1. Introduction
A serious concern with Bayesian methodology is that the choice of the prior could result in conclusions that to some degree are predetermined before seeing the data. In certain circumstances, this is correct. This can be seen by considering the problem associated with what is known as the Jeffreys–Lindley paradox where posterior probabilities of hypotheses, as well as associated Bayes factors, will produce increasing support for the hypothesis as the prior becomes more diffuse. Thus, while one may feel that a very diffuse prior is putting in very little information, it is in fact biasing the results in favor of the hypothesis in the sense that that there is a significant prior probability that evidence will be found in favor of the hypothesized value when it is false. It has been argued, see [
1,
2], that the measurement and control of bias is a key element of a Bayesian analysis as, without it, and the assurance that bias is minimal, the validity of any inference is suspect.
While attempts have been made to avoid the Jeffreys–Lindley paradox through the choice of the prior, modifying the prior to avoid bias is contrary to the ideals of a Bayesian analysis which requires the elicitation of a prior based upon knowledge of the phenomenon under study. Why should one change such a prior because of bias? Indeed, there is bias in favor and bias against and typically choosing a prior to minimize one type of bias simply increases the other. Roughly speaking, in a hypothesis assessment problem, bias against means that there is a significant prior probability of finding evidence against a hypothesized value when it is true, and bias in favor means that there is a significant prior probability of finding evidence in favor of a hypothesized value when it is false. The real method for controlling bias of both types is through the amount of data collected. Bias can be measured post-hoc, and it then provides a way to assess the weight that should be given to the results of an analysis. For example, if a study concludes that there is evidence in favor of a hypothesis, but it can be shown that there was a high prior probability that such evidence would be obtained, then the results of such an analysis can’t be considered to be reliable.
Previous discussion concerning bias for Bayesian methodology has focused on hypothesis assessment and, in many ways, this is a natural starting point. This paper is concerned with adding some aspects to those developments and to extending the approach to estimation and prediction problems as discussed in
Section 3.3 where bias in favor and bias against are expressed in terms of a priori coverage probabilities. Furthermore, it is argued that measuring and controlling bias is essentially frequentist in nature. Although not the same, it is convenient to think of bias against in a hypothesis assessment problem as playing a role similar to the size in a frequentist hypothesis test or, in an estimation problem, playing a role similar to 1 minus the coverage probability of a confidence region. Bias in favor can be thought of as somewhat similar to power in a hypothesis assessment problem and simlar to the probability of a confidence region covering a false value in an estimation problem. Thus, consideration of bias leads to a degree of unification between different ways of thinking about statistical reasoning.
The measurement of bias, and thus its control, is dependent upon measuring evidence. The principle of evidence is adopted here: evidence in favor of a specific value of an unknown occurs when the posterior probability of the value is greater than its prior probability, evidence against occurs when the posterior probability of the value is less than its prior probability and there is no evidence either way when these are equal. The major part of what is discussed here depends only on this simple principle, but sometimes a numerical measure is needed and, for this, we use the relative belief ratio defined as the ratio of the posterior to prior probability. The relative belief ratio is related to the Bayes factor but has some nicer properties such as providing a measure of the evidence for each value of a parameter without the need to modify the prior.
The inferences discussed here are based on the relative belief ratio and these inferences are invariant to any 1–1, increasing function of this quantity. For example, the logarithm of the relative belief ratio can be used instead to derive inferences. The expected value of the logarithm of the relative belief ratio under the posterior is the relative entropy, also called the Kullback–Leibler divergence, between the posterior and prior. This is an object of considerable interest in and of itself and, from the perspective of measuring evidence, can be considered as a measure of how much evidence the observed data are providing about the unknown parameter value in question. This aspect does not play a role here, however, but indicates a close association between the measurement of statistical evidence and the concept of entropy. In addition, many divergence measures involve the relative belief ratio and play a role in [
3], which is concerned with checking for prior-data conflict.
There is not much discussion in the Bayesian literature of the notion of bias in the sense that is meant here. There is considerable discussion, however, concerning the Jeffreys–Lindley paradox and our position is that bias plays a key role in the issues that arise. Relevant recent papers on this include [
4,
5,
6,
7,
8,
9], and these contain extensive background references. Ref. [
10] is concerned with the validation of quantum theory using Bayesian methodology applied to well-known data sets, and the principle of evidence and an assessment of the bias play a key role in the argument.
As already noted, the approach to inference and the measurement of bias adopted here is dependent on the principle of evidence. This principle is not well-known in the statistical community and so
Section 2 contains a discussion of this principle and why it is felt to be an appropriate basis for the development of a theory of inference. In
Section 3, the concepts that underlie our approach to bias measurement are defined, and their properties are considered and illustrated via a simple example where the Jeffreys–Lindley paradox is relevant. In addition, it is seen that a well-known
p-value does not satisfy the principle of evidence but can still be used to characterize evidence for or against provided the significance level goes to 0 with increasing sample size or increasing diffuseness of the prior. In
Section 4, the relationship with frequentism is discussed and a number of optimality results are established for the approach taken here to measure and control bias. In
Section 5, a variety of examples are considered and analyzed from the point-of-view of bias. All proofs of theorems are in the
Appendix A.
2. Statistical Evidence
Attempts to develop a theory of inference based upon a definition, or at least provide a characterization, of statistical evidence exist in the statistical literature. For example, see [
2,
11,
12,
13,
14,
15,
16,
17]. The treatments in [
12,
14] have some aspects in common with the approach taken here, but there are also substantial differences. There is a significant amount of discussion of statistical evidence in the philosophy of science literature and this is much closer in spirit to the treatment here. For example, see [
18] p. 6, where it is stated “for a fact
e to be evidence that a hypothesis
h is true, it is both necessary and sufficient for
e to increase
h’s probability over its prior probability” which is what is called the principle of evidence here.
2.1. The Principle of Evidence
One characteristic of our, and the philosophical, treatment is that evidence is a probabilistic concept and thus a proper definition only requires a single probability model as opposed to a statistical model. This explains in part why our treatment requires a proper prior as then there is a joint probability model for the model parameter and data. The following two examples illustrate the relevance of characterizing evidence in such a context. Example 1 is a simple game of chance where the probabilities in question are unambiguous. The utility aspects of the game are ignored because these are irrelevant to the discussion of evidence but surely are relevant if some action like betting was involved. This is characteristic of the treatment here where loss functions play no role in the characterization of evidence but do play a role in determining actions when required as discussed in the well-known Example 2. The examples also illustrate that characterizing evidence in favor of or against is not enough, as it is necessary to also say something about the strength of the evidence.
Suppose that there are two players in a card game, labeled I and II, and each is dealt m cards, where from a randomly shuffled deck of 52 playing cards. Further suppose that player I, after seeing their hand, is concerned, for whatever reason dependent on the rules of the game, with the truth or falsity of the hypothesis : player II has exactly two aces. It seems clear that the hand of player I will contain evidence concerning this. For example, if player I has three or four aces in their hand, then there is categorical evidence that is false. However, what about the evidence when the event observed is “the number of aces in the hand of player I is ” with or
There are two questions to be answered: (i) is there evidence in favor of or against
and (ii) how strong is this evidence? The prior probability
and posterior probability
that
is true are provided in
Table 1 for various
What conclusions can be drawn from this table? In every case, other than
the conditional probability
does not support
being true. In fact, in many cases, some would argue that the value of this probability indicates evidence against
This points to a significant problem with trying to use probabilities to determine evidence, as it is not at all clear what the cutoff should be to determine evidence for or against
It seems clear, however, that if the data, here the observation that
is true, has increased belief in
over initial beliefs, then there is evidence in the data pointing to the truth of
Whether or not the posterior probability is greater than the prior probability is indicated by
, the relative belief ratio of
being greater than 1. Certainly, it is intuitive that, when
then our belief in
being true, a posteriori could increase, but, from the table and some reflection, it is clear that this cannot always be true as the amount of data,
m in this case, grows. While
is evidence in favor of
, it is evidence against only for
The relationship between the prior probabilities and posterior probabilities is somewhat subtle and not easy to predict, but a comparison of these quantities makes it clear when there is evidence in favor of
and when there isn’t. This answers question (i).
The measurement of the strength of evidence is not always obvious, but, in this case, effectively a binary event, the posterior probability of the event in question seems like a reasonable approach as it is measuring the belief that the event in question is true. Thus, if we get evidence in favor of and is small, then this suggests that the evidence can only be regarded as weak and similarly if there is evidence against and is large, then there is only weak evidence against . Some might argue that a large value of should always be evidence in favor of , but note that the data could contradict this by resulting in a decrease from a larger initial probability. Measuring strength in this way, the table indicates that there is strong evidence in favor of with and weak to moderate evidence in favor otherwise when By contrast, there is typically quite strong evidence against in cases where with the exception of Intuitively, it couldn’t be expected that there would be strong evidence in favor of for small m, but there can still be evidence in favor. Note that a comparison, for and of the values of illustrates that the relative belief ratio itself does not provide a measure of the strength of the evidence in favor. In general, the value of a relative belief ratio needs to be calibrated and the posterior probability of is a natural way to do this here.
Example 2. Prosecutor’s fallacy.
Assume a uniform probability distribution on a population of size N of which some member has committed a crime. DNA evidence has been left at the crime scene and suppose that this trait is shared by of the population. A prosecutor is criticized because they conclude that, because the trait is rare and a particular member possesses the trait, they are guilty. In fact, “has trait”guilty is misinterpreted as the probability of guilt rather than “guilty”“has trait”, which is small if m is large. However, this probability does not reflect the evidence of guilt. If you have the trait, then clearly this is evidence in favor of guilt and indeed “guilty”“has trait” and “guilty”“has trait” Thus, there is evidence of guilt, and the prosecutor is correct to conclude this. However, the evidence is weak whenever m is large and a conviction then does not seem appropriate. Since the posterior probability of “not guilty”is large whenever m is, it may seem obvious to conclude this. However, suppose that “guilty” corresponds to being a carrier of a highly infectious deadly disease and “has trait” corresponds to some positive, but not definitive, test for this. The same numbers should undoubtedly lead to a quarantine. Thus, the utilities determine the action taken and not just the evidence.
2.2. Confirmation Theory
As noted, discussion concerning statistical evidence has a long history, although mainly in the philosophy of science literature, where it is sometimes referred to as confirmation theory. An introduction to confirmation theory can be found in [
19], but the history of this topic is much older. For example, see Appendix ix in [
20] where, with
x and
y denoting events, the following is stated.
If we are asked to give a criterion of the fact that the evidence y supports or corroborates a statement the most obvious reply is: that y increases the probability of
The book [
20] references older papers and some sources cite [
21] where the relative belief ratio
is called the
coefficient of influence of B upon A. In the Confirmation entry in [
22], the definition of
probabilistic relevance confirmation is what has been called here the principle of evidence. The following quote is from the third paragraph of this entry and it underlines the importance of this topic.
Confirmation theory has proven a rather difficult endeavour. In principle, it would aim at providing understanding and guidance for tasks such as diagnosis, prediction, and learning in virtually any area of inquiry. However, popular accounts of confirmation have often been taken to run into trouble even when faced with toy philosophical examples. Be that as it may, there is at least one real-world kind of activity that has remained a prevalent target and benchmark, i.e., scientific reasoning, and especially key episodes from the history of modern and contemporary natural science. The motivation for this is easily figured out. Mature sciences seem to have been uniquely effective in relying on observed evidence to establish extremely general, powerful, and sophisticated theories. Indeed, being capable of receiving genuine support from empirical evidence is itself a very distinctive trait of scientific hypotheses as compared to other kinds of statements. A philosophical characterization of what science is would then seem to require an understanding of the logic of confirmation. In addition, thus, traditionally, confirmation theory has come to be a central concern of philosophers of science.
