
Information Bottleneck Theory Based Exploration of Cascade Learning


Abstract
:1. Introduction
1.1. Information Theory and Learning
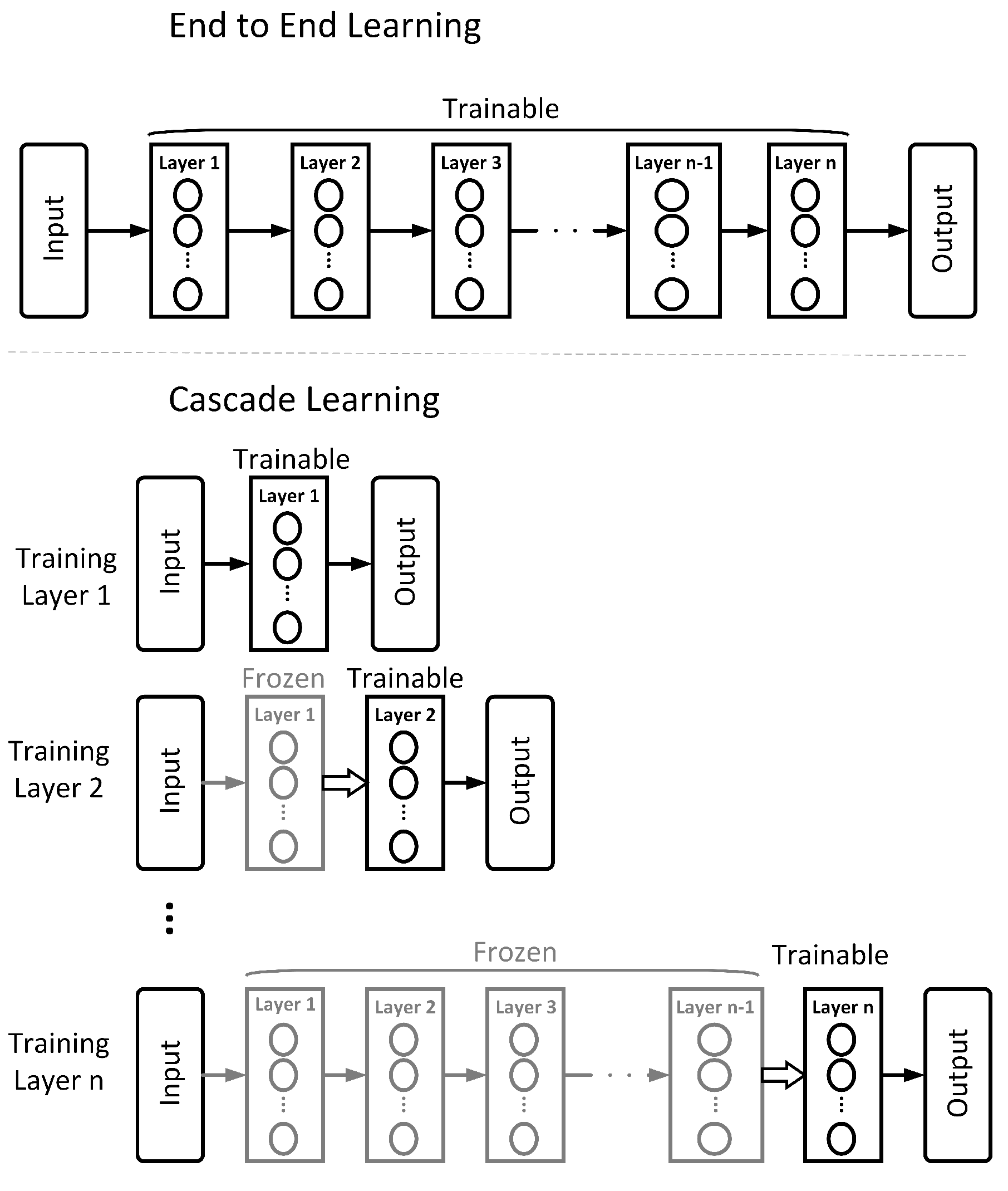
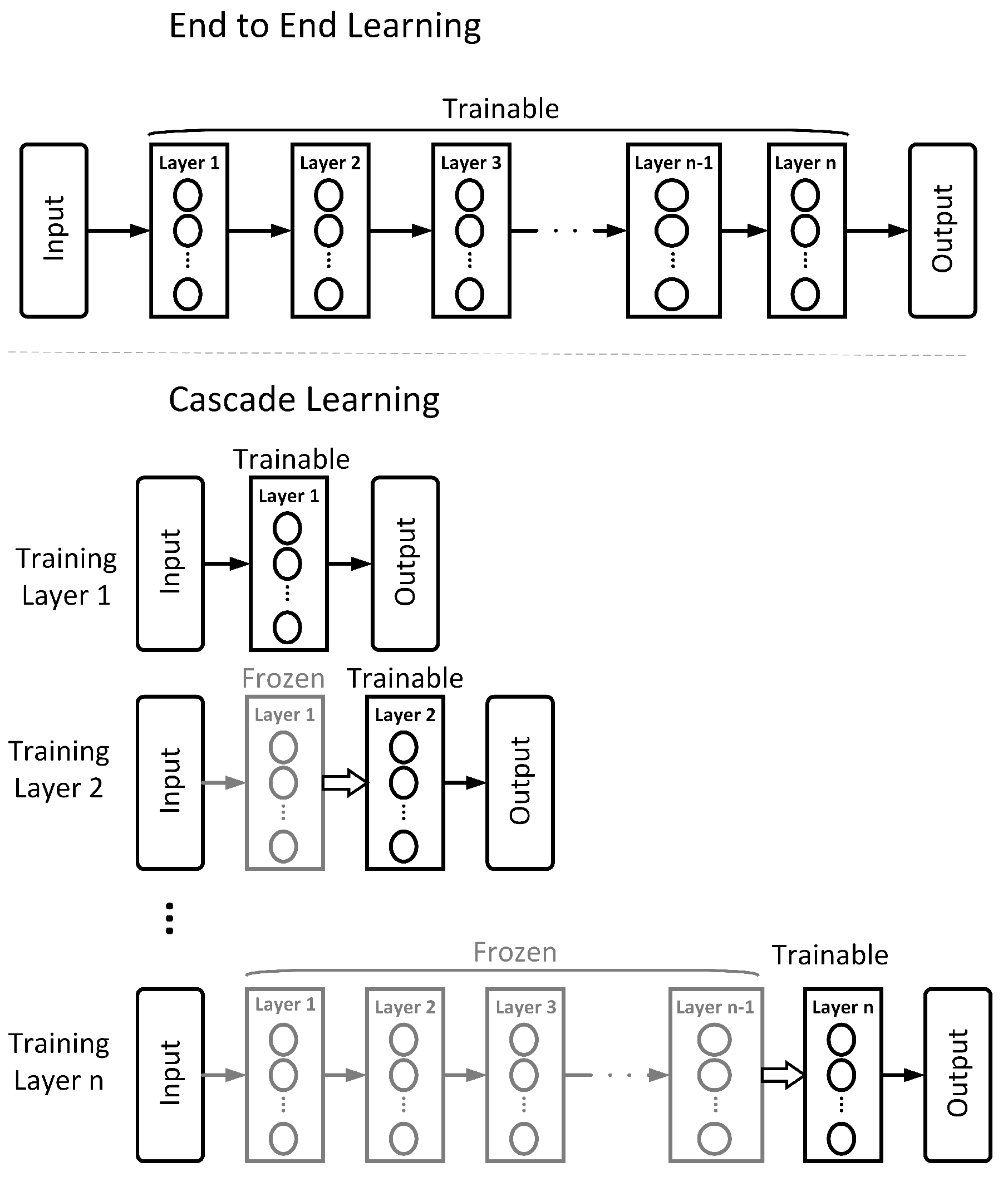
1.2. Cascade Learning
1.3. Contributions
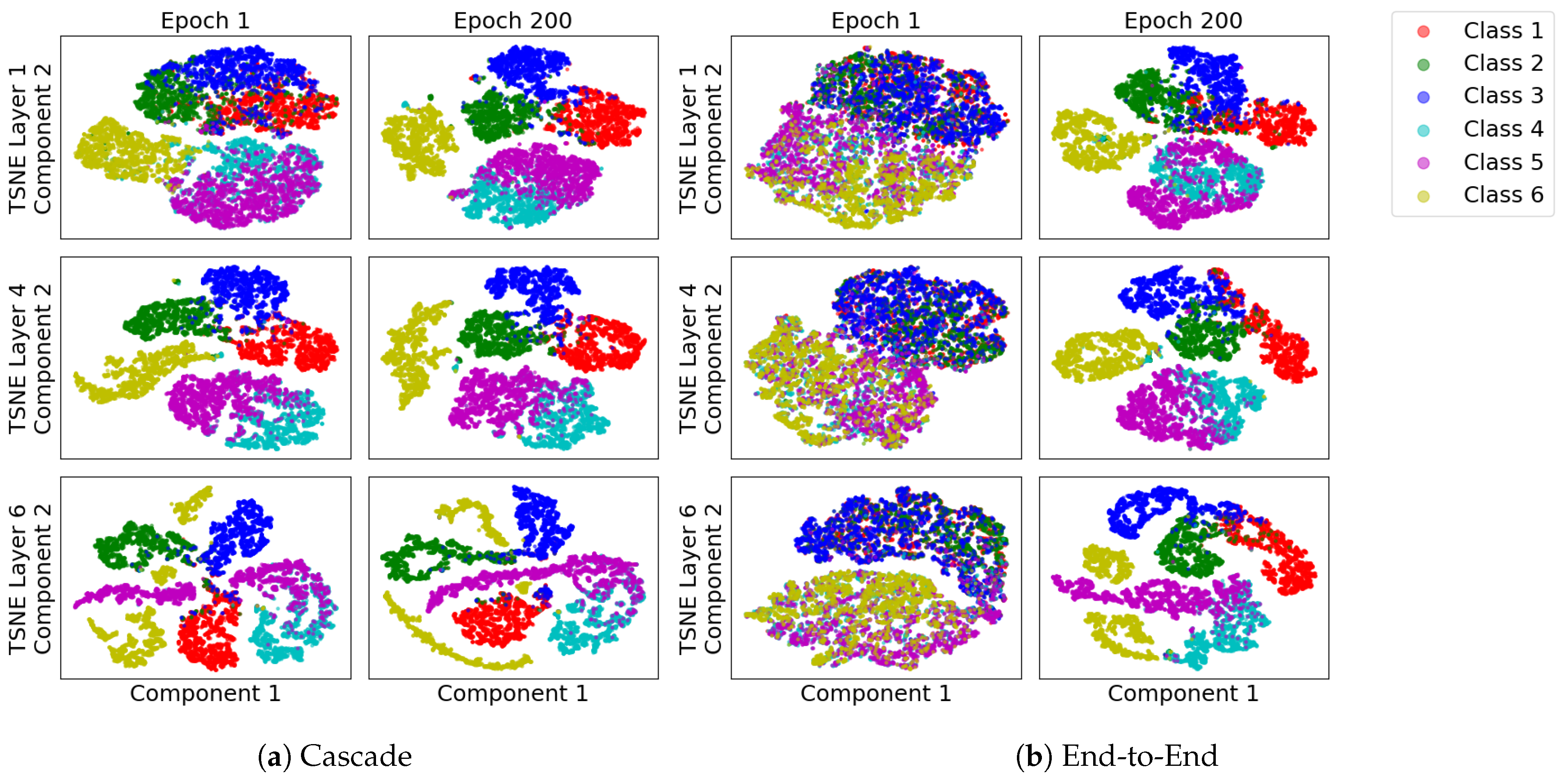
- We show visualisations of how learning dynamics differ between E2E and cascade trained networks on the information plane, illustrating that, by packing information layer-by-layer, we can achieve adequate performance from networks that show no systematic dynamics on the information plane.
