
Assessing the Europe 2020 Strategy Implementation Using Interval Entropy and Cluster Analysis for Interrelation between Two Groups of Headline Indicators

Abstract
1. Introduction
2. Overview of Europe 2020 Strategy Targets and Headline Indicators
- Increasing combined public and private investment in research and development (R&D) to 3% of GDP (gross domestic product);
- Reducing school drop-out rates to less than 10%;
- Increasing the share of the population aged 30–34 having completed tertiary education to at least 40%;
- Reducing greenhouse gas emissions by at least 20% compared to 1990 levels;
- Increasing the share of renewable energy in final energy consumption to 20%;
- Moving towards a 20% increase in energy efficiency;
- Increasing the employment rate of the population aged 20–64 to at least 75%;
- Lifting at least 20 million people out of the risk of poverty and social exclusion.
3. Materials and Methods
3.1. Description of the Europe 2020 Headline Indicators
3.2. The Concept of Interval Entropy
3.3. The Procedure of the WEBIRA Method for Calculating Criteria Weights
3.4. Algorithm for Criteria Weight Calculation
- (i)
- Algorithm parameters are determined:
- (ii)
- The initial vector of weights satisfying conditions (8) is chosen:
- (iii)
- Randomly selected vector of direction:
- (iv)
- Vector is calculated. If it does not satisfy conditions (8), the following corrections must be done:
- (a)
- If change ;
- (b)
- , change ;
- (c)
- If , change .
- (v)
- The number of iterations is calculated.
- (vi)
- If , then the algorithm is finishing calculations.
- (vii)
- If F(w1) > F(w0) then go to point (iii) of the algorithm, or else assign w0 = w1 and go to point (iii) of the algorithm.
4. Results
4.1. Prioritization of Europe-28 Headline Indicators
4.2. Results of Criteria Weight Calculation
4.3. Ranking the Alternatives
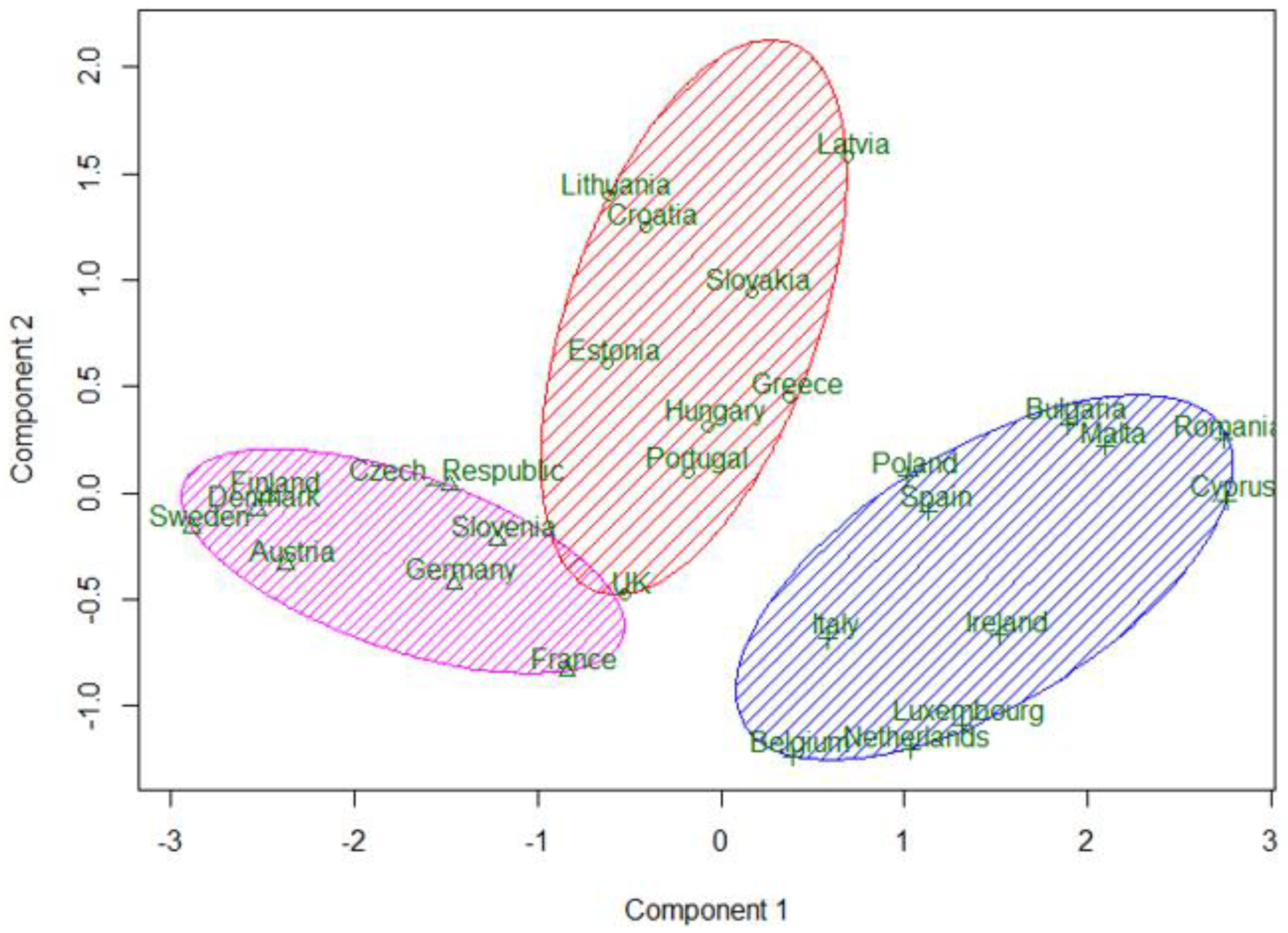
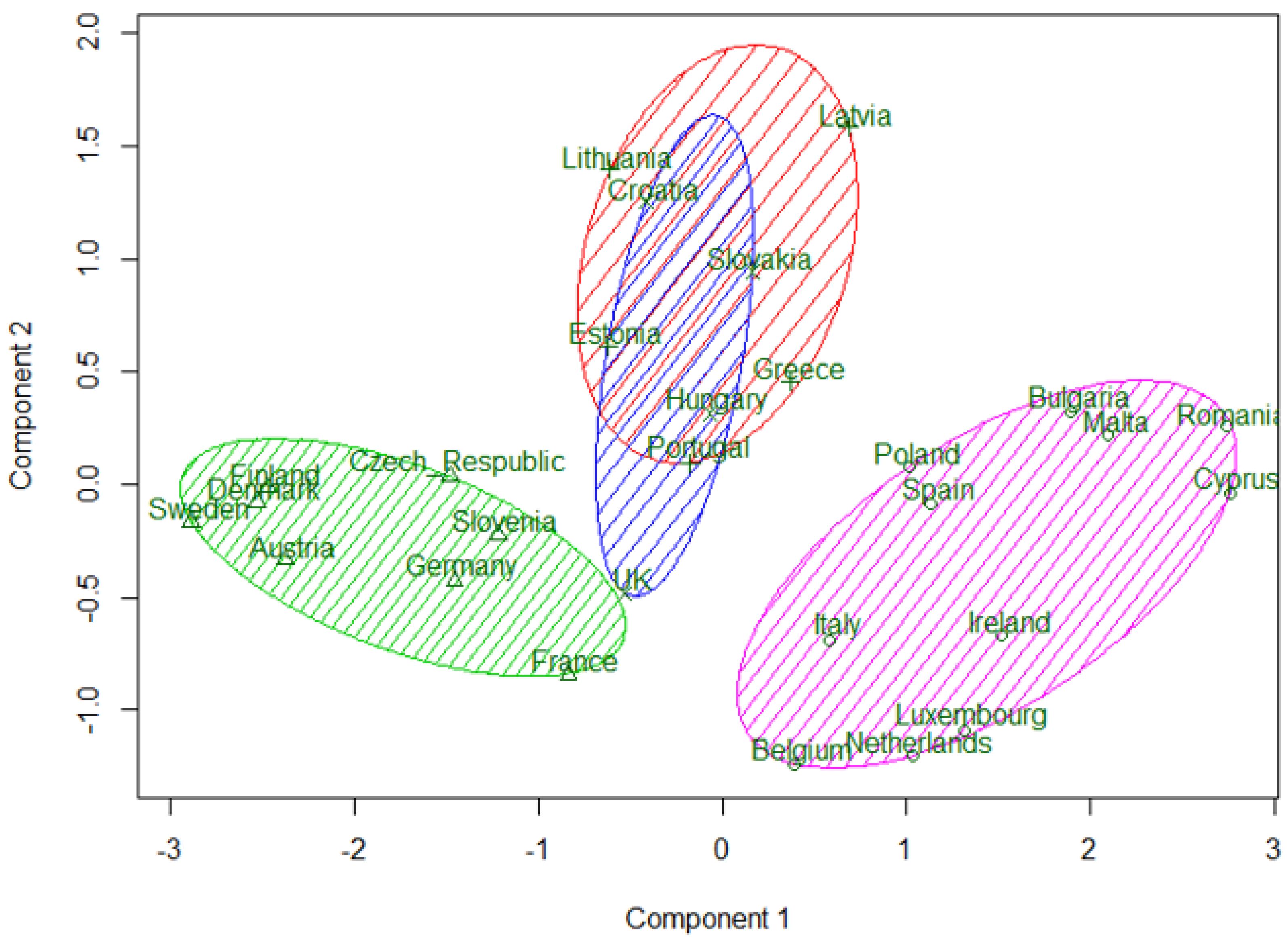
4.4. Countries Clustering Solution
5. Discussion
6. Conclusions and Future Research
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Smarter, Greener, More Inclusive? Indicators to Support the Europe 2020 Strategy, Eurostat (European Commission) 2019 edition. Available online: https://op.europa.eu/s/oGP3 (accessed on 15 January 2021).
