
An Improvised Machine Learning Model Based on Mutual Information Feature Selection Approach for Microbes Classification

Abstract
1. Introduction
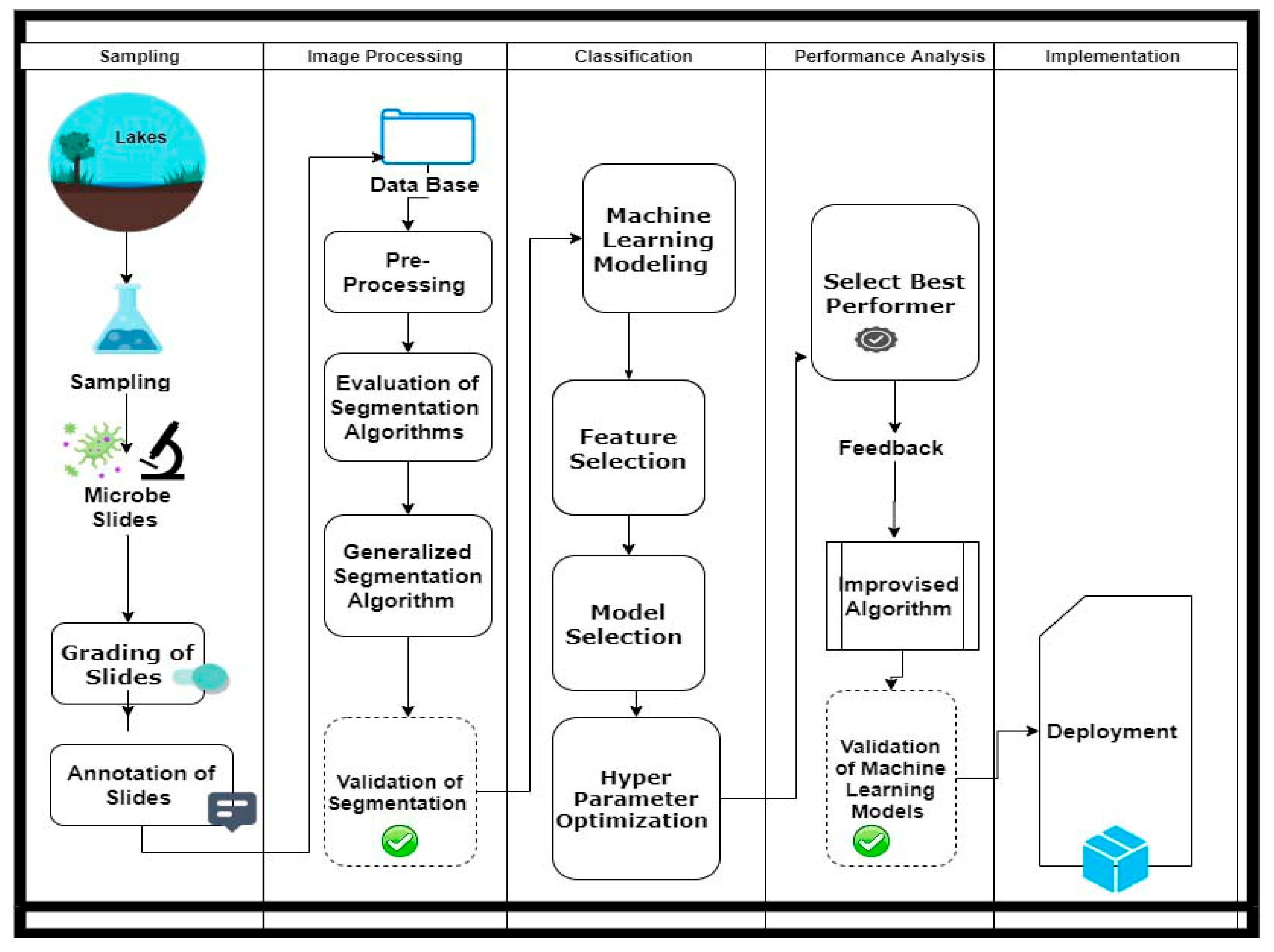
2. Materials and Methods
2.1. Sampling
2.2. Image Processing
2.2.1. Image Preprocessing
- Aspect Ratio: All images were standardized into aspect ratio (1:1.2) so that computation of features such as center of mass of the region of interest does not deviate far away from the normal trend of values.
- Area-based Object Removal: Some images had unwanted objects such as debris etc. Removal of objects fewer than a configurable size value was done with the help of a custom filter.
- Irregular Object Removal: Highly deformed or highly irregular shapes of the objects were identified and filtered so that only useful information is left within the semantics of the image.
- Noise Removal: The median filter was applied to remove any other noise that may be left after applying the steps listed above.
