1. Introduction
In his seminal paper, Wyner [
1] introduced the wiretap channel as a model of secure communication over a degraded broadcast channel, without using a secret key, where the legitimate receiver has access to the output of the good channel and the wiretapper receives the output of the bad channel. The main idea is that the excess noise at the output of the wiretapper channel is utilized to secure the message intended to the legitimate receiver. Wyner fully characterized the best achievable trade-off between reliable communication to the legitimate receiver and the equivocation rate at the wiretapper, which was quantified in terms of the conditional entropy of the source given the output of the wiretapper channel. One of the most important concepts, introduced by Wyner, was the
secrecy capacity, that is, the supremum of all coding rates that allow both reliable decoding at the legitimate receiver and full secrecy, where the equivocation rate saturates at the (unconditional) entropy rate of the source, or equivalently, the normalized mutual information between the source and the wiretap channel output is vanishingly small for large blocklength. The idea behind the construction of a good code for the wiretap channel is basically the same as the idea of binning: one designs a big code, that can be reliably decoded at the legitimate receiver, which is subdivided into smaller codes that are fed by purely random bits that are unrelated to the secret message. Each such sub-code can be reliably decoded individually by the wiretapper to its full capacity, thus leaving no further decoding capability for the remaining bits, which all belong to the real secret message.
During the nearly five decades that have passed since [
1] was published, the wiretap channel model was extended and further developed in many aspects. We mention here just a few. Three years after Wyner, Csiszár and Körner [
2] extended the wiretap channel to a general broadcast channel that is not necessarily degraded, allowing also a common message intended to both receivers. In the same year, Leung-Yan-Cheong and Hellman [
3], studied the Gaussian wiretap channel, and proved, among other things, that its secrecy capacity is equal to the difference between the capacity of the legitimate channel and that of the wiretap channel. In [
4], Ozarow and Wyner considered a somewhat different model, known as the type II wiretap channel, where the channel to the legitimate receiver is clean (noiseless), and the wiretapper can access a subset of the coded bits. In [
5], Yamamoto extended the wiretap channel to include two parallel broadcast channels that connect one encoder and one legitimate decoder, and both channels are wiretapped by wiretappers that do not cooperate with each other. A few years later, the same author [
6] further developed the scope of [
1] in two ways: first, by allowing a private secret key to be shared between the encoder and the legitimate receiver, and secondly, by allowing a given distortion in the reproducing the source at the legitimate receiver. The main coding theorem of [
6] suggests a three-fold separation principle, which asserts that no asymptotic optimality is lost if the encoder first applies a good lossy source code, then encrypts the compressed bits, and finally, applies a good channel code for the wiretap channel. In [
7], this model in turn was generalized to allow source side information at the decoder and at the wiretapper in a degraded structure with application to systematic coding for the wiretap channel. The Gaussian wiretap channel model of [
3] was also extended in two ways: the first is the Gaussian multiple access wiretap channel of [
8], and the second is Gaussian interference wiretap channel of [
9,
10], where the encoder has access to the interference signal as side information. Wiretap channels with feedback were considered in [
11], where it was shown that feedback is best used for the purpose of sharing a secret key as in [
6,
7]. More recent research efforts were dedicated to strengthening the secrecy metric from weak secrecy to strong secrecy, where the mutual information between the source and the wiretap channel output vanishes, even without normalization by the blocklength, as well as to semantic security, which is similar but refers even to the worst-case message source distribution; see, for example, Refs. [
12,
13,
14,
15,
16], (Section 3.3 in [
14]).
