
On Architecture Selection for Linear Inverse Problems with Untrained Neural Networks



Abstract
:1. Introduction
- Untrained neural networks invariably come with architectural hyperparameters (e.g., input size, number of layers, convolutional filters used, etc.), and while impressive results have been observed under various architectures, relatively little attention has been paid to how best to select these parameters.
- Untrained neural networks have primarily been applied in the context of recovering images (e.g., natural images, medical images, etc.), but to our knowledge, no detailed study has been given on how the architectural hyperparameters may vary across different signal types (e.g., rough vs. smooth), and different measurement types (e.g., inpainting vs. denoising vs. compressive sensing), nor on the robustness to changing from one setting to another.
- Regarding the signal type, while one-dimensional time-series data has been considered in numerous works on sparsity-based compressive sensing (e.g., neuro-electrical signals [9] and sensor network data [10]), to our knowledge, such signals have received significantly less attention in the context of neural network based priors, with one exception being a one-dimensional Deep Image Prior in [11].
- (i)
- To what extent do the optimal hyperparameters vary for different measurement models and signal types?
- (ii)
- To what extent does the performance degrade when the hyperparameters are tuned for one setting but applied to another?
- (iii)
- To what extent are the various hyperparameters robust to deviations from their optimal value?
1.1. Related Work
- In [12], several variants of Deep Decoder are introduced depending the presence/absence of upsampling and certain convolution operations. The success of Deep Decoder is primarily attributed to the presence of convolutions with fixed interpolating filters in the neural network architecture. Further details are given in Section 1.2.
- Theoretical guarantees for compressive sensing were given in [14,21]. The former studies the convergence of a projected gradient descent algorithm in underparametrized settings, whereas the latter shows that regular gradient descent is able to recover sufficiently smooth signals even in overparametrized settings.
- Variations of Deep Decoder for medical imaging are given in [7,22], with an additional challenge being combining measurements from multiple coils measuring the same signal in parallel. Additional applications of deep decoder include quantitative phase microscopy [23] and image fusion [20]. In addition, another variant of Deep Decoder for graph signals is given in [24].
- In [25], a method is proposed for combining the benefits of trained and untrained methods, by imposing priors that are a combination of the two.
- In [26], various robustness considerations for neural network based methods (both trained and untrained) are investigated. In particular, (i) both are shown to be sensitive to adversarial perturbations in the measurements; (ii) both may suffer from significant performance degradation under distribution shifts; and (iii) evidence is provided that the overall reconstruction performance is strongly correlated with the ability to recover specific fine details.
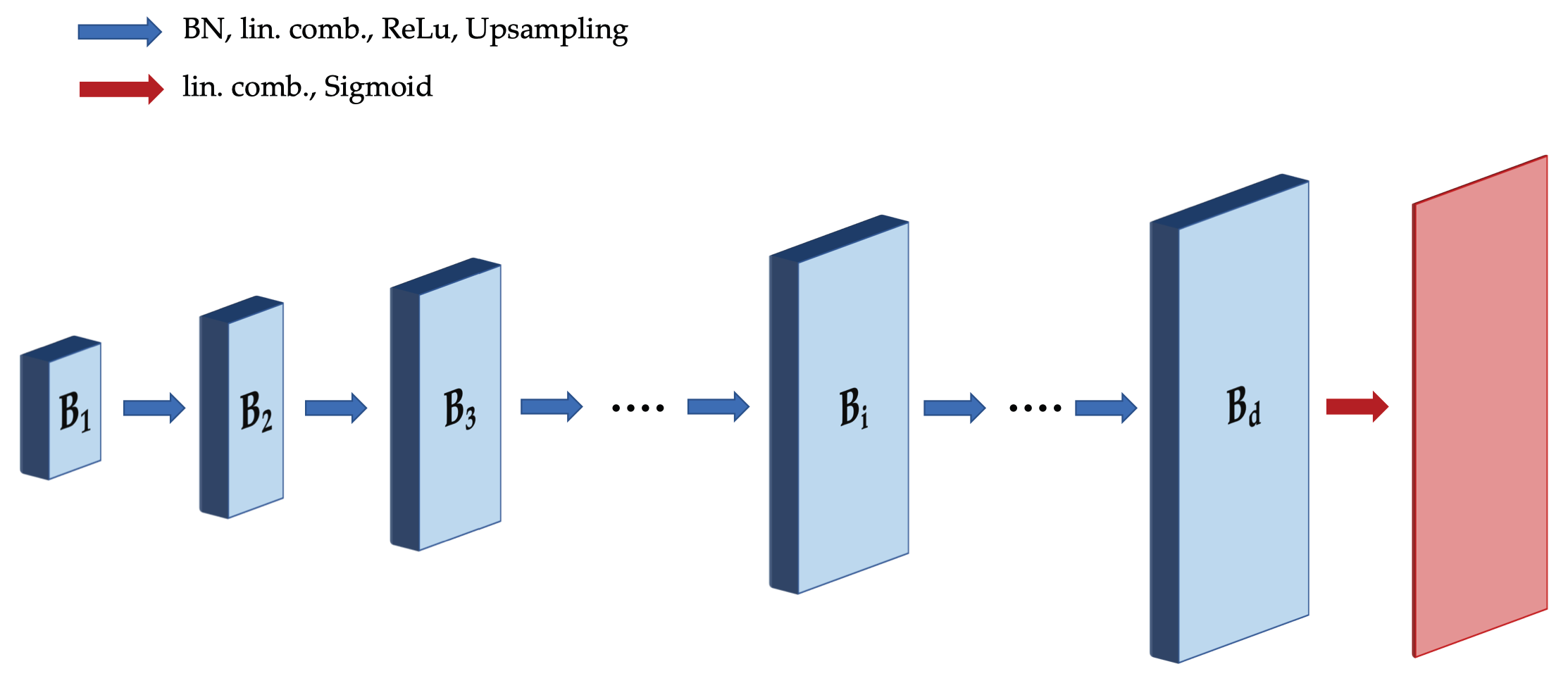
1.2. Background: Deep Decoder
1.3. Hyperparameters and Problem Variables
2. Hyperparameter Selection
2.1. Theoretical Viewpoint
2.2. Successive Halving
- The function generates a set of n random configurations, i.e., for each such configuration, each hyperparameter value is chosen uniformly at random from the pre-specified finite set of possible values.
