
Soft Compression for Lossless Image Coding Based on Shape Recognition



Abstract
:1. Introduction
1.1. Image Compression Method
1.2. Related Work
1.3. Soft Compression
2. Theory
2.1. Preliminary
2.1.1. Information Theory
2.1.2. Image Fundamentals
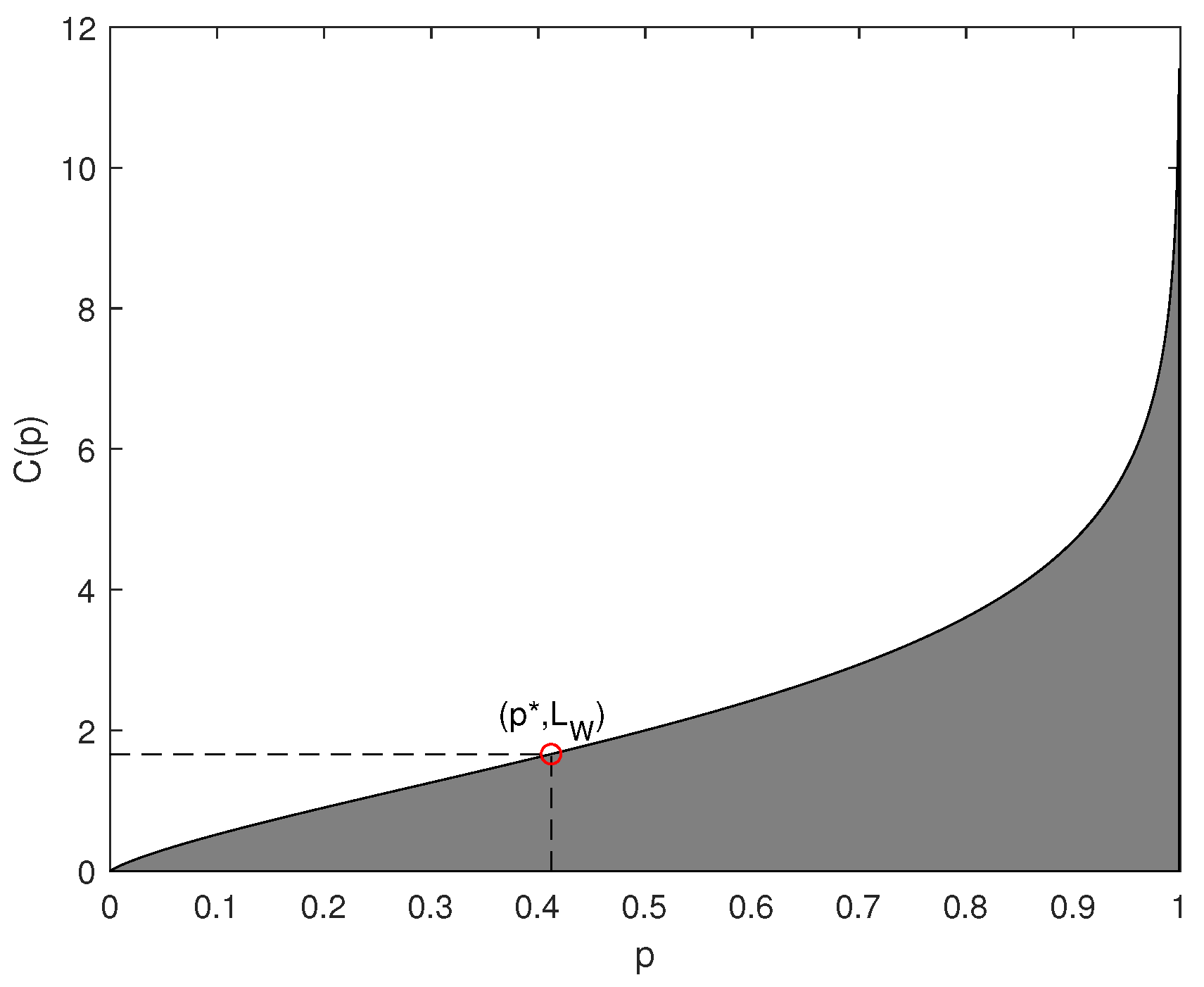
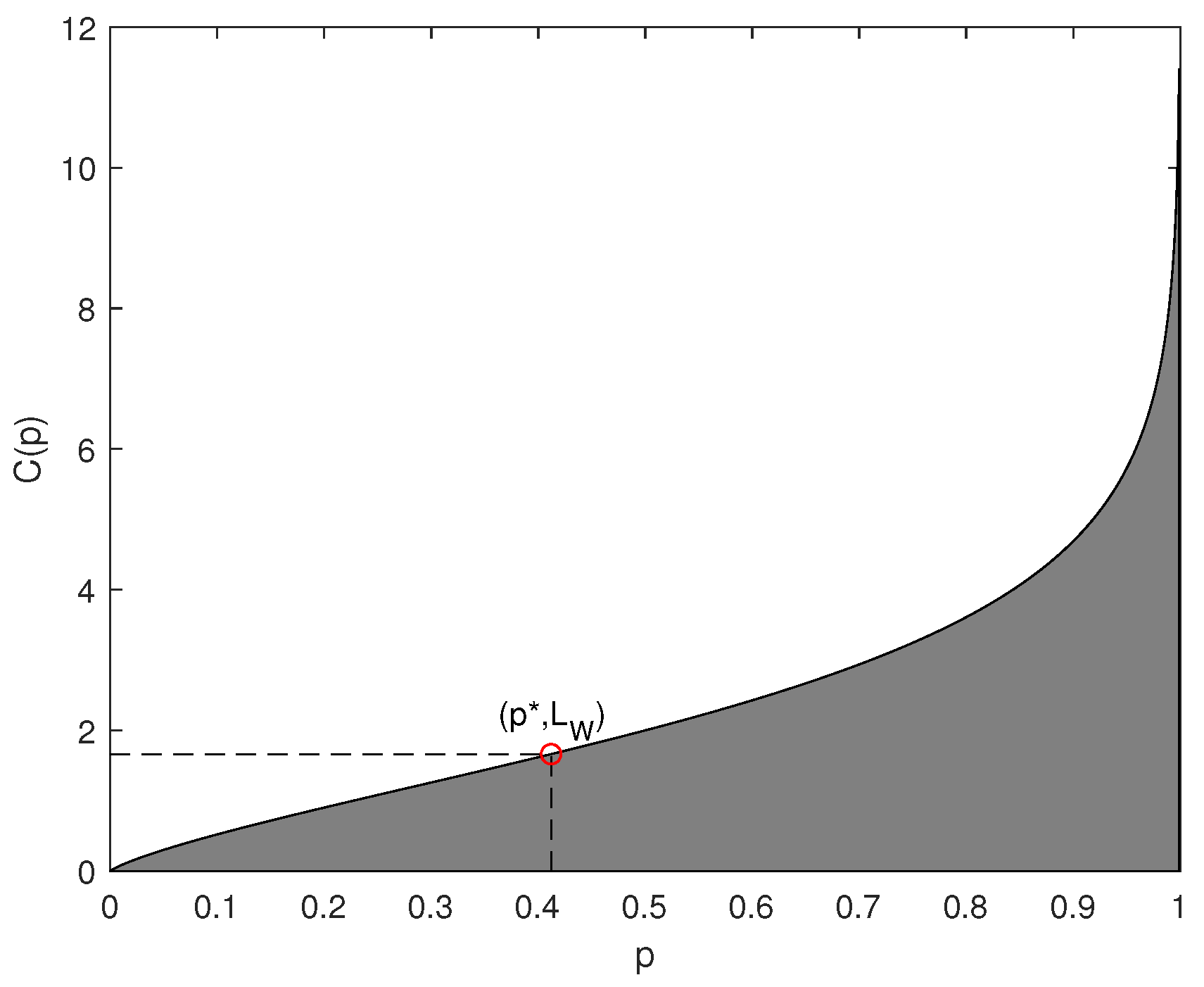
2.2. Soft Compression
3. Implementation Algorithm
3.1. Binary Image
3.2. Gray Image
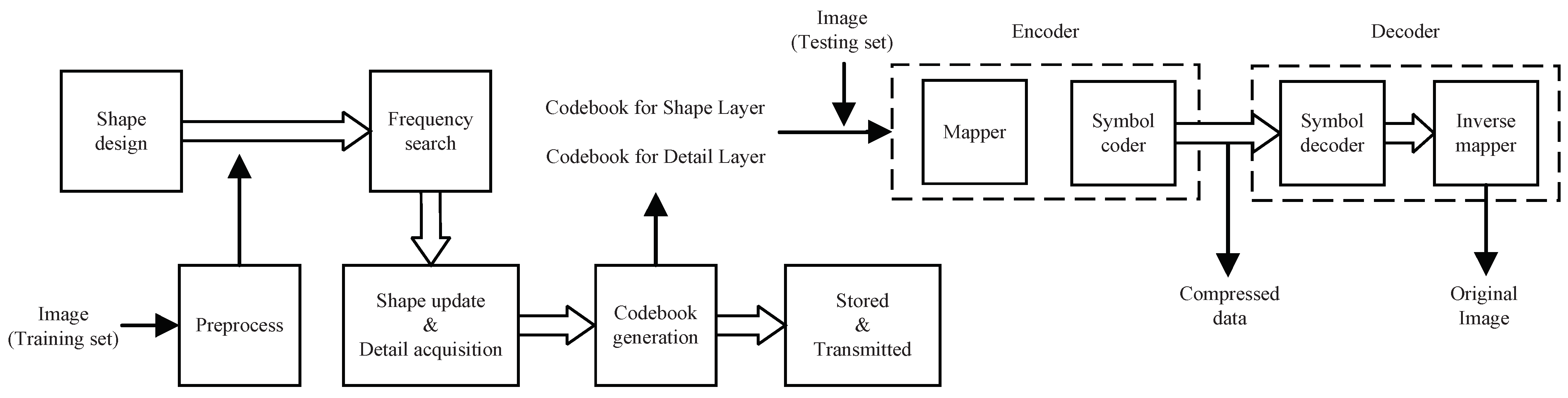
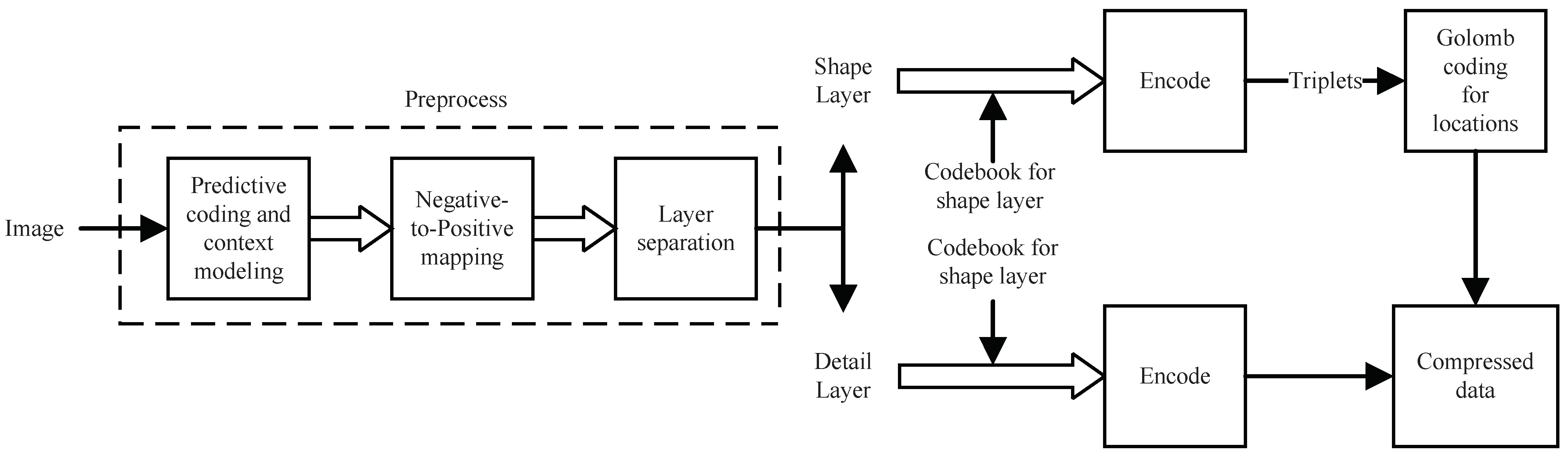
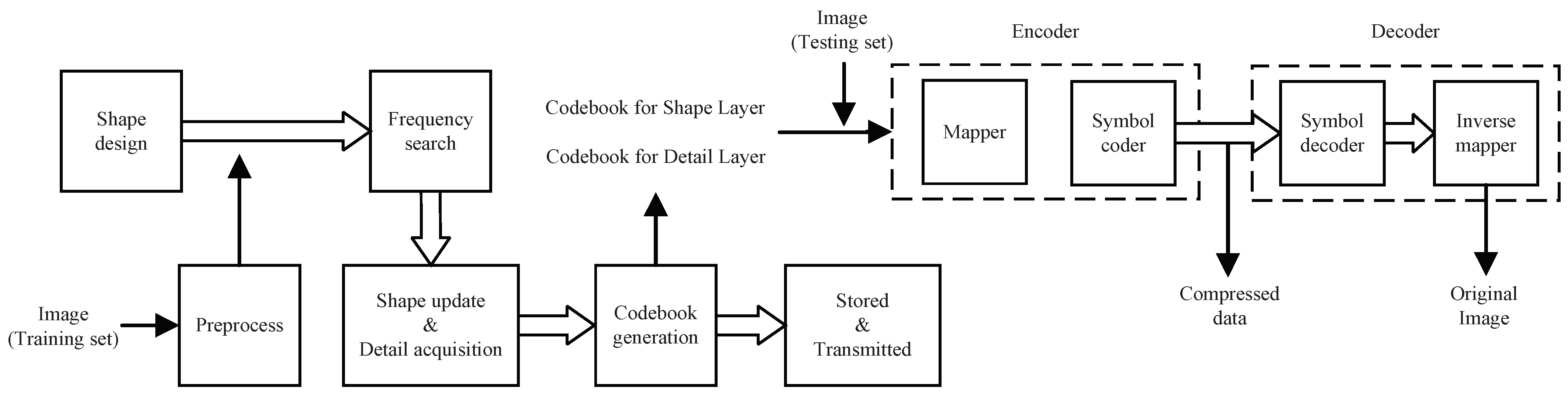
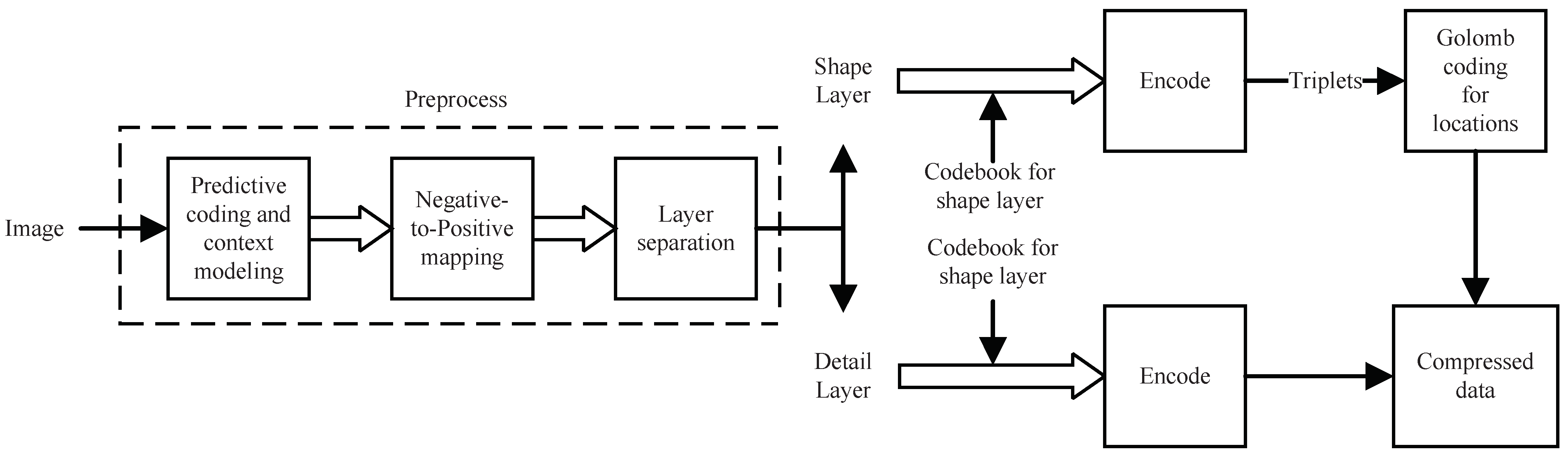
3.2.1. Overall Architecture
