
Beware the Black-Box: On the Robustness of Recent Defenses to Adversarial Examples


Abstract
:1. Introduction
Major Contributions, Related Literature and Paper Organization
- Comprehensive black-box defense analysis—Our experiments are comprehensive and rigorous in the following ways: we work with 9 recent defenses and a total of 12 different attacks. Every defense is trained on the same dataset and with the same base CNN architecture whenever possible. Every defense is attacked under the same adversarial model. This allows us to directly compare defense results. It is important to note some papers use different adversarial models which makes comparisons across papers invalid [19].
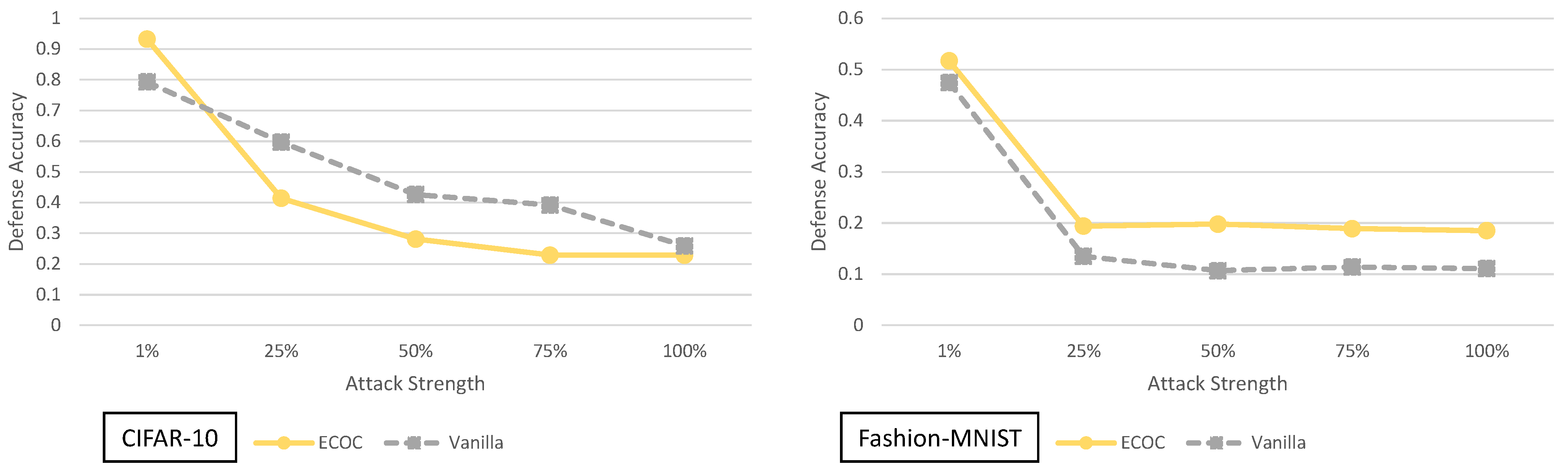
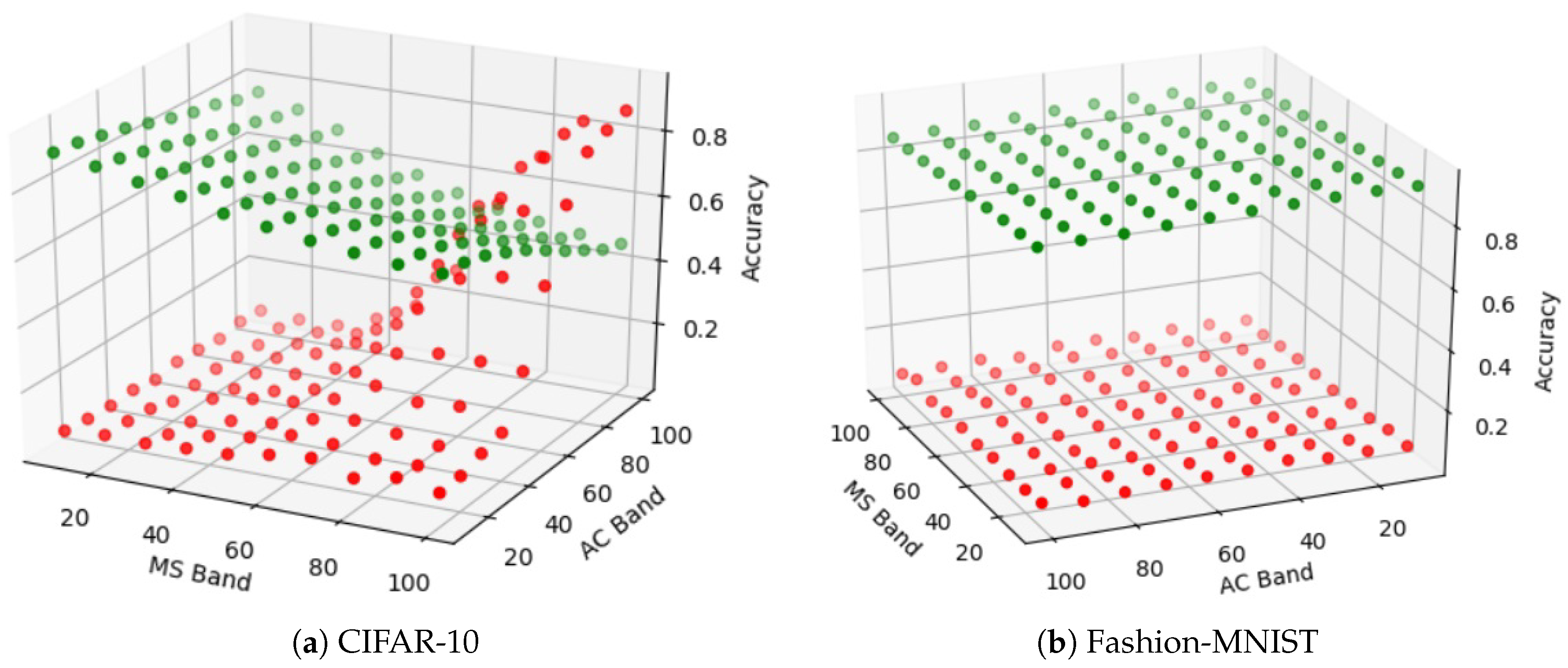
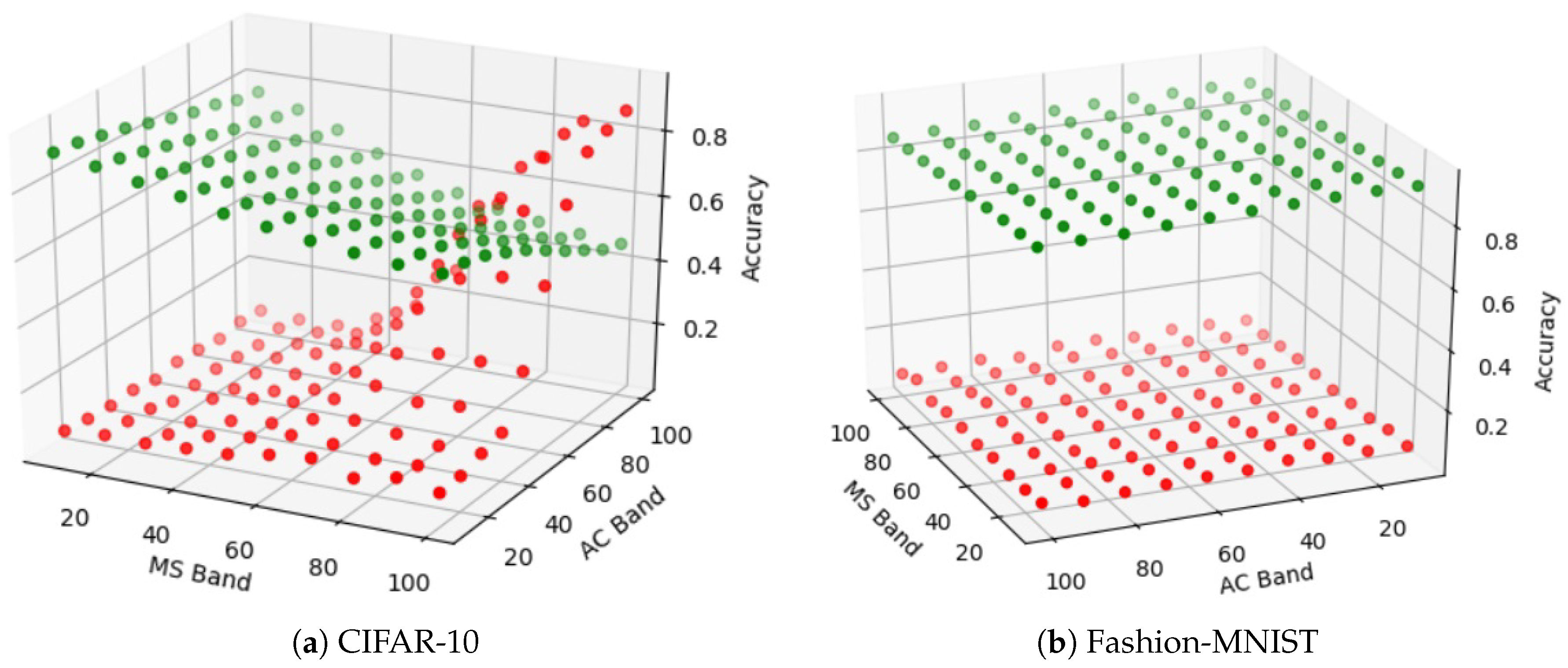
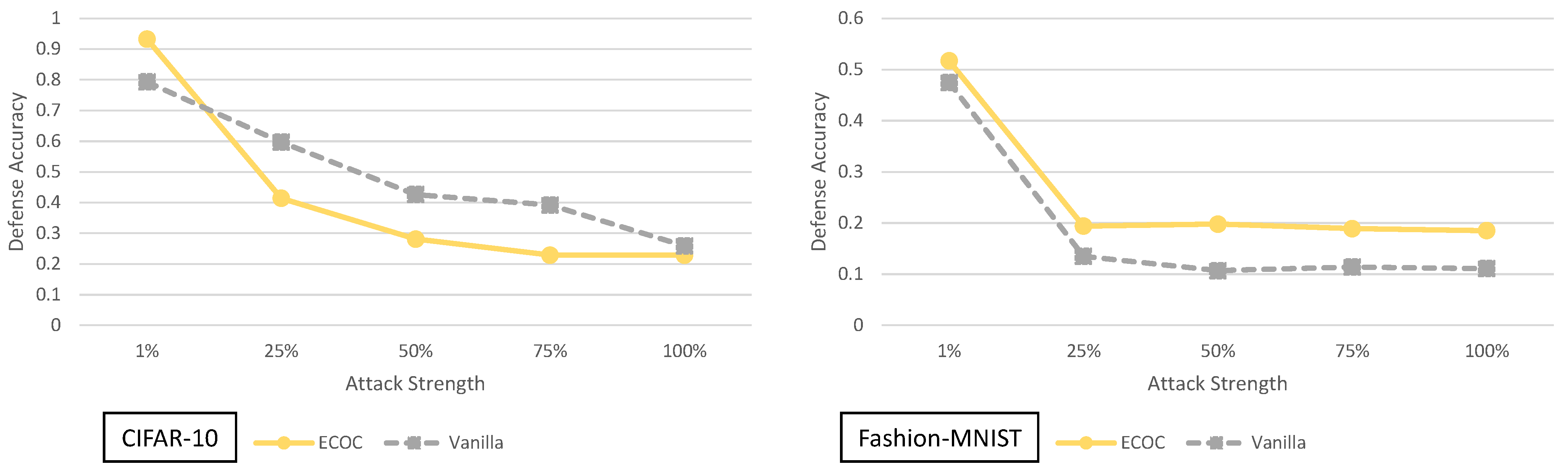
- Adaptive adversarial strength study—In this paper we are the first (to the best of our knowledge) to show the relationship between each of the 9 defenses and the strength of an adaptive black-box adversary. Specifically, for every defense we are able to show how its security is effected by varying the amount of training data available to an adaptive black-box adversary (i.e., , , , and ).
- Open source code and detailed implementations—One of our main goals of this paper is to help the community develop stronger black-box adversarial defenses. To this end, we publicly provide code for our experiments: https://github.com/MetaMain/BewareAdvML (accessed on 20 May 2021). In addition, in Appendix A we give detailed instructions for how we implemented each defense and what experiments we ran to fine tune the hyperparameters of the defense.
2. Attacks
2.1. Attack Setup
- The adversarial example must make the classifier produce a certain class label: . Here the certain class label c depends on whether the adversary is attempting a targeted, or untargeted type of attack. In a targeted attack c is a specific wrong class label (e.g., a picture of cat MUST be recognized as a dog by the classifier). On the other hand, if the attack is untargeted, the only criteria for c is that it must not be the same as the original class label: (e.g., as long as a picture of a cat is labeled by the classifier as anything except a cat, the attack is successful).
- The noise used to create the adversarial image must be barely recognizable by humans. This constraint is enforced by limiting the size of perturbation such that the difference between the original input x and the perturbed input is less than a certain distance d. This distance d is typically measured [19] using the norm:
2.2. Adversarial Capabilities
- Having knowledge of the trained parameters and architecture of the classifier. For example, when dealing with CNNs (as is the focus of this paper) knowing the architecture means knowing precisely which type of CNN is used. Example CNN architectures include VGG-16, ResNet56 etc. Knowing the trained parameters for a CNN means the values of the weights and biases of the network (as well as any other trainable parameters) are visible to the attacker [19].
- Query access to the classifier. If the architecture and trained parameters are kept private, then the next best adversarial capability is having query access to the target model as a black-box. The main concept here is that the adversary can adaptively query the classifier [26] with different inputs to help create the adversarial perturbation . Query access can come in two forms. In the stronger version, when the classifier is queried, the entire probability score vector is returned (i.e., the softmax output from a CNN). Naturally this gives the adversary more information to work with because the confidence in each label is given. In the weaker version, when the classifier is queried, only the final class label is returned (the index of the score vector with the highest value).
- Having access to (part of the) training or testing data. In general, for any adversarial machine learning attack, at least one example must be used to start the attack. Hence, every attack requires some input data. However, how much input data the adversary has access to depends on the type of attack (or parameters in the attack). Knowing part or all of the training data used to build the classifier can be especially useful when the architecture and trained parameters of the classifier are not available. This is because the adversary can try to replicate the classifier in the defense, by training their own classifier with the given training data [8].
2.3. Types of Attacks
- Query only black-box attacks [26]. The attacker has query access to the classifier. In these attacks, the adversary does not build any synthetic model to generate adversarial examples or make use of training data. Query only black-box attacks can further be divided into two categories: score based black-box attacks and decision based black-box attacks.
- Score based black-box attacks. These are also referred to as zeroth order optimization based black-box attacks [5]. In this attack, the adversary adaptively queries the classifier with variations of an input x and receives the output from the softmax layer of the classifier . Using the adversary attempts to approximate the gradient of the classifier and create an adversarial example. SimBA is an example of one of the more recently proposed score based black-box attacks [29].
- Decision based black-box attacks. The main concept in decision based attacks is to find the boundary between classes using only the hard label from the classifier. In these types of attacks, the adversary does not have access to the output from the softmax layer (they do not know the probability vector). Adversarial examples in these attacks are created by estimating the gradient of the classifier by querying using a binary search methodology. Some recent decision based black-box attacks include HopSkipJump [6] and RayS [30].
- Model black-box attacks. In model black-box attacks, the adversary has access to part or all of the training data used to train the classifier in the defense. The main idea here is that the adversary can build their own classifier using the training data, which is called the synthetic model. Once the synthetic model is trained, the adversary can run any number of white-box attacks (e.g., FGSM [3], BIM [31], MIM [32], PGD [27], C&W [28] and EAD [33]) on the synthetic model to create adversarial examples. The attacker then submits these adversarial examples to the defense. Ideally, adversarial examples that succeed in fooling the synthetic model will also fool the classifier in the defense. Model black-box attacks can further be categorized based on how the training data in the attack is used:
- Adaptive model black-box attacks [4]. In this type of attack, the adversary attempts to adapt to the defense by training the synthetic model in a specialized way. Normally, a model is trained with dataset X and corresponding class labels Y. In an adaptive black-box attack, the original labels Y are discarded. The training data X is re-labeled by querying the classifier in the defense to obtain class labels . The synthetic model is then trained on before being used to generate adversarial examples. The main concept here is that by training the synthetic model with , it will more closely match or adapt to the classifier in the defense. If the two classifiers closely match, then there will (hopefully) be a higher percentage of adversarial examples generated from the synthetic model that fool the classifier in the defense. To run adaptive black-box attacks, access to at least part of the training data and query access to the defense is required. If only a small percentage of the training data is known (e.g., not enough training data to train a CNN), the adversary can also generate synthetic data and label it using query access to the defense [4].
- Pure black-box attacks [7,8,9,10]. In this type of attack, the adversary also trains a synthetic model. However, the adversary does not have query access to make the attack adaptive. As a result, the synthetic model is trained on the original dataset and original labels . In essence this attack is defense agnostic (the training of the synthetic model does not change for different defenses).
2.4. Our Black-Box Attack Scope
3. Defense Summaries, Metrics and Datasets
- Multiple models—The defense uses multiple classifiers’ for prediction. The classifiers outputs may be combined through averaging (i.e., ADP), majority voting (BUZz) or other methods (ECOC).
- Fixed input transformation—A non-randomized transformation is applied to the input before classification. Examples of this include, image denoising using an autoencoder (Comdefend), JPEG compression (FD) or resizing and adding (BUZz).
- Random input transformation—A random transformation is applied to the input before classification. For example both BaRT and DistC randomly select from multiple different image transformations to apply at run time.
- Adversarial detection—The defense outputs a null label if the sample is considered to be adversarially manipulated. Both BUZz and Odds employ adversarial detection mechanisms.
