.07414. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Proceedings of the Advances in Neural Information Processing Systems 32, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Farías, D.I.H.; Patti, V.; Rosso, P. Irony detection in twitter: The role of affective content. In Proceedings of the ACM Transactions on Internet Technology (TOIT); Association for Computing Machinery: New York, NY, USA, 2016; pp. 1–24. [Google Scholar]
- Tay, Y.; Luu, A.T.; Hui, S.C.; Su, J. Reasoning with Sarcasm by Reading In-Between. In Proceedings of the 56th Annual Meeting of the ACL, Melbourne, Australia, 15–20 July 2018; pp. 1010–1020. [Google Scholar]
- Clark, K.; Khandelwal, U.; Levy, O.; Manning, C.D. What Does BERT Look at? An Analysis of BERT’s Attention. In Proceedings of the 2019 ACL Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, Florence, Italy, 1 August 2019; pp. 276–286. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Source | Train | Test | Total | Sarcastic | Non Sarcastic |
|---|---|---|---|---|---|
| Twitter, 2013 | 1368 | 588 | 1956 | 308 | 1648 |
| Dialogues, 2016 | 3754 | 938 | 4692 | 2346 | 2346 |
| Twitter, 2017 | 51,189 | 3742 | 54,931 | 25,872 | 29,059 |
| Reddit, 2018 | 154,702 | 64,666 | 219,368 | 109,684 | 109,684 |
| Headlines, 2019 | 22,895 | 5724 | 28,619 | 13,634 | 14,985 |
| Models | Precision | Recall | F1 | AUC |
|---|---|---|---|---|
| NBOW | 71.2 | 62.3 | 64.1 | - |
| Vanilla CNN | 71.0 | 67.1 | 68.5 | - |
| Vanilla LSTM | 67.3 | 67.2 | 67.2 | - |
| Attention LSTM | 68.7 | 68.6 | 68.7 | - |
| Bootstrapping [14] | 62.0 | 44.0 | 51.0 | - |
| EmotIDM [40] | - | - | 75.0 | - |
| Fracking Sarcasm [24] | 88.3 | 87.9 | 88.1 | - |
| GRNN [20] | 66.3 | 64.7 | 65.4 | - |
| ELMo-BiLSTM [6] | 75.9 | 75.0 | 75.9 | - |
| ELMo-BiLSTM FULL [6] | 77.8 | 73.5 | 75.3 | - |
| ELMo-BiLSTM AUG [6] | 68.4 | 70.8 | 69.4 | - |
| A2Text-Net [9] | 91.7 | 91.0 | 90.0 | 97.0 |
| Our Model | 97.9 | 99.6 | 98.7 | 99.6 |
| (+6.2 ↑) | (+8.6 ↑) | (+8.7 ↑) | (+2.6 ↑) |
| Models | Precision | Recall | F1 | AUC |
|---|---|---|---|---|
| Sarcasm Magnet [5] | 73.3 | 71.7 | 72.5 | - |
| Sentence-level attention [7] | 74.9 | 75.0 | 74.9 | - |
| Self Matching Networks [8] | 76.3 | 72.5 | 74.4 | - |
| A2Text-Net [9] | 80.3 | 80.2 | 80.1 | 88.4 |
| Our Model | 80.9 | 81.8 | 81.2 | 88.6 |
| (+0.6 ↑) | (+1.6 ↑) | (+1.1 ↑) | (+0.2 ↑) |
| Models | Main-Balanced | Political | ||
|---|---|---|---|---|
| Accuracy | F1 | Accuracy | F1 | |
| Bag-of-words | 63.0 | 64.0 | 59.0 | 60.0 |
| CNN | 65.0 | 66.0 | 62.0 | 63.0 |
| CNN-SVM [16] | 68.0 | 68.0 | 70.65 | 67.0 |
| CUE-CNN [17] | 70.0 | 69.0 | 69.0 | 70.0 |
