1. Introduction
Network physiology, as a paradigm, aims to describe the interaction across diverse organ systems in the form of physiological networks. Within this framework, each system is represented as a node of the network, and interactions across systems are projected as edges between the nodes [
1,
2]. This approach allows the monitoring of complex physiological interactions in the body, through the detection of topological transitions which occur within the networks when their physiological state changes. Consequently, a vital step in this process is the utilization of methods that would allow the extraction of features for the characterization and monitoring of the investigated network. In its initial implementation, network physiology was used for the study of sleep stages and was limited in the utilisation of features extracted by the bivariate measurement of pair-wise coupling using the Time Delay Stability (TDS) method. TDS measures the time delay with which modulation in the output dynamics of a given node are consistently followed by corresponding modulations in the output of another node after appropriate preprocessing of the analyzed physiological signals [
3]. The initial implementation of this framework was further expanded by recent research through the combination of network physiology and entropy quantification algorithms. Within this scope, non-linear entropy quantification algorithms have been used extensively due to their capacity for effective measurement of irregularity in biological signals [
4,
5]. Both univariate and multivariate algorithms have been applied to multivariate signals with limited preprocessing for the extraction of features from each node and from connections between two or more nodes, respectively [
6,
7].
Entropy quantification algorithms are based on Shannon entropy, the initial extension of the concept of Entropy to information theory by Shannon [
8], and on Conditional Entropy, defined as the amount of information observed in a sample at a time point
n, that cannot be explained based on previous samples from up to time point
[
9]. Univariate and multivariate algorithms based on Shannon Entropy, such as Dispersion Entropy (DisEn) [
10,
11,
12] and Permutation Entropy (PEn) [
13,
14] alongside algorithms based on Conditional Entropy, such as Approximate Entropy (ApEn) [
15], Sample Entropy (SampEn) [
16,
17], and Fuzzy Entropy (FuzzyEn) [
18,
19] have been implemented for the extraction of features from physiological recordings, to be used as nonlinear indexes for disease diagnosis and prognosis. However, while their utilisation within a network physiology paradigm could aid in the monitoring of physiological systems, the challenges introduced by the existence of artifactual outlier samples, which are a common occurrence in physiological recordings due to electromagnetic interference, loose equipment attachment, and user movement, have to be addressed [
20,
21,
22]. When tested, the performance of the univariate ApEn, SampEn, and DisEn algorithms was significantly disrupted during the analysis of signal segments containing outlier samples [
23,
24,
25].
For the purposes of this study, DisEn was selected for the extraction of univariate and multivariate features from formulated network segments. DisEn was selected due to its favorable performance characteristics, such as increased discrimination capacity and low computation time [
11,
12]. Since its original introduction in 2016 [
10], novel variations have been proposed, such as Fluctuation-based Dispersion Entropy (FDisEn) [
11], Reverse Dispersion Entropy (RDE) [
26], and Reverse Fluctuation-based Dispersion Entropy (FRDE) [
27]. In this study, the original DisEn is utilised due to the availability of an efficient multivariate implementation [
12] and to test whether its sensitivity to artifactual outliers can be used as an advantage for the separation between high-quality versus artifactual network segments.
Addressing low data quality, arising from artifactual outliers, is a necessary step in order to ensure that algorithmic implementations based on network physiology are efficient at providing useful information when deployed in physiological monitoring applications. From an effectiveness standpoint, the performance of disease prognosis and clinical support algorithms can be severely limited when trained on noisy datasets [
28,
29]. Most importantly however, inaccuracy in the extracted features can lead to the already life-threatening phenomenon of “alarm fatigue” [
30,
31]. Alert systems currently deployed in intensive care units (ICU) are susceptible to producing excessive amounts of false positive alarms by mistaking artifactual outliers as indications that the patients are in a non-stable physiological state. The phenomenon of “alarm fatigue” is observed when clinical staff start ignoring alarms which they perceive as false, even when they are accurate, and as a result, put patients at risk [
32,
33]. While within the scope of network physiology, the characterization of the physiological state of individuals is not based simply on the univariate analysis of each separate physiological signal, but on the multivariate analysis of its representative network, it is important to ensure that deployed algorithms are capable of separating between viable network segments and network segments whose information content is disrupted from artifactual outliers. This is a prerequisite step prior to extracting insights concerning the physiological state of monitored individuals.
With this study, we aim to address the challenge of artifactual outliers in the utilisation of entropy quantification algorithms within a network physiology framework. The main objectives of the presented work are:
The quantification of the effect of artifactual outliers in the accuracy of univariate and multivariate DisEn feature values extracted from physiological network segments.
The assessment of whether a simple logistic regression classifier could be effectively trained on distributions of features extracted from “normal” and “artifactual” network segments to differentiate between the two.
For these objectives, network segments are formulated from four synchronised physiological time-series: electroencephalogram (EEG), nasal respiratory (RESP), arterial blood pressure (BP), and electrocardiogram (ECG) signals. Artifactual outliers are simulated across all four signal morphologies with one signal being “disrupted” at a time to allow for the study of differences in the effect of outliers based on the signal containing them. Multiple experiments are conducted with varying percentages of outlier samples. The values of features extracted from network segments containing artifactual outliers are compared with the respective values of features extracted from the original network segments to quantify the disruptive capacity of outliers.
Finally, the logistic regression classifier is tested in two configurations—a univariate, and a network-based multivariate configuration. The two configurations are deployed to allow for comparisons between the two approaches and identify benefits, as well as potential challenges when moving from univariate to multivariate analysis for the classification of network segments.
