Abstract
Multivariate time series anomaly detection is a widespread problem in the field of failure prevention. Fast prevention means lower repair costs and losses. The amount of sensors in novel industry systems makes the anomaly detection process quite difficult for humans. Algorithms that automate the process of detecting anomalies are crucial in modern failure prevention systems. Therefore, many machine learning models have been designed to address this problem. Mostly, they are autoencoder-based architectures with some generative adversarial elements. This work shows a framework that incorporates neuroevolution methods to boost the anomaly detection scores of new and already known models. The presented approach adapts evolution strategies for evolving an ensemble model, in which every single model works on a subgroup of data sensors. The next goal of neuroevolution is to optimize the architecture and hyperparameters such as the window size, the number of layers, and the layer depths. The proposed framework shows that it is possible to boost most anomaly detection deep learning models in a reasonable time and a fully automated mode. We ran tests on the SWAT and WADI datasets. To the best of our knowledge, this is the first approach in which an ensemble deep learning anomaly detection model is built in a fully automatic way using a neuroevolution strategy.
1. Introduction
In the anomaly detection field, deep learning models achieve the best results on well-known benchmarks. These are mainly deep autoencoders based on Long-Short Term Memory (LSTM) layers, convolutional layers, and a fully connected sequence of layers. A wide variety of autoencoders are used, such as variational, denoising, and adversarial autoencoders. Research shows that further improvements, such as adding a discriminator as an additional verification module or other Generative Adversarial Network (GAN) based autoencoder modifications, can boost the detection results. Recently, promising results using deep graph neural networks in anomaly detection have also been shown [1].
Neuroevolution is a form of artificial intelligence that uses evolutionary algorithms to generate artificial neural networks (ANNs), parameters, topologies, and rules. The most popular algorithms are NEAT, HyperNEAT, and coDeepNEAT [2]. In the presented approach, neuroevolution is used to generate an optimal ensemble anomaly detection model.
In this paper, we propose a high-level ensemble approach fine tuned by a neuroevolution algorithm. The presented method is model independent and can be adapted to any deep learning anomaly detection model. The main advantage of the algorithm is its fully automated mode. The novelty of the proposed algorithm is that we added new search dimensions, including the training data distribution, dividing data into subgroups, and searching for the optimal composition of the ensemble model.
The proposed neuroevolution search space is based on creating encoders and decoders from single neural layers, such as fully connected, convolutional, recurrent, and attention layers. There are two main dimensions of optimization. Therefore, two populations are inside the algorithm. The first is the population of the models from which genetic operators evolve new generations of models. The second is the subgroup population, which is needed to form the ensemble model from the models’ population. This work concentrates on the data optimization stage and the setting up of the ensemble model. It shows how this aspect can improve nonensemble models. The last step in the neural architecture search (NAS) is fitness definition. Fitness is the sum of losses from the training dataset and the random reduced validation dataset in the presented approach.
The main advantages of the presented algorithm are that it enables building the ensemble model in automatic mode and creates a vast search space between various deep learning autoencoders, GAN architectures, and optimal training data subgroups.