In this work, we look at Wyner’s wiretap channel model from a different perspective. Following the individual sequence approach pioneered by Ziv in [
17,
18,
19], and continued in later works, such as [
20,
21], we consider the problem of encoding a deterministic source sequence (i.e., an individual sequence) for the degraded wiretap channel using finite-state encoders and finite-state decoders. One of the non-trivial issues associated with individual sequences, in the context of the wiretap channel, is how to define the security metric, as there is no probability distribution assigned to the source, and therefore, the equivocation, or the mutual information between the source and the wiretap channel output, cannot be well defined. In [
20], a similar dilemma was encountered in the context of private key encryption of individual sequences, and in the converse theorem therein, it was assumed that the system is perfectly secure in the sense that the probability distribution of the cryptogram does not depend on the source sequence. In principle, it is possible to apply the same approach here, where the word ‘cryptogram’ is replaced by the ‘wiretap channel output’. However, in order to handle residual dependencies, which will always exist, it would be better to use a security metric that quantifies those small dependencies. To this end, it makes sense to adopt the above-mentioned maximum mutual information security metric (or, equivalently the semantic security metric), where the maximum is over all input assignments. After this maximization, this quantity depends only on the ‘channel’ between the source and the wiretap channel output.
Our first main result is a necessary condition (i.e., a converse to a coding theorem) for both reliable and secure transmission, which depends on: (i) the given individual source sequence, (ii) the bandwidth expansion factor, (iii) the secrecy capacity, (iv) the number of states of the encoder, (v) the number of states of the decoder, (vi) the allowed bit error probability at the legitimate decoder and (vii) the allowed maximum mutual information secrecy. Equivalently, this necessary condition can be presented as a converse bound (i.e., a lower bound) to the smallest achievable bandwidth expansion factor. The bound is asymptotically achievable by Lempel–Ziv (LZ) compression followed by a good channel coding scheme for the wiretap channel. Given that this lower bound is saturated, we then derive also a lower bound on the minimum necessary rate of purely random bits needed for adequate local randomness at the encoder, in order to meet the security constraint. This bound too is achieved by the same achievability scheme, a fact which may be of independent interest regardless of individual sequences and finite-state encoders and decoders (i.e., also for ordinary block codes in the traditional probabilistic setting). Finally, we extend the main results to the case where the legitimate decoder has access to a side information sequence, which is another individual sequence that may be related to the source sequence, and where a noisy version of the side information sequence leaks to the wiretapper. It turns out that in this case, the best strategy is the same as if one assumes that the wiretapper sees the clean side information sequence. While this may not be surprising as far as sufficiency is concerned (i.e., as an achievability result), it is less obvious in the context of necessity (i.e., a converse theorem).
The remaining part of this article is organized as follows. In
Section 2, we establish the notation, provide some definitions and formalize the problem setting. In
Section 3, we provide the main results of this article and discuss them in detail. In
Section 4, the extension that incorporates side information is presented. Finally, in
Section 5, the proofs of the main theorems are given.
2. Notation, Definitions, and Problem Setting
2.1. Notation
Throughout this paper, random variables are denoted by capital letters; specific values they may take are denoted by the corresponding lower case letters; and their alphabets are denoted by calligraphic letters. Random vectors, their realizations, and their alphabets are denoted, respectively, by capital letters, the corresponding lower case letters and calligraphic letters, all superscripted by their dimensions. For example, the random vector , (n – positive integer) may take a specific vector value in , the n-th order Cartesian power of , which is the alphabet of each component of this vector. Infinite sequences are denoted using the bold face font, e.g., . Segments of vectors are denoted by subscripts and superscripts that correspond to the start and the end locations; for example, , for integers, denotes . When , the subscript is omitted.
Sources and channels are denoted by the letter P or Q, subscripted by the names of the relevant random variables/vectors and their conditionings, if applicable, following the standard notation conventions, e.g., , , and so on, or by abbreviated names that describe their functionality. When there is no room for ambiguity, these subscripts are omitted. The probability of an event will be denoted by , and the expectation operator with respect to (w.r.t.) a probability distribution P is denoted by . Again, the subscript is omitted if the underlying probability distribution is clear from the context or explicitly explained in the following text. The indicator function of an event is denoted by , that is, if occurs; otherwise, .
