
History Marginalization Improves Forecasting in Variational Recurrent Neural Networks

Abstract
:1. Introduction
- A new inference model. We establish a new type of variational family for inference in sequential latent variable models. Instead of a structured variational approximation, VDM marginalizes over past states. This leads to an efficient mean-field factorization where each variational factor is multi-modal by construction.
- An evaluation metric for multi-modal forecasting. The negative log-likelihood measures predictive accuracy but neglects an important aspect of multi-modal forecasts—sample diversity. In Section 4, we propose a score inspired by the Wasserstein distance [7] which evaluates both prediction quality and diversity. This metric complements our evaluation based on log-likelihoods.
- An extensive empirical study. In Section 4, we use VDM to study various datasets, including synthetic data, a stochastic Lorenz attractor, taxi trajectories, basketball player trajectories, and a U.S. pollution dataset with the measurements of various pollutants over time. We illustrate VDM’s ability in modeling multi-modal dynamics and provide quantitative comparisons to other methods showing that VDM compares favorably to previous work.
2. Related Work
3. Method–Variational Dynamic Mixtures
3.1. The Generative Model of VDM
3.2. The Variational Posterior of VDM
- reflects the generative model’s transition dynamics and combines it with the current observation . It is a Gaussian distribution whose parameters are obtained by propagating through the RNN of the generative model and using an inference network to combine the output with .
- is a distribution we will use to sample past states for approximating the marginalization in Equation (3). Its name suggests that it is generally intractable and will be approximated via self-normalized importance sampling.
3.2.1. Parametrization of the Variational Posterior
3.2.2. Generalized Mixture Weights
| Algorithm 1: Generative model. |
|
Inputs: Outputs: for do Equation (1) Equation (2) end for |
| Algorithm 2: Inference model. |
|
Inputs: Outputs: for do Equation (5) Equation (6) Equation (8) end for |
3.3. The Variational Objective of VDM
3.4. Alternative Modeling Choices
4. Evaluation and Experiments
4.1. Evaluation Metrics
4.2. Baselines
4.3. Ablations
4.4. Results
4.4.1. Synthetic Data with Multi-Modal Dynamics
4.4.2. Stochastic Lorenz Attractor
4.4.3. Taxi Trajectories
4.4.4. NBA SportVu Data
4.4.5. U.S. Pollution Data
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. ELBO Derivations
Appendix B. Supplementary to Stochastic Cubature Approximation
Appendix C. Supplementary to Experiments Setup
Appendix C.1. Stochastic Lorenz Attractor Setup
Appendix C.2. Taxi Trajectories Setup
Appendix C.3. U.S. Pollution Data Setup
Appendix C.4. NBA SportVu Data Setup
Appendix D. Implementation Details
- Latent RNN: summarize the historic latent states in the hidden states .
- Transition network: transit the latent states temporally.
- Emission network: map the latent states and hidden states to observations .
- Inference network: update states given observations and hidden states .
- Latent RNN: one layer GRU of input size and hidden size
- Transition network: input size is ; 3 linear layers of size 64, 64, and , with ReLUs.
- Emission network: input size is ; 3 linear layers of size 32, 32 and , with ReLUs.
- Inference network: input size is ; 3 linear layers of size 64, 64, and , with ReLUs.