2. Related Works
Anomaly detection is a popular research subject. The basic unsupervised methods include linear-model-based methods [3], distance-based methods [4,5], density-based methods [6], isolation-based methods [7], and many others. The best f1-score for these methods is 23% on the SWAT and 9% on the WADI datasets. However, deep learning methods have recently gained significant improvements in anomaly detection over the aforementioned approaches. The most popular deep learning models for multivariate anomaly detection are autoencoder (AE) models, which use the reconstruction error for the anomaly inspection. Zong et al. proposed a deep autoencoding Gaussian mixture model (DAGMM) [8] that jointly optimizes the deep autoencoder parameters and the mixture model simultaneously. This solution yields an f1-score of 55% for the SWAT and 20% for the WADI datasets. Park et al. introduced the LSTM-VAE model [9], replacing the feedforward network in the variational autoencoder (VAE) with LSTM. As a result of this approach, it was possible to gain an f1-score of 75% for the SWAT and 25% for WADI the datasets. Russo et al. used an autoencoder that consists of 1D convolution layers [10]. This model was tested with the Urban Water Observatory Initiative (www.eawag.ch/uwo, accessed on 1 November 2021) datasets and has an anomaly detection accuracy of 35%. Audibert et al. proposed a fast and stable method called USAD [11], which is based on adversely trained autoencoders. This model contains only fully connected layers and achieves a 79% detection anomaly for the SWAT and 23% for the WADI dataset. Generative adversarial networks (GANs) as anomaly detectors were proposed in [12]. The authors applied LSTM as the generator and discriminator models in the GAN framework and used a combination of both model errors (DR-score) to detect anomalies. The anomaly accuracy for this model is 77% for the SWAT and 37% for the WADI datasets. Deng et al. [1] achieved an f1-score of 81% for the SWAT and 57% for the WADI datasets through the use of a graph neural network (GNN). The mentioned deep learning models, LSTM, USAD, and CNN 1D, are the baseline for the solutions proposed in this paper. Our preliminary observations showed that a single model (autoencoder) very often cannot handle many input signals efficiently. The hypothesis is that the ensemble model (especially that based on bagging) can improve anomaly detection in such cases. The next aspect is that the architectures of the models presented in the mentioned papers have not been sufficiently explored. The search for optimal architectures in other fields such as image classification showed that this approach could explore more possibilities and outperform models designed by humans. Among the search criteria was speed. Therefore, the neuroevolution technique was chosen to perform a search in addition to the reinforcement learning approach.
Recently, neuroevolution algorithms have been used in many machine learning tasks to improve the accuracy of deep learning models [13]. In [14], neuroevolution search was used to evolve neural networks for object classification in high-resolution remote sensing images. In [15], the authors presented a neuroevolution algorithm for standard image classification. The authors in [2] showed the neuroevolution strategy scheme for language modeling, image classification, and object detection tasks. This was based on the co-evolutionary NEAT algorithm, which has the two following levels of optimization: the first one is single deep learning subblock optimization; the second one is a composition of subblocks to form a whole network. The presented results showed that optimized models achieved better results than those of models designed by humans in most cases.
3. Autoencoder Architecture
Autoencoders are unsupervised learning models in which the neural network is trained to learn the compressed representation of raw data. These models consist of two parts: an encoder E and a decoder D. The encoder learns how to efficiently compress and encode the input data X to represent them in reduced dimensionality—latent variables Z. The decoder is taught how to reconstruct the latent variables Z back to their original shape. The model is trained to minimize reconstruction loss, which means reducing the difference between the output of the decoder and the original input data; this can be expressed as:
where:
The most straightforward kind of autoencoder is an undercomplete autoencoder (UAE). These models learn the most essential and relevant attributes of the input data by using a bottleneck with a smaller dimension than the input data. Another type of autoencoder, called the denoising autoencoder (DAE), extracts essential features from the data by reconstructing the original input after it has been contaminated by noise. In unsupervised tasks, the most popular type of autoencoder is the variational autoencoder (VAE). This type of autoencoder replaces the bottleneck vector with two vectors: one representing the mean of the distribution and the second representing the standard deviation of the distribution. The VAE for a given input in the encoding phase determines the distribution of the latent variables. By contrast, the decoder determines the distribution of the inputs corresponding to the given latent variables. Autoencoders are widely used in many fields, such as online intrusion detection [16], malware detection [17], and anomaly detection in streaming data [18]. This model can consist of various layers, e.g., fully connected layers, CNN, and LSTM.
4. Neuroevolution Ensemble Approach
The prototype of our framework presented in Figure 1 consists of two separate populations. The first is the models’ population, and the second is the data subgroup population. Equation (3) describes the definition of the model population where is a weight tensor. Each model is a sequence of layers of encoders and decoders (Equations (4) and (5)) that describes the input multivariate signal. The framework enables the formation of the ensemble model using an approach similar to the bagging-based technique. The whole ensemble model is a set of submodels working on subgroups of the input signals (Equations (6) and (7)). The ensemble models form a population set (Equation (9)).