2. Methods
2.1. Stages of the Study
The research presented in this manuscript is conducted in the following stages:
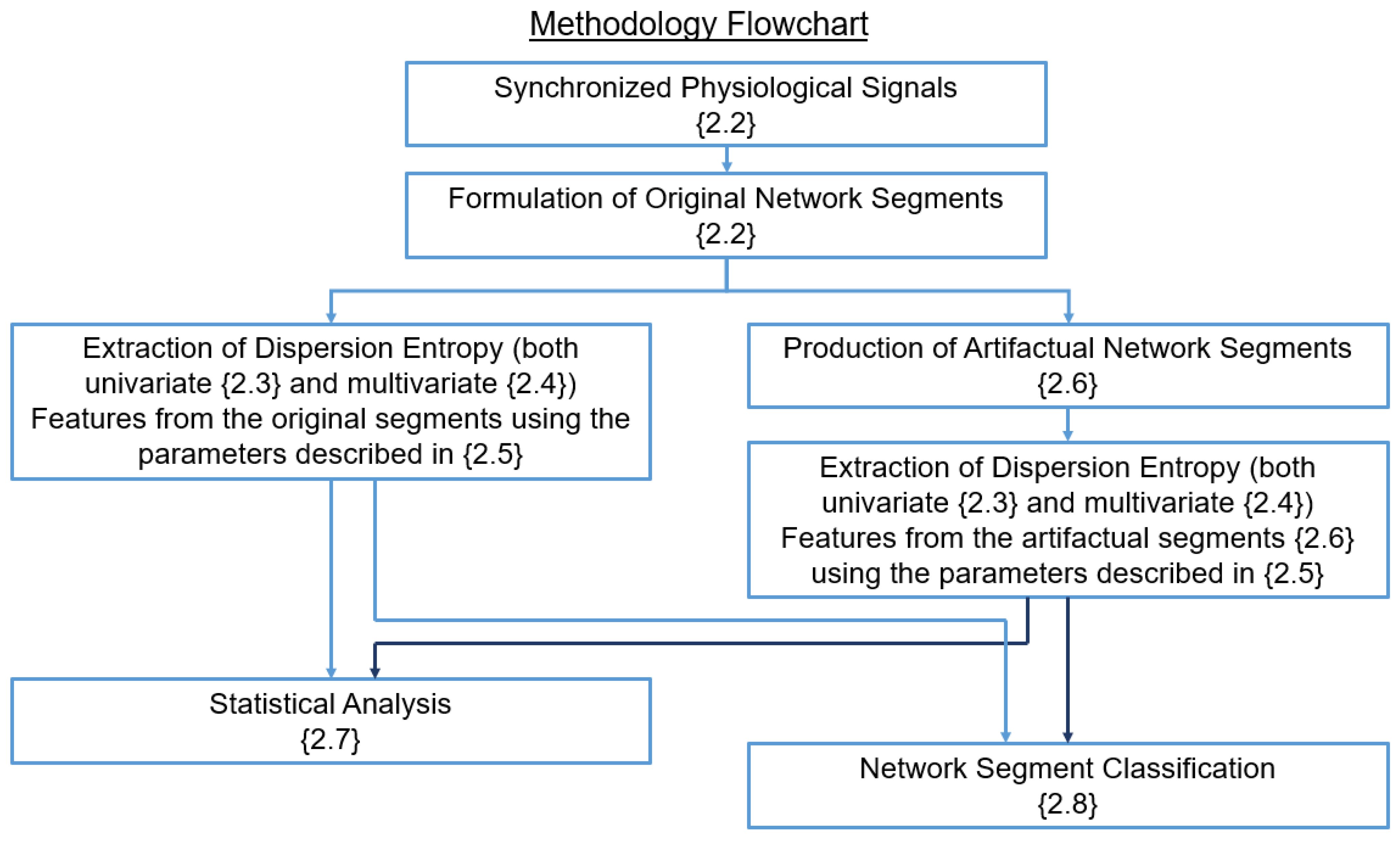
Figure 1 displays a flowchart where the methodological steps of the study are shown. The interconnections between steps indicate the way in which the outputs of one step are utilized as inputs by the following. The methodological steps are discussed in detail in the following sections.
2.2. Experimental Data and Preprocessing
For the formulation of a network based on multiple synchronised physiological recordings, the publicly available MIT-BIH Polysomnographic Database is chosen, which contains a total of 18 records of multiple physiological signals initially recorded for the evaluation of chronic obstructive sleep apnea syndrome and digitized at a sampling interval of 250 Hz [
34,
35]. For the purposes of this study, 11 records are selected based on the availability of complete and synchronised recordings of EEG, RESP, BP, and ECG signals.
Each signal recording is segmented in non-overlapping windows of 7500 samples, resulting in a total of 1463 physiological signal segments, 133 per record. Within the framework of network physiology, the extracted segments are analyzed in sets of 1463 multivariate “network segments” consisting of four synchronised windows, one from each physiological signal, following the process described in
Section 2.5. The length of the window is chosen, after consulting the respective literature [
11,
12] to ensure that it is long enough as to allow a sufficient amount of samples for the effective calculation of the output DisEn values, while at the same time being short enough to provide an adequate temporal resolution for effective monitoring of the system. No further preprocessing is applied to the signals prior to the application of a mapping function and the respective DisEn algorithms.
2.3. Univariate Dispersion Entropy
DisEn arises from the integration of Shannon entropy with symbolic dynamics, aiming to quantify the degree of irregularity in an input signal segment, in low computational time, while achieving increased discrimination capacity [
10,
11]. Prior to the application of DisEn, an optional but recommended preprocessing step is the application of a non-linear mapping function to the input time-series. The process followed by the algorithm for the analysis of either the original or the mapped input univariate time-series
of length
N is the following:
Production of a “quantised” time-series: A number of classes (c) are distributed along the amplitude range of the time-series, and each sample is allocated to the nearest respective class based on its amplitude. This results in the production of a "quantised" time-series .
Formulation of embedded vectors: An embedding dimension (m) and a time delay (d) are set for the creation of embedded vectors, , of length m, for each .
Mapping to dispersion patterns: Each embedded vector is mapped to a respective dispersion pattern based on its corresponding classified samples. The number of potential unique dispersion patterns is , as defined by the number of classes and the embedding dimension.
Calculation of Dispersion Pattern Relative Frequency: For each of the
unique dispersion patterns, their relative frequency is calculated as follows:
Calculation of Univariate Dispersion Entropy: Utilizing the obtained relative frequencies, the time-series’ output DisEn value is calculated using the following equation [
10,
11], based on Shannon’s definition of entropy:
Following the aforementioned steps, an input signal described by a single dispersion pattern would result in a minimum output DisEn value (i.e., 0) as opposed to one requiring the utilization of all possible dispersion patterns in equal probability, which would result in a maximum output value. An in-depth analysis concerning suggested mapping functions and optimisation of parameter values is available in [
11].
