
On Epistemics in Expected Free Energy for Linear Gaussian State Space Models


Abstract
:1. Introduction
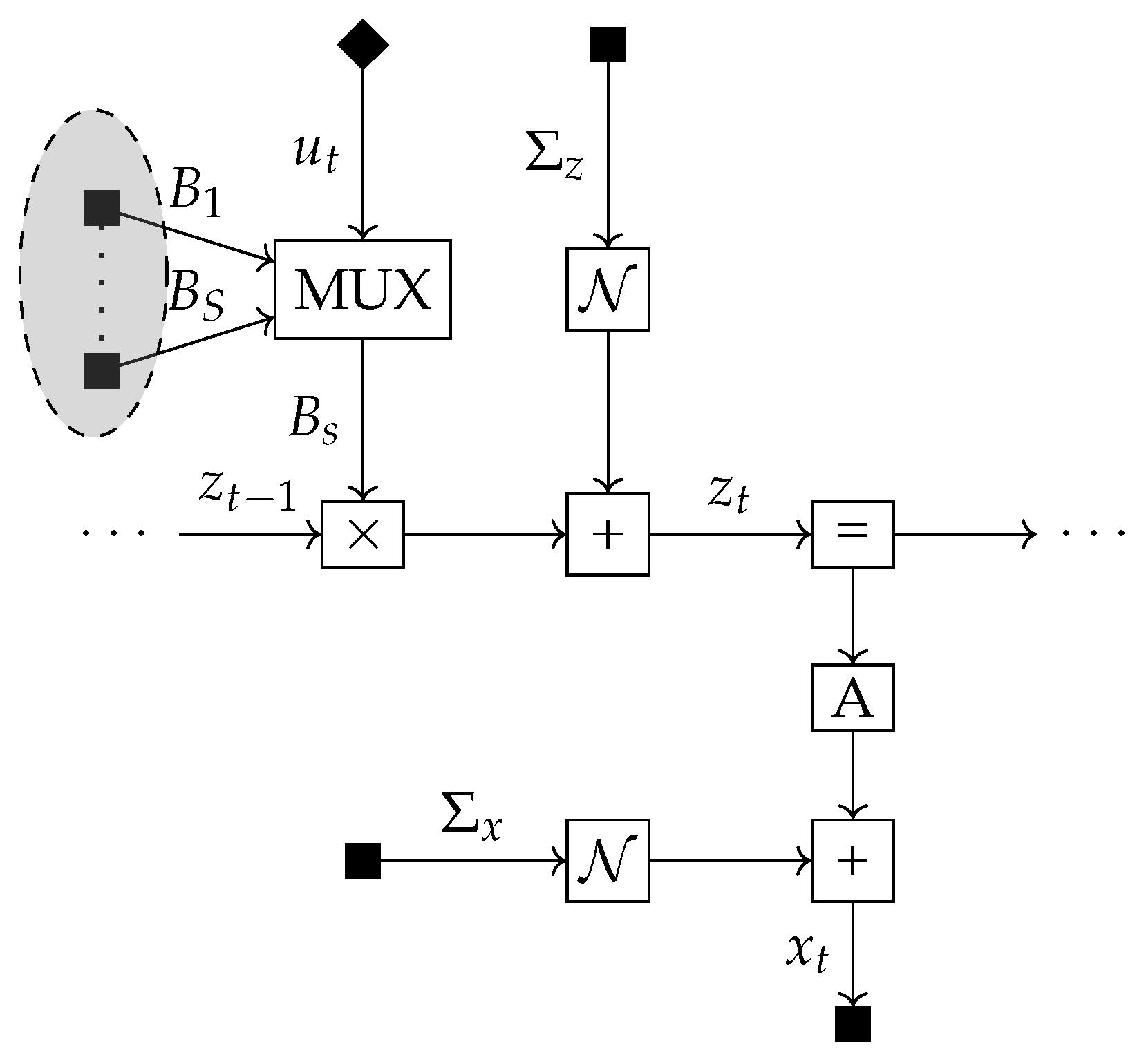
- We consider the epistemic term of EFE in isolation and show that in the case of additive controls actions become decoupled from state transitions when computing the epistemic term of EFE, Section 5.3. Therefore, we do not find meaningful exploration in this case.
