
Entropy and Wealth



Abstract
| Dedicated to the memory of Themistocles Xanthopoulos |
| whose book series “Requiem with Crescendo?” [1,2,3] triggered [4] this paper |
| Wealth is not about having a lot of money; it’s about having a lot of options |
| Chris Rock (American comedian, writer, producer and director) |
| Πάντα τὰ ἐμὰ μετ’ ἐμοῦ φέρω (All that is mine I carry with me) |
| Bias of Priene (one of the seven Greek sages; 6th c. BC; |
| quoted in Latin by Cicero, Paradoxa Stoicorum I, 8, as “Omnia mea mecum porto”) |
1. Introduction
the fundamental problems of societal analysis with a nonequilibrium approach, a new frame of reference built upon contemporary macrological principles, including general systems theory and information theory.
Neto et al. [16], who also used Bailey’ theory, provided little help in clarifying what social entropy is. Recently, Dinga et al. [17], building on Bailey’s theory, clarified, rather qualitatively, the concept of social entropy as follows: (i) it cannot be of a thermodynamic type; (ii) it must be connected with social order; (iii) its connection with social order must be inversely proportional; (iv) it must hold connotations of the relationship between the homogeneity and heterogeneity of a system/process; and (v) it is fundamentally grounded by normativity. Interestingly, however, Balch [18] used the term “social entropy” as a measure of robot group diversity, proposing a formal mathematical definition.Never is the theory applied to real sociological data or anything like a real social situation.
Davis was influenced by Saridis [21], according to whom “entropy measures the waste produced when work is done for the improvement of the quality of human life”; he highlighted the following quotation by Saridis:Entropy has been characterized variously and vaguely by the words decadence, decay, anarchy, dystopia, randomness, chaos, decay, waste, inefficiency, dissipation, loss of available energy, irreversibility, indeterminacy, most probable states, equilibrium, thermal death […]. In the social sphere it has been characterized as apocalypse, disorder, disorganization, disappearance of distinctions, meaninglessness, absurdity, uncertainty, pandemonium, loss of information, inert uniformity, incoherence. […] In [humanistic] areas, the concept is used more or less as a metaphor or a synonym for chaos, disorder, breakdowns, dysfunctions, waste of material and energy, enervation, friction, inefficiencies.
The concept of Entropy creates a pessimistic view for the future of our universe. The equalization of all kinds of sources of activities is leading to the equivalent of thermal death and universal boredom of our world.
Following these, a series of papers and books studied similarities between economics and thermodynamic entropy [25,29,30,31,32,33,34,35,36,37,38,39,40,41,42]. McMahon and Mrozek used entropy, within the context of neoclassical economic thought, as a limit to economic growth [43]. In the same spirit, Smith and Smith used the Second Law of thermodynamics to again determine limits to growth [44]. In a review paper, Hammond and Winnett [45] presented the influence of thermodynamics on the emerging transdisciplinary field of ecological economics. However, Kovalev [46] claimed that entropy cannot be used as a measure of economic scarcity.Early in the 20th century, both Frederick Soddy and Nicholas Georgescu-Roegen discussed the relationship between entropy and economics. Soddy called for an index system to regulate the money supply and a reform of the fractional reserve banking system, while Georgescu-Roegen pointed to the need for Ecological Economics, a steady-state economy, and population stabilization.
2. What Is Entropy?
2.1. The Origin of the Entropy Concept
In addition to its semantic content, this quotation contains a very important insight: the recognition that entropy is related to transformation and change, and the contrast between entropy and energy, whereby the latter is a quantity that is conserved in all changes. This meaning has been more clearly expressed in Clausius’ famous aphorism [62]:We might call S the transformational content of the body […]. But as I hold it to be better to borrow terms for important magnitudes from the ancient languages, so that they may be adopted unchanged in all modern languages, I propose to call the magnitude S the entropy of the body, from the Greek word τροπή, transformation. I have intentionally formed the word entropy so as to be as similar as possible to the word energy; for the two magnitudes to be denoted by these words are so nearly allied their physical meanings, that a certain similarity in designation appears to be desirable.
Die Energie der Welt ist constant. Die Entropie der Welt strebt einem Maximum zu.
In other words, entropy and its ability to increase (as contrasted to energy, momentum and other quantities that are conserved) is the driving force of change. This property of entropy is acknowledged only rarely [63,64,65]. Instead, as we have already seen, in common perception entropy epitomizes all “bad things”, as if it were disconnected from change, or as if change can only have negative consequences, always leading to deterioration.(The energy of the world is constant. The entropy of the world strives to a maximum).
He also cited an earlier work (1929) in physics by Szilard [75], who implied the same definition of entropy in a thermodynamic system.An important observation about this definition is that it bears close resemblance to the statistical definition of the entropy of a thermodynamical system. […] Pursuing this, one can construct a mathematical theory of the communication of information patterned after statistical mechanics.
2.2. Are Thermodynamic and Probabilistic Entropy Different?
They should never have been called by the same name; the experimental entropy makes no reference to any probability distribution, and the information entropy makes no reference to thermodynamics. Many textbooks and research papers are flawed fatally by the author’s failure to distinguish between these entirely different things.
2.3. Does Entropy Measure Disorder?
Clearly, he speaks about the irregular motion of molecules in the kinetic theory of gases, for which his expression makes perfect sense. Boltzmann also used the notion of disorder with the same meaning, in his Lectures on Gas Theory [83]. On the other hand, Gibbs [68], Shannon [69] and von Neumann [74] did not use the terms disorder or disorganization at all.agreement of the concept of entropy with the mathematical expression of the probability or disorder of a motion.
Epistemologically, it is interesting that a physicist prefers the “more familiar” but fuzzy concept of disorder over the “subtle and difficult”, yet well-defined at his time, concept of entropy.The purpose of this article has been to establish a connection between the subtle and difficult notion of entropy and the more familiar concept of disorder. Entropy is a measure of disorder, or more succinctly yet, entropy is disorder: that is what a physicist would like to say.
Additionally, in his influential book Cybernetics [73] (p. 11), he stated thatInformation measures order and entropy measures disorder.
wherein he replaced the term “disorder” with “disorganization”, as in this book he extensively used the former term for mental illness.the entropy of a system is a measure of its degree of disorganization
More recently, Bailey [87] claimed:Entropy measures the degree of disorder, chaos, randomness, in a physical system. A crystal has low entropy, and a gas (say, at room temperature) has high entropy.
It is relevant to remark that in the latter quotations disorder has been used as equivalent to uncertainty or randomness—where the latter two terms are in essence identical [88]. Furthermore, the claim that a high-entropy system lacks sustainability is at least puzzling, given that the highest entropy occurs when a system is in the most probable (and hence most stable) state (cf. [78]).As a preliminary definition, entropy can be described as the degree of disorder or uncertainty in a system. If the degree of disorder is too great (entropy is high), then the system lacks sustainability. If entropy is low, sustainability is easier. If entropy is increasing, future sustainability is threatened.
That the world is getting worse, that it is sinking purposelessly into corruption, the corruption of the quality of energy, is the single great idea embodied in the Second Law of thermodynamics.
In an even more recent article, Styer [99] stated:The too commonly used disorder metaphor for entropy is roundly rejected.
we cannot stop people from using the word “entropy” to mean “disorder” or “destruction” or “moral decay.” But we can warn our students that this is not the meaning of the word “entropy” in physics.
This looks to be a very strong statement. Undoubtedly, elites that want to control the world have exactly this dream (cf. [101] and references above). However, this does not necessarily mean that all of humanity has the same dream as the elites. When speaking about entropy, we should have in mind that the scale is an important element, and that entropy per se, being a probabilistic concept, presupposes a macroscopic view of phenomena, rather than a focus on individuals or small subsets. If we viewed the motion of a particular die-throw, we might say that it was irregular, uncertain, unpredictable, chaotic, or random. However, macroscopization, by removing the details, may also remove irregularity. For example, the application of the principle of maximum entropy to the outcomes of a die-throw results in equal probabilities (1/6) for each outcome. This is the perfect order that can be achieved macroscopically. Likewise, as already mentioned, the maximum uncertainty in a particular water molecule’s state (in terms of position, kinetic state and phase), on a macroscopic scale results in the Clausius–Clapeyron law. Again, we have perfect order, as the accuracy of this law is so high that most people believe that it is a deterministic law.The kinetic theory of gas is an assertion of ultimate chaos. In plain words, Chaos was the law of nature; Order was the dream of man.
Entropy measures freedom, and this allows a coherent interpretation of entropy formulas and of experimental facts. To associate entropy and disorder implies defining order as absence of freedom.
2.4. On Negentropy
Apparently, if we get rid of the disorder interpretation of entropy, we may also be able to stop seeking a negentropic “life principle”, which was never found and probably will never be. For, if we see entropy as uncertainty, we also understand that life is fully consistent with entropy maximization. Human-invented steam engines (and other similar machines) increase entropy all the time, and are fully compatible with the Second law, yet they produce useful work. Likewise, the biosphere increases entropy, yet it produces interesting patterns, much more admirable than steam engines. Life generates new options and increases uncertainty [113]. Compare Earth with a lifeless planet: Where is uncertainty greater? On which of the two planets would a newspaper have more events to report every day?The ceaseless decline in the quality of energy expressed by the Second Law is a spring that has driven the emergence of all the components of the current biosphere. […] The spring of change is aimless, purposeless corruption, yet the consequences of interconnected change are the amazingly delightful and intricate efflorescences of matter we call grass, slugs, and people.
2.5. Final Theses on Entropy
- Entropy is a stochastic concept with a simple and general definition that will be formally stated in Section 2.6. Notably, according to its stochastic definition, entropy is a dimensionless quantity;
- As a stochastic concept, entropy can be interpreted as a measure of uncertainty, leaving aside the traditional but obscure and misleading “disorder” interpretation;
- The classical definition of thermodynamic entropy is not necessary, and it can be abandoned and replaced by the probabilistic definition;
- Applied in thermodynamics, entropy thus defined is the fundamental quantity, which supports the definition of all other derived ones. For example, temperature is defined as the inverse of the partial derivative of entropy with respect to internal energy. Entropy retains its dimensionless character in thermodynamics, thus rendering the kelvin an energy unit. Notably, the extended and sophisticated study of entropy in thermodynamics can serve, after the removal of the particulars pertinent to this specific field, as a paradigm for other disciplines, given that entropy is a generic concept;
- The entropy concept is complemented by the principle of maximum entropy, which states that entropy tends to take the maximum value that is allowed, given the available information about the system. The latter is incorporated into maximization in the form of constraints. This can be regarded both as a physical (ontological) principle obeyed by natural systems, as well as a logical (epistemological) principle applicable when making inferences about natural systems;
- The tendency of entropy to reach its maximum is the driving force of natural change;
- Life, biosphere and social processes are all consistent with the principle of maximum entropy, as they augment uncertainty. Therefore, no additional “life principle” is necessary to explain them. Changes in life and evolution are also driven by the principle of maximum entropy.