- Landaluce-Calvo, M.I.; Gozalo-Delgado, M. Proposal for a Dynamic Composite Indicator: Application in a Comparative Analysis of Trends in the EU Member States Towards the Europe 2020 Strategy. Soc. Indic. Res. 2020. [Google Scholar] [CrossRef]
- Stumbriene, D.; Camanho, A.S.; Jakaitiene, A. The performance of education systems in the light of Europe 2020 strategy. Ann. Oper. Res. 2020, 288, 577–608. [Google Scholar] [CrossRef]
- Fedajev, A.; Stanujkic, D.; Karabašević, D.; Brauers, W.K.M.; Zavadskas, E.K. Assessment of progress towards “Europe 2020” strategy targets by using the MULTIMOORA method and the Shannon Entropy Index. JOCP 2020, 244, 118895. [Google Scholar] [CrossRef]
- Walheer, B. Disentangling Heterogeneity Gaps and Pure Performance Differences in Composite Indexes over Time: The Case of the Europe 2020 Strategy. Soc. Indic. Res. 2019, 143, 25–45. [Google Scholar] [CrossRef]
- Rogge, N. EU countries’ progress towards ‘Europe 2020 strategy targets’. J. Policy Model. 2019, 41, 255–272. [Google Scholar] [CrossRef]
- Vié, A.; Colapinto, C.; La Torre, D.; Liuzzi, D. The long-run sustainability of the European Union countries: Assessing the Europe 2020 strategy through a fuzzy goal programming model. Manag. Decis. 2019, 57, 523–542. [Google Scholar] [CrossRef]
- Moreno, B.; García-Álvarez, M.T. Measuring the progress towards a resource-efficient European Union under the Europe 2020 strategy. JOCP 2018, 170, 991–1005. [Google Scholar] [CrossRef]
- Fura, B.; Wojnar, J.; Kasprzyk, B. Ranking and classification of EU countries regarding their levels of implementation of the Europe 2020 strategy. JOCP 2017, 165, 968–979. [Google Scholar] [CrossRef]
- Minarcikova, E. Assessment of regional development in the selected EU countries in the context of Europe 2020 Strategy. In Proceedings of the 18th International Colloquium on Regional Sciences, Hustopece, Czech Republic, 17–19 June 2015; pp. 25–33. [Google Scholar]
- Balcerzak, A.P. Europe 2020 Strategy and Structural Diversity between Old and New Member States. Application of Zero Unitarization Method for Dynamic Analysis in the Years 2004–2013. Econ. Sociol. 2015, 8, 190–210. [Google Scholar] [CrossRef]
- Spišáková, E.D.; Gontkovičová, B.; Hajduová, Z. Education from the Perspective of the Europe 2020 Strategy: The Case of Southern Countries of the European Union. Econ. Sociol. 2016, 9, 266–278. [Google Scholar] [CrossRef]
- Liobikiene, G.; Butkus, M.; Bernatoniene, J. Drivers of greenhouse gas emissions in the Baltic states: Decomposition analysis related to the implementation of Europe 2020 strategy. Renew. Sustain. Energy Rev. 2016, 54, 309–317. [Google Scholar] [CrossRef]
- Spisakova, D.E.; Gontkovicova, B.; Majernikova, J. Management of research and development activities in the context of strategy Europe 2020. Pol. J. Manag. Stud. 2018, 10, 21–37. [Google Scholar] [CrossRef]
- Dobrovic, J.; Gallo, P.; Mihalcova, B. Competitiveness Measurement in Terms of the Europe 2020 Strategy. J. Compet. 2018, 10, 21–37. [Google Scholar] [CrossRef]
- Lafuente, J.Á.; Marco, A.; Monfort, M.; Ordóñez, J. Social Exclusion and Convergence in the EU: An Assessment of the Europe 2020 Strategy. Sustainability 2020, 12, 1843. [Google Scholar] [CrossRef]
- Pal’ova, D.; Vejacka, M. Analysis of Employment in EU According to Europe 2020 Strategy Targets. Econ. Sociol. 2018, 11, 96–112. [Google Scholar] [CrossRef]
- Stanickova, M. Can the implementation of the Europe 2020 Strategy goals be efficient? The challenge for achieving social equality in the European Union. Equilib. Q. J. Econ. Econ. Policy 2017, 12, 383–398. [Google Scholar] [CrossRef]
- Stec, M.; Grzebyk, M. The implementation of the Strategy Europe 2020 objectives in European Union countries: The concept analysis and statistical evaluation. Qual. Quant. 2018, 52, 119–133. [Google Scholar] [CrossRef]
- Szymanska, A.; Zalewska, E. Towards the Goals of the Europe 2020 Strategy: Convergence or Divergence of the European Union Countries? Comp. Econ. Res. 2018, 21, 67–82. [Google Scholar] [CrossRef]
- Eurostat. Europe 2020 Headline Indicators. Available online: https://ec.europa.eu/eurostat/web/europe-2020-indicators/europe-2020-strategy/main-tables (accessed on 15 January 2021).
- Frascati Manual. Proposed Standard Practice for Surveys on Research and Experimental Development. Available online: https://www.oecd-ilibrary.org/science-and-technology/frascati-manual-2002_9789264199040-en (accessed on 15 January 2021).