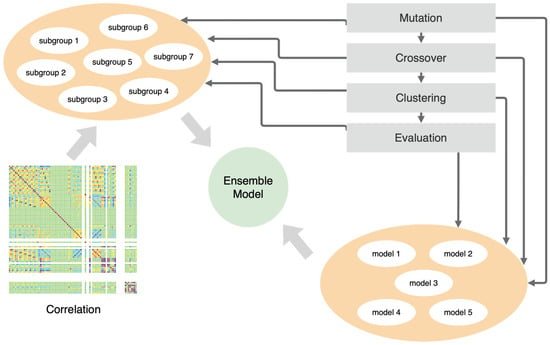
Figure 1.
The architecture of the framework.
The framework starts with generating initial groups of input signals using correlation (this is explained in detail in the subsections below); then, it mutates models and groups via the genetic algorithm. In parallel, the genetic operators optimize the single models in each subgroup by making changes in the topology of the neural models (e.g., the length of the model and layer parameters). The final effect of these actions is an ensemble model optimized to detect anomalies. The ensemble model is defined as follows (where ):
4.1. General Schema of the Proposed Solution
During our experiments with various models, we noticed that almost all models detect a similar set of anomalies despite changes in their hyperparameters. Of course, the results differed depending on the hyperparameters, but none of the changes significantly impacted the detection. Therefore, we decided to apply an ensemble model based on dividing available input signals into smaller groups and training each model on a separate subset of signals. As a result of this, the models could discover more specific dependencies and relations between signals. We present a simplified schema of our approach in Algorithm 1. Additionally, models inside each subgroup are optimized by changing their internal architectures (Algorithms 2–4). The evolution of the single model is conducted in four main steps in a loop (Algorithm 2): clustering by model length, crossover, mutation, and choosing the best models in clusters. Algorithms 3 and 4 contain detailed descriptions of the crossover and mutation. We define the crossover as a function that has two parent models and an id of the layer as input parameters (Equation (10)). It generates two new children models (Equation (11)).
The crossover can exchange between parents’ activation functions, convolutional, LSTM, or fully connected layers (Equations (12) and (13)). The last option is to exchange the hyperparameters between parents, such as the learning rate and weight decay. We define mutation as a function with a model, layer id, and layer features to be mutated as input parameters (Equation (14)).
In this case, the feature and layer_id determine what the mutation operator will do. They can change the activation function or parameters of the convolutional, LSTM, or fully connected layers (e.g., depth and kernel_size). The other option is to change the length of the model (adding or removing a layer) or update the hyperparameters. The result is a new modified model (Equation (15)).
Then, the neuroevolution approach is applied to search for an optimal partition into groups (Line 1, Algorithm 1). After classifying data points using every model (Line 2, Algorithm 1), we used a voting mechanism to determine whether a data point should be considered as an anomaly by the whole ensemble model (Line 3, Algorithm 1).
| Algorithm 1: Simplified general schema of our approach. |
| Result: Classification of the anomalies |
|
| Algorithm 2: Model evolution. |
 |
| Algorithm 3: Single model crossover. |
| Input: parent_1, parent_2 |
|
To find an optimal partition of input signals into groups, we applied a genetic algorithm. Algorithm 5 presents a simplified schema of the genetic algorithms.
The single gene provides information showing that a feature f is present in a group t. The single solution represents k groups, each containing zero or more input signals. A sample solution for could be: , where numbers in groups indicate which input signals are present. Population P contains solutions.