2.4. Multivariate Dispersion Entropy
Multivariate Dispersion Entropy (mvDE) allows the multivariate quantification of DisEn from multiple input time-series. Similarly to its univariate equivalent, the preprocessing of each individual time-series using a mapping function is recommended. Assuming a multivariate set of p-input time-series of length N each, the computational steps of mvDE are the following:
Production of univariate “quantised” time-series: In a process similar to its univariate variation, a number of classes (c) are distributed along the amplitude range of each time-series separately. For every time-series, their samples are allocated to their nearest respective class based on their amplitude. As a result, a quantised time-series is produced for each respective input time-series, resulting in a set of p-quantised time-series .
Formulation of multivariate embedded vectors: For the production of multivariate embedded vectors, an embedding dimension m and a time delay d are set for construction of initially univariate embedded vectors of length m from each separate signal, similarly to the respective process for univariate DisEn. The univariate embedded vectors are then combined in sets of p-synchronised vectors, one from each input signal. The vectors within each group are then serially concatenated for the production of respective multivariate embedded vectors of length , for each .
Mapping to multiple dispersion patterns: In mvDE, each embedded vector is mapped to multiple dispersion patterns. Each subset of m elements in is accessed, following all possible combinations. This formulates subvectors, that are then mapped to their corresponding dispersion pattern. As a result, the total number of dispersion pattern instances is and the number of unique dispersion patterns is .
Calculation of Dispersion Pattern Relative Frequency: The relative frequency of each dispersion pattern is calculated in a manner similar to Equation (
1), but with the correct adjustment for the increased number of instances:
Calculation of Multivariate Dispersion Entropy: The extracted relative frequencies are used for the calculation of the respective multivariate DisEn value based on Shannon’s definition of entropy.
The algorithmic variation utilised in this study and described in the aforementioned steps is the fourth and, by its designers, recommended variation of the mvDE algorithm. Further details concerning the operation of the algorithm, its other variations, and the comparative evaluation of their performance are available in [