{kind=link}
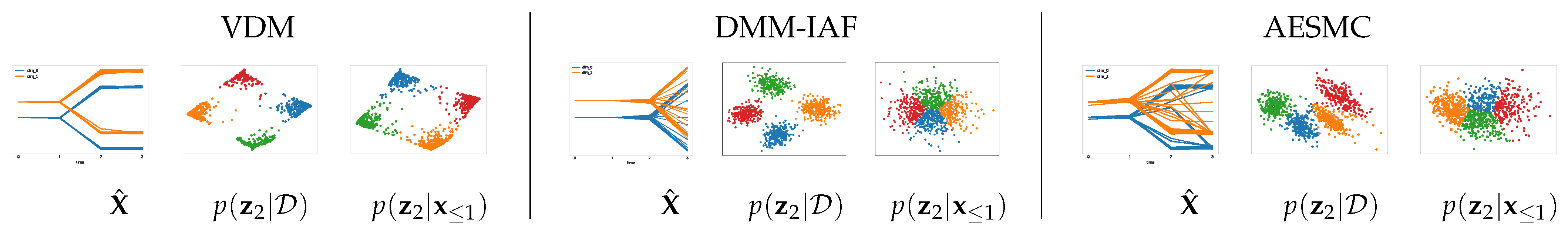{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Lorenz | 3 | 6 | 32 |
| Taxi | 2 | 6 | 32 |
| Pollution | 12 | 8 | 48 |
| SportVu | 2 | 6 | 32 |
| RKN | VRNN | CF-VAE | DMM-IAF | AESMC | VDM | |
|---|---|---|---|---|---|---|
| Lorenz | 23,170 | 22,506 | 7,497,468 | 24,698 | 22,218 | 22,218 |
| Taxi | 23,118 | 22,248 | 7,491,123 | 24,536 | 22,056 | 22,056 |
| Pollution | 35,774 | 33,192 | 8,162,850 | 36,328 | 31,464 | 31,464 |
| SportVu | 23,118 | 22,248 | 7,491,123 | 24,536 | 22,056 | 22,056 |
References
- Le, T.A.; Igl, M.; Rainforth, T.; Jin, T.; Wood, F. Auto-Encoding Sequential Monte Carlo. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Krishnan, R.G.; Shalit, U.; Sontag, D. Structured inference networks for nonlinear state space models. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Kingma, D.P.; Salimans, T.; Jozefowicz, R.; Chen, X.; Sutskever, I.; Welling, M. Improved Variational Inference with Inverse Autoregressive Flow. In Advances in Neural Information Processing Systems; Lee, D., Sugiyama, M., Luxburg, U., Guyon, I., Garnett, R., Eds.; Curran Associates, Inc.: New York, NY, USA, 2016; Volume 29. [Google Scholar]
- Bhattacharyya, A.; Hanselmann, M.; Fritz, M.; Schiele, B.; Straehle, C.N. Conditional Flow Variational Autoencoders for Structured Sequence Prediction. arXiv 2019, arXiv:1908.09008. [Google Scholar]
- Chung, J.; Kastner, K.; Dinh, L.; Goel, K.; Courville, A.C.; Bengio, Y. A recurrent latent variable model for sequential data. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 2980–2988. [Google Scholar]
- Becker, P.; Pandya, H.; Gebhardt, G.; Zhao, C.; Taylor, J.; Neumann, G. Recurrent Kalman Networks: Factorized Inference in High-Dimensional Deep Feature Spaces. In Proceedings of the Thirty-sixth International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019. [Google Scholar]
- Villani, C. Optimal Transport: Old and New; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2008; Volume 338. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Fraccaro, M.; Sønderby, S.K.; Paquet, U.; Winther, O. Sequential neural models with stochastic layers. In Advances in Neural Information Processing Systems; Curran Associates Inc.: Red Hook, NY, USA, 2016; pp. 2199–2207. [Google Scholar]
- Gemici, M.; Hung, C.C.; Santoro, A.; Wayne, G.; Mohamed, S.; Rezende, D.J.; Amos, D.; Lillicrap, T. Generative temporal models with memory. arXiv 2017, arXiv:1702.04649. [Google Scholar]
- Li, Y.; Mandt, S. Disentangled sequential autoencoder. In Proceedings of the Thirty-fifth International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Goyal, A.G.A.P.; Sordoni, A.; Côté, M.A.; Ke, N.R.; Bengio, Y. Z-forcing: Training stochastic recurrent networks. In Advances in Neural Information Processing Systems; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 6713–6723. [Google Scholar]
- Naesseth, C.; Linderman, S.; Ranganath, R.; Blei, D. Variational sequential monte carlo. In Proceedings of the International Conference on Artificial Intelligence and Statistics (PMLR), Banff, AB, Canada, 4–8 July 2004; pp. 968–977. [Google Scholar]
