1. Introduction
The Bayesian Cramér–Rao bound or Van Trees bound [
1] has been extended in a number of directions (e.g., [
1,
2,
3]). For example, multivariate cases for such bounds are discussed by [
4]. These bounds are used in many practical fields such as signal processing and nonlinear filtering. However, these bounds are not always sharp. To improve them, Bhattacharrya type extensions for them were provided by [
5,
6]. These Bayesian bounds are split into two categories, the Weiss–Weinstein family [
7,
8,
9] and the Ziv–Zakai family [
10,
11,
12]. The work in [
13] serves as an excellent reference of this topic.
Recently, the authors in [
14] showed that the Borovkov–Sakhanenko bound is asymptotically better than the Van Trees bound, and asymptotically optimal in a certain class of bounds. The authors in [
15] compared some Bayesian bounds from the point of view of asymptotic efficiency. Furthermore, necessary and sufficient conditions for the attainment of Borovkov–Sakhanenko and the Van Trees bounds were given by [
16] for an exponential family with conjugate and Jeffreys priors.
On the other hand, the Bobrovsky–Mayor–Wolf–Zakai bound ([
17]) is known as a difference-type (Chapman–Robbins type) variation of the Van Trees bound. In this paper, we consider the improvement of the Bobrovsky–Mayor–Wolf–Zakai bound by applying the Chapman–Robbins type extension of the Borovkov–Sakhanenko bound. This bound is categorized into Weiss–Weinstein family.
As discussed later, the obtained bound is asymptotically superior to the Bobrovsky–Mayor–Wolf–Zakai bound for a sufficiently small perturbation and large sample size. We also provide several examples for finite and large sample size settings which include conjugate normal and Bernoulli logit models.
2. Improvement of Bobrovsky–Mayor–Wolf–Zakai Bound
Let be a sequence of independent, identically distributed (iid) random variables with density function with respect to a -finite measure . Suppose that is twice partial differentiable with respect to , and support of is independent of . The joint probability density function of is , where . Let be a prior density of with respect to the Lebesgue measure. Consider the Bayesian estimation problem for a function of under quadratic loss . The joint pdf of is given by . Hereafter, expectations under probability densities and are denoted by and , respectively. We often use prime notation for partial derivatives with respect to for brevity, for example, is expressed as .
In this paper, we assume the following regularity conditions (A1)–(A3).
- (A1)
is twice differentiable.
- (A2)
Fisher information number
for arbitrary
and is continuously differentiable in
.
- (A3)
Prior density of is positive and differentiable for arbitrary and
.
Let . Considering variance–covariance inequality for , we have the following theorem for the Bayes risk.
Theorem 1. Assume (A1)–(A3). For an estimator of and a real number h, inequality for the Bayes risk holds.
Bound (
1) is directly derived as a special case of the Weiss–Weinstein class [
7]. However, we prove it in the
Appendix B for the sake of clarity.
Note that
The Borovkov–Sakhanenko bound is obtained from the variance–covariance inequality for
([
2]). Since Bound (
1) converges to Bound (
3) as
under Condition (B1) in
Appendix A, Bound (
1) for a sufficiently small
h is very close to Bound (
3).
In a similar way, the Bobrovsky–Mayor–Wolf–Zakai bound is obtained from variance–covariance inequality
where
([
17]). By applying
to the variance–covariance inequality, we have the Van Trees bound, that is,
Since
, the value of Bobrovsky–Mayor–Wolf–Zakai Bound (
4) converges to Van Trees Bound (
5) as
under (B2) in
Appendix A. Hence, the value of Bound (
4) for a sufficiently small
h is very close to the one of Bound (
5) in this case.
On the other hand, we often consider the
normalized risk
(see [
3,
14]). For the evaluation of the normalized risk (
6), Bayesian Cramér–Rao bounds can be used. For example, from Bound (
3),
Moreover, the authors in [
14,
15] showed that the Borovkov–Sakhanenko bound is asymptotically optimal in some class, and asymptotically superior to the Van Trees bound, that is,
Denote Borovkov–Sakhanenko Bound (
3), Van Trees Bound (
5), Bobrovsky–Mayor–Wolf–Zakai Bound (
4), and Bound (
1) as
,
,
and
, when sample size is
n and perturbation is
h, respectively. Then, (
8) means
Hence, from (
9),
holds for a sufficiently large
n. Moreover, for this large
,
under (B1) and (B2). Hence, if Inequality (
8) is strict, then
for this large
and a sufficiently small
h by (
10) and (
11). The equality in (
8) holds if and only if
is proportional to
. Therefore, Bound (
1) is asymptotically superior to the Bobrovsky–Mayor–Wolf–Zakai bound (
4) for a sufficiently small
h.