- Clausius, R. Ueber die bewegende Kraft der Wärme und die Gesetze, welche sich daraus für die Wärmelehre selbst ableiten lassen. Ann. Phys. 1850, 155, 368–397. [Google Scholar] [CrossRef]
- Shannon, C.E. A Mathematical Theory of Communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Guggenheim, E.A. Statistical basis of thermodynamics. Res. J. Sci. Appl. 1949, 2, 450–454. [Google Scholar]
- Kosareva, N.; Zavadskas, E.K.; Krylovas, A.; Dadelo, S. Entropy-KEMIRA Approach for MCDM Problem Solution in Human Resources Selection Task. IJITDM 2017, 16, 1183–1209. [Google Scholar] [CrossRef]
- Dadelo, S.; Turskis, Z.; Zavadskas, E.K.; Kačerauskas, T.; Dadelienė, R. Is the evaluation of the students’ values possible? An integrated approach to determining the weights of students’ personal goals using multiple-criteria methods. EURASIA J. Math. Sci. Technol. Ed. 2016, 12, 2771–2781. [Google Scholar] [CrossRef]
- Krylovas, A.; Dadeliene, R.; Kosareva, N.; Dadelo, S. Comparative Evaluation and Ranking of the European Countries Based on the Interdependence between Human Development and Internal Security Indicators. Mathematics 2019, 7, 293. [Google Scholar] [CrossRef]
- Krylovas, A.; Kosareva, N.; Dadelo, S. European Countries Ranking and Clustering Solution by Children’s Physical Activity and Human Development Index Using Entropy-Based Methods. Mathematics 2020, 8, 1705. [Google Scholar] [CrossRef]
- Krylovas, A.; Kosareva, N.; Dadeliene, R.; Dadelo, S. Evaluation of elite athletes training management efficiency based on multiple criteria measure of conditioning using fewer data. Mathematics 2020, 8, 66. [Google Scholar] [CrossRef]
- Krylovas, A.; Kosareva, N.; Zavadskas, E.K. WEBIRA—Comparative Analysis of Weight Balancing Method. IJCCC 2017, 12, 238–253. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
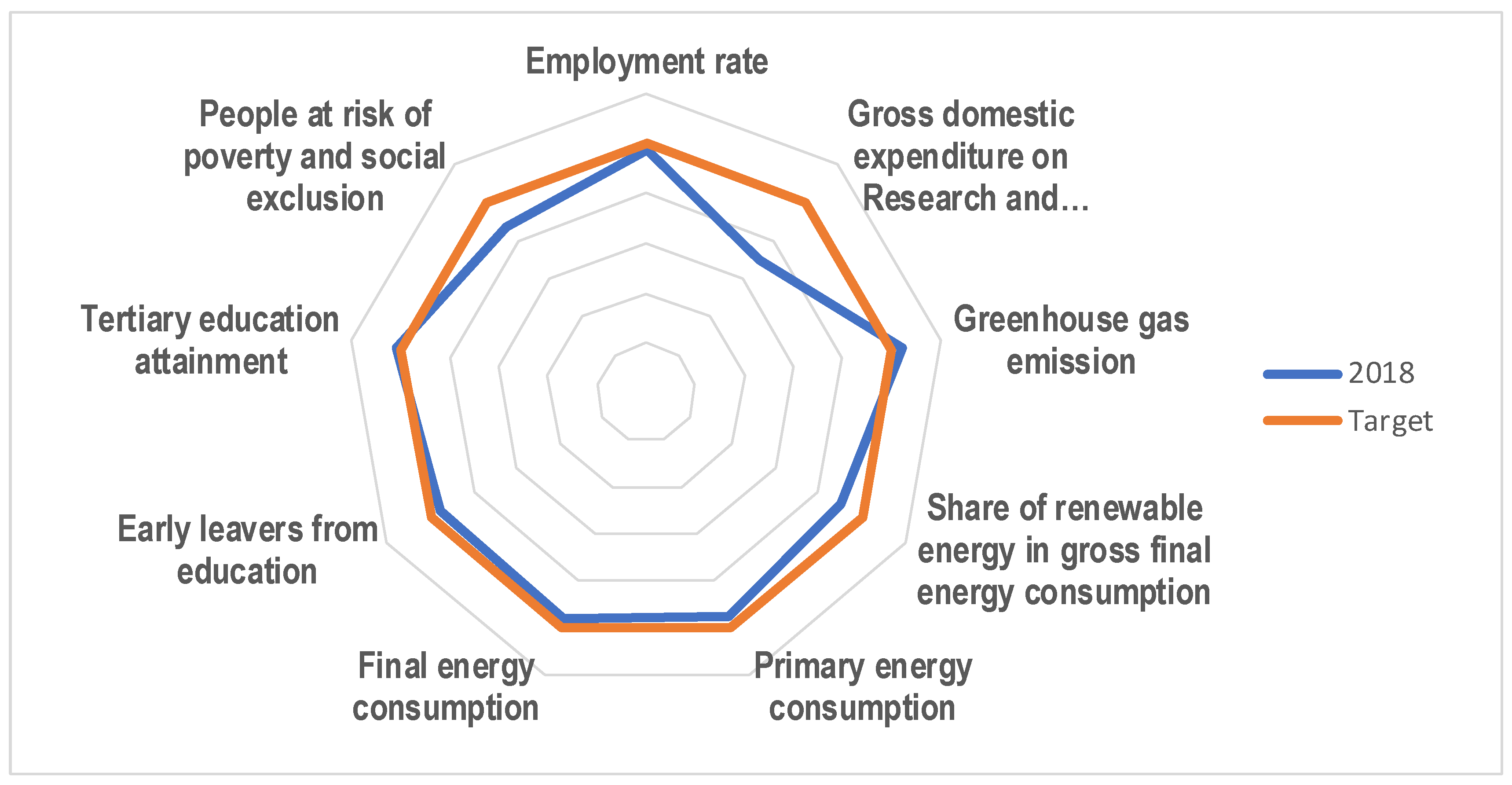
| Indicator | 2016 | 2017 | 2018 | Target | |
|---|---|---|---|---|---|
| C1 | Employment Rate, age group 20–64 (%) | 71.10 | 72.20 | 73.20 | 75 |
| C2 | Gross Domestic Expenditure on Research and Development (% of GDP) | 2.04 | 2.08 | 2.11 | 3 |
| C3 | Greenhouse Gas Emission, Base Year 1990, Index (1990 = 100) | 77.92 | 78.38 | 76.76 | 80 |
| C4 | Share of Renewable Energy in Gross Final Energy Consumption (%) | 16.995 | 17.474 | 17.98 | 20 |
| C5 | Primary Energy Consumption (million tonnes of oil equivalent (TOE) ) | 1544.93 | 1562.40 | 1551.92 | 1483 |
| C6 | Final Energy Consumption (million TOE) | 1110.02 | 1122.93 | 1124.14 | 1086.00 |
| C7 | Early Leavers From Education and Training (% of the Population aged 18–24) | 10.7 | 10.5 | 10.5 | 10 |
| C8 | Tertiary Education Attainment, Age Group 30–34 (%) | 39.2 | 39.9 | 40.7 | 40 |
| C9 | People at Risk of Poverty and Social Exclusion (Million People) | 118.06 | 112.93 | 109.87 | 96.2 |
| C1 | C2 | C3 | C4 | C5 | C6 | C7 | C8 | C9 | |
|---|---|---|---|---|---|---|---|---|---|
| Belgium | 67.70 | 2.52 | 81.96 | 8.71 | 4.35 | 3.22 | 8.80 | 45.60 | 20.90 |
| Bulgaria | 67.70 | 0.77 | 58.52 | 18.76 | 2.47 | 1.35 | 13.80 | 33.80 | 40.40 |
| Czech Republic | 76.70 | 1.68 | 66.06 | 14.93 | 3.79 | 2.35 | 6.60 | 32.80 | 13.30 |
| Denmark | 76.00 | 3.09 | 73.74 | 31.84 | 3.08 | 2.56 | 7.50 | 46.50 | 16.80 |
| Germany | 78.60 | 2.94 | 74.17 | 14.89 | 3.62 | 2.64 | 10.30 | 33.20 | 19.70 |
| Estonia | 76.60 | 1.25 | 48.98 | 28.68 | 4.48 | 2.16 | 10.90 | 45.40 | 24.40 |
| Ireland | 71.40 | 1.17 | 113.34 | 9.26 | 3.09 | 2.45 | 6.00 | 54.60 | 24.40 |
| Greece | 56.20 | 0.99 | 89.74 | 15.39 | 2.12 | 1.55 | 6.20 | 42.70 | 35.60 |
| Spain | 63.90 | 1.19 | 116.51 | 17.43 | 2.57 | 1.77 | 19.00 | 40.10 | 27.90 |
| France | 70.00 | 2.22 | 85.44 | 15.68 | 3.60 | 2.24 | 8.80 | 43.70 | 18.20 |
| Croatia | 61.40 | 0.86 | 76.15 | 28.27 | 1.92 | 1.58 | 2.80 | 29.30 | 27.90 |
| Italy | 61.60 | 1.37 | 85.80 | 17.42 | 2.44 | 1.91 | 13.80 | 26.20 | 30.00 |
| Cyprus | 68.70 | 0.52 | 151.00 | 9.86 | 2.86 | 2.09 | 7.60 | 53.40 | 27.70 |
| Latvia | 73.20 | 0.44 | 43.55 | 37.14 | 2.18 | 1.94 | 10.00 | 42.80 | 28.50 |
| Lithuania | 75.20 | 0.84 | 42.77 | 25.61 | 2.09 | 1.77 | 4.80 | 58.70 | 30.10 |