- We note that there is not a direct link between information compression and generalisation, in CL models that achieve the same performance as E2E trained models, thus breaking the overly simplistic link between information bottleneck theory and high empirical performance in deep neural networks.
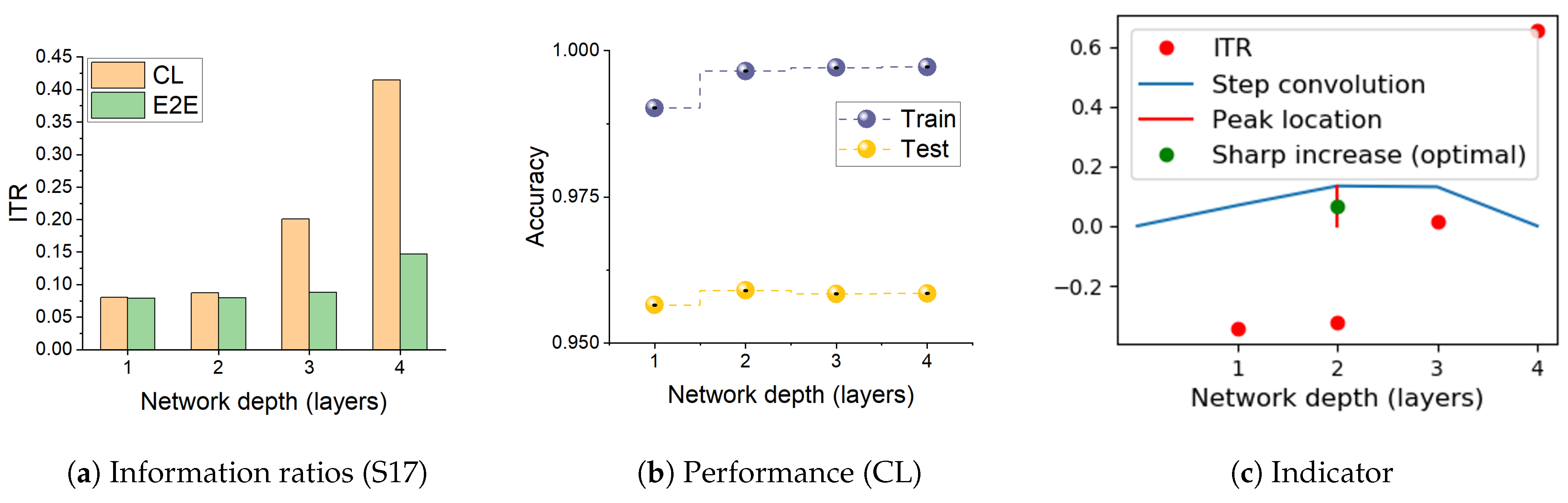
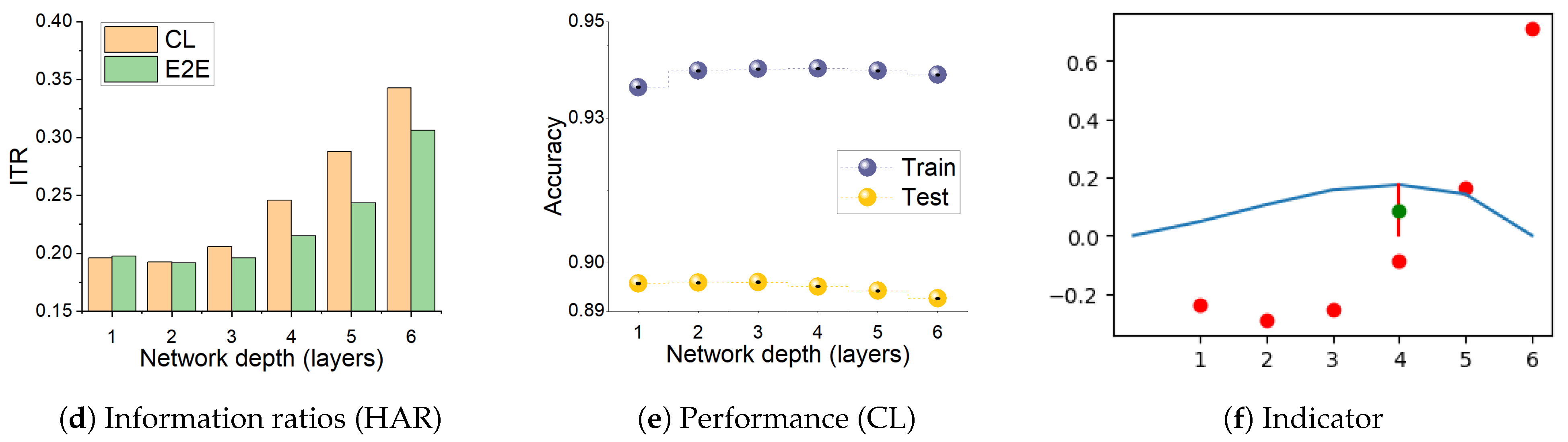
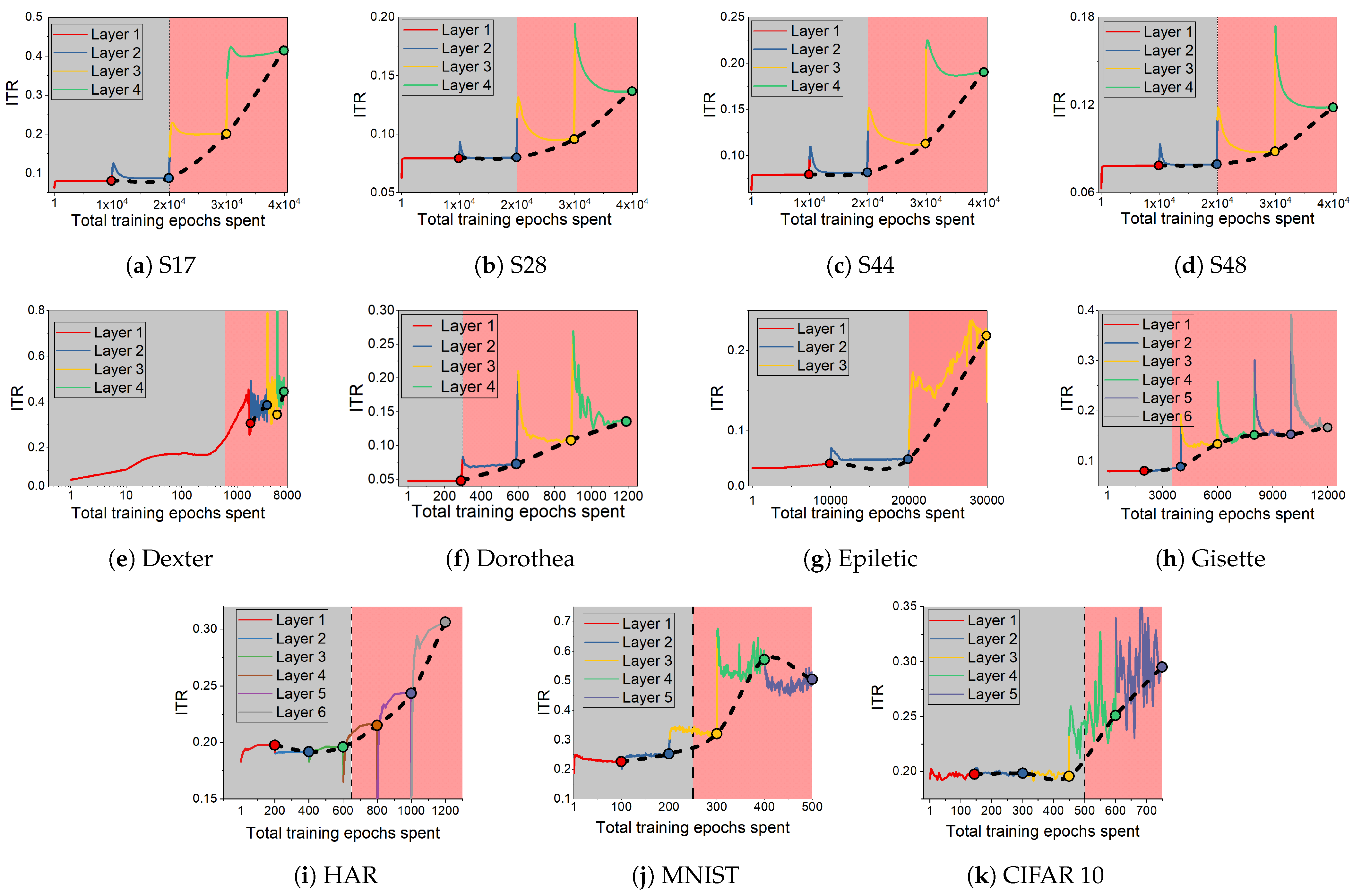
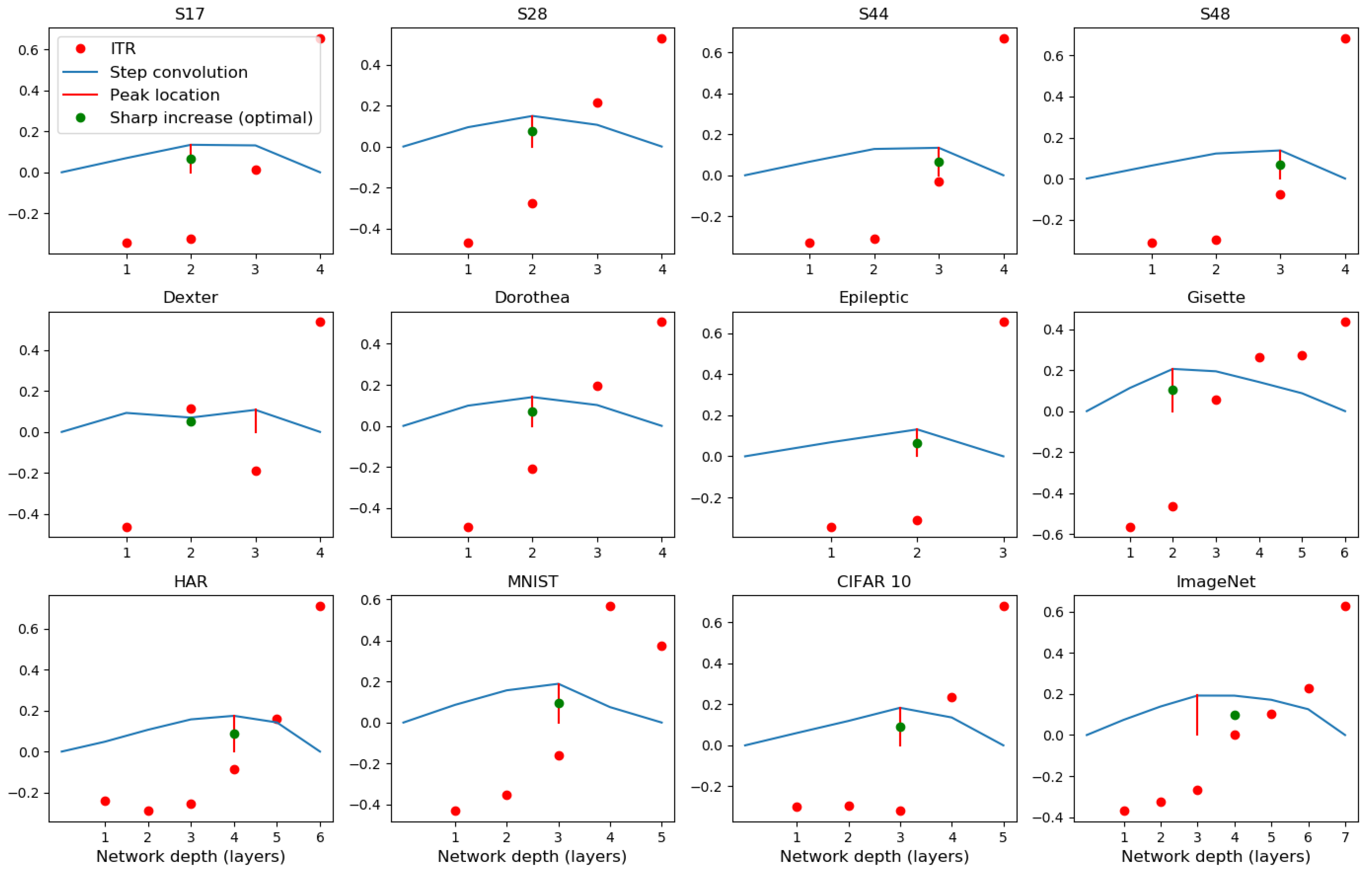