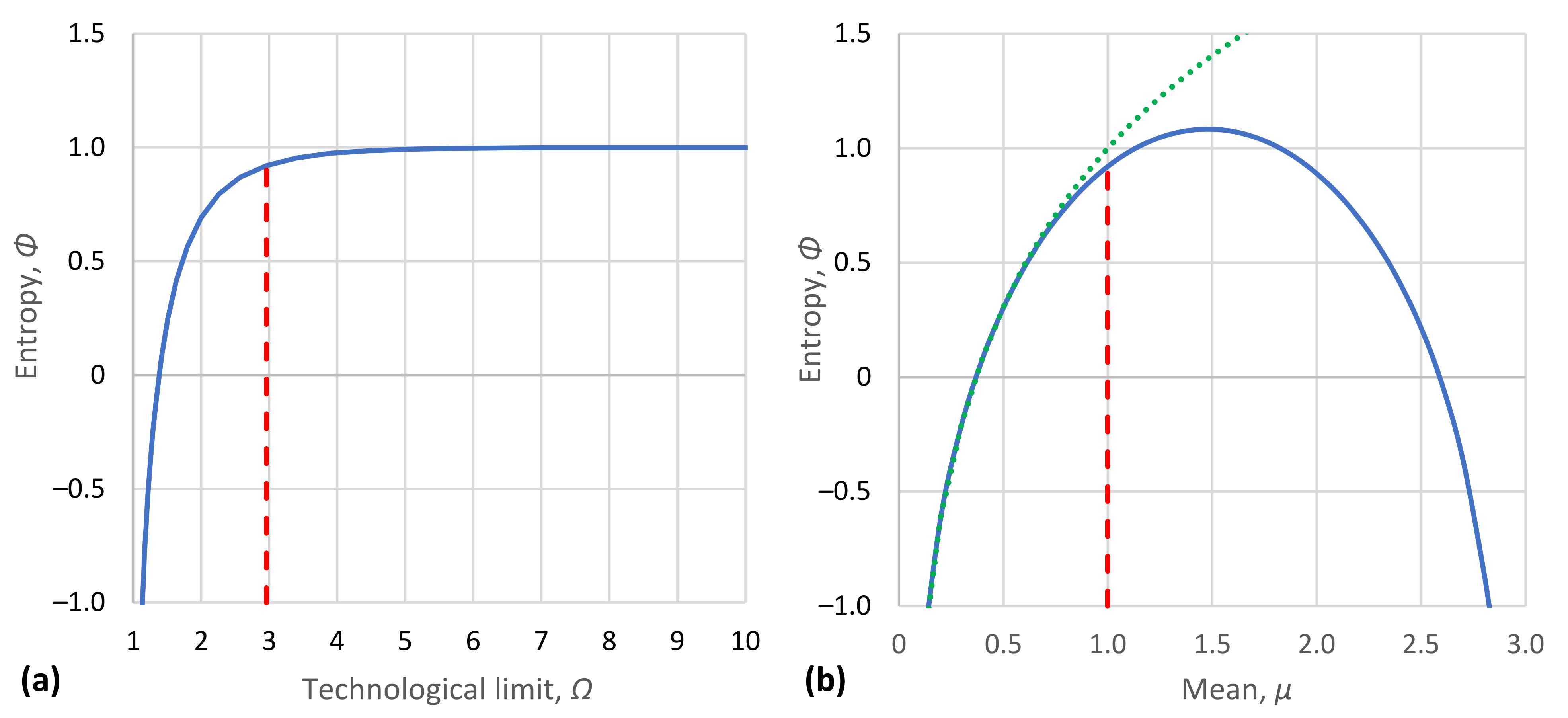
2.6. Mathematical Formulation
- (a)
- It is possible to set up a numerical measure of the amount of uncertainty, which is expressed as a real number;
- (b)
- Φ is a continuous function of ;
- (c)
- If all the are equal (), then should be a monotonic increasing function of ;
- (d)
- If there is more than one way of working out the value of , then we should get the same value for every possible way.
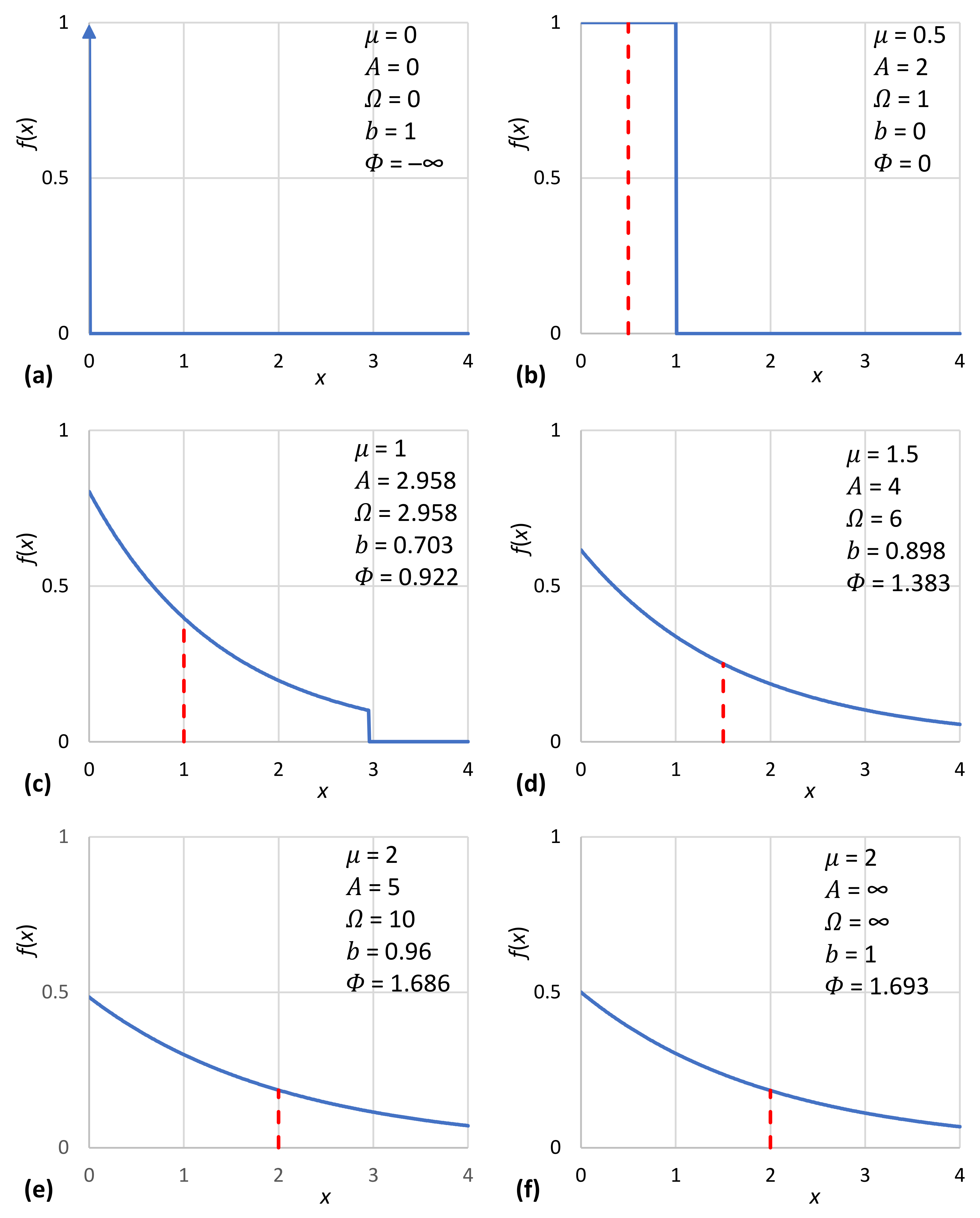
3. Entropy Maximizing Distribution for Constrained Mean
3.1. Lebesgue Background Measure and the Exponential Distribution
However, it is the relationship between thermodynamics and economics (hardly a new topic), with its burden of “entropy” and information, that remains at the heart of any econophysics view of production. In a nutshell, the point is: thermodynamics implies the conservation of energy, a principle that so far has not been confirmed in economic processes.
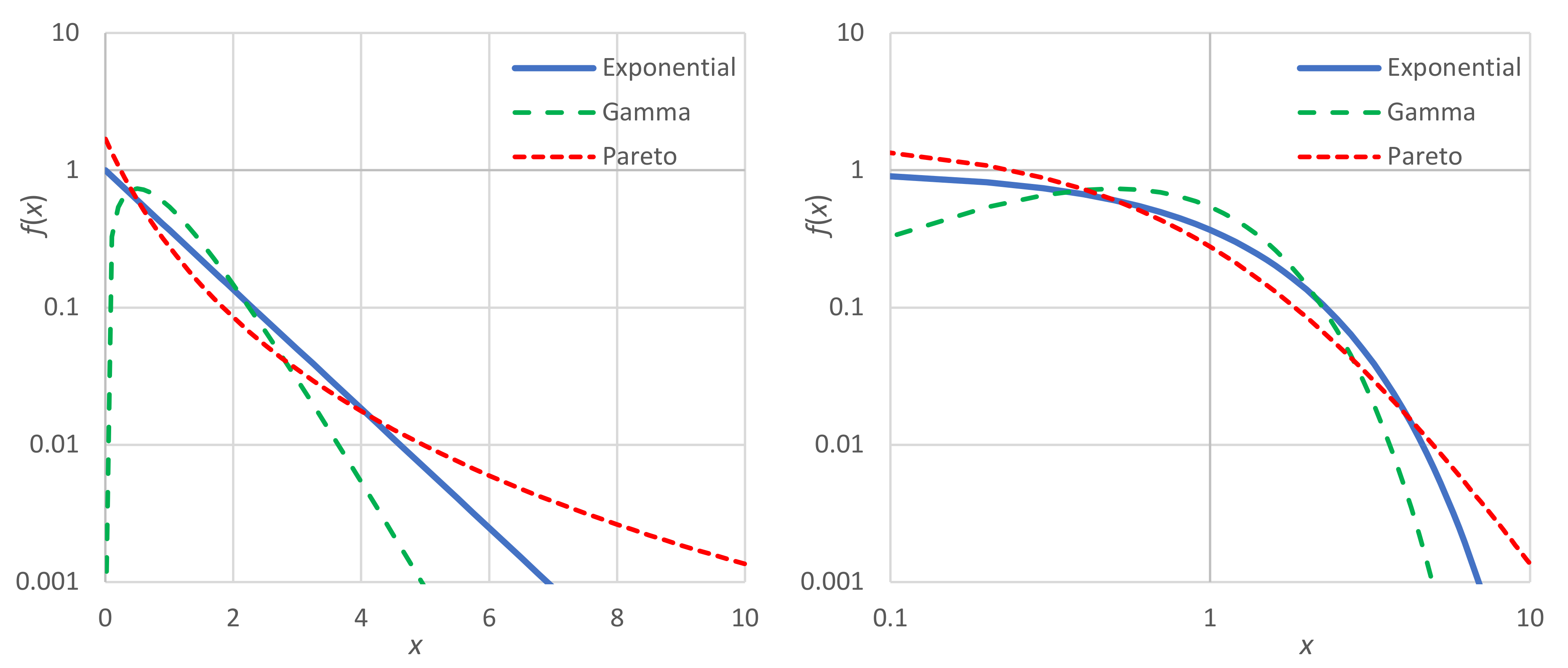
3.2. Hyperbolic Background Measure and the Pareto Distribution
The shape of the curve […] of Figure 54, which is derived from statistics, does not correspond by any means to the curve of errors [i.e., the normal distribution], i.e., to the shape the curve would have if the acquisition and preservation of wealth depended only on chance. Moreover, statistics reveal that the curve […] varies very little in time and space; different nations at different times have very similar curves. There is thus a remarkable stability in the shape of this curve. […] There is a certain minimum income […] below which men cannot descend without dying of poverty and hunger.