Throughout considerably large parts of the paper, the analysis is carried out w.r.t. joint distributions that involve several random variables. Some of these random variables are induced from empirical distributions of deterministic sequences, while others are ordinary random variables. Random variables from the former kind are denoted with ‘hats’. As a simple example, consider a deterministic sequence, , that is fed as an input to a memoryless channel defined by a single-letter transition matrix, , and let denote a realization of the corresponding channel output. Let denote the joint empirical distribution induced from . In addition to , we also define , where now Y is an ordinary random variable. Clearly, the relation between the two distributions is given by , where is the empirical marginal of . Such mixed joint distributions underlie certain information-theoretic quantities, for example, and denote, respectively, the mutual information between and Y and the conditional entropy of Y given , both induced from . The same notation rules are applicable in more involved situations too.
2.2. Definitions and Problem Setting
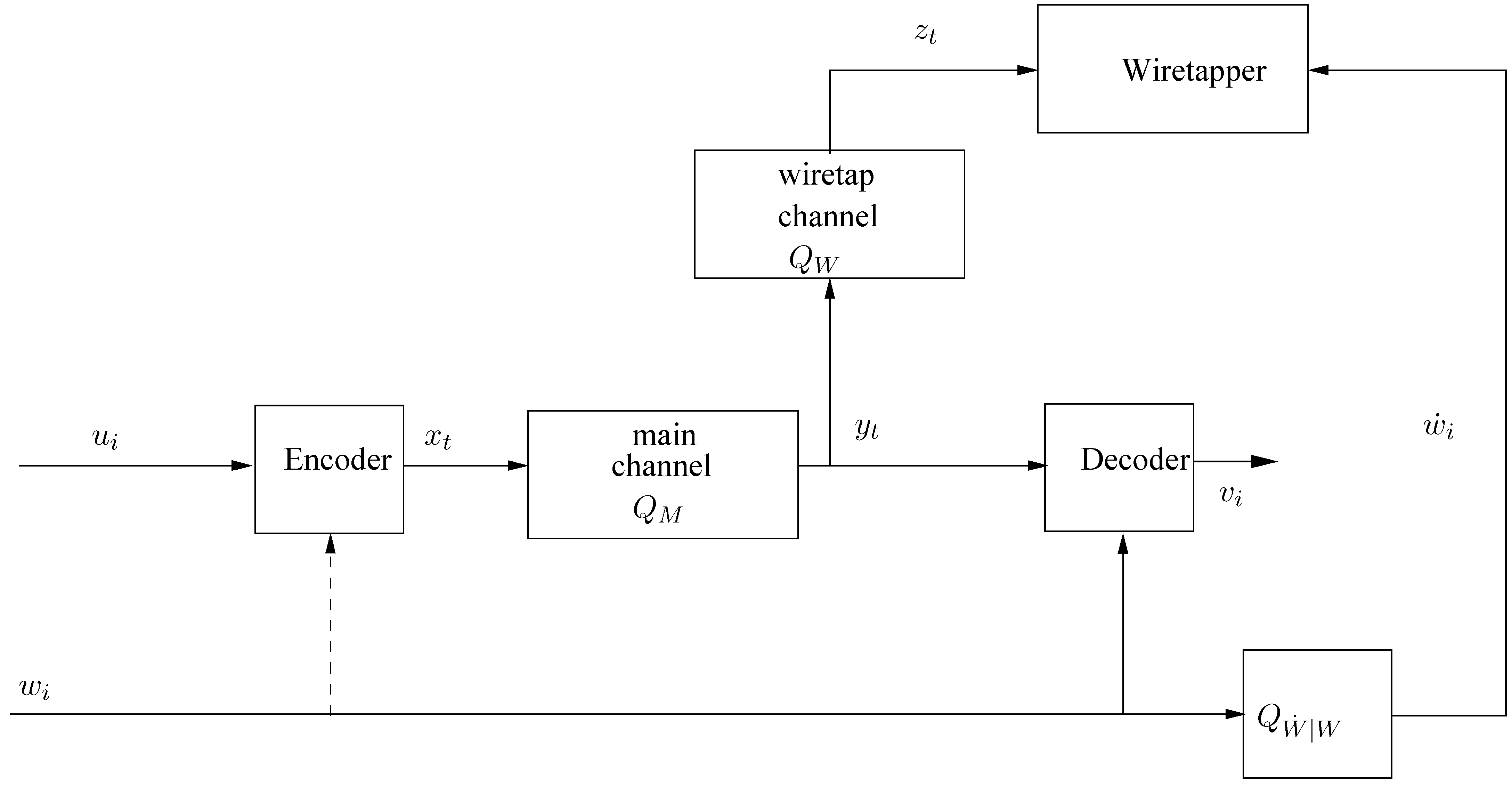
We consider the system configuration of the degraded wiretap channel, depicted in
Figure 1. Let
be a deterministic source sequence (i.e., individual sequence), whose symbols take values in a finite alphabet,
, of size
. This source sequence is to be conveyed reliably to a legitimate decoder while keeping it secret from a wiretapper, as described below. The encoding mechanism is as follows. The source sequence,
u is first is divided into chunks of length
k,
,
, which are fed into a stochastic finite-state encoder, defined by the following equations:
We allow a stochastic encoder, in view of the fact that even the traditional, probabilistic setting, optimal coding for the wiretap channel (see [
1] and later works) must be randomized in order to meet the security requirements. Here,
is a random vector taking values in
,
being the
-ary input alphabet of the channel and
m being a positive integer;
is a realization of
; and
is the state of the encoder at time
i, which designates the memory of the encoder with regard to the past of the source sequence. In other words, at time instant
i, whatever the encoder ‘remembers’ from
is stored in the variable
(for example, in the case of trellis coding, it can be a shift register of finite length, say