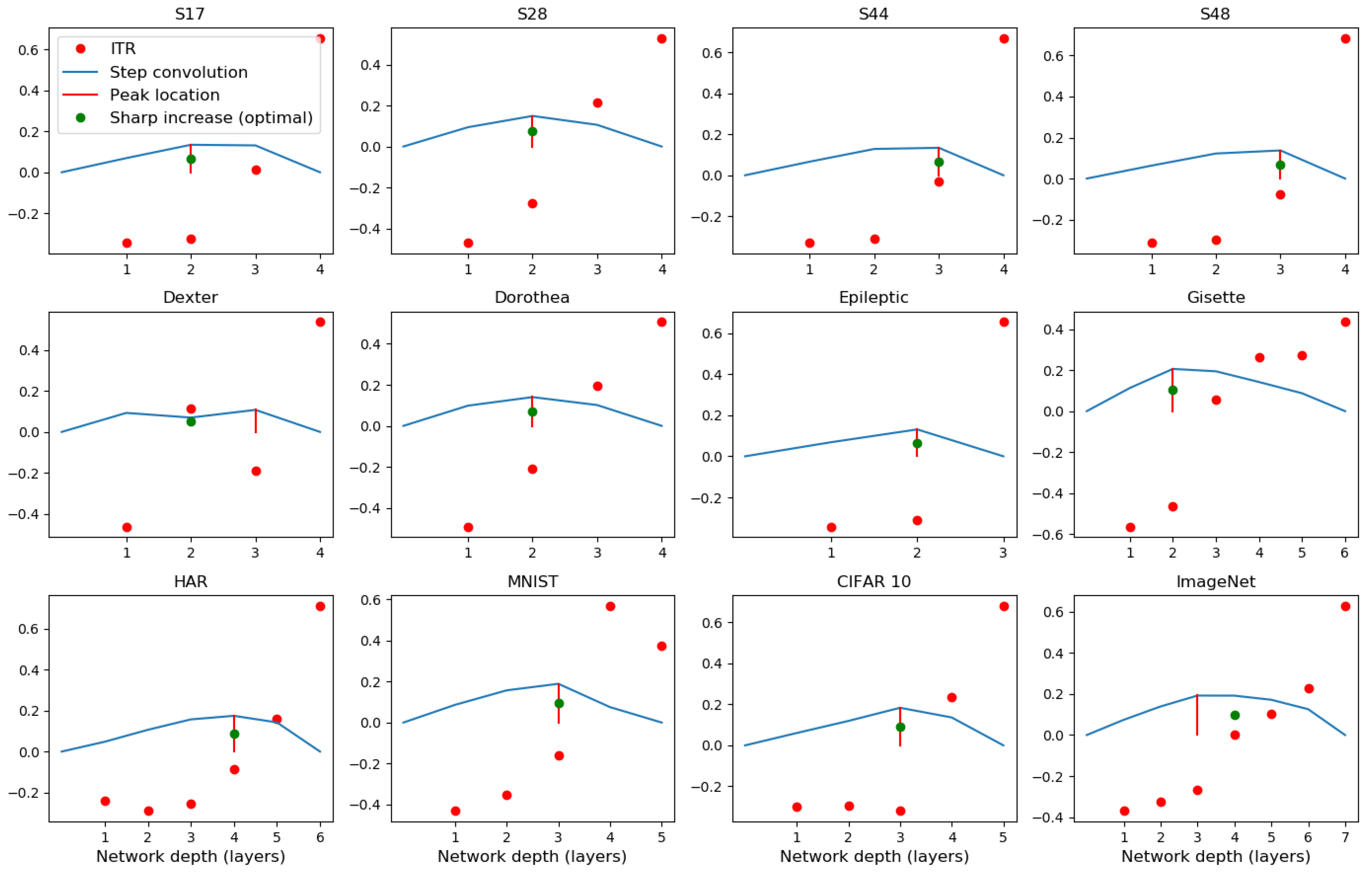
- We find that, during CL, the relative changes in the two mutual information terms, the ratio , make sharp increases when the network develops over-fitting. We propose this as a useful heuristic for automatically controlling the number of layers needed in solving a pattern recognition problem, such adaptive architectures being the original motivation of the cascade correlation algorithm [17].