- Network retraining—The network is retrained to accommodate the implemented defense. For example BaRT and BUZz require network retraining to achieve acceptable clean accuracy. This is due to the significant transformations both defenses apply to the input. On the other hand, different architectures mandate the need for network retraining like in the case of ECOC, DistC and k-WTA. Note network retraining is different from adversarial training. In the case of adversarial training, it is a fundamentally different technique in the sense that it can be combined with almost every defense we study. Our interest however is not to make each defense as strong as possible. Our aim is to understand how much each defense improves security on its own. Adding in techniques beyond what the original defense focuses on is essentially adding in confounding variables. It then becomes even more difficult to determine from where security may arise. As a result, we limit the scope of our defenses to only consider retraining when required and do not consider adversarial training.
- Architecture change—A change in the architecture which is made solely for the purposes of security. For example k-WTA uses different activation functions in the convolutional layers of a CNN. ECOC uses a different activation function on the output of the network.
3.1. Barrage of Random Transforms
3.2. End-to-End Image Compression Models
3.3. The Odds Are Odd
3.4. Feature Distillation
3.5. Buffer Zones
3.6. Improving Adversarial Robustness via Promoting Ensemble Diversity
3.7. Enhancing Transformation-Based Defenses against Adversarial Attacks with a Distribution Classifier
3.8. Error Correcting Output Codes
3.9. k-Winner-Take-All
3.10. Defense Metric
3.11. Datasets
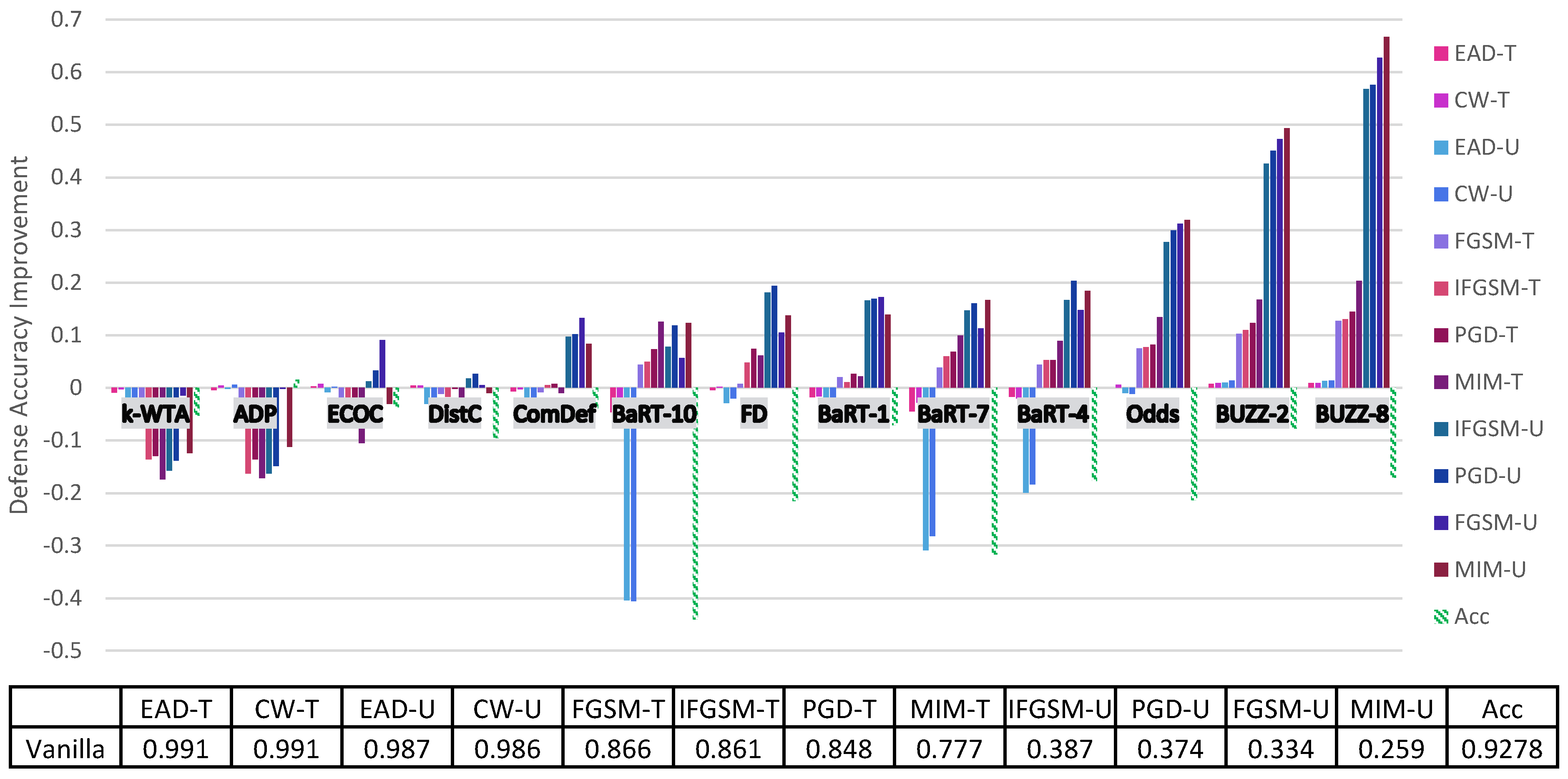
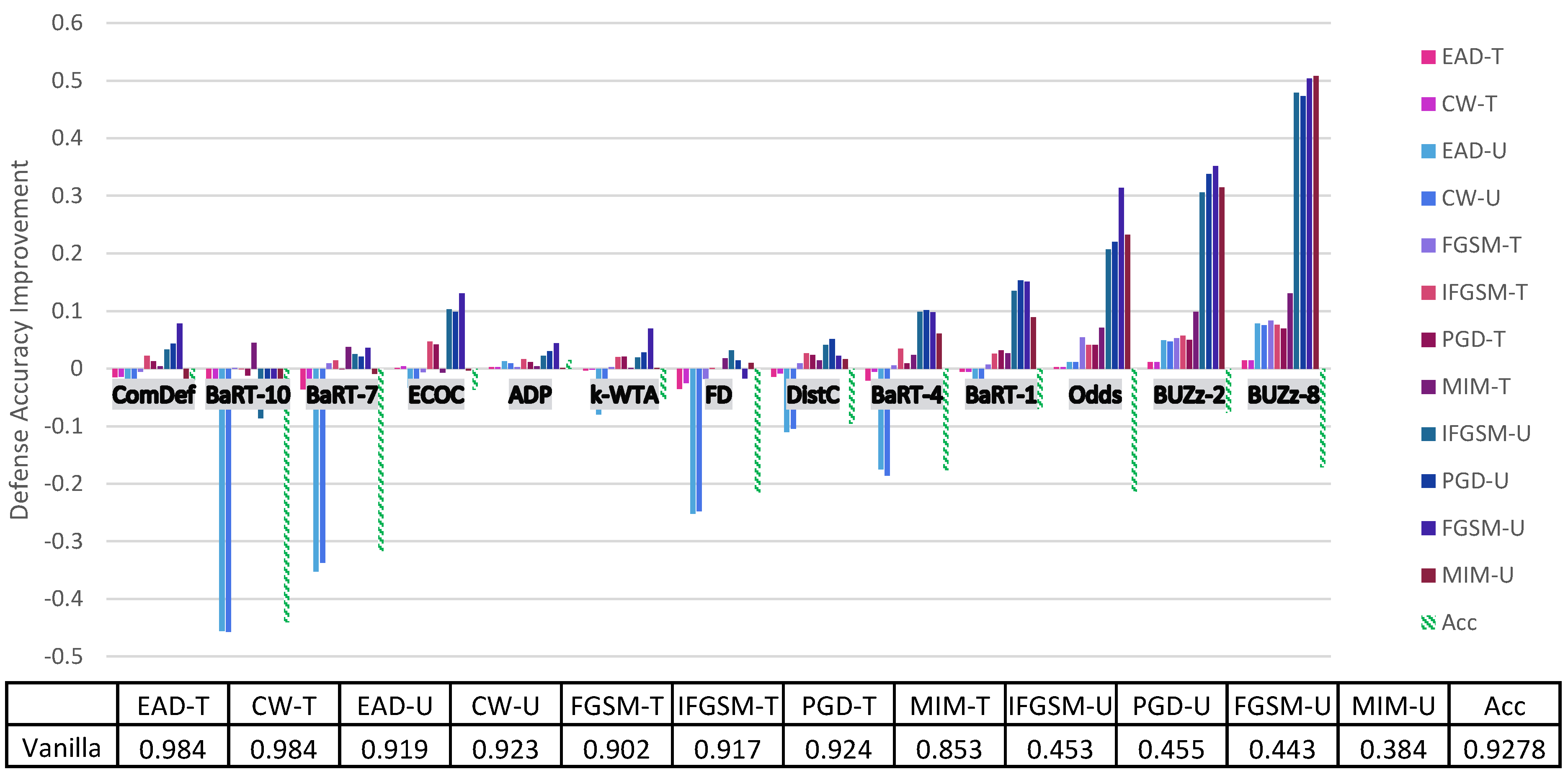
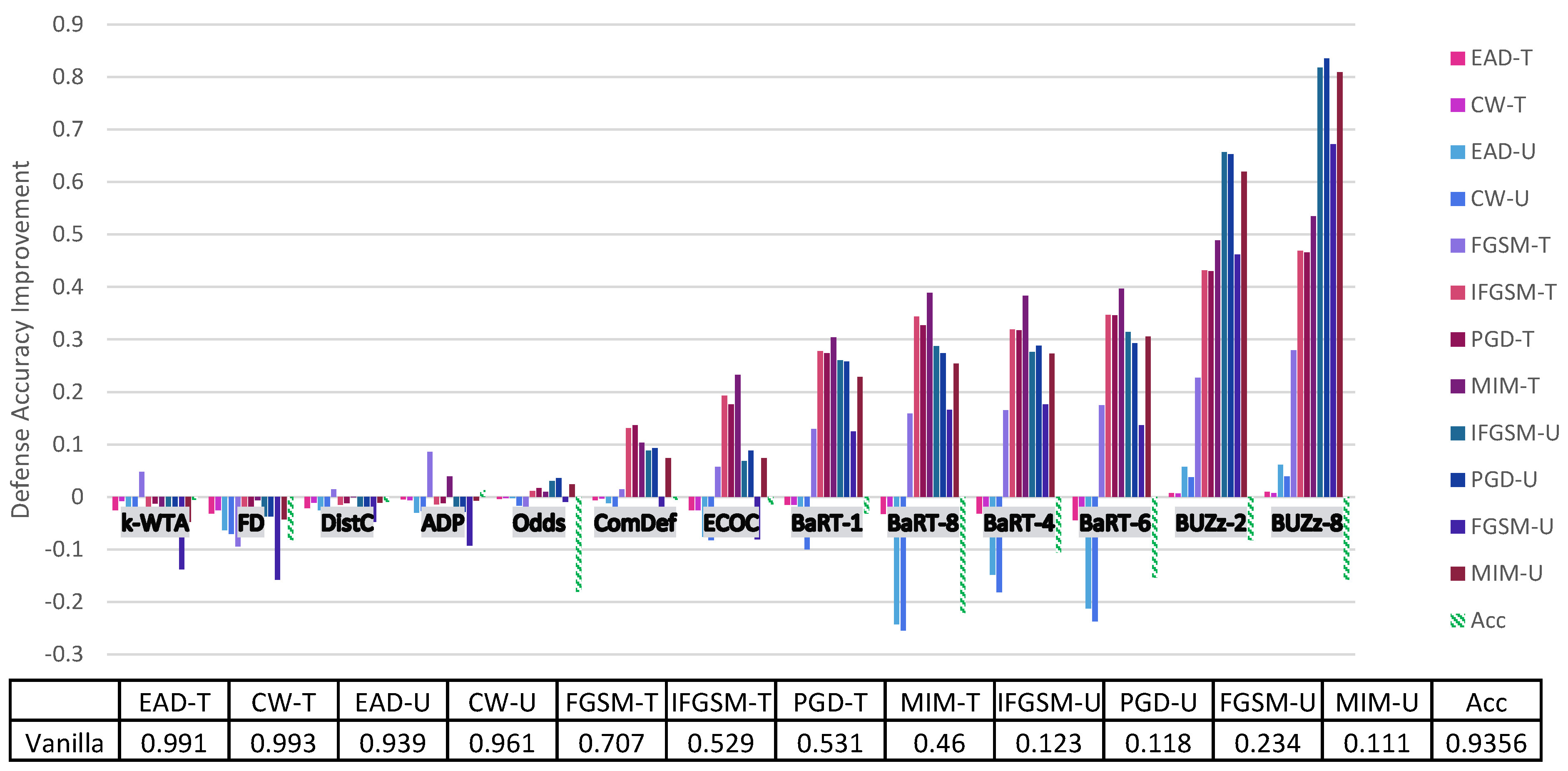
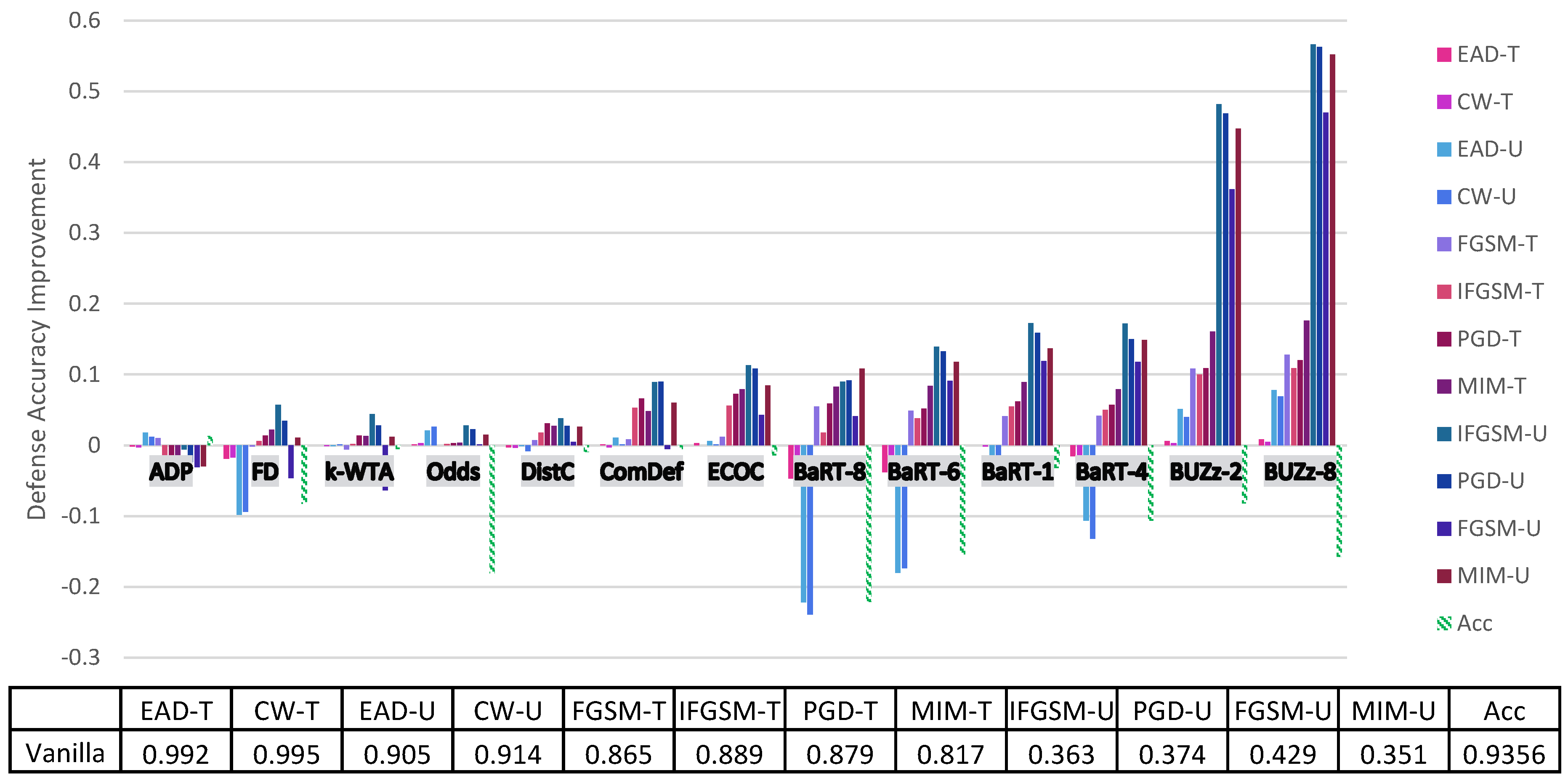
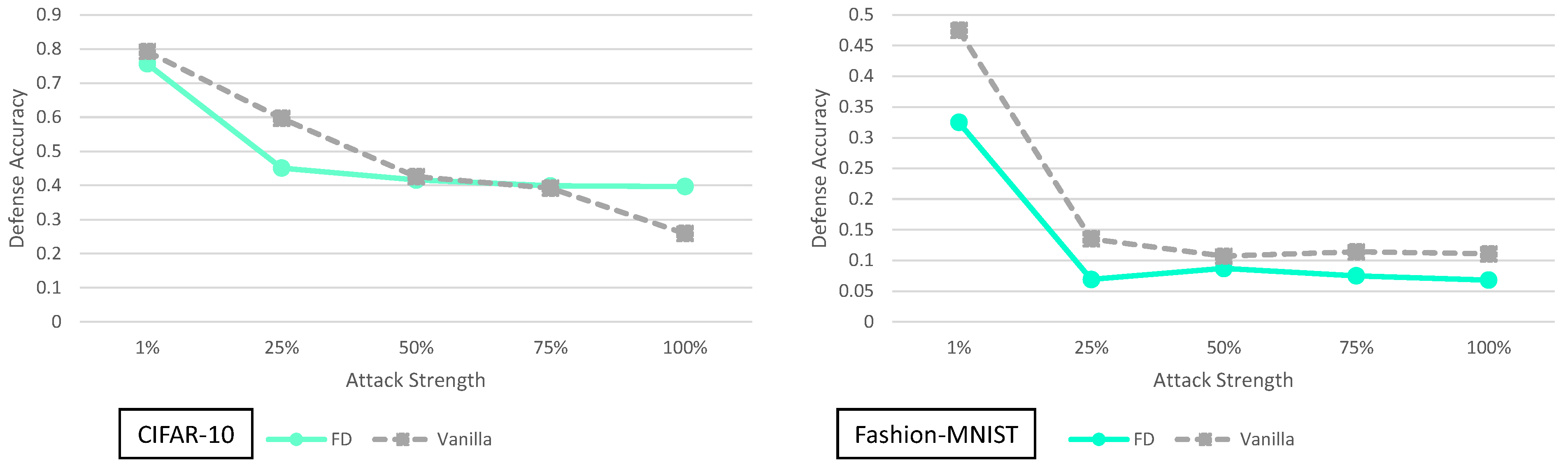
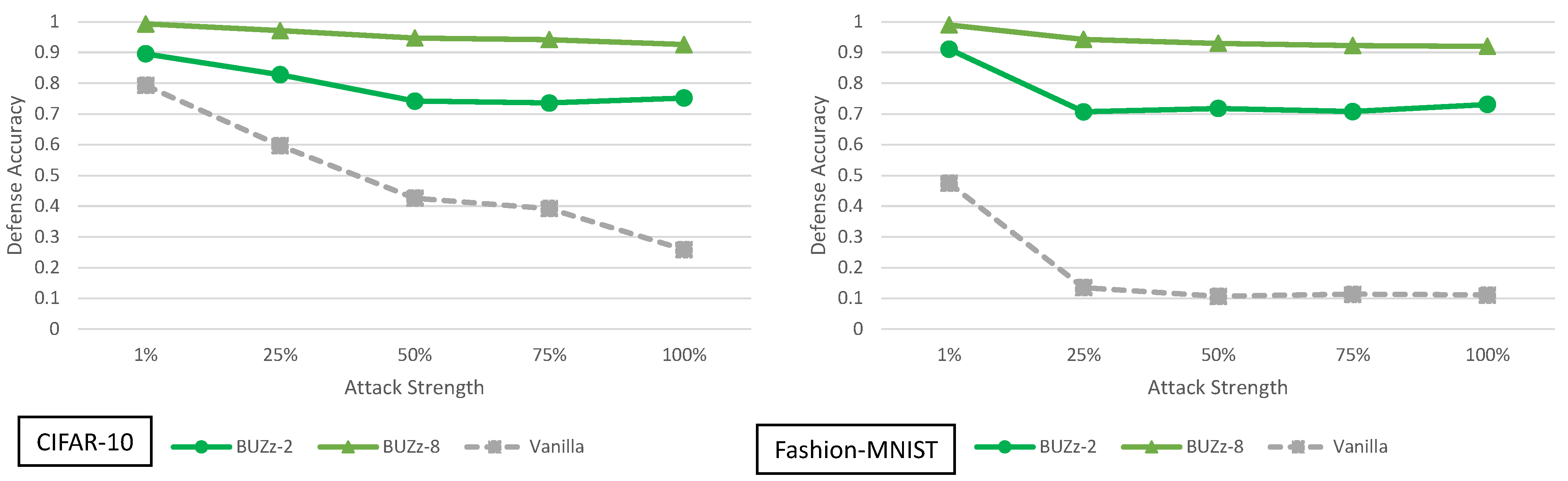
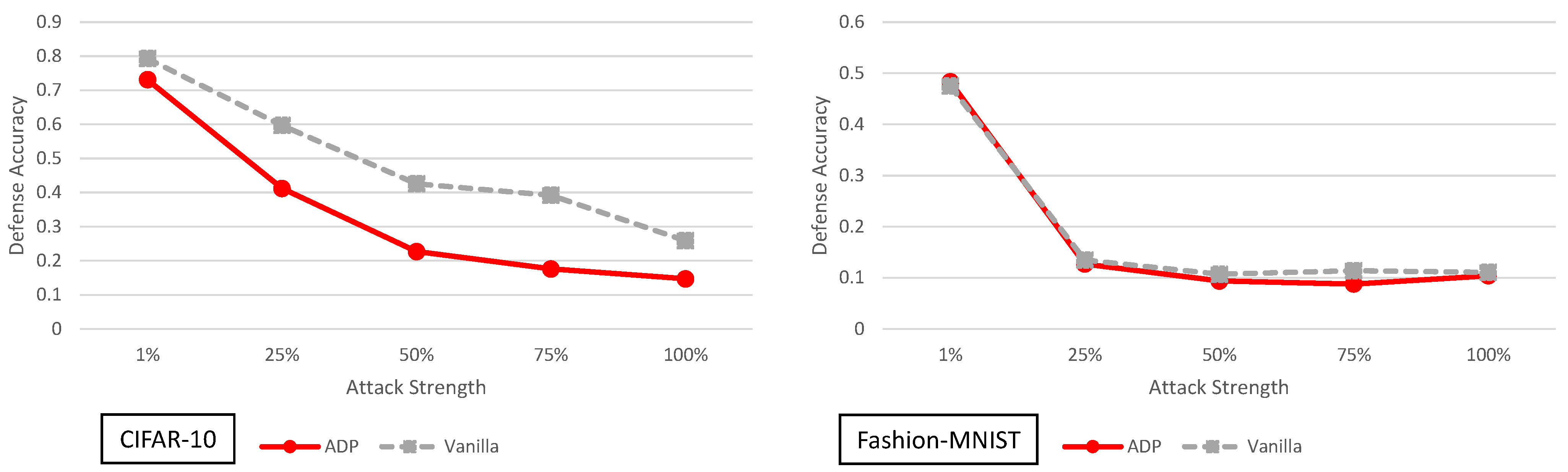
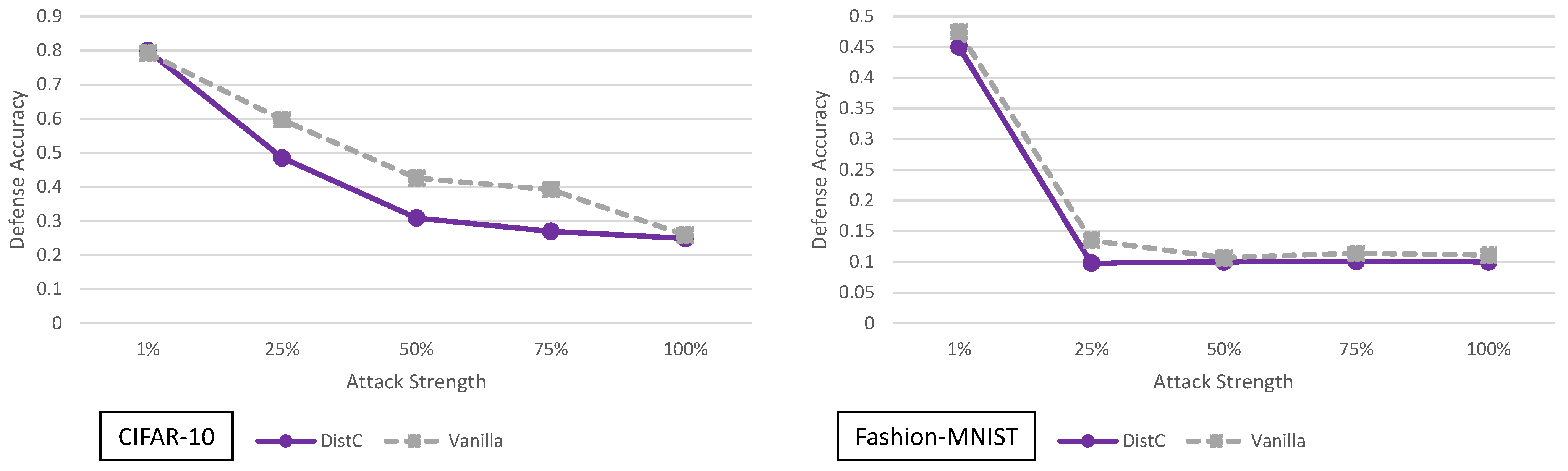
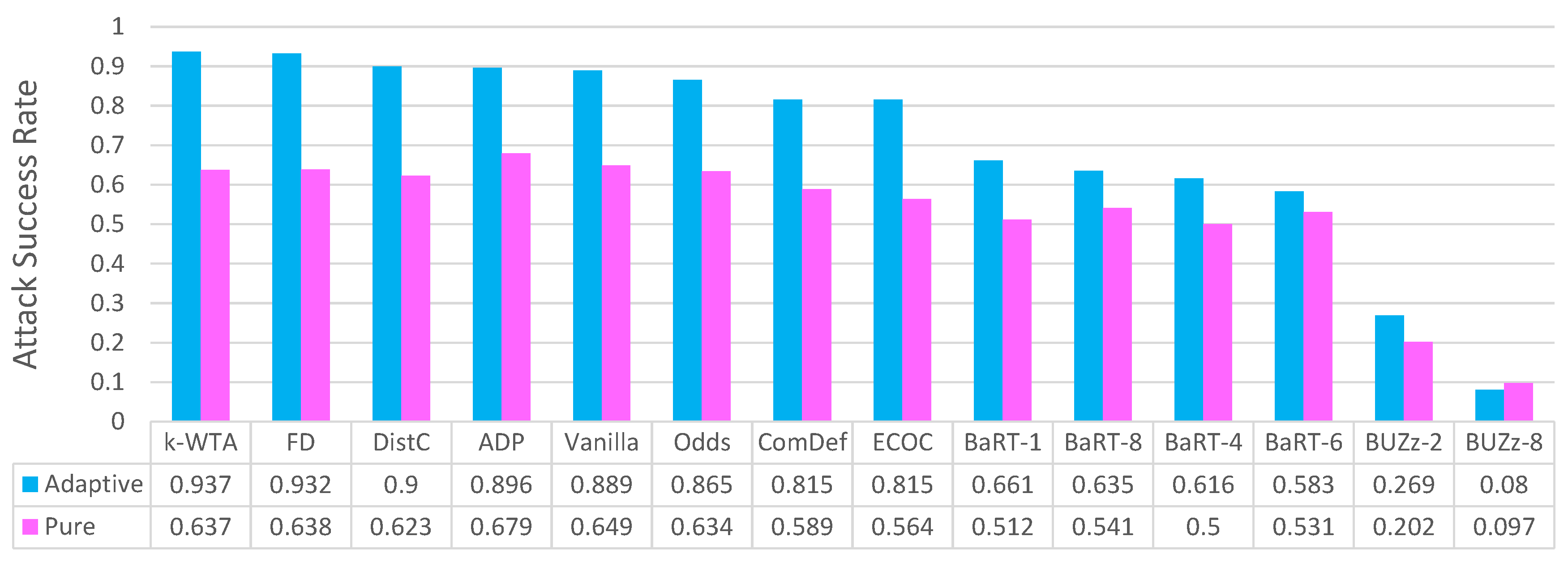
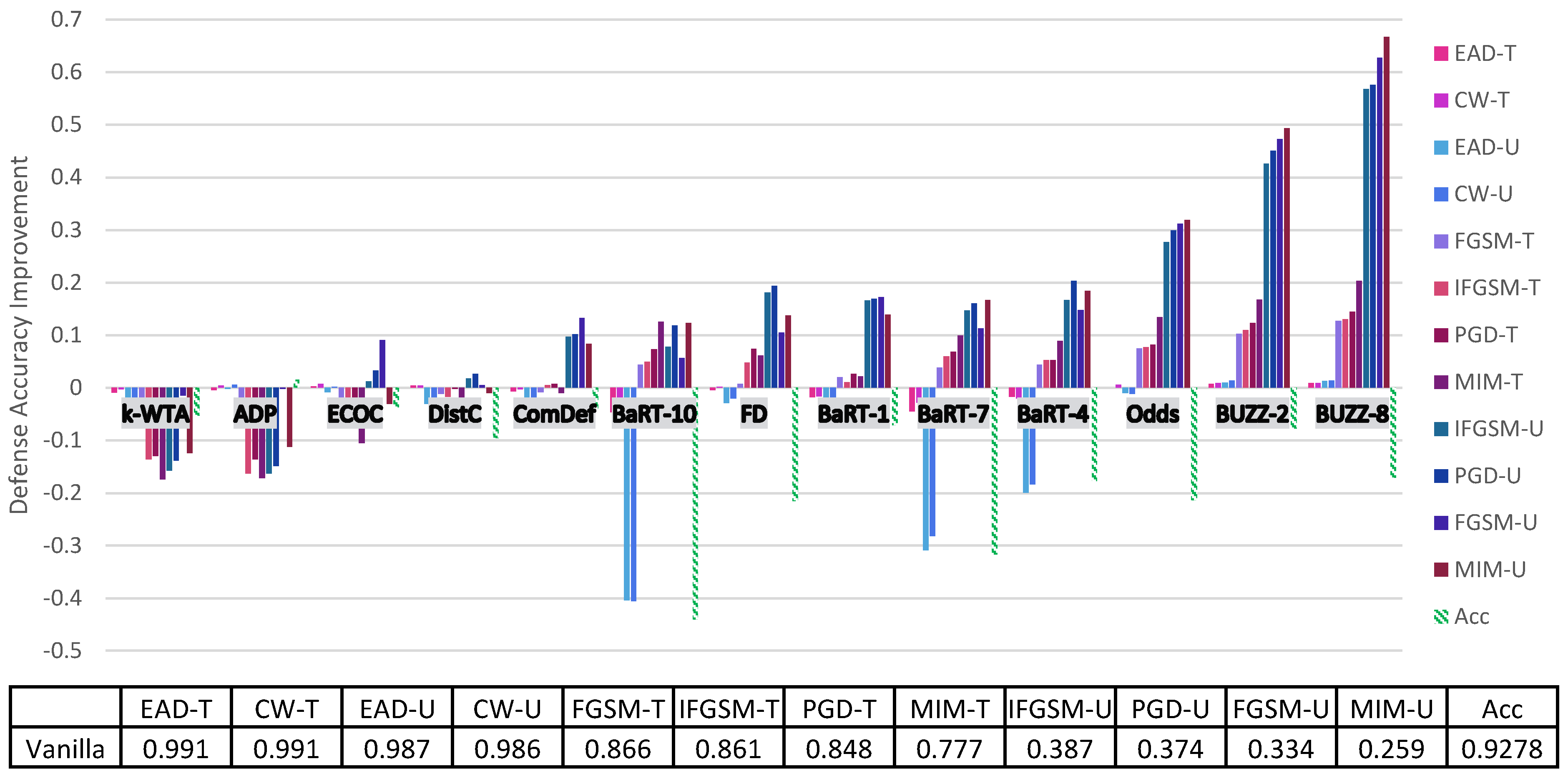
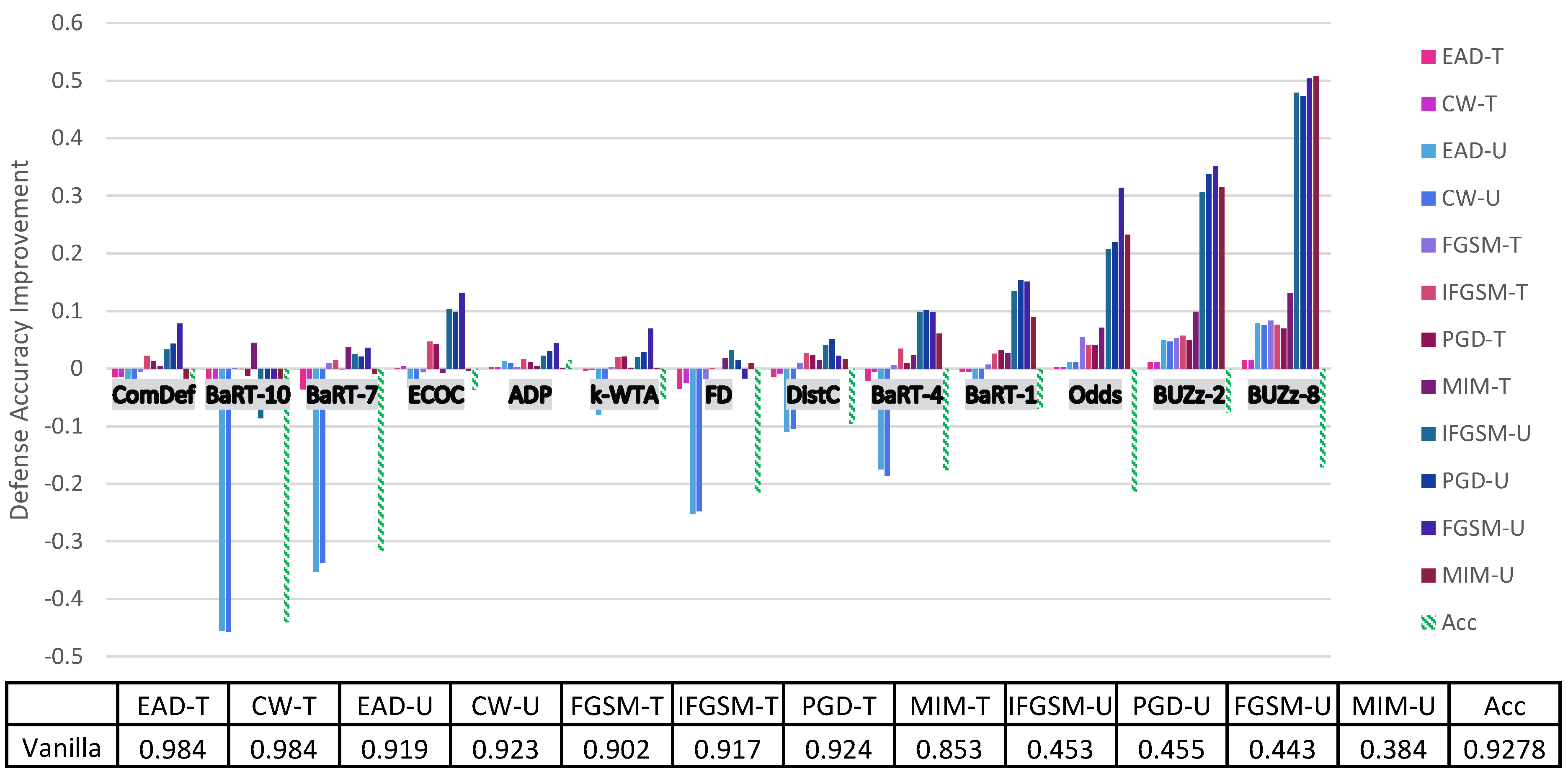
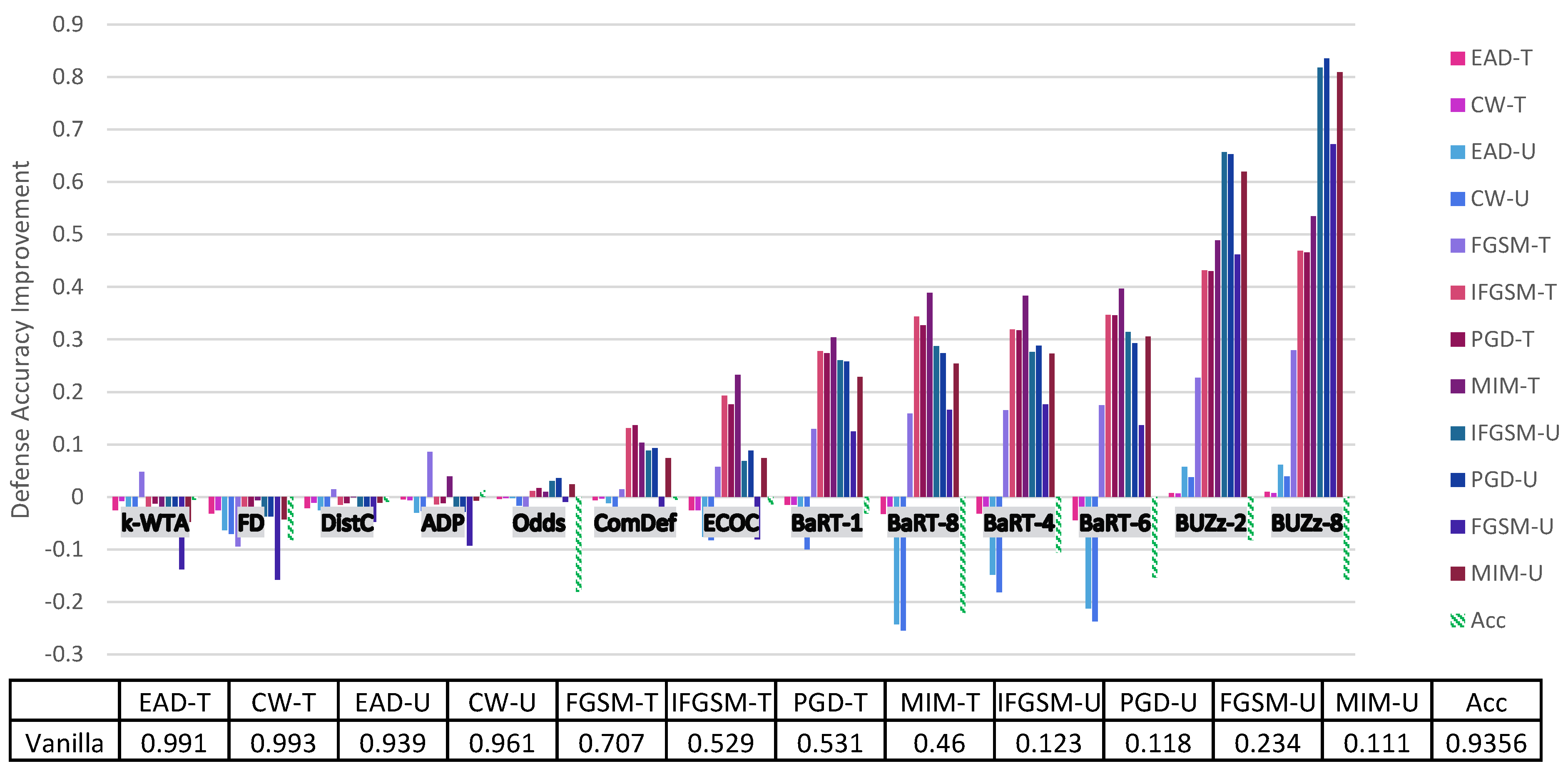
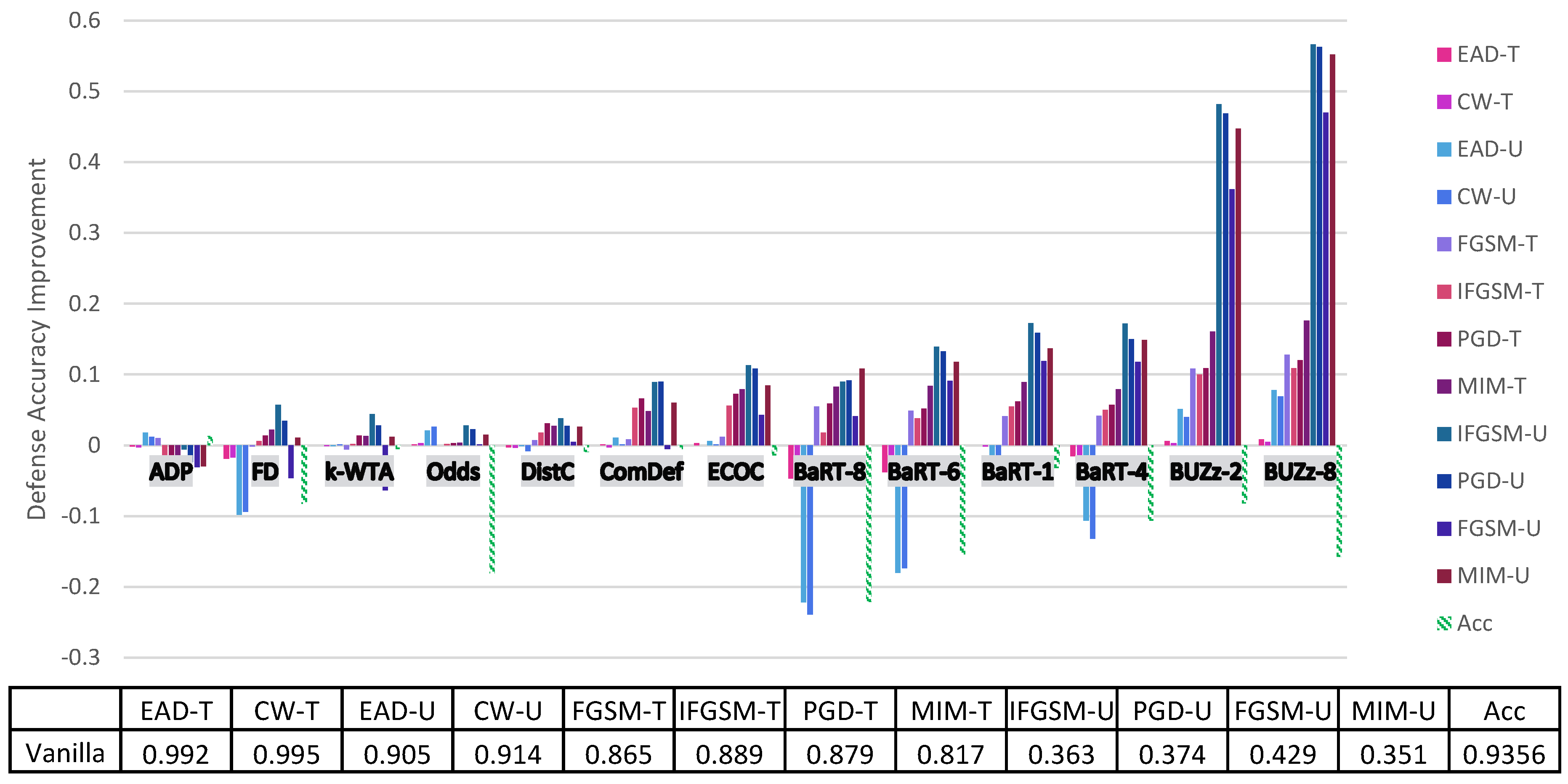
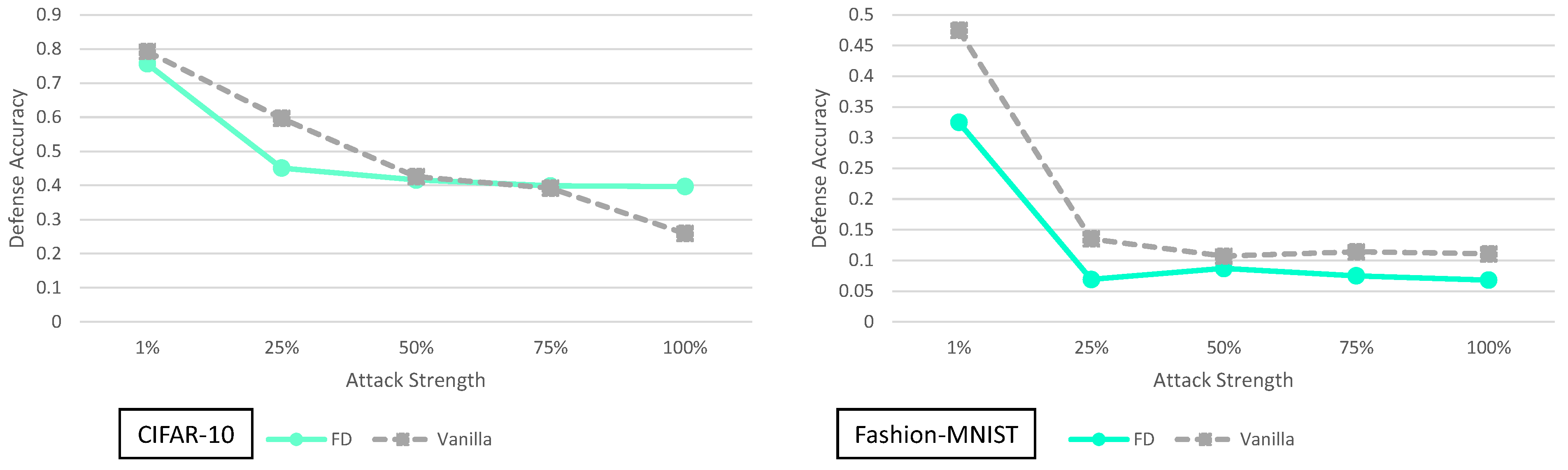
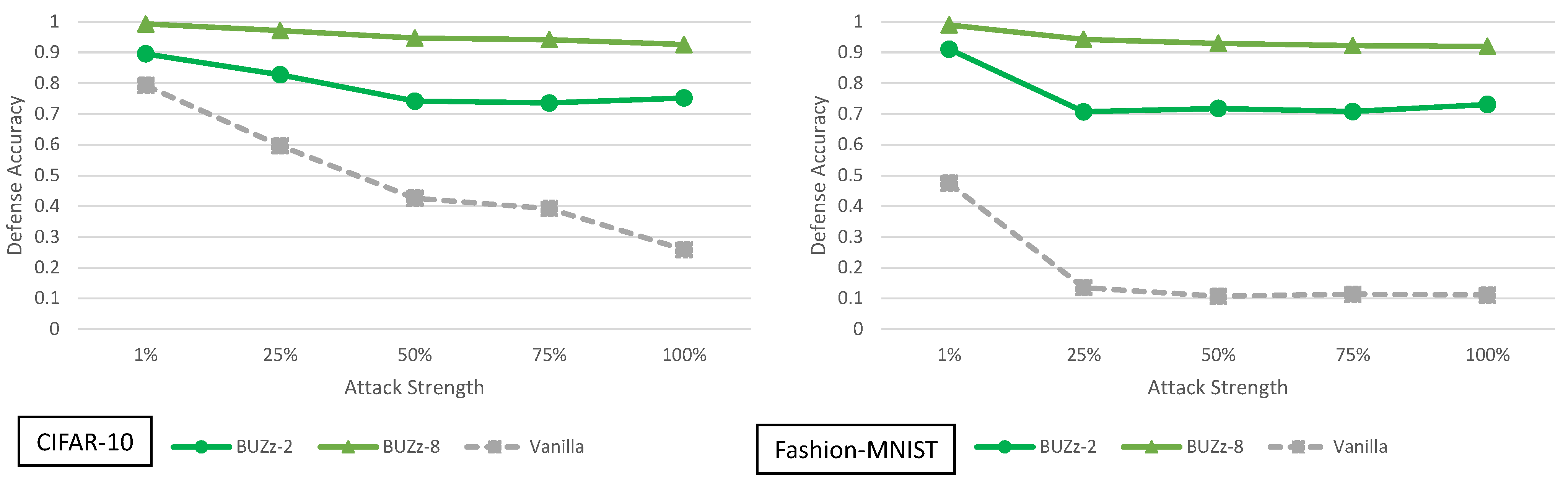
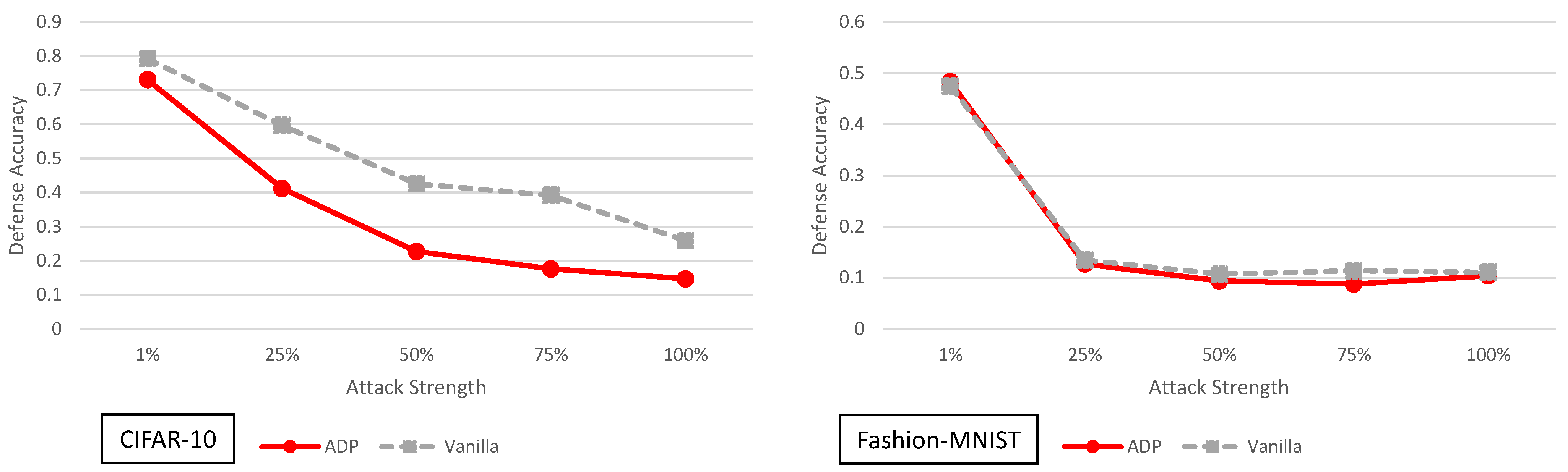
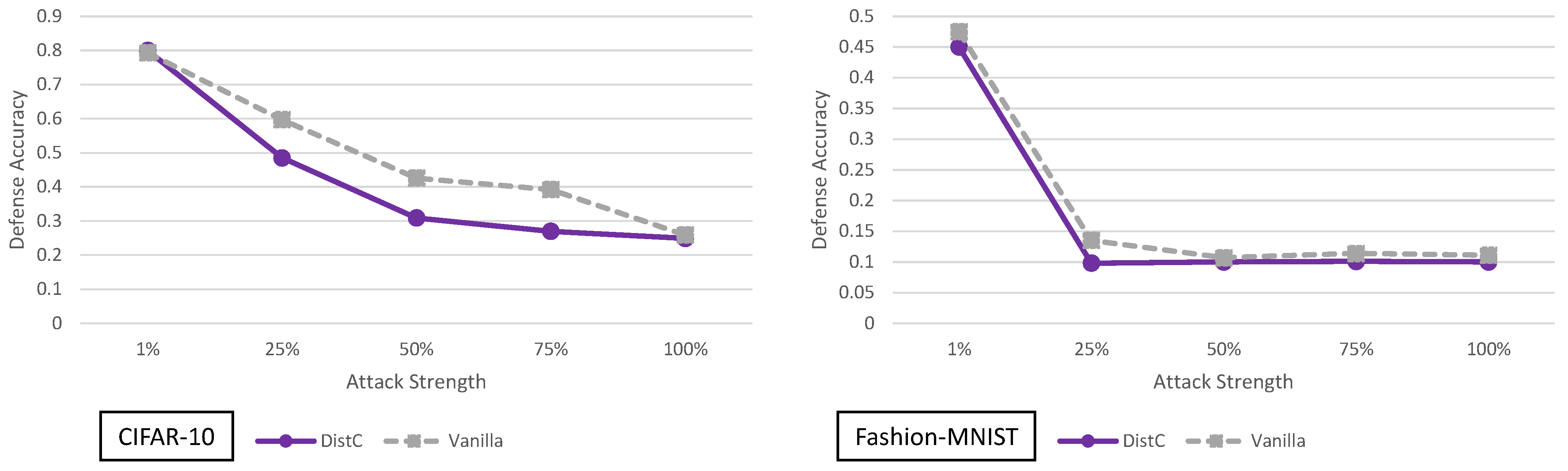
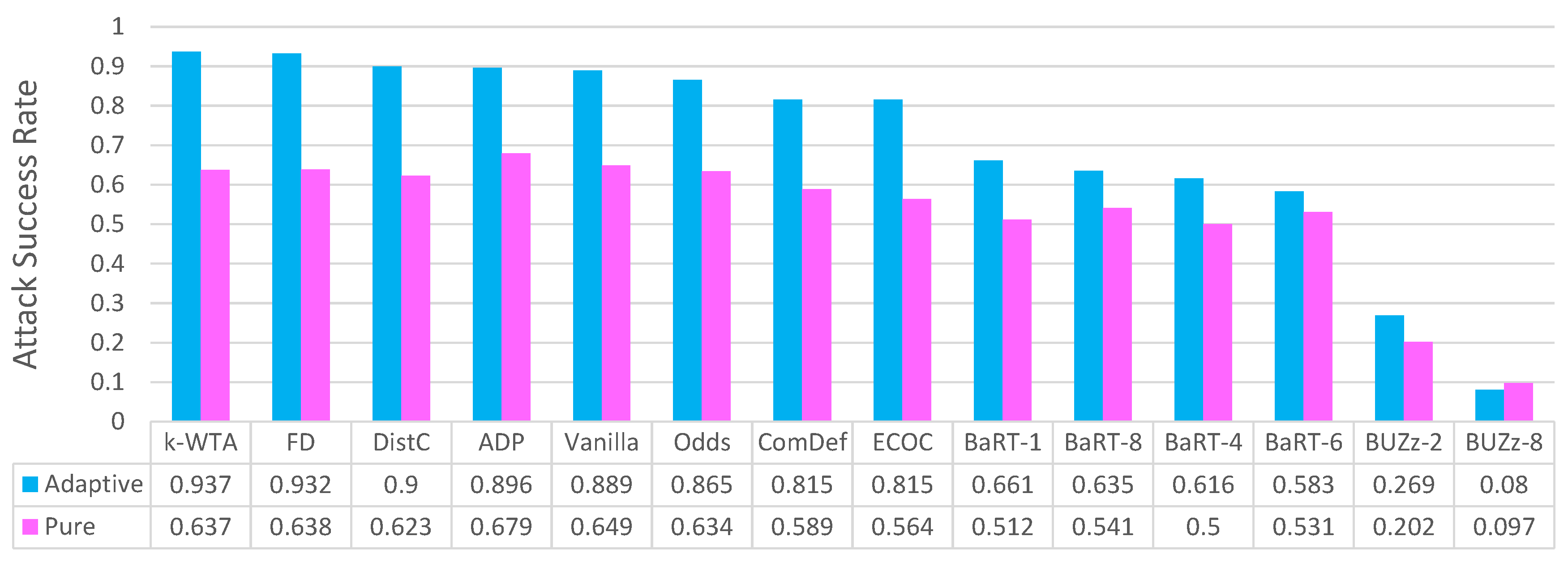
4. Principal Experimental Results
Principal Results
5. Individualized Experimental Defense Results
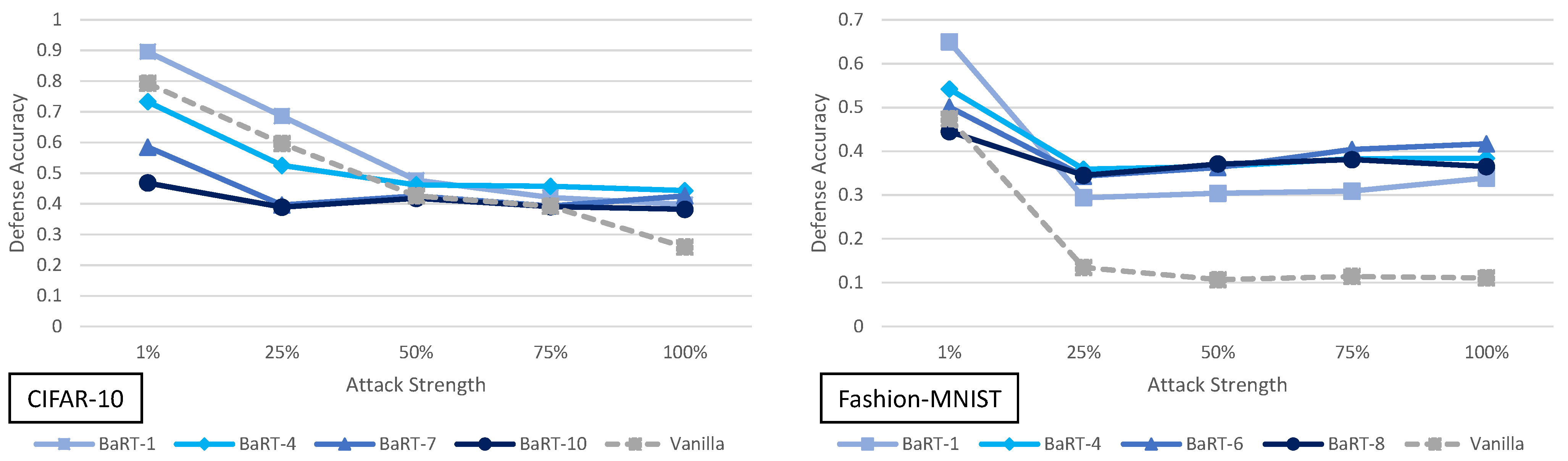
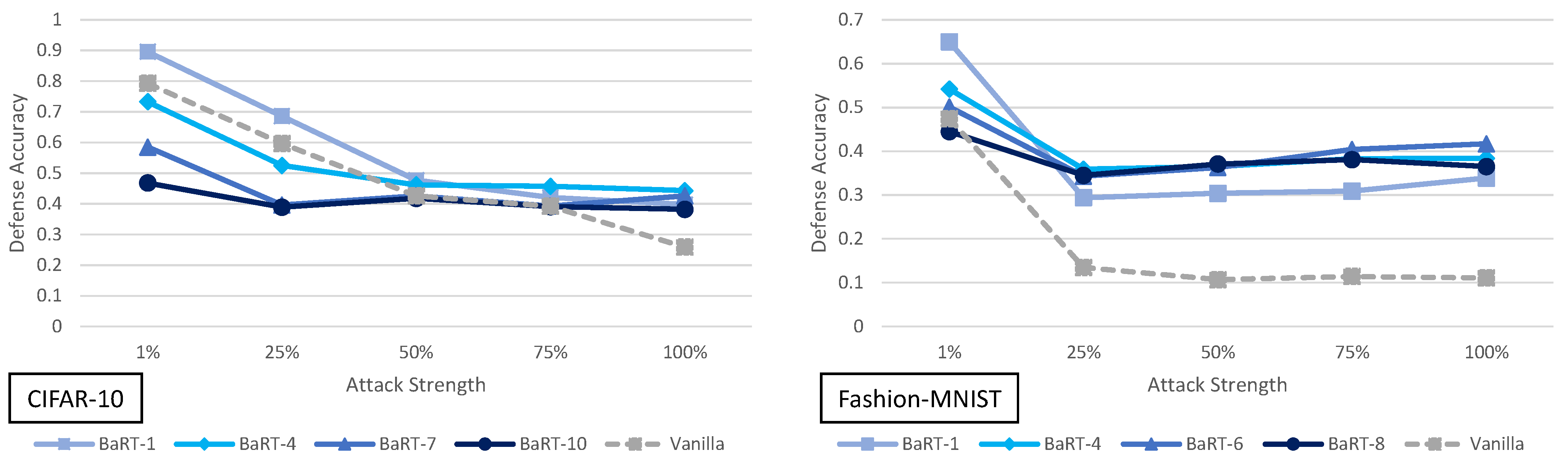
5.1. Barrage of Random Transforms Analysis
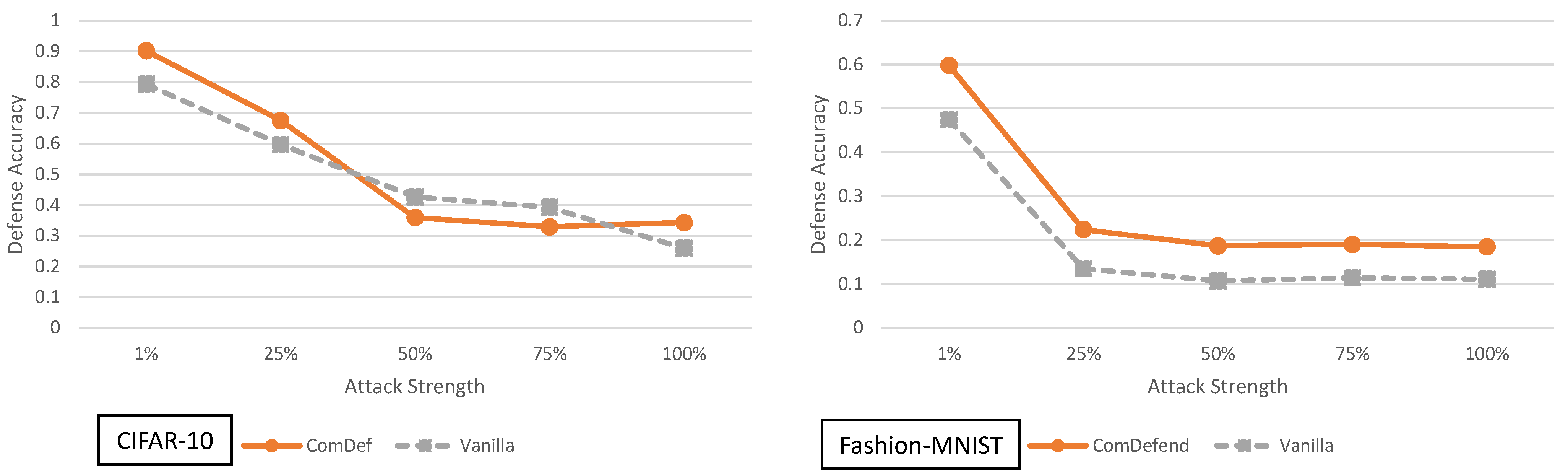
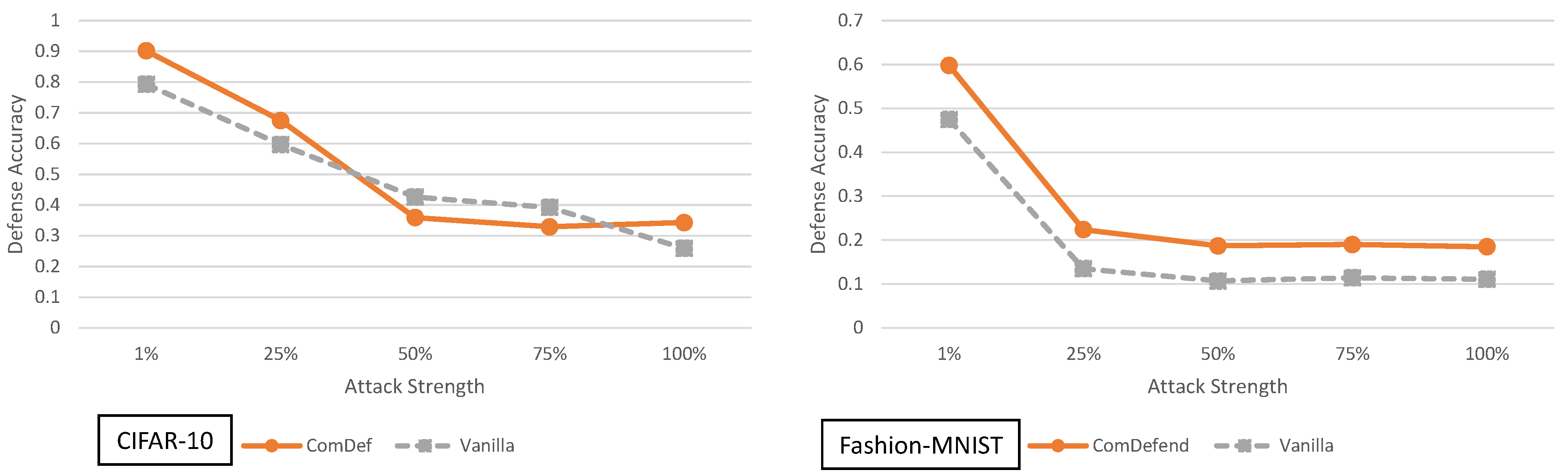
5.2. End-to-End Image Compression Models Analysis
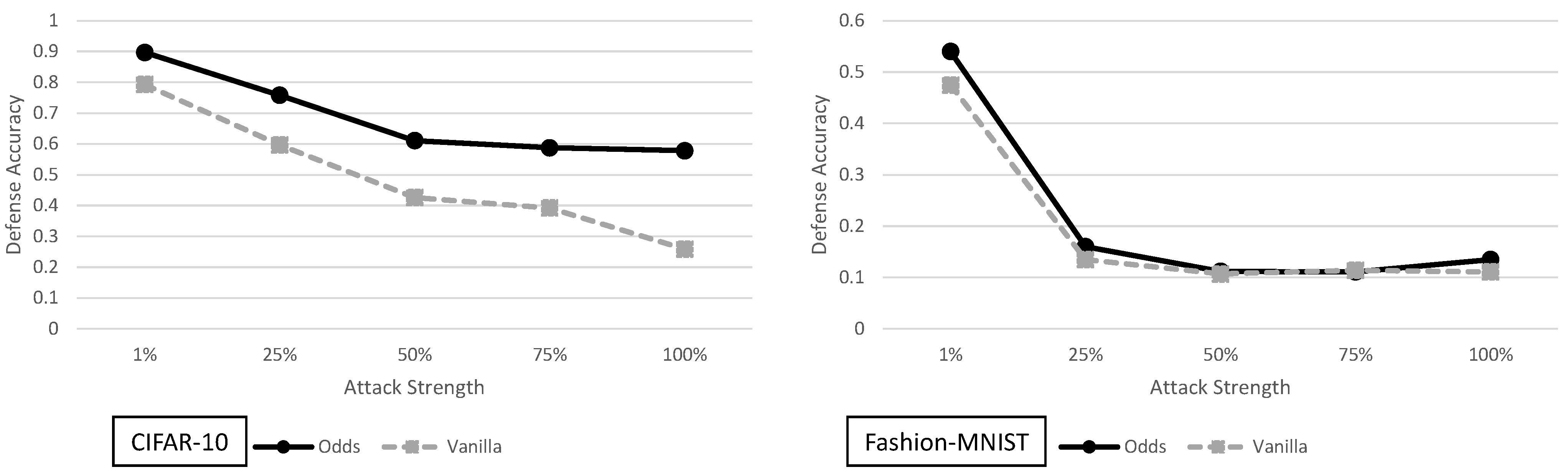
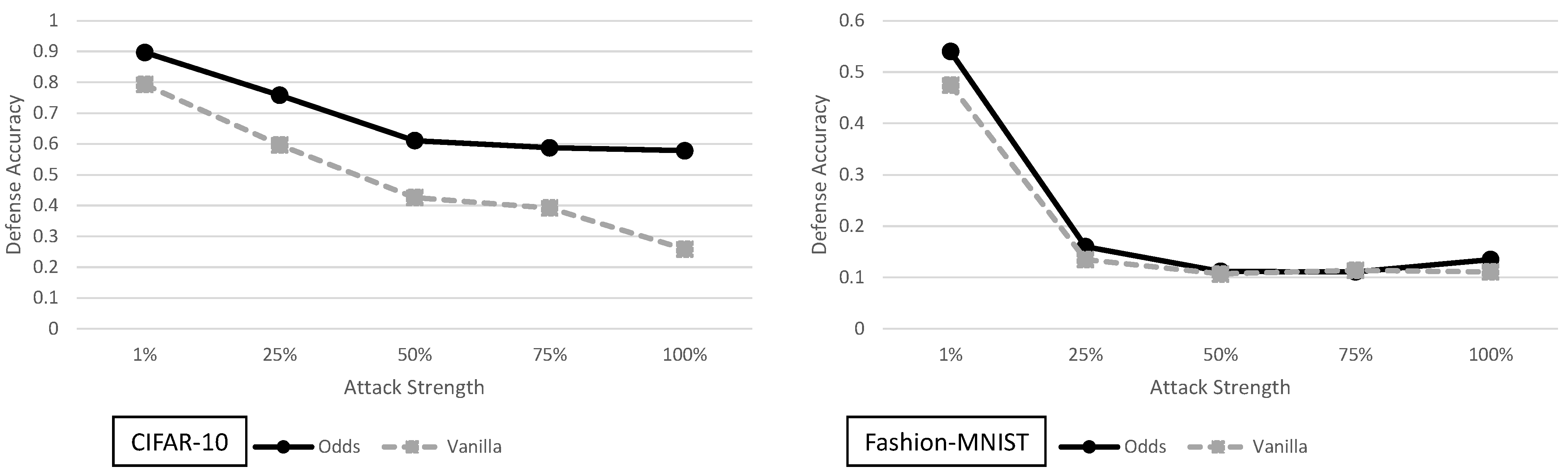
5.3. The Odds Are Odd Analysis
5.4. Feature Distillation Analysis
5.5. Buffer Zones Analysis
5.6. Improving Adversarial Robustness via Promoting Ensemble Diversity Analysis
5.7. Enhancing Transformation-Based Defenses against Adversarial Attacks with a Distribution Classifier Analysis
5.8. Error Correcting Output Codes Analysis
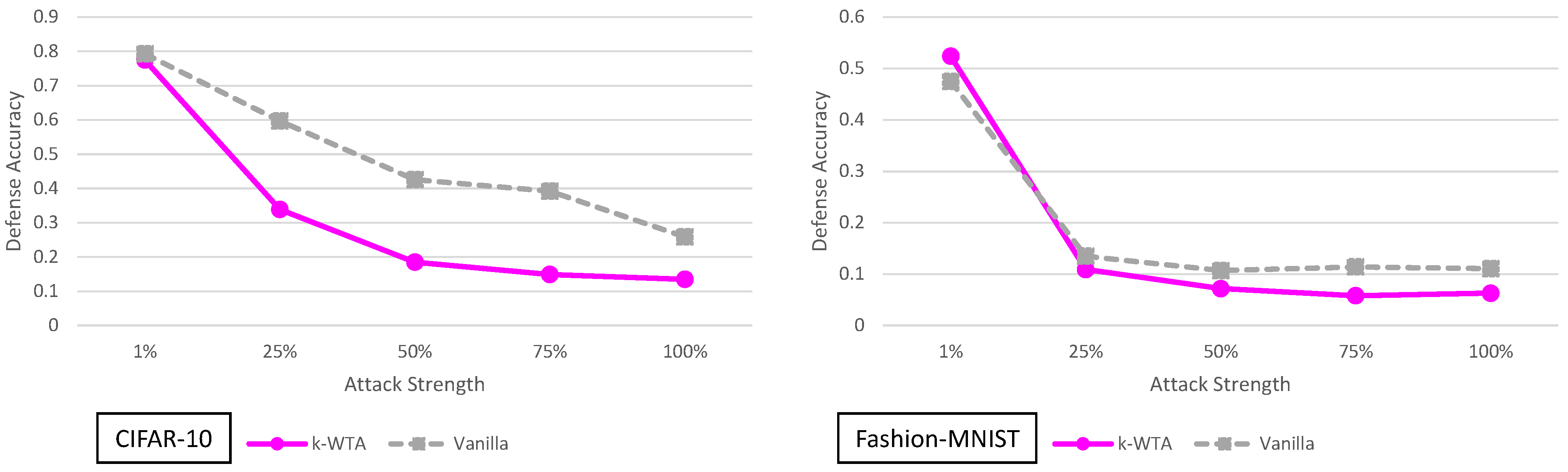
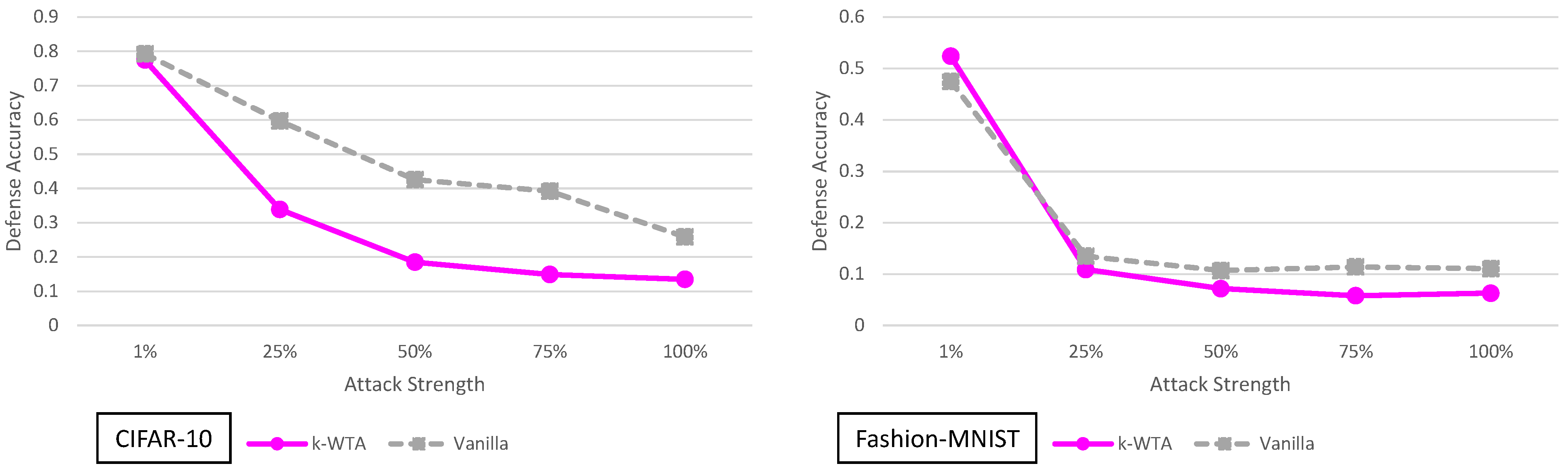
5.9. k-Winner-Take-All Analysis
5.10. On the Adaptability of the Adaptive Black-Box Attack
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
Appendix A.1. Black-Box Settings
| Algorithm 1 Construction of synthetic network g in Papernot’s oracle based black-box attack [24] |
|

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training Parameter | Value |
|---|---|
| Optimization Method | ADAM |
| Learning Rate | 0.0001 |
| Batch Size | 64 |
| Epochs | 100 |
| Data Augmentation | None |
| N | |||
|---|---|---|---|
| CIFAR-10 | 50,000 | 4 | 0.1 |
| Fashion-MNIST | 60,000 | 4 | 0.1 |
| Layer Type | Fashion-MNIST and CIFAR-10 |
|---|---|
| Convolution + ReLU | 3 × 3 × 64 |
| Convolution + ReLU | 3 × 3 × 64 |
| Max Pooling | 2 × 2 |
| Convolution + ReLU | 3 × 3 × 128 |
| Convolution + ReLU | 3 × 3 × 128 |
| Max Pooling | 2 × 2 |
| Fully Connected + ReLU | 256 |
| Fully Connected + ReLU | 256 |
| Softmax | 10 |
Appendix A.2. The Adapative Black-Box Attack on Null Class Label Defenses
Appendix A.3. Vanilla Model Implementation
Appendix A.4. Barrage of Random Transforms Implementation
Appendix A.5. Improving Adversarial Robustness via Promoting Ensemble Diversity Implementation
Appendix A.6. Error Correcting Output Codes Implementation
Appendix A.7. Distribution Classifier Implementation
Appendix A.8. Feature Distillation Implementation
Appendix A.9. End-to-End Image Compression Models Implementation
Appendix A.10. The Odds Are Odd Implementation
| FGSM-T | IFGSM-T | MIM-T | PGD-T | CW-T | EAD-T | FGSM-U | IFGSM-U | MIM-U | PGD-U | CW-U | EAD-U | Acc | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ADP | 0.003 | 0.016 | 0.004 | 0.011 | 0.003 | 0.003 | 0.044 | 0.022 | 0.001 | 0.03 | 0.009 | 0.013 | 0.0152 |
| BaRT-1 | 0.007 | 0.026 | 0.027 | 0.032 | −0.005 | −0.005 | 0.151 | 0.135 | 0.089 | 0.153 | −0.07 | −0.066 | −0.0707 |
| BaRT-10 | 0.001 | −0.001 | 0.045 | −0.012 | −0.052 | −0.053 | −0.039 | −0.086 | −0.019 | −0.041 | −0.457 | −0.456 | −0.4409 |
| BaRT-4 | 0.006 | 0.035 | 0.024 | 0.009 | −0.005 | −0.021 | 0.098 | 0.099 | 0.061 | 0.101 | −0.186 | −0.175 | −0.1765 |