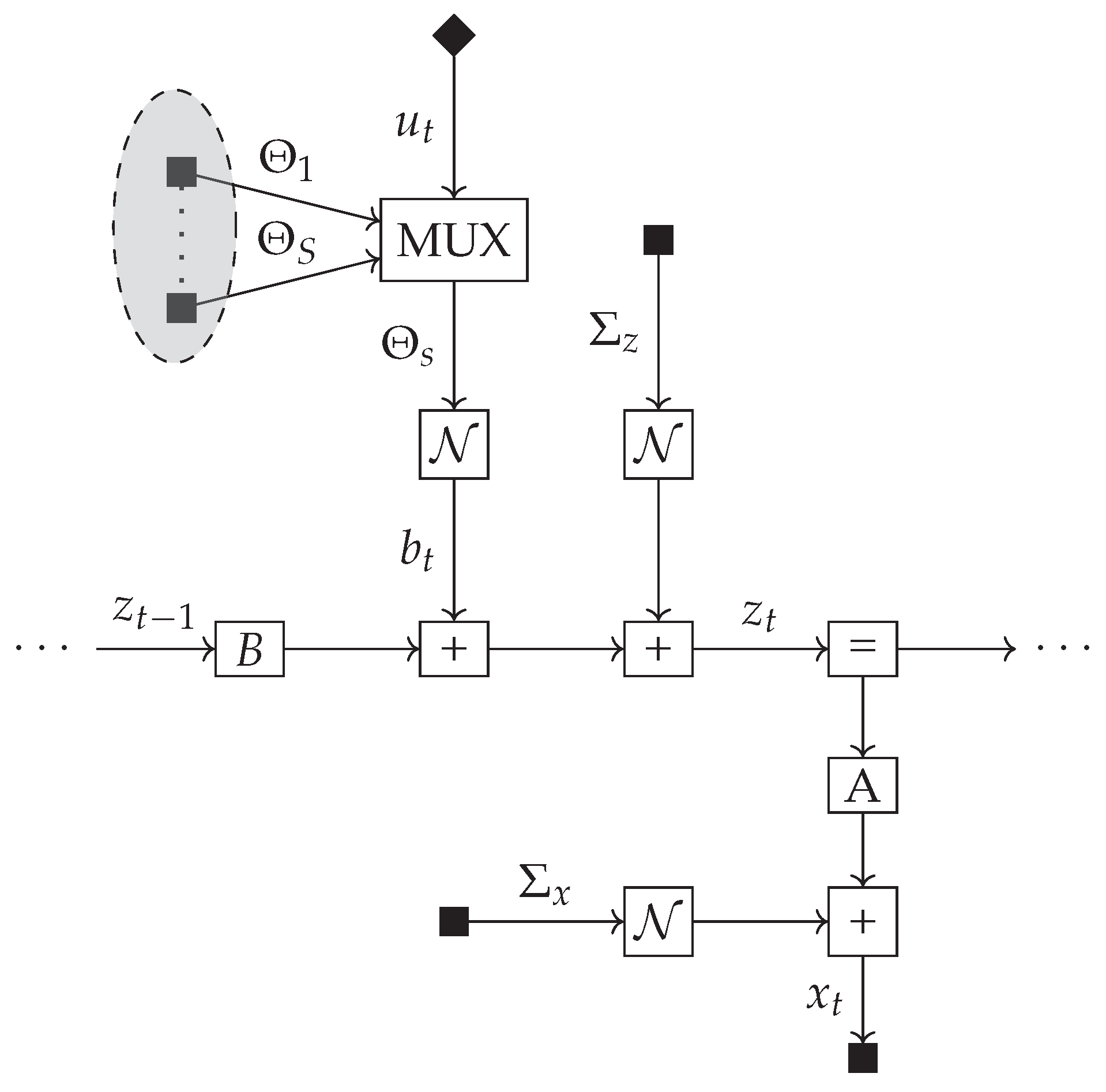
- We show that in the case of multiplicative controls, meaningful exploratory behaviour re-emerges when isolating the epistemic term of EFE, Section 5.4.