| Luxembourg | 70.70 | 1.30 | 87.98 | 5.44 | 7.20 | 7.01 | 5.50 | 54.60 | 19.80 |
| Hungary | 71.50 | 1.19 | 65.48 | 14.32 | 2.41 | 1.81 | 12.40 | 33.00 | 26.30 |
| Malta | 71.10 | 0.57 | 83.84 | 6.21 | 1.58 | 1.29 | 19.20 | 32.00 | 20.30 |
| Netherlands | 77.10 | 2.00 | 91.57 | 5.83 | 3.81 | 2.93 | 8.00 | 45.70 | 16.70 |
| Austria | 74.80 | 3.12 | 103.05 | 33.37 | 3.67 | 3.23 | 6.90 | 40.10 | 18.00 |
| Poland | 69.30 | 0.96 | 84.56 | 11.27 | 2.50 | 1.75 | 5.20 | 44.60 | 21.90 |
| Portugal | 70.60 | 1.28 | 115.32 | 30.87 | 2.10 | 1.57 | 14.00 | 34.60 | 25.10 |
| Romania | 66.30 | 0.48 | 46.29 | 25.03 | 1.55 | 1.13 | 18.50 | 25.60 | 38.80 |
| Slovenia | 70.10 | 2.01 | 94.69 | 21.29 | 3.17 | 2.36 | 4.90 | 44.20 | 18.40 |
| Slovakia | 69.80 | 0.79 | 57.72 | 12.03 | 2.83 | 1.92 | 7.40 | 31.50 | 18.10 |
| Finland | 73.40 | 2.72 | 83.16 | 39.01 | 5.91 | 4.59 | 7.90 | 46.10 | 16.60 |
| Sweden | 81.20 | 3.25 | 76.99 | 53.37 | 4.61 | 3.25 | 7.40 | 51.00 | 18.30 |
| United Kingdom | 77.50 | 1.66 | 63.76 | 8.98 | 2.74 | 2.05 | 11.20 | 48.10 | 22.20 |
| C1 | C2 | C3 | C4 | C5 | C6 | C7 | C8 | C9 | |
|---|---|---|---|---|---|---|---|---|---|
| Belgium | 68.50 | 2.66 | 82.14 | 9.06 | 4.32 | 3.18 | 8.90 | 45.90 | 20.60 |
| Bulgaria | 71.30 | 0.74 | 60.88 | 18.70 | 2.58 | 1.39 | 12.70 | 32.80 | 38.90 |
| Czech Republic | 78.50 | 1.79 | 65.56 | 14.80 | 3.81 | 2.41 | 6.70 | 34.20 | 12.20 |
| Denmark | 76.60 | 3.05 | 70.67 | 34.72 | 3.11 | 2.58 | 8.80 | 48.20 | 17.20 |
| Germany | 79.20 | 3.07 | 73.22 | 15.47 | 3.61 | 2.65 | 10.10 | 34.00 | 19.00 |
| Estonia | 78.70 | 1.28 | 52.26 | 29.13 | 4.29 | 2.18 | 10.80 | 48.40 | 23.40 |
| Ireland | 73.00 | 1.24 | 113.29 | 10.59 | 3.01 | 2.45 | 5.00 | 54.50 | 22.70 |
| Greece | 57.80 | 1.13 | 93.62 | 16.95 | 2.15 | 1.56 | 6.00 | 43.70 | 34.80 |
| Spain | 65.50 | 1.21 | 121.49 | 17.56 | 2.70 | 1.82 | 18.30 | 41.20 | 26.60 |
| France | 70.60 | 2.21 | 86.35 | 16.01 | 3.58 | 2.22 | 8.80 | 44.40 | 17.00 |
| Croatia | 63.60 | 0.86 | 78.71 | 27.28 | 2.01 | 1.67 | 3.10 | 28.70 | 26.40 |
| Italy | 62.30 | 1.37 | 85.05 | 18.27 | 2.46 | 1.90 | 14.00 | 26.90 | 28.90 |
| Cyprus | 70.80 | 0.55 | 155.75 | 10.49 | 2.96 | 2.19 | 8.50 | 55.90 | 25.20 |
| Latvia | 74.80 | 0.51 | 43.94 | 39.02 | 2.29 | 2.06 | 8.60 | 43.80 | 28.20 |
| Lithuania | 76.00 | 0.90 | 43.24 | 26.04 | 2.16 | 1.88 | 5.40 | 58.00 | 29.60 |
| Luxembourg | 71.50 | 1.27 | 90.88 | 6.29 | 7.26 | 7.08 | 7.30 | 52.70 | 21.50 |
| Hungary | 73.30 | 1.33 | 68.25 | 13.52 | 2.50 | 1.89 | 12.50 | 32.10 | 25.60 |
| Malta | 73.00 | 0.58 | 93.45 | 7.27 | 1.76 | 1.35 | 17.70 | 33.50 | 19.30 |
| Netherlands | 78.00 | 1.98 | 90.78 | 6.46 | 3.81 | 2.94 | 7.10 | 47.90 | 17.00 |
| Austria | 75.40 | 3.05 | 106.17 | 33.14 | 3.74 | 3.26 | 7.40 | 40.80 | 18.10 |
| Poland | 70.90 | 1.03 | 87.70 | 10.96 | 2.61 | 1.87 | 5.00 | 45.70 | 19.50 |
| Portugal | 73.40 | 1.32 | 123.78 | 30.61 | 2.21 | 1.61 | 12.60 | 33.50 | 23.30 |
| Romania | 68.80 | 0.50 | 47.39 | 24.45 | 1.65 | 1.18 | 18.10 | 26.30 | 35.70 |
| Slovenia | 73.40 | 1.87 | 93.47 | 21.06 | 3.26 | 2.40 | 4.30 | 46.40 | 17.10 |
| Slovakia | 71.10 | 0.89 | 59.31 | 11.47 | 2.97 | 2.05 | 9.30 | 34.30 | 16.30 |
| Finland | 74.20 | 2.73 | 79.59 | 40.92 | 5.83 | 4.59 | 8.20 | 44.60 | 15.70 |
| Sweden | 81.80 | 3.37 | 76.52 | 54.20 | 4.65 | 3.23 | 7.70 | 51.30 | 17.70 |
| United Kingdom | 78.20 | 1.68 | 62.70 | 9.73 | 2.69 | 2.03 | 10.60 | 48.20 | 22.00 |
| C1 | C2 | C3 | C4 | C5 | C6 | C7 | C8 | C9 | |
|---|---|---|---|---|---|---|---|---|---|
| Belgium | 69.70 | 2.76 | 82.67 | 9.42 | 4.11 | 3.19 | 8.60 | 47.60 | 20.00 |
| Bulgaria | 72.40 | 0.76 | 57.16 | 20.53 | 2.60 | 1.41 | 12.70 | 33.70 | 32.80 |
| Czech Republic | 79.90 | 1.93 | 64.82 | 15.15 | 3.81 | 2.39 | 6.20 | 33.70 | 12.20 |
| Denmark | 77.50 | 3.03 | 70.69 | 35.71 | 3.11 | 2.59 | 10.40 | 48.40 | 17.00 |
| Germany | 79.90 | 3.13 | 70.44 | 16.48 | 3.52 | 2.60 | 10.30 | 34.90 | 18.70 |
| Estonia | 79.50 | 1.40 | 49.98 | 30.00 | 4.68 | 2.24 | 11.30 | 47.20 | 24.40 |
| Ireland | 74.10 | 1.15 | 113.60 | 11.06 | 3.01 | 2.54 | 5.00 | 56.30 | 21.10 |
| Greece | 59.50 | 1.18 | 90.84 | 18.00 | 2.09 | 1.48 | 4.70 | 44.30 | 31.80 |
