
Interactive System for Similarity-Based Inspection and Assessment of the Well-Being of mHealth Users

 ,
,  ,
,  ,
,  ,
, 
Abstract
:1. Introduction
- RQ1-
- How to predict a user’s EMA in the near and far future, on the basis of similarities to other users?
- RQ2-
- How to identify and show outlierness in users’ EMAs?
- RQ3-
- How to show similarities and differences in the EMAs of users who are similar in their clinical data?
- We demonstrate the users neighborhood comparisons over data (i.e., both static, dynamic, and timestamped EMA) and utilize them for predicting user’s EMA recordings and show that users neighborhood are indeed useful in making the ahead predictions.
- We introduce a voting-based outlier detection methodology to identify users who behave differently in their interaction with the app and also introduce tailored interactive visualizations that can be inspected.
- We introduce a medical analytics tool with the introduction of tailored interactive visualizations to demonstrate the nearest neighboring user’s behaviors recorded through the app, and a visualization to show the ahead predictions for a study based on the identified nearest neighbors by constructing pathways.
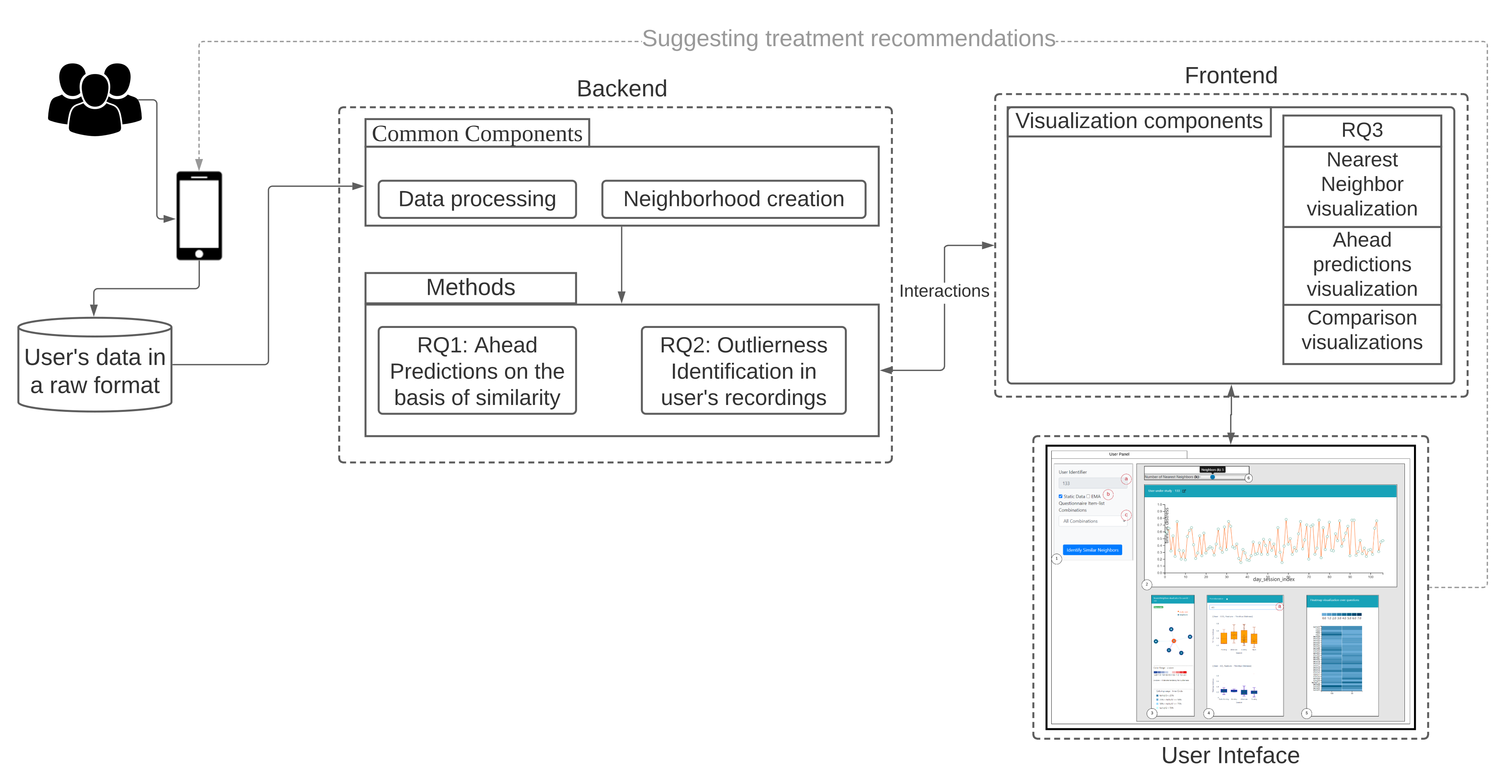
2. Materials
2.1. The TinnitusTipps Mobile Health App
2.2. Data of the CHRODIS+ Pilot Study on Tinnitus
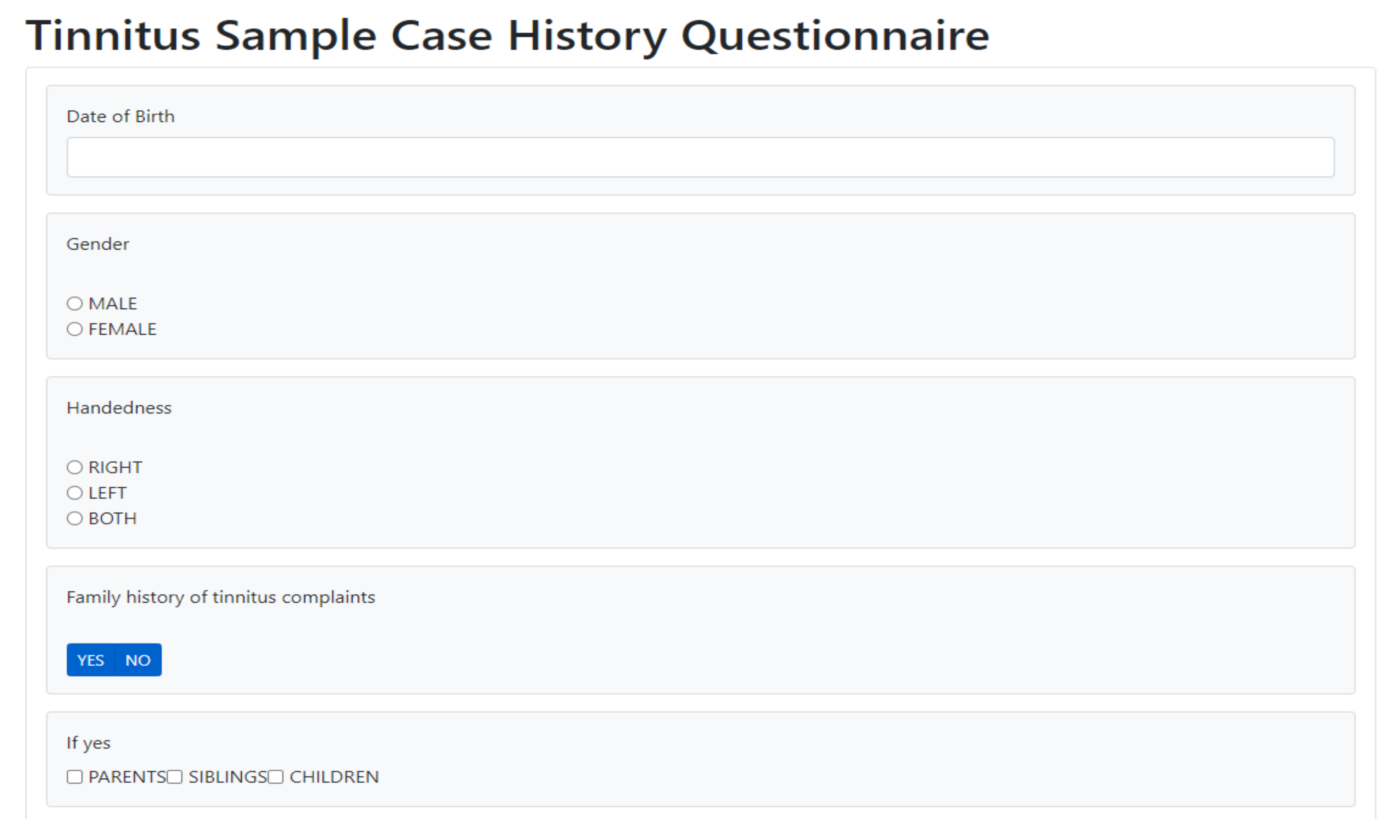
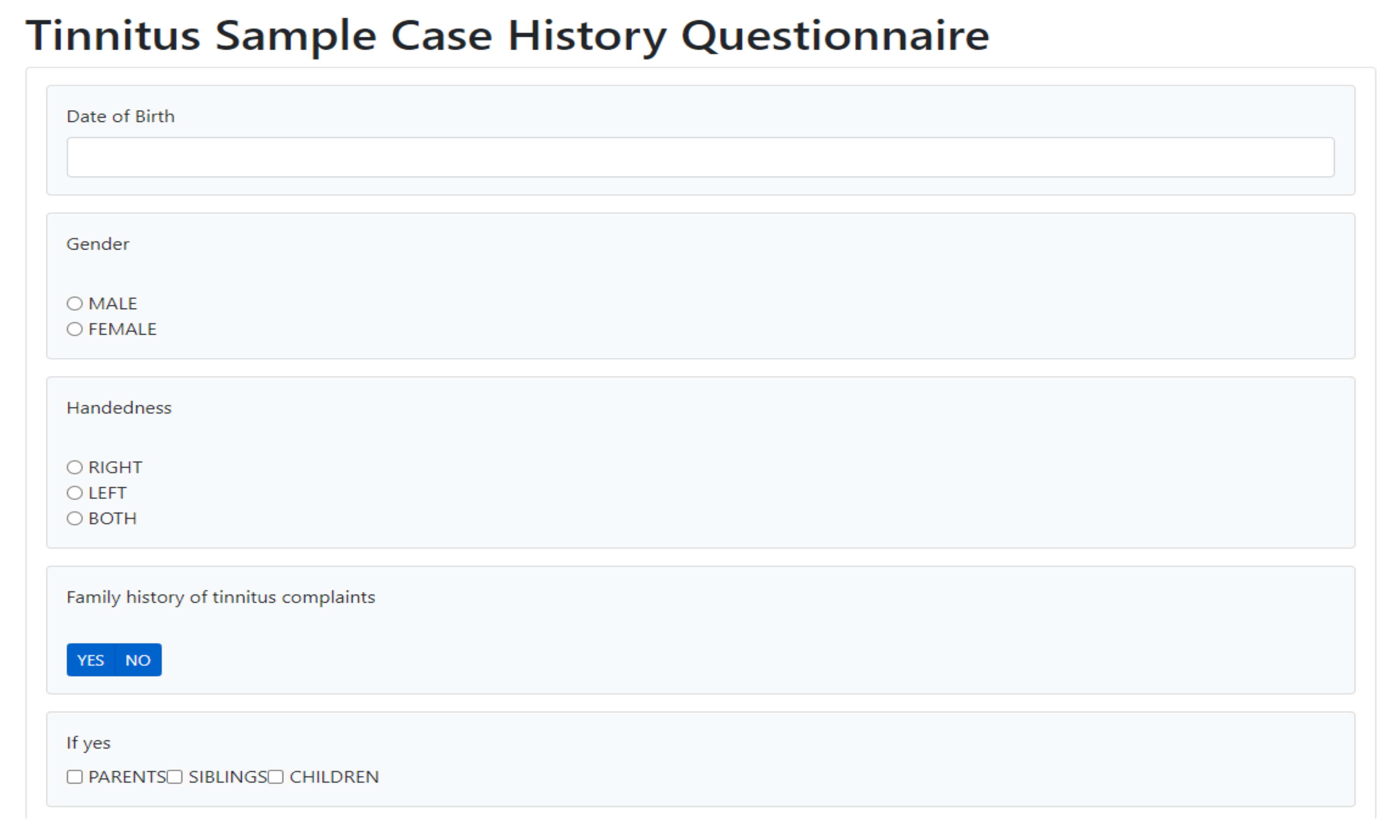
- Registration data with the Tinnitus Sample Case History Questionnaire (TSCHQ, 35 items) [22] and the Tinnitus Hearing Questionnaire (THQ, 6 questions) (cf. Appendix A Table A1) completed by all app users.
- EMA data: with an EMA questionnaire (8 items) that captures within-day fluctuations of tinnitus loudness, distress, of hearing ability, stress and further aspects of mood and health condition (cf. Appendix A Table A2). As it can be seen in Appendix A Table A2, this questionnaire consists of 6 short questions to be answered with a numerical value between 0 and 100%, where larger values indicate worse condition.Users are notified by the smartphone multiple times within a day, and randomly, to record the current EMA.
3. Methods
3.1. Data Conversion
3.2. Time Series Alignment
3.3. Creation of Neighborhood
3.3.1. Neighborhoods on Static Data
3.3.2. Neighborhoods on the Dynamic Data of the EMA Time Series—One per EMA Item
- ‘Day matching’ between x and z: number of days from day 0 onward and until the last day of the shortest between the two time series. For example, if x has EMA observations for 30 days and z for 60 days, then the matching is on the first 30 days, with day of x matched to the corresponding day of z.
- For each of the matched days for x and z, a euclidean distance is computed. A counter is maintained to capture the number of days when both the users have reported their observations, denoted by, and the distance obtained for each day is summed up and is denoted as .
- Finally, a fraction of the is returned as the similarity between the user x and z.
3.4. Creation of Feature Combinations
- C1:
- user background and tinnitus complaints information (items tschq02-04); tinnitus historical information (items tschq05-18), including the initial onset of tinnitus, loudness, tinnitus awareness, and different past treatments
- C2:
- experienced effects of tinnitus (tschq19-25), and questions on hearing quality/loss (hq01, hq03)
- C3:
- further conditions, such as neck pain, dizziness etc. (tschq28-35), as well as the items on hearing quality/hearing loss (hq02, hq04)
- C4:
- all the TSCHQ and HQ items
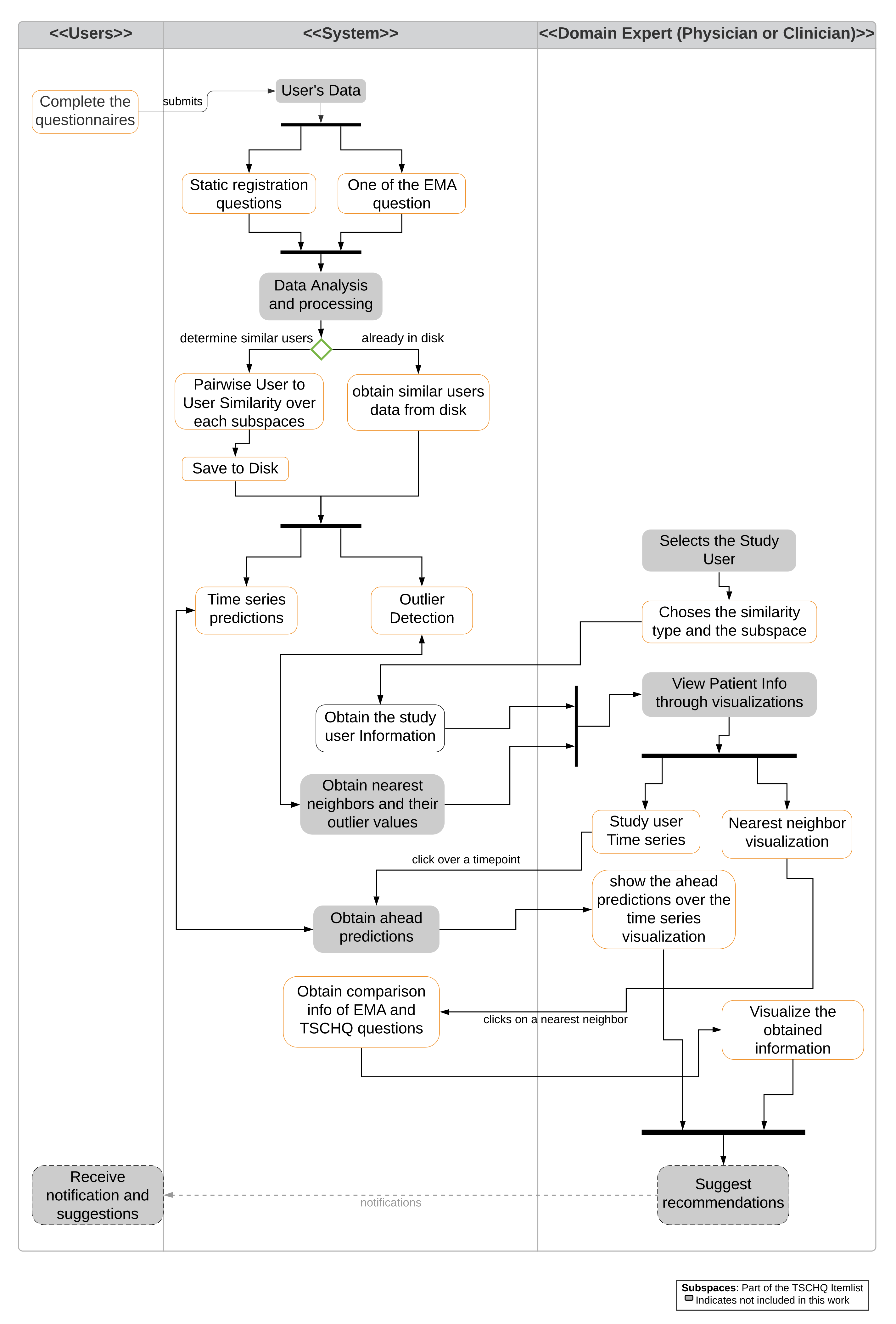
4. RQ1: How to Predict a User’s EMA in the Near and Far Future, on the Basis of Similarity to Other Users?
4.1. Ahead Prediction of the Target Variable
- Weighted average in a user’s neighborhood: At timepoint , the predicted value of an EMA recording is then the average of the values of this EMA recording over the users in . This computation can be done for timepoints at once.