- The function returns the PSNR after running the minimization (4) with the hyperparameter configuration H and resource level .
- The function finds the highest values of PSNR in the list , and returns the corresponding configurations in .
| Algorithm 1: Successive Halving for Hyperparameter Optimization. |
 |
2.3. Greedy Fine-Tuning
| Algorithm 2: Greedy Fine-Tuning for Hyperparameter Optimization. |
 |
3. Experiments
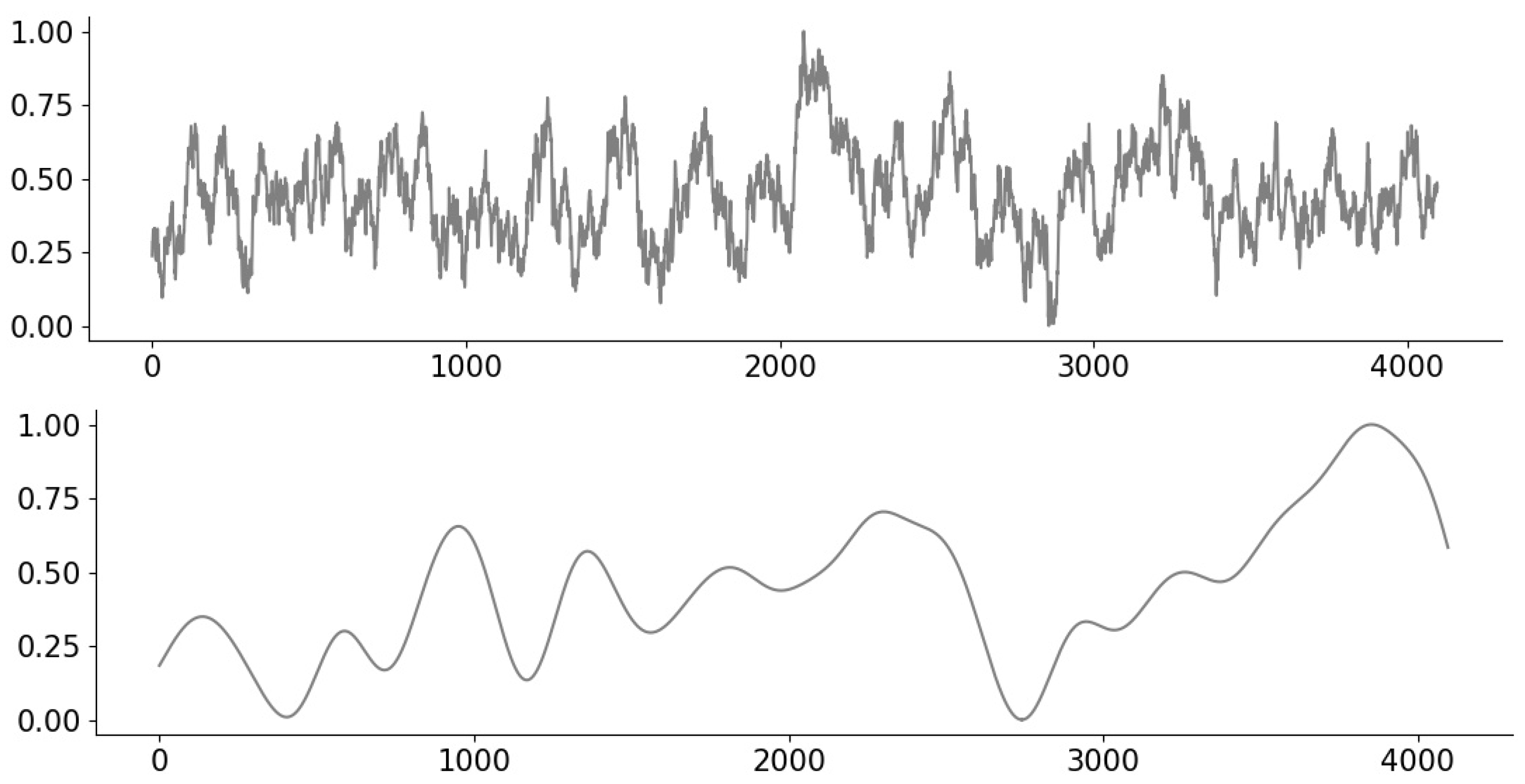
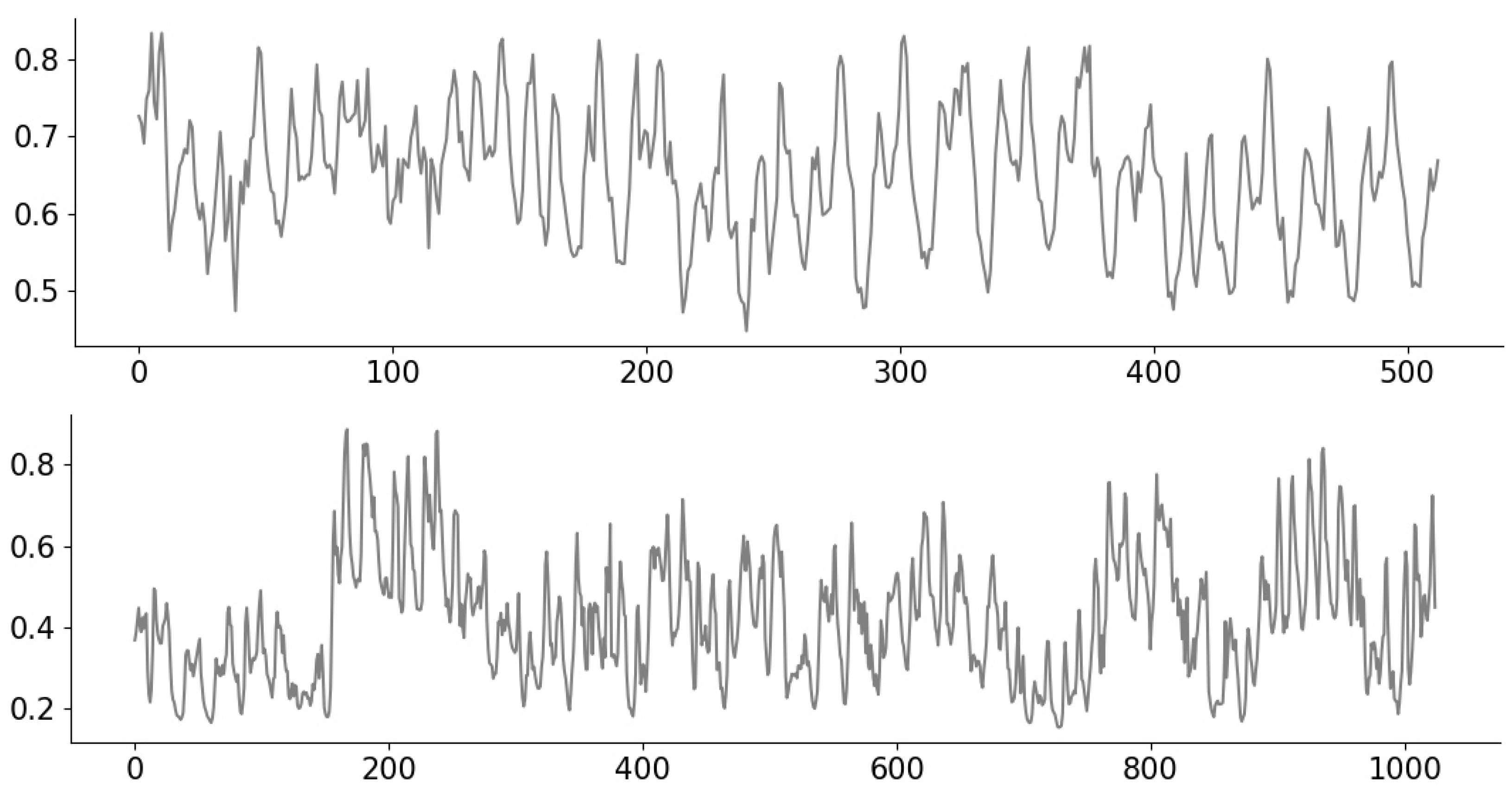
3.1. Measurement Models and Signals
- For random inpainting, a given fraction of the signal values are masked (i.e., not observed), and we consider the fractions , , , , and .
- For block inpainting, the signal is divided into blocks (taken to be of length 16 for all 1D signals and of block size 8 × 8 for all 2D signals), and a given fraction of the blocks are masked (i.e., not observed).