The parameters for the neuroevolution approach in this work are as follows:
- k—maximal number of submodels in an ensemble model;
- —probability of the mutation in a single group of input signals;
- —number of generations in a genetic algorithm;
- —size of the population in a genetic algorithm;
- —number of parents mating;
- —number of epochs to train while calculating fitness.
| Algorithm 4: Single model mutation |
| Input: solution |
|
| Algorithm 5: Genetic algorithm. |
 |
4.2. Genetic Algorithm for Building the Ensemble Model
To improve the convergence of the genetic algorithm, we created it based on the correlation between input signals instead of using a random initial population. We used hierarchical clustering with the addition of some randomness to achieve a diverse population.
Algorithm 6 presents a method for calculating the fitness for a single solution. For each dataset used (SWAT and WADI), we split a normal part of the data into training and validation datasets. We calculated the fitness for every feature group in the solution. As the first step, we trained a chosen model on selected input signals from the training data for a given number of epochs (Line 3, Algorithm 6). After that, we evaluated the trained model on training and validation data (Lines 4 and 5, Algorithm 6), calculating the losses. To normalize the loss, we calculated the weighted loss from the training and validation datasets (Lines 6 and 7), and we also divided the weighted loss by the number of input signals in the group (Line 8, Algorithm 6). The final fitness for every solution is a negated sum of losses for groups in the solution (Lines 9 and 10, Algorithm 6). The value is negated because we wanted to minimize the total loss of an ensemble model, while in the genetic algorithm, the goal is to maximize the fitness.
During the crossover part (Line 6, Algorithm 5), we created a new solution based on two selected parents (Equation (16). Algorithm 7 presents the detailed steps of the crossover. For every pair of groups of parents, we determined which range of input signals is present in the groups and chose the random split point (Lines 3–5, Algorithm 7). The new group of offspring then contains parts of the groups from both parents (Lines 6–13, Algorithm 7 and Equations (17) and (18)).
| Algorithm 6: Fitness calculation. |
 |
| Algorithm 7: Crossover algorithm. |
 |
Offspring created via a crossover algorithm can also be affected by mutations (Line 7, Algorithm 5).
- Duplicating a selected feature in another group (presented in Algorithm 8), Equation (21);
- Vanishing input signals that exist in more than one group in a single solution (presented in Algorithm 9), Equation (22);
- Adding input signals that do not exist in any group in a single solution (presented in Algorithm 10), Equation (23).
The goal of mutations is to help maintain diversity in the population. Mutation 1 allows for the same features to be available in a few groups. Mutation 2 protects solutions from having a few groups with the same input signals and from overusing any feature. Mutation 3 makes it possible to restore input signals lost in other genetic operations.
| Algorithm 8: Moving mutation. |
 |
| Algorithm 9: Vanishing mutation. |
 |
| Algorithm 10: New input signals mutation. |
 |
5. Results
In this section, we describe the used datasets and models. We also demonstrate the improvements that were possible to achieve by the usage of the proposed solutions. We provide a comparison with methods from the state-of-the-art articles. We ran all the presented calculations on an Nvidia Tesla V100-SXM2-32GB (https://www.nvidia.com/en-us/data-center/v100/, accessed on 1 November 2021). In order to reduce both training times, i.e., during the evolution algorithm and the final training, each subgroup was calculated on a separate GPGPU. The genetic algorithm parameters were the same for all experiments and are presented in Table 1 (the column basic value). Moreover, the model that gained the best results (CNN 1D) was also run once again with a higher value of the parameters population size and parents mating (the column Rerun value in Table 1) to determine how this affects the efficiency of the algorithms.

Table 1.
Parameters of the genetic algorithm.
5.1. Datasets
We used the following as the training and testing data:
- The Secure Water Treatment (SWaT) Dataset [19], which contains data gathered from a scaled-down version of a real water treatment plant. The data were collected for 11 d in two modes—7 d of normal operation of the plant and 4 d during which there were cyber and physical attacks executed;
- The Water Distribution (WADI) Dataset [20], which contains data from a scaled-down version of a water distribution network in a city. The collected data contain 14 d of normal operation and 2 d during which there were 15 attacks executed. As presented in Table 2, there are two WADI collections from 2017 and 2019 available. In our experiments, we used the newest version as per the recommendation of the authors of the dataset.
