
Personal Interest Attention Graph Neural Networks for Session-Based Recommendation


Abstract
:1. Introduction
- For personalized recommendation scenarios, we use a new user-based personalized graph neural network (PGNN), which can capture complex item transformations for different user interests.
- For the different interests of users, we add the interest attention module, which can activate different user interests adaptively for different targets and improve the expressiveness of the model.
- We have studied the model on two real-world datasets. Experiments demonstrate the effectiveness of the proposed model.
2. Relate Work
2.1. Traditional Recommendation Method
2.2. Deep-Learning-Based Methods
2.3. Graph Neural Networks
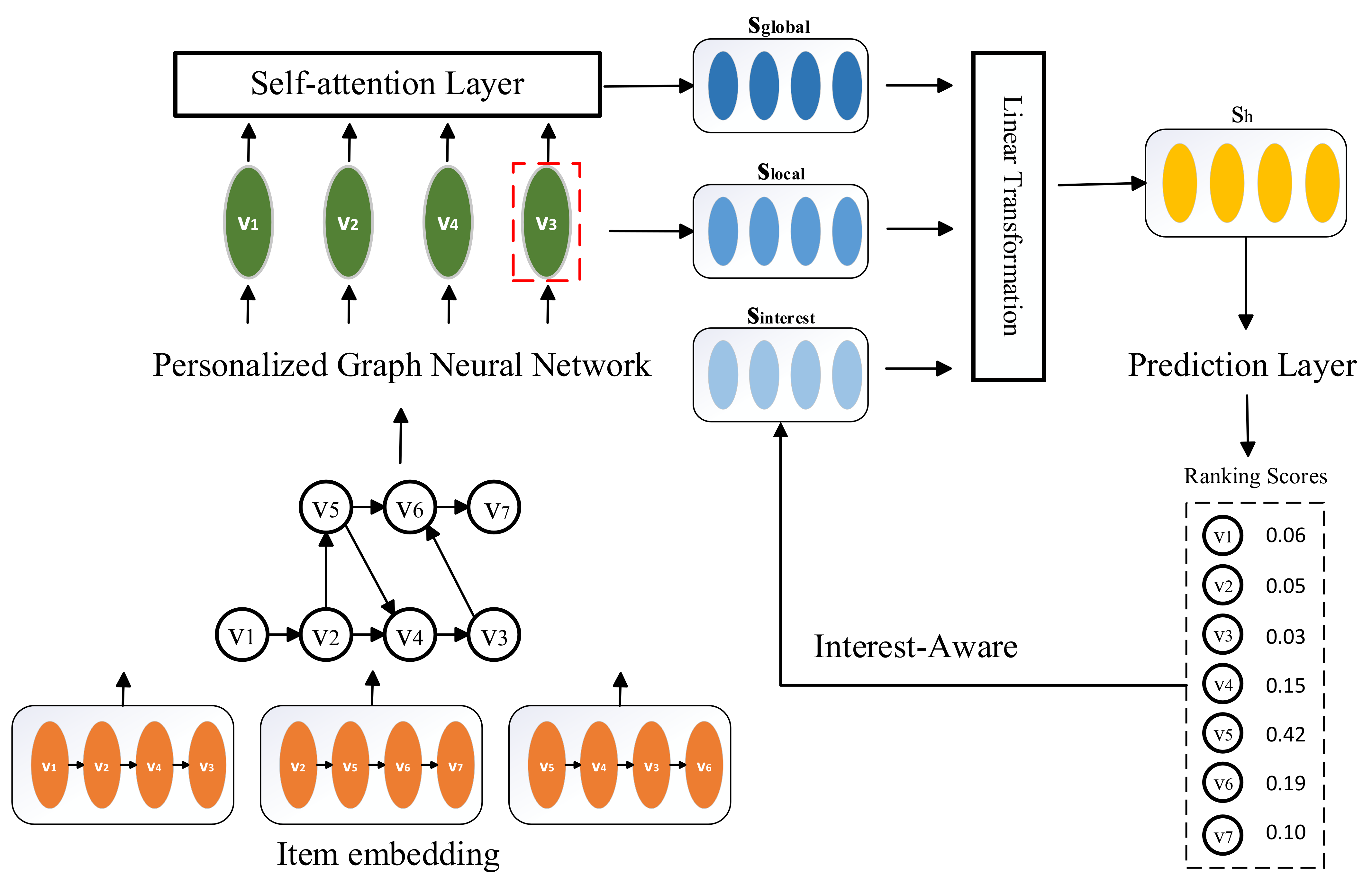
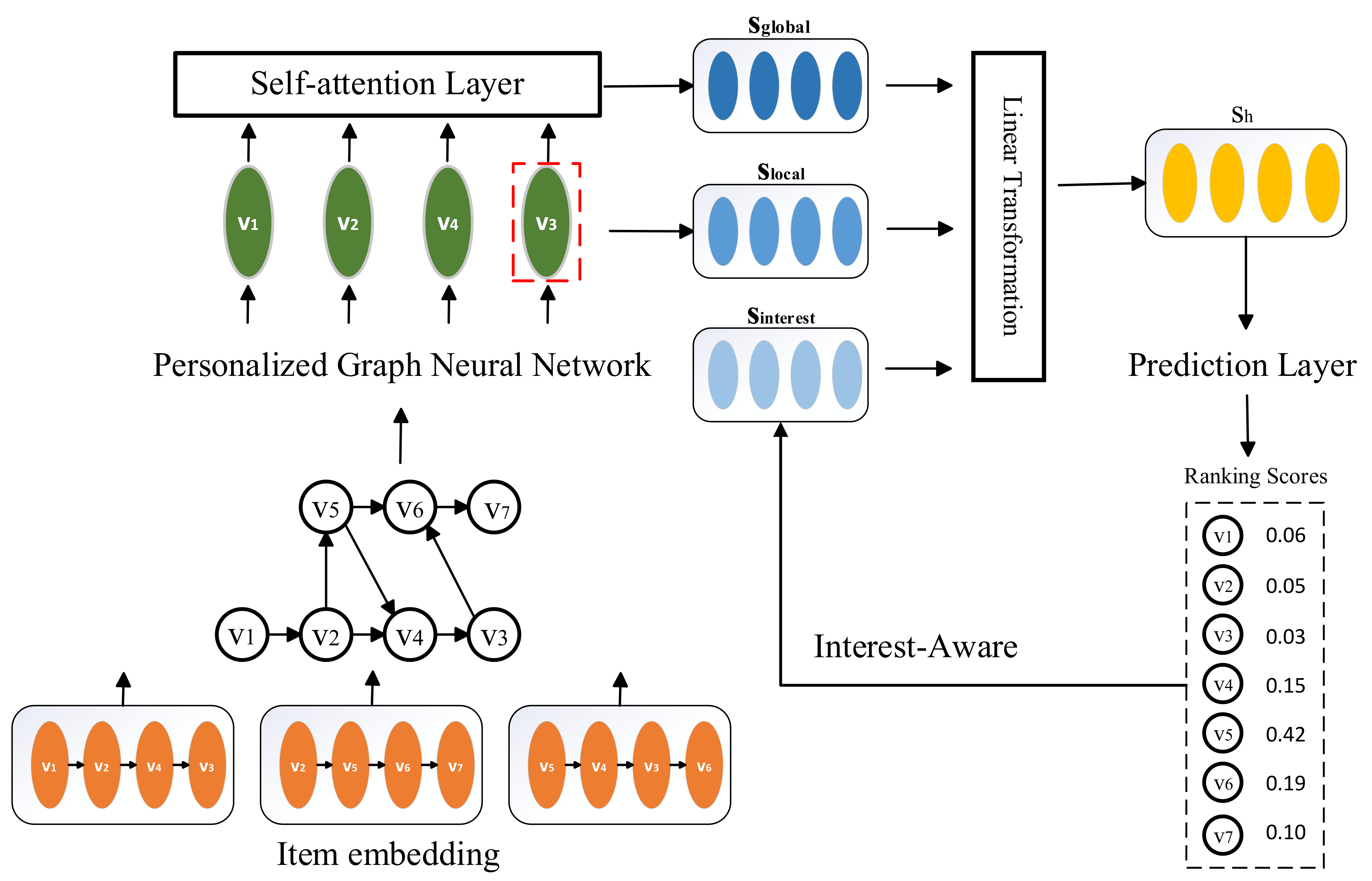
3. The Proposed Method
3.1. Problem Statement
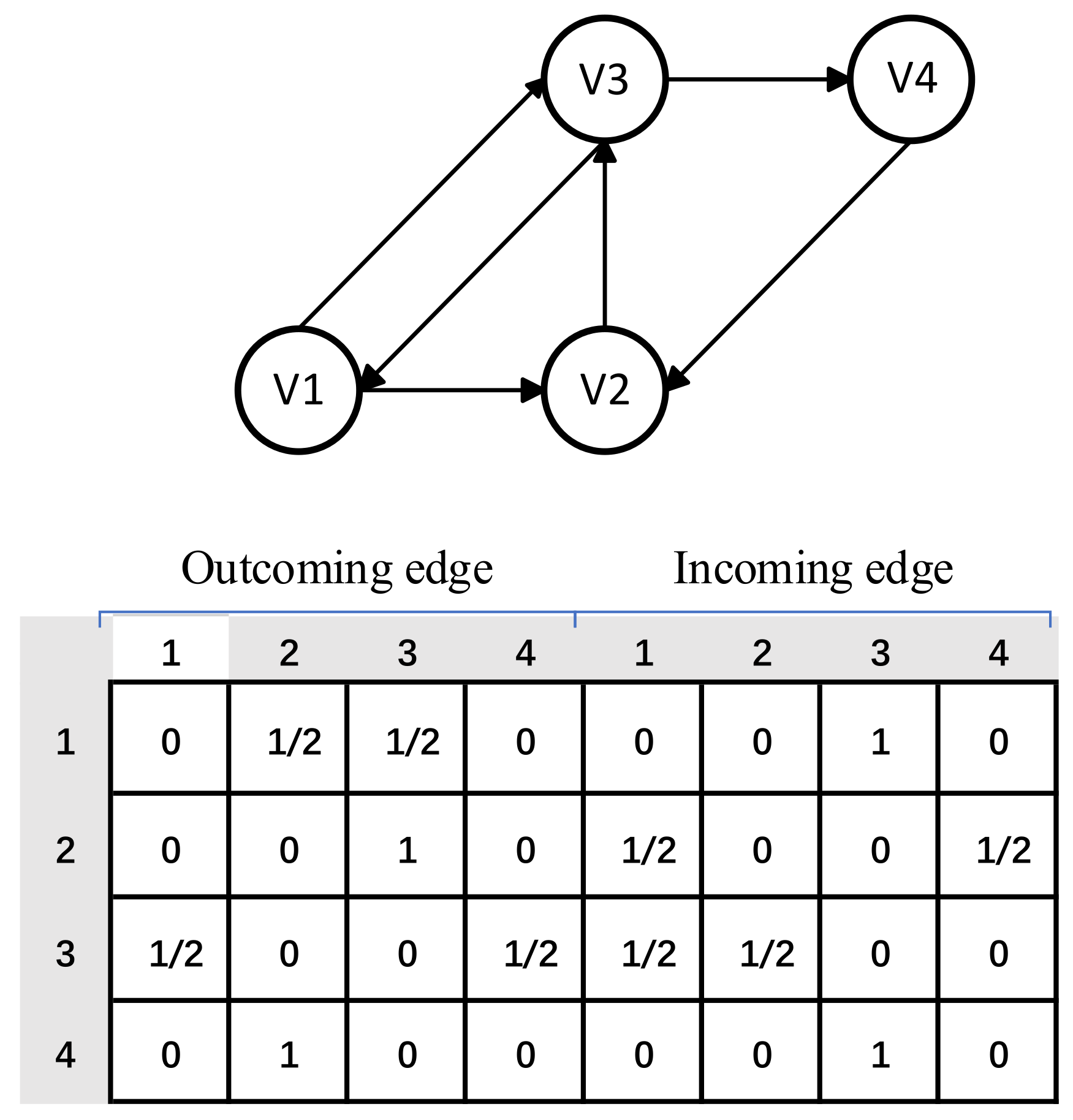
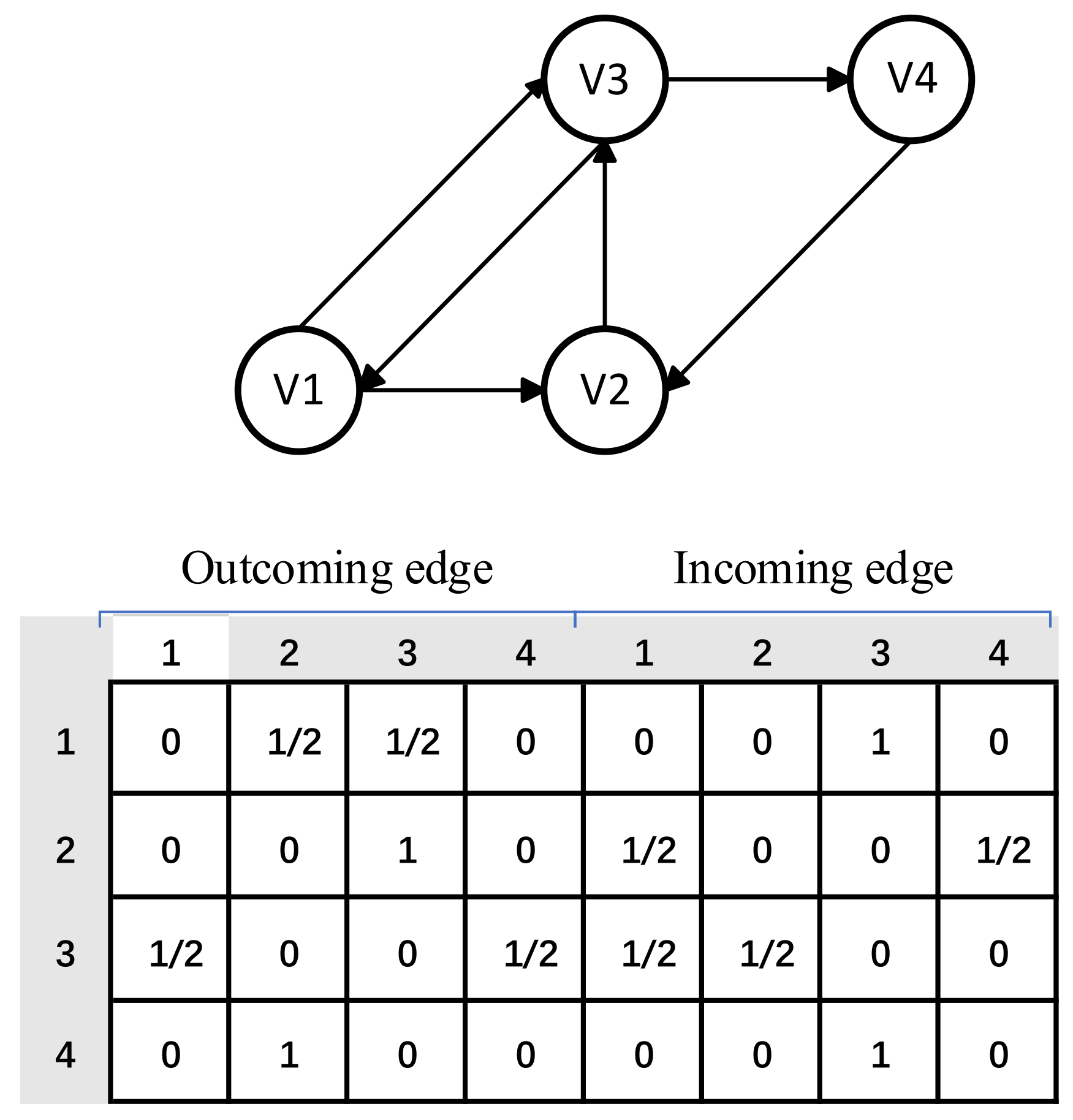
3.2. Constructing Session Graphs
3.3. Personalized Graph Neural Network
3.4. Constructing Interest-Aware Embeddings
3.5. Self-Attention Layers
3.5.1. Point-Wise Feed-Forward Network
3.5.2. Multi-Layer Self-Attention
3.6. Generating Session Embeddings
3.7. Making Recommendation and Model Training
4. Experiment and Analysis
4.1. Datasets
4.2. Baseline
- POP always recommends the most popular program in the entire training set, and despite its simplicity, it can serve as a powerful baseline in certain situations.