- Hirt, M.; Dellaportas, P. Scalable bayesian learning for state space models using variational inference with smc samplers. In Proceedings of the 22nd International Conference on Artificial Intelligence and Statistics, Naha, Japan, 16–18 April 2019; pp. 76–86. [Google Scholar]
- Saeedi, A.; Kulkarni, T.D.; Mansinghka, V.K.; Gershman, S.J. Variational particle approximations. J. Mach. Learn. Res. 2017, 18, 2328–2356. [Google Scholar]
- Schmidt, F.; Hofmann, T. Deep state space models for unconditional word generation. In Advances in Neural Information Processing Systems; Curran Associates Inc.: Red Hook, NY, USA, 2018; pp. 6158–6168. [Google Scholar]
- Schmidt, F.; Mandt, S.; Hofmann, T. Autoregressive Text Generation Beyond Feedback Loops. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 3391–3397. [Google Scholar]
- Ziegler, Z.M.; Rush, A.M. Latent normalizing flows for discrete sequences. In Proceedings of the Thirty-Sixth International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019. [Google Scholar]
- Chen, X.; Duan, Y.; Houthooft, R.; Schulman, J.; Sutskever, I.; Abbeel, P. Infogan: Interpretable representation learning by information maximizing generative adversarial nets. In Advances in Neural Information Processing Systems; Curran Associates Inc.: Red Hook, NY, USA, 2016; pp. 2172–2180. [Google Scholar]
- Li, Y.; Song, J.; Ermon, S. Infogail: Interpretable imitation learning from visual demonstrations. In Advances in Neural Information Processing Systems; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 3812–3822. [Google Scholar]
- Bhattacharyya, A.; Schiele, B.; Fritz, M. Accurate and diverse sampling of sequences based on a “best of many” sample objective. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8485–8493. [Google Scholar]
- Sadeghian, A.; Kosaraju, V.; Sadeghian, A.; Hirose, N.; Rezatofighi, H.; Savarese, S. Sophie: An attentive gan for predicting paths compliant to social and physical constraints. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1349–1358. [Google Scholar]
- Kosaraju, V.; Sadeghian, A.; Martín-Martín, R.; Reid, I.; Rezatofighi, H.; Savarese, S. Social-bigat: Multimodal trajectory forecasting using bicycle-gan and graph attention networks. In Advances in Neural Information Processing Systems; Curran Associates Inc.: Red Hook, NY, USA, 2019; pp. 137–146. [Google Scholar]
- Karl, M.; Soelch, M.; Bayer, J.; Van der Smagt, P. Deep variational bayes filters: Unsupervised learning of state space models from raw data. In Proceedings of the 5th International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Fraccaro, M.; Kamronn, S.; Paquet, U.; Winther, O. A disentangled recognition and nonlinear dynamics model for unsupervised learning. In Advances in Neural Information Processing Systems; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 3601–3610. [Google Scholar]
- Rangapuram, S.S.; Seeger, M.W.; Gasthaus, J.; Stella, L.; Wang, Y.; Januschowski, T. Deep state space models for time series forecasting. In Advances in Neural Information Processing Systems; Curran Associates Inc.: Red Hook, NY, USA, 2018; pp. 7785–7794. [Google Scholar]