12].
2.5. Extraction of DisEn Features
For each normal network segment, a total of 15 features are extracted, four of which are univariate, one for each physiological signal, and 11 of which are multivariate, based on the subnetwork combinations of: EEG-RESP, EEG-BP, EEG-ECG, RESP-BP, RESP-ECG, BP-ECG, EEG-BP-ECG, RESP-BP-ECG, EEG-RESP-BP, EEG-RESP-ECG, and EEG-RESP-ECG-BP.
In the case of univariate features, for each signal, its respective 7500 sample window is fed as input to the univariate DisEn algorithm. For each multivariate feature, the respective combination of synchronised 7500 sample windows is fed as input to the multivariate DisEn algorithm for its calculation.
Table 1 displays the parameter values which are the same for univariate and multivariate DisEn. The values were selected after consulting the performance benchmarks provided in the respective studies [
11,
12] and taking into consideration the number of 7500 samples contained within each input window. As a preprocessing step, each individual time-series is mapped using the normal cumulative distribution function (NCDF).
2.6. Production of Artifactual Network Segments
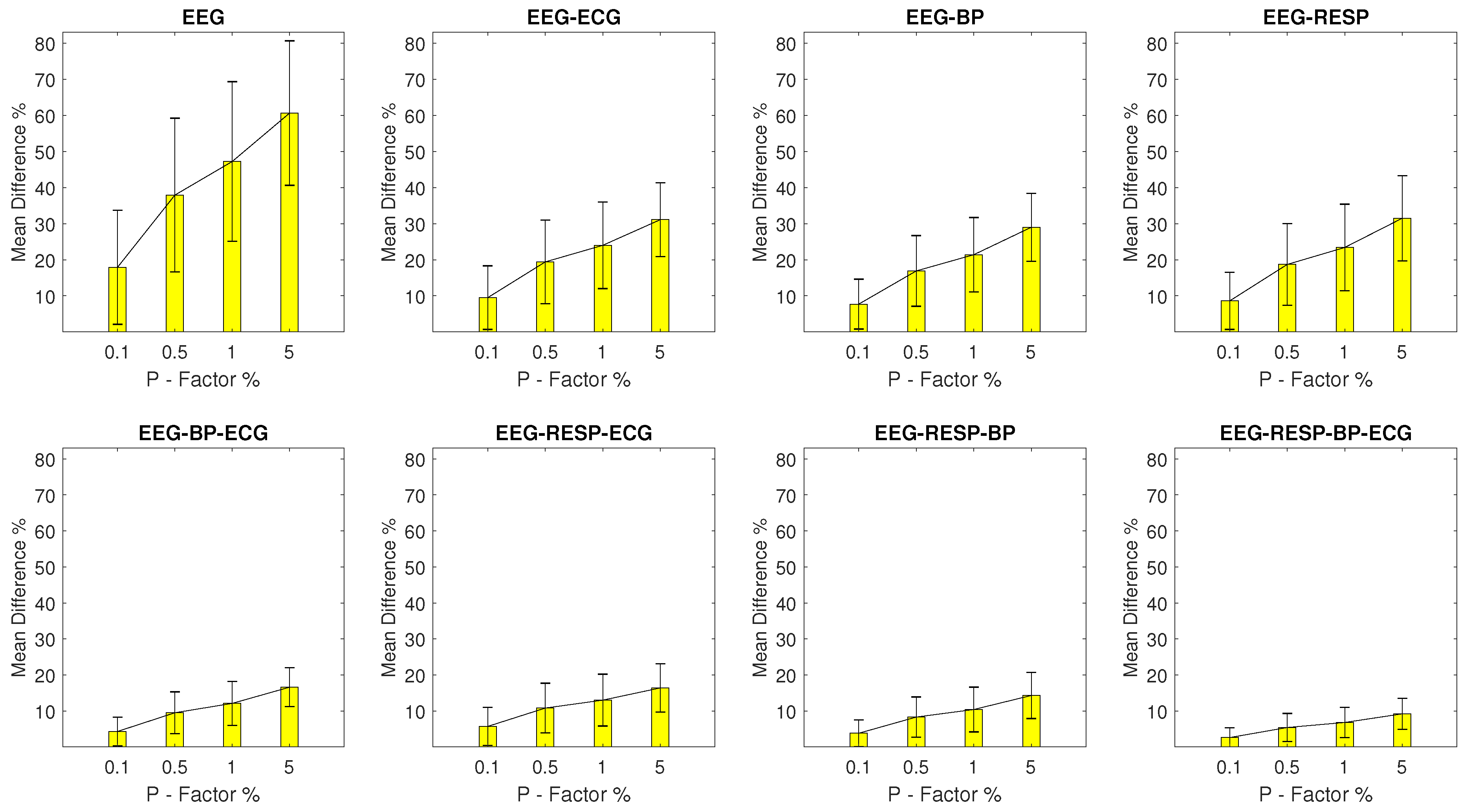
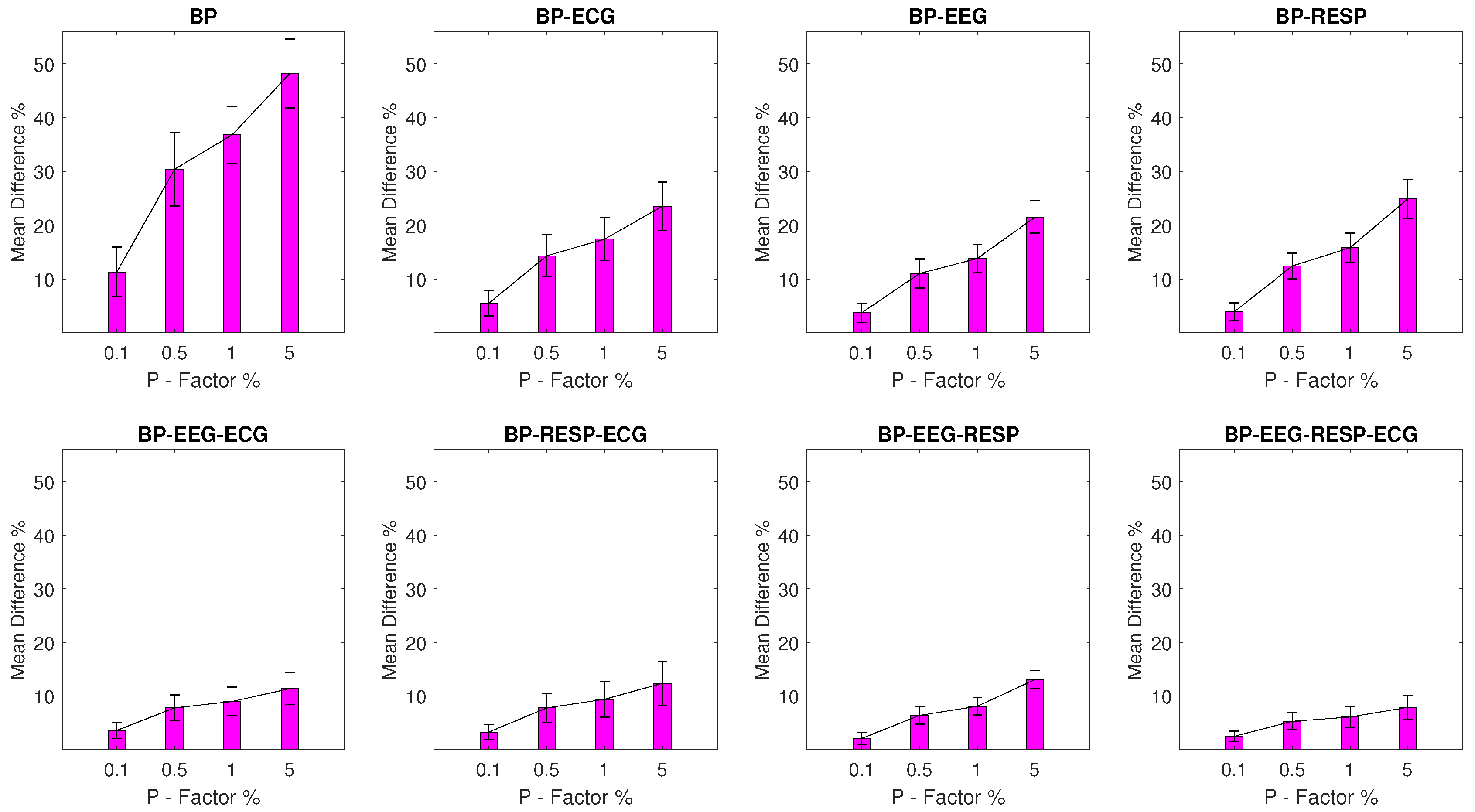
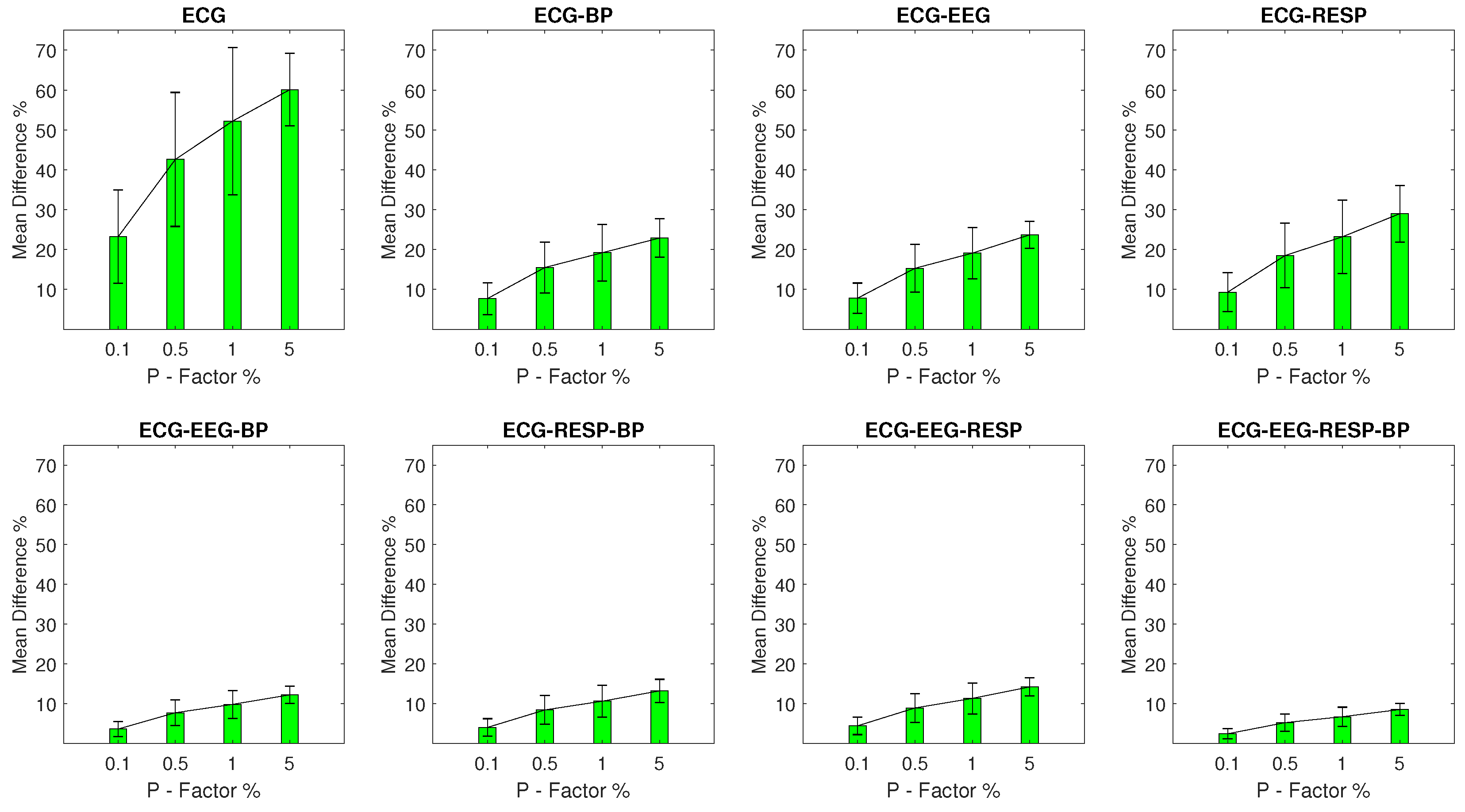
Within the scope of this study, artifactual outlier samples are simulated across all four signal morphologies—EEG, RESP, BP, and ECG—with one signal being “disrupted” at a time. Furthermore, the percentage of samples being outliers is determined by the percentage factor P whose value varies across experimental setups in the levels of 0.1%, 0.5%, 1%, and 5%. As a result, a total of 16 experimental setups are formulated, containing the 1463 normal network segments and a corresponding variation of 1463 artifactual network segments.
The process through which the 1463 artifactual network segments of each experimental setup are produced, is the following:
Marking of Outlier Samples: Based on the percentage factor P, a percentage of samples are uniformly drawn from each 7500-sample window, and their amplitude is replaced with a value in the outlier amplitude range.
Setting the Value of Outlier Samples: The amplitude of each outlier is obtained from a Gaussian distribution with a standard deviation (
) equal to the absolute maximum amplitude of each signal:
. Concerning the distribution mean (