| Spain | 67.00 | 1.24 | 119.74 | 17.45 | 2.67 | 1.86 | 17.90 | 42.40 | 26.10 |
| France | 71.30 | 2.20 | 83.10 | 16.59 | 3.57 | 2.19 | 8.70 | 46.20 | 17.40 |
| Croatia | 65.20 | 0.97 | 75.23 | 28.02 | 1.99 | 1.67 | 3.30 | 34.10 | 24.80 |
| Italy | 63.00 | 1.39 | 84.41 | 17.78 | 2.43 | 1.93 | 14.50 | 27.80 | 27.30 |
| Cyprus | 73.90 | 0.55 | 153.81 | 13.88 | 2.95 | 2.15 | 7.80 | 57.10 | 23.90 |
| Latvia | 76.80 | 0.64 | 45.95 | 40.29 | 2.42 | 2.16 | 8.30 | 42.70 | 28.40 |
| Lithuania | 77.80 | 0.94 | 42.64 | 24.45 | 2.25 | 1.98 | 4.60 | 57.60 | 28.30 |
| Luxembourg | 72.10 | 1.21 | 94.16 | 9.06 | 7.41 | 7.23 | 6.30 | 56.20 | 21.90 |
| Hungary | 74.40 | 1.53 | 67.82 | 12.49 | 2.50 | 1.90 | 12.50 | 33.70 | 19.60 |
| Malta | 75.50 | 0.57 | 96.14 | 7.98 | 1.72 | 1.39 | 17.40 | 34.70 | 19.00 |
| Netherlands | 79.20 | 2.16 | 88.58 | 7.39 | 3.77 | 2.93 | 7.30 | 49.40 | 16.70 |
| Austria | 76.20 | 3.17 | 102.66 | 33.43 | 3.60 | 3.16 | 7.30 | 40.70 | 17.50 |
| Poland | 72.20 | 1.21 | 87.42 | 11.28 | 2.66 | 1.89 | 4.80 | 45.70 | 18.90 |
| Portugal | 75.40 | 1.36 | 118.90 | 30.32 | 2.20 | 1.64 | 11.80 | 33.50 | 21.60 |
| Romania | 69.90 | 0.50 | 46.84 | 23.88 | 1.66 | 1.20 | 16.40 | 24.60 | 32.50 |
| Slovenia | 75.40 | 1.95 | 94.35 | 21.15 | 3.23 | 2.41 | 4.20 | 42.70 | 16.20 |
| Slovakia | 72.40 | 0.84 | 59.16 | 11.90 | 2.90 | 2.04 | 8.60 | 37.70 | 16.30 |
| Finland | 76.30 | 2.75 | 81.41 | 41.16 | 5.98 | 4.69 | 8.30 | 44.20 | 16.50 |
| Sweden | 82.40 | 3.32 | 75.28 | 54.65 | 4.62 | 3.16 | 7.50 | 51.80 | 18.00 |
| United Kingdom | 78.70 | 1.70 | 61.59 | 11.02 | 2.66 | 2.03 | 10.70 | 48.80 | 23.10 |
| C1 | C2 | C3 | C4 | C5 | C6 | C7 | C8 | C9 | |
|---|---|---|---|---|---|---|---|---|---|
| Belgium | 0.1796 | 0.2697 | 0.8163 | 0.0712 | 0.7591 | 0.7693 | 0.8403 | 0.2034 | 0.8403 |
| Bulgaria | 0.1796 | 0.0824 | 0.8689 | 0.1532 | 0.8631 | 0.9034 | 0.7495 | 0.1508 | 0.6913 |
| Czech Republic | 0.2035 | 0.1798 | 0.8520 | 0.1219 | 0.7898 | 0.8316 | 0.8802 | 0.1463 | 0.8984 |
| Denmark | 0.2016 | 0.3306 | 0.8348 | 0.2600 | 0.8294 | 0.8164 | 0.8639 | 0.2075 | 0.8716 |
| Germany | 0.2085 | 0.3146 | 0.8338 | 0.1216 | 0.7993 | 0.8110 | 0.8131 | 0.1481 | 0.8495 |
| Estonia | 0.2032 | 0.1338 | 0.8902 | 0.2343 | 0.7516 | 0.8454 | 0.8022 | 0.2026 | 0.8136 |
| Ireland | 0.1894 | 0.1252 | 0.7460 | 0.0756 | 0.8287 | 0.8242 | 0.8911 | 0.2436 | 0.8136 |
| Greece | 0.1491 | 0.1059 | 0.7989 | 0.1257 | 0.8823 | 0.8887 | 0.8875 | 0.1905 | 0.7280 |
| Spain | 0.1695 | 0.1273 | 0.7389 | 0.1423 | 0.8577 | 0.8732 | 0.6551 | 0.1789 | 0.7868 |
| France | 0.1857 | 0.2376 | 0.8086 | 0.1281 | 0.8003 | 0.8395 | 0.8403 | 0.1950 | 0.8609 |
| Croatia | 0.1629 | 0.0920 | 0.8294 | 0.2309 | 0.8936 | 0.8865 | 0.9492 | 0.1307 | 0.7868 |
| Italy | 0.1634 | 0.1466 | 0.8077 | 0.1422 | 0.8648 | 0.8631 | 0.7495 | 0.1169 | 0.7708 |
| Cyprus | 0.1823 | 0.0556 | 0.6616 | 0.0805 | 0.8413 | 0.8506 | 0.8621 | 0.2382 | 0.7884 |
| Latvia | 0.1942 | 0.0471 | 0.9024 | 0.3033 | 0.8793 | 0.8610 | 0.8185 | 0.1910 | 0.7823 |
| Lithuania | 0.1995 | 0.0899 | 0.9042 | 0.2092 | 0.8841 | 0.8735 | 0.9129 | 0.2619 | 0.7700 |
| Luxembourg | 0.1876 | 0.1391 | 0.8029 | 0.0444 | 0.6009 | 0.4979 | 0.9002 | 0.2436 | 0.8487 |
| Hungary | 0.1897 | 0.1273 | 0.8533 | 0.1169 | 0.8662 | 0.8701 | 0.7749 | 0.1472 | 0.7991 |
| Malta | 0.1886 | 0.0610 | 0.8121 | 0.0507 | 0.9127 | 0.9078 | 0.6515 | 0.1428 | 0.8449 |
| Netherlands | 0.2046 | 0.2140 | 0.7948 | 0.0476 | 0.7886 | 0.7900 | 0.8548 | 0.2039 | 0.8724 |
| Austria | 0.1985 | 0.3339 | 0.7691 | 0.2725 | 0.7968 | 0.7685 | 0.8748 | 0.1789 | 0.8625 |
| Poland | 0.1839 | 0.1027 | 0.8105 | 0.0920 | 0.8616 | 0.8744 | 0.9056 | 0.1990 | 0.8327 |
| Portugal | 0.1873 | 0.1370 | 0.7416 | 0.2521 | 0.8834 | 0.8878 | 0.7459 | 0.1544 | 0.8082 |
| Romania | 0.1759 | 0.0514 | 0.8963 | 0.2044 | 0.9141 | 0.9194 | 0.6642 | 0.1142 | 0.7036 |
| Slovenia | 0.1860 | 0.2151 | 0.7878 | 0.1739 | 0.8244 | 0.8307 | 0.9111 | 0.1972 | 0.8594 |
| Slovakia | 0.1852 | 0.0845 | 0.8707 | 0.0982 | 0.8430 | 0.8627 | 0.8657 | 0.1405 | 0.8617 |
| Finland | 0.1947 | 0.2911 | 0.8137 | 0.3186 | 0.6725 | 0.6713 | 0.8566 | 0.2057 | 0.8732 |
| Sweden | 0.2154 | 0.3478 | 0.8275 | 0.4359 | 0.7446 | 0.7670 | 0.8657 | 0.2275 | 0.8602 |