- Linear regression in a user’s neighborhood: for a test user , a linear regressor is built on the time series observations of each of the nearest neighbor users until the timepoint and averaging the slope () and the intercept: () parameters of each of the nearest neighbor user to create a combined model as introduced in [25].
4.2. Evaluation for RQ1
- For a test user , the nearest neighbors are obtained (either for static or dynamic). Once after obtaining the nearest neighbors of , their respective time series are aligned, and wherever multiple observations are present for a given day, they are aggregated using either the minimum(), mean(), or maximum() functions.
- Next, based upon ahead prediction timepoint (in a day), future EMA recordings (l), and the nearest neighbors time series information; ahead predictions are obtained based on the proposed methodologies as per Section 4.1.
- For a test user, the error for a feature is measured using Root Mean Squared Error (RMSE) against the true value of that feature as follows:where denotes the predicted values obtained for a feature , and l denotes the number of ahead days to predict.
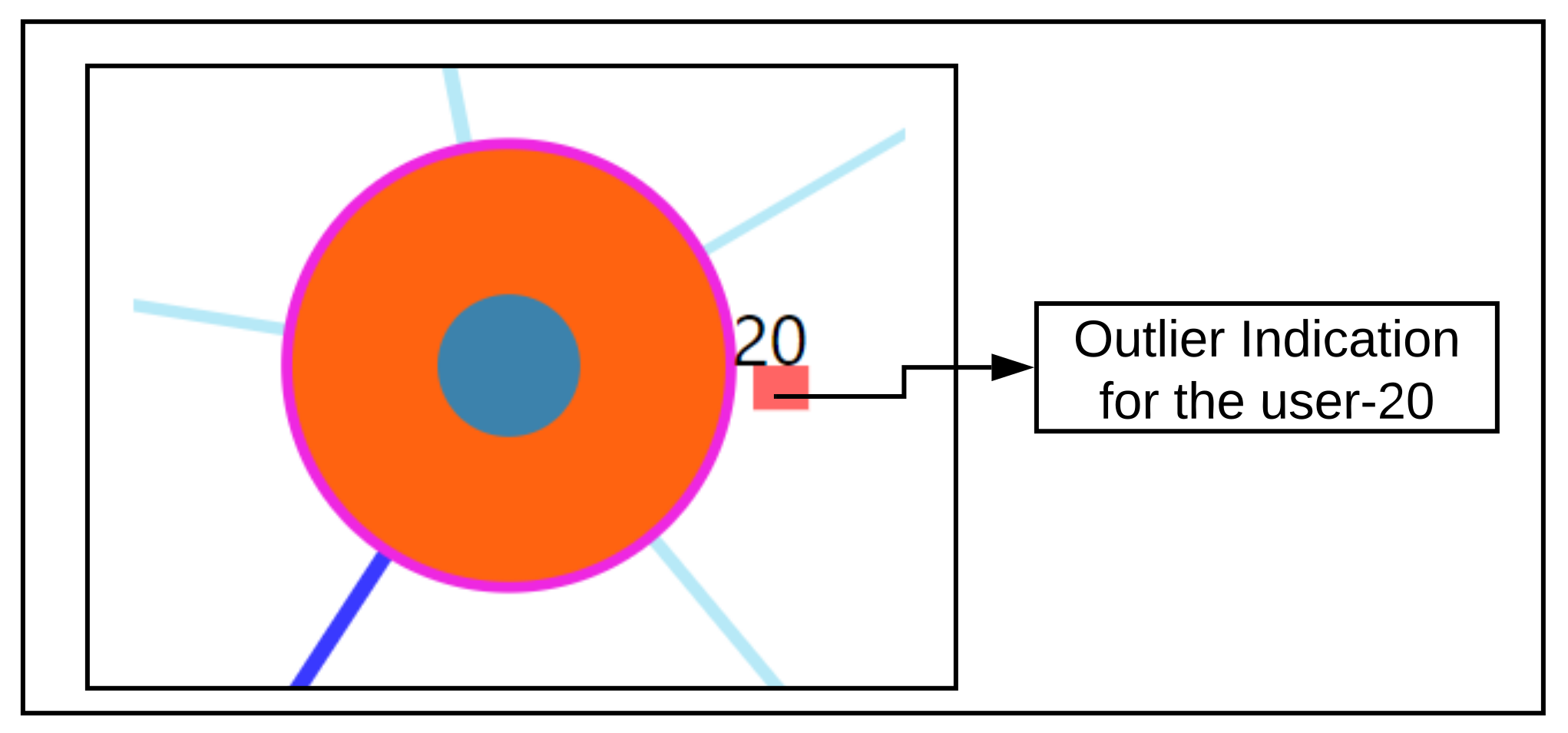
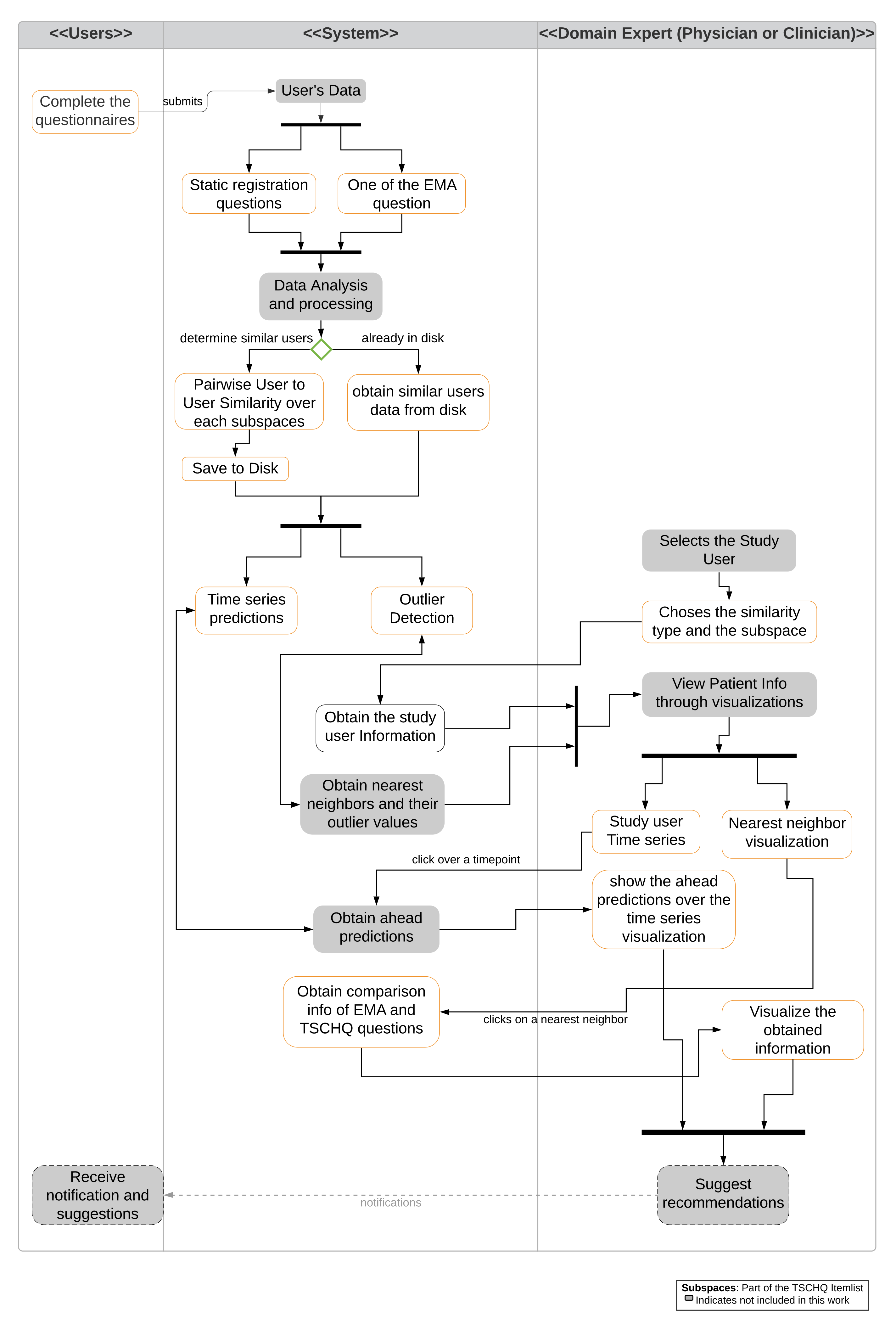
5. RQ2: How to Identify and Show Outlierness in User’s EMA
Methodology
6. RQ3: How to Show Similarities and Differences in the EMA of Users Who Are Similar in Their Clinical Data?
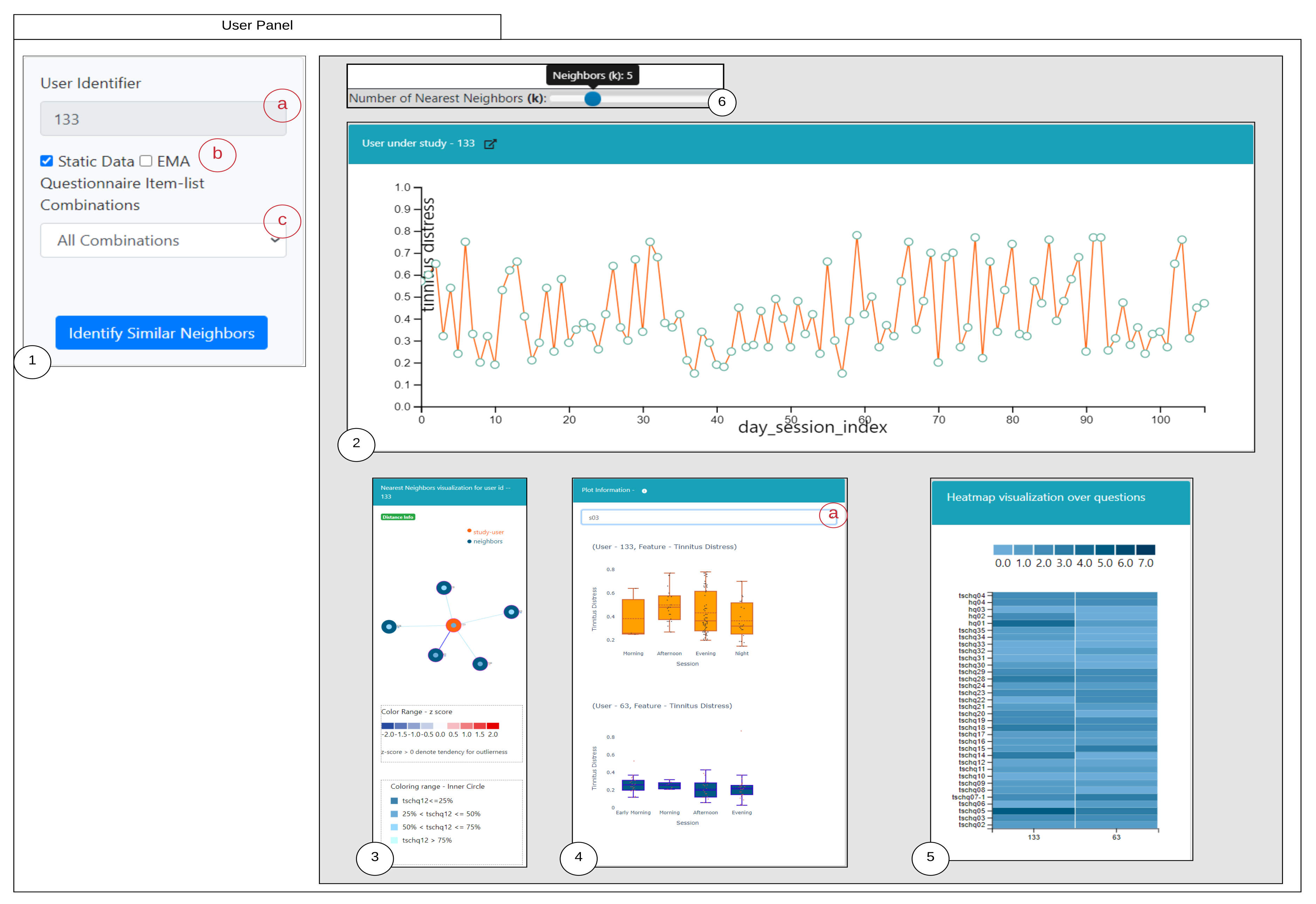
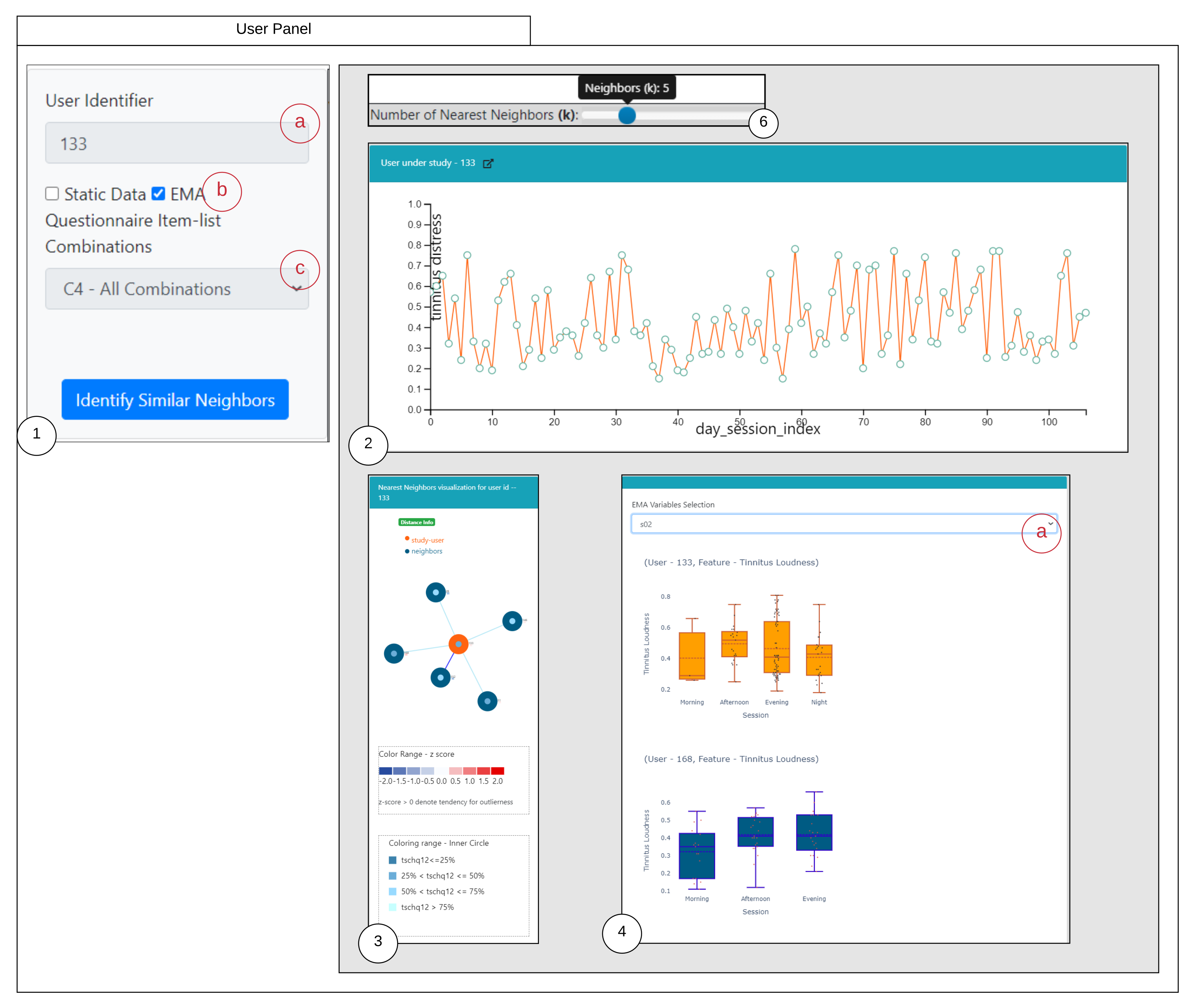
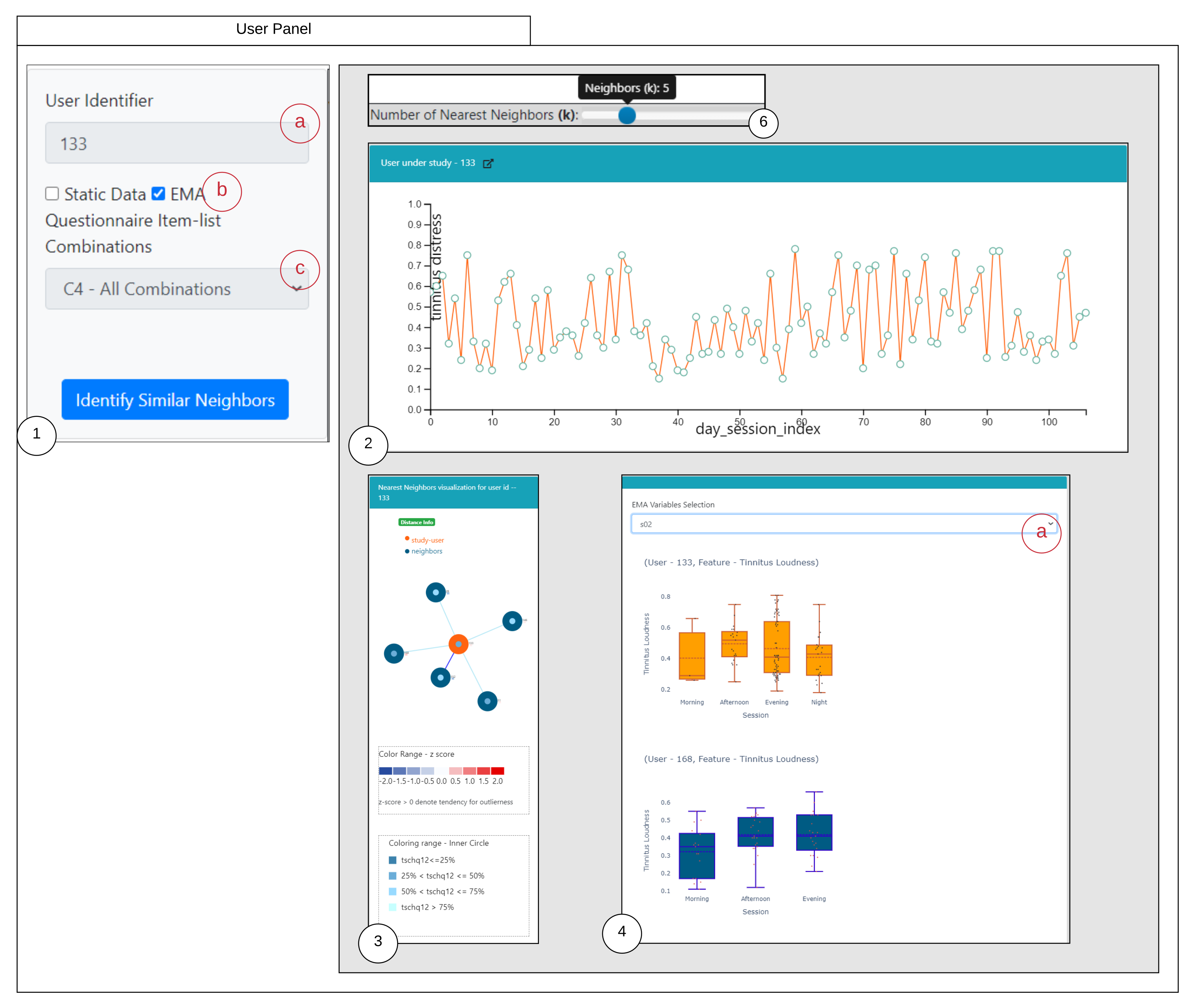
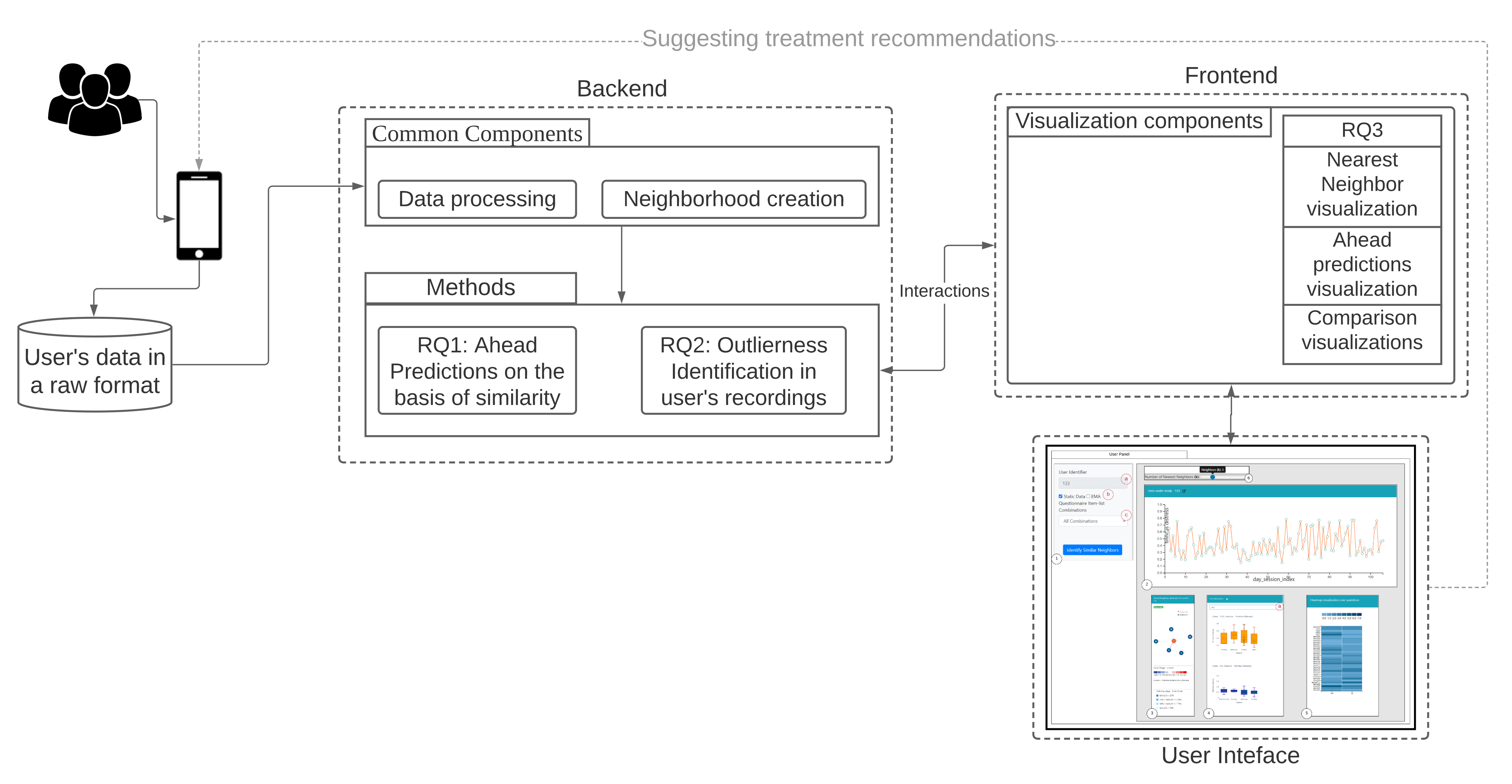
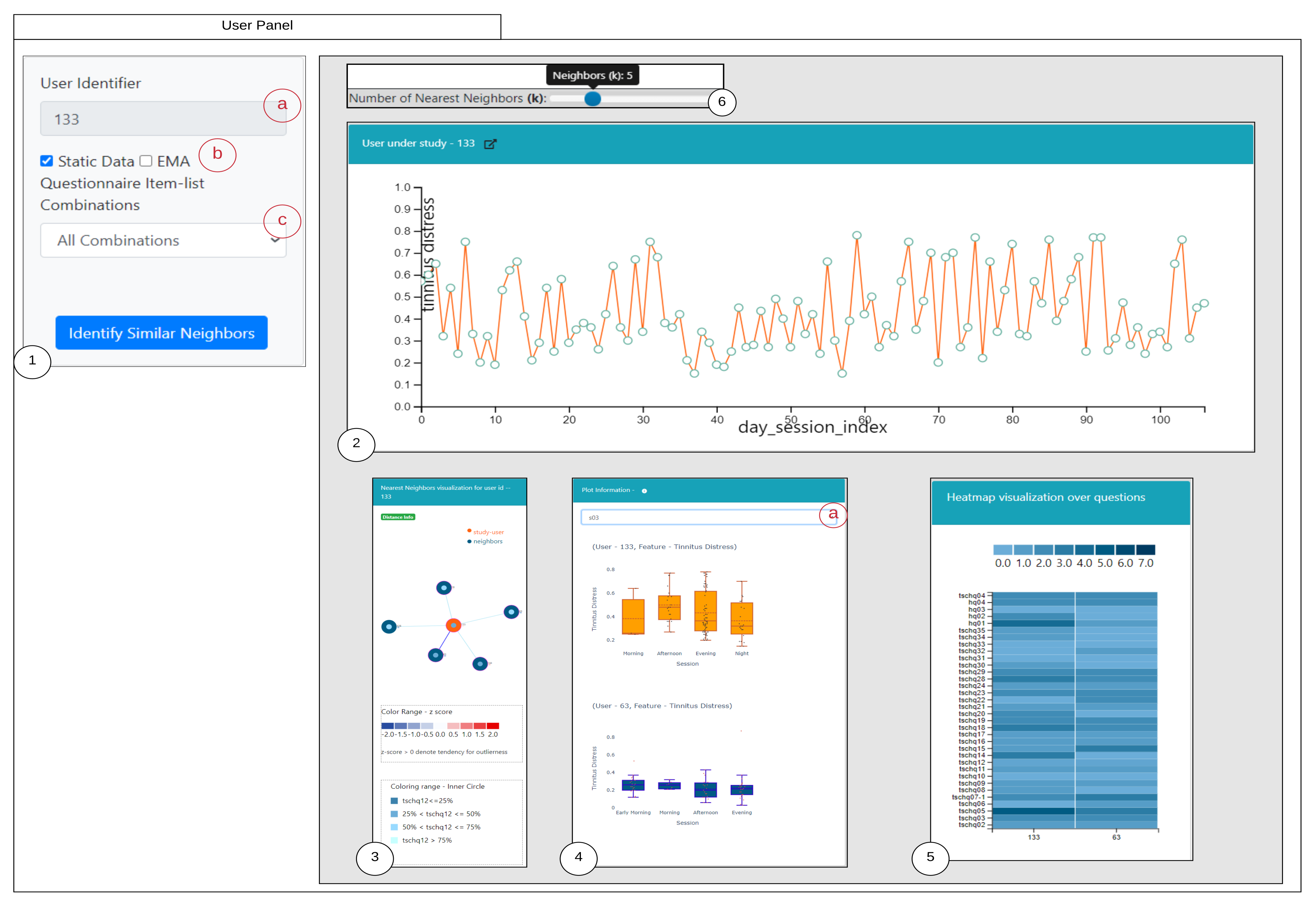
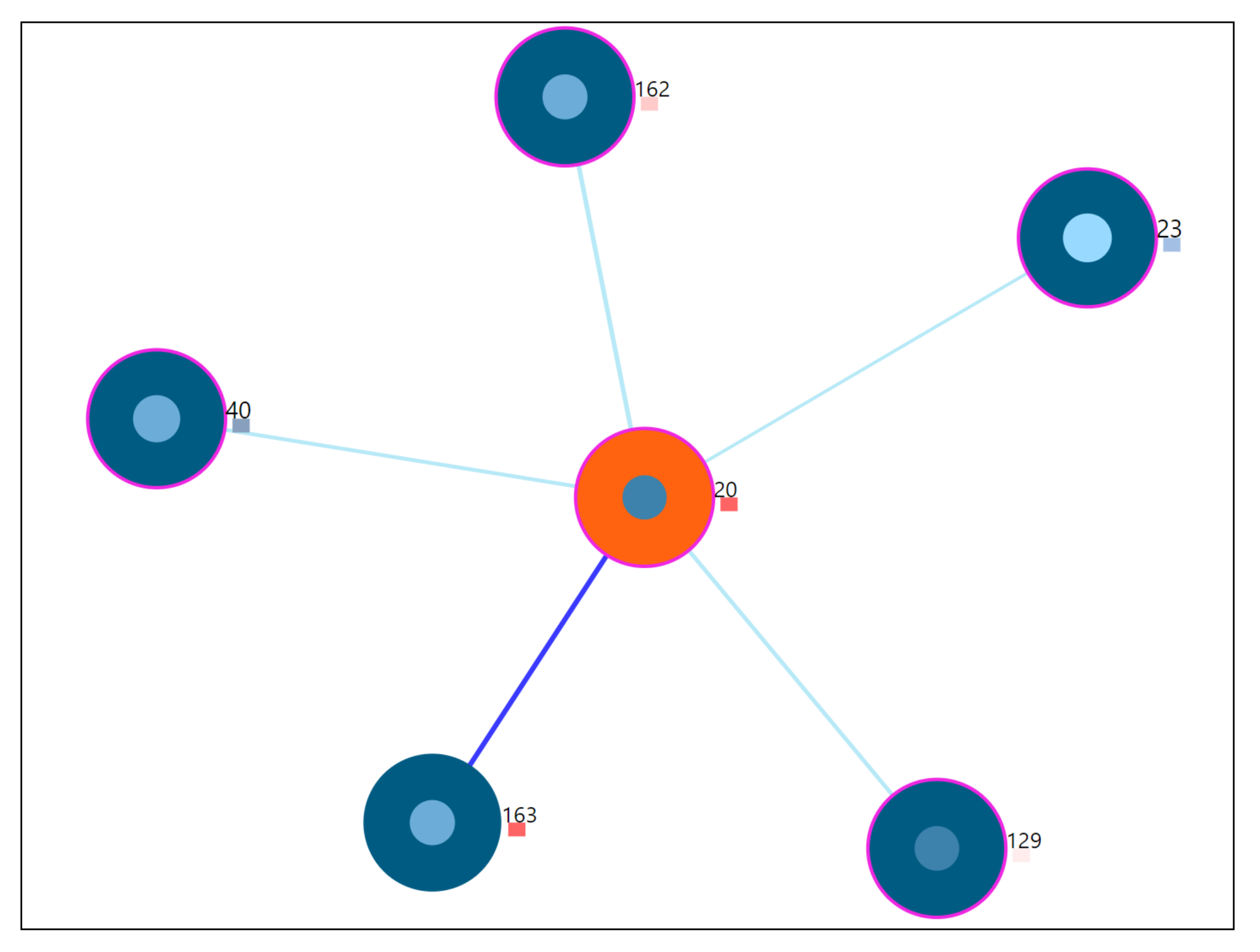