As far as we know, Ref. [
2] summarizes one of the first attempts to use the principle of evidence as a basis for a theory of statistical inference. Some of the paradoxes/puzzles that arise in the philosophical literature, such as Hempel’s the Raven paradox, are discussed there. Adding the measurement of the strength of evidence and the a priori measurement of bias to the principle of evidence leads to the resolution of many difficulties, see [
2]. Whether one is convinced of the value of the principle of evidence or not, this is an idea that needs to be better known and investigated by statisticians.
2.3. Popper’s Principle of Science as Falsification
Another aspect requiring comment is that the principle of evidence allows for finding either evidence against or evidence in favor of a hypothesis while, for example, a
p-value cannot find evidence in favor. This one-sided aspect of a
p-value is often justified by Popper’s idea that the role of science lies in falsification of hypotheses and not their confirmation. In the context of Examples 1 and 2, this seems wrong as the hypothesis in question is either true or false, so it is desirable to be able to find evidence either way. When applied to a statistical context, at least as formulated in
Section 3, inferences about a quantity of interest are dependent on the choice of a statistical model and a prior. It is well understood that the model is typically false and it isn’t meaningful to talk of the truth or falsity of the prior. Since there is only one chosen model, it can only be falsified via model checking rather than confirmed, namely, determining if the observed data are in the tails of every distribution in the model. Actually, all that is being asked in such a procedure is whether or not the model is at least reasonably compatible with the observed data. Similarly, the prior is checked through checking for prior-data conflict, namely, given that the model has passed its check, is there an indication that the true value lies in the tails of the prior. For example, see [
3,
23,
24] for some discussion. Again, all that is being asked is whether or not the prior is at least reasonably compatible with the data.
For checking the model or checking the prior, there is one object that is being considered. Thus, it makes sense that only an indication that the entity in question is not appropriate is available, and a
p-value can play a role in this aspect of a statistical argument. However, when making an inference, the model is accepted as being correct and, as such, one of the distributions in the model is true, and so it is natural to want to be able to find evidence in favor of or against a specific value of an object dependent on the true distribution. This situation is analogous to what arises in logic where a sound argument is distinguished from a valid argument. A logical argument is based upon premises and rules of inference like modus ponens. An argument is valid if the rules of logic are correctly applied to obtain the conclusions. However, an argument is sound only if the argument is valid and the premises are true. It is a basic rule of logical reasoning that one doesn’t confound the correctness of the argument with the correctness of the premises. In the statistical context, there may indeed be problems with the model or prior, but the inference step, which assumes the correctness of the model and prior, needs to be able to find evidence in favor as well as evidence against a particular value of the object of interest. As part of the general approach as presented in [
2], both model checking and checking for prior-data conflict are advocated before inference. If there are serious problems with either, then modifications of the ingredients are in order, but this is not the topic of this paper where it is assumed that the model and prior are acceptable. Thus, Popper’s falsification idea plays a role but not in the inference step.
3. Evidence and Bias
For the discussion here, there is a model given by densities for data x and a proper prior probability distribution given by density It is supposed that interest is in inferences about , where is onto and for economy the same notation is used for the function and its range. For the most part, it is safe to assume all the probability distributions are discrete with results for the continuous case obtained by taking limits.
A measure of the evidence that
is the true value is given by the relative belief ratio
where
are the prior and posterior probability measures of
with densities
and
respectively, and
is a sequence of sets converging nicely to
The last equality in (
1) requires some conditions, but the prior density positive and continuous at
is enough. In addition, when
for
the indicator of
A, then we write
for
Thus,
implies evidence for the true value being
, etc. It is also possible that a prior is dependent on previous data. In such a situation, it is natural to replace
in (
1) by the initial prior, as the posterior remains the same, but now the evidence measure is based on all of the observed data. There may be contexts, however, where the concern is only with the evidence provided by the additional data, for example, as when new data arise from random sampling from the relevant population(s), but the first dataset came from an observational study.
Any
valid measure of evidence should satisfy the principle of evidence, namely, the existence of a cut-off value that determines evidence for or against as prescribed by the principle. Naturally, this cut-off is 1 for the relative belief ratio. The Bayes factor is also a valid measure of evidence and with the same cut-off. When
, then the Bayes factor of
A equals
and thus can be defined in terms of the relative belief ratio, but not conversely. In addition,
iff
and thus the Bayes factor is not really a comparison of the evidence for
A being true with the evidence for its negation. In the continuous case, if we define the Bayes factor for
as a limit as in (
1), then this limit equals
Further discussion on the choice of a measure of evidence can be found in [
2] as there are other candidates beyond these two. One significant advantage for the relative belief ratio is that all inferences derived based on it are invariant under smooth reparameterizations. Furthermore, the relative belief ratio only serves to order the values of
with respect to evidence, and the value
is not to be considered as measuring evidence on a universal scale. It is important to note that the discussion of bias here depends only on the principle of evidence and is the same no matter what valid measure of evidence is used.
Since the model and prior are subjectively chosen, the characterization and measurement of statistical evidence has a subjective component. This creates the possibility that these choices are biased, namely, they were chosen with some goal in mind other than letting the data determine the conclusions. Model checking and checking for prior-data conflict exposes these choices to criticism via the data, but these checks will not reveal inappropriate conduct like tailoring a model or prior based on the observed data. Perhaps a more important check on such behavior is to measure and control bias. As will now be shown, controlling the bias through the a priori determination of the amount of data collected can leave us with greater confidence that the data are the primary driver of whatever inferences are drawn, and this is surely the goal in scientific applications. Thus, while informed subjective choices are a good thing, there are also tools that can be used to mitigate concerns about subjectivity, as these allow an analysis to at least approach the scientific goal of an objective analysis. The lack of a precise definition of objectivity, and a clear methodology for attaining it, is not a failure since the issue can be addressed. This is a somewhat nuanced view of the objective/subjective concern and is perhaps more in line with the views on this topic as expressed in [
25,
26].
3.1. Bias in Hypothesis Assessment Problems
Suppose the problem of interest is to assess whether or not there is evidence in favor of or against
as is determined here by
being greater than or less than 1. It is to be noted that no restrictions, beyond propriety, are placed on priors here so
could very well be a mixture of a prior on
and a prior on
with
assigned some positive mass as is commonly done in Bayesian testing problems. Certainly, such a prior is necessary when
and
so the relevant relative belief ratio is
While this formulation is accommodated, there is no reason to insist that every hypothesis assessment be expressed this way. When
is a quantity like a mean, variance, quantile, etc., it seems natural to compare the value
with each of the other possible values
for
to calibrate, as is done subsequently via (
2), how strong the evidence is concerning
The following example is carried along as it illustrates a number of things.
Example 3. Location normal.
Suppose
is i.i.d.
with
a
prior. Then,
and so
equals
Observe that, as , then for every and in particular for a hypothesized value Thus, it would appear that overwhelming evidence is obtained for the hypothesis when the prior is very diffuse, and this holds irrespective of what the data says. In addition, when the standardized value is fixed, then as These phenomena also occur if a Bayes factor (which equals in this case) or a posterior probability based upon a discrete prior mass at , are used to assess Accordingly, all these measures lead to a sharp disagreement with the frequentist p-value when it is small. This is the Jeffreys–Lindley paradox, and it arises quite generally.
The Jeffreys–Lindley paradox shows that the strength of evidence cannot be measured strictly by the size of the measure of evidence. A logical way to assess strength is to compare the evidence for
with the evidence for the other values for
The
strength can then be measured by
the posterior probability that the true value has evidence no greater than the evidence for
Thus, if
and (
2) is small, then there is strong evidence against
, while, if
and (
2) is large, then there is strong evidence in favor of
The inequalities
hold and thus, when
is small, there is strong evidence against
and, when
and
is big, then there is strong evidence in favor of
Note, however, that
does not guarantee
and, if
, this means that there is weak evidence against
In addition, there is no reason why multiple measures of the strength of the evidence can’t be used (see the discussion in
Section 3.2). In fact, when
is binary-valued, it is better to use
to measure the strength, as we did in Examples 1 and 2, and there are also some issues with (
2) in the continuous case that can require a modification. These issues are ignored here, as the strength does not play a role when considering bias, and the reader can see [
2] for further discussion. The important point is that it is necessary to calibrate the measure of evidence using probability to measure how strong belief in the evidence is and (
2) is a reasonable way to do this in many contexts.
- 1.
Example 3 Location normal (continued).
A simple calculation shows that, with
fixed, (
2) then converges to
as
Thus, if the
p-value is small, this indicates that a large value of
is only weak evidence in favor of
It is to be noted that the
p-value
is not a valid measure of evidence as described here because there is no cut-off that corresponds to evidence for and evidence against. Thus, its appearance as a measure of the strength of the evidence is not circular.
Simple algebra shows (see the
Appendix A), however, that
a difference of two
p-values, is a valid measure of evidence via the cut-off 0. From this, it is seen that the values of the first
p-value
that lead to evidence against, generally become smaller as
For example, with
and
the standard
p-value equals
Setting
and
, the second
p-value equals
and thus there is evidence against
, with
being the second term equal to
and, with
, it equals
so there is evidence in favor of
in both cases. When
n increases, these values become smaller, as, with
, the first
p-value equal to
is always evidence in favor. Similar results are obtained with a uniform prior on
reflecting perhaps a desire to treat many values equivalently, as
or
For example, with
and
,
then the second
p-value equals
, and there is evidence in favor of
These findings are similar to those in [
27,
28].
It is very simple to elicit based on prescribing an interval that contains the true with some high probability such as , taking to be the mid-point and so is determined. There is no reason to take to be arbitrarily large. However, one still wonders if the choice made is inducing some kind of bias into the problem as taking too large clearly does.
Certainly, default choices of priors should be avoided when possible, but even when eliciting, how can we know if the chosen prior is inducing bias? To assess this, a numerical measure is required. The principle of evidence suggests that
bias against is measured by
where
is the prior predictive distribution of the data given that the hypothesis is true. Thus, (
3) is the prior probability that evidence in favor of
will not be obtained when
is the true value. If (
3) is large, then there is an a priori bias against
For the bias in favor of
, it is necessary to assess if evidence against
will not be obtained with high prior probability even when
is false. One possibility is to measure
bias in favor by
the prior probability of not obtaining evidence against
when it is false. When
(
4) equals
, where
M is the prior predictive for the data. For continuous parameters, it can be argued that it doesn’t make sense to consider values of
so close to
that they are practically indistinguishable. Suppose that there is a measure of distance
on
and a value
such that, if
then
and
are indistinguishable in the application. The
bias in favor of
is then measured by replacing
in (
4) by
leading to the upper bound
Typically,
decreases as
moves away from
so (
5) can be computed by finding the supremum over the set
and, when
is real-valued and
is Euclidian distance, this set equals
It is to be noted that the measures of bias given by (
3)–(
5) do not depend on using the relative belief ratio to measure evidence. Any valid measure of evidence will determine the same values when the relevant cut-off is substituted for 1. It is only (
2) that depends on the specific choice of the relative belief ratio as the measure of evidence.
Under general circumstances, see [
2], both biases will converge to 0 as the amount of data increases and thus they can be controlled by the amount of data collected. There is no point in reporting the results of an analysis when there is a lot of bias unless the evidence contradicts the bias.
- 2.
Example 3 Location normal (continued).
Under
then
Thus, putting
then (
3) is given by
This goes to 0 as
or as
Thus, bias against can be controlled by sample size
n or by the diffuseness of the prior although, as subsequently shown, a diffuse prior induces bias in favor. It is also the case that (
6) converges to 0 when
or when
is fixed and
Thus, it would appear that using a prior with a location quite different than the hypothesized value or a prior that was much more concentrated than the sampling distribution can be used to lower bias against. These are situations, however, where one can expect to have prior-data conflict after observing the data.