2. Methodology
2.1. Datasets
2.2. Simulation Details
3. Results and Discussion
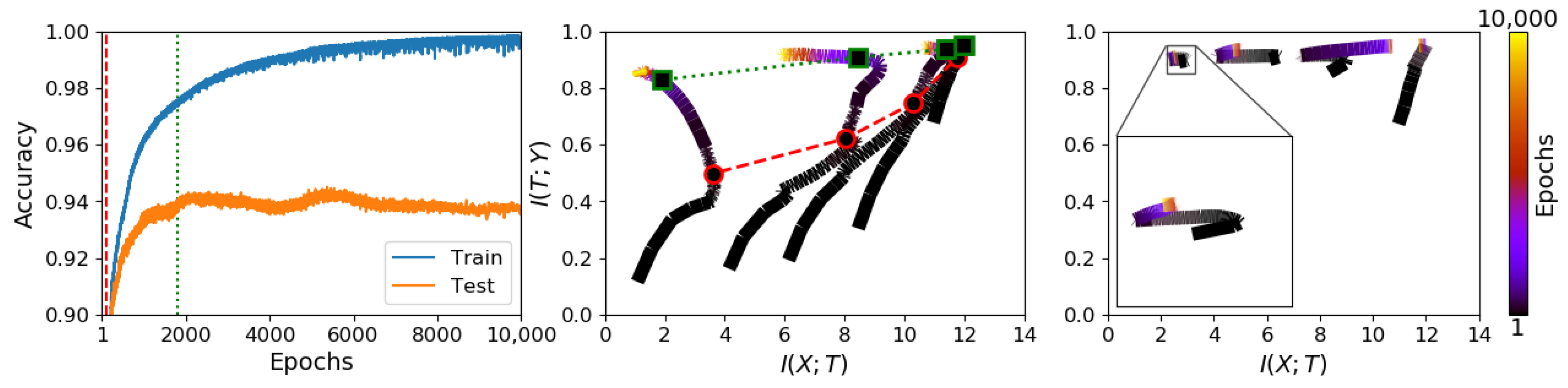
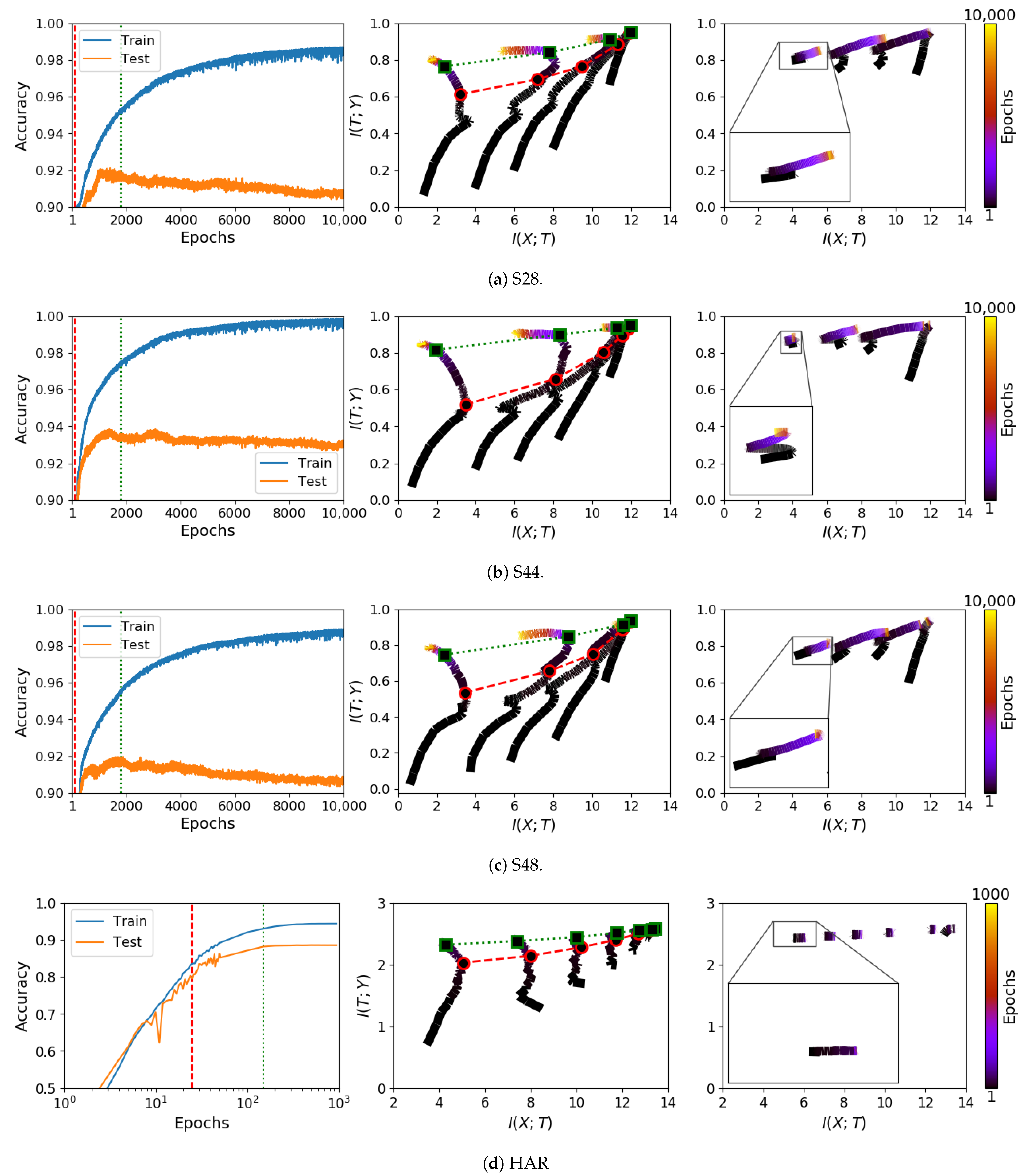
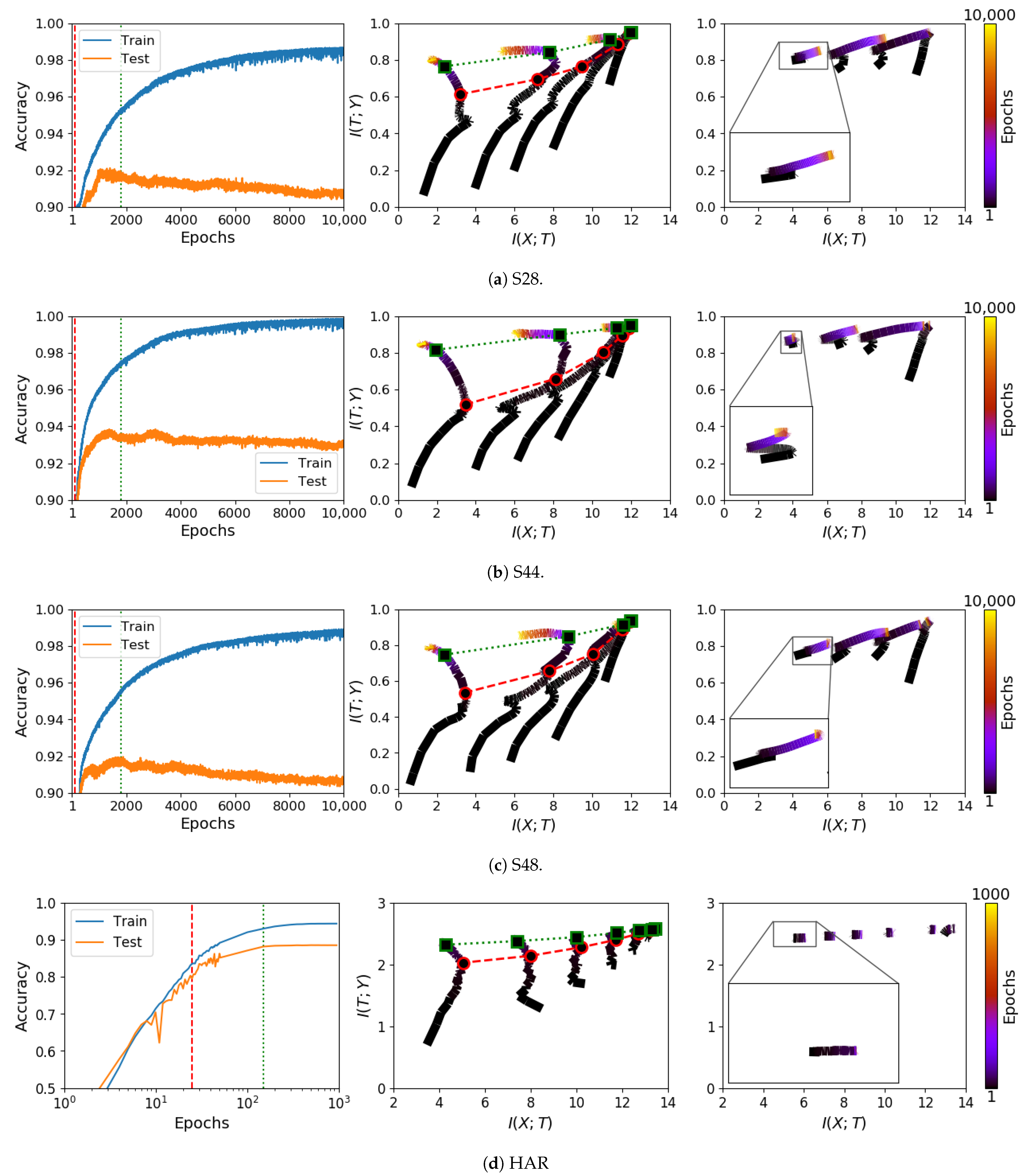
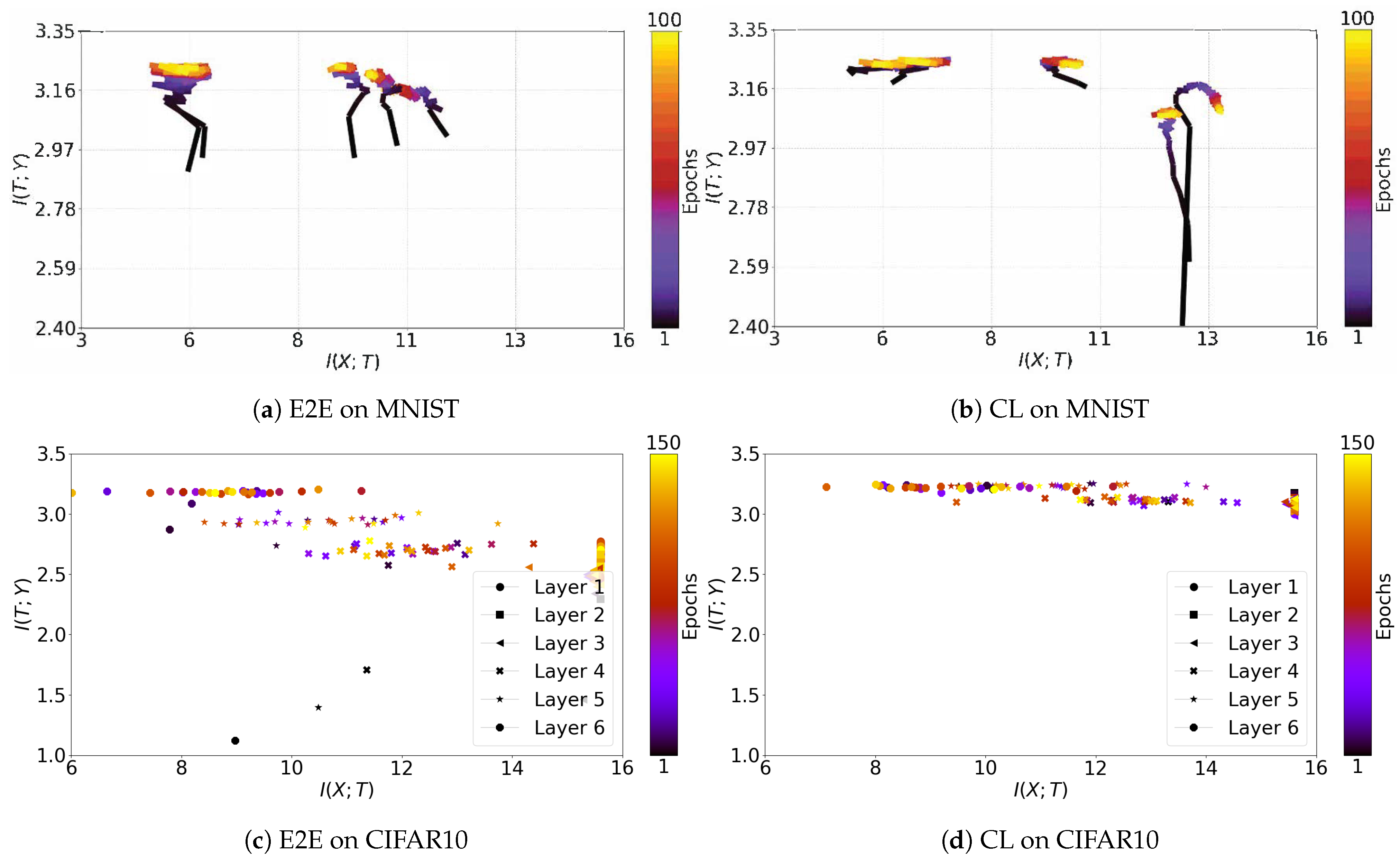
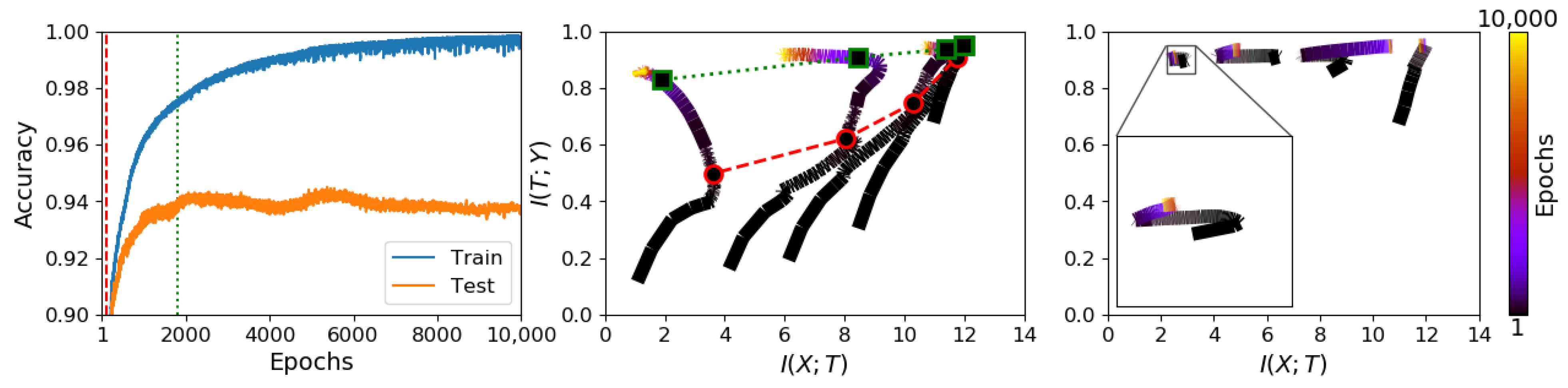
3.1. Information Plane Dynamics of Cascade Learning
3.2. Inconsistency of Information Plane Dynamics on Real Data
3.3. Generalisation and Information Compression
3.4. Information Transition Ratio
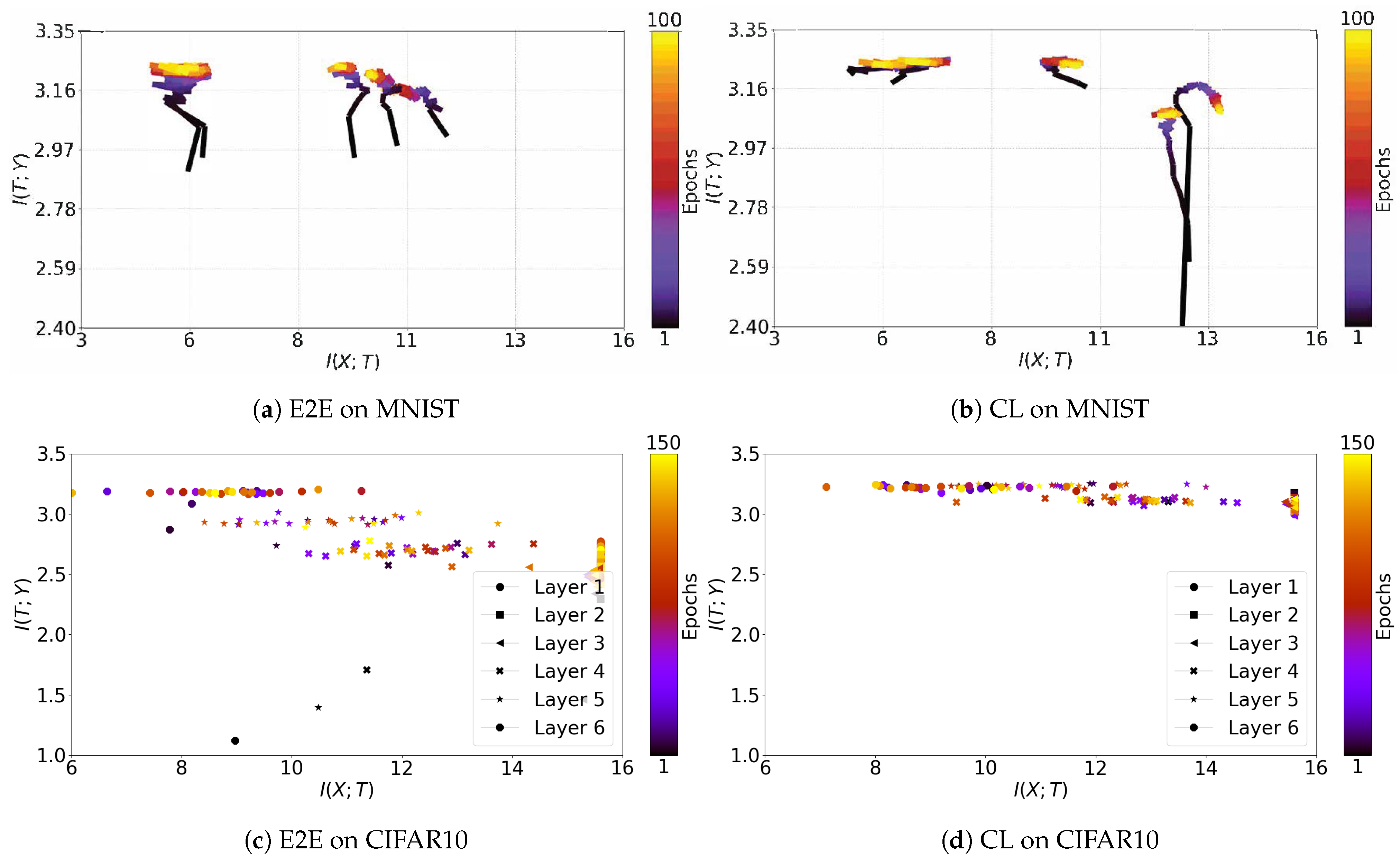
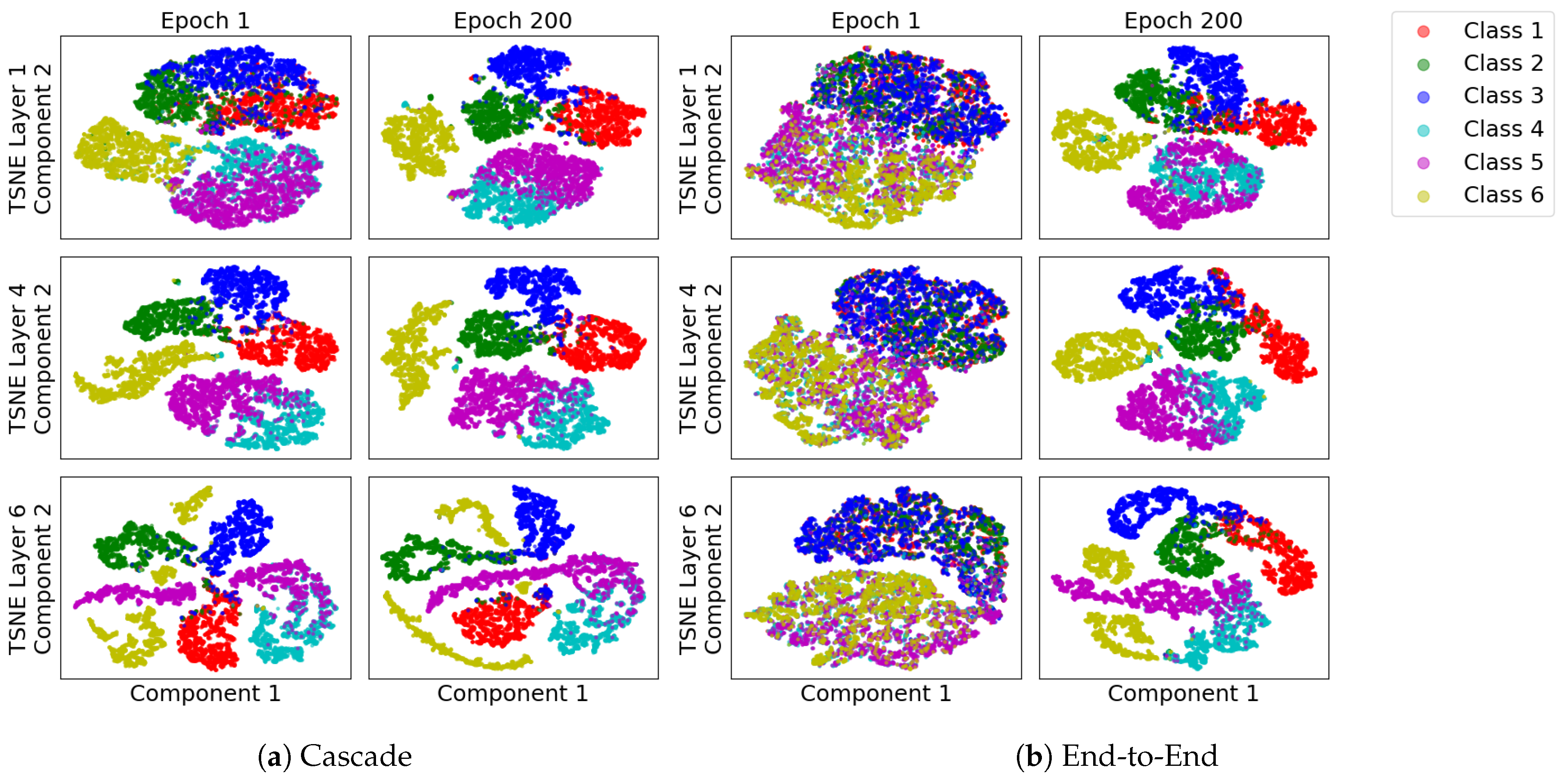
3.5. Subspace Visualization
3.6. Discussion
3.6.1. Cascade Learning on the Information Plane
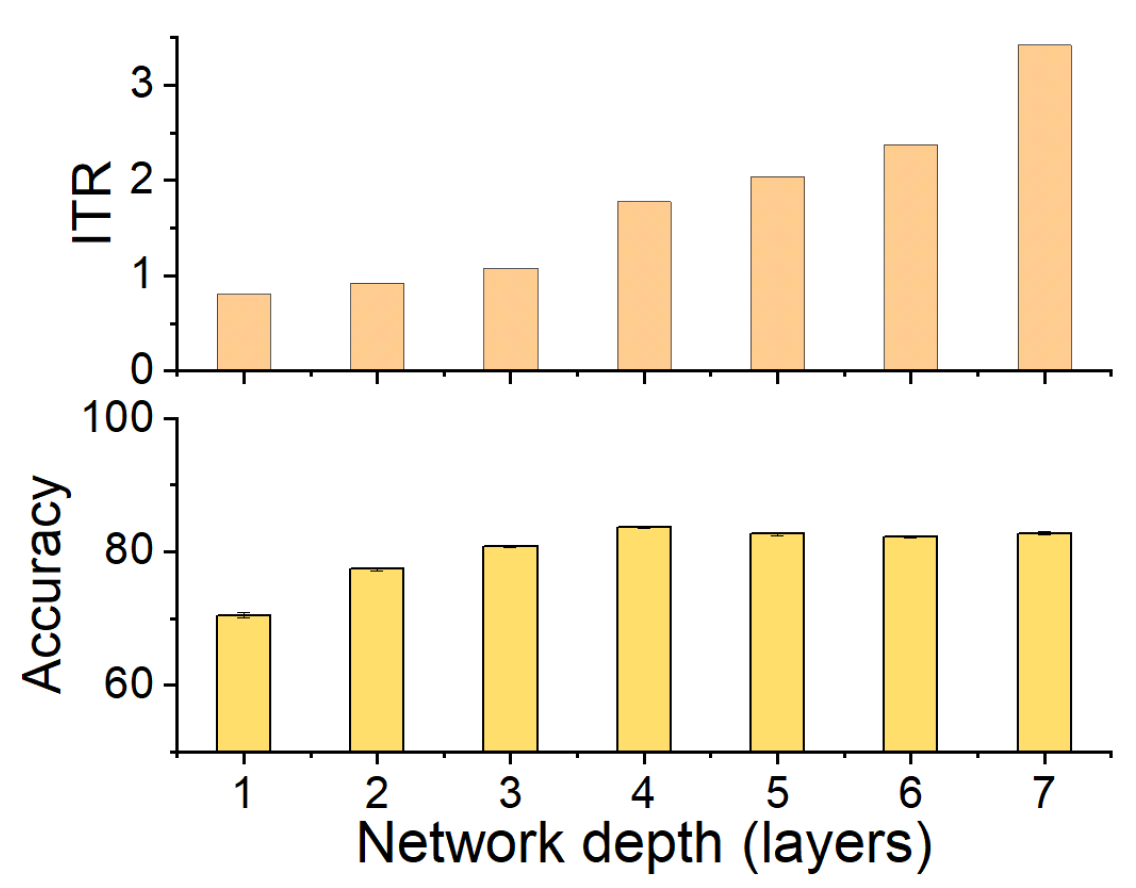
3.6.2. Information Transition Ratio and Network Depth
3.6.3. Local Objective Function
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
Additional Details and Results

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Architecture | LR | Dataset | Architecture | LR |
|---|---|---|---|---|---|
| Synthetic | [10,7,5,3] | 0.001 | Epileptic | [32,16,14,12,8,4] | 0.01 |
| Dexter | [6,5,4,3] | 0.01 | Gisette | [32,16,14,10,8,6] | 0.001 |
| Dorothea | [20,10,7,3] | 0.001 | MNIST | [20,20,20,20,20] | 0.01 |
| HAR | [10,32,16,10,8,6,4] | 0.1 | CIFAR 10 | layer 1-8:256 layer 9-12:128 | 0.001 |
| ImageNet | [256,256,256,256,256,256,256] | 0.01 |


References
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; John Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef] [Green Version]
- Krishnan, R.; Sivakumar, G.; Bhattacharya, P. Extracting decision trees from trained neural networks. Pattern Recognit. 1999, 32, 1999–2009. [Google Scholar] [CrossRef]
- Witten, I.H.; Frank, E. Data mining: Practical machine learning tools and techniques with java implementations. SIGMOD Rec. 2002, 31, 76–77. [Google Scholar] [CrossRef]
- Pearl, J. An application of rate-distortion theory to pattern recognition and classification. Pattern Recognit. 1976, 8, 11–22. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Silver, D.; Hubert, T.; Schrittwieser, J.; Antonoglou, I.; Lai, M.; Guez, A.; Lanctot, M.; Sifre, L.; Kumaran, D.; Graepel, T.; et al. Mastering chess and shogi by self-play with a general reinforcement learning algorithm. arXiv 2017, arXiv:1712.01815. [Google Scholar]
- Zhang, C.; Bengio, S.; Hardt, M.; Recht, B.; Vinyals, O. Understanding deep learning requires rethinking generalization. Commun. ACM 2021, 64, 107–115. [Google Scholar] [CrossRef]