- For compressive sensing, we consider taking the form of randomly subsampled Gaussian circulant measurements, e.g., see [35]. Such matrices can be viewed as approximating the behavior of i.i.d. Gaussian matrices (e.g., as considered in [2]), but with considerably faster matrix operations. We mostly use 100, 500, or 1024 measurements, but sometimes also consider other values.
- For denoising, is the identity matrix (i.e., every entry is observed), but the noise term in (1) corrupts the measurements. We consider i.i.d. Gaussian noise with standard deviations and .
3.2. Algorithmic Details
- #layers .
- #channels .
- input_size .
- filter_size .
- step_size .
3.3. Optimized Parameters for Varying Settings
3.4. Cross-Performance and Transferability
3.5. Effects of Single Hyperparameters
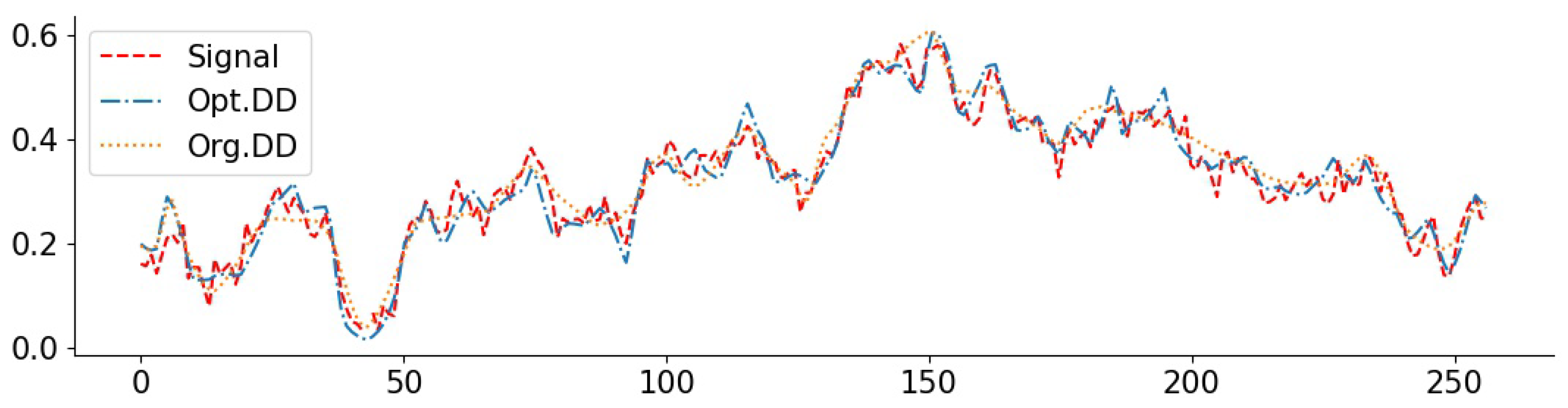
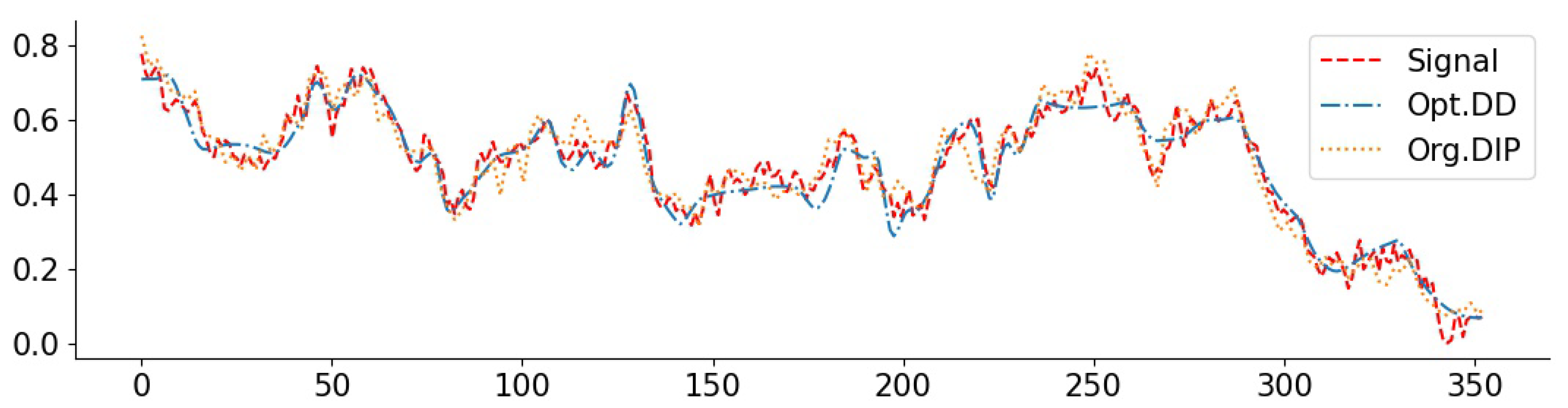
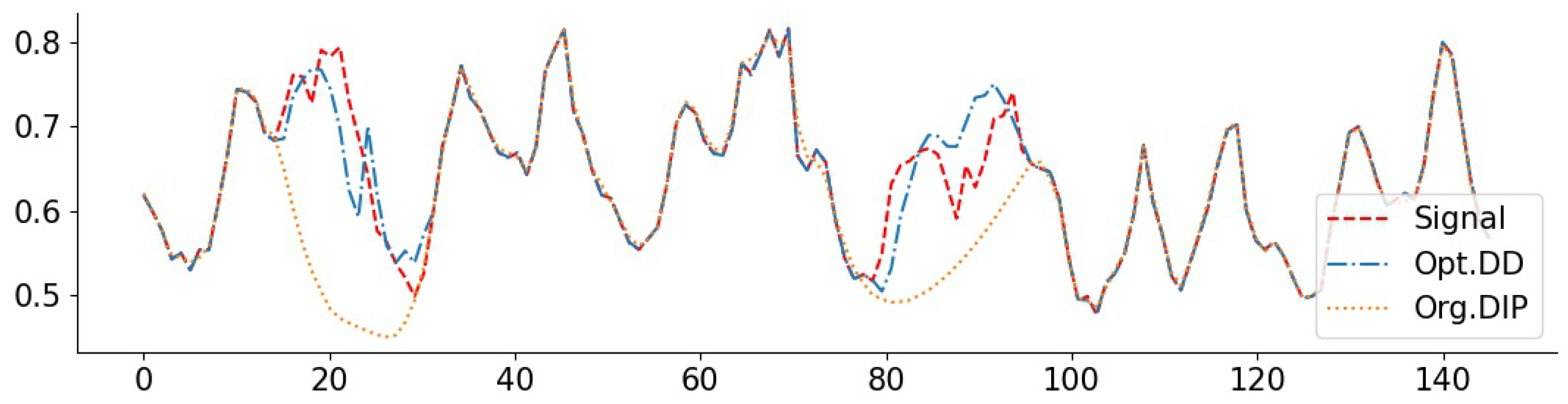
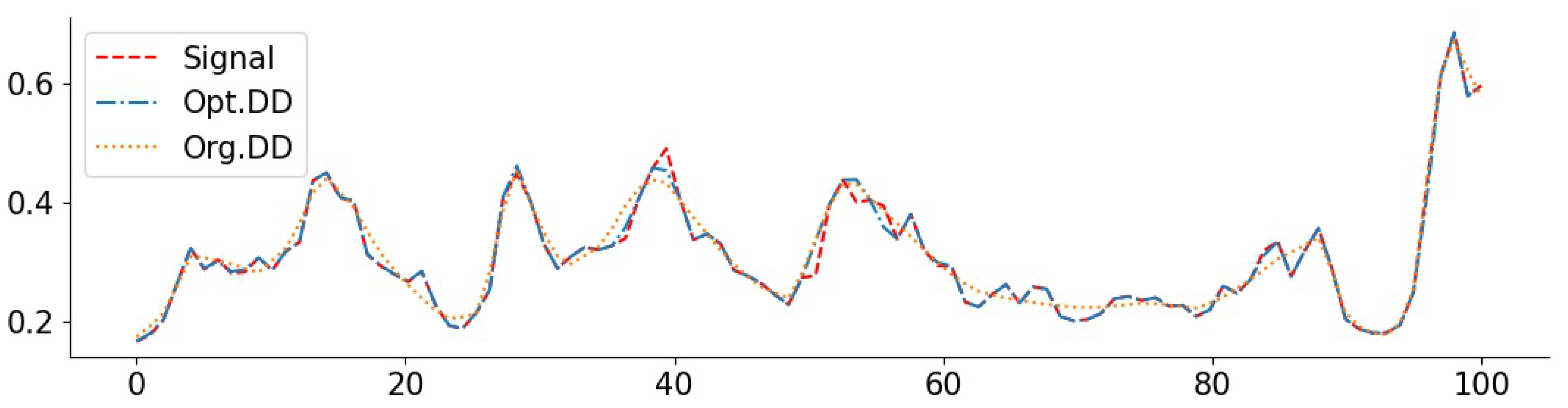
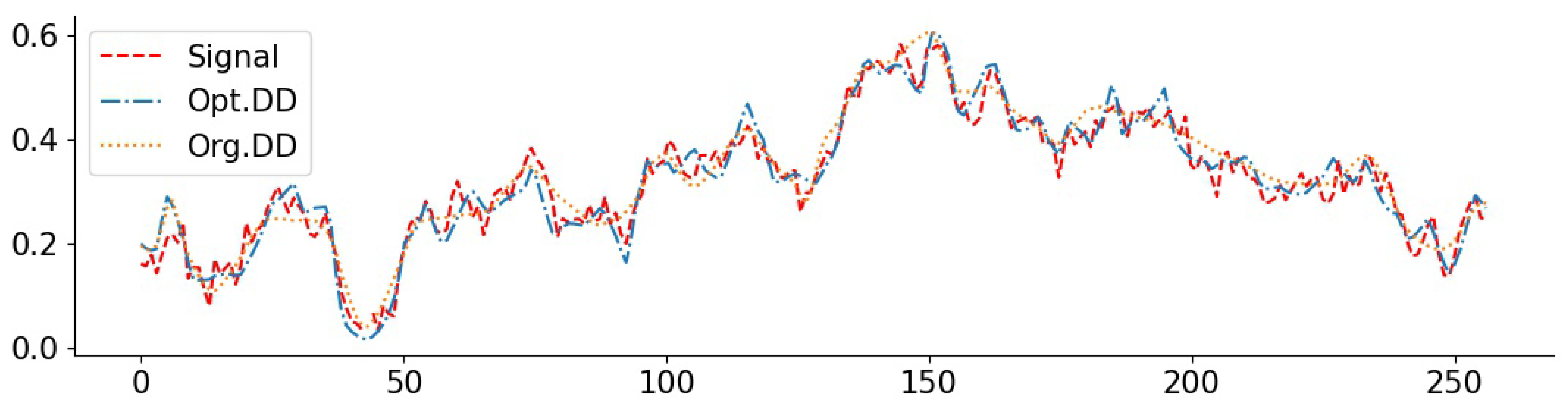
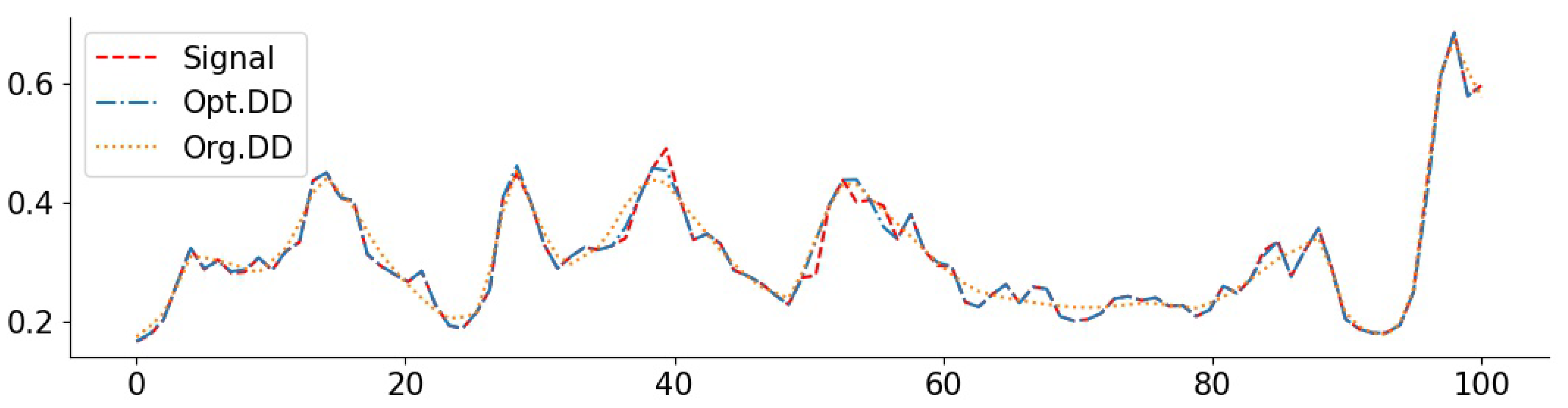
3.6. Real-World Data and Comparisons to Baselines
3.7. Accelerated Multi-Coil MRI Data
- The mask is chosen to be a standard variable-density mask (i.e., random or equi-spaced vertical lines across the Fourier space), and is randomly chosen for each run. We do not add explicitly, as the ground truth images already contain some noise.
- Following [7], three additional image comparison metrics are considered along with the PSNR, namely, the Visual Information Fidelity (VIF) [41], Structural Similarity Index (SSIM) [42], and Multi-Scale SSIM (MS-SSIM) [43]. However, following our previous sections, all hyperparameter tuning is done with respect to the PSNR.
- We optimize the same hyperparameters for ConvDecoder as our previous experiments, but the possible settings of filter_size for ConvDecoder during Successive Halving are adjusted as filter_size ∈ [2,3,4,5,6,7], in view of all considered filter sizes being small in [7]. For consistency with [7], we also change the number of optimization iterations to 20,000 for all methods.
- Each scan of a knee from fastMRI consists of a number of slices, each of which is a 2D image, and together the images form a 3D volume. We choose the the middle slice of the volume to obtain each image, and discard the other slices. The train and test sizes are set as 4 and 16, respectively.