The entries in
Table 2 record the bias against for a specific case and illustrate that increasing
n does indeed reduce bias. The entries also show that bias against can be greater when the prior is centered on the hypothesis.
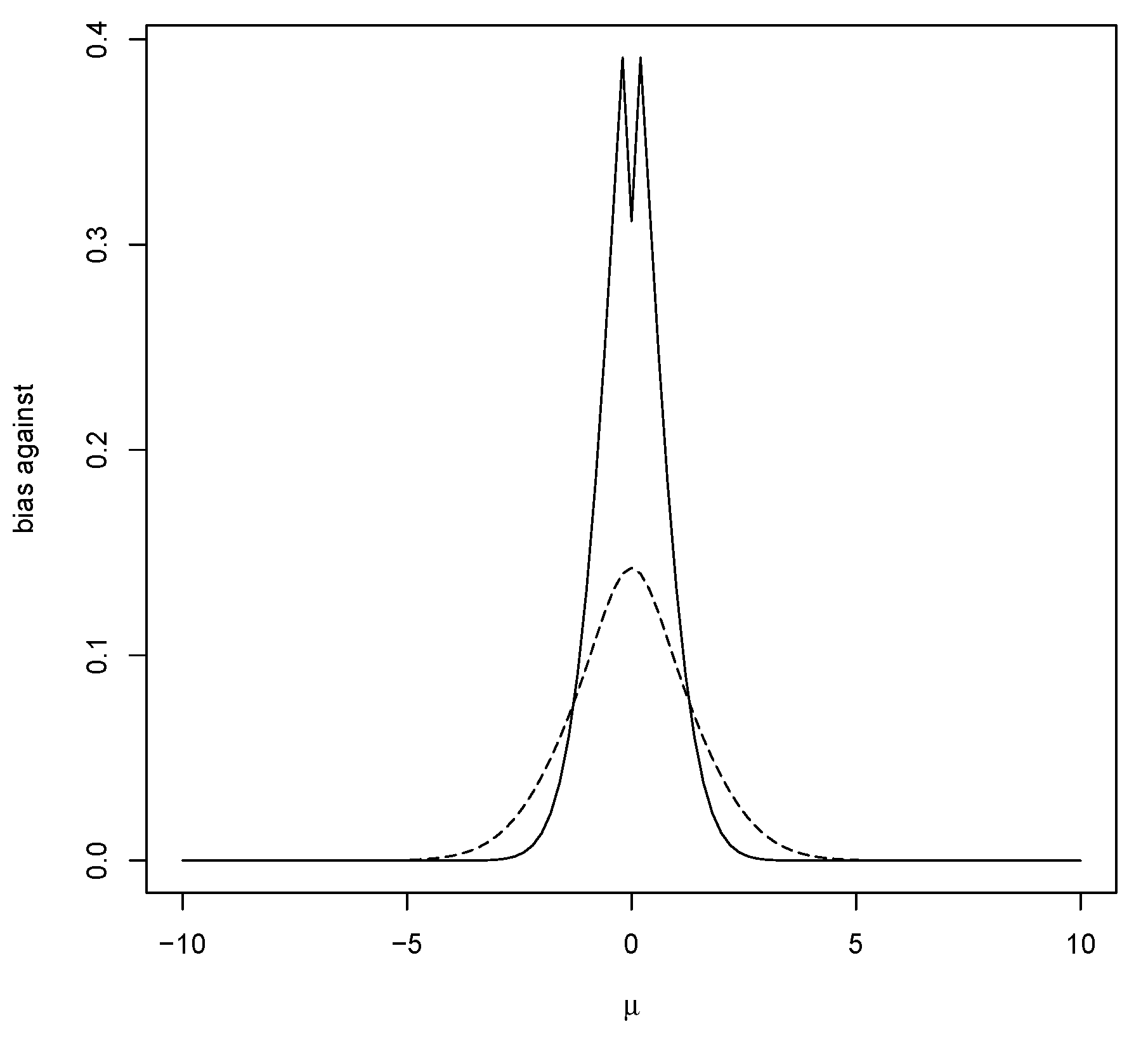
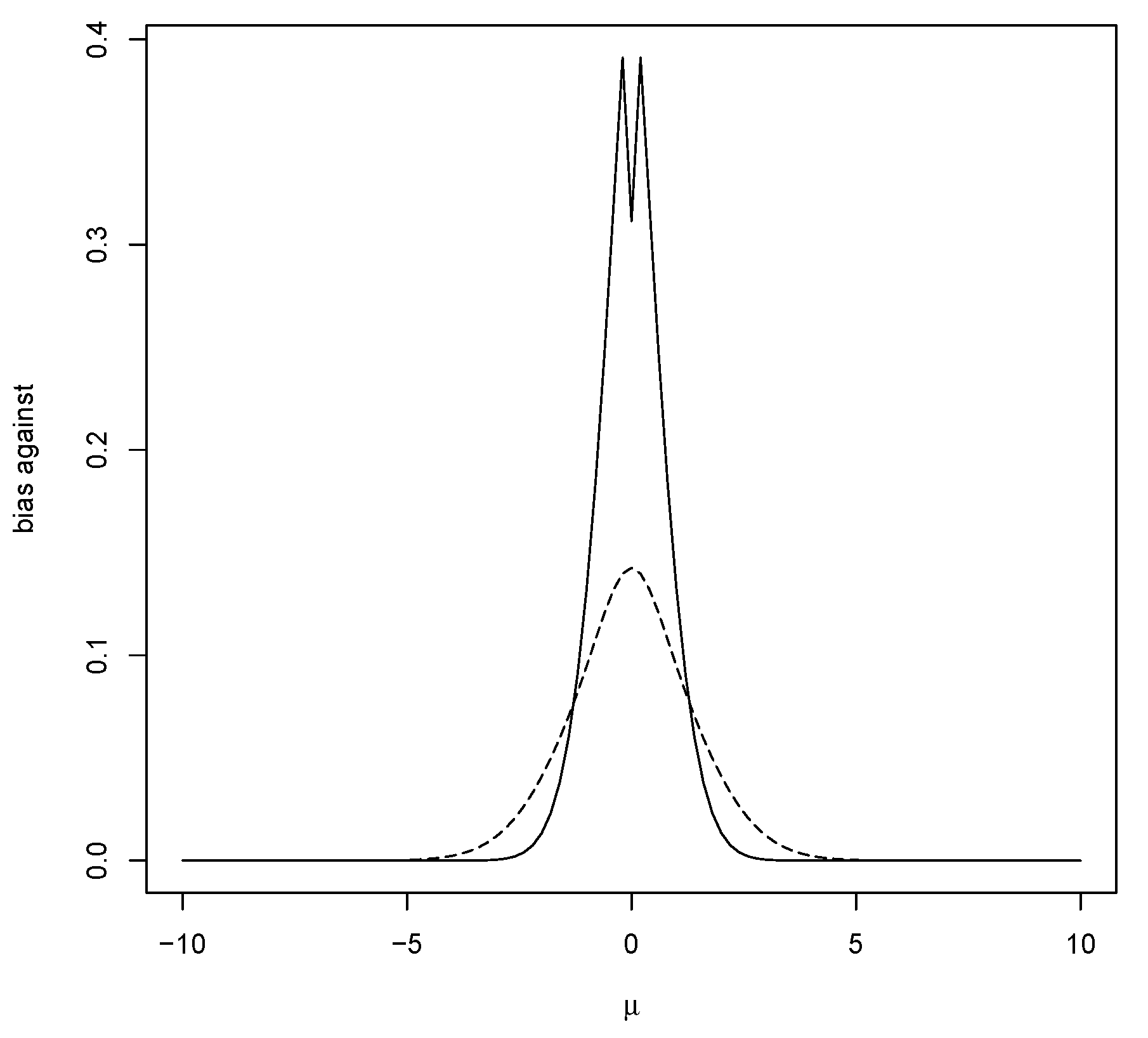
Figure 1 contains a plot of the bias against
as a function of
when using a
prior. Note that the maximum bias against occurs at the mean of the prior (and equals
), and this typically occurs when
namely, when the data are more concentrated than the prior.
Figure 1 also contains a plot of the bias against when using a prior more concentrated than the data distribution. That the bias against is maximized, as a function of the hypothesized mean
when
equals the value associated with the strongest belief under the prior, seems odd. This phenomenon arises quite often, and the mathematical explanation for this is that the greater the amount of prior probability assigned to a value, the harder it is for the posterior probability to increase and so it is quite logical when considering evidence. It will be seen that this phenomenon is very convenient for the control of bias in estimation problems and could be used as an argument for using a prior centered on the hypothesis, although this is not necessary as beliefs may be different.
Now, consider (
5), namely, bias in favor of
Putting
then (
5) equals
where
which converges to 0 as
and also as
However, (
7) converges to 1 as
so, if the prior is too diffuse, there will be bias in favor of
Thus, resolving the Jeffreys–Lindley paradox requires choosing the sample size
n, after choosing the prior, so that (
7) is suitably small. Note that choosing
to be larger reduces bias against but increases bias in favor and so generally bias cannot be avoided by choice of prior.