| United Kingdom | 0.2056 | 0.1776 | 0.8571 | 0.0734 | 0.8483 | 0.8535 | 0.7967 | 0.2146 | 0.8304 |
| 0.25 | 0.30 | 0.85 | 0.9 | |
| 2 | 3 | 3 | 2 | |
| 0.2 | 0.3 | 0.3 | 0.2 |
| R3 | [0.1, 0.55) | [0.55, 1.0) |
| di | 5 | 5 |
| pi | 0.5 | 0.5 |
| R4 | [0.1, 0.55) | [0.55, 1.0) |
| di | 4 | 6 |
| pi | 0.4 | 0.6 |
| R3, R4 | [0.1, 0.28) | [0.28, 0.46) | [0.46, 0.64) | [0.64, 0.82) | [0.82, 1.0) |
| di | 2 | 2 | 2 | 2 | 2 |
| pi | 0.2 | 0.2 | 0.2 | 0.2 | 0.2 |
| C1 | C2 | C3 | C4 | C5 | C6 | C7 | C8 | C9 | |
|---|---|---|---|---|---|---|---|---|---|
| E(R) | 0.9851 | 0.9851 | 1.0000 | 0.9851 | 1.0000 | 0.9851 | 0.9554 | 0.9703 | 0.9703 |
| E2 | 0.8631 | 0.9059 | 0.6769 | 0.7496 | 0.5917 | 0.3712 | 0.8631 | 0.9852 | 0.9059 |
| E4 | 0.9147 | 0.9509 | 0.7995 | 0.7990 | 0.7763 | 0.5492 | 0.9147 | 0.9225 | 0.9337 |
| E7 | 0.8861 | 0.9343 | 0.8166 | 0.8214 | 0.7820 | 0.6357 | 0.8853 | 0.8687 | 0.8977 |
| E8 | 0.8787 | 0.9220 | 0.8420 | 0.8505 | 0.8255 | 0.6158 | 0.8607 | 0.8935 | 0.8401 |
| E14 | 0.8877 | 0.8966 | 0.7944 | 0.8502 | 0.7948 | 0.6924 | 0.8662 | 0.8582 | 0.8653 |
| E16 | 0.8593 | 0.8713 | 0.7864 | 0.8628 | 0.8136 | 0.6815 | 0.8086 | 0.8517 | 0.8356 |
| E2,4,7,14 | 0.8879 | 0.9219 | 0.7719 | 0.8050 | 0.7362 | 0.5621 | 0.8823 | 0.9086 | 0.9007 |
| E2,4,8,16 | 0.8790 | 0.9125 | 0.7762 | 0.8155 | 0.7518 | 0.5544 | 0.8618 | 0.9132 | 0.8788 |
| C1 | C2 | C3 | C4 | C5 | C6 | C7 | C8 | C9 | |
|---|---|---|---|---|---|---|---|---|---|
| E(R) | 0.9703 | 0.9851 | 0.9703 | 1.0000 | 0.9851 | 1.0000 | 0.9703 | 0.9703 | 0.9851 |
| E2 | 0.7496 | 0.8631 | 0.6769 | 0.7496 | 0.4912 | 0.3712 | 0.8631 | 0.9852 | 0.9059 |
| E4 | 0.8534 | 0.9020 | 0.8086 | 0.7990 | 0.7157 | 0.5089 | 0.9015 | 0.9225 | 0.9392 |
| E7 | 0.8822 | 0.9089 | 0.8773 | 0.8564 | 0.7820 | 0.6424 | 0.9265 | 0.8630 | 0.8793 |
| E8 | 0.8760 | 0.8955 | 0.8564 | 0.8459 | 0.7954 | 0.6012 | 0.8848 | 0.9341 | 0.8940 |
| E14 | 0.8628 | 0.8662 | 0.8815 | 0.8723 | 0.8145 | 0.6585 | 0.8628 | 0.8653 | 0.8850 |
| E16 | 0.8347 | 0.8245 | 0.8534 | 0.8414 | 0.8034 | 0.6605 | 0.8780 | 0.8950 | 0.8578 |
| E2,4,7,14 | 0.8370 | 0.8851 | 0.8111 | 0.8193 | 0.7009 | 0.5453 | 0.8885 | 0.9090 | 0.9023 |
| E2,4,8,16 | 0.8284 | 0.8713 | 0.7988 | 0.8090 | 0.7014 | 0.5355 | 0.8819 | 0.9342 | 0.8992 |
| C1 | C2 | C3 | C4 | C5 | C6 | C7 | C8 | C9 | |
|---|---|---|---|---|---|---|---|---|---|
| E(R) | 0.9554 | 0.9851 | 1.0000 | 1.0000 | 0.9851 | 0.9851 | 0.9554 | 0.9498 | 1.0000 |
| E2 | 0.7496 | 0.9403 | 0.6769 | 0.6769 | 0.5917 | 0.3712 | 0.9059 | 0.9666 | 0.9666 |
| E4 | 0.8654 | 0.9621 | 0.7995 | 0.767 | 0.7608 | 0.5089 | 0.9454 | 0.9020 | 0.9629 |
| E7 | 0.8947 | 0.9393 | 0.8539 | 0.8521 | 0.7617 | 0.6357 | 0.9406 | 0.9808 | 0.9302 |
| E8 | 0.8897 | 0.8743 | 0.8445 | 0.8294 | 0.7646 | 0.5996 | 0.8935 | 0.8790 | 0.9356 |
| E14 | 0.8769 | 0.8769 | 0.8511 | 0.8591 | 0.7834 | 0.6549 | 0.9366 | 0.8896 | 0.9003 |
| E16 | 0.8748 | 0.8737 | 0.8534 | 0.8338 | 0.7596 | 0.6704 | 0.8482 | 0.8097 | 0.8458 |
| E2,4,7,14 | 0.8466 | 0.9297 | 0.7954 | 0.7888 | 0.7244 | 0.5427 | 0.9321 | 0.9347 | 0.9400 |
| E2,4,8,16 | 0.8449 | 0.9126 | 0.7936 | 0.7768 | 0.7192 | 0.5375 | 0.8983 | 0.8893 | 0.9277 |
| 2016 | |||||||||
| Wx4 | Wx3 | Wx5 | Wx6 | Wy2 | Wy8 | Wy9 | Wy1 | Wy7 | |
| 0.8173 | 0.1816 | 0.0011 | 0 | 0.9290 | 0.0182 | 0.0182 | 0.0173 | 0.0173 | 204.109514 |
| 2017 | |||||||||
| Wx4 | Wx3 | Wx5 | Wx6 | Wy8 | Wy9 | Wy7 | Wy2 | Wy1 | |
| 0.6719 | 0.3281 | 0 | 0 | 0.4019 | 0.1572 | 0.1572 | 0.1419 | 0.1419 | 230.062190 |
| 2018 | |||||||||
| Wx3 | Wx4 | Wx5 | Wx6 | Wy9 | Wy2 | Wy7 | Wy8 | Wy1 | |
| 0.5745 | 0.4135 | 0.0099 | 0.0021 | 0.3482 | 0.3086 | 0.2385 | 0.1042 | 0.0005 | 220.053163 |
| α | Aα | Country | No | Rank |
|---|---|---|---|---|
| 0.3616 | 27 | Sweden | 27 | 1 |
| 0.3477 | 20,27 | Austria | 20 | 2 |
| 0.3452 | 4,20,27 | Denmark | 4 | 3 |
| 0.3082 | 4,20,26,27 | Finland | 26 | 4 |
| 0.2524 | 4,10,20,26,27 | France | 10 | 5 |
| 0.2517 | 4,5,10,20,26,27 | Germany | 5 | 6 |
| 0.2380 | 4,5,10,20,24,26,27 | Slovenia | 24 | 7 |
| 0.2072 | 1,4,5,10,20,24,26,27 | Belgium | 1 | 8 |
| 0.2048 | 1,3,4,5,10,20,24,26,27 | Czech Republic | 3 | 9 |