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Proof of Theorem 1
References
- Candès, E.J. Compressive Sampling. In Proceedings of the International Congress of Mathematicians, Madrid, Spain, 22–30 August 2006; Volume 3, pp. 1433–1452. [Google Scholar]
- Bora, A.; Jalal, A.; Price, E.; Dimakis, A.G. Compressed Sensing Using Generative Models. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 537–546. [Google Scholar]
- Ulyanov, D.; Vedaldi, A.; Lempitsky, V. Deep image prior. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 9446–9454. [Google Scholar]
- Heckel, R.; Hand, P. Deep Decoder: Concise Image Representations from Untrained Non-convolutional Networks. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Quan, Y.; Ji, H.; Shen, Z. Data-driven multi-scale non-local wavelet frame construction and image recovery. J. Sci. Comput. 2015, 63, 307–329. [Google Scholar] [CrossRef]
- Van Veen, D.; Jalal, A.; Soltanolkotabi, M.; Price, E.; Vishwanath, S.; Dimakis, A.G. Compressed sensing with deep image prior and learned regularization. arXiv 2018, arXiv:1806.06438. [Google Scholar]
- Darestani, M.Z.; Heckel, R. Accelerated MRI with un-trained neural networks. IEEE Trans. Comput. Imaging 2021, 7, 724–733. [Google Scholar] [CrossRef]
- Baguer, D.O.; Leuschner, J.; Schmidt, M. Computed tomography reconstruction using deep image prior and learned reconstruction methods. Inverse Probl. 2020, 36, 094004. [Google Scholar] [CrossRef]
- Baldassarre, L.; Li, Y.H.; Scarlett, J.; Gözcü, B.; Bogunovic, I.; Cevher, V. Learning-Based Compressive Subsampling. IEEE J. Sel. Top. Signal Process. 2016, 10, 809–822. [Google Scholar] [CrossRef] [Green Version]
- Budhaditya, S.; Pham, D.S.; Lazarescu, M.; Venkatesh, S. Effective anomaly detection in sensor networks data streams. In Proceedings of the IEEE International Conference on Data Mining, Miami, FL, USA, 6–9 December 2009; pp. 722–727. [Google Scholar]
- Ravula, S.; Dimakis, A.G. One-dimensional Deep Image Prior for Time Series Inverse Problems. arXiv 2019, arXiv:1904.08594. [Google Scholar]
- Heckel, R. Regularizing Linear Inverse Problems with Convolutional Neural Networks. arXiv 2019, arXiv:1907.03100. [Google Scholar]
- Dhar, M.; Grover, A.; Ermon, S. Modeling sparse deviations for compressed sensing using generative models. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Jagatap, G.; Hegde, C. Algorithmic guarantees for inverse imaging with untrained network priors. In Proceedings of the 33th Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 14832–14842. [Google Scholar]
- Asim, M.; Daniels, M.; Leong, O.; Ahmed, A.; Hand, P. Invertible generative models for inverse problems: Mitigating representation error and dataset bias. In Proceedings of the 37th International Conference on Machine Learning, Virtual Conference. 12–18 July 2020. [Google Scholar]
- Yin, W.; Yang, W.; Liu, H. A neural network scheme for recovering scattering obstacles with limited phaseless far-field data. J. Comput. Phys. 2020, 417, 109594. [Google Scholar] [CrossRef]
- Ongie, G.; Jalal, A.; Metzler, C.A.; Baraniuk, R.G.; Dimakis, A.G.; Willett, R. Deep learning techniques for inverse problems in imaging. IEEE J. Sel. Areas Inf. Theory 2020, 1, 39–56. [Google Scholar] [CrossRef]
- Kattamis, A.; Adel, T.; Weller, A. Exploring properties of the deep image prior. In Proceedings of the NeurIPS 2019 workshop Deep Learning and Inverse Problems, Vancouver, BC, Canada, 13 December 2019. [Google Scholar]
- Dittmer, S.; Kluth, T.; Maass, P.; Baguer, D.O. Regularization by architecture: A deep prior approach for inverse problems. J. Math. Imaging Vis. 2020, 62, 456–470. [Google Scholar] [CrossRef] [Green Version]
- Uezato, T.; Hong, D.; Yokoya, N.; He, W. Guided deep decoder: Unsupervised image pair fusion. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 87–102. [Google Scholar]
- Heckel, R.; Soltanolkotabi, M. Compressive sensing with un-trained neural networks: Gradient descent finds a smooth approximation. In Proceedings of the 37th International Conference on Machine Learning, Virtual Conference. 12–18 July 2020. [Google Scholar]
- Arora, S.; Roeloffs, V.; Lustig, M. Untrained modified deep decoder for joint denoising parallel imaging reconstruction. In Proceedings of the International Society for Magnetic Resonance in Medicine Annual Meeting, Virtual Conference. 8–14 August 2020. [Google Scholar]
- Bostan, E.; Heckel, R.; Chen, M.; Kellman, M.; Waller, L. Deep phase decoder: Self-calibrating phase microscopy with an untrained deep neural network. Optica 2020, 7, 559–562. [Google Scholar] [CrossRef] [Green Version]
- Rey, S.; Marques, A.G.; Segarra, S. An underparametrized deep decoder architecture for graph signals. In Proceedings of the 8th International Workshop on Computational Advances in Multi-Sensor Adaptive Processing (CAMSAP), Le Gosier, Guadeloupe, 15–18 December 2019; pp. 231–235. [Google Scholar]