The study of income distribution has a long history. Pareto [127] proposed in 1897 that income distribution obeys a universal power law valid for all times and countries. Subsequent studies have often disputed this conjecture. In 1935, Shirras [135] concluded: “There is indeed no Pareto Law. It is time it should be entirely discarded in studies on distribution”. Mandelbrot [136] proposed a “weak Pareto law” applicable only asymptotically to the high incomes. In such a form, Pareto’s proposal is useless for describing the great majority of the population.
3.3. Empirical Investigation
4. Application to Societies’ Income Distribution
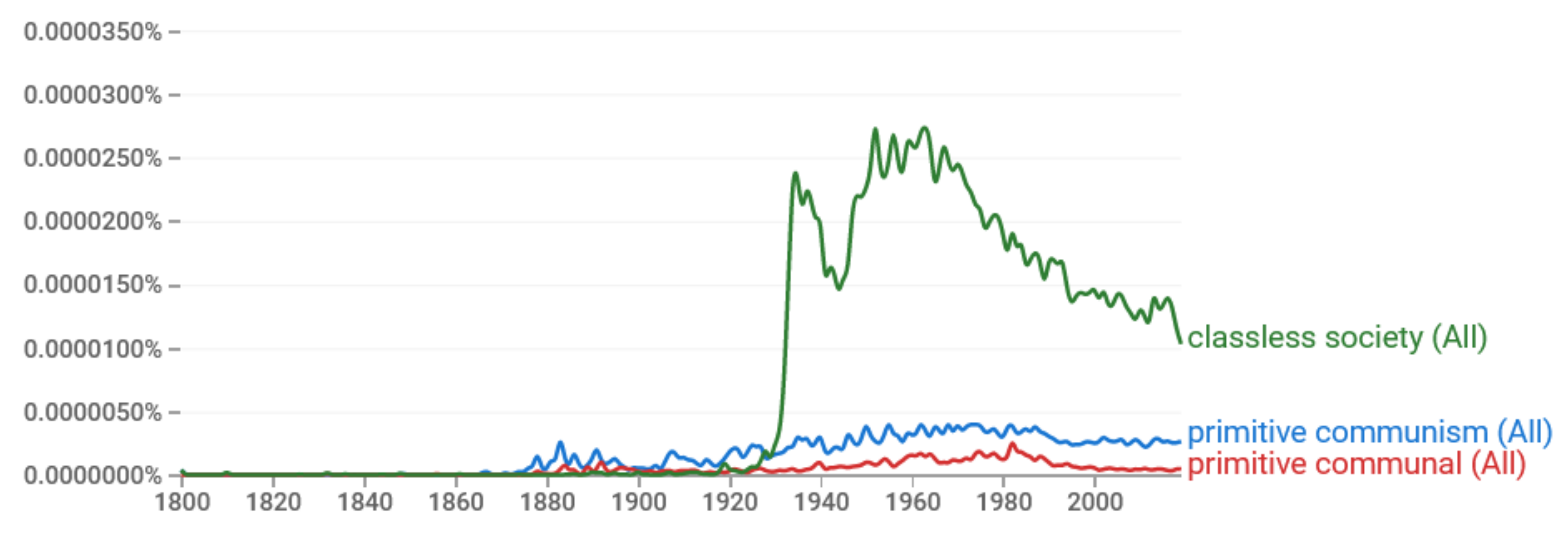
4.1. From the Ancient Classless Society to Modern Stratified Societies
4.2. The Elites’ Role
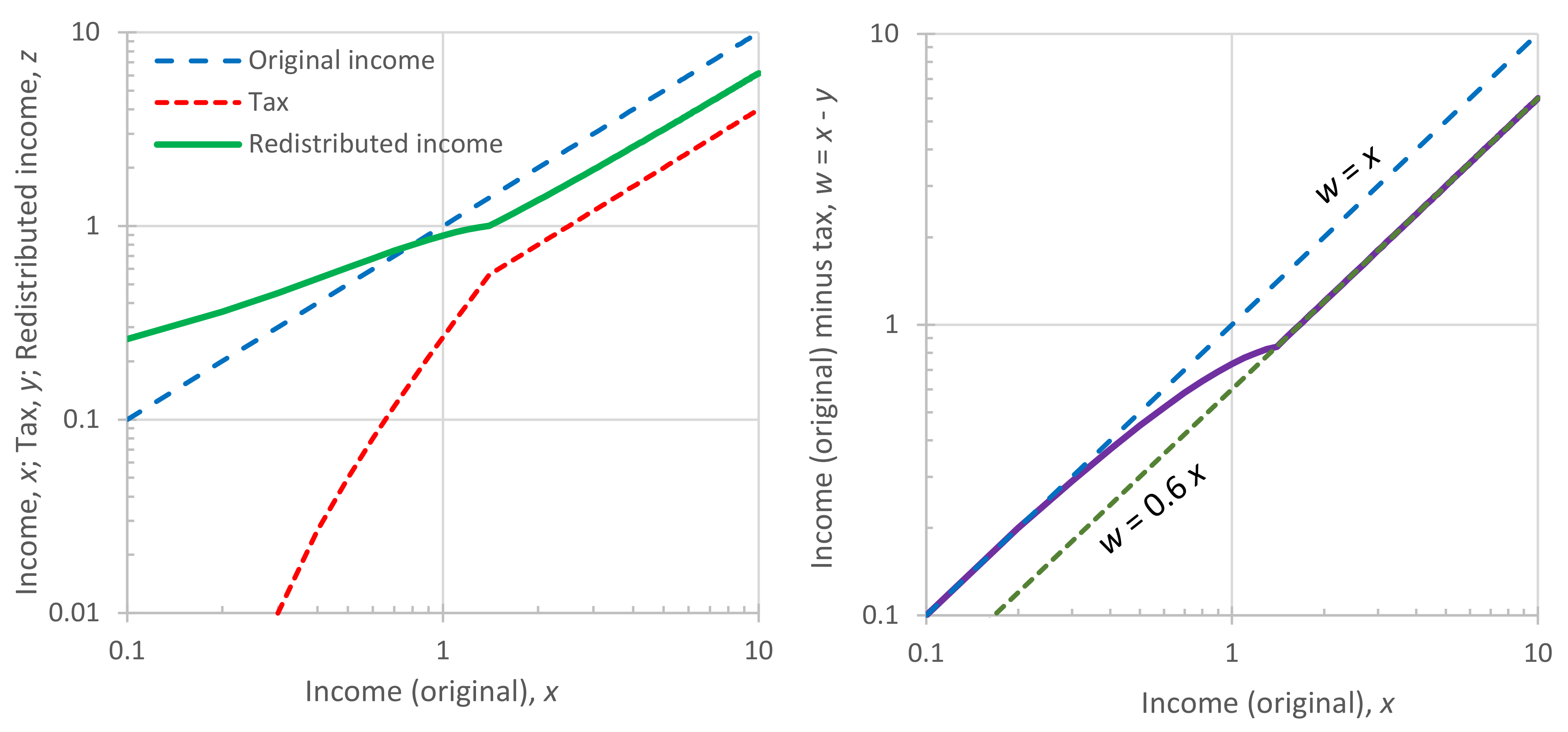
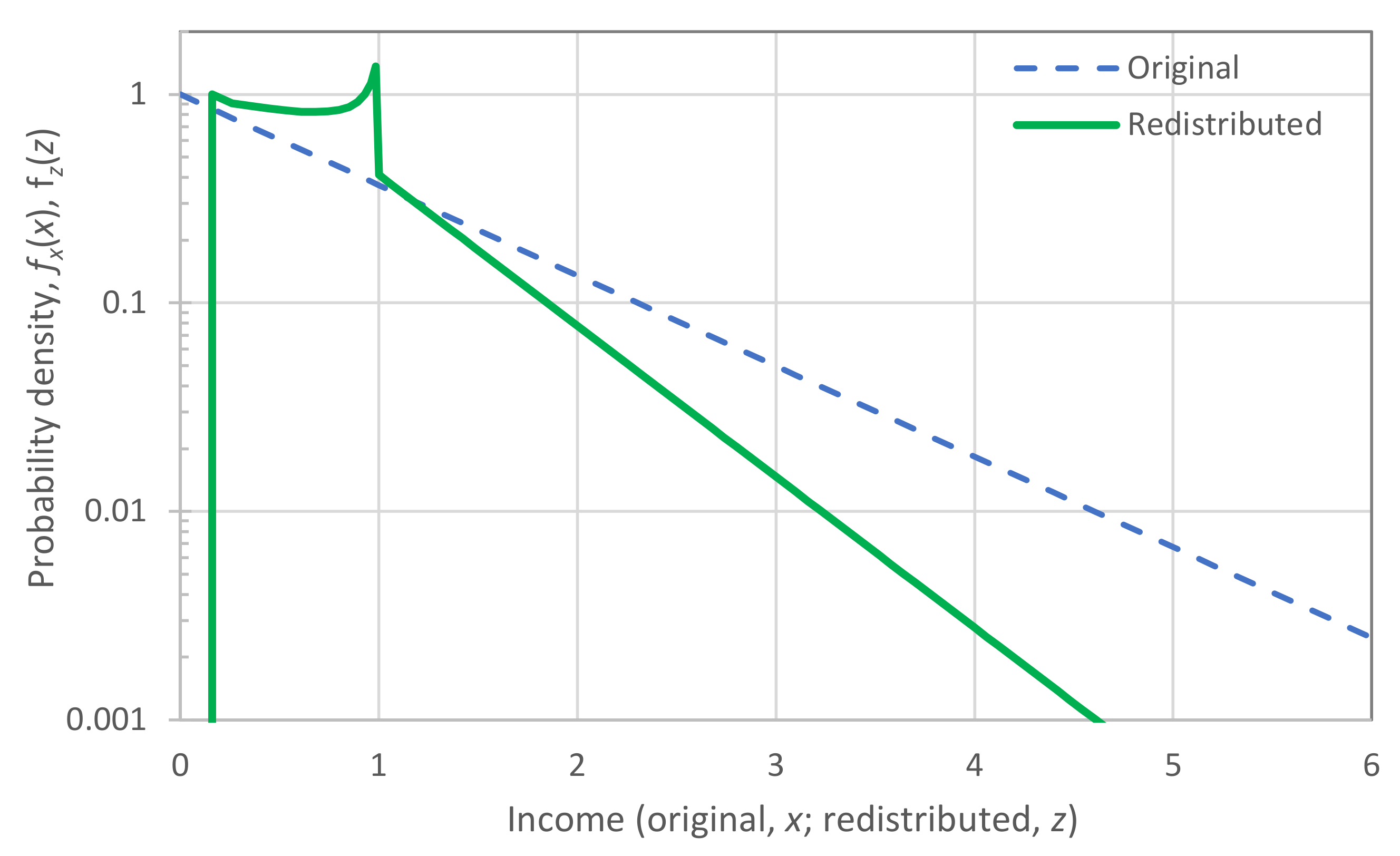
4.3. Income Redistribution in Organized Societies
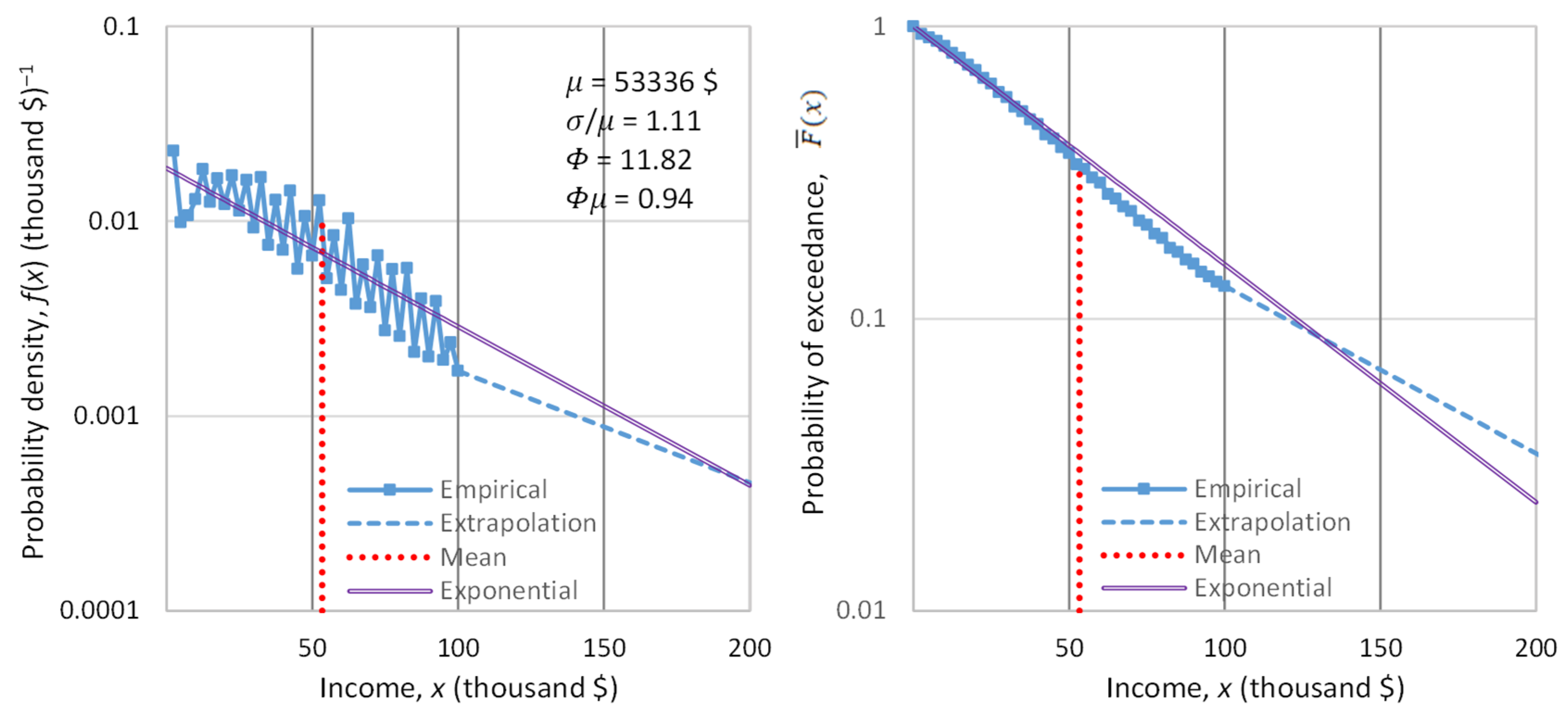
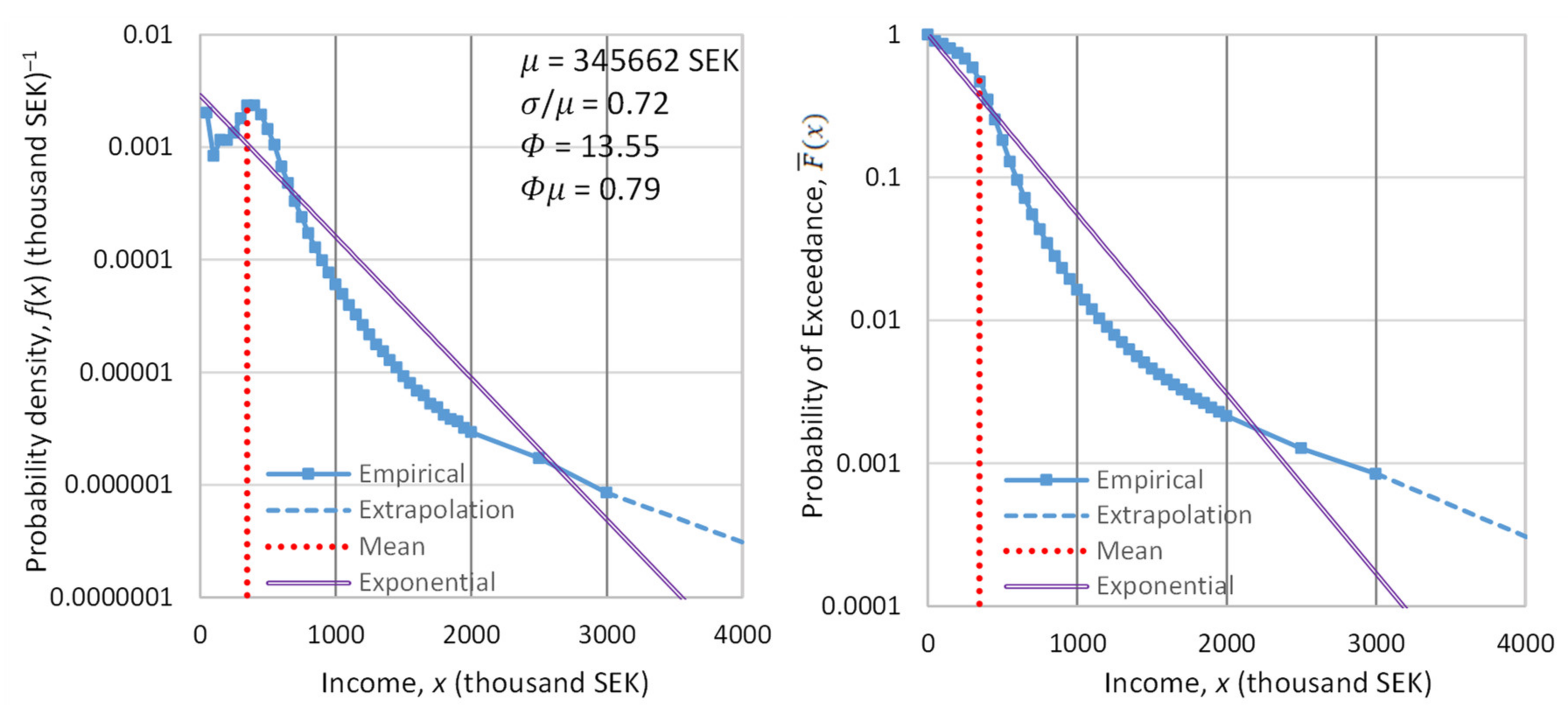
4.4. Empirical Investigation