However, the comparison between Bounds (
1) and (
4) is not easy for a finite
n. Hence, we now show comparisons of various existing bounds in two simple examples for fixed
and
.
Example 1. Let be a sequence of iid random variables according to . We show that Bound (
1)
is asymptotically tighter than Bobrovsky–Mayor–Wolf–Zakai Bound (4) for a sufficiently large n. Suppose that the prior of θ is , where m and are known constants. Denote and . In this model, Fisher information per observation equals 1. We consider the estimation problem for since Bound (
1)
coincides with Bound (
4)
for (see also [5,6]). First, we calculated Bobrovsky–Mayor–Wolf–Zakai Bound (
4).
The ratio of and iswhere . Since the conditional distribution of T given θ is and the moment generating function isthe conditional expectation iswhere denotes the conditional expectation with respect to the conditional distribution of T given θ. Then, from (
12)
and (
14),
we have thatWe can easily obtain . Hence, Bobrovsky–Mayer–Wolf–Zakai Bound (
4)
is equal tofrom (
15).
Next, we calculated Bound (
1).
Since , and ,Sincewe havefrom (
18)
and (
14).
Here, since moment-generating function of θ is ,So, from (
20),
we obtainHence, from (
19)
and (
21),
Moreover, we haveandFrom (
22)–(
24),
Therefore, Bound (
1)
is equal toLastly, we compare (
1)
and (
4).
From Bounds (
1)
and (
4),
we havefor arbitrary . In general, while the Bayes risk is , bounds and are or decrease exponentially for as . Thus, we take the limit as in order to obtain an asymptotically tighter bound. Define and . Since from (
16)
and (
26),
we may compare their reciprocals, and , in order to compare and . and are the Van Trees and Borovkov–Sakhanenko bounds, respectively. The Borovkov–Sakhanenko bound is asymptotically tighter than the Van Trees bound. In this case, the Borovkov–Sakhanenko bound is also tighter than the Van Trees bound for fixed n. In fact, since the difference is from (
28),
so and hence for all . Next, we compare these bound to the Bayes risk of the Bayes estimator of . The Bayes estimator is given byThen, the Bayes risk of (
30)
isThen, the normalized risk satisfiesThus, the Van Trees bound is not asymptotically tight, while the Borovkov–Sakhanenko bound is asymptotically tight. Example 2. We considered the Bernoulli logit model of Example 2 in [16] when the sample size was 1. Bound (
1)
was not always better than Bobrovsky–Mayor–Wolf–Zakai Bound (
4).
Let X have Bernoulli distribution (). Then, the probability density function of X given θ is It is assumed that the prior density of θ is the conjugate, a version of Type IV generalized logistic distribution (e.g., [18]); then, We set the hyperparameters to these values for some moment conditions. In this case, Fisher information for Model (33) is given by and we considered the estimation problem of . In this example, we calculated Bound (
1)
in the first place. Combining (
33)–(
35),
we have for . Since X given θ is distributed as , it holds where means the expectation with respect to the conditional distribution of X given θ. Then, we haveby (
35)
and (
37),
where is the hyperbolic cosine. Moreover, we have where is the cumulative distribution function of . In a similar way, we have andHence, we can show from (
38)–(
41)
that the right-hand side of (
1)
equals where is the hyperbolic sine. The Borovkov–Sakhanenko bound (3) is calculated as In the second place, we calculate Bound (
4).