p, that stores the most recent symbols of
p,
, or, in block coding, it can be the contents of the current block starting from its beginning up to the present). The state,
, takes values in a finite set of states,
, of size
. In the above equation, the variable
is any member of
. The function
is called the
next-state function of the encoder. (More generally, we could define both
and
to be random functions of the
by a conditional joint distribution,
. However, it makes sense to let the encoder state sequence evolve deterministically in response to the input
u since the state designates the memory of the encoder to past inputs.) Finally,
,
,
,
, is a conditional probability distribution function, i.e.,
are all non-negative and
for all
. The vector
designates the current output vector from the encoder in response to the current input source vector,
and its current state,
. Without loss of generality, we assume that the initial state of the encoder,
, is some fixed member of
. The ratio
is referred to as the
bandwidth expansion factor. It should be pointed out that the parameters
k and
m are fixed integers, which are not necessarily large (e.g.,
and
are valid values of
k and
m). The concatenation of the output vectors from the encoder,
, is viewed as a sequence chunks of channel input symbols,
, with
, similarly to the above-defined partition of the source sequence.
The sequence of encoder outputs,
, is fed into a discrete memoryless channel (DMC), henceforth referred to as the
main channel, whose corresponding outputs,
, are generated according to
for every positive integer
N and every
and
. The channel output symbols,
, take values in a finite alphabet,
, of size
.
The sequence of channel outputs,
, is divided into chunks of length
m,
,
, which are fed into a deterministic finite-state decoder, defined according to the following recursive equations:
where the variables in the equations are defined as follows:
is the sequence of states of the decoder (which again, designate the finite memory, this time, at the decoder). Each
takes values in a finite set,
of size
. The variable
is the
i-th chunk of
k source reconstruction symbols, i.e.,
,
, which form the decoder output. The function
is called the
output function of the decoder and the function
is the next-state function of the decoder. The concatenation of the decoder output vectors,
, forms the entire stream of reconstruction symbols,
.