| BaRT-7 | 0.009 | 0.014 | 0.037 | −0.001 | −0.032 | −0.036 | 0.036 | 0.025 | −0.009 | 0.021 | −0.337 | −0.353 | −0.3164 |
| BUZz-2 | 0.053 | 0.057 | 0.099 | 0.05 | 0.011 | 0.011 | 0.352 | 0.306 | 0.315 | 0.338 | 0.047 | 0.049 | −0.0771 |
| BUZz-8 | 0.083 | 0.076 | 0.131 | 0.07 | 0.014 | 0.014 | 0.504 | 0.479 | 0.508 | 0.473 | 0.075 | 0.078 | −0.1713 |
| ComDef | −0.005 | 0.022 | 0.004 | 0.013 | −0.014 | −0.015 | 0.078 | 0.033 | −0.02 | 0.043 | −0.054 | −0.059 | −0.043 |
| DistC | 0.009 | 0.027 | 0.014 | 0.024 | −0.008 | −0.014 | 0.022 | 0.041 | 0.016 | 0.051 | −0.104 | −0.11 | −0.0955 |
| ECOC | −0.006 | 0.047 | −0.007 | 0.042 | 0.004 | 0.001 | 0.131 | 0.103 | −0.003 | 0.099 | −0.029 | −0.033 | −0.0369 |
| FD | −0.018 | 0.001 | 0.018 | 0 | −0.025 | −0.035 | −0.017 | 0.032 | 0.01 | 0.014 | −0.248 | −0.252 | −0.2147 |
| k-WTA | 0.003 | 0.02 | 0.001 | 0.021 | −0.002 | −0.003 | 0.07 | 0.019 | 0.001 | 0.028 | −0.07 | −0.08 | −0.0529 |
| Odds | 0.054 | 0.041 | 0.071 | 0.041 | 0.003 | 0.002 | 0.314 | 0.207 | 0.233 | 0.22 | 0.011 | 0.011 | −0.2137 |
| Vanilla | 0.902 | 0.917 | 0.853 | 0.924 | 0.984 | 0.984 | 0.443 | 0.453 | 0.384 | 0.455 | 0.923 | 0.919 | 0.9278 |
| FGSM-T | IFGSM-T | MIM-T | PGD-T | FGSM-U | IFGSM-U | MIM-U | PGD-U | CW-T | CW-U | EAD-T | EAD-U | Acc | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ADP | −0.015 | −0.001 | −0.017 | −0.013 | −0.055 | 0.002 | −0.062 | −0.007 | 0.008 | −0.001 | 0.002 | −0.003 | 0.0152 |
| BaRT-1 | 0.011 | 0.017 | 0.013 | 0.013 | 0.125 | 0.128 | 0.103 | 0.121 | 0.009 | −0.061 | 0.009 | −0.061 | −0.0695 |
| BaRT-10 | −0.05 | −0.044 | −0.071 | −0.042 | −0.287 | −0.277 | −0.325 | −0.28 | −0.058 | −0.439 | −0.053 | −0.394 | −0.4408 |
| BaRT-4 | −0.003 | 0.001 | −0.014 | −0.011 | −0.019 | 0.002 | −0.06 | −0.016 | −0.008 | −0.213 | −0.01 | −0.185 | −0.1834 |
| BaRT-7 | −0.035 | −0.023 | −0.016 | −0.017 | −0.151 | −0.125 | −0.208 | −0.149 | −0.026 | −0.307 | −0.024 | −0.284 | −0.319 |
| BUZz-2 | 0.002 | 0.017 | 0.012 | 0.015 | 0.148 | 0.149 | 0.103 | 0.148 | 0.015 | 0.005 | 0.016 | 0.004 | −0.0771 |
| BUZz-8 | 0.026 | 0.027 | 0.024 | 0.024 | 0.234 | 0.228 | 0.2 | 0.227 | 0.017 | 0.005 | 0.017 | 0.006 | −0.1713 |
| ComDef | 0.014 | 0.016 | 0.012 | 0.016 | 0.13 | 0.137 | 0.109 | 0.131 | 0.01 | −0.007 | 0.004 | −0.004 | −0.0424 |
| DistC | −0.003 | 0.003 | 0.001 | 0.01 | 0.043 | 0.067 | 0.007 | 0.076 | 0.004 | −0.033 | 0.004 | −0.029 | −0.0933 |
| ECOC | 0.017 | 0.022 | 0.014 | 0.022 | 0.186 | 0.192 | 0.14 | 0.194 | 0.008 | 0.002 | 0.005 | 0.001 | −0.0369 |
| FD | −0.014 | 0.006 | −0.009 | 0.007 | −0.026 | 0.012 | −0.036 | 0.001 | 0.003 | −0.012 | −0.006 | −0.01 | −0.2147 |
| k-WTA | −0.022 | −0.004 | −0.019 | −0.006 | −0.023 | 0.04 | −0.018 | 0.042 | 0.003 | −0.008 | −0.01 | −0.011 | −0.0529 |
| Odds | 0.009 | 0.014 | 0.005 | 0.004 | 0.135 | 0.124 | 0.104 | 0.125 | 0.014 | −0.002 | 0.013 | 0.001 | −0.214 |
| Vanilla | 0.973 | 0.973 | 0.976 | 0.974 | 0.751 | 0.766 | 0.793 | 0.764 | 0.983 | 0.995 | 0.982 | 0.994 | 0.9278 |
| FGSM-T | IFGSM-T | MIM-T | PGD-T | FGSM-U | IFGSM-U | MIM-U | PGD-U | CW-T | CW-U | EAD-T | EAD-U | Acc | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ADP | −0.024 | −0.049 | −0.087 | −0.047 | −0.074 | −0.12 | −0.185 | −0.131 | −0.012 | −0.007 | −0.008 | −0.006 | 0.0152 |
| BaRT-1 | 0.015 | 0.032 | 0.018 | 0.029 | 0.184 | 0.099 | 0.089 | 0.11 | −0.012 | −0.057 | 0.001 | −0.04 | −0.0724 |
| BaRT-10 | −0.025 | 0.006 | −0.012 | 0.015 | −0.142 | −0.179 | −0.208 | −0.182 | −0.046 | −0.398 | −0.053 | −0.425 | −0.4384 |
| BaRT-4 | 0.003 | 0.003 | 0 | 0.019 | 0.004 | −0.015 | −0.072 | −0.047 | −0.036 | −0.196 | −0.026 | −0.187 | −0.1764 |
| BaRT-7 | −0.014 | −0.013 | −0.022 | −0.007 | −0.106 | −0.125 | −0.201 | −0.15 | −0.055 | −0.302 | −0.04 | −0.316 | −0.3089 |
| BUZz-2 | 0.032 | 0.053 | 0.051 | 0.05 | 0.274 | 0.228 | 0.231 | 0.232 | 0.003 | 0.007 | 0.003 | 0.011 | −0.0771 |
| BUZz-8 | 0.069 | 0.07 | 0.084 | 0.078 | 0.419 | 0.336 | 0.374 | 0.335 | 0.003 | 0.009 | 0.005 | 0.015 | −0.1713 |
| ComDef | 0.031 | 0.041 | 0.029 | 0.039 | 0.137 | 0.126 | 0.078 | 0.111 | −0.004 | −0.009 | −0.005 | −0.004 | −0.0421 |
| DistC | −0.044 | −0.007 | −0.049 | −0.011 | −0.022 | −0.019 | −0.112 | −0.02 | −0.01 | −0.036 | −0.011 | −0.032 | −0.0944 |
| ECOC | −0.044 | −0.056 | −0.119 | −0.041 | 0.004 | −0.073 | −0.183 | −0.091 | −0.004 | −0.006 | −0.011 | −0.009 | −0.0369 |
| FD | −0.045 | −0.023 | −0.045 | −0.014 | −0.062 | −0.05 | −0.146 | −0.055 | −0.011 | −0.035 | −0.014 | −0.031 | −0.2147 |
| k-WTA | −0.052 | −0.068 | −0.112 | −0.066 | −0.074 | −0.174 | −0.258 | −0.2 | −0.008 | −0.021 | −0.009 | −0.019 | −0.0529 |
| Odds | 0.045 | 0.047 | 0.048 | 0.051 | 0.237 | 0.182 | 0.161 | 0.16 | −0.003 | −0.001 | −0.003 | 0 | −0.2132 |
| Vanilla | 0.924 | 0.924 | 0.91 | 0.921 | 0.551 | 0.638 | 0.597 | 0.644 | 0.997 | 0.991 | 0.994 | 0.985 | 0.9278 |
| FGSM-T | IFGSM-T | MIM-T | PGD-T | FGSM-U | IFGSM-U | MIM-U | PGD-U | CW-T | CW-U | EAD-T | EAD-U | Acc | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ADP | −0.036 | −0.116 | −0.137 | −0.107 | −0.077 | −0.21 | −0.199 | −0.229 | −0.002 | 0.001 | 0.006 | 0.001 | 0.0152 |
| BaRT-1 | 0.034 | 0.011 | 0.021 | 0.028 | 0.148 | 0.071 | 0.051 | 0.071 | −0.009 | −0.062 | −0.013 | −0.064 | −0.0753 |
| BaRT-10 | 0.036 | 0.046 | 0.086 | 0.037 | −0.044 | −0.092 | −0.008 | −0.104 | −0.043 | −0.414 | −0.034 | −0.433 | −0.4399 |