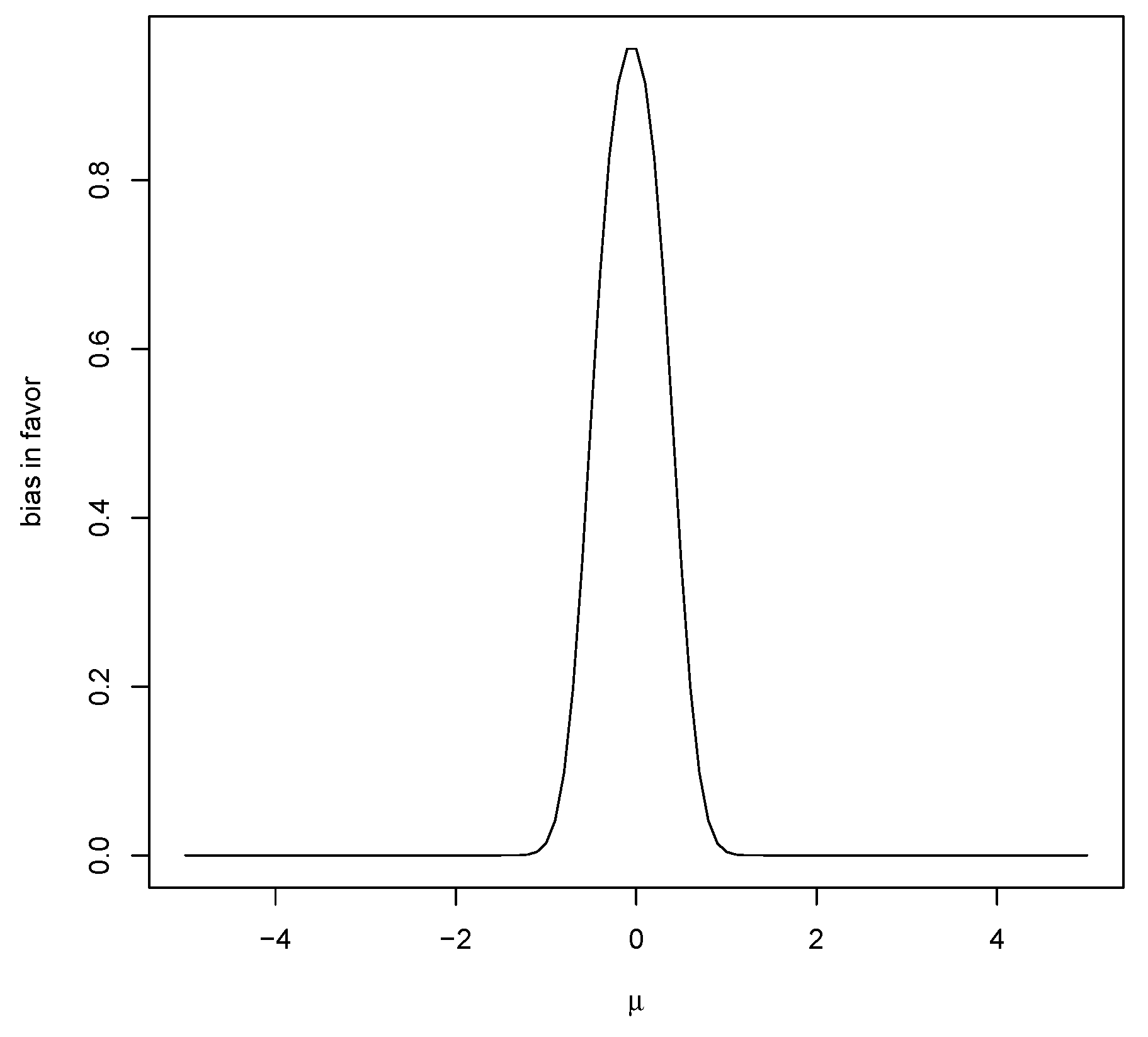
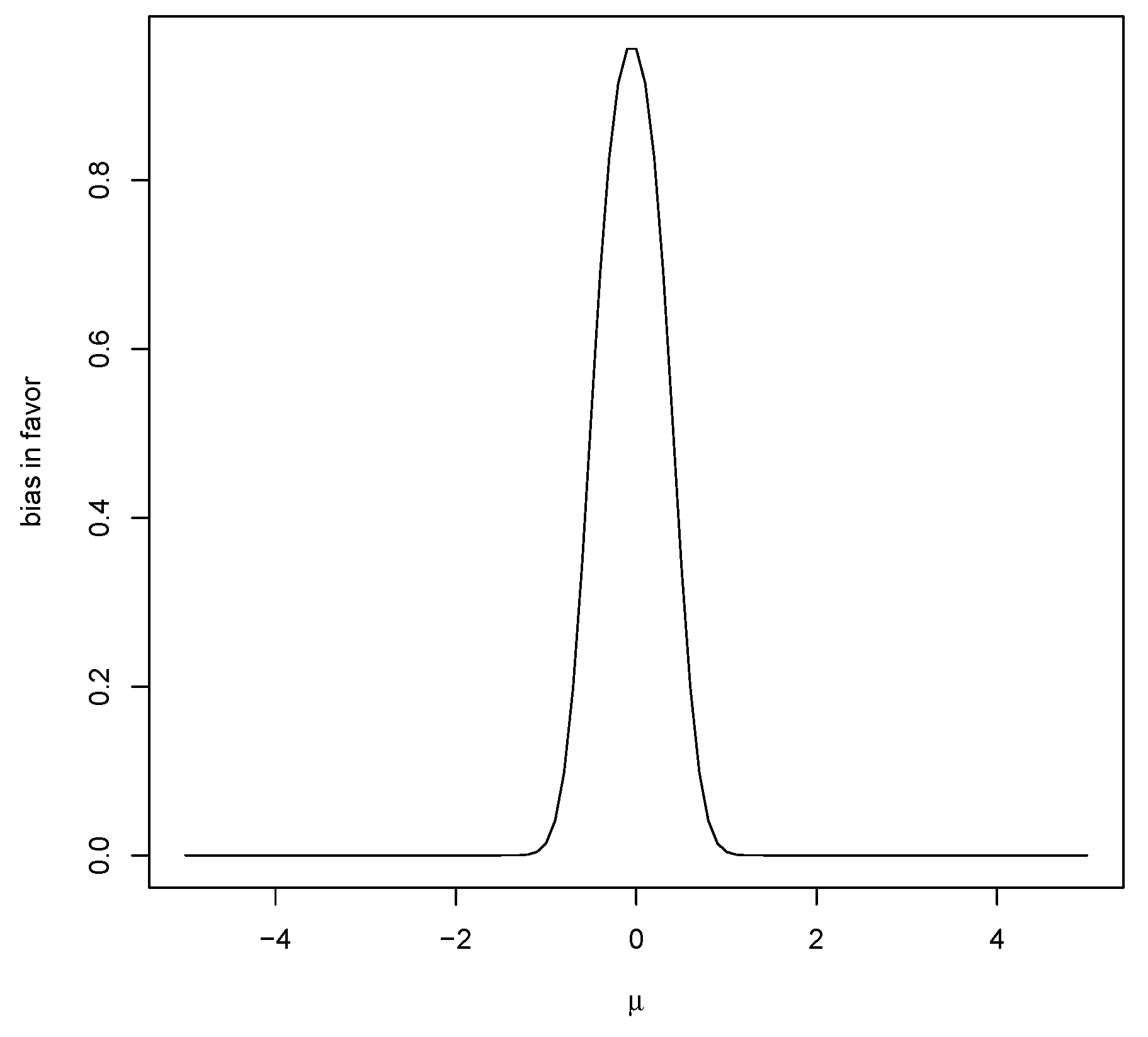
Figure 2 is a plot of
for a particular case and this strictly decreases as
moves away from
.
In
Table 3, we have recorded some specific values of the bias in favor using (
4) and using (
5) where
is Euclidean distance. It is seen that bias in favor can be quite serious for small samples. When using (
5), this can be mitigated by making
larger. For example, with
, the bias in favor equals
Note, however, that
is not chosen to make the bias in favor small; rather, it is determined in an application as the difference from the null that is just practically important. The virtues of a suitable value of
are readily apparent as (
5) is much smaller than (
4) for larger
A comparison of
Table 2 and
Table 3 shows that a study whose purpose is to demonstrate evidence in favor of
is much more demanding than one whose purpose is to determine whether or not there is evidence against
As a cautionary note too, it is worth reminding the reader that bias is not to be used in the selection of a prior. The prior is to be selected by elicitation and the biases measured for that prior. If one or both biases are too large, then that is telling us that more data are needed to ensure that the conclusions drawn are primarily driven by the data and not the prior. It is tempting to look at
Table 2 and
Table 3 and compare the priors, but this is not the way to proceed and it can be seen that choosing a prior to minimize one bias simply increases the other. It is also the case that bias can be measured when a default proper prior is chosen, see Example 3, as is often done when considering sparsity inducing priors, but the discussion here will focus on the ideal where elicitation can be carried out. One can argue that bias is also model dependent and that is certainly true so, while our focus is on the prior, in reality, the biases are a measure of the model-prior combination. The same comment applies to the model, however, that bias measurements are not to be used to select a model.
3.2. The Role of the Difference that Matters
The role and value of require some further discussion as some may find the need to specify this quantity controversial. The value of depends on the application as well as the characteristic of interest . For the developments here, specifying is a necessary part of the investigation. There may well be contexts where the precise value of is unclear. That seems to suggest, however, that the investigator does not fully understand what is as a real-world object and formal inference in such a context seems questionable, although perhaps some kind of exploratory analysis is reasonable. In a well-designed study, a measurement process is selected which, together with sampling from the population, determines the data. In deciding on the measurement process, and sample size, an investigator has to decide on the accuracy required and that is where enters the picture.
Consider a problem where an investigator is measuring the length of some quantity associated with each member of a population and wants to make inferences about the mean length
If the investigator chooses to measure each length to the nearest cm, then there is no way that the true value of the mean can be known to an accuracy beyond
cm, even if the entire population is measured. As another example, suppose that
represents the proportion of individuals in a population infected with a virus. Surely, it is imperative to settle on how accurately we wish to know
and that will play a key role in a number of statistical activities like determining sample size for the consideration of a hypothesis concerning the true value of
For example, does the application require that
be known within an absolute error of
or within a relative error of
See [
29] for discussion on this point in the context of logistic regression. To simply proceed to collect data and do a statistical analysis without taking such considerations into account does not seem like good practice.
While discussion of
may be limited, it has certainly not disappeared from the statistical literature. For example, consider power studies where a
is required. In addition, one of the many criticisms of the
p-value arises because, for a large enough sample size, a difference may be detected that is of no importance. The general recommendation is to then quote a confidence interval to see if that is the case, but it is difficult to see how that is helpful unless one knows what difference
matters. This has long been an issue when discussing testing problems, see [
30], and yet it still seems unresolved as it is not always clear how to obtain an appropriate
p-value that incorporates
. One of the benefits of the approach here is that it is straightforward to incorporate
into the analysis and, in fact, it often makes an analysis easier. Thus, specifying
is a part of every well-designed statistical investigation.
3.3. Bias in Estimation Problems
The relative belief estimate of is the value that maximizes the measure of evidence, namely, It is easy to show that with the inequality strict except in trivial contexts. The accuracy of this estimate can be measured by the “size” of the plausible region the set of values of that have evidence in their favor and note To say that is an accurate estimate requires that be “small”, perhaps as measured by , where is some measure of volume, and also has high posterior content which measures the belief that the true value is in Note that does not depend on the specific measure of evidence chosen, in this case the relative belief ratio. Any valid estimator must satisfy the principle of evidence and thus be in It is now argued that, in an estimation problem, bias is measured by various coverage probabilities for the plausible region.
Note too that, if there is evidence in favor of then and so represents the natural estimate of provided there was a clear reason, like the assessment of a scientific theory, for assessing the evidence for this value. This assumes too that there isn’t substantial bias in favor of . The strength of the evidence in favor of could then also be measured by the size of Similarly, if evidence against is obtained, then the implausible region, and there is strong evidence against provided has small volume and large posterior probability. A virtue of this approach to measuring the strength of the evidence is that it does not depend upon using the relative belief ratio in hypothesis assessment problems.
The prior probability that the plausible region does not cover the true value measures bias against when estimating
If this probability is large, then the estimate and the plausible region are a priori likely to be misleading as to the true value. The prior probability that
doesn’t contain
when
is
which is also the average bias against over all hypothesis testing problems
Note
which is the prior coverage probability of
. In addition,
is an upper bound on (
8). Therefore, controlling (
9) controls the bias against in estimation and all hypothesis assessment problems involving
. In addition,
Thus, using (
9) implies lower bounds for the coverage probability and for the expected posterior content of the plausible region. In general, both (
8) and (
9) converge to 0 with increasing amounts of data. Thus, it is possible to control for bias against in estimation problems by the amount of data collected.
- 3.
Example 3 Location normal (continued).
The value of
is given in (
6) and examples are plotted in
Figure 1. When
, then
, so
which is notably independent of the prior mean
. The dominated convergence theorem implies
as
or as
Thus, provided
is large enough, there is hardly any estimation bias against.
Table 4 illustrates some values of this bias measure. Subtracting the probabilities in
Table 4 from 1 gives the prior probability that the plausible region covers the true value and the expected posterior content of the plausible region. Thus, when
the prior probability of
containing the true value is
so
is a
Bayesian confidence interval for
To use (
9), it is necessary to maximize
as a function of
and it is seen that, at least when the prior is not overly concentrated, this maximum occurs at
Figure 1 shows that, when using the
prior, the maximum occurs at
when
and, from the second column of
Table 2, the maximum equals
. The average bias against is given by
as recorded in
Table 4. Note that the maximum also occurs at
for the other values of
n recorded in
Table 2.