- We prove that when considering the full EFE construct, parts of the instrumental and epistemic value terms cancel each other out. This renders the epistemic value constant. In turn, the EFE functional becomes equivalent to KL control plus an additive constant, Section 5.5.
- Finally, we provide simulations that corroborate our claims. We first demonstrate the differences in exploration when considering purely epistemic agents using both additive and multiplicative control signals. Finally we show that LGDS agents optimising the full EFE do not exhibit epistemic drives under any circumstances, Section 6.
2. Exploration and Exploitation
3. Generative Model
4. Perception as Bayesian Filtering
5. Action Selection under Active Inference
5.1. Computing G—Expected Free Energy
5.2. Mutual Information Computation
5.3. Pure Exploration as a Function of Additive Control Signals
5.4. Pure Exploration as a Function of Multiplicative Control Signals
5.5. Instrumental Value and Expected Free Energy
6. Experiments
6.1. Pure Epistemics for Additive Controls
6.2. Pure Epistemics for Multiplicative Controls
6.3. Lack of Epistemics for Expected Free Energy
7. Discussion
8. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A. Derivations
Appendix A.1. Perception as Bayesian Filtering
Appendix A.2. Linearly Related Gaussian Variables
Appendix A.3. Mutual Information Bound
Appendix A.4. Mutual Information Derivation
References
- Sajid, N.; Costa, L.D.; Parr, T.; Friston, K. Active inference, Bayesian optimal design, and expected utility. arXiv 2021, arXiv:2110.04074. [Google Scholar]
- Friston, K.; FitzGerald, T.; Rigoli, F.; Schwartenbeck, P.; Doherty, J.; Pezzulo, G. Active inference and learning. Neurosci. Biobehav. Rev. 2016, 68, 862–879. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Baltieri, M.; Buckley, C. PID Control as a Process of Active Inference with Linear Generative Models. Entropy 2019, 21, 257. [Google Scholar] [CrossRef] [Green Version]
- Friston, K.; Ao, P. Free Energy, Value, and Attractors. Comput. Math. Methods Med. 2012, 2012, 937860. [Google Scholar] [CrossRef] [PubMed]
- Buckley, C.L.; Kim, C.S.; McGregor, S.; Seth, A.K. The free energy principle for action and perception: A mathematical review. J. Math. Psychol. 2017, 81, 55–79. [Google Scholar] [CrossRef]
- van de Laar, T.W.; de Vries, B. Simulating Active Inference Processes by Message Passing. Front. Robot. AI 2019, 6. [Google Scholar] [CrossRef] [Green Version]
- Baltieri, M.; Buckley, C.L. An active inference implementation of phototaxis. arXiv 2017, arXiv:1707.01806. [Google Scholar]
- Friston, K.; Rigoli, F.; Ognibene, D.; Mathys, C.; Fitzgerald, T.; Pezzulo, G. Active inference and epistemic value. Cogn. Neurosci. 2015, 6, 187–214. [Google Scholar] [CrossRef]
- Sajid, N.; Ball, P.J.; Friston, K.J. Active inference: Demystified and compared. arXiv 2020, arXiv:1909.10863. [Google Scholar] [CrossRef]
- Ghavamzadeh, M.; Mannor, S.; Pineau, J.; Tamar, A. Bayesian Reinforcement Learning: A Survey. arXiv 2016, arXiv:1609.04436. [Google Scholar] [CrossRef] [Green Version]