| CASCADE [18] | 77.0 | 77.0 | 74.0 | 75.0 |
| SARC 2.0 [37] | 75.0 | - | 76.0 | - |
| ELMo-BiLSTM [6] | 72.0 | - | 78.0 | - |
| ELMo-BiLSTM FULL [6] | 76.0 | 76.0 | 72.0 | 72.0 |
| Our Model | 81.0 | 81.0 | 80.0 | 80.0 |
| (+4.0 ↑) | (+4.0 ↑) | (+2.0 ↑) | (+5.0 ↑) | |
| Models | Precision | Recall | F1 | AUC |
|---|---|---|---|---|
| NBOW | 66.0 | 66.0 | 66.0 | - |
| Vanilla CNN | 68.4 | 68.1 | 68.2 | - |
| Vanilla LSTM | 68.3 | 63.9 | 60.7 | - |
| Attention LSTM | 70.0 | 69.6 | 69.6 | - |
| GRNN [20] | 62.2 | 61.8 | 61.2 | - |
| CNN-LSTM-DNN [24] | 66.1 | 66.7 | 65.7 | - |
| SIARN [41] | 72.1 | 71.8 | 71.8 | - |
| MIARN [41] | 72.9 | 72.9 | 72.7 | - |
| ELMo-BiLSTM [6] | 74.8 | 74.7 | 74.7 | - |
| ELMo-BiLSTM FULL [6] | 76.0 | 76.0 | 76.0 | - |
| Our Model | 77.4 | 77.2 | 77.2 | 0.834 |
| (+1.2 ↑) | (+1.4 ↑) | (+1.2 ↑) |
| Models | Precision | Recall | F1 | Accuracy | AUC |
|---|---|---|---|---|---|
| Hybrid [38] | - | - | - | 89.7 | - |
| A2Text-Net [9] | 86.3 | 86.2 | 86.2 | - | 0.937 |
| Our Model | 0.919 | 91.8 | 91.8 | 91.6 | 97.4 |
| (+5.6 ↑) | (+5.6 ↑) | (+5.6 ↑) | (+1.9 ↑) | (+3.7 ↑) |
| #L-Layers | Precision | Recall | F1 |
|---|---|---|---|
| 0 (GRU only) | 75.6 | 75.6 | 75.6 |
| 1 Layer | 76.2 | 76.1 | 76.1 |
| 3 Layers | 77.4 | 77.2 | 77.2 |
| 5 Layers | 77.6 | 77.6 | 77.6 |
| #H-Heads | Precision | Recall | F1 |
|---|---|---|---|
| 1 Head | 74.9 | 74.5 | 74.4 |
| 4 Heads | 76.9 | 76.8 | 76.8 |
| 8 Heads | 77.4 | 77.2 | 77.2 |
| Models | Embeddings | Precision | Recall | F1 | AUC |
|---|---|---|---|---|---|
| MIARN [41] | - | 72.9 | 72.9 | 72.7 | - |
| ELMo-BiLSTM FULL [6] | ELMO | 76.0 | 76.0 | 76.0 | - |
| Our Model | BERT | 77.4 | 77.2 | 77.2 | 83.4 |
| ELMO | 76.7 | 76.7 | 76.7 | 80.8 | |
| FastText | 75.7 | 75.7 | 75.7 | 81.6 | |
| Glove 6B | 76.0 | 76.0 | 76.0 | 82.3 | |
| Glove 840B | 77.0 | 77.0 | 77.0 | 82.9 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Akula, R.; Garibay, I. Interpretable Multi-Head Self-Attention Architecture for Sarcasm Detection in Social Media. Entropy 2021, 23, 394. https://doi.org/10.3390/e23040394
Akula R, Garibay I. Interpretable Multi-Head Self-Attention Architecture for Sarcasm Detection in Social Media. Entropy. 2021; 23(4):394. https://doi.org/10.3390/e23040394
Chicago/Turabian StyleAkula, Ramya, and Ivan Garibay. 2021. "Interpretable Multi-Head Self-Attention Architecture for Sarcasm Detection in Social Media" Entropy 23, no. 4: 394. https://doi.org/10.3390/e23040394
APA StyleAkula, R., & Garibay, I. (2021). Interpretable Multi-Head Self-Attention Architecture for Sarcasm Detection in Social Media. Entropy, 23(4), 394. https://doi.org/10.3390/e23040394