- Contrast Enhancement: Adaptive contrast enhancer [45] was used to increase the overall difference of intensities so that the segmentation algorithm finds it easy to process.
2.2.2. Segmentation
2.2.3. Generalized Segmentation Algorithm (GSA)
| Algorithm 1: Generalized Segmentation Algorithm Input: Set of Microscopy Images, ‘MI’, Global Intensity Threshold (git), Tile Size = Ts //window size. Kirsch_Filter_Mask = {Gx, Gy}, {Gx, Gy}, {Gx, Gy}, {Gx, Gy}, {Gx, Gy}, {Gx, Gy}, {Gx, Gy}, {Gx, Gy} Output: Microorganism Shape Matrix: ‘BO’ 1 Initialize Variables: Path of Microscopy Images ‘MD’ folder, filename = ‘f’, Counter ‘C’= 0 2 Compute global standard deviation: for each Microscopy Image file: ‘MI’ in ‘MD’ Irbg = Read Image Matrix (I) Irg = Normalize, Resize Image Matrix (Irgb) Gray = Gray_Scale(Irg) Gray_Std = Compute_Global_Std(Gray) 3 Segment micoorganism: If Gray_Std (< Global_Std) { G = Apply_Adaptive_Enchancer (Gray) CF = Run_2D_ Kirsch_Filter(Kirsh_Filter_Mask,G) //Convolution Filter BO = Global_Thresholding(git); } else { CF = Run_2D_ Kirsch_Filter(G) //Image Derivative Filter BO = OTSU_Global_Thresholding(); C = C + 1 }End for |
2.3. Classification
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Turak, E.; Harrison, I.; Dudgeon, D.; Abell, R.; Bush, A.; Darwall, W.; Finlayson, C.M.; Ferrier, S.; Freyhof, J.; Hermoso, V.; et al. Essential Biodiversity Variables for Measuring Change in Global Freshwater Biodiversity. Biol. Conserv. 2017, 3, 272–279. [Google Scholar] [CrossRef]
- Morris, R.A. Biodiversity Informatics. In Encyclopedia of Biodiversity, 2nd ed.; Levin, S., Ed.; Elsevier: Amsterdam, The Netherlands, 2013; pp. 440–445. [Google Scholar]
- Carranza-Rojas, J.; Goeau, H.; Bonnet, P.; Mata-Montero, E.; Joly, A. Going Deeper in the Automated Identification of Herbarium Specimens. BMC Evol. Biol. 2017, 17, 181. [Google Scholar] [CrossRef] [PubMed]
- Guo, X.; Coops, N.C.; Tompalski, P.; Nielsen, S.E.; Bater, C.W.; John Stadt, J. Regional Mapping of Vegetation Structure for Biodiversity Monitoring Using Airborne Lidar Data. Ecol. Inform. 2017, 38, 50–61. [Google Scholar] [CrossRef]
- Janicki, J.; Narula, N.; Ziegler, M.; Guénard, B.; Economo, E.P. Visualizing and Interacting with Large-Volume Biodiversity Data Using Client-Server Web-Mapping Applications: The Design and Implementation of Antmaps. Org. Ecol. Inform. 2016, 32, 185–193. [Google Scholar] [CrossRef]
- Khan, W.Z.; Rehman, M.H.; Zangoti, H.M.; Afzal, M.K.; Armi, N.; Salah, K. Industrial Internet of Things: Recent Advances, Enabling Technologies and Open Challenges. Comput. Electr. Eng. 2020, 81, 1–13. [Google Scholar] [CrossRef]
- Romaní, A.M.; Chauvet, E.; Febria, C.; Mora-Gómez, J.; Risse-Buhl, U.; Timoner, X.; Weitere, M.; Zeglin, L. The Biota of Intermittent Rivers and Ephemeral Streams: Prokaryotes, Fungi, and Protozoans. In Intermittent Rivers and Ephemeral Streams: Ecology and Management; Academic Press: Cambridge, MA, USA, 2017; pp. 161–188. [Google Scholar]
- Amsellem, L.; Brouat, C.; Duron, O.; Porter, S.S.; Vilcinskas, A.; Facon, B. Importance of Microorganisms to Macroorganisms Invasions: Is the Essential Invisible to the Eye? (The Little Prince, A. de Saint-Exupéry, 1943). In Advances in Ecological Research; Elsevier: Amsterdam, The Netherlands, 2017; Volume 57, pp. 99–146. [Google Scholar]
- Buszewski, B.; Rogowska, A.; Pomastowski, P.; Złoch, M.; Railean-Plugaru, V. Identification of Microorganisms by Modern Analytical Techniques. J. AOAC Int. 2017, 100, 1607–1623. [Google Scholar] [CrossRef] [PubMed]