| BaRT-4 | 0.036 | 0.02 | 0.055 | 0.058 | 0.075 | 0.043 | 0.036 | 0.02 | −0.024 | −0.173 | −0.039 | −0.183 | −0.1772 |
| BaRT-7 | 0.03 | 0.016 | 0.055 | 0.048 | 0.026 | −0.034 | 0 | −0.025 | −0.045 | −0.297 | −0.046 | −0.306 | −0.3181 |
| BUZz-2 | 0.088 | 0.08 | 0.11 | 0.093 | 0.367 | 0.289 | 0.316 | 0.293 | 0.007 | 0.012 | 0.01 | 0.011 | −0.0771 |
| BUZz-8 | 0.124 | 0.106 | 0.162 | 0.12 | 0.542 | 0.428 | 0.521 | 0.434 | 0.007 | 0.013 | 0.01 | 0.014 | −0.1713 |
| ComDef | 0.01 | −0.033 | −0.039 | −0.014 | 0.03 | −0.015 | −0.067 | −0.036 | −0.005 | −0.012 | −0.002 | −0.016 | −0.0411 |
| DistC | −0.021 | −0.036 | −0.059 | −0.014 | −0.041 | −0.065 | −0.117 | −0.059 | −0.014 | −0.042 | −0.012 | −0.045 | −0.0922 |
| ECOC | −0.025 | −0.045 | −0.11 | −0.035 | 0.02 | −0.079 | −0.145 | −0.09 | 0.001 | −0.004 | 0.001 | −0.019 | −0.0369 |
| FD | 0.013 | 0.002 | 0.008 | 0.029 | 0.018 | 0.021 | −0.01 | 0.015 | −0.014 | −0.035 | −0.014 | −0.038 | −0.2147 |
| k-WTA | −0.002 | −0.139 | −0.171 | −0.131 | −0.064 | −0.226 | −0.241 | −0.248 | −0.002 | −0.022 | −0.005 | −0.029 | −0.0529 |
| Odds | 0.073 | 0.064 | 0.098 | 0.074 | 0.283 | 0.181 | 0.185 | 0.181 | −0.002 | −0.002 | −0.006 | −0.005 | −0.2133 |
| Vanilla | 0.87 | 0.886 | 0.826 | 0.872 | 0.423 | 0.529 | 0.426 | 0.531 | 0.993 | 0.987 | 0.99 | 0.986 | 0.9278 |
| FGSM-T | IFGSM-T | MIM-T | PGD-T | FGSM-U | IFGSM-U | MIM-U | PGD-U | CW-T | CW-U | EAD-T | EAD-U | Acc | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ADP | −0.038 | −0.167 | −0.201 | −0.167 | −0.092 | −0.231 | −0.216 | −0.234 | −0.009 | −0.006 | −0.001 | 0 | 0.0152 |
| BaRT-1 | 0.002 | 0.027 | 0.007 | 0.015 | 0.117 | 0.072 | 0.029 | 0.069 | −0.013 | −0.067 | −0.006 | −0.069 | −0.0706 |
| BaRT-10 | 0.018 | 0.052 | 0.061 | 0.03 | −0.055 | −0.036 | −0.001 | −0.03 | −0.065 | −0.428 | −0.058 | −0.417 | −0.4349 |
| BaRT-4 | 0.014 | 0.034 | 0.045 | 0.038 | 0.083 | 0.088 | 0.065 | 0.066 | −0.035 | −0.2 | −0.031 | −0.197 | −0.1829 |
| BaRT-7 | 0.016 | 0.057 | 0.072 | 0.05 | 0.048 | 0.03 | 0.001 | 0.014 | −0.035 | −0.3 | −0.036 | −0.334 | −0.308 |
| BUZz-2 | 0.074 | 0.094 | 0.104 | 0.086 | 0.332 | 0.328 | 0.344 | 0.324 | 0.007 | 0.011 | 0.007 | 0.014 | −0.0771 |
| BUZz-8 | 0.105 | 0.126 | 0.159 | 0.114 | 0.541 | 0.484 | 0.55 | 0.464 | 0.007 | 0.011 | 0.008 | 0.015 | −0.1713 |
| ComDef | −0.013 | 0.003 | −0.034 | −0.008 | 0.014 | −0.013 | −0.063 | −0.007 | −0.001 | −0.019 | −0.001 | −0.017 | −0.0434 |
| DistC | −0.051 | −0.042 | −0.083 | −0.042 | −0.078 | −0.073 | −0.122 | −0.077 | −0.012 | −0.055 | −0.016 | −0.059 | −0.0913 |
| ECOC | −0.06 | −0.049 | −0.143 | −0.054 | −0.008 | −0.086 | −0.163 | −0.099 | 0.004 | −0.009 | 0.002 | −0.008 | −0.0369 |
| FD | −0.013 | 0.055 | 0.004 | 0.024 | 0.006 | 0.097 | 0.007 | 0.048 | −0.01 | −0.032 | −0.007 | −0.02 | −0.2147 |
| k-WTA | −0.036 | −0.157 | −0.254 | −0.162 | −0.094 | −0.252 | −0.243 | −0.283 | −0.007 | −0.031 | −0.014 | −0.044 | −0.0529 |
| Odds | 0.05 | 0.07 | 0.088 | 0.05 | 0.246 | 0.19 | 0.196 | 0.179 | −0.002 | −0.009 | −0.003 | −0.014 | −0.2133 |
| Vanilla | 0.887 | 0.864 | 0.822 | 0.875 | 0.425 | 0.478 | 0.392 | 0.496 | 0.993 | 0.989 | 0.992 | 0.984 | 0.9278 |
| FGSM-T | IFGSM-T | MIM-T | PGD-T | FGSM-U | IFGSM-U | MIM-U | PGD-U | CW-T | CW-U | EAD-T | EAD-U | Acc | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ADP | −0.023 | −0.163 | −0.172 | −0.136 | −0.002 | −0.163 | −0.112 | −0.148 | 0.004 | 0.006 | −0.004 | −0.002 | 0.0152 |
| BaRT-1 | 0.02 | 0.011 | 0.022 | 0.027 | 0.173 | 0.166 | 0.139 | 0.169 | −0.016 | −0.069 | −0.018 | −0.054 | −0.0707 |
| BaRT-10 | 0.044 | 0.05 | 0.126 | 0.073 | 0.057 | 0.078 | 0.123 | 0.118 | −0.063 | −0.405 | −0.047 | −0.404 | −0.4409 |
| BaRT-4 | 0.044 | 0.053 | 0.089 | 0.053 | 0.148 | 0.167 | 0.184 | 0.203 | −0.02 | −0.183 | −0.017 | −0.199 | −0.1765 |
| BaRT-7 | 0.038 | 0.06 | 0.1 | 0.069 | 0.113 | 0.147 | 0.167 | 0.161 | −0.028 | −0.282 | −0.045 | −0.309 | −0.3164 |
| BUZz-2 | 0.103 | 0.11 | 0.168 | 0.123 | 0.473 | 0.426 | 0.493 | 0.451 | 0.009 | 0.014 | 0.008 | 0.01 | −0.0771 |
| BUZz-8 | 0.127 | 0.13 | 0.203 | 0.145 | 0.628 | 0.568 | 0.667 | 0.576 | 0.009 | 0.014 | 0.009 | 0.013 | −0.1713 |
| ComDef | −0.008 | 0.005 | −0.01 | 0.007 | 0.133 | 0.097 | 0.084 | 0.102 | −0.003 | −0.019 | −0.007 | −0.022 | −0.043 |
| DistC | −0.011 | −0.017 | −0.041 | −0.002 | 0.005 | 0.018 | −0.01 | 0.026 | 0.004 | −0.025 | 0.004 | −0.031 | −0.0955 |
| ECOC | −0.04 | −0.056 | −0.105 | −0.054 | 0.091 | 0.012 | −0.03 | 0.033 | 0.008 | 0.002 | 0.003 | −0.008 | −0.0369 |
| FD | 0.007 | 0.048 | 0.062 | 0.074 | 0.105 | 0.181 | 0.138 | 0.194 | 0.002 | −0.02 | −0.004 | −0.029 | −0.2147 |
| k-WTA | −0.019 | −0.136 | −0.174 | −0.129 | −0.015 | −0.157 | −0.124 | −0.138 | −0.003 | −0.029 | −0.009 | −0.034 | −0.0529 |
| Odds | 0.075 | 0.077 | 0.134 | 0.082 | 0.312 | 0.277 | 0.319 | 0.299 | 0.006 | −0.012 | 0 | −0.01 | −0.2137 |
| Vanilla | 0.866 | 0.861 | 0.777 | 0.848 | 0.334 | 0.387 | 0.259 | 0.374 | 0.991 | 0.986 | 0.991 | 0.987 | 0.9278 |
| FGSM-T | IFGSM-T | MIM-T | PGD-T | CW-T | EAD-T | FGSM-U | IFGSM-U | MIM-U | PGD-U | CW-U | EAD-U | Acc | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ADP | 0.01 | −0.05 | −0.035 | −0.018 | −0.003 | −0.002 | −0.031 | −0.006 | −0.03 | −0.024 | 0.012 | 0.018 | 0.013 |
| BaRT-1 | 0.041 | 0.055 | 0.089 | 0.062 | −0.002 | 0 | 0.119 | 0.173 | 0.137 | 0.159 | −0.021 | −0.017 | −0.0317 |