In a similar way to (
38)
and (
39),
we have and . Hence, by substituting (
44)
into (
4),
we have The Van Trees bound is calculated as In last place, we compute the Bayes risk of the Bayes estimator of θ, as follows. Since the posterior density of θ, given , is given bythe Bayes estimator is calculated as , . Then, by easy but tedious calculation, the Bayes risk of is Then, we can plot the values of , , , and the Bayes risk of from (
42)–(
46)
and (
48)
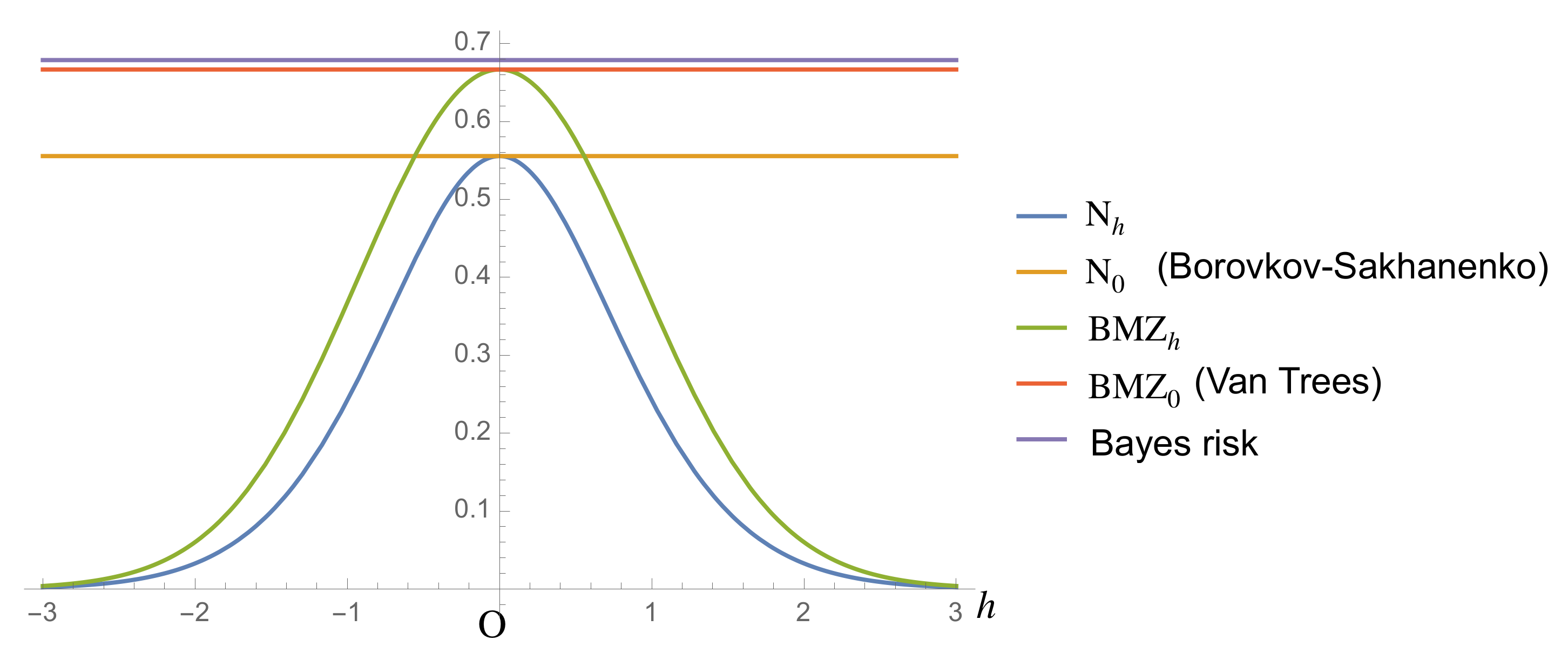
(Figure 1). Figure 1 shows that Bound (
1)
is lower than Bound (
4)
for any h under Prior (
34)
when the sample size equals 1. However, in Section 3, we show by using the Laplace method that Bound (
1)
is tighter than Bound (
4)
for a large sample size. 3. Asymptotic Comparison by Laplace Approximation
In this section, we consider Example 2 in the previous section, again in the case when sample size is
n. Bound (
1) is asymptotically better than Bound (
4) for a sufficiently large
n by using the Laplace method. These bounds are only approximations as
. The probability density function of
given
is
and the likelihood ratio of (
49) is
Assume that the prior density of
is
Then, the ratio of (
51) is equal to
By denoting
, and
, the ratio of joint probability density functions of
is
by the iid assumption of
, (
50), and (
52). From (
53), we have
By (
37), we have
Here, we consider the Laplace approximation of integral
(see e.g., [
19]).
can be expressed as
where
and
.
Since
if
, then
.
k takes its maximum at
,
and
(
). Therefore, the Laplace approximation of
gives
as
from (
57)–(
59). Here, we have
since
from the arithmetic-geometric mean inequality. The equality holds if and only if
. Hence, the leading term of Bobrovsky–Mayor–Wolf–Zakai Bound (
4) is
as
, from (
55) and (
60), where
In a similar way to the above, defining
we calculate
Here, we consider the Laplace approximation of the integral
where
and
is defined in (
57). The Laplace approximation of
gives
as
. Similarly to (
41), we have
Hence, by using (
64)–(
67), the leading term of Bound (
1) is
as
. Dividing (
61) by (
68) yields
The second inequality from the end follows from
by the arithmetic-geometric mean inequality. Hence, (
68) is asymptotically greater than (
61) for any
h in this setting.



{kind=link}