Bias in favor when estimating
occurs when the prior probability that
does not cover a false value is large, namely, when
is large as this would seem to imply that the plausible region will cover a randomly selected false value from the prior with high prior probability. Note that (
10) is the prior mean of (
4) and, in the continuous case, equals
. As previously discussed, however, it often doesn’t make sense to distinguish values of
that are close to
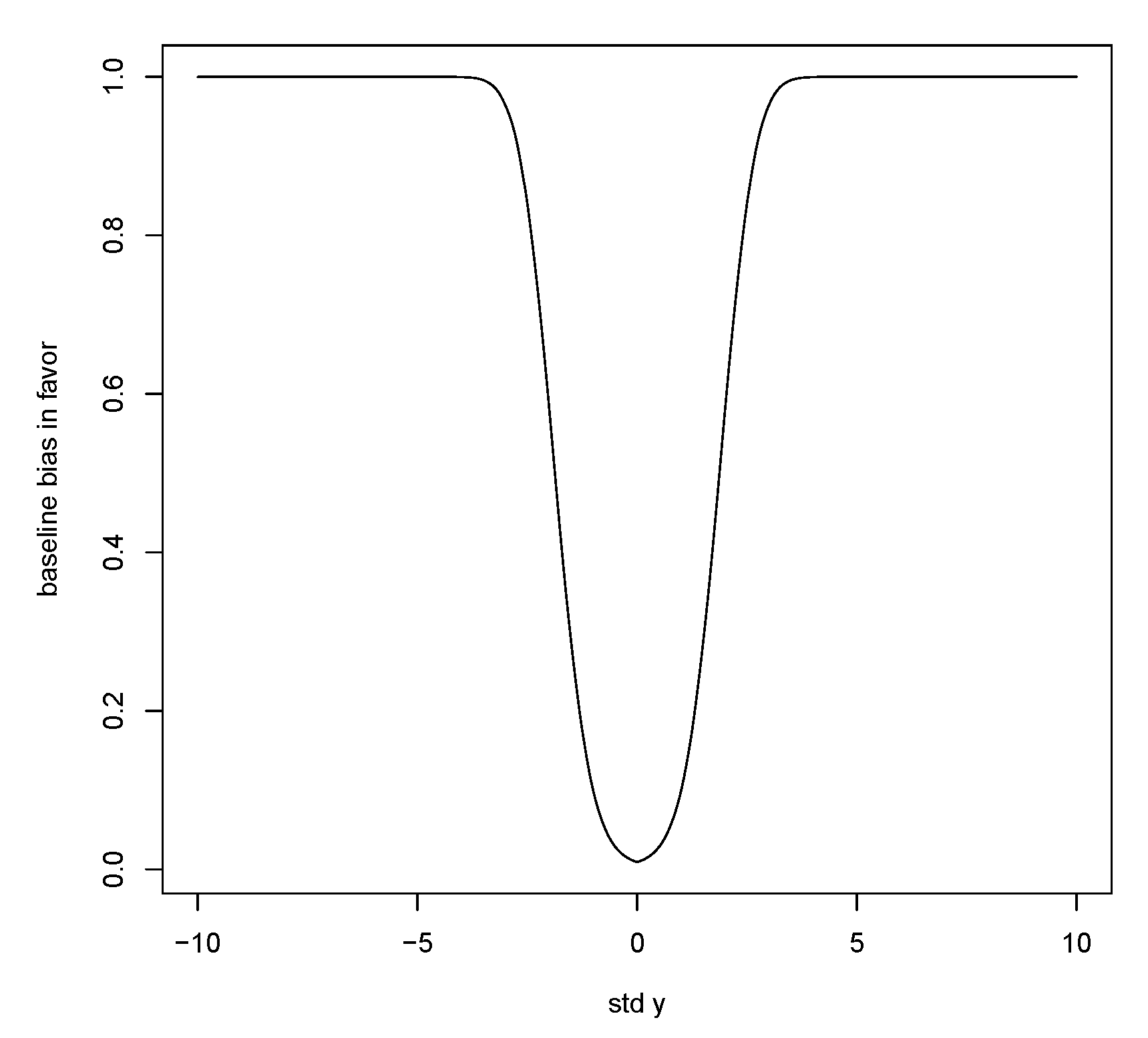
The bias in favor for estimation can then be measured by
An upper bound on (
11) is commonly equal to 1, as illustrated in
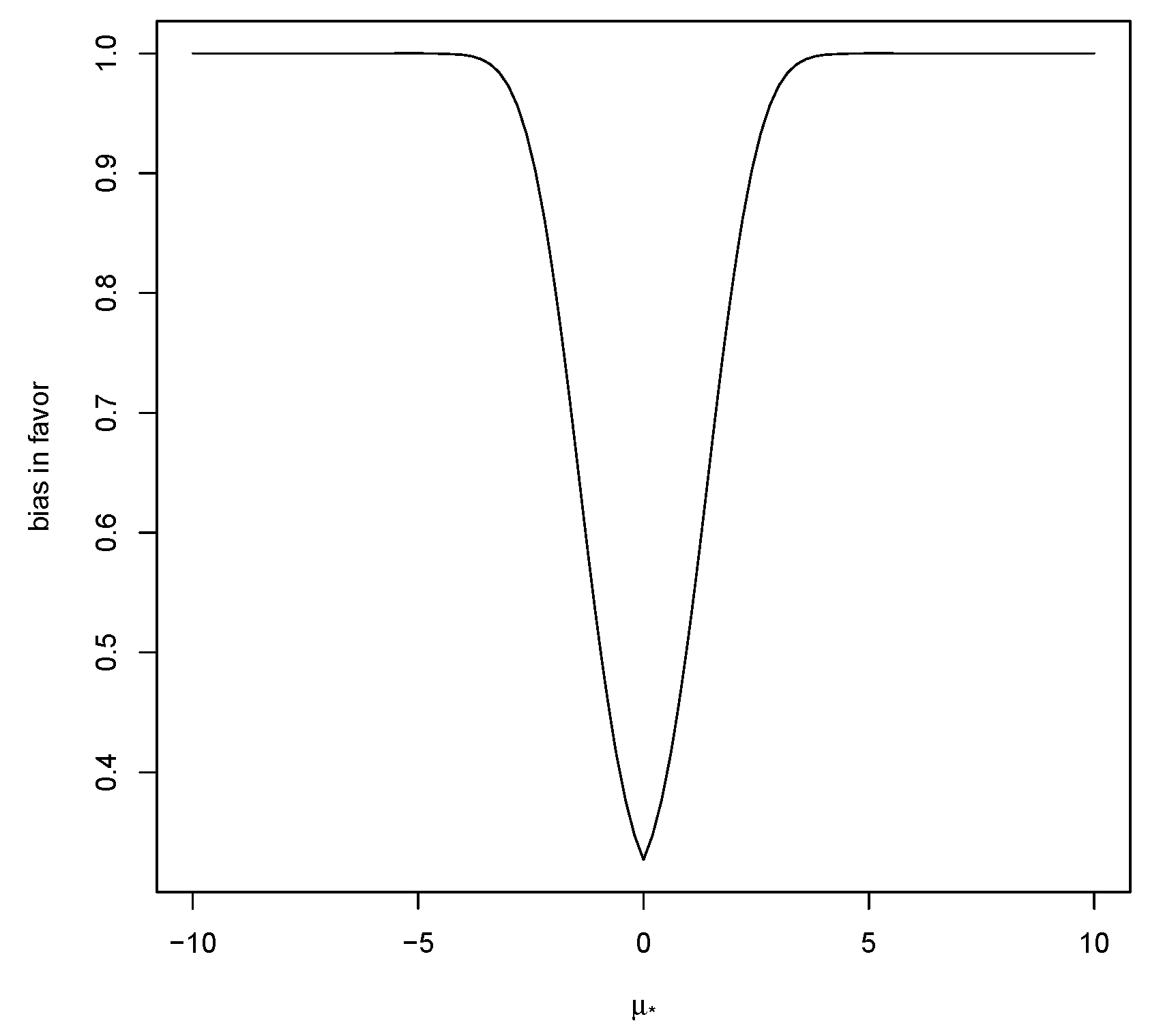
Figure 3, and thus is not useful.
It is the size and posterior content of
that provides a measure of the accuracy of the estimate
As previously discussed, the a priori expected posterior content of
can be controlled by bias against. The a priori expected volume of
satisfies
Notice that, when for every this can be interpreted as a kind of average of the prior probabilities of the plausible region covering a false value.
- 4.
Example 3 Location normal (continued).
Note that, as
, then
when
see
Figure 3, and converges to 0 if
so it would appear that the better circumstance for guarding against bias in favor is when the prior is putting in more information than the data. As previously noted, however, this is a situation where we might expect prior data-conflict to arise and, except in exceptional circumstances, should be avoided.
Table 5 contains values of (
11) for this situation with different values of
. Again, these values are just for illustrative purposes and are not to be used to compare or choose priors.
Some elementary calculations give
with
where
under
It is notable that the prior distribution of the width is independent of the prior mean.
Table 6 contains some expected half-widths together with the coverage probabilities of
While the plausible region
is advocated for assessing the accuracy of estimates, it is also possible to use a
relative belief credible region
where
There is one proviso with this, however, as the principle of evidence requires that
otherwise,
will contain values of
for which there is evidence against. Notice that, while controlling the bias against allows control of the coverage probability of
, this does not control the coverage probability of a credible region since
is not known until the data are observed. For this reason, reporting the plausible region always seems necessary. All these regions are invariant under smooth reparameterizations and in [
31] various optimality results are established for these credible regions.
4. Frequentist and Optimal Properties
Consider now the bias against namely, If we repeatedly generate then this probability is the long-run proportion of times that This frequentist interpretation depends on the conditional prior and, when there are no nuisance parameters, this is a “pure” frequentist probability. Even in the latter case, there is some dependence on the prior, however, as so x satisfies iff , where Thus, in general, the region depends on , but the probability depends only on the conditional prior predictive given namely, and not on the marginal prior on We refer to probabilities that depend only on as frequentist, for example, coverage probabilities are called confidences, and those that depend on the full prior as Bayesian confidences. The frequentist label is similar to use of the confidence terminology when dealing with random effects’ models as nuisance parameters have been integrated out.
Suppose now that some other general rule, not necessarily the principle of evidence, is used to determine whether there is evidence in favor of or against and this leads to the set as those data sets that do not give evidence in favor of The rules of potential interest will satisfy since this implies better performance a priori in terms of identifying when data has evidence in favor of via the set than the principle of evidence. For example, for some satisfies this, but note that a value satisfying violates the principle of evidence if it is claimed that there is evidence in favor of . Putting leads to the following result.
Theorem 1. Consider satisfying (i) The prior probability is maximized among such rules by (ii) If then maximizes the prior probability of not obtaining evidence in favor of when it is false and otherwise maximizes this probability among all rules satisfying
When rules may exist having greater prior probability of not getting evidence in favor of when it is false, but the price paid for this is the violation of the principle of evidence. In addition, when comparing rules based on their ability to distinguish falsity, it only seems fair that the rules perform the same under the truth. Thus, Theorem 1 is a general optimality result for the principle of evidence applied to hypothesis assessment when considering bias against.
Now, consider
, the set of
values for which there is evidence in their favor after observing
x according to some alternative evidence rule. Since
then
and so the Bayesian coverage of
C is at least as large as that of
and thus represents a viable alternative to using
The following establishes an optimality result for
.
Theorem 2. (i) The prior probability that the region C doesn’t cover a value generated from the prior, namely, is maximized among all regions satisfyingfor every by (ii) If for all then maximizes the prior probability of not covering a false value and otherwise maximizes this probability among all C satisfying for all Again, when , the existence of a region with better properties with respect to not covering false values than can’t be ruled out, but, when considering such a property, it seems only fair to compare regions with the same coverage probability, and, in that case, is optimal. Thus, Theorem 2 is also a general optimality result for the principle of evidence applied to estimation when considering bias against. In addition, if there is a value then serves as a lower bound on the coverage probabilities, and thus is a -confidence region for and this is a pure frequentist -confidence region when Since then Example 3 shows that it is reasonable to expect that such a exists.