- Holden, S.B.; Niranjan, M. On the practical applicability of VC dimension bounds. Neural Comput. 1995, 7, 1265–1288. [Google Scholar] [CrossRef]
- Shwartz-Ziv, R.; Tishby, N. Opening the black box of deep neural networks via information. arXiv 2017, arXiv:1703.00810. [Google Scholar]
- Tishby, N.; Pereira, F.C.; Bialek, W. The information bottleneck method. In Proceedings of the Annual Allerton Conference on Communications, Control and Computing, Allerton, IL, USA, 22–24 September 1999; pp. 368–377. [Google Scholar]
- Saxe, A.M.; Bansal, Y.; Dapello, J.; Advani, M.; Kolchinsky, A.; Tracey, B.D.; Cox, D.D. On the information bottleneck theory of deep learning. In Proceedings of the International Conference on Learning Representations (ICLR), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Amjad, R.A.; Geiger, B.C. How (not) to train Your neural network using the information bottleneck principle. arXiv 2018, arXiv:1802.09766. [Google Scholar]
- Geiger, B.C. On information plane analyses of neural network classifiers—A review. IEEE Trans. Neural Netw. Learn. Syst. 2021, 1, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Geiger, B.C.; Kubin, G. Information bottleneck: Theory and applications in deep learning. Entropy 2020, 22, 1408. [Google Scholar] [CrossRef] [PubMed]
- Marquez, E.S.; Hare, J.S.; Niranjan, M. Deep cascade learning. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 1–11. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fahlman, S.E.; Lebiere, C. The cascade-correlation learning architecture. In Proceedings of the International Conference on Neural Information Processing Systems (NeurIPS), Denver, CO, USA, 26–29 November 1990; pp. 524–532. [Google Scholar]
- Belilovsky, E.; Eickenberg, M.; Oyallon, E. Greedy layerwise learning can scale to ImageNet. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; Volume 97, pp. 583–593. [Google Scholar]
- Trinh, L.Q. Greedy Layerwise Training of Convolutional Neural Networks. Ph.D. Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 2019. [Google Scholar]
- Du, X.; Farrahi, K.; Niranjan, M. Transfer learning across human activities using a cascade neural network architecture. In Proceedings of the 23rd International Symposium on Wearable Computers (ISWC), London, UK, 9–13 September 2019; ACM: New York, NY, USA, 2019; pp. 35–44. [Google Scholar]
- Bengio, Y.; Lamblin, P.; Popovici, D.; Larochelle, H. Greedy layer-wise training of deep networks. In Proceedings of the 19th International Conference on Neural Information Processing Systems (NeurIPS), Vancouver, BC, USA, 4–7 December 2006; MIT Press: Cambridge, MA, USA, 2006; pp. 153–160. [Google Scholar]