The output of the main channel,
, is fed into another DMC, henceforth referred to as the
wiretap channel, which generates, in response, a corresponding sequence,
, according to
where
and
take values in a finite alphabet
. We denote the cascade of channels
and
by
, that is
We seek a communication system which satisfies two requirements:
For a given
, the system satisfies the following reliability requirement: The bit error probability is guaranteed to be less than
, i.e.,
for every
and every combination of initial states of the encoder and the decoder, where
is defined w.r.t. the randomness of the encoder and the main channel.
For a given
, the system satisfies the following security requirement: For every sufficiently large positive integer
n,
where
and
is the mutual information between
and
, induced by an input distribution
and the system,
.
As for the reliability requirement, note that the larger
k is, the less stringent the requirement becomes. Concerning the security requirement, ideally, we would like to have perfect secrecy, which means that
would be independent of
(see also [
20]), but it is more realistic to allow a small deviation from this idealization. This security metric is actually the maximum mutual information metric, or equivalently (see [
15]) the semantic security, as mentioned in the Introduction.
2.3. Preliminaries and Background
We need two more definitions along with some background associated with them. The first is the
secrecy capacity [
1,
14], which is the supremum of all coding rates for which there exist block codes that maintain both an arbitrarily small error probability at the legitimate decoder and an equivocation arbitrarily close to the unconditional entropy of the source. The secrecy capacity is given by
with
for all
.
The second quantity we need to define is the LZ complexity [
22]. In their famous paper [
22], Ziv and Lempel actually developed a deterministic counterpart of source coding theory, where instead of imposing assumptions on probabilistic mechanisms that generate the data (i.e., memoryless sources, Markov sources, and general stationary sources), whose relevance to real-world data compression may be subject to dispute, they considered arbitrary, deterministic source sequences (i.e., individual sequences, in their terminology), but they imposed instead a limitation on the resources of the encoder (or the data compression algorithm): they assumed that it has limited storage capability (i.e., limited memory) of past data when encoding the current source symbol. This limited storage was modeled in terms of a finite-state machine, where the state variable of the encoder evolves recursively in time in response to the input and designates the information that the encoder ‘remembers’ from the past input (just like in the model description in
Section 2.2 above). As mentioned earlier, a simple example of such a state variable can be the contents of a finite shift register, fed sequentially by the source sequence in which case the state contains a finite number of the most recent source symbols. This individual-sequence approach is appealing, because it is much more realistic to assume practical limitations on the encoder (which is under the control of the system designer) than to make assumptions on the statistics of the data to be compressed.
Ziv and Lempel developed an asymptotically optimal, practical compression algorithm (which is used in almost every computer), that is well known as the Lempel–Ziv (LZ) algorithm. This algorithm has several variants. One of them, which is called the LZ78 algorithm (where ‘78’ designates the year 1978), is based on the notion of
incremental parsing: given the the source vector,
, the incremental parsing procedure sequentially parses this sequence into distinct phrases such that each new parsed phrase is the shortest string that has not been obtained before as a phrase, with a possible exception of the last phrase, which might be incomplete. Let
denote the number of resulting phrases. For example, if
and
, then incremental parsing (from left to right) yields
and so,
. We define the
LZ complexity of the individual sequence,
, as
As was shown by Ziv and Lempel in their seminal paper [
22], for large
n, the LZ complexity,
, is essentially the best compression ratio that can be achieved by any information lossless, finite-state encoder (up to some negligibly small terms, for large
n), and it can be viewed as the individual-sequence analogue of the entropy rate.
3. Results
Before moving on to present our first main result, a simple comment is in order. Even in the traditional probabilistic setting, given a source with entropy H and a channel with capacity C, reliable communication cannot be accomplished unless , where is the bandwidth expansion factor. Since both H and C are given and only is under the control of the system designer, it is natural to state this condition as a lower bound to bandwidth expansion factor, i.e., . By the same token, in the presence of a secrecy constraint, must not fall below . Our converse theorems for individual sequences are presented in the same spirit, where the entropy H at the numerator is replaced by an expression whose main term is the Lempel–Ziv compressibility.