The principle of evidence leads to the following satisfying properties which connect the concept of bias as discussed here with the frequentist concept.
Theorem 3. (i) Using the principle of evidence, the prior probability of getting evidence in favor of when it is true is greater than or equal to the prior probability of getting evidence in favor of given that is false. (ii) The prior probability of covering the true value is always greater than or equal to the prior probability of covering a false value.
The properties stated in Theorem 3 are similar to a property called unbiasedness for frequentist procedures. For example, a test is unbiased if the probability of rejecting a null is always larger when it is false than when it is true and a confidence region is unbiased if the probability of covering the true value is always greater than the probability of covering a false value. While the inferences discussed here are “unbiased” in this generalized sense, they could still be biased against or in favor in the sense of this paper, as it is the amount of data that controls this.
Now, consider bias in favor and suppose there is an alternative characterization of evidence that leads to the region
consisting of all data sets that do not lead to evidence against
Putting
we restrict attention to regions satisfying
Using (
4) to measure bias in favor leads to the following results.
Theorem 4. (i) The prior probability is minimized among all satisfying by (ii) If then the set minimizes the prior probability of not obtaining evidence against when it is false and otherwise minimizes this probability among all rules satisfying
Theorem 5. (i) The prior probability region C covers a value generated from the prior, namely, is minimized among all regions satisfying for every by (ii) If for all then minimizes the prior probability of covering a false value and otherwise minimizes this probability among all rules satisfying for all
Thus, Theorems 4 and 5 are optimality results for the principle of evidence when considering bias in favor.
Clearly, the bias against is playing a role similar to size in frequentist statistics and the bias in favor is playing a role similar to power. A study that found evidence against but had a high bias against, or a study that found evidence in favor of but had a high bias in favor, could not be considered to be of high quality. Similarly, a study concerned with estimating a quantity of interest could not be considered of high quality if there is high bias against or in favor. There are some circumstances, however, where some bias is perhaps not an issue. For example, in a situation where sparsity is to be expected, then, allowing for high bias in favor of certain hypotheses accompanied by low bias against, may be tolerable, although this does reduce the reliability of any hypotheses where evidence is found in favor.
The concept of a
severe test is introduced in [
32], and this has a similar motivation to measuring bias. This is described now with some small modifications that allow for a more general discussion than the special situations used in the reference. Suppose
is the test statistic for an test of size
so that
is rejected when
and accepted otherwise. A deviation
that is
substantively important is specified. When the test leads to the acceptance of
, the severity of the test is assessed by the
attained power for
values satisfying
where
is a distance measure on
To get a single number for the severity measure, it makes sense to use
as generally
will increase as
increases. The hypothesis
is accepted with
high severity when the attained power is high. The motivation for adding this measure of the test is that it claimed that it is incorrect to simply accept
when
unless the probability of obtaining a value of the test statistic as least as large as that observed is high when the hypothesis is meaningfully false. When
is rejected, then the severity of the test is measured by
for
values satisfying
and, to obtain a single number one could use
It is then required that this probability be small to claim a rejection with high severity.
The use of the
quantity seems identical to the difference that matters
and we agree that this is an essential aspect of a statistical analysis. In hypothesis assessment, this guards against “the large
n problem” where large sample sizes will detect deviations from
that are not practically meaningful. There are, however, numerous differences with the discussion of bias here. The severity approach is expressed within the context where either
or
is accepted and the relative belief approach is more general than this binary classification. The testing approach suffers from the lack of a clear choice of
to determine the cut-off, and this is not the case for the principle of evidence. The bias measures are frequentist performance characteristics, albeit somewhat dependent on the prior, but the measures of severity are conditional on the observed
x leaving one wondering about their frequentist performance characteristics, see [
33] for more discussion on this point. The assessment of
via relative belief is based on the observed data and datasets not observed are irrelevant, at least for the expression of the evidence. The relevance of unobserved data are for us better addressed a priori where such considerations lead to an assessment of the merits of the study, but these play no role in the actual inferences. The major difference is that a proper prior is required here as this leads to a characterization of evidence via the principle of evidence.
5. Examples
A number of examples are now considered.
Example 4. Binomial proportion.
Suppose
is a sample from the Bernoulli
with
unknown so
binomial
and interest is in
For the prior, let
beta
where the hyperparameters are elicited as in, for example [
34], so
beta
Then,
is unimodal with mode at
so
is an interval containing
Note that
is the binomial
probability measure and the bias against
is given by
while the bias in favor of
, using (
5), is given by
for
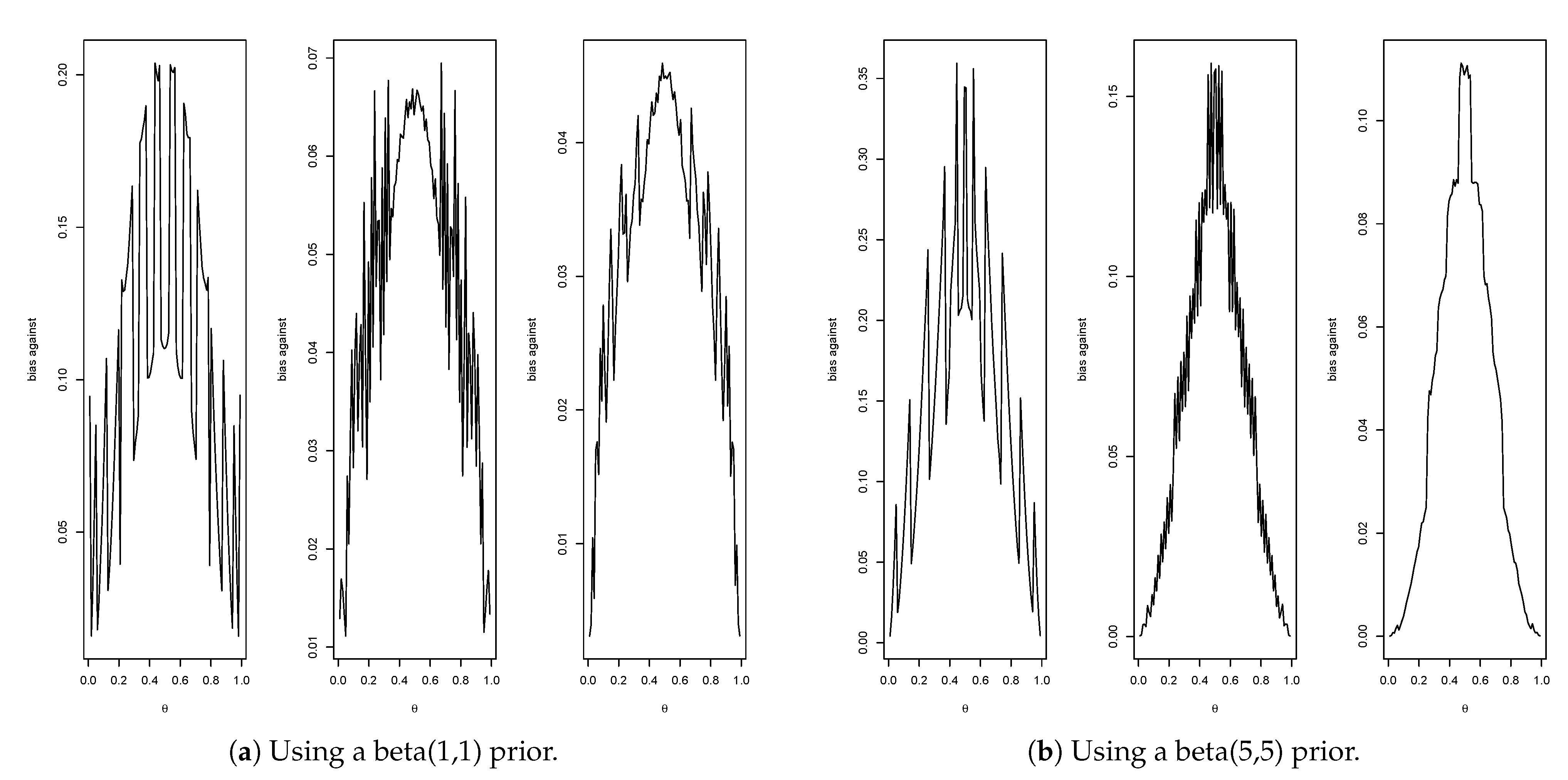
Consider first the prior given by
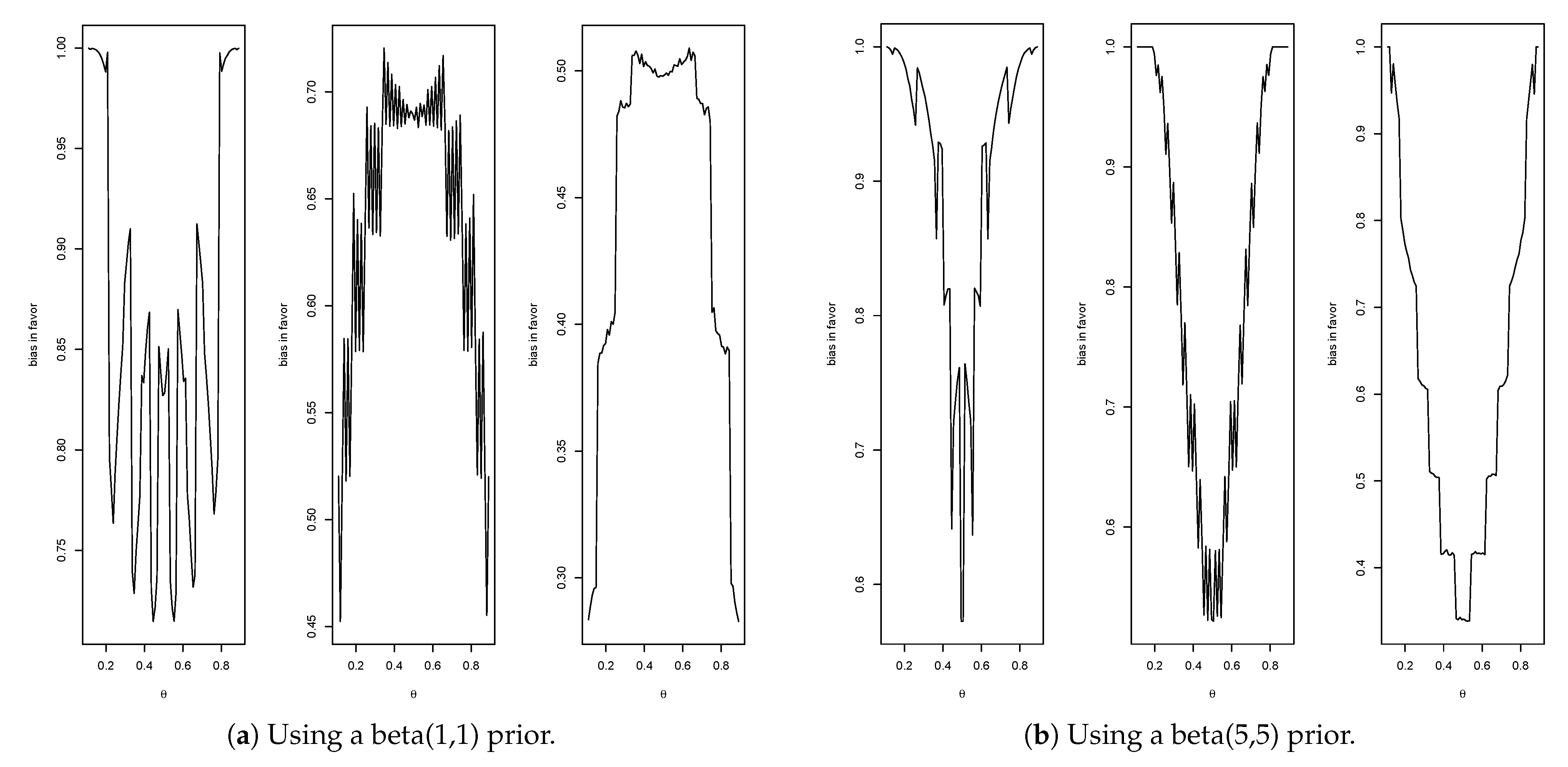
Figure 4a gives the plots of the bias against for
(max. =
, average =
),
(max.=
, average =
) and
(max. =
, average =
). Therefore, when
then
is a
-confidence interval for
when
, it is a
-confidence interval for
and, when
, it is a
-confidence interval for
For the informative prior given by
,
Figure 4b gives the plots of the bias against for
(max. =
, average =
),
(max. =
, average =
) and
(max. =
, average =
). Thus, when
, then
is a
-confidence interval for
when
, it is a
-confidence interval for
and, when
, it is a
-confidence interval for
One feature immediately stands out, namely, when using a more informative prior the bias against increases. As previously explained, this phenomenon occurs because when the prior probability of
is small, it is much easier to obtain evidence in favor than when the prior probability of
is large.