3.2.2. Predictive Coding and Negative-to-Positive Mapping
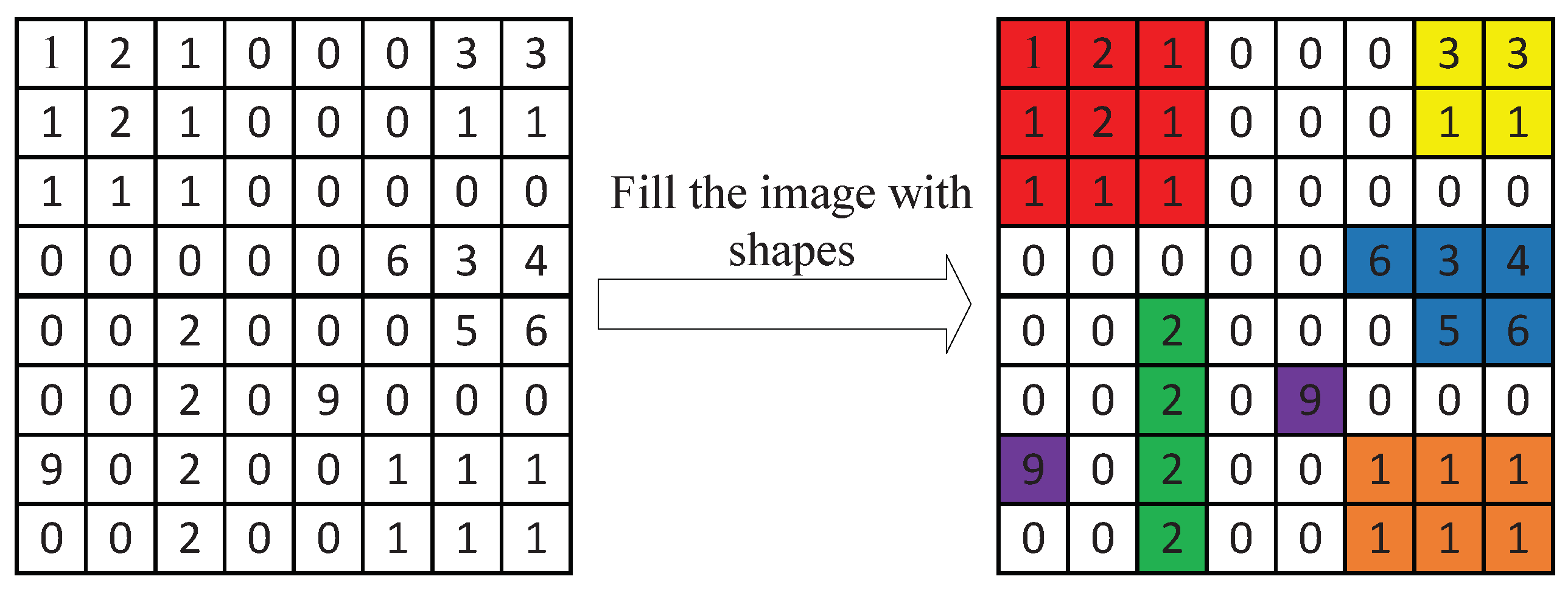
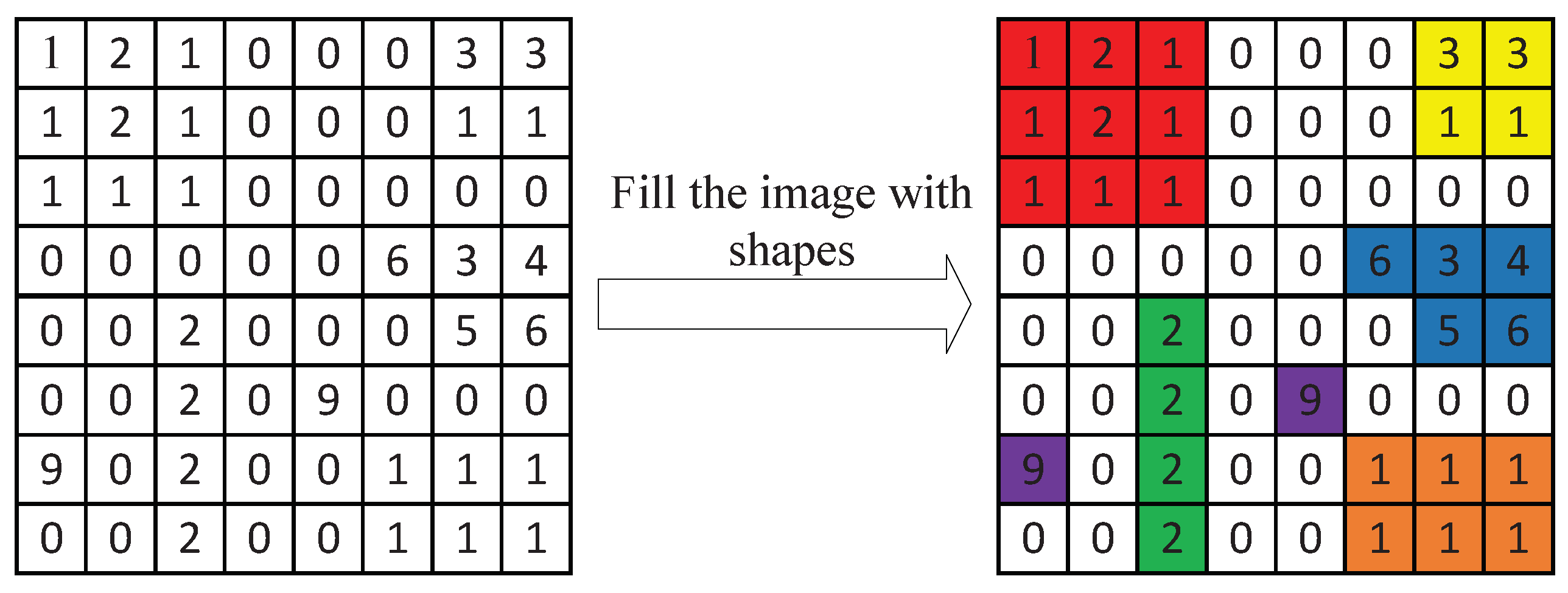
3.2.3. Layer Separation
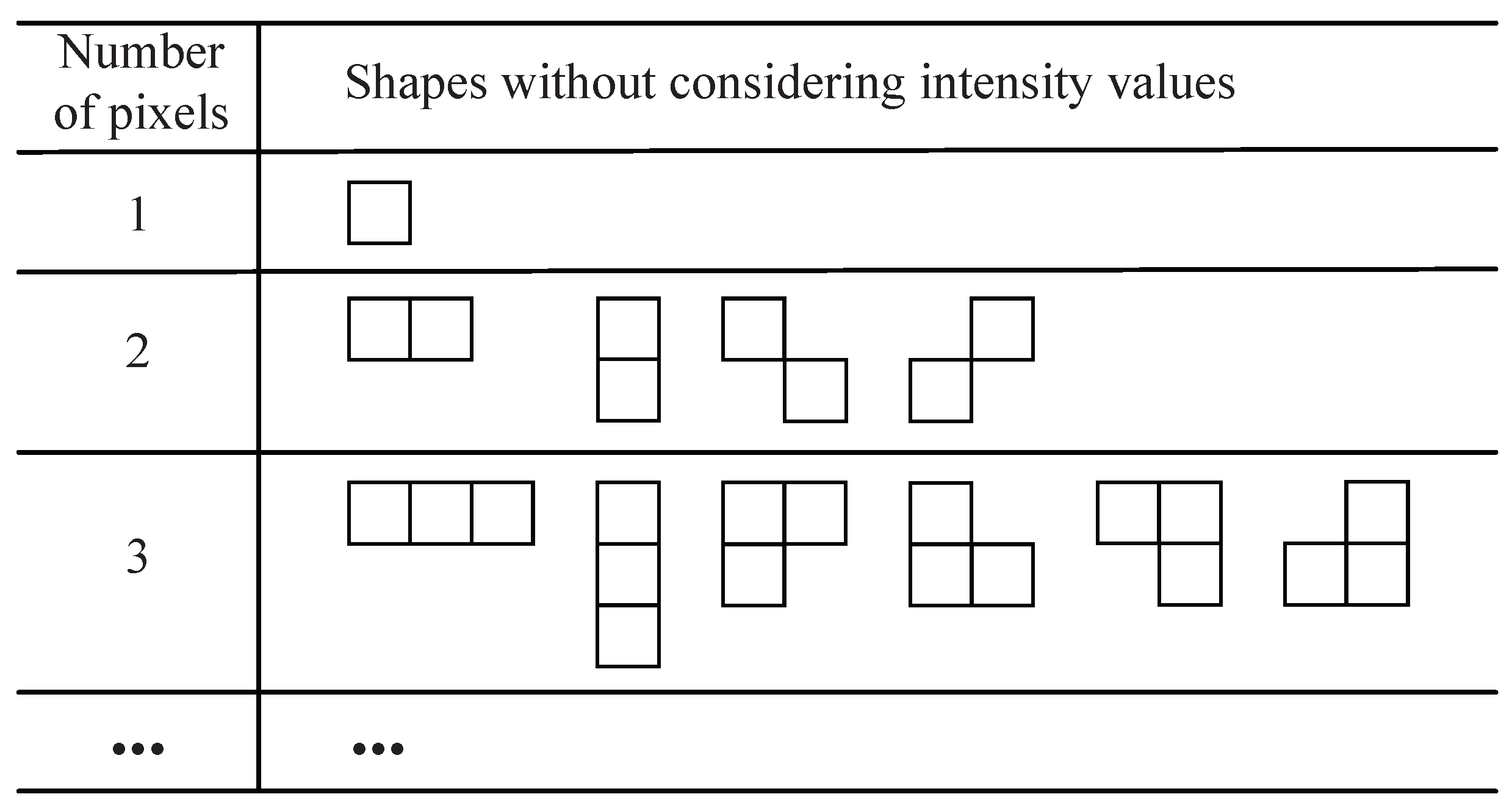
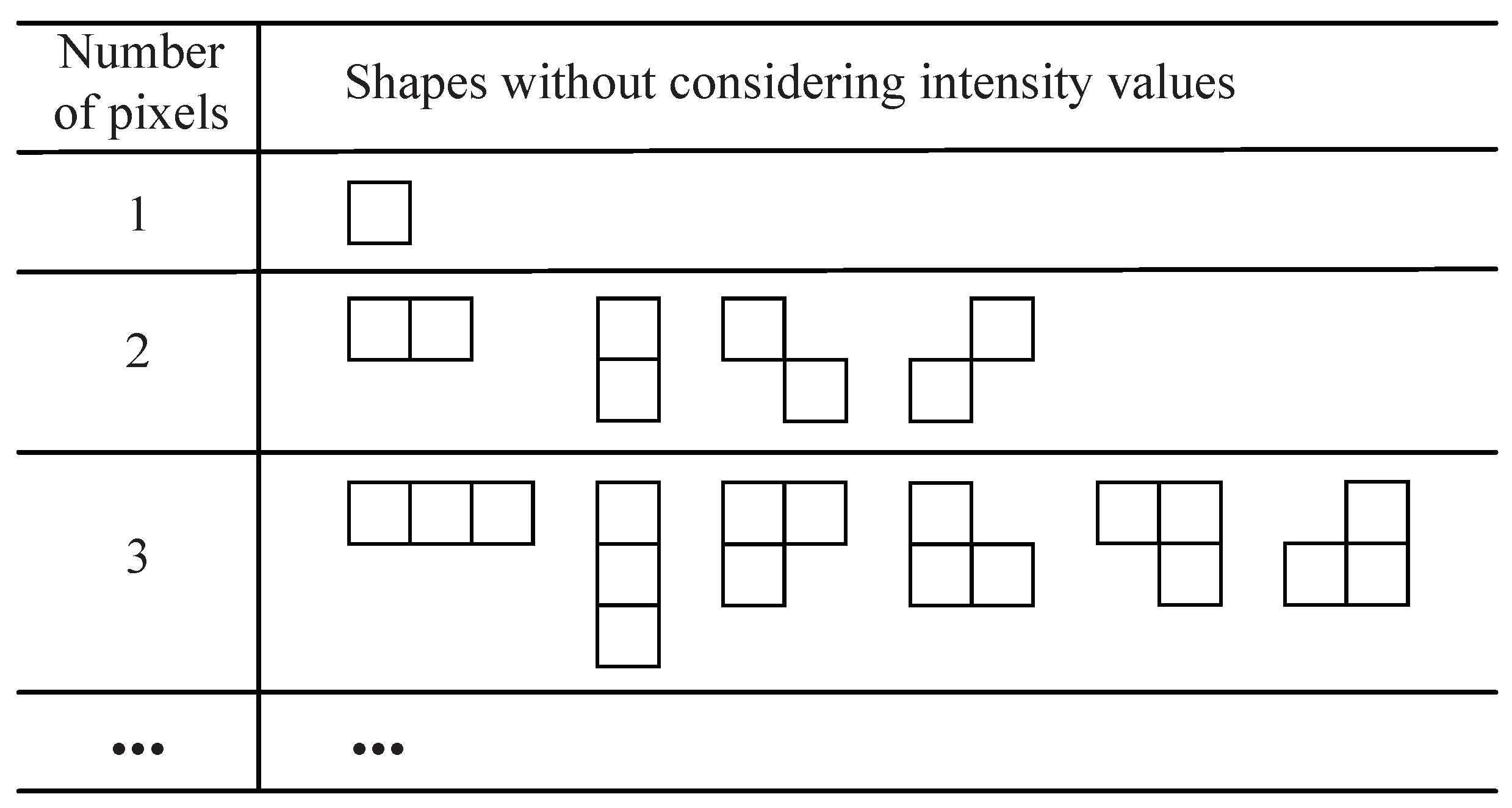
3.2.4. Shape Search and Codebook Generation
| Algorithm 1: The training part of the soft compression algorithm for gray image. |
|
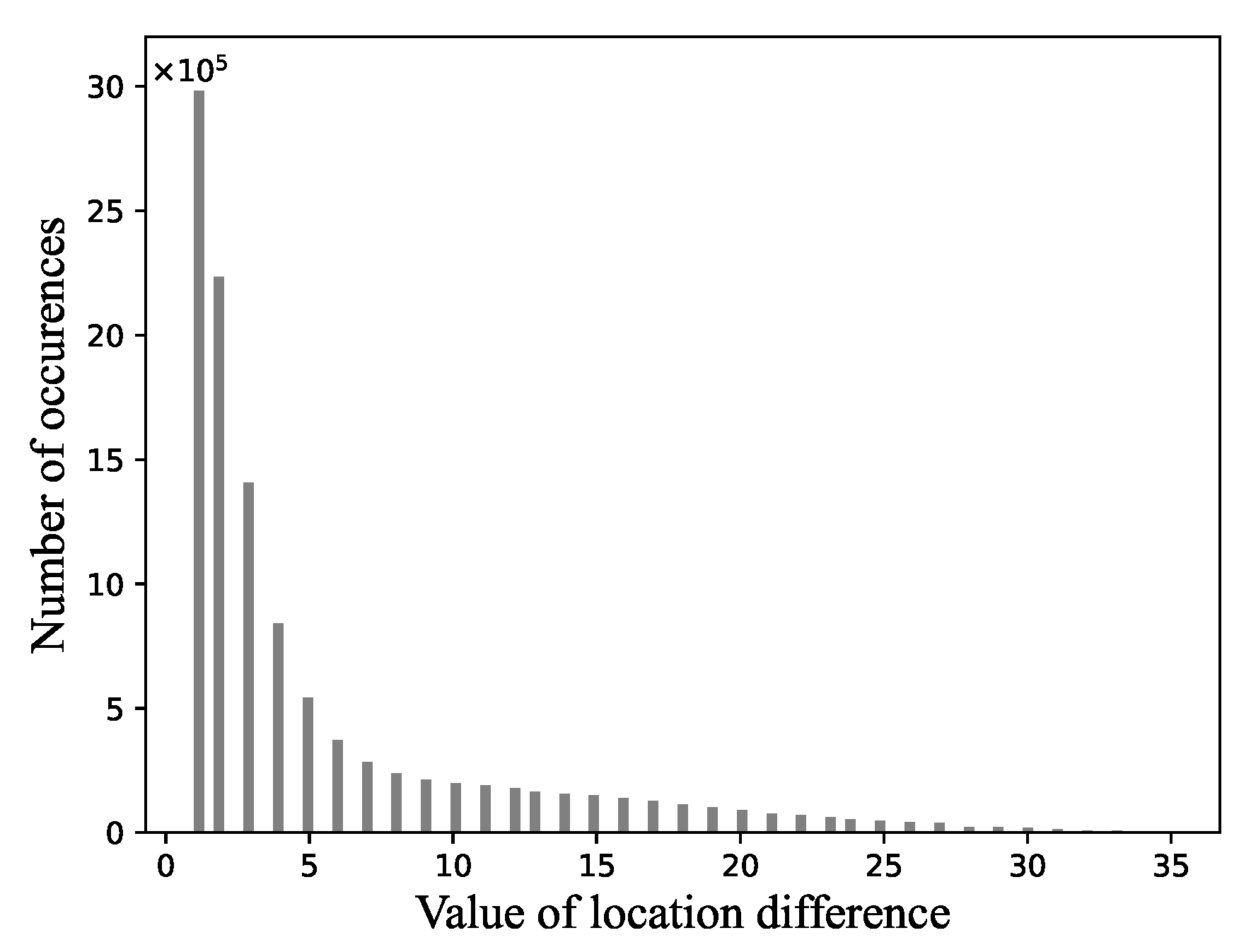
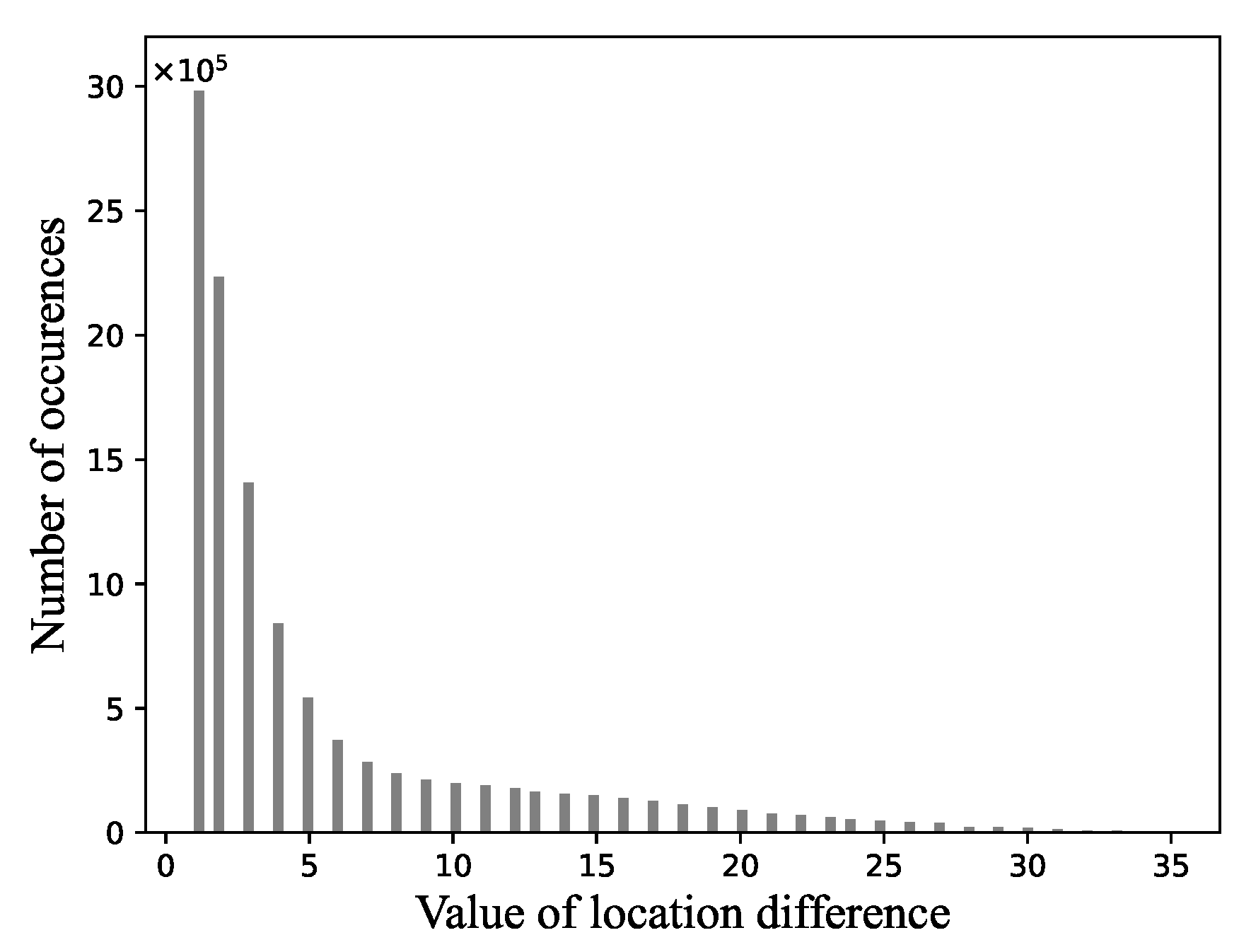
3.2.5. Golomb Coding for Locations
- Step 1. Calculate the distance difference from the previous location.
- Step 2. Get a positive integer m by giving or searching in advance.