| BaRT-4 | 0.042 | 0.05 | 0.079 | 0.057 | −0.019 | −0.015 | 0.118 | 0.172 | 0.149 | 0.15 | −0.132 | −0.106 | −0.1062 |
| BaRT-6 | 0.049 | 0.038 | 0.084 | 0.052 | −0.029 | −0.038 | 0.091 | 0.139 | 0.118 | 0.133 | −0.174 | −0.18 | −0.1539 |
| BaRT-8 | 0.055 | 0.018 | 0.083 | 0.059 | −0.036 | −0.047 | 0.041 | 0.09 | 0.108 | 0.092 | −0.239 | −0.222 | −0.2212 |
| BUZz-2 | 0.108 | 0.1 | 0.161 | 0.109 | 0.003 | 0.006 | 0.362 | 0.482 | 0.447 | 0.469 | 0.04 | 0.051 | −0.0819 |
| BUZz-8 | 0.128 | 0.109 | 0.176 | 0.12 | 0.005 | 0.008 | 0.47 | 0.566 | 0.552 | 0.563 | 0.069 | 0.078 | −0.1577 |
| ComDef | 0.008 | 0.053 | 0.048 | 0.066 | −0.003 | 0.001 | −0.005 | 0.089 | 0.06 | 0.09 | 0.001 | 0.011 | −0.0053 |
| DistC | 0.007 | 0.018 | 0.027 | 0.031 | −0.004 | −0.003 | 0.005 | 0.038 | 0.026 | 0.027 | −0.008 | −0.001 | −0.0093 |
| ECOC | 0.012 | 0.056 | 0.079 | 0.073 | 0 | 0.003 | 0.043 | 0.113 | 0.085 | 0.108 | 0.001 | 0.006 | −0.0141 |
| FD | −0.002 | 0.006 | 0.022 | 0.014 | −0.017 | −0.019 | −0.046 | 0.057 | 0.011 | 0.035 | −0.094 | −0.098 | −0.0823 |
| k-WTA | −0.006 | 0.002 | 0.013 | 0.014 | −0.001 | 0 | −0.064 | 0.044 | 0.012 | 0.028 | 0.001 | −0.001 | −0.0053 |
| Odds | 0 | 0.002 | 0.004 | 0.003 | 0.003 | 0.001 | 0.001 | 0.028 | 0.015 | 0.023 | 0.026 | 0.021 | −0.1809 |
| Vanilla | 0.865 | 0.889 | 0.817 | 0.879 | 0.995 | 0.992 | 0.429 | 0.363 | 0.351 | 0.374 | 0.914 | 0.905 | 0.9356 |
| FGSM-T | IFGSM-T | MIM-T | PGD-T | FGSM-U | IFGSM-U | MIM-U | PGD-U | CW-T | CW-U | EAD-T | EAD-U | Acc | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ADP | 0.03 | −0.018 | −0.009 | −0.004 | 0.051 | −0.029 | 0.008 | −0.027 | −0.018 | 0.023 | 0.005 | 0.031 | 0.013 |
| BaRT-1 | 0.083 | 0.063 | 0.05 | 0.061 | 0.229 | 0.137 | 0.175 | 0.171 | 0.041 | −0.022 | 0.009 | −0.026 | −0.0308 |
| BaRT-4 | 0.069 | 0.04 | 0.034 | 0.049 | 0.153 | 0.056 | 0.067 | 0.055 | −0.035 | −0.182 | −0.032 | −0.165 | −0.0999 |
| BaRT-6 | 0.046 | 0.033 | −0.006 | 0.013 | 0.113 | 0.008 | 0.026 | 0.036 | −0.081 | −0.274 | −0.062 | −0.215 | −0.1615 |
| BaRT-8 | 0.046 | 0.012 | −0.028 | 0.018 | 0.048 | −0.027 | −0.03 | −0.053 | −0.098 | −0.326 | −0.111 | −0.296 | −0.2258 |
| BUZz-2 | 0.155 | 0.122 | 0.111 | 0.117 | 0.529 | 0.425 | 0.436 | 0.436 | 0.061 | 0.079 | 0.022 | 0.039 | −0.0819 |
| BUZz-8 | 0.187 | 0.136 | 0.123 | 0.126 | 0.679 | 0.488 | 0.515 | 0.504 | 0.064 | 0.086 | 0.026 | 0.05 | −0.1577 |
| ComDef | 0.032 | 0.055 | 0.02 | 0.025 | 0.086 | 0.114 | 0.123 | 0.13 | 0.038 | 0.042 | 0.011 | 0.013 | −0.0058 |
| DistC | −0.021 | −0.033 | −0.029 | −0.039 | −0.024 | −0.057 | −0.025 | −0.029 | 0.007 | 0.029 | −0.002 | 0.008 | −0.0093 |
| ECOC | −0.01 | 0.03 | 0.008 | 0.019 | 0.061 | 0.038 | 0.042 | 0.051 | −0.033 | −0.1 | −0.026 | −0.08 | −0.0141 |
| FD | −0.073 | −0.08 | −0.099 | −0.06 | −0.099 | −0.168 | −0.15 | −0.136 | −0.043 | −0.1 | −0.028 | −0.097 | −0.0823 |
| k-WTA | 0.035 | 0.036 | 0.027 | 0.044 | 0.072 | 0.044 | 0.049 | 0.068 | 0.02 | 0.05 | 0.016 | 0.035 | −0.0053 |
| Odds | 0.031 | 0.043 | 0.019 | 0.038 | 0.064 | 0.051 | 0.065 | 0.085 | 0.021 | 0.033 | 0.006 | 0.017 | −0.1833 |
| Vanilla | 0.807 | 0.864 | 0.876 | 0.873 | 0.29 | 0.503 | 0.475 | 0.486 | 0.935 | 0.91 | 0.972 | 0.947 | 0.9356 |
| FGSM-T | IFGSM-T | MIM-T | PGD-T | FGSM-U | IFGSM-U | MIM-U | PGD-U | CW-T | CW-U | EAD-T | EAD-U | Acc | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ADP | 0.089 | 0.025 | 0.036 | 0.004 | 0.035 | −0.038 | −0.008 | −0.038 | −0.04 | −0.092 | −0.013 | −0.032 | 0.013 |
| BaRT-1 | 0.11 | 0.238 | 0.195 | 0.217 | 0.191 | 0.165 | 0.159 | 0.145 | −0.038 | −0.134 | −0.019 | −0.097 | −0.0314 |
| BaRT-4 | 0.141 | 0.293 | 0.268 | 0.256 | 0.215 | 0.246 | 0.224 | 0.256 | −0.067 | −0.216 | −0.041 | −0.218 | −0.1018 |
| BaRT-6 | 0.113 | 0.285 | 0.261 | 0.273 | 0.209 | 0.224 | 0.208 | 0.206 | −0.065 | −0.28 | −0.056 | −0.217 | −0.1627 |
| BaRT-8 | 0.133 | 0.29 | 0.294 | 0.285 | 0.198 | 0.195 | 0.21 | 0.197 | −0.091 | −0.341 | −0.055 | −0.278 | −0.221 |
| BUZz-2 | 0.224 | 0.42 | 0.411 | 0.415 | 0.542 | 0.603 | 0.572 | 0.601 | 0.033 | 0.067 | 0.034 | 0.073 | −0.0819 |
| BUZz-8 | 0.288 | 0.465 | 0.452 | 0.454 | 0.783 | 0.818 | 0.808 | 0.815 | 0.034 | 0.073 | 0.035 | 0.083 | −0.1577 |
| ComDef | 0.003 | 0.17 | 0.08 | 0.159 | 0.043 | 0.112 | 0.089 | 0.105 | 0.022 | 0.016 | 0.015 | −0.004 | −0.0048 |
| DistC | −0.052 | −0.034 | −0.062 | −0.044 | 0.013 | −0.043 | −0.037 | −0.054 | −0.006 | −0.058 | −0.001 | −0.037 | −0.0096 |
| ECOC | 0.047 | 0.188 | 0.169 | 0.175 | 0.014 | 0.063 | 0.059 | 0.06 | −0.07 | −0.282 | −0.067 | −0.242 | −0.0141 |
| FD | −0.086 | −0.012 | −0.037 | −0.025 | −0.048 | −0.05 | −0.066 | −0.072 | −0.01 | −0.063 | −0.036 | −0.088 | −0.0823 |
| k-WTA | 0.012 | 0.017 | −0.001 | −0.014 | −0.043 | −0.029 | −0.026 | −0.031 | −0.279 | −0.411 | −0.437 | −0.402 | −0.8516 |
| Odds | −0.064 | 0.02 | 0.017 | 0.024 | −0.007 | 0.042 | 0.025 | 0.025 | −0.017 | −0.037 | −0.022 | −0.022 | −0.1807 |
| Vanilla | 0.696 | 0.53 | 0.538 | 0.539 | 0.108 | 0.141 | 0.135 | 0.149 | 0.966 | 0.927 | 0.965 | 0.917 | 0.9356 |
| FGSM-T | IFGSM-T | MIM-T | PGD-T | FGSM-U | IFGSM-U | MIM-U | PGD-U | CW-T | CW-U | EAD-T | EAD-U | Acc | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ADP | 0.115 | −0.015 | 0.021 | −0.024 | 0.01 | −0.022 | −0.013 | −0.027 | −0.019 | −0.065 | −0.011 | −0.044 | 0.013 |