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Xanthopoulos, T. Requiem with Crescendo? Homo Sapiens the Ultimate Genus of Human, Volume A; National Technical University of Athens: Athens, Greece, 2017. (In Greek) [Google Scholar]
- Xanthopoulos, T. Requiem with Crescendo? Homo Sapiens the Ultimate Genus of Human, Volume B, End of 15th Century–Beginning of 21st Century; National Technical University of Athens: Athens, Greece, 2020. (In Greek) [Google Scholar]
- Xanthopoulos, T. Requiem with Crescendo? Trapped in the Despotisms and Whirlpools of the Artificial Pangea and Panthalassa, Emancipate, Volume C, Tracking the Exit in 21st Century; National Technical University of Athens: Athens, Greece, 2020. (In Greek) [Google Scholar]
- Koutsoyiannis, D. Requiem with Crescendo; Xanthopoulos, T., Ed.; National Technical University of Athens: Athens, Greece, 2018; (In Greek). [Google Scholar] [CrossRef]
- Razumovskaya, V.A. Information entropy of literary text and its surmounting in understanding and translation. J. Sib. Fed. Univ. Humanities Soc. Sci. 2010, 2, 259–267. Available online: https://core.ac.uk/download/pdf/38633204.pdf (accessed on 9 August 2021).