- Daniels, M.; Hand, P.; Heckel, R. Reducing the Representation Error of GAN Image Priors Using the Deep Decoder. arXiv 2020, arXiv:2001.08747. [Google Scholar]
- Darestani, M.Z.; Chaudhari, A.S.; Heckel, R. Measuring Robustness in Deep Learning Based Compressive Sensing. In Proceedings of the 38th International Conference on Machine Learning, Virtual Conference. 18–24 July 2021. [Google Scholar]
- Zoph, B.; Le, Q.V. Neural architecture search with reinforcement learning. In Proceedings of the 5th International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Pham, H.; Guan, M.; Zoph, B.; Le, Q.; Dean, J. Efficient neural architecture search via parameters sharing. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Liu, H.; Simonyan, K.; Yang, Y. DARTS: Differentiable architecture search. In Proceedings of the 7th International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Elsken, T.; Metzen, J.H.; Hutter, F. Neural architecture search: A survey. J. Mach. Learn. Res. 2019, 20, 1997–2017. [Google Scholar]
- Jamieson, K.; Talwalkar, A. Non-stochastic best arm identification and hyperparameter optimization. In Proceedings of the 18th Artificial Intelligence and Statistics, Cadiz, Spain, 9–11 May 2016; pp. 240–248. [Google Scholar]
- Li, L.; Jamieson, K.; DeSalvo, G.; Rostamizadeh, A.; Talwalkar, A. Hyperband: A novel bandit-based approach to hyperparameter optimization. J. Mach. Learn. Res. 2017, 18, 6765–6816. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Shalev-Shwartz, S.; Ben-David, S. Understanding Machine Learning: From Theory to Algorithms; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar]
- Dirksen, S.; Jung, H.C.; Rauhut, H. One-bit compressed sensing with partial Gaussian circulant matrices. Inf. Inference A J. IMA 2020, 9, 601–626. [Google Scholar] [CrossRef] [Green Version]
- Rasmussen, C.E. Gaussian Processes for Machine Learning; MIT Press: Cambridge, MA, USA, 2006. [Google Scholar]
- De Vito, S.; Massera, E.; Piga, M.; Martinotto, L.; Di Francia, G. On field calibration of an electronic nose for benzene estimation in an urban pollution monitoring scenario. Sens. Actuators B Chem. 2008, 129, 750–757. [Google Scholar] [CrossRef]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep Learning Face Attributes in the Wild. In Proceedings of the International Conference on Computer Vision (ICCV 2015), Santiago, Chile, 11–18 December 2015. [Google Scholar]
- Lustig, M.; Donoho, D.L.; Santos, J.M.; Pauly, J.M. Compressed sensing MRI. IEEE Signal Process. Mag. 2008, 25, 72–82. [Google Scholar] [CrossRef]
- Zbontar, J.; Knoll, F.; Sriram, A.; Murrell, T.; Huang, Z.; Muckley, M.J.; Defazio, A.; Stern, R.; Johnson, P.; Bruno, M.; et al. fastMRI: An open dataset and benchmarks for accelerated MRI. arXiv 2018, arXiv:1811.08839. [Google Scholar]
- Sheikh, H.R.; Bovik, A.C. Image information and visual quality. IEEE Trans. Image Process. 2006, 15, 430–444. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, Z.; Simoncelli, E.P.; Bovik, A.C. Multiscale structural similarity for image quality assessment. In Proceedings of the 37th Asilomar Conference on Signals, Systems & Computers, Pacific Grove, CA, USA, 9–12 November 2003; Volume 2, pp. 1398–1402. [Google Scholar]
- Boucheron, S.; Lugosi, G.; Massart, P. Concentration Inequalities: A Nonasymptotic Theory of Independence; Oxford University Press: Oxford, UK, 2013. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| block 9/10 | 110 | 29 | 2 | 11 | 0.0030 |
| block 3/4 | 158 | 25 | 5 | 12 | 0.0030 |
| block 1/2 | 180 | 21 | 18 | 15 | 0.0030 |
| block 1/4 | 180 | 15 | 40 | 30 | 0.0030 |
| block 1/8 | 240 | 9 | 120 | 100 | 0.0070 |
| random 9/10 | 196 | 11 | 45 | 73 | 0.0030 |
| random 3/4 | 158 | 6 | 33 | 73 | 0.0030 |
| random 1/2 | 200 | 4 | 512 | 73 | 0.0030 |
| random 1/4 | 250 | 4 | 512 | 46 | 0.0030 |
| random 1/8 | 250 | 8 | 512 | 2 | 0.0050 |
| compress 100 | 83 | 24 | 21 | 11 | 0.0100 |
| compress 500 | 146 | 20 | 22 | 9 | 0.0030 |
| compress 1024 | 141 | 29 | 24 | 18 | 0.0030 |
| denoise 0.1 | 128 | 10 | 63 | 29 | 0.0020 |
| denoise 0.05 | 150 | 4 | 120 | 26 | 0.0070 |
| block 9/10 | 301 | 3 | 9 | 27 | 0.0055 |
| block 3/4 | 343 | 6 | 14 | 10 | 0.0025 |
| block 1/2 | 227 | 6 | 12 | 37 | 0.0035 |
| block 1/4 | 399 | 2 | 14 | 6 | 0.0100 |
| block 1/8 | 244 | 2 | 38 | 20 | 0.0035 |
| random 9/10 | 112 | 5 | 34 | 27 | 0.0040 |
| random 3/4 | 147 | 7 | 34 | 16 | 0.0045 |
| random 1/2 | 178 | 8 | 42 | 38 | 0.0030 |
| random 1/4 | 166 | 8 | 108 | 26 | 0.0045 |
| random 1/8 | 192 | 10 | 128 | 4 | 0.0025 |
| compress 100 | 94 | 7 | 8 | 41 | 0.0080 |
| compress 500 | 107 | 10 | 21 | 38 | 0.0050 |
| compress 1024 | 128 | 12 | 19 | 16 | 0.0040 |
| denoise 0.1 | 269 | 2 | 13 | 48 | 0.0095 |
| denoise 0.05 | 173 | 3 | 15 | 4 | 0.0025 |
| Train | Block 1/2 | Block 1/8 | Random 1/2 | Random 1/8 | Compress 100 | Compress 500 | Noise 0.1 | Noise 0.05 | |
|---|---|---|---|---|---|---|---|---|---|
| Test | |||||||||
| block 1/2 | 22.71 | 20.21 | 22.71 | 23.11 | 23.23 | 23.40 | 21.26 | ||