- Lengellé, R.; Denoeux, T. Training MLPs layer by layer using an objective function For internal representations. Neural Netw. 1996, 9, 83–97. [Google Scholar] [CrossRef]
- T Nguyen, T.; Choi, J. Markov information bottleneck to improve information flow in stochastic neural networks. Entropy 2019, 21, 976. [Google Scholar] [CrossRef] [Green Version]
- Xu, D.; Principe, J.C. Training MLPs layer-by-layer with the information potential. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Washington, DC, USA, 10–16 July 1999; IEEE: Piscataway, NJ, USA, 1999; Volume 3, pp. 1716–1720. [Google Scholar]
- Raghu, M.; Gilmer, J.; Yosinski, J.; Sohl-Dickstein, J. SVCCA: Singular vector canonical correlation analysis for deep learning dynamics and interpretability. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Long Beach, CA, USA, 4–9 December 2017; Curran Associates, Inc.: New York, NY, USA, 2017; pp. 6076–6085. [Google Scholar]
- Dheeru, D.; Karra Taniskidou, E. UCI Machine Learning Repository. Available online: http://archive.ics.uci.edu/ml (accessed on 14 October 2021).
- Anguita, D.; Ghio, A.; Oneto, L.; Parra, X.; Reyes-Ortiz, J.L. A public domain dataset for human activity recognition using smartphones. In Proceedings of the European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning (ESANN), Bruges, Belgium, 24–26 April 2013; Volume 3, pp. 437–442. [Google Scholar]
- Krizhevsky, A. Learning Multiple Layers of Features from Tiny Images. Master’s Thesis, University of Tront, Toronto, ON, Canada, 2009. [Google Scholar]
- Deng, J.; Wei, D.; Socher, R.; Li, L.J.; Li, K.; Li, F.F. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR); IEEE: Piscataway, NJ, USA, 2009; pp. 248–255. [Google Scholar]
- Kolchinsky, A.; Tracey, B.D. Estimating mixture entropy with pairwise distances. Entropy 2017, 19, 361. [Google Scholar] [CrossRef] [Green Version]
- Noshad, M.; Zeng, Y.; Hero, A.O. Scalable mutual information estimation using dependence graphs. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 2962–2966. [Google Scholar]
- Silverman, B.W. Density Estimation for Statistics and Data Analysis; Routledge: London, UK, 2018. [Google Scholar]
- Endres, D.; Foldiak, P. Bayesian bin distribution inference and mutual information. IEEE Trans. Inf. Theory 2005, 51, 3766–3779. [Google Scholar] [CrossRef]
- Kailath, T. The divergence and Bhattacharyya distance measures in signal selection. IEEE Trans. Commun. Technol. 1967, 15, 52–60. [Google Scholar] [CrossRef]