- Anger, S. Evolution and entropy. In A Companion to British Literature, Scientific Contexts in the Nineteenth Century; DeMaria, R., Chang, H., Zacher, S., Eds.; Wiley Online Library: London, UK, 2014. [Google Scholar] [CrossRef]
- Entropy Poems. Available online: http://www.poemhunter.com/poems/entropy/ (accessed on 9 August 2021).
- Hello Poetry. Available online: http://hellopoetry.com/words/entropy/ (accessed on 9 August 2021).
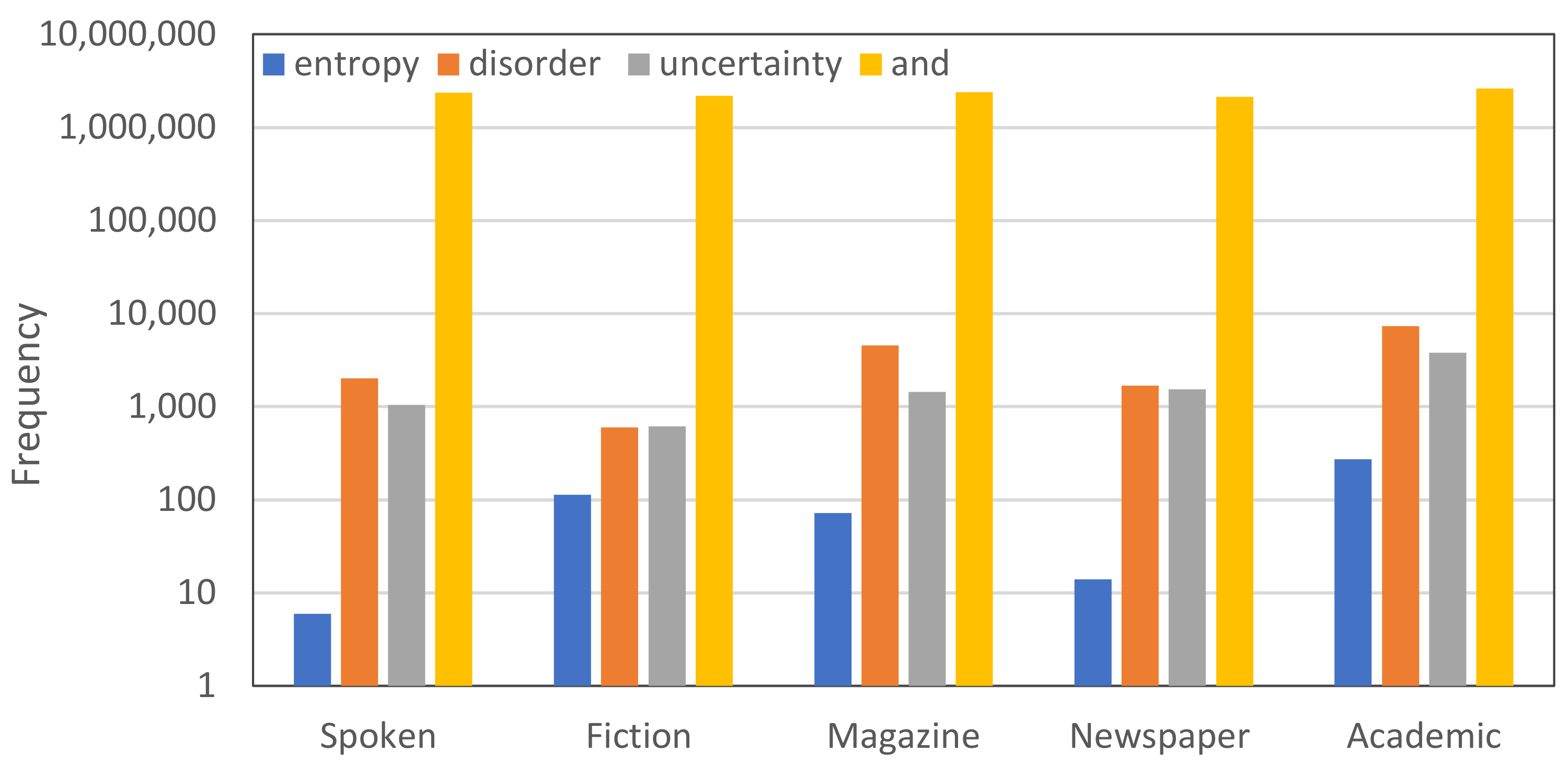
- Corpus of Contemporary American English. Available online: http://www.english-corpora.org/coca/ (accessed on 9 August 2021).
- Word and Phrase Info. Available online: http://www.wordandphrase.info/frequencyList.asp (accessed on 9 August 2021).
- Scopus Database. Available online: https://www.scopus.com/ (accessed on 13 August 2021).
- Overbury, R.E. Features of a closed-system economy. Nature 1973, 242, 561–565. [Google Scholar] [CrossRef]
- Bailey, K.D. Social Entropy Theory; State University of New York: New York, NY, USA, 1990. [Google Scholar]
- Bailey, K.D. Social entropy theory: An overview. Syst. Pract. 1990, 3, 365–382. [Google Scholar] [CrossRef]
- Mayer, T.F. Review of “Social Entropy Theory” by Kenneth, D. Bailey. Am. J. Sociol. 1991, 96, 1544–1546. Available online: https://www.jstor.org/stable/2781914 (accessed on 13 August 2021). [CrossRef]
- Netto, V.M.; Meirelles, J.; Ribeiro, F.L. Social interaction and the city: The effect of space on the reduction of entropy. Complexity 2017, 2017, 6182503. [Google Scholar] [CrossRef]
- Dinga, E.; Tănăsescu, C.-R.; Ionescu, G.-M. Social entropy and normative network. Entropy 2020, 22, 1051. [Google Scholar] [CrossRef]
- Balch, T. Hierarchic social entropy: An information theoretic measure of robot group diversity. Auton. Robots 2000, 8, 209–238. [Google Scholar] [CrossRef]
- Mavrofides, T.; Kameas, A.; Papageorgiou, D.; Los, A. On the entropy of social systems: A revision of the concepts of entropy and energy in the social context. Syst. Res. 2011, 28, 353–368. [Google Scholar] [CrossRef]
- Davis, P.J. Entropy and society: Can the physical/mathematical notions of entropy be usefully imported into the social sphere? J. Humanist. Math. 2011, 1, 119–136. [Google Scholar] [CrossRef]
- Saridis, G.N. Entropy as a philosophy. In Proceedings of the 2004 Performance Metrics for Intelligent Systems Workshop; National Institute of Standards & Technology (NIST), Manufacturing Engineering Lab: Gaithersburg, MD, USA, 2004; Available online: http://apps.dtic.mil/sti/citations/ADA515701 (accessed on 15 August 2021).
- Soddy, F. Wealth. In Virtual Wealth and Debt: The Solution of the Economic Paradox; Britons Publishing Company: London, UK, 1933; Available online: http://www.fadedpage.com/showbook.php?pid=20140873 (accessed on 9 August 2021).
- Manel, D. Frederick Soddy: The scientist as prophet. Ann. Sci. 1992, 49, 351–367. [Google Scholar] [CrossRef]
- Daly, H.E. The economic thought of Frederick Soddy. Hist. Polit. Econ. 1980, 12, 469–488. [Google Scholar] [CrossRef]
- Georgescu-Roegen, N. The Entropy Law and the Economic Process; Harvard University Press: Cambridge, MA, USA, 1971. [Google Scholar] [CrossRef]
- Georgescu-Roegen, N. The entropy law and the economic process in retrospect. East. Econ. J. 1986, 12, 3–25. Available online: https://www.jstor.org/stable/40357380 (accessed on 14 August 2021).
- Beard, T.R. Economics, Entropy and the Environment: The Extraordinary Economics of Nicholas Georgescu-Roegen; Edward Elgar Publishing: London, UK, 1999. [Google Scholar]
- Avery, J.S. Entropy and economics. In Cadmus: The Wealth of Nations Revisited, A Papers Series of the South-East European Division; 2012; Volume I, Available online: http://cadmusjournal.org/node/146 (accessed on 9 August 2021).
- Candeal, J.C.; de Miguel, J.R.; Induráin, E.; Mehta, G.B. Utility and entropy. Econ. Theory 2001, 17, 233–238. Available online: http://www.jstor.org/stable/25055372 (accessed on 31 July 2021). [CrossRef]
- Jakimowicz, A. The role of entropy in the development of economics. Entropy 2020, 22, 452. [Google Scholar] [CrossRef]
- Jaynes, E.T. How Should We Use Entropy in Economics? University of Cambridge: Cambridge, UK, 1991; Available online: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.41.4606&rep=rep1&type=pdf (accessed on 9 August 2021).
- Beard, T.R.; Lozada, G.A. Economics, Entropy and the Environment; Edward Elgar Publishing: London, UK, 1999. [Google Scholar]
- Kümmel, R. The Second Law of Economics: Energy, Entropy, and the Origins of Wealth; Springer Science & Business Media: London, UK, 2011. [Google Scholar]
- Faber, M.; Niemes, H.; Stephan, G. Entropy, Environment and Resources: An Essay in Physico-Economics; Springer: London, UK, 1987. [Google Scholar]
- Mayumi, K.; Giampietro, M. Entropy in ecological economics. In Modelling in Ecological Economics; Proops, J., Safonov, P., Eds.; Edward Elgar: Cheltenham, UK, 2004; pp. 80–101. Available online: https://books.google.gr/books?id=ar4rEAAAQBAJ (accessed on 10 August 2021).
