1. Introduction
The development of industrial informatization has given rise to a large amount of data in various fields. This has led to data processing becoming a difficult problem in the industry, especially for fault diagnosis. The explosive growth of data provides more information, and therefore, typical data analysis theories often fail in achieving the necessary results. The main reason for this failure can be attributed to the typical data analysis theory that often sets the data distribution type through prior information and performs analyses based on this assumption. Once the distribution type is set, the subsequent analysis can perform the estimation and parametric analysis based on only that distribution type; however, with the growth of data, more information is provided, and thus, the type of data distribution will need to be modified. As a nonparametric estimation method, kernel density estimation (KDE) is the most suitable method for the massive amount of the current data. KDE does not employ a priori assumption for the overall data distribution, and it directly starts from the sample data. When the sample size is sufficient, the KDE can approximate different distributions. Furthermore, Sheather and Jones [
1] provides the optimal bandwidth estimation formula for a one-dimensional KDE and proves that the kernel function is asymptotically unbiased and consistent in the density estimation. However, with the growth of the dimension, the multidimensional KDE becomes more complex, and its optimal bandwidth formula is not provided. The distribution of multidimensional data has been described to a certain extent by estimating the kernel density of the reduced data in different dimensions Muir [
2], Laurent [
3]. In fact, the optimal KDE of multidimensional data is a problem that needs to be studied further.
In the field of fault diagnosis, an essential problem is measuring the difference between samples. A frequency histogram has been used to indicate the distribution difference between two samples Sugumaran and Ramachandran [
4], Scott [
5]; however, there are three shortcomings to this method: (1) the large number of discrete operations require a higher amount of time; (2) the process depends on the selection of the interval, which is more subjective; (3) there is no intuitive index to reflect this difference. In fact, based on KDE, the JS divergence can be used to measure the difference in data distribution, which can overcome the above shortcomings to a certain extent. For example, the failure of a rolling bearing, which is a key component of mechanical equipment, will have a serious effect on the safe and stable operation of the equipment, and the incipient fault detection of rolling bearings can help avoid equipment running with faults and avoid causing serious safety accidents and economic losses, which has important practical and engineering significance.
In Saruhan et al. [
6], vibration analysis of rolling element bearings (REBs) defects is studied. The REBs are the most widely used mechanical parts in rotating machinery under high load and high rotational speeds. In addition, characteristics of bearing faults are analyzed in detail in references Razavi-Far et al. [
7], Harmouche et al. [
8]. Compared with traditional fault diagnosis, the fault diagnosis of rolling bearings is more complex:
The fault signal is weak: Bearing data is a type of high-frequency data, and the fault signal is often covered by these high-frequency signals, thereby leading to the failure of traditional fault diagnosis methods. KDE is highly accurate in describing data distribution, so it can identify weak signals.
Data is highly coupled: Bearing data is reflected in the form of a vibration signal, and there is strong coupling in different dimension signals, thereby making fault diagnosis difficult. Multi-dimensional KDE plays an important role in depicting the correlation of data, which can characterize the relationship between different dimensions of data.
Incomplete data set: Most bearings work under normal conditions, and the fault data collected are often fewer, which makes the data incomplete, thereby resulting in the imperfection of the fault data set and increasing the difficulty of fault detection. The fault detection method constructed by JS divergence can deal with unknown faults and incomplete data sets without using additional data sets.
To overcome these problems, in-depth research has been conducted on this topic. Fault detection technology based on trend elimination and noise reduction has been proposed previously He et al. [
9], Demetriou and Polycarpou [
10]. The signal trend ratio is enhanced by eliminating the trend, and the signal–noise ratio is enhanced by noise reduction, and therefore, the fault detection effect is improved. However, this method uses the traditional detection method and cannot effectively solve the problem of data coupling. In reference Zhang et al. [
11], Fu et al. [
12], a fault detection method based on PCA dimension reduction and modal decomposition feature extraction is proposed. For multidimensional data, PCA dimension reduction is performed to reduce data dimensions and eliminate correlation between different dimensions. Then, the modal decomposition method is used to extract features among dimensions for fault detection. This method can effectively solve the strong coupling between data; however, it will lose some information in the process of PCA dimension reduction, and it leads to a reduction in the fault detection effect. In reference Itani et al. [
13], Kong et al. [
14], Jones and Sheather [
15], Desforges et al. [
16], a bearing fault detection method based on KDE is proposed. These studies analyzed the feasibility of KDE method in fault detection, and combined different classification methods for experiments. However, these methods only use one-dimensional KDE, and cannot directly describe high-dimensional data.