- Ganegoda, S.; Chinthaka, S.D.M.; Manage, P.M. Geosmin Contamination Status of Raw and Treated Waters in Sri Lanka. J. Natl. Sci. Found. Sri Lanka 2019, 47, 245–259. [Google Scholar] [CrossRef]
- Yao, X.; Liu, Y. Machine Learning, Search Methodologies: Introductory Tutorials in Optimization and Decision Support Techniques; Burke, E.K., Kendall, G., Eds.; Springer: New York, NY, USA, 2005. [Google Scholar]
- Gunatilleke, N.; Pethiyagoda, R.; Gunatilleke, S. Biodiversity of Sri Lanka. J. Natl. Sci. Found. Sri Lanka 2017, 36, 25–61. [Google Scholar] [CrossRef]
- Paczuska, B.; Paczuski, R. Small Water Ponds as Reservoirs of Algae Biodiversity. Oceanol. Hydrobiol. Stud. 2015, 44, 480. [Google Scholar] [CrossRef]
- Burdo, A.; Abakumov, E. Biodiversity of Algae of Some Waterbodies of the Southern Yamal. IOP Conf. Ser.: Earth Environ. Sci. 2019, 263, 012001. [Google Scholar] [CrossRef]
- Blackwell, M.; Vega, F.E. Lives within Lives: Hidden Fungal Biodiversity and the Importance of Conservation. Fungal Ecol. 2018, 35, 127–134. [Google Scholar] [CrossRef]
- Cofré, M.N.; Soteras, F.; del Rosario Iglesias, M.; Velázquez, S.; Abarca, C.; Risio, L.; Ontivero, E.; Cabello, M.N.; Domínguez, L.S.; Lugo, M.A. Biodiversity of Arbuscular Mycorrhizal Fungi in South America: A Review. In Mycorrhizal Fungi in South America; Pagano, M.C., Lugo, M.A., Eds.; Springer: Cham, Switzerland, 2019; pp. 49–72. [Google Scholar]
- Raina, V.; Panda, A.N.; Mishra, S.R.; Nayak, T.; Suar, M. Microbial Biodiversity Study of a Brackish Water Ecosystem in Eastern India. In Microbial Diversity in the Genomic Era; Academic Press: Cambridge, MA, USA, 2019; pp. 47–63. [Google Scholar]
- Kalafi, E.Y.; Town, C.; Dhillon, S.K. How Automated Image Analysis Techniques Help Scientists in Species Identification and Classification? Folia Morphol. 2018, 179–193. [Google Scholar] [CrossRef]
- Promdaen, S.; Wattuya, P.; Sanevas, N. Automated Microalgae Image Classification. Procedia Comput. Sci. 2014. [Google Scholar] [CrossRef]
- Coltelli, P.; Barsanti, L.; Evangelista, V.; Frassanito, A.M.; Gualtieri, P. Water Monitoring: Automated and Real Time Identification and Classification of Algae Using Digital Microscopy. Environ. Sci. Process. Impacts 2014, 16, 2656–2665. [Google Scholar] [CrossRef]
- Cao, X.; Miao, J. Bacterial Image Segmentation Algorithm Based on Improved Level Set. In 2017 7th International Conference on Advanced Design and Manufacturing Engineering (ICADME 2017); Atlantis Press: Amsterdam, The Netherlands, 2017; pp. 204–208. [Google Scholar]
- Li, C.; Wang, K.; Xu, N. A Survey for the Applications of Content-Based Microscopic Image Analysis in Microorganism Classification Domains. Artif. Intell. Rev. 2017, 51, 577–646. [Google Scholar] [CrossRef]
- Sahu, S.P.; Kamble, B.; Doriya, R. 3D Lung Segmentation Using Thresholding and Active Contour Method. In Advances in Intelligent Systems and Computing; Springer: Singapore, 2020; pp. 369–380. [Google Scholar]
- Gregoretti, F.; Cesarini, E.; Lanzuolo, C.; Oliva, G.; Antonelli, L. An Automatic Segmentation Method Combining an Active Contour Model and a Classification Technique for Detecting Polycomb-Group Proteins in High-Throughput Microscopy Images. Methods Mol. Biol. 2016, 1480, 181–197. [Google Scholar] [PubMed]
- Ali, M.; Siarry, P.; Pant, M. Multi-Level Image Thresholding Based on Hybrid Differential Evolution Algorithm. Application on Medical Images. In Metaheuristics for Medicine and Biology; Springer: Berlin/Heidelberg, Germany, 2017; pp. 23–36. [Google Scholar]