- Belghazi, M.I.; Baratin, A.; Rajeshwar, S.; Ozair, S.; Bengio, Y.; Courville, A.; Hjelm, D. Mutual information neural estimation. In Proceedings of the International Conference on Machine Learning (ICML), Stockholm Sweden, 10–15 July 2018; pp. 531–540. [Google Scholar]
- Wickstrøm, K.; Løkse, S.; Kampffmeyer, M.; Yu, S.; Principe, J.; Jenssen, R. Information plane analysis of deep neural networks via matrix–based Renyi’s entropy and tensor kernels. arXiv 2020, arXiv:1909.11396. [Google Scholar]
- Yu, S.; Alesiani, F.; Yu, X.; Jenssen, R.; Principe, J. Measuring dependence with matrix-based entropy functional. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 10781–10789. [Google Scholar]
- Balda, E.R.; Behboodi, A.; Mathar, R. An information theoretic view on learning of artificial neural networks. In Proceedings of the 12th International Conference on Signal Processing and Communication Systems (ICSPCS), Cairns, QLD, Australia, 17–19 December 2018; pp. 1–8. [Google Scholar]
- Balda, E.R.; Behboodi, A.; Mathar, R. On the Trajectory of Stochastic Gradient Descent in the Information Plane. Available online: https://openreview.net/forum?id=SkMON20ctX (accessed on 14 October 2021).
- Chelombiev, I.; Houghton, C.; O’Donnell, C. Adaptive estimators show information compression in deep neural networks. In Proceedings of the International Conference on Learning Representations (ICLR), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Schiemer, M.; Ye, J. Revisiting the Information Plane. Available online: https://openreview.net/forum?id=Hyljn1SFwr (accessed on 14 October 2021).
- Wang, Y.; Ni, Z.; Song, S.; Yang, L.; Huang, G. Revisiting locally supervised learning: An alternative to end-to-end training. In Proceedings of the International Conference on Learning Representations (ICLR), Lisbon, Portugal, 28–29 October 2021. [Google Scholar]
- Amjad, R.A.; Geiger, B.C. Learning representations for neural network-based classification using the information bottleneck principle. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2225–2239. [Google Scholar] [CrossRef] [Green Version]
- Cheng, H.; Lian, D.; Gao, S.; Geng, Y. Utilizing information bottleneck to evaluate the capability of deep neural networks for image classification. Entropy 2019, 21, 456. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Duan, S.; Yu, S.; Chen, Y.; Principe, J.C. On kernel method–based connectionist models and supervised deep learning without backpropagation. Neural Comput. 2020, 32, 97–135. [Google Scholar] [CrossRef] [PubMed]