We assume, without essential loss of generality, that k divides n (otherwise, omit the last symbols of and replace n by without affecting the asymptotic behavior as ). Our first main result is the following.
Theorem 1. Consider the problem setting defined in Section 2. If there exists a stochastic encoder with states and a decoder with states that together satisfy the reliability constraint (9) and the security constraint (10), then the bandwidth expansion factor λ must be lower bounded as follows.wherewith being the binary entropy function, andwith as . The proof of Theorem 1, like all other proofs in this article, is deferred to
Section 5.
Discussion. A few comments are in order with regard to Theorem 1.
- 1.
Irrelevance of . It is interesting to note that as far as the encoding and decoding resources are concerned, the lower bound depends on k and , but not on the number of states of the encoder, . This means that the same lower bound continues to hold, even if the encoder has an unlimited number of states. Pushing this to the extreme, even if the encoder has room to store the entire past, the lower bound of Theorem 1 would remain unaltered. The crucial bottleneck is, therefore, in the finite memory resources associated with the decoder, where the memory may help to reconstruct the source by exploiting empirical dependencies with the past. The dependence on , however, appear later when we discuss local randomness resources as well as in the extension to the case of decoder side information.
- 2.
The redundancy term . A technical comment is in order concerning the term , which involves minimization over all divisors of , where we have already assumed that is integer. Strictly speaking, if happens to be a prime, this minimization is not very meaningful, as would be relatively large. If this the case, a better bound is obtained if one omits some of the last symbols of , thereby reducing n to, say, so that has a richer set of factors. Consider, for example, the choice (instead of minimizing over ℓ) and replace by the , without essential loss of tightness. This way, would tend to zero as , for fixed k and .
- 3.
Achievability. Having established that
, and given that
and
are small, it is clear that the main term at the numerator of the lower bound of Theorem 1 is the term
, which is, as mentioned earlier, the individual-sequence analogue of the entropy of the source [
22]. In other words,
cannot be much smaller than
. A matching achievability scheme would most naturally be based on separation: first apply variable-rate compression of
to about
bits using the LZ algorithm [
22], and then feed the resulting compressed bit-stream into a good code for the wiretap channel [
1] with codewords of length about
where
is an arbitrarily small (but positive) margin to keep the coding rate strictly smaller than
. However, to this end, the decoder must know
N. One possible solution is that before the actual encoding of each
, one would use a separate, auxiliary fixed code that encodes the value of the number of compressed bits,
, using
bits (as
is about the number of possible values that
can take) and protect it using a channel code of rate less than
. Since the length of this auxiliary code grows only logarithmically with
n (as opposed to the ‘linear’ growth of
), the overhead in using the auxiliary code is asymptotically negligible. The auxiliary code and the main code are used alternately: first the auxiliary code, and then the main code for each
n-tuple of the source. The main channel code is actually an array of codes, one for each possible value of
. Once the auxiliary decoder has decoded this number, the corresponding main decoder is used. Overall, the resulting bandwidth expansion factor is about
Another, perhaps simpler and better, approach is to use the LZ algorithm in the mode of a variable-to-fixed length code: let the length of the channel codeword,
N, be fixed, and start to compress
until obtaining
compressed bits. Then,
Of course, these coding schemes require decoder memory that grows exponentially in
n, and not just a fixed number,
, and therefore strictly speaking, there is a gap between the achievability and the converse result of Theorem 2. However, this gap is closed asymptotically, once we take the limit of
after the limit
, and we consider successive application of these codes over many blocks. The same approach appears also in [
17,
18,
19,
22] as well as in later related work.