- Zhang, P.; Gao, W.; Hu, J.; Li, Y. Multi-Label Feature Selection Based on High-Order Label Correlation Assumption. Entropy 2020, 22, 797. [Google Scholar] [CrossRef] [PubMed]
- Chandrashekar, G.; Sahin, F. A Survey on Feature Selection Methods. Comput. Electr. Eng. 2014, 40, 16–28. [Google Scholar] [CrossRef]
- Zheng, H.; Wang, R.; Yu, Z.; Wang, N.; Gu, Z.; Zheng, B. Automatic Plankton Image Classification Combining Multiple View Features via Multiple Kernel Learning. BMC Bioinform. 2017, 18, 570. [Google Scholar] [CrossRef]
- El Mallahi, A.; Minetti, C.; Dubois, F. Automated Three-Dimensional Detection and Classification of Living Organisms Using Digital Holographic Microscopy with Partial Spatial Coherent Source: Application to the Monitoring of Drinking Water Resources. Appl. Opt. 2013, 52, A68–A80. [Google Scholar] [CrossRef]
- Mosleh, M.A.A.; Manssor, H.; Malek, S.; Milow, P.; Salleh, A. A Preliminary Study on Automated Freshwater Algae Recognition and Classification System. BMC Bioinform. 2012, 13, S25. [Google Scholar] [CrossRef]
- Beijbom, O.; Edmunds, P.J.; Kline, D.I.; Mitchell, B.G.; Kriegman, D. Automated Annotation of Coral Reef Survey Images. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Santhi, N.; Pradeepa, C.; Subashini, P.; Kalaiselvi, S. Automatic Identification of Algal Community from Microscopic Images. Bioinform. Biol. Insights 2013, 7, 327–334. [Google Scholar] [CrossRef] [PubMed]
- Reimann, R.; Zeng, B.; Jakopec, M.; Burdukiewicz, M.; Petrick, I.; Schierack, P.; Rödiger, S. Classification of Dead and Living Microalgae Chlorella Vulgaris by Bioimage Informatics and Machine Learning. Algal Res. 2020, 48, 101908. [Google Scholar] [CrossRef]
- Giraldo-Zuluaga, J.H.; Salazar, A.; Diez, G.; Gomez, A.; Martínez, T.; Vargas, J.F.; Peñuela, M. Automatic Identification of Scenedesmus Polymorphic Microalgae from Microscopic Images. Pattern Anal. Appl. 2018, 21, 601–612. [Google Scholar] [CrossRef]
- Park, J.; Lee, H.; Park, C.Y.; Hasan, S.; Heo, T.Y.; Lee, W.H. Algal Morphological Identification in Watersheds for Drinking Water Supply Using Neural Architecture Search for Convolutional Neural Network. Water 2019, 11, 1338. [Google Scholar] [CrossRef]
- Ebadi, A.G.; Hisoriev, H. Biodiversity of Algae from the Tajan River Basin (Mazandaran-Iran). Egypt. J. Aquat. Biol. Fish. 2017, 21, 33–52. [Google Scholar] [CrossRef][Green Version]
- Wicaksono, P.; Aryaguna, P.A.; Lazuardi, W. Benthic Habitat Mapping Model and Cross Validation Using Machine-Learning Classification Algorithms. Remote Sens. 2019, 11, 1279. [Google Scholar] [CrossRef]
- Knudby, A.; Roelfsema, C.; Lyons, M.; Phinn, S.; Jupiter, S. Mapping Fish Community Variables by Integrating Field and Satellite Data, Object-Based Image Analysis and Modeling in a Traditional Fijian Fisheries Management Area. Remote Sens. 2011, 3, 460–483. [Google Scholar] [CrossRef]
- Deniz, O.; Pedraza, A.; Cristóbal, G.; Borrego-Ramos, M.; Bueno, G.; Blanco, S. Automated Diatom Classification (Part B): A Deep Learning Approach. Appl. Sci. 2017, 7, 460. [Google Scholar]
- Pardeshi, R.; Deshmukh, P.D. Classification of Microscopic Algae: An Observational Study with AlexNet. In Advances in Intelligent Systems and Computing; Springer: Singapore, 2020; Volume 1118, pp. 309–316. [Google Scholar]
- Manzoor, K.; Raj, P.; Sheoran, R.; Dey, S.; Gupta, E.J.; Zaman, B.; Rao, C. Water Quality Assessment through GIS: A Case Study of Sukhna Lake, Chandigarh, India. Int. Res. J. Eng. Technol. 2017, 4, 1773–1776. [Google Scholar]