- Zheng, X.; Zaheer, M.; Ahmed, A.; Wang, Y.; Xing, E.P.; Smola, A.J. State space LSTM models with particle MCMC inference. arXiv 2017, arXiv:1711.11179. [Google Scholar]
- Doerr, A.; Daniel, C.; Schiegg, M.; Nguyen-Tuong, D.; Schaal, S.; Toussaint, M.; Trimpe, S. Probabilistic recurrent state-space models. In Proceedings of the Thirty-fifth International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- De Brouwer, E.; Simm, J.; Arany, A.; Moreau, Y. GRU-ODE-Bayes: Continuous modeling of sporadically-observed time series. In Advances in Neural Information Processing Systems; Curran Associates Inc.: Red Hook, NY, USA, 2019; pp. 7377–7388. [Google Scholar]
- Gedon, D.; Wahlström, N.; Schön, T.B.; Ljung, L. Deep State Space Models for Nonlinear System Identification. arXiv 2020, arXiv:2003.14162. [Google Scholar] [CrossRef]
- Linderman, S.; Johnson, M.; Miller, A.; Adams, R.; Blei, D.; Paninski, L. Bayesian learning and inference in recurrent switching linear dynamical systems. In Proceedings of the Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 914–922. [Google Scholar]
- Nassar, J.; Linderman, S.; Bugallo, M.; Park, I.M. Tree-Structured Recurrent Switching Linear Dynamical Systems for Multi-Scale Modeling. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Becker-Ehmck, P.; Peters, J.; Van Der Smagt, P. Switching Linear Dynamics for Variational Bayes Filtering. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 553–562. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Auger-Méthé, M.; Field, C.; Albertsen, C.M.; Derocher, A.E.; Lewis, M.A.; Jonsen, I.D.; Flemming, J.M. State-space models’ dirty little secrets: Even simple linear Gaussian models can have estimation problems. Sci. Rep. 2016, 6, 26677. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Maaløe, L.; Sønderby, C.K.; Sønderby, S.K.; Winther, O. Auxiliary deep generative models. In Proceedings of the International conference on Machine Learning (PMLR), New York, NY, USA, 20–22 June 2016; pp. 1445–1453. [Google Scholar]
- Ranganath, R.; Tran, D.; Blei, D. Hierarchical variational models. In Proceedings of the International Conference on Machine Learning (PMLR), New York, NY, USA, 20–22 June 2016; pp. 324–333. [Google Scholar]
- Sobolev, A.; Vetrov, D. Importance weighted hierarchical variational inference. arXiv 2019, arXiv:1905.03290. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Owen, A.B. Monte Carlo Theory, Methods and Examples; 2013. Available online: https://artowen.su.domains/mc/ (accessed on 30 September 2021).
- Schön, T.B.; Lindsten, F.; Dahlin, J.; Wågberg, J.; Naesseth, C.A.; Svensson, A.; Dai, L. Sequential Monte Carlo methods for system identification. IFAC-Pap. 2015, 48, 775–786. [Google Scholar]
- Wan, E.A.; Van Der Merwe, R. The unscented Kalman filter for nonlinear estimation. In Proceedings of the IEEE 2000 Adaptive Systems for Signal Processing, Communications, and Control Symposium (Cat. No. 00EX373), Lake Louise, AB, Canada, 4 October 2000; pp. 153–158. [Google Scholar]
- Wu, Y.; Hu, D.; Wu, M.; Hu, X. A numerical-integration perspective on Gaussian filters. IEEE Trans. Signal Process. 2006, 54, 2910–2921. [Google Scholar] [CrossRef]