The data distribution is reconstructed by KDE and the cross-entropy function is constructed to measure the distribution difference for improving the fault detection results. However, this method cannot reflect the correlation between different dimensions, and the cross-entropy function is not precise in the description of density distribution, which leads to a reduction in the fault detection effect, especially for unknown fault detection, which is not included in the fault set.
In this study, the KDE method is extended to multidimensional data to avoid information loss caused by the KDE for each dimension, and to better describe the density probability distribution of the data. Meanwhile, this study improves the traditional method using the cross-entropy function as the measurement of density distribution difference, and it uses JS divergence as the measurement of density distribution difference, thereby avoiding the relativity caused by the cross-entropy function. Most fault identification methods are based only on distance measurement; however, only relying on distance measurement cannot effectively detect unknown faults. Based on JS divergence, distribution characteristics of JS divergence between the sample density distribution and population density distribution are derived using the sliding window principle. Thus, the detection threshold of fault identification is assigned to realize the identification of unknown faults.
This paper is based on the following structure. In
Section 2, the trend elimination method and detection method are introduced, and the intrinsic and extrinsic signals in the observation data are separated. Then, the fault detection threshold is constructed via statistics. In
Section 3, the KDE method is extended to multidimensional data, and the optimal bandwidth is derived. Then, JS divergence is employed to measure the difference between probability distributions of different densities. In
Section 4, the sliding window principle is used to sample the training data to obtain the distribution characteristics of JS divergence between the sample density distribution and the overall density distribution, and the detection threshold of fault identification is obtained using the KDE method. In
Section 5, the normal data, two known faults, and one unknown fault are identified using the bearing data of the Case Western Reserve University Bearing Data Center as the fault diagnosis data. The experimental results show that the method can identify all types of faults well.
2. Statistics Fault Detection
In the operation process of the complex equipment or systems, the common observation state can be divided into intrinsic and extrinsic parts. In general, the intrinsic part represents the main working state of the system, which has a certain trend, monotony, and periodicity. The extrinsic part represents system noise, which has a certain zero mean value, high frequency vibration, and statistical stability. For the intrinsic part, the state equation of the system can be used to describe the law. When a fault occurs in the intrinsic part, the symptoms are relatively significant, and the corresponding fault detection methods are relatively mature. However, for high-frequency vibration signals, the incipient fault is often hidden in the extrinsic part, which is easily covered by noise. Therefore, it is necessary to analyze the observed data in depth.
2.1. Signal Decomposition
In the initial operation stage of the equipment, the unstable operation of the system causes large data fluctuations, which will not only have a great effect on the system trend, but also affect the statistical characteristics of the data. Therefore, it is necessary to truncate the data to remove unstable signals [
9]. The corresponding time of the time series after removing the nonstationary period data is
, and the following
m observation data are obtained:
Each sampling
contains
n features, which are expressed as components in the form of
Then, the data
can be decomposed into
where
denotes the intrinsic part, which is composed of trend, and
denotes the extrinsic part, which is composed of observation noise and fault data.
The intrinsic part is composed of multiple signals. Selecting the appropriate basis function
can help describe the intrinsic part. By traversing
m data to model the nonlinear data
,
Then, Equation (
4) can be expressed as
Thus, the efficient estimator of
is
Using Equations (
3) and (
7), the signal can be decomposed into
Usually, the choice of the basis function is a problem worthy of discussion, and it depends on prior knowledge of practical application scenarios; however, this is not the focus of this paper, and is therefore not covered here.