| 0.2014 | 1,3,4,5,10,20,24,26,27,28 | UK | 28 | 10 |
| 0.1841 | 1,3,4,5,10,19,20,24,26,27,28 | Netherlands | 19 | 11 |
| 0.1681 | 1,3,4,5,10,12,19,20,24,26,27,28 | Italy | 12 | 12 |
| 0.1679 | 1,3,4,5,10,12,16,19,20,24,26,27,28 | Luxembourg | 16 | 13 |
| 0.1609 | 1,3,4,5,10,12,16,19,20,22,24,26,27,28 | Portugal | 22 | 14 |
| 0.1601 | 1,3,4,5,6,10,12,16,19,20,22,24,26,27,28 | Estonia | 6 | 15 |
| 0.1542 | 1,3,4,5,6,7,10,12,16,19,20,22,24,26,27,28 | Ireland | 7 | 16 |
| 0.1522 | 1,3,4,5,6,7,10,12,16,17,19,20,22,24,26,27,28 | Hungary | 17 | 17 |
| 0.1501 | 1,3,4,5,6,7,9,10,12,16,17,19,20,22,24,26,27,28 | Spain | 9 | 18 |
| 0.1330 | 1,3,4,5,6,7,8,9,10,12,16,17,19,20,22,24,26,27,28 | Greece | 8 | 19 |
| 0.1330 | 1,3,4,5,6,7,8,9,10,12,16,17,19,20,21,22,24,26,27,28 | Poland | 21 | 20 |
| 0.1215 | 1,3,4,5,6,7,8,9,10,12,15,16,17,19,20,21,22,24,26,27,28 | Lithuania | 15 | 21 |
| 0.1214 | 1,3,4,5,6,7,8,9,10,11,12,15,16,17,19,20,21,22,24,26,27,28 | Croatia | 11 | 22 |
| 0.1150 | 1,3,4,5,6,7,8,9,10,11,12,15,16,17,19,20,21,22,24,25,26,27,28 | Slovakia | 25 | 23 |
| 0.1079 | 1,2,3,4,5,6,7,8,9,10,11,12,15,16,17,19,20,21,22,24,25,26,27,28 | Bulgaria | 2 | 24 |
| 0.0892 | 1,2,3,4,5,6,7,8,9,10,11,12,15,16,17,18,19,20,21,22,24,25,26,27,28 | Malta | 18 | 25 |
| 0.0884 | 1,2,3,4,5,6,7,8,9,10,11, 12,13,15,16,17,18,19,20,21,22,24,25,26,27,28 | Cyprus | 13 | 26 |
| 0.0790 | 1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,24,25,26,27,28 | Latvia | 14 | 27 |
| 0.0771 | 1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28 | Romania | 23 | 28 |
| α | Aα | Country | No | Rank |
|---|---|---|---|---|
| 0.4409 | 27 | Sweden | 27 | 1 |
| 0.4262 | 4,27 | Denmark | 4 | 2 |
| 0.4178 | 4,26,27 | Finland | 26 | 3 |
| 0.4156 | 4,20,26,27 | Austria | 20 | 4 |
| 0.4055 | 4,15,20,26,27 | Lithuania | 15 | 5 |
| 0.3873 | 4,6,15,20,26,27 | Estonia | 6 | 6 |
| 0.3739 | 4,6,15,20,24,26,27 | Slovenia | 24 | 7 |
| 0.3666 | 4,6,14,15,20,24,26,27 | Latvia | 14 | 8 |
| 0.3604 | 3,4,6,14,15,20,24,26,27 | Czech Republic | 3 | 9 |
| 0.3593 | 3,4,6,11,14,15,20,24,26,27 | Croatia | 11 | 10 |
| 0.3585 | 3,4,5,6,11,14,15,20,24,26,27 | Germany | 5 | 11 |
| 0.3545 | 3,4,5,6,11,14,15,20,22,24,26,27 | Portugal | 22 | 12 |
| 0.3519 | 3,4,5,6,10,11,14,15,20,22,24,26,27 | France | 10 | 13 |
| 0.3518 | 3,4,5,6,8,10,11,14,15,20,22,24,26,27 | Greece | 8 | 14 |
| 0.3496 | 3,4,5,6,8,10,11,14,15,17,20,22,24,26,27 | Hungary | 17 | 15 |
| 0.3470 | 3,4,5,6,8,10,11,14,15,17,20,22,24,25,26,27 | Slovakia | 25 | 16 |
| 0.3352 | 3,4,5,6,8,10,11,14,15,17,20,22,24,25,26,27,28 | UK | 28 | 17 |
| 0.3350 | 3,4,5,6,8,9,10,11,14,15,17,20,22,24,25,26,27,28 | Spain | 9 | 18 |
| 0.3284 | 3,4,5,6,8,9,10,11,12,14,15,17,20,22,24,25,26,27,28 | Italy | 12 | 19 |
| 0.3240 | 2,3,4,5,6,8,9,10,11,12,14,15,17,20,22,24,25,26,27,28 | Bulgaria | 2 | 20 |
| 0.3238 | 2,3,4,5,6,8,9,10,11,12,14,15,17,20,21,22,24,25,26,27,28 | Poland | 21 | 21 |
| 0.3177 | 1,2,3,4,5,6,8,9,10,11,12,14,15,17,20,21,22,24,25,26,27,28 | Belgium | 1 | 22 |
| 0.3034 | 1,2,3,4,5,6,7,8,9,10,11,12,14,15,17,20,21,22,24,25,26,27,28 | Ireland | 7 | 23 |
| 0.2999 | 1,2,3,4,5,6,7,8,9,10,11,12,14,15,17,18,20,21,22,24,25,26,27,28 | Malta | 18 | 24 |
| 0.2975 | 1,2,3,4,5,6,7,8,9,10,11,12,14,15,17,18,19,20,21,22,24,25,26,27,28 | Netherlands | 19 | 25 |
| 0.2965 | 1,2,3,4,5,6,7,8,9,10,11,12,14,15,16,17,18,19,20,21,22,24,25,26,27,28 | Luxembourg | 16 | 26 |
| 0.2963 | 1,2,3,4,5,6,7,8,9,10,11,12,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28 | Romania | 23 | 27 |
| 0.2724 | 1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28 | Cyprus | 13 | 28 |
| α | Aα | Country | No | Rank |
|---|---|---|---|---|
| 0.6289 | 27 | Sweden | 27 | 1 |
| 0.6082 | 26,27 | Finland | 26 | 2 |
| 0.6081 | 4,26,27 | Denmark | 4 | 3 |
| 0.5618 | 4,20,26,27 | Austria | 20 | 4 |
| 0.5506 | 3,4,20,26,27 | Czech Republic | 3 | 5 |
| 0.5479 | 3,4,5,20,26,27 | Germany | 5 | 6 |
| 0.5455 | 3,4,5,11,20,26,27 | Croatia | 11 | 7 |
| 0.5440 | 3,4,5,11,20,25,26,27 | Slovakia | 25 | 8 |
| 0.5420 | 3,4,5,11,20,25,26,27,28 | UK | 28 | 9 |
| 0.5391 | 3,4,5,11,15,20,25,26,27,28 | Lithuania | 15 | 10 |
| 0.5368 | 3,4,5,11,15,17,20,25,26,27,28 | Hungary | 17 | 11 |