- Step 3. Form the unary code of quotient . (The unary code of an integer q is defined as q 1s followed by a 0.)
- Step 4. Let , , , and compute truncated remainder such that
- Step 5. Concatenate the results of steps 3 and 4.
3.2.6. Encoder and Decoder
3.2.7. Concrete Example
3.3. Multi-Component Image
4. Experimental Results and Theoretical Analysis
4.1. Binary Image
4.2. Gray Image and Multi-Component Image
4.3. Implementation Details
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Xin, G.; Li, Z.; Zhu, Z.; Wan, S.; Fan, P.; Letaief, K.B. Soft Compression: An Approach to Shape Coding for Images. IEEE Commun. Lett. 2020, 25, 798–801. [Google Scholar] [CrossRef]
- Gonzalez, R.C.; Woods, R.E.; Masters, B.R. Digital Image Processing, 3rd ed.; Pearson Prentice Hall: Hoboken, NJ, USA, 2008; pp. 527–553. [Google Scholar]
- Huffman, D.A. A method for the construction of minimum-redundancy codes. Proc. IRE 1952, 40, 1098–1101. [Google Scholar] [CrossRef]
- Rissanen, J.; Langdon, G.G. Arithmetic coding. IBM J. Res. Dev. 1979, 23, 149–162. [Google Scholar] [CrossRef] [Green Version]
- Golomb, S. Run-length encodings (corresp.). IEEE Trans. Inf. Theory 1966, 12, 399–401. [Google Scholar] [CrossRef] [Green Version]
- Meyr, H.; Rosdolsky, H.; Huang, T. Optimum run length codes. IEEE Trans. Commun. 1974, 22, 826–835. [Google Scholar] [CrossRef]
- Welch, T.A. A technique for high-performance data compression. Computer 1984, 17, 8–19. [Google Scholar] [CrossRef]
- Starosolski, R. Hybrid adaptive lossless image compression based on discrete wavelet transform. Entropy 2020, 22, 751. [Google Scholar] [CrossRef]
- Cao, S.; Wu, C.Y.; Krähenbühl, P. Lossless image compression through super-resolution. arXiv 2020, arXiv:2004.02872. [Google Scholar]
- Consultative Committee for Space Data Systems. Available online: https://www.ccsds.org/ (accessed on 9 December 2021).