- Arasaratnam, I.; Haykin, S. Cubature kalman filters. IEEE Trans. Autom. Control 2009, 54, 1254–1269. [Google Scholar] [CrossRef] [Green Version]
- Lee, N.; Choi, W.; Vernaza, P.; Choy, C.B.; Torr, P.H.; Chandraker, M. Desire: Distant future prediction in dynamic scenes with interacting agents. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 336–345. [Google Scholar]
- Tomczak, J.M.; Welling, M. VAE with a VampPrior. In Proceedings of the 21st International Conference on Artificial Intelligence and Statistics, Playa Blanca, Spain, 9–11 April 2018. [Google Scholar]
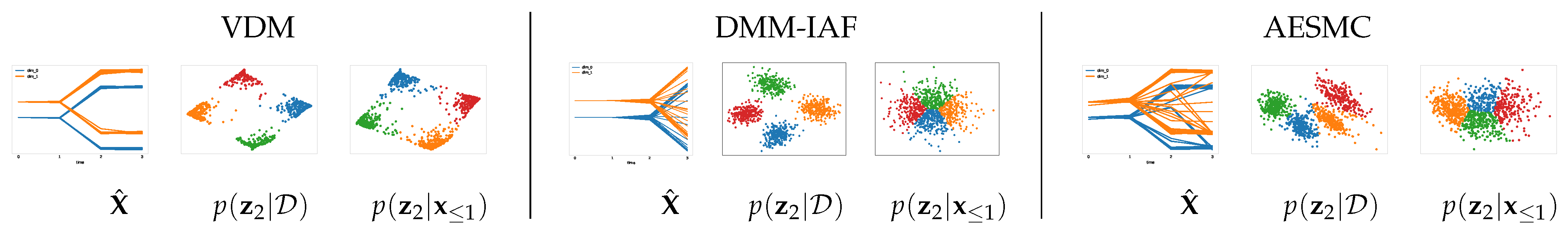



| VDM | VDM () | VDM-SCA-S | VDM-MC-S | VDM-MC-U | |
|---|---|---|---|---|---|
| Sampling | SCA | SCA | SCA | Monte-Carlo | Monte-Carlo |
| Weights | hard | hard | soft | soft | uniform |
| Loss |
| Stochastic Lorenz Attractor | Taxi Trajectories | |||||
|---|---|---|---|---|---|---|
| Multi-Step | One-Step | W-Distance | Multi-Step | One-Step | W-Distance | |
| RKN | 104.41 | 1.88 | 16.16 | 4.25 | −2.90 | 2.07 |
| VRNN | 65.89 ± 0.21 | −1.63 | 16.14 ± 0.006 | 5.51 ± 0.002 | −2.77 | 2.43 ± 0.0002 |
| CF-VAE | 32.41 ± 0.13 | n.a | 8.44 ± 0.005 | 2.77 ± 0.001 | n.a | 0.76 ± 0.0003 |
| DMM-IAF | 25.26 ± 0.24 | −1.29 | 7.47 ± 0.014 | 3.29 ± 0.001 | −2.45 | 0.70 ± 0.0003 |
| AESMC | 25.01 ± 0.22 | −1.69 | 7.29 ± 0.005 | 3.31 ± 0.001 | −2.87 | 0.66 ± 0.0004 |
| VDM | 24.49 ± 0.16 | −1.81 | 7.29 ± 0.003 | 2.88 ± 0.002 | −3.68 | 0.56 ± 0.0008 |
| 25.01 ± 0.27 | −1.74 | 7.30 ± 0.004 | 3.10 ± 0.005 | −3.05 | 0.61 ± 0.0003 | |
| 24.69 ± 0.16 | −1.83 | 7.30 ± 0.009 | 3.09 ± 0.001 | −3.24 | 0.64 ± 0.0005 | |
| 24.67 ± 0.16 | −1.84 | 7.30 ± 0.005 | 3.17 ± 0.001 | −3.21 | 0.68 ± 0.0008 | |
| 25.04 ± 0.28 | −1.81 | 7.31 ± 0.002 | 3.30 ± 0.002 | −2.42 | 0.69 ± 0.0002 | |
| NBA SportVu | US Pollution | |||
|---|---|---|---|---|
| Multi-Steps | One-Step | Multi-Steps | One-Step | |
| RKN | 4.88 | 1.55 | 53.13 | 6.98 |
| VRNN | 5.42 ± 0.009 | −2.78 | 49.32 ± 0.13 | 8.69 |
| CF-VAE | 3.24 ± 0.003 | n.a | 45.86 ± 0.04 | n.a |
| DMM-IAF | 3.63 ± 0.002 | −3.74 | 44.82 ± 0.11 | 9.41 |
| AESMC | 3.74 ± 0.003 | −3.91 | 41.14 ± 0.13 | 6.93 |
| VDM | 3.23 ± 0.003 | −5.44 | 37.64 ± 0.07 | 6.91 |
| 3.29 ± 0.003 | −5.04 | 39.87 ± 0.04 | 7.60 | |
| 3.31 ± 0.001 | −5.08 | 39.58 ± 0.09 | 7.82 | |
| 3.35 ± 0.007 | −5.00 | 40.33 ± 0.03 | 8.12 | |
| 3.39 ± 0.006 | −4.82 | 41.81 ± 0.10 | 7.71 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qiu, C.; Mandt, S.; Rudolph, M. History Marginalization Improves Forecasting in Variational Recurrent Neural Networks. Entropy 2021, 23, 1563. https://doi.org/10.3390/e23121563
Qiu C, Mandt S, Rudolph M. History Marginalization Improves Forecasting in Variational Recurrent Neural Networks. Entropy. 2021; 23(12):1563. https://doi.org/10.3390/e23121563
Chicago/Turabian StyleQiu, Chen, Stephan Mandt, and Maja Rudolph. 2021. "History Marginalization Improves Forecasting in Variational Recurrent Neural Networks" Entropy 23, no. 12: 1563. https://doi.org/10.3390/e23121563
APA StyleQiu, C., Mandt, S., & Rudolph, M. (2021). History Marginalization Improves Forecasting in Variational Recurrent Neural Networks. Entropy, 23(12), 1563. https://doi.org/10.3390/e23121563