- S-POP recommends the top TOP-N most popular items for the current session.
- Item-KNN [27] recommends items that are similar to the items clicked in previous sessions, where similarity is defined as the cosine similarity between session vectors. Regularization is introduced to avoid the high similarity problem between unvisited items.
- BPR-MF [34] proposed a BPR objective function to compute pairwise ranking losses, using stochastic gradient descent to optimize the pairwise ranking objective function. The matrix decomposition is applied to session-based recommendations using the average potential vector of items in a session.
- FPMC [14] is a Markov chain-based sequence prediction method.
- GRU4REC [2] uses RNNs to model user sequences for session-based recommendations, stacking multiple GRU layers to encode session sequences into a final state. A ranking loss is used to train the model.
- NARM [28] uses RNN with attention mechanism to capture the main purpose and sequential behavior of the user.
- STAMP [4] uses the attention layer to replace the RNN encoder, and even completely relies on the self-attention of the last item in the sequence to make the model more powerful.
- SR-GNN [5] uses the gated graph convolutional layer to obtain the embedding of all items, and then it pays attention to each last item like STAMP to calculate the sequence-level embedding.
4.3. Evaluation Metrics
4.4. Parameter Setting
4.5. Comparison with Baseline Methods
4.6. Ablation Studies
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhao, P.; Zhu, H.; Liu, Y.; Xu, J.; Li, Z.; Zhuang, F.; Sheng, V.S.; Zhou, X. Where to Go Next: A Spatio-Temporal Gated Network for Next POI Recommendation. IEEE Trans. Knowl. Data Eng. 2020, 33, 1–8. [Google Scholar] [CrossRef]
- Hidasi, B.; Karatzoglou, A.; Baltrunas, L.; Tikk, D. Session-Based Recommendations with Recurrent Neural Networks. In Proceedings of the 4th International Conference on Learning Representations, ICLR 2016, San Juan, Puerto Rico, 2–4 May 2016; pp. 1–10. [Google Scholar]
- Li, J.; Ren, P.; Chen, Z.; Ren, Z.; Lian, T.; Ma, J. Neural Attentive Session-Based Recommendation. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, Singapore, 6–10 November 2017; pp. 1419–1428. [Google Scholar]
- Liu, Q.; Zeng, Y.; Mokhosi, R.; Zhang, H. STAMP: Short-Term Attention/Memory Priority Model for Session-based Recommendation. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 1831–1839. [Google Scholar]
- Wu, S.; Tang, Y.; Zhu, Y.; Wang, L.; Xie, X.; Tan, T. Session-Based Recommendation with Graph Neural Networks. In Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January 27–1 February 2019; pp. 346–353. [Google Scholar]
- Hu, F.; Zhu, Y.; Wu, S.; Huang, W.; Wang, L.; Tan, T. GraphAIR: Graph Representation Learning with Neighborhood Aggregation and Interaction. Pattern Recognit. 2021, 112, 107754. [Google Scholar] [CrossRef]
- Zhang, Y.; Yu, X.; Cui, Z.; Wu, S.; Wen, Z.; Wang, L. Every Document Owns Its Structure: Inductive Text Classification via Graph Neural Networks. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Seattle, WA, USA, 5–10 July 2020; pp. 334–339. [Google Scholar]
- Mnih, A.; Salakhutdinov, R. Probabilistic matrix factorization. In Proceedings of the 20th International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 3–6 December 2007; pp. 1257–1264. [Google Scholar]
- Koren, Y.; Bell, R.; Volinsky, C. Matrix factorization techniques for recommender systems. Computer 2009, 42, 30–37. [Google Scholar] [CrossRef]
- Koren, Y.; Bell, R. Advances in collaborative filtering. In Recommender Systems Handbook; Springer: Berlin/Heidelberg, Germany, 2011; pp. 145–186. [Google Scholar]