- Blanes, I.; Magli, E.; Serra-Sagrista, J. A tutorial on image compression for optical space imaging systems. IEEE Geosci. Remote Sens. Mag. 2014, 2, 8–26. [Google Scholar] [CrossRef] [Green Version]
- Augé, E.; Sánchez, J.E.; Kiely, A.B.; Blanes, I.; Serra-Sagrista, J. Performance impact of parameter tuning on the CCSDS-123 lossless multi-and hyperspectral image compression standard. J. Appl. Remote Sens. 2013, 7, 074594. [Google Scholar] [CrossRef] [Green Version]
- Sezer, O.G.; Harmanci, O.; Guleryuz, O.G. Sparse orthonormal transforms for image compression. In Proceedings of the 2008 15th IEEE International Conference on Image Processing, San Diego, CA, USA, 12–15 October 2008; pp. 149–152. [Google Scholar]
- Zhou, Y.; Wang, C.; Zhou, X. DCT-based color image compression algorithm using an efficient lossless encoder. In Proceedings of the 2018 14th IEEE International Conference on Signal Processing (ICSP), Beijing, China, 2–16 August 2018; pp. 450–454. [Google Scholar]
- Ma, H.; Liu, D.; Yan, N.; Li, H.; Wu, F. End-to-End Optimized Versatile Image Compression With Wavelet-Like Transform. IEEE Trans. Pattern Anal. Mach. Intell. 2020. [Google Scholar] [CrossRef]
- Antonini, M.; Barlaud, M.; Mathieu, P.; Daubechies, I. Image coding using wavelet transform. IEEE Trans. Image Process. 1992, 1, 205–220. [Google Scholar] [CrossRef] [Green Version]
- Remya, S. Wavelet Based Compression Techniques: A Survey. In Proceedings of the International Conference on Advances in Communication, Network, and Computing, Chennai, India, 24–25 February 2012; pp. 394–397. [Google Scholar]
- Starosolski, R. Employing New Hybrid Adaptive Wavelet-Based Transform and Histogram Packing to Improve JP3D Compression of Volumetric Medical Images. Entropy 2020, 22, 1385. [Google Scholar] [CrossRef] [PubMed]
- Kumar, R.N.; Jagadale, B.; Bhat, J. A lossless image compression algorithm using wavelets and fractional Fourier transform. SN Appl. Sci. 2019, 1, 1–8. [Google Scholar]
- Lin, J. Reversible Integer-to-Integer Wavelet Filter Design for Lossless Image Compression. IEEE Access 2020, 8, 89117–89129. [Google Scholar] [CrossRef]
- Kabir, M.; Mondal, M. Edge-based and prediction-based transformations for lossless image compression. J. Imaging 2018, 4, 64. [Google Scholar] [CrossRef] [Green Version]
- Punnappurath, A.; Brown, M.S. Learning raw image reconstruction-aware deep image compressors. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 1013–1019. [Google Scholar] [CrossRef] [PubMed]
- Yang, Y.; Sun, J.; Li, H.; Xu, Z. ADMM-CSNet: A deep learning approach for image compressive sensing. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 42, 521–538. [Google Scholar] [CrossRef]
- Zhang, X.; Wu, X. Attention-guided Image Compression by Deep Reconstruction of Compressive Sensed Saliency Skeleton. arXiv 2021, arXiv:2103.15368. [Google Scholar]
- Ballé, J.; Laparra, V.; Simoncelli, E.P. End-to-end optimized image compression. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, 24–26 April 2017. [Google Scholar]
- Theis, L.; Shi, W.; Cunningham, A.; Huszár, F. Lossy image compression with compressive autoencoders. arXiv 2017, arXiv:1703.00395. [Google Scholar]
- Baig, M.H.; Koltun, V.; Torresani, L. Learning to inpaint for image compression. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 1246–1255. [Google Scholar]
- Rippel, O.; Bourdev, L. Real-time adaptive image compression. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 2922–2930. [Google Scholar]
- Ballé, J.; Minnen, D.; Singh, S.; Hwang, S.J.; Johnston, N. Variational image compression with a scale hyperprior. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Toderici, G.; Vincent, D.; Johnston, N.; Hwang, S.J.; Minnen, D.; Shor, J.; Covell, M. Full Resolution Image Compression with Recurrent Neural Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5435–5443. [Google Scholar]
- Agustsson, E.; Tschannen, M.; Mentzer, F.; Timofte, R.; Gool, L.V. Generative adversarial networks for extreme learned image compression. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, South Korea, 27 October–2 November 2019; pp. 221–231. [Google Scholar]
- Minnen, D.; Ballé, J.; Toderici, G. Joint Autoregressive and Hierarchical Priors for Learned Image Compression. In Proceedings of the NeurIPS 2018, Montreal, QC, Canada, 3–8 December 2018. [Google Scholar]
- Lee, J.; Cho, S.; Beack, S.K. Context-adaptive Entropy Model for End-to-end Optimized Image Compression. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 Aprial–3 May 2018. [Google Scholar]
- He, D.; Zheng, Y.; Sun, B.; Wang, Y.; Qin, H. Checkerboard Context Model for Efficient Learned Image Compression. arXiv 2021, arXiv:2103.15306. [Google Scholar]
- Gulrajani, I.; Kumar, K.; Ahmed, F.; Taiga, A.A.; Visin, F.; Vazquez, D.; Courville, A. Pixelvae: A latent variable model for natural images. arXiv 2016, arXiv:1611.05013. [Google Scholar]
- Chen, X.; Mishra, N.; Rohaninejad, M.; Abbeel, P. Pixelsnail: An improved autoregressive generative model. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 864–872. [Google Scholar]
- Mentzer, F.; Gool, L.V.; Tschannen, M. Learning better lossless compression using lossy compression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6638–6647. [Google Scholar]
- Li, M.; Ma, K.; You, J.; Zhang, D.; Zuo, W. Efficient and Effective Context-Based Convolutional Entropy Modeling for Image Compression. IEEE Trans. Image Process. 2020, 29, 5900–5911. [Google Scholar] [CrossRef] [Green Version]
- Van Oord, A.; Kalchbrenner, N.; Kavukcuoglu, K. Pixel recurrent neural networks. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 1747–1756. [Google Scholar]
- Oord, A.v.d.; Kalchbrenner, N.; Vinyals, O.; Espeholt, L.; Graves, A.; Kavukcuoglu, K. Conditional image generation with pixelcnn decoders. arXiv 2016, arXiv:1606.05328. [Google Scholar]
- Salimans, T.; Karpathy, A.; Chen, X.; Kingma, D.P. Pixelcnn++: Improving the pixelcnn with discretized logistic mixture likelihood and other modifications. arXiv 2017, arXiv:1701.05517. [Google Scholar]
- Kingma, F.; Abbeel, P.; Ho, J. Bit-swap: Recursive bits-back coding for lossless compression with hierarchical latent variables. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; pp. 3408–3417. [Google Scholar]
- Townsend, J.; Bird, T.; Barber, D. Practical lossless compression with latent variables using bits back coding. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Hoogeboom, E.; Peters, J.W.; Berg, R.V.d.; Welling, M. Integer discrete flows and lossless compression. arXiv 2019, arXiv:1905.07376. [Google Scholar]
- Ho, J.; Lohn, E.; Abbeel, P. Compression with flows via local bits-back coding. arXiv 2019, arXiv:1905.08500. [Google Scholar]
- Mentzer, F.; Agustsson, E.; Tschannen, M.; Timofte, R.; Gool, L.V. Practical full resolution learned lossless image compression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10629–10638. [Google Scholar]
- Zhu, C.; Zhang, H.; Tang, Y. Lossless Image Compression Algorithm Based on Long Short-term Memory Neural Network. In Proceedings of the 2020 5th International Conference on Computational Intelligence and Applications (ICCIA), Beijing, China, 19–21 June 2020; pp. 82–88. [Google Scholar]
- Boutell, T.; Lane, T. PNG (Portable Network Graphics) Specification Version 1.0. Available online: https://www.hjp.at/doc/rfc/rfc2083.html (accessed on 9 December 2021).