| block 1/8 | 30.73 | 27.93 | 30.85 | 30.47 | 30.52 | 30.51 | 29.93 | ||
| random 1/2 | 34.06 | 36.11 | 36.11 | 33.44 | 34.54 | 33.48 | 35.00 | ||
| random 1/8 | 34.73 | 37.67 | 41.61 | 33.96 | 35.62 | 36.45 | 35.83 | ||
| compress 100 | 17.13 | 8.56 | 8.51 | 8.56 | 17.84 | 15.08 | 12.78 | ||
| compress 500 | 25.87 | 25.72 | 17.75 | 18.56 | 26.12 | 22.11 | 25.97 | ||
| denoise 0.1 | 24.41 | 21.49 | 20.02 | 20.12 | 25.18 | 24.51 | 24.52 | ||
| denoise 0.05 | 29.70 | 27.61 | 25.60 | 26.03 | 29.83 | 29.74 | 28.92 | ||
| Train | Block 1/2 | Block 1/8 | Random 1/2 | Random 1/8 | Compress 100 | Compress 500 | Noise 0.1 | Noise 0.05 | |
|---|---|---|---|---|---|---|---|---|---|
| Test | |||||||||
| block 1/2 | 43.70 | 35.94 | 25.19 | 39.72 | 39.17 | 28.11 | 45.03 | ||
| block 1/8 | 61.33 | 62.41 | 47.80 | 60.66 | 59.69 | 35.28 | 56.72 | ||
| random 1/2 | 67.34 | 52.59 | 65.50 | 63.34 | 67.55 | 29.69 | 59.88 | ||
| random 1/8 | 67.53 | 53.69 | 72.25 | 63.17 | 70.12 | 32.39 | 58.87 | ||
| compress 100 | 39.05 | 38.87 | 28.95 | 18.61 | 38.59 | 30.28 | 41.86 | ||
| compress 500 | 60.52 | 50.28 | 54.44 | 44.42 | 58.96 | 34.94 | 55.04 | ||
| denoise 0.1 | 28.89 | 34.77 | 25.73 | 21.74 | 32.57 | 28.31 | 34.45 | ||
| denoise 0.05 | 36.64 | 40.26 | 33.08 | 29.09 | 39.26 | 35.04 | 27.36 | ||
| Est. | Opt. DD | Org. DD | Org. DIP | TV Norm | LassoW | |
|---|---|---|---|---|---|---|
| Mea. | ||||||
| block 1/2 | 20.99 | 21.45 | 22.67 | 17.72 | ||
| random 3/4 | 27.74 | 25.85 | 26.67 | 17.49 | ||
| compress 100 | 11.44 | 16.07 | 16.59 | 5.69 | ||
| dno 0.05 | 26.81 | 28.32 | 29.44 | 26.86 | ||
| Est. | Opt. DD | Org. DD | Org. DIP | TV Norm | LassoW | |
|---|---|---|---|---|---|---|
| Mea. | ||||||
| block 1/2 | 43.39 | 29.36 | 32.58 | 18.25 | ||
| random 3/4 | 64.69 | 50.04 | 42.78 | 19.47 | ||
| compress 100 | 42.78 | 17.48 | 21.21 | 6.20 | ||
| dno 0.05 | 36.76 | 29.03 | 40.95 | 27.36 | ||
| Est. | Opt. DD | Org. DD | Org. DIP | TV Norm | LassoW | |
|---|---|---|---|---|---|---|
| Mea. | ||||||
| block 3/4 | 16.60 | 16.94 | 18.81 | 16.72 | ||
| block 1/2 | 19.95 | 19.57 | 19.04 | 19.19 | ||
| block 1/8 | 26.25 | 27.71 | 24.43 | 21.59 | ||
| random 3/4 | 24.73 | 24.81 | 20.73 | 17.39 | ||
| random 1/2 | 29.82 | 27.93 | 23.01 | 18.67 | ||
| random 1/8 | 37.90 | 34.81 | 27.22 | 24.47 | ||
| compress 25 | 13.36 | 10.92 | 11.99 | 5.42 | ||
| compress 256 | 30.90 | 20.97 | 18.48 | 16.89 | ||
| dno 0.1 | 24.66 | 20.53 | 22.64 | 21.41 | ||
| dno 0.05 | 27.58 | 26.77 | 28.24 | 22.55 | ||
| Est. | Opt. DD | Org. DD | Org. DIP | TV Norm | LassoW | |
|---|---|---|---|---|---|---|
| Mea. | ||||||
| block 3/4 | 16.00 | 15.22 | 15.95 | 15.71 | ||
| block 1/2 | 16.92 | 18.13 | 18.64 | 17.65 | ||
| block 1/8 | 24.91 | 24.23 | 21.79 | 21.53 | ||
| random 3/4 | 21.45 | 21.10 | 20.95 | 16.33 | ||
| random 1/2 | 27.23 | 24.49 | 25.19 | 18.73 | ||
| random 1/8 | 34.43 | 31.73 | 33.71 | 23.65 | ||
| compress 25 | 11.90 | 8.10 | 14.72 | 6.60 | ||
| compress 256 | 22.42 | 21.80 | 20.34 | 15.21 | ||
| dno 0.1 | 20.43 | 22.55 | 22.45 | 20.46 | ||
| dno 0.05 | 27.11 | 27.63 | 27.04 | 20.88 | ||
| Est. | Opt. DD | Org. DD | Org. DIP | TV Norm | LassoW | |
|---|---|---|---|---|---|---|
| Mea. | ||||||
| block 3/4 | 16.66 | 16.23 | 16.03 | 12.80 | ||
| block 1/2 | 22.67 | 20.82 | 18.03 | 15.68 | ||
| block 1/4 | 27.43 | 25.42 | 22.21 | 17.35 | ||
| random 3/4 | 28.15 | 24.59 | 19.93 | 16.63 | ||
| random 1/2 | 32.21 | 29.84 | 25.98 | 16.63 | ||
| random 1/4 | 36.63 | 32.44 | 31.21 | 18.09 | ||
| compress 400 | 17.59 | 18.27 | 9.35 | 6.48 | ||
| compress 4096 | 26.06 | 23.77 | 14.89 | 12.57 | ||
| dno 0.1 | 38.22 | 31.15 | 24.07 | 18.47 | ||
| dno 0.05 | 38.01 | 31.15 | 28.27 | 19.77 | ||
| Method | VIF | MS-SSIM | SSIM | PSNR | #Channels | #Layers | Input_Size | Filter_Size | Step_Size |
|---|---|---|---|---|---|---|---|---|---|
| Opt. ConvDD | 0.8212 | 252 | 8 | 5 | 3 | 0.002 | |||
| Org. ConvDD | 0.9599 | 0.9422 | 31.0642 | 256 | 8 | 4 | 3 | 0.008 | |
| Opt. DD | 0.6021 | 0.8204 | 0.6515 | 28.2947 | 352 | 9 | 18 | - | 0.002 |
| Org. DD | 0.5725 | 0.8029 | 0.6529 | 28.2217 | 368 | 10 | 16 | - | 0.008 |
| Org. DIP | 0.5644 | 0.8644 | 0.5163 | 26.9310 | 256 | 16 | (640,368) | 3 | 0.008 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, Y.; Zhao, H.; Scarlett, J. On Architecture Selection for Linear Inverse Problems with Untrained Neural Networks. Entropy 2021, 23, 1481. https://doi.org/10.3390/e23111481
Sun Y, Zhao H, Scarlett J. On Architecture Selection for Linear Inverse Problems with Untrained Neural Networks. Entropy. 2021; 23(11):1481. https://doi.org/10.3390/e23111481
Chicago/Turabian StyleSun, Yang, Hangdong Zhao, and Jonathan Scarlett. 2021. "On Architecture Selection for Linear Inverse Problems with Untrained Neural Networks" Entropy 23, no. 11: 1481. https://doi.org/10.3390/e23111481
APA StyleSun, Y., Zhao, H., & Scarlett, J. (2021). On Architecture Selection for Linear Inverse Problems with Untrained Neural Networks. Entropy, 23(11), 1481. https://doi.org/10.3390/e23111481