Remark 1. For the bearing data, the data is generally stable and periodic. Therefore, Fourier transform is usually used to extract periodic features instead of more complex basis functions, such as a polynomial basis function and wavelet basis function.
2.2. Statistics Detection
For simplicity, remember
. According to Equation (
8), the training data after signal decomposition are
, which is generally considered a normal random vector with expectation of
, so that
where
denotes the total covariance matrix. When the covariance matrix
is unknown, the unbiased estimation is given by
Let
be the data in the test window to be tested; the sample mean value
is
Then,
is still normal distributed and
The
statistics can be constructed as
Reference Solomons and Hotelling [
17] reports that the distribution of the
statistic satisfies
Therefore, if the significance level is
, we can get that
The testing data and the training data both come from the same mode; otherwise, they are considered different. The error rate of this criterion is .
3. Optimal Kernel Density Estimation
Section 2 introduces the fault detection method based on
statistics, including the signal decomposition technology and fault detection method based on the
statistics. However, the fault detection method based on the
statistics assumes that data satisfies the normal distribution, while the actual observation data may not meet the hypothesis, which can lead the discriminant performance of the
statistics to not satisfy the design requirements. In addition, the statistics test the data from the angle of the intrinsic part
and covariance matrix
. These two attributes are not sufficient to describe all statistical characteristics of the system. When the incipient fault is submerged by data noise, it is easy to miss the detection. In this study, a KDE method for multidimensional data is constructed to describe the probability and statistical characteristics of the data more accurately.
3.1. Optimal Bandwidth Theorem
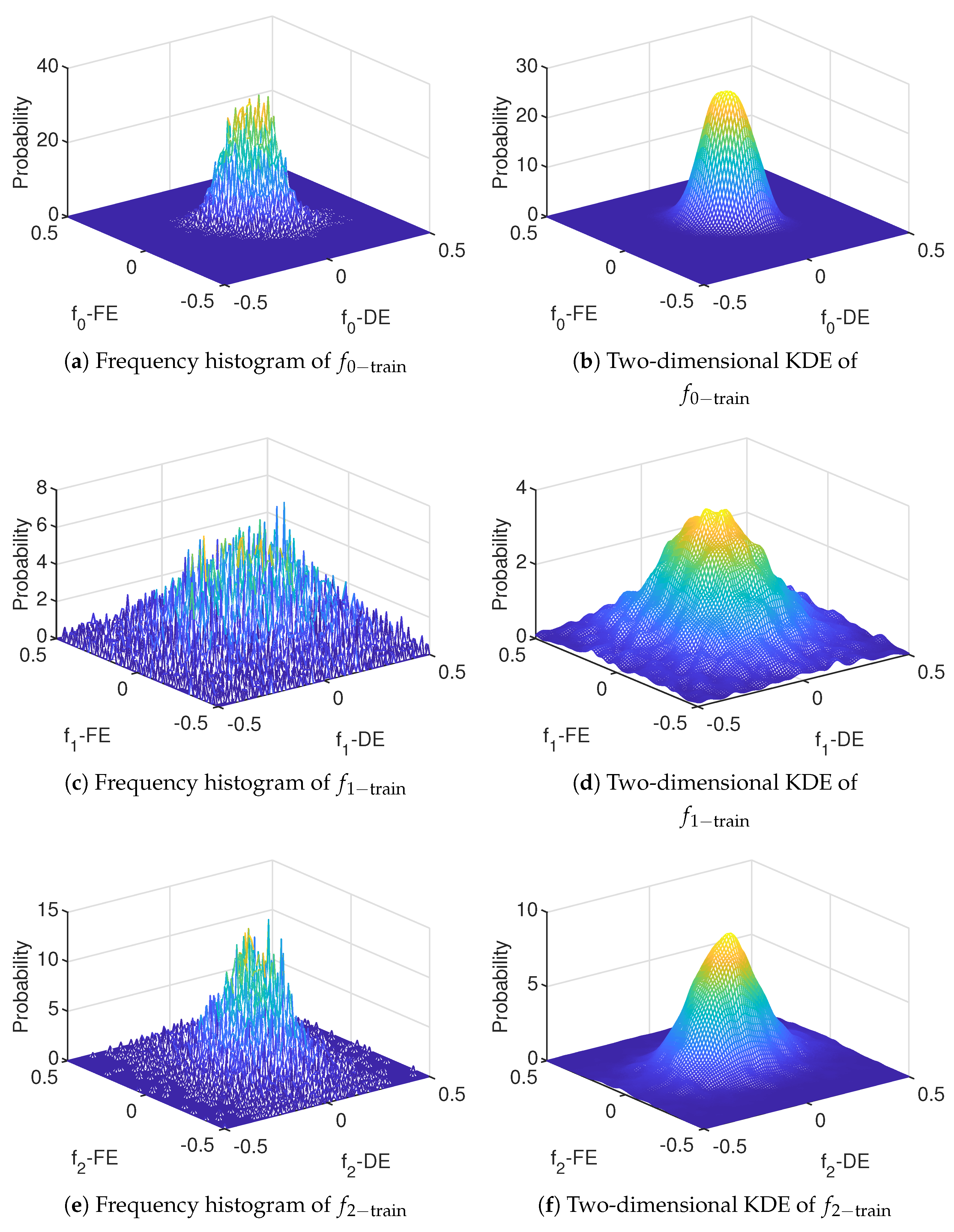
For the observed data, the frequency histogram can be used to show its statistical characteristics directly. However, in the actual application process, the frequency histogram is a discrete statistical method, the interval number of the histogram is difficult to divide, and more importantly, the discretization operation inconveniences the subsequent data processing. To overcome these limitations, the KDE method is proposed. This method is a nonparametric estimation method that estimates the population probability density distribution directly by sampling data.