- Dufaux, F.; Sullivan, G.J.; Ebrahimi, T. The JPEG XR image coding standard [Standards in a Nutshell]. IEEE Signal Process Mag. 2009, 26, 195–204. [Google Scholar] [CrossRef] [Green Version]
- Weinberger, M.J.; Seroussi, G.; Sapiro, G. The LOCO-I lossless image compression algorithm: Principles and standardization into JPEG-LS. IEEE Trans. Image Process. 2000, 9, 1309–1324. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Si, Z.; Shen, K. Research on the WebP image format. In Advanced Graphic Communications, Packaging Technology and Materials; Springer: Berlin/Heidelberg, Germany, 2016; pp. 271–277. [Google Scholar]
- Wallace, G.K. The JPEG still picture compression standard. IEEE Trans. Consum. Electron. 1992, 38, 18–34. [Google Scholar] [CrossRef]
- Skodras, A.; Christopoulos, C.; Ebrahimi, T. The jpeg 2000 still image compression standard. IEEE Signal Process Mag. 2001, 18, 36–58. [Google Scholar] [CrossRef]
- Ahmed, N.; Natarajan, T.; Rao, K.R. Discrete cosine transform. IEEE Trans. Comput. 1974, 100, 90–93. [Google Scholar] [CrossRef]
- Mallat, S.G. A theory for multiresolution signal decomposition: The wavelet representation. IEEE Trans. Pattern Anal. Mach. Intell. 1989, 11, 674–693. [Google Scholar] [CrossRef] [Green Version]
- Sneyers, J.; Wuille, P. FLIF: Free lossless image format based on MANIAC compression. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 66–70. [Google Scholar]
- Ascher, R.N.; Nagy, G. A means for achieving a high degree of compaction on scan-digitized printed text. IEEE Trans. Comput. 1974, 100, 1174–1179. [Google Scholar] [CrossRef]
- Shen, Z.; Frater, M.; Arnold, J. Optimal Pruning Quad-Tree Block-Based Binary Shape Coding. In Proceedings of the 2007 IEEE International Conference on Image Processing, San Antonio, TX, USA, 16 September–19 October 2007; pp. 437–440. [Google Scholar]
- Shu, Z.; Liu, G.; Xie, Z.; Ren, Z. Shape adaptive texture coding based on wavelet-based contourlet transform. In Proceedings of the 2018 11th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Beijing, China, 13–15 October 2018; pp. 1–5. [Google Scholar]
- Jacquin, A.E. Image coding based on a fractal theory of iterated contractive image transformations. IEEE Trans. Image Process. 1992, 1, 18–30. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Weinzaepfel, P.; Jégou, H.; Pérez, P. Reconstructing an image from its local descriptors. In Proceedings of the CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011; pp. 337–344. [Google Scholar]
- Yue, H.; Sun, X.; Wu, F.; Yang, J. SIFT-based image compression. In Proceedings of the 2012 IEEE International Conference on Multimedia and Expo, Melbourne, Australia, 9–13 July 2012; pp. 473–478. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vision 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Yue, H.; Sun, X.; Yang, J.; Wu, F. Cloud-Based Image Coding for Mobile Devices—Toward Thousands to One Compression. IEEE Trans. Multimed. 2013, 15, 845–857. [Google Scholar] [CrossRef]
- Bégaint, J.; Thoreau, D.; Guillotel, P.; Guillemot, C. Region-Based Prediction for Image Compression in the Cloud. IEEE Trans. Image Process. 2018, 27, 1835–1846. [Google Scholar] [CrossRef]
- Liu, X.; Cheung, G.; Lin, C.; Zhao, D.; Gao, W. Prior-Based Quantization Bin Matching for Cloud Storage of JPEG Images. IEEE Trans. Image Process. 2018, 27, 3222–3235. [Google Scholar] [CrossRef]
- Zhang, X.; Lin, W.; Zhang, Y.; Wang, S.; Ma, S.; Duan, L.; Gao, W. Rate-Distortion Optimized Sparse Coding With Ordered Dictionary for Image Set Compression. IEEE Trans. Circuits Syst. Video Technol. 2018, 28, 3387–3397. [Google Scholar] [CrossRef]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef] [Green Version]
- Cover, T.M. Elements of Information Theory; John Wiley & Sons: Hoboken, NJ, USA, 1999. [Google Scholar]
- Wu, X.; Memon, N. Context-based, adaptive, lossless image coding. IEEE Trans. Commun. 1997, 45, 437–444. [Google Scholar] [CrossRef]