This concludes the discussion on Theorem 1. □
We next focus on local randomness resources that are necessary when the full secrecy capacity is exploited. Specifically, suppose that the stochastic encoder
is implemented as a deterministic encoder with an additional input of purely random bits, i.e.,
where
is a string of
j purely random bits. The question is the following: how large must
j be in order to achieve full secrecy? Equivalently, what is the minimum necessary rate of random bits for local randomness at the encoder for secure coding at the maximum reliable rate? In fact, this question may be interesting on its own right, regardless of the individual-sequence setting and finite-state encoders and decoders, but even for ordinary block coding (which is the special case of
) and in the traditional probabilistic setting. The following theorem answers this question.
Theorem 2. Consider the problem setting defined in Section 2 and let λ meet the lower bound of Theorem 1. If there exists an encoder (19) with states and a decoder with states that jointly satisfy the reliability constraint (9) and the security constraint (10), thenwhere is the random variable that achieves and ℓ is the achiever of . Note that the lower bound of Theorem 2 depends on
, as opposed to Theorem 1, where it depends only on
. Since
is assumed small and
, it is clear that main term is
, i.e., the bit rate must be essentially at least as large as
random bits per channel use, or equivalently,
bits per source symbol. It is interesting to note that Wyner’s code [
1] asymptotically achieves this bound when the coding rate saturates the secrecy capacity because the subcode that can be decoded by the wiretapper (within each given bin) is of the rate of about
, and it encodes just the bits of the local randomness. So when working at the full secrecy capacity, Wyner’s code is optimal not only in terms of the optimal trade-off between reliability and security, but also in terms of minimum consumption of local, purely random bits.
4. Side Information at the Decoder with Partial Leakage to the Wiretapper
Consider next an extension of our model to the case where there are side information sequences,
and
, available to the decoder and the wiretapper, respectively; see
Figure 2. For the purpose of a converse theorem, we assume that
is available to the encoder too, whereas in the achievability part, we comment also on the case where it is not. We assume that
is a deterministic sequence, but
is a realization of a random vector
, which is a noisy version of
. In other words, it is generated from
by another memoryless channel,
. The symbols of
and
take values in finite alphabets,
and
, respectively. There are two extreme important special cases: (i)
almost surely, which is the case of totally insecure side information that fully leaks to the wiretapper, and (ii)
is degenerated (or independent of
), which is the case of secure side information with no leakage to the wiretapper. Every intermediate situation between these two extremes is a situation of partial leakage. The finite-state encoder model is now re-defined according to
where
,
. Likewise, the decoder is given by
and the wiretapper has access to
and
. Accordingly, the security constraint is modified as follows: for a given
and for every sufficiently large
n,
where
is the conditional mutual information between
and
given
, induced by
and the system,
, where
.
In order to present the extension of Theorem 1 to incorporate side information, we first need to define the extension of the LZ complexity to include side information, namely, to define the conditional LZ complexity (see also [
23]). Given
and
, let us apply the incremental parsing procedure of the LZ algorithm to the sequence of pairs
. According to this procedure, all phrases are distinct with a possible exception of the last phrase, which might be incomplete. Let
denote the number of distinct phrases. As an example (which appears also in [
23]), if
then
. Let
denote the resulting number of distinct phrases of
, and let
denote the
l-th distinct
w-phrase,
. In the above example,
. Denote by
the number of occurrences of
in the parsing of
, or equivalently, the number of distinct
u-phrases that jointly appear with
. Clearly,
. In the above example,
,
,
,
, and
. Now, the conditional LZ complexity of
given
is defined as
We are now ready to present the main result of this section.