| BaRT-1 | 0.143 | 0.227 | 0.263 | 0.24 | 0.183 | 0.205 | 0.197 | 0.195 | −0.047 | −0.114 | −0.02 | −0.1 | −0.0312 |
| BaRT-4 | 0.179 | 0.325 | 0.327 | 0.314 | 0.241 | 0.246 | 0.258 | 0.224 | −0.059 | −0.216 | −0.024 | −0.184 | −0.1 |
| BaRT-6 | 0.175 | 0.331 | 0.357 | 0.336 | 0.251 | 0.278 | 0.256 | 0.268 | −0.045 | −0.248 | −0.03 | −0.243 | −0.1563 |
| BaRT-8 | 0.188 | 0.324 | 0.342 | 0.325 | 0.201 | 0.24 | 0.264 | 0.235 | −0.064 | −0.296 | −0.046 | −0.258 | −0.2174 |
| BUZz-2 | 0.264 | 0.446 | 0.473 | 0.444 | 0.534 | 0.627 | 0.611 | 0.625 | 0.017 | 0.057 | 0.019 | 0.06 | −0.0819 |
| BUZz-8 | 0.321 | 0.482 | 0.514 | 0.482 | 0.766 | 0.835 | 0.823 | 0.826 | 0.018 | 0.061 | 0.02 | 0.067 | −0.1577 |
| ComDef | 0.044 | 0.143 | 0.123 | 0.158 | 0.016 | 0.083 | 0.08 | 0.084 | 0.003 | −0.01 | −0.004 | −0.015 | −0.0067 |
| DistC | 0.029 | −0.024 | −0.009 | −0.029 | 0.038 | −0.019 | −0.007 | −0.035 | −0.006 | −0.038 | −0.012 | −0.054 | −0.0094 |
| ECOC | 0.097 | 0.23 | 0.238 | 0.235 | 0.013 | 0.075 | 0.091 | 0.072 | −0.049 | −0.133 | −0.05 | −0.129 | −0.0141 |
| FD | −0.019 | 0 | 0.009 | 0 | −0.055 | −0.019 | −0.02 | −0.043 | −0.02 | −0.049 | −0.024 | −0.069 | −0.0823 |
| k-WTA | 0.057 | −0.006 | −0.018 | −0.013 | −0.037 | −0.042 | −0.035 | −0.058 | −0.012 | −0.028 | −0.032 | −0.049 | −0.0053 |
| Odds | −0.012 | 0.027 | 0 | 0.016 | −0.024 | 0.013 | 0.005 | 0.006 | −0.005 | 0.011 | −0.011 | 0.004 | −0.1828 |
| Vanilla | 0.666 | 0.516 | 0.479 | 0.516 | 0.132 | 0.127 | 0.107 | 0.132 | 0.982 | 0.939 | 0.98 | 0.933 | 0.9356 |
| FGSM-T | IFGSM-T | MIM-T | PGD-T | FGSM-U | IFGSM-U | MIM-U | PGD-U | CW-T | CW-U | EAD-T | EAD-U | Acc | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ADP | 0.089 | 0.024 | 0.103 | 0.018 | −0.033 | −0.028 | −0.026 | −0.016 | −0.016 | −0.054 | −0.006 | −0.054 | 0.013 |
| BaRT-1 | 0.144 | 0.299 | 0.336 | 0.297 | 0.151 | 0.239 | 0.195 | 0.254 | −0.027 | −0.112 | −0.002 | −0.078 | −0.0316 |
| BaRT-4 | 0.173 | 0.347 | 0.41 | 0.345 | 0.196 | 0.304 | 0.269 | 0.36 | −0.046 | −0.17 | −0.022 | −0.167 | −0.107 |
| BaRT-6 | 0.175 | 0.372 | 0.437 | 0.354 | 0.202 | 0.309 | 0.29 | 0.327 | −0.043 | −0.23 | −0.027 | −0.183 | −0.1503 |
| BaRT-8 | 0.148 | 0.368 | 0.422 | 0.35 | 0.159 | 0.303 | 0.267 | 0.297 | −0.063 | −0.309 | −0.035 | −0.281 | −0.2154 |
| BUZz-2 | 0.232 | 0.471 | 0.522 | 0.478 | 0.5 | 0.626 | 0.594 | 0.636 | 0.01 | 0.05 | 0.02 | 0.055 | −0.0819 |
| BUZz-8 | 0.281 | 0.501 | 0.563 | 0.504 | 0.715 | 0.838 | 0.809 | 0.857 | 0.01 | 0.051 | 0.021 | 0.061 | −0.1577 |
| ComDef | 0.029 | 0.226 | 0.192 | 0.221 | −0.044 | 0.127 | 0.076 | 0.145 | 0.002 | −0.006 | 0.009 | −0.015 | −0.0052 |
| DistC | −0.01 | −0.049 | −0.007 | −0.03 | −0.004 | −0.025 | −0.013 | −0.002 | −0.016 | −0.043 | −0.013 | −0.056 | −0.0096 |
| ECOC | 0.04 | 0.218 | 0.275 | 0.232 | −0.033 | 0.075 | 0.075 | 0.099 | −0.063 | −0.156 | −0.043 | −0.151 | −0.0141 |
| FD | −0.087 | 0.003 | 0.026 | 0.004 | −0.099 | −0.03 | −0.039 | −0.01 | −0.025 | −0.039 | −0.013 | −0.054 | −0.0823 |
| k-WTA | 0.009 | −0.042 | −0.007 | −0.036 | −0.126 | −0.035 | −0.056 | −0.018 | −0.002 | −0.011 | −0.006 | −0.024 | −0.0053 |
| Odds | −0.043 | 0.063 | 0.064 | 0.049 | −0.054 | 0.049 | −0.003 | 0.068 | −0.002 | 0 | 0.004 | −0.01 | −0.1807 |
| Vanilla | 0.698 | 0.494 | 0.423 | 0.49 | 0.195 | 0.116 | 0.114 | 0.096 | 0.99 | 0.949 | 0.979 | 0.939 | 0.9356 |
| FGSM-T | IFGSM-T | MIM-T | PGD-T | FGSM-U | IFGSM-U | MIM-U | PGD-U | CW-T | CW-U | EAD-T | EAD-U | Acc | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ADP | 0.086 | −0.014 | 0.039 | −0.012 | −0.093 | −0.038 | −0.007 | −0.029 | −0.006 | −0.027 | −0.005 | −0.03 | 0.013 |
| BaRT-1 | 0.129 | 0.278 | 0.304 | 0.274 | 0.125 | 0.26 | 0.228 | 0.258 | −0.015 | −0.1 | −0.015 | −0.062 | −0.0317 |
| BaRT-4 | 0.165 | 0.319 | 0.383 | 0.317 | 0.176 | 0.276 | 0.273 | 0.288 | −0.052 | −0.182 | −0.032 | −0.148 | −0.1062 |
| BaRT-6 | 0.175 | 0.347 | 0.397 | 0.346 | 0.136 | 0.314 | 0.306 | 0.293 | −0.058 | −0.237 | −0.044 | −0.213 | −0.1539 |
| BaRT-8 | 0.159 | 0.344 | 0.389 | 0.327 | 0.166 | 0.287 | 0.254 | 0.274 | −0.051 | −0.255 | −0.033 | −0.243 | −0.2212 |
| BUZz-2 | 0.227 | 0.432 | 0.489 | 0.43 | 0.462 | 0.657 | 0.62 | 0.653 | 0.006 | 0.037 | 0.007 | 0.057 | −0.0819 |
| BUZz-8 | 0.279 | 0.469 | 0.535 | 0.466 | 0.672 | 0.818 | 0.809 | 0.835 | 0.007 | 0.039 | 0.009 | 0.061 | −0.1577 |
| ComDef | 0.014 | 0.131 | 0.103 | 0.136 | −0.029 | 0.088 | 0.074 | 0.093 | −0.003 | −0.018 | −0.006 | −0.012 | −0.0053 |
| DistC | 0.014 | −0.015 | −0.001 | −0.012 | −0.047 | −0.035 | −0.011 | −0.029 | −0.011 | −0.034 | −0.021 | −0.026 | −0.0093 |
| ECOC | 0.057 | 0.193 | 0.233 | 0.176 | −0.081 | 0.068 | 0.074 | 0.088 | −0.026 | −0.083 | −0.026 | −0.076 | −0.0141 |
| FD | −0.094 | −0.038 | −0.006 | −0.041 | −0.158 | −0.037 | −0.043 | −0.037 | −0.026 | −0.071 | −0.032 | −0.064 | −0.0823 |
| k-WTA | 0.047 | −0.032 | −0.024 | −0.013 | −0.138 | −0.045 | −0.048 | −0.04 | −0.008 | −0.018 | −0.026 | −0.041 | −0.0053 |
| Odds | −0.036 | 0.011 | 0.009 | 0.017 | −0.01 | 0.03 | 0.024 | 0.036 | −0.002 | −0.017 | −0.004 | −0.002 | −0.1809 |
| Vanilla | 0.707 | 0.529 | 0.46 | 0.531 | 0.234 | 0.123 | 0.111 | 0.118 | 0.993 | 0.961 | 0.991 | 0.939 | 0.9356 |
| FPR | 1% | 10% | 20% | 30% | 40% | 50% | 80% |
| FashionMNIST | 78.6% | 79.6% | 78.5% | 79.5% | 78.6% | 78.8% | 79.1% |
| CIFAR-10 | 0.3% | 27.8% | 43.2% | 61.1% | 75.2% | 86.2% | 99.3% |