| 0.5328 | 3,4,5,11,15,17,20,24,25,26,27,28 | Slovenia | 24 | 12 |
| 0.5322 | 3,4,5,10,11,15,17,20,24,25,26,27,28 | France | 10 | 13 |
| 0.5302 | 3,4,5,6,10,11,15,17,20,24,25,26,27,28 | Estonia | 6 | 14 |
| 0.5286 | 3,4,5,6,10,11,15,17,20,22,24,25,26,27,28 | Portugal | 22 | 15 |
| 0.5278 | 3,4,5,6,8,10,11,15,17,20,22,24,25,26,27,28 | Greece | 8 | 16 |
| 0.5099 | 3,4,5,6,8,10,11,15,17,20,21,22,24,25,26,27,28 | Poland | 21 | 17 |
| 0.5090 | 1,3,4,5,6,8,10,11,15,17,20,21,22,24,25,26,27,28 | Belgium | 1 | 18 |
| 0.5059 | 1,3,4,5,6,8,10,11,14,15,17,20,21,22,24,25,26,27,28 | Latvia | 14 | 19 |
| 0.4982 | 1,3,4,5,6,8,10,11,12,14,15,17,20,21,22,24,25,26,27,28 | Italy | 12 | 20 |
| 0.4951 | 1,3,4,5,6,8,10,11,12,14,15,17,19,20,21,22,24,25,26,27,28 | Netherlands | 19 | 21 |
| 0.4908 | 1,3,4,5,6,8,10,11,12,14,15,16,17,19,20,21,22,24,25,26,27,28 | Luxembourg | 16 | 22 |
| 0.4882 | 1,3,4,5,6,8,9,10,11,12,14,15,16,17,19,20,21,22,24,25,26,27,28 | Spain | 9 | 23 |
| 0.4865 | 1,3,4,5,6,8,9,10,11,12,14,15,16,17,18,19,20,21,22,24,25,26,27,28 | Malta | 18 | 24 |
| 0.4756 | 1,3,4,5,6,7,8,9,10,11,12,14,15,16,17,18,19,20,21,22,24,25,26,27,28 | Ireland | 7 | 25 |
| 0.4729 | 1,2,3,4,5,6,7,8,9,10,11,12,14,15,16,17,18,19,20,21,22,24,25,26,27,28 | Bulgaria | 2 | 26 |
| 0.4448 | 1,2,3,4,5,6,7,8,9,10,11,12,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28 | Romania | 23 | 27 |
| 0.4336 | 1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28 | Cyprus | 13 | 28 |
| Rank 2016 | Rank 2017 | Rank 2018 | Three Clusters k-Means | Rank Fedajev et al. | Category Fedajev et al. | Four Clusters k-Means | |
|---|---|---|---|---|---|---|---|
| Belgium | 8 | 22 | 18 | 3 | 20 | Periphery | 3 |
| Bulgaria | 24 | 20 | 26 | 3 | 24 | Periphery | 3 |
| Czech Republic | 9 | 9 | 5 | 1 | 9 | Core | 1 |
| Denmark | 3 | 2 | 3 | 1 | 2 | Core | 1 |
| Germany | 6 | 11 | 6 | 1 | 11 | Semi-Periphery | 1 |
| Estonia | 15 | 6 | 14 | 2 | 10 | Semi-Periphery | 4 |
| Ireland | 16 | 23 | 25 | 3 | 19 | Semi-Periphery | 3 |
| Greece | 19 | 14 | 16 | 2 | 16 | Semi-Periphery | 4 |
| Spain | 18 | 18 | 23 | 3 | 25 | Periphery | 3 |
| France | 5 | 13 | 13 | 1 | 8 | Core | 1 |
| Croatia | 22 | 10 | 7 | 2 | 6 | Core | 2 |
| Italy | 12 | 19 | 20 | 3 | 22 | Periphery | 3 |
| Cyprus | 26 | 28 | 28 | 3 | 26 | Periphery | 3 |
| Latvia | 27 | 8 | 19 | 2 | 12 | Semi-Periphery | 4 |
| Lithuania | 21 | 5 | 10 | 2 | 4 | Core | 4 |
| Luxembourg | 13 | 26 | 22 | 3 | 28 | Periphery | 3 |
| Hungary | 17 | 15 | 11 | 2 | 18 | Semi-Periphery | 2 |
| Malta | 25 | 24 | 24 | 3 | 27 | Periphery | 3 |
| Netherlands | 11 | 25 | 21 | 3 | 22 | Periphery | 3 |
| Austria | 2 | 4 | 4 | 1 | 3 | Core | 1 |
| Poland | 20 | 21 | 17 | 3 | 13 | Semi-Periphery | 3 |
| Portugal | 14 | 12 | 15 | 2 | 15 | Semi-Periphery | 4 |
| Romania | 28 | 27 | 27 | 3 | 20 | Periphery | 3 |
| Slovenia | 7 | 7 | 12 | 1 | 5 | Core | 1 |
| Slovakia | 23 | 16 | 8 | 2 | 17 | Semi-Periphery | 2 |
| Finland | 4 | 3 | 2 | 1 | 7 | Core | 1 |
| Sweden | 1 | 1 | 1 | 1 | 1 | Core | 1 |
| UK | 10 | 17 | 9 | 2 | 14 | Semi-Periphery | 2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kosareva, N.; Krylovas, A. Assessing the Europe 2020 Strategy Implementation Using Interval Entropy and Cluster Analysis for Interrelation between Two Groups of Headline Indicators. Entropy 2021, 23, 345. https://doi.org/10.3390/e23030345
Kosareva N, Krylovas A. Assessing the Europe 2020 Strategy Implementation Using Interval Entropy and Cluster Analysis for Interrelation between Two Groups of Headline Indicators. Entropy. 2021; 23(3):345. https://doi.org/10.3390/e23030345
Chicago/Turabian StyleKosareva, Natalja, and Aleksandras Krylovas. 2021. "Assessing the Europe 2020 Strategy Implementation Using Interval Entropy and Cluster Analysis for Interrelation between Two Groups of Headline Indicators" Entropy 23, no. 3: 345. https://doi.org/10.3390/e23030345
APA StyleKosareva, N., & Krylovas, A. (2021). Assessing the Europe 2020 Strategy Implementation Using Interval Entropy and Cluster Analysis for Interrelation between Two Groups of Headline Indicators. Entropy, 23(3), 345. https://doi.org/10.3390/e23030345