- Ma, W.D.K.; Lewis, J.; Kleijn, W.B. The HSIC bottleneck: Deep learning without back-propagation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 5085–5092. [Google Scholar]
- Jónsson, H.; Cherubini, G.; Eleftheriou, E. Convergence behavior of DNNs with mutual-information-based regularization. Entropy 2020, 22, 727. [Google Scholar] [CrossRef] [PubMed]
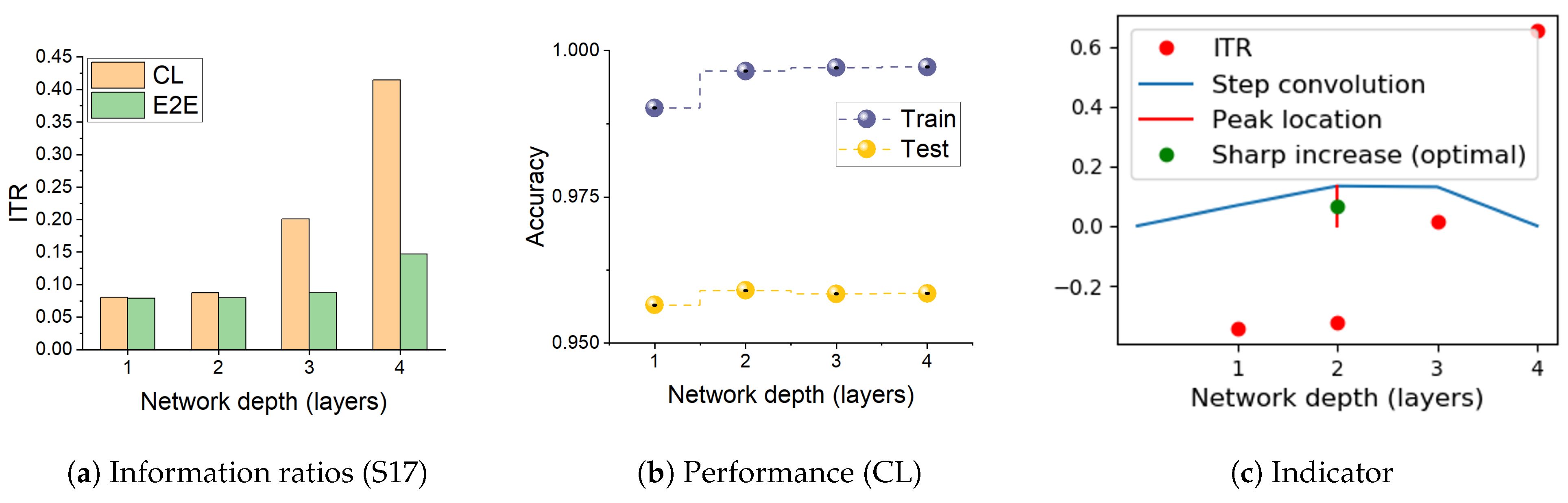
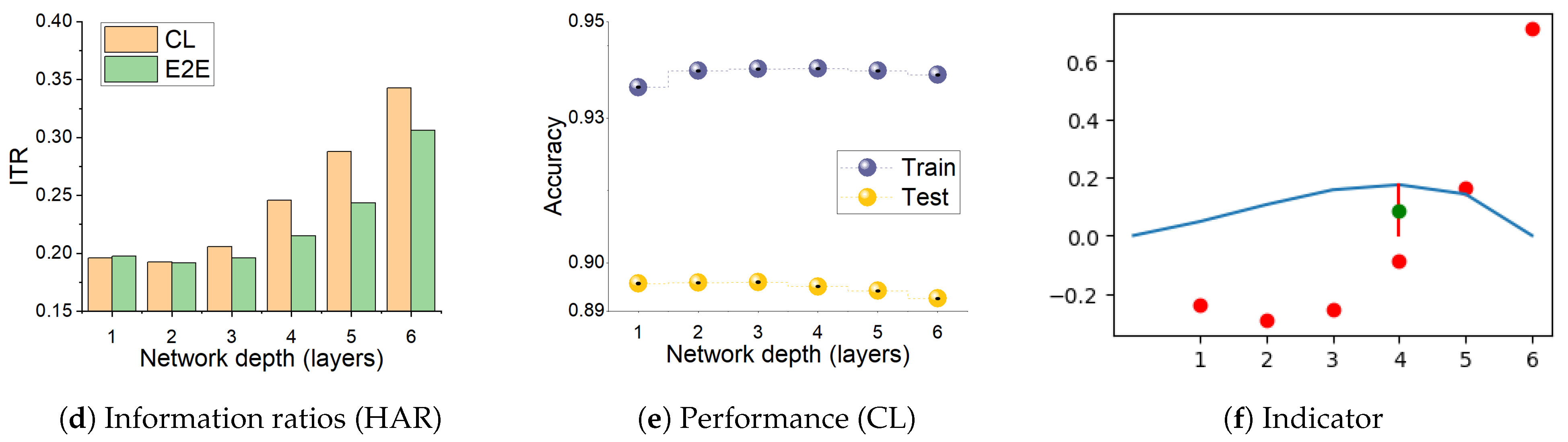
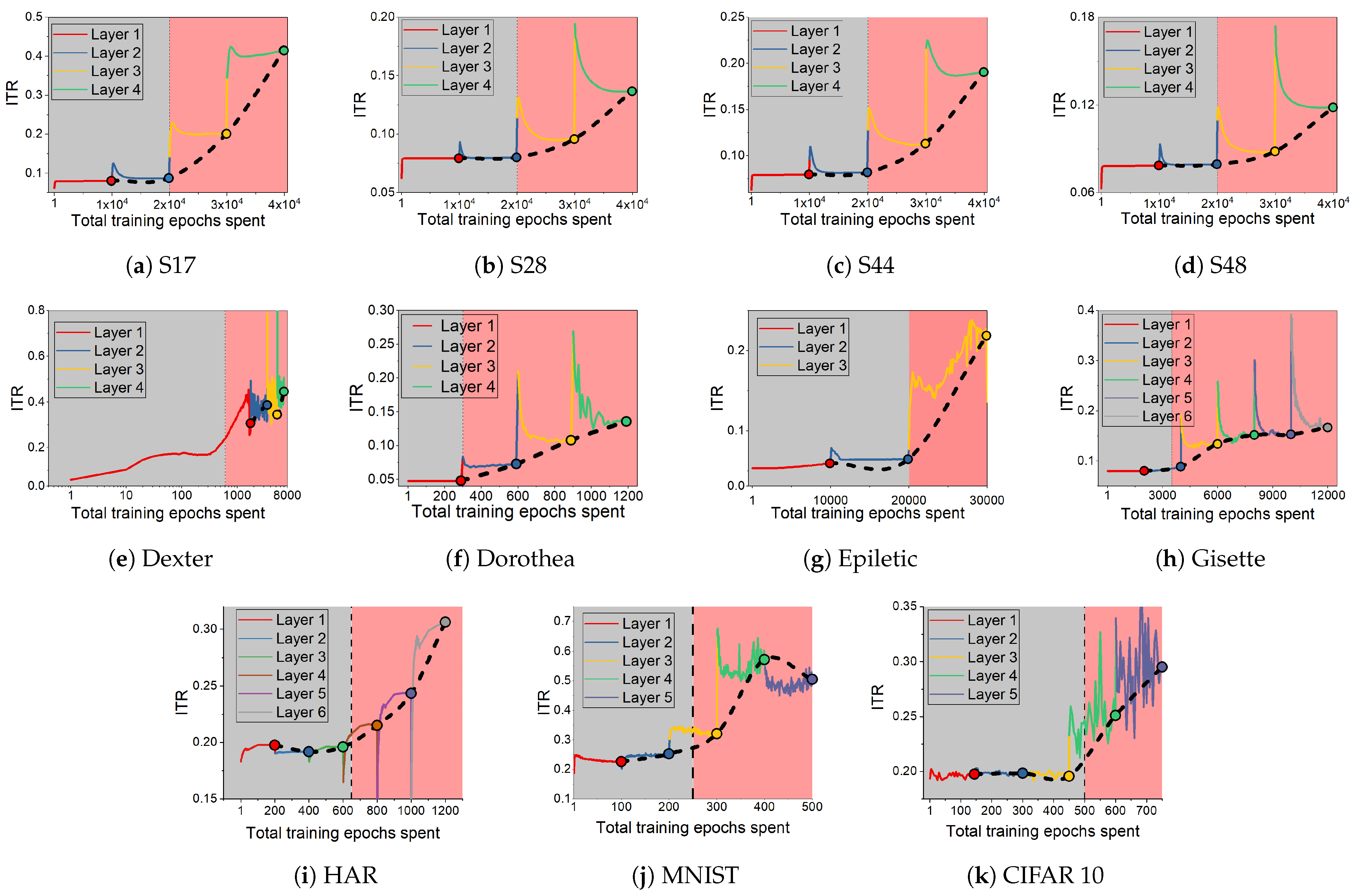

| Dataset | (n, p) | Domain | Input | % Pos | % Neg |
|---|---|---|---|---|---|
| S17 | Artificial | Binary | 63 | 37 | |
| S28 | Artificial | Binary | 62.8 | 37.2 | |
| S44 | Artificial | Binary | 37 | 63 | |
| S48 | Artificial | Binary | 35 | 65 | |
| Dexter | (600, 20,000) | Text classification | Continuous sparse | 50 | 50 |
| Dorothea | (1150, 100,000) | Drug discovery | Binary sparse | 50 | 50 |
| Epileptic | (11,500, 178) | Epileptic seizure detection | Continuous dense | 80 | 20 |
| Gisette | Digit recognition | ⋮ | 30 | 70 | |
| Human activity recognition (HAR) (6-class) [27] | (16,043, 561) | Sensor record | ⋮ | - | - |
| MNIST | (70,000, 784) | Image | ⋮ | - | - |
| CIFAR-10 [28] | (60,000, 1024) | Image | ⋮ | - | - |
| ImageNet [29] | (11,500, 50,176) | Image | ⋮ | - | - |
| Dataset | CL | Dataset | CL | ||
|---|---|---|---|---|---|
| Ratio | Test | Ratio | Test | ||
| S17 | Layer 3 | Layer 2 | S28 | Layer 3 | Layer 2 |
| S44 | Layer 3 | Layer 2 | S48 | Layer 3 | Layer 2 |
| Dexter | Layer 2 | Layer 1/2 | Dorothea | Layer 2 | Layer 1 |
| Epileptic | Layer 3 | Layer 2 | Gisette | Layer 3 | Layer 2 |
| HAR | Layer 4 | Layer 3 | MNIST | Layer 3 | Layer 2 |
| CIFAR 10 | Layer 4 | Layer 3/4 | ImageNet | Layer 4 | Layer 4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Du, X.; Farrahi, K.; Niranjan, M. Information Bottleneck Theory Based Exploration of Cascade Learning. Entropy 2021, 23, 1360. https://doi.org/10.3390/e23101360
Du X, Farrahi K, Niranjan M. Information Bottleneck Theory Based Exploration of Cascade Learning. Entropy. 2021; 23(10):1360. https://doi.org/10.3390/e23101360
Chicago/Turabian StyleDu, Xin, Katayoun Farrahi, and Mahesan Niranjan. 2021. "Information Bottleneck Theory Based Exploration of Cascade Learning" Entropy 23, no. 10: 1360. https://doi.org/10.3390/e23101360
APA StyleDu, X., Farrahi, K., & Niranjan, M. (2021). Information Bottleneck Theory Based Exploration of Cascade Learning. Entropy, 23(10), 1360. https://doi.org/10.3390/e23101360