For any point
, assuming that the probability density of a certain mode is
, the kernel density of
is estimated based on the sampling data
in
Section 2.1. As reported in reference Rao [
18], the estimation formula is
where
and
denote the number of sampling data, dimension of sampling data, kernel function, and bandwidth, respectively.
For the sake of convenience in the following discussions, in the case of no doubt,
The kernel function
satisfies
; therefore,
, that is,
. Thus,
satisfies both positive definiteness, continuity, and normality. Therefore, it is reasonable to use it as the KDE. The Gaussian kernel function is a good choice as given by
In this study, the performance of the kernel density estimator is characterized by the mean integral square error (MISE).
Reference Rao [
18] shows that the estimation result
is not sensitive to the selection of the kernel function
; that is, the MISE of the estimation results obtained using different kernel functions is almost the same, which is reflected in the subsequent derivation process. In addition, the MISE depends on the selection of the bandwidth
. If
is too small, the density estimation
shows an irregular shape because of the increase in the randomness. While
is too large, density estimation
is too averaged to show sufficient detail.
The optimal bandwidth formula is provided in the following theorem, and it is one of the key theoretical results of this study.
Theorem 1. For any dimensional probability density function and any kernel function with a symmetric form, if in Equation (16) is used to estimate , and if the function with respect to is integrable when the in Equation (19) is the minimum, the bandwidth satisfies where and are two constant values given by Equation (20) is called the optimal bandwidth formula and denotes the optimal bandwidth. A detailed proof of this theorem is given below.
Proof. It can be proved that the following two equations hold
From Equation (
23),
where
represents a constant value between 0 and 1. According to Equations (
23) and (
24),
According to the Equations (
25) and (
26), the following equation holds.
To facilitate the subsequent reasoning, the following theorem is given.