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems 25 (NIPS 2012), Lake Tahoe, NV, USA, 3–8 December 2012; pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. Available online: https://arxiv.org/abs/1409.1556 (accessed on 16 September 2021).
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. arXiv 2014, arXiv:1412.6572. Available online: https://arxiv.org/abs/1412.6572 (accessed on 16 September 2021).
- Papernot, N.; McDaniel, P.D.; Goodfellow, I.J.; Jha, S.; Celik, Z.B.; Swami, A. Practical Black-Box Attacks against Machine Learning. ACM Asia CCS 2017, 2017, 506–519. [Google Scholar]
- Chen, P.Y.; Zhang, H.; Sharma, Y.; Yi, J.; Hsieh, C.J. Zoo: Zeroth order optimization based black-box attacks to deep neural networks without training substitute models. In Proceedings of the 10th ACM Workshop on Artificial Intelligence and Security, Dallas, TX, USA, 3 November 2017; pp. 15–26. [Google Scholar]
- Chen, J.; Jordan, M.I. Boundary Attack++: Query-Efficient Decision-Based Adversarial Attack. arXiv 2014, arXiv:1904.02144v1. Available online: https://gaokeji.info/abs/1904.02144v1 (accessed on 16 September 2021).
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.J.; Fergus, R. Intriguing properties of neural networks. arXiv 2013, arXiv:1312.6199. Available online: https://arxiv.org/abs/1312.6199 (accessed on 16 September 2021).
- Papernot, N.; McDaniel, P.; Goodfellow, I. Transferability in machine learning: From phenomena to black-box attacks using adversarial samples. arXiv 2016, arXiv:1605.07277. Available online: https://arxiv.org/abs/1605.07277 (accessed on 16 September 2021).
- Athalye, A.; Carlini, N.; Wagner, D. Obfuscated Gradients Give a False Sense of Security: Circumventing Defenses to Adversarial Examples. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 274–283. [Google Scholar]
- Liu, Y.; Chen, X.; Liu, C.; Song, D. Delving into Transferable Adversarial Examples and Black-box Attacks. arXiv 2017, arXiv:1611.02770. Available online: https://arxiv.org/abs/1611.02770 (accessed on 16 September 2021).
- Pang, T.; Xu, K.; Du, C.; Chen, N.; Zhu, J. Improving Adversarial Robustness via Promoting Ensemble Diversity. Int. Conf. Mach. Learn. 2019, 97, 4970–4979. [Google Scholar]
- Verma, G.; Swami, A. Error Correcting Output Codes Improve Probability Estimation and Adversarial Robustness of Deep Neural Networks. In Proceedings of the 33rd Conference on Neural Information Processing Systems (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Jia, X.; Wei, X.; Cao, X.; Foroosh, H. Comdefend: An efficient image compression model to defend adversarial examples. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6084–6092. [Google Scholar]
- Raff, E.; Sylvester, J.; Forsyth, S.; McLean, M. Barrage of random transforms for adversarially robust defense. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6528–6537. [Google Scholar]
- Xiao, C.; Zhong, P.; Zheng, C. Enhancing Adversarial Defense by k-Winners-Take-All. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Kou, C.; Lee, H.K.; Chang, E.C.; Ng, T.K. Enhancing transformation-based defenses against adversarial attacks with a distribution classifier. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Roth, K.; Kilcher, Y.; Hofmann, T. The Odds are Odd: A Statistical Test for Detecting Adversarial Examples. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; pp. 5498–5507. [Google Scholar]
- Liu, Z.; Liu, Q.; Liu, T.; Xu, N.; Lin, X.; Wang, Y.; Wen, W. Feature distillation: Dnn-oriented jpeg compression against adversarial examples. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 10–15 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 860–868. [Google Scholar]
- Carlini, N.; Athalye, A.; Papernot, N.; Brendel, W.; Rauber, J.; Tsipras, D.; Goodfellow, I.; Madry, A.; Kurakin, A. On evaluating adversarial robustness. arXiv 2019, arXiv:1902.06705. Available online: https://arxiv.org/abs/1902.06705 (accessed on 16 September 2021).
- Carlini, N.; Wagner, D. Adversarial examples are not easily detected: Bypassing ten detection methods. In Proceedings of the 10th ACM Workshop on Artificial Intelligence and Security, Dallas, TX, USA, 3 November 2017; pp. 3–14. [Google Scholar]
- He, W.; Wei, J.; Chen, X.; Carlini, N.; Song, D. Adversarial example defense: Ensembles of weak defenses are not strong. In Proceedings of the 11th {USENIX} Workshop on Offensive Technologies ({WOOT} 17), Vancouver, BC, Canada, 14–15 August 2017. [Google Scholar]
- Tramer, F.; Carlini, N.; Brendel, W.; Madry, A. On adaptive attacks to adversarial example defenses. arXiv 2020, arXiv:2002.08347. Available online: https://arxiv.org/abs/2002.08347 (accessed on 16 September 2021).
- Dong, Y.; Fu, Q.A.; Yang, X.; Pang, T.; Su, H.; Xiao, Z.; Zhu, J. Benchmarking Adversarial Robustness on Image Classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Mahmood, K.; Nguyen, P.H.; Nguyen, L.M.; Nguyen, T.; van Dijk, M. BUZz: BUffer Zones for defending adversarial examples in image classification. arXiv 2019, arXiv:1910.02785. Available online: https://arxiv.org/abs/1910.02785 (accessed on 16 September 2021).