Theorem 3. Consider the problem setting defined in Section 2 along with the above–mentioned modifications to incorporate side information. If there exists a stochastic encoder with states and a decoder with states that together satisfy the reliability constraint (9) and the security constraint (25), then its bandwidth expansion factor λ must be lower bounded as follows.wherewith as and , ω being the size of . Note that the lower bound of Theorem 3 does not depend on the noisy side information at the wiretapper or on the channel that generates it from . It depends only on and in terms of the data available in the system. Clearly, as it is a converse theorem, if it allows the side information to be available also at the encoder, then it definitely applies also to the case where the encoder does not have access to . Interestingly, the encoder and the legitimate decoder act as if the wiretapper has the clean side information, . While it is quite obvious that protection against availability of at the wiretapper is sufficient for protection against availability of (as is a degraded version of ), it is not quite trivial that this should be also necessary, as the above converse theorem asserts. It is also interesting to note that here, the bound depends also on , and not only , as in Theorem 1. However, this dependence on disappears in the special case where with probability one.
We next discuss the achievability of the lower bound of Theorem 3. If the encoder has access to
, then the first step would be to apply the conditional LZ algorithm (see ([
23], proof of Lemma 2) [
24]), thus compressing
to about
bits. The second step would be good channel coding for the wiretap channel, using the same methods as described in the previous section. If, however, the encoder does not have access to
, the channel coding part is still as before, but the situation with the source coding part is somewhat more involved since neither the encoder nor the decoder can calculate the target bit rate,
, as neither party has access to both
and
. However, this source coding rate can essentially be achieved, provided that there is a low-rate noiseless feedback channel from the legitimate decoder to the encoder. The following scheme is in the spirit of the one proposed by Draper [
25], but with a few modifications.
The encoder implements random binning for all source sequences in
, that is, for each member of
an index is drawn independently, under the uniform distribution over
, which is represented by its binary expansion,
, of length
bits. We select a large positive integer
r, but keep
(say,
or
). The encoder transmits the bits of
incrementally,
r bits at a time, until it receives from the decoder
ACK. Each chunk of
r bits is fed into a good channel code for the wiretap channel, at a rate slightly less than
. At the decoder side, this channel code is decoded (correctly, with high probability, for large
r). Then, for each
i (
), after having decoded the
i-th chunk of
r bits of
, the decoder creates the list
, where
denotes the string formed by the first
l bits of
. For each
, the decoder calculates
. We fix an arbitrarily small
, which controls the trade-off between error probability and compression rate. If
for some
, the decoder sends
ACK on the feedback channel and outputs the reconstruction,
, with the smallest
among all members of
. If no member of
satisfies
, the receiver waits for the next chunk of
r compressed bits, and it does not send
ACK. The probability of source-coding error after the
i-th chunk is upper bounded by
where in (a), the factor
is the probability that
for each member of the set
and (b) is based on ([
23], Equation (A.13)). Clearly, it is guaranteed that an
ACK is received at the encoder (and hence the transmission stops), no later than after the transmission of chunk no.
, where
is the smallest integer
i such that
, namely,
, which is the stage at which at least the correct source sequence begins to satisfy the condition
. Therefore, the compression ratio is no worse than
. The overall probability of source-coding error is then upper bounded by
which still tends to zero as
. As for channel-coding errors, the probability that at least one chunk is decoded incorrectly is upper bounded by
, where
E is an achievable error exponent of channel coding at the given rate. Thus, if
r grows at any rate faster than logarithmic, but sub-linearly in
n, then the overall channel-coding error probability tends to zero and, at the same time, the compression redundancy,
, tends to zero too.
To show that the security constraint (
25) is satisfied too, consider an arbitrary assignment
of random vectors
, and let us denote by
B the string of
bits of local randomness in Wyner’s code [
1]. Then,
where (a) is due to
being a Markov chain, (b) is due to conditioning reducing entropy, (c) is due to
being a Markov chain, (d) is due to
B being independent of
, (e) is due to conditioning reducing entropy, and (f) is due to, in Wyner coding,
B being able to be reliably decoded given that
(
is understood to be small, and recall that
is not needed in the channel decoding phase, but only in the Slepian–Wold decoding phase), and that the length of
B is chosen to be
. Comparing the right-most side to the left-most side, we readily obtain
which can be made arbitrarily small.


{kind=link}
{kind=link}