6.1. Similarity Overview User Panel
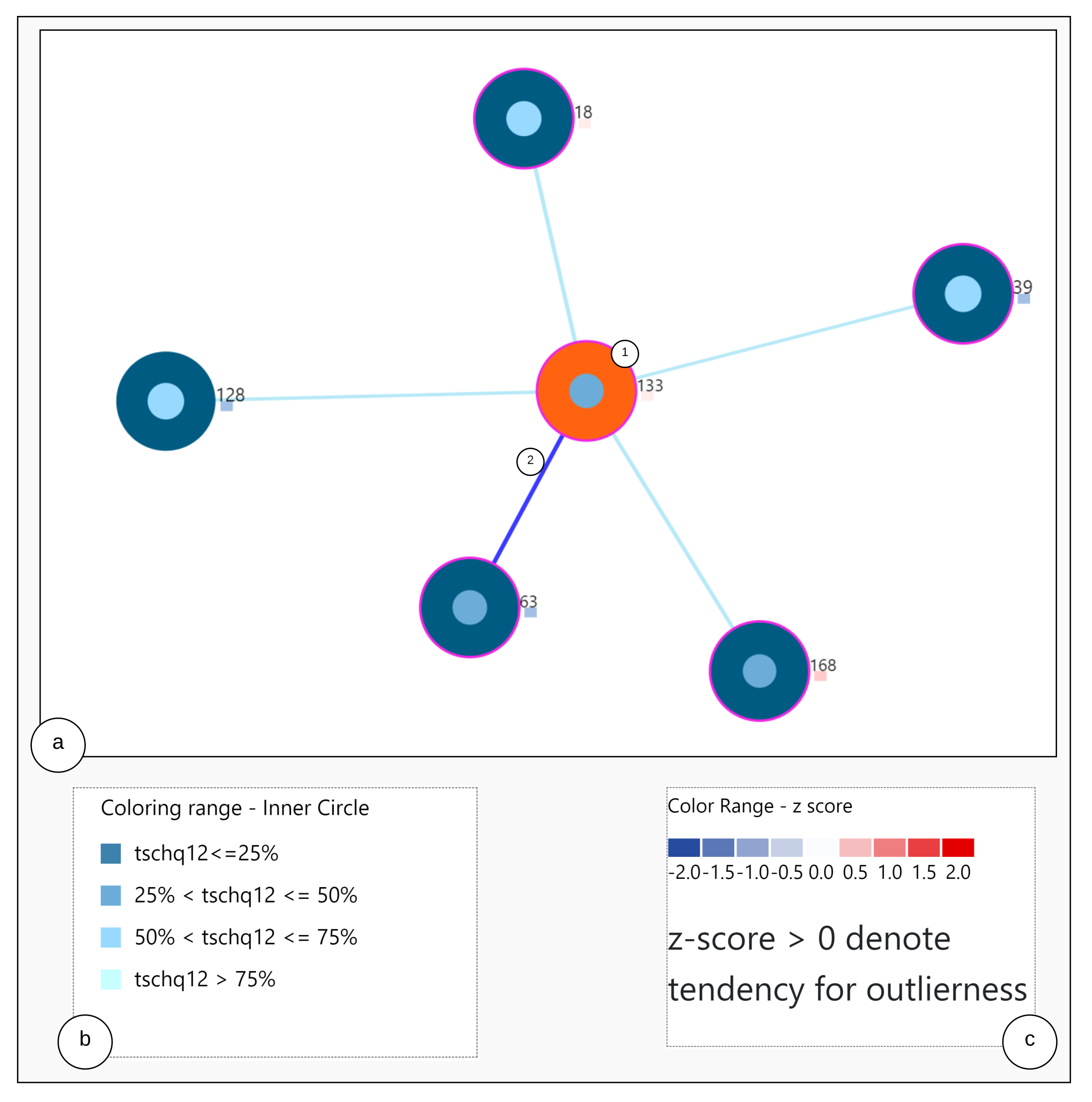
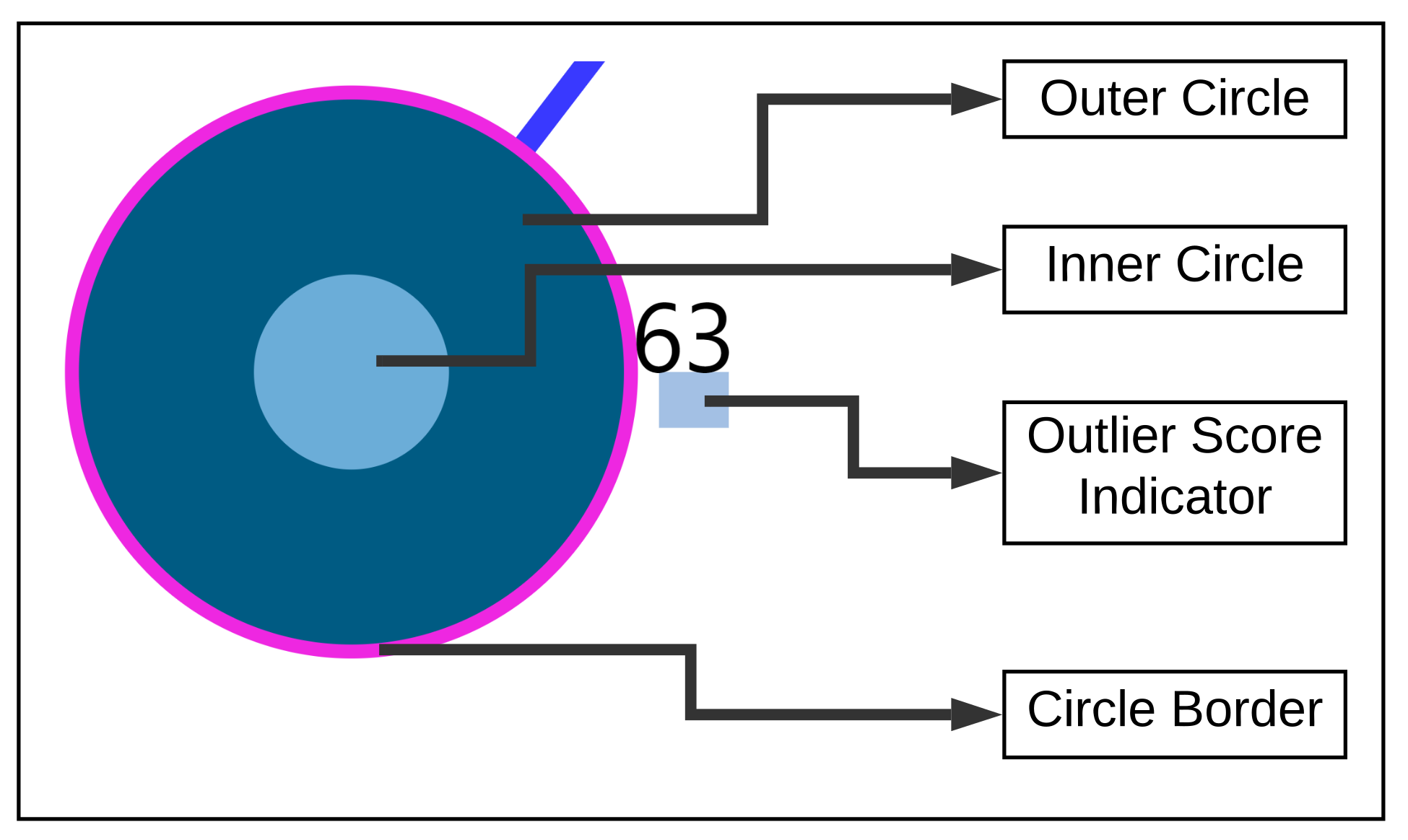
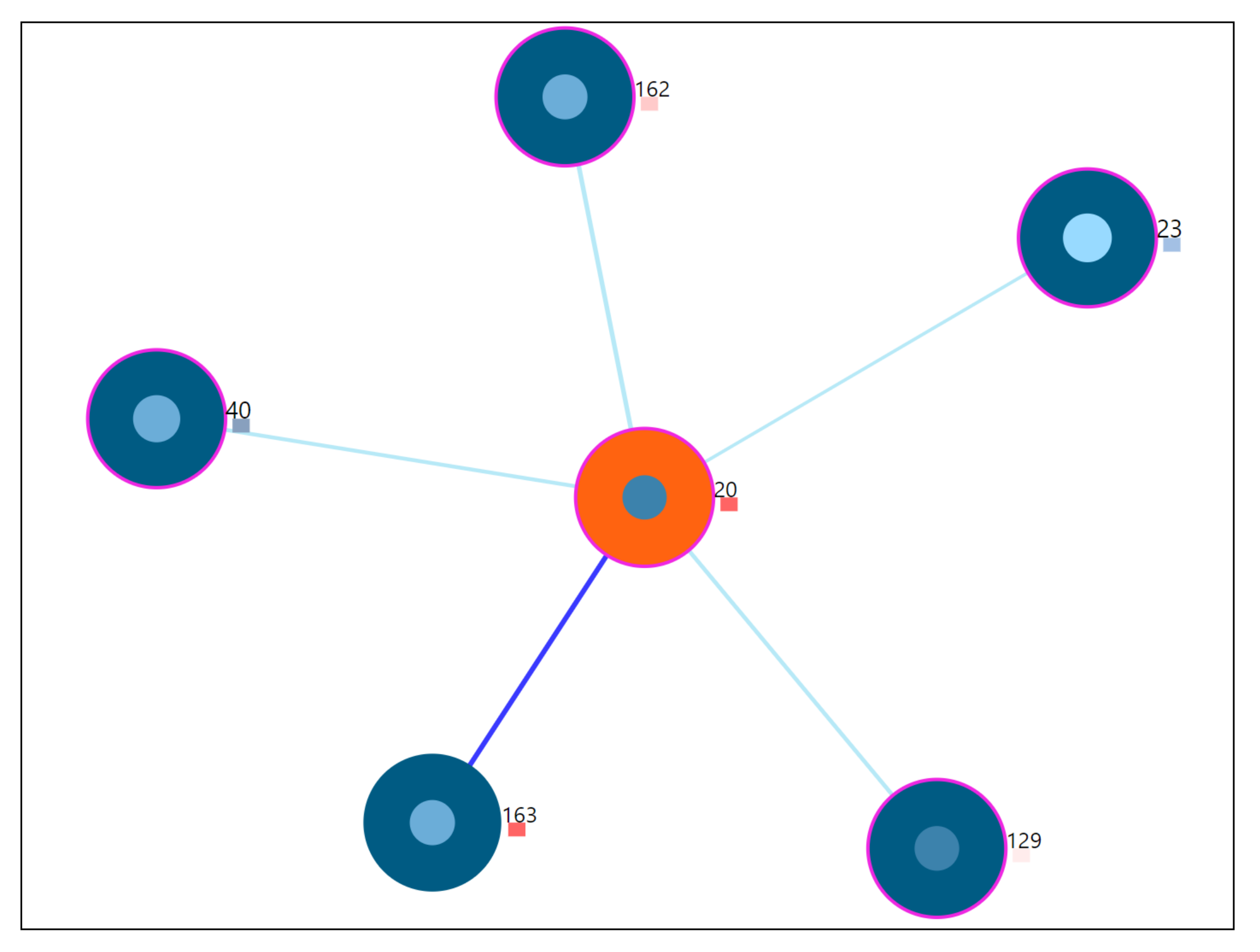
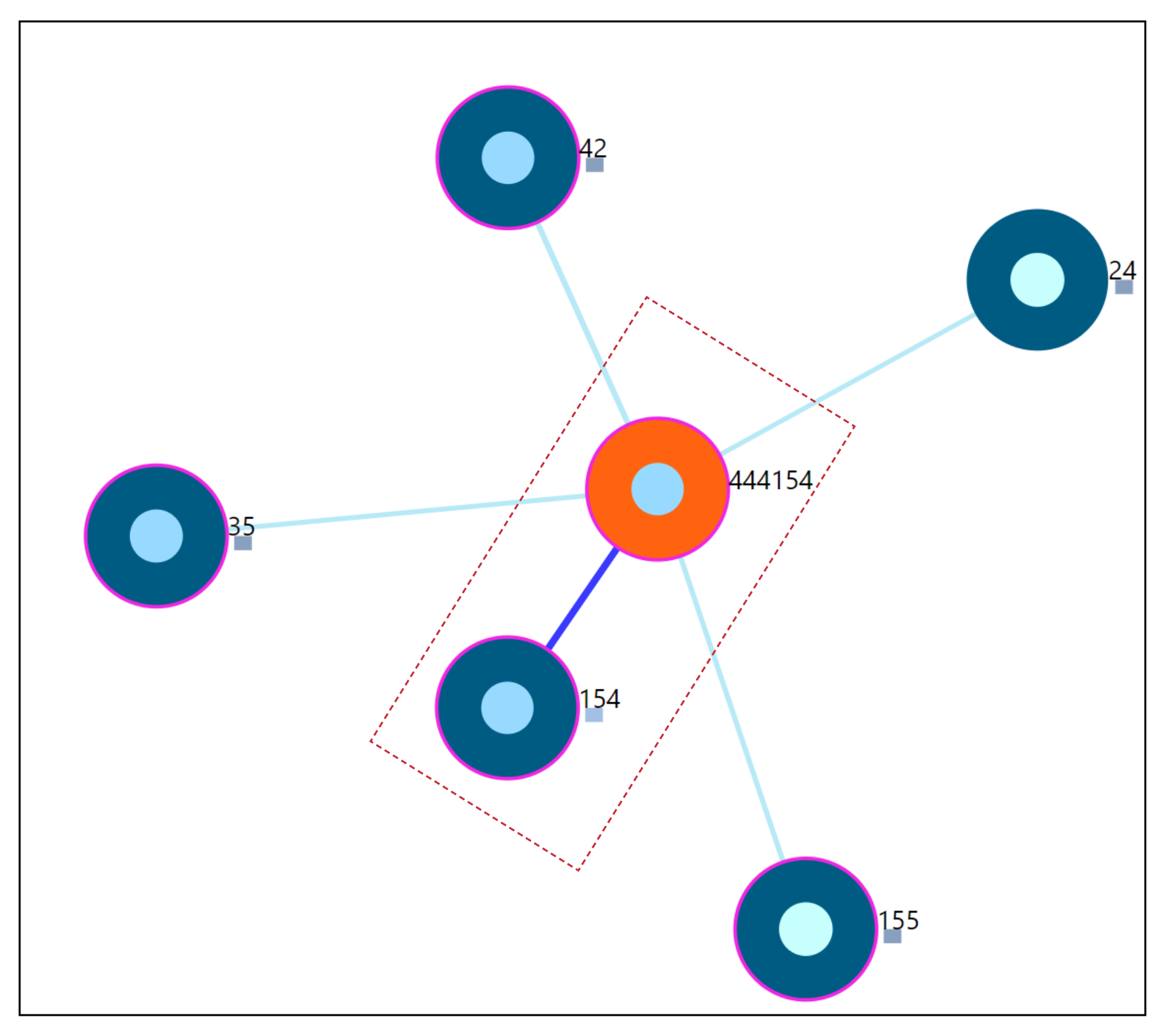
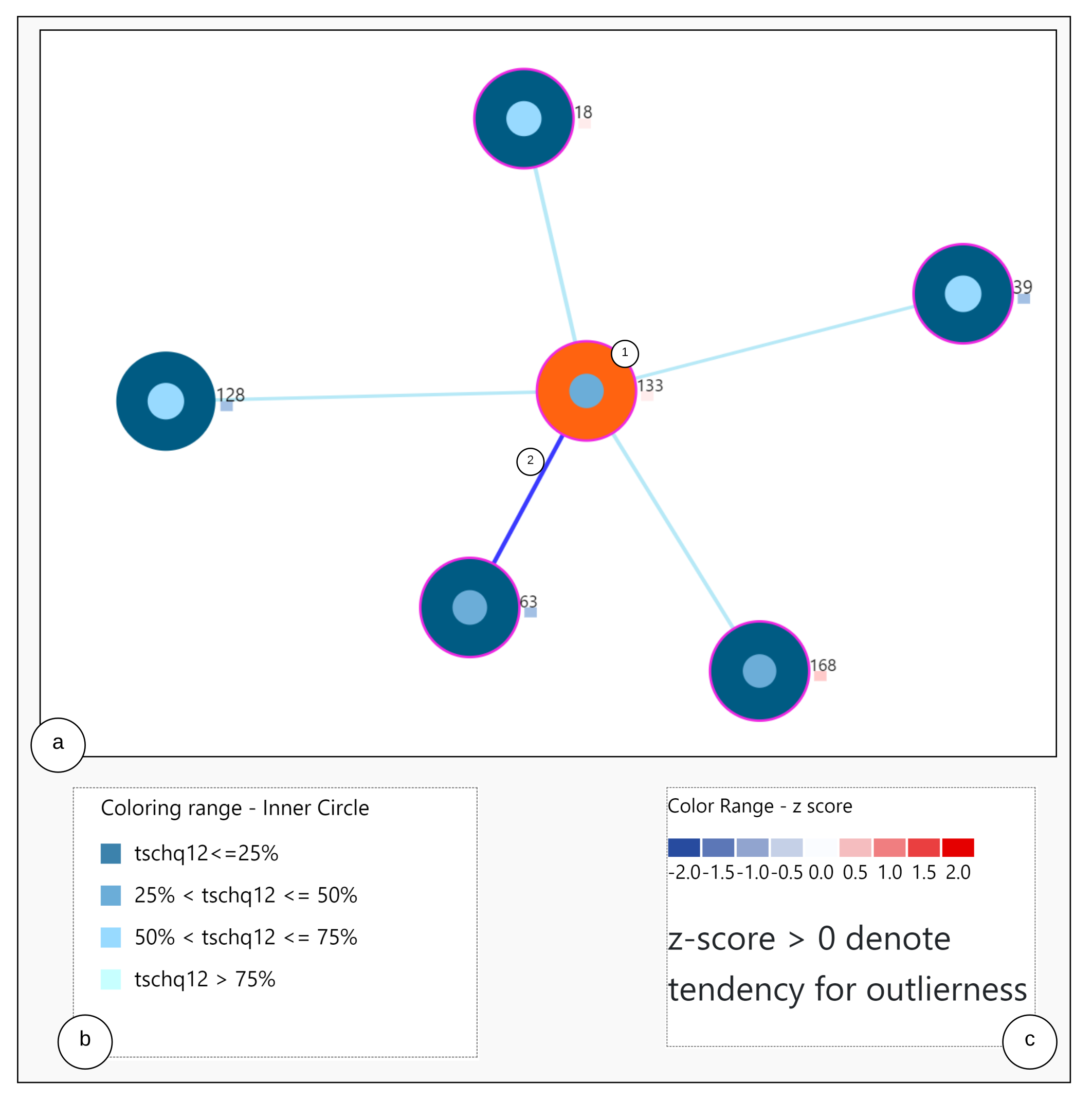
6.2. Nearest Neighbor Visualization
Interactions
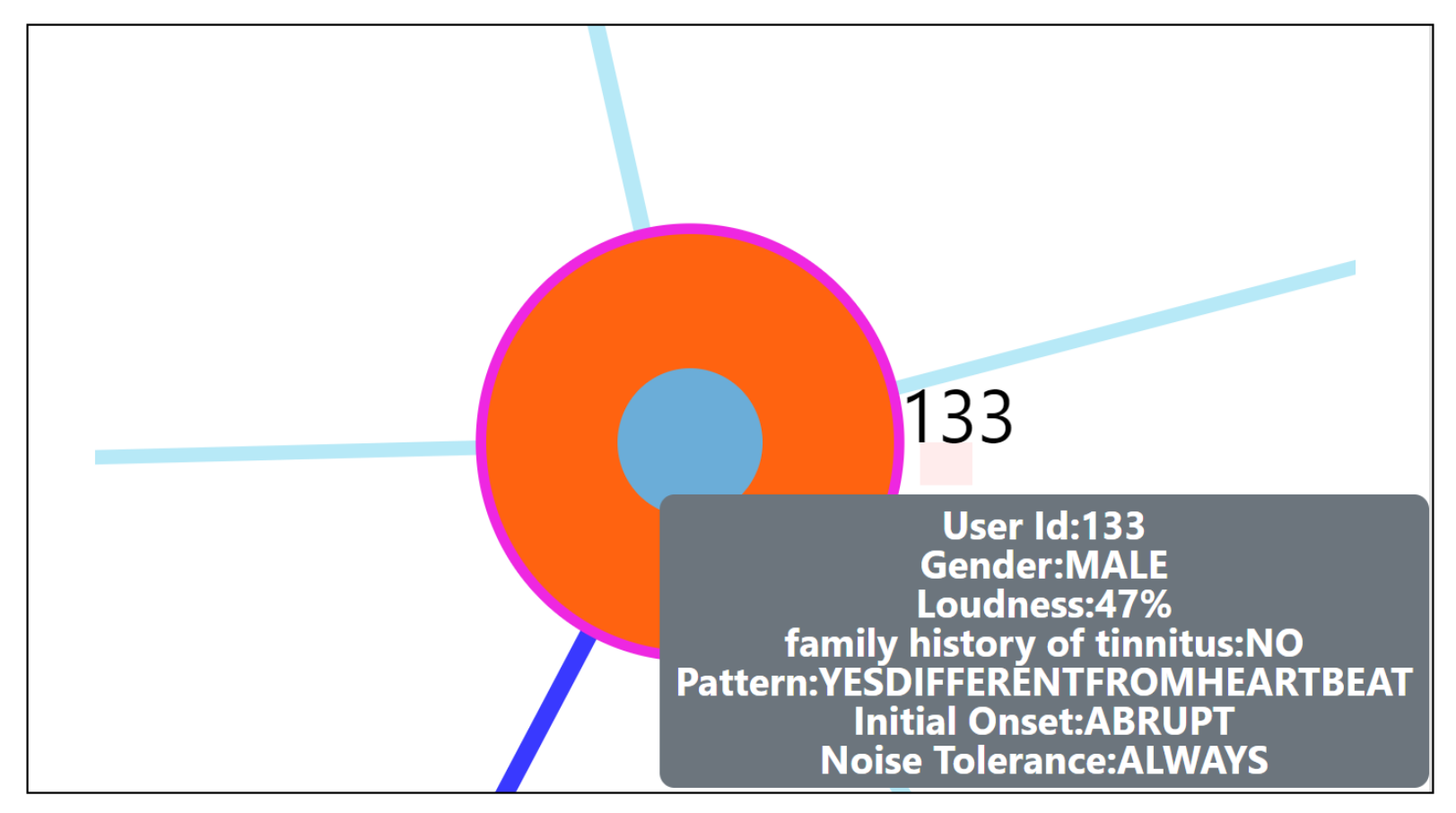
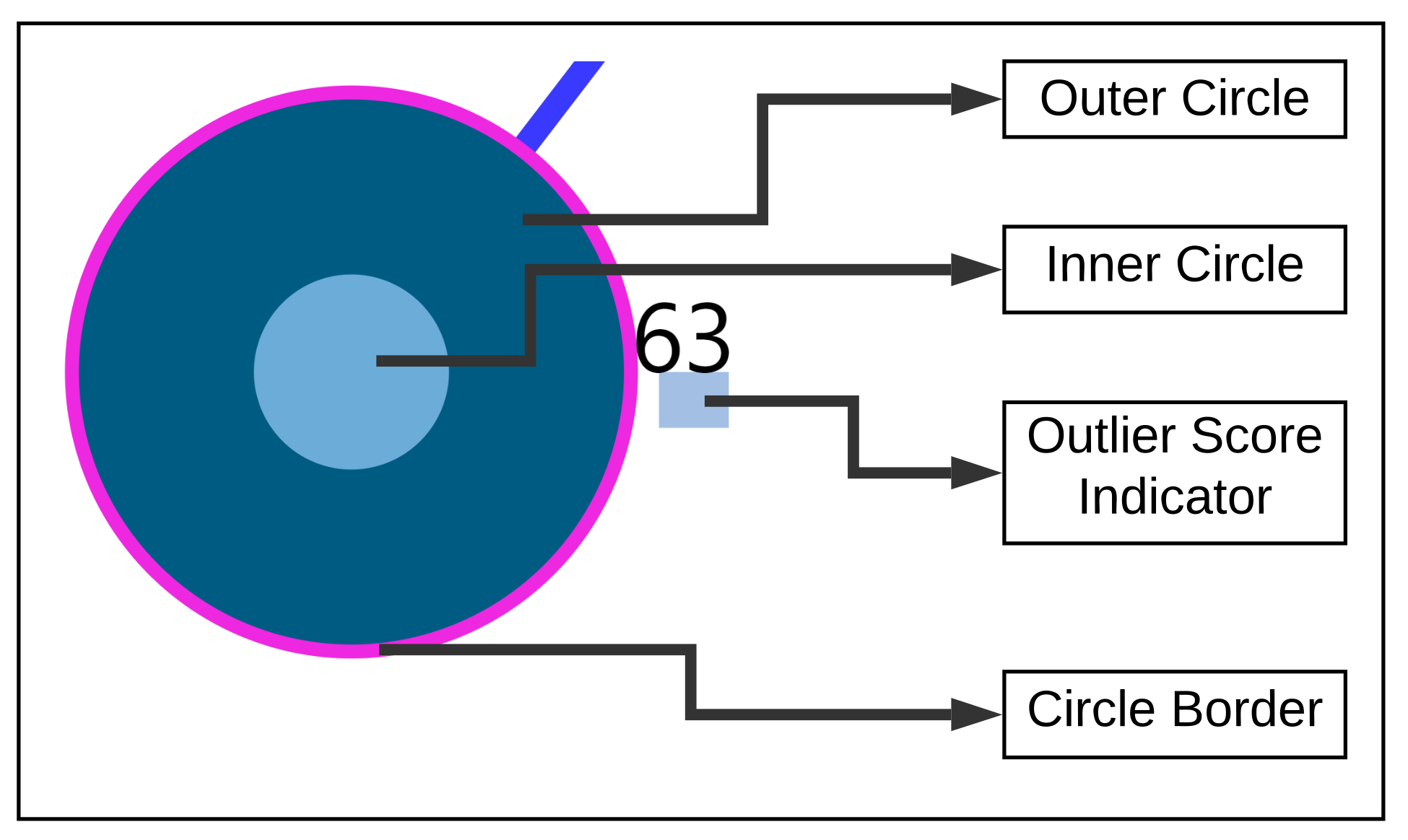
- Zoom into each of the user’s nodes to understand the level of the loudness (TSCHQ12) shown in the inner circle and the presence or absence of the hearing problem (TSCHQ26) answer shown in the circle boundary.
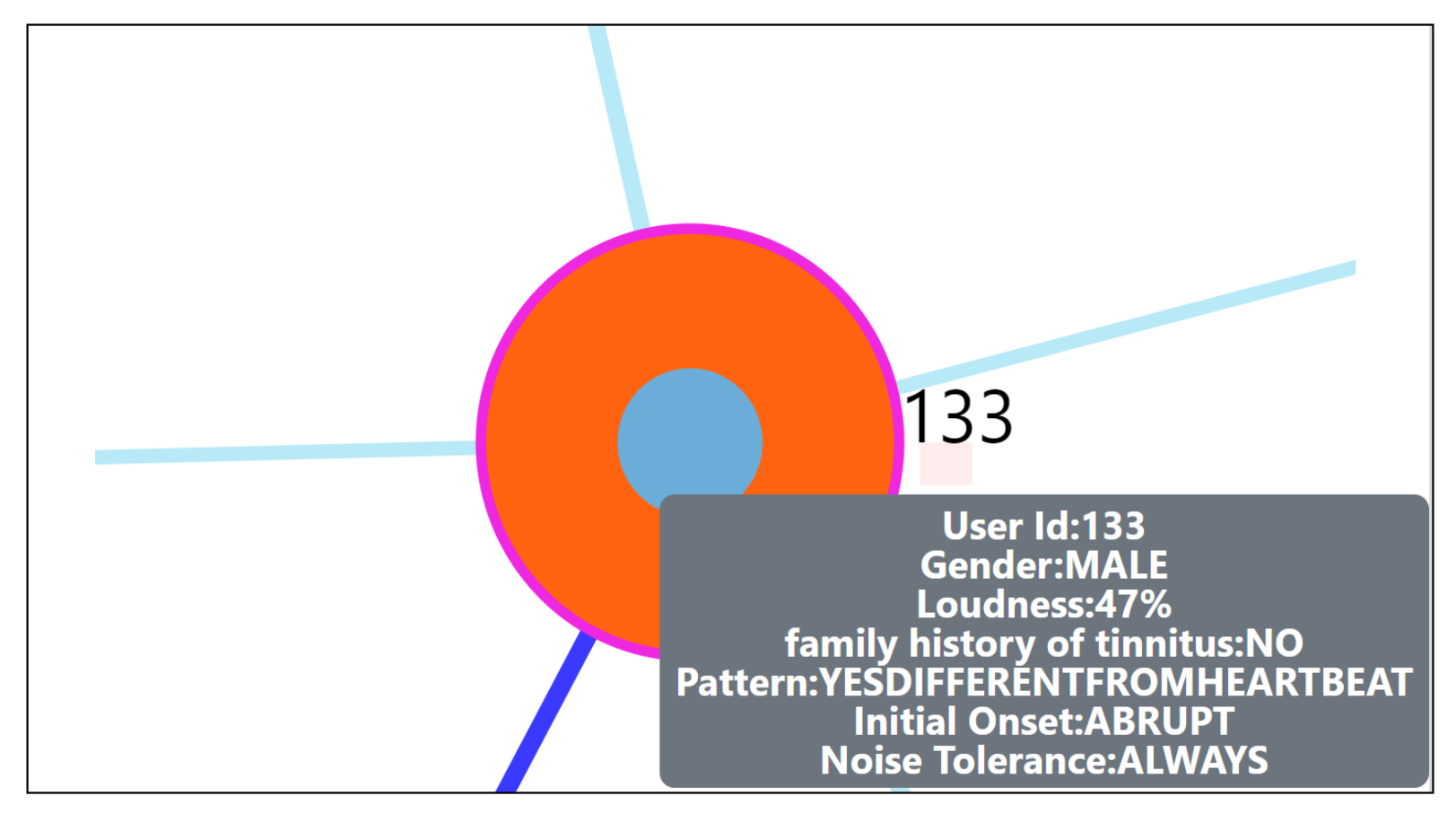
- Hover in the center of user node to obtain the user clinical data. (Refer: Figure A2 in Appendix D for more information). By such information easily, a domain expert can identify the differences amongst the obtained similar users.