), there are two choices to be considered. The first choice, which is in alignment with the simulation processes followed by previous studies testing the effect of outlier samples in the performance of ApEn, SampEn, and univariate DisEn [
23,
24,
25], would be to ensure that outlier values are outside the physiological range of each recorded signal while maintaining the amplitude boundaries of respective sensing equipment, leading to a distribution
equal to
. The second choice would be to set a lower distribution
to ensure that a minority of outliers remain within physiological range to also cover certain scenarios where sensor miscalibration and recording interferences could produce outliers of the respective magnitude, and for that purpose, a
equal to
would be set. In order to provide results that are comparable to previous studies while at the same time covering all possible scenarios, each experimental setup is replicated for both outlier
; however, since the second case covers a wider range of scenarios, its corresponding results are reported and discussed in detail, while the results of the first case (
) are available in the Appendix, in
Figure A1,
Figure A2,
Figure A3 and
Figure A4 and
Table A1,
Table A2,
Table A3 and
Table A4 of this manuscript. In all experimental setups, the sign of half the outliers is set to positive and the other half to negative, following random assignment.
Calculation of Artifactual DisEn Features: For each experimental setup, the corresponding 1463 artifactual network segments are used to calculate the respective univariate and multivariate artifactual DisEn Features based on the same process that was followed for the normal network segments in
Section 2.5.
To facilitate the reproducibility of the presented study, the function used for the simulation of outlier samples is made publicly available as
Supplementary Material.
2.7. Statistical Analysis
To quantify the disruptive capacity of outlier samples in the accuracy of extracted network features, the following three-stage statistical analysis is applied.
Kolmogorov–Smirnov Test: Initially, each feature distribution is standardised and compared to a standard normal distribution using the Kolmogorov–Smirnov Test.
Mann–Whitney U Test: At the second stage, and after consulting the results of the Kolmogorov–Smirnov test, the Mann–Whitney U test is chosen to compare each feature distribution extracted from artifactual network segments with its corresponding feature distribution extracted from the respective normal network segments, to verify statistically significant differences between the distributions of each pair.