- Fisk, D. Thermodynamics on main street: When entropy really counts in economics. Ecol. Econ. 2011, 70, 1931–1936. [Google Scholar] [CrossRef]
- Lozada, G.A. Entropy, free energy, work, and other thermodynamic variables in economics. Ecol. Econ. 2006, 56, 71–78. [Google Scholar] [CrossRef]
- Giffin, A. From physics to economics: An econometric example using maximum relative entropy. Phys. A Stat. Mech. Appl. 2009, 388, 1610–1620. [Google Scholar] [CrossRef]
- Townsend, K.N. Is the entropy law relevant to the economics of natural resource scarcity? Comment. J. Environ. Econ. Manag. 1992, 23, 96–100. [Google Scholar] [CrossRef]
- Burkett, P. Entropy in ecological economics: A marxist intervention. In Marxism and Ecological Economics; Brill: Leiden, The Netherlands, 2006. [Google Scholar] [CrossRef]
- Ruth, M. Entropy, economics, and policy. In Thermodynamics and The Destruction of Resources; Bakshi, B., Gutowski, T., Sekulić, D., Eds.; Cambridge University Press: Cambridge, UK, 2011; pp. 402–422. [Google Scholar] [CrossRef]
- Raine, A.; Foster, J.; Potts, J. The new entropy law and the economic process. Ecol. Complex. 2006, 3, 354–360. [Google Scholar] [CrossRef]
- McMahon, G.F.; Mrozek, J.R. Economics, entropy and sustainability. Hydrol. Sci. J. 1997, 42, 501–512. [Google Scholar] [CrossRef][Green Version]
- Smith, C.E.; Smith, J.W. Economics, ecology and entropy: The second law of thermodynamics and the limits to growth. Popul. Environ. 1996, 17, 309–321. [Google Scholar] [CrossRef]
- Hammond, G.P.; Winnett, A.B. The influence of thermodynamic ideas on ecological economics: An interdisciplinary critique. Sustainability 2009, 1, 1195–1225. [Google Scholar] [CrossRef]
- Kovalev, A.V. Misuse of thermodynamic entropy in economics. Energy 2016, 100, 129–136. [Google Scholar] [CrossRef]
- Scharfenaker, E.; Yang, J. Maximum entropy economics: Where do we stand? Eur. Phys. J. Spec. Top. 2020, 229, 1573–1575. [Google Scholar] [CrossRef]
- Scharfenaker, E.; Yang, J. Maximum entropy economics. Eur. Phys. J. Spec. Top. 2020, 229, 1577–1590. [Google Scholar] [CrossRef]
- Ryu, H.K. Maximum entropy estimation of income distributions from Bonferroni indices. In Modeling Income Distributions and Lorenz Curves. Economic Studies in Equality, Social Exclusion and Well-Being; Chotikapanich, D., Ed.; Springer: New York, NY, USA, 2008; Volume 5. [Google Scholar] [CrossRef]
- Fu, Q.; Villas-Boas, S.B.; Judge, G. Entropy-based China income distributions and inequality measures. China Econ. J. 2019, 12, 352–368. [Google Scholar] [CrossRef]
- Mayer, A.L.; Donovan, R.P.; Pawlowski, C.W. Information and entropy theory for the sustainability of coupled human and natural systems. Ecol. Soc. 2014, 19, 11. [Google Scholar] [CrossRef]
- Chakrabarti, B.K.; Sinha, A. Development of econophysics: A biased account and perspective from Kolkata. Entropy 2021, 23, 254. [Google Scholar] [CrossRef]
- Chakrabarti, B.K.; Chakraborti, A.; Chakravarty, S.R.; Chatterjee, A. Econophysics of Income and Wealth Distributions; Cambridge University Press: Cambridge, UK, 2013. [Google Scholar]
- Yakovenko, V.M.; Rosser, J.B., Jr. Colloquium: Statistical mechanics of money, wealth, and income. Rev. Mod. Phys. 2009, 81, 1703–1724. [Google Scholar] [CrossRef]
- Chakraborti, A.; Toke, I.M.; Patriarca, M.; Abergel, F. Econophysics review: I. Empirical facts. Quant. Financ. 2011, 11, 991–1012. [Google Scholar] [CrossRef]
- Chakraborti, A.; Toke, I.M.; Patriarca, M.; Abergel, F. Econophysics review: II. Agent-based models. Quant. Financ. 2011, 11, 1013–1041. [Google Scholar] [CrossRef]
- Schinckus, C. Methodological comment on Econophysics review I and II: Statistical econophysics and agent-based econophysics. Quant. Financ. 2012, 12, 1189–1192. [Google Scholar] [CrossRef]
- Bo, Z.; Xiong-Fei, J.; Peng-Yun, N. A mini-review on econophysics: Comparative study of Chinese and western financial markets. Chin. Phys. B 2014, 23, 078903. [Google Scholar]
- Liddell, Scott, Jones (LSJ): Ancient Greek Lexicon. Available online: https://lsj.gr/wiki/ἐντροπία (accessed on 31 July 2021).
- Clausius, R. A contribution to the history of the mechanical theory of heat. Phil. Mag. 1872, 43, 106–115. [Google Scholar] [CrossRef]
- Clausius, R. The Mechanical Theory of Heat: With Its Applications to the Steam-Engine and to the Physical Properties of Bodies; Macmillian and Co.: London, UK, 1867; Available online: http://books.google.gr/books?id=8LIEAAAAYAAJ (accessed on 31 July 2021).
- Clausius, R. Über verschiedene für die Anwendung bequeme Formen der Hauptgleichungen der mechanischen Wärmetheorie. Annal. Phys. Chem. 1865, 125, 353–400. Available online: http://books.google.gr/books?id=qAg4AAAAMAAJ (accessed on 31 July 2021). [CrossRef]
- Hill, G.; Holman, J. Entropy–The Driving Force of Change; Royal Society of Chemistry: London, UK, 1986; p. 17. ISBN 0-15186-967-X. [Google Scholar]
- Atkins, P. Galileo’s Finger: The Ten Great Ideas of Science; Oxford University Press: New York, NY, USA, 2003. [Google Scholar]
- Atkins, P. Four Laws that Drive the Universe; Oxford University Press: Oxford, UK, 2007; p. 131. [Google Scholar]
- Boltzmann, L. Über die Beziehung zwischen dem zweiten Hauptsatze der mechanischen Wärmetheorie und der Wahrscheinlichkeitsrechnung respektive den Sätzen über das Wärmegleichgewicht. Wien. Ber. 1877, 76, 373–435. [Google Scholar]
- Swendsen, R.H. Statistical mechanics of colloids and Boltzmann’s definition of the entropy. Am. J. Phys. 2006, 74, 187–190. [Google Scholar] [CrossRef]
- Gibbs, J.W. Elementary Principles of Statistical Mechanics; Reprinted by Dover, New York, 1960; Yale University Press: New Haven, CT, USA, 1902; p. 244. Available online: https://www.gutenberg.org/ebooks/50992 (accessed on 31 July 2021).
- Shannon, C.E. The mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Robertson, H.S. Statistical Thermophysics; Prentice Hall: Englewood Cliffs, NJ, USA, 1993; p. 582. [Google Scholar]
- Brissaud, J.-B. The meanings of entropy. Entropy 2005, 7, 68–96. [Google Scholar] [CrossRef]
- Koutsoyiannis, D. Hurst-Kolmogorov dynamics as a result of extremal entropy production. Phys. A 2011, 390, 1424–1432. [Google Scholar] [CrossRef]
- Wiener, N. Cybernetics or Control and Communication in the Animal and the Machine; MIT Press: Cambridge, MA, USA, 1948; p. 212. [Google Scholar]
- von Neumann, J. Probabilistic logics and the synthesis of reliable organisms from unreliable components. Autom. Stud. 1956, 34, 43–98. [Google Scholar] [CrossRef]
- Szilard, L. Über die Entropieverminderung in einem thermodynamischen System bei Eingriffen intelligenter Wesen. Zeitschr. Phys. 1929, 53, 840–856. [Google Scholar] [CrossRef]
- Jaynes, E.T. Information theory and statistical mechanics. Phys. Rev. 1957, 106, 620–630. [Google Scholar] [CrossRef]
- Swendsen, R.H. How physicists disagree on the meaning of entropy. Am. J. Phys. 2011, 79, 342–348. [Google Scholar] [CrossRef]
- Moore, T.A. Six Ideas that Shaped Physics. Unit T—Thermodynamics, 2nd ed.; McGraw-Hill: New York, NY, USA, 2003. [Google Scholar]
- Koutsoyiannis, D. Physics of uncertainty, the Gibbs paradox and indistinguishable particles. Stud. Hist. Philos. Mod. Phys. 2013, 44, 480–489. [Google Scholar] [CrossRef]
- Koutsoyiannis, D. Entropy: From thermodynamics to hydrology. Entropy 2014, 16, 1287–1314. [Google Scholar] [CrossRef]
- Boltzmann, L. On the indispensability of atomism in natural science. Annal. Phys. Chem. 1897, 60, 231. [Google Scholar] [CrossRef]
- Boltzmann, L. On the necessity of atomic theories in physics. Monist 1901, 12, 65–79. Available online: https://www.jstor.org/stable/27899285 (accessed on 31 July 2021). [CrossRef]
- Boltzmann, L. Lectures on Gas Theory; Dover Publications: New York, NY, USA, 1995; p. 443. [Google Scholar]
- Darrow, K.K. The concept of entropy. Am. J. Phys. 1944, 12, 183. [Google Scholar] [CrossRef]
- Wiener, N. Time, communication, and the nervous system. Ann. N. Y. Acad. Sci. 1948, 50, 197–220. [Google Scholar] [CrossRef] [PubMed]
- Chaitin, G.J. Computers, paradoxes and the foundations of mathematics. Am. Sci. 2002, 90, 164–171. [Google Scholar] [CrossRef]
- Bailey, K.D. Entropy Systems Theory: Systems Science and Cybernetics; Eolss Publishers: Oxford, UK, 2009; p. 169. [Google Scholar]
- Koutsoyiannis, D. A random walk on water. Hydrol. Earth Syst. Sci. 2010, 14, 585–601. [Google Scholar] [CrossRef]
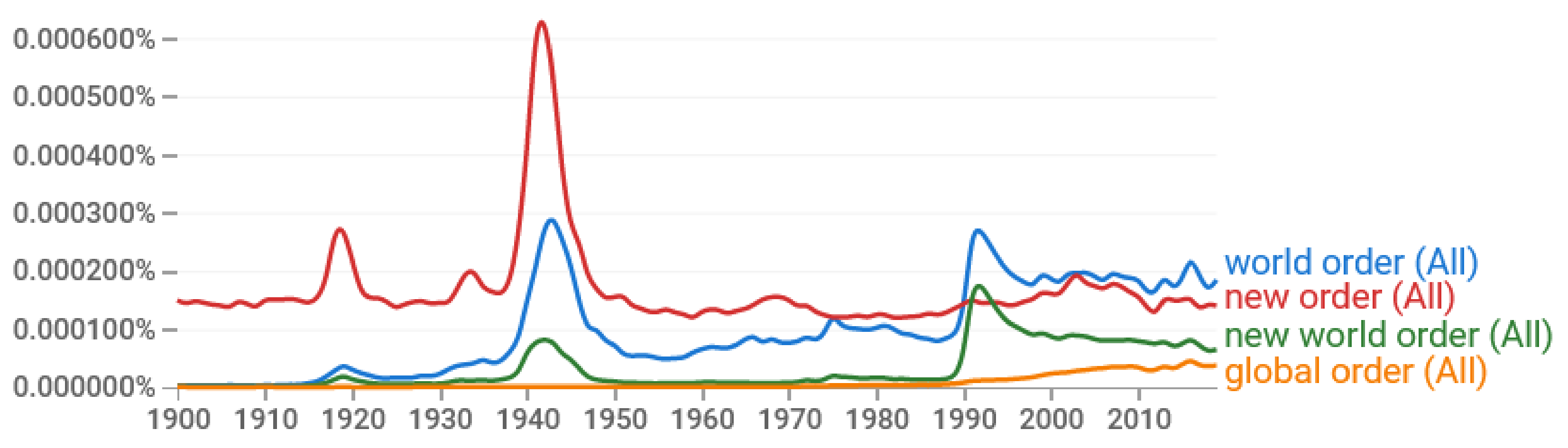
- Google Scholar. Available online: https://scholar.google.com/scholar?hl=en&as_sdt=0%2C5&q=author%3Ah-kissinger+%22world+order%22 (accessed on 8 August 2021).