- Schwartz, J.W.; Barker, R.C. Bit-Plane Encoding: A Technique for Source Encoding. IEEE Trans. Aerosp. Electron. Syst. 1966, AES-2, 385–392. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-mnist: A novel image dataset for benchmarking machine learning algorithms. arXiv 2017, arXiv:1708.07747. [Google Scholar]
- DRIVE: Digital Retinal Images for Vessel Extraction. Available online: https://drive.grand-challenge.org/ (accessed on 9 December 2021).
- Mendonça, T.; Ferreira, P.M.; Marques, J.S.; Marcal, A.R.; Rozeira, J. PH 2-A dermoscopic image database for research and benchmarking. In Proceedings of the 2013 35th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Osaka, Japan, 3–7 July 2013; pp. 5437–5440. [Google Scholar]
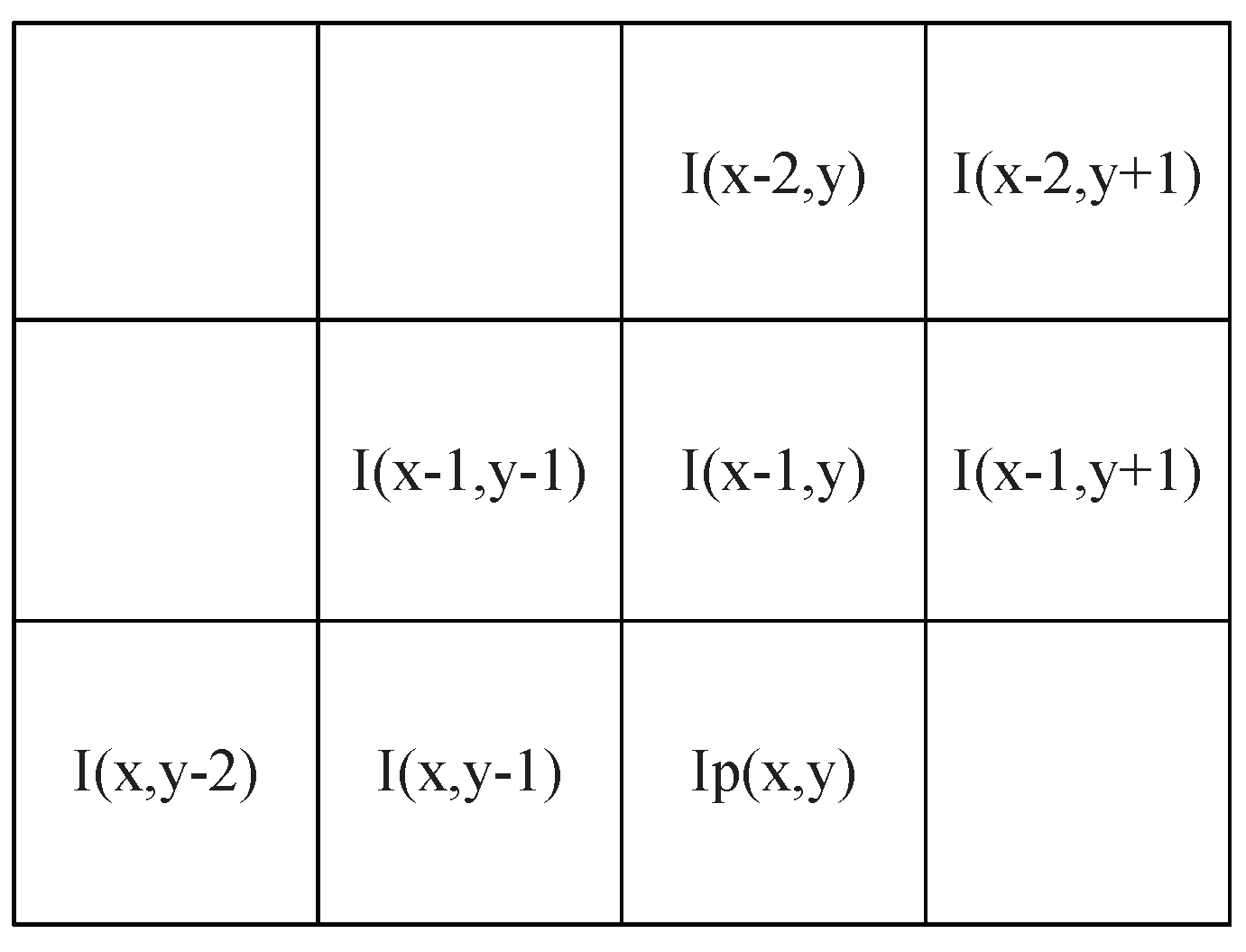


{kind=link}
{kind=link}
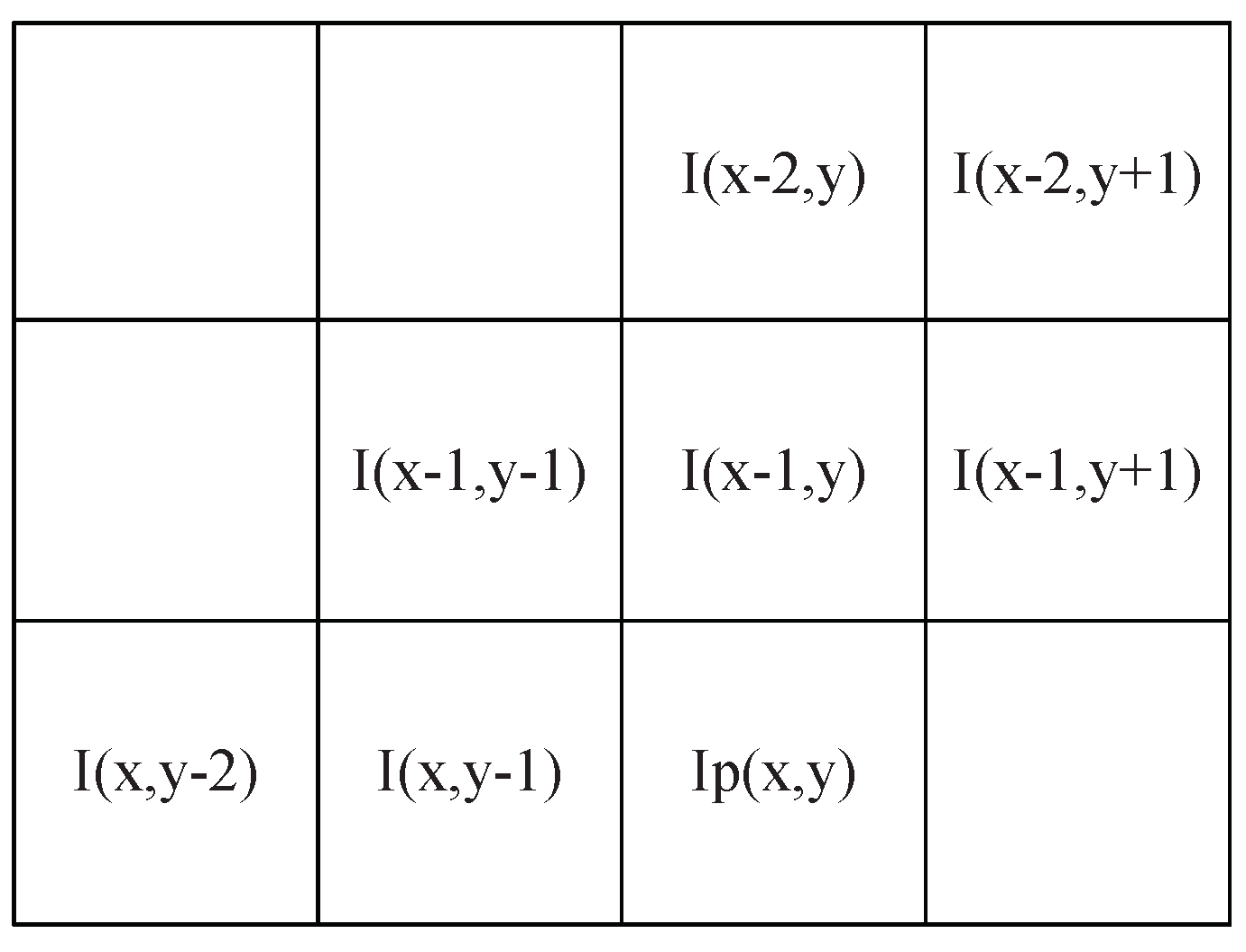{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|---|
| CIV | 3.87 | 5.14 | 4.09 | 4.17 | 4.42 | 4.30 | 4.17 | 4.51 | 4.06 | 4.37 |
| Compression ratio | 2.84 | 6.02 | 3.17 | 3.20 | 3.77 | 3.40 | 3.20 | 4.05 | 2.81 | 3.52 |
| Class | Method | |||
|---|---|---|---|---|
| Soft Compression | PNG | JPEG2000 | JPEG-LS | |
| T-Shirt | 1.53 | 1.23 +24% | 1.06 +44% | 1.47 +4.1% |
| Trouser | 2.30 | 1.50 +53% | 1.32 +74% | 2.13 +8.0% |
| Pullover | 1.48 | 1.12 +32% | 1.02 +45% | 1.36 +8.8% |
| Dress | 1.85 | 1.41 +31% | 1.20 +54% | 1.79 +3.4% |
| Coat | 1.45 | 1.14 +27% | 1.03 +41% | 1.36 +6.7% |
| Sandals | 1.95 | 1.82 +7.1% | 1.33 +47% | 1.82 +7.1% |
| Shirt | 1.42 | 1.14 +25% | 1.03 +38% | 1.34 +6.0% |
| Sneaker | 2.07 | 1.88 +10% | 1.39 +49% | 1.89 +9.5% |
| Bag | 1.50 | 1.32 +14% | 1.07 +40% | 1.42 +5.6% |
| Ankle boots | 1.66 | 1.46 +14% | 1.14 +46% | 1.52 +9.2% |
| Dataset | Statistic | Method | ||||
|---|---|---|---|---|---|---|
| Soft Compression | PNG | JPEG2000 | JPEG-LS | L3C | ||
| DRIVE [74] 565 × 584 px | Mean | 3.201 | 2.434 +32% | 2.972 +7.7% | 3.064 +4.5% | 2.989 +7.1% |
| Minimum | 2.893 | 2.331 +24% | 2.790 +3.7% | 2.731 +5.9% | 2.841 +1.8% | |
| Maximum | 4.171 | 2.760 +51% | 3.671 +14% | 3.941 +5.8% | 3.604 +16% | |
| Variance | 0.0657 | 0.0072 | 0.0333 | 0.0632 | 0.0287 | |
| PH2 [75] 767 × 576 px | Mean | 2.570 | 1.727 +49% | 2.450 +4.9% | 2.488 +3.3% | 2.300 +12% |
| Minimum | 1.686 | 1.501 | 1.812 | 1.737 | 1.790 | |
| Maximum | 3.388 | 2.021 +68% | 2.975 +14% | 3.045 +11% | 2.920 +16% | |
| Variance | 0.1538 | 0.0108 | 0.0749 | 0.0835 | 0.1047 | |
| Class | T-Shirt | Trouser | Pullover | Dress | Coat | Sandals | Shirt | Sneaker | Bag | Ankle Boots |
|---|---|---|---|---|---|---|---|---|---|---|
| T-shirt | 1.55 | 2.19 | 1.50 | 1.83 | 1.48 | 1.90 | 1.44 | 2.00 | 1.51 | 1.65 |
| Trouser | 1.48 | 2.35 | 1.43 | 1.82 | 1.41 | 1.91 | 1.38 | 2.03 | 1.46 | 1.61 |
| Pullover | 1.55 | 2.20 | 1.50 | 1.82 | 1.48 | 1.88 | 1.44 | 1.99 | 1.51 | 1.65 |
| Dress | 1.54 | 2.32 | 1.48 | 1.87 | 1.46 | 1.96 | 1.43 | 2.08 | 1.51 | 1.66 |
| Coat | 1.54 | 2.20 | 1.50 | 1.83 | 1.48 | 1.88 | 1.44 | 2.00 | 1.51 | 1.65 |
| Sandals | 1.53 | 2.27 | 1.47 | 1.85 | 1.45 | 2.01 | 1.42 | 2.11 | 1.51 | 1.68 |
| Shirt | 1.55 | 2.20 | 1.50 | 1.83 | 1.48 | 1.89 | 1.44 | 2.00 | 1.51 | 1.65 |
| Sneaker | 1.52 | 2.27 | 1.46 | 1.84 | 1.45 | 1.99 | 1.41 | 2.11 | 1.51 | 1.67 |
| Bag | 1.55 | 2.25 | 1.49 | 1.84 | 1.47 | 1.94 | 1.44 | 2.06 | 1.53 | 1.67 |
| Ankle boots | 1.54 | 2.24 | 1.49 | 1.84 | 1.47 | 1.94 | 1.43 | 2.06 | 1.51 | 1.67 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xin, G.; Fan, P. Soft Compression for Lossless Image Coding Based on Shape Recognition. Entropy 2021, 23, 1680. https://doi.org/10.3390/e23121680
Xin G, Fan P. Soft Compression for Lossless Image Coding Based on Shape Recognition. Entropy. 2021; 23(12):1680. https://doi.org/10.3390/e23121680
Chicago/Turabian StyleXin, Gangtao, and Pingyi Fan. 2021. "Soft Compression for Lossless Image Coding Based on Shape Recognition" Entropy 23, no. 12: 1680. https://doi.org/10.3390/e23121680
APA StyleXin, G., & Fan, P. (2021). Soft Compression for Lossless Image Coding Based on Shape Recognition. Entropy, 23(12), 1680. https://doi.org/10.3390/e23121680