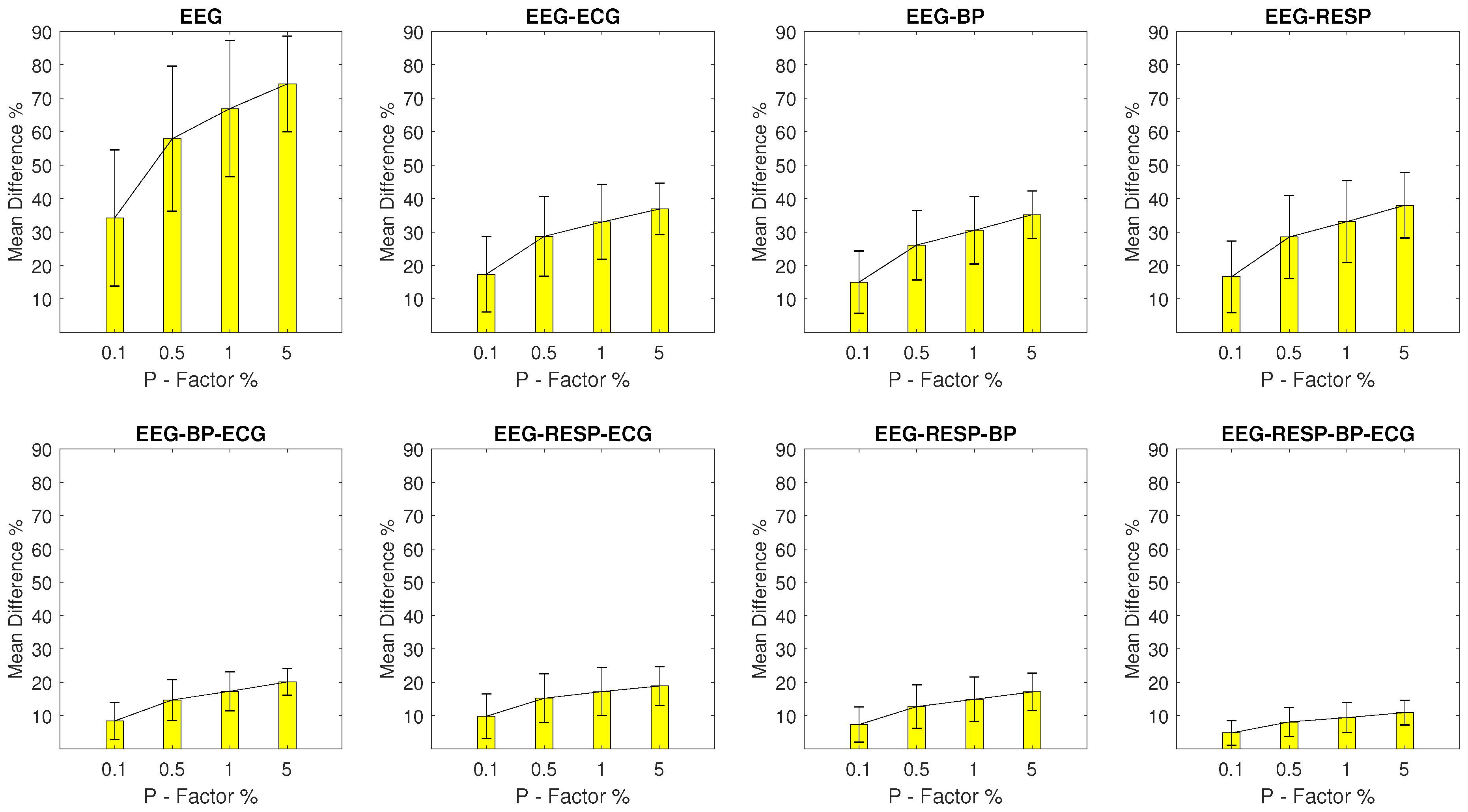
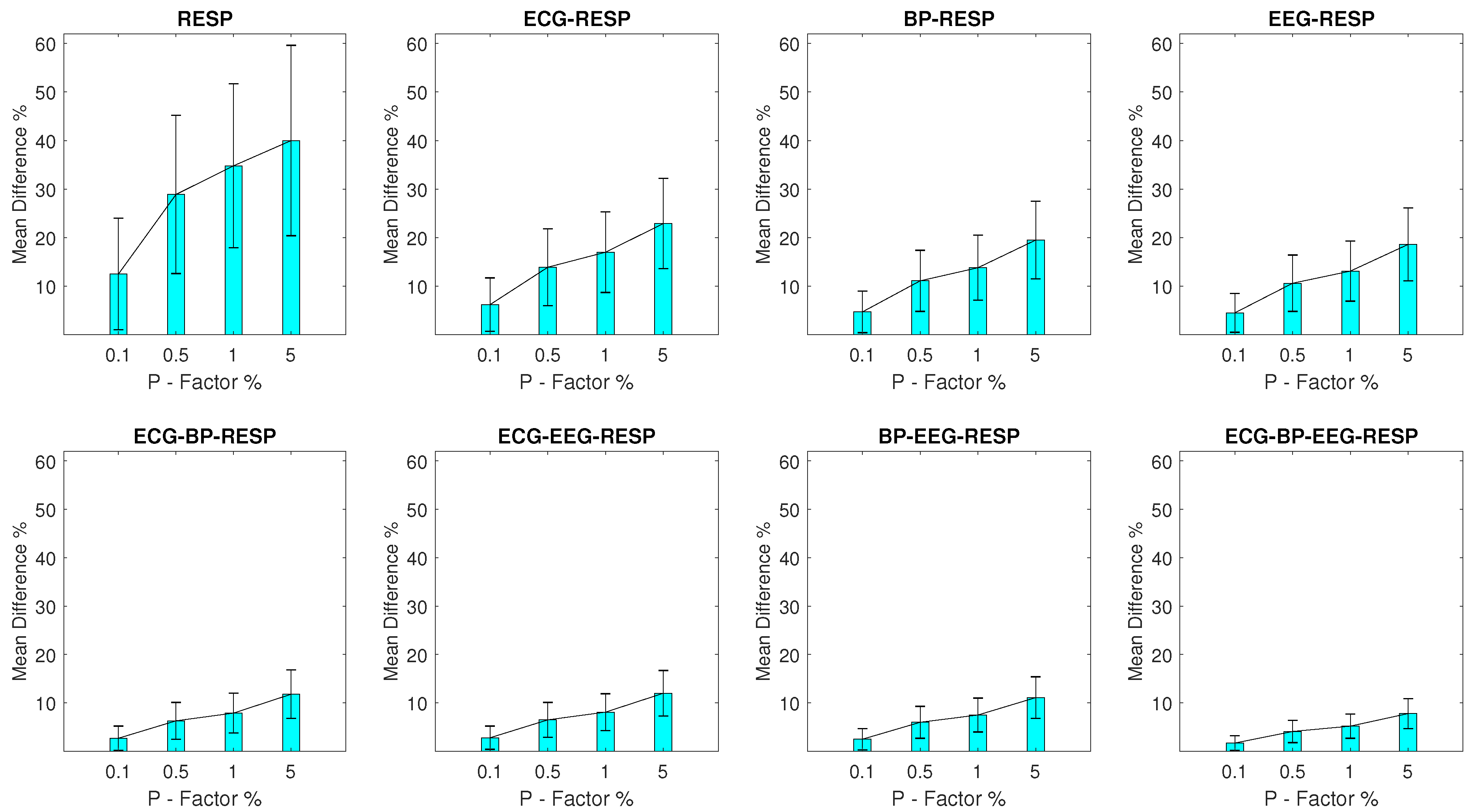
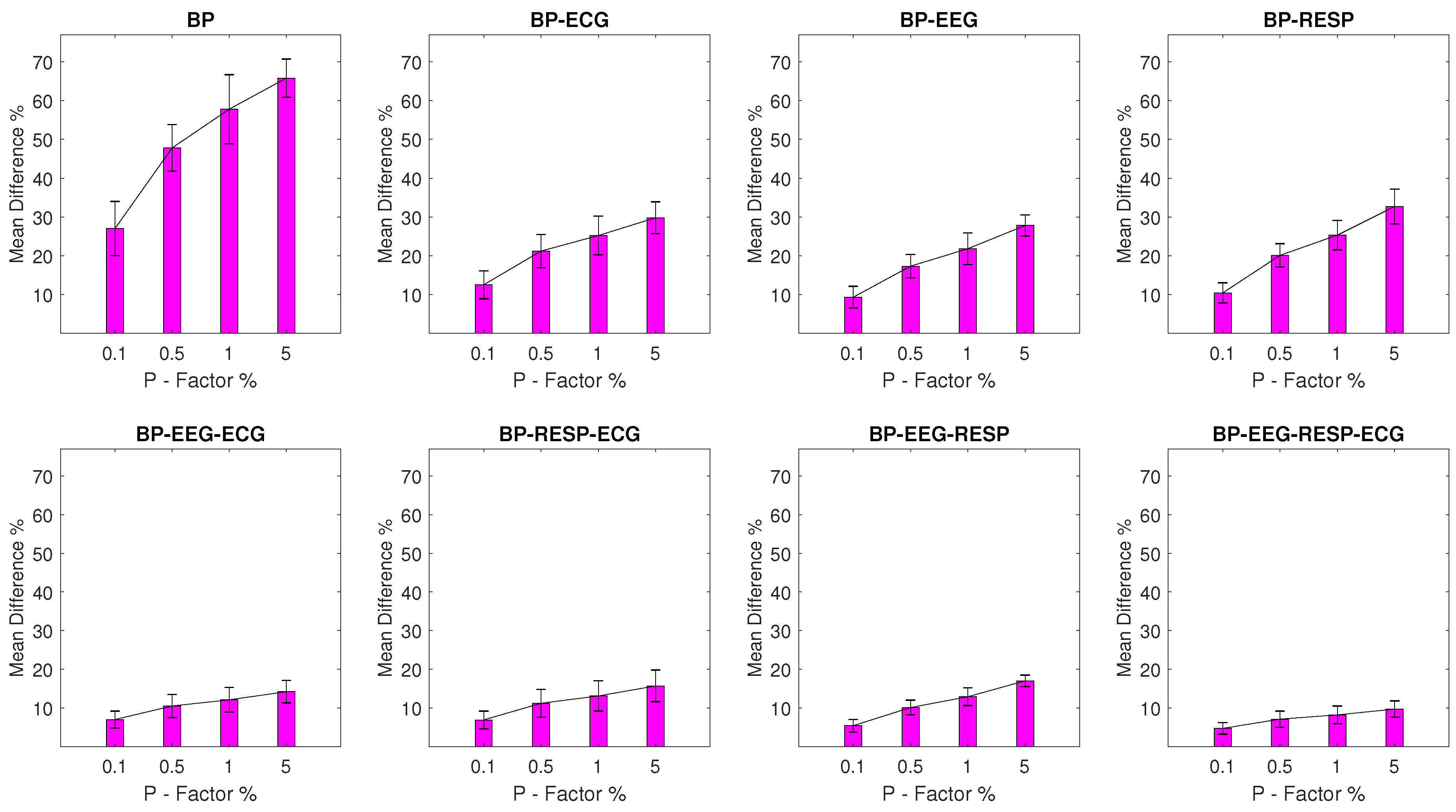
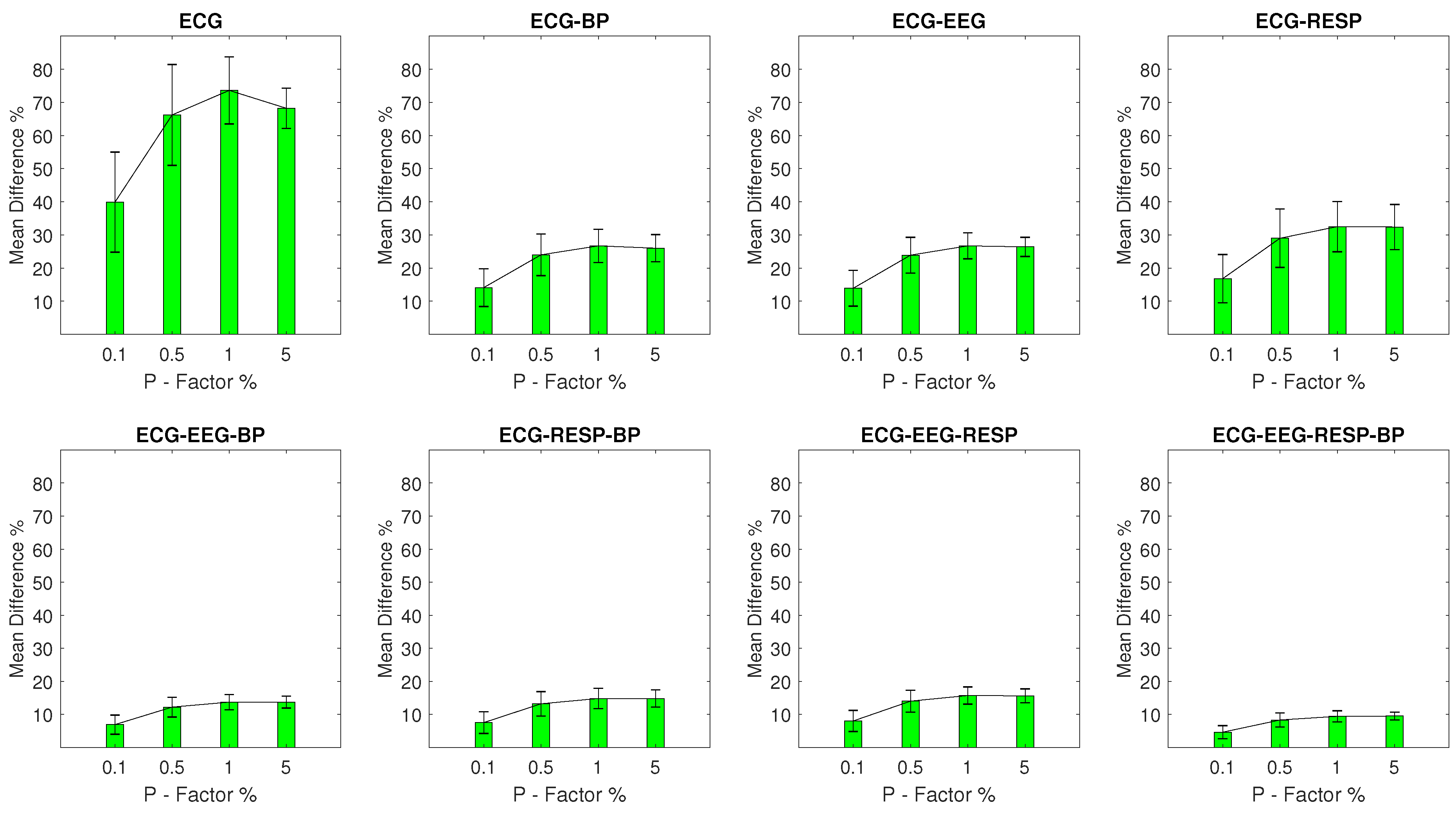
Mean Percentage Difference: Finally, for each DisEn feature extracted from an artifactual network segment, the absolute percentage difference from its original value, the one calculated from the respective network segment without outliers, is calculated. To provide a summary for every feature extracted during each experimental setup, its mean percentage difference () and of the percentage difference are calculated.
2.8. Artifactual Network Segment Detection
For the detection of artifactual network segments, a logistic regression classifier is applied in two configurations, a univariate and a multivariate one. The univariate configuration is utilising, from each network segment, only the the four DisEn features that are extracted using the physiological signal segments as separate input to the univariate DisEn algorithm, while the multivariate configuration utilises all the available 15 features of each network segment. The choice to implement two separate algorithmic configurations is made with the following aims in mind:
To derive insights concerning the potential benefits but also challenges that arise when moving from univariate to multivariate analysis for network segment classification.
To identify differences in classification performance, for both configurations, based on the physiological signal containing outlier samples in each experimental setup.
For this purpose, both algorithmic configurations were tested under the same 16 experimental setups. Each setup contains features extracted from a total of 2926 segments, out of which 1463 are the original network segments, and the other 1463 are their artifactual variations, as determined by the parameters of the experiment. As mentioned in