- Cullen, M.; Davey, B.; Friston, K.J.; Moran, R.J. Active Inference in OpenAI Gym: A Paradigm for Computational Investigations Into Psychiatric Illness. Biol. Psychiatry Cogn. Neurosci. Neuroimaging 2018, 3, 809–818. [Google Scholar] [CrossRef] [Green Version]
- Parr, T.; Friston, K.J. Generalised free energy and active inference. Biol. Cybern. 2019, 113, 495–513. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Friston, K.; Da Costa, L.; Hafner, D.; Hesp, C.; Parr, T. Sophisticated Inference. arXiv 2020, arXiv:2006.04120. [Google Scholar] [CrossRef]
- Fountas, Z.; Sajid, N.; Mediano, P.A.M.; Friston, K. Deep active inference agents using Monte-Carlo methods. arXiv 2020, arXiv:2006.04176. [Google Scholar]
- Tschantz, A.; Seth, A.K.; Buckley, C.L. Learning action-oriented models through active inference. PLoS Comput. Biol. 2020, 16, e1007805. [Google Scholar] [CrossRef] [Green Version]
- Tschantz, A.; Millidge, B.; Seth, A.K.; Buckley, C.L. Reinforcement Learning through Active Inference. arXiv 2020, arXiv:2002.12636. [Google Scholar]
- Millidge, B. Deep Active Inference as Variational Policy Gradients. arXiv 2019, arXiv:1907.03876. [Google Scholar] [CrossRef] [Green Version]
- Tschantz, A.; Baltieri, M.; Seth, A.K.; Buckley, C.L. Scaling active inference. arXiv 2019, arXiv:1911.10601. [Google Scholar]
- Ueltzhöffer, K. Deep Active Inference. Biol. Cybern. 2018, 112, 547–573. [Google Scholar] [CrossRef] [Green Version]
- Forney, G.D. Codes on graphs: Normal realizations. IEEE Trans. Inf. Theory 2001, 47, 520–548. [Google Scholar] [CrossRef] [Green Version]
- Loeliger, H.A.; Dauwels, J.; Hu, J.; Korl, S.; Ping, L.; Kschischang, F.R. The Factor Graph Approach to Model-Based Signal Processing. Proc. IEEE 2007, 95, 1295–1322. [Google Scholar] [CrossRef] [Green Version]
- Loeliger, H.A. An introduction to factor graphs. Signal Process. Mag. IEEE 2004, 21, 28–41. [Google Scholar] [CrossRef] [Green Version]
- Sarkka, S. Bayesian Filtering and Smoothing; Cambridge University Press: Cambridge, UK, 2013. [Google Scholar] [CrossRef]
- Schwartenbeck, P.; FitzGerald, T.; Dolan, R.J.; Friston, K. Exploration, novelty, surprise, and free energy minimization. Front. Psychol. 2013, 4. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Da Costa, L.; Parr, T.; Sajid, N.; Veselic, S.; Neacsu, V.; Friston, K. Active inference on discrete state-spaces: A synthesis. arXiv 2020, arXiv:2001.07203. [Google Scholar] [CrossRef] [PubMed]
- Şenöz, İ.; van de Laar, T.; Bagaev, D.; de Vries, B. Variational Message Passing and Local Constraint Manipulation in Factor Graphs. Entropy 2021, 23, 807. [Google Scholar] [CrossRef]
- Blei, D.M.; Kucukelbir, A.; McAuliffe, J.D. Variational Inference: A Review for Statisticians. J. Am. Stat. Assoc. 2017, 112, 859–877. [Google Scholar] [CrossRef] [Green Version]
- Schwartenbeck, P.; Passecker, J.; Hauser, T.U.; FitzGerald, T.H.B.; Kronbichler, M.; Friston, K. Computational mechanisms of curiosity and goal-directed exploration. Neuroscience 2018. [Google Scholar] [CrossRef]
- Millidge, B.; Tschantz, A.; Buckley, C.L. Whence the Expected Free Energy? arXiv 2020, arXiv:2004.08128. [Google Scholar] [CrossRef]