- Click on one of the nearest neighbors to obtain comparison plots to compare the time series observations as sessions, and the registration properties with the study user.
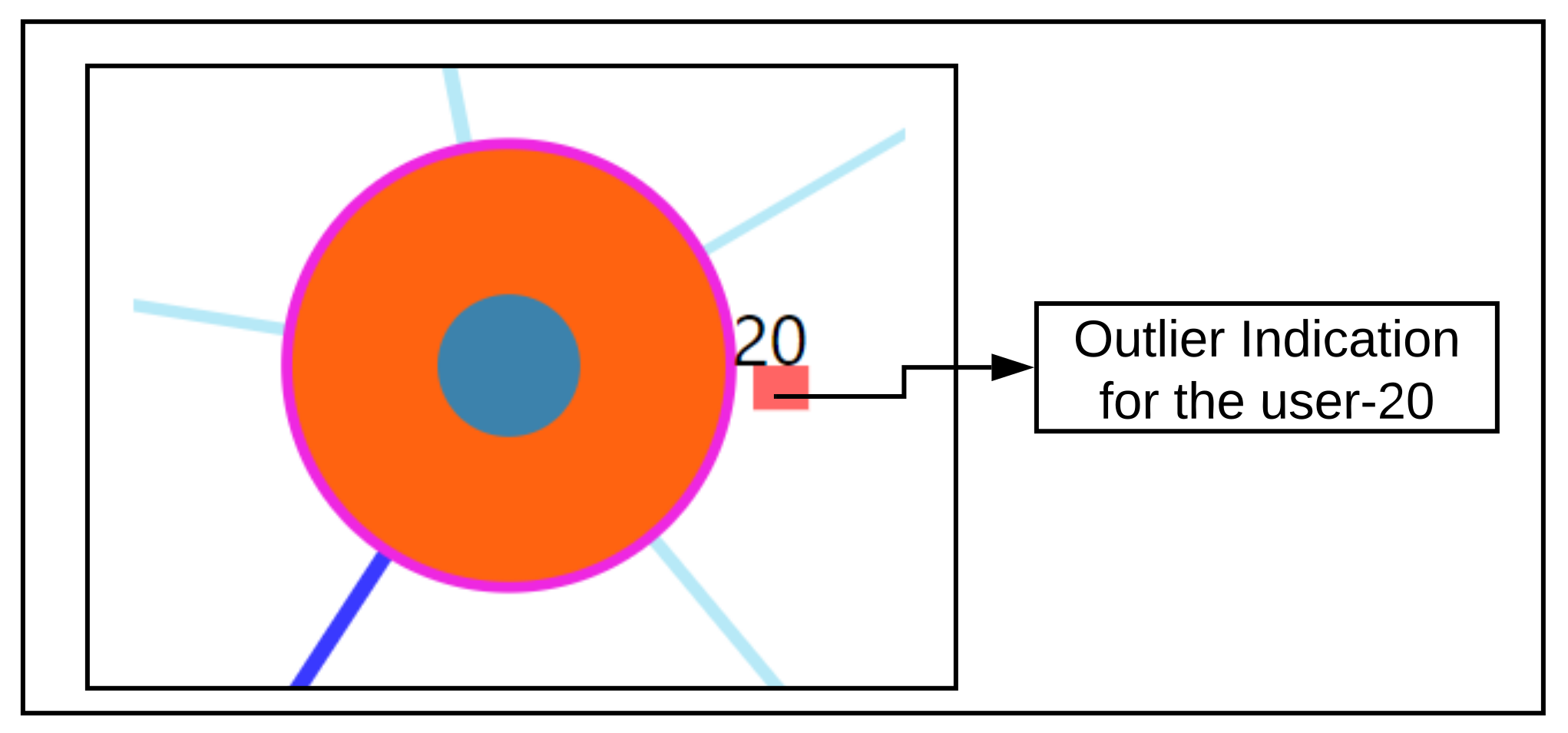
- Additionally, the distance information is provided within the nearest neighbor visualization on click, which generates a table (Refer Use Case Example: Figure A4) calculated as the difference in distance of each of the nearest neighbors from the first nearest neighbor. A cell within the generated table is colored pink when the obtained difference in distance value of a nearest neighbor is greater than a threshold () defined as the mean * standard_deviation of the distance differences amongst all the nearest neighbors. This provides the information of the dissimilar users in the computed neighborhood.