- Yuan, X.; He, P.; Zhu, Q.; Li, X. Adversarial Examples: Attacks and Defenses for Deep Learning. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 2805–2824. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Brendel, W.; Rauber, J.; Bethge, M. Decision-Based Adversarial Attacks: Reliable Attacks Against Black-Box Machine Learning Models. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April 30–3 May 2018. [Google Scholar]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards deep learning models resistant to adversarial attacks. arXiv 2021, arXiv:1706.06083. Available online: https://arxiv.org/abs/1706.06083 (accessed on 16 September 2021).
- Carlini, N.; Wagner, D. Towards evaluating the robustness of neural networks. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (sp), San Jose, CA, USA, 22–26 May 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 39–57. [Google Scholar]
- Guo, C.; Gardner, J.R.; You, Y.; Wilson, A.G.; Weinberger, K.Q. Simple black-box adversarial attacks. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019. [Google Scholar]
- Chen, J.; Gu, Q. Rays: A ray searching method for hard-label adversarial attack. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual Event, 6–10 July 2020; pp. 1739–1747. [Google Scholar]
- Kurakin, A.; Goodfellow, I.; Bengio, S. Adversarial examples in the physical world. arXiv 2017, arXiv:1607.02533. [Google Scholar]
- Dong, Y.; Liao, F.; Pang, T.; Su, H.; Zhu, J.; Hu, X.; Li, J. Boosting adversarial attacks with momentum. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 9185–9193. [Google Scholar]
- Chen, P.Y.; Sharma, Y.; Zhang, H.; Yi, J.; Hsieh, C.J. Ead: Elastic-net attacks to deep neural networks via adversarial examples. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Chen, J.; Jordan, M.I.; Wainwright, M.J. Hopskipjumpattack: A query-efficient decision-based attack. In Proceedings of the 2020 IEEE Symposium on Security and Privacy (sp), San Francisco, CA, USA, 17–21 May 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1277–1294. [Google Scholar]
- Byun, J.; Go, H.; Kim, C. Small Input Noise is Enough to Defend Against Query-based Black-box Attacks. arXiv 2021, arXiv:2101.04829. Available online: https://arxiv.org/abs/2101.04829 (accessed on 16 September 2021).
- Athalye, A.; Engstrom, L.; Ilyas, A.; Kwok, K. Synthesizing robust adversarial examples. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 284–293. [Google Scholar]
- Carlini, N.; Wagner, D. MagNet and “Efficient Defenses against Adversarial Attacks” Are Not Robust to Adversarial Examples. arXiv 2017, arXiv:cs.LG/1711.08478. Available online: https://arxiv.org/abs/1711.08478 (accessed on 16 September 2021).
- Xie, C.; Wang, J.; Zhang, Z.; Ren, Z.; Yuille, A. Mitigating adversarial effects through randomization. arXiv 2018, arXiv:1711.01991. Available online: https://arxiv.org/abs/1711.01991 (accessed on 16 September 2021).
- Krizhevsky, A.; Nair, V.; Hinton, G. Learning Multiple Layers of Features from Tiny Images. Available online: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.222.9220&rep=rep1&type=pdf (accessed on 16 September 2021).
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-MNIST: A Novel Image Dataset for Benchmarking Machine Learning Algorithms. arXiv 2017, arXiv:1708.07747. Available online: https://arxiv.org/abs/1708.07747 (accessed on 16 September 2021).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. Available online: https://arxiv.org/abs/1412.6980 (accessed on 16 September 2021).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity Mappings in Deep Residual Networks. Lect. Notes Comput. Sci. 2016, 630–645. [Google Scholar] [CrossRef] [Green Version]
- Kou, C.K.L.; Lee, H.K.; Ng, T.K. A compact network learning model for distribution regression. Neural Netw. 2019, 110, 199–212. [Google Scholar] [CrossRef] [PubMed] [Green Version]
| Defense Mechanism | Ensemble Diversity (ADP) [11] | Error Correcting Codes (ECOC) [12] | Buffer Zones (BUZz) [24] | Com Defend [13] | Barrage (BaRT) [14] | Distribution Classifier (DistC) [16] | Feature Distillation (FD) [18] | Odds Are Odd [17] | K-Winner (k-WTA) [15] |
|---|---|---|---|---|---|---|---|---|---|
| Mutiple Models | ✓ | ✓ | ✓ | ||||||
| Fixed Input Transformation | ✓ | ✓ | ✓ | ||||||
| Random Input Transformation | ✓ | ✓ | ✓ | ✓ | |||||
| Adversarial Detection | ✓ | ✓ | |||||||
| Network Retraining | ✓ | ✓ | ✓ | ✓ | ✓ | ||||
| Architecture Change | ✓ | ✓ | ✓ |
| Adversarial Capabilities | ||||
|---|---|---|---|---|
| Training/Testing Data | Hard Label Query Access | Score Based Query Access | Trained Parameters | |
| White-Box | ✓ | ✓ | ✓ | |
| Score Based Black-Box | ✓ | ✓ | ||
| Decision Based Black-Box | ✓ | |||
| Adaptive Black-Box | ✓ | ✓ | ||
| Pure Black-Box | ✓ | |||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mahmood, K.; Gurevin, D.; van Dijk, M.; Nguyen, P.H. Beware the Black-Box: On the Robustness of Recent Defenses to Adversarial Examples. Entropy 2021, 23, 1359. https://doi.org/10.3390/e23101359
Mahmood K, Gurevin D, van Dijk M, Nguyen PH. Beware the Black-Box: On the Robustness of Recent Defenses to Adversarial Examples. Entropy. 2021; 23(10):1359. https://doi.org/10.3390/e23101359
Chicago/Turabian StyleMahmood, Kaleel, Deniz Gurevin, Marten van Dijk, and Phuoung Ha Nguyen. 2021. "Beware the Black-Box: On the Robustness of Recent Defenses to Adversarial Examples" Entropy 23, no. 10: 1359. https://doi.org/10.3390/e23101359
APA StyleMahmood, K., Gurevin, D., van Dijk, M., & Nguyen, P. H. (2021). Beware the Black-Box: On the Robustness of Recent Defenses to Adversarial Examples. Entropy, 23(10), 1359. https://doi.org/10.3390/e23101359