- Sarwar, B.; Karypis, G.; Konstan, J.; Riedl, J. Item-based collaborative filtering recommendation algorithms. In Proceedings of the WWW01: Hypermedia Track of 10th International Conference on World Wide Web, Hong Kong, China, 1–5 May 2001; pp. 285–295. [Google Scholar]
- Zimdars, A.; Chickering, D.M.; Meek, C. Using Temporal Data for Making Recommendations. In Proceedings of the 17th Conference in Uncertainty in Artificial Intelligence, Seattle, WA, USA, 2–5 August 2001; pp. 580–585. [Google Scholar]
- Mikolov, T.; Karafiát, M.; Burget, L.; Černocký, J.; Khudanpur, S. Recurrent neural network based language model. Interspeech 2010, 2, 1045–1048. [Google Scholar]
- Rendle, S.; Freudenthaler, C.; Schmidt-Thieme, L. Factorizing personalized Markov chains for next-basket recommendation. In Proceedings of the 19th International Conference on World Wide Web, Raleigh, NC, USA, 26–30 April 2010; ACM: New York, NY, USA, 2010; pp. 811–820. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the 26th International Conference on Neural Information Processing Systems, Sydney, Australia, 12–15 December 2013; pp. 3111–3119. [Google Scholar]
- Cho, K.; van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase rep-resentations using RNN Encoder-Decoder for statistical machine translation. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014; pp. 1724–1734. [Google Scholar]
- Serban, I.V.; Sordoni, A.; Bengio, Y.; Courville, A.; Pineau, J. Building end-to-end dialogue systems using generative hierarchical neural network models. In Proceedings of the 30th AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 3776–3784. [Google Scholar]
- Hidasi, B.; Quadrana, M.; Karatzoglou, A.; Tikk, D. Parallel recurrent neural network architectures for feature-rich session-based recommendations. In Proceedings of the 10th ACM Conference on Recommender Systems, Boston, MA, USA, 15–19 September 2016; ACM: New York, NY, USA, 2016; pp. 241–248. [Google Scholar]
- Ying, H.; Zhuang, F.; Zhang, F.; Liu, Y.; Xu, G.; Xie, X.; Xiong, H.; Wu, J. Sequential recommender system based on hierarchical attention networks. In Proceedings of the 27th International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 3926–3932. [Google Scholar]
- Perozzi, B.; Al-Rfou, R.; Skiena, S. Deepwalk: Online learning of social representations. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; ACM: New York, NY, USA, 2014; pp. 701–710. [Google Scholar]
- Shani, G.; Brafman, R.I.; Heckerman, D. An MDP-Based Recommender System. In Proceedings of the 18th Conference in Uncertainty in Anartificial Intelligence, Edmonton, Canada, 1–4 August 2002; pp. 1265–1295. [Google Scholar]
- Tang, J.; Qu, M.; Wang, M.; Zhang, M.; Yan, J.; Mei, Q. Line: Large-scale information network embedding. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; ACM: New York, NY, USA, 2015; pp. 1067–1077. [Google Scholar]
- Grover, A.; Leskovec, J. Node2vec: Scalable feature learning for networks. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, ser. KDD’16. ACM, San Francisco, CA, USA, 13–17 August 2016; pp. 855–864. [Google Scholar]
- Duvenaud, D.; Maclaurin, D.; AguileraIparraguirre, J.; Gómez-Bombarelli, R.; Hirzel, T.; Aspuru-Guzik, A.; Adams, R.P. Convolutional networks on graphs for learning molecular fingerprints. In Proceedings of the 28th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 2215–2223. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. In Proceedings of the 5th International Conference on Learning Representations, Toulon, France, 24–26 April 2017; pp. 1–14. [Google Scholar]
- Gori, M.; Monfardini, G.; Scarselli, F. A new model for learning in graph domains. In Proceedings of the 2005 IEEE International oint Conference on Neural Networks, Montreal, QC, Canada, 31 July–4 August 2005; Volume 2, pp. 729–734. [Google Scholar]