- Gupta, N.; Mathew, A.; Khandelwal, S. Analysis of Cooling Effect of Water Bodies on Land Surface Temperature in Nearby Region: A Case Study of Ahmedabad and Chandigarh Cities in India. Egypt. J. Remote Sens. Sp. Sci. 2019, 22, 81–93. [Google Scholar] [CrossRef]
- Kaur, R.; Garg, V.; Kaur, R.; Pandit, S.; Attri, S.V.; Ahluwalia, A.S. Assessment of Water Quality, Heavy Metal Contamination and Its Indexing Approach of Dhanas Lake in Patiala Ki Rao Reserved Forest Area, Chandigarh. Indian J. Environ. Prot. 2018, 38, 751–758. [Google Scholar]
- Vasuki, P.; Kanimozhi, J.; Devi, M.B. A Survey on Image Preprocessing Techniques for Diverse Fields of Medical Imagery. In Proceedings of the 2017 IEEE International Conference on Electrical, Instrumentation and Communication Engineering, Karur, India, 27–28 April 2017; pp. 1–6. [Google Scholar]
- Bidishaw, J.P.; Nalini, T. A Survey on Various Image Enhancement Techniques. Int. J. Adv. Res. Comput. Sci. 2014, 5, 160–162. [Google Scholar]
- Rahman, M.A.; Wang, Y. Optimizing Intersection-Over-Union in Deep Neural Networks for Image Segmentation Md. In International Symposium on visual Computing; Springer: Cham, Switzerland, 2016; pp. 234–244. [Google Scholar]
- Ma, J.; Jiang, X.; Fan, A.; Jiang, J.; Yan, J. Image Matching from Handcrafted to Deep Features: A Survey. Int. J. Comput. Vis. 2021, 129, 23–79. [Google Scholar] [CrossRef]
- Lorencin, I.; Anđelić, N.; Španjol, J.; Car, Z. Using Multi-Layer Perceptron with Laplacian Edge Detector for Bladder Cancer Diagnosis. Artif. Intell. Med. 2020, 102, 101746. [Google Scholar] [CrossRef]
- Li, D.; Wang, Q.; Kong, F. Superpixel-Feature-Based Multiple Kernel Sparse Representation for Hyperspectral Image Classification. Signal Process. 2020, 176, 107682. [Google Scholar] [CrossRef]
- Xu, P.; He, Z.; Qiu, T.; Ma, H. Quantum Image Processing Algorithm Using Edge Extraction Based on Kirsch Operator. Opt. Express 2020, 28, 12508–12517. [Google Scholar] [CrossRef]
- Guo, S.Q.; Wang, L.Q.; Fan, H.H. An Image Segmentation Method for Eliminating Illumination Inuence. J. Inf. Hiding Multimed. Signal Process. 2016, 7, 1100–1109. [Google Scholar]
- Goh, T.Y.; Basah, S.N.; Yazid, H.; Safar MJ, A.; Saad, F.S.A. Performance Analysis of Image Thresholding: Otsu Technique. Meas. J. Int. Meas. Confed. 2018, 114, 298–307. [Google Scholar] [CrossRef]
- Chong, R.M.; Tanaka, T. Image Extrema Analysis and Blur Detection with Identification. In Proceedings of the SITIS 2008—Proceedings of the 4th International Conference on Signal Image Technology and Internet Based Systems, Bali, Indonesia, 30 November–3 December 2008; pp. 320–326. [Google Scholar]
- Lin, X.; Ji, J.; Gu, Y. The Euler Number Study of Image and Its Application. In Proceedings of the ICIEA 2007: 2007 Second IEEE Conference on Industrial Electronics and Applications, Harbin, China, 23–25 May 2007; pp. 910–912. [Google Scholar]
- Lempitsky, V.; Kohli, P.; Rother, C.; Sharp, T. Image Segmentation with a Bounding Box Prior. In Proceedings of the IEEE International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 277–284. [Google Scholar]
- John, J.; Mini, M.G. Multilevel Thresholding Based Segmentation and Feature Extraction for Pulmonary Nodule Detection. Procedia Technol. 2016, 24, 957–963. [Google Scholar] [CrossRef]
- Rachmawanto, E.H.; Anarqi, G.R.; Sari, C.A. Handwriting Recognition Using Eccentricity and Metric Feature Extraction Based on K-Nearest Neighbors. In Proceedings of the 2018 International Seminar on Application for Technology of Information and Communication: Creative Technology for Human Life, iSemantic 2018, Semarang, Indonesia, 21–22 September 2018; pp. 411–416. [Google Scholar]