Section 2.2, the 1463 network segments correspond to 11 records, or 133 segments per record. The segments selected for training and testing during each experimental setup are selected in the following two data splits.
The first data split is done at the record level, with the first nine records used for training and the last two for testing purposes. This is done to ensure that the training of the classifier is done on different patients than the ones it is tested on, and therefore, its recorded performance is patient-agnostic. This leads to the feature sets of a total of 2394 segments (1197 normal vs. 1197 artifactual ones) being used for training, and a total of 532 feature sets (266 normal vs. 266 artifactual ones) being used for testing.
At this point, a second data split is introduced in the training set. It is important to consider that in a field application, the classifier would never have access to the exact same network segments in both normal and artifactual variations. For this reason, only half, or 1197 training sets are used, the first 599 of which correspond to feature sets of a normal network segment, while the other 598 correspond to different artifactual ones. As a result, for each experimental setup, both classifier configurations are trained on 1197 distinct training feature sets and tested on 532 testing feature sets.
Finally, the performance of each configuration for a certain experimental setup is calculated as the percentage of correct network segment classifications observed for each configuration when applied to the respective testing dataset.
5. Conclusions
This study investigated and quantified the effect of artifactual outlier samples in the accuracy of univariate and multivariate DisEn features extracted from network segments consisting of four synchronised physiological signals. Furthermore, it presented a proof-of-concept artifactual segment detection tool deployed in univariate and multivariate configurations using the corresponding extracted features.
The results indicate that the distribution of values for each feature extracted from a network segment containing artifactual outliers is significantly altered. The largest magnitude of disruption is observed in univariate features with an MDP value in the range of 20–48% for most experimental setups, while the multivariate features display a relative robustness, which increases based on the number of signals from which they are extracted. The feature extracted from all four available signals in a network segment displays an MDP value that remains lower than 10% across experimental setups. The classification results of the study indicate that the univariate classifier performance surpasses 90% of correct segment classifications for the majority of experimental setups. A strong exception are the setups with outliers in the RESP signal where a performance of 90% correct segment classifications is surpassed only with the multivariate classifier for a P factor of 5%. The multivariate classifier outperforms the univariate one in setups with EEG and RESP outliers, but underperforms when compared to the univariate one in the case of ECG outliers. These results highlight the importance of using a machine learning architecture capable of effective feature selection when moving from univariate to multivariate analysis within the framework of network physiology.
Finally, the changes observed both in terms of the percentage differences and the classification effectiveness when comparing across experimental setups in which outliers are present in different signals indicate that, in alignment with prior research [
25], the characteristics of each physiological signal should be taken into consideration when assessing the impact of outlier samples in the process of entropy quantification.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