Now, consider bias in favor using (
11). When
and
Figure 5a gives the plots of the bias in favor for
(max. =
, average =
),
(max. =
, average =
) and
(max. =
, average =
). Therefore, when
, the maximum probability that
contains a false value at least
away from the true value is
when
this probability is
and, when
, it is a
When
Figure 5b gives the plots of the bias in favor for
(max. =
, average =
), for
(max. =
, average =
) and for
(max. =
, average =
). Thus, in this case, the maximum probability that
contains a false value at least
away from the true value is always
but, when averaged with respect to the prior, the values are considerably less. It is necessary to either increase
n or
to decrease bias in favor. For example, with
and
, the maximum bias in favor is
and the average bias in favor is
and, when
, these quantities equal 0 to two decimals. When
and
, the maximum bias in favor is
and the average bias in favor is
and, when
, the maximum bias in favor is
and the average bias in favor is
Another interesting case is when the prior is taken to be Jeffreys prior which in this case is the beta
distribution. This reference prior, see [
35], is proper and thus can be used with the principle of evidence. The prior does represent somewhat extreme beliefs, however, as
of the beliefs are that
. The corresponding biases against are for
(max. =
, average =
),
(max. =
, average =
) and
(max. =
, average =
). The biases in favor are, using (
11) with
for
(max. =
, average =
),
(max. =
, average =
) and
(max. =
, average =
). Although the plots of the bias functions can be seen to be quite different than those for the beta(1,1) prior, the summary values presented are very similar. The beta(1/2,1/2) prior does a bit better with respect to bias against but a bit worse with respect to bias in favor. This reinforces the point that the biases do not serve as a basis for the choice of the prior.
The strange oscillatory nature of the plots for the binomial is difficult to understand but is a common feature with such calculations. For example, Ref. [
36] studies the coverage probabilities for various confidence intervals for the binomial, and the following comment is made “The oscillation in the coverage probability is caused by the discreteness of the binomial distribution, more precisely, the lattice structure of the binomial distribution”, which still doesn’t fully explain the phenomenon.
Example 5. Location-scale normal quantiles.
Suppose
is a sample from
with
unknown with prior
gamma
. The hyperparameters
can be obtained via an elicitation as, for example, discussed in Evans and Tomal (2018) for the more general regression model. This example is easily generalized to the regression context. A MSS is
where
, with the posterior distribution given by
gamma
where
and
Suppose interest is in the -th quantile where To determine the bias for or against , we need the prior and posterior densities of for which there is not a closed form. It is easy, however, to work with the discretized by simply generating from the prior and posterior of estimate the contents of the relevant intervals and then approximate the relative belief ratio using these. Thus, we are essentially approximating the densities by density histograms here, although alternative density estimates could be used. A natural approach to the discretization is to base it on the prior mean and variance where Thus, for a given we discretize using intervals where and c is chosen so that the collection of intervals covers the effective support of which is easily assessed as part of the simulation. For example, with the prior given by hyperparameters and then and, on generating values from the prior, these intervals contained of the values and with then , and these intervals contained of the generated values. Similar results are obtained for more extreme quantiles because the intervals shift.
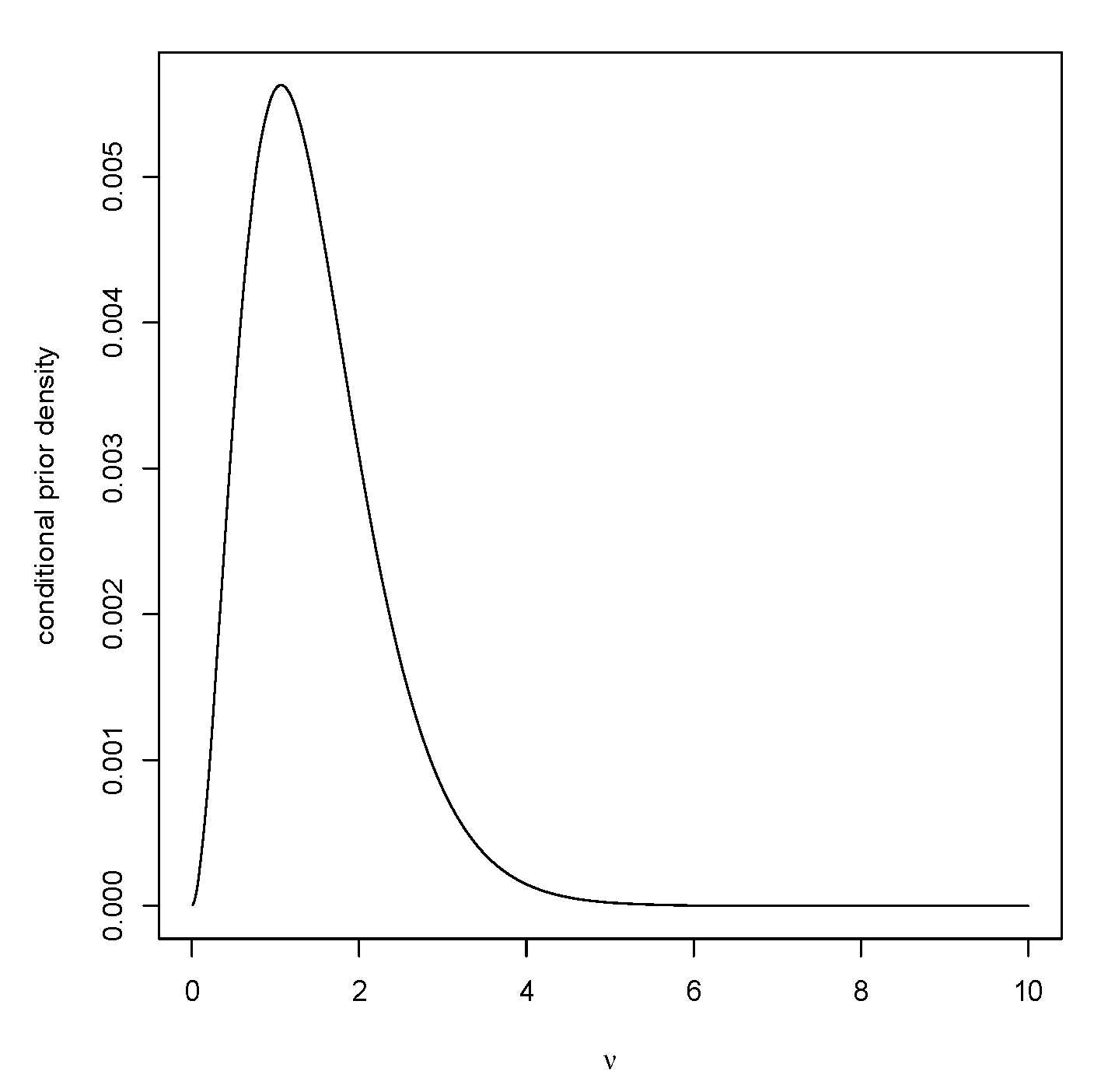
For the bias against for estimation, the value of is needed for a range of values. For this, we need to generate from the conditional prior distribution of T given , and an algorithm for generating from the conditional prior of given is needed. Putting the transformation has Jacobian equal to 1, so the conditional prior distribution of has density proportional to The following gives a rejection algorithm for generating from this distribution:
generate gamma
generate unif independent of
if return else go to 1.
As
moves away from the prior expected value
, this algorithm becomes less efficient, but, even when the expected number of iterations is 86 (when
generating a sample of
is almost instantaneous.
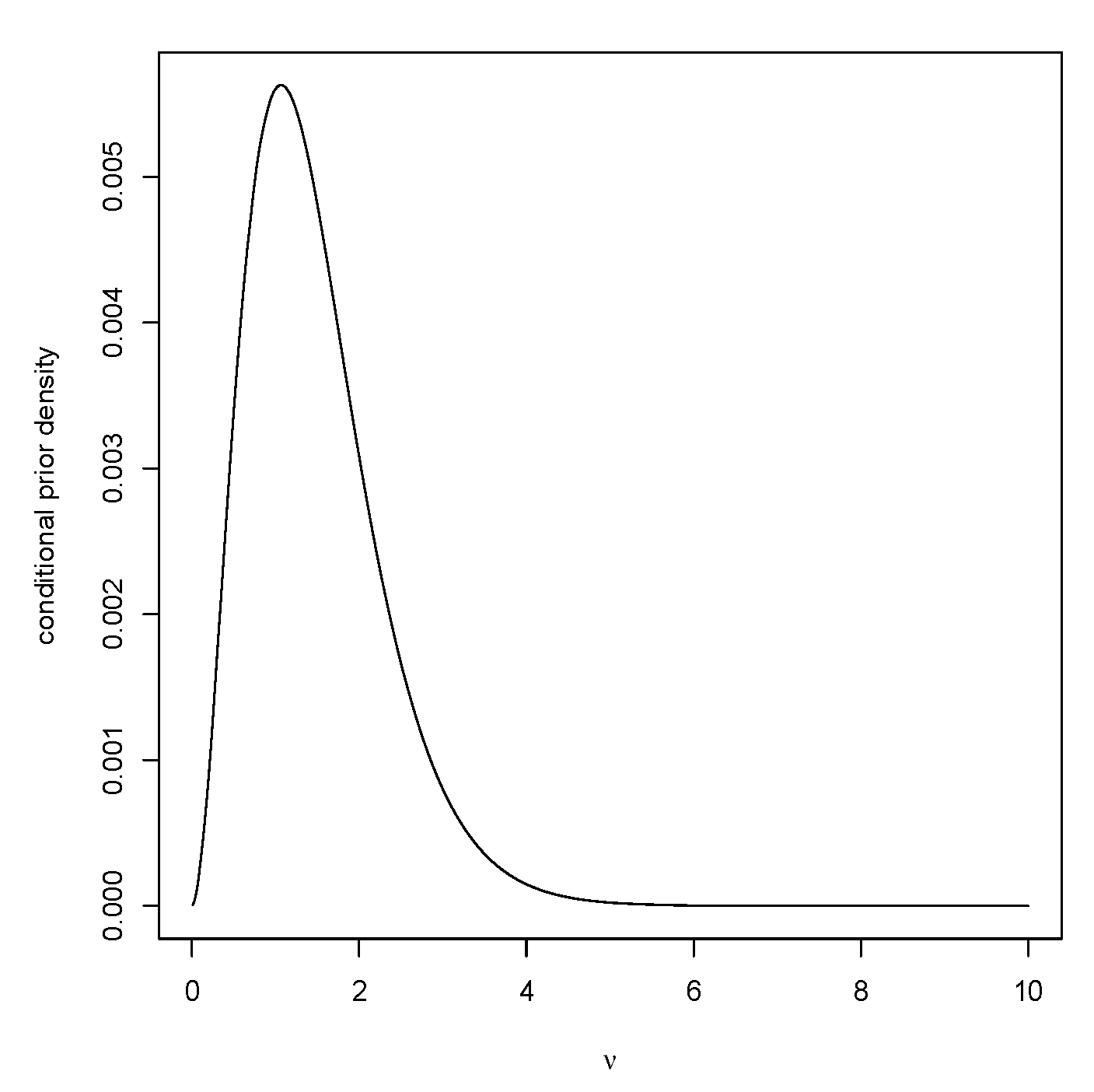
Figure 6 is a plot of the conditional prior of
given that
After generating
, then generate
chi-squared
and
to complete the generation of a value from
The bias against as a function of
has maximum value
when
and so
is a
-confidence region for
while the average bias against is
implying that the Bayesian coverage is
Table 7 gives the coverages for other values of
n as well.