- Google Scholar. Available online: https://scholar.google.com/scholar?hl=en&as_sdt=0%2C5&q=author%3Ah-kissinger+%22new+world+order%22 (accessed on 8 August 2021).
- Kissinger, H.A. The Chance for a New World Order. The New York Times. 12 January 2009. Available online: https://www.nytimes.com/2009/01/12/opinion/12iht-edkissinger.1.19281915.html (accessed on 8 August 2021).
- Kissinger, H.A. The Coronavirus Pandemic Will Forever Alter the World Order. The Wall Street Journal. 3 April 2020. Available online: https://www.wsj.com/articles/the-coronavirus-pandemic-will-forever-alter-the-world-order-11585953005 (accessed on 8 August 2021).
- Onuf, P.S.; Onuf, N.G. American constitutionalism and the emergence of a liberal world order. In American Constitutionalism Abroad: Selected Essays in Comparative Constitutional History; Billias, G.A., Ed.; Greenwood Press: New York, NY, USA, 1990. [Google Scholar]
- Schwab, K.; Malleret, T. Covid-19: The Great Reset; World Economic Forum: Geneva, Switzerland, 2020. [Google Scholar]
- Google Books Ngram Viewer. Available online: https://books.google.com/ngrams/ (accessed on 1 August 2021).
- Michel, J.B.; Shen, Y.K.; Aiden, A.P.; Veres, A.; Gray, M.K.; Pickett, J.P.; Hoiberg, D.; Clancy, D.; Norvig, P.; Orwant, J.; et al. Quantitative analysis of culture using millions of digitized books. Science 2011, 331, 176–182. [Google Scholar] [CrossRef]
- Wright, P.G. Entropy and disorder. Contemp. Phys. 1970, 11, 581–588. [Google Scholar] [CrossRef]
- Leff, H.S. Removing the mystery of entropy and thermodynamics—Part V. Phys. Teach. 2012, 50, 274–276. [Google Scholar] [CrossRef]
- Styer, D. Entropy as disorder: History of a misconception. Phys. Teach. 2019, 57, 454. [Google Scholar] [CrossRef]
- Adams, H. The Education of Henry Adams; Houghton Mifflin Company: Boston, MA, USA, 1918. [Google Scholar]
- Nordangård, J. Rockefeller: Controlling the Game; Stiftelsen Pharos: Lidingö, Sweden, 2019; p. 386. ISBN 978-91-985843-0-1. [Google Scholar]
- Van der Sluijs, J. Uncertainty as a monster in the science–policy interface: Four coping strategies. Water Sci. Technol. 2005, 52, 87–92. [Google Scholar] [CrossRef]
- Curry, J.A.; Webster, P.J. Climate science and the uncertainty monster. Bull. Am. Meteorol. Soc. 2011, 92, 1667–1682. [Google Scholar] [CrossRef]
- Koutsoyiannis, D.; Makropoulos, C.; Langousis, A.; Baki, S.; Efstratiadis, A.; Christofides, C.; Karavokiros, G.; Mamassis, N. Interactive comment on “HESS Opinions, Climate, hydrology, energy, water: Recognizing uncertainty and seeking sustainability” by Koutsoyiannis, D. et al. Hydrol. Earth Syst. Sci. Discuss. 2008, 5, S1761–S1774. Available online: www.hydrol-earth-syst-sci-discuss.net/5/S1761/2008/ (accessed on 14 August 2021).
- Marc Chagall, Palette 1974. The Metropolitan Museum of Art, New York, NY, USA. Available online: https://www.metmuseum.org/art/collection/search/493731 (accessed on 13 August 2021).
- Marc Chagall. Self-Portrait with Seven Fingers. 1913. Available online: https://en.wikipedia.org/wiki/Self-Portrait_with_Seven_Fingers (accessed on 13 August 2021).
- Guye, C.-E. L’Évolution Physico-Chimique; Etienne Chiron: Paris, France, 1922. [Google Scholar]
- Brillouin, L. Life, thermodynamics, and cybernetics. In Maxwells Demon. Entropy, Information, Computing; Princeton University Press: Princeton, NJ, USA, 1949; pp. 89–103. [Google Scholar] [CrossRef]
- Brillouin, L. Thermodynamics and information theory. Am. Sci. 1950, 38, 594–599. Available online: https://www.jstor.org/stable/27826339 (accessed on 1 August 2021).
- Schrödinger, E. What is Life? The Physical Aspect of the Living Cell; Cambridge University Press: Cambridge, UK, 1944. [Google Scholar]
- Lago-Fernández, L.F.; Corbacho, F. Using the negentropy increment to determine the number of clusters. In International Work-Conference on Artificial Neural Networks; Springer: Berlin/Heidelberg, Germany, 2009; pp. 448–455. [Google Scholar]
- Larouche, L.H., Jr. On Larouche’s Discovery. 1993. Available online: http://www.archive.schillerinstitute.com/fidelio_archive/1994/fidv03n01-1994Sp/fidv03n01-1994Sp_037-on_larouches_discovery-lar.pdf (accessed on 1 August 2021).
- Sargentis, G.-F.; Iliopoulou, T.; Sigourou, S.; Dimitriadis, P.; Koutsoyiannis, D. Evolution of clustering quantified by a stochastic method—case studies on natural and human social structures. Sustainability 2020, 12, 7972. [Google Scholar] [CrossRef]
- Kolmogorov, A.N. Grundbegriffe der Wahrscheinlichkeitsrechnung. Ergeb. Math. 1933, 2, 3. [Google Scholar]
- Kolmogorov, A.N. Foundations of the Theory of Probability, 2nd ed.; Chelsea Publishing Company: New York, NY, USA, 1956; p. 84. [Google Scholar]
- Jaynes, E.T. Probability Theory: The Logic of Science; Cambridge University Press: Cambridge, UK, 2003; p. 728. [Google Scholar]
- Uffink, J. Can the maximum entropy principle be explained as a consistency requirement? Stud. Hist. Philos. Mod. Phys. 1995, 26, 223–261. [Google Scholar] [CrossRef]
- Koutsoyiannis, D. Stochastics of Hydroclimatic Extremes-A Cool Look at Risk; Kallipos: Athens, Greece, 2021; p. 333. ISBN 978-618-85370-0-2. Available online: http://www.itia.ntua.gr/2000/ (accessed on 1 August 2021).
- Sargentis, G.-F.; Iliopoulou, T.; Dimitriadis, P.; Mamassis, N.; Koutsoyiannis, D. Stratification: An entropic view of society’s structure. World 2021, 2, 153–174. [Google Scholar] [CrossRef]
- Tusset, G. Plotting the words of econophysics. Entropy 2021, 23, 944. [Google Scholar] [CrossRef]
- Havrda, J.; Charvát, F. Concept of structural a-entropy. Kybernetika 1967, 3, 30–35. [Google Scholar]
- Tsallis, C. Possible generalization of Boltzmann-Gibbs statistics. J. Statist. Phys. 1988, 52, 479–487. [Google Scholar] [CrossRef]
- Biro, T.S.; Neda, Z. Unidirectional random growth with resetting. Phys. A Stat. Mech. Appl. 2018, 499, 335–361. [Google Scholar] [CrossRef]
- Biró, T.S.; Néda, Z. Gintropy: Gini index based generalization of entropy. Entropy 2020, 22, 879. [Google Scholar] [CrossRef]
- Pareto, V. La courbe de la répartition de la richesse (The curve of the distribution of wealth). In Ecrits sur la Courbe de la Répartition de la Richesse; Pareto, V., Ed.; Librairie Droz: Geneva, Switzerland, 1967; pp. 1–15. [Google Scholar]
- Mornati, F. The law of income distribution and various statistical complements. In Vilfredo Pareto: An Intellectual Biography Volume II.; Palgrave Studies in the History of Economic Thought; Palgrave Macmillan: London, UK, 2018. [Google Scholar] [CrossRef]
- Pareto, V. Manual of Political Economy; Oxford University Press: New York, NY, USA, 2014. [Google Scholar]
- Blanchet, T.; Fournier, J.; Piketty, T. Generalized Pareto Curves: Theory and Applications, WID. World Working Paper, 2017/3. Available online: https://wid.world/document/blanchet-t-fournier-j-piketty-t-generalized-pareto-curves-theory-applications-2017/ (accessed on 7 February 2021).
- Craft, R.C.; Leake, C. The Pareto principle in organizational decision making. Manag. Decis. 2002, 40, 729–733. [Google Scholar] [CrossRef]
- Juran, J.M. The non-Pareto principle mea culpa. Arch. Juran Inst. 1975. Available online: https://www.juran.com/wp-content/uploads/2021/03/The-Non-Pareto-Principle-1974.pdf (accessed on 16 August 2021).
- Juran, J.M. Universals in management planning and controlling. Manag. Rev. 1954, 43, 748–761. Available online: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.461.1456&rep=rep1&type=pdf (accessed on 16 August 2021).
- Néda, Z.; Gere, I.; Biró, T.S.; Tóth, G.; Derzsy, N. Scaling in income inequalities and its dynamical origin. Phys. A Stat. Mech. Appl. 2020, 549, 124491. [Google Scholar] [CrossRef]
- Gere, I.; Kelemen, S.; Tóth, G.; Biró, T.S.; Néda, Z. Wealth distribution in modern societies: Collected data and a master equation approach. Phys. A Stat. Mech. Appl. 2021, 581, 126194. [Google Scholar] [CrossRef]
- Drăgulescu, A.; Yakovenko, V.M. Evidence for the exponential distribution of income in the USA. Eur. Phys. J. B-Condens. Matter Complex Syst. 2001, 20, 585–589. [Google Scholar] [CrossRef]
- Shirras, G.F. The Pareto Law and the distribution of income. Econ. J. 1935, 45, 663–681. [Google Scholar] [CrossRef]
- Mandelbrot, B. The Pareto-Levy law and the distribution of income. Int. Econ. Rev. 1960, 1, 79–106. [Google Scholar] [CrossRef]
- The Complete World Billionaire Lists. Available online: https://stats.areppim.com/stats/links_billionairexlists.htm (accessed on 13 July 2021).