Table 2. Statistics of the used datasets.
5.2. Models
In this paper, in order to detect anomalies, we used three models of the autoencoder. The first of these was proposed in [10], where the encoder contained three 1D CNN layers with kernel sizes , , and and filter maps , , and . Each CNN layer is followed by the LReLU [21] activation function and batch normalization calculation. The decoder is a mirror reflection of the encoder where transposed CNN layers replace CNN layers. The second model is a variational autoencoder [9] where both the encoder and the decoder contain two LSTM layers with hidden sizes equaling 16, followed by the LReLU activation function. The batch size is thirty-two for the training phase and one for the test phase. The third model is the USAD model proposed in the literature [11]. It utilizes the idea of GANs and the architecture of autoencoders. The USAD model consists of two autoencoders built from one shared encoder and two decoders. They are trained using the proposed two-phase training, including standard autoencoder training and adversarial training specific to GANs.
In the evolution algorithm (see Section 4), each model was trained over 15 epochs, and during the final training, each model was trained over 70 epochs. We divided the multivariate time series into subsequences with a sliding window parameter as an additional parameter for optimization. To speed up the training, we used downsampling with a ratio of five, which reduces the size of the data. As indicated in the literature [11], this operation did not cause a significant drop in accuracy. Table 3 contains the number of trainable parameters for each model used, the optimal values for some of them, and the time that was necessary to perform the whole process. As can be observed, the USAD model contains the highest number of parameters and took the longest time to train.
Table 3.
Parameters of the models.
5.3. Experiments
Table 4 contains the collected results from [1,3,4,8,9,11,12]. Additionally, the table contains results produced for this paper. In the case of the WADI dataset, we used the WADI 2019 version (marked as *). Moreover, for our baseline models (USAD, LSTM-VAE, and CNN 1D), we present the outcomes from our experiments for the SWAT dataset. The results were slightly different from the original result, as required to prepare the implementation on our own (marked as **).
Table 4.
Anomaly detection accuracy (precision (%), recall (%), f1-score (%)) on two datasets without splitting into groups. Results marked as * were generated by the usage of the WADI-2019 dataset. ** means that we had to reimplement a model on our own.
Table 5 contains the gained results after splitting the groups through the use of genetic algorithms. Each experiment was run ten times, and the presented result is the best one observed. We can observe a significant improvement on the WADI dataset in the case of the USAD model and CNN-based autoencoder. It had a minor impact on the LSTM-VAE model.
Table 5.
Anomaly detection accuracy (precision (%), recall (%), f1-score (%)) on two datasets after splitting into groups.
We gained the best results for the CNN 1D autoencoder, and as such, we reran the experiment for this model with a higher value of the following parameters of the genetic algorithm: population size and parents mating. As a result, it was possible to improve the f1-score by about 2% in the case of the SWAT and WADI datasets. These results are marked as (***) in Table 5. The optimal number of generated subgroups for CNN LSTM-VAE and USAD equals five. For each model, most anomalies were located in two subgroups. We can observe that each proposed autoencoder working on smaller groups of sensors was more sensitive in anomaly detection (a couple of percentage points in the SWAT dataset and over a dozen percentage points in the WADI dataset). Optimal sliding windows already found had sizes of 2 for autoencoders with CNN layers, 4 in the case of LSTM-VAE, and 12 in the case of USAD.
Additionally, by using a single model of neuroevolution, some single base models were improved. The best single model achieved by using the presented algorithm was the CNN 1D-based autoencoder, which had the following parameters: , , , filter maps , , and , as well as sliding windows equaling two (in the base models, the optimal sliding windows is four). The remaining layers were analogous to the basic model. The single model evolution was run in a population with a size equal to 24. After crossover and the mutation operation, the distance function (mainly based on the length of the model) was computed to diversify the offspring population (in addition to the best models, those that were different from each other were also chosen for the next iteration).