- A slider is provided to the domain expert to dynamically increase or decrease the number of nearest neighbors for a study user.
6.3. Comparison Visualization
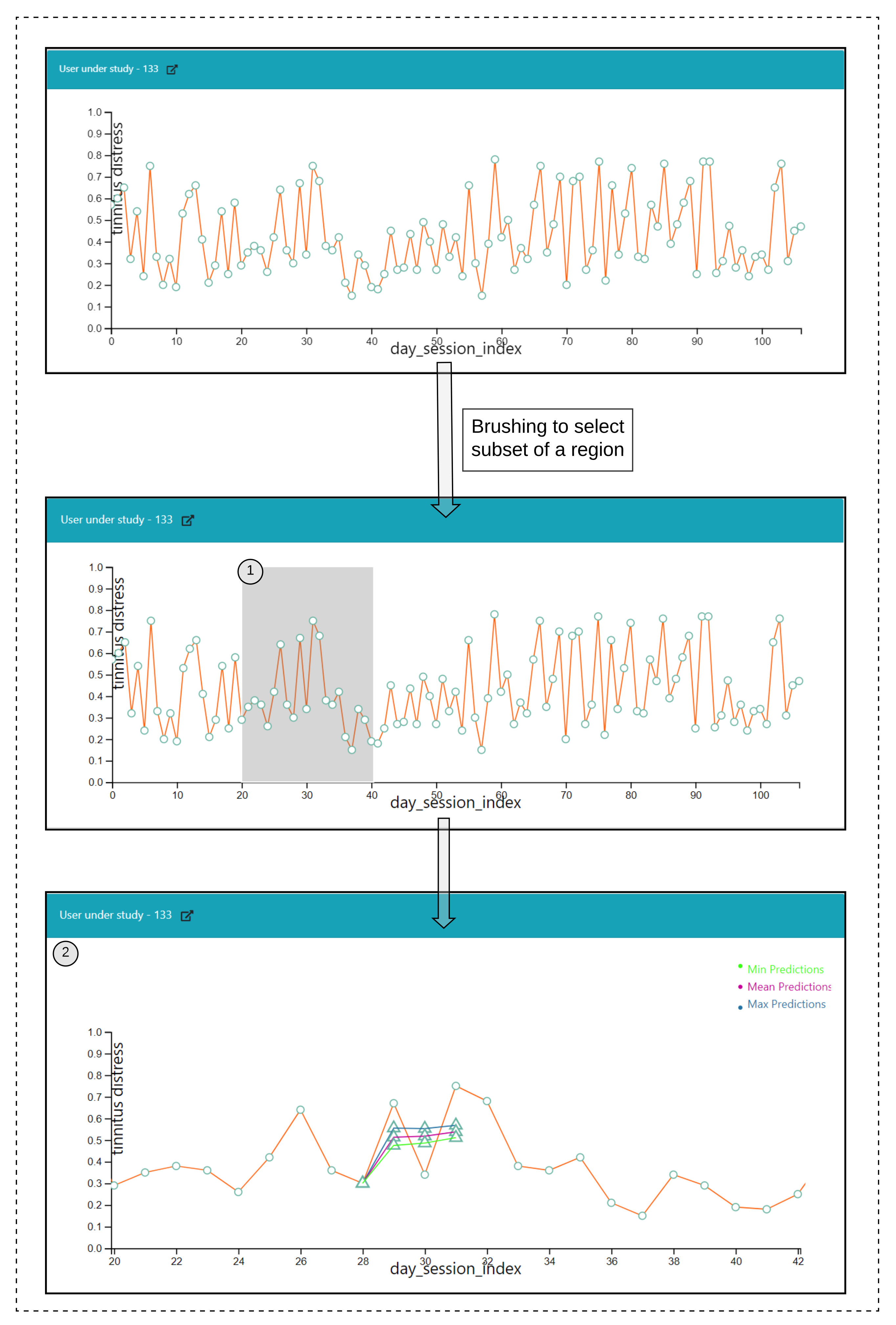
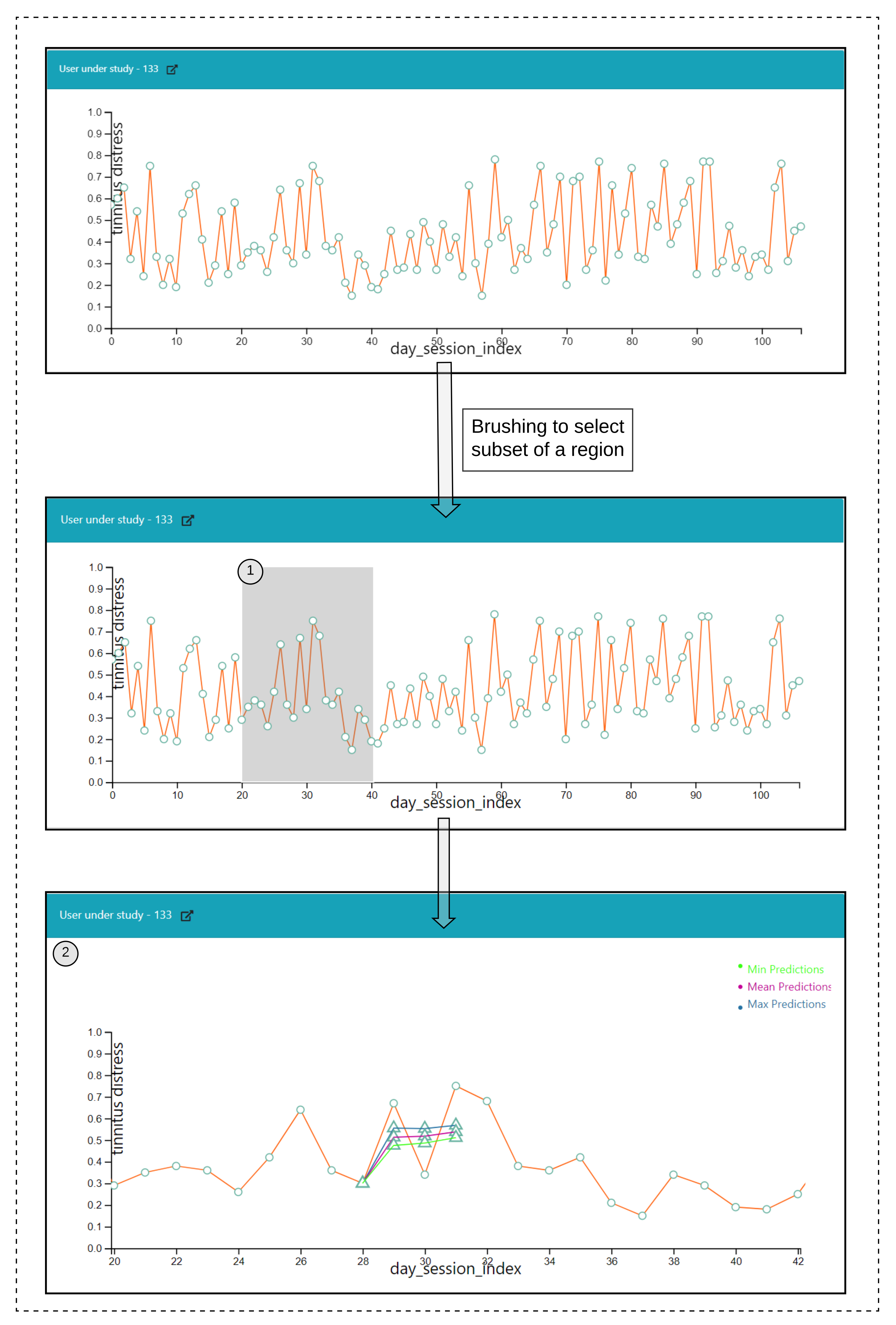
6.4. Predictive Visualization over the Line Plot of the Study User
Interactions
- Click over each of the data points on the plot and a prediction is made for the next timepoints over a selected data point, and the pathway is visualized in Figure 6(2).
- Hover functionality; compare the predicted with the actual values.
- Brush (Figure 6(1)) a region of timepoint; perform a prediction in that region.
7. Results
7.1. RQ1: Experimental Setup
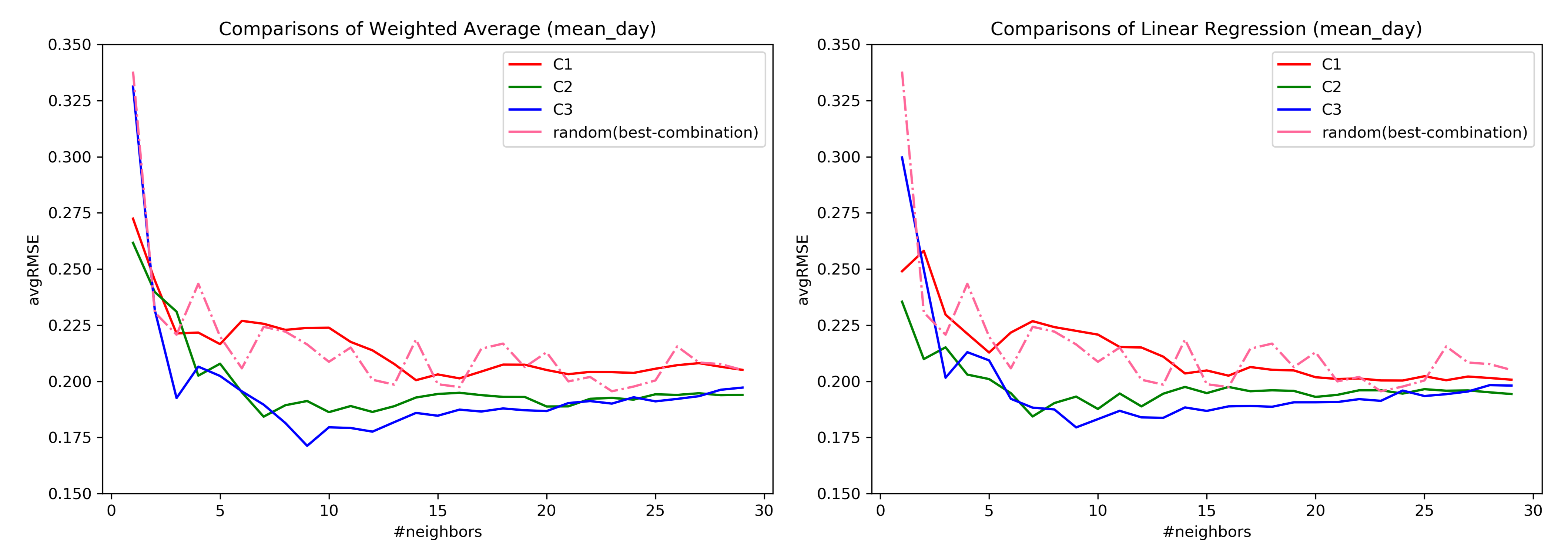
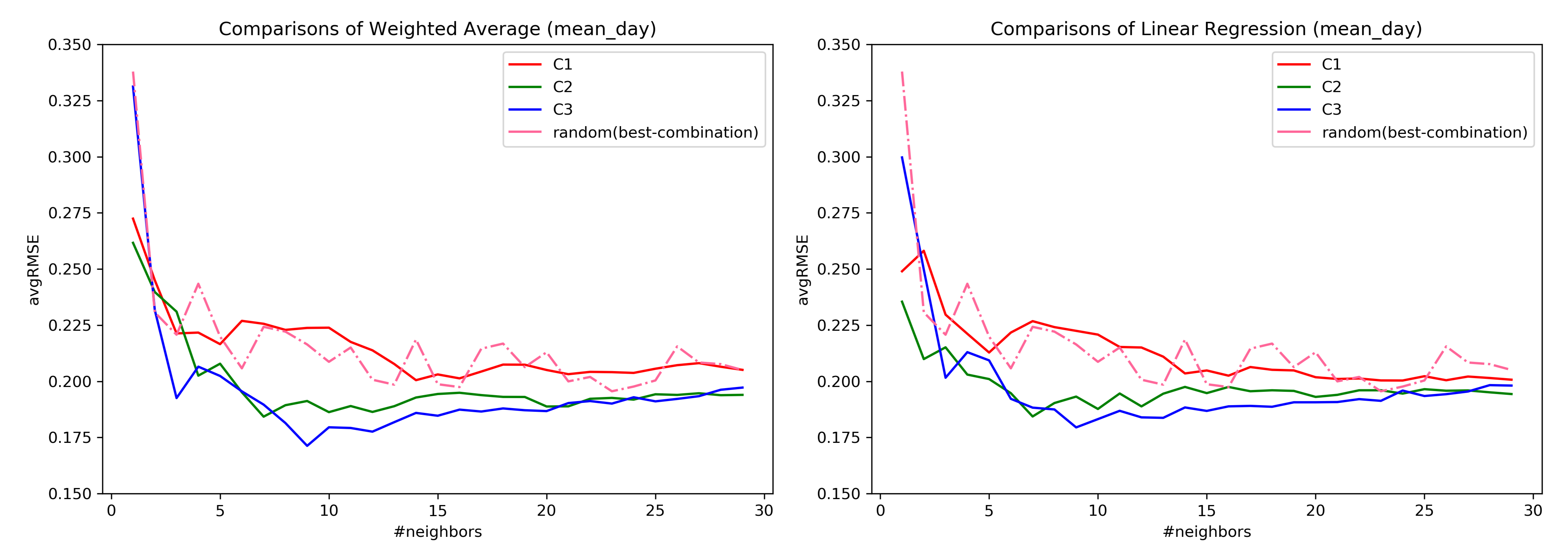
7.2. RQ1: Comparison across Combinations
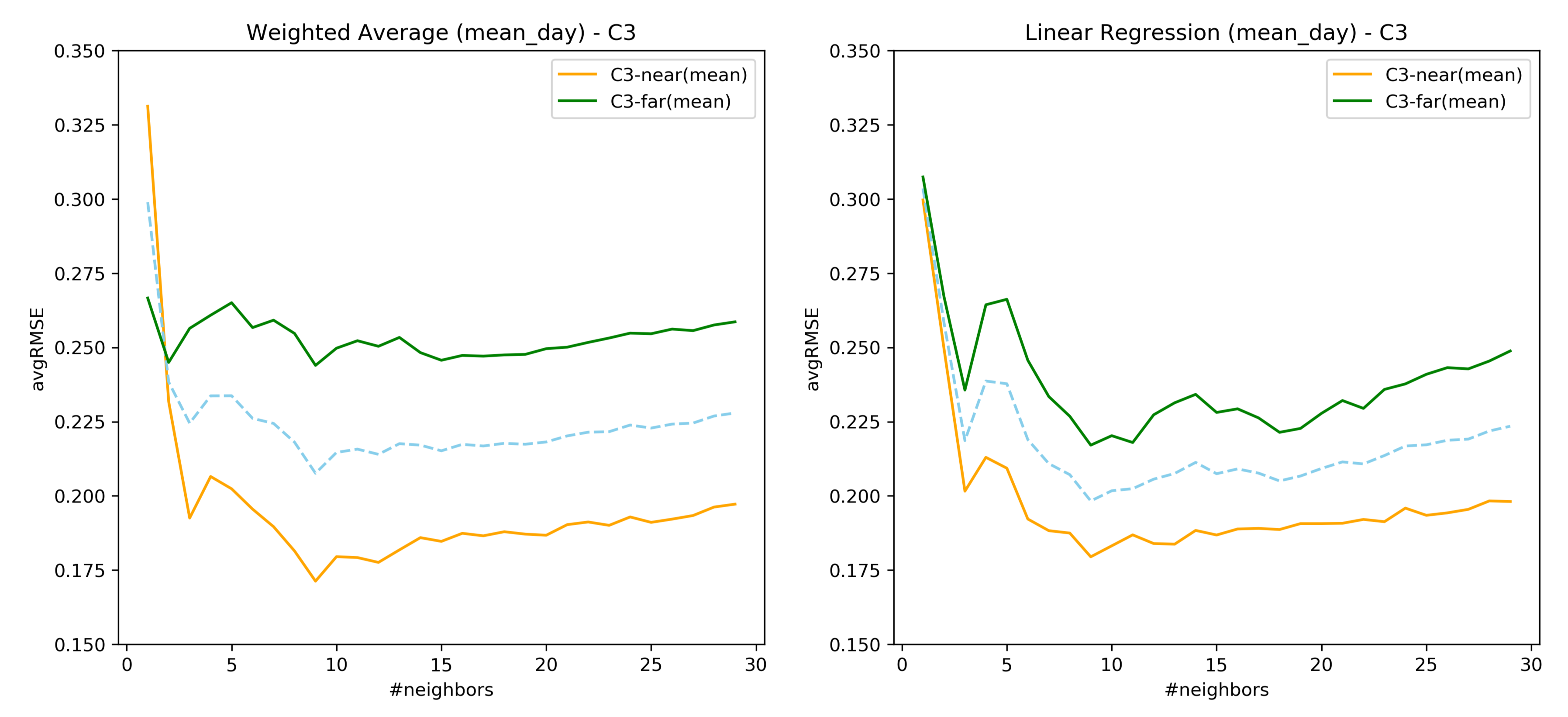
7.3. RQ1: AvgRMSE for Near and Far Predictions
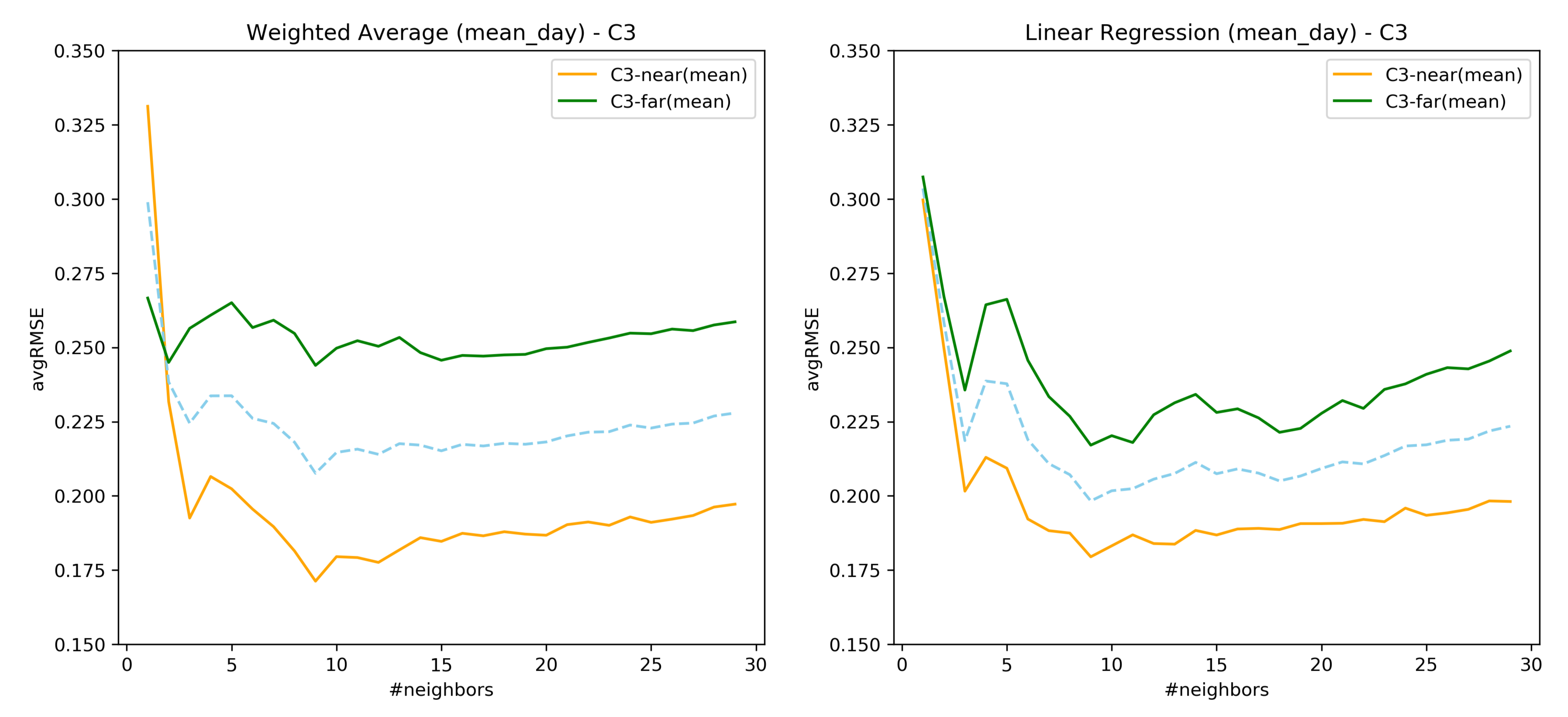
7.4. RQ1: Comparison over the Similarity Constructed through Loudness-s02
7.5. Important Findings of RQ1
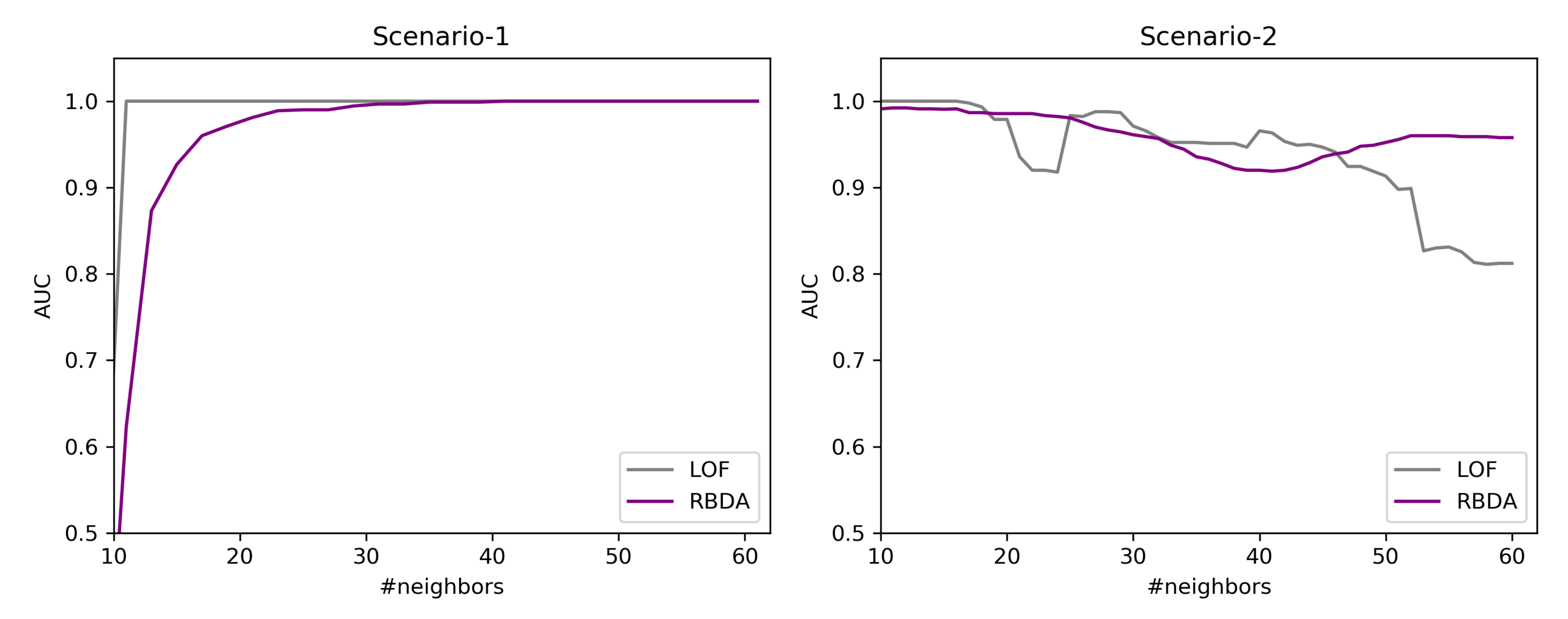
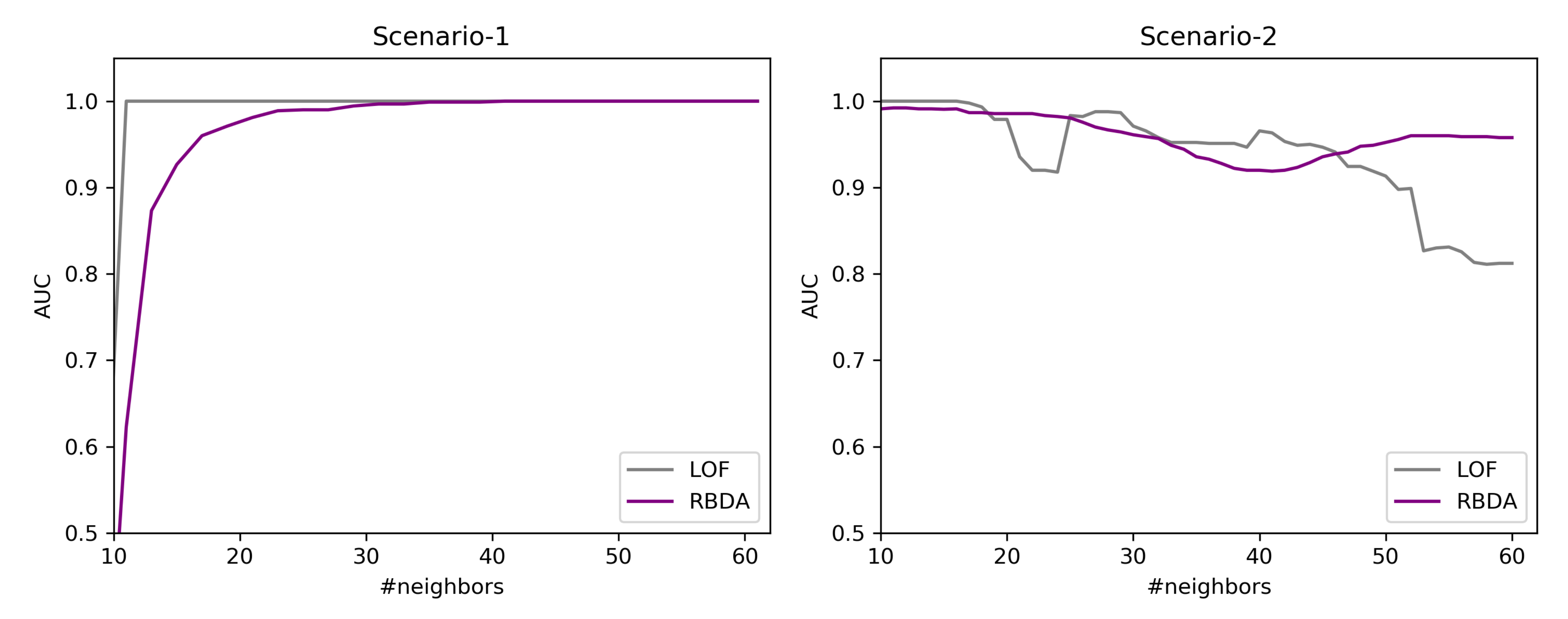
7.6. RQ2: Results of Outlier Detection Mechanisms
7.6.1. Results over the Created Synthetic Data
7.6.2. By Using the Tinnitus Data
7.7. RQ3: Validation of the Visual Interface through Usage Scenarios
7.7.1. Simulated Users Data Creation for Validation
7.7.2. Outlier User Scenario
7.7.3. Twin User Scenario
8. Discussion
9. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CDSS | Clinical Decision Support System |
| CSV | Comma Separated Values |
| EHR | Electronic Health Records |
| EMR | Electronic Medical Records |
| PSM | Patient Similarity Metric |
| EMA | Ecological Momentary Assessment |
| HEOM | Heterogeneous Euclidean Overlap Metric |
| ICU | Intensive Care Unit |
| JSON | Javascript Object Notation |
| kNN | k Nearest Neighbors |
| LOF | Local Outlier Factor |