Theorem 2. For any matrixΦ, is a kernel density function with symmetric form; then, Proof. If the odd function
is integrable on
, there must be
. Similarly, it can be verified that the kernel function
with a symmetric form satisfies
Thus, the Theorem 2 is proved. □
For any unit length vector
, the Taylor expansion can be used to obtain
If the bandwidth
satisfies the condition
Then, from Equations (
22)–(
32), we get that
Based on Equation (
33), if
is integrable, there is
When
is the smallest, the derivative of Equation (
35) with respect to
is 0, which means
Thus, the optimal bandwidth
in Theorem 1 is obtained as
□
Remark 2. When the number of samples m is determined, the appropriate bandwidth can be selected using Equation (20) to construct the KDE, which can better fit the sample distribution. In Equation (20), the influence of the kernel function on bandwidth selection is on and , which are almost the same under different kernel function selection, and they have a slight effect on the final bandwidth selection. 3.2. Optimal Bandwidth Algorithm
The optimal bandwidth formula is given by Equation (
20). However,
is unknown in Equation (
20), and therefore,
is also unknown. An approximate value of the bandwidth parameter
can be obtained by replacing
with
in Equation (
16). Furthermore, an iterative algorithm can be used to calculate a more accurate bandwidth parameter. Theorem 3 shows that the algorithm is convergent.
Theorem 3. For any n-dimensional probability density function and Gaussian kernel function , if in Equation (16) is used to estimate , then the iterative calculation formula of is obtained as and it is convergent, where is the value of during the iteration.
Proof. For a particular Gaussian kernel function
is a
distribution with degree of freedom
n, and the expectation is equal to the degree of freedom.