- Tunwal, M.; Mulchrone, K.F.; Meere, P.A. Image Based Particle Shape Analysis Toolbox (IPSAT). Comput. Geosci. 2020, 135, 104391. [Google Scholar] [CrossRef]
- Dhindsa, A.; Bhatia, S.; Agrawal, S.; Sohi, B.S. Dataset for Efficient Microbes Classification System. Mendeley Data 2021. [Google Scholar] [CrossRef]
- Saito, T.; Rehmsmeier, M. The Precision-Recall Plot Is More Informative than the ROC Plot When Evaluating Binary Classifiers on Imbalanced Datasets. PLoS ONE 2015, 10, e0118432. [Google Scholar] [CrossRef] [PubMed]
- Sokolova, M.; Japkowicz, N.; Szpakowicz, S. Beyond Accuracy, F-Score and ROC: A Family of Discriminant Measures for Performance Evaluation. In AAAI Workshop–Technical Report; Springer: Berlin/Heidelberg, Germany, 2006; pp. 1015–1021. [Google Scholar]
- Ali, A.; Qadri, S.; Mashwani, W.K.; Kumam, W.; Kumam, P.; Naeem, S.; Goktas, A.; Jamal, F.; Chesneau, C.; Anam, S.; et al. Machine Learning Based Automated Segmentation and Hybrid Feature Analysis for Diabetic Retinopathy Classification Using Fundus Image. Entropy 2020, 22, 567. [Google Scholar] [CrossRef]
- Yousef Kalafi, E.; Tan, W.B.; Town, C.; Dhillon, S.K. Automated Identification of Monogeneans Using Digital Image Processing and K-Nearest Neighbour Approaches. BMC Bioinform. 2016, 17, 511. [Google Scholar] [CrossRef] [PubMed]
- Canedo, E.D.; Mendes, B.C. Software Requirements Classification Using Machine Learning Algorithms. Entropy 2020, 22, 1057. [Google Scholar] [CrossRef]
- Chen, S.; Shan, S.; Zhang, W.; Wang, X.; Tong, M. Automated Red Tide Algae Recognition by the Color Microscopic Image. In Proceedings of the 13th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Chengdu, China, 17–19 October 2020; pp. 852–861. [Google Scholar]
- Bi, X.; Lin, S.; Zhu, S.; Yin, H.; Li, Z.; Chen, Z. Species Identification and Survival Competition Analysis of Microalgae via Hyperspectral Microscopic Images. Optik 2019, 176, 191–197. [Google Scholar] [CrossRef]
- Shao, Y.; Jiang, L.; Zhou, H.; Pan, J.; He, Y. Identification of Pesticide Varieties by Testing Microalgae Using Visible/Near Infrared Hyperspectral Imaging Technology. Sci. Rep. 2016, 6, 24221. [Google Scholar] [CrossRef]
- Lin, C.; Wang, K.; Mueller, S. MCVIS: A New Framework for Collinearity Discovery, Diagnostic, and Visualization. J. Comput. Graph. Stat. 2020, 1–13. [Google Scholar] [CrossRef]
- Linardatos, P.; Papastefanopoulos, V.; Kotsiantis, S. Explainable AI: A Review of Machine Learning Interpretability Methods. Entropy 2021, 23, 18. [Google Scholar] [CrossRef] [PubMed]
- Raju, V.N.G.; Lakshmi, K.P.; Jain, V.M.; Kalidindi, A.; Padma, V. Study the Influence of Normalization/Transformation Process on the Accuracy of Supervised Classification. In Proceedings of the 3rd International Conference on Smart Systems and Inventive Technology, ICSSIT 2020, Tirunelveli, India, 20–22 August 2020; pp. 729–735. [Google Scholar]
- Guillén, A.; Martínez, J.; Carceller, J.M.; Herrera, L.J. A Comparative Analysis of Machine Learning Techniques for Muon Count in Uhecr Extensive Air-Showers. Entropy 2020, 22, 1216. [Google Scholar] [CrossRef] [PubMed]
- Ross, B.C. Mutual Information between Discrete and Continuous Data Sets. PLoS ONE 2014, 9, e87357. [Google Scholar] [CrossRef]
- Kraskov, A.; Stögbauer, H.; Grassberger, P. Erratum: Estimating Mutual Information (Phys. Rev. E (2004) 69 (066138)). Phys. Rev. E 2011, 83, 019903. [Google Scholar] [CrossRef]