- Hafner, D.; Ortega, P.A.; Ba, J.; Parr, T.; Friston, K.; Heess, N. Action and Perception as Divergence Minimization. arXiv 2020, arXiv:2009.01791. [Google Scholar]
- Buisson-Fenet, M.; Solowjow, F.; Trimpe, S. Actively learning gaussian process dynamics. In Proceedings of the 2nd Conference on Learning for Dynamics and Control, Online, 11–12 June 2020; pp. 5–15. [Google Scholar]
- Bai, S.; Wang, J.; Chen, F.; Englot, B. Information-theoretic exploration with Bayesian optimization. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Korea, 9–14 October 2016; pp. 1816–1822. [Google Scholar] [CrossRef]
- Berseth, G.; Geng, D.; Devin, C.; Finn, C.; Jayaraman, D.; Levine, S. SMiRL: Surprise Minimizing RL in Dynamic Environments. arXiv 2019, arXiv:1912.05510. [Google Scholar]
- Friston, K. A free energy principle for a particular physics. arXiv 2019, arXiv:1906.10184. [Google Scholar]
- Solopchuk, O. Information Theoretic Approach to Decision Making in Continuous Domains. Ph.D. Thesis, UCL-Université Catholique de Louvain, Ottigny, Belgium, 2021. [Google Scholar]
- Kappen, H.J.; Gómez, V.; Opper, M. Optimal control as a graphical model inference problem. Mach. Learn. 2012, 87, 159–182. [Google Scholar] [CrossRef] [Green Version]
- Schwoebel, S.; Kiebel, S.; Markovic, D. Active Inference, Belief Propagation, and the Bethe Approximation. Neural Comput. 2018, 30, 2530–2567. [Google Scholar] [CrossRef] [PubMed]
- Millidge, B.; Tschantz, A.; Seth, A.; Buckley, C. Understanding the Origin of Information-Seeking Exploration in Probabilistic Objectives for Control. arXiv 2021, arXiv:2103.06859. [Google Scholar]


{kind=link}
{kind=link}
| Transition | −MI |
|---|---|
| −1.386 | |
| −1.386 | |
| −1.609 | |
| −1.609 |
| Transition | −MI |
|---|---|
| −0.698 | |
| −1.099 | |
| −4.625 | |
| −9.211 |
| Transition | KL | Ambiguity | G | Instrumental | Epistemic |
|---|---|---|---|---|---|
| 1.33 | 2.84 | 4.17 | 5.27 | −1.10 | |
| 0.64 | 2.84 | 3.48 | 5.27 | −1.79 | |
| 1.37 | 2.84 | 4.21 | 6.60 | −2.40 | |
| 3.54 | 2.84 | 6.38 | 9.27 | −2.89 |
| Transition | KL | Ambiguity | G | Instrumental | Epistemic |
|---|---|---|---|---|---|
| 3.05 | 2.84 | 5.88 | 7.27 | −1.39 | |
| 0.38 | 2.84 | 3.22 | 4.60 | −1.39 | |
| 3.16 | 2.84 | 5.99 | 7.60 | −1.61 | |
| 0.49 | 2.84 | 3.33 | 4.94 | −1.61 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Koudahl, M.T.; Kouw, W.M.; de Vries, B. On Epistemics in Expected Free Energy for Linear Gaussian State Space Models. Entropy 2021, 23, 1565. https://doi.org/10.3390/e23121565
Koudahl MT, Kouw WM, de Vries B. On Epistemics in Expected Free Energy for Linear Gaussian State Space Models. Entropy. 2021; 23(12):1565. https://doi.org/10.3390/e23121565
Chicago/Turabian StyleKoudahl, Magnus T., Wouter M. Kouw, and Bert de Vries. 2021. "On Epistemics in Expected Free Energy for Linear Gaussian State Space Models" Entropy 23, no. 12: 1565. https://doi.org/10.3390/e23121565
APA StyleKoudahl, M. T., Kouw, W. M., & de Vries, B. (2021). On Epistemics in Expected Free Energy for Linear Gaussian State Space Models. Entropy, 23(12), 1565. https://doi.org/10.3390/e23121565