Table 6 presents the hyperparameters of the most effective generated CNN 1D model, which on all input sensors (one group) improved the f1-score by about 15% (44% on the WADI dataset, which was the best result gained by a single model). The depth was the same as in the base model, but the hyperparameters changed in the neuroevolution process and, therefore, were better adjusted to the given task. The presented experiments proved that evolution works in two dimensions. It can improve single base models and further improve detection results by generating an ensemble model.
Table 6.
CNN 1D model hyperparameters.
6. Conclusions and Future Work
The results showed that the data distribution, dividing the input signals into subgroups, and using an ensemble model can significantly improve the efficiency of the anomaly detection process. The neuroevolution process helps to find near-optimal subgroups. The tests were run on the WADI and SWAT benchmarks. In both cases, the best results were achieved among models other than graph neural network models. The improvements in the WADI dataset were more significant than those in the SWAT dataset, because there are more sensors and samples in the WADI dataset than in the SWAT dataset.
Our paper proved that the neuroevolution approach might have a positive impact on results. Our future work will concentrate on further enhancements of the algorithm. We consider the following the most critical enhancements: an ensemble model based on graph networks; a new crossover to mix different architectures, e.g., attention with a discriminator; graph networks with USAD. We will also run more extended simulations (with more significant populations and more iterations), which can determine the f1-score.
Author Contributions
Conceptualization: M.P., K.F. and D.Z.; formal analysis: M.P. and D.Z.; investigation: D.Z. and K.F.; methodology: M.P.; software: M.P., K.F. and D.Z.; supervision: M.P.; validation: M.P., K.F. and D.Z.; visualization: M.P., K.F. and D.Z.; writing—original draft: M.P., K.F. and D.Z.; writing—review and editing: M.P., K.F. and D.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Restrictions apply to the availability of these data. Data was obtained from iTrust, Centre for Research in Cyber Security, Singapore University of Technology and Design and are available at iTrust with the permission of iTrust, Centre for Research in Cyber Security, Singapore University of Technology and Design.
Acknowledgments
This research was supported in part by PLGrid Infrastructure.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Deng, A.; Hooi, B. Graph Neural Network-Based Anomaly Detection in Multivariate Time Series. arXiv 2021, arXiv:cs.LG/2106.06947. [Google Scholar]
- Miikkulainen, R.; Liang, J.; Meyerson, E.; Rawal, A.; Fink, D.; Francon, O.; Raju, B.; Shahrzad, H.; Navruzyan, A.; Duffy, N.; et al. Evolving Deep Neural Networks. arXiv 2017, arXiv:1703.00548. [Google Scholar]
- Isermann, R. Model-Based Fault Detection and Diagnosis - Status and Applications. In Proceedings of the 16th IFAC Symposium on Automatic Control in Aerospace 2004, Saint-Petersburg, Russia, 14–18 June 2004; Volume 37, pp. 49–60. [Google Scholar] [CrossRef]
- Angiulli, F.; Pizzuti, C. Fast Outlier Detection in High Dimensional Spaces. In Principles of Data Mining and Knowledge Discovery; Elomaa, T., Mannila, H., Toivonen, H., Eds.; Springer: Berlin/Heidelberg, Germany, 2002; pp. 15–27. [Google Scholar]
- Breunig, M.M.; Kriegel, H.P.; Ng, R.T.; Sander, J. LOF: Identifying Density-Based Local Outliers. SIGMOD Rec. 2000, 29, 93–104. [Google Scholar] [CrossRef]
- Ma, J.; Perkins, S. Time-series novelty detection using one-class support vector machines. In Proceedings of the International Joint Conference on Neural Networks, Jantzen Beachm Portland, OR, USA, 20–24 July 2003; Volume 3, pp. 1741–1745. [Google Scholar] [CrossRef]