- Armaghani, D.J.; Asteris, P.G.; Askarian, B.; Hasanipanah, M.; Tarinejad, R.; Huynh, V. Van. Examining Hybrid and Single SVM Models with Different Kernels to Predict Rock Brittleness. Sustainability 2020, 12, 2229. [Google Scholar] [CrossRef]
- Pharswan, R.; Singh, J. Performance Analysis of SVM and KNN in Breast Cancer Classification: A Survey. In Intelligent Systems Reference Library; Springer: Cham, Switzerland, 2020; pp. 133–140. [Google Scholar]
- Morales, N.S.; Fernández, I.C. Land-Cover Classification Using Maxent: Can We Trust in Model Quality Metrics for Estimating Classification Accuracy? Entropy 2020, 22, 342. [Google Scholar] [CrossRef]
- Madhawa, K.; Murata, T. Active Learning for Node Classification: An Evaluation. Entropy 2020, 22, 1164. [Google Scholar] [CrossRef]
- Nabipour, M.; Nayyeri, P.; Jabani, H.; Mosavi, A.; Salwana, E.; Shahab, S. Deep Learning for Stock Market Prediction. Entropy 2020, 22, 840. [Google Scholar] [CrossRef]
- Yang, Z.; Yu, W.; Liang, P.; Guo, H.; Xia, L.; Zhang, F.; Ma, Y.; Ma, J. Deep transfer learning for military object recognition under small training set condition. Neural Comput. Appl. 2019, 31, 6469–6478. [Google Scholar] [CrossRef]


{kind=link}
| S.No | Microorganism Class | Microorganism Type | Number of Instances |
|---|---|---|---|
| 1 | Spirogyra | Algae | 4012 |
| 2 | Volvox | Algae | 7002 |
| 3 | Phithophora | Algae | 2303 |
| 4 | Yeast | Fungi | 4302 |
| 5 | Rhizopus | Fungi | 3910 |
| 6 | Penicillium | Fungi | 3410 |
| 7 | Aspergillus sp | Fungi | 3230 |
| 8 | Protozoa | Eukaryotes | 1230 |
| 9 | Diatom | Algae | 1450 |
| 10 | Ulothrix | Algae | 1930 |
| Total | 32,779 |
| S.No | Convolution Filter | Accepted/Sample | Average Accuracy | ||
|---|---|---|---|---|---|
| 25 | 50 | 75 | |||
| 1 | Prewitt Filter [47] | 20 | 23 | 39 | 0.59 |
| 2 | LOG Filter [32] | 13 | 31 | 39 | 0.55 |
| 3 | Laplacian Filter [48] | 15 | 39 | 67 | 0.76 |
| 4 | Low Pass Gaussian [47] | 14 | 38 | 66 | 0.73 |
| 5 | Sobel Filter [32] | 19 | 36 | 69 | 0.80 |
| 6 | Mean Filter [49] | 20 | 40 | 68 | 0.84 |
| 7 | Kirsch Filter [50] | 22 | 45 | 70 | 0.90 |
| Evaluation Round | Sample Size ‘S’ | Accuracy (AC/S) | Average Accuracy | |
|---|---|---|---|---|
| Otsu | 1 | 10 | 1 | 0.88 |
| 2 | 30 | 0.93 | ||
| 3 | 40 | 0.90 | ||
| 4 | 50 | 0.79 | ||
| 5 | 100 | 0.79 | ||
| ISO Data | 6 | 10 | 1 | 0.81 |
| 7 | 30 | 0.83 | ||
| 8 | 40 | 0.90 | ||
| 9 | 50 | 0.62 | ||
| 10 | 100 | 0.73 |
| Microbe | Original | Contrast Enhanced | Microbe Body Extracted | Segmented Image |
|---|---|---|---|---|
| Spirogyra |  |  |  |  |
| Pithophora |  |  |  |  |
| Yeast |  |  |  |  |
| Raizopus |  |  |  |  |
| Penicillum |  |  |  |  |
| Aspergillus sp |  |  |  |  |
| Protozoa |  |  |  |  |
| Diatom |  |  |  |  |
| Ulothrix |  |  |  |  |
| Metric | Formula |
|---|---|
| Precision [60] | |
| Recall [60] | |
| Accuracy [60] | |
| F1-Score [61] |
| Model | Hyper Parameters and Their Ranges | Best Hyper Parameters Found (PCA) | Best Hyper Parameters Found (MI) | PCA | MI | ||||
|---|---|---|---|---|---|---|---|---|---|
| A | P | R | A | P | R | ||||
| LR | Penalty: ‘l2’; Solver: [‘newton-cg’,’lbfgs’,’liblinear’, ‘sag’, ‘saga’] | penalty: l2 Solver: newton-cg | penalty: l2 Solver: newton-cg | 23.1 | 5.1 | 23.2 | 24.9 | 5.9 | 24.9 |
| KNN | n_neighbors: 1–15; Weights: [‘uniform’, ‘distance’]; Leaf Size: [1, 3, 5]; Algorithm: [‘auto’, ‘kd_tree’] | n_neighbors: 3,Weights: distance, leaf_size: 3, algorithm: auto | n_neighbors: 3, Weights: distance, leaf_size: 3, algorithm: kd tree | 96.1 | 96.1 | 96.2 | 96.1 | 96.1 | 96.0 |