Substituting Equations (
39)–(
40) into Equation (
20) and substituting
in Equation (
16) for
, the iterative form of calculating
is obtained as
To facilitate the subsequent reasoning, the following lemma is given as
Lemma 1. For any function , inequality If and only if holds almost everywhere.
Proof. In fact, for any function
, there are
Thus, the two sides of Equation (
44) are integrated as
It is obvious that the sign of Equation (
43) holds the condition that
is almost everywhere. □
Because the second derivative of Equation (
39) with respect to
is
From Lemma 1 and Equation (
47)
When
is sufficiently large, we can assume that
is almost the same everywhere, i.e., the equal sign in Equation (
48) is tenable.
When is large, the iterative process decreases. Because has a lower bound, the algorithm converges. □
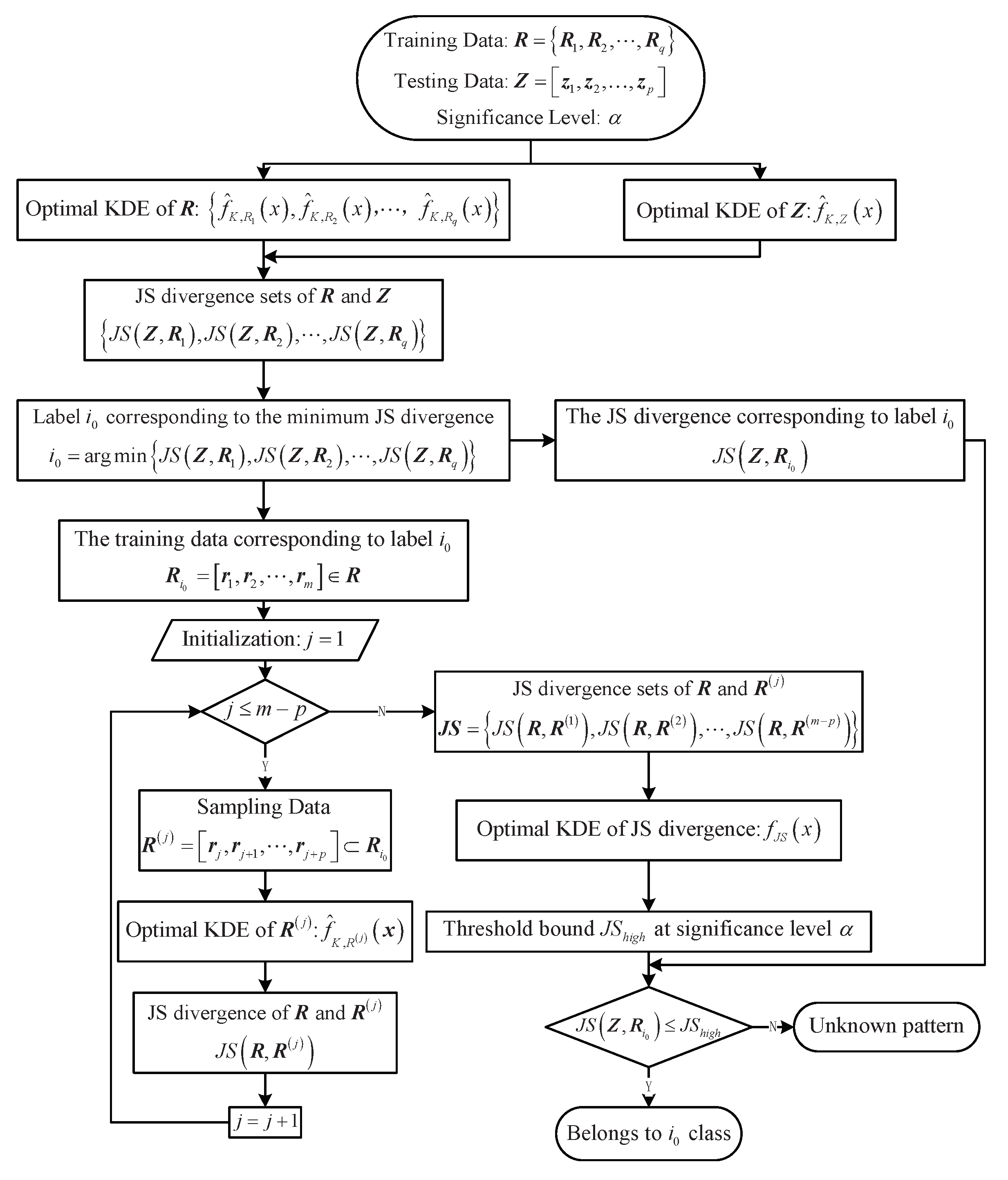
In summary, the KDE method based on optimal bandwidth is given (See Algorithm 1), and the flowchart of the KDE method is shown in
Figure 1.
| Algorithm 1: Kernel density estimation (KDE) method based on optimal bandwidth. |
 |
6. Conclusions
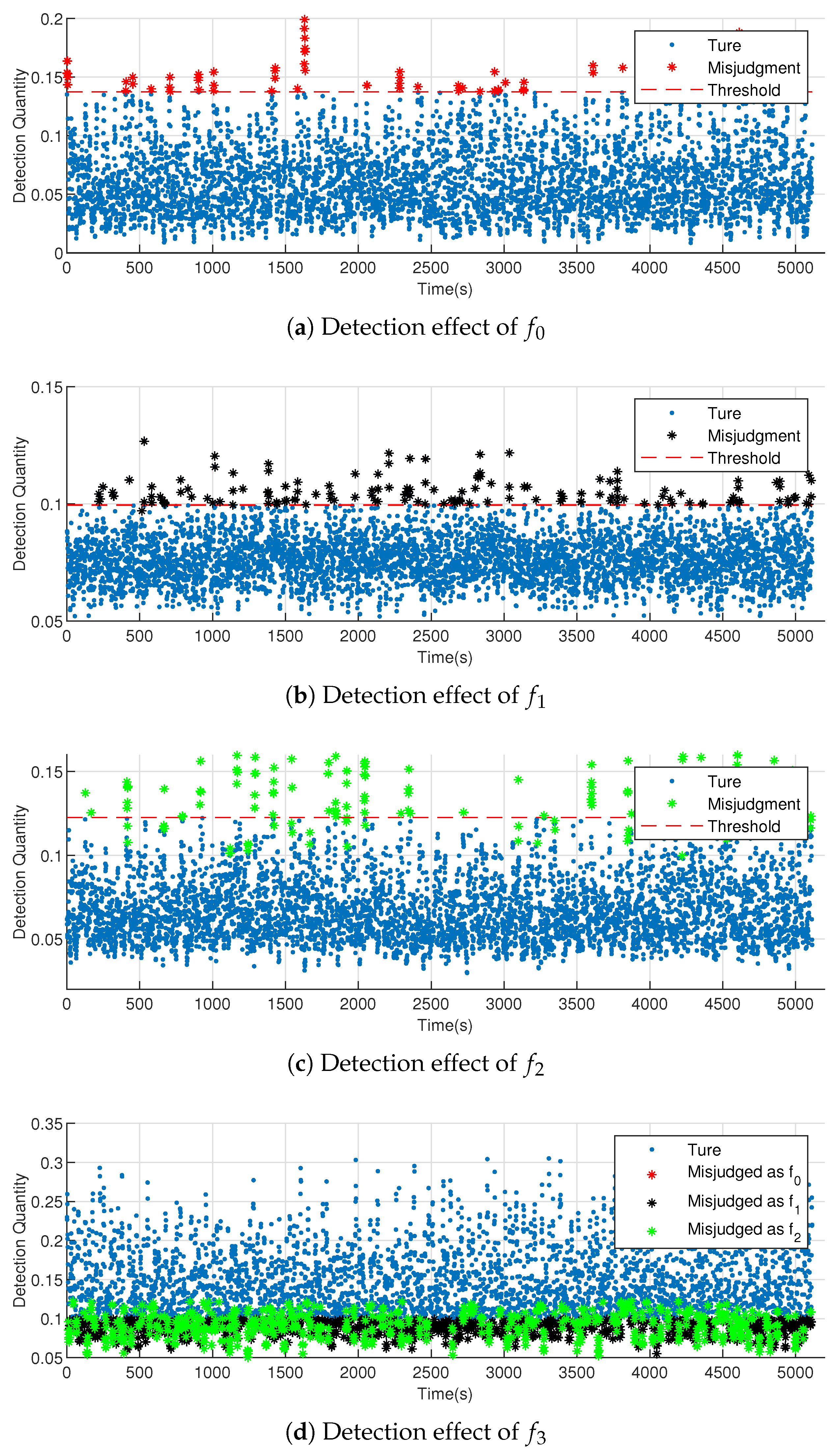
In this study, a method of bearing fault detection and identification was constructed using multidimensional KDE and JS divergence. The distribution characteristics of JS divergence between the sample density distribution and population density distribution were derived using the sliding sampling window method. Thus, the threshold of fault detection was provided, and therefore, different faults, especially unknown faults, could be identified. The theory showed that the multidimensional KDE method could reduce information loss caused by processing each dimension; the JS divergence is more accurate than the traditional cross entropy to measure the difference in density distribution. The experimental results verified the above conclusions.
For a known fault, the detection effect of this method was obviously better than that of the traditional method, and it also had a certain degree of improvement compared with the cross-entropy method. Second, for unknown faults, the traditional method could not detect the distribution difference accurately, while the detection effect of the proposed method was significantly improved.
Furthermore, the detection effect of this method depends on the window width. The detection effect improved with a growth in the detection window. In this paper, under the condition of a given window width, the estimation formula for the optimal bandwidth of a multidimensional KDE was provided. The experimental results showed that the formula was applicable to any mode of data, and therefore, it had a certain universality.
However, this study has certain limitations. Firstly, although the calculation formula of multidimensional KDE is given in this study, the computational complexity will increase when the dimension is large, which may restrict the further application of the method. Secondly, the calculation of JS divergence is time consuming, which is not conducive to rapid fault diagnosis.
In future research, we can try to use the PCA dimension reduction method to solve the computational complexity caused by very large dimension, and optimize the algorithm flow of JS divergence to expedite the calculation. In the latest study Ginzarly et al. [
24], prognosis of the vehicle’s electrical machine is treated using a hidden Markov model after modeling the electrical machine using the finite element method. Therefore, we will try to combine this method in future work and apply it to the fault detection of other systems.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}