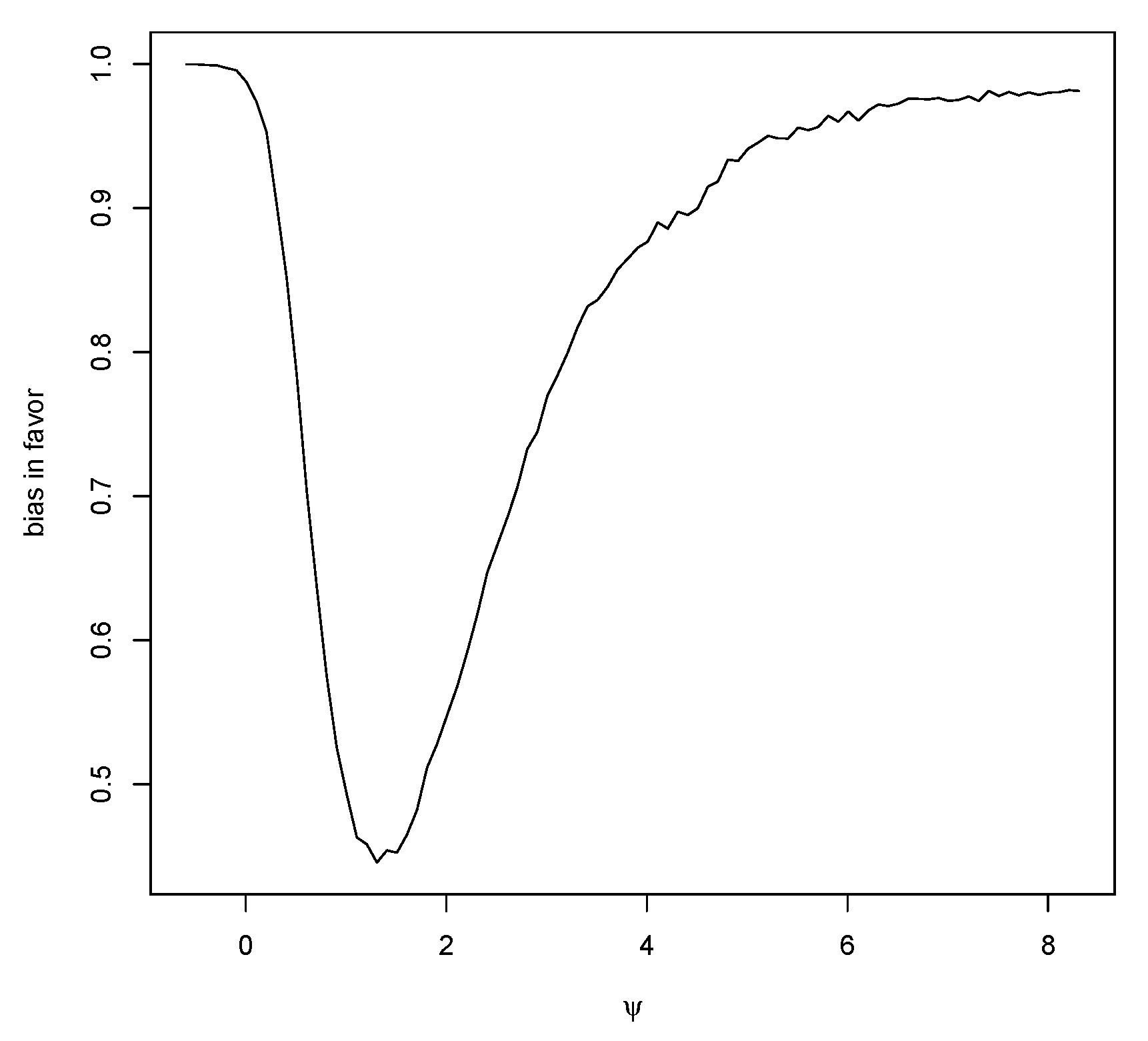
Figure 7 is a plot of the bias in favor as a function of
with
and
The jitter in the right tail is a result of Monte Carlo sampling error, but this error is not of significance as bias measurements are not required to be known to high accuracy. The average bias in favor is
When
, the average bias in favor is
The case so is also of interest. For , then has frequentist coverage and Bayesian coverage; when , the coverages are and while, when , the coverages are and When , the average bias in favor is when , this is and, for , the average bias in favor is
Example 6. Normal Regression—Prediction.
Prediction problems have some unique aspects when compared to inferences about parameters. To see this, consider first the location normal model of Example 3, and the problem is to make an inference about a future value
The prior predictive distribution is
and the posterior predictive is
where
so
For a given
y, the bias against is
and, for this, we need the conditional prior predictive of
The joint prior predictive is
, where
and so
From this, we see that, as
, the conditional prior distribution of
converges to the
distribution. Thus, with
,
, and
then
as
Thus, the bias against does not go to 0 as
, and there is a limiting lower bound to the prior probability that evidence in favor of a specific
y will not be obtained. This baseline is dependent on both
and
r. As
, this baseline bias against goes to 0 and so it is necessary to ensure that the prior variance is not too small.
Table 8 gives some values for the bias against, and it is seen that, if
is too small, then there is substantial bias against even when
y is a reasonable value from the distribution. When
and
, the bias against is computed to be
, which is quite close to the baseline, so increasing sample size will not reduce bias against by much and similar results are obtained for the other cases.
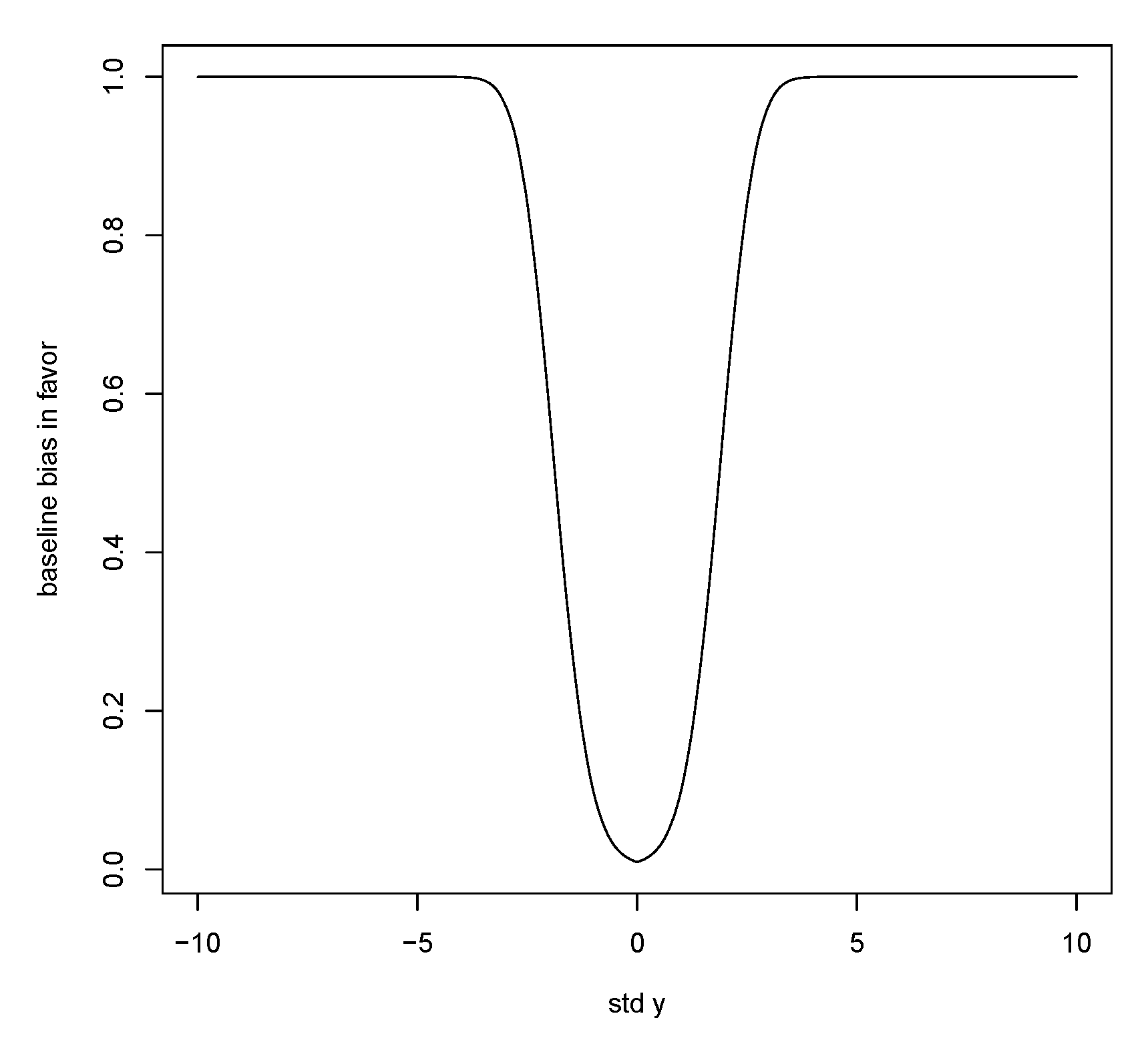
Now consider bias in favor of
y, namely,
for some choice of
False values for
y correspond to values in the tails so we consider, for example,
as a value in the central region of the prior and then a large value of
puts
y in the tails. Again, the bias in favor has a baseline value as
A similar argument leads to the bias in favor of
y satisfying
Figure 8 is a plot of
Thus, the bias in favor is low for central values of
y, but, once again, there is a trade-off as when
r increases the bias in favor goes to 1.
Prediction plays a bigger role in regression problems, but we can expect the same issues to apply as in the location problem. Suppose
, where
is of rank
is unknown, our interest is in predicting a future value
for some fixed known
w and, putting
the conjugate prior
gamma
is used. Specifying the hyperparameters
can be carried out using elicitation as discussed in [
37].
For the bias calculations, it is necessary to generate values of the MSS
from the conditional prior predictive
This is accomplished by generating from the conditional prior of
and then generating
independent of
chi-squared
The conditional prior of
is proportional to
where
Thus, generating
is accomplished via
gamma
,
For each generated , it is necessary to compute the relative belief ratio and determine if it is less than or equal to There are closed forms for the prior and conditional densities of since where denotes a Student random variable and These results permit the calculation of the biases as in the location problem.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}