- Liu, F.T.; Ting, K.M.; Zhou, Z.H. Isolation Forest. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Washington, DC, USA, 15–19 December 2008; pp. 413–422. [Google Scholar] [CrossRef]
- Zong, B.; Song, Q.; Min, M.R.; Cheng, W.; Lumezanu, C.; ki Cho, D.; Chen, H. Deep Autoencoding Gaussian Mixture Model for Unsupervised Anomaly Detection. In Proceedings of the 6th International Conference on Learning Representations (ICLR 2018), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Park, D.; Hoshi, Y.; Kemp, C.C. A Multimodal Anomaly Detector for Robot-Assisted Feeding Using an LSTM-Based Variational Autoencoder. IEEE Robot. Autom. Lett. 2018, 3, 1544–1551. [Google Scholar] [CrossRef] [Green Version]
- Russo, S.; Disch, A.; Blumensaat, F.; Villez, K. Anomaly Detection using Deep Autoencoders for in-situ Wastewater Systems Monitoring Data. arXiv 2020, arXiv:2002.03843. [Google Scholar]
- Audibert, J.; Michiardi, P.; Guyard, F.; Marti, S.; Zuluaga, M.A. USAD: UnSupervised Anomaly Detection on Multivariate Time Series. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery Data Mining, KDD ’20, online, 6–10 July 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 3395–3404. [Google Scholar] [CrossRef]
- Li, D.; Chen, D.; Jin, B.; Shi, L.; Goh, J.; Ng, S.K. MAD-GAN: Multivariate Anomaly Detection for Time Series Data with Generative Adversarial Networks. In Artificial Neural Networks and Machine Learning—ICANN 2019: Text and Time Series; Tetko, I.V., Kůrková, V., Karpov, P., Theis, F., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 703–716. [Google Scholar]
- Galvan, P.M.E. Neuroevolution in Deep Neural Networks: Current Trends and Future Challenges. arXiv 2020, arXiv:2006.05415. [Google Scholar]
- Ma, A.; Wan, Y.; Zhong, Y.; Wang, J. SceneNet: Remote sensing scene classification deep learning network using multi-objective neural evolution architecture search. ISPRS J. Photogramm. Remote. Sens. 2021, 172, 171–188. [Google Scholar] [CrossRef]
- Sun, Y.; Xue, B.; Zhang, M.; Yen, G.G. Evolving Deep Convolutional Neural Networks for Image Classification. arXiv 2017, arXiv:1710.10741. [Google Scholar] [CrossRef] [Green Version]
- Mirsky, Y.; Doitshman, T.; Elovici, Y.; Shabtai, A. Kitsune: An Ensemble of Autoencoders for Online Network Intrusion Detection. arXiv 2018, arXiv:1802.09089. [Google Scholar]
- Jin, X.; Xing, X.; Elahi, H.; Wang, G.; Jiang, H. A Malware Detection Approach Using Malware Images and Autoencoders. In Proceedings of the 2020 IEEE 17th International Conference on Mobile Ad Hoc and Sensor Systems (MASS), Delhi, India, 10–13 December 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Dong, Y.; Japkowicz, N. Threaded ensembles of autoencoders for stream learning. Comput. Intell. 2018, 34, 261–281. [Google Scholar] [CrossRef]
- Mathur, A.P.; Tippenhauer, N.O. SWaT: A water treatment testbed for research and training on ICS security. In Proceedings of the 2016 International Workshop on Cyber-Physical Systems for Smart Water Networks (CySWater), Vienna, Austria, 11 April 2016; pp. 31–36. [Google Scholar] [CrossRef]
- Ahmed, C.; Palleti, V.; Mathur, A. WADI: A water distribution testbed for research in the design of secure cyber physical systems. In Proceedings of the 3rd International Workshop on Cyber-Physical Systems for Smart Water Networks, Pittsburgh, PA, USA, 21 April 2017; pp. 25–28. [Google Scholar] [CrossRef]
- Maas, A.L.; Hannun, A.Y.; Ng, A.Y. Rectifier nonlinearities improve neural network acoustic models. In Proceedings of the ICML Workshop on Deep Learning for Audio, Speech and Language Processing, Atlanta, GA, USA, 16–21 June 2013. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).