| SVM radial | gamma: log(−2, 2, 5); C: log(−2, 2, 5) | gamma: 100.0, C: 1.0 | gamma: 92.0, C: 4.3 | 96.2 | 96.3 | 96.3 | 97.2 | 97.3 | 97.0 |
| MLP | hidden layer sizes: [(10–50)]; Activation: [‘identity’, ‘logistic’, ‘tanh’, ‘relu’]; Solver: [‘lbfgs’, ‘sgd’, ‘adam’]; Alpha: log(−5, 3, 5); Learning Rate: [‘constant’, ‘invscaling’,’adaptive’]; Max Iteration: [100, 500, 1000] | hidden_layer_sizes: 50, activation: relu, solver: lbfgs, alpha: 0.001, learning_rate: constant, max_iter: 1000 | hidden_layer_sizes: 50, activation: relu, solver: adam, alpha: 0.002, learning_rate: constant, max_iter: 1000 | 29.6 | 26.8 | 29.7 | 31.2 | 27.8 | 31.7 |
| QDA | priors: [None]; reg_param: (0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9) | priors: None, reg_param: 0.2 | priors: None, reg_param: 0.3 | 24.8 | 10.1 | 24.8 | 26.8 | 11.1 | 26.4 |
| Feature Name | Estimated Mutual Information |
|---|---|
| Solidity | 1.686472 |
| Eccentricity | 1.669454 |
| EquivDiameter | 1.576661 |
| Extrema | 1.091982 |
| Filled Area | 1.606655 |
| Extent | 1.697518 |
| Orientation | 1.723908 |
| Euler Number | 0.539431 |
| Bounding Box 1 | 1.091185 |
| Bounding Box 2 | 0.970946 |
| Bounding Box 3 | 0.656073 |
| Bounding Box 4 | 0.666515 |
| Convex Hull 1 | 1.078976 |
| Convex Hull 2 | 1.08001 |
| Convex Hull 3 | 1.109029 |
| Convex Hull 4 | 1.18575 |
| Major Axis | 1.748819 |
| Minor Axis | 1.744697 |
| Perimeter | 1.735635 |
| Convex Area | 1.68434 |
| Centroid 1 | 1.744533 |
| Centroid 2 | 1.721187 |
| Area | 1.578785 |
| Radii | 2.10396 |
| Python Script | Description |
|---|---|
| def apply_IQR(X): [q1,q2,q3] = ComputeQuartiles(X) iqr = (q3 − q1) return X-iqr | The value of IQR is computed on the basis of quartiles. It is basically the difference between the q3 and q1. Each quartile is a median computed using the following rules: Given an even 2n or odd 2n + 1 number of values, first quartile Q1 = median of the n smallest values, third quartile Q3 = median of the n largest values. The second quartile Q2 is the same as the ordinary median. |
| def modified_rbf(X,Y,IQR = True): Xm = Apply_IQR(X) K = np.zeros((Xm.shape[0],Y.shape[0])) for i,x in enumerate(Xm): for j,y in enumerate(Y): K[i,j] = np.exp(-1*np.linalg.norm(x-y)**2) return K | This is the definition of the modified rbf kernel in which; first IQR is computed for each feature and then the rbf equation is applied. |
| Model | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) |
|---|---|---|---|---|
| SVM | 96.1 | 96.2 | 96.1 | 96.1 |
| ISVM | 98.2 | 98.2 | 98.1 | 98.1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dhindsa, A.; Bhatia, S.; Agrawal, S.; Sohi, B.S. An Improvised Machine Learning Model Based on Mutual Information Feature Selection Approach for Microbes Classification. Entropy 2021, 23, 257. https://doi.org/10.3390/e23020257
Dhindsa A, Bhatia S, Agrawal S, Sohi BS. An Improvised Machine Learning Model Based on Mutual Information Feature Selection Approach for Microbes Classification. Entropy. 2021; 23(2):257. https://doi.org/10.3390/e23020257
Chicago/Turabian StyleDhindsa, Anaahat, Sanjay Bhatia, Sunil Agrawal, and Balwinder Singh Sohi. 2021. "An Improvised Machine Learning Model Based on Mutual Information Feature Selection Approach for Microbes Classification" Entropy 23, no. 2: 257. https://doi.org/10.3390/e23020257
APA StyleDhindsa, A., Bhatia, S., Agrawal, S., & Sohi, B. S. (2021). An Improvised Machine Learning Model Based on Mutual Information Feature Selection Approach for Microbes Classification. Entropy, 23(2), 257. https://doi.org/10.3390/e23020257