| MIMIC | Multiparameter Intelligent Monitoring In Intensive Care |
| OM | Overlap Metric |
| RBDA | Rank Based Detection Algorithm |
| RMSE | Root Mean Squared Error |
| TYT | TrackYourTinnitus |
| TSCHQ | Tinnitus Sample Case History Questionnaire |
Appendix A. Data Description
- −
- Hearing Questionnaire (HQ)

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable Name | Question | Data Type |
|---|---|---|
| hq01 | How often do you have hearing problems? | Single Choice |
| hq02 | How much do your hearing problems affect you? | Single Choice |
| hq03 | Did an ENT physician or acoustician diagnose you with a hearing loss? | Boolean-(YES/NO) |
| hq04 | Do you wear hearing aids? | Single Choice |
| hq05 | If yes, which hearing aids do you wear? | Free Text |
| hq06 | If yes, how often do you wear hearing aids? | Single Choice |
- −
- Tinnitus Diary (EMA)
| Variable Name | Question | Data Type |
|---|---|---|
| s01 | Did you perceive the tinnitus right now? | Boolean-(Yes/No) |
| s02 | How loud is the tinnitus right now? | Numeric-[0–100] |
| s03 | How stressful is the tinnitus right now? | Numeric-[0–100] |
| s04 | How well are you hearing right now? | Numeric-[0–100] |
| s05 | How much are you limited by your hearing ability right now? | Numeric-[0–100] |
| s06 | Do you feel stressed right now? | Numeric-[0–100] |
| s07 | How exhausted do you feel right now? | Numeric-[0–100] |
| s08 | Are you wearing a hearing aid right now? | Boolean-(Yes/No) |
Appendix B. Description of LOF
- For each of the points, where D represents the underlying dataset. The k-nearest neighbors are obtained and in case of a tie in the distance then more than the provided k neighbors are used.
- By using the obtained k-nearest neighbors , a local density estimation for the data object is calculating using Local reachability density (LRD) given as:where denotes the reachability distance. More details are provided in [38].