- WaybackMachine. Available online: https://archive.org/web/, search field: www.forbes.com/billionaires/ (accessed on 13 July 2021).
- Klass, O.S.; Biham, O.; Levy, M.; Malcai, O.; Solomon, S. The Forbes 400 and the Pareto wealth distribution. Econ. Lett. 2006, 90, 290–295. [Google Scholar] [CrossRef]
- WaybackMachine. Available online: https://archive.org/web, search field: https://www.bloomberg.com//billionaires/ (accessed on 13 July 2021).
- Marx, K.; Engels, F. The German Ideology; International Publishers: New York, NY, USA, 1970; Volume 1, Available online: https://archive.org/details/germanideology00marx/ (accessed on 11 August 2021).
- Selsam, H.; Martel, H. Reader in Marxist Philosophy: From the Writings of Marx, Engels and Lenin; Rabul Foundation: Lucknow, India, 2010; p. 380. [Google Scholar]
- Piketty, T. Capital in the Twenty-First Century; Harvard University Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Koutsoyiannis, D. The Political Origin of the Climate Change Agenda, Self-Organized Lecture; School of Civil Engineering–National Technical University of Athens: Athens, Greece, 2020. [Google Scholar] [CrossRef]
- Koutsoyiannis, D.; Mamassis, N. From mythology to science: The development of scientific hydrological concepts in the Greek antiquity and its relevance to modern hydrology. Hydrol. Earth Syst. Sci. 2021, 25, 2419–2444. [Google Scholar] [CrossRef]
- Tresch, R.W. The social welfare function in policy analysis. In Public Finance, 3rd ed.; Tresch, R.W., Ed.; Academic Press: London, UK, 2015; Chapter 4; pp. 57–78. ISBN 9780124158344. [Google Scholar] [CrossRef]
- Lorenz Curve. Available online: http://www.sciencedirect.com/topics/economics-econometrics-and-finance/lorenz-curve (accessed on 5 October 2020).
- Bellù, L.G.; Liberati, P. Charting Income Inequality: The Lorenz Curve; Food and Agriculture Organization of the United Nations (FAO). 2005. Available online: http://www.fao.org/3/a-am391e.pdf (accessed on 28 December 2020).
- Income Inequality. Available online: https://ourworldindata.org/income-inequality (accessed on 5 October 2020).
- Gini Index. Available online: https://www.investopedia.com/terms/g/gini-index.asp (accessed on 5 October 2020).
- Bellù, L.G.; Liberati, P. Inequality Analysis. The Gini Index. Food and Agriculture Organization of the United Nations (FAO), 2006. Available online: http://www.fao.org/3/a-am352e.pdf (accessed on 28 December 2020).
- Atkinson, A.B.; Bourguignon, F. Income distribution. In International Encyclopedia of the Social & Behavioral Sciences; Smelser, N.J., Baltes, P.B., Eds.; Pergamon: Oxford, UK, 2001; pp. 7265–7271. ISBN 9780080430768. [Google Scholar] [CrossRef]
- Morelli, S.; Smeeding, T.; Thompson, J. Post-1970 Trends in within-country inequality and poverty: Rich and middle-income countries. In Handbook of Income Distribution; Atkinson, A.B., Bourguignon, F., Eds.; Elsevier: Amsterdam, The Nehterlands, 2015; Chapter 8; Volume 2, pp. 593–696. [Google Scholar] [CrossRef]
- Förster, M.F.; Tóth, I.G. Cross-country evidence of the multiple causes of inequality changes in the OECD area. In Handbook of Income Distribution; Atkinson, A.B., Bourguignon, F., Eds.; Elsevier: Amsterdam, The Netherlands, 2015; Chapter 19; Volume 2, pp. 1729–1843. [Google Scholar] [CrossRef]
- Income Distribution, Redefining Capitalism in Global Economic Development. 2017. Available online: http://www.sciencedirect.com/topics/economics-econometrics-and-finance/income-distribution (accessed on 5 October 2020).
- United States Census Bureau, PINC-08. Source of Income-People 15 Years Old and Over, by Income of Specified Type, Age, Race, Hispanic Origin, and Sex. Available online: https://www.census.gov/data/tables/time-series/demo/income-poverty/cps-pinc/pinc-08.2019.html (accessed on 29 July 2021).
- United States Census Bureau, PINC-08. Source of Income in 2019--People 15 Years Old and Over by Income of Specified Type in 2019, Age, Race, Hispanic Origin, and Sex. Available online: https://www2.census.gov/programs-surveys/cps/tables/pinc-08/2020/pinc08_1_1_1.xlsx (accessed on 29 July 2021).
- SCB–Statistics Sweden, Income and Tax Statistics. Available online: https://www.scb.se/en/finding-statistics/statistics-by-subject-area/household-finances/income-and-income-distribution/income-and-tax-statistics/ (accessed on 29 July 2021).
- SCB–Statistics Sweden, Number of Persons in Brackets of Total Earned Income by Age 2019. Available online: https://www.scb.se/en/finding-statistics/statistics-by-subject-area/household-finances/income-and-income-distribution/income-and-tax-statistics/pong/tables-and-graphs/income--persons-the-entire-country/total-income-from-employment-and-business-2019--by-income-brackets/ (accessed on 29 July 2021).

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
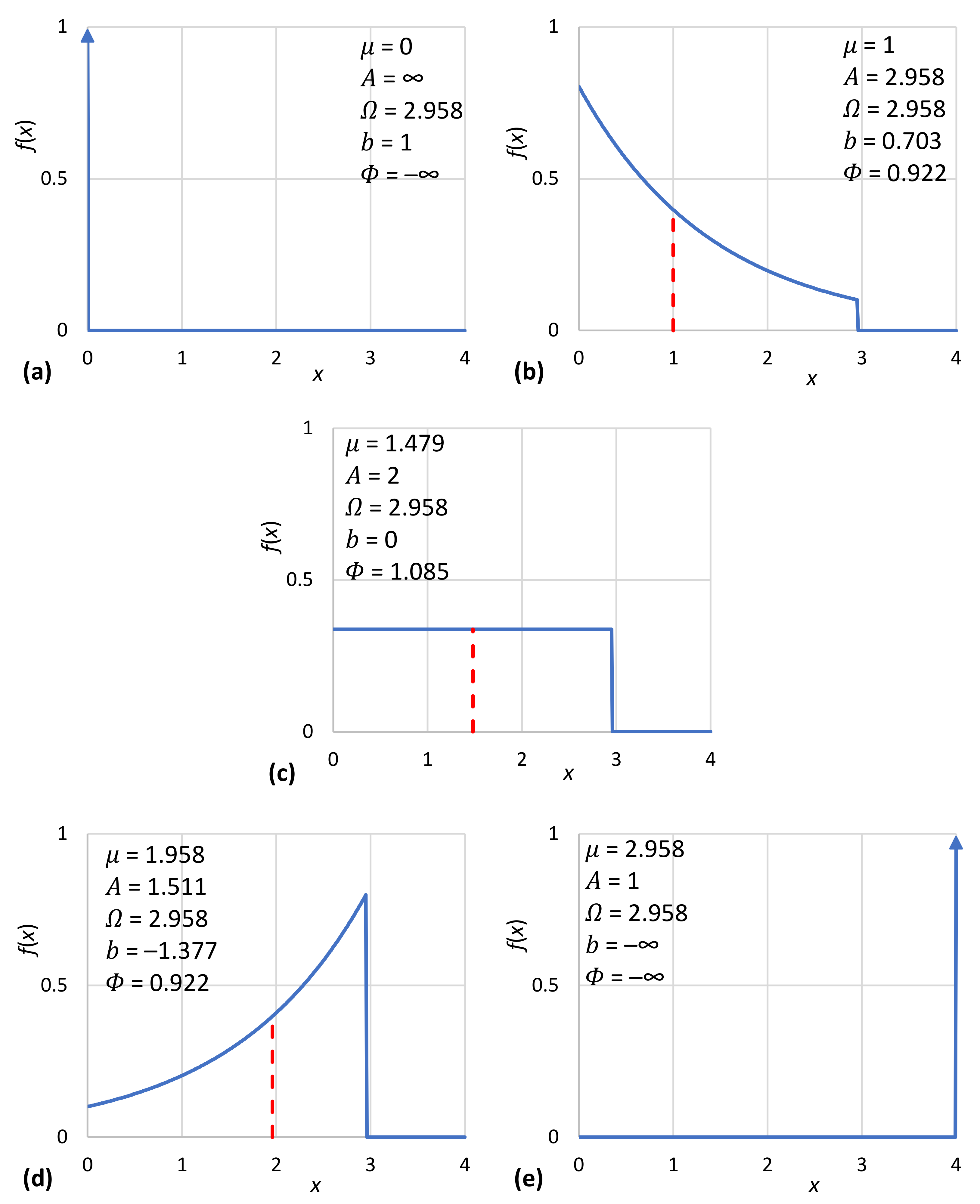
| # | Distribution | ||||
|---|---|---|---|---|---|
| 1 | 1 | ||||
| 2 | Truncated anti- exponential | ||||
| 3 | 2 | 0 | Uniform | ||
| 4 | Truncated exponential | ||||
| 5 | 1 | Unbounded exponential |
| # | Distribution | ||||
|---|---|---|---|---|---|
| 1 | 1 | Certain () | |||
| 2 | Truncated anti- exponential | ||||
| 3 | 2 | 0 | Uniform | ||
| 4 | Truncated exponential | ||||
| 5 | 1 | Certain () |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Koutsoyiannis, D.; Sargentis, G.-F. Entropy and Wealth. Entropy 2021, 23, 1356. https://doi.org/10.3390/e23101356
Koutsoyiannis D, Sargentis G-F. Entropy and Wealth. Entropy. 2021; 23(10):1356. https://doi.org/10.3390/e23101356
Chicago/Turabian StyleKoutsoyiannis, Demetris, and G.-Fivos Sargentis. 2021. "Entropy and Wealth" Entropy 23, no. 10: 1356. https://doi.org/10.3390/e23101356
APA StyleKoutsoyiannis, D., & Sargentis, G.-F. (2021). Entropy and Wealth. Entropy, 23(10), 1356. https://doi.org/10.3390/e23101356