- Scarselli, F.; Gori, M.; Tsoi, A.C.; Hagenbuchner, M.; Monfardini, G. The graph neural network model. IEEE Trans. Eural Netw. 2009, 20, 61–80. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, Y.; Tarlow, D.; Brockschmidt, M.; Zemel, R.J.A.P.A. Gated graph sequence neural networks. In Proceedings of the International Conference on Learning Representations Caribe Hilton, San Juan, Puerto Rico, 2–4 May 2016; pp. 1–20. [Google Scholar]
- Veliković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Liò, P.; Bengio, Y. Graph attention networks. In Proceedings of the 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, 30 April–3 May 2018; pp. 1–12. [Google Scholar]
- Qiu, R.; Li, J.; Huang, Z.; Yin, H. Rethinking the Item Order in Session-Based Recommendation with Graph Neural Networks. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 579–588. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Kang, W.; McAuley, J. Self-attentive sequential recommendation. In Proceedings of the 2018 IEEE International Conference on Data Mining (ICDM 2018), Singapore, 17–20 November 2018; IEEE: New York, NY, USA, 2018; pp. 197–206. [Google Scholar]
- Zhou, C.; Bai, J.; Song, J.; Liu, X.; Zhao, Z.; Chen, X.; Gao, J. Atrank: An attention-based user behavior modeling framework for recommendation. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI 2018), New Orleans, LA, USA, 2–7 February 2018; pp. 1–9. [Google Scholar]
- Xu, C.; Zhao, P.; Liu, Y.; Sheng, V.S.; Xu, J.; Zhuang, F.; Fang, J.; Zhou, X. Graph Contextualized Self-Attention Network for Session-Based Recommendation. In Proceedings of the 28th International Joint Conference on Artificial Intelligence (IJCAI 2019), Macau, China, 10–16 August 2019; pp. 3940–3946. [Google Scholar]

{kind=link}
{kind=link}
| Statistics | Diginetica | Yoochoose 1/64 |
|---|---|---|
| #Clicks | 982,961 | 557,248 |
| #Training sessions | 719,470 | 369,859 |
| #Test sessions | 60,858 | 55,898 |
| #Unique items | 43,097 | 16,766 |
| Average length | 5.12 | 6.16 |
| Method | Diginetica | Yoochoose 1/64 | ||
|---|---|---|---|---|
| Recall@20 | MRR@20 | Recall@20 | MRR@20 | |
| POP | 0.89 | 0.20 | 6.71 | 1.65 |
| BPR-MF | 5.24 | 1.98 | 31.31 | 12.08 |
| S-POP | 21.06 | 13.68 | 30.44 | 18.35 |
| FPMC | 26.53 | 6.95 | 45.62 | 15.01 |
| GRU4REC | 29.45 | 8.33 | 60.64 | 22.89 |
| Item-KNN | 35.75 | 11.57 | 51.60 | 21.81 |
| NARM | 49.70 | 16.17 | 68.32 | 28.63 |
| STAMP | 45.64 | 14.32 | 68.74 | 29.67 |
| SR-GNN | 50.73 | 17.59 | 70.57 | 30.94 |
| PIA-GNN | 52.62 | 18.39 | 71.46 | 31.27 |
| Method | Diginetica | Yoochoose 1/64 | ||
|---|---|---|---|---|
| Recall@20 | MRR@20 | Recall@20 | MRR@20 | |
| PIA-GNN | 52.62 | 18.39 | 71.46 | 31.27 |
| PIA-GNN(-U) | 51.83 | 18.26 | 71.02 | 31.22 |
| PIA-GNN(-I) | 51.28 | 18.19 | 70.98 | 31.08 |
| PIA-GNN(-I-U-A) | 50.94 | 17.85 | 70.69 | 30.99 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Zhou, Y.; Wang, J.; Lu, X. Personal Interest Attention Graph Neural Networks for Session-Based Recommendation. Entropy 2021, 23, 1500. https://doi.org/10.3390/e23111500
Zhang X, Zhou Y, Wang J, Lu X. Personal Interest Attention Graph Neural Networks for Session-Based Recommendation. Entropy. 2021; 23(11):1500. https://doi.org/10.3390/e23111500
Chicago/Turabian StyleZhang, Xiangde, Yuan Zhou, Jianping Wang, and Xiaojun Lu. 2021. "Personal Interest Attention Graph Neural Networks for Session-Based Recommendation" Entropy 23, no. 11: 1500. https://doi.org/10.3390/e23111500
APA StyleZhang, X., Zhou, Y., Wang, J., & Lu, X. (2021). Personal Interest Attention Graph Neural Networks for Session-Based Recommendation. Entropy, 23(11), 1500. https://doi.org/10.3390/e23111500