- By comparing the LRD with the data object and the obtained k-nearest neighbors, the LOF score is obtained as:
Appendix C. Description of RBDA
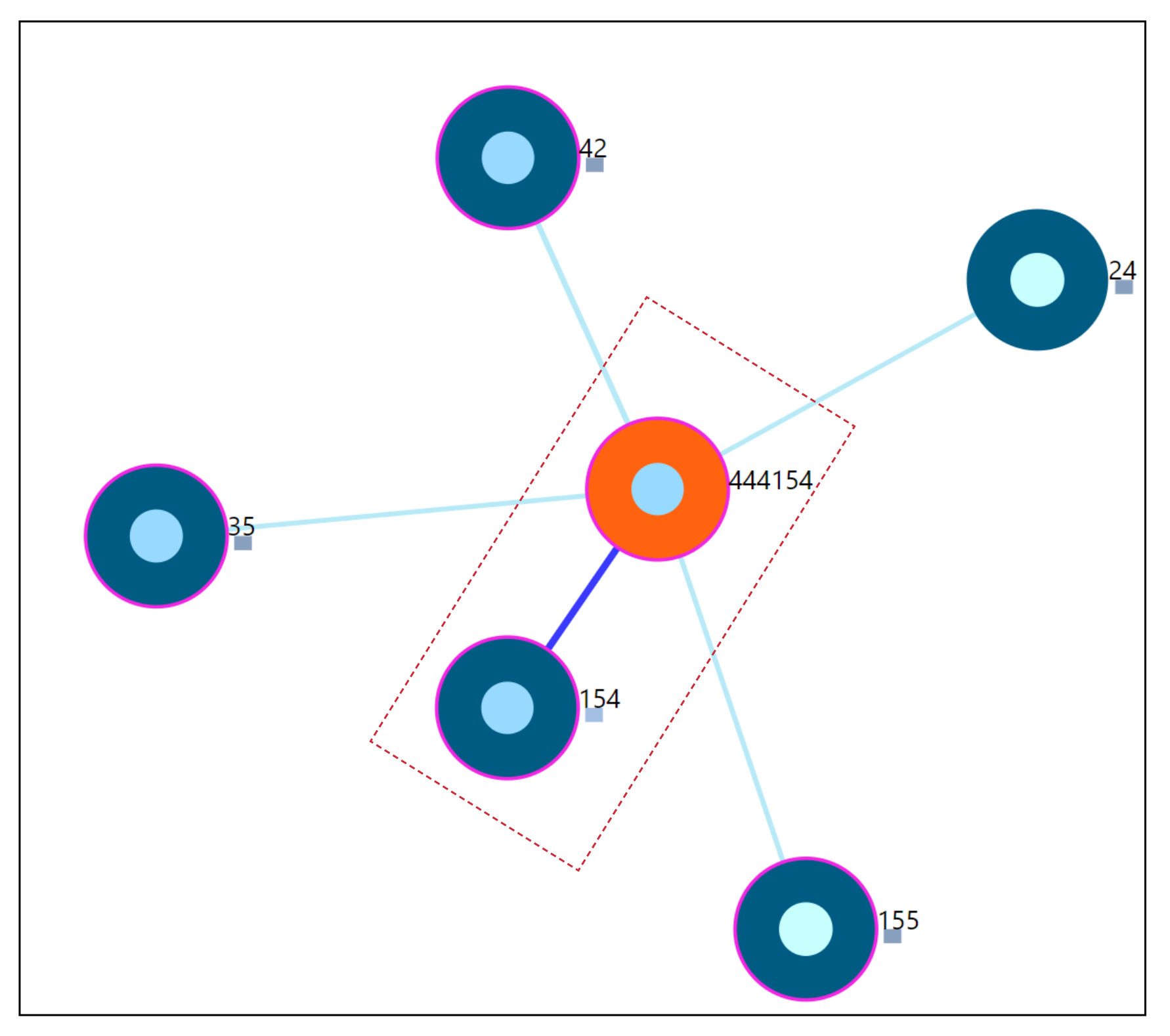
Appendix D. Other Visualizations and Facilities
- −
- User panel view when EMA is selected as the similarity criteria
- −
- Hover on the user node to obtain clinical information
- −
- A facility to collect the tinnitus static information data (TSCHQ) is also provided in the proposed visualization tool

References
- Pryss, R. Mobile crowdsensing services for tinnitus assessment and patient feedback. In Proceedings of the 2017 IEEE International Conference on AI & Mobile Services (AIMS), Honolulu, HI, USA, 25–30 June 2017; pp. 22–29. [Google Scholar]
- Stone, A.A.; Shiffman, S. Ecological momentary assessment (EMA) in behavioral medicine. Ann. Behav. Med. 1994, 16, 199–202. [Google Scholar] [CrossRef]
- Ortiz, A.; Grof, P. Electronic monitoring of self-reported mood: The return of the subjective? Int. J. Bipolar Disord. 2016, 4, 28. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Porras-Segovia, A.; Molina-Madueño, R.M.; Berrouiguet, S.; López-Castroman, J.; Barrigón, M.L.; Pérez-Rodríguez, M.S.; Marco, J.H.; Díaz-Oliván, I.; de León, S.; Courtet, P.; et al. Smartphone-based ecological momentary assessment (EMA) in psychiatric patients and student controls: A real-world feasibility study. J. Affect. Disord. 2020, 274, 733–741. [Google Scholar] [CrossRef]
- Wilson, M.B.; Kallogjeri, D.; Joplin, C.N.; Gorman, M.D.; Krings, J.G.; Lenze, E.J.; Nicklaus, J.E.; Spitznagel, E.E.; Piccirillo, J.F. Ecological momentary assessment of tinnitus using smartphone technology: A pilot study. Otolaryngology 2015, 152, 897–903. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Colombo, D.; Palacios, A.G.; Alvarez, J.F.; Patané, A.; Semonella, M.; Cipresso, P.; Kwiatkowska, M.; Riva, G.; Botella, C. Current state and future directions of technology-based ecological momentary assessments and interventions for major depressive disorder: Protocol for a systematic review. Syst. Rev. 2018, 7, 1–26. [Google Scholar] [CrossRef] [PubMed]
- Schlee, W.; Pryss, R.C.; Probst, T.; Schobel, J.; Bachmeier, A.; Reichert, M.; Langguth, B. Measuring the moment-to-moment variability of Tinnitus: The TrackYourTinnitus smart phone app. Front. Aging Neurosci. 2016, 8, 1–8. [Google Scholar] [CrossRef] [Green Version]
- Shiffman, S.; Stone, A.A.; Hufford, M.R. Ecological Momentary Assessment. Annu. Rev. Clin. Psychol. 2008, 4, 1–32. [Google Scholar] [CrossRef] [PubMed]
- Pryss, R. Prospective crowdsensing versus retrospective ratings of tinnitus variability and tinnitus–stress associations based on the TrackYourTinnitus mobile platform. Int. J. Data Sci. Anal. 2019, 8, 327–338. [Google Scholar] [CrossRef] [Green Version]
- Bruckert, S.; Finzel, B.; Schmid, U. The Next Generation of Medical Decision Support: A Roadmap Toward Transparent Expert Companions. Front. Artif. Intell. 2020, 3, 75. [Google Scholar] [CrossRef] [PubMed]
- Alther, M.; Reddy, C.K. Clinical decision support systems. Healthc. Data Anal. 2015, 625–656. [Google Scholar] [CrossRef] [Green Version]
- Caballero-Ruiz, E.; García-Sáez, G.; Rigla, M.; Villaplana, M.; Pons, B.; Hernando, M.E. A web-based clinical decision support system for gestational diabetes: Automatic diet prescription and detection of insulin needs. Int. J. Med. Inform. 2017, 102, 35–49. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Feuillâtre, H.; Auffret, V.; Castro, M.; Le Breton, H.; Garreau, M.; Haigron, P. Study of similarity measures for case-based reasoning in transcatheter aortic valve implantation. Comput. Cardiol. 2017, 44, 1–4. [Google Scholar] [CrossRef]
- Graham, A.K.; Greene, C.J.; Kwasny, M.J.; Kaiser, S.M.; Lieponis, P.; Powell, T.; Mohr, D.C. Coached Mobile App Platform for the Treatment of Depression and Anxiety Among Primary Care Patients. JAMA Psychiatry 2020, 77, 906–914. [Google Scholar] [CrossRef] [PubMed]
- Khorakhun, C.; Bhatti, S.N. Wellbeing as a proxy for a mHealth study. In Proceedings of the 2014 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Belfast, UK, 2–5 November 2014; pp. 32–39. [Google Scholar]
- Li, J.; Zhang, C.; Li, X.; Zhang, C. Patients’ emotional bonding with MHealth apps: An attachment perspective on patients’ use of MHealth applications. Int. J. Inf. Manag. 2020, 51, 102054. [Google Scholar] [CrossRef]
- Lin, Y.; Tudor-Sfetea, C.; Siddiqui, S.; Sherwani, Y.; Ahmed, M.; Eisingerich, A.B. Effective behavioral changes through a digital mHealth app: Exploring the impact of hedonic well-being, psychological empowerment and inspiration. JMIR mHealth uHealth 2018, 6, e10024. [Google Scholar] [CrossRef] [PubMed]
- De Korte, E.M.; Wiezer, N.; Janssen, J.H.; Vink, P.; Kraaij, W. Evaluating an mHealth app for health and well-being at work: Mixed-method qualitative study. JMIR mHealth uHealth 2018, 6, e6335. [Google Scholar] [CrossRef]
- Aboelmaged, M.; Hashem, G.; Mouakket, S. Predicting subjective well-being among mHealth users: A readiness–value model. Int. J. Inf. Manag. 2021, 56, 102247. [Google Scholar] [CrossRef]
- Kraft, R.; Schlee, W.; Stach, M.; Reichert, M.; Langguth, B.; Baumeister, H.; Probst, T.; Hannemann, R.; Pryss, R. Combining mobile crowdsensing and ecological momentary assessments in the healthcare domain. Front. Neurosci. 2020, 14, 164. [Google Scholar] [CrossRef]
- Insel, T.R. Digital phenotyping: Technology for a new science of behavior. JAMA 2017, 318, 1215–1216. [Google Scholar] [CrossRef]
- Langguth, B.; Goodey, R.; Azevedo, A.; Bjorne, A.; Cacace, A.; Crocetti, A.; Del Bo, L.; De Ridder, D.; Diges, I.; Elbert, T.; et al. Consensus for tinnitus patient assessment and treatment outcome measurement: Tinnitus Research Initiative meeting, Regensburg, July 2006. Prog. Brain Res. 2007, 166, 525–536. [Google Scholar] [CrossRef] [Green Version]
- Wilson, D.R.; Martinez, T.R. Improved heterogeneous distance functions. J. Artif. Intell. Res. 1997, 6, 1–34. [Google Scholar] [CrossRef]
- Hielscher, T.; Spiliopoulou, M.; Völzke, H.; Kühn, J.P. Using participant similarity for the classification of epidemiological data on hepatic steatosis. Proc. IEEE Symp. Comput. Based Med. Syst. 2014, 1–7. [Google Scholar] [CrossRef]
- Unnikrishnan, V.; Beyer, C.; Matuszyk, P.; Niemann, U.; Pryss, R.; Schlee, W.; Ntoutsi, E.; Spiliopoulou, M. Entity-level stream classification: Exploiting entity similarity to label the future observations referring to an entity. Int. J. Data Sci. Anal. 2020, 9, 1–15. [Google Scholar] [CrossRef]
- Huang, H.; Mehrotra, K.; Mohan, C.K. Rank-based outlier detection. J. Stat. Comput. Simul. 2013, 83, 518–531. [Google Scholar] [CrossRef] [Green Version]
- Dogan, A.; Birant, D. A Two-Level Approach based on Integration of Bagging and Voting for Outlier Detection. J. Data Inf. Sci. 2020, 5, 111–135. [Google Scholar] [CrossRef]
- Salehi, M.; Rashidi, L. A Survey on Anomaly detection in Evolving Data: [with Application to Forest Fire Risk Prediction]. ACM sigKDD Explor. Newsl. 2018, 20, 13–23. [Google Scholar] [CrossRef]
- Pokrajac, D.; Lazarevic, A.; Latecki, L.J. Incremental local outlier detection for data streams. In Proceedings of the 2007 IEEE Symposium on Computational Intelligence and Data Mining, Honolulu, HI, USA, 1 March–5 April 2007; pp. 504–515. [Google Scholar]
- Shneiderman, B. The eyes have it: A task by data type taxonomy for information visualizations. In Proceedings of the 1996 IEEE Symposium on Visual Languages, Boulder, CO, USA, 3–9 September 1996; pp. 336–343. [Google Scholar] [CrossRef] [Green Version]
- Badam, S.K.; Zhao, J.; Sen, S.; Elmqvist, N.; Ebert, D. TimeFork: Interactive prediction of time series. Conf. Hum. Factors Comput. Syst. Proc. 2016, 5409–5420. [Google Scholar] [CrossRef]
- Zhao, Y.; Nasrullah, Z.; Li, Z. Pyod: A python toolbox for scalable outlier detection. arXiv 2019, arXiv:1901.01588. [Google Scholar]
- Goldstein, M.; Uchida, S. A comparative evaluation of unsupervised anomaly detection algorithms for multivariate data. PLoS ONE 2016, 11, e0152173. [Google Scholar] [CrossRef] [Green Version]
- Unnikrishnan, V.; Schleicher, M.; Shah, Y.; Jamaludeen, N.; Pryss, R.; Schobel, J.; Kraft, R.; Schlee, W.; Spiliopoulou, M. The Effect of Non-Personalised Tips on the Continued Use of Self-Monitoring mHealth Applications. Brain Sci. 2020, 10, 924. [Google Scholar] [CrossRef]
- Hiller, W.; Goebel, G. When tinnitus loudness and annoyance are discrepant: Audiological characteristics and psychological profile. Audiol. Neurotol. 2007, 12, 391–400. [Google Scholar] [CrossRef] [PubMed]
- Perez, M.V.; Mahaffey, K.W.; Hedlin, H.; Rumsfeld, J.S.; Garcia, A.; Ferris, T.; Balasubramanian, V.; Russo, A.M.; Rajmane, A.; Cheung, L.; et al. Large-scale assessment of a smartwatch to identify atrial fibrillation. New Engl. J. Med. 2019, 381, 1909–1917. [Google Scholar] [CrossRef] [PubMed]
- Agarwal, S.; LeFevre, A.E.; Lee, J.; L’engle, K.; Mehl, G.; Sinha, C.; Labrique, A. Guidelines for reporting of health interventions using mobile phones: Mobile health (mHealth) evidence reporting and assessment (mERA) checklist. BMJ 2016, 352, i1174. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Breunig, M.M.; Kriegel, H.P.; Ng, R.T.; Sander, J. LOF: Identifying density-based local outliers. In Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data, Dallas, TX, USA, 16–18 May 2000; Volume 29, pp. 93–104. [Google Scholar]
| Notation | Description |
|---|---|
| u | a user of the application |
| x and z | Whenever a sentence refers to more than one user, these users are denoted them as denote as |
| U | the set of all users who use the mHealth application, which is the data source of this study |
| D | the (sub)set of users used for training the models; |
| T | the (sub)set of test users, who are not used during model training, but are used to assess model quality; |
| k | neighborhood size |
| the k nearest neighbors of u | |
| the feature space of the registration data, with being a feature, for | |
| F | the feature space of EMA recordings, with being a feature, for ; |
| a timepoint | |
| A feature belonging to EMA feature space F | |
| the timepoints in the future for which we make predictions, i.e., we predict at for user u | |
| A predicted value for feature |
| Feature Combinations | Max_DAY | Mean_DAY | Min_DAY | |||
|---|---|---|---|---|---|---|
| WA | LR | WA | LR | WA | LR | |
| C1 | 0.23407 | 0.2332 | 0.21105 | 0.2096 | 0.20481 | 0.20414 |
| ±0.00656 | ±0.0059 | ±0.0084 | ±0.00948 | ±0.00857 | ±0.01003 | |
| C2 | 0.2156 | 0.2188 | 0.19403 | 0.19539 | 0.19252 | 0.1973 |
| ±0.00808 | ±0.0048 | ±0.00859 | ±0.00529 | ±0.00899 | ±0.00454 | |
| C3 | 0.2077 | 0.2099 | 0.18882 | 0.19191 | 0.18948 | 0.19619 |
| ±0.00925 | ±0.00923 | ±0.00745 | ±0.007320 | ±0.0116 | ±0.0122 | |
| Category | Num Users | Total Number of Observations (s03) | Probability |
|---|---|---|---|
| Low | 45 | 1911 | 0.497 |
| Moderate | 48 | 1155 | 0.30 |
| High | 37 | 773 | 0.201 |
| Total | - | 3839 | 1.0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Prakash, S.; Unnikrishnan, V.; Pryss, R.; Kraft, R.; Schobel, J.; Hannemann, R.; Langguth, B.; Schlee, W.; Spiliopoulou, M. Interactive System for Similarity-Based Inspection and Assessment of the Well-Being of mHealth Users. Entropy 2021, 23, 1695. https://doi.org/10.3390/e23121695
Prakash S, Unnikrishnan V, Pryss R, Kraft R, Schobel J, Hannemann R, Langguth B, Schlee W, Spiliopoulou M. Interactive System for Similarity-Based Inspection and Assessment of the Well-Being of mHealth Users. Entropy. 2021; 23(12):1695. https://doi.org/10.3390/e23121695
Chicago/Turabian StylePrakash, Subash, Vishnu Unnikrishnan, Rüdiger Pryss, Robin Kraft, Johannes Schobel, Ronny Hannemann, Berthold Langguth, Winfried Schlee, and Myra Spiliopoulou. 2021. "Interactive System for Similarity-Based Inspection and Assessment of the Well-Being of mHealth Users" Entropy 23, no. 12: 1695. https://doi.org/10.3390/e23121695
APA StylePrakash, S., Unnikrishnan, V., Pryss, R., Kraft, R., Schobel, J., Hannemann, R., Langguth, B., Schlee, W., & Spiliopoulou, M. (2021). Interactive System for Similarity-Based Inspection and Assessment of the Well-Being of mHealth Users. Entropy, 23(12), 1695. https://